71171772 libro de estadistica
TRANSCRIPT

Probabilidades
1
Capítulo 1. Probabilidades
1.1 Modelos matemáticos La aplicación de las matemáticas para describir el universo es una práctica que ha dado muy
buenos resultados durante siglos. Las matemáticas conforman un lenguaje completamente lógico que puede aplicarse a la descripción de la naturaleza porque los sucesos y los objetos de la naturaleza tie-nen propiedades que ofrecen un paralelo suficiente a las matemáticas. Aunque la descripción de la na-turaleza en términos matemáticos nunca es completamente exacta, hay suficiente concordancia entre las formas de la naturaleza y las de la expresión matemática para que la descripción sea aceptable. La aproximación es a menudo tan grande que una vez que se ha aplicado la descripción matemática, se puede proseguir con esa lógica matemática para hacer deducciones que también se apliquen a la natu-raleza.
1.1.1 Definiciones: Se denomina experimento a la reproducción controlada de un fenómeno cualquiera que ocurre
en la naturaleza.
Un modelo matemático se emplea para describir un fenómeno que ocurre en la naturaleza, y puede ser: determinístico o no determinístico.
Un modelo es determinístico cuando las condiciones bajo las cuales se verifica el experimento determinan su resultado. Por ejemplo: si se deja caer un cuerpo en el vacío, desde una altura h, hasta el piso, la velocidad que alcanza es:
ghv 2=
Este modelo determina la velocidad con que el cuerpo cae al piso todas las veces que se repita el experimento, si se repiten las mismas condiciones del experimento.
Un modelo es no determinístico o probabilístico cuando las condiciones bajo las cuales se veri-fica el experimento no determinan su resultado. Según el fenómeno que se estudie, es posible determi-nar un modelo. Por ejemplo: si se quiere saber cuántos autos llegan a una gasolinera entre las 7 y las 8 a.m.; con base en datos históricos se puede diseñar un modelo que dé un resultado aproximado con cierto grado de confiabilidad. La forma de diseñar este modelo se verá en el capítulo 4. Se sabrá, por ejemplo, qué tan probable es que no llegue ningún vehículo, que lleguen menos de 5 vehículos, que lleguen entre 6 y 10 vehículos, o que lleguen entre 11 y 15 vehículos, etc.
A diferencia del experimento anterior, no es posible mantener las mismas condiciones del expe-rimento, pues no están al alcance del que investiga.
1.1.2 Características de un fenómeno probabilístico:
• Sin cambiar las condiciones bajo las cuales se verifica el experimento, se pueden obtener dis-tintos resultados.
• Se puede describir el conjunto de todos los resultados posibles.
• Inicialmente los resultados parecen ocurrir en forma caprichosa; pero cuando el experimento se repite muchas veces, aparece un modelo definido de regularidad que hace posible la cons-trucción de un modelo matemático preciso, con el cual se puede analizar el fenómeno.

Probabilidades
2
1.2 Permutaciones y combinaciones Para calcular ciertas probabilidades es necesario calcular permutaciones y combinaciones. Para
un mejor entendimiento de estas definiciones se emplean ejemplos sencillos, muchos de los cuales tie-nen relación con los juegos de azar, aunque puedan resultar poco útiles para efectos prácticos.
Una permutación es un arreglo, en un determinado orden, de un conjunto de elementos. Por ejemplo, con las letras del abecedario se pueden formar las siguientes permutaciones de dos letras: ab, ba, ac, ca, bc, cb,..., xy, yx, yz, zy.
Una combinación es un arreglo, sin que importe el orden, de un conjunto de elementos. Por ejemplo, con las letras del abecedario se pueden formar las siguientes combinaciones de tres letras: abc, abd, abe,..., bcd, bce, bcf,..., cde,..., xyz.
1.2.1 Teoremas relativos a permutaciones y combinaciones TEOREMA 1: El número de permutaciones de r elementos que se pueden formar a partir de un
conjunto de N elementos diferentes, es:
)!(!),(rN
NrNP−
=
Se demuestra este teorema de la siguiente manera: para escoger el primer elemento hay N posi-bilidades, para escoger el siguiente hay (N – 1) posibilidades, luego (N – 2) posibilidades, y así suce-sivamente. Se deduce que, para escoger el r-ésimo elemento hay N – (r – 1) posibilidades. El número de formas en que se pueden permutar estas posibilidades es: N (N – 1) (N – 2)...N – (r – 1), que es igual al cociente dado por el teorema.
Ejemplo 1:
¿Cuántos números de tres dígitos pueden formarse con los dígitos impares?
N = 5 (los dígitos impares son: 1, 3, 5, 7, 9) r = 3
)!35(!5),(
−=rNP = 60
Pueden formarse 60 números diferentes con los dígitos impares.
Ejemplo 2:
Se va a realizar una prueba de atletismo con 6 participantes. ¿De cuántas formas se pueden en-tregar las medallas para los tres primeros puestos?
N = 6 r = 3
)!36(!6),(
−=rNP = 120
Las medallas para los tres primeros puestos se pueden entregar de 120 formas diferentes.
COROLARIO 1: El número de permutaciones de N elementos que se pueden formar a partir de
un conjunto de N elementos diferentes, es:
!),( NNNP =
Ejemplo:
¿Cuántos números de cinco dígitos pueden formarse con los dígitos impares?
N = 5 (los dígitos impares son: 1, 3, 5, 7, 9)

Probabilidades
3
120!5),( ==NNP
Pueden formarse 120 números diferentes empleando los cinco dígitos impares.
COROLARIO 2: Dado un grupo de N elementos, conformado por k grupos diferentes, de tal
forma que n1 elementos iguales conforman el primer grupo, n2 elementos iguales conforman el segun-do grupo, ..., nk elementos iguales conforman el k-ésimo grupo, donde n1 + n2 + ... + nk = N ; el núme-ro de permutaciones que pueden formarse, tomando los N elementos a la vez, es:
!...,!!!)...,,,;(
2121
kk nnn
NnnnNP =
Este corolario puede comprobarse siguiendo el siguiente razonamiento: si los elementos del primer grupo fuesen diferentes, el número total de permutaciones que pueden formarse quedaría mul-tiplicado por n1!; y si los elementos del segundo grupo también fuesen diferentes, el total anterior que-daría multiplicado por n2!; y si, al igual que los grupos anteriores, los elementos del k-ésimo grupo también fuesen diferentes, el total también quedaría multiplicado por nk!; resultando finalmente que el número total de permutaciones con N elementos diferentes es N!, como era de esperarse.
Ejemplo:
¿Cuántos números pueden formarse con los siguientes dígitos: 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 5, to-mando todos a la vez?
P(11; 4, 2, 1, 1, 3) = 11!/ 4! 2! 1! 1! 3! = 138 600
Pueden formarse 138 600 números diferentes.
TEOREMA 2: El número de permutaciones de r elementos que se pueden formar a partir de un conjunto de N elementos diferentes, si se admite repetición de los elementos, es:
rR NrNP =),(
La demostración es similar a la del teorema 1, con la diferencia de que, para escoger cada uno de los r términos, hay siempre N posibilidades, resultando N × N × ... × N, (r veces), es decir, N r permu-taciones.
Ejemplo:
¿Cuántos números de tres cifras pueden formarse con los dígitos impares, si se admite repetición de cualquiera de los dígitos?
PR (5, 3) = 53 = 125 números
TEOREMA 3: El número de combinaciones de r elementos que se pueden formar a partir de un
conjunto de N elementos diferentes, es:
)!(!!),(
rNrNrNC
−=
Se demuestra este teorema considerando que C(N, r) multiplicado por el número de permutacio-nes que se pueden formar con los r elementos, r!, debe ser igual a P(N, r), es decir, N! / (N – r)!
Ejemplo:
Un profesor quiere escoger 8 alumnos de un conjunto de 15. ¿De cuántas formas puede hacerlo?
Resulta evidente que no importa el orden en que se escogen los 8 alumnos

Probabilidades
4
)!815(!8!15)8,15(−
=C = 6 435
El profesor puede escoger 8 alumnos de 6 435 formas.
TEOREMA 4: El número de combinaciones de r elementos que se pueden formar a partir de un conjunto de N elementos diferentes, si se admite repetición de los elementos, es:
)!1(!)!1(),(
−−+
=Nr
rNrNCR
Se demuestra por inducción matemática:
Para un conjunto de N elementos, sea r = 2. Se podrán formar las siguientes combinaciones:
(1,1), (1,2), (1,3), (1,4), …, (1,N) ⇒ N (2,2), (2,3), (2,4), …, (2,N) ⇒ N – 1
(3,3), (3,4), …, (3,N) ⇒ N – 2 N +(N – 1)+(N – 2) + … + 1 = 2
)1( +NN =
+2
1N
… (N,N) ⇒ 1 Para r = 3 se podrán formar las siguientes combinaciones:
Cuando el primer dígito es 1:
(1,1,1), (1,1,2), (1,1,3), (1,1,4), …, (1,1,N) (1,2,2), (1,2,3), (1,2,4), …, (1,2,N)
(1,3,3), (1,3,4), …, (1,3,N)
+2
1N
… (1,N,N)
Cuando el primer dígito es 2:
(2,2,2), (2,2,3), (2,2,4), …, (2,2,N) (2,3,3), (2,3,4), …, (2,3,N)
(2,4,4), …, (2,4,N)
2N
… (2,N,N)
Cuando el primer dígito sea 3, resultará:
−2
1N
Y así, cuando el primer dígito sea N, resultará:
22
= 1
Considerando la siguiente propiedad:
kN
=
−−11
kN
+
−−
12
kN
+ … +
−−
11
kk
El número de combinaciones para r = 3 será:
+2
1N+
2N
+
−2
1N+ … + 1 =
+3
2N

Probabilidades
5
Por inducción, el número de combinaciones, para r = 4 será:
+4
3N
Y así, para r, el número de combinaciones será:
−+rrN 1
= )!1(!)!1(
−−+
NrrN
Ejemplo:
Un club está conformado por ingenieros, administradores, médicos, contadores y economistas. Considerando estas profesiones, ¿de cuántas formas se puede formar un comité de tres profesio-nales?
N = 5 r = 3
)!37(!3
!7)3,5(−
=RC = 35
Problemas resueltos
1) Se extrae una “mano” de 5 cartas de una baraja completa.
a) ¿Cuántas “manos” distintas se pueden obtener?
9605982!5!47
!52)5,52( ==C
b) ¿En cuántas de estas “manos” habrán tres ases?
Se tiene que calcular el número de formas en que se pueden escoger 3 ases de un total de 4 y luego 2 cartas cualesquiera (sin considerar el as que queda) de las 48 restantes.
5124!2!46
!48!1!3
!4)2,48()3,4( =×=×CC
2) ¿De cuántas maneras se pueden sentar 6 personas en una banca, de tal manera que dos de ellas, Elena y Graciela, nunca estén juntas?
Para conseguir esto, conviene suponer que Elena y Graciela conforman un solo elemento, para calcular así el número de formas en que se pueden permutar 5 elementos, multiplicado por 2, pues Elena y Graciela pueden permutarse. Este resultado se resta del número de formas en que se pueden permutar 6 elementos.
480240720)5,5(2)6,6( =−=− PP
3) ¿De cuántas maneras se puede elegir un comité de 4 personas de un grupo de 10 personas, de tal manera que esté el único abogado del grupo?
Primero se calculará el número de formas en que se puede escoger el único abogado y luego el número de formas en que se puede escoger las 3 personas restantes, de las 9 que quedan.
84)3,9()1,1( =×CC
4) En un aula de 30 alumnos hay 20 deportistas, de los cuales 8 practican deportes individuales y 12 deportes colectivos.
a) ¿Cuántos grupos de 5 alumnos se pueden formar?
Como no importa si los 5 alumnos son o no deportistas, el número de grupos de 5 alumnos que se pueden formar es:
C(30, 5) = 142 506
Se pueden formar 142 506 grupos de 5 alumnos.

Probabilidades
6
b) ¿En cuántos grupos todos son deportistas?
Ahora hay que calcular el número de formas en que se pueden escoger 5 deportistas de un total de 20.
C(20, 5) = 15 504
Se pueden formar 15 504 grupos donde todos son deportistas.
c) ¿En cuántos grupos hay 3 que practican deportes colectivos?
Como hay 12 alumnos que practican deportes colectivos y el resto no, hay que calcular el número de formas en que se puede escoger 3 de esos 12 alumnos, y luego 2 de los restantes 18.
C(12, 3) × C(18, 2) = 33 660
Se pueden formar 33 660 grupos donde haya tres alumnos que practican deportes colectivos.
d) ¿En cuántos de los grupos donde todos son deportistas hay 3 que practican deportes colecti-vos?
Considerando sólo los grupos donde todos los alumnos son deportistas, hay 12 alumnos que practican deportes colectivos y el resto, 8, deportes individuales; se calcula entonces el nú-mero de formas en que se puede escoger 3 de esos 12 alumnos y luego 2 de los 8 restantes.
C(12, 3) × C(8, 2) = 6 160
De los grupos donde todos son deportistas, hay 6 160 grupos donde 3 practican deportes co-lectivos
e) ¿En cuántos grupos hay al menos un alumno que no practica deportes individuales?
Resulta más práctico calcular el número de grupos donde no haya ningún alumno que no practique deportes individuales (todos practican deportes individuales) y restarlo del total de grupos que se pueden formar.
C(30, 5) – C(8, 5) = 142 450
Se pueden formar 142 450 grupos donde al menos un alumno no practica deportes indivi-duales
5) Las letras a, b, b, c, d, d, d se distribuyen al azar.
a) ¿Cuántos arreglos distintos pueden hacerse?
Considerando los 4 subgrupos que hay:
P(7; 1, 2, 1, 3) = 420
Se pueden hacer 420 arreglos distintos.
b) ¿En cuántos de estos arreglos las 3 letras “d” quedan juntas?
Si las 3 letras “d” quedan juntas, pueden considerarse como un solo elemento:
P(5; 1, 2, 1, 1) = 60
En 60 arreglos las 3 letras “d” quedan juntas.
6) ¿Cuántos números de tres cifras pueden formarse con los dígitos 1, 2, si se admite repetición?
N = 2 r = 3
N r = 23 = 8
Se pueden formar 8 números.

Probabilidades
7
1.3 Experimentos y eventos Como ya se ha definido, un experimento es la reproducción controlada de un fenómeno. En Es-
tadística sólo se consideran experimentos que se pueden representar mediante modelos probabilísticos.
A los resultados de los experimentos se les denomina eventos, los cuales pueden ser simples o compuestos. Los eventos compuestos pueden contener dos o más eventos simples.
1.4 Espacio muestra. Es la representación de todos los eventos posibles de un experimento. Esta representación puede
ser gráfica o analítica, como se ve en los siguientes ejemplos.
1.5 Variable aleatoria. Es una función definida sobre un espacio muestra S, donde a cada evento del espacio muestra le
corresponde un número real:
X(ei) = xi
Una variable aleatoria puede ser:
Discreta: si el número de eventos posibles es finito o numerablemente infinito. Continua: si el número de eventos posibles es infinito (no numerable).
Dado un espacio muestra, se pueden definir varias variables aleatorias, como se verá en los si-guientes ejemplos.
Problemas resueltos
1) Un experimento consiste en lanzar 2 monedas. La moneda puede mostrar cara (C) o sello (S).
El espacio muestra, que consta de 4 eventos simples, será:
S = {CC, CS, SC, SS}
Gráficamente, este espacio muestra se puede representar de dos formas (figura 1.1):
Figura 1.1. Representaciones de espacio muestra del lanzamiento de dos monedas
Un evento compuesto puede ser, por ejemplo, el resultado “una cara y un sello”: E = {CS, SC}
Para el espacio muestra S se podrían definir las siguientes variables aleatorias:
X = Número de caras
Cara
Sello
Cara
Sello
Cara
Sello
Primerlanzamiento
Segundolanzamiento
Primerlanzamiento
Segundolanzamiento
Cara Sello
Cara
Sello

Probabilidades
8
Y = Número de sellos Z = Número de caras – Número de sellos W = 2(Número de caras) + (Número de sellos)2 …
etc.
En todos estos casos la variable aleatoria es discreta.
2) Un experimento consiste en lanzar 2 dados (o lanzar un dado dos veces).
El espacio muestra será en este caso: S = {(1, 1),(1, 2),...,(1, 6), ...,(6, 6)}. En la figura 1.2 se re-presenta gráficamente este espacio muestra.
Figura 1.2. Representación de un espacio muestra
Cada intersección de la figura 1.2 representa un evento simple. Hay, por lo tanto, 36 eventos simples, es decir, 36 posibles resultados.
Para este espacio muestra, la variable aleatoria se podría definir de las siguientes formas:
X = suma de lo que muestran los dos dados. Y = (Número que muestra el dado 1) – (Número que muestra el dado 2). … etc.
En todos estos casos la variable aleatoria es discreta.
3) Un experimento consiste en pesar el contenido de café de una bolsa extraída al final de un pro-ceso de llenado automático.
El espacio muestra será: S = {0,...,700}, suponiendo que las bolsas nunca pueden llegar a pesar más de 700 gr.
Gráficamente, este espacio muestra se representa en la figura 1.3.
Primerlanzamiento
Segundolanzamiento
1 32 654
6
5
4
3
2
1

Probabilidades
9
Figura 1.3. Representación del espacio muestra de una variable aleatoria continua.
En este caso la variable aleatoria es continua.
1.6 Probabilidad Se distinguen tres tipos de probabilidad: a priori, experimental y subjetiva.
1.6.1. Probabilidad a priori: Si observamos algunos espacios muestra nos daremos cuenta de que, en la mayoría de los casos,
todos los eventos simples tienen la misma posibilidad de ocurrencia. Si cuantificamos estas posibilida-des, llamándoles probabilidades, de tal forma que la suma de éstas sea la unidad, se puede entonces definir la probabilidad de que ocurra un evento simple de la siguiente manera:
P(ei) = Número no negativo asociado al evento ei del espacio muestra S, de tal manera que: ∑ P(ei) = 1 y S = e1 ∪ e2 ∪ ... ∪ eN
Entonces, si, por ejemplo:
A = e1 ∪ e2 ∪ ... ∪ ek se deduce que:
P(A) = P(e1) + P(e2) + ... + P(ek)
Nk
NNNAP =+++=
1...11)(
De esta forma, se puede decir que la probabilidad de que ocurra un evento cualquiera es posible calcularla empleando la siguiente fórmula:
totaleventosdenéxitoeventosden
NkP
°°
==
Problemas resueltos:
1) Se lanza un dado. ¿Cuál es la probabilidad de obtener 5?
P = 1/6
2) Se lanzan dos dados. ¿Cuál es la probabilidad de obtener suma 5?
P = 4/36 = 1/9
¿...de obtener suma menor que 5?
P = (1 + 2 + 3)/36 = 6/36 = 1/6
3) Se lanzan dos monedas. ¿Cuál es la probabilidad de obtener dos caras?
Eventos posibles: {CC, CS, SC, SS} Eventos éxito: {CC}
P = 1/4
¿Cuál es la probabilidad de obtener sólo una cara?
P = (1 + 1)/4 = 2/4 = 1/2
4) En un lote de 100 pernos hay 4 defectuosos. Si un comprador escoge 20 pernos aleatoriamente, ¿cuál es la probabilidad de que se lleve 2 pernos defectuosos?
Peso (gr)700

Probabilidades
10
El comprador se lleva 2 pernos defectuosos, de un total de 4, y 18 pernos no defectuosos, de un total de 96. Entonces:
1531,0)20,100(
)18,96()2,4(==
CCCP
Ahora, el lector debe estar en condiciones de contestar la siguiente pregunta: ¿cuál es la proba-bilidad de que el comprador se lleve al menos dos pernos defectuosos?
5) De una baraja completa de 52 cartas, se extrae una "mano" de 5 cartas. ¿Cuál es la probabilidad de obtener:
a) dos espadas, dos corazones y un diamante?
Hay que determinar el número de formas en que se pueden escoger 2 espadas de un total de 13, y luego 2 corazones de un total de 13 y luego un diamante de un total de 13.
0304,0)5,52(
)1,13()2,13()2,13(==
CCCCP
b) un póker? (cuatro cartas con la misma numeración o letra)
4104,2)5,52(
)1,48()1,13( −×==C
CCP
1.6.2. Probabilidad experimental En algunas ocasiones, los posibles resultados de un experimento no tienen la misma probabili-
dad de ocurrencia, lo cual dificulta la predicción de estas probabilidades.
Si un experimento de esta naturaleza se repitiera muchas veces, podríamos ver la frecuencia con que ocurrirían los posibles resultados. Mientras más veces se repita el experimento, las frecuencias re-lativas se aproximarán cada vez más a las verdaderas probabilidades de ocurrencia de cada uno de di-chos resultados. Entonces:
Nf
erimentoelrepitesequevecesdenresultadounocurrequeconfrecuenciaP =
°=
exp
En la práctica, la mayoría de las probabilidades sólo pueden determinarse por la vía experimen-tal. Si, por ejemplo, se quiere saber cuál es la probabilidad de que un foco funcione por lo menos las horas que especifica el fabricante, se tendrá que tomar una muestra grande de focos (N) y ver cuántos de éstos cumplen con dicha especificación (f). Cuanto más grande sea N, el cociente f / N se aproxima-rá más a la probabilidad requerida. Como se ve, la única forma de calcular una probabilidad de este tipo es mediante la experimentación.
En muchas situaciones no hace falta experimentar pues se cuenta con datos históricos suficien-tes. Por ejemplo, ¿cómo calcularía un pastelero la probabilidad de que la demanda de sus pasteles de manzana en un día sea de 10 a 15 unidades? Necesitaría datos de la demanda de N días, para determi-nar en cuántas ocasiones (f) la demanda fue de 10 a 15 unidades. La probabilidad será f / N.
Una probabilidad que ha sido calculada "a priori" puede verificarse, con cierta aproximación, repitiendo el experimento. Por ejemplo, si queremos comprobar que la probabilidad de obtener dos ca-ras y un sello, al lanzar tres monedas, es igual a 0,375; tenemos que lanzar las tres monedas una gran cantidad de veces. A continuación se muestra la frecuencia con que se obtuvo dicho resultado, luego de N lanzamientos.
Número de lanzamientos (N) 10 20 100 200 500 1 000 10 000 Frecuencia observada (f) 5 9 34 76 162 367 3 738 Probabilidad (f /N) 0,5 0,45 0,35 0,385 0,352 0,365 0,3724

Probabilidades
11
Se puede concluir entonces que, conforme N crece, la frecuencia relativa o probabilidad experi-mental tiende al verdadero valor de la probabilidad. Esta tendencia se visualiza mucho más en el gráfi-co de la figura 1.4, donde la línea horizontal representa la probabilidad real: 0,375.
Figura 1.4. Tendencia de una probabilidad experimental
1.6.3 Probabilidad subjetiva En muchas ocasiones se necesita determinar la probabilidad de que ocurra un fenómeno que es
imposible repetir, o cuya repetición no tiene significado.
Por ejemplo, si se va a construir un puente en cierto lugar, ¿cómo determinar la probabilidad de que, a 10 m. de profundidad el terreno no sea arenoso sino de arcilloso? En este caso, la probabilidad de que ocurra dicho suceso no puede ser más que una medida subjetiva del grado de confianza que tenga un especialista para predecirlo. Si él opina que dicha probabilidad es de 0,25; estará expresando un grado de credibilidad de su juicio; pues el terreno será arcilloso o no, pero no será arcilloso en el 25% de las observaciones que se haga.
La precisión de una probabilidad subjetiva depende de la habilidad o conocimiento que tenga una persona para juzgar una determinada situación.
La probabilidad subjetiva también puede aplicarse a fenómenos repetitivos. Por ejemplo, un ins-pector que está revisando unos lotes de artículos producidos en una jornada, puede hacer caso omiso a su experiencia previa, y decidir revisar más artículos, porque tiene el presentimiento de que este día hay más artículos defectuosos de lo habitual.
Ahora que se entiende claramente el concepto de probabilidad, se ve que es correcto afirmar que
una probabilidad se puede interpretar como una proporción, como una fracción o como un por-centaje. Por ejemplo, si, en un supermercado, la probabilidad de elegir aleatoriamente a un cliente con un consumo mayor de $20, es 0,16; se puede afirmar que el 16% de los clientes gasta más de $20, o que la proporción de clientes que gasta más de $20 es 0,16.
1.7 Teoremas de probabilidad. En este apartado se verán una serie de teoremas que son útiles, y en algunos casos indispensa-
bles para calcular ciertas probabilidades.
1.7.1 Suma de probabilidades: Sean A y B dos eventos definidos en el espacio muestra S. La probabilidad de que ocurra el
evento A o el evento B, o ambos, es:
)()()()( BAPBPAPBAP ∩−+=∪
donde:
0,30
0,35
0,40
0,45
0,50
10 100 1000 10000
f/N
N

Probabilidades
12
A
S
A ∩ B
B
B ∩ A’
P(A) representa la probabilidad de ocurra A,
P(B) representa la probabilidad de ocurra B,
P(A ∪ B) representa la probabilidad de ocurra A o B, o ambos, y
P(A ∩ B) representa la probabilidad de ocurran A y B conjuntamente.
Cuando dos o más eventos están definidos de tal manera que la ocurrencia de uno imposibilita la ocurrencia de los demás, se dice que son mutuamente excluyentes, y la probabilidad de que ocurran conjuntamente es entonces igual a cero.
Se puede deducir que, para dos eventos mutuamente excluyentes, por ejemplo Q y R:
Q = {e1,e2,e3} ; R = {e4,e5} ;
Es evidente que:
P(Q) = P(e1) + P(e2) + P(e3)
P(R) = P(e4) + P(e5)
y por lo tanto:
P(Q ∪ R) = P(e1) + P(e2) + P(e3)+ P(e4) + P(e5) = P(Q) + P(R)
Si dos eventos A y B no son mutuamente excluyentes, como se muestra en el diagrama de Venn de la figura 1.5, se puede deducir que:
Figura 1.5. Eventos A y B no excluyentes
P(A ∪ B) = P(A) + P(B ∩ A')
P(B) = P(A ∩ B) + P(B ∩ A')
Sustituyendo P(B ∩ A') de la segunda ecuación en la primera, resulta:
P(A ∪ B) = P(A) + P(B) – P(A ∩ B)
con lo que queda demostrado el teorema.
Ejemplo:
Se lanzan dos dados. ¿Cuál es la probabilidad de que se obtenga una suma igual a 10 ó una dife-rencia igual a 1?
Sean los eventos: A: suma igual a 10 B: diferencia igual a 1
Dado que A y B son mutuamente excluyentes (es fácil darse cuenta), se puede emplear la si-guiente fórmula:
P(A ∪ B) = P(A) + P(B) = 3/36 + 10/36 = 13/36

Probabilidades
13
En el gráfico de la figura 1.6 se aprecia que los dos eventos compuestos: el evento A, represen-tado por círculos, y el evento B, representado por aspas, son mutuamente excluyentes.
Figura 1.6. Eventos A y B mutuamente excluyentes
¿Y cuál será la probabilidad de obtener una suma igual a 8 ó una diferencia igual a 2?
Sean los eventos: C: suma igual a 8 D: diferencia igual a 2
En el gráfico de la figura 1.7 se aprecian estos dos eventos compuestos: el C, representado por círculos, y el D, por aspas. Se puede apreciar que hay dos eventos simples que pertenecen a am-bos eventos C y D; se concluye entonces que los eventos C y D no son excluyentes.
Figura 1.7. Eventos C y D no mutuamente excluyentes
Dado que C y D no son mutuamente excluyentes:
P(C ∪ D) = P(C) + P(D) – P(C ∩ D) = 5/36 + 8/36 – 2/36 = 11/36
Primerlanzamiento
Segundolanzamiento
1 32 654
6
5
4
3
2
1
Primerlanzamiento
Segundolanzamiento
1 32 654
6
5
4
3
2
1

Probabilidades
14
El teorema de la suma se puede generalizar de la siguiente manera: la probabilidad de que ocurra el evento E1, o el evento E2, ..., o el evento EN, es:
)...(...
...)()()(...)()()...(
21
2121
N
kjijiNN
EEEP
EEEPEEPEPEPEPEEEP
∩∩±
−∩∩∑+∩∑−+++=∪∪
Ejemplo:
Suponga que, en la ciudad de Piura, el 25 % de la población adulta lee el diario El Tiempo, el 40% lee el diario Correo, el 10% lee el diario República y el 25% restante lee otros diarios. Además, se sabe que el 10% lee El Tiempo y Correo, el 5% lee El Tiempo y República, el 5% lee El Tiempo y otros, el 8% lee Correo y otros, y el 3% lee El Tiempo, Correo y otros. Si se se-lecciona aleatoriamente un poblador, ¿cuál es la probabilidad de que lea Correo, El Tiempo u otros?
Aunque el diagrama de Venn de la figura 8 es suficiente para visualizar y determinar esta proba-bilidad, a continuación se hace el cálculo aplicando el teorema generalizado de la suma:
P(Correo ∪ El T. ∪ otros) = P(Correo) + P(El T.) + P(otros) – P(Correo ∩ El T.)
– P(Correo ∩ otros) – P(El T. ∩ otros) + P(Correo ∩ El T. ∩ otros)
= 0,40 + 0,25 + 0,25 – 0,10 – 0,08 – 0,05 + 0,03 = 0,70
Dicha probabilidad se puede corroborar elaborando un diagrama de Venn, como el de la figura 1.8, e incluso se pueden calcular otras probabilidades con suma facilidad.
Figura 1.8. Diagrama de Venn del problema de los diarios.
1.7.2 Probabilidad condicional y regla de la multiplicación: Sean dos eventos A y B:
)()()\(
BPBAPBAP ∩
=
donde P(A \ B) representa la probabilidad de que ocurra el evento A, dado que ha ocurrido el evento B, y se le denomina probabilidad condicional.
Ejemplo:
Se lanzaron dos dados y se sabe que la suma resultó igual a 8. ¿Cuál es la probabilidad de que la diferencia sea igual a 2?
Sean los eventos: A: diferencia igual a 2 B: suma igual a 8
Si la suma es 8, entonces el espacio muestra queda restringido a:
SB = {(2,6),(3,5),(4,4),(5,3),(6,2)}

Probabilidades
15
por lo tanto, si de los 5 eventos posibles, se tendría éxito en 2 de ellos, (3, 5) y (5, 3):
5/2B)\( =AP
Como se ve en la figura 1.7, el numerador "2" representa el número de veces en que pueden ocurrir A y B conjuntamente, y el denominador "5" representa el número de veces en que puede ocurrir B.
Entonces se puede deducir:
)(
)(/)(
/)()(
)(B)\(BP
BAPNBN
NBANBN
BANAP ∩=
∩=
∩=
Aplicando esta fórmula al problema, se tiene el mismo resultado:
52
36/536/2B)\( ==AP
De la definición de probabilidad condicional se puede deducir que:
P(A ∩ B) = P(B) × P(A \ B)
P(A ∩ B) = P(A) × P(B \ A)
Estas expresiones resultan muy útiles para determinar una probabilidad conjunta, que usualmen-te es más difícil de determinar que la probabilidad condicional.
Ejemplo:
Una caja contiene 4 canicas blancas y 6 negras. Si se extraen dos aleatoriamente, ¿cuál es la probabilidad de que:
a) las dos sean blancas?
Sean los eventos:
1B: canica blanca en la primera extracción 2B: canica blanca en la segunda extracción
P(1B ∩ 2B) = P(1B) × P(2B\1B) = (4/10) × (3/9) = 2/15
b) la primera sea blanca y la segunda negra?
Sea el evento 2N: canica negra en la segunda extracción
P(1B y 2N) = P(1B) × P(2N\1B) = (4/10) × (6/9) = 4/15
c) una sea blanca y la otra negra?
Sea el evento 1N: canica negra en la primera extracción
Hay dos formas excluyentes de obtener una canica blanca y una negra:
P = P(1B) × P(2N\1B) + P(1N) × P(2B\1N) = 4/15 + 4/15 = 8/15 Sean los eventos E1, E2,..., EN ; se puede generalizar la regla de la multiplicación:
)...\(...)\()E\()()...( 12121312121 −∩∩××∩××=∩∩ NNN EEEEPEEEPEPEPEEEP
En el primer miembro se expresa la probabilidad de que ocurran conjuntamente los eventos E1, E2,..., EN. Si la probabilidad de que ocurran estos N eventos, en cualquier orden, es siempre la misma; entonces esa probabilidad se puede obtener multiplicando )...( 21 NEEEP ∩∩ por el número de for-mas en que se pueden permutar los N eventos.

