voertuigidentificatie bij multi-camera tunnelbewaking ... · letsels en materi ele schade. om in...
TRANSCRIPT

Alexander Ide
Voertuigidentificatie bij multi-camera tunnelbewaking
Academiejaar 2009-2010Faculteit IngenieurswetenschappenVoorzitter: prof. dr. ir. Herwig BruneelVakgroep Telecommunicatie en informatieverwerking
Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van
Begeleider: Vedran JelacaPromotoren: prof. dr. ir. Aleksandra Pizurica, prof. dr. ir. Wilfried Philips

ii

Alexander Ide
Voertuigidentificatie bij multi-camera tunnelbewaking
Academiejaar 2009-2010Faculteit IngenieurswetenschappenVoorzitter: prof. dr. ir. Herwig BruneelVakgroep Telecommunicatie en informatieverwerking
Master in de ingenieurswetenschappen: computerwetenschappen Masterproef ingediend tot het behalen van de academische graad van
Begeleider: Vedran JelacaPromotoren: prof. dr. ir. Aleksandra Pizurica, prof. dr. ir. Wilfried Philips

Dankwoord
Eerst en vooral wens ik Prof. Dr. Ir. Aleksandra Pizurica en Prof. Dr. Ir. Wilfried
Philips te bedanken voor het creeren van de mogelijkheid om onderzoek te verrichten in
dit vakgebied. Mijn oprechte dank gaat ook uit naar Ir. Vedran Jelaca en Ir. Andres Frıas
Velazquez voor hun fundamentele bijdrage aan deze masterproef in de vorm van nuttige
tips, een grote portie geduld en de verhelderende discussies, rijkelijk doorspekt met hun
aanstekelijke en uitbundige lach. Ook wens ik Dr. Ir. Hiep Quang Luong te bedanken
voor het nalezen van mijn masterproef en de suggesties in verband met alternatieven voor
de thresholdingtechniek.
Een woord van dank gaat uit naar mijn vrienden die meer dan eens het rubberen eendje
speelden in de “Rubber duck debugging” methode, mijn familie, voor het verbeteren van
de eindeloze rij taalfouten in de eerste versies van deze masterproef en speciaal naar mijn
vriendin Elien voor de steun doorheen het jaar en de vele keren dat ze de verzuchtingen
mocht aanhoren die met deze masterproef gepaard gingen.
Toelating tot bruikleen
”De auteur geeft de toelating deze masterproef voor consultatie beschikbaar te stellen
en delen van de masterproef te kopieren voor persoonlijk gebruik. Elk ander gebruik
valt onder de beperkingen van het auteursrecht, in het bijzonder met betrekking tot de
verplichting de bron uitdrukkelijk te vermelden bij het aanhalen van resultaten uit deze
masterproef.”
”The author gives permission to make this master dissertation available for consultation
and to copy parts of this master dissertation for personal use. In the case of any other
use, the limitations of the copyright have to be respected, in particular with regard to the
obligation to state expressly the source when quoting results from this master dissertati-
on.”
Alexander Ide 4 juni 2010
iv

Voertuigidentificatie bij multi-camera tunnelbewaking
door
Alexander Ide
Masterproef ingediend tot het behalen van de academische graad van Master in de inge-
nieurswetenschappen: computerwetenschappen
Academiejaar 2009-2010
Universiteit Gent: Faculteit Toegepaste Wetenschappen
Promotoren: Prof. Dr. Ir. Aleksandra Pizurica, Prof. Dr. Ir. Wilfried Philips
Begeleider: Ir. Vedran Jelaca
Samenvatting
Tunnels zijn omgevingen die gevoelig zijn voor verkeersongevallen met ernstige fysieke
letsels en materiele schade. Om in staat te zijn om snel en adequaat te reageren zodat de
schade en het aantal verloren levens tot een minimum beperkt kan worden, is het tunne-
loperatoren van belang om bepaalde voertuigen in een tunnel (bijvoorbeeld voertuigen die
gevaarlijke goederen vervoeren) te volgen. In deze masterproef beschrijven we een iden-
tificatie techniek voor multi-camera tracking van voertuigen in tunnels. We stellen een
aanpassing van een gezichtsherkenningstechniek voor om voertuigen, door middel van een
beeld van dat voertuig, te identificeren in de ene camera zodat deze terug kan gevonden
worden in de daaropvolgende camera.
De techniek maakt gebruik van een offline training fase waarin de differentierende ken-
merken van voertuigen bepaald worden. Vervolgens creeert het algoritme een descriptor
van een nieuw beeld op basis van deze kenmerken. Om een voertuig terug te vinden in de
tweede camera wordt de descriptor van dat voertuig in de eerste camera vergeleken met
de descriptoren van alle beelden uit de tweede camera. Het voertuig dat afgebeeld staat
op de descriptor van camera 2 die het dichtste bij de camera 1 descriptor staat wordt
als hetzelfde voertuig gedefinieerd. De techniek presteert goed in de gevallen waarin de
beelden voldoende gedetailleerde kenmerken van het voertuig bevatten. Het is mogelijk
om een systeem, gebaseerd op deze techniek, te bouwen waardoor voertuigen over ver-
schillende camera’s gevolgd kunnen worden. Bovendien is het niet nodig om op beelden
uit alle camera’s te trainen, dit vermindert het geheugengebruik en zal het gemakkelijker
maken om een defecte camera te vervangen.
Trefwoorden: Voertuigidentificatie, Multi-camera, Verkeersbewaking
v

Vehicle Identification for Multi-camera TunnelSurveillance
Alexander Ide
Promotors: Prof. Dr. Ir. Aleksandra Pizurica, Prof. Dr. Ir. Wilfried PhilipsSupervisor: Ir. Vedran Jelaca, Ir. Andres Frıas Velazquez
Abstract—For surveillance purposes it is necessary to track certain vehi-cles (e.g. vehicles which transport dangerous goods) in tunnels through thefield of view of multiple cameras. In a multi-camera tracking algorithm itis vital to correctly identify vehicles in each of the cameras so they can betracked through the whole tunnel. To do this we propose a technique foridentification of vehicles in tunnels, based on principal components anal-ysis. The proposed technique is an adaptation of the eigenfaces techniquethat is often used for face recognition. It has an offline training phase to cre-ate a set of salient features derived from a training set of vehicle images. Inthe online phase, each image is represented by a descriptor that defines inwhat degree each salient feature is present in the image. Our experimentsare done on 200 vehicle images, extracted from three low resolution tun-nel surveillance videos. The experiments show a good performance in thecases where the images are taken close to the camera. Furthermore, theyalso show that it is not necessary to have a training set in each camera; thisreduces memory usage and the time needed for training.
Keywords—Vehicle identification, Multi-camera, Traffic surveillance
I. INTRODUCTION
Tunnels are environments prone to traffic accidents with se-vere human casualties and material damage. To be able to re-act fast and adequate to save lives and keep the damage min-imal, for tunnel operators it is important to track certain vehi-cles throughout a tunnel (e.g. vehicles which transport danger-ous goods). For this purpose, multiple surveillance cameras aretypically mounted along a tunnel, often with non-overlappingfields of view. Computer vision algorithms are then used toenable automatic detection and tracking of vehicles in the ac-quired videos. Such algorithms consist of three parts: vehicledetection, vehicle tracking in a field of view of one camera andvehicle identification which is used for a “handover” of vehiclesbetween cameras, i.e. multi-camera tracking.
Our work is focused on developing a robust vehicle identifica-tion method, efficient enough to be deployed for real-time trafficsurveillance and able to cope with challenges of a real tunnel en-vironment. The challenges are caused by either the system: i.e.changes in viewing angle on the vehicle, different zoom proper-ties of the cameras, etc or by the tunnel and traffic conditions:i.e. reflections of lights (tunnel lights, other vehicles, etc), poorlighting conditions, etc. Figure 1 contains three examples ofvehicle images from a real tunnel.
II. RELATED WORK
There are many techniques used for object recognition[1].One which is very often used is designed for detection andrecognition of faces. Kirby and Sirovich have shown that anyparticular face could be reconstructed by its similarity to otherfaces described by eigenvectors, which they call eigenfaces[2],[3]. Based on those eigenfaces, a descriptor of a face can be
(a) (b) (c)
Fig. 1. An example of (a) typical image of a truck, (b) a vehicle with reflectionson its side, (c) a car with its rear lights on.
created. Later, Turk and Pentland have designed a face recog-nition method based on eigenfaces[4], which compares the de-scriptor of the test face with those of the faces used for training.It classifies test images as “known faces”, “unknown faces” or“non-faces”. Figure 2(a) gives an example of an eigenface. Weadapted this technique to identify vehicles in tunnels.
(a) (b)
Fig. 2. Example of (a) an eigenface created by AT&T Laboratories Cambridgeand (b) an eigenvechicle.
III. THE PROPOSED TECHNIQUE
The proposed technique applies the eigenfaces technique onvehicles to match two images of the same vehicle in two differ-ent cameras. The eigenvectors of vehicle images we call “eigen-vehicles”. Figure 2(b) is an example of an eigenvehicle.
As descriptor of a vehicle image we use the weight vector,which is the dot product of that image with all eigenvehiclescreated in the training phase. This weightvector represents inwhat degree a specific feature is present in the original image.It is a point in the space spanned by all eigenvehicles. We mea-sure the Euclidean distance between the descriptors of images incamera N and the descriptors of images in camera N − 1. Thedescriptors with the smallest Euclidean distance are matched toeach other.
Due to physical constraints of traffic we do not compare allvehicles in camera N − 1 to all vehicles in camera N . Instead
it is possible, by taking into account the speed of vehicles ina tunnel, to reduce the amount of vehicles in camera N − 1to which each vehicle in camera N should be compared. Wecalculate a matrix of Euclidean distances between weightvectorsand carry out the assignment by minimizing the total cost on thismatrix.
Calculating the assignment with the lowest total cost is doneby a Hungarian algorithm, which is a combinatorial optimiza-tion algorithm which solves the assignment problem in polyno-mial time[5].
IV. TESTS AND RESULTS
Our experiments are done on two datasets, named the IPI-dataset and the Traficon-dataset. Both datasets are created fromthe same video sequences by manual extraction of the vehicleimages. They both contain one image of each vehicle per cam-era. In the IPI-dataset these images are taken when the com-plete vehicle enters the field of view of each camera, whilein the Traficon-dataset they are taken at a random moment.Therefore, the Traficon-dataset contains vehicles with signifi-cant scale, viewing angle and appearance variations, which ismore challenging for their identification, but closer to the realscenario.
Furthermore we have manually divided each dataset in dif-ferent subsets, each with their own specifications and size e.g.“100 cars”, “100 trucks”, “100 mixed”, etc. The number in thename of the subset represents how many different vehicles thereare in each subset. The “100 cars” subset has 100 different cars,represented by one image in each camera or 300 images in to-tal. This is analogous for the “100 trucks” subset. The subset“100 mixed” contains 70 cars and 30 trucks. A higher numberof cars is used to simulate the real traffic scenario. We did thetests multiple times using different set of training and testingvehicles. The results are then averaged over all exectutions andpresented in table 1. The results on the “100 mixed” subset aregiven to show the performance in the case when there is no clas-sification on cars and trucks done, which simplifies the trainingphase.
Tab. 1. Results of “100 cars”, “100 trucks” and “100 mixed”, trained on 25randomly chosen training vehicles and 50 test vehicles.
100 cars 100 trucks 100 mixedIPI-dataset ∼72% ∼90% ∼82%
Traficon-dataset ∼36% ∼ 82% ∼48%
The results for the IPI-dataset are higher in all three cases andthe difference between IPI-dataset and the Traficon-dataset isespecially large in the “100 cars” and the “100 mixed” subsets.This means that these subsets are more difficult to match cor-rectly if the image of the vehicle is taken at a random location inthe field of view of the camera. Especially for cars, there are notenough detailed features of the vehicle visible, when the imagesare taken far from the camera.
Further we want to know the influence of using one trainingset constructed from the images of vehicles from three differentcameras instead of having an equal amount of training imagesbut from one camera. Because we use an equal amount of train-ing images, the latter set has three times more vehicles than the
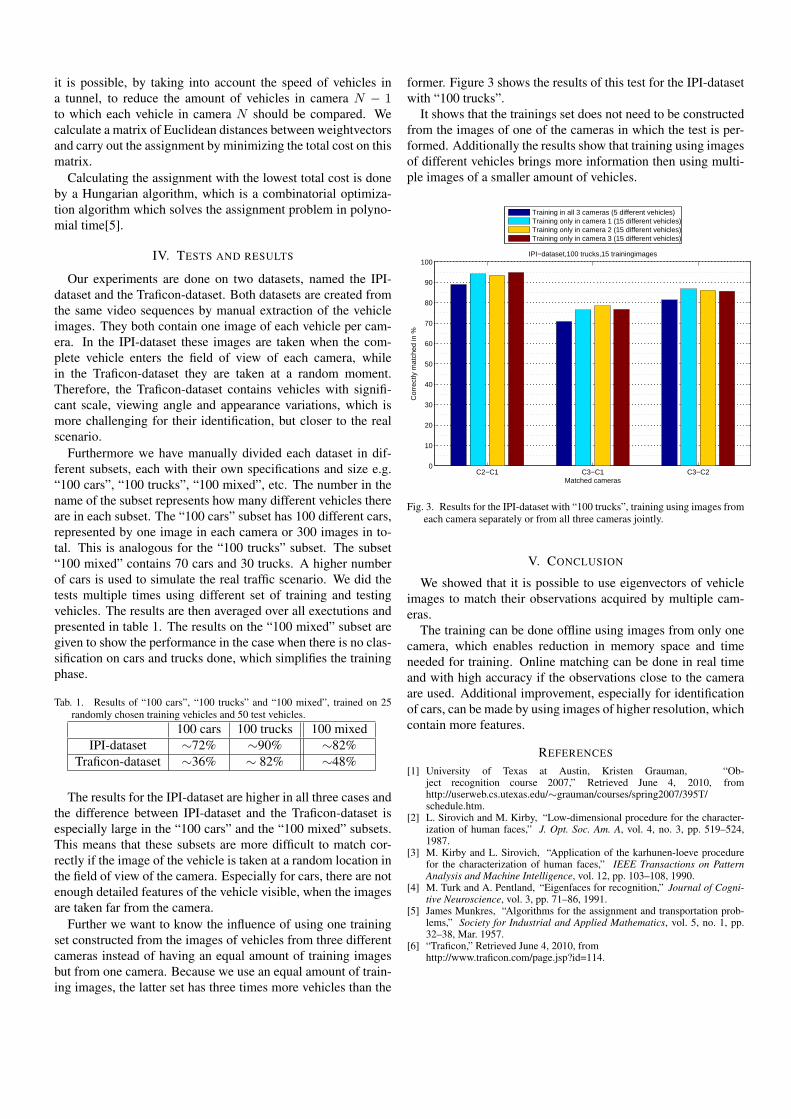
former. Figure 3 shows the results of this test for the IPI-datasetwith “100 trucks”.
It shows that the trainings set does not need to be constructedfrom the images of one of the cameras in which the test is per-formed. Additionally the results show that training using imagesof different vehicles brings more information then using multi-ple images of a smaller amount of vehicles.
C2−C1 C3−C1 C3−C20
10
20
30
40
50
60
70
80
90
100IPI−dataset,100 trucks,15 trainingimages
Cor
rect
ly m
atch
ed in
%
Matched cameras
Training in all 3 cameras (5 different vehicles)Training only in camera 1 (15 different vehicles)Training only in camera 2 (15 different vehicles)Training only in camera 3 (15 different vehicles)
Fig. 3. Results for the IPI-dataset with “100 trucks”, training using images fromeach camera separately or from all three cameras jointly.
V. CONCLUSION
We showed that it is possible to use eigenvectors of vehicleimages to match their observations acquired by multiple cam-eras.
The training can be done offline using images from only onecamera, which enables reduction in memory space and timeneeded for training. Online matching can be done in real timeand with high accuracy if the observations close to the cameraare used. Additional improvement, especially for identificationof cars, can be made by using images of higher resolution, whichcontain more features.
REFERENCES
[1] University of Texas at Austin, Kristen Grauman, “Ob-ject recognition course 2007,” Retrieved June 4, 2010, fromhttp://userweb.cs.utexas.edu/∼grauman/courses/spring2007/395T/schedule.htm.
[2] L. Sirovich and M. Kirby, “Low-dimensional procedure for the character-ization of human faces,” J. Opt. Soc. Am. A, vol. 4, no. 3, pp. 519–524,1987.
[3] M. Kirby and L. Sirovich, “Application of the karhunen-loeve procedurefor the characterization of human faces,” IEEE Transactions on PatternAnalysis and Machine Intelligence, vol. 12, pp. 103–108, 1990.
[4] M. Turk and A. Pentland, “Eigenfaces for recognition,” Journal of Cogni-tive Neuroscience, vol. 3, pp. 71–86, 1991.
[5] James Munkres, “Algorithms for the assignment and transportation prob-lems,” Society for Industrial and Applied Mathematics, vol. 5, no. 1, pp.32–38, Mar. 1957.
[6] “Traficon,” Retrieved June 4, 2010, fromhttp://www.traficon.com/page.jsp?id=114.

Inhoudsopgave
1 Inleiding en beschrijving van de problemen 2
1.1 Inleiding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Beschrijving van de problemen . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 State of the art 9
2.1 Extractie van de karakteristieken op basis van een trainingsset . . . . . . . 11
2.1.1 Informatieve kenmerken voor visuele identificatie lokaliseren . . . . 11
2.1.2 Thresholding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1.3 Eigenfaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.4 Corefaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.2 Extractie van de karakteristieken zonder trainingsset . . . . . . . . . . . . 23
2.2.1 SIFT (Scale-Invariant Feature Transform) . . . . . . . . . . . . . . 23
2.2.2 Fourier, Wavelet en Curvelet transformaties . . . . . . . . . . . . . 24
2.3 Gekozen technieken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3 Het voertuigidentificatie algoritme 26
3.1 Toepassen van de eigenfacestechniek . . . . . . . . . . . . . . . . . . . . . . 26
3.1.1 Voorbeeld . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2 Vergelijken van de verschillende descriptoren . . . . . . . . . . . . . . . . . 28
3.3 Selectie beste koppel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3.1 Een descriptor per keer koppelen . . . . . . . . . . . . . . . . . . . 30
3.3.2 Hongaars algoritme . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
viii

4 Experimenten 34
4.1 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.1.1 Traficon-beelden . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.1.2 IPI-beelden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2 Thresholding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.2.1 Op zoek naar een drempelwaarde via vensters . . . . . . . . . . . . 36
4.2.2 Drempelwaarde via het histogram . . . . . . . . . . . . . . . . . . . 36
4.2.3 Drempelwaarde via het uitgemiddeld beeld . . . . . . . . . . . . . . 37
4.2.4 Eerste testen: resultaten en conclusie . . . . . . . . . . . . . . . . . 37
4.3 Eigenvehicles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.3.1 Hoe getest? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.3.2 Resultaten en discussie over de vragen . . . . . . . . . . . . . . . . 44
5 Conclusie, praktijktoepassing en toekomstig werk 53
5.1 Eindconclusie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.2 Praktijktoepassing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.3 Toekomstig werk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
A 59
A.1 IPI-beelden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
A.2 Traficon-beelden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
B 63
B.1 IPI-beelden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
B.2 Traficon-beelden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
C 66
C.1 IPI-beelden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
C.2 Traficon-beelden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
1

Hoofdstuk 1
Inleiding en beschrijving van deproblemen
1.1 Inleiding
Figuur 1.1: Schematische weergave van een tunnel die uitgerust is met een camerasysteem.
Situering van de masterproef:
De mens legt vandaag de dag elk jaar ettelijke kilometers af. Dagelijks verplaatsen
miljoenen mensen zich tientallen kilometers enkel en alleen om te gaan werken. We laten
producten aan huis afleveren van letterlijk de andere kant van de wereld en we gaan op
vakantie naar de verste uithoeken van onze planeet. Een van de benodigdheden om zoveel
te kunnen reizen is een omvangrijk transportnetwerk. De aarde zit gevangen in een groot
net van wegen, bruggen en tunnels, die ons zonder problemen over of doorheen de grootste
obstakels leiden. Deze masterproef heeft alles te maken met dit laatste type bouwwerk,
namelijk de tunnels.
Tunnels zijn in vele opzichten een groot gemak, maar kunnen ook verschillende proble-
men met zich meebrengen. Aangezien al het verkeer door een smalle koker moet, is een
ongeval of brand extra gevaarlijk. De geschiedenis leert ons dat de gevolgen van een
brand in een tunnel catastrofaal kunnen zijn. Momenteel zijn vele tunnels uitgerust met
verschillende systemen om ongelukken sneller te kunnen detecteren. Zo kan men er dan
2

efficienter op reageren. In figuur 1.1 ziet u een voorbeeld van een tunnel die uitgerust is
met een camerasysteem. Een vaak gebruikt systeem zijn lange rijen camera’s die in de
tunnels geınstalleerd zijn. Deze camera’s zenden continu beelden door naar een centraal
controlestation waar deze verwerkt en enige tijd bijgehouden worden. Om dit vlotter te
doen verlopen worden deze camerabeelden meestal gereduceerd tot een lagere resolutie.
Doel van de masterproef:
Stel dat er een voertuig, meer bepaald een vrachtwagen met een gevaarlijke lading, de
tunnel binnenrijdt, dan wil je als beheerder van de tunnel aan dit voertuig extra aandacht
besteden. Het liefst van al wil je dan het voertuig gaan volgen vanaf het begin van de
tunnel tot het einde. Stel dat er bijvoorbeeld brand uitbreekt in de tunnel, dan weet je
direct of de gevolgde vrachtwagen zich voor of achter de brandhaard bevindt. Om deze
functie mogelijk te maken moet je de voertuigen op een of andere manier identificeren.
Omdat het identificeren van de voertuigen een heel belangrijk onderdeel is in het volgen
van de voertuigen doorheen de camera’s is de titel van deze masterproef: “Voertuigi-
dentificatie bij multi-camera tunnelbewaking”. De meeste voertuigidentificatietechnieken
baseren zich op de nummerplaat van een voertuig maar door de lage resolutie van de ca-
merabeelden is de nummerplaat gereduceerd tot enkele pixels, waardoor de nummerplaat
onleesbaar is. Er moet dus een andere manier gezocht worden.
De masterproef is in samenwerking met het bedrijf Traficon [1]. Traficon is een bedrijf dat
gespecialiseerd is in verkeersanalyse gebaseerd op videobewerking. Hun hoofdkwartier is
in het West-Vlaamse Wevelgem en ze hebben afdelingen in Frankrijk, Duitsland, Azie en
de VS.
De invoergegevens:
Als invoer krijgt het identificatie-algoritme een verzameling van beelden die komen van
een “trackingsalgoritme” dat per camera meerdere voertuigen doorheen het gezichtsveld
volgt en van elk voertuig op een willekeurig tijdstip een beeld neemt. Dit gebeurt door
een “bounding box” rond het voertuig te plaatsen en alles wat zich buiten dit bounding
box bevindt weg te knippen. Op een beeld staat dus een voertuig met zo weinig mogelijk
achtergrond, zoals te zien is in de figuren 1.2 ,1.2 en 1.2 staan enkele voorbeelden. De in-
voerbeelden worden dus een per een ter beschikking gesteld aan het identificatie-algoritme,
waarna ons de opdracht rest om bij elk beeld uit de ene camera het corresponderende beeld
uit de volgende camera te vinden.
De kwaliteitsvereisten:
De verkeersstroom door een tunnel stopt nooit, er rijden doorlopend nieuwe voertuigen
binnen in de tunnel en deze moeten door het identificatie-algoritme verwerkt worden.
Het identificatie-algoritme moet dus de verkeersstroom kunnen volgen en niet achterop
3

(a) (b)
Figuur 1.2: (a) Voorbeeld van een figuur met een laag dynamisch bereik en (b) het histogramvan deze figuur
geraken. Daarnaast moet het natuurlijk ook betrouwbaar en robuust zijn. Het moet met
de verschillende problemen in de invoerbeelden overweg kunnen en nog altijd de juiste
beelden aan elkaar koppelen.
Eigen bijdragen:
We hebben eerst gebruik gemaakt van enkele thresholdingtechnieken maar deze gaven
niet het verhoopte resultaat. Vervolgens hebben we het voorgestelde algoritme ontwikkeld
op basis van de eigenfacestechniek. Dat hebben we dan met meer succes toegepast op de
invoerbeelden. Deze techniek maakt een descriptor van elk beeld, waarna op basis van
deze descriptoren de best passende beelden aan elkaar gekoppeld worden.
1.2 Beschrijving van de problemen
De invoerbeelden van het identificatie-algoritme zijn niet allemaal onder perfecte omstan-
digheden genomen, hierdoor kunnen ze een aantal eigenschappen hebben die misschien
tot problemen kunnen leiden.
Eigenschappen van de camerabeelden.
Eerst en vooral volgt er wat uitleg over de stand van de camera’s en wat er allemaal
in beeld gebracht wordt. De camera’s staan zo op de verkeersstroom georienteerd dat ze
altijd de achterkant van de voertuigen in beeld hebben. In ons geval worden drie rijstroken
in beeld gebracht en hangt de camera boven de middelste rijstrook. Dit zorgt ervoor dat
naast de achterkant ook het dak en de zijkant van het voertuig op het beeld kan staan.
Met dergelijke camerabeelden kunnen zich volgende problemen voordoen:
4

• Alle rijstroken zijn afgebeeld in een camerabeeld met een resolutie van 720×576.
Indien we er vanuit gaan dat een voertuig niet breder is dan een rijstrook, kan een
beeld van dit voertuig theoretisch maximaal 240×576 groot zijn (720/3=240). Deze
resolutie van 720×576 is bepaald door Traficon en zorgt voor een lagere kost op vlak
van opslag en transport van de filmbeelden.
• De beelden hebben een laag dynamisch bereik, dit wilt zeggen dat een groot deel
van de informatie in een beperkt interval van het histogram vervat zit. Meestal zijn
enkel de lichten duidelijk te onderscheiden in het histogram. Zie figuur 1.2.
• In de achtergrond kunnen er nog wegmarkeringen op het wegdek staan, die in hoog
contrast staan met de rest van het beeld.
Kijkhoek
Lichten
De lichten van een voertuig zijn heel goed te zien op de beelden. De heldere witte
vlekken staan meestal in schril contrast met de rest van het voertuig. Hierdoor kunnen ze
misschien gebruikt worden in het identificatie-algoritme, maar ze kunnen ook verschillende
problemen veroorzaken:
• Gedoofde lichten:
Verschillende chauffeurs vergeten hun lichten aan te steken in een tunnel. Dit is
vooral een probleem indien de chauffeur iets later dan toch besluit om zijn lichten
aan te steken. Meestal is het voertuig dan al in het gezichtsveld van een volgende
camera en zal dit de identificatie bemoeilijken. Zie figuur 1.4(a) voor een voertuig
met gedoofde lichten.
• Reflecties:
Naast de echte lichten kunnen er verschillende andere heldere lichtpunten in het
beeld voorkomen. Deze kunnen onder andere veroorzaakt worden door reflecties
van lichten van andere voertuigen of van de tunnelverlichting. Daarnaast kunnen
de lichten van het voertuig zelf gereflecteerd worden op de omgeving bijvoorbeeld
op een nat wegdek. Zie figuur 1.4(b).
• Remlichten:
Als een voertuig remt dan springen er meestal extra remlichten aan. Daarnaast
schijnen de normale achterlichten een stuk feller dan voorheen. Dit kan ervoor
zorgen dat een deel van het voertuig slechter zichtbaar is in het beeld. Dit probleem
komt vooral voor als het voertuig verder van de camera verwijderd is. Zie figuur
1.4(c).
5

(a) (b)
(c) (d)
Figuur 1.3: Normale (a) auto en (b) vrachtwagen. Problemen met kijkhoek: kijkhoek in camera1 (c) en 2 (d) op het hetzelfde voertuig. Merk ook hoe moeilijk het is om voertuig (a) en (c)van elkaar te onderscheiden.De kijkhoek van een camera op een voertuig kan doorheen de tunnel veranderen. Hieron-der volgen enkele redenen:
• De camera’s zelf kunnen boven andere rijstroken hangen.
• Er kan een bocht in de tunnel zijn.
• Het voertuig kan van rijstrook veranderen.
Zie figuren 1.3(c) en 1.3(d) voor een voorbeeld.
• Zwaailichten:
Sommige voertuigen hebben zwaailichten en dit zwaailicht kan dus per toeval recht
in de eerste camera schijnen juist wanneer er een beeld genomen wordt en bij de
tweede camera niet.
Afstand tot de camera.
Doordat de invoerbeelden op een willekeurige afstand van de camera’s genomen zijn,
6

(a) (b)
(c)
Figuur 1.4: Problemen met lichten: (a) gedoofde lichten (b) reflectie van andere lichten op derechterzijde (c) saturatie van het beeld door de remlichten.
heeft dit als effect dat de voertuigen die dichtbij genomen zijn meer details bevatten dan
deze met een grotere afstand tot de camera. Daarnaast is het effect van saturerende
lichten sterker als het voertuig zich verder van de camera bevindt. Het beeld in figuur
1.5(a) is een stuk dichter bij de camera genomen dan in figuur 1.5(b).
Bounding box
Aangezien de detectie van de voertuigen in de camerabeelden op een automatische
manier gebeurt, kunnen er hierin fouten sluipen. De voertuigen worden eerst omgeven
door een omgeschreven rechthoek, de ”bounding box”genaamd en daarna wordt alles
buiten deze bounding box weggeknipt. Indien deze rechthoek te klein is zullen delen van
het voertuig niet op het beeld staan. Daarnaast kan de omgeschreven rechthoek te groot
zijn of kan het voertuig niet volledig in het midden van de rechthoek staan. In beide
gevallen zal niet enkel het voertuig, maar ook veel van de achtergrond in het beeld vervat
zijn.
7
(a) (b)
(c) (d)
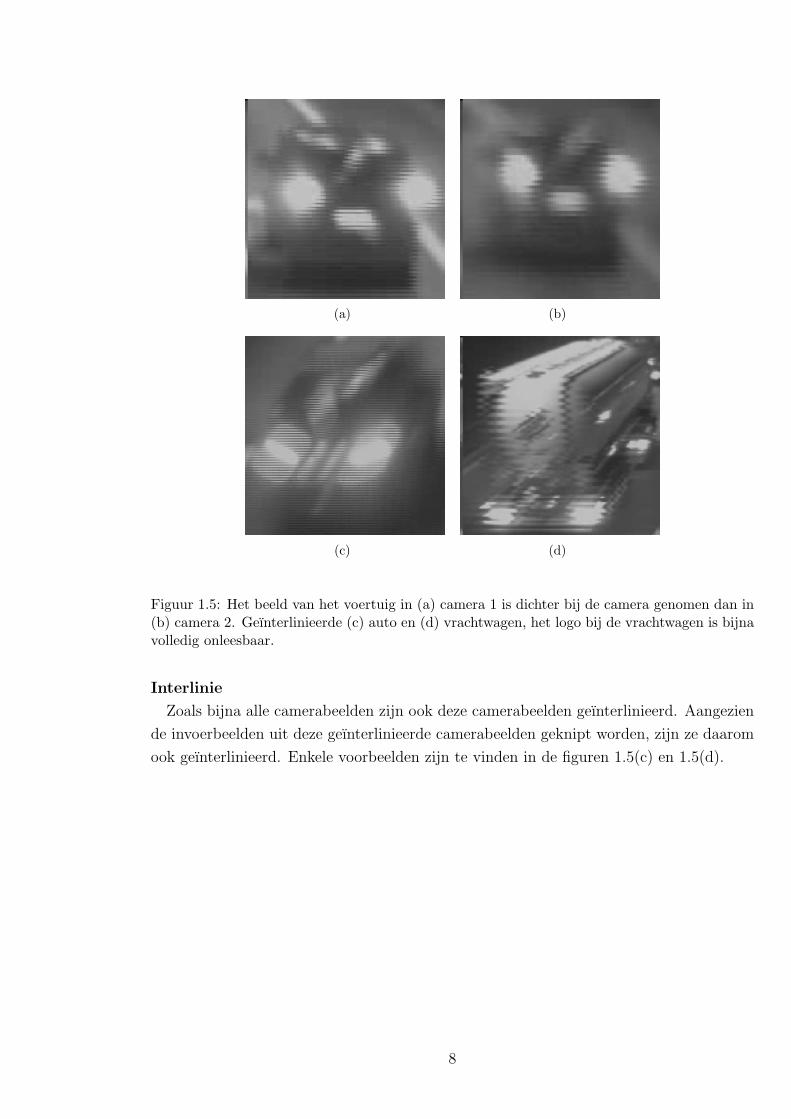
Figuur 1.5: Het beeld van het voertuig in (a) camera 1 is dichter bij de camera genomen dan in(b) camera 2. Geınterlinieerde (c) auto en (d) vrachtwagen, het logo bij de vrachtwagen is bijnavolledig onleesbaar.
Interlinie
Zoals bijna alle camerabeelden zijn ook deze camerabeelden geınterlinieerd. Aangezien
de invoerbeelden uit deze geınterlinieerde camerabeelden geknipt worden, zijn ze daarom
ook geınterlinieerd. Enkele voorbeelden zijn te vinden in de figuren 1.5(c) en 1.5(d).
8

Hoofdstuk 2
State of the art
In dit hoofdstuk leggen we uit welke technieken er gebruikt kunnen worden om het gestelde
probleem op te lossen. Bij elke techniek proberen we steeds zijn specifieke eigenschappen
te toetsen aan de vereisten van deze masterproef en op eventuele problemen te anticiperen.
Zoals reeds aangehaald is het de bedoeling in deze masterproef om afbeeldingen van het-
zelfde voertuig uit verschillende camera’s aan elkaar te koppelen. Een naıeve oplossing
voor dit probleem is elke pixel van het ene beeld te vergelijken met de pixel op dezelfde
plaats in het andere beeld. Deze oplossing wordt al vlug een zware klus als je met grote
verzamelingen van beelden werkt. Om het identificatie-algoritme vlotter te laten verlopen
is het aan te raden om op een of andere manier enkel de belangrijke informatie uit een
beeld te filteren en deze dan te vergelijken met dezelfde informatie van een ander beeld.
Het spreekt voor zich dat louter op basis van deze informatie, ook wel de karakteristieken
van een beeld genoemd, moet kunnen beslist worden op welke beelden hetzelfde voertuig
afgebeeld staat. Het is natuurlijk de bedoeling dat het extraheren, verwerken en ver-
gelijken van deze karakteristieken uit een verzameling beelden een minder zware klus is
dan alle pixels van de beelden onderling te vergelijken. Een algoritme zoals hierboven
beschreven bevat dus drie grote stappen:
1. Extractie van de karakteristieken
In deze stap wordt het beeld verwerkt zodat enkel de karakteristieken van het beeld
geselecteerd zijn.
2. Maken van een descriptor
De karakteristieken van het beeld worden in een descriptor omgezet. Deze is dan
eenvoudig met andere descriptoren te vergelijken.
3. Vergelijken van de verschillende descriptoren
De descriptoren gecreeerd in de vorige stap worden nu onderling vergeleken. In-
dien twee descriptoren weinig van elkaar verschillen wil dit zeggen dat op de bij de
descriptoren horende beelden hetzelfde object afgebeeld wordt.
9

Figuur 2.1: Blokdiagram van het algemeen algoritme om beelden te vergelijken.
In figuur 2.1 zijn deze drie stappen grafisch in een blokdiagram weergegeven. Het is dus de
bedoeling dat de descriptoren van de onderste twee beelden aan elkaar gekoppeld worden.
De specifieke invulling van deze drie stappen kan op vele manieren gebeuren. Elke techniek
die hieronder beschreven wordt heeft zijn typerende eigenschappen maar zoals voordien
aangehaald moet het identificatie-algoritme aan enkele randvoorwaarden voldoen:
• Het moet robuust genoeg zijn om niet teveel last te hebben van de verschillende
problemen die worden opgesomd in sectie 1.2.
• De snelheid van het identificatie-algoritme is ook van belang. Het algoritme moet
de verkeersstroom door de tunnel kunnen volgen.
• Natuurlijk moet het daarnaast ook zo weinig mogelijk fouten maken.
Deze randvoorwaarden maken dat sommige technieken beter of minder goed toepasbaar
zijn in de context van deze masterproef.
10

(a) (b)
Figuur 2.2: Het stuk (a) van het algemeen algoritme in figuur 2.1 wordt vervangen door (b).
Figuur 2.3: Voorbeeld van een objectidentificatieprobleem: de twee auto’s aan de linkerzijdekomen uit camera 1 en de vier aan de rechterzijde uit camera 2. De vraag is op welke van debeelden uit camera 2 worden dezelfde auto’s als in de beelden uit camera 1 afgebeeld.
2.1 Extractie van de karakteristieken op basis van
een trainingsset
Een trainingsset is een verzameling van beelden die uitsluitend gebruikt wordt om er
bepaalde eigenschappen uit te filteren. Deze beelden zijn meestal zo gekozen dat ze
representatief zijn voor de volledige verzameling beelden waarop de techniek toegepast
zal worden. Dit wil zeggen dat indien de techniek enkel toegepast wordt op beelden van
gezichten dan zal de trainingsset ook volledig uit gezichten bestaan. Met behulp van deze
bekomen eigenschappen wordt er een andere verzameling beelden, de testset genaamd,
verwerkt. Deze trainingsset hoeft meestal maar een keer verwerkt te worden waarna de
bekomen eigenschappen voor een langere tijd gebruikt kunnen worden. Deze manier van
werken zorgt ervoor dat figuur 2.1 iets aangepast moet worden. Naast het blok met de
extractie van de karakteristieken komt er nu een extra blok waarin de training van het
algoritme gebeurd. In figuur 2.2 zijn deze aanpassingen grafisch voorgesteld.
2.1.1 Informatieve kenmerken voor visuele identificatie lokalise-ren
In dit artikel gaat het specifiek over het objectidentificatieprobleem, een voorbeeld van
dit probleem wordt in het artikel gegeven door figuur 2.3[2]. De techniek die in dit artikel
wordt voorgesteld is speciaal ontworpen voor de situatie waarin de variatie tussen de
objecten in een klasse (bijvoorbeeld auto’s) heel miniem is en er per klasse maar enkele
11

beelden beschikbaar zijn om op te trainen.
Eerst en vooral moet de trainingsset gemaakt worden. Deze trainingsset is opgebouwd uit
een lijst van beelden die per twee aan elkaar gekoppeld zijn. Deze koppeling kan positief
of negatief zijn en dit wil respectievelijk zeggen dat op beide beelden hetzelfde object
afgebeeld staat of niet. De rest van het algoritme gaat als volgt:
1. (offline) In de eerste stap wordt er informatie verzameld over een specifieke klas-
se bijvoorbeeld over gezichten. Dit gebeurt door de verschillende koppels in de
trainingsset te gaan verwerken. Voor elk koppel worden verschillende regio’s, bij-
voorbeeld de ogen, haarlijn en mond, in de beelden met elkaar vergeleken. Door
zowel koppels van beelden die wel en niet bij elkaar horen te verwerken wordt er een
model gecreeerd waarin te vinden is in welke omstandigheden regio’s wel of niet op
elkaar gelijken. Zo kan bijvoorbeeld uit deze stap blijken dat in 90% van de geval-
len waar in twee beelden de ogen gelijk zijn ook daadwerkelijk twee keer dezelfde
persoon afgebeeld staat.
2. (online) In deze stap wordt een “identificatiecascade” opgebouwd voor een specifiek
object gebaseerd op een beeld van dit object. Deze cascade wordt opgebouwd met
behulp van het globaal model opgebouwd in de eerste stap. Bovenaan in deze
cascade staan de regio’s die het meeste invloed hebben op een juiste identificatie en
onderaan deze met de minste invloed. In een cascade staat dus maar een selectie
van de regio’s uit de eerste stap.
3. (online) Pas de “identificatiecascade” uit de vorige stap toe op een nieuw beeld.
Hieruit wordt afgeleid of op het nieuwe beeld hetzelfde object, waarvoor die speci-
fieke cascade gebouwd is, afgebeeld wordt.
2.1.1.1 Is deze techniek toepasbaar op de gegeven beelden?
De techniek kan heel handig zijn om camera specifieke verstoringen van een beeld weg te
filteren. Indien er bijvoorbeeld enkel in camera 2 een bepaalde reflectie voorkomt zal het
al dan niet voorkomen van deze reflectie niet veel invloed hebben op een al dan niet juiste
koppeling van twee beelden. De reflectie zal hierdoor geen of heel weinig belang krijgen
in het model uit de eerste stap.
2.1.1.2 Mogelijke problemen:
• De creatie van de trainingsset is niet eenvoudig en moet manueel gebeuren, daar-
naast zijn de trainingssets vermoedelijk niet te gebruiken in een andere tunnel. Het
zou kunnen dat iedere keer dat er in tunnel een verandering gebeurd, zoals het
12

vervangen van een lamp of een kapotte camera, de trainingsset volledig opnieuw
manueel zal moeten aangepast worden.
• De trainingsset moet heel secuur gekozen worden zodat er zeker geen verkeerde
regio’s voor de identificatie gebruikt worden. Indien toevallig alle koppels met in
beide beelden eenzelfde reflectie ook positieve koppels zijn zal deze reflectie heel hoog
scoren in het model uit de eerste stap. In 100% van de gevallen waar in twee beelden
die reflectie voorkomt is ook daadwerkelijk twee keer hetzelfde object afgebeeld. Als
vervolgens twee afbeeldingen van een verschillend object toevallig beide die reflectie
hebben, is de kans groot dat het algoritme ze als gelijk zal classificeren.
• Hoe bruikbaar deze techniek is hangt sterk af van hoe compact de representatie van
een “identificatiecascade” is en hoe snel deze kan toegepast worden op een nieuw
beeld.
2.1.2 Thresholding
Deze techniek zal op basis van het histogram en door gebruik te maken van drempelwaar-
den specifieke delen van een beeld selecteren. Bij beelden met uitsluitend grijswaarden
zal alles boven een bepaalde drempelwaarde wit ingekleurd worden en alles eronder zwart.
Het is altijd een kunst om een goede drempelwaarde te vinden die overal in de beelden
kan gebruikt worden. Er bestaan verschillende technieken om deze drempelwaarde(n) te
bepalen. In paragraaf 4.2 testen we verschillende van deze technieken.
2.1.2.1 Is deze techniek toepasbaar op de gegeven beelden?
Er is een mogelijkheid dat bepaalde eigenschappen van een voertuig, bijvoorbeeld de vorm
en positie van logo’s, lichten en eventuele reflectoren op het voertuig, uit een beeld kunnen
gedestilleerd worden. Het succes van deze techniek hangt natuurlijk af van het feit of de
juiste drempelwaarden voor deze eigenschappen gevonden werden of niet. In een ideaal
geval zouden dezelfde drempelwaarden toepasbaar kunnen zijn voor alle camerabeelden.
Indien er een mogelijkheid bestaat om de positie van deze eigenschappen relatief ten
opzichte van elkaar te berekenen, heeft deze oplossing, zolang het voertuig zich volledig
binnen het beeld bevindt, weinig tot geen last van een verkeerd gepositioneerde “bounding
box”.
2.1.2.2 Mogelijke problemen:
• Het is moeilijk drempelwaarden te vinden die toepasbaar zijn op alle mogelijke
beelden.
13

• Detecteren van het verschil tussen de lichten van het voertuig en reflecties van andere
lichten op het voertuig is niet vanzelfsprekend.
• Subtiele veranderingen in de grijswaarden worden door deze techniek over het hoofd
gezien.
2.1.3 Eigenfaces
Automatische beeldherkenning en meer specifiek gezichtsherkenning, is al geruime tijd een
populair onderwerp. Bij gezichtsherkenning wil men een verzameling beelden verdelen in
drie deelverzamelingen, namelijk een waar alle beelden inzitten die geen gezicht zijn, een
waar alle gekende gezichten inzitten en een laatste met onbekende gezichten. Een techniek
voorgesteld door Turk en Pentland[3] maakt hiervoor gebruik van eigenvectoren. Kirby
en Sirovic toonden daarvoor al aan dat, gebaseerd op de Karhunen-Loeve expansie uit de
patroon herkenning, elk gezicht voorgesteld kan worden in functie van zijn gelijkenissen
met andere gezichten. Deze gelijkenissen worden beschreven door eigenvectoren, ook wel
eigenfaces genaamd[4, 5]. In de masterproef van I. Atalay[6] is deze techniek gezichtsher-
kenningstechniek en de mogelijke toepassingen ervan zeer goed uitgelegd. In de figuur
2.1.3 ziet u (a) een verzameling gezichten en (b) de eigenfaces van deze verzameling. Deze
beelden zijn gemaakt door Santiago Serrano van de “Drexel University”[7].
Zoals reeds even aangehaald werkt deze techniek met een verzameling van gekende ge-
zichten. Deze verzameling fungeert dus als trainingsset voor het algoritme.
Deze techniek is een methode waar een relatief kleine trainingsset gebruikt wordt om
de verschillen tussen beelden te gaan beschrijven. Dit gebeurd door de eigenvectoren te
berekenen van de covariantie matrix van de distributie, opgespannen door de trainingsset.
Eigenvectoren x1...h zijn vectoren die aan de volgende formule voldoen:
Ax1 = λ1x1
... =...
Axh = λhxh
Hierbij zijn A, h, λi...h respectievelijk een matrix, het aantal eigenvectoren en een verza-
meling van scalairen die de eigenwaarden genoemd worden. De eigenvectoren van de
covariantie matrix van de distributie, opgespannen door de trainingsset hebben de eigen-
schap dat ze heel sterk op de trainingsset gelijken. Indien er dus alleen maar afbeeldingen
van gezichten in de trainingsset zitten dan worden deze eigenvectoren ook wel “eigenfa-
ces” genoemd. Toegepast op deze masterproef, met het gebruik van voertuigen, zullen
deze eigenvectoren dus “eigenvehicles” genoemd worden. Indien de eigenvectoren van af-
beeldingen in het algemeen bedoeld worden, dan wordt ook wel de term eigenbeelden of
14