Probabilidades
16
Ejemplo 1:
En un lote de 100 pernos hay 4 defectuosos. Si un comprador escoge 20 pernos aleatoriamente, ¿cuál es la probabilidad de que se lleve 2 pernos defectuosos? (Esta probabilidad a priori ya fue calculada en el ejemplo 4 del apartado 1.6.1).
Si el comprador se lleva 2 pernos defectuosos, de un total de 4; se llevará también 18 pernos no defectuosos, de un total de 96.
1531,0!18!2
!208179...
9694
9795
9896
993
1004
=×
×××××
×=P
Ejemplo 2:
De una baraja completa de 52 cartas, se extrae una "mano" de 5 cartas. ¿Cuál es la probabilidad de obtener: (Estas probabilidades ya fueron calculadas en el ejemplo 5 del apartado 1.6.1).
a) dos espadas, dos corazones y un diamante?
0304,0!1!2!2
!54813
4912
5013
5112
5213
=×
×
××
×=P
b) un póker?
00024,0!1!4
!54848
491
502
513
5252
=×
×
×××=P
1.7.3 Eventos independientes Se dice que dos eventos A y B son independientes, si la ocurrencia (o no ocurrencia) de uno de
ellos no influye en la ocurrencia (o no ocurrencia) del otro. Es decir:
P(A \ B) = P(A) y P(B \ A) = P(B)
Si se cumple una de estas dos ecuaciones, también se verifica la otra. Por ejemplo, si:
P(A \ B) = P(A)
Entonces:
P(B)
A)\()()(
)()( BPAPBP
BAPAP ×=
∩=
Por lo tanto:
P(B \ A) = P(B), tal como se quería demostrar.
Finalmente se concluye que, para que dos eventos sean mutuamente independientes, es condi-ción necesaria y suficiente que:
P(A ∩ B) = P(A) P(B)
Inversamente, si dos eventos A y B son mutuamente independientes, entonces es válida la ecua-ción anterior.
Generalizando, la probabilidad de que ocurran conjuntamente N eventos independientes es:
P(E1 ∩ E2 ∩ ... ∩ EN) = P(E1) P(E2)...P(EN)
Problemas resueltos:
1) Una fábrica elabora los productos A, B, C y D mediante cuatro procesos que son independientes entre sí. Usualmente son defectuosos el 3%, 5%, 5% y 4% de los productos A, B, C y D respec-tivamente. Si se extrae aleatoriamente un producto de cada tipo, ¿cuál es la probabilidad de que:

Probabilidades
17
a) los cuatro sean defectuosos?
610304,005,005,003,0 −×=×××=P
b) A y B sean defectuosos, y C y D no lo sean?
310368,196,095,005,003,0 −×=×××=P
2) De una ciudad donde fuman el 30% de los ciudadanos mayores de edad, se toma una muestra de 6 de ellos. ¿Cuál es la probabilidad de que 3 de ellos fumen?
Se calcula la probabilidad de que los tres primeros fumen y los tres últimos no fumen, y se mul-tiplica por el número de formas en que se pueden ordenar tres fumadores y tres no fumadores.
1852,0!3!3
!67,07,07,03,03,03,0 =××××××=P
3) Un sistema consta de seis relés que están conectados en serie y en paralelo, tal como se muestra en la siguiente figura 1.9.
Figura 1.9. Relés conectados en serie y paralelo
La probabilidad de que cada relé esté cerrado es 0,90. Si los relés funcionan independientemen-te, ¿cuál es la probabilidad de que pase la corriente de A a B?
Sea Ci el evento: cerrado el i-ésimo relé. Para que pase la corriente de A a B debe pasar por el relé 1, luego por el relé 2 ó por el relé 3, y luego por los relés 4 y 5 ó por el relé 6. Por lo tanto:
P = P[C1 ∩ (C2 ∪ C3) ∩ [(C4 ∩ C5) ∪ C6 ] ]
La probabilidad de que la corriente pase por 2 ó 3 (o por ambos) se puede calcular fácilmente como: 1 – P(no pase por 2 ni 3). De la misma forma se puede calcular la probabilidad de que pase por 4 y 5, o por 6, como se muestra a continuación:
P = (0,90)[1 – (0,10)(0,10)][1 – (1 – 0,90×0,90)(0,10)] = 0,874
4) Una persona lanza dos dados indefinidamente hasta obtener una suma igual a 2. ¿Cuál es la pro-babilidad de que sea necesario realizar un quinto lanzamiento?
Para que sea necesario realizar el quinto lanzamiento, en los 4 primeros no debe haber salido suma igual a 2. Por lo tanto:
P = (35/36)4 = 0,893
1.7.4 Teorema de suma y multiplicación: particiones Sean los eventos E1, E2, E3 ... ,EN una partición del espacio muestra S, es decir, todos mutua-
mente excluyentes, de tal forma que la unión de todos conformen el espacio muestral S. Sea además un evento E, perteneciente a S, como se muestra (sombreado) en la figura 1.10.
Entonces podemos decir: P(E) = P(E ∩ S) = P [E ∩ (E1 ∪ E2 ∪ ... ∪ EN)]
P(E) = P(E ∩ E1) ∪ P(E ∩ E2) ∪ ... ∪ P(E ∩ EN) P(E) = P(E1)P(E \ E1) + P(E2)P(E \ E2) + ... + P(EN)P(E \ EN)
P(E) = ∑ P(Ei)P(E \ Ei)
2
6
5
3
4
1A B

Probabilidades
18
Figura 1.10. Particiones de S.
Ejemplo 1:
Una empresa produce un componente mecánico. De la experiencia adquirida se ha determinado que el 10% de la producción es defectuosa. La producción es sometida a un control de calidad que acepta con una precisión del 95% los componentes que realmente son buenos, y rechaza con una precisión del 85% los componentes que realmente son defectuosos. Determine la pro-babilidad de que un componente sea aceptado.
Sean:
P(B) = 0,90 = probabilidad de que un componente sea bueno P(D) = 0,10 = probabilidad de que un componente sea defectuoso P(A) = probabilidad de que un componente sea aceptado P(R) = probabilidad de que un componente sea aceptado
P(A \ B) = 0,95 ; P(R \ B) = 0,05
P(A \ D) = 0,15 ; P(R \ D) = 0,85
En la figura 1.11 se representa un diagrama de árbol donde se ve que un componente puede ser aceptado de dos formas (mutuamente excluyentes): siendo bueno o siendo defectuoso.
Figura 1.11. Diagrama de árbol del problema de los componentes mecánicos
En la figura 1.12 se representa el mismo problema mediante un diagrama de Venn. En este caso la probabilidades son representadas como porcentajes. El área sombreada representa el porcen-taje de componentes mecánicos que han sido aceptados en el control de calidad, ya sean com-ponentes buenos o defectuosos. Si el 95% de los componentes buenos son aceptados, se deduce que el porcentaje de componentes aceptados y buenos será el 95% del 90%. Si el 15% de los componentes defectuosos son aceptados, se deduce que el porcentaje de componentes aceptados
Bueno
Defectuoso
Aceptado
Aceptado
Rechazado
Rechazado
0,9
0,1
0,95
0,05
0,15
0,85

Probabilidades
19
y defectuosos será el 15% del 10%. El porcentaje de componentes aceptados será entonces la suma de 95×90/100 + 15×10/100, es decir 87%.
Figura 1.12. Diagrama de Venn del problema de los componentes mecánicos
Aplicando el teorema de suma y multiplicación se llega a la misma respuesta:
P(A) = P(B)P(A \ B) + P(D)P(A \ D)
P(A) = (0,90)(0,95) + (0,10)(0,15) = 0,87
Es decir, el 87% de los componentes mecánicos son aceptados por el control de calidad.
Otra forma de visualizar este problema, expresando las probabilidades como porcentajes, se muestra en la siguiente tabla, donde se resaltan los datos del problema.
Aceptado Rechazado TotalBueno 0,95 × 90 = 85,5 0,05 × 90 = 4,5 90 Defectuoso 0,15 × 10 = 1,5 0,85 × 10 = 8,5 10 Total 85,5 + 1,5 = 87 4,5 + 8,5 = 13 100
La probabilidad de que el componente sea aceptado o de que sea rechazado puede calcularse sumando las columnas correspondientes.
Ejemplo 2:
Un método muy empleado por investigadores estadísticos para obtener información es el de efectuar encuestas personales. A menudo resulta importante investigar sobre temas muy perso-nales, que pondrían en aprietos al sujeto encuestado, ocasionando que dé respuestas falsas o que no conteste, deformando así los resultados de la encuesta. Para aminorar este problema, Warner ideó la "Técnica de la respuesta aleatoria", que permite que el encuestado escoja al azar una de dos preguntas: la pregunta personal, motivo de la encuesta, o una pregunta de control. Así, sólo él sabrá qué pregunta contestó en realidad, y se mantiene su privacidad. Por ejemplo, supóngase que se desea estimar el porcentaje de alumnos secundarios de una ciudad que no resuelven por su cuenta las tareas para la casa. Se hacen 1000 encuestas con las siguientes instrucciones: An-tes de contestar lance una moneda: si sale cara conteste la pregunta A, y si sale sello conteste la pregunta B. Sólo conteste SÍ o NO.
A: ¿resuelve usted las tareas para la casa por su cuenta? B: ¿nació su padre en enero, febrero, marzo, abril o mayo?
Supóngase que, una vez efectuadas las encuestas, hay 455 respuestas afirmativas y 545 negati-vas. ¿Qué porcentaje de alumnos no resuelve por su cuenta las tareas para la casa? Esto equivale a calcular la probabilidad de que un alumno no resuelva por su cuenta las tareas para la casa.
Sean: P(NO) = probabilidad de contestar NO a cualquiera de las dos preguntas. P(A) = probabilidad de que al alumno conteste la pregunta A (que obtenga cara). P(B) = probabilidad de que al alumno conteste la pregunta B (que obtenga sello).
Buenos90%
Defectuosos10%
Aceptados
Rechazados
95%
15%85%
5%

Probabilidades
20
Considerando que se puede contestar NO de dos formas diferentes (a las dos preguntas), mu-tuamente excluyentes, se plantea:
P(NO) = P(A)P(NO \ A) + P(B)P(NO \ B)
0,545 = (0,5)P(NO \ A) + (0,5)(7/12)
P(NO \ A) = 0,5067
En la figura 1.13 se traza un diagrama de árbol que nos permite visualizar con suma facilidad el planteamiento anterior.
Figura 1.13. Diagrama de árbol del problema de las encuestas
Se concluye que, aproximadamente, el 50,67 % de los alumnos secundarios de la ciudad no re-suelve por su cuenta las tareas para la casa.
De la misma forma que con el problema anterior, se puede plantear la siguiente tabla:
SI NO TotalA 455 – 208,33 = 246,67 545 – 291,67 = 253,33 500 B 5/12 × 500 = 208,33 7/12 × 500 = 291,67 500
Total 455 545 1000
Como se ve, los datos de la primera fila pueden obtenerse restando los de la segunda fila del to-tal. Se deduce entonces que la probabilidad de contestar NO, dado que se trata de la pregunta A es: 253,33/500 = 0,5067. Esto equivale a decir que 50.67 % de los alumnos secundarios de la ciudad no resuelve por su cuenta las tareas para la casa
Ejemplo 3:
Supóngase que el 35% de los alumnos de una universidad que estudian una carrera de ciencias provienen de los estratos socioeconómicos A y B, y que el 55% de los que no estudian una ca-rrera de ciencias también provienen de los estratos socioeconómicos A y B. Si el 40% de los alumnos estudian una carrera de Ciencias, ¿qué porcentaje de alumnos provienen de los estratos socioeconómicos A y B?
Sean: P(A y B) = probabilidad de un alumno provenga de los estratos A y B. P(C) = probabilidad de que un alumno estudie Ciencias. P(N) = probabilidad de que un alumno no estudie Ciencias.
)\()()\()()( NByAPNPCByAPCPByAP ×+×=
= 0,40 × 0,35 + 0,60 × 0,55 = 0,47
Por lo tanto, el 47% de los alumnos provienen de los estratos socioeconómicos A y B.
El lector estará ahora en condiciones de completar la siguiente tabla para calcular la probabili-dad o porcentaje requerido:
A
B
SI
SI
NO
NO
0,5
0,5
?
?
5/12
7/12

Probabilidades
21
C N Total A y B No A y B Total 40 60 100
Aunque no haga falta para contestar la pregunta del problema, se podría completar también la segunda fila de la tabla. Como ya se ha calculado previamente, el porcentaje de alumnos que provienen de los estratos A y B debe resultar 47%.
1.7.5 Teorema de Bayes Dada la misma partición conformada por los eventos E1, E2, ... ,EN; y el evento E, comentados en
el teorema de suma y multiplicación, se puede deducir fácilmente:
)(
)()\(
EPEEP
EEP kk
∩=
)\()()\()(
)\(ii
kkk EEPEP
EEPEPEEP
Σ=
Se trata de una probabilidad condicional, que incluye las reglas de suma y multiplicación de probabilidades. Tiene mucha importancia pues ha servido para desarrollar la inferencia o estimación bayesiana, que, mediante el empleo de datos experimentales llega a estimar probabilidades subjetivas con buena precisión.
Ejemplo 1:
Suponga que el concesionario de la cafetería de la UDEP está tratando de reducir el número de clientes no pagan sus cuentas al final del año. Él está dispuesto a cancelarles el crédito a los clientes que se demoren más de una semana en los pagos que deben realizar a fin de cada mes. El concesionario ha visto en sus archivos que, de todos los clientes que finalmente no pagaron sus cuentas al final del año, el 95% se habían demorado más de una semana en sus pagos men-suales. Además, sabe que el 4% de los clientes que tienen crédito no pagan su cuenta, y que, de los que sí pagan su cuenta a fin de año, el 35% se ha demorado alguna vez más de una semana. Determine la probabilidad de que un cliente que se ha demorado alguna vez más de una semana en sus pagos mensuales, no pague su cuenta al final del año.
Los datos de este problema se pueden interpretar de la siguiente forma:
P(No pague) = 0,04; P(Sí pague) = 0,96
P(Haya demorado \ No pagó) = 0,95 ; P(No haya demorado \ No pagó) = 0,05
P(Haya demorado \ Sí pagó) = 0,35 ; P(No haya demorado \ Sí pagó) = 0,65
La probabilidad de que un cliente no pague, dado que se demoró será:
=∩
=)(
)()/(DemoreP
DemorepagueNoPDemorópagueNoP
)\()()\()()\()(
pagóNoDemorePpagueNoPpagóSíDemorePpagueSíPpagóNoDemorePpagueNoP
+=
1016,0374,0038,0
95,004,035,096,095,004,0
==×+×
×=
La probabilidad de que un cliente que se ha demorado alguna vez más de una semana en sus pa-gos mensuales no pague su cuenta al final del año es 0,1016. O sea que el 10,16% de los moro-sos no pagan al final su cuenta.

Probabilidades
22
Nuevamente, se puede plantear este problema mediante una tabla, como la que se completa a continuación:
Demore No demore TotalPague 0,35 × 96 = 33,6 0,65 × 96 = 62,4 96 No pague 0,95 × 4 = 3,8 0,05 × 4 = 0,2 4 Total 33,6 + 3,8 = 37,4 62,4 + 0,2 = 62,6 100
Por lo tanto, la probabilidad de que un cliente que se ha demorado alguna vez más de una sema-na en sus pagos no pague su cuenta al final del año es: 3,8/37,4 = 0,1016.
Ejemplo 2:
Con los datos del ejemplo 1 del apartado 1.7.4, determine la probabilidad de que un componente que ha sido aceptado sea bueno.
9827,087,0855,0
87,095,090,0
)()/()()/( ==
×==
APBAPBPABP
Antes del control de calidad se tenía una certeza del 90% de producir un componente no defec-tuoso. Después del control de calidad, se tiene una certeza del 98,27% de escoger un componen-te no defectuoso.
Este mismo resultado se puede obtener a partir de la tabla que se elaboró en el problema 1 del apartado 1.7.4. Verifique el lector este resultado.
Ejemplo 3:
Una persona tiene dos dados: uno normal que marca 1,2,3,4,5,6 en sus caras y otro anormal que marca 2,2,4,4,6,6 en sus caras. Si se escoge un dado al azar, se lanza dos veces y en las dos oca-siones se obtiene un número par, ¿cuál es la probabilidad de que el dado escogido sea el anor-mal?
8,015,025,05,0
15,0),(
)/,()(),/( =×+×
×==
parparPAnormalparparPAnormalPparparAnormalP
donde: P(par, par) = P(Anormal) P(par, par / Anormal) + P(Normal) P(par, par / Normal)
Como era de esperarse, en vista del resultado de los dos lanzamientos, es más probable que el dado escogido haya sido el dado anormal: 0,8 > 0,5.

Probabilidades
23
Problemas propuestos. 1. Carmen y Mario lanzan 3 y 4 monedas, respectivamente. ¿Cuál es la probabilidad de que Mario
obtenga exactamente el doble de sellos que Carmen?
2. Un comerciante quiere comprar un lote de 25 piñas, y decide comprarlo solamente si al seleccio-nar 3 aleatoriamente, ninguna está malograda. Supóngase que realmente hay 4 piñas malogradas (el comerciante no lo sabe), ¿cuál es la probabilidad de que no compre el lote?
Respuesta: 0,4217
3. José, Bruno y Mónica lanzan sucesivamente una moneda. Si el primero en obtener cara gana el juego:
a) ¿Cuáles son las respectivas probabilidades de ganar el juego si cada uno lanza sólo una vez? Respuesta: P(gane José) = 1/2 P(gane Bruno) = 1/4 P(gane Mónica) = 1/8 b) ¿Cuáles son sus respectivas probabilidades de triunfo si, en caso sea necesario, el juego conti-
núa hasta un máximo de dos lanzamientos para cada uno? Respuesta: P(gane José) = 9/16 P(gane Bruno) = 9/32 P(gane Mónica) = 9/64
4. Supóngase que, en Piura, la probabilidad de que un día sea nublado es 1/18 en verano y 5/54 en cualquier otra estación. ¿Qué porcentaje de días del año se espera que sean nublados?
5. Se extraen aleatoriamente k boletos premiados de una urna que contiene n boletos enumerados 1, 2, ..., n. Determine la probabilidad de que:
a) El número premiado más alto sea el r. b) El número premiado más alto sea el r y el más bajo sea el s.
AYUDA: Primero resuelva ambos apartados para n = 10; k = 5; r = 8; s = 2.
6. Suponga que hay tres semáforos entre la casa de Quique y la UDEP. Al llegar a cada uno de ellos, éstos pueden estar en rojo (R) o verde (V). Considérese que el ámbar dura un tiempo despreciable. Quique ha verificado que, en el primer semáforo, el rojo dura tanto como el verde; pero en el se-gundo, el rojo dura el doble que el verde; y en el tercero, el verde dura el doble que el rojo. ¿Cuál es la probabilidad de que en el siguiente viaje a la UDEP:
a) Tenga que parar por exactamente una luz roja? Respuesta: 7/18
b) Tenga que parar al menos por una luz roja? Respuesta: 8/9
7. Cuatro canicas A, B, C, D, se pueden colocar en cinco vasijas numeradas del 1 al 5. Por ejemplo, A1,B2,C3,D1 significa que A está en la vasija 1, B en la vasija 2, C en la 3 y D en la 1. ¿De cuán-tas formas se pueden colocar las 4 canicas en las 5 vasijas, si en cada una caben hasta:
a) 4 canicas? Respuesta: 625 b) 3 canicas? Respuesta: 620
8. Se eligen 5 cartas de una baraja completa de 52. La baraja está conformada por cuatro “palos” (co-razones, espadas, tréboles y cocos) y por trece denominaciones (1, 2, ..., 13). ¿Cuál es la probabi-lidad de que:
a) Todas las cartas sean del mismo palo? b) Haya dos “1” y tres “13”? c) Haya dos cartas de una denominación y tres de otra?

Probabilidades
24
d) Todas las cartas sean de distintas denominaciones?
9. En el curso de Estadística hay 5 alumnos del IV ciclo, 34 del V, 21 del VI, 5 del VII y 2 del VIII. Si se eligiera un comité de 5 personas, ¿cuál es la probabilidad de que:
a) todos los ciclos estén representados en el comité? Respuesta: 0,00369 b) sólo el VI ciclo tenga miembros en el comité? Respuesta: 0,0021
10. Una familia tiene 5 hijos. Suponiendo que la probabilidad de que un hijo sea varón o mujer es la misma, determine la probabilidad de que:
a) Los 5 sean del mismo sexo. Respuesta: 1/16 b) Cuatro sean varones. Respuesta: 0,15625
11. Se extraen tres cartas de una baraja. Determine la probabilidad de que:
a) Las tres sean de distinta figura. Respuesta: 0,3976 b) Al menos dos números sean iguales. Respuesta: 0,171764
12. Una urna contiene canicas numeradas 1, 2, ..., n. Si se escogen dos canicas al azar, ¿cuál es la pro-babilidad de que los dos números sean consecutivos? Nota: Puede resolver este problema de dos formas: dividiendo eventos éxito entre eventos totales o aplicando algún teorema.
13. Se lanzan tres monedas, y, si se obtienen 2 caras y un sello, se extraen dos canicas, aleatoriamente, de una urna que contiene canicas numeradas del 1 al 100. Si las tres monedas muestran el mismo resultado (tres caras o tres sellos), se extraen dos canicas, de otra urna que contiene canicas nume-radas del 1 al 50. ¿Cuál es la probabilidad de que se extraigan dos canicas que muestren dos núme-ros consecutivos?
Respuesta: 7/400
14. Una persona elige 10 números de una lista de números del 1 al 80. Luego, de una urna donde hay 80 canicas enumeradas del 1 al 80, se extraen 20 canicas. ¿Cuál es la probabilidad de que en la se-gunda extracción no se extraiga ninguno de los 10 números elegidos al principio?
15. Una caja contiene nueve etiquetas numeradas consecutivamente del 1 al 9. Si se extraen dos de estas etiquetas al azar, ¿cuál es la probabilidad de que sumen 8?
16. Dos amigos compraron pasajes para viajar en un pequeño ómnibus. El ómnibus consta de 48 asientos, en filas de 4, con 24 asientos al lado izquierdo y 24 al lado derecho. Si los asientos fue-ron asignados aleatoriamente, determine la probabilidad de que los dos amigos,
a) Se sienten en el mismo lado. Respuesta: 0,48936 b) Se sienten en la misma fila. Respuesta: 0,06383 c) Se sienten juntos (uno al lado del otro o uno detrás del otro). Respuesta: 0,06028
17. Hay 8 amigos solteros y la probabilidad de que cualquiera de ellos se case en los próximos 15 años es 1/4. ¿Cuál es la probabilidad de que por lo menos uno se case?
Respuesta: 0,8999
18. ¿De cuántos modos puede dividirse una tarea de 10 ejercicios, en dos tareas de 5 ejercicios cada una?
Respuesta: de 252 formas

Probabilidades
25
19. Una persona compra un boleto de la LOTTO todas las semanas. Siempre apuesta a los mismos 6 números, seleccionados entre los enteros del 1 al 36. Para ganar, los seis números seleccionados deben coincidir con los que se escogen al azar en una urna. Determine:
a) El tamaño del espacio muestra. b) La probabilidad de que gane en una semana particular. c) La probabilidad de que gane en cada una de las próximas tres semanas. d) La probabilidad de que gane por lo menos una vez durante las próximas 52 semanas.
20. La empresa CRAG S.A. es demandada por supuesta violación de patente sobre el proceso de ma-nufactura de un producto. El asesor de la empresa, que es un ingeniero industrial que sabe de mé-todos cuantitativos para la toma de decisiones, ha hecho el diagnóstico de este problema emplean-do un árbol de decisiones. Dentro de su análisis estima que la probabilidad de ganar un juicio es X, y que la probabilidad de perder es 1 – X. Si CRAG S.A. gana el juicio, los demandantes pueden apelar o no, con probabilidades 0,90 y 0,10 respectivamente. Si pierde el juicio, estima que CRAG S.A. puede apelar o no, con probabilidades de 0,20 y 0,80 respectivamente. Además, estima que quien gana el juicio tiene 0,75 de probabilidad de ganar la apelación correspondiente.
a) Si la probabilidad de ganar el juicio (X) es 0,40, ¿Cuál es la probabilidad de ganar el litigio? Respuesta: 0,34
b) Si la probabilidad de ganar el litigio fuese 0,10, ¿Cuál sería entonces la probabilidad de ganar el juicio (X)? Respuesta: 0,069
c) ¿Cuál es la máxima probabilidad de ganar el litigio? Respuesta: 0,775
21. Un estudiante de Ingeniería ha estimado que en 4 horas puede estudiar un tema para el examen del día siguiente. Comienza a estudiar a las 8 p.m. con el riesgo de que haya un "apagón" en cualquier momento. ¿Cuál es la probabilidad de que, como consecuencia de un "apagón", lo que le falte es-tudiar sea menos de la quinta parte de lo que haya estudiado? Asuma que el apagón puede ocurrir en cualquier instante debido a problemas con el generador.
Respuesta: 1/6
22. Los compradores de grandes volúmenes de mercancías utilizan el muestreo de aceptación para ca-lificar las mercancías que compran. Los lotes de mercancías son rechazados o aceptados con base en los resultados obtenidos al inspeccionar una muestra del lote. Suponga que un inspector de una planta procesadora de alimentos ha aceptado el 97% de los lotes que son de calidad “buena”, y ha rechazado, incorrectamente, 3% de lotes que eran de calidad “buena”. Además se sabe que el ins-pector acepta el 95% de todos los lotes y que sólo el 3% de los lotes son de “calidad mala”. En-cuentre la probabilidad de que:
a) un lote sea de calidad “buena” y que además sea aceptado. Respuesta: 0,9409
b) un lote sea de calidad “mala” y que sea aceptado. Respuesta: 0,0091
c) un lote de calidad “mala”sea aceptado. Respuesta: 0,3033
23. Una persona lanza un dado cuyas seis caras muestran: un "1", dos "2" y tres "3". Si obtiene "1" en el primer lanzamiento, gana el juego. Si no obtiene "1" puede seguir lanzando el dado y gana si repite el resultado del primer lanzamiento. Si obtiene "1" antes de repetir el resultado del primer lanzamiento, pierde el juego. ¿Cuál es la probabilidad de ganar? Nota: Puede ser útil la siguiente fórmula: 1 + x + x2 + x3 + ... = 1/(1 – x), si 0 < x < 1.
Respuesta: 0,76388.
24. Una caja contiene 9 etiquetas numeradas consecutivamente del 1 al 9. Si se extraen dos de estas etiquetas al azar, ¿cuál es la probabilidad de que sean consecutivas o sumen ocho?
Respuesta: 11/36

Probabilidades
26
25. En un conocido juego con dados (timba) el jugador participante lanza dos dados. Si obtiene suma siete, gana. Si no, debe seguir lanzando hasta obtener el mismo resultado del primer lanzamiento, antes de que salga siete. Si sale siete antes de conseguir el mismo resultado del primer lanzamien-to, pierde.
a) Si el jugador obtiene suma cuatro en el primer lanzamiento. ¿Qué probabilidad tiene de ganar? Respuesta: 1/3 b) ¿Cuál es la probabilidad de que el jugador obtenga suma tres en el primer lanzamiento, y lue-
go pierda el juego? Respuesta: 1/24
26. Una urna contiene cuatro canicas enumeradas del 1 al 4. Si se extraen sucesivamente las canicas, una por una, ¿cuál es la probabilidad de que por lo menos uno de los números extraídos coincida con el orden de extracción de la canica? (Por ejemplo, que la tercera canica tenga el número 3)
Respuesta: 15/24
27. En un examen de Estadística sólo hay que contestar verdadero (V) o falso (F), para cada una de las cinco preguntas
a) ¿De cuántas formas se puede contestar el examen? b) Si contestase al azar, ¿cuál sería la probabilidad de contestar todas bien? c) Si un alumno estima que la probabilidad de que conteste bien cada pregunta es 2/3, ¿cuál será
la probabilidad de que conteste bien al menos cuatro preguntas?
28. Diga si se trata de una probabilidad a priori, experimental o subjetiva:
a) Probabilidad de que haya empate entre los dos candidatos a la presidencia de un comité. Respuesta: Subjetiva. b) Probabilidad de que una lata de conservas de pescado contenga algún objeto extraño. Respuesta: Experimental. c) Probabilidad de que dentro de tres años ocurra el fenómeno de El Niño. Respuesta: Subjetiva d) Probabilidad de que encontremos un semáforo en rojo. Respuesta: A priori.
29. En una urna hay siete esferas, que tienen marcadas las siguientes letras: C, A, L, C, U, L, O. Si se extraen, una por una, las siete esferas, y se van colocando de izquierda a derecha, ¿cuál es la pro-babilidad de que se forme la palabra CALCULO?
Respuesta: 7,94 × 10–4
30. Un vendedor estima que la probabilidad de venderle a un cliente en su primera visita es 0,4, pero que aumenta a 0,55 en la segunda visita, si en la primera no efectuó la venta. Calcule la probabili-dad de que:
a) El vendedor venda a un cliente b) El cliente no compre
31. En una urna se colocan n esferas blancas numeradas 1, 2, ..., n; y n esferas rojas numeradas 1, 2, ..., n. Si se extraen luego dos esferas aleatoriamente, ¿cuál es la probabilidad de que:
a) Sean blancas y consecutivas? b) Sean blancas o consecutivas? c) Sean consecutivas de distinto color?
32. En una urna hay seis canicas blancas y seis negras. Se escogen nueve de éstas aleatoriamente y se colocan en tres filas. Determine la probabilidad de que:
a) en cada fila haya sólo un color. b) en cada fila hayan dos canicas blancas.

Probabilidades
27
33. Una tabla para jugar está conformada por 15 casilleros. En 11 de éstos se encuentran las letras de la palabra ESTADISTICA y los 4 restantes están en blanco. Un jugador debe escoger, descono-ciendo lo que hay en cada casillero, casillero por casillero, hasta que conforme la palabra ESTA-DISTICA, sin importar el orden. Por cada casillero en blanco que se escoja, al jugador se le quita $20 de los $60 que le dan inicialmente. ¿Cuál es la probabilidad de que el jugador:
a) Gane $60 Respuesta: 1/1365 b) Gane $40 Respuesta: 11/1365 c) Gane $20 Respuesta: 66/1365 d) No gane Respuesta: 286/1365 e) Pierda $20 Respuesta: 1001/1365
34. ¿De cuántas formas puede un sindicato elegir entre sus 30 miembros a: un presidente, un vicepre-sidente, un secretario y tres vocales?
Respuesta: de 71 253 000 formas
35. Se lanza una moneda cuya probabilidad de que el resultado sea cara es 2/3. Si aparece cara, se ex-trae una canica de una urna que contiene dos rojas y tres verdes. Si el resultado es sello, se extrae una canica de otra urna que contiene dos rojas y dos verdes. ¿Cuál es la probabilidad de extraer una canica roja?
36. De una baraja completa de 52 cartas se extrae una mano de 5 cartas al azar. ¿Cuál es la probabili-dad de obtener una escalera? (5 números consecutivos).
37. Suponga que en una región se ha determinado que en un año lluvioso llueve aproximadamente el 50% de los días del año y en un año no lluvioso llueve aproximadamente el 25% de los días del año. Un agricultor quiere tomar las previsiones del caso y, transcurrida la primera semana del año, se percata de que ha llovido 2 días. ¿Cuál es la probabilidad de que se trate de un año no lluvioso? Supóngase que el 40% de los años son considerados lluviosos.
Respuesta: 0,7402
38. Se lanzan cinco monedas. Determine la probabilidad de que:
a) El número de caras exceda al número de sellos en 2 ó más. b) Los 5 resultados sean iguales.
39. Suponga que se escribe aleatoriamente un número de 4 dígitos (se permiten dígitos repetidos). ¿Cuál es la probabilidad de que no haya ningún dígito repetido?
40. En una urna hay 15 canicas blancas y seis negras. Se extrae una canica y luego otra hasta que ésta sea negra. Determine la probabilidad de que haya que realizar una cuarta extracción, si:
a) Las canicas se extraen sin sustitución. b) Las canicas se extraen con sustitución.
41. Se sabe que el veredicto dado por un jurado es un 90% confiable cuando el sospechoso es culpable y un 98% confiable cuando es inocente. En otras palabras, declara inocente al 10% de los culpa-bles y declara culpable al 2% de los inocentes. El sospechoso se selecciona entre un grupo de per-sonas, de las cuales sólo el 5% ha cometido un delito alguna vez. Si el jurado lo declara culpable, ¿cuál es la probabilidad de que esa persona sea inocente?
Respuesta: 0,2969
42. Una urna contiene 3 canicas blancas y 5 negras. Si se extraen canicas al azar, una por una, hasta que no quede ninguna, ¿cuál es la probabilidad de que las dos últimas canicas sean negras?

Probabilidades
28
Respuesta: 0,357
43. Doce estudiantes se disponen a sentarse en una sola fila, al azar. Si dos de ellos son hermanos, ¿Cuál es la probabilidad de que no se sienten juntos?
Respuesta: 5/6
44. Una asociación consiste en 14 miembros. Seis de los miembros son varones y los otros ocho miembros son mujeres. Ellos desean seleccionar un comité de tres hombres y tres mujeres. ¿De cuántas maneras puede seleccionarse este comité si :
a) no hay restricciones? b) dos de los hombres se rehúsan a estar juntos en el comité si el otro está? c) uno de los hombres y una de las mujeres rehúsan estar juntos en el comité si el otro está? d) Ana sólo participará en el comité si Juana también participa? e) el comité debe tener un presidente y un secretario y estos dos oficiales deben ser del mismo
sexo?
45. ¿De cuántas maneras se puede formar un equipo de fulbito que debe estar compuesto por cuatro jugadores novatos y dos veteranos, a partir de un grupo de diez novatos y cinco veteranos, si todos ellos pueden jugar en cualquier posición?
46. Un jugador lanza un dado y gana un juego si obtiene 5 ó 6. Si lanza varias veces seguidas hasta que gane dos veces.
a) ¿Cuál es la probabilidad de que necesite hacer un mínimo de 5 intentos? b) ¿Cuál es la probabilidad de que gane al menos dos veces en más de 4 intentos?
47. Una compañía procesadora de alimentos está considerando implantar una nueva línea de almuer-zos instantáneos. Las estimaciones actuales indican una probabilidad de gran éxito de 0,1, una probabilidad de éxito moderado de 0,4 y una probabilidad de no tener éxito de 0,5. La compañía hace una prueba a nivel regional, antes de implantarla a nivel nacional y obtiene resultados signifi-cativos, aunque no concluyentes. La confiabilidad de tal prueba está dada por las probabilidades condicionales de la siguiente tabla:
La prueba indicó Dado que un producto fue Gran éxito Éxito moderado Sin éxito Muy aceptado 0,6 0,4 0 Medianamente aceptado 0,2 0,6 0,2 No aceptado 0,1 0,3 0,6
Construya una diagrama de árbol y calcule las probabilidades condicionales: a) P(muy aceptado \ prueba indica gran éxito) b) P(muy aceptado \ prueba indica éxito moderado) c) P(muy aceptado \ prueba indica sin éxito) d) P(medianamente aceptado \ prueba indica gran éxito); etc.
48. En una prueba de aptitud conformada por 25 preguntas, 4 son de cultura general. Si a cada alumno se le asignan 20 preguntas al azar, ¿Cuál es la probabilidad de que:
a) no se le asigne ninguna pregunta de cultura general? Respuesta: 3,95 × 10–4
b) le asignen al menos 2 preguntas de cultura general? Respuesta: 0,98379
49. Tres amigos comienzan un juego de dados llamado “dudo”. Cada uno debe lanzar 5 dados sin que los demás vean su resultado (se cubre los dados con el vaso o “cacho”). Si a uno de ellos le toca el siguiente resultado: 5, 1, 5, 5, 3; ¿cuál es la probabilidad de que:
a) En total haya 3 cincos? b) En total haya un mínimo de 4 cincos?