(a)
(b)
Figuur 2.4: (a) een verzameling gezichten en (b) de eigenfaces van deze verzameling
“eigenimages” gebruikt. Deze eigenvectoren zijn een representatie van de grootste ver-
schillen tussen de beelden in de trainingsset. In het geval van gezichtsherkenning zijn deze
15

verschillen meestal complexer dan louter de ogen, wenkbrauwen of neus van een persoon.
Elk gezicht kan gereconstrueerd worden door de som over alle eigenfaces te berekenen
waarbij elke eigenface een bepaald gewicht krijgt. Dit gewicht bepaalt de mate waarin
een specifiek kenmerk (eigenface) aanwezig is in het origineel beeld. Deze gewichten wor-
den voorgesteld door de gewichtsvector van een beeld. Op basis van deze gewichtsvectoren
kunnen testbeelden verdeeld worden in gezichten of geen gezichten en kunnen gezichten
uit een referentiedatabank herkent worden. Deze verdeling gebeurt op basis van de eu-
clidische afstand van de gewichtsvector van elk testbeeld tot de gewichtsvectoren van de
trainingsbeelden.
De eigenfaces techniek bestaat uit twee grote delen namelijk het berekenen van de eigen-
vectoren op basis van trainingsbeelden en het berekenen van de gewichtsvector van een
nieuw beeld. Hieronder wordt de techniek stap voor stap uitgelegd en geıllustreerd door
middel van een voorbeeld.
2.1.3.1 Berekenen van de eigenvectoren
Op basis van de trainingsbeelden worden in deze stap de juiste karakteristieken geıdentificeerd,
zodat deze kunnen gebruikt worden bij de create van de gewichtsvectoren van een nieuw
beeld.
Stap 1: De beelden worden herschaald, zodat ze allemaal dezelfde dimensie N1 × N2
hebben. Hierna wordt het beeld getransformeerd van matrix van N1×N2 naar een vector
met N1 ∗ N2 elementen. Stel dat we deze laatste vector gelijk stellen aan x dan is x de
gemiddelde waarde van x.
Stap 2: De tweede stap in het algoritme is de normalisatie van de trainingsbeelden.
De beelden worden genormaliseerd om de effecten van een verschillende helderheid tussen
de beelden te minimaliseren. Deze normalisatie gebeurt via formule 2.1 waarbij α het
genormaliseerde beeld voorstelt. Ustd en um zijn twee variabelen die op voorhand bepaald
werden en respectievelijk staan voor de gemiddelde standaarddeviatie en het gemiddelde
van alle gemiddelde waarde van de beelden in een bepaalde dataset.
α =(x− x+ um) ∗ ustdstandaarddeviatie(x)
(2.1)
standaarddeviatie(x) =
√√√√(1
(N1 ∗N2)− 1
N1∗N2∑i=1
(x(i)− x)2)
16

Stap 3: Het gemiddelde beeld β van alle genormaliseerde beelden αi...γ wordt berekend.
Hierbij is γ het aantal trainingsbeelden en β(r) de waarde van β op positie r.
β(r) = 1/γ
γ∑i=1
αi(r) (2.2)
Stap 4: Vervolgens worden verschilbeelden δi...γ berekend tussen elk van de genorma-
liseerde beelden αi...γ en het gemiddeld genormaliseerde beeld β. Dit gebeurd met de
formule δi = αi − β.
Stap 5: Bereken de covariantiematrix C van de verschilbeelden δi...γ uit de vorige stap.
Stel A gelijk aan een matrix waar kolom i gelijk is aan δi, dan wordt de covariantiematrix
berekend volgens C = AAT . Elke waarde Cij van deze matrix stelt de covariantie voor.
De covariantie geeft aan of en indirect in welke mate δi en δj lineaire samenhang vertonen.
Indien de beelden een grote resolutie hebben, zal dit ervoor zorgen dat er veel rijen in
matrix A zijn. Dan is de berekening van de covariantiematrix C een enorme taak.
Aangezien in de volgende stap enkel de eigenwaarden en eigenvectoren van de covarian-
tiematrix van belang zijn en indien γ relatief klein is ten opzichte van het aantal rijen
N1 ∗N2 in A kan dit probleem vertaald worden naar een kleiner probleem met dezelfde
oplossing. Stel dat vi een eigenvector van ATA is met zijn bijhorende eigenwaarde µi dan
geldt het volgende:
ATAvi = µivi
⇔ AATAvi = Aµivi
⇔ AATAvi = µiAvi
⇔ CAvi = µiAvi (2.3)
Uit formule 2.3 volgt dat Avi een eigenvector is van C met eigenwaarde µi. Hieruit volgt
dat de eigenwaarden van C gelijk zijn aan de eigenwaarden van ATA en de eigenvectoren
U = [u1 . . . uγ] van C gelijk zijn aan AV , waarbij V = [v1 . . . vγ] de eigenvectoren van
ATA zijn.
In deze stap is het dus voldoende om ATA te berekenen.
Stap 6: Deze stap bestaat uit drie kleine delen:
• We berekenen effectief de eigenvectoren V en de eigenwaarden µi...γ van ATA.
• We passen het Kaiser criterium [8] toe waarbij de eigenvectoren die een eigenwaarde
hebben die kleiner is dan 1 uit de lijst verwijderd worden. We bekomen de reduceerde
set V ′ = [v′1 . . . v′τ ] met τ ≤ γ.
17

• Normaliseren van de eigenvectoren V ′ via de volgende formule:
v′1 = v′1./
√√√√ η∑j=1
(v′1(j))2 (2.4)
... =...
v′τ = v′τ ./
√√√√ η∑j=1
(v′τ (j))2
Waarbij η de lengte is van de eigenvectoren en elk van de waarden in v′i gedeeld
wordt door√∑η
j=1(v′i(j))
2.
Stap 7: Deze stap bestaat uit twee kleine delen:
• We berekenen de gereduceerde set eigenvectoren U ′ van de covariantiematrix C uit
V ′ via formule:
u1 = Av′1... =
...
uτ = Av′τ
• Normaliseren van de eigenvectoren U ′ via forumule 2.4
Voorbeeld
Om bovenstaand stappen te illustreren hebben we gebruik gemaakt van een paar sterk
vereenvoudigde invoerbeelden. Ze ondergaan dezelfde stappen als wat er in de praktijk
zou gebeuren, maar omdat ze vereenvoudigd zijn is het makkelijker om stap per stap te
volgen wat er gebeurt. Figuur 2.5 bevat de drie invoerbeelden van dit voorbeeld.
Stap 1: De invoerbeelden worden herschaald naar een resolutie van 180×180, waarna
ze getransformeerd zijn naar een vector met 32400 elementen.
Stap 2: Doordat de figuren uit 2.5 artificieel zijn, hebben de beelden geen verschillen
in helderheid. De eerste stap in het algoritme verandert dus niets aan de figuren.
Stap 3: In deze stap werd het gemiddeld genormaliseerd beeld β berekend. Zie figuur
2.6.
18

(a) (b)
(c)
Figuur 2.5: Eenvoudige trainingsbeelden.
Figuur 2.6: Gemiddeld genormaliseerd beeld van de herschaalde beelden uit figuur 2.5.
Stappen 4,5,6 en 7: Deze stappen zijn louter berekeningen en geven geen visueel
resultaat. We slaan deze dus over in dit voorbeeld.
19

(a) (b)
Figuur 2.7: Eigenvectoren van de herschaalde beelden uit figuur 2.5.
Eindresultaat: Tot slot hebben we het eigenlijke doel bereikt, namelijk de eigenvec-
toren in figuur 2.7. Deze eigenvectoren lijken sterk op de figuren uit 2.5 en zullen we
daarom eigenbeelden noemen. Hoe sterker een regio in de eigenbeelden van een uniform
grijze kleur verschilt hoe meer er op basis van deze regio onderscheid kan gemaakt worden
tussen de trainingsbeelden.
2.1.3.2 Brekenen van de gewichtsvector van een nieuw beeld.
Op basis van de eigenvectoren bekomen uit onderdeel 2.1.3.1 wordt er nu een beschrijving
gemaakt van een nieuw invoerbeeld.
Stap 1: De beelden ondergaan dezelfde stappen als de trainingsbeelden. Ze worden
herschaald zodat ze allemaal dezelfde dimensie N1 × N2 hebben en daarna wordt het
beeld getransformeerd van matrix van N1×N2 naar een vector met N1 ∗N2 elementen.
Stap 2: Eerst en vooral wordt het invoerbeeld, via de methode beschreven in formule
2.1, genormaliseerd.
Stap 3: Daarna wordt het verschil ϕ berekend tussen dit genormaliseerde beeld en het
gemiddeld genormaliseerde beeld β uit formule 2.2.
20

(a) (b)
(c) (d)
Figuur 2.8: Eenvoudige testbeelden.
Stap 4: Vervolgens wordt het inproduct berekend tussen ϕ en elk van de eigenvectoren
U’ die berekend werden in onderdeel 2.1.3.1.
λ1 = ϕ · u′1... =
...
λτ = ϕ · u′τ
Deze waarden, ook wel gewichten genoemd, worden dan gecombineerd in een vector Ω =
[λ1 . . . λτ ], de gewichtsvector genaamd.
Voorbeeld
Dit voorbeeld bouwt verder op de eigenvectoren in figuur 2.7. Ook hier hebben we
ervoor gekozen een paar sterk vereenvoudigde testbeelden te gebruiken. Figuur 2.8 bevat
de drie invoerbeelden van dit voorbeeld.
21

testbeeld 2.8(a) testbeeld 2.8(b) testbeeld 2.8(c) testbeeld 2.8(d)
eigenvector a -6.049 -5.828 -117.475 -187.339eigenvector b -5.661 -5.458 110.308 183.0276
Tabel 2.1: Gewichten van de verschillende testbeelden uit figuur 2.8.
Stap 1: De invoerbeelden worden herschaald naar een resolutie van 180×180, waarna
ze getransformeerd zijn naar een vector met 32400 rijen.
Stap 2: Doordat de figuren uit 2.5 artificieel zijn, hebben de beelden geen verschillen
in helderheid. De eerste stap in het algoritme verandert dus niets in dit voorbeeld.
Stappen 3 en 4: Deze stappen zijn louter berekeningen en geven geen visueel resultaat.
We slaan deze dus over in dit voorbeeld.
Eindresultaat: In tabel 2.1 ziet u per kolom de verschillende gewichten die horen bij
de eigenvectoren van de testbeelden uit figuur 2.8.
2.1.3.3 Is deze techniek toepasbaar op de gegeven beelden?
In een gecontroleerde omgeving werkt deze techniek heel goed, maar de techniek is ge-
voelig aan radicale veranderingen in bijvoorbeeld gezichtsuitdrukkingen, helderheid en
occlusies[9]. Zoals reeds aangehaald zijn onze beelden zeker en vast niet in een gecontro-
leerde laboratorium omgeving opgenomen. Gelukkig hebben de beelden wel enkele goede
eigenschappen, zo veranderen vrachtwagens en auto’s onderling nauwelijks van vorm, zijn
occlusies uit de beelden gefilterd en kan de helderheid van een beeld aangepast worden
zodat deze gelijk is aan de helderheid van de beelden in de trainingsset.
Het classificeren van de testset is voor deze masterproef niet voldoende. We moeten een
stap verder gaan en proberen om twee beelden van hetzelfde voertuig aan elkaar te gaan
koppelen. Dit kan mogelijk gedaan worden door de gewichtsvectoren van alle camera 1
beelden te vergelijken met de gewichtsvectoren van de camera twee beelden.
2.1.3.4 Mogelijke problemen:
• Auto’s en vrachtwagens samen verwerken is niet vanzelfsprekend.
• Een niet perfect op het voertuig geplaatste bounding box kan voor veel problemen
zorgen.
• Veranderingen in helderheid tussen de verschillende camera’s kan roet in het eten
strooien.
22

2.1.4 Corefaces
Deze methode is een combinatie van de eigenfaces methode en een geavanceerde correlatie-
filter. De eerste methode wordt gebruikt om de verschillen in een set van trainingsbeelden
te detecteren. De tweede methode is dan weer heel robuust tegen veranderingen in de
helderheid van het beeld[10, 11]. De techniek creeert een soort “kerngezicht” dat re-
latief invariant is tegen veranderingen in de helderheid, verschuiving van het beeld en
occlusies[12, 13].
2.1.4.1 Is deze techniek toepasbaar op de gegeven beelden?
De techniek, eigenlijk een verbetering van de eigenfaces techniek, heeft in het artikel heel
hoopgevende resultaten, hierdoor ziet de techniek er heel bruikbaar uit voor onze beelden.
We stellen dus voor om deze techniek te gaan implementeren indien het gebruik van louter
eigenfaces te veel problemen met zich meebrengt op het vlak van helderheidsverschillen
en verschuivingen in het beeld.
2.1.4.2 Mogelijke problemen:
• Deze techniek is robuust tegen situaties die misschien niet veel in deze masterproef
voorkomen, dit maakt het algoritme complexer waardoor er meer rekenkracht nodig
is.
2.2 Extractie van de karakteristieken zonder trainings-
set
2.2.1 SIFT (Scale-Invariant Feature Transform)
In artikel [14] wordt een techniek beschreven die in artikel [15] gebruikt wordt bij het
aan elkaar koppelen van verschillende beelden van hetzelfde voertuig. Deze techniek is
robuust tegen ruis, gedeeltelijke occlusie, veranderingen van helderheid, rijvak en in de
grootte van het voertuig. De techniek bestaat uit vier stappen:
1. Detectie van de extrema in de schaal-ruimte:
Deze stap zoekt de extrema over alle mogelijke beeldschalen en -locaties. Dit wordt
efficient gedaan via een “difference-of-Gaussian” functie die de potentiele punten
identificeert waar de schaal en orientatie invariant blijven.
2. Lokalisatie van sleutelpunten:
Voor elk potentieel punt uit stap een wordt de locatie en schaal van dit punt berekend
via een model. De sleutelpunten worden geselecteerd op basis van hun stabiliteit.
23

3. Assignatie van orientatie:
In deze stap krijgt elk sleutelpunt een of meer richtingen toegewezen. Hierdoor zijn
alle verdere operaties, die worden uitgevoerd op beelddata, relatief naar de toege-
wezen richting, schaal en locatie getransformeerd en zijn deze vervolgens invariant
voor deze transformaties.
4. Creatie van een sleutelpuntdescriptor:
Elk van de sleutelpunten wordt in een descriptor gegoten.
Deze techniek extraheert stabiele schaal-invariante sleutelpunten uit het beeld. Het creeert
een grote groep karakteristieken die van overal in het beeld en uit alle mogelijke schalen
van dit beeld komen. Een beeld van 500×500 kan rond de 2000 van deze karakteristieken
hebben.
2.2.1.1 Is deze techniek toepasbaar op de gegeven beelden?
Deze techniek is robuust tegen een groot deel van de problemen beschreven in hoofdstuk
1.2 en is daarom veelbelovend. Het is ook bemoedigend dat de techniek reeds succesvol
toegepast is geweest in een soortgelijke situatie.
2.2.1.2 Mogelijke problemen:
• De beelden uit de masterproef hebben een lagere resolutie dan deze uit de artikels.
• Deze techniek is robuust tegen situaties die misschien niet veel in deze masterproef
voorkomen, dit maakt het algoritme complexer waardoor er meer rekenkracht nodig
is.
2.2.2 Fourier, Wavelet en Curvelet transformaties
Door deze drie transformaties wordt het beeld voorgesteld in het frequentiedomein in
plaats van het ruimtedomein. Deze voorstelling bestaat uit een grote verzameling ge-
tallen die coefficienten genoemd worden. De curvlettransformatie is gespecialiseerd in
het beschrijven van krommen[16, 17]. De wavelettransformatie kan gebruikt worden om
kenmerken te detecteren uit een beeld genomen in een omgeving met weinig licht door
gebruik te maken van een adaptatie van het framewerk van de SIFT techniek[18].
Robust Feature Detection Using 2D Wavelet Transform Under Low Light Environment
24

2.2.2.1 Is deze techniek toepasbaar op de gegeven beelden?
In artikel [19] werd er een vergelijkende studie gemaakt naar de toepasbaarheid van de
drie transformaties bij voertuigherkenning. Deze studie gaf heel goede resultaten bij alle
transformaties. Voor de keuze van de descriptor kunnen de eerste x coefficienten van de
transformatie gebruikt worden. De waarde van x kan hierdoor zo gekozen worden dat de
descriptor aan bepaalde hardwarerestricties voldoet.
2.2.2.2 Mogelijke problemen:
• Door de geringe resolutie van de beelden in deze masterproef zijn ze soms wazig en
sterk ondergevig aan ruis. Welke techniek hier het minste last van zal hebben moet
nog verder onderzocht worden.
• In het artikel worden tussen de 6000 en 13000 coefficienten gebruikt om een beeld in
de juiste categorie te classificeren Het opslaan en verwerken van al deze coefficienten
is mogelijk niet zo vanzelfsprekend indien we met grote verzamelingen van beelden
gaan werken.
2.3 Gekozen technieken
Aangezien het de bedoeling is dat de beelden in deze masterproef op in een korte tijdspan-
ne verwerkt worden, hebben we ervoor gekozen om eerst de relatief eenvoudige threshol-
dingtechniek verder uit te werken. De resultaten van deze uitwerking staan beschreven in
onderdeel 4.2. Indien deze techniek niet de verhoopte resultaten bied kan eigenfacestech-
niek gebruikt worden. Deze techniek heeft al zijn bruikbaarheid bewezen in de wereld van
de gezichtsherkenning en is hierdoor zeker ook het uitproberen waard. Indien deze laatste
techniek teveel last heeft van bijvoorbeeld schaalproblemen door de grote verschillen in
afstand tot de camera waarop de beelden genomen zijn, kan de SIFT techniek misschien
soelaas bieden. Bij problemen met een niet ideaal geplaatste “bounding box” kan er dan
wellicht overgestapt worden naar de techniek met de corefaces.
25

Hoofdstuk 3
Het voertuigidentificatie algoritme
Eigendecompositie wordt, zoals aangehaald in hoofdstuk 2, gebruikt in de wereld van de
gezichtsherkenning. De gezichten die daarin gebruikt worden zijn allemaal in een gecon-
troleerde omgeving met ongeveer dezelfde belichting, afstand tot de camera en kijkhoek
gefotografeerd. Deze masterproef zal de eigenfaces techniek proberen toe te passen op
beelden uit tunnels waar de omgeving moeilijker controleerbaar is. De problemen die
hiermee gepaard gaan zijn uitvoerig beschreven in onderdeel 1.2.
Naast al deze mogelijke problemen zijn er gelukkig ook enkele meevallers. Zo hebben
de camera’s maar een verkeersstroom in beeld, namelijk deze die zich van de camera
verwijdert. Zo zal altijd op zijn minst de achterzijde van het voertuig in beeld zijn.
Daarnaast staan de camera’s, waarvan wij de beelden gekregen hebben allemaal ongeveer
boven de middelste rijstrook opgesteld en hebben ze ongeveer dezelfde instellingen qua
contrast en helderheid. Ook de tunnel zelf verandert niet radicaal van richting, kleur of
ondergrond tussen de drie camera’s in. Indien de tunnel wel radicaal zou veranderen kan er
gekozen worden om de tunnel op te delen in secties, die elk hun eigen trainingsset hebben.
Bij deze laatste configuratie kan het volgen van de voertuigen tussen de verschillende
secties een struikelblok zijn.
3.1 Toepassen van de eigenfacestechniek
In de eerste stap van het voorgestelde algoritme gaan we op basis van een trainingsset de
verschillen tussen voertuigen gaan beschrijven. Deze verschillen worden voorgesteld door
eigenvectoren, hier eigenvehicles genoemd. Vervolgens gaan we elk beeld uit de camera’s
gaan voorstellen door de gewichtsvector van dit beeld. We stellen dus de descriptor van
het beeld gelijk aan zijn gewichtsvector. De gewichtsvector bestaat uit een reeks gewichten
waarbij elk gewicht de mate bepaalt waarin een specifiek kenmerk (eigenvehicle) aanwezig
is in het origineel beeld. Het feit dat we deze gewichtsvectoren gebruiken om verschillende
26

Figuur 3.1: Een voorbeeld van een koppeling van twee voertuigen over drie cameras
beelden, uit verschillende camera’s, van hetzelfde voertuig aan elkaar te koppelen is iets
nieuws.
Er rest ons dan alleen nog bij elke descriptor in de ene camera de best passende descriptor
uit de vorige camera te zoeken. Op deze manier kan een voertuig doorheen alle camera’s
gevolgd worden. In figuur 3.1 ziet u een voorbeeld van een koppeling van twee voertuigen
over drie cameras.
Een bijkomend voordeel bij het gebruik van de gewichtsvector als descriptor is dat de
maximale grootte van een descriptor altijd gekend is eens de trainingsset gekozen is. Dit
komt omdat een gewichtsvector altijd even groot is als het aantal eigenvehicles. Het aantal
eigenvehicles kan dan weer maximaal evenveel zijn als het aantal beelden in de trainingsset.
Indien we op voorhand weten hoe groot een descriptor zal zijn is het makkelijker om het
geheugengebruik van deze techniek te voorspellen.
27

3.1.1 Voorbeeld
In dit voorbeeld bouwen verder op de voorbeelden in onderdeel 2.1.3. In tabel 2.1 ziet u
per kolom de verschillende descriptoren van de testbeelden uit figuur 2.8. De eigenvectoren
die als basis dienen voor deze descriptoren zijn te zien in figuur 2.7. De descriptor van
testbeeld 2.8(a) is dus (−6.049,−5.661).
Stel we nemen nu aan dat de figuren 2.8(c) en 2.8(d) twee beelden zijn van hetzelfde
object uit twee verschillende camera’s dan is de bedoeling van deze masterproef dat op
een of andere manier gedetecteerd wordt dat deze twee figuren bij elkaar passen.
Uit de tabel is ook af te leiden dat hoewel de beelden 2.8(a) en 2.8(b) totaal verschillend
zijn van elkaar, de descriptoren dit niet zijn. In dit geval zal er dus een foutieve koppeling
gemaakt worden tussen deze twee beelden. Dit komt omdat in de trainingsset alle beelden
dezelfde waarden hadden in de linkser bovenhoek. Indien in de trainingsset ook een beeld
gestopt wordt waarin wel iets in de linker bovenhoek staat, zal het verschil tussen de
beelden 2.8(a) en 2.8(b) wel kunnen gedetecteerd worden.
3.2 Vergelijken van de verschillende descriptoren
Er zijn verschillende technieken bekend die kunnen gebruikt worden om deze descriptoren
te vergelijken. We hebben gekozen om de gekende en snelle technieken, “Mean Square
Error” (MSE) en Euclidische afstand te testen.
Euclidische afstand
Deze metriek berekent de afstand tussen twee punten, zoals die met een lat gemeten
zou zijn in een ruimte van een tot oneindig dimensies. In de formule 3.1 vindt u hoe de
Euclidische afstand berekend wordt en waarbij X en Y de twee descriptoren zijn en N de
lengte van een descriptor is.
EUC =
√√√√N−1∑i=0
(X(i)− Y (i))2 (3.1)
“Mean Square Error” (MSE)
Deze techniek berekent de gemiddelde kwadratische fout tussen twee descriptoren vol-
gens formule 3.2. De techniek wordt in de statistiek gebruikt om het verschil tussen wat
een voorspeller voorspeld heeft en wat er echt gebeurd is te gaan meten.
MSE =1
N
N−1∑i=0
(X(i)− Y (i))2 (3.2)
28

Figuur 3.2: Grafische voorstelling van het vergelijken van twee descriptoren uit camera 2 mettwee descriptoren uit camera 1.
Keuze techniek:
Aangezien beide technieken hetzelfde berekenen, maar enkel anders geschaald, zal er
geen verschil in conclusie zijn tussen deze twee maten. We hebben er vervolgens voor
gekozen om enkel gebruik te maken van de techniek die de Euclidische afstand berekend
tussen twee descriptoren.
Samengevat:
We gaan de Euclidische afstand gebruiken om de descriptoren van alle camera 2 beelden
te vergelijken met deze van de camera 1 beelden. Aangezien de gewichtsvector van een
beeld eigenlijk de projectie van het beeld is in de ruimte opgespannen door de eigenvehicles
kunnen we de het vergelijken van descriptoren grafisch voorstellen door figuur 3.2.
3.3 Selectie beste koppel
Elk moment van de dag komen er nieuwe voertuigen de tunnel binnen. Dit zorgt ervoor
dat de verzameling descriptoren in snel tempo te groot wordt om vlug in te gaan zoeken.
Vervolgens zijn voertuigen gebonden aan snelheidslimieten in een tunnel en kan een de-
scriptor in de praktijk niet aan gelijk welke andere descriptor gekoppeld worden. Er kan
dus vanuit gegaan worden dat enkel een deel van de descriptoren met elkaar vergeleken
worden. Daarnaast moet er op een gegeven moment geselecteerd worden hoe je descrip-
toren met elkaar zal vergelijken. Hieronder zijn twee technieken beschreven die gebruikt
kunnen worden bij de selectie van het best passende koppel beelden. Om de technieken
goed in de praktijk bruikbaar te maken zullen ze nog moeten bijgeschaafd worden zodat
de nadelen van elke techniek weg gewerkt worden. Om de uitleg overzichtelijker te maken,
29

hebben we ervoor gekozen om de verzamelingen van de camera 1 en camera 2 descriptoren
respectievelijk Υ en Ψ te noemen. Een koppel beelden bevat altijd twee beelden, namelijk
een uit de ene camera en een uit de volgende camera bijvoorbeeld (Υ1,Ψ1). Het is de
bedoeling dat de twee beelden hetzelfde voertuig afbeelden. Tot slot gaan we in beide
technieken ervan uit dat er al een verzameling Υ1...z met lengte z bestaat, waarmee de
descriptoren in Ψ vergeleken worden.
De keuze van Υ1...z kan voor problemen zorgen want niet alle voertuigen rijden steeds met
dezelfde snelheid. De volgorde waarin ze in de verschillende camera’s voorkomen kan dus
doorheen de tunnel veranderen. De verzameling Υ1...z moet dus zo gekozen worden dat
deze altijd minstens de passende descriptor Υx bevat voor de descriptor uit Ψ.
3.3.1 Een descriptor per keer koppelen
Bij deze techniek worden de descriptoren in Ψ een per een verwerkt. Iedere keer dat er
een Ψi berekend is, zal deze direct vergeleken worden met Υ1...z. Hierna wordt het best
passende koppel (Υk,Ψi) met 1 ≤ k ≤ z gecreeerd. Het algoritme kijkt niet verder dan Ψi
en zal dus altijd voor het lokale optimum in Υ1...z kiezen. Dit lokale optimum is niet altijd
gelijk aan het globale optimum en indien je Υk zou verwijderen uit Υ1...z kan dit ervoor
zorgen dat een beter passende Ψj met j ≥ i niet meer kan gekoppeld worden aan Υk. We
hebben er daarom voor gekozen om Υk niet te verwijderen uit Υ1...z. Dit impliceert dat
zowel (Υk,Ψi) als (Υk,Ψj) toegelaten is. Op die manier wordt altijd het optimale koppel
gevormd. Om tegen te gaan dat de verzameling Υ1...z oneindig groot wordt, kunnen de
descriptoren, die al langer dan een bepaalde tijd in Υ1...z zitten, verwijderd worden. Zie
figuur 3.3 voor een grafische weergave.
Voordelen
• De selectie van het beste koppel wordt direct gedaan, vanaf dat Ψi gekend is.
• Elke descriptor uit Ψ zal onafhankelijk van de andere descriptoren uit Ψ aan de
meest passende descriptor uit Υ1...z gekoppeld worden.
Nadelen
• De kans bestaat dat er meerdere descriptoren uit Ψ gekoppeld worden aan dezelfde
Υi. In dit geval zullen niet alle descriptoren uit Υ aan een descriptor uit Ψ ge-
koppeld zijn. Dit zou impliceren dat er tussen twee camera’s in twee voertuigen
samengesmolten zijn en een nieuwe plots opgedoken is. Dit is hier uiteraard niet de
bedoeling.
30

Figuur 3.3: MSE toegepast op het descriptor per descriptor koppelselectie-algoritme.
3.3.2 Hongaars algoritme
Er is naast bovenstaande techniek nog een andere oplossing mogelijk, namelijk in plaats
van de descriptoren uit Ψ een per een te verwerken, kan er gewacht worden tot er een
aantal descriptoren gemaakt zijn. Deze descriptoren worden voorgesteld door de verza-
meling Ψ1...q met grootte q. Iedere keer dat er een descriptor gemaakt is kan wel al de
afstand berekend worden van deze descriptor tot alle elementen in de Ψ1...q. Indien we de
Euclidische afstand tussen twee descriptoren defineren als een maat voor de kost om deze
descriptoren aan elkaar te koppelen kunnen we, nadat er genoeg descriptoren gemaakt
zijn, via een Hongaars algoritme de koppeling met de kleinste totale kost zoeken van alle
elementen uit de verzameling Ψ1...q met een van de elementen uit Υ1...z[20]. We kunnen
ervanuit gaan dat q ≤ z en indien q < z zullen de beste q koppels teruggegeven worden.
Figuur 3.4 beschrijft schematisch hoe dit dan in zijn werk gaat.
Het Hongaars algoritme wordt meestal uitgelegd op de volgende manier: stel je hebt een
bedrijf dat zijn werknemers bepaalde taken wilt laten uitvoeren. Elke werknemer kan
maar een taak tegelijk doen en aan elke taak is er een specifieke kost per werknemer ver-
bonden. Zo kan de ene werknemer een bepaalde taak goedkoper uitvoeren dan een andere
werknemer. Indien je alle werknemers overloopt en in die volgorde aan elke werknemer
de overgebleven taak met de laagste kost geeft dan ben je niet zeker dat je daadwerkelijk
de laagste totale kost bekomen hebt. Om toch de laagste totale kost te bekomen komt
het Hongaars algoritme van pas.
31

Pseudocode werking van het Hongaars algoritme
1. Indien de maximumkost gezocht wordt, maak je alle getallen in de matrix negatief
en bereken je de minimumkost.
2. Verminder elke rij met het minimum in de rij.
3. Verminder elke kolom met het minimum van de kolom.
4. Probeer met zo weinig mogelijk lijnen de nullen in de matrix te bedekken. Stel n het
aantal kolommen en rijen in de matrix en k het aantal lijnen die de nullen bedekken.
• als k<n:
Stel m gelijk aan het minimum van de onbedekte nummers en tel dan m bij
elk door een lijn bedekte nummer en verminder alle onbedekte nummers met
m.
• als k=n ga naar de volgende stap
5. Beginnend bij de bovenste rij, begin je assignaties toe te kennen. Als er juist een nul
in de rij is kan je een assignatie doen. Je gaat van boven naar onder en indien je geen
assignaties meer kan doen ga je van links naar rechts en begin je op dezelfde manier
assignaties , maar nu per kolom, te doen. Indien je dan weer vast zit verander je
terug naar rijen. Als een assignatie gemaakt is verwijder je de rij en kolom in de
matrix.
Voordelen
• De identificatie is optimaal over een verzameling Ψ1...q en niet enkel voor een de-
scriptor.
• De descriptoren uit Ψ moeten sowieso een tijdje bijgehouden worden voor de kop-
peling tussen Ψ en de descriptoren uit de volgende camera. Er hoeft dus geen extra
geheugen gebruikt te worden om de descriptoren uit Ψ bij te houden.
Nadelen
• Je moet wachten tot er een bepaalde verzameling Ψ1...q gevuld is.
• Indien er gewerkt wordt met overlappende deelverzamelingen in Υ kunnen er pro-
blemen voorkomen. In het geval dat de volgende q descriptoren uit Ψ namelijk
Ψ1...2q gekoppeld moeten worden aan een verzameling Υ′1...z die gedeeltelijk overlapt
met de Υ1...z kan een descriptoren uit Υ1...z gekoppeld kunnen worden aan meerdere
descriptoren uit Ψ.
32
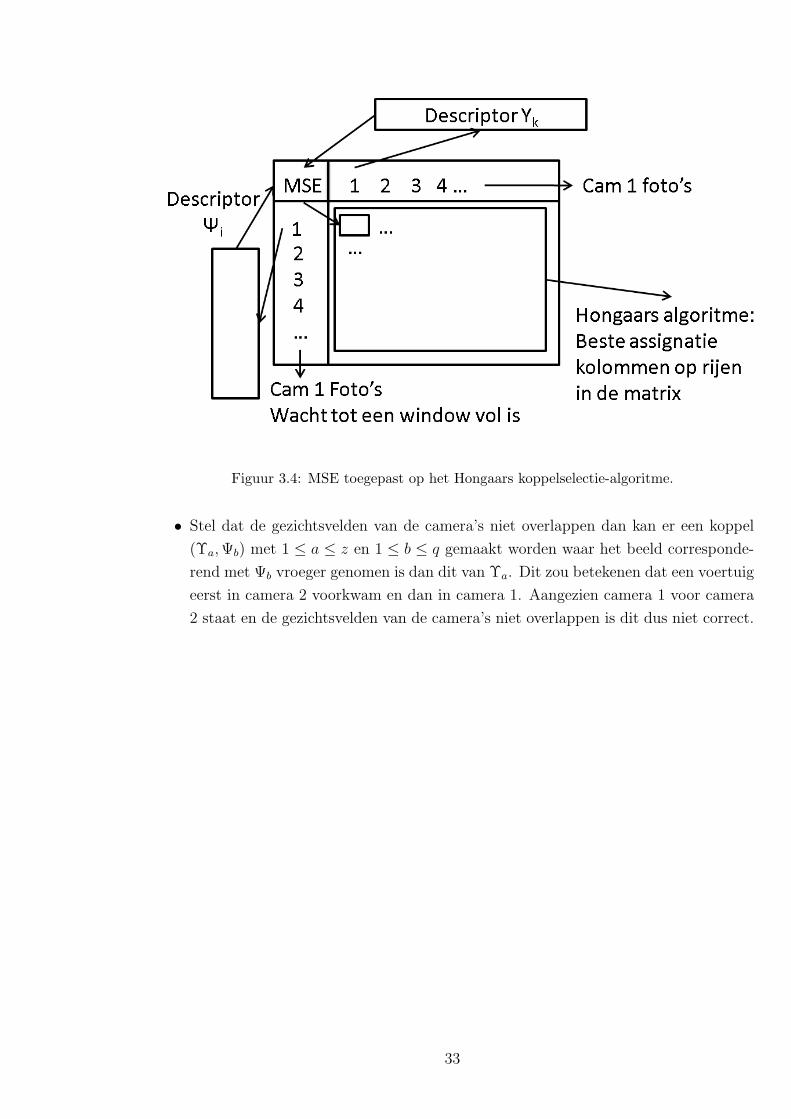
Figuur 3.4: MSE toegepast op het Hongaars koppelselectie-algoritme.
• Stel dat de gezichtsvelden van de camera’s niet overlappen dan kan er een koppel
(Υa,Ψb) met 1 ≤ a ≤ z en 1 ≤ b ≤ q gemaakt worden waar het beeld corresponde-
rend met Ψb vroeger genomen is dan dit van Υa. Dit zou betekenen dat een voertuig
eerst in camera 2 voorkwam en dan in camera 1. Aangezien camera 1 voor camera
2 staat en de gezichtsvelden van de camera’s niet overlappen is dit dus niet correct.
33

Hoofdstuk 4
Experimenten
Na de theoretische uitleg volgen de experimenten. Eerst en vooral hebben we wat geexperi-
menteerd met de thresholdingtechniek. Na enkele tegenvallende resultaten zijn we naar
de techniek met de eigenfaces, hier omgedoopt tot eigenvehicles, overgestapt. In dit
hoofdstuk komt het hoe en waarom van de experimenten en een kleine discussie over de
resultaten aan bod. Conclusies zijn dan weer te vinden in hoofdstuk 5.1.
4.1 Datasets
Eerst beschrijven we de bron van de invoergegevens, hoe deze opgedeeld is en welke
eigenschappen elke dataset heeft. Een beschrijving van de eigenschappen zijn te vinden
in hoofdstuk 1.2. Van Traficon kregen we drie videofragmenten van elk 11 minuten. Elk
van deze fragmenten kwam van een opeenvolgende camera in de tunnel. Zie figuur 1.1
op pagina 2 voor een voorbeeld opstelling van camera’s in een tunnel. Beide datasets,
de IPI-beelden en de Traficon-beelden, die hieronder beschreven worden komen uit deze
drie videofragmenten. Beide verschillen in het feit dat sommige problemen uit hoofdstuk
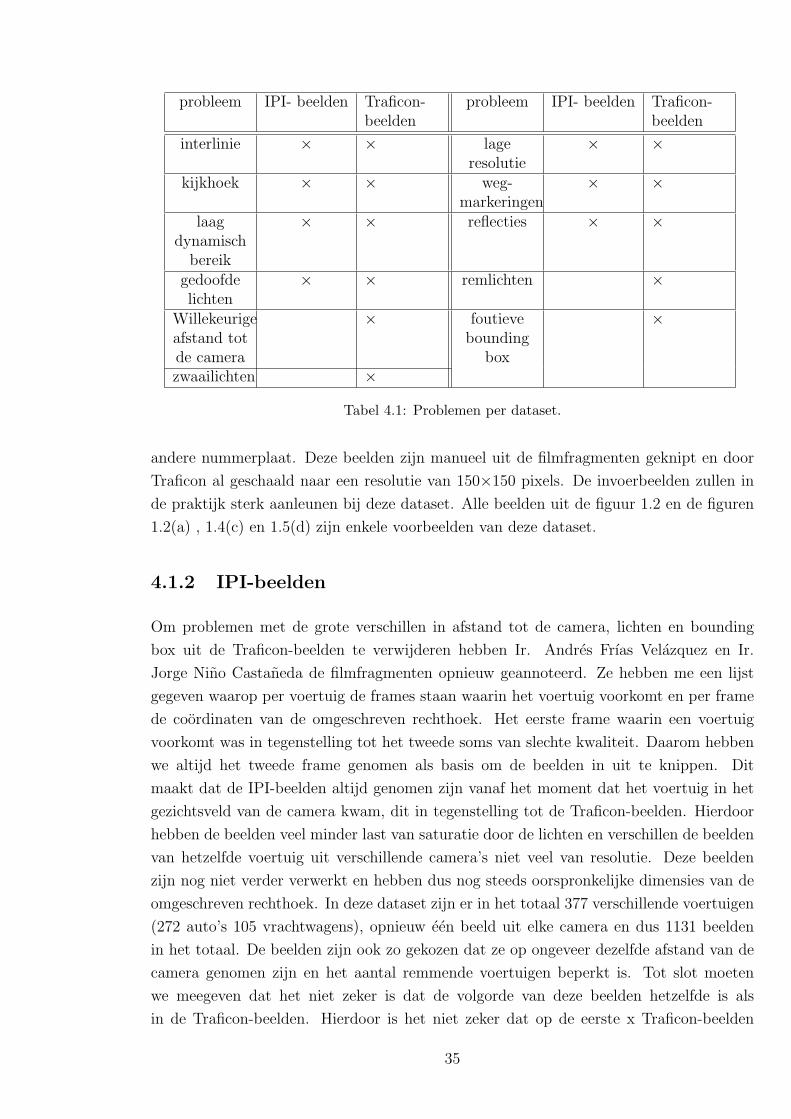
1.2 in de ene dataset wel en in de andere dataset niet voorkomen. Zie tabel 4.1 voor een
overzicht.
4.1.1 Traficon-beelden
Deze beelden zijn verkregen via Traficon. Het zijn beelden van 500 verschillende voertui-
gen (346 auto’s en 154 vrachtwagens) waarbij uit elke camera 1 beeld genomen is. Dit
beeld kan gelijk wanneer in het gezichtsveld van de camera genomen zijn en dit kan voor
problemen zorgen. Het spreekt voor zich dat een beeld die dicht bij de camera genomen
is, meer details bevat dan een beeld heel ver van de camera. In het totaal zijn er dus
1500 beelden. Met verschillend bedoelen we dat ze fysiek een ander voertuig zijn. De
voertuigen kunnen wel van hetzelfde merk of type zijn maar ze hebben allemaal wel een
34
probleem IPI- beelden Traficon-beelden
probleem IPI- beelden Traficon-beelden
interlinie × × lageresolutie
× ×
kijkhoek × × weg-markeringen
× ×
laagdynamisch
bereik
× × reflecties × ×
gedoofdelichten
× × remlichten ×
Willekeurigeafstand totde camera
× foutievebounding
box
×
zwaailichten ×Tabel 4.1: Problemen per dataset.
andere nummerplaat. Deze beelden zijn manueel uit de filmfragmenten geknipt en door
Traficon al geschaald naar een resolutie van 150×150 pixels. De invoerbeelden zullen in
de praktijk sterk aanleunen bij deze dataset. Alle beelden uit de figuur 1.2 en de figuren
1.2(a) , 1.4(c) en 1.5(d) zijn enkele voorbeelden van deze dataset.
4.1.2 IPI-beelden
Om problemen met de grote verschillen in afstand tot de camera, lichten en bounding
box uit de Traficon-beelden te verwijderen hebben Ir. Andres Frıas Velazquez en Ir.
Jorge Nino Castaneda de filmfragmenten opnieuw geannoteerd. Ze hebben me een lijst
gegeven waarop per voertuig de frames staan waarin het voertuig voorkomt en per frame
de coordinaten van de omgeschreven rechthoek. Het eerste frame waarin een voertuig
voorkomt was in tegenstelling tot het tweede soms van slechte kwaliteit. Daarom hebben
we altijd het tweede frame genomen als basis om de beelden in uit te knippen. Dit
maakt dat de IPI-beelden altijd genomen zijn vanaf het moment dat het voertuig in het
gezichtsveld van de camera kwam, dit in tegenstelling tot de Traficon-beelden. Hierdoor
hebben de beelden veel minder last van saturatie door de lichten en verschillen de beelden
van hetzelfde voertuig uit verschillende camera’s niet veel van resolutie. Deze beelden
zijn nog niet verder verwerkt en hebben dus nog steeds oorspronkelijke dimensies van de
omgeschreven rechthoek. In deze dataset zijn er in het totaal 377 verschillende voertuigen
(272 auto’s 105 vrachtwagens), opnieuw een beeld uit elke camera en dus 1131 beelden
in het totaal. De beelden zijn ook zo gekozen dat ze op ongeveer dezelfde afstand van de
camera genomen zijn en het aantal remmende voertuigen beperkt is. Tot slot moeten
we meegeven dat het niet zeker is dat de volgorde van deze beelden hetzelfde is als
in de Traficon-beelden. Hierdoor is het niet zeker dat op de eerste x Traficon-beelden
35

dezelfde voertuigen staan als in de eerste x IPI-beelden. Dit kan van belang zijn in het
partitiesysteem dat verder uitgelegd wordt. Aangezien Ir. Andres Frıas Velazquez en Ir.
Jorge Nino Castaneda twee leden zijn van de vakgroep IPI[21] hebben we deze beelden
de IPI-beelden genoemd. Omdat deze beelden genomen zijn vanaf het moment dat een
voertuig in het gezichtsveld van de camera komt, zijn er meer details van dit voertuig te
zien in het beeld. Door de resultaten met de IPI-beelden te vergelijken met deze met de
Traficon-beelden kunnen we het effect hiervan op het identificatie-algoritme onderzoeken.
De beelden 1.4(a) , 1.4(b) en 1.5(c) zijn enkele voorbeelden van deze dataset.
4.2 Thresholding
Deze techniek is uitsluitend getest op de Traficon-beelden. De IPI-beelden werden op
dat moment nog geannoteerd en waren dus nog niet ter beschikking. Zoals reeds uit-
gelegd in onderdeel 2.1.2 werkt deze techniek met drempelwaarden. Alles boven deze
drempelwaarde wordt wit ingekleurd en alles eronder krijgt een zwarte kleur.
4.2.1 Op zoek naar een drempelwaarde via vensters
Eerst en vooral hebben we het beeld opgedeeld in verschillende vensters. Vervolgens
hebben we de gemiddelde waarde van elk venster berekend en deze als drempelwaarde
toegepast in het venster. Door het aantal vensters per beeld te laten varieren zochten we
naar een optimale verdeling van het beeld in vensters. Nadat alle vensters in een beeld
verwerkt waren, testten we visueel het bekomen resultaat, we keken vooral of bepaalde
eigenschappen van het voertuig beter zichtbaar waren of niet. De resultaten vielen in het
merendeel van de gevallen nogal tegen en zoals vermoed kon worden, had elk beeld een
andere optimale verdeling in vensters.
4.2.2 Drempelwaarde via het histogram
Nadat de vorige aanpak niet veel bruikbaars opleverde zijn we begonnen met het histo-
gram van de beelden te analyseren. De bedoeling is om, op basis van het histogram, de
waarden te bepalen, waartussen bepaalde eigenschappen van het voertuig zich bevinden.
Het histogram werd eerst gladder gemaakt waarna de lokale minima van het histogram
gebruikt werden als lokale minima. Om in een beeld een overzicht te krijgen hoe goed
deze techniek werkt hebben we alle pixels die tussen twee lokale minima liggen een andere
kleur gegeven. Figuur 4.1(b) is hier een voorbeeld van. Uit deze techniek konden we aflei-
den dat, bij het merendeel van de vrachtwagens, het voertuig zelf meestal een grijswaarde
heeft van boven de 60 op een schaal van 255. Hierdoor konden we alles wat zich onder
deze drempelwaarde bevindt volledig negeren en is daarom in figuur 4.1(b) de achtergrond
36

volledig zwart. Door de grote verscheidenheid in de kleuren van de tekst en logos op de
vrachtwagens is het moeilijk om goede waarden te vinden waartussen het merendeel van
deze kenmerken zich bevinden. Meestal zitten de waarden van de logos en tekst in dezelfde
piek van het histogram waar ook de rest van de vrachtwagen zich bevindt. Deze techniek
kan dus gebruikt worden om de kenmerken die zich in een aparte piek van het histogram
bevinden, bijvoorbeeld het wegdek of de lichten van een vrachtwagen, te selecteren maar
is niet bruikbaar om de logos van de rest van de vrachtwagen te onderscheiden. In figuur
4.1(c) zijn de waarden zo gekozen dat enkel de helderste vlakken van het histogram in het
paars en de rest van het voertuig in het geel ingekleurd zijn.
Uit figuur 4.1(b) blijkt dat het niet gemakkelijk is om op deze manier alleen de logo’s en
tekst op de achterkant van de vrachtwagen te selecteren. De lichten zijn dan weer zonder
veel problemen uit het histogram te selecteren, dit kan je goed zien in figuur 4.1(c).
4.2.3 Drempelwaarde via het uitgemiddeld beeld
Uit de vorige techniek bleek dat er problemen zijn met de selectie van de logo’s of tekst op
de achterzijde van een vrachtwagen. Om deze eigenschappen uit het beeld te selecteren
hebben we volgende stappen uitgeprobeerd:
1. Creeer een uitgemiddeld beeld waar elke pixel het gemiddelde is van zijn omgevende
pixels binnen een venster.
2. Maak een nieuw beeld door elke pixel in het origineel beeld te verminderen met de
waarde op dezelfde plaats in het uitgemiddeld beeld. Een negatieve waarde in dit
nieuw beeld wil zeggen dat de omgeving van de pixel op deze plaats donkerder is
dan de pixel zelf, een positieve waarde wil het omgekeerde zeggen.
3. Alle negatieve waarden in het beeld uit de vorige stap krijgen een grijswaarde 0
(zwart) en alle positieve waarden een grijswaarde 255 (wit).
In figuur 4.2 zijn de verschillende stappen grafisch voorgesteld, het eindresultaat in figuur
4.2(c) toont nu goed de plaats van de tekst op het voertuig.
4.2.4 Eerste testen: resultaten en conclusie
Aangezien de lichten heel gemakkelijk uit de beelden te selecteren zijn hebben we besloten
om eerst een eenvoudige test te doen op de Traficon-beelden uit camera 1 en twee. Indien
deze test redelijke resultaten geeft kunnen we verder testen met de technieken waar de
logo’s van een beeld beter te zien zijn.
37