Probabilidades
29
50. Se tiene una baraja de 52 cartas. Si se seleccionan 5 cartas al azar, ¿cuál es la probabilidad de ob-tener el 2 de espadas, el 2 de corazones y las otras tres cartas de diamantes?
Respuesta: 1,1 × 10-4
51. Un grupo de amigos están jugando "millonario" y uno de ellos desea obtener suma "4" al arrojar los dados. Un dado tiene las opciones: 0, 0, 1, 2, 3, 4 y el otro dado: 0, 0, 1, 2, 2, 4. ¿Cuál es la probabilidad de obtener la suma deseada?
Respuesta: 7/37
52. Un jugador tiene un dado normal. ¿Cuál es la probabilidad de que:
a) necesite hacer 8 ó más lanzamientos para obtener un seis? Respuesta: 0,2790 b) en 8 lanzamientos sólo obtenga un seis? Respuesta: 0,3721 c) recién obtenga un seis en el octavo lanzamiento? Respuesta: 0,0465
53. Una persona tiene dos dados, uno de los cuales es normal y el otro tiene dos "2",dos "4" y dos "6". Si se lanzan los dos dados, ¿cuál es la probabilidad de que:
a) ambos resultados sean pares? b) un resultado sea par y el otro impar? c) ambos resultados sean iguales?
54. En la UDEP aproximadamente el 52% del alumnado estudia Ingeniería, el 21% Administración de Empresas, el 18% estudia Información y el 9% restante estudia Educación. En Ingeniería, el 82% son varones, en Administración el 48%, en Información el 15% y en Educación el 5%. Si se esco-ge una persona al azar y resulta que es varón.
a) ¿Cuál es la probabilidad de que no estudie Ingeniería? b) ¿Cuál es la probabilidad de que estudie Administración o Información?
55. En la ciudad de Piura se publican los diarios A, B y C. Una encuesta indica que el 36% lee A, el 26% lee B y el 27% lee C; 11% leen A y B, 10% leen A y C, 6% leen B y C y 3% leen A, B y C. Se escoge a una persona adulta al azar. Calcule la probabilidad de que:
a) lea al menos un diario. b) lea sólo un diario. c) lea al menos A y C, si se sabe que lee al menos uno de los diarios.
56. Un pequeño club formado por diez parejas de casados va a elegir a dos representantes al azar. ¿Cuál es la probabilidad de que:
a) no sea elegido un matrimonio.? b) sean de sexo opuesto? c) sean mujeres?
57. De 30 objetos elegimos 5 al azar, con sustitución.
a) ¿Cuál es la probabilidad de que ningún objeto sea elegido más de una vez? Respuesta: 0,70373 b) ¿Cuál es la probabilidad de que sólo un objeto se repita una vez? Respuesta: 0,27066
58. Un jugador tiene un dado normal.
a) ¿Cuál es la probabilidad de que necesite hacer 10 ó más lanzamientos para obtener un seis? Respuesta: 0,1938 b) ¿Cuál es la probabilidad de que recién obtenga un seis en el décimo lanzamiento? Respuesta: 0,0323 c) ¿Cuál es la probabilidad de que en 10 lanzamientos sólo obtenga un seis?

Probabilidades
30
Respuesta: 0,323
59. En un examen formado por 25 preguntas pueden omitirse 5 de ellas.
a) ¿Cuántas selecciones de 20 preguntas pueden hacerse? Respuesta: 53 130 b) ¿En cuántas de éstas estarán las 6 preguntas más fáciles? Respuesta: 11 628
60. En un grupo de 20 problemas hay dos muy fáciles y uno muy difícil. Si a un estudiante se le deja un trabajo de 6 problemas, ¿Cuál es la probabilidad de que le toque el problema más difícil y uno de los dos más fáciles?
61. Se lanzan tres dados. Si dos de los resultados son impares, ¿cuál es la probabilidad de que la suma total sea menor que siete?
Respuesta: 4/27
62. Suponga que usted y dos amigos participan en un juego. Cada uno lanza cinco dados y sólo pue-den ver su propio juego. Si usted tiene dos "1", ¿cuál es la probabilidad de que al menos hayan cuatro "1" en total?
Respuesta: 0,5155
63. Un alumno de Estadística quiere medir la capacidad de un meteorólogo. Los datos recolectados en el pasado indican lo siguiente:
- La probabilidad de que el meteorólogo prediga sol en días asoleados es 0.80 - La probabilidad de que el meteorólogo prediga sol en días nublados es 0.40 - La probabilidad de un día asoleado es 0.90
Determine la probabilidad de que:
a) Haya sol, si el meteorólogo lo pronosticó. Respuesta: 0,9474
b) El meteorólogo pronostique que habrá sol. Respuesta: 0,76
64. Una caja contiene esferas numeradas 1, 2, ..., n. Se escogen tres al azar. ¿Cuál es la probabilidad de que los tres números sean consecutivos?
Respuesta: 6/n(n + 1)
65. Miguel lanza tres dados y sólo dice que no salió ningún 2 y ningún 6. ¿Cuál es la probabilidad de que:
a) la suma de los tres dados sea par? b) la suma de los tres dados sea mayor que 12?
66. Si a, b, c, c, d, d, e, f se distribuyen al azar. ¿Cuál es la probabilidad de que las dos letras "c" que-den separadas?
Respuesta: 0,75
67. Se van a seleccionar cinco soldados de un grupo de doce voluntarios para una misión peligrosa.
a) ¿De cuántos modos se podrán seleccionar? Respuesta: 792 b) ¿Cuántas veces podrán ser incluidos los dos más valientes? Respuesta: 120 c) ¿Cuántas veces será incluido sólo uno de los dos más valientes? Respuesta: 420
68. Se tiene una baraja de 52 cartas.
a) ¿Cuántas "manos" de 5 cartas se pueden seleccionar?

Probabilidades
31
Repuesta: 2 598 960 b) ¿En cuántas de estas "manos" se tendrán tres números iguales? Respuesta: 58 656
69. De un grupo de ocho hermanos se eligen tres al azar. Luis tiene 18 años, Jorge 17 años, Miguel 15 años, Raúl 12 años, Mario 10 años, Ana 9 años, Lucía 6 años y David 5 años. Determine la proba-bilidad de que:
a) Luis sea elegido. Respuesta: 3/8 b) Ana y Lucía sean elegidas Respuesta: 3/28 c) la suma de las edades de los tres elegidos sea menor que 28. Respuesta: 1/7 d) el menor de los tres sea Raúl. Respuesta: 3/56 e) el mayor de los tres sea Raúl. Respuesta: 3/28 f) el mayor de los tres sea Raúl, dado que este sí fue elegido. Respuesta: 2/7 g) el mayor de los tres sea Raúl, si David no fue elegido. Respuesta: 3/35 h) el mayor de los tres sea Raúl y David no sea elegido. Respuesta: 3/56
70. Se va a elegir por sorteo un comité de seis personas a partir de un grupo de diez hombres; tres de los cuales son profesionales. ¿Cuál es la probabilidad de que:
a) por lo menos haya dos profesionales en el comité? Respuesta: 2/3 b) no haya ningún profesional en el comité?
Respuesta: 1/30
71. Las probabilidades que tienen tres alumnos de aprobar Estadística son: 0,20; 0,40; 0,50. Determine la probabilidad de que:
a) Solamente apruebe uno. Respuesta: 0,46
b) Solamente apruebe el segundo. Respuesta: 0,16
c) Si aprueban al menos dos, esté incluido el primero. Respuesta: 0,4666
72. Supóngase que de un grupo de 20 objetos se eligen 5, reponiendo cada uno de los que se va eli-giendo antes de extraer el siguiente. ¿Cuál es la probabilidad de que:
a) sólo uno de los objetos se repita una vez? b) ningún objeto salga repetido? c) sólo dos objetos salgan elegidos?
73. Un club está conformado por 5 abogados, 10 ingenieros y 3 médicos.
a). De cuántas maneras se puede elegir un comité conformado por 2 abogados, 2 ingenieros y 2 médicos.
b). En cuántos de estos comités estarán la ingeniera Peralta y el doctor Zapata.
74. En una caja hay 10 canicas enumeradas del 1 al 10.
a) ¿De cuántas formas se pueden pintar, 3 de color rojo, 2 de color azul y 5 de color verde? b) ¿En cuántas de éstas formas, las 3 canicas que se pinten de color rojo serán consecutivas? c) ¿En cuántas de éstas formas, las 3 canicas rojas son consecutivas y las dos azules también?

Probabilidades
32
75. Aproximadamente 2/5 de las personas en el Perú pertenecen al grupo sanguíneo A. ¿Cuál es la probabilidad de que, en una muestra aleatoria de cinco personas, al menos tres pertenezcan al gru-po A?
76. En una escuela el 25% de los alumnos son hombres. El 25% de los hombres y el 20% de las muje-res tuvieron muy buen rendimiento el año anterior. Si se escoge un alumno al azar. ¿Cuál es la probabilidad de que haya tenido muy bien rendimiento el año anterior?
77. Un fabricante de computadoras ha indicado que la demanda mensual es de uno a siete equipos. Si se supone que cualquier nivel de demanda (dentro del rango de 1 a 7) es igualmente probable, de-termine las siguientes probabilidades:
a) Que se vendan dos computadoras en un mes determinado. b) Que se vendan menos de cuatro computadoras en un mes determinado. c) Que se vendan no más de cinco computadoras en un mes determinado. d) Que se vendan por lo menos tres computadoras en un mes determinado.
78. Un inversionista cuenta con la opción de invertir en dos de cuatro tipos de acción. El inversionista ignora que, de estos cuatro tipos, sólo dos aumentarán sustancialmente de valor dentro de los próximos cinco años. Si el inversionista elige los dos tipos de acción al azar, determine el espacio muestra correspondiente. Determine además qué eventos simples conforman los siguientes even-tos compuestos:
a) Por lo menos uno de los tipos de acción redituable fue escogido. b) Por lo menos uno de los tipos de acción redituable no fue escogido.
79. Se le pide a una ama de casa su opinión sobre cuatro marcas de conservas de atún (A, B, C y D), indicando el orden de su preferencia, marcando con el 1 la que más prefiere, con el 2 la que le si-gue, etc. Suponga que la señora en realidad no tiene ninguna preferencia por ninguna marca, y de-cide dar los números del 1 al 4 al azar. ¿Cuál es la probabilidad de que:
a) la marca A quede como la 1? Respuesta: 1/4
b) C quede en primer lugar y D en segundo? Respuesta: 1/12
c) A quede en alguno de los dos primeros lugares? Respuesta: 1/2
80. Una compañía produce un foco ahorrador en tres líneas de producción. Estos focos se envían en grandes lotes y, debido a que la inspección de la calidad es destructiva, la mayoría de los compra-dores muestrean un número pequeño de focos de cada lote. En general las tres líneas de produc-ción trabajan al mismo ritmo y, el porcentaje de defectuosos, que es el mismo para las tres, es de sólo 2%. Durante el mes de septiembre, la línea 1 sufrió un desperfecto y estuvo produciendo con un porcentaje de 5% de defectuosos, lo cual se supo mucho después. Un cliente recibió un lote producido en septiembre, del cual probó 3 focos, y resultó uno defectuoso. ¿Cuál es la probabili-dad de que este lote haya venido de las líneas de producción 2 ó 3?
81. Suponga que en la UDEP el 44% de los alumnos estudian Ingeniería y el 12% de éstos son muje-res. Además, el 60% de los otros programas son mujeres. Si se selecciona un alumno al azar y re-sulta que es hombre. ¿Cuál es la probabilidad de que no estudie Ingeniería?
Respuesta: 0,3665
82. Se va a elegir por sorteo el Comité de Deportes de la Facultad de Ingeniería entre los 30 alumnos que se han presentado a una reunión convocada por la Directora de Estudios. De estos 30 alumnos, 20 son hombres y 10 mujeres. Si el comité debe estar formado por 6 alumnos ¿Cuál es la probabi-lidad de que:
a) en el comité haya el doble número de hombres que de mujeres? b) en el comité no haya hombres?

Probabilidades
33
83. Una fábrica de balones de básquet impone los siguientes controles de calidad: un balón se rechaza si rebota demasiado o muy poco, o si tiene un defecto en su cuero. El 12% de los balones que se producen, rebotan demasiado o muy poco, y el 50 % de éstos tienen defecto en el cuero. El 10% de los balones producidos tienen defectos de cuero. ¿Qué porcentaje de balones:
a) serán rechazados por defecto en el rebote? Respuesta: 12% b) serán rechazados por defecto en el cuero? Respuesta: 10% c) serán rechazados por ambos tipos de defecto? Respuesta: 6% d) serán rechazados? Respuesta: 16%
84. Una fábrica de harina de pescado clasifica su producción según la calidad: A, B y C. En promedio, el 20% es de calidad A, el 30% de calidad B y el 50% de calidad C. Supóngase que procesa dos ti-pos de pescado: 60% de la producción de harina proviene del pescado P1 y 40% del pescado P2, con la característica de que no los mezcla durante el proceso. Supóngase además que el 40% de la harina de calidad A proviene del pescado P1 y el 40% de la harina de calidad B proviene del pes-cado P2. Determine la probabilidad de que:
a) Un saco de harina de calidad C provenga del pescado P1. b) Un saco de harina proveniente del pescado P1 sea de calidad C.
85. Un empleado de una fábrica inspecciona siempre 10 unidades extraídas aleatoriamente de la pro-ducción del día. Supóngase que un día se produjeron 50 unidades, 5 de las cuales eran defectuosas. Si el gerente de producción llegase al puesto del empleado justo cuando le falta inspeccionar 2 unidades, ¿cuál es la probabilidad de que:
a) las 2 unidades sean defectuosas? Respuesta: 0,008163 b) las 2 unidades sean defectuosas, si no había salido ninguna defectuosa antes? Respuesta: 0,0116
86. Tres cajas iguales contienen dados de la siguiente manera: la primera contiene un dado normal y dos anormales, la segunda contiene dos dados normales y uno anormal, y la tercera contiene tres dados anormales. Un dado normal marca 1, 2, 3, 4, 5 y 6 en sus caras, mientras que un dado anor-mal marca 2, 2, 4, 4, 6, 6 en sus caras.
a) Se extrae un dado de una de las cajas, en forma aleatoria y se lanza dos veces. ¿Cuál es la pro-babilidad de que los dos dados muestren resultado par?
b) Se extrae un dado de una de las cajas, en forma aleatoria y se lanza dos veces, obteniéndose par en los dos lanzamientos. ¿Cuál es la probabilidad de que el dado elegido sea el anormal?
87. Se estima que el 35% de los autos estacionados en Piura no tienen alarma contra robos. Además, la probabilidad de que uno de estos autos sea robado es 0,10; en cambio esta probabilidad es 0,005 en los autos con alarma. Si se han robado un auto, ¿cuál es la probabilidad de que no tenga alar-ma?
88. Se dispone de una urna con 6 canicas blancas y cuatro canicas negras. Se lanza un dado y, a conti-nuación, se extraen de la urna tantas canicas como lo indica el resultado del dado. Suponiendo que obtuvieron exactamente 3 canicas blancas, ¿cuál es la probabilidad de que el resultado del dado haya sido 5?
89. Una hamburguesería ofrece a sus clientes cinco tipos de ingredientes: lechuga, tomate, papitas, salsa de tomate y mayonesa. ¿Cuántos tipos de hamburguesas se pueden preparar? Considere que es posible un tipo de hamburguesa sin ingredientes, o con uno o más ingredientes.

Introducción a la Estadística
34
Capítulo 2. Introducción a la Estadística
2.1 Definición de Estadística Aunque estemos acostumbrados a que la palabra Estadística se emplee para designar descrip-
ciones numéricas o conjuntos de datos, es conveniente definirla como una ciencia que ha llegado a emplearse en casi todas las ciencias.
Se dice con razón que la Estadística es el lenguaje universal de las ciencias. Se emplea, por ejemplo, en: Producción, Calidad, Finanzas, Marketing, Logística, Economía, Psicología, Sociología, Educación, Medicina, Informática, Biología, Química, etc.
La Estadística es la ciencia que recopila, clasifica, presenta, describe e interpreta conjuntos de datos. Generalmente se ocupa de estudiar fenómenos aleatorios.
2.2 Definición de algunos términos básicos
2.2.1 Universo o población: Es el conjunto de datos o elementos cuyas propiedades se van a analizar. Cuando se quiere reali-
zar una investigación estadística, debe definirse cuidadosamente el universo. Si se quiere investigar, por ejemplo, qué proporción de la población de Piura fuma cigarrillos, debe definirse claramente el universo, diciendo quiénes lo conforman. No sería correcto decir que lo conforman los adultos, pues este término no está claramente definido. Podría definirse correctamente el universo diciendo, por ejemplo, que lo conforman aquellos que tienen 18 años cumplidos. En este ejemplo el universo está conformado por personas, o mejor dicho, por un atributo de dichas personas; pero el universo podría estar conformado por atributos o mediciones de personas, objetos o animales.
2.2.2 Muestra Es un conjunto de datos seleccionados de un universo, de tal forma que refleje las características
de éste. Se dice entonces que la muestra es representativa del universo.
A pesar de que sólo se debe llamar muestra a un conjunto de datos representativos del universo, se suele clasificar las muestras en: probabilísticas y no probabilísticas. Las primeras suelen ser re-presentativas de la población; las segundas no.
Se dice que una muestra es probabilística cuando cada elemento del universo tiene una probabi-lidad conocida de ser seleccionado en la muestra. La muestra es no probabilística cuando sus elemen-tos se eligen con base en el juicio o criterio del investigador. Esto puede dar lugar a una “muestra” que no sea representativa del universo del cual fue extraída. Generalmente, cuando se hace una investiga-ción, se extraen muestras probabilísticas, por razones evidentes.
Una muestra probabilística puede ser: muestra aleatoria simple, muestra estratificada o muestra por conglomerados.
Se denomina muestra aleatoria simple a aquélla que es seleccionada de tal forma que cada elemento del universo tiene la misma probabilidad de ser seleccionado. Un buen método para conse-guir esto consiste en enumerar previamente todos los elementos que conforman el universo, y, em-pleando números aleatorios, seleccionar la muestra del tamaño deseado.
Si el universo es de gran tamaño, puede resultar muy engorroso este último método, pues se ne-cesitaría mucho tiempo y/o dinero. Conviene en este caso dividir el universo en estratos, y tratar a ca-

Introducción a la Estadística
35
da uno de éstos como un universo.
Se denomina muestra estratificada a aquélla que se obtiene dividiendo el universo en estratos, para luego seleccionar “submuestras” de cada uno de éstos.
Se denomina muestra por conglomerados a aquélla que se obtiene estratificando el universo, para luego tomar todos los elementos de algunos estratos, seleccionados aleatoriamente.
Como conclusión, es conveniente tener en cuenta que el tipo de muestra que se debe emplear depende de lo que se va a investigar, y para seleccionar ésta adecuadamente, en caso que el universo sea grande y complicado, conviene estudiar con más detalle la Teoría del Muestreo.
2.3 Estadística descriptiva e inferencial La estadística se divide en dos partes: descriptiva e inferencial
La estadística descriptiva se encarga de recopilar, clasificar, presentar y describir un conjunto de datos. Como generalmente se estudian poblaciones muy grandes, este conjunto de datos suele ser una muestra.
La estadística inferencial se encarga de interpretar los datos estudiados por las técnicas descrip-tivas. De los datos obtenidos de las muestras, saca conclusiones que da como válidas para todo el uni-verso. Es de esperarse que al sacar estas conclusiones siempre exista una pequeña probabilidad de error, pues la inferencia es inductiva. Existe, pues, cierta incertidumbre al sacar dichas conclusiones; pero tal incertidumbre puede ser cuantificada.
2.4 Importancia de la Estadística A continuación se presentan cuatro razones (Guilford y Fruchter) por las cuales es recomenda-
ble alcanzar cierto dominio de la Estadística:
1. Para poder leer literatura profesional.
Para nadie es un secreto que un buen profesional siempre debe estar leyendo sobre su especiali-dad, y difícilmente podrá leer gran cosa sin encontrarse con símbolos, conceptos e ideas estadísti-cas. Quienes esquivan estas partes seguramente no podrán opinar ni sacar conclusiones propias, y tendrán que depender de lo que opinen los demás.
2. Para dominar técnicas que se necesitan en otras materias.
Generalmente es imposible hacer un buen análisis de los resultados sin emplear un mínimo de téc-nicas estadísticas.
3. Porque es parte esencial de la formación profesional.
En casi todas las profesiones.
4. Porque es parte fundamental en la Investigación.
“El progreso de cualquier profesión y de la competencia de sus miembros depende de la perma-nente actitud de investigación y de los esfuerzos de investigación de esos miembros”.
La estadística es fundamental en la investigación por las siguientes razones:
Permite describir con mayor exactitud cualquier fenómeno.
Obliga a ser claros y exactos en los procedimientos y en el pensar.
Sin el empleo de la Estadística se puede ser vago sin equivocarse; pero lo ideal es ser claro y exacto sin equivocarse.
Permite resumir resultados significativamente.
Esto mediante distintos tipos de tablas y gráficos.
Permite deducir conclusiones generales.

Introducción a la Estadística
36
Además, se puede saber qué tan confiables son esas conclusiones generales sacadas en un es-tudio, y hasta dónde se pueden ampliar nuestras generalizaciones.
Permite hacer predicciones.
Si se conocen las condiciones en que se encuentra algo o alguien, podemos predecir qué suce-derá a futuro. Por ejemplo, si la producción en un proceso de manufactura se ve afectada por diversos factores, y se tiene registrados valores que cuantifiquen estos factores, se puede de-terminar una ecuación predictiva que relacione la producción con dichos factores.
Permite analizar algunos factores causales en sucesos complejos.
Se pueden determinar, por ejemplo, los factores causales por los que un producto tiene acepta-ción en el mercado, y analizar cuánto influye cada uno.

Estadística Descriptiva
37
Capítulo 3. Estadística Descriptiva
3.1 Introducción Si se tuviera que informar respecto a datos obtenidos en una investigación, no serviría de mucho
que éstos se presenten en un simple listado, o que sólo se exprese alguna medida descriptiva (por ejemplo, la media o promedio) de dichos datos. En el primer caso la información resultará excesiva y en el segundo puede ser pobre. Lo más práctico sería presentar los datos de una forma condensada, ya sea mediante el uso de tablas o de gráficos.
En este capítulo se van a presentar las medidas descriptivas más empleadas en análisis de datos, y las distintas formas de representar dichos datos en tablas y gráficos.
3.2 Medidas descriptivas A continuación se definen las medidas descriptivas más usadas en las investigaciones estadísti-
cas, que nos permiten localizar con cierta precisión un conjunto de datos. Estas medidas pueden ser: de tendencia central, de variabilidad, de posición y de forma.
Las medidas de tendencia central, como la media aritmética, la mediana y el modo, tratan de ubicar la parte central de un conjunto de datos.
3.2.1 Media aritmética Dado un conjunto de n datos de una muestra, se define la media aritmética:
∑=
=n
iix
nx
1
1
Dado un conjunto de los N datos de una población, se define la media aritmética:
∑=
=N
iix
N 1
1µ
Dada una muestra conformada por un conjunto de k valores; si cada uno de éstos se repite con una frecuencia fi, o si cada uno tiene un peso o ponderado wi, entonces las medias aritméticas serán, respectivamente:
∑
∑
=
== k
ii
k
iii
f
xfx
1
1
∑
∑
=
== k
ii
k
iii
w
xwx
1
1
A esta última se le denomina media aritmética ponderada.
Si en lugar de contar sólo con datos muestrales se tuviera todos los datos poblacionales, para calcular la media aritmética se emplearían estas dos mismas fórmulas.

Estadística Descriptiva
38
Si se tienen k muestras de tamaños N1, N2, ... , Nk, con medias aritméticas ,,...,, 21 kxxx respec-tivamente; entonces la media aritmética del conjunto será:
∑
∑
=
== k
ii
k
iii
N
xNx
1
1
Ejemplo 1:
Una entidad financiera ofrece los siguientes intereses anuales, según los montos que depositen los ahorristas a plazo fijo: 6% para depósitos A (de 1000 dólares); 8% para depósitos B (de 2000 dólares) y 10% para depósitos C (de 5000 dólares). ¿Cuál es el interés anual promedio que está pagando el banco si hay 15 depósitos A, 10 depósitos B y 5 depósitos C?
%33,730
105810615=
×+×+×=x
Ejemplo 2:
Se han registrado los pesos de las bolsas de arroz empacadas por una empresa durante 7 horas, resultando un promedio de 0,992 Kg. Si cada hora se embolsan 30 unidades, ¿cuál será el peso promedio si en la octava hora se registra un peso promedio de 1,025 Kg?
En este caso se debe hallar la media de dos medias aritméticas, donde los pesos o ponderaciones pueden ser 7 y 1, ó 210 y 30.
996,08
025,11992,07=
×+×=x Kg.
3.2.2 La mediana Dado un conjunto de n datos, la mediana es aquél que ocupa la posición central, cuando los da-
tos se ordenan en orden creciente (o decreciente). Si el número de datos es par, la mediana será la me-dia aritmética de los dos datos que ocupen la posición central.
Si algunos datos se repiten con una determinada frecuencia, el cálculo de la mediana se compli-ca; pero no vale la pena ahondar en esto, pues se puede recurrir a una herramienta tan accesible como Excel para hacer este cálculo.
3.2.3 La moda Dado un conjunto de datos, la moda (Mo) es el valor que se repite con mayor frecuencia. Cuan-
do dos o más datos son los que tienen la mayor frecuencia, se dice que el conjunto de datos es bimodal o multimodal, respectivamente.
Las medidas de variabilidad, como la amplitud, la desviación media, la varianza y la desvia-
ción estándar, indican qué tan dispersos se encuentran los datos.
En muchas situaciones es importante conocer la variabilidad de los datos. Por ejemplo, entre dos procesos de elaboración de planchas de acero del mismo espesor, es más eficiente aquél cuyas medi-das de espesor tienen una menor variabilidad. Igualmente, entre dos negocios con similar promedio de ganancias, quien tiene aversión al riesgo preferirá aquél que tenga menor variabilidad, pues así puede evitar una posible ganancia muy baja o una pérdida.

Estadística Descriptiva
39
3.2.4 La amplitud Dado un conjunto de datos, la amplitud es la diferencia entre el mayor y el menor. Es una medi-
da que puede ser muy útil, dada la facilidad con que se calcula; pero en ciertas ocasiones puede dar una idea equivocada de la variabilidad de los datos; por ejemplo, cuando uno de los datos difiere signi-ficativamente de los demás.
3.2.5 La desviación media Dado un conjunto de datos, la desviación media es la media aritmética de los valores absolutos
de lo que se desvía cada valor respecto a la media aritmética. Es una medida poco usada debido a la dificultad al hacer cálculos con la función valor absoluto.
∑=
−=n
ii xx
nMD
1
1..
3.2.6 La varianza Dado un conjunto de n datos, se define la varianza:
( )2
1
2 1 ∑=
−=n
ii xx
ns
Dado un conjunto de k datos; si cada uno se repite con una frecuencia fi, la varianza será:
( )2
1
2 1 ∑=
−=k
iii xxf
ns
Algunos autores emplean n – 1 en lugar de n en las dos últimas fórmulas. Más adelante se verá que es recomendable emplear n – 1 cuando la muestra extraída es pequeña. Para n grande esto no oca-siona una diferencia numérica apreciable.
Si se cuenta con el total de datos (N) de una población, la varianza es:
( )2
1
2 1 ∑=
−=N
iix
Nµσ ó ( )
2
1
2 1 ∑=
−=k
iii xf
Nµσ
3.2.7 La desviación estándar Es la raíz cuadrada positiva de la varianza. Es la medida de variabilidad que más se emplea, de-
bido a que se expresa en las mismas unidades que los datos y la media aritmética.
3.2.8 El coeficiente de variación Se define como el cociente entre la desviación estándar y la media aritmética de un conjunto de
datos. Según se trate de una muestra o población, el coeficiente de variación será:
µσ
=V xsv =
Esta medida se suele usar para comparar el grado de dispersión de dos o más conjuntos de datos; incluso si se trata de medidas diferentes. Suele ser de gran utilidad cuando se desea comparar las dis-persiones de dos conjuntos de datos cuyas medias difieren significativamente.
Ejemplo:
Medio año después de haber sembrado 50 semillas, se miden las alturas de las plantas, obtenién-dose una media de 43,6 cm. y una desviación estándar de 5,1 cm. Al cumplir un año, se vuelven a medir las alturas de las plantas, encontrándose una media de 128,7 cm. y una desviación es-tándar de 6,6 cm. Compare las dispersiones de las plantas en ambos momentos.

Estadística Descriptiva
40
Al medio año: V1 = 5,1/43,6 = 0,117
Al año: V2 = 6,6/128,7 = 0,051
Si se comparasen las desviaciones estándar, se afirmaría que la dispersión aumentó; pero com-parando las dispersiones respecto a las alturas (representadas por las medias aritméticas), se puede afirmar que la dispersión relativa ha disminuido.
Las medidas de posición, como los cuartiles y los percentiles, localizan los datos respecto a los
demás.
3.2.9 Los cuartiles Dado un conjunto de datos ordenados en forma ascendente, los cuartiles lo dividen en cuatro
partes iguales.
El primer cuartil, Q1, es un valor tal que, a lo sumo, la cuarta parte de los datos es menor que Q1, y, a lo sumo, las tres cuartas partes son mayores.
El segundo cuartil, Q2, coincide con la mediana.
El tercer cuartil, Q3, es un valor tal que, a lo sumo, las tres cuartas partes de los datos son meno-res que Q3, y, a lo sumo, la cuarta parte es mayor.
Ejemplo 1:
,15,13,12 ,20,19,18 ,26,25,21 34,30,28
Ejemplo 2:
,17,16,15,12,10 28,27,26,23,19
Para el cálculo de los cuartiles se recomienda recurrir a una herramienta tan accesible y de tan fácil uso como Excel. Obsérvese, en el ejemplo 1, que Q1 no es la media de 15 y 18.
3.2.10 Los percentiles Dado un conjunto de datos ordenados en forma ascendente, los percentiles lo dividen en cien
partes iguales.
El k-ésimo percentil, Pk, es un valor tal que, a lo sumo, el k por ciento de los datos son menores que Pk. Para determinar los percentiles se sigue el mismo procedimiento que para los cuartiles.
Las medidas de forma, como el coeficiente de asimetría y la curtosis, expresan la forma como
se distribuye un conjunto de datos.
3.2.11 Coeficiente de asimetría Mide si un conjunto de datos están más dispersos por encima de la media aritmética o por deba-
jo de ella. Si hay más datos por encima de la media, el coeficiente de asimetría es positivo; si hay más datos por debajo de la media, el coeficiente de asimetría es negativo; y si los datos están igualmente dispersos por encima y por debajo de la media, el coeficiente de asimetría es cero.
El coeficiente de asimetría puede calcularse mediante la siguiente fórmula (de Excel), aunque lo más práctico es calcularlo en Excel.
Q1=17,25 Q3=26,5Q2=20,5
Q1=15,25 Q2=18 Q3=25,25

Estadística Descriptiva
41
3
)2)(1( ∑
−−−
=s
xxnn
nsk i
Existen otras fórmulas para medir la asimetría, como el coeficiente de Asimetría de Pearson:
sMoxsk −
=
3.2.12 Curtosis Mide el grado en que los datos están agrupados alrededor de la media aritmética. Si la mayor
parte de los datos están cerca de la media, la curtosis es positiva, y se dice que los datos tienen una dis-tribución leptocúrtica; en caso contrario, si la mayor parte de los datos están lejos de la media, la cur-tosis es negativa, y se dice que los datos tienen una distribución platocúrtica. Si los datos se distribu-yen normalmente (capítulo 8), la curtosis es cero, y se dice que la distribución es mesocúrtica.
Es importante aclarar que la curtosis no es una medida de la variabilidad de los datos; que un conjunto de datos tenga una distribución leptocúrtica no indica que tenga menor desviación estándar.
Para medir la curtosis se puede emplear la siguiente fórmula (de Excel), aunque lo más práctico es calcularla en Excel.
∑ −−−
−
−−−−
+=
)3)(2()1(3
)3)(2)(1()1( 24
nnn
sxx
nnnnnk i
3.3 Exactitud y precisión La mayoría de la gente usa estos dos términos indistintamente, y por lo tanto, incorrectamente.
Exactitud es la proximidad de un resultado o de un conjunto de resultados de un experimento con el resultado verdadero o real. Precisión es la cercanía entre los resultados de un experimento.
Así, se pueden tener resultados precisos pero no exactos, o exactos y precisos; aunque es difícil tener resultados exactos e imprecisos. Los científicos experimentales hacen una distinción entre dos tipos de errores: aleatorios y sistemáticos.
Los errores aleatorios provocan que los resultados se dispersen alrededor del valor promedio, es decir, afectan la precisión o reproducibilidad de un experimento. La varianza o desviación estándar miden qué tan grande o pequeño será el error aleatorio.
Los errores sistemáticos provocan que los resultados se desvíen en el mismo sentido, es decir, afectan la exactitud de los resultados. La diferencia entre la media de los resultados y el valor verdade-ro es una medida del error sistemático.
En 1936, A. Benedetti-Pichler ilustró estos conceptos, como se muestra en la figura 3.1.
Figura 3.1 Exactitud y precisión
Valor verdadero
Exacto y preciso
Preciso e inexacto
Impreciso e inexacto

Estadística Descriptiva
42
3.4 Medidas descriptivas en Excel Resulta sumamente fácil calcular las medidas descriptivas de un conjunto de datos con Excel.
Sólo basta ingresar los datos en una hoja de cálculo, ubicarse en la celda donde se desea expresar la medida, y hacer click en el icono . Excel abre un cuadro de diálogo con todas las funciones dispo-nibles, por categorías, como se muestra en la figura 3.1.
Figura 3.1. Cuadro de diálogo de funciones de Excel
Una vez seleccionada una función, Excel indica, en el mismo cuadro de diálogo, qué resultado
va a devolver, y qué datos necesita, explicando en qué consiste cada uno de éstos. Las medidas des-criptivas estudiadas en este capítulo que están en el listado de funciones de Excel se muestran en la ta-bla 3.1.
Tabla 3.1. Funciones de Excel para el cálculo de algunas medidas descriptivas
Medida descriptiva Función de Excel Media aritmética PROMEDIO Mediana MEDIANA Moda MODA Varianza (muestra) Varianza (población)
VAR VARP
Desviación estándar (muestra) Desviación estándar (población)
DESVEST DESVESTP
Cuartil CUARTIL Percentil PERCENTIL Coeficiente de asimetría COEFICIENTE.ASIMETRÍACurtosis CURTOSIS
Cabe aclarar que las funciones VARP y DESVESTP emplean n en el denominador, a diferencia de las funciones VAR y DESVEST que emplean n – 1.
Excel tiene también, en el menú de Herramientas, la opción Análisis de datos (si no aparece, puede activarse en la opción Complementos, escogiendo la opción Herramientas para Análisis). Esta opción Análisis de Datos abre un cuadro de diálogo con un listado de herramientas estadísticas. Una de estas herramientas es: Estadística Descriptiva, que abre el cuadro de diálogo que se muestra en la figura 3.2.

Estadística Descriptiva
43
Figura 3.2. Cuadro de diálogo de Estadística descriptiva de Excel para el ingreso de datos
Ejemplo:
Se ingresan los siguientes 20 datos en Excel, en una fila o columna; por ejemplo, desde la celda A1 hasta la celda A20.
73 69 65 87 86 61 65 77 80 72 75 85 63 75 73 78 74 81 73 81.
En el rango de entrada del cuadro de diálogo saldrá: A1:A20. Ejecutando la opción Resumen de estadísticas, Excel muestra el resultado que se muestra en la tabla 2.
Tabla 3.2. Medidas descriptivas del Análisis de datos de Excel
Fila1
Media 74,65
Error típico 1,67846264
Mediana 74,5
Moda 73
Desviación estándar 7,50631313
Varianza de la muestra 56,3447368
Curtosis -0,64638537
Coeficiente de asimetría -0,13330001
Rango 26
Mínimo 61
Máximo 87
Suma 1493
Cuenta 20

Estadística Descriptiva
44
3.5 Representaciones de datos
3.5.1 Distribución de frecuencias: diagrama de barras Al repetirse sucesivamente un experimento, los resultados obtenidos constituyen los valores que
toma la variable aleatoria definida, X. Cada uno de estos resultados se representa con xi (minúscula). La cantidad de veces que se repite cada resultado se denomina frecuencia, f.
Al conjunto de parejas de valores {xi, fi} se le denomina distribución de frecuencias, y se repre-senta en una tabla de distribución de frecuencias como la que se muestra en la tabla 3.3.
Tabla 3.3. Tabla de distribución de frecuencias
X x1 x2 ... xn
f f1 f2 ... fn
Esta distribución de frecuencias suele representarse mediante diagramas de barras, que represen-
ta cada una de las frecuencias en barras proporcionales.
Ejemplo:
Los siguientes datos expresan las cantidades de piezas que produjeron 20 trabajadores durante una semana en un taller de manufactura:
73 79 75 77 76 76 75 77 74 72 75 75 73 75 73 78 74 76 73 80
La distribución de frecuencias correspondiente a estos datos se expresa en la tabla 3.4, que da una idea más clara de cómo están distribuidos los datos que conforman la muestra.
Tabla 3.4 Distribución de frecuencias de la piezas producidas por los 20 trabajadores
X 72 73 74 75 76 77 78 79 80 f 1 4 2 5 3 2 1 1 1
Para este ejemplo, el diagrama de barras de la figura 3.3 nos da una visión mucho más clara de cómo están distribuidos estos datos. Como se ve, la mayoría de los trabajadores (14 de 20) elaboraron entre 73 y 76 piezas.
Figura 3.3 Diagrama de barras del número de piezas producidas por los 20 trabajadores
0
1
2
3
4
5
6
72 73 74 75 76 77 78 79 80
f

Estadística Descriptiva
45
Si en una distribución de frecuencias se suman sucesivamente las frecuencias, de tal forma que éstas se van acumulando: f1 , f1 + f2 , f1 + f2 + f3 , etc., se obtiene una distribución de frecuencias acumuladas. Para el ejemplo anterior, esta distribución se representa en la tabla 3.5.
Tabla 3.5 Distribución de frecuencias acumuladas del número de piezas producidas por los 20 trabajadores
X 72 73 74 75 76 77 78 79 80 facum 1 4 7 12 15 17 18 19 20
3.5.2 Representaciones tallo-hoja Las representaciones tallo-hoja (stem-and-leaf) muestran en la columna que está a la izquierda
de la barra, la(s) cifra(s) de la izquierda de cada dato (tallos), y a la derecha de la barra, las cifras de las unidades (hojas). Así, cada hoja, junto con su tallo, conforma un dato. Si todos o casi todos los da-tos de una muestra tienen la misma cifra de las decenas, como en el ejemplo anterior, la representación tallo-hoja no es útil.
Ejemplo:
Se ha medido el tiempo que tarda vehículo que transporta productos terminados desde una fábri-ca a uno de sus almacenes, durante 30 días, obteniéndose los siguientes resultados, en minutos:
41 33 47 56 56 58 30 42 55 34 47 41 31 35 36 40 38 40 46 40 41 40 56 44 42 39 58 53 59 37
La representación tallo-hoja para el ejemplo del apartado anterior se muestra en la figura 3.4.
3 3 0 4 1 5 6 8 9 7
4 1 7 2 7 1 0 0 6 0 1 0 4 2
5 6 6 8 5 6 8 3 9
Figura 3.4 Representación tallo-hoja de la piezas producidas por los 20 trabajadores
En este ejemplo, esta representación puede resultar útil para formarse una idea de la distribución de los datos, decena por decena. Como se ve, los datos no necesitan ser representados en un orden de-finido.
3.5.3 Diagrama de caja-bigote Representa un conjunto de datos mediante una caja formada con los siguientes valores: mínimo,
máximo, primer cuartil, segundo cuartil y tercer cuartil. De esta forma se visualiza fácilmente cómo están distribuidos un conjunto de datos.
Ejemplo:
El administrador de una gasolinera ha anotado el número de vehículos que llegan a su local cada dos minutos, de 7 a 11 a.m. y de 3 a 7 p.m., con el propósito de comparar la afluencia de vehícu-los por la mañana y por la tarde. A continuación se muestran los datos obtenidos en ambos ho-rarios. Trace dos diagramas de caja y bigote.
Ingresando los datos a Excel, se calculan fácilmente los datos que se necesita para construir los diagramas de caja – bigote, es decir:
Para el horario de la mañana: Min = 2; Max = 17; Q1 = 7; Q2 = 8,5; Q3 = 11 Para el horario de la tarde: Min = 1; Max = 15; Q1 = 6; Q2 = 7; Q3 = 10

Estadística Descriptiva
46
Tabla 3.4. Número de vehículos que llegan a una gasolinera cada dos minutos
Horario de la mañana Horario de la tarde 9 7 7 7 6 7 6 10 6 11 15 8 9 4 9 11 6 8 5 4 1 4 7 8 7 11 15 6 6 11 9 2 9 4 9 17 6 5 9 12 8 14 6 4 9 8 6 7 9 8 4 6 6 8 7 7 9 10 10 4 8 8 11 3 6 10 11 5 4 5 6 6
10 12 12 11 5 11 7 11 12 10 10 7 7 8 5 13 10 11 11 11 2 8 10 7 12 5 8 8 10 12 6 13 7 12 8 10 7 7 5 4 7 5 8 9 12 14 8 4 10 14 8 10 9 5 6 8 8 11 6 6 8 11 7 3 6 4 10 6 15 5 4 13 5 9 11 9 10 8 5 11 7 4 8 12 11 6 4 6 11 6 7 9 4 13 7 6
10 15 11 9 14 6 10 8 11 9 8 8 11 8 9 11 6 3 6 5 11 10 11 6 11 11 6 3 8 10 9 7 9 13 10 6 12 10 4 8 4 8 6 4 10 8 10 6 13 6 9 7 8 7 8 13 7 2 5 12 6 9 9 8 5 7 10 11 11 6 6 10
En la figura 3.5 se presentan los dos diagramas de caja – bigote, juntos y con la misma escala, para poder hacer una comparación de ambos grupos de datos.
Figura 3.5. Diagramas de caja – bigote del número de vehículos que llegan a una gasolinera en dos minutos.
Aunque bastaría hallar las medias aritméticas de los dos turnos para darse cuenta que por la tar-de hay una pequeña disminución en el número de vehículos que llegan a la gasolinera, los diagramas de caja-bigote nos dan más información. Se puede afirmar, por ejemplo, que por la mañana, en la cuar-ta parte (25%) de los intervalos de dos minutos llegaron entre 2 y 7 vehículos; sin embargo, por la tar-de, en la mitad de los intervalos de dos minutos llegaron entre 1 y 7 vehículos.
3.6 Distribuciones de frecuencias agrupadas
3.6.1 Agrupación de datos. Si se tiene un conjunto de datos que corresponden a una variable aleatoria continua, o a una va-
riable aleatoria discreta en cuya tabla de distribución de frecuencias hay demasiadas frecuencias, es conveniente agrupar los datos en intervalos, pues el diagrama de barras correspondiente tendría dema-siadas barras y no mostraría con claridad de qué forma se distribuyen dichos datos.
Agrupar un conjunto de datos en intervalos, y representarlo gráficamente, suele ser más un arte que una técnica. Existen fórmulas matemáticas que se emplean para determinar el número de interva-los que conviene tener, y a partir de este resultado se determinan los tamaños de estos intervalos, obte-niéndose en la mayoría de los casos valores numéricos poco prácticos y/o inmanejables.
Para agrupar en forma adecuada un conjunto de datos, se propone seguir los siguientes pasos:
1) Determinar la amplitud, A.
0
2
4
6
8
10
12
14
16
18
0
2
4
6
8
10
12
14
16
18

Estadística Descriptiva
47
2) Determinar el número de agrupaciones o clases, m, y la longitud de cada clase, k, de tal for-ma que el producto mk sea mayor o igual que A. Es recomendable que el número de clases esté comprendido entre 6 y 15, para una mejor interpretación, y que la longitud de las clases sea impar, si se quiere trabajar con las marcas de clase (se definen más adelante).
3) Determinar uno por uno los límites de cada clase, procurando que, los límites inferiores o los superiores, sean múltiplos de 5, 10, 100, 1 000, etc., para facilitar su visualización.
4) Contar el número de elementos de cada clase. Es muy importante establecer la precisión de las cifras con las que se va a trabajar. Por ejemplo,
si los datos representan diámetros de ciertas piezas cilíndricas, en mm.: 125,5; 127,3; 124,0; etc; los límites se expresarán también con una cifra decimal.
Antes de seguir adelante, conviene definir:
1) Frecuencia de clase: Es el número de elementos que hay en cada clase.
2) Límites de clase: Son los valores extremos de cada clase.
3) Fronteras de clase: Son valores que no están presentes en los datos. Se localizan en los pun-tos medios entre el límite superior de una clase, y el inferior de la clase siguiente. Incluyen por lo tanto una aproximación superior a la que consideró al agrupar los datos (dos decima-les para el ejemplo de los diámetros).
4) Longitud de clase: Es la extensión o tamaño de las clases. Se obtiene calculando la diferen-cia entre las fronteras de una clase, o la diferencia entre dos límites superiores (o inferiores) consecutivos.
5) Marca de clase: Es el punto medio de cada clase. Se obtiene calculando la semisuma de los límites superior e inferior de cada clase.
Vale la pena aclarar que, dado un conjunto de datos, éstos se pueden agrupar de varias maneras, sin que se pueda decir en muchos casos que sólo una es la manera correcta. Se podría decir, sin em-bargo, que la mejor agrupación es aquella que se elabora de una forma rápida y que permite mostrar de una manera clara cómo se distribuyen los datos, ya sea de forma tabular o gráfica.
Ejemplo:
Suponga que los siguientes datos representan el número de piezas que produjeron 100 trabajadores durante la última semana:
23 20 16 18 30 22 26 15 13 18 14 17 11 37 21 16 10 20 22 25 19 19 19 20 12 23 24 17 18 16 27 26 28 26 15 29 19 18 20 17 12 24 21 22 20 15 18 16 23 24 15 24 28 19 24 22 17 19 8 18 17 18 23 21 25 19 20 22 21 21 16 20 19 11 23 17 23 13 17 26 26 14 15 16 27 18 21 24 33 20 21 27 18 22 17 20 14 21 22 19
A continuación se siguen los pasos recomendados:
1) A = 37 – 8 = 29

Estadística Descriptiva
48
2) Podría ser: k = 5 y m = 6, de tal forma que: mk = 30 > 29.
3) Así, los límites de clase serían:
1a. clase: de 8 a 12 2a. clase: de 13 a 17 3a. clase: de 18 a 22 ... ... 6a. clase: de 33 a 37
También podrían agruparse de esta forma: 1a. clase: de 5 a 9 2a. clase: de 10 a 14 3a. clase: de 15 a 19 ... ... 6a. clase: de 30 a 34 7a. clase: de 35 a 39
que resulta mucho más cómodo para trabajar.
Tomando esta última agrupación, se tendrá finalmente:
Límites de clase Fronteras de clase Marca de clase Frecuencia Frecuencia acumulada 5 – 9 4,5 – 9,5 7 1 1
10 – 14 9,5 – 14,5 12 10 11 15 – 19 14,5 – 19,5 17 37 48 20 – 24 19,5 – 24,5 22 36 84 25 – 29 24,5 – 29,5 27 13 97 30 – 34 29,5 – 34,5 32 2 99 35 – 39 34,5 – 39,5 37 1 100
En esta tabla se puede apreciar la ventaja de que la longitud de clase sea impar, ya que así las marcas de clase resultan con la misma aproximación decimal que los datos y límites de clase.
Las fronteras de clase, en cambio, tienen una cifra decimal más.
3.6.2 Histograma, polígono de frecuencias y ojiva. Aunque la tabla de distribución de frecuencias agrupadas nos da una idea de cómo están distri-
buidos los datos, una representación gráfica nos permitirá mejorar esta idea.
El histograma es una gráfica que expresa la frecuencia con que sucede cada clase. La forma que tenga el histograma permitirá formarse una idea no sólo de cómo están distribuidos los datos, sino, en muchos casos, descubrir por qué causa(s) los datos están distribuidos de esa forma.
En el eje de abcisas se identifica la variable X, ya sea mediante las fronteras de clase, las marcas de clase, o mediante los límites inferiores o superiores de clase. En el eje de ordenadas se expresan las frecuencias de clase. Cada clase formará un rectángulo de altura igual a su frecuencia y base igual a la longitud de clase.
El polígono de frecuencias se puede trazar fácilmente sobre el mismo histograma, uniendo los puntos medios de la parte superior de cada rectángulo, partiendo y finalizando en dos clases ficticias de frecuencia cero y de la misma longitud de clase.
Las figuras 3.6 y 3.7 muestran el histograma y el polígono de frecuencias correspondientes al ejemplo anterior.
Considerando que las alturas de los rectángulos del histograma vienen dadas por las frecuencias de cada clase, y que la base de estos rectángulos es k, la longitud de clase; se puede deducir el área que hay bajo el histograma:

Estadística Descriptiva
49
A = f1 k + f2 k + ... + fN k = (∑ fi) k = Nk
Figura 3.6. Histograma y polígono de frecuencias
Observando la figura 3.6 se deduce que el área que hay bajo el polígono de frecuencias es tam-
bién igual a Nk. Más adelante (capítulo 6) se verá la importancia que tiene esta área.
Se le denomina ojiva a la representación gráfica de la distribución de frecuencias acumuladas, expresando las fronteras de clase en el eje de abcisas y las frecuencias acumuladas en el eje de ordena-das. Para el ejemplo anterior se tiene la ojiva de la figura 3.7.
Figura 3.7. Ojiva: frecuencias acumuladas
4,5 9,5 14,5 19,5 24,5 29,5 34,5 39,5
2 7 12 17 22 27 32 37 42
x
f
4,5 9,5 14,5 19,5 24,5 29,5 34,5 39,5
10
80
70
60
50
40
30
20
100
90
x
facum

Estadística Descriptiva
50
3.6.3 Cálculo de algunas medidas descriptivas. Cuando se cuenta con una distribución de frecuencias agrupadas, y no con el conjunto de datos,
puede hacerse el cálculo de la media aritmética, la varianza y la desviación estándar, considerando que los valores de X son las marcas de clase. Los resultados que se consiguen de esta forma son muy aproximados a los verdaderos.
3.7 Tablas y gráficas para la representación de datos en Excel
3.7.1 Tabla y gráfico de distribución de frecuencias no agrupadas Dado un conjunto de datos, conformado por valores discretos, se puede elaborar una tabla de
distribución de frecuencias con la ayuda de Excel. Como ya se dijo antes, Excel muestra un cuadro de diálogo con todas sus funciones al hacer click en el icono de función (fx). La función FRECUENCIA calcula las frecuencias (fi) con que se repiten los valores (xi) de un conjunto de datos y las devuelve en una matriz vertical de números. Seleccionando un número de celdas verticales donde se desea que apa-rezcan las frecuencias y escogiendo luego la función FRECUENCIA, aparece un cuadro de diálogo donde Excel pide:
• Datos: aquí se ingresa el rango de celdas donde están los datos. • Grupos: aquí se ingresa el rango de celdas donde están los valores xi.
Generalmente no se conocen todos los valores xi del conjunto de datos; pero como tales valores son discretos, es posible determinarlos hallando previamente el menor y el mayor de todos los datos, empleando las funciones MIN y MAX, respectivamente.
Para que la fórmula ingresada sea matricial, una vez seleccionadas las celdas donde irán los re-sultados, se digita control–shift–enter al final de la fórmula.
El número de elementos de la matriz devuelta puede superar en una unidad el número de ele-mentos de Grupos. El elemento adicional de la matriz devuelta corresponde a la suma de todos los va-lores superiores al mayor xi.
Para construir el diagrama de barras correspondiente basta con recurrir al asistente de gráficos de Excel. Si se tiene problemas para construir este diagrama, conviene ingresar primero los datos de frecuencias y luego, en el cuadro de diálogo de Datos de origen, añadir el rango de los xi en Rótulos del eje de categorías (X).
3.7.2 Tabla de distribución de frecuencias agrupadas e histogramas en Excel Dado un conjunto de datos que convenga agrupar en intervalos, se puede recurrir a Excel para
que haga la agrupación de acuerdo a su criterio (de Excel), o definir los límites superiores de clase que se consideren apropiados (ver apartado 3.6.1).
Esta opción se encuentra en Herramientas/Análisis de datos/Histograma. Excel abre un cuadro de diálogo que pide:
Para los datos de entrada:
• Rango de entrada: aquí se ingresa el rango de celdas donde están los datos. • Rango de clases: aquí se ingresa el rango de celdas donde están los límites superiores de cla-
se, que el usuario ha ingresado previamente en Excel. Si no se ingresa nada en Rango de cla-ses, es Excel quien escoge los límites superiores de clase. Estos límites pueden servir de guía para que el usuario escoja unos límites más apropiados.
Para los datos de salida, se puede escoger entre las siguientes tres opciones de salida:
• Rango de salida: aquí se ingresa la celda desde donde se va a construir la tabla de distribución de frecuencias agrupadas y el histograma, si se desea hacerlo en la misma hoja de cálculo.
• En una hoja nueva: aquí se puede ingresar el nombre de la hoja de cálculo donde se desea construir la tabla de distribución de frecuencias agrupadas y el histograma. Si se deja en blan-co, Excel le asignará un nombre, por ejemplo, Hoja4.

Estadística Descriptiva
51
• En un libro nuevo: se elige esta opción si se desea construir la tabla de distribución de fre-cuencias agrupadas y el histograma en un nuevo archivo. Excel le asigna un nombre a este ar-chivo, por ejemplo, Libro2. Posteriormente, si lo desea, el usuario puede cambiarle el nombre a este archivo.
Finalmente se selecciona la opción Crear gráfico, y Porcentaje acumulado, si se desea graficar la ojiva. La opción Pareto, que no es recomendable, ordena el histograma en orden descendente de frecuencias.
Ejemplo:
Elabore un histograma a partir del siguiente conjunto de 100 datos:
397,00 393,10 396,73 416,61 385,56 374,22 406,94 400,72 422,06 404,44 387,22 383,10 396,30 383,88 391,53 414,48 403,23 408,30 414,44 406,18 402,44 381,53 413,43 405,39 384,78 387,20 390,60 408,62 413,04 402,13 412,76 390,22 399,15 409,02 396,37 393,46 397,59 393,63 401,13 389,73 411,98 392,26 398,14 419,19 399,68 407,58 401,32 390,77 400,02 412,38 417,33 378,82 394,87 399,15 400,28 404,67 405,58 411,11 404,54 396,89 378,16 394,32 419,72 394,76 396,77 408,75 401,39 387,99 399,74 391,60 397,66 395,96 408,66 406,75 421,95 405,96 390,89 384,41 389,45 391,79 410,95 401,35 423,76 396,19 382,58 386,28 418,85 407,11 382,25 395,71 389,13 396,35 393,45 407,58 392,64 388,84 404,87 406,38 408,28 395,47
En este ejemplo se van a trazar dos histogramas: en el primero se dejará que Excel decida el número de clases, y, en el segundo, el usuario elegirá el número de clases, siguiendo las suge-rencias vistas en el apartado 3.5.1.
En la figura 3.8 se muestra el cuadro de diálogo que muestra Excel al entrar al menú: Herra-mientas/Análisis de datos/Histograma. Nótese que ya se ha ingresado el rango de entrada y se ha seleccionado una hoja nueva como opción de salida, con el nombre Histograma1.
Figura 3.8. Cuadro de diálogo de Histograma1
Además, se ha dejado en blanco el rango de clases; de esta manera Excel elegirá los límites su-periores de clase.
En la figura 3.9 se muestra el resultado de esta operación, con unos límites superiores de clase inadecuados, y un número de clases muy pequeño (m = 4).
.

Estadística Descriptiva
52
Clase Frecuencia
374.22 1390.73 20407.25 54
y mayor... 25
Histograma
0
10
20
30
40
50
60
374.22 390.73 407.25 y mayor...
Clase
Frec
uenc
ia
Frecuencia
Figura 3.9. Histograma1
Para conseguir que dichos parámetros sean adecuados, habría que averiguar antes el menor y el mayor de los datos, que en este caso son 374,22 y 423,76. Así, se ve conveniente que los límites superiores de clase sean, por ejemplo: 380, 390, 400, 410, 420, 430. Precisamente estos datos se ingresan en unas celdas de Excel, las cuales se seleccionan como Rango de clases, tal como se muestra en la figura 3.10.
Figura 3.10. Cuadro de diálogo de Histograma2
En la figura 3.11 se muestra el resultado de esta operación. Los límites superiores son mucho más claros (múltiplos de 10) y el número de clases (m = 6) es el adecuado para el conjunto de 100 datos. Además se ha mejorado la presentación del histograma, como se puede apreciar cla-ramente, empleando algunas opciones que da Excel con el clic derecho.
Vale la pena aclarar que los valores en el eje X del histograma que construye Excel correspon-den al límite superior de cada barra, y que el límite inferior de la primera clase comienza en 370.

Estadística Descriptiva
53
Clase Frecuencia380 3390 16400 34410 30420 14430 3
y mayor... 0
Histograma
0
5
10
15
20
25
30
35
40
380 390 400 410 420 430 ymayor...
Clase
Frec
uenc
ia
Figura 3.11. Histograma2

Estadística Descriptiva
54
Problemas propuestos. 1. El promedio de sueldos de los empleados de una fábrica es una cierta cantidad. ¿Qué contestaría
usted, como Jefe de Personal, ante una queja de que nadie debería ganar por debajo del promedio, sea cual fuere éste?
Respuesta: La única forma de satisfacerlos es haciendo que todos ganen igual, lo cual no es posi-ble.
2. Hasta el semestre pasado un alumno de la UDEP había aprobado 108 de 141 créditos matricula-dos, con un índice acumulado de 10,43. Si este semestre se ha matriculado en 21 créditos, ¿Hasta cuánto puede subir su índice acumulado como máximo?
Respuesta: Hasta 11,67
3. ¿Puede la desviación media tener un valor cero? ¿Puede ser negativa?
4. ¿Qué puede decirse de una distribución en la que s = 0?
5. Una asociación de ahorro y préstamo tiene las siguientes hipotecas con sus respectivas tasas de in-terés: $40 000 al 10%; $25 000 al 9%; $20 000 al 8%; $10 000 al 7% y $5 000 al 6%. ¿Cuál es la tasa de interés promedio que se paga?
6. En las cuatro aulas donde se rindió una prueba de Estadística hubieron 14, 27, 27 y 36 alumnos. Las medias (o promedios) en estas aulas fueron 14,4; 12,1; 9,9 y 10,2 respectivamente. ¿Cuál es la media general?
7. Un grupo de amigos que salieron juntos del colegio, egresaron de la UDEP el último semestre. Cuatro de Ingeniería con un índice promedio de 14,95; seis de Administración de Empresas con un índice promedio de 14,12 y tres de Información con un índice promedio de 15,10. ¿Cuál es el índi-ce promedio del grupo? ¿Cuál es la desviación estándar?
8. Dada la siguiente distribución de salarios, en dólares, en una empresa extranjera: 80 52 92 75 82 96 80 70 90 69 83 94 67 63 61 96 88 63 78 83 99 85 75 81 73 97 109 87 100 85 95 88 98 78 98 98 76 100 58 108 89 84 88 64 81 70 105 64 64 81 91 59 72 97 77 97
a) Construya una tabla de distribución de frecuencia, utilizando intervalos de $10, desde $50. b) Dibuje el histograma y el polígono de frecuencia. c) Determine la media y la desviación estándar. d) Comente brevemente cómo es la distribución de salarios en esta empresa. e) Construya una tabla de frecuencias acumulativas. f) Encuentre el salario sobre el cual está el 25% de los empleados.
9. El diámetro de 180 tornillos varía entre 0,829 a 1,286 cm. Sugiera un agrupamiento indicando sus límites, fronteras y marcas de clase.
10. Considere la siguiente muestra: resistencia de 50 lotes de algodón (Kg. necesarios para romper una madeja)
7,4 10,0 9,0 9,9 9,7 8,9 10,8 9,4 8,7 7,9 10,1 9,0 10,5 8,3 9,1 9,6 8,1 9,8 8,1 9,8 10,5 11,0 9,1 9,9 10,1 9,4 10,6 9,8 9,3 8,2 9,0 8,6 9,6 8,8 9,7 10,3 8,5 10,6 9,2 11,5 9,7 10,1 10,2 9,6 10,0 7,6 9,6 8,1 10,1 9,3
a) Haga una tabla de distribución de frecuencias de la muestra no agrupada y represéntela gráfi-camente.
Estadística Descriptiva
55
b) Agrupe la muestra de tal forma que las marcas de clase sean 75, 80, 85, etc. y represente gráfi-camente la distribución de frecuencias resultante.
c) Calcule la media y la desviación estándar de los datos no agrupados. d) Calcule la media y la desviación estándar de los datos agrupados y compare estos resultados
con el apartado anterior.
11. El grosor de 400 arandelas varía entre 0,421 y 0,563 centímetros. Determine las fronteras y marcas de clase para el primero y último intervalos de clase.
12. En una muestra de 125 valores de la resistencia a la ruptura bajo cargas de tensión (en lb/pulg2) de cilindros de concreto, el mínimo es 408 y el máximo es 465. Determine los límites, fronteras y marcas de clase que mejor le parezca.
13. Los precios de venta de 60 casas en una comunidad varían de $58050 a $184900. Determine unos límites de clase considerando 7 clases en las cuales se podría agrupar estos precios.
14. En la oficina de un periódico, el tiempo empleado en colocar los tipos de la página frontal fue re-gistrado durante 50 días. A continuación se muestran los datos:
20,8 22,8 21,9 22,0 20,7 20,9 25,0 22,2 22,8 20,1 25,3 20,7 22,5 21,2 23,8 23,3 20,9 22,9 23,5 19,5 23,7 20,3 23,6 19,0 25,1 25,0 19,5 24,1 24,2 21,8 21,3 21,5 23,1 19,9 24,2 24,1 19,8 23,9 22,8 23,9 19,7 24,2 23,8 20,7 23,8 24,3 21,1 20,9 21,6 22,7
a) Agrupe estos datos expresándolos en una tabla de distribución de frecuencias, empleando lon-
gitudes de clase de 0,8 minutos. b) Construya el histograma y el polígono de frecuencia correspondientes. c) Calcule la media aritmética y la varianza, a partir de la tabla elaborada, considerando que los
valores de X están dados por las marcas de clase.
15. En un taller donde se confecciona calzado a mano, se anotó cada día el número de unidades que confeccionaron 10 trabajadores elegidos aleatoriamente, como se muestra en la siguiente tabla.
a) Construya un diagrama de barras con los 100 datos de la tabla y comente el resultado. b) Trace un diagrama de caja bigote para cada semana y comente los resultados.
Semana 1 Semana 2
Lun Mar Miér Juev Vier Lun Mar Miér Juev Vier 7 5 5 5 5 10 7 9 7 8 4 5 3 6 5 9 8 10 8 9 4 5 5 6 6 9 10 5 12 4 2 6 7 6 4 10 6 9 7 6 3 1 5 2 6 8 8 9 5 9 6 7 8 5 3 5 9 9 10 9 6 6 6 7 5 9 5 8 5 7 3 6 3 4 6 7 7 7 9 8 4 6 4 4 6 9 7 9 8 7 6 4 4 4 5 7 10 6 10 7
16. Una muestra de 60 barras de manjar blanco producidas por una empresa da los siguientes pesos (en gramos):
499,6 498,3 500,3 501,7 501,6 502,3 497,2 499,7 501,4 498,6 499,1 497,8 497,6 498,7 499,0497,2 499,3 499,5 500,2 499,5 499,6 499,5 501,7 499,9 499,8 499,3 502,6 501,1 503,1 499,1502,2 497,9 500,7 501,2 502,5 499,9 499,3 500,9 499,5 501,0 498,1 498,9 498,0 499,5 500,0500,0 499,6 502,9 497,7 499,0 496,6 501,9 498,3 499,2 501,0 500,6 501,1 500,8 498,2 498,5 a) Construya una tabla de distribución de frecuencia. b) Dibuje el histograma y el polígono de frecuencia.

Estadística Descriptiva
56
c) Interprete el histograma.
17. Se ha anotado la velocidad a la que pasaron por el kilómetro 25 de la carretera Piura–Paita, de una muestra de 60 autos, durante este verano. En la siguiente tabla se muestran los datos.
76 95 78 87 60 94 83 92 105 75 52 87 66 92 86 87 83 75 72 89 81 65 73 87 99 83 75 76 78 65 94 92 97 75 68 76 75 86 106 71 66 75 66 75 54 67 80 71 73 90 105 69 70 67 68 69 94 69 74 69
a) Trace un histograma e interprételo. b) Trace un diagrama caja–bigote e interprételo. (Q1 = 69; Q2 = 75,5; Q3 = 87). c) ¿Cree usted que valga la pena hacer una tabla de distribución de frecuencias no acumuladas?
¿Por qué?
18. Los datos de la siguiente tabla son los cobros de electricidad durante un mes, de una muestra de 50 casas de Piura.
96 171 202 178 147 102 153 197 127 82 157 185 90 116 172 111 148 213 130 165141 149 206 175 123 128 144 168 109 16795 163 150 154 130 143 187 166 139 149108 119 183 151 114 135 191 137 129 158
a) Trace un diagrama tallo hoja. b) Trace un histograma. c) Comente cómo son los pagos mensuales de electricidad en Piura.
19. Un alumno de Estadística de la UDEP quiere averiguar cómo se distribuyen los pagos que hacen los alumnos universitarios por una habitación individual en las casas de una urbanización cercana a la UDEP. Después de unos días tomando datos, casa por casa, ha averiguado que en 15 casas pa-gan S/.200, en 21 casas pagan S/.210, en 29 casas pagan S/.220, en 41 casas pagan S/.230, en 21 casas pagan S/.240, en 15 casas pagan S/.250, en 11 casas pagan S/.260 y en 8 casas pagan S/.270. (Nota: suponga que sólo existen estos 8 tipos de pagos)
a) Halle la pensión promedio y la desviación estándar de los pagos por habitación en esa muestra de casas.
b) Represente gráficamente los pagos por habitación de esa muestra y haga un comentario res-pecto a dichos pagos
20. ¿Qué medida descriptiva utilizaría para medir la eficiencia de una máquina que debe cortar plan-chas de una pulgada de espesor? ¿Por qué?
21. Se toma una muestra de 60 alumnos de la Facultad de Ingeniería de la Universidad de Piura, a quienes se les pregunta el número de horas que estudia en una semana, fuera de las horas de clase, obteniéndose las siguientes respuestas:
20 17 23 22 20 28 4 17 22 28 16 24 27 21 30 29 17 30 19 17 15 17 15 10 13 21 26 13 14 17 15 10 25 4 19 29 10 14 20 23 21 10 22 16 26 14 5 17 27 18 19 21 12 8 24 11 18 23 21 24
a) Trace un histograma y comente cómo ve la distribución del número de horas que estudian los
alumnos de UDEP semanalmente. b) Trace un diagrama de caja y coméntelo. Los cuartiles 1, 2 y 3 son: 14,75; 19 y 23 respectiva-
mente.