(a) (b)
(c)
Figuur 4.1: Een vrachtwagen waar verschillende delen van het histogram ingekleurd zijn. (a)Het origineel beeld en (b) de ingekleurde versie. (c) Rechts: Het getransformeerd histogramvan de vrachtwagen, alle waarden die origineel onder de 60 lagen zijn gereduceerd tot 0. Dezewaarden zijn zwart op de figuur links. Links: De helderste vlakken van de vrachtwagen zijn inhet paars gekleurd en de rest van de vrachtwagen in het geel. De pijlen tonen welk deel van hethistogram welke kleur kreeg.
1. Selecteer enkel de helderste delen in het beeld. De beelden met vrachtwagens,
in tegenstelling tot deze met auto’s, hebben veel last van reflecties op het dak van
het voertuig. Om deze reflecties weg te filteren worden enkel bij vrachtwagens de
heldere vlakken die zich in de onderste helft van het beeld bevinden overgehouden.
2. Creeer de descriptor van het beeld. Aangezien de beelden allemaal herschaald
zijn naar een resolutie van 150×150 pixels en er geen bocht is in het stuk tunnel
38

(a) (b)
(c)
Figuur 4.2: (a) Origineel beeld. (b) Uitgemiddeld beeld van figuur 4.2(a).(c) Het verschil tussenfiguur 4.2(a) en figuur 4.2(b).
waaruit de beelden komen kunnen misschien de afstanden tussen de middelpunten
van de lichten gebruikt worden om een beeld te beschrijven. Daarom zoeken we bij
benadering het middelpunt van elk vlak en bereken de euclidische afstandsmatrix
over al deze middelpunten. Deze matrix wordt gebruikt als descriptor van het beeld.
3. Vergelijk de descriptoren. Voor de eenvoud hebben we gekozen om de voertuigen
waarbij de descriptoren uit beide camera’s niet even groot zijn niet met elkaar te
vergelijken. Deze kunnen namelijk nooit goed aan elkaar gekoppeld worden. Twee
descriptoren worden aan elkaar gekoppeld indien de MSE minimaal is. De variabelen
X en Y stellen in deze formule de descriptoren van twee verschillende beelden voor.
De resultaten van deze test waren niet zo goed. Eerst en vooral hebben we gecontroleerd
hoeveel voertuigen zonder lichten rijden: bij de beelden van auto’s was er maar een voer-
tuig zonder lichten, bij deze van vrachtwagens waren dit er 16. Het aantal voertuigen die
we uit de testset gehaald hebben omdat de descriptoren in beide camera’s niet even groot
waren kwam bij de auto’s en de vrachtwagens op respectievelijk 272 en 79 voertuigen.
39

Na deze selectie is de testset voor de auto’s en de vrachtwagens nog respectievelijk 73
en 59 voertuigen groot. De volgende stap is het aan elkaar koppelen van de descriptoren
en vervolgens het controleren hoeveel descriptoren correct aan elkaar gekoppeld zijn. De
eindresultaten zijn de volgende: van de 73 auto’s zijn er 14 (=19%) correct aan elkaar
gekoppeld, bij de vrachtwagens kwam dit op 32 van de in het totaal 59 (=54%) vrachtwa-
gens. Deze resultaten zijn voor deze test onvoldoende, na beraad met Ir. Vedran Jelaca,
Ir. Andres Frıas Velazquez en Dr. Ir. Hiep Quang Luong is er dan voor gekozen om de
thresholdingtechniek te laten voor wat het is en de techniek met de eigenfaces verder te
gaan exploreren.
4.3 Eigenvehicles
Na de uitleg over hoe de techniek met eigenvehicles werkt in onderdeel 2.1.3 zijn we op
het moment aangekomen om de techniek te gaan testen. De testen zijn zo gekozen dat ze
een zo goed mogelijk antwoord bieden op de volgende vragen:
• Wat is het effect als we enkel de even of oneven lijnen van een beeld gebruiken?
• Welke verbetering brengt het Hongaars ten opzichte van het descriptor per descriptor
koppelselectie-algoritme?
• Wat gebeurt er als we de grootte van de trainingsset varieren en de testset even
groot blijft?
• Wat zijn de resultaten indien we de invoerbeelden classificeren in auto’s en vracht-
wagens.?
• Wat is de invloed van de problemen die enkel bij de Traficon-dataset voorkomen?
• Welke beelden stoppen we het best in een trainingsset?
4.3.1 Hoe getest?
Om een goed antwoord te kunnen geven op bovenstaande vragen moeten er eerst enkele
beslissingen genomen worden i.v.m. verschillende parameters. Daarnaast moeten de
datasets van hierboven nog verder verwerkt worden.
Herschaling.
Zoals beschreven in de eerste stap van het eigenfaces-algoritme in 2.1.3.1 moeten de
beelden herschaald worden. De Traficon-beelden waren allemaal al herschaald tot een
resolutie van 150×150 maar de IPI-beelden zijn nog in hun oorspronkelijke resolutie.
40

Vervolgens hebben we de gemiddelde resolutie van alle IPI-beelden berekend en dit kwam
op ongeveer 180×180. We hebben dan beslist om in stap 1 alle IPI-beelden te herschalen
naar een resolutie van 180×180.
Interlinie.
Doordat de snelheid van het identificatie-algoritme van belang is hebben we geen com-
plexe deınterliniering algoritmen uitgetest. Zowel bij de IPI-beelden als bij de Traficon-
beelden hebben we een eenvoudige oplossing voor de problemen rond interlinie uitgepro-
beerd door enkel de even of oneven lijnen van een foto te gebruiken. Bij de Traficon-
beelden gaf dit niet het gewenste, zuivere, beeld zonder een spoor van de interlinie. Dit
komt doordat de beelden al geschaald waren naar een resolutie van 150×150 pixels. De
IPI-beelden staan nog in hun oorspronkelijke resolutie en daarom gaf deze methode wel
een mooi zuiver beeld als resultaat. Na de selectie van de even of oneven lijnen van een
beeld is de resolutie van de Traficon-beelden gereduceerd tot 150×75 en van de IPI-beelden
tot 180×90. In figuur 4.3 ziet u de resultaten van deze selectie op beide datasets.
Opdeling dataset in subsets.
De grote datasets die hierboven beschreven staan hebben we opgedeeld in verschillende
onderdelen. Aangezien er minder IPI-beelden zijn dan Traficon-beelden hebben we ervoor
gekozen om een deel van de Traficon-beelden niet te gebruiken. Dit maakt het onderling
vergelijken van de resultaten een stuk makkelijker.
De datasets hebben we eerst in twee grote delen opgedeeld. Deze opsplitsing gebeurt
volgens de aard van het voertuig op de afbeelding. De voertuigen worden opgedeeld
in auto’s en vrachtwagens. Het onderscheid tussen auto’s en vrachtwagens is manueel
gebeurd en hebben we zelf gedaan voor de IPI-beelden en Ir. Vedran Jelaca voor de
Traficon-beelden. Daarna hebben we deze twee delen in kleinere delen gesplitst met
een veranderende grootte. Nu bekomen we de volgende 5 subsets: “100 auto’s”, “100
vrachtwagens”, “100 gemengd”, “200 auto’s” en “300 gemengd”. Het getal vooraan,
bijvoorbeeld het getal 200 bij de “200 auto’s” subset, wil zeggen dat in de dataset de eerste
200 verschillende auto’s van de Traficon-beelden of de IPI-beelden zitten. Het spreekt voor
zich dat dit wil zeggen dat bijvoorbeeld de “100 auto’s” subset een deelverzameling is van
de “200 auto’s” subset. In elke subset zitten de beelden van alle drie de camera’s. In
de “200 auto’s” subset zitten er dus 600 beelden, 200 per camera, van 200 verschillende
auto’s. Het woord gemengd wilt zeggen dat er geen onderscheid gemaakt is tussen auto’s
en vrachtwagens. In tabel 4.2 ziet u voor zowel de IPI-beelden als de Traficon-beelden de
verdeling van het aantal auto’s en vrachtwagens in de gemengde subsets.
um en ustd.
De variabelen um en ustd uit paragraaf 2.1 werden altijd berekend op de volledige
41

(a) (b)
(c) (d)
Figuur 4.3: (a) Geınterlinieerde auto in de IPI-beelden en (b) hetzelfde beeld waarbij enkel deeven lijnen geselecteerd werden. (c) Geınterlinieerde vrachtwagen in de Traficon-beelden en (d)hetzelfde beeld waarbij enkel de even lijnen geselecteerd werden.
dataset100 gemengd 300 gemengd
Vrachtwagens Auto’s Vrachtwagens Auto’sIPI-beelden 29 71 91 (=∼30%) 209 (=∼70%)
Traficon-beelden 30 70 96 (=∼32%) 204 (=∼68%)
Tabel 4.2: Verdeling vrachtwagens en auto’s in de verschillende gemengde subsets.
datasets. Bij de auto subsets werden deze dus op alle 272 of 346 auto’s in respectievelijk de
IPI-en Traficon-beelden berekend. Voor de Traficon-beelden werden ze dan dus berekend
op alle 346 auto’s in deze dataset.
Partitie systeem.
Na het opdelen van de dataset in subsets hebben we elke subset verdeeld in twintig
kleinere partities. In figuur 4.4 ziet u een grafische representatie van deze verdeling, waar-
bij elke kolom is een partitie is. Indien er dus in een subset 100 verschillende voertuigen
zitten zullen er in elke partitie 15 beelden zitten van 5 verschillende voertuigen. Hoeveel
42

Figuur 4.4: Opdeling van een willekeurige dataset in partities. tien testpartities, een trainings-partitie en negen ongebruikte partities zijn aangeduid.
beelden er in een partitie zitten is dus afhankelijk van de grootte van de subset. De par-
tities worden in de testen gebruikt om de trainings- en testsets aan te duiden, zo hebben
we de twintig partities gegroepeerd in volgende niet overlappende delen:
• tien testpartities, een trainingspartitie en negen ongebruikte partities.
• tien testpartities, vijf trainingspartitie en vijf ongebruikte partities.
• tien testpartities, tien trainingspartitie en nul ongebruikte partities.
Indien er getraind wordt zal, in de configuratie met een trainingspartitie, de trainingsset
uit de drie onderdelen A11, B11 en C11 bestaan. De tien partities ervoor zullen in de
testset ingedeeld worden. De negen partities erna worden voorlopig niet gebruikt. In de
test zullen alle beelden uit de onderdelen A1 tot A10 vergeleken worden met die uit B1
tot B10 en met die uit C1 tot C10. Daarna worden ook de beelden uit de onderdelen
B1 tot B10 met die van C1 tot C10 vergeleken. Hierna schuift alles een partitie op en
zal de trainingsset de onderdelen A12, B12 en C12 omvatten. De tien partities ervoor
worden opnieuw in de testset ingedeeld en de negen erna worden nu niet gebruikt. Er
wordt doorgeschoven tot men terug aan het begin is. Hetzelfde principe wordt toegepast
met vijf of tien trainingspartities.
In alle experimenten trainen we met alle drie de camera’s. Het totaal aantal beelden en
verschillende voertuigen, waarop getraind is geweest per subset en per aantal partities is
terug te vinden in tabel 4.3. In het laatste experiment gebruiken we een andere configu-
ratie want daar onderzoeken we specifiek of trainen met een trainingscamera even goede
resultaten geeft als trainen met alle drie de camera’s.
Het mechanisme van doorschuiven zoals hierboven beschreven zorgt ervoor dat alle beel-
den in de subset minstens eens gebruikt worden om te testen en eens om te trainen.
Elke configuratie is dus twintig keer uitgevoerd met iedere keer iets andere data. De
uiteindelijke resultaten zijn het gemiddelde van deze twintig uitvoeringen.
43

100Vrachtwagens/
Gemengd/Auto’s
200 Auto’s 300 Gemengd
1 trainingspartitie 15 30 455 trainingspartities 75 150 22510 trainingspartities 150 300 450
Tabel 4.3: Het aantal beelden in de verschillende partities wanneer er over de drie camera’sgetraind wordt. Het aantal verschillende voertuigen in deze beelden is altijd 1/3 van het aantalbeelden. Bijeen subset met 100 voertuigen is de trainingset 15 beelden groot, van 5 verschillendevoertuigen, elk voertuig heeft dus 3 beelden, 1 uit elke camera.
Trainen in een camera trainen in plaats van over alle camera’s.
Aangezien alle trainingsbeelden uit een camera moeten komen en in het bovenstaande
partitiesysteem de helft van de subsets gereserveerd worden voor de testset kunnen er
maximaal 50, 100 en 150 beelden uit een camera gebruikt worden om te trainen bij
respectievelijk de subsets met 100, 200 en 300 voertuigen. Uit tabel 4.3 volgt dat enkel
voor de testen met 1 trainingspartitie het aantal trainingsbeelden onder deze maxima
liggen. Om de resultaten van deze test te kunnen vergelijken met de resultaten uit bijlage
A hebben we ervoor gekozen om in deze test voor de subsets met 100, 200 en 300 voertuigen
met respectievelijk 15, 30 en 45 trainingsbeelden te testen. Al deze trainingsbeelden komen
dus uit een camera en zullen daardoor ook evenveel verschillende voertuigen bevatten
als het aantal trainingsbeelden terwijl in de testen uit bijlage A er drie keer minder
verschillende voertuigen zijn dan trainingsbeelden. Dit is een feit waarmee rekening zal
moeten gehouden worden in de conclusie.
4.3.2 Resultaten en discussie over de vragen
In de volgende tekst wordt er, in verschillende onderdelen, verwezen naar een groot aantal
grafieken. Om het overzicht te bewaren in deze paragraaf hebben we ervoor gekozen om
alle grafieken te bundelen in de bijlagen op de pagina 59.
Van de verschillende testen is er een test gefaald, namelijk de test met de parameters “300
gemengd”, geınterlinieerd, IPI-beelden en 10 trainingspartities gaf in matlab een ”Out of
memory”fout. Al de andere testen gaven geen fouten. Het systeem waarop we testten
had de volgende uitvoer voor het matlab ”memory”commando:
Maximum possible array: 443 MB (4.650e+008 bytes)
Memory available for all arrays: 1498 MB (1.570e+009 bytes)Het verschil tussen deze test en dezelfde test met de Traficon-beelden is dat in deze laatste
de beelden een dimensie hebben van 150×150 en de IPI-beelden een stuk groter zijn met
een dimensie van 180×180. De code kan zeker nog verder geoptimaliseerd worden zodat
deze fout niet meer voorkomt.
44

Selectie van de even of oneven lijnen van een beeld:
Uit de grafieken kan afgeleid worden dat de selectie van de even lijnen van een beeld
praktisch geen invloed heeft op de resultaten met de Traficon-beelden. Bij de IPI-beelden
echter zijn er wel enkele veranderingen te merken, zo zijn de resultaten voor de auto sub-
sets na het toepassen van deze selectie zelfs slechter dan zonder dit toe te passen. Dit
is merkbaar indien we kijken naar de resultaten met interliniering in figuur A.2(b) en
zonder in figuur A.2(a), meer bepaald bij de kolommen met het Hongaars koppelselectie-
algoritme, is er een gemiddeld verschil te zien van rond de 20%. Uit deze resultaten
kunnen we afleiden dat deze selectie voor een groot informatie verlies zorgt en dit het
eigenvehicles algoritme niet ten goede komt. Een complexere manier van deınterliniering
zal de resultaten beınvloeden maar dit zal meestal ten koste gaan van een langere uitvoe-
ringstijd.
Een mogelijk antwoord op de vraag waarom deze selectie juist voor slechtere resultaten
zorgt in de auto datatsets kan gevonden worden in figuur 4.5 waar de eigenvechicles van de
geınterlinieerde “100 auto” subset met de IPI-beelden in afgebeeld staan. In deze figuur
zijn de verschillende subfiguren sterk geınterlinieerd, dit wilt zeggen dat de interlinie een
onderscheidend element bij deze beelden is. Indien je op deze interlinie wegwerkt zal
dit onderscheidend element wegvallen en moeten er andere, mogelijk slechtere elementen
gezocht worden. Aangezien met interlinie de resultaten een stuk beter zijn sterkt dit het
vermoeden dat de interlinie, samen met nog andere kenmerken, een goede basis kan zijn
om de voertuigen te beschrijven.
Bij de vrachtwagen subset met de IPI-beelden was dit grote verschil niet te zien. Als we
dan naar de eigenvehicles van de vrachtwagens kijken in figuur 4.6 is de interliniering, in
tegenstelling tot de auto subsets, maar heel vaag te zien. Dit verschil komt vermoedelijk
omdat er tussen de verschillende vrachtwagens veel meer verschillen zijn dan tussen de
auto’s. Bij vrachtwagens zijn er dus voldoende sterkere onderscheidende elementen dan
de interliniering van de beelden. Dit is ook het geval indien we kijken naar figuur 4.7
waar we de eigenvechicles van de “100 auto’s” subset met de Traficon-beelden zien. De
interliniering heeft hierin een grijswaarde die heel dicht bij het uniform grijs ligt en zal
daarom niet zoveel effect hebben bij de creatie van de descriptor.
Om meer duidelijkheid te krijgen over het feit of de interlinie kan gebruikt worden als ka-
rakteristieke eigenschap van de beelden moeten er meer uitgebreide testen gedaan worden
op bijvoorbeeld een grotere dataset. We vermoeden dat de interlinie van de beelden ook
iets kan vertellen over de snelheid van het voertuig op dat moment. Indien de interlinie
in beide camera’s ongeveer dezelfde is kan dit impliceren dat de snelheid van het voertuig
in de verschillende camera’s niet zoveel verschilt.
Koppelselectie-algoritme:
Het Hongaars koppelselectie-algoritme scoort in alle testresultaten, zowel bij de IPI-
45

Figuur 4.5: De eigenvehicles van 15 trainingsbeelden van 5 verschillende voertuigen uit IPI-beelden, “100 auto’s”, geınterlinieerd.
beelden en de Traficon-beelden, een stuk beter dan het descriptor per descriptor algoritme.
De verbetering kan zelfs oplopen tot bijna 20% zoals te zien is tussen de resultaten met
de parameters “C3-C1 een per een” (=descriptor per descriptor algoritme) en “C3-C1
Hongaars” in figuur A.4(d). Dit groot verschil komt door de verschillende voordelen van
het Hongaars algoritme beschreven in punt 3.3.
Grootte van de trainingsset:
Training is een belangrijk onderdeel van het voorgestelde algoritme en de keuze van
hoeveel en welke beelden je daarin gebruikt is natuurlijk cruciaal. In alle testen waarvan
46