Estadística Descriptiva
57
22. Los precios de venta de 160 casas en una comunidad varían de $28050 a $124900. Determine unos límites de clase adecuados.
23. Se han tomado muestras de 64 sacos de un alimento balanceado para ganado que han enviado dos proveedores, para medir el porcentaje de proteína. En la siguiente tabla se muestran los valores ob-tenidos. Trace un histograma y comente el resultado
73,8 69,9 76,0 80,1 79,8 59,3 67,4 65,3 81,9 66,3 74,1 79,4 70,7 59,5 63,7 64,6 72,2 68,2 67,6 71,1 71,9 64,4 69,9 62,3 66,5 72,7 73,4 75,5 73,5 64,0 64,9 68,1 73,7 73,5 77,4 74,7 74,3 64,8 64,4 66,0 72,9 82,9 78,5 84,5 72,4 67,1 61,5 60,3 81,6 68,6 77,2 78,6 82,7 64,0 70,9 60,5 76,7 72,9 77,7 73,5 78,0 62,5 64,0 64,2

58 Función de Probabilidad
Capítulo 4. Función de probabilidad
4.1 Definición de función de probabilidad. Una función de probabilidad (f. de p.) de una variable aleatoria discreta X, se define como el
conjunto de parejas ordenadas {xi, f(xi)}, donde xi representa un valor que puede tomar X, y f(xi) es la probabilidad de que X asuma dicho valor, de tal forma que ∑ f(xi) = 1.
Se le suele llamar distribución de probabilidad a dicho conjunto de parejas, y función de pro-babilidad a la función f(x), la cual asigna las probabilidades a los valores que puede tomar X.
Ejemplo 1:
Un experimento consiste en lanzar un dado, cargado de manera que la probabilidad de ocurren-cia de cada cara es proporcional al número de puntos que tiene. Si se define X como el resultado de un lanzamiento, se deduce que:
f(x) = 21x
de manera que:
Ejemplo 2:
Se lanzan dos monedas. Si se define X como el número de caras que se obtiene en un lanza-miento, no hay forma de expresar f(x) como en el ejemplo anterior; la función de probabilidad se expresa simplemente con la tabla:
x 0 1 2
f(x) 41
21
41
La f. de p. se suele representar gráficamente con diagramas de barras, tal como la distribución de frecuencias no agrupadas.
Ejemplo 3:
Se quiere determinar la distribución de probabilidad del número de pacientes que llegan a una clínica dental en un intervalo de una hora. En primer lugar, se debe tomar datos del número de pacientes que llegan a la clínica dental, en varios intervalos de una hora, durante varios días. Su-póngase que se obtienen los siguientes resultados:
1 1 2 3 0 1 1 2 1 3 1 3 3 4 4 3 2 2 4 3 3 3 2 1 4 1 3 3 4 1 3 3 2 4 4 1 3 0 0 3 0 1 1 0 2 2 3 7 1 1 0 1 2 0 1 1 2 2 2 3 2 1 2 2 2 3 3 0 1 3 3 3 1 0 1 1 1 1 5 1
En segundo lugar, se construye una tabla de distribución de frecuencias:
x 0 1 2 3 4 5 6 7 f 9 24 17 21 7 1 0 1
x 1 2 3 4 5 6
f(x) 211
212
213
214
215
216

Función de Probabilidad 59
Finalmente, se estiman las probabilidades “experimentales” f(x), dividiendo cada frecuencia en-tre la suma de frecuencias, que es 80, resultando:
x 0 1 2 3 4 5 6 7 f(x) 0,1125 0,3000 0,2125 0,2625 0,0875 0,0125 0 0,0125
Lógicamente, estas probabilidades experimentales serán más certeras mientras mayor sea el nú-mero de veces que se repite el experimento, es decir, mientras más datos se tomen del número de pacientes que llegan a la clínica en un intervalo de una hora.
4.2 La función de distribución (acumulativa). La función de distribución, F(x), acumula en forma sucesiva las probabilidades f(x) de la si-
guiente forma: si los posibles valores que puede tomar X, ordenados en forma ascendente, son: x1, x2, x3, ... , xn; entonces:
F(x1) = f(x1) F(x2) = f(x1) + f(x2) F(x3) = f(x1) + f(x2) + f(x3) ... F(xn) = f(x1) + f(x2) + f(x3) + ... + f(xn) = 1 El conjunto de parejas de valores {x ,F(x)} se expresa en una tabla, tal como la f.de p., y gráfi-
camente en forma escalonada, tal como la distribución de frecuencias acumulativas no agrupadas.
4.3 El valor esperado de una variable aleatoria discreta. Se ha visto que la media aritmética de un conjunto de n datos se calcula mediante la expresión:
i
n
i
ii
n
ii x
nf
xfn
x ∑∑==
==11
1
Cuando n tiende a ser un valor muy grande, fi / n puede sustituirse por la probabilidad f(x), ya que representa una probabilidad experimental, tal como se vio en el primer capítulo. Así, dicha media aritmética representa la media de la población o el valor esperado de la variable aleatoria X.
Por lo tanto, dada una variable aleatoria con f.de p. {x, f(x)}, la media aritmética teórica o valor esperado de X es:
∑=
==n
iii xxfxEµ
1
)()(
Si un experimento se repite indefinidamente y se anotan los resultados que se van obteniendo; es decir, los valores que va tomando la variable aleatoria X, la media aritmética de éstos tenderá a µ.
Ejemplo 1:
Se lanza un dado normal. ¿Cuál es el valor esperado?
Conocida la función de probabilidad, se calcula:
µ = 1(1/6) + 2(1/6) + 3(1/6) + 4(1/6) + 5(1/6) + 6(1/6) = 3,5
Se entiende que, si un dado se lanza varias veces, la media de los resultados que se van obte-niendo se aproxima cada vez más a 3,5.
Ejemplo 2:
En un juego de azar, el jugador participante debe escoger aleatoriamente 3 esferas de una urna que contiene 9 esferas numeradas del 1 al 9. Si los tres números son consecutivos, el jugador ganará $2. Si sólo 2 números son consecutivos, ganará $4. Si no obtiene números consecutivos perderá $6. ¿Cuál es la ganancia o pérdida esperada?

60 Función de Probabilidad
P(3 consec) = 7/C(9,3) = 1/12
P(2 consec) = )3,9(
)1,5(6)1,6(2C
CC + = 1/2
P(no consec) = 1 – 1/12 – 1/2 = 5/12
La f.de p. correspondiente será:
x 2 4 – 6 f(x) 1/12 1/2 5/12
Y el valor esperado será µ = 2(1/12) + 4(1/2) + (–6)(5/12) = – 0,333, que representa la ganancia esperada.
No sería correcto concluir que un jugador espera perder $0,33 si participa en este juego una vez, pues él ganará $2 o $4, o perderá $6; pero si juega muchas veces, en promedio perderá $0,33 por juego.
Ejemplo 3:
¿Cuántos pacientes se espera que lleguen a la clínica dental (ejemplo 3 del apartado 4.1) en un intervalo de una hora?
El valor esperado será: µ = 0(0,1125) + 1(0,3000) + … + 7(0,0125) = 2,013 pacientes.
Se ve claramente que, aunque el número de pacientes que llegue a la clínica dental en un inter-valo de una hora, puede ser 0, 1, 2, … etc., es correcto afirmar que el número esperado de pa-cientes que llegan es 2,013, interpretándose este valor como un promedio. Por lo tanto, no tiene sentido redondear dicho valor, argumentando que se trata de una variable aleatoria discreta.
4.4 Varianza y desviación estándar de una variable aleatoria discreta A partir de la definición de varianza muestral, se deduce fácilmente la varianza de una variable
aleatoria, con f.de p. conocida:
( ) ( )∑∑==
−
=−=k
ii
ik
iii xx
nf
xxfn
s1
2
1
2 1
Cuando n tiende a ser un valor muy grande, fi / n puede sustituirse por la probabilidad f(x), ya que representa una probabilidad experimental, y la media muestral ( x ) puede sustituirse por la media poblacional (µ). Así, esta varianza representa la varianza de la población o la varianza de la variable aleatoria X.
∑=
−=n
iii µxxfσ
1
22 ))((
También se deduce fácilmente que:
∑=
−=n
iii µxxfσ
1
222 ))((
La desviación estándar es la raíz cuadrada positiva de la varianza.
Ejemplo:
Determine la desviación estándar del número de pacientes que llegan a la cínica dental del pro-blema anterior.
σ 2 = 0,1125(0)2 + 0,3000(1)2 + 0,2125(2)2 + … + 0,0125(7)2 – (2,013)2 = 3,825
σ = 1,956

Función de Probabilidad 61
Generalmente el valor numérico de la desviación estándar de una variable aleatoria, por sí solo, no da información de qué tan dispersos están los valores que tome dicha variable aleatoria, salvo que ésta tenga una distribución normal, como se verá en el capítulo 8. Sin embargo, puede ser útil para compararlo con el valor numérico de la desviación estándar de otra muestra.
4.5 Teoremas sobre el valor esperado y la varianza. Definida una variable aleatoria X, se deducen el valor esperado y la varianza de una función
h(X):
[ ] ∑== )()()( )( iixh xhxfµXhE
[ ][ ]2)(
2 )()()(∑ −= iiiXh xhExhxfσ
Se deducen además seis teoremas, que se presentan a continuación con sus respectivas demos-traciones:
T1. E(kX) = kE(X)
E(kX) = Σ f(xi)(kxi) = k Σf(xi)(xi) = kE(X).
T2. E(X+k) = E(X)+k
E(X+k) = Σ f(xi)(xi + k) = Σ f(xi)(xi) + k Σ f(xi) = E(X) + k
T3. E(k) = k
E(k) = Σ f(xi)k = k Σ f(xi) = k
T4. E(X – µ) = 0
E(X – µ) = Σ f(xi)(xi – µ) = Σ f(xi)(xi) – µ Σ f(xi) = µ – µ = 0
T5. σ 2
kX = k2 σ 2X
σ 2kX = Σ f(xi)(kxi – µkX)2 = k2 Σ f(xi)(xi – µ x)2 = k2σ 2
X
T6. σ 2
X+a = σ2X
σ 2X+a = Σ f(xi)[(xi + a) – µ X+a]2 = Σ f(xi)(xi – µX)2 = σ 2
X
A partir de la varianza σ 2 h(X) se deduce fácilmente que la varianza de X es el valor esperado del
cuadrado de la desviación de la media µ, es decir: 22 )( µσ −= XEx
NOTA: Estos teoremas también son válidos para la media aritmética de una muestra, x ,y para la varianza de una muestra, s.
Ejemplos:
1) Dada la siguiente función de probabilidad:
x 1 2 3 4 f(x) 0,1 0,2 0,3 0,4

62 Función de Probabilidad
Si Y = 2X + 5, determine el valor esperado y la varianza de Y.
E(X) = 1(0,1) + 2(0,2) + 3(0,3) + 4(0,4) = 3
E(Y) = 2E(X) + 5 = 2(3) + 5 = 11
σ2X = 12 (0,1) + 22 (0,2) + 32 (0,3) + 42 (0,4) – 32 = 1
σ2Y = 22 (1) = 4
2) La calificación promedio en una prueba de Estadística fue 9,24, con una desviación estándar igual a 1,25. El profesor desea ajustar todas las calificaciones por igual, de manera que el pro-medio resulte 11 y la desviación estándar 2,50. ¿Qué debe hacer para conseguirlo?
Sean las variables: X, las calificaciones iniciales.
Y, las calificaciones corregidas.
Evidentemente: aXkY += sY = ksX
Entonces: 11 = 9,24k + a
2,5 = 1,25k
Resolviendo: k = 2 ; a = – 6,52
El profesor debe multiplicar cada calificación por 2, y luego restarle 6,52.
4.6 La desigualdad de Tchebycheff. Sea una variable aleatoria X, cuya f.de p. {xi, f(xi)} está definida. Denomínense x'i a todos los va-
lores que se desvían de la media, µ, por lo menos k veces la desviación estándar; es decir, a todos los valores xi que cumplen la siguiente condición:
|xi – µ | ≥ kσ ... para todo k > 1,
Se sabe que: Σ f(xi)(xi – µ)2 = σ 2
Entonces, se cumplirá que: Σ f(x'i)(x'i – µ)2 ≤ σ 2
Y por lo tanto: Σ f(x'i) k2σ2 ≤ σ 2
( )∑ ≤ 21'k
xf i
Esta desigualdad se conoce como el teorema de Tchebycheff y se interpreta de la siguiente forma: "La probabilidad de que un valor de X, escogido aleatoriamente, se desvíe de la media por lo menos k veces la desviación estándar, no es mayor que 1/k2".
El teorema de Tchebycheff puede aplicarse también a una muestra, con una distribución cual-quiera. En este caso se le daría la siguiente interpretación: "La fracción de elementos que se desvían de la media por lo menos k veces la desviación estándar, no es mayor que 1/k2".
Ejemplo:
Una máquina que se utiliza para llenar cajas de cereales descarga en promedio 12 onzas por ca-ja. El fabricante quiere que la descarga real, en onzas, quede a una onza del promedio al menos el 75% de las veces. ¿Cuál es la mayor desviación estándar que se puede admitir si deben cum-plirse los objetivos del fabricante?
Sea: X = descarga real (onzas)
µ = 12 onzas
P(|X – 12| ≤ 1) ≥ 0,75 ; P(|X – 12| ≥ 1) ≤ 0,25

Función de Probabilidad 63
Según Tchebycheff: P(|xi – µ | ≥ kσ) ≤ 1/k2
Entonces: 1/k2 = 0,25 y kσ = 1
Por lo tanto: σ = 0,5
La mayor desviación estándar que se puede admitir es 0,5 onzas.
4.7 La función bivariante de probabilidad. En algunas ocasiones surge la necesidad de analizar simultáneamente dos características de al-
gún fenómeno aleatorio, y conviene definir por lo tanto dos variables aleatorias.
4.7.1 Definición de función bivariante de probabilidad. Si X e Y son dos variables aleatorias discretas, se define la función bivariante de probabilidad:
f(x, y) = P(X = xi ; Y = yj) ; para: i = 1, 2,..., m. j = 1, 2,..., n.
donde f(x, y) representa la probabilidad de que X e Y asuman los valores xi e yj, respectivamente, de manera que: Σi Σj f(x, y) = 1.
La distribución bivariante de probabilidad se representa de la siguiente manera:
x / y y1 y
2 ... y
n f(x)
x1 P(x1, y1) P(x1, y2) ... P(x1, yn) f(x1) x2 P(x2, y1) P(x2, y2) ... P(x2, yn) f(x2) ... ... ... ... ... ... xm P(xm, y1) P(xm, y2) ... P(xm, yn) f(xm) f(y) f(y1) f(y2) ... f(yn) 1
A f(x) y f(y) se les denomina funciones de probabilidad marginales.
Ejemplo:
Se tiene un lote de 20 artículos de la producción diaria de una fábrica, de los cuales 14 han sido clasificados de calidad A, 4 de calidad B y 2 de calidad C. Se seleccionan aleatoriamente 2 artí-culos de este lote. Sea X el número de artículos de calidad A e Y el número de artículos de cali-dad B. Determine la distribución de probabilidad bivariante de X e Y.
La siguiente tabla se construye calculando previamente las probabilidades de que ocurran las 9 combinaciones posibles:
X / Y 0 1 2 Total 0 1/190 8/190 6/190 15/190 1 28/190 56/190 0 84/190 2 91/190 0 0 91/190
Total 120/190 64/190 6/190 1
Nótese que en las columnas que dan los totales están expresadas las funciones de probabilidad marginales: f(x) y f(y), que se muestran a continuación:
x 0 1 2 f(x) 15/190 84/190 91/190
y 0 1 2 f(y) 120/190 64/190 6/190

64 Función de Probabilidad
Se deduce, por lo visto en el capítulo de probabilidades, que las variables X e Y de una función bivariante de probabilidad son independientes si se cumple que: f(xi, yj) = f(xi) f(yj).
En la función bivariante del ejemplo anterior:
f(0, 0) = 1/190 ≠ f(0) f(0) = 180/3610
f(0, 1) = 28/190 ≠ f(0) f(1) = 1008/3610
..................... .............................
f(2, 2) = 0 ≠ f(2) f(2) = 546/36100
Verificándose, como era de esperarse, que X e Y son dependientes.
4.7.2 El valor esperado de funciones de dos variables. A continuación se ven algunos teoremas relativos a los valores esperados de algunas funciones
de dos variables aleatorias X e Y, como: X + Y, X – Y, XY.
Teorema 7: E(X ± Y) = E(X) ± E(Y)
Demostración:
E(X ± Y) = Σi Σj f(xi, yj)(xi ± yj)
= Σi Σj f(xi, yj)xi ± Σi Σj f(xi, yj)yj
= Σi xiΣj f(xi, yj) ± Σj yj Σi f(xi, yj)
= Σi xi f(xi) ± Σj yj f(yj)
= E(X) ± E(Y)
En el ejemplo anterior, ¿cuál es el valor esperado de la suma de artículos útiles y recuperables?
E(X + Y) = E(X) + E(Y) = 266/190 + 76/190 = 1,8
Este teorema puede generalizarse para varias variables:
E(X1 + X2 + X3 + ...+ Xn) = E(X1) + E(X2) + E(X3) +...+ E(Xn)
La demostración se puede hacer por inducción matemática, considerando que ya se ha hecho la demostración para n = 2.
El valor esperado del producto de dos variables aleatorias X e Y es:
E(XY) = Σi Σ j f(xi, yj)(xi yj)
Para el ejemplo anterior:
190560000)1()1(
190560000)( =++++++++=XYE
Teorema 8: Si X e Y son independientes, con función bivariante de probabilidad f(x, y), enton-ces: E(XY) = E(X)E(Y).
Demostración:
E(XY) = Σi Σj f(xi, yj)(xi yj) = Σi Σ j f(xi) f(yj)xi yj = Σi f(xi)xi Σj f(yj)yj = E(X)E(Y)
4.7.3 Varianza y covarianza de dos variables aleatorias. Se define la covarianza de dos variables aleatorias X e Y:
σXY = E(X – µ X)E(Y –µ Y) = Σi Σj f(xi, yj)(xi – µ X)(yj – µY)

Función de Probabilidad 65
Para el ejemplo anterior, la covarianza será:
−
−+
−
−+
−
−=
190762
1902660
1906
190761
1902660
1908
190760
1902660
1901
XYσ
0190761
1902661
19056
190760
1902661
19028
+
−
−+
−
−+
2653,000190760
1902662
19091
−=++
−
−+
Si la varianza de una variable X es: σ 2X = E(X – µ X)2, se puede definir la varianza de la suma o diferencia de dos variables aleatorias:
σ 2 X±Y = E[(X ± Y) – µ X±Y)]2
Entonces:
σ 2 X±Y = E[(X ± Y) – (µ X ± µY)]2
= E[(X – µX) ± (Y – µ Y)]2
= E[(X – µX)2 ± 2(X – µX)(Y – µY) + (Y – µY)2]
= E(X – µX)2 ± 2E(X – µX)(Y – µY) + E(Y – µY)2
YXYXYX222 2 σσσσ +±=±
Teorema 9: ( ) ( ) ( )YEXEXYEσ XY −=
Demostración:
σ XY = E[(X – µX)(Y – µY)]
= E(XY – µXY – µ YX + µXµY )
= E(XY) – µX E(Y) – µYE(X) + µXµY
= E(XY) – E(X)E(Y)
Aplicando este último teorema resulta más fácil el cálculo de la covarianza. Para el ejemplo an-terior, la covarianza es:
2653,019076
190266
19056
−=
−=XYσ
tal como se había calculado.
Se deduce de los dos teoremas anteriores que si X e Y son dos variables aleatorias independien-tes, su covarianza es cero.
Se deduce también que si X e Y son dos variables aleatorias independientes, entonces:
σ2X±Y = σ2
X + σ 2Y
4.8 Distribuciones de probabilidad en Excel Existe una herramienta de Excel que puede ayudar a interpretar correctamente la función de
probabilidad. Esta herramienta genera un conjunto de números aleatorios que sigue una función de probabilidad determinada.
Ejemplo:
La demanda semanal de cierto artículo es una variable aleatoria, cuya función de probabilidad es la siguiente:

66 Función de Probabilidad
x 0 1 2 3 4 5 f(x) 0,10 0,20 0,30 0,20 0,15 0,05
Simule la demanda de este artículo durante 400 semanas consecutivas y verifique si la demanda promedio coincide con el valor esperado de la demanda semanal, es decir, µ.
Ingresando a Herramientas/Análisis de datos/Generación de números aleatorios, Excel muestra un cuadro de diálogo que pide:
• Número de variables: aquí se ingresa el número de columnas donde se generarán los números. • Cantidad de números aleatorios: aquí se ingresa la cantidad de números que se generarán en
cada columna. • Distribución: aquí se escoge la distribución discreta • Rango de entrada de valores y probabilidades: aquí se ingresa el rango de celdas donde están
las parejas de valores {xi, f(xi)} (en dos columnas). En la figura 4.1 se muestra este cuadro de diálogo con los valores ya ingresados.
Figura 4.1. Cuadro de diálogo de Generación de números aleatorios.
A continuación se muestran los números aleatorios generados por Excel, que simulan las de-mandas semanales durante 400 semanas consecutivas. El promedio de estos valores es 2,278, que es bastante aproximado al valor de µ = 2,25.
2 2 3 2 4 3 1 1 1 2 3 1 1 2 2 2 4 3 4 2 4 1 5 0 5 2 3 0 3 2 2 3 1 1 4 1 3 2 0 2 3 3 1 2 2 4 3 1 3 3 5 1 0 2 2 0 2 3 3 4 4 3 1 3 5 2 4 4 4 2 3 3 2 0 1 3 4 2 2 2 1 0 1 0 1 4 3 1 3 2 2 2 4 3 3 1 3 4 3 2 2 4 2 1 3 3 4 2 1 0 1 2 1 1 4 2 3 2 1 4 1 5 1 2 4 1 1 4 1 1 2 1 1 2 3 1 0 3 4 3 3 1 0 4 3 3 3 1 1 1 2 2 1 4 0 3 1 3 3 4 2 1 0 3 4 2 1 2 1 5 2 3 2 1 2 0 2 2 2 1 1 2 2 4 3 3 3 4 1 0 4 4 1 3 0 2 0 4 1 2

Función de Probabilidad 67
3 1 0 2 4 1 2 3 0 1 0 1 0 4 2 5 4 4 2 0 2 2 3 1 0 0 4 4 2 2 1 3 0 4 1 4 3 1 1 0 1 3 2 4 3 3 4 5 4 2 2 2 4 5 0 3 3 3 1 3 2 0 4 4 4 1 0 2 0 3 2 4 3 3 0 0 5 3 0 2 1 0 3 3 3 4 3 4 2 2 3 2 2 4 1 4 1 1 1 3 3 1 3 4 2 4 5 4 2 4 5 3 5 3 1 1 1 2 4 1 5 2 2 4 3 0 4 4 3 2 5 1 2 4 2 2 1 2 4 0 0 3 1 2 3 3 2 5 1 0 2 2 1 2 2 4 2 2 2 3 0 1 2 4 4 5 2 2 0 2 2 3 4 2 4 1 0 2 2 5 2 2 3 1 3 2 4 3 2 1 3 3 2 4 1 2 3 0 4 2
A manera de ejercicio, el lector podría ingresar estos 400 datos a Excel, construir la tabla de dis-tribución de frecuencias (con la función FRECUENCIA) y luego, dividiendo entre 400 cada una de las frecuencias, determinar la distribución de probabilidad, que debería corresponder, aproximadamente, con la distribución de probabilidad dada al inicio del problema.

68 Función de Probabilidad
Problemas propuestos. 1. Una persona que está participando en un juego, lanza un dado. Si sale un número par, el juego
termina y gana $10. Si no sale par, debe lanzar el dado nuevamente. Si sale un resultado mayor que el del primer lanzamiento, gana $5; de lo contrario, pierde $20. ¿Cuánto espera ganar o per-der? Interprete este resultado.
2. Una persona que participa en un juego lanza un dado. Si obtiene 5 ó 6 en el primer lanzamiento gana $10. Si no, vuelve a lanzar el dado, y si repite el resultado del primer lanzamiento, gana $8. Si no repite este resultado, pero obtiene un número mayor, gana $4; pero si obtiene un número menor, lanza el dado por tercera vez. Si esta vez repite el resultado del primer lanzamiento, se re-tira sin ganar ni perder; pero si no se repite dicho resultado, pierde $20. ¿Le parece que el juego es justo? Explique.
3. En una urna hay seis dados blancos y cuatro dados negros. Una persona debe escoger un dado al azar y lanzarlo. Si el dado escogido es blanco o negro, pierde o gana tantos dólares como puntos muestre la cara superior, respectivamente. ¿Cuánto espera ganar o perder?
Respuesta: µ = – 0,7
4. La calificación promedio en una prueba de Estadística fue 42,5. El profesor desea ajustar las cali-ficaciones de manera que el promedio sea 50. ¿Qué debe hacer?
5. Un dado está cargado de forma tal que la probabilidad de que quede hacia arriba cualquiera de sus lados es proporcional al número de puntos que tiene dicho lado.
a) Sea X el número de puntos que quedan hacia arriba después de arrojar el dado ¿Cuál es el va-lor esperado de X?
Respuesta: 4,33 b) Si a usted le proponen el siguiente juego con este dado cargado: gana $1 000 si el resultado de
lanzamiento es par, y pierde $1 000 si es impar. ¿Aceptaría jugar? Explique su respuesta y fundaméntela.
Respuesta: Aceptaría, pues esperaría ganar $142,81 por juego, después de muchos juegos.
6. La demanda semanal de cierto artículo es una variable aleatoria cuya función de probabilidad es la siguiente:
x 0 1 2 3 4 5 f(x) 0,10 0,20 0,30 0,20 0,15 0,05
Un fabricante puede producir estos artículos a un costo unitario de $300, fijando su precio de ven-ta en $800 cada uno; pero, por cada artículo que no venda en la semana, debe pagar $50 por alma-cenaje. Si el fabricante dice producir tres artículos semanales, ¿cuál es su utilidad semanal espera-da?
7. Se tiene el siguiente juego de azar: El jugador participante debe hacer un máximo de 2 lanzamien-tos de tres monedas. Si obtiene tres caras o tres sellos en cualquiera de estos lanzamientos, gana $10. Si no ocurre esto, y repite el resultado del primer lanzamiento, gana $5. Si no ocurre ninguna de estas dos cosas, pierde $20. Determine la ganancia o pérdida esperada, interpretando este resul-tado.
8. Se lanzan dos dados cuyas caras muestran: (0,0,1,2,3,4) y (0,0,1,2,2,3).
a) Construya una función de probabilidad para la suma obtenida y construya su gráfico. b) Grafique la función de distribución. c) Determine el valor esperado y la desviación estándar.
9. Suponga que usted tiene dos dados como los del problema 8. Si al lanzarlos obtiene una suma me-nor que tres, pierde $100; si obtiene suma 3 no gana ni pierde; y si obtiene una suma mayor que 3 gana $100. ¿Cuál es la ganancia esperada?

Función de Probabilidad 69
Número de ventas 0 1 2 3 4 Probabilidad 0,49 0,28 0,18 0,04 0,01
10. La calificación promedio en una prueba de Matemáticas fue 65,2 con una desviación estándar de 10. El profesor desea ajustar todas las calificaciones de manera que el promedio sea 70 y la des-viación estándar de 8. ¿Qué debe hacer?
11. Una moneda se lanza al aire 4 veces. Represéntense los resultados cara y sello por "0" y "1" res-pectivamente. Sea X la suma de los resultados de los 2 primeros lanzamientos e Y la suma de los resultados de los 4 lanzamientos.
a) Represente el espacio muestra. b) Construya la tabla de la función bivariante de probabilidad. c) Determine: E(XY), E(X + Y), E(X – Y), σXY. Respuesta: 2,5; 3; –1; 0,5.
12. Un grupo de alumnos de la UDEP está conformado por 6 alumnos de Ingeniería, de los cuales 3 son hombres y 3 son mujeres; y 4 de Administración de Empresas, de los cuales 2 son hombres y 2 son mujeres. Se va a seleccionar aleatoriamente un comité de 2 personas para que organicen la fiesta de fin de semestre. Sea X el número de mujeres seleccionados e Y el número de estu-diantes de Ingeniería seleccionados.
a) Elabore la tabla de la función bivariante de probabilidad. b) Si en el comité hay sólo una mujer, ¿cuál es la probabilidad de que las dos personas sean de
Ingeniería? Respuesta: 9/25.
c) Si en el comité no hay nadie de Ingeniería, ¿cuál es la probabilidad de que las dos personas sean mujeres? Respuesta: 1/6.
13. Dos jugadores A y B tienen 18 y 24 cartas, respectivamente, rojas y negras. A extrae una carta de B, y B extrae una de A, simultáneamente. Se considera que un jugador tiene éxito cuando ex-trae una carta roja. La probabilidad de que B tenga éxito es 1/4, la probabilidad de que ambos fracasen simultáneamente es 1/3 y la probabilidad de que B tenga éxito y A fracase es 1/9. ¿Cuántas cartas rojas tiene cada jugador?
Respuesta: A tiene 10 y B tiene 6.
14. Una máquina que llena bolsas de café descarga en promedio 200 g. por bolsa. El gerente de pro-ducción, que sabe que lo adecuado en el proceso de llenado es la menor variabilidad posible, quiere que el peso de las bolsas no se aleje más de 2 g. del promedio en más del 90% de las bol-sas. ¿Cuál es la máxima desviación estándar que debe tener este proceso para que se cumpla el objetivo del gerente de producción?
15. En un juego de azar, la probabilidad de ganar es de 9/20. Un jugador participa en 20 juegos con-secutivos, apostando un dólar en cada juego.
a) ¿Cuál es la ganancia o pérdida esperada? b) ¿Cuál es la probabilidad de que su ganancia sea, por lo menos, tres dólares?
16. A un constructor le aseguran que las bolsas de cemento que está comprando tienen un peso pro-medio de 50 Kg. con una desviación estándar de 0,11 Kg. ¿Qué porcentaje de bolsas espera que pesen menos de 49 Kg?
17. Los registros de ventas diarias de una empresa fabricante de computadoras muestran que se ven-derán 0, 1 ó 2 sistemas centrales de cómputo con las siguientes probabilidades:
Número de ventas 0 1 2 Probabilidad 0,7 0,2 0,1
a) Determine la distribución de probabilidad del número de ventas en un período de 2 días, supo-
niendo que las ventas son independientes de un día a otro. Respuesta:

70 Función de Probabilidad
b) Calcule la probabilidad de que al menos se formalice una venta en un período de 2 días. Respuesta: 0,51
18. Se tiene el siguiente juego de azar: el jugador participante debe hacer un máximo de dos lanza-mientos de tres monedas. Si obtiene tres caras o tres sellos en cualquiera de estos lanzamientos, gana S/.10 000. Si no ocurre esto, y repite el resultado del primer lanzamiento, gana S/.5 000. Si no ocurre ninguna de estas dos cosas, pierde S/.20 000. Determine la ganancia o pérdida es-perada e interprete este resultado.
19. Si un alumno contesta las 144 preguntas de un examen verdadero/falso lanzando una moneda (cara = verdadero; sello = falso).
a) ¿Cuál es la probabilidad de contestar correctamente más de 48 y menos de 96 preguntas? b) Determine la misma probabilidad empleando la desigualdad de Tchebychev.
20. Considere el experimento de lanzar dos dados al aire. Sea X la variable aleatoria que representa el valor absoluto de la diferencia de los valores observados. Encuentre la función de probabili-dad de X.
Respuesta:
x 0 1 2 3 4 5 P(x) 6/36 10/36 8/36 6/36 4/36 2/36
21. Un aparato electrónico tiene cuatro transistores, de los cuales se sabe que dos están defectuosos. Los transistores se prueban siempre, uno a la vez, hasta identificar los dos defectuosos. Sea n1 el número de pruebas hasta encontrar el primer transistor defectuoso y n el número de pruebas adi-cionales hasta encontrar el segundo. Encuentre la función conjunta de probabilidad de n1 y n2. (Escriba esta función en forma de tabla expresando las probabilidades con fracciones).
22. Se tiene el siguiente juego de azar: el jugador participante debe lanzar una moneda sucesivamen-te. Si la diferencia entre el número de caras y de sellos (o viceversa) llega a ser igual a 3 al tercer lanzamiento, gana $20. Si esto ocurre al quinto lanzamiento, gana $10. Si ocurre al séptimo lan-zamiento, gana $5. Si necesita más de 7 lanzamientos para conseguir dicha diferencia, pierde $10. ¿Cuál es la ganancia esperada?

Distribuciones discretas de probabilidad 71
Capítulo 5. Distribuciones discretas de probabilidad
5.1 La distribución uniforme discreta Si una variable aleatoria discreta X puede tomar cualesquiera de n valores distintos: x1, x2, …, xn,
igualmente probables, se dice que tiene una distribución uniforme discreta. Por lo tanto la probabilidad de que X tome un valor xi será:
nxf i
1)( =
El valor esperado y la varianza de una variable uniforme discreta se calculan de la siguiente ma-nera:
∑=
⋅=n
ii n
xµ1
1 ; ( )∑
=
⋅−=n
ii n
x1
22 1µσ
Un caso especial de distribución uniforme discreta se tiene cuando X = 1, 2, 3, …, n. En este ca-so el valor esperado y la varianza resultan:
2
12
)1(111
11
+=
+⋅==⋅= ∑∑
==
nnnn
xnn
xµn
ii
n
ii
21+
=nµ
( ) ( ) ∑ ∑ ∑∑∑= = ===
=−+=−=⋅−=n
i
n
i
n
iii
n
ii
n
ii µx
nµ
nx
nµx
nnµxσ
1 1 1
22
1
2
1
22 11111
( )( ) ( )( ) ( )
121
41
6121
21
6121 222 −
=+
−++
=
+
−++
=nnnnnnn
1212
2 −=
nσ
5.2 La distribución binomial
5.2.1 Probabilidad binomial A continuación se muestran dos ejemplos donde se calcula la probabilidad de que, de una mues-
tra de n elementos, una cantidad x cumpla con cierta característica, conociendo cuál es la proporción de la población que cumple con dicha característica. Esta proporción puede interpretarse como la pro-babilidad de que un elemento de la población tenga la mencionada característica.
Ejemplo 1
El 30% de todos los vehículos que llegan por una calle a cierta intersección giran hacia la iz-quierda. Si en un determinado momento se encuentran en dicha intersección 8 autos detenidos por la luz roja del semáforo ¿cuál es la probabilidad de que giren hacia la izquierda exactamente tres?