Figuur 4.6: De eigenvehicles van 15 trainingsbeelden van 5 verschillende voertuigen uit IPI-beelden, “100 vrachtwagens”, geınterlinieerd.
de resultaten in bijlage A zijn weergegeven is de grootte van de testset gelijk gebleven en
is deze van de trainingsset veranderd. Zo hebben we getest met een trainingsset grootte
van 1/20ste (=5%), 5/20ste (=25%) en 10/20ste (=50%) van de complete subset.
De resultaten waarbij gebruik gemaakt is van de subsets met 100 verschillende voertuigen
zijn heel interessant. Bij deze subsets zijn er vooral grote verschillen te vinden tussen de
resultaten met 1 of 5 trainingspartities en dit zowel voor de geınterlinieerde beelden als
deze waarbij enkel de even lijnen overblijven. Het verschil tussen de 5 of 10 trainings-
partities is in het merendeel van de gevallen maximum maar enkele procenten. Dit is
bijvoorbeeld goed te zien in figuur A.2(b) waar het verschil tussen de resultaten voor 1
trainingspartitie en 5 trainingspartities in de kolommen C3-C1 Hongaars rond de 20%
ligt. Het verschil tussen de 5 en de 10 trainingspartities is in dezelfde grafiek daarentegen
maar rond de 2%. Hetzelfde geldt voor de Traficon-beelden in bijvoorbeeld figuur A.4(b)
waar het verschil tussen de resultaten voor 1 trainingspartitie en de 5 trainingspartities
rond de 12% ligt.
In tegenstelling met de subsets met 100 voertuigen is het verschil tussen de resultaten met
1 en 5 partities in de grotere subsets niet zo sterk. Zoals te zien in figuur A.1(b) waar de
47
Figuur 4.7: De eigenvehicles van 15 trainingsbeelden van 5 verschillende voertuigen uit Traficon-beelden, “100 auto’s”, geınterlinieerd.
“200 auto’s” subset gebruikt is, is het grote verschil van 20% bij de “100 auto’s” subset
geslonken tot een kleine 4%.
Deze vaststellingen doen het vermoeden rijzen dat het op een bepaald moment niet meer
opportuun is om een nog grotere trainingsset te gebruiken. De winst die je haalt door meer
beelden dan deze waarde te gebruiken is dan verwaarloosbaar. We hebben vervolgens
enkele extra testen gedaan om meer duidelijkheid te hebben over deze waarde. Bij de
subsets met 100 auto’s en 100 vrachtwagens hebben we naast de testen met een, vijf en
tien trainingspartities waar respectievelijk 15, 75 en 150 trainingsbeelden voor gebruikt
zijn ook eens dezelfde testen gedaan met 24 (= 8 ∗ 3) en 30 (= 10 ∗ 3) trainingsbeelden.
Bij de “200 auto’s” subset hebben we naast de testen met 30, 150 en 300 trainingsbeelden
48

ook getest met 15 (= 5∗3) en 24 (= 8∗3) voertuigen. De factor drie in deze berekeningen
komt zoals reeds uitgelegd van het feit dat er drie camera’s zijn en er met alle drie
de camera’s getraind wordt. Zoals in de vorige testen wordt er opnieuw 20 keer een
partitie doorgeschoven en is het resultaat van de nieuwe testen het gemiddelde van deze
20 uitvoeringen. In bijlage B beginnend op de pagina 63 zijn de resultaten van deze extra
testen te zien.
De resultaten van de nieuwe testen tonen aan dat de waarde, waarbij je weinig winst in
performantie krijgt indien je nog meer trainingsbeelden gebruikt, sterk afhankelijk is van
de eigenschappen van de gebruikte beelden. Bijvoorbeeld deze waarde ligt bij de IPI-
beelden waarbij enkel de even lijnen geselecteerd zijn in figuur B.2(a) vermoedelijk rond
de 30 trainingsbeelden maar bij de geınterlinieerde versie in figuur B.2(b) ligt deze dichter
bij de 75 trainingsbeelden. Indien we kijken naar de figuren B.3(c) (“100 auto’s”, even
lijnen), B.3(d) (“100 auto’s”, geınterlinieerd), B.3(a) (“100 vrachtwagens”, even lijnen) en
B.3(b) (“100 vrachtwagens”, even lijnen) is er bij de Traficon-beelden dan weer praktisch
geen verschil te zien tussen de waarde bij de geınterlinieerde beelden en deze waarbij enkel
de even lijnen overblijven. Over het algemeen ligt de waarde bij de Traficon-beelden in
de “100 auto’s” subset dicht bij de 30 trainingsvoertuigen en bij de “100 vrachtwagens”
subset dichter bij de 75 trainingsvoertuigen. Het is duidelijk dat er een specifieke waarde
bestaat per subset maar meer testen zijn nodig om deze waarde exacter te berekenen.
Classificatie in auto’s en vrachtwagens.
We vermoeden dat het mogelijk is om op een automatische manier de invoerbeelden te
classificeren in vrachtwagens of auto’s. Om een idee te hebben hoe het voorgestelde algo-
ritme presteert op beelden van enkel auto’s of vrachtwagens hebben we de invoerbeelden
manueel geclassificeerd. In de praktijk kunnen de invoerbeelden op een automatische ma-
nier geclassificeerd worden waarna elke klasse apart verwerkt wordt door het voorgestelde
algoritme, inclusief trainingsset met enkel beelden van deze klasse.
Ongeacht of we met de IPI-beelden of met de Traficon-beelden werken zijn er grote ver-
schillen te zien tussen de resultaten met de auto subset en met de vrachtwagen subset.
In tabellen 4.4 en 4.5 hebben we enkele resultaten opgesomd. We hebben ervoor gekozen
om de resultaten met parameters “5 trainingspartities, C3-C1 Hongaars, geınterlinieerd”
in de tabel te plaatsen. De resultaten met 10 trainingspartities gaven namelijk wat pro-
blemen met het geheugen. In de tabel valt vooral op dat de subsets waarin enkel auto’s
zitten een heel stuk lager scoren dan de andere. Zo zijn in de Traficon-beelden de auto
resultaten de laagste van de volledige tabel. In de volgende paragraaf gaan we dieper in
op het verschil tussen de resultaten met de IPI-beelden en de Traficon-beelden.
Het nut van classificatie in auto’s en vrachtwagens kunnen we niet uit deze resultaten
destilleren. Dit komt omdat in de gemengde subsets het aantal auto’s en vrachtwagens in
de training- en testset bij elke test veranderde. We kunnen wel vermoeden dat het niet
49

5 trainingspartities, C3-C1 Hongaars, 100 voertuigen, geınterlinieerdAuto’s Vrachtwagens Gemengd
IPI-beelden∼72% ∼90% ∼82%
(Zie fig. A.2(b)) (Zie fig. A.2(d)) (Zie fig. A.2(f))
Traficon-beelden∼36% ∼82% ∼48%
(Zie fig. A.4(b)) (Zie fig. A.4(d)) (Zie fig. A.4(f))
Tabel 4.4: Resultaten van de 100 voertuigen subsets.
5 trainingspartities, C3-C1 Hongaars200 auto’s 300 Gemengd
IPI-beelden∼64% ∼72%
(Zie fig. A.1(b)) (Zie fig. A.1(c))
Traficon-beelden∼32% ∼44%
(Zie fig. A.3(b)) (Zie fig. A.3(c))
Tabel 4.5: Resultaten van “200 auto’s” en “300 gemengd” subsets.
classificeren van de IPI-beelden maakt dat er meer auto’s correct gekoppeld worden omdat
het resultaat voor de “100 gemengd” subset midden tussen deze van de “100 auto’s” en
“100 vrachtwagens” in ligt, dit hoewel er rond de 70% auto’s in deze subset zitten.
Wat is de invloed van de problemen die enkel bij de Traficon-dataset voorko-
men?
Saturatie van het beeld door de lichten, foutieve bounding box, problemen met zwaai-
lichten en grote verschillen in afstand van de voertuigen tot de camera zijn de problemen
die enkel bij de Traficon-beelden voorkomen en niet bij de IPI-beelden. In de tabellen 4.4
en 4.5 is te zien dat de resultaten met de IPI-beelden in het merendeel van de gevallen
beter dan deze met de Traficon-beelden. Dit is vooral te zien aan het grote verschil van
meer dan 30% bij de auto subsets. Bij de vrachtwagens datasets is dit verschil maxi-
mumaal 8% geworden. De hoge verschillen bij de gemengde subsets kunnen misschien
verklaard worden door het feit dat deze subsets voor ∼70% bestaan uit auto’s maar om-
dat in deze subsets het aantal auto’s en vrachtwagens in de training- en testset bij elke
test veranderde, kunnen we dit niet zeker weten.
Om deze resultaten beter te begrijpen moeten we eerst kijken hoeveel beelden van auto’s
en vrachtwagens er in de Traficon-beelden last hebben van saturatie van het beeld door
de lichten, foutieve bounding box en grote verschillen in afstand van de voertuigen tot de
camera. Problemen i.v.m. zwaailichten komen maar heel sporadisch voor en hebben we
daarom niet geteld. Tabel 4.6 geeft een overzicht van deze aantallen.
Uit de tabel is af te leiden dat de subset met 100 vrachtwagens heel weinig problemen heeft.
Dit verklaart het kleine verschil in de resultaten tussen de IPI-beelden en de Traficon-
beelden. In de auto en gemengde subsets is op 20 a 30% van de beelden gesatureerd door
50

100Vrachtwa-
gens
100 Gemengd 100 Auto’s 200 Auto’s 300 Gemengd
groteverschillen
in deafstand totde camera
2 6 9 27 (=13,5%) 28 (=9,3%)
Saturatiedoor delichten
0 23 32 60 (=30%) 62 (=20,6%)
grotebounding
box fouten
1 6 7 17 (=8,5%) 18 (=6%)
Tabel 4.6: Het aantal voertuigen met problemen in verband met afstand tot de camera, lichtenof bounding box in de verschillende subsets in de Traficon-beelden.
de lichten. Aangezien er in de IPI-beelden weinig gesaturatureerde beelden voorkomen
wekt dit het vermoeden dat juist deze beelden zorgen voor het slechtere resultaat bij de
Traficon-beelden. Daarnaast moet er ook rekening gehouden worden met het feit dat de
IPI-beelden altijd in het begin van het gezichtsveld van de camera genomen zijn en de
Traficon-beelden op een random plaats in dit gezichtsveld, dit heeft een invloed op hoeveel
details er te zien zijn in het beeld. Om te weten wat juist de oorzaak is van de slechtere
herkenning in de Traficon-beelden moeten meer testen gedaan worden. In deze testen kan
er dan onderzocht wordt hoe robuust het identificatie-algoritme is tegen grote verschillen
in de afstand tot de camera, saturatie door de lichten en fouten met de bounding box.
Welke beelden stoppen we het best in een trainingsset?
Zoals reeds aangehaald hebben we in dit onderdeel voor de subsets met 100, 200 en
300 voertuigen gebruik gemaakt van respectievelijk 15, 30 en 45 trainingsbeelden. Deze
trainingsbeelden kwamen allemaal uitsluitend uit een van de drie camera’s. De resultaten
van deze testen zijn te zien in bijlage C beginnend op de pagina 66. Indien we enkel kijken
naar het verschil tussen de training met camera 1, twee of drie zien we dat ongeacht met
welke camerabeelden we testen dit verschil nooit meer dan 6% bedraagt. Sterker nog in
het merendeel van de gevallen klimt het verschil niet hoger dan enkele procenten.
Als we nu de resultaten met drie trainingscamera’s erbij nemen, zien we dat deze resultaten
meestal lichtjes lager liggen dan wanneer er met een camera getraind is. De volgende
opmerking moet wel in acht genomen worden: stel dat er 15 trainingsbeelden gebruikt
zijn en er getraind wordt op alle drie de camera’s dan betekent dit dat er eigenlijk op
5 verschillende voertuigen getraind is geweest. Dit komt omdat er van elk voertuig drie
beelden genomen zijn, namelijk een uit elke camera. Indien er daarentegen getraind wordt
51

in een camera bevatten deze 15 trainingsbeelden ook 15 verschillende voertuigen. Dit feit
kan een verklaring zijn waarom het resultaat met drie trainingscamera’s lichtjes lager is
dan met een trainingscamera.
52

Hoofdstuk 5
Conclusie, praktijktoepassing entoekomstig werk
5.1 Eindconclusie
In deze masterproef hebben we met behulp van een adaptatie van de eigenfacestechniek
getracht om voertuigen te identificeren in een camera zodat we deze kunnen terugvinden
in een volgende camera. Dit identificeren gebeurd op basis van een beeld van het voertuig
dat genomen is op een willekeurige locatie in het gezichtsveld van de camera. De koppeling
van beelden uit twee verschillende camera’s gebeurd op basis van de descriptoren van deze
beelden. Als descriptor van een beeld hebben we de gewichtsvector van dit beeld genomen,
deze bepaald in welke mate een specifiek kenmerk (voorgesteld door een eigenvector) in
het origineel beeld voorkomt.
Hongaars algoritme.
Om de uitvoeringstijd te beperken hebben we ervoor gekozen om de descriptoren per
camera te verdelen in deelverzamelingen. Deze deelverzamelingen kunnen in de praktijk
gemaakt worden op basis van de gemiddelde snelheid van voertuigen in de tunnel. Vervol-
gens worden door middel van een een Hongaars algoritme de descriptoren van voertuigen
uit een deelverzameling van de ene camera gekoppeld koppelen aan de descriptoren uit
een deelverzameling van de vorige camera. Het Hongaars algoritme is een combinatorisch
optimalisatie-algoritme dat het assignatieprobleem oplost in polynomiale tijd. Het zorgt
voor de koppeling met de kleinste totale Euclidische afstand van alle descriptoren uit de
ene verzameling aan deze uit de andere verzameling. Op die manier is de assignatie ge-
optimaliseerd over beide deelverzamelingen.
Toepassen van het Hongaars algoritme zorgt voor een stijging van rond de 20% van het
aantal correct aan elkaar gekoppelde beelden. Deze stijging is ten opzichte van een tech-
niek die elke keer een descriptor gecreeerd is de best passende descriptor uit de vorige
53

camera zoekt en deze aan elkaar koppelt. We raden dan ook aan om het Hongaars algo-
ritme in de praktijk toe te passen.
Interlinie.
De invoerbeelden van het voorgestelde algoritme zijn geınterlinieerd en daarom hebben
we getest wat het effect is op de resultaten indien we deze interlinie op een eenvoudige
manier verwijderen. Om de interlinie te verwijderen hebben we enkel de even lijnen van
een beeld geselecteerd. Toepassing van deze selectie had geen verbeterend effect op de
resultaten en daarom raden we ook aan om deze selectie niet toe te passen. Een complexere
deınterliniering kan wel verbeteringen brengen maar deze zullen vermoedelijk ten koste
gaan van een langere uitvoeringstijd.
Classificatie in auto’s en vrachtwagens en de invloed van de afstand tussen het
voertuig en de camera.
We merken op dat bij een kleine afstand tussen het voertuig en de camera alle resultaten
hoger zijn dan indien deze afstand groter is. Hieruit kunnen we concluderen dat het
beperken van de afstand tussen het voertuig en de camera zijn nut heeft. Dit komt
vermoedelijk omdat er meer details van het voertuig op het beeld te zien zijn dan bij
een kleinere afstand tussen het voertuig en de camera. Bij een grotere afstand tussen het
voertuig en de camera scoren vooral de beelden van enkel auto’s en de niet geclassificeerde
beelden een heel stuk lager dan bij een kleine afstand. Uit het lage resultaat van de
beelden met enkel auto’s kunnen we concluderen dat vooral de auto’s veel last hebben
van verminderende details door de grote afstand.
Het is moeilijk om besluiten te trekken over de invloed van het al dan niet classificeren
op de resultaten van auto’s en vrachtwagens apart want bij de testen zonder classificatie
veranderde aantal auto’s en vrachtwagens in de training- en testset bij elke test. We
kunnen dus bijvoorbeeld niet specifiek zeggen dat bij classificatie meer auto’s correct
gekoppeld worden dan wanneer we geen classificatie toepassen.
Selectie van de trainingsbeelden.
Ten slotte kan het interessant zijn om te weten welke beelden, van welke camera’s we
een trainingsset moeten stoppen. Uit onze testen concluderen we dat de beelden die in
de trainingsset zitten niet uit dezelfde camera moeten komen als de beelden waarop we
testen. We kunnen dus een trainingsset samenstellen van beelden uit de eerste camera om
de beelden van een tweede camera te koppelen aan deze van een derde camera. Dit maakt
het mogelijk om de eigenvectoren gecreeerd door een set trainingsbeelden uit een camera
te gebruiken om de beelden uit een volledige groep camera’s met elkaar te vergelijken.
Indien we nu trainen op in het totaal evenveel beelden maar nu uit alle drie de camera’s
in plaats van uit een camera zien we dat de resultaten lichtjes lager uitvallen. Dit verschil
54

kan verklaard worden omdat er bij de training in de drie camera’s er op drie keer minder
verschillende voertuigen getraind is dan in het geval van een training in een camera.
Hieruit concluderen we dus dat het belangrijker is om te trainen op veel verschillende
voertuigen, uit gelijk welke camera, dan te maken dat er van elke camera beelden in de
trainingsset zitten.
Grootte van de trainingsset.
Vervolgens hebben we enkele testen gedaan om te onderzoeken hoe groot een trai-
ningsset moet zijn. Uit de testen kan in eerste instantie afgeleid worden dat, hoe meer
trainingsbeelden, hoe beter de resultaten worden. Dit effect verminderd echter vanaf een
bepaald aantal trainingsbeelden, meer trainingsbeelden gebruiken zorgt dan voor weinig
winst in performantie. Deze waarde is afhankelijk van de subset waarop er getest wordt,
zo neigt deze meer naar de 30 beelden bij een subset met enkel auto’s en bij een subset
met enkel vrachtwagens neigt deze meer naar de 75 beelden. Bij al deze testen is er voor
elk voertuig een beeld uit elk van de drie trainingscamera’s gebruikt. Er staan dus op
deze 30 en 75 trainingsbeelden respectievelijk 10 en 25 verschillende voertuigen. Indien
de beelden voordien geclassificeerd worden in auto’s of vrachtwagens stellen we voor om,
op basis van de conclusie uit de vorige paragraaf, in de trainingsset beelden van minstens
10 verschillende auto’s of 25 verschillende vrachtwagens te gebruiken.
5.2 Praktijktoepassing
De techniek van de eigenvehicles, die in deze masterproef voorgesteld en uitgetest is, moet
natuurlijk op een of andere manier in de praktijk gebracht worden. We stellen hieronder
een mogelijk stappenplan voor om dit te doen en ga ervan uit dat de volgende situaties
gelden:
• De ideale grootte van de trainingsset is gekend.
• Er is voldoende hard- en software aanwezig, zodat het identificatie-algoritme niet
achterop loopt ten opzichte van de verkeersstroom.
• Er bestaat een techniek om verzamelingen eigenvehicles met elkaar te vergelijken en
zo te voorspellen welke verzamelingen redundant zijn. Dit wil zeggen dat gelijkaar-
dige resultaten geboekt worden indien je traint met de ene verzameling of met de
redundante verzameling.
• We gaan er tenslotte ook nog vanuit dat het identificatie-algoritme de beelden uit
twee opvolgende secties in een tunnel, elk met hun eigen verzameling eigenvehicles,
voldoende efficient aan elkaar kan koppelen.
Hieronder besteden we meer aandacht aan de volgende drie belangrijke fasen:
55

Figuur 5.1: Een tunnel inclusief alle camera’s en de bijhorende verzameling van eigenvehicles(a. . .f).
Opstart in een tunnel:
De trainingsset(s) en de daarbij horende verzameling(en) met eigenvehicles moet(en)
gecreeerd worden. We stellen het volgende stappenplan voor:
1. Maak in eerste instantie een verzameling eigenvehicles voor elke camera in de tunnel.
Zie figuur 5.1, de blokken a tot f zijn de verzamelingen met de eigenvehicles van een
trainingsset uit een camera.
2. Vergelijk de verschillende verzamelingen uit de eerste stap onderling en reduceer het
aantal verzamelingen indien mogelijk tot het absolute minimum, door redundante
verzamelingen te verwijderen. Op die manier wordt een verzameling eigenvehicles
door meerdere camera’s gebruikt en wordt er geheugen uitgespaard. Toegepast
op figuur 5.1 stellen we dat bijvoorbeeld de verzamelingen a,b,e en f redundant
van elkaar. Er kan dan gekozen worden om een verzameling in het geheugen te
plaatsen, bijvoorbeeld verzameling a, en de andere drie te verwijderen. Stel dat
de verzamelingen c en d ook redundant zijn van elkaar, zal ook hier maar een
verzameling in het geheugen bijgehouden worden. Deze tunnel is dan in twee secties
opgedeeld, namelijk een sectie met de camera’s 1, 2, 5 en 6 en een sectie met de
camera’s 3 en 4. Alle beelden van de camera’s uit een sectie worden met dezelfde
verzameling eigenvehicles verwerkt. In dit voorbeeld is dat voor de eerste sectie de
verzameling a en bij de tweede sectie verzameling c.
Tijdens de normale looptijd:
Het voorgestelde algoritme is nu in regime, om geheugen te besparen worden descripto-
ren automatisch na een tijd verwijderd en indien nodig wordt de verzameling eigenvehicles
manueel aangepast naar het seizoen of weer op dat moment.
56

Bij onderhoud van de tunnel of het camerasysteem:
Op gezette tijden krijgt een tunnel een goede opknapbeurt, camera’s worden vervangen,
wegmarkeringen aangepast of er wordt een volledig nieuwe asfaltlaag gegoten, het voorge-
stelde algoritme moet hiervoor voorzien zijn. We stellen voor, dat in dit geval, voor elke
camera waarin deze verandering een effect heeft, een nieuwe verzameling eigenvehicles
gecreeerd wordt, gebaseerd op een trainingsset uit die camera. Daarna wordt deze nieuwe
verzameling eigenvehicles vergeleken met de reeds aanwezige verzamelingen eigenvehicles
in die tunnel. Nu kunnen er twee situaties voorkomen:
• De nieuwe verzameling is redundant met een van de reeds aanwezige verzamelingen
in de tunnel. Hoogstens moet in dit geval de veranderde camera in een andere sectie
van de tunnel ingedeeld worden. Ten slotte wordt de nieuwe verzameling verwijderd
en is er dus geen extra geheugen gebruikt.
• De nieuwe verzameling is niet redundant en stelt hierdoor dus een nieuwe sectie in
de tunnel voor. De nieuwe verzameling wordt bewaard en het voorgestelde algoritme
gaat door zoals voorheen.
Stel dat we dit toepassen op het voorbeeld van hierboven met de twee verschillende secties,
namelijk een met de camera’s 1, 2, 5 en 6 en een met de camera’s 3 en 4, waarin de tweede
camera vervangen wordt. Dan kan bijvoorbeeld in de eerste situatie de eerste sectie enkel
nog de camera’s 1, 5 en 6 bevatten en de tweede sectie de camera’s 2, 3 en 4 en kan bij
de tweede situatie een derde sectie ingevoerd worden met enkel camera twee, waarbij de
eerste sectie dan gereduceerd is tot de camera’s 1, 5 en 6.
5.3 Toekomstig werk
Ondanks de vele uren die in deze masterproef gekropen zijn, zijn er nog tal van pis-
tes die onderzocht moeten worden. Hieronder volgen enkele suggesties over toekomstige
onderzoeken:
• Hoe kunnen resultaten van de subsets met enkel auto’s verbeterd worden?
• Wat is de hoofdoorzaak van de slechtere resultaten bij de auto subset tussen de
Traficon-beelden en de IPI-beelden?
• Het voorgestelde algoritme is nu getest op filmfragmenten van 11 minuten lang.
Hoe presteert het algoritme wanneer de eigenvehicles uren, dagen of jaren vroeger
gemaakt zijn?
• Hoe robuust is het voorgestelde algoritme bij veranderingen in het weer of van
seizoen.
57

• Hoe presteert het voorgestelde algoritme in andere omgevingen, bijvoorbeeld in een
volledig andere tunnel of bij een plots veranderende achtergrond in een en dezelfde
tunnel? Moet een tunnel in verschillende secties opgedeeld worden waarbij elke
sectie een specifieke trainingsset heeft of niet? Hoe kunnen die secties dan efficient
aan elkaar gekoppeld worden?
• Welke hardware is nodig zodat het voorgestelde algoritme de verkeersstroom kan
bijhouden?
• Geeft complexere deınterliniering betere resultaten zonder het algoritme te veel te
vertragen?
58