72 Distribuciones discretas de probabilidad
Aplicando el teorema generalizado de la multiplicación, para eventos independientes, y multi-plicando por el número de formas en que se pueden ordenar los 8 autos, que conforman un sub-grupo de 3 autos que giran hacia la izquierda y otro subgrupo de 5 autos que no giran hacia la izquierda:
P = (0,3)(0,3)(0,3)(0,7)(0,7)(0,7)(0,7)(0,7) !5!3
!8
P = !5!3
!8 (0,3)3(0,7)5 = 0,2541
Ejemplo 2
La probabilidad de que un operario haga menos de 10 piezas en una jornada de trabajo es 0,20. Determine la probabilidad de que durante la próxima semana (de 6 días laborables), en 3 días haga menos de 10 piezas por jornada.
P = (0,2)(0,2)(0,2)(0,8)(0,8)(0,8)!3!3
!6
P =!3!3
!6 (0,2)3 (0,8)3 = 0,0819
Se puede notar que en ambos problemas se calcula la probabilidad de que, de una muestra de n elementos, x tengan cierta característica, y los restantes (n – x) no la tengan; siendo constante la pro-babilidad (p) de que un elemento cualquiera tenga dicha característica, así como la probabilidad de que no tenga la mencionada característica (q = 1 – p).
Nótese que, aunque se extraen varios elementos de la población, todos juntos o uno por uno, la probabilidad de que sea extraído un elemento cualquiera (p) se mantiene constante.
En situaciones como ésta, la probabilidad de que, de una muestra de n elementos, x tengan dicha característica, es:
xnx qpxnx
nxP −
−=
)!(!!)(
A esta probabilidad, P(x), se le denomina probabilidad binomial. Usualmente a n se le denomina número de pruebas binomiales, a p probabilidad de éxito, y a q probabilidad de fracaso, en cada prue-ba binomial.
5.2.2 La función binomial de probabilidad. La función binomial de probabilidad, o distribución binomial, está formada por el conjunto de
parejas ordenadas {xi, P(xi)}, donde X puede tomar los valores 0, 1, 2, 3, ... , n; y P(x) es la probabili-dad binomial ya definida. Se dice entonces que la variable X (número de elementos de la muestra que tienen cierta característica) tiene una distribución binomial.
Es necesario probar que ∑ P(x) es igual a 1. Para esto veamos el siguiente desarrollo binomial (binomio de Newton):
(p + q)n =
0n
p0 qn +
1n
p1 qn + ... +
−1nn
pn – 1 q1 +
nn
pn q0
Los términos de esta sumatoria coinciden con las probabilidades binomiales P(0), P(1), ..., P(n).
Dado que (p + q)n es siempre igual a 1, queda demostrado que ∑ P(x) = 1. De esta propiedad de-riva el nombre de "probabilidad binomial".
La distribución binomial se representa gráficamente mediante diagramas de barras. A estos dia-gramas trazados con barras de ancho unitario se les suele llamar histogramas binomiales. A continua-ción (figura 5.1) se muestran algunos ejemplos de histogramas binomiales.

Distribuciones discretas de probabilidad 73
Figura 5.1 Histogramas binomiales
Estos histogramas binomiales son muy útiles para visualizar qué tan probables son los posibles resultados de un muestreo. Por ejemplo, si en una población, conformada por familias de Piura, el 50% consumen leche en polvo; la probabilidad de que, de una muestra de 12 familias, 8 consuman leche en polvo (resulta aproximadamente 0,12) está representada por el rectángulo que corresponde a x = 8 en el tercer gráfico. Si el porcentaje de familias de Piura que consumen leche en polvo fuese 30%, la pro-babilidad de que, de una muestra de 12 familias, 8 consuman leche en polvo, está representada por el rectángulo que corresponde a x = 8 en el cuarto gráfico. Como se ve, esta última probabilidad es casi nula (aproximadamente 0,008). Se podría afirmar, inclusive, que es prácticamente improbable que, dado que el 30% de las familias consumen leche en polvo, en una muestra de 12 familias, 8 ó más consuman leche en polvo.
5.2.3 El valor esperado y la varianza El valor esperado de una variable X es Σxi f(xi). En el caso de la función binomial de probabili-
dad, donde X puede tomar los valores 0, 1, 2, 3, ... , n; se tendrá:
µ = ΣxP(x)
µ = Σ x xnx qpxn −
donde
xn
=)!(!
!xnx
n−
µ = p Σ x xnx qpxn −−
1
Pero:
pδδ
Σ xnx qpxn −
= Σ x xnx qp
xn −−
1
Entonces:
n = 6; p = 0,2
0
0,2
0,4
0,6
0 1 2 3 4 5 6
x
P(x)
n = 12; p = 0.5
0
0,1
0,2
0,3
0 1 2 3 4 5 6 7 8 9 10 11 12
x
P(x)
n = 10; p = 0,9
0
0,2
0,4
0,6
0 1 2 3 4 5 6 7 8 9 10
x
P(x)
n = 12; p = 0,3
0
0,1
0,2
0,3
0 1 2 3 4 5 6 7 8 9 10 11 12
x
P(x)

74 Distribuciones discretas de probabilidad
µ = p
pδδ Σ
− xnx qpxn
= p
+ nqp
pδδ )(
µ = pn (p + q)n – 1 = pn
µ = np
Si p representa la proporción de la población que tiene cierta característica, np representará , ló-gicamente, cuántos elementos de la muestra se espera que tengan dicha característica.
La varianza de X, con función binomial de probabilidad, será:
σ 2 = Σx2P(x) – µ2 = Σ x2 xnx qpxn −
– µ2
Pero:
2
2
pδδ
Σ xnx qpxn −
= Σ x(x – 1) xnx qp
xn −−
2 =
= Σ x2 xnx qpxn −−
2 – Σ x xnx qpxn −−
2 =
=
2
1p
Σ x2 xnx qpxn −
–
2
1p
Σ x xnx qpxn −
=
=
2
1p
Σ x2 xnx qpxn −
–
2
1p
np =
Pero también:
2
2
pδδ (p + q)n = n(n – 1)( p + q)n – 2 = n(n – 1) = n2 – n
Entonces:
2
1p
Σ x2 xnx qpxn −
–
2
1p
np = n2 – n
Σ x2 xnx qpxn −
= n2 p2 – np2 + np
Por lo tanto:
σ 2 = n2 p2 – np2 + np – n2 p2
σ 2 = np – np2 = np(1 – p)
σ 2 = npq
5.2.4 Cálculo de probabilidades binomiales acumulativas. El cálculo de probabilidades binomiales puede simplificarse considerablemente mediante el em-
pleo de tablas, como las del apéndice (pág. 253), que nos proporcionan directamente probabilidades acumulativas. Esta tabla permite calcular probabilidades acumulativas para distribuciones binomiales con p = 0,05; 0,10; 0,15; 0,20; 0,25; ... 0,50; y para n = 1, 2, 3, ..., 19, 20. Para estos dos parámetros, n y p, se puede calcular:

Distribuciones discretas de probabilidad 75
∑=
−
n
kx
xnx qpxn
... donde k puede ser: 1, 2, 3,..., ó n.
Por ejemplo, para n = 8 se tiene:
p n k 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50 8 1 0,3366 0,5695 0,7275 0,8322 0,8999 0,9424 0,9681 0,9832 0,9916 0,9961 2 0,0572 0,1869 0,3428 0,4967 0,6329 0,7447 0,8309 0,8936 0,9368 0,9648 3 0,0058 0,0381 0,1052 0,2031 0,3215 0,4482 0,5722 0,6846 0,7799 0,8555 4 0,0004 0,0050 0,0214 0,0563 0,1138 0,1941 0,2936 0,4059 0,5230 0,6367 5 0,0000 0,0004 0,0029 0,0104 0,0273 0,0580 0,1061 0,1737 0,2604 0,3633 6 0,0000 0,0000 0,0002 0,0012 0,0042 0,0113 0,0253 0,0498 0,0885 0,1445 7 0,0000 0,0000 0,0000 0,0001 0,0004 0,0013 0,0036 0,0085 0,0181 0,0352 8 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0002 0,0007 0,0017 0,0039
Ejemplo 1:
Para el primer ejemplo de este capítulo (n = 8; p = 0,3), determine la probabilidad de que por lo menos 3 vehículos giren hacia la izquierda.
P(X ≥ 3) = P(3) + P(4) + ... + P(8) = ∑=
−
8
3
87,03,08
x
xx
x
En la tabla encontraremos, para n = 8, p = 0,30 y k = 3
P(X ≥ 3) = 0,4482
Ejemplo 2:
¿Y cuál será la probabilidad de que giren hacia la izquierda menos de 5 vehículos?
P(X < 5) = P(0) + P(1) + ... + P(4) = ∑=
−
4
0
87,03,08
x
xx
x= 1 – [P(5) + P(6) + ... + P(8)] =
= 1 – ∑=
−
8
5
87,03,08
x
xx
x
Viendo en la tabla, para p = 0,30 y k = 5
P(X < 5) = 1 – 0,0580 = 0,9420
Ejemplo 3:
Supongamos que el 60% de los vehículos siguen de frente. ¿Cuál es la probabilidad de que, del grupo de 8, al menos 5 sigan de frente?
P = P(5) + P(6) + P(7) + P(8) = ∑=
−
8
5
84,06,08
x
xx
x
Considerando aquella propiedad del desarrollo binomial, por ejemplo, de (p + q)n, que los tér-minos equidistantes resultan iguales si se intercambian los exponentes de p y q, se tiene:
∑=
−
8
5
84,06,08
x
xx
x = ∑
=
−
3
0
86,04,08
x
xx
x
Por lo tanto:

76 Distribuciones discretas de probabilidad
P = 1 – ∑=
−
8
4
86,04,08
x
xx
x
P = 1 – 0,4059 = 0,5941
5.2.5 La proporción muestral como estimación de la proporción poblacional. Si X, que representa cuántos elementos de una muestra de tamaño n tienen cierta característica,
es una variable binomial, siendo p la proporción de la muestra que tiene dicha característica; la varia-ble X/n, que representa la proporción de la muestra que tiene tal característica, también es binomial con media igual a p y desviación estándar igual a npq / .
Según el teorema de Tchebycheff, la probabilidad de que X/n se desvíe de la media p una distan-cia mayor o igual a kσ, no puede ser mayor que 1/k2. Es decir:
P ≤ 21
k
Si a la distancia kσ se le llama d:
d = kσ = k npq /
Se puede deducir que:
22
/1d
npqk
=
Por lo tanto:
nd
pqP 2≤
Cuando n tiende a infinito, esta probabilidad tiende a cero, lo que indica que X/n será práctica-mente igual a p.
5.2.6 La distribución binomial en Excel La función DISTR.BINOM de Excel permite calcular una probabilidad binomial específica o
probabilidades acumulativas, para cualesquiera valores de n y p.
Aprovechando las bondades de Excel, es posible calcular todas las probabilidades P(x) que con-forman una función binomial de probabilidad y trazar el histograma binomial correspondiente.
5.3 La distribución binomial negativa La probabilidad de que, de una muestra de n elementos, una cantidad x cumpla con cierta carac-
terística, conociendo qué proporción de la población tiene dicha característica (p), es la probabilidad binomial P(x).
Como se ha visto en los ejemplos de probabilidad binomial del apartado 5.2.1, la extracción de n elementos puede interpretarse como una extracción sucesiva de elementos, uno por uno, hasta comple-tar n. Recuérdese que a p se le denomina probabilidad de éxito, o también, la probabilidad de que un elemento de la población tenga cierta característica; y a q probabilidad de fracaso, o también, la pro-babilidad de que un elemento de la población no tenga dicha característica.
En algunas situaciones puede resultar interesante calcular la probabilidad de que en la n-ésima extracción ocurra el k-ésimo éxito. Para que esto ocurra, es necesario que en las n – 1 extracciones an-teriores hayan ocurrido k – 1 éxitos, y que en la siguiente extracción (la n-ésima) ocurra otro éxito (el k-ésimo). Esta probabilidad será entonces:

Distribuciones discretas de probabilidad 77
pqpkn
P knk ⋅
−−
= −−1
11
Lo que resulta:
knk qpkn
pknP −
−−
=11
),;( para n = k, k + 1, k + 2, …
Por lo tanto, el número de la extracción en la cual ocurre el k-ésimo éxito es una variable aleato-ria que tiene una distribución binomial negativa con parámetros k y p.
El nombre distribución binomial negativa se debe a que los valores de P(n; k, p), para n = k, k +
1, k + 2, …, son los términos sucesivos del desarrollo binomial de k
pq
p
−
−
1 .
A la distribución binomial negativa se le conoce también como distribución de Pascal.
Ejemplo 1:
Una máquina que produce cierto tipo de piezas mecánicas no está bien ajustada, por lo que el porcentaje de piezas defectuosas es 4,2%.
a) ¿Cuál es la probabilidad de que produzca la décima pieza buena cuando ya se han producido dos piezas defectuosas?
p = 1 – 0,042 = 0,958 n = 12 k = 10
P(n; k, p) = P(12; 2, 0,042) = knk qpkn −
−−
11
= 06317,0)042,0()958,0(9
11 210 =
b) ¿Cuál es la probabilidad de que produzca la décima pieza buena cuando se han producido más de dos piezas defectuosas?
Esta probabilidad es igual a uno menos la probabilidad de que se produzca la décima pieza buena cuando ya se han producido menos de dos piezas defectuosas:
1 – P = 01225,0)042,0()958,0(9
11)042,0()958,0(
910
)042,0()958,0(99 210110010 =
+
+
P = 0,98775
Ejemplo 2:
El 30% de los niños expuestos a cierta enfermedad contagiosa, la contraen. ¿Cuál es la probabi-lidad de que el octavo niño expuesto a esa enfermedad, sea el tercero en contraerla?
P(8; 3, 0,3) = 0953,0)7,0()3,0(27 53 =
5.4 La distribución de Poisson.
5.4.1 La función de probabilidad de Poisson
Sea X una variable aleatoria que puede tomar los valores: 0, 1, 2, 3, ... . Si !
)(x
µexPxµ−
= , en-
tonces la variable aleatoria discreta X tiene una función de probabilidad de Poisson, con parámetro µ.

78 Distribuciones discretas de probabilidad
La probabilidad de Poisson, P(x), expresa, por ejemplo, la probabilidad de que, en un determi-nado intervalo de tiempo, ocurran exactamente x eventos, siendo µ la frecuencia media de ocurrencia, es decir, el valor esperado de X.
Muchas variables aleatorias siguen distribuciones de Poisson. Por ejemplo, el número de vehícu-los que llegan a una gasolinera, o el número de clientes que llegan a un banco en un determinado in-tervalo de tiempo, o el número de defectos que hay en un lote de unidades producidas.
Se demuestra a continuación que {x, P(x)} es una función de probabilidad:
1...!3!2!1
1!
)(00
==
++++== −−
∞
=
−∞
=∑∑ µµµ
x
xµ
x
eeµµµex
µexP
Ejemplo 1:
En un taller donde cada operario trabaja con su respectiva máquina, hay un promedio de 3 má-quinas en reparación. Si el taller cuenta con 4 máquinas de repuesto, ¿cuál es la probabilidad de que haya dos operarios desocupados?
Se asume que el número de máquinas que hay en reparación tiene una distribución de Poisson. Habrá dos operarios desocupados cuando haya 6 máquinas en reparación. La probabilidad de que haya 6 máquinas en reparación es:
0504,0!63
!)6(
63
=×
==−− e
xµeP
xµ
La probabilidad de que haya dos operarios desocupados es por lo tanto 0,0504.
Ejemplo 2:
Supóngase que número de clientes que llega a un banco sigue una distribución de Poisson, con una media de 36 clientes por hora. ¿Cómo será la distribución de probabilidad del número de clientes que llega cada 5 minutos?
El promedio de clientes que llega cada 5 minutos será: 360
536=
×=µ clientes
Aplicando la fórmula, para x = 0, 1, 2, ... se obtiene:
x 0 1 2 3 4 5 6 7 8 9 10 > 10 P(x) 0,0498 0,1494 0,2240 0,2240 0,1680 0,1008 0,0504 0,0216 0,0081 0,0027 0,0008 0,0003
Como se puede apreciar, ya resulta poco probable que en 5 minutos lleguen más de 6 clientes.
5.4.2 El valor esperado y la varianza. Se demuestra que el valor esperado de una variable aleatoria con distribución de Poisson, es
igual al parámetro µ.
∑∑∞
=
−∞
=
−
−=⋅=
10 )!1(!)(
x
xµ
x
xµ
xµe
xµexxE
Haciendo el siguiente cambio de variable: s = x – 1
µs
µeµsµexxE
s
sµ
s
sµ
==⋅= ∑∑∞
=
−∞
=
+−
00
1
!!)(
Una característica de una variable con distribución de Poisson es que la varianza resulta igual al valor esperado. Esto se demuestra a continuación:
222 )( µσ −= xE

Distribuciones discretas de probabilidad 79
∑∑∞
=
−∞
=
−
−⋅=⋅=
10
22
)!1(!)(
x
xµ
x
xµ
xµex
xµexxE
Haciendo el cambio de variable: x = s – 1
µµs
µeµs
µesµsµesxE
s
sµ
s
sµ
s
sµ
+=+⋅=⋅+= ∑∑∑∞
=
−∞
=
−∞
=
+−2
000
12
!!!)1()(
Por lo tanto:
µµµµσ =−+= 222
En la figura 6.1 se muestran distribuciones de Poisson para distintos valores de µ. Para evitar superposiciones de barras, se han trazado gráficos continuos en vez de los clásicos gráficos de barras.
Figura 6.1 Distribuciones de Poisson
5.4.3 Cálculo de probabilidades acumulativas de Poisson Para calcular probabilidades acumulativas de Poisson se puede recurrir a algunas tablas, como la
del apéndice (pág. 258), que ha sido elaborada para distintos valores de µ , que van desde 0,1 hasta 10, con incrementos de 0,1; y desde 11 hasta 20, con incrementos de 1.
Ejemplo:
El número de órdenes de trabajo que llegan a una oficina es una variable con una distribución de Poisson. Si en promedio llegan 5 órdenes por hora, ¿cuál es la probabilidad de que en la próxi-ma hora lleguen menos de 5 órdenes?
Siendo µ = 5
P = P(0) + P(1) + ... + P(4) = ∑=
−
=4
0
5
!5
x
x
xe 0,4405
La probabilidad de que en la próxima hora lleguen menos de 5 órdenes es 0,4405.
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
P(x)
µ = 1
µ = 2
µ = 3
µ = 4
µ = 5
µ = 7µ = 9

80 Distribuciones discretas de probabilidad
5.4.4 Aproximación de la distribución binomial a la distribución de Poisson. En el apartado 5.2.2 se vio que la probabilidad binomial es:
xnxxnx qpx
xnnnnqpxnx
nxP −− +−−−=
−=
!)1(...)2()1(
)!(!!)(
Sustituyendo: nµp =
xnx
nµ
nµ
xxnnnnxP
−
−
+−−−
= 1!
)1(...)2()1()(
Dividiendo cada uno de los x factores del numerador entre n, resulta:
( )xnx
nµ
nµ
nnxµ
xP−
−
−
−
−
= 11...21111
!)(
Cuando n tiende a infinito y p tiende a cero, de tal forma que np se mantiene constante, la pro-babilidad binomial P(x) tiende a:
µx
exµxP −
=
!)(
Y esta es precisamente la probabilidad de Poisson definida en el apartado 5.4.1:
!
)(x
µexPxµ−
=
Ejemplo:
En una fábrica, el 0,5% de la producción es defectuosa. ¿Cuál es la probabilidad de que haya menos de 5 defectuosos:
a) en un lote de 2000 artículos? n = 2000; p = 0,005 µ = np = 10
P = P(0) + P(1) + ... P(4) = 0,0293
b) en un lote de 1000 artículos? n = 1000 ; p = 0,005 µ = np = 5
P = P(0) + P(1) + ... P(4) = 0,4405
5.4.5 La distribución de Poisson en Excel La función POISSON de Excel permite calcular una probabilidad de Poisson específica o pro-
babilidades acumulativas, para cualquier valor de µ.
Aprovechando las bondades de Excel, es posible calcular todas las probabilidades P(x) que con-forman una función de probabilidad de Poisson.

Distribuciones discretas de probabilidad 81
5.5 La distribución hipergeométrica.
5.5.1 La probabilidad hipergeométrica A continuación se muestra un ejemplo donde se calcula la probabilidad de que, de una muestra
de n elementos, una cantidad x cumpla con cierta característica, conociendo cuántos elementos de la población cumplen con dicha característica.
A diferencia de la probabilidad binomial, que considera poblaciones muy grandes; en este caso se consideran poblaciones pequeñas, de tal manera que al seleccionar uno a uno los elementos de la muestra, la probabilidad de seleccionar cada elemento no es constante.
Ejemplo:
Un fabricante de motores debe enviar un lote de 30 unidades de un modelo a un distribuidor. Por un problema con el material de un proveedor, en el lote hay 5 motores defectuosos. Si el pro-veedor selecciona aleatoriamente 6 motores para inspeccionarlos, ¿cuál es la probabilidad de que escoja dos motores defectuosos?
Se va a calcular la probabilidad de que, de 25 motores buenos y 5 defectuosos, seleccione 3 buenos y 3 defectuosos.
La probabilidad que el primer motor seleccionado sea bueno es: 25/30. La probabilidad que el segundo motor seleccionado sea bueno es: 24/29.
La probabilidad que el tercer motor seleccionado sea bueno es: 23/28.
La probabilidad que el cuarto motor seleccionado sea defectuoso es: 5/27. La probabilidad que el quinto motor seleccionado sea bueno es: 4/26. La probabilidad que el sexto motor seleccionado sea bueno es: 3/25.
Entonces, aplicando el teorema generalizado de la multiplicación, la probabilidad de seleccionar 3 motores buenos y 3 defectuosos es:
03874,0!3!3
!6253
264
275
2823
2924
3025
=
⋅⋅⋅⋅⋅=P
Pero, si la muestra fuese más grande, resultaría mucho más práctico calcular esta probabilidad de la siguiente manera:
03874,0)6,30(
)3,5()3,25(=
×=
CCCP
Es decir:
=
630
35
325
P
Se puede notar que, de una población de N elementos donde k tienen la característica y N – k no la tienen, se ha calculado la probabilidad de que se extraiga una muestra de n elementos, de tal manera que x tengan dicha característica, y los restantes (n – x) no la tengan.
A dicha probabilidad se le denomina probabilidad hipergeométrica:
−−
=
nN
xnkN
nk
kNnxP ),,,(

82 Distribuciones discretas de probabilidad
5.5.2 La distribución hipergeométrica Sea una variable aleatoria discreta X, que puede tomar los valores 0, 1, …, n. Se dice que X si-
gue una distribución hipergeométrica si P(x) es igual a:
−−
=
nN
xnkN
nk
kNnxP ),,,(
5.5.2 La media y la varianza La media y la varianza de la distribución hipergeométrica son:
Nnkµ = ;
)1())((
22
−−−
=NN
nNkNnkσ

Distribuciones discretas de probabilidad 83
Problemas propuestos. 1. Luego de una serie de experimentos se determinó que la probabilidad de que una tachuela caiga en
cierta posición es de 0,45. ¿Cuál es la probabilidad de que, en un nuevo experimento se lance la tachuela 18 veces y caiga en dicha posición 5 veces o menos?
2. La probabilidad de un lanzamiento exitoso es igual a 0,8. Si se hacen lanzamientos sucesivamente, ¿Cuál es la probabilidad de que en el décimo lanzamiento ocurra el quinto éxito, luego en el deci-moquinto lanzamiento ocurra el octavo éxito, y, finalmente, en el vigésimo lanzamiento ocurra el décimo éxito?
3. Un profesor de Estadística tiene una moneda deformada. Después de experimentar con ella, ha lle-gado a la conclusión de que si la lanza muchas veces, obtendrá el triple número de caras que de se-llos. Si se lanza dicha moneda 20 veces, ¿cuál es la probabilidad de obtener más de 15 caras?
4. En general, el 40% de los estudiantes que ingresan a una universidad terminan satisfactoriamente la carrera. En un grupo de 18 recién ingresados escogidos aleatoriamente, ¿cuál es la probabilidad de que al menos el 75% termine la carrera satisfactoriamente?
Respuesta: 0,0013
5. Supóngase que en cierta población el 55% son mujeres. Si una familia tiene 5 hijos. ¿Cuál es la probabilidad de que no todos sean del mismo sexo?
Respuesta: 0,9312.
6. En un examen de Estadística conformado por 10 preguntas, sólo se debe contestar verdadero (V) o falso (F) en las 5 primeras, y escoger una de cinco respuestas en cada una de las 5 restantes. Si un alumno decide contestar todas las preguntas, al azar:
a) ¿Cuál es el número esperado de respuestas correctas? Interprete este valor. Respuesta: Si el alumno repite este experimento muchas veces, en promedio tiende a contestar
3,5 preguntas correctamente. b) Si todas las preguntas tienen el mismo puntaje, y no hay descuentos por preguntas mal contes-
tadas, ¿cuál es la probabilidad de aprobar? Respuesta: 0,08229
7. Una persona participa en un juego donde la probabilidad de ganar es 0,40. ¿Cuántas veces debe jugar si quiere que la probabilidad de ganar al menos 3 veces sea mayor que 0,80?
Respuesta: Debe jugar más de 10 veces.
8. Un experimento consiste en realizar pruebas binomiales hasta que ocurran exactamente k éxitos. Si la probabilidad de éxito en cada prueba binomial es p, ¿cuál es la probabilidad de concluir dicho experimento con x fracasos?
9. En una empresa que vende artefactos domésticos se sabe que la oportunidad de vender es mayor mientras más contactos realicen con los clientes potenciales. Si la probabilidad de que una persona compre una lustradora después de la visita es constante e igual a 0,20, y si las visitas son indepen-dientes unas de otras, ¿cuántos clientes potenciales debe visitar un vendedor, para que la probabi-lidad de vender por lo menos una lustradora sea al menos 0,8?
10. En un juego de azar, la probabilidad de ganar es de 9/20. Un jugador participa en 20 juegos conse-cutivos, apostando un dólar en cada juego.
a) ¿Cuál es la ganancia o pérdida esperada? Respuesta: Espera perder 2 dólares. b) ¿Cuál es la probabilidad de que su ganancia sea, por lo menos, tres dólares?
Respuesta: 0,1308.
11. El número de clientes que llega a un banco es una variable aleatoria de Poisson. Si en promedio llegan 120 clientes por hora ¿Cuál es la probabilidad de que:

84 Distribuciones discretas de probabilidad
a) en un minuto lleguen por lo menos 4 clientes? b) en 5 minutos lleguen menos de 10 clientes?
12. El jefe del centro de cómputo de un banco afirma que la probabilidad de que las digitadoras pulsen la tecla de un carácter incorrectamente, es igual a 0,001. Bajo este supuesto, ¿cuál es la probabili-dad de que, de 10 000 teclas pulsadas, se cometan más de 15 errores?
13. Se ha estimado que el 2% de los alumnos de la UDEP provienen de Morropón. ¿Cuál es la proba-bilidad de que, en una muestra de 400 alumnos, 15 sean de Morropón?
14. El número de errores que comete cierta secretaria al escribir una página, tiene una distribución de Poisson, con un promedio de 2 errores. Si escribe un trabajo de 75 páginas, ¿en cuántas páginas espera encontrar:
a) un error? Respuesta: en 20,3 b) dos errores? Respuesta: en 20,3 c) tres errores? Respuesta: en 13,533 d) más de tres errores? Respuesta: en 10,717
15. En cierto distrito escolar donde hay 2 000 maestros, la proporción media de maestros ausentes por día escolar es de 0,5%. Determine la probabilidad de que un cierto día todos los maestros estén en su trabajo.
16. En general, el 1% de ciertas piezas son defectuosas. Si se compran 200, ¿cuál es la probabilidad de que haya menos de 8 defectuosas?
Respuesta: 0,998903
17. El jefe de seguridad de una planta industrial dio a conocer el número de accidentes semanales ocu-rridos en los últimos años, mediante la siguiente tabla:
N° de accidentes 0 1 2 3 4 5 6 7 8 9 10 11 12 13 Frecuencia 0 3 9 18 27 31 34 27 21 14 8 5 2 1
a) ¿Se ajusta a una distribución de Poisson la distribución de frecuencias de accidentes semanales en dicha planta?
b) ¿Qué probabilidad hay de cuatro a más accidentes semanales? Respuesta: Aproximadamente 0,8488 (con µ = 6)
18. Se encuentran en promedio 9,4 ralladuras por cada 10 m2 de planchas de acero que se producen en
una fábrica. ¿Cuál es la probabilidad de que una plancha de 1 m2 no tenga ralladuras?
19. El inspector de productos terminados de una fábrica debe hacer una rápida inspección de una muestra de 8 unidades, extraída de un lote de 20 unidades. Si en el lote hay 3 unidades defectuosas
a) ¿Cuál es la probabilidad de que no extraiga ninguna unidad defectuosa? b) ¿Cuántas unidades defectuosas espera extraer el inspector?
20. Un alumno contesta las 20 preguntas de un examen verdadero/falso lanzando una moneda (cara = verdadero; sello = falso). Cada pregunta bien contestada vale +1; mal contestada -0,5.
a) ¿Cuál es la probabilidad de aprobar el examen? b) ¿Cuál es la nota esperada? c) Otro alumno que rinde este mismo examen ha estudiado lo suficiente como para afirmar que la
probabilidad de acertar cualquier respuesta es 0,8. ¿Cuál es la probabilidad de que apruebe el examen, si también contesta las 20 preguntas? ¿Cuál es su nota esperada?
21. Una experta tiradora falla en el 5% de los tiros al blanco. ¿Cuál es la probabilidad de que falle por segunda vez en el tiro número 15?

Distribuciones discretas de probabilidad 85
22. El número promedio de descomposturas por mes de una PC es 1,8. Determine la probabilidad de que esta PC funcione durante un mes:
a) sin descomposturas Respuesta: 0,1653 b) con al menos 3 descomposturas. Respuesta: 0,2694
23. Se selecciona una caja con 20 CDs producidos mediante un nuevo proceso. Si en esta caja se espe-ra encontrar 2 CDs defectuosos, ¿cuál es la probabilidad de que haya más de dos CDs defectuo-sos?
24. La central telefónica de una empresa recibe un promedio de dos llamadas por minuto. Si la telefo-nista se distrae durante un minuto, ¿cuál es la probabilidad de que no haya respondido al menos una llamada?
25. Supóngase que el 90% de los cables que se producen en una fábrica soportan una tensión mayor que 200 Kg. ¿Cuál es la probabilidad de que, de una muestra de 6 cables:
a) todos soporten una tensión mayor que 200 Kg? Respuesta: 0,5314
b) recién el quinto cable muestreado no soporte una tensión mayor que 200 Kg? Respuesta: 0,0656
26. El director de un centro de cómputo se pregunta si el número de solicitudes para acceso a una computadora sigue aproximadamente una distribución de Poisson. Para verificarlo, cuenta con los datos de la siguiente tabla:
Nº de solicitudes de acceso por hora 0 1 2 3 4 5 6 7 8 9 y más Frecuencia 55 61 50 32 18 9 5 2 1 0
a) Verifique si la media y la varianza son similares. b) Determine las frecuencias que se esperaría tener si realmente el número de solicitudes para ac-
ceso a una computadora sigue una distribución de Poisson, y compárelas con las frecuencias reales
27. Suponga que el número de clientes que salen de un consultorio médico tiene una distribución de Poisson, con una media de 4,6 clientes por hora. Determine la probabilidad de que salgan más de 3 pacientes del consultorio en el lapso de media hora.

86 Distribuciones continuas de probabilidad
Capítulo 6. Distribuciones continuas de probabilidad
6.1 La función densidad de probabilidad.
6.1.1 Introducción Dado un conjunto de datos que definen una variable aleatoria continua, se puede conformar una
distribución de frecuencias agrupadas, cuyo histograma y polígono de frecuencias nos dan una idea clara de cómo se distribuye dicha variable aleatoria. Si el número de clases es pequeño, el polígono de frecuencias se verá claramente discontinuo como se ve en la figura 6.1; pero si el número de clases es muy grande, el polígono se parecerá más a una curva continua.
Figura 6.1 Polígono de frecuencias cuando la longitud de clase decrece
El área bajo el polígono de frecuencias es Nk (N = nº de datos; k = longitud de clase). Dividien-do cada frecuencia fi entre Nk, se consigue que dicha área sea igual a 1, como se ve en la figura 6.2.
Figura 6.2 Polígono de frecuencias con área igual a 1.
El área entre dos valores cualesquiera de X, por ejemplo a y b, representará la probabilidad de que la variable aleatoria X tome un valor que esté comprendido entre a y b.
La función f(x), cuya gráfica es la curva límite que se obtiene a partir del polígono de frecuen-cias cuando la longitud de las clases tiende a cero, es decir, cuando el número de clases tiende a infini-to, es la función densidad de probabilidad para la variable aleatoria continua X.
6.1.2 La función densidad de probabilidad. Se define la función densidad de probabilidad como aquella función f(x), tal que:
x
f
x
f
x
A = 1
Nkf

Distribuciones continuas de probabilidad 87
1) f(x) ≥ 0, para: – ∞ < x < ∞
2) ∫+∞
∞−
=1)( dxxf
3) P(a ≤ x ≤ b) = ∫b
a
dxxf )(
donde a y b son dos valores cualesquiera, como se ve en la figura 6.3.
Figura 6.3 Probabilidad de que X tome un valor comprendido entre a y b.
Se deduce, a partir del gráfico, que la probabilidad de que X tome exactamente un valor xi es ce-ro. Esto no significa que es imposible que X tome ese valor; sino que es muy poco probable. Por ejem-plo, la probabilidad de que un alumno escogido al azar en un colegio, pese exactamente 65,3492 Kg., es prácticamente nula.
Para las distintas variables aleatorias continuas que se puedan analizar en los distintos campos de la ciencia, se tendrán distribuciones cuyos polígonos de frecuencia serán muy parecidos a ciertas funciones densidad de probabilidad. El análisis de estas variables se simplifica enormemente em-pleando las funciones densidad de probabilidad que resulten más apropiadas. A partir de este capítulo se estudiarán algunas de éstas, como la función normal, uniforme, t de Student, Ji-cuadrada y F.
6.1.3 La media y la varianza. A partir de las definiciones de valor esperado y varianza de una variable aleatoria discreta, y
considerando la definición de la función densidad de probabilidad, se deduce que, para una variable aleatoria continua, el valor esperado y la varianza serán:
∫+∞
∞−
⋅= dxxfx )(µ
∫+∞
∞−
−= dxxfx )()( 22 µσ
6.2 La distribución normal
6.2.1 La función densidad normal de probabilidad En investigaciones realizadas sobre una gran cantidad de variables aleatorias continuas, se ha
visto que éstas tienen una distribución bastante simétrica en forma de campana, como se ve en la figu-ra 6.4.
Se puede afirmar inclusive que la gran mayoría de medidas que se puedan tomar en cualquier proceso productivo tienen esta distribución simétrica en forma de campana, si el proceso está bajo control.
x
f(x)
a b

88 Distribuciones continuas de probabilidad
Figura 6.4 Histograma simétrico en forma de campana
Variables aleatorias como ésta, pueden analizarse tomando como modelo una función denomi-nada función densidad normal de probabilidad.
La función densidad normal de probabilidad es la siguiente:
2
21
21)(
−
−= σ
µx
eσπ
xf
Su representación gráfica, conocida como curva normal o "campana de Gauss", se muestra en la figura 6.5.
Figura 6.5. Curva normal o campana de Gauss
La curva normal es simétrica y asintótica al eje x. Además, puede comprobarse, integrando la función f(x), que el área bajo la curva normal es igual a uno.
Los parámetros µ y σ representan la media y la desviación estándar, respectivamente, de la va-riable aleatoria X, y determinan la posición y la forma (variabilidad) de la función f(x).
En la figura 6.6 se puede apreciar cómo cambia la posición de la curva normal al variar la me-dia. Se ve que: µ 1 < µ 2 < µ 3 ; y que las tres desviaciones estándar son iguales.
Figura 6.6. Curvas normales con distinta media.
x
f(x)
x
f(x)
µ
µ 1 µ 2 µ 3 x
f(x)

Distribuciones continuas de probabilidad 89
En la figura 6.7 se ve, en cambio, cómo cambia la forma de la curva al cambiar la desviación es-tándar. Evidentemente, si aumenta desviación estándar, la curva normal se hace más ancha, y por lo tanto más baja. Recuérdese que el área bajo cualquier curva normal es siempre igual a uno. Se puede apreciar que: σ 1 < σ 2 < σ 3 , y que las tres medias son iguales.
Figura 6.7. Curvas normales con distinta desviación estándar
6.2.2 La forma estandarizada. La ventaja de tomar la función densidad normal de probabilidad como modelo de muchas distri-
buciones está en la facilidad de calcular probabilidades. Si, por ejemplo, los pesos de las bolsas de de-tergente que llena una máquina automática tienen una distribución normal, con un promedio de 30 on-zas y una desviación estándar de 0,3 onzas, se podría determinar, por ejemplo, qué porcentaje pesa menos de 29,5 onzas, es decir, cuál es la probabilidad de que una bolsa pese menos de 29,5 onzas.
Considerando la diversidad de variables cuya distribución es normal, se hace necesario emplear una función densidad normal que sea independiente de los valores y unidades que puedan tomar di-chas variables. Para esto, se define la variable estandarizada, Z, de la siguiente forma:
σµxz −
=
Esta variable estandarizada mide el número de desviaciones estándares que un valor de X se desvía de la media µ. Del ejemplo anterior, si una bolsa de detergente pesa 30,45 onzas, se puede afirmar que se desvía de la media 0,45 onzas, o sea, z = (30,45 – 30)/0,30 = 1,5 desviaciones estándar.
Para esta variable estandarizada, se define la función densidad normal estandarizada, cuya repre-sentación gráfica, conocida como curva normal estandarizada, se aprecia en la figura 6.8.
Figura 6.8. Curva normal estandarizada.
µ x
f(x)
σ 1
σ 3
σ 2
z
φ (z)
2
21
21)(
ze
πzφ
−=

90 Distribuciones continuas de probabilidad
El área bajo la curva normal estandarizada es también igual a uno; la media es cero y la desvia-ción estándar uno. Esto último puede verificarse fácilmente aplicando los teoremas 4, 5 y 6 del aparta-do 4.5.
El empleo de esta forma estandarizada ha permitido construir una única tabla para calcular pro-babilidades, en vez de hacerlo para cada una de las infinitas funciones densidad normal de probabili-dad que existen.
En la figura 6.9 se muestran tres curvas normales con medias 50, 100 y 150, y desviaciones es-tándar 10, 20 y 10, respectivamente. Para cada curva se ha señalado un valor de X que se desvía de su respectiva media 1,5 desviaciones estándar (z = 1,5). A la derecha se muestra la curva normal estanda-rizada que representa a las tres curvas normales, con el valor de z correspondiente.
Figura 6.9. Representación de tres curvas normales mediante la curva normal estandarizada.
6.2.3 Áreas bajo la curva normal. La probabilidad de que X esté comprendido entre dos valores x1 y x2 es igual al área que hay en-
tre dichos valores, bajo la curva normal, y es igual al área comprendida entre sus correspondientes va-lores z1 y z2, bajo la curva normal estandarizada.
Así, por ejemplo, en la figura 6.9, el área que hay a la derecha de 65, 130 y 165, bajo cada una de las tres curvas normales, es la misma, y corresponde al área que hay hacia la derecha de z = 1,5 bajo la curva normal estandarizada.
Para calcular áreas bajo esta última curva se puede recurrir a la tabla del apéndice (pág. 264), que permite hallar el área que hay desde cualquier valor no negativo de Z hasta infinito. Cualquier otra área puede deducirse a partir de dicha tabla, que aquí se presenta en forma resumida:
z 0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09
0,0 0,500000 0,496011 0,492022 0,488033 0,484047 0,480061 0,476078 0,472097 0,468119 0,464144 0,1 0,460172 0,456205 0,452242 0,448283 0,444330 0,440382 0,436441 0,432505 0,428576 0,424655 0,2 0,420740 0,416834 0,412936 0,409046 0,405165 0,401294 0,397432 0,393580 0,389739 0,385908 ... ... ... ... ... ... ... ... ... ... ... 0,9 0,184060 0,181411 0,178786 0,176186 0,173609 0,171056 0,168528 0,166023 0,163543 0,161087 ... ... ... ... ... ... ... ... ... ... ... 4,8 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 4,9 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000
Por ejemplo, el área que hay desde z = 0,24 hacia la derecha es 0,405165; el área que hay desde z = 0,90 hacia la izquierda es 1 – 0,184060 = 0,815939.
6.2.4 Ordenadas de la curva normal. Empleando una tabla similar a la anterior, que se muestra en el apéndice (pág. 265), se pueden
determinar las ordenadas de la curva normal estandarizada, para ciertos valores de la variable Z.
Esto resulta de mucha utilidad para trazar curvas normales, como se verá más adelante.
50 100 150 x
f(x)
65 130 165 z
φ (z)
1,5
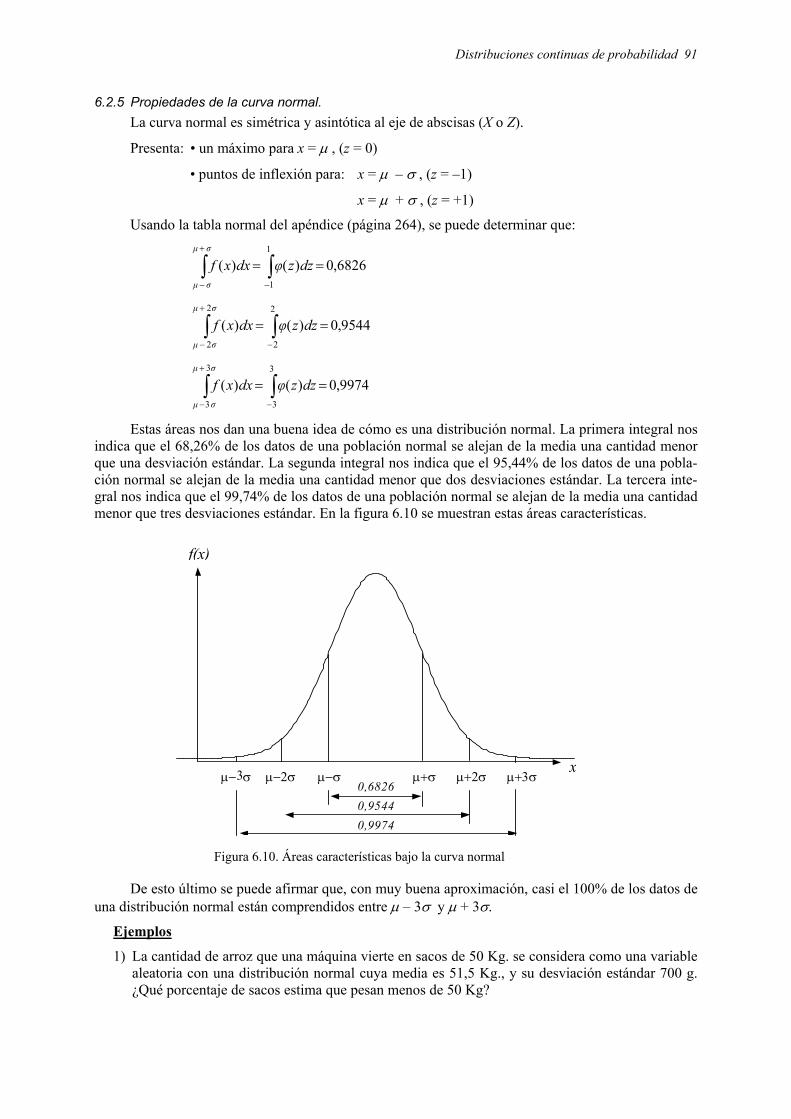
Distribuciones continuas de probabilidad 91
6.2.5 Propiedades de la curva normal. La curva normal es simétrica y asintótica al eje de abscisas (X o Z).
Presenta: • un máximo para x = µ , (z = 0)
• puntos de inflexión para: x = µ – σ , (z = –1)
x = µ + σ , (z = +1)
Usando la tabla normal del apéndice (página 264), se puede determinar que:
∫∫−
+
−
==1
1
6826,0)()( dzzφdxxfσµ
σµ
∫∫−
+
−
==2
2
2
2
9544,0)()( dzzφdxxfσµ
σµ
∫∫−
+
−
==3
3
3
3
9974,0)()( dzzφdxxfσµ
σµ
Estas áreas nos dan una buena idea de cómo es una distribución normal. La primera integral nos indica que el 68,26% de los datos de una población normal se alejan de la media una cantidad menor que una desviación estándar. La segunda integral nos indica que el 95,44% de los datos de una pobla-ción normal se alejan de la media una cantidad menor que dos desviaciones estándar. La tercera inte-gral nos indica que el 99,74% de los datos de una población normal se alejan de la media una cantidad menor que tres desviaciones estándar. En la figura 6.10 se muestran estas áreas características.
Figura 6.10. Áreas características bajo la curva normal
De esto último se puede afirmar que, con muy buena aproximación, casi el 100% de los datos de una distribución normal están comprendidos entre µ – 3σ y µ + 3σ.
Ejemplos
1) La cantidad de arroz que una máquina vierte en sacos de 50 Kg. se considera como una variable aleatoria con una distribución normal cuya media es 51,5 Kg., y su desviación estándar 700 g. ¿Qué porcentaje de sacos estima que pesan menos de 50 Kg?
x
f(x)
µ−3σ µ−2σ µ−σ µ+2σ µ+3σµ+σ
0,99740,95440,6826

92 Distribuciones continuas de probabilidad
48.5 49 49.5 50 50.5 51 51.5 52 52.5 53 53.5 54 54.5
0 100 200 300 400x d
µ = 51,5 kg. σ = 0,70 kg.
14,270,0
5,5150−=
−=z
A = 0,0162
Respuesta: se estima que el 1,62% de los sacos de arroz pesan menos de 50 Kg.
2) La demanda mensual de cierto producto tiene una distribución normal con una media de 200 unidades y una desviación estándar de 40 unidades. ¿Qué tan grande debe ser el inventario disponible a principio de un mes para que la probabilidad de que la existencia se agote no sea mayor de 0,05?
µ = 200 unidades
σ = 40 unidades
Para que la existencia xd se agote, la demanda debe ser mayor o igual que xd, y la probabilidad de que esto ocurra debe ser menor de 0,05.
40
200645,105,0
−== dx
z ; xd = 265,8
Respuesta: debe tener un inventario de 266 unidades a principio de mes.
6.2.6 Aproximación a la distribución binomial. A continuación se muestra cómo determinadas distribuciones binomiales se aproximan a una
distribución normal, a tal punto que puede ser sustituida por ésta en situaciones en que el manejo de la distribución binomial se torna complicado para el cálculo de probabilidades acumulativas.
En la figura 6.11 se muestra el histograma binomial para una distribución con n = 10 y p = 0,5; véase que hay simetría gracias a que p es igual a q. Nótese que se parece mucho a una curva normal.
Figura 6.11. Histograma binomial para n = 10 ; p = 0,5
0
0.05
0.1
0.15
0.2
0.25
0.3
0 1 2 3 4 5 6 7 8 9 10x
f(x)

Distribuciones continuas de probabilidad 93
Para una distribución binomial con n = 10 y p = 0,1 el histograma binomial resulta bastante asi-métrico, como se ve en la figura 6.12.
Figura 6.12. Histograma binomial para n = 10; p = 0,1.
En esta última distribución binomial, con n = 10 y p = 0,1, el histograma binomial resulta menos simétrico que el anterior porque p y q difieren mucho; sin embargo, para n = 60 y p = 0,1 el histogra-ma binomial es casi simétrico a pesar de la diferencia entre p y q, como se muestra en la figura 6.13.
Figura 6.13. Histograma binomial para n = 60; p = 0,1
Se ha podido apreciar que mientras más cercanos estén los valores de p y q a 0,5, y mientras más grande sea n, más simétrico resulta el histograma binomial y más se parece a una curva normal.
Por experiencia, se ha determinado que si se cumplen las siguientes condiciones:
np > 5 ; nq > 5
la aproximación de la distribución binomial a la distribución normal es buena.
Cuando se emplee la distribución normal para calcular probabilidades binomiales, será necesario aplicar un factor de corrección. Si se desea calcular, por ejemplo, la probabilidad (binomial) de que X esté comprendido entre x1 y x2 (incluidos), como se muestra en el histograma binomial de la figura 6.14, se tendrá que sumar las áreas de cada uno de los rectángulos sombreados. En dicha figura se aprecia que el área total sombreada se aproxima mucho al área bajo la curva normal comprendida en-tre (x1 – 0,5) y (x2 + 0,5).
Como se ve, se emplea un factor de corrección de + 0,5 cuando se quiere calcular un área desde cierto valor de X hacia la izquierda, o de – 0,5 cuando se quiere calcular un área desde cierto valor de X hacia la derecha.
0
0.1
0.2
0.3
0.4
0.5
0 1 2 3 4 5 6 7 8 9 10x
f(x)
0
0.05
0.1
0.15
0.2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16x
f(x)

94 Distribuciones continuas de probabilidad
Figura 6.14. Aplicación del factor de corrección
La curva normal que se está ajustando tiene la misma media y desviación estándar que la distri-bución binomial; es decir:
µ = np
npqσ =
La variable estandarizada para dicha distribución normal será, entonces:
npq
npxz −±=
5,0
Ejemplo:
Un distribuidor compra pernos a un fabricante que afirma que tiene un máximo de 5% de defec-tuosos. Ante la duda, decide probar si esto es cierto y toma una muestra aleatoria de 120 pernos. ¿Cuál es la probabilidad de que encuentre al menos 10 defectuosos?
µ = 120(0,05) = 6 pernos
387,295,005,0120 =××=σ pernos.
47,1387,2
65,010=
−−=z
A = 0,0708
Respuesta: La probabilidad de que encuentre al menos 10 pernos defectuosos en una muestra de 120 pernos es 0,0708.
6.2.7 Ajuste de la curva normal. Si se sospecha que una variable aleatoria tiene una distribución aproximadamente normal, se
puede conseguir una buena cantidad de datos de dicha variable y construir un histograma; y, sobre és-te, trazar la curva normal que más se le ajuste.
x1 x2 x
y
x1 - 0,5 x2 + 0,5

Distribuciones continuas de probabilidad 95
Para trazar esta curva normal se estima que la media y la desviación estándar del conjunto de da-tos corresponden a µ y σ, respectivamente. Luego, para las marcas de clase del histograma se deter-minan las frecuencias normales siguiendo los siguientes pasos:
1) Determinar los zi para cada marca de clase xi, haciendo: zi = σ
µ−ix
2) Determinar los φ(zi) empleando la tabla del apéndice (página 265).
3) Determinar los f(xi), haciendo: f(xi) = φ(zi) /σ
4) Determinar finalmente las frecuencias normales f 'i, a partir de: f 'i = f(xi)(nk)
donde n es la suma de frecuencias y k la longitud de clase del histograma.
Una vez trazada la curva normal sobre el histograma, se puede determinar, por simple inspec-ción, si la variable aleatoria tiene una distribución aproximadamente normal. Más adelante se verá un método analítico (prueba de bondad de ajuste con la distribución Ji-cuadrada) que determinará si este ajuste es aceptable o no.
Ejemplo:
En un análisis de los diámetros de los pistones fabricados en un taller, se tomó una muestra de 140 pistones, cuya distribución de frecuencias se muestra en la siguiente tabla. Trace la curva normal que más se ajuste a dicha distribución.
Límites Frecuencia 7,20 – 7,24 3 7,25 - 7,29 7 7,30 - 7,34 12 7,35 - 7,39 16 7,40 - 7,44 19 7,45 - 7,49 24 7,50 - 7,54 22 7,55 - 7,59 19 7,60 - 7,64 12 7,65 - 7,69 6
La media y la desviación estándar de dicha muestra son: =x 7,466; s = 0,1101. Se estima que estos dos valores se aproximan a µ y σ, respectivamente.
Siguiendo los pasos establecidos previamente, se construye la siguiente tabla. Por comodidad, los valores de z se han redondeado a dos cifras decimales, evitando así el tener que interpolar en la tabla de ordenadas de φ(z).
x z φ (z) f (x) f ' 7,22 -2,24 0,0325 0,2947 2,06 7,27 -1,78 0,0818 0,7430 5,20 7,32 -1,33 0,1647 1,4958 10,47 7,37 -0,88 0,2709 2,4593 17,22 7,42 -0,42 0,3653 3,3164 23,22 7,47 0,03 0,3988 3,6206 25,34 7,52 0,49 0,3538 3,2125 22,49 7,57 0,94 0,2565 2,3287 16,30 7,62 1,39 0,1518 1,3786 9,65 7,67 1,85 0,0721 0,6543 4,58 7,72 2,30 0,0283 0,2572 1,80
Para el cálculo de las f ' se ha considerado que n = 140 y k = 0,05, siendo n el tamaño de la muestra y k la longitud de clase.

96 Distribuciones continuas de probabilidad
En la siguiente figura se traza la curva normal que más se ajusta al histograma que representa la distribución de los diámetros de los pistones.
0
5
10
15
20
25
30
7.22 7.27 7.32 7.37 7.42 7.47 7.52 7.57 7.62 7.67 7.72
Se puede concluir que los diámetros de los pistones tienen una distribución aproximadamente normal.
6.3 La distribución uniforme continua Una variable aleatoria continua, X, tiene una distribución uniforme continua si su función densi-
dad de probabilidad es:
<<
−=casosdemáslosen
bxaparaabxf
0
1)(
donde: a y b son constantes y a < b.
En la figura 6.15 se muestra esta función densidad de probabilidad, donde resulta evidente que
el área total bajo dicha función es igual a uno, es decir, ∫ =−
b
a
dxab
11
f(x)
xa b
1/(b-a)
Figura 6.15. Distribución uniforme continua

Distribuciones continuas de probabilidad 97
A partir de las fórmulas del apartado 6.1.3, se obtienen, por integración, la media y la varianza de esta variable aleatoria continua con distribución uniforme:
2
baµ +=
12)( 2
2 abσ −=
Ejemplo 1:
La cantidad de café que despacha diariamente una máquina ubicada en la sala de espera del ae-ropuerto de Piura está distribuida uniformemente entre 6 y 10 litros.
a) Determine la probabilidad de que hoy día se despache un máximo de 9,2 litros.
8,061062,9)2,9( =
−−
=≤XP
b) ¿Cuántos litros se espera que despache un día?
82
610=
+=µ litros
Ejemplo 2:
Ricardo y Eduardo se ponen de acuerdo para encontrarse en la puerta Nº 1 del estadio entre la 1:00 y la 2:00 p.m. Si cada uno no esperará al otro más de 10 minutos y Ricardo llega a la 1:20 p.m., ¿cuál es la probabilidad de que se encuentren?
Como Ricardo estará en la puerta del estadio entre la 1:20 y la 1:30, Eduardo debe llegar entre la 1:10 y la 1:30 p.m. La probabilidad de que se encuentren será entonces:
333,031
6020
===P

98 Distribuciones continuas de probabilidad
Problemas propuestos. 1. Una máquina está programada para llenar recipientes con 20 onzas de líquido. Sin embargo, se sa-
be que la variabilidad inherente a cualquier tipo de máquina es la causa de que las cantidades de contenido sean distintas de recipiente a recipiente. La distribución de dichos contenidos es normal con una desviación estándar de 0,02 onzas. ¿Cuál debe ser la cantidad media de llenado para que sólo el 4% de los recipientes reciban menos de 20 onzas?
Respuesta: 20,035 onzas.
2. Un estudiante de Estadística ha comprobado que los pesos y las estaturas de los alumnos de la UDEP siguen distribuciones aproximadamente normales con media y desviación estándar de 72 Kg, 4,6 Kg. y 1,74m; 0,08 m. respectivamente. Determine la probabilidad de que un grupo de 10 alumnos escogidos aleatoriamente, la mayoría esté por encima de 70 Kg. y 1,70 m.
3. Suponga que los índices acumulados de los alumnos de la Facultad de Ingeniería están distribuidos normalmente alrededor de 12,50. Si el 75% de estos índices están comprendidos entre 9,5 y 15,5, ¿Qué porcentaje de alumnos tendrá índice aprobado? (índice ≥ 11).
4. La demanda mensual de cierto producto A tiene distribución normal con una media de 200 unida-des y desviación estándar igual a 40 unidades. La demanda de otro producto B también tiene una distribución normal con media de 500 unidades y desviación estándar igual a 80 unidades. Un co-merciante que vende estos productos tiene en su almacén 280 unidades de A y 650 de B al co-mienzo de un mes. ¿Cuál es la probabilidad de que en el mes se vendan todas las unidades de am-bos productos?
5. Una fábrica produce pistones cuyos diámetros no tienen la precisión deseada. Se ha encontrado que los pistones tienen un diámetro que oscila alrededor de 5 cm. con una desviación estándar de 0,001 cm. El control de calidad ha determinado que si el diámetro del pistón es menor que 4,998 se desecha, y si es mayor que 5,002 se puede reprocesar. ¿Qué porcentaje de pistones se aceptan inmediatamente?
6. Los diámetros de unas piezas mecánicas están distribuidos normalmente con media 0,4008 pulga-das y desviación estándar 0,0020 pulgadas. Los límites de especificación están dados como 0,4000 ± 0,0010 pulgadas. ¿Cuál es el porcentaje de unidades defectuosas?
Respuesta: 64,43%
7. Los diámetros de unas piezas mecánicas están distribuidos normalmente con media 0,4002 pulga-das. Los límites de especificación están dados como 0,4000 ± 0,0010 pulgadas. ¿Cuál es la máxi-ma desviación estándar aceptable que permitirá no más de un defectuoso de cada mil producidos?
Respuesta: 0,000097 pulgadas.
8. Las estaturas de 200 empleados se distribuyen así:
Estaturas en pulgadas Frecuencia observada 57,5 - 60,5 9 60,5 - 63,5 20 63,5 - 66,5 45 66,5 - 69,5 55 69,5 - 72,5 43 72,5 - 75,5 17 75,5 - 78,5 11
TOTAL 200
Determine la curva normal que más se ajuste a esta distribución.
9. Una máquina troqueladora produce tapas de latas cuyos diámetros están normalmente distribuidos, con una desviación estándar de 0,01 pulgadas. ¿En qué diámetro "nominal" promedio debe ajus-tarse la máquina de tal manera que no más del 5% de las tapas producidas tengan diámetros que excedan las 3 pulgadas?

Distribuciones continuas de probabilidad 99
Respuesta: 2,98355 pulgadas.
10. La puntuación media de un examen fue 72 y la desviación media 8. De un total de 90 alumnos, a los 18 mejores se les quiere dar la calificación A. ¿Cuál es el puntaje mínimo que un alumno debe tener para recibir un A? Suponga que los puntajes obtenidos se distribuyen normalmente.
Respuesta: 78,72.
11. Suponga que la lluvia anual que cae en el Departamento de Piura es una variable distribuida nor-malmente con un promedio de 75,4 mm. y desviación estándar 4,2 mm.
a) ¿Cuál es la probabilidad de que se tenga un año con más de 85 mm? Respuesta: 0,011 b) ¿Se podrá admitir un pronóstico de más de 100 mm. para el próximo año? Explique. Respuesta: Se puede admitir, pero es muy poco probable.
12. Una academia pre-universitaria de mucho prestigio cuenta con tres aulas A, B y C con capacidades para 50, 70 y 80 alumnos, para Ingeniería. Como se han presentado 500 alumnos, se les ha hecho rendir un examen de ingreso. Los puntajes obtenidos por los 500 alumnos se distribuyen normal-mente con media 151 y desviación estándar 85. Si se desea seleccionar a los mejores en las aulas A, B y C sucesivamente, ¿qué puntajes se deben establecer como mínimos para ingresar a cada au-la?
Respuesta: 260 para A, 211 para B y 172 para C.
13. Suponga que los promedios de prácticas de los alumnos de Estadística están distribuidos normal-mente alrededor de 12. Si el 95% de estos promedios están comprendidos entre 09 y 15. ¿Qué por-centaje de alumnos estarán aprobados? (Nota aprobatoria mínima: 10,5)
Respuesta: 83,65%
14. Los postulantes a una Escuela Militar tienen estaturas que se distribuyen normalmente alrededor de 1,72m., con una desviación estándar de 0,04m. Las calificaciones que obtuvieron se encuentran distribuidas también normalmente alrededor de 220 puntos, con una desviación estándar de 65. Si se desea que ingresen 200 postulantes de un total de 880, con una estatura mínima de 1,70m., ¿cuál debe ser la calificación mínima para ingresar?
Respuesta: 249.
15. Suponga que se ha medido el nivel intelectual en la escala para preescolar y primaria WPPSI de Wechsler en Piura (la máxima puntuación posible es 50), y se llegó a afirmar que tal medida sigue una distribución muy aproximada a la distribución normal con media 24 y desviación estándar 6,5.
a) ¿Qué porcentaje de la población piurana tiene un nivel intelectual mayor a 40? b) ¿Cuál es la probabilidad de que un alumno de primaria de Piura escogido al azar tenga un ni-
vel intelectual comprendido entre 10 y 20?
16. La cantidad real de café instantáneo que coloca una máquina llenadora en bolsas se puede conside-rar como una variable aleatoria distribuida normalmente con desviación estándar 0,04 onzas. Un requerimiento importante es que sólo el 2% de las bolsas contengan menos de 6 onzas de café. ¿Cuál debe ser el contenido medio de las bolsas?
17. Los diámetros de unas piezas mecánicas están distribuidos normalmente con media 0,4001 pulga-das. Los límites de especificación están dados como 0,4000 ± 0,06 pulgadas. ¿Cuál es la máxima desviación estándar aceptable que permitirá no más de un defectuoso de cada diez producidos?
Respuesta: 0,000289 pulgadas.
18. Una empresa que tiene una flota de autos de alquiler ha averiguado que la duración de las zapatas del freno tiene una distribución normal, con una media de 88 000 Km. y una desviación estándar de 7 200 Km. ¿Cuál es la probabilidad de que, de 8 zapatas, al menos 5 duren más de 100 000 Km?

100 Distribuciones continuas de probabilidad
19. En una fábrica de cables eléctricos, un tipo de cable tiene las siguientes especificaciones: diáme-tro nominal: 8,50 mm.; diámetro mínimo: 8,28 mm.; diámetro máximo: 8,72 mm. Se selecciona una muestra de 800 cables, obteniéndose un diámetro promedio de 8,58 mm. y una desviación es-tándar de 0,10 mm. a) ¿Cuántos cables se espera que no cumplan con las especificaciones? b) Si ajustando la maquinaria se consigue cambiar el diámetro promedio, manteniendo constante
la desviación estándar, ¿cuál es el mínimo porcentaje de cables defectuosos que se puede con-seguir?
c) ¿Qué se debe hacer para reducir a cero el porcentaje de cables defectuosos?
20. Considerando que existen 10 dígitos, halle la probabilidad de que, de 100 000 elecciones aleato-rias, el dígito 6 salga al menos 9 971 veces.
21. Una persona que viaja diariamente a su trabajo en ómnibus hace un trasbordo. Tanto en la parada frente a su casa como en la parada donde hace el trasbordo, el tiempo de espera está distribuido uniformemente entre 0 y 10 minutos. ¿Cuál es la probabilidad de que, de los 20 viajes que hace en un mes, en menos de 5 viajes la espera total no supere los 15 minutos? Ayuda: para calcular la probabilidad de que en un viaje el tiempo de espera no supere los 15 minutos, trace cada tiempo de trasbordo en cada eje del sistema de coordenadas cartesianas.
22. Un fabricante de insecticidas asegura que el 85% de los zancudos que son rociados por su produc-to, mueren ¿Cuál es la probabilidad de que en una sala con 200 zancudos se aniquilen al menos 150 zancudos con este insecticida?
23. Supóngase que el 65% de los gerentes en el Perú tienen un grado de maestría. Si se toma una muestra de 100 gerentes, ¿cuál es la probabilidad de que haya menos de 50 que tengan grado de maestría?

Distribuciones de proporciones 101
Capítulo 7. Distribuciones de proporciones
7.1 La distribución multinomial. Ejemplo:
El 30% de todos los vehículos que llegan por una calle a cierta intersección, giran hacia la iz-quierda, el 20% giran a la derecha y el 50% restante siguen derecho. Si en un determinado mo-mento se encuentran en dicha intersección 8 autos detenidos por la luz roja del semáforo ¿cuál es la probabilidad de que 3 giren hacia la izquierda, 2 giren a la derecha y 3 sigan de frente?
Aplicando el teorema generalizado de la multiplicación, y considerando independencia entre lo que hagan los conductores:
!3!2!3
!8)5,0()2,0()3,0( 323=P
Se puede generalizar esta fórmula de probabilidad para los casos en que, de una muestra de n elementos, x1 tengan cierta característica, x2 tengan otra característica,..., y xk tengan otra característi-ca; siendo p1 , p2 ,..., pk , las probabilidades de que un elemento tenga cada una de las características mencionadas, de tal forma que ∑xi sea igual a n, y ∑ pi sea igual a 1. Entonces:
kxk
xx
k
pppxxx
nP )(...)()(...!!!
2121
21
=
es denominada probabilidad multinomial, por parecerse mucho a la probabilidad binomial, con la diferencia de que presenta k posibilidades para cada elemento de la muestra, en lugar de dos.
A la distribución conjunta de x1, x2, ..., xk, se le conoce como distribución multinomial.
Considerada en forma independiente, cada variable Xi es binomial con parámetros pi y n; por lo tanto tiene un valor esperado igual a npi y una varianza igual a npi(1 – pi).
7.2 La distribución de una proporción. Si la variable binomial X, que representa el número de elementos de una muestra de tamaño n
que poseen cierta característica, se divide entre n, resulta otra variable aleatoria, X/n, que representa la proporción de elementos de la muestra, que tienen dicha característica. A la proporción de elementos de la población que poseen tal característica se le denomina p.
Se ha visto que la variable estandarizada:
npqnpxz −±
=5,0
se distribuye normalmente cuando np y nq > 5.
Si se divide cada término de la fracción entre n, resulta lo siguiente:
npq
pn
p
npq
pnn
x
z−±
=−±
= 21
21
1

102 Distribuciones de proporciones
donde a la proporción X/n se le ha denominado p1.
Esta última expresión nos dice que la proporción p1 se distribuye normalmente alrededor de p, con desviación estándar igual a npq / . En la figura 7.1 se muestra esta distribución normal.
Figura 7.1. Distribución de p1 alrededor de p.
Es importante resaltar que esta nueva variable p1 es discreta, aunque no tome valores enteros.
Como se puede deducir, la desviación estándar disminuye al aumentar el tamaño de la muestra, lo cual se expresa en la figura 7.2, donde σ 1 < σ 2 < σ 3.
Figura 7.2. Disminución de la variabilidad al aumentar el tamaño de la muestra
Se deduce fácilmente que al aumentar el tamaño de la muestra, es decir, al disminuir la variabi-lidad de p1, los valores de p1 que se puedan obtener estarán más cerca de p, lo cual equivale a afirmar que se reduce el error de estimación, conocido como error muestral, e.
e = p1 – p
Ejemplo:
En la fabricación de cierto tipo de pernos se ha determinado que, en promedio, el 15% de la pro-ducción no es de calidad óptima. Ante esta situación, el jefe de mantenimiento decidió hacer al-gunos cambios en el proceso de producción, con el propósito de bajar considerablemente dicho porcentaje. Suponiendo que los cambios que se hizo no hubieran bajado el porcentaje de pro-ductos que no son de calidad óptima, ¿cuál es la probabilidad de que en una muestra de 200 pernos se encuentre que el porcentaje que no son de calidad óptima sea del 10% o menos?
p 1 p
p p 1
σ 1
σ 3
σ 2

Distribuciones de proporciones 103
En primer lugar, se verifica si la distribución de p1 es aproximadamente normal:
np = 200(0,15) = 30 > 5 nq = 200(0,85) = 170 > 5
0252,0200
85,015,0=
×=σ
08,20252,0
15,02002110,0
−=−
×−
=z P = 0,0188
Como se puede ver, es muy poco probable que en una muestra de 200 pernos se encuentre que el porcentaje que no son de calidad óptima sea del 10% o menos; por lo tanto se puede concluir que es muy probable que el verdadero porcentaje de pernos que no son de calidad óptima ya no sea 15% sino menor.
7.3 Determinación del tamaño de una muestra en poblaciones infinitas
7.3.1 Determinación del tamaño de una muestra para estimar una proporción de una población infini-ta Generalmente se desea determinar proporciones (o porcentajes, que es lo mismo) poblacionales
que resultan de interés para las fábricas, empresas, o para la sociedad; pero esto no es posible porque las poblaciones de interés suelen ser muy grandes. Por ejemplo, se desea saber:
• El porcentaje de productos defectuosos que elaboran en una fábrica. • El porcentaje de clientes que no están satisfechos con el servicio que dan en un banco. • El porcentaje de ciudadanos que aprueban la gestión del presidente de un país. • El porcentaje de familias que consumen un determinado jabón. • El porcentaje de familias que ven un determinado programa de TV.
Como no es posible determinar con precisión tales porcentajes (o proporciones), porque se nece-sitaría invertir mucho dinero y/o tiempo para encuestar a toda la población, se recurre a la estimación de dicha proporción poblacional, extrayendo una muestra de la población y calculando la proporción muestral correspondiente.
Por ejemplo, para estimar el porcentaje de familias de Piura que compran un determinado jabón, bastará con extraer una muestra de 400 familias y encuestarlas. Si hay 75 familias que lo compran, la proporción muestral será:
%75,181875,040075
1 ====nxp
Pero este es el porcentaje de familias de la muestra que compran ese jabón, que puede ser una buena estimación del porcentaje de familias de Piura que compran dicho jabón. Se dice que p1 es un estimador puntual de p.
Lógicamente, mientras más grande sea la muestra, p1 será mejor estimación de p. ¿Pero qué tan grande debe ser la muestra? La respuesta lógica será: lo más grande que sea posible. ¿Y hasta cuánto será posible? Esto dependerá del presupuesto y tiempo disponibles.
Generalmente, para definir el tamaño de una muestra el interesado se fija los siguientes paráme-tros, limitados por el dinero y tiempo disponibles.
Confiabilidad
Cuando se quiere hacer una estimación de una proporción poblacional, el interesado quiere tener cierta probabilidad de acertar, es decir, cierta confiabilidad. Por ejemplo, puede querer estar 95% seguro de acertar el verdadero valor de la proporción poblacional. Tal estimación se hace
p1 es aproximadamente normal

104 Distribuciones de proporciones
dando un rango, dentro del cual debería estar la proporción poblacional. Para tener dicha confia-bilidad necesitará elegir un determinado tamaño de muestra. Si quisiera una confiabilidad ma-yor, necesitará, lógicamente, una muestra más grande.
Error muestral
A la diferencia entre la proporción muestral hallada y la verdadera proporción poblacional (des-conocida) se le llama error muestral.
e = p1 – p
Cuando se quiere estimar una proporción poblacional, el interesado quiere aproximarse lo más que pueda a dicha proporción. Lógicamente, mientras más grande sea la muestra, más se acerca-rá a la proporción poblacional, y por lo tanto menor será el error muestral.
Si la población es bastante grande (N → ∞), la muestra será lo suficientemente grande y enton-
ces: np y nq > 5; por lo tanto p1 se distribuiría normalmente alrededor de p, como se ha visto anterior-mente. Para efectos prácticos, se suele considerar infinita una población conformada por 100 000 ele-mentos ó más.
Ejemplo:
En la figura 7.3 se representa la distribución de una proporción muestral p1 cuando se quiere es-timar una proporción poblacional p con una confiabilidad del 95% de que el error muestral no supere el 5%.
p 1 p p - 0,05 p + 0,05
95%
Figura 7.3. Estimación de p con 95% confiabilidad de un error muestral máximo del 5%
Como se ve en la figura 7.3, el máximo error muestral que se desea cometer es 5%.
Entonces, en general, para p1 = p + emax la variable estandarizada será:
npq
e
npq
ppz max1 =−
=
No se ha considerado el factor de corrección ± 1/2n pues resulta despreciable para muestras grandes, como las que se emplean cuando se requiere al menos una confiabilidad del 95% y un error muestral máximo de 5%.
De esta última expresión se puede despejar n, es decir, el tamaño de la muestra:

Distribuciones de proporciones 105
2max
2
epqzn =
Donde:
• z: queda determinado por la confiabilidad que se desee. Con la ayuda de la tabla que proporciona áreas bajo la curva normal, se puede determinar el valor de la variable es-tandarizada z que corresponde a una determinada confiabilidad. Por ejemplo, para una confiabilidad del 95%, el área de la cola derecha a partir de (p + emax) es 0,025; a esta área le corresponde un valor de z = 1,96
• pq: será 0,25 en el peor de los casos. (el máximo valor que puede tener pq es 0,25).
• emax : es el máximo error muestral que se está dispuesto a cometer.
Si se define el tamaño de una muestra y la confiabilidad, el error muestral se obtiene fácilmente, despejando emax:
npqze =max
Ejemplo 1:
¿Cuál será el tamaño de muestra necesario para estimar el porcentaje de familias de Piura que compran un determinado jabón, si se quiere tener una confiabilidad del 95% de que el error muestral no supere el 5%?
16,384)05,0(
25,096,12
2
2max
2
=×
==e
pqzn
Será necesario entonces entrevistar a 385 familias. (Nótese que con n = 384 el error muestral su-peraría el 5%).
O sea que si el verdadero valor de p fuese 0,20; es decir, si realmente el 20% de las familias de Piura compraran cierto jabón, y, si con una muestra de 385 familias se determina, por ejemplo, p1 = 0,1875 = 18,75%, entonces el error muestral sería: e = 0,1875 – 0,20 = – 0,0125 = – 1,25%
El resultado de esta encuesta se hubiese expresado de la siguiente manera: El porcentaje de fa-milias de Piura que consume dicho jabón es:
p = 18,75% ± 5%
Como resultado de dicha encuesta se afirma entonces que, con una confiabilidad del 95%, el porcentaje de familias de Piura que consume dicho jabón está comprendido entre 13,75% y 23,75%. Como se ve, la encuesta ha acertado con el resultado; pero, ¿qué tan probable era no acertar? Precisamente había una probabilidad del 5% de no acertar.
Ejemplo 2:
Supóngase que se desea estrechar el rango de la estimación, es decir, disminuir el máximo error muestral posible. Para esto será necesario aumentar el tamaño de la muestra:
Sean: confiabilidad = 95% y emax = 2%
2401)02,0(
25,096,12
2
2max
2
=×
==e
pqzn
O sea que si el verdadero valor de p fuese 0,20; es decir, si realmente el 20% de las familias de Piura compran cierto jabón, y, si con una muestra de 2401 familias se determina, por ejemplo, p1 = 0,1924 = 19,24%, entonces el error muestral hubiese sido: e = 0,1924 – 0,20 = – 0,0076 = – 0,76%

106 Distribuciones de proporciones
El resultado de esta encuesta se hubiese expresado de la siguiente manera: El porcentaje de fa-milias de Piura que consume dicho jabón es:
p = 19,24% ± 2%
Como resultado de dicha encuesta se afirma entonces, con una confiabilidad del 95%, que el porcentaje de familias de Piura que consume dicho jabón está comprendido entre 17,24% y 21,24%.
7.3.2 Determinación del tamaño de una muestra estratificada para estimar proporciones de los estra-tos de una población infinita. Si se quiere estimar una proporción poblacional para cada uno de los estratos en que se ha divi-
dido una población, se tendrá que fijar la confiabilidad y el máximo error muestral que se desea tener en cada uno de estos estratos. Prácticamente, es como si se considerase cada estrato como una pobla-ción.
Para decidir el tamaño de cada uno de los estratos de la muestra se pueden seguir dos métodos:
Método 1: Estratos de la muestra proporcionales a los estratos de la población.
Ejemplo:
¿Cuál debe ser el tamaño de una muestra y cómo debe estar constituida, para estimar el porcen-taje de familias de los estratos socioeconómicos AB, C y D de Piura que compran un determi-nado jabón (J), si se quiere tener una confiabilidad del 95% de que el error muestral no supere el 5% en ningún caso?
Supóngase que en Piura los estratos socioeconómicos tienen la siguiente distribución:
Estrato socioeconómico AB C D Porcentaje 11,3 33,7 55
Si la muestra fuese de tamaño n = 385 familias, como se obtuvo en el ejemplo anterior, debería
estar conformada de la siguiente manera:
Estrato socioeconómico AB C D ni 43,51 129,75 211,75
Por lo tanto, redondeando: nAB = 44 ; nC = 130 ; nD = 212
Pero si se considerasen estas muestras, cuando se expresen los resultados de la encuesta para ca-da estrato, se tendrá que considerar el error muestral máximo que se comete con cada estrato, y éste se tendrá que calcular a partir de la misma fórmula que se ha deducido antes:
npqze =max
Para cada estrato, los errores muestrales serán:
eAB max = 4425,096,1 = 0,1477 = 14,77 %
eC max = 130
25,096,1 = 0,0860 = 8,60 %
eD max = 212
25,096,1 = 0,0673 = 6,73 %

Distribuciones de proporciones 107
Como se ve, aunque los errores muestrales para la estimación en los estratos C y D no son tan grandes, para el estrato más pequeño (el AB), el error muestral es demasiado grande: 14,77%.
Si se quisiera mantener las proporciones de los estratos, de tal manera que el error muestral del estrato más pequeño, es decir, el máximo de los errores muestrales, no supere el 5%, la muestra del estrato AB tendría que ser:
nAB = 2
2
05,025,096,1 × = 385 familias.
De esta manera, el error muestral máximo del estrato más pequeño (AB) será:
eAB max = 5%.
Si esta muestra representa el 11,3%, la muestra total tendrá que ser de tamaño:
n = 385 × 100 / 11,3 =3 407,08 ⇒ 3 407 familias.
El error muestral máximo de la muestra completa será:
emax = 3407
25,096,1 = 0,0168 = 1,68 %
El tamaño de la muestra del estrato C se puede calcular a partir del tamaño de la muestra total:
nC = 3 407 × 33,7 / 100 = 1 148,16 ⇒ 1 148 familias.
El error muestral máximo del estrato C será:
eC max = 1148
25,096,1 = 0,0290 = 2,89 %
El tamaño de la muestra del estrato D será:
nD = 3 407 × 55 / 100 = 1 873,85 ⇒ 1 874 familias.
El error muestral máximo del estrato D será:
eD max = 1874
25,096,1 = 0,0226 = 2,26 %
En la siguiente tabla se presentan las muestras y sus respectivos errores muestrales máximos:
Estrato socio-económico Tamaño de la submuestra Error muestral máximo AB 385 5% C 1 148 2,89% D 1 874 2,26%
Total 3 407 1,68%
De esta forma, si, por ejemplo, las encuestas realizadas mostrasen los siguientes resultados:
Estrato socio-económico Familias consumen jabón J % que consumen jabón J AB 34 8,83% C 210 18,29% D 412 21,99%
Se deduce fácilmente, para toda la muestra, el porcentaje de familias que consumen jabón J:
%25,191925,03407
412210341 ==
++=p
También se podría calcular este porcentaje como una media ponderada:

108 Distribuciones de proporciones
%25,19100
5599,217,3329,183,1183,81 =
×+×+×=p
Finalmente, ¿qué porcentaje de familias de Piura, de los distintos estratos, se estima que com-pran el jabón J?
PAB = 8,83% ± 5%
PC = 18,29% ± 2,89%
PD = 21,99% ± 2,26%
El porcentaje estimado de familias de Piura que consumen jabón J será:
P = 19,25% ± 1,68%
Método 2: Estratos de la muestra no proporcionales a los estratos de la población.
El método 1 tiene un inconveniente que salta a la vista: el número de encuestas que hay que hacer es muy grande. ¿Cómo se podría evitar esto, sin llegar a tener algún error muestral máxi-mo muy elevado?
Una solución posible es considerar el mismo error muestral máximo para cada estrato; así se tendría el mismo tamaño de muestra para cada estrato.
Ejemplo:
Si se decide tener una confiabilidad del 95% de que el error muestral máximo de cada estrato sea el 5%, se tendría:
nAB = 2
2
05,025,096,1 × = 385 familias.
nC = 2
2
05,025,096,1 × = 385 familias.
nD = 2
2
05,025,096,1 × = 385 familias.
Una vez realizadas las encuestas y obtenidos los porcentajes de familias que compran jabón J, se tendrá que calcular el porcentaje de familias de todo Piura que consumen ese jabón.
Supóngase que en las encuestas se obtuvieron los siguientes resultados:
Estrato socio-económico Familias consumen jabón J % que consumen jabón J AB 31 8,05% C 74 19,22% D 93 24,16%
Se deduce, para toda la muestra, que el porcentaje de familias que consumen jabón J es:
%67,20100
5516,247,3322,193,1105,81 =
×+×+×=p
¿Qué porcentaje de familias de Piura, de los distintos estratos, se estima que compran el jabón J?
PAB = 8,05% ± 5%
PC = 19,22% ± 5%
PD = 24,16% ± 5%

Distribuciones de proporciones 109
El porcentaje estimado de familias de Piura que consumen jabón J será:
P = 19,25% ± ¿? %
¿Cuál será el error muestral máximo para la muestra total?
Como la muestra total es de tamaño: 385 × 3 = 1155, entonces:
emax = 1155
25,096,1 = 0,0288 = 2,88 %
7.4 Determinación del tamaño de una muestra en poblaciones finitas Cuando se trata de estimar una proporción de una población finita, se recomienda emplear la si-
guiente fórmula que demuestra Hásek (1960) para determinar el tamaño de la muestra:
pqzNe
pqNzn 22max
2
)1( +−=
Donde:
• N: es el tamaño de la población.
• z: queda determinado por la confiabilidad que se desee. Con la ayuda de la tabla que proporciona áreas bajo la curva normal, se puede determinar el valor de la variable es-tandarizada z que corresponde a una determinada confiabilidad. Por ejemplo, para una confiabilidad del 95%, el área de la cola derecha a partir de (p + emax) es 0,025; a esta área le corresponde un valor de z = 1,96.
• pq: será 0,25 en el peor de los casos. (el máximo valor que puede tener pq es 0,25).
• emax : es el máximo error muestral que se está dispuesto a cometer.
Se suele considerar finita una población cuando su tamaño es N < 100 000.
Si se define el tamaño de una muestra y la confiabilidad, el error muestral se obtiene fácilmente, despejando emax:
1max −
−=
NnN
npqze
7.5 La distribución de la diferencia de dos proporciones. Sean dos universos independientes donde px y py representan proporciones de elementos con
cierta característica en cada uno. De ambos universos se extraen dos muestras de tamaño Nx y Ny, don-de x e y indican la cantidad de elementos de cada muestra que tienen tal característica, de modo que:
yx n
ypnxp == 21 ;
Si ambas proporciones p1 y p2 se distribuyen normalmente alrededor de px y py respectivamente; entonces la diferencia (p1 – p2) también se distribuye normalmente alrededor de la diferencia (px – py). Si p1 y p2 son independientes, la desviación estándar de (p1 – p2) será, tal como se vio al final del capí-tulo 4:
222)( 2121 pppp σσσ +=−
y
yy
x
xxpp n
qpnqp
+=−2
)( 21σ

110 Distribuciones de proporciones
La variable estandarizada correspondiente será:
y
yy
x
xx
yx
nqp
nqp
cfppppz
+
±−−−=
..)()( 21
donde el factor de corrección (f.c.) es:
yx
yx
yx nnnn
nncf
221
21..
+=+=
Las aplicaciones de la diferencia de dos proporciones se ven en el capítulo 9 (Contrastes de hipótesis).

Distribuciones de proporciones 111
Problemas propuestos. 1. Las compañías auditoras generalmente seleccionan una muestra aleatoria de los clientes de un
banco y verifican los balances contables reportados por el banco. Si una compañía de este tipo se encuentra interesada en estimar la proporción de cuentas para las cuales existe una discrepancia entre el cliente y el banco, ¿cuántas cuentas deberán seleccionarse de manera tal que con una con-fiabilidad del 99%, la proporción de la muestra se encuentre a menos de 0,02 de la proporción re-al?
2. Un fabricante de insecticidas asegura que el 85% de los zancudos que son rociados por su produc-to, mueren ¿Cuál es la probabilidad de que en una sala con 200 zancudos se aniquilen al menos el 75% con este insecticida?
Respuesta: 0,999975
3. Un estudiante de Estadística quiere estimar la proporción de familias de la Urbanización Miraflo-res que ve un determinado programa de televisión. Debido al elevado número de familias, resulta-ría muy laborioso tomar los datos de todas éstas. El alumno desea tomar una muestra y estimar di-cha proporción con una probabilidad de 0,98 no exceder un error de ± 10% ¿Qué tamaño de mues-tra debe tomar?
4. Un dado tiene tres caras rojas, dos blancas y una azul. Si este dado se lanza nueve veces, ¿cuál es la probabilidad de que cada uno de los colores aparezca tres veces?
5. Un comerciante quiere comprar un lote muy grande de tornillos. Para decidir si compra el lote ex-trae en primer lugar 150 tornillos. Si encuentra más de 5% defectuosos, no compra el lote; en caso contrario, escoge 150 tornillos más. Si encuentra más de 3% defectuosos, no compra el lote; en ca-so contrario, compra el lote. Si realmente el porcentaje de tornillos defectuosos es del 3%, ¿cuál es la probabilidad de que el comerciante no compre el lote de tornillos?
6. Suponga que un grupo de estudiantes de Estadística encuestó a pobladores de cuatro ciudades del norte del Perú (Tumbes, Piura, Chiclayo y Trujillo) para saber si están de acuerdo con unas decla-raciones del Ministro de Economía. Suponga que las poblaciones de dichas ciudades son: 100 000, 300 000, 400 000 y 700 000 habitantes, respectivamente. Para ahorrar tiempo y dinero, decidieron considerar una confiabilidad del 90% y encuestar a 200 pobladores de cada ciudad, obteniendo que 46, 42, 54 y 56 pobladores de las respectivas ciudades sí estaban de acuerdo con dichas decla-raciones.
a) ¿Qué % de cada ciudad están de acuerdo con dichas declaraciones? b) ¿Qué % de las cuatro ciudades están de acuerdo con dichas declaraciones?
7. Una empresa encuestadora afirma que hay “empate técnico” entre dos candidatos de electorales. ¿Qué datos le pediría usted a dicha empresa para verificar tal afirmación?
8. Un estudiante de Estadística diseñó una encuesta para averiguar, entre otras cosas, qué porcentaje de la población universitaria del Perú estudia más de 20 horas semanales. Él quiso estar 90% segu-ro de estimar correctamente dicho porcentaje, y decidió encuestar a 450 alumnos, encontrando que 300 estudiaban más de 20 horas semanales. Suponiendo que la población universitaria en el Perú es de 200 000 alumnos, ¿cuántos alumnos diría usted que estudian más de 20 horas semanales en el Perú?
9. Supóngase que el 65% de los gerentes en el Perú tienen un grado de maestría. Si se toma una muestra de 100 gerentes, ¿cuál es la probabilidad de que haya menos de 50 que tengan grado de maestría?
10. Suponga que el gerente de CRASA quiere averiguar qué porcentaje de cada uno de los estratos so-cioeconómicos A, B y C de la ciudad (de 10 millones de habitantes) han comprado alguna vez en su cadena de supermercados. Antes de hacer una encuesta averigua que los porcentajes de dichos estratos en la ciudad son: 5%, 15% y 30%. ¿Qué muestra recomendaría (detallada) si desea que el error muestral no supere el 2% en ningún caso, si:

112 Distribuciones de proporciones
a) se considera la muestra con las mismas proporciones de los estratos de la población? b) se considera la muestra de tal forma que las proporciones de los estratos sean iguales?
Suponga que el gerente de CRASA decide encuestar a 3000 personas de los estratos A, B y C (1000 personas de cada estrato), y obtiene los siguientes resultados:
- En la muestra A, el 23,5% han comprado alguna vez CRASA. - En la muestra B, el 19,2% han comprado alguna vez CRASA. - En la muestra C, el 13,1% han comprado alguna vez CRASA.
c) ¿Qué porcentajes de cada estrato de la ciudad han comprado alguna vez CRASA? d) ¿Qué porcentaje de la ciudad ha comprado alguna vez CRASA?
11. Se desea averiguar qué porcentaje de la población de Piura y Castilla consume gas para la cocina. Para esto, se están discutiendo dos posibilidades:
• A: tener una confiabilidad del 97% de que el error muestral no supere el 5%. • B: tener una confiabilidad del 97% de que el error muestral no supere el 2%.
Evidentemente la segunda posibilidad implica una muestra mucho más grande, por lo cual se opta por una solución intermedia (C): un tamaño de muestra que sea el promedio de los tamaños que implicarían las dos posibilidades mencionadas, pero con un error muestral máximo del 3%.
a) ¿Qué confiabilidad tendría este muestreo? b) Trace las curvas que representan cómo se distribuye la proporción muestral para los tres mues-
treos descritos (A, B y C). c) ¿Cuál es la probabilidad de que se estime el porcentaje de la población de Piura y Castilla que
consume gas para la cocina con un error muestral menor del 1%?
12. Un ingeniero industrial cree que el 30% de todos los accidentes industriales en su planta se deben a que los empleados no cumplen con las disposiciones de seguridad.
a) Si eso es cierto, ¿cuál es la probabilidad de que, entre 80 accidentes que ocurrieron el año pa-sado, menos de 20 se deban a ese motivo?
b) Si realmente el 40% de todos los accidentes industriales en su planta se deben a que los em-pleados no cumplen con las disposiciones de seguridad, ¿cuál es la probabilidad de que, entre los 80 accidentes que ocurrieron el año pasado, menos de 20 se deban a ese motivo?
13. Una muestra de 400 amas de casa de Piura que realizan sus compras semanales en el mercado re-vela que 360 incluyen leche en sus compras. ¿Con qué confiabilidad se podrá afirmar que el por-centaje de amas de casa de Piura que incluyen leche en sus compras semanales en el mercado está entre 88% y 92%? Asuma que dicho porcentaje es 90%.
Respuesta: 81,65%
14. Una encuestadora ha publicado los siguientes resultados de su última encuesta realizada a una muestra de 600 votantes de Lima:
Candidato A: 38,2 % Candidato B: 34,8 %
Suponiendo que se consideró una confiabilidad del 95%, ¿se puede afirmar que hay empate técni-co, como afirma el comentarista de un diario?
15. Si p > 0,1; determine si la probabilidad P(p1 < 0.1) es mayor o menor cuando se toma una muestra n1 o cuando se toma una muestra n2, siendo n1 > n2.

Distribución de las medias muestrales
113
Capítulo 8: Distribución de las medias muestrales
8.1 Introducción En este capítulo se estudia la distribución que sigue la media de una muestra extraída de una po-
blación y la distribución que sigue la diferencia de las medias de dos muestras extraídas de la misma población, o de poblaciones diferentes.
Una media puede ser, por ejemplo, el promedio de las edades de los suscriptores a una revista económica, en el Perú, o el diámetro promedio de los pistones que se elaboran en una fábrica, o el pe-so promedio de las bolsas de sal que se empacan automáticamente en una fábrica, o el promedio men-sual de las ventas de un supermercado, etc.
En todos los casos, para estimar la media poblacional, se extrae una muestra y se calcula la me-dia aritmética de dicha muestra.
8.2 Distribución de la media muestral Teorema del límite central Si se extraen varias muestras de tamaño n de cualquier población con media µ y desviación es-
tándar σ, las medias de estas muestras (medias muestrales) tendrán una distribución aproximadamente normal con media µ y desviación estándar σ / n , si n es grande. Si la población tiene distribución normal, la media muestral tendrá también distribución normal aunque n sea pequeño.
Puede ilustrarse este teorema mediante el siguiente ejemplo: se seleccionan aleatoriamente, de una empresa, 100 muestras de 50 vendedores cada una. Considerando que cada vendedor ha efectuado un determinado número de ventas durante el último mes, se calcula la media del número de ventas en cada una de las muestras. Las 100 medias calculadas se agrupan en clases y se traza el histograma que las representa. Este histograma se aproxima mucho a una curva normal. Si se supiera el verdadero va-lor de la media y la desviación estándar del número de ventas efectuadas por los vendedores de esa empresa en el Perú (parámetros poblacionales), se estaría verificando también que la media de las me-dias de las 100 muestras casi coincide con la media poblacional y la desviación estándar de las medias, dividida entre n casi coincide con la desviación estándar poblacional.
La variable estandarizada correspondiente es:
nσµxz
/−
=
Si no se conociera la desviación estándar de la población (σ ) y la muestra fuese grande, se po-dría estimar ésta calculando la desviación estándar de la muestra (s).
Ya que la desviación estándar de la media muestral es σ / n , se deduce fácilmente que la preci-sión de la media muestral para estimar la media de la población aumenta conforme aumenta el tamaño de la muestra, como se aprecia en la figura 8.1.

Distribución de las medias muestrales
114
Figura 8.1. Distribuciones de la media muestral para n1 > n2 > n3
Viendo cómo se estrecha la distribución normal alrededor de la verdadera media de la población conforme aumenta el tamaño de la muestra, se deduce que para hacer una buena estimación de la me-dia poblacional es necesario considerar muestras muy grandes, que tiendan a infinito. La figura 8.2 muestra cómo varía la desviación estándar de la media muestral conforme aumenta el tamaño de la muestra.
x
xσ
σ Figura 2. Variación de la desviación estándar de la media muestral
Figura 8.2. Variación de la desviación estándar de las medias muestrales
Como se ve en la figura 8.2, la desviación estándar de la media muestral disminuye rápidamente al aumentar n, el tamaño de la muestra, hasta n = 30; pero a partir de n = 50 la disminución se hace ca-da vez más lenta. A partir de este tamaño de muestra se puede considerar que es lo suficientemente grande para hacer una buena estimación de la media de la población a partir de la media de una mues-tra.
8.3. Distribución de la diferencia de las medias muestrales Teorema
Si se extraen dos muestras independientes de tamaños nx y ny, de dos poblaciones cualesquiera
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0 10 20 30 40 50 60 70 80 90
µ
n 1
n 3
n 2
x
n

Distribución de las medias muestrales
115
con medias µx y µy, y desviaciones estándar σx y σy, respectivamente, la diferencia de las medias muestrales, yx − , se distribuye normalmente alrededor de la diferencia de las medias de las poblacio-nes, con una desviación estándar yxσ − , siempre que las muestras sean lo suficientemente grandes (no menores que 50).
y
y
x
xyx nn
22 σσσ +=−
Si las poblaciones de procedencia son normales, es decir, si X e Y se distribuyen normalmente, entonces la distribución de yx − será normal aunque las muestras sean pequeñas. La variable estanda-rizada correspondiente será entonces:
y
y
x
x
yx
nσ
nσ
µµyxz
22
)()(
+
−−−=
Si se desconocen las desviaciones estándar σx y σy , y las muestras extraídas son grandes, éstas pueden estimarse calculando las desviaciones estándar de las muestras, sx y sy.
8.4. La distribución t de Student: aplicaciones a las medias poblacionales Se ha dicho que si la desviación estándar de una población es desconocida, como suele ocurrir
casi siempre, es posible estimarla calculando la desviación estándar de una muestra grande (no menor de 50); pero, ¿qué hacer si no se puede extraer una muestra grande? Para muestras pequeñas, la des-viación estándar calculada suele ser muy distinta de la desviación estándar de la población, y se come-terá un error considerable si se emplea la distribución normal con desviación estándar s en vez de σ. Ante esta situación, se puede emplear la distribución t de Student en vez de la distribución normal.
8.4.1 La distribución t de Student Es una distribución muy parecida a la distribución normal, que depende de un parámetro nl, lla-
mado número de grados de libertad. La función densidad de probabilidad de la variable t de Student es la siguiente:
212
1)(+
−
+=
n
lntktf
Esta función es simétrica con media igual a cero (igual que la normal estandarizada). Su desvia-ción estándar es )2/( −ll nn .
En el apéndice se presenta una tabla (pág. 266) que proporciona valores de t (no negativos) para determinadas áreas de cola derecha, para nl = 1, 2, … , 50, 60, 120, ∞.
Conforme aumenta nl, la curva de Student se parece más a la curva normal. Compárese, por ejemplo, el valor de t que le corresponde a un área bajo la curva de Student igual a 0,05, para nl = ∞, con el valor de z que le corresponde a la misma área bajo la curva normal.
8.4.2 Distribución t de la media muestral Si se extraen varias muestras de tamaño n (menor que 50), de una población normal con media µ
y desviación estándar σ desconocida, entonces la siguiente variable:
1/ −
−=
nsx
tµ
tiene una distribución de Student con nl = n – 1 grados de libertad.

Distribución de las medias muestrales
116
Se ha definido la desviación estándar s con denominador n; pero, cuando se extraen muestras pequeñas, el mejor estimador de la desviación estándar de la población emplea n – 1 como denomina-dor. Se distinguen entonces:
n
xxs
n
ii
n
∑=
−= 1
2)(;
1
)(1
2
1 −
−=
∑=
− n
xxs
n
ii
n
En conclusión, cuando n es pequeño conviene usar sn-1 para estimar σ, y cuando n es grande am-bas expresiones dan prácticamente el mismo valor.
Se puede deducir fácilmente que:
11
−
−= nn s
n
ns
Si se sustituye este valor de sn en lugar de s, en la expresión de t, el denominador resultará:
nsn /1−
que es como lo presentan algunos autores.
El concepto de grados de libertad se puede explicar de la siguiente manera: al calcular la desvia-ción estándar de una muestra de tamaño n, se suman los cuadrados de n desviaciones respecto a la me-dia muestral. Como la suma de estas desviaciones es igual a cero, se tendrá libertad para asignar valo-res a cualesquiera n – 1 desviaciones. La restante ya queda determinada y no se le puede dar cualquier valor.
8.4.3 Distribución t de la diferencia de las medias muestrales. Cuando se quiere inferir respecto a la diferencia de las medias de dos poblaciones normales cu-
yas desviaciones estándar son desconocidas, a partir de la diferencia de las medias de dos muestras pequeñas, no se pueden utilizar las desviaciones estándar de las muestras como estimaciones de las desviaciones estándar de dichas poblaciones. En situaciones como ésta, la siguiente variable:
+
−+
+
−−−=
yxyx
yxxx
yx
nnnnsnsn
yxt
112
)()(22
µµ
tiene una distribución t de Student con nx + ny – 2 grados de libertad, siempre que las desviacio-nes estándar de las dos poblaciones sean iguales.
Si las desviaciones estándar de las poblaciones fuesen diferentes, no se podría emplear la distri-bución t de Student. En 9.7 se explica cómo probar si las desviaciones estándar de dos poblaciones son iguales.

Distribución de las medias muestrales
117
Problemas propuestos 1. La duración media de una resistencia es de 1 000 horas, con una desviación estándar de 100 horas.
Se utilizan 3 resistencias de manera consecutiva en el mismo aparato, es decir, apenas se quema una resistencia, se coloca la siguiente.
a) ¿Cuál es la probabilidad de que el aparato funcione al menos 3 600 horas? Respuesta: 0,00027 b) Y si tuviera 20 resistencias, ¿cuál sería la probabilidad de que el aparato funcione más de 19
500 horas? Respuesta: 0,846136
2. Para controlar un proceso de llenado automático de bebidas gaseosas, se toman muestras de 10 bo-tellas cada hora, durante 20 horas. A continuación se muestra el volumen promedio (en ml.) de ca-da muestra:
499,82 499,23 500,15 500,77 500,72 501,04 498,69 499,86 500,66 499,35 499,59 498,99 498,89 499,41 499,54 498,73 499,66 499,76 500,08 499,78
¿Cuál es la probabilidad de que una botella contenga más de 501,5 ml?
3. Una panificadora envía diariamente una remesa de panes a sus tiendas. Cada día se pesa una muestra de 35 panes en cada una de las tiendas. El administrador ha visto que el 80% de los pro-medios (pesos) obtenidos en dichas muestras están comprendidos entre 24,7 y 25,3 g., con un promedio de 25g. ¿En qué rango estará comprendido el 99% de los pesos de los panes de esta pa-nificadora? Asuma que los pesos de los panes se distribuyen normalmente.
Respuesta: Entre 21,43 g. y 28,57g.
4. Suponga que el peso promedio de los pobladores de una ciudad es de 75 Kg., con una desviación estándar de 8,75 Kg. La población de pesos está normalmente distribuida. Si la capacidad máxima de un ascensor con capacidad para 16 personas es de 1 250 Kg., ¿cuál es la probabilidad de que el ascensor nunca exceda su capacidad máxima?
5. El recorrido promedio de viaje (ida y vuelta a casa) de todos los trabajadores de una fábrica es de 50,5 Km. con una desviación estándar de 3,6 Km. La población de recorridos está normalmente distribuida. ¿Cuál es la probabilidad de que una muestra de 25 trabajadores revele una distancia promedio que se encuentre