Bijlage A
A.1 IPI-beelden
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,200 auto’s,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (10 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (100 verschillende voertuigen, uit elke camera 1 beeld)
(a)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,200 auto’s,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (10 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (100 verschillende voertuigen, uit elke camera 1 beeld)
(b)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,300 gemengd,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (15 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (75 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (150 verschillende voertuigen, uit elke camera 1 beeld)
(c)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,300 gemengd,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (15 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (75 verschillende voertuigen, uit elke camera 1 beeld)
(d)
Figuur A.1: De resultaten voor de testen op de IPI-beelden waarbij getraind is op beelden uitalle drie de camera’s met het Hongaars en descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “200 auto’s” en (c,d) “300 mixed” met de parameters (a,c) “selectievan enkel de even lijnen” en (b,d) interlineerd.
59
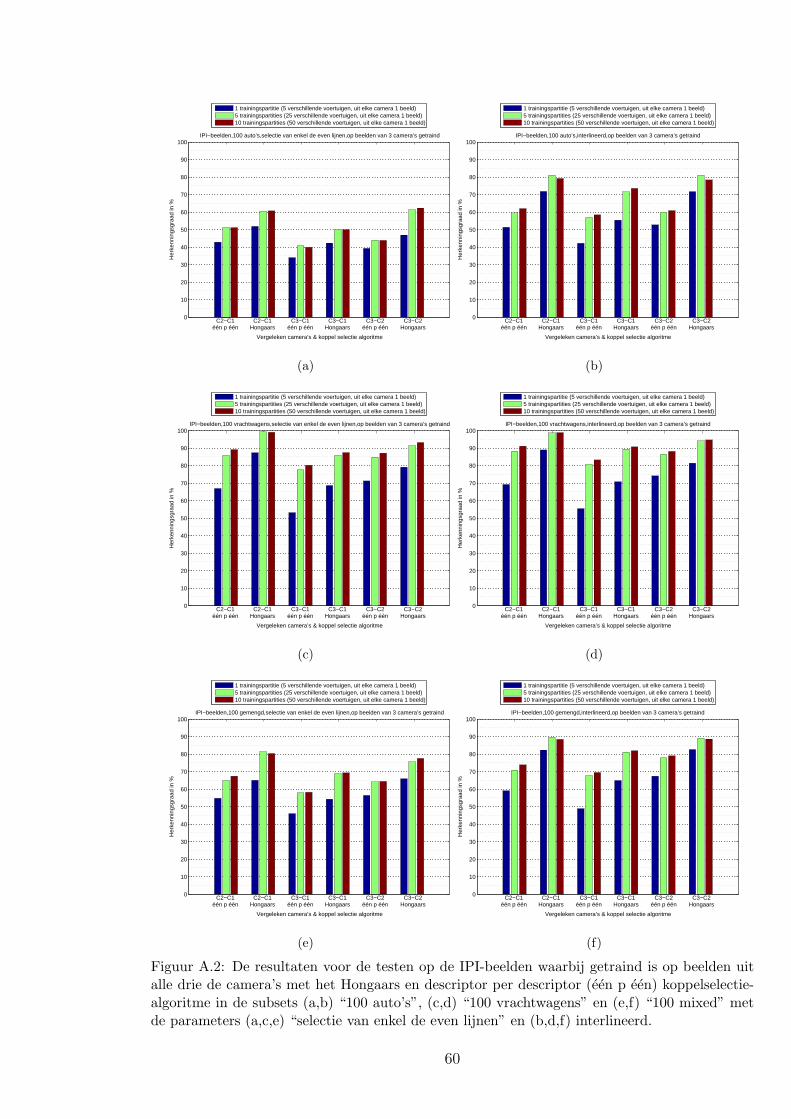
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 auto’s,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(a)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 auto’s,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(b)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 vrachtwagens,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(c)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 vrachtwagens,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(d)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 gemengd,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(e)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 gemengd,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(f)
Figuur A.2: De resultaten voor de testen op de IPI-beelden waarbij getraind is op beelden uitalle drie de camera’s met het Hongaars en descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “100 auto’s”, (c,d) “100 vrachtwagens” en (e,f) “100 mixed” metde parameters (a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd.
60
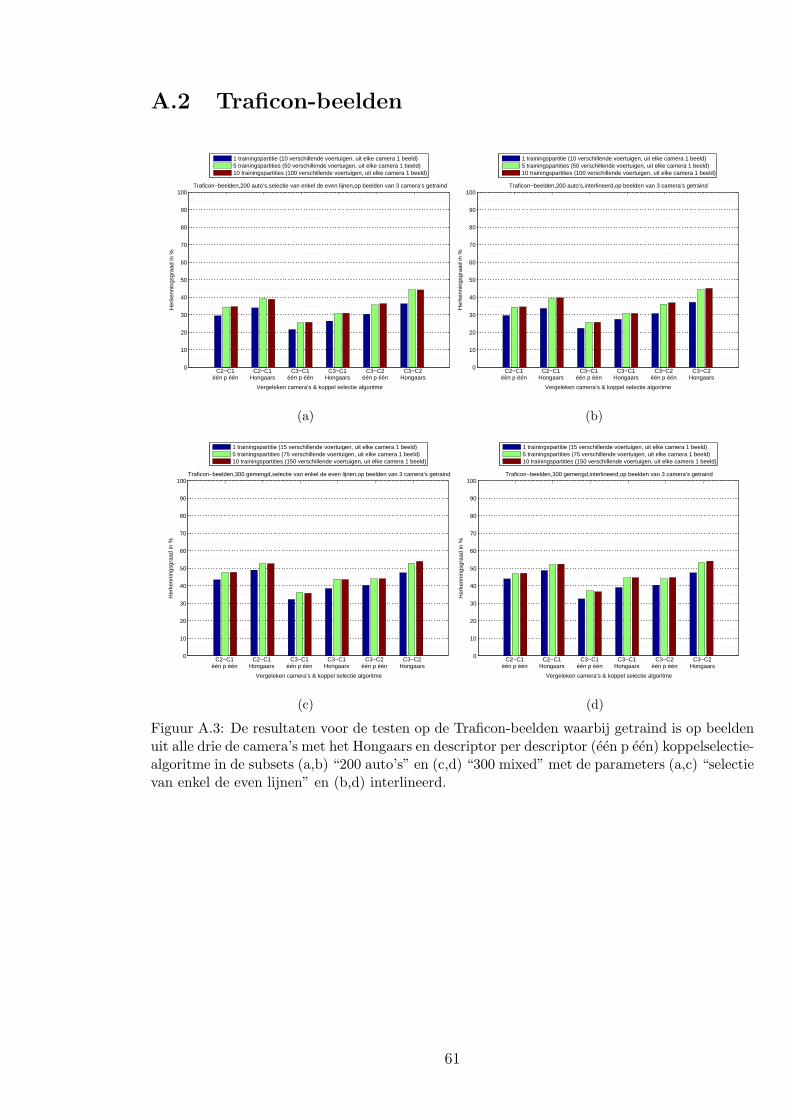
A.2 Traficon-beelden
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,200 auto’s,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (10 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (100 verschillende voertuigen, uit elke camera 1 beeld)
(a)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,200 auto’s,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (10 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (100 verschillende voertuigen, uit elke camera 1 beeld)
(b)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,300 gemengd,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (15 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (75 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (150 verschillende voertuigen, uit elke camera 1 beeld)
(c)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,300 gemengd,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (15 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (75 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (150 verschillende voertuigen, uit elke camera 1 beeld)
(d)
Figuur A.3: De resultaten voor de testen op de Traficon-beelden waarbij getraind is op beeldenuit alle drie de camera’s met het Hongaars en descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “200 auto’s” en (c,d) “300 mixed” met de parameters (a,c) “selectievan enkel de even lijnen” en (b,d) interlineerd.
61
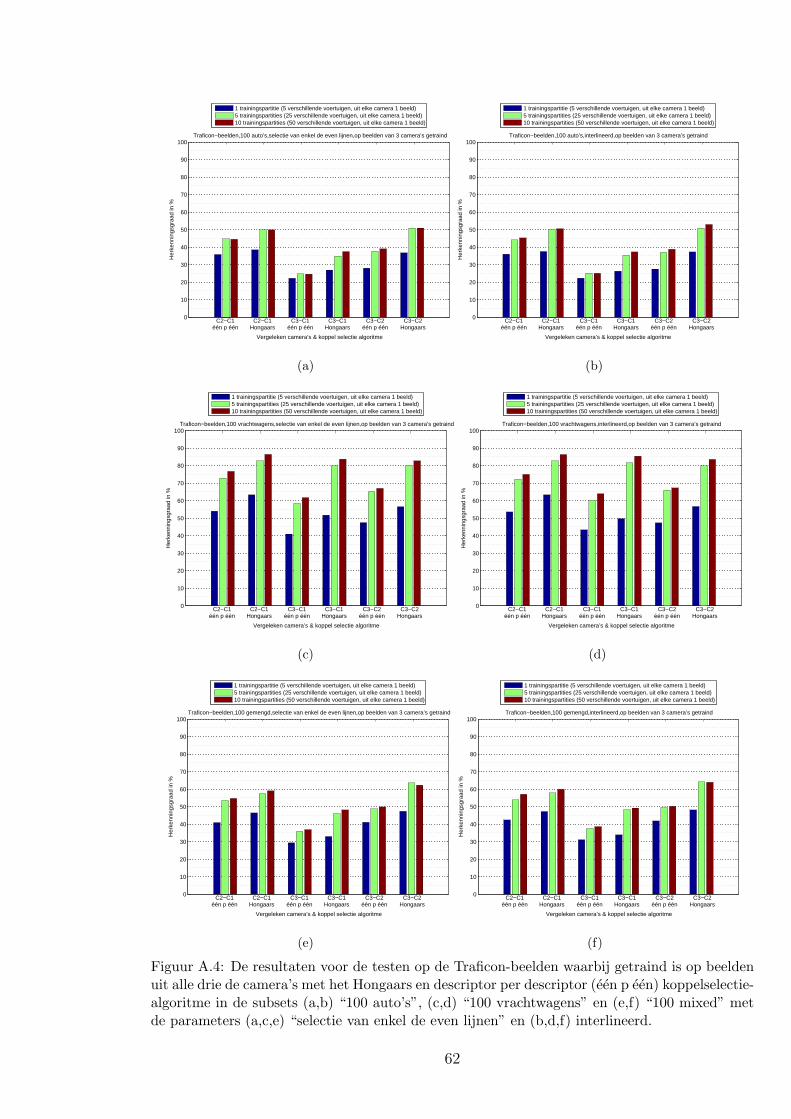
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 auto’s,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(a)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 auto’s,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(b)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 vrachtwagens,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(c)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 vrachtwagens,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(d)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 gemengd,selectie van enkel de even lijnen,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(e)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 gemengd,interlineerd,op beelden van 3 camera’s getraind
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
1 trainingspartitie (5 verschillende voertuigen, uit elke camera 1 beeld)5 trainingspartities (25 verschillende voertuigen, uit elke camera 1 beeld)10 trainingspartities (50 verschillende voertuigen, uit elke camera 1 beeld)
(f)
Figuur A.4: De resultaten voor de testen op de Traficon-beelden waarbij getraind is op beeldenuit alle drie de camera’s met het Hongaars en descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “100 auto’s”, (c,d) “100 vrachtwagens” en (e,f) “100 mixed” metde parameters (a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd.
62

Bijlage B
B.1 IPI-beelden
15 24 30 75 1500
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 vrachtwagens,selectie van enkel de even lijnen,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(a)
15 24 30 75 1500
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 vrachtwagens,interlineerd,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(b)
Figuur B.1: De resultaten voor het koppelen via het Hongaars koppelselectie-algoritme van decamera 3 beelden aan de camera 1 beelden uit de IPI-beelden waarbij getraind is op beelden uitalle drie de camera’s maar met een verschillend aantal trainingsbeelden. Deze testen zijn gedaanop de subset (a,b) “100 vrachtwagens” met de parameters (a) “selectie van enkel de even lijnen”en (b) interlineerd.
63
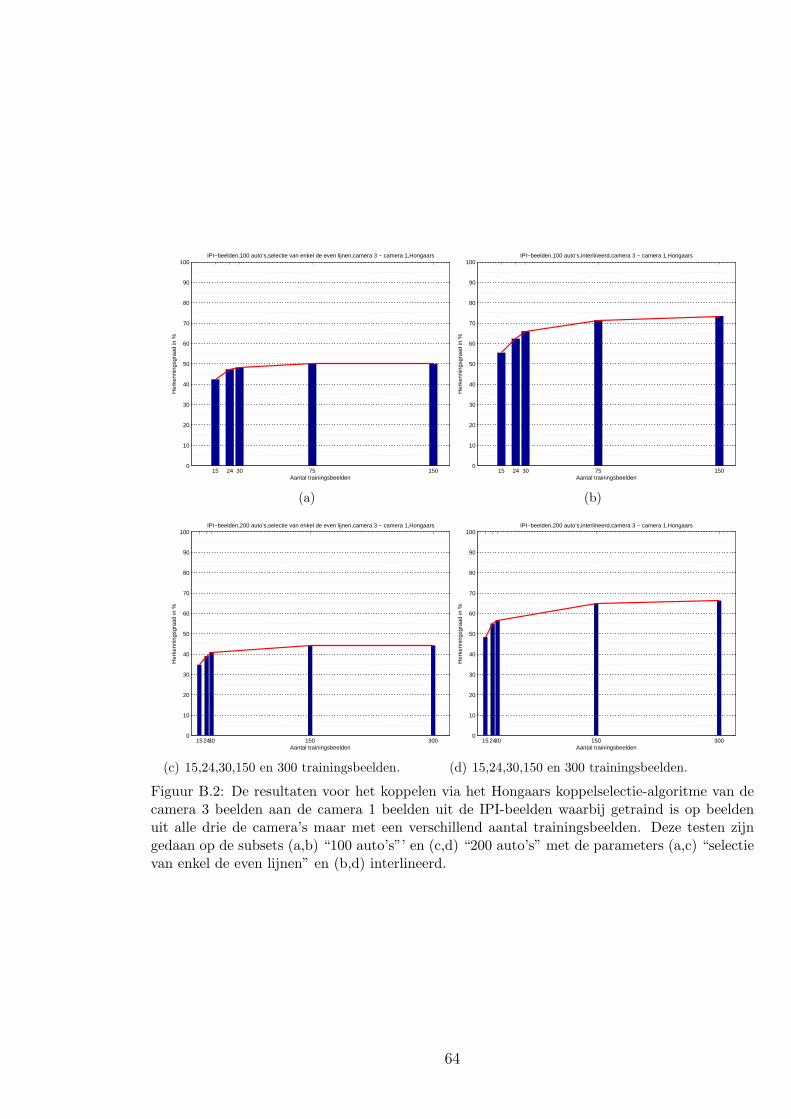
15 24 30 75 1500
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 auto’s,selectie van enkel de even lijnen,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(a)
15 24 30 75 1500
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 auto’s,interlineerd,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(b)
15 2430 150 3000
10
20
30
40
50
60
70
80
90
100IPI−beelden,200 auto’s,selectie van enkel de even lijnen,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(c) 15,24,30,150 en 300 trainingsbeelden.
15 2430 150 3000
10
20
30
40
50
60
70
80
90
100IPI−beelden,200 auto’s,interlineerd,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(d) 15,24,30,150 en 300 trainingsbeelden.
Figuur B.2: De resultaten voor het koppelen via het Hongaars koppelselectie-algoritme van decamera 3 beelden aan de camera 1 beelden uit de IPI-beelden waarbij getraind is op beeldenuit alle drie de camera’s maar met een verschillend aantal trainingsbeelden. Deze testen zijngedaan op de subsets (a,b) “100 auto’s”’ en (c,d) “200 auto’s” met de parameters (a,c) “selectievan enkel de even lijnen” en (b,d) interlineerd.
64
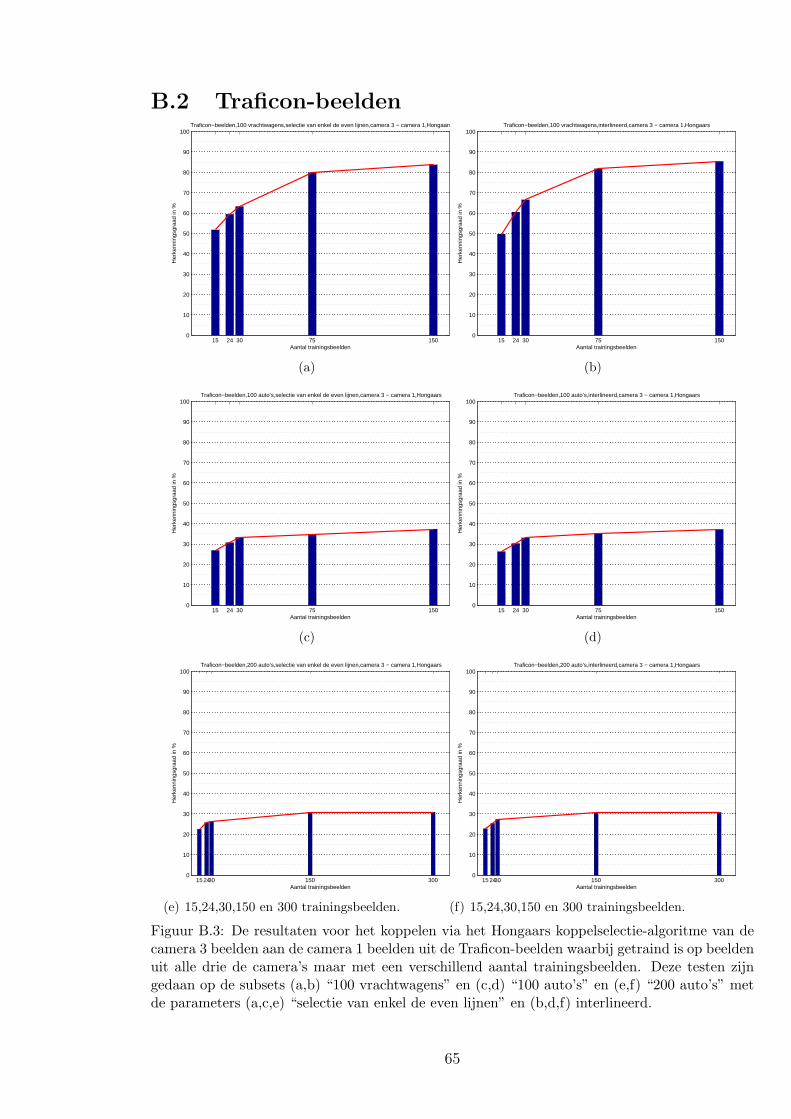
B.2 Traficon-beelden
15 24 30 75 1500
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 vrachtwagens,selectie van enkel de even lijnen,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(a)
15 24 30 75 1500
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 vrachtwagens,interlineerd,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(b)
15 24 30 75 1500
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 auto’s,selectie van enkel de even lijnen,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(c)
15 24 30 75 1500
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 auto’s,interlineerd,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(d)
15 2430 150 3000
10
20
30
40
50
60
70
80
90
100Traficon−beelden,200 auto’s,selectie van enkel de even lijnen,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(e) 15,24,30,150 en 300 trainingsbeelden.
15 2430 150 3000
10
20
30
40
50
60
70
80
90
100Traficon−beelden,200 auto’s,interlineerd,camera 3 − camera 1,Hongaars
Her
kenn
ings
graa
d in
%
Aantal trainingsbeelden
(f) 15,24,30,150 en 300 trainingsbeelden.
Figuur B.3: De resultaten voor het koppelen via het Hongaars koppelselectie-algoritme van decamera 3 beelden aan de camera 1 beelden uit de Traficon-beelden waarbij getraind is op beeldenuit alle drie de camera’s maar met een verschillend aantal trainingsbeelden. Deze testen zijngedaan op de subsets (a,b) “100 vrachtwagens” en (c,d) “100 auto’s” en (e,f) “200 auto’s” metde parameters (a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd.
65
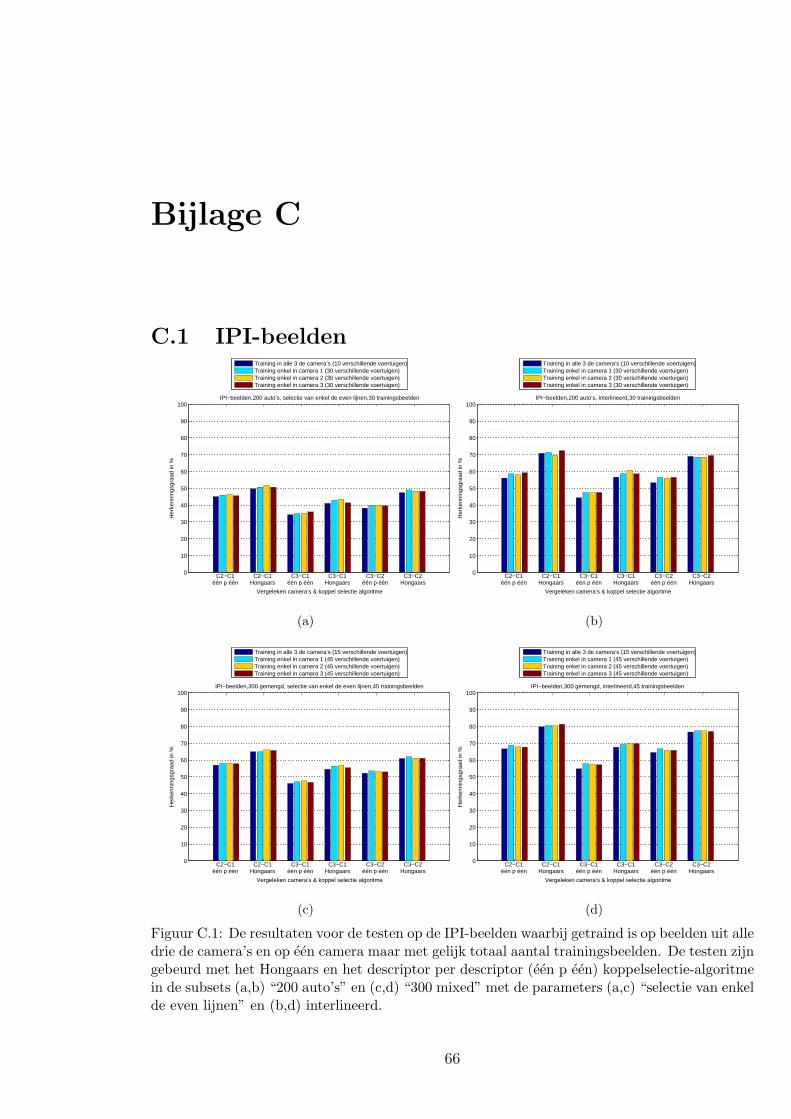
Bijlage C
C.1 IPI-beelden
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,200 auto’s, selectie van enkel de even lijnen,30 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (10 verschillende voertuigen)Training enkel in camera 1 (30 verschillende voertuigen)Training enkel in camera 2 (30 verschillende voertuigen)Training enkel in camera 3 (30 verschillende voertuigen)
(a)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,200 auto’s, interlineerd,30 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (10 verschillende voertuigen)Training enkel in camera 1 (30 verschillende voertuigen)Training enkel in camera 2 (30 verschillende voertuigen)Training enkel in camera 3 (30 verschillende voertuigen)
(b)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,300 gemengd, selectie van enkel de even lijnen,45 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (15 verschillende voertuigen)Training enkel in camera 1 (45 verschillende voertuigen)Training enkel in camera 2 (45 verschillende voertuigen)Training enkel in camera 3 (45 verschillende voertuigen)
(c)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,300 gemengd, interlineerd,45 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (15 verschillende voertuigen)Training enkel in camera 1 (45 verschillende voertuigen)Training enkel in camera 2 (45 verschillende voertuigen)Training enkel in camera 3 (45 verschillende voertuigen)
(d)
Figuur C.1: De resultaten voor de testen op de IPI-beelden waarbij getraind is op beelden uit alledrie de camera’s en op een camera maar met gelijk totaal aantal trainingsbeelden. De testen zijngebeurd met het Hongaars en het descriptor per descriptor (een p een) koppelselectie-algoritmein de subsets (a,b) “200 auto’s” en (c,d) “300 mixed” met de parameters (a,c) “selectie van enkelde even lijnen” en (b,d) interlineerd.
66
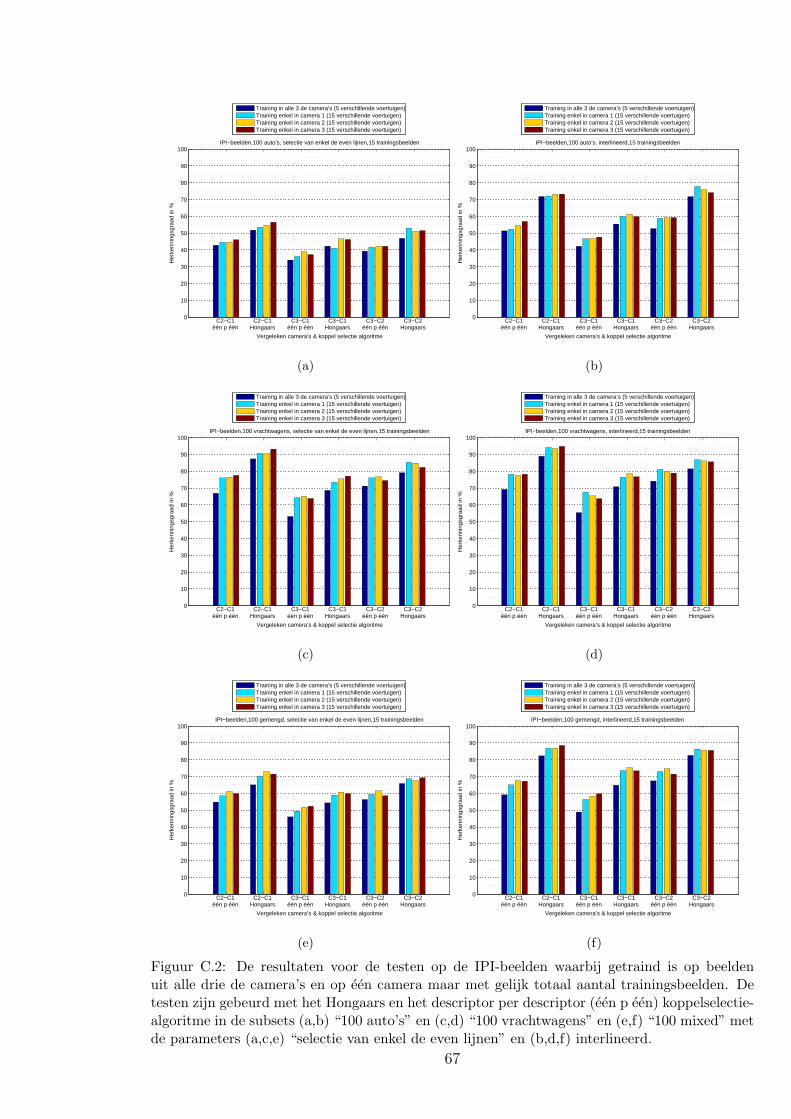
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 auto’s, selectie van enkel de even lijnen,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(a)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 auto’s, interlineerd,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(b)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 vrachtwagens, selectie van enkel de even lijnen,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(c)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 vrachtwagens, interlineerd,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(d)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 gemengd, selectie van enkel de even lijnen,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(e)
0
10
20
30
40
50
60
70
80
90
100IPI−beelden,100 gemengd, interlineerd,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(f)
Figuur C.2: De resultaten voor de testen op de IPI-beelden waarbij getraind is op beeldenuit alle drie de camera’s en op een camera maar met gelijk totaal aantal trainingsbeelden. Detesten zijn gebeurd met het Hongaars en het descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “100 auto’s” en (c,d) “100 vrachtwagens” en (e,f) “100 mixed” metde parameters (a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd.
67
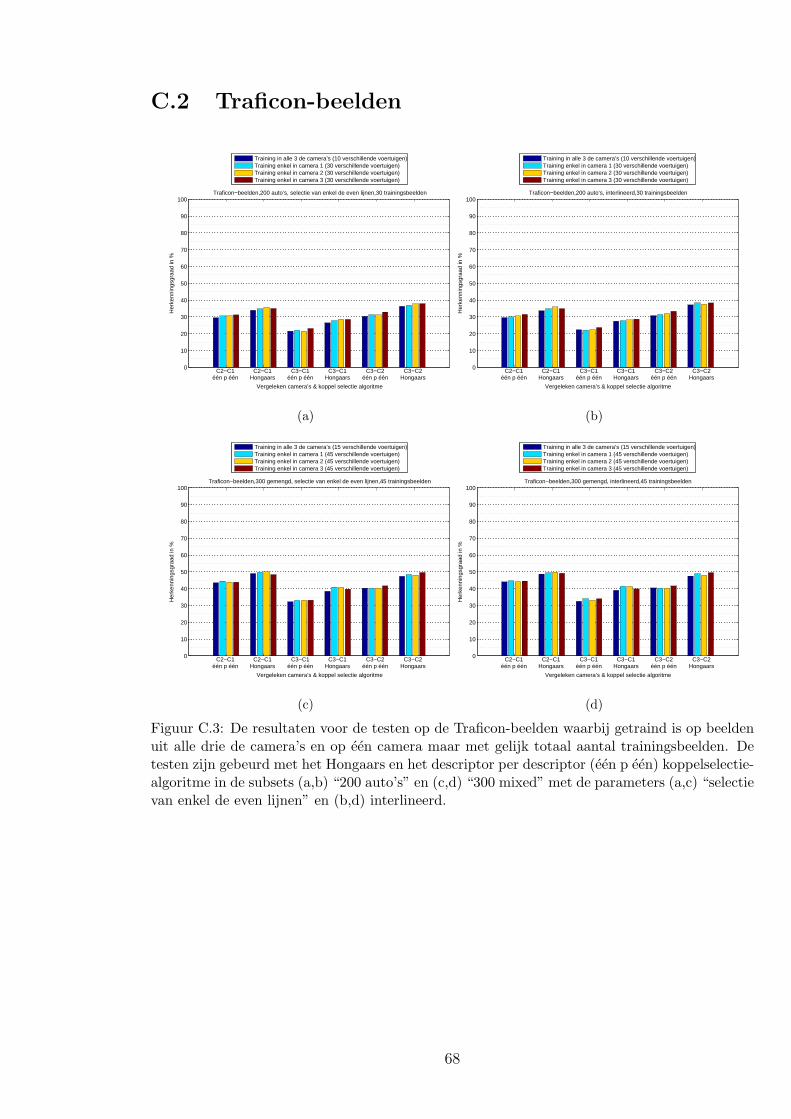
C.2 Traficon-beelden
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,200 auto’s, selectie van enkel de even lijnen,30 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (10 verschillende voertuigen)Training enkel in camera 1 (30 verschillende voertuigen)Training enkel in camera 2 (30 verschillende voertuigen)Training enkel in camera 3 (30 verschillende voertuigen)
(a)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,200 auto’s, interlineerd,30 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (10 verschillende voertuigen)Training enkel in camera 1 (30 verschillende voertuigen)Training enkel in camera 2 (30 verschillende voertuigen)Training enkel in camera 3 (30 verschillende voertuigen)
(b)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,300 gemengd, selectie van enkel de even lijnen,45 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (15 verschillende voertuigen)Training enkel in camera 1 (45 verschillende voertuigen)Training enkel in camera 2 (45 verschillende voertuigen)Training enkel in camera 3 (45 verschillende voertuigen)
(c)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,300 gemengd, interlineerd,45 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (15 verschillende voertuigen)Training enkel in camera 1 (45 verschillende voertuigen)Training enkel in camera 2 (45 verschillende voertuigen)Training enkel in camera 3 (45 verschillende voertuigen)
(d)
Figuur C.3: De resultaten voor de testen op de Traficon-beelden waarbij getraind is op beeldenuit alle drie de camera’s en op een camera maar met gelijk totaal aantal trainingsbeelden. Detesten zijn gebeurd met het Hongaars en het descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “200 auto’s” en (c,d) “300 mixed” met de parameters (a,c) “selectievan enkel de even lijnen” en (b,d) interlineerd.
68

0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 auto’s, selectie van enkel de even lijnen,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(a)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 auto’s, interlineerd,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(b)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 vrachtwagens, selectie van enkel de even lijnen,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(c)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 vrachtwagens, interlineerd,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(d)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 gemengd, selectie van enkel de even lijnen,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(e)
0
10
20
30
40
50
60
70
80
90
100Traficon−beelden,100 gemengd, interlineerd,15 trainingsbeelden
Her
kenn
ings
graa
d in
%
Vergeleken camera’s & koppel selectie algoritme
C2−C1één p één
C2−C1Hongaars
C3−C1één p één
C3−C1Hongaars
C3−C2één p één
C3−C2Hongaars
Training in alle 3 de camera’s (5 verschillende voertuigen)Training enkel in camera 1 (15 verschillende voertuigen)Training enkel in camera 2 (15 verschillende voertuigen)Training enkel in camera 3 (15 verschillende voertuigen)
(f)
Figuur C.4: De resultaten voor de testen op de Traficon-beelden waarbij getraind is op beeldenuit alle drie de camera’s en op een camera maar met gelijk totaal aantal trainingsbeelden. Detesten zijn gebeurd met het Hongaars en het descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “100 auto’s” en (c,d) “100 vrachtwagens” en (e,f) “100 mixed” metde parameters (a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd.
69

Bibliography
[1] “Traficon.” http://www.traficon.com/page.jsp?id=114 - geraadpleegd in mei 2010.
[2] A. Ferencz, E. G. Learned-Miller, and J. Malik, “Learn-
ing to locate informative features for visual identification.”
http://www.eecs.berkeley.edu/Research/Projects/CS/vision/shape/vid/.
[3] M. Turk and A. Pentland, “Eigenfaces for recognition,” Journal of Cognitive Neuro-
science, vol. 3, pp. 71–86, 1991.
[4] M. Kirby and L. Sirovich, “Application of the karhunen-loeve procedure for the char-
acterization of human faces,” IEEE Transactions on Pattern Analysis and Machine
Intelligence, vol. 12, pp. 103–108, 1990.
[5] L. Sirovich and M. Kirby, “Low-dimensional procedure for the characterization of
human faces,” J. Opt. Soc. Am. A, vol. 4, no. 3, pp. 519–524, 1987.
[6] I. Atalay, “Face recognition using eigenfaces,” Master’s thesis, Istanbul Technical
University, Jan. 1996.
[7] S. Serrano, “Eigenface tutorial.” http://www.pages.drexel.edu/ sis26/Eigenfacegeraadpleegd
in mei 2010.
[8] D. Karlis, G. Saporta, and A. Spinakis, “A simple rule for the selection of principal
components.,” Communications in Statistics: Theory & Methods, vol. 32, no. 3,
p. 643, 2003. Dit artikel beschrijft een mogelijke verbetering van het Kaiser critirium.
[9] C. Au, J.-S. Legare, and R. Shaikh, “Face recognition robustness of the eigenface
approach.”.
[10] M. Savvides and B. V. Kumar, “Quad-phase minimum average correlation energy fil-
ters for reduced-memory illumination-tolerant face authentication,” udio and Visual
Biometrics based Person Authentication, 2003.
[11] M. Savvides, B. V. Kumar, and P. Khosla, “Robust, shift-invariant biometric identi-
fication from partial face images,” Biometric Technologies for Human Identification,
2004.
70

[12] M. Savvides, B. V. Kumar, and P. Khosla, “Corefaces - robust shift invariant pca
based correlation filter for illumination tolerant face recognition.”.
[13] A. Leonardis and H. Bischof, “Dealing with occlusions in the eigenspace approach,”
Conference on Computer Vision and Pattern Recognition, pp. 453–458, 1996.
[14] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” Interna-
tional Journal of Computer Vision, vol. 60, pp. 91–110, Nov. 2004.
[15] J.-Y. Choi, K.-S. Sung, and Y.-K. Yang, “Multiple vehicles detection and track-
ing based on scale-invariant feature transform.” Intelligent Transportation Systems
Conference Seattle, WA, USA, Sept. 30 - Oct. 3, 2007.
[16] D. Donoho and E. J. Candes, “Curvelets: A surprisingly effective nonadaptive rep-
resentation of objects with edges,” Curves and Surface, pp. 123–143, 1999.
[17] E. J. Candes, “What is curvelet,” Notices of American Mathematical Society, vol. 50,
pp. 1402–1403, 2003.
[18] J. Lee, Y. Kim, and C. Park, Robust Feature Detection Using 2D Wavelet Transform
Under Low Light Environment, vol. 345 of Lecture Notes in Control and Information
Sciences. Springer Berlin / Heidelberg, 2006.
[19] F. M. Kazemi, S. Samadi, H. Pourreza, and M. R. Akbarzadeh, “Vehicle recognition
based on fourier, wavelet and curvelet transforms - a comparative study,” Journal of
Computer Science and Network Security, vol. 7, Feb. 2007.
[20] J. Munkres, “Algorithms for the assignment and transportation problems,” Society
for Industrial and Applied Mathematics, vol. 5, pp. 32–38, Mar. 1957.
[21] “Ipi-vakgroep.” http://telin.ugent.be/ipi/index.shtml - geraadpleegd in mei 2010.
71

Lijst van figuren
1.1 Schematische weergave van een tunnel die uitgerust is met een camerasys-
teem. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 (a) Voorbeeld van een figuur met een laag dynamisch bereik en (b) het
histogram van deze figuur . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Normale (a) auto en (b) vrachtwagen. Problemen met kijkhoek: kijkhoek
in camera 1 (c) en 2 (d) op het hetzelfde voertuig. Merk ook hoe moeilijk
het is om voertuig (a) en (c) van elkaar te onderscheiden. . . . . . . . . . . 6
1.4 Problemen met lichten: (a) gedoofde lichten (b) reflectie van andere lichten
op de rechterzijde (c) saturatie van het beeld door de remlichten. . . . . . . 7
1.5 Het beeld van het voertuig in (a) camera 1 is dichter bij de camera genomen
dan in (b) camera 2. Geınterlinieerde (c) auto en (d) vrachtwagen, het logo
bij de vrachtwagen is bijna volledig onleesbaar. . . . . . . . . . . . . . . . 8
2.1 Blokdiagram van het algemeen algoritme om beelden te vergelijken. . . . . 10
2.2 Het stuk (a) van het algemeen algoritme in figuur 2.1 wordt vervangen door
(b). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Voorbeeld van een objectidentificatieprobleem: de twee auto’s aan de lin-
kerzijde komen uit camera 1 en de vier aan de rechterzijde uit camera 2.
De vraag is op welke van de beelden uit camera 2 worden dezelfde auto’s
als in de beelden uit camera 1 afgebeeld. . . . . . . . . . . . . . . . . . . . 11
2.4 (a) een verzameling gezichten en (b) de eigenfaces van deze verzameling . . 15
2.5 Eenvoudige trainingsbeelden. . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.6 Gemiddeld genormaliseerd beeld van de herschaalde beelden uit figuur 2.5. 19
2.7 Eigenvectoren van de herschaalde beelden uit figuur 2.5. . . . . . . . . . . 20
2.8 Eenvoudige testbeelden. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1 Een voorbeeld van een koppeling van twee voertuigen over drie cameras . . 27
72

3.2 Grafische voorstelling van het vergelijken van twee descriptoren uit camera
2 met twee descriptoren uit camera 1. . . . . . . . . . . . . . . . . . . . . . 29
3.3 MSE toegepast op het descriptor per descriptor koppelselectie-algoritme. . 31
3.4 MSE toegepast op het Hongaars koppelselectie-algoritme. . . . . . . . . . . 33
4.1 Een vrachtwagen waar verschillende delen van het histogram ingekleurd
zijn. (a) Het origineel beeld en (b) de ingekleurde versie. (c) Rechts: Het
getransformeerd histogram van de vrachtwagen, alle waarden die origineel
onder de 60 lagen zijn gereduceerd tot 0. Deze waarden zijn zwart op de
figuur links. Links: De helderste vlakken van de vrachtwagen zijn in het
paars gekleurd en de rest van de vrachtwagen in het geel. De pijlen tonen
welk deel van het histogram welke kleur kreeg. . . . . . . . . . . . . . . . . 38
4.2 (a) Origineel beeld. (b) Uitgemiddeld beeld van figuur 4.2(a).(c) Het ver-
schil tussen figuur 4.2(a) en figuur 4.2(b). . . . . . . . . . . . . . . . . . . . 39
4.3 (a) Geınterlinieerde auto in de IPI-beelden en (b) hetzelfde beeld waarbij
enkel de even lijnen geselecteerd werden. (c) Geınterlinieerde vrachtwagen
in de Traficon-beelden en (d) hetzelfde beeld waarbij enkel de even lijnen
geselecteerd werden. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.4 Opdeling van een willekeurige dataset in partities. tien testpartities, een
trainingspartitie en negen ongebruikte partities zijn aangeduid. . . . . . . . 43
4.5 De eigenvehicles van 15 trainingsbeelden van 5 verschillende voertuigen uit
IPI-beelden, “100 auto’s”, geınterlinieerd. . . . . . . . . . . . . . . . . . . . 46
4.6 De eigenvehicles van 15 trainingsbeelden van 5 verschillende voertuigen uit
IPI-beelden, “100 vrachtwagens”, geınterlinieerd. . . . . . . . . . . . . . . . 47
4.7 De eigenvehicles van 15 trainingsbeelden van 5 verschillende voertuigen uit
Traficon-beelden, “100 auto’s”, geınterlinieerd. . . . . . . . . . . . . . . . . 48
5.1 Een tunnel inclusief alle camera’s en de bijhorende verzameling van eigen-
vehicles (a. . .f). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
A.1 De resultaten voor de testen op de IPI-beelden waarbij getraind is op beel-
den uit alle drie de camera’s met het Hongaars en descriptor per descriptor
(een p een) koppelselectie-algoritme in de subsets (a,b) “200 auto’s” en (c,d)
“300 mixed” met de parameters (a,c) “selectie van enkel de even lijnen” en
(b,d) interlineerd. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
73

A.2 De resultaten voor de testen op de IPI-beelden waarbij getraind is op beel-
den uit alle drie de camera’s met het Hongaars en descriptor per descriptor
(een p een) koppelselectie-algoritme in de subsets (a,b) “100 auto’s”, (c,d)
“100 vrachtwagens” en (e,f) “100 mixed” met de parameters (a,c,e) “selec-
tie van enkel de even lijnen” en (b,d,f) interlineerd. . . . . . . . . . . . . . 60
A.3 De resultaten voor de testen op de Traficon-beelden waarbij getraind is
op beelden uit alle drie de camera’s met het Hongaars en descriptor per
descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “200
auto’s” en (c,d) “300 mixed” met de parameters (a,c) “selectie van enkel
de even lijnen” en (b,d) interlineerd. . . . . . . . . . . . . . . . . . . . . . 61
A.4 De resultaten voor de testen op de Traficon-beelden waarbij getraind is
op beelden uit alle drie de camera’s met het Hongaars en descriptor per
descriptor (een p een) koppelselectie-algoritme in de subsets (a,b) “100
auto’s”, (c,d) “100 vrachtwagens” en (e,f) “100 mixed” met de parameters
(a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd. . . . . . . 62
B.1 De resultaten voor het koppelen via het Hongaars koppelselectie-algoritme
van de camera 3 beelden aan de camera 1 beelden uit de IPI-beelden waarbij
getraind is op beelden uit alle drie de camera’s maar met een verschillend
aantal trainingsbeelden. Deze testen zijn gedaan op de subset (a,b) “100
vrachtwagens” met de parameters (a) “selectie van enkel de even lijnen”
en (b) interlineerd. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
B.2 De resultaten voor het koppelen via het Hongaars koppelselectie-algoritme
van de camera 3 beelden aan de camera 1 beelden uit de IPI-beelden waarbij
getraind is op beelden uit alle drie de camera’s maar met een verschillend
aantal trainingsbeelden. Deze testen zijn gedaan op de subsets (a,b) “100
auto’s”’ en (c,d) “200 auto’s” met de parameters (a,c) “selectie van enkel
de even lijnen” en (b,d) interlineerd. . . . . . . . . . . . . . . . . . . . . . 64
B.3 De resultaten voor het koppelen via het Hongaars koppelselectie-algoritme
van de camera 3 beelden aan de camera 1 beelden uit de Traficon-beelden
waarbij getraind is op beelden uit alle drie de camera’s maar met een ver-
schillend aantal trainingsbeelden. Deze testen zijn gedaan op de subsets
(a,b) “100 vrachtwagens” en (c,d) “100 auto’s” en (e,f) “200 auto’s” met de
parameters (a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd. 65
74

C.1 De resultaten voor de testen op de IPI-beelden waarbij getraind is op beel-
den uit alle drie de camera’s en op een camera maar met gelijk totaal aantal
trainingsbeelden. De testen zijn gebeurd met het Hongaars en het descrip-
tor per descriptor (een p een) koppelselectie-algoritme in de subsets (a,b)
“200 auto’s” en (c,d) “300 mixed” met de parameters (a,c) “selectie van
enkel de even lijnen” en (b,d) interlineerd. . . . . . . . . . . . . . . . . . . 66
C.2 De resultaten voor de testen op de IPI-beelden waarbij getraind is op beel-
den uit alle drie de camera’s en op een camera maar met gelijk totaal
aantal trainingsbeelden. De testen zijn gebeurd met het Hongaars en het
descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets
(a,b) “100 auto’s” en (c,d) “100 vrachtwagens” en (e,f) “100 mixed” met de
parameters (a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd. 67
C.3 De resultaten voor de testen op de Traficon-beelden waarbij getraind is op
beelden uit alle drie de camera’s en op een camera maar met gelijk totaal
aantal trainingsbeelden. De testen zijn gebeurd met het Hongaars en het
descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets
(a,b) “200 auto’s” en (c,d) “300 mixed” met de parameters (a,c) “selectie
van enkel de even lijnen” en (b,d) interlineerd. . . . . . . . . . . . . . . . . 68
C.4 De resultaten voor de testen op de Traficon-beelden waarbij getraind is op
beelden uit alle drie de camera’s en op een camera maar met gelijk totaal
aantal trainingsbeelden. De testen zijn gebeurd met het Hongaars en het
descriptor per descriptor (een p een) koppelselectie-algoritme in de subsets
(a,b) “100 auto’s” en (c,d) “100 vrachtwagens” en (e,f) “100 mixed” met de
parameters (a,c,e) “selectie van enkel de even lijnen” en (b,d,f) interlineerd. 69
75

Lijst van tabellen
2.1 Gewichten van de verschillende testbeelden uit figuur 2.8. . . . . . . . . . . 22
4.1 Problemen per dataset. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2 Verdeling vrachtwagens en auto’s in de verschillende gemengde subsets. . . 42
4.3 Het aantal beelden in de verschillende partities wanneer er over de drie ca-
mera’s getraind wordt. Het aantal verschillende voertuigen in deze beelden
is altijd 1/3 van het aantal beelden. Bijeen subset met 100 voertuigen is de
trainingset 15 beelden groot, van 5 verschillende voertuigen, elk voertuig
heeft dus 3 beelden, 1 uit elke camera. . . . . . . . . . . . . . . . . . . . . 44
4.4 Resultaten van de 100 voertuigen subsets. . . . . . . . . . . . . . . . . . . 50
4.5 Resultaten van “200 auto’s” en “300 gemengd” subsets. . . . . . . . . . . . 50
4.6 Het aantal voertuigen met problemen in verband met afstand tot de camera,
lichten of bounding box in de verschillende subsets in de Traficon-beelden. 51
76

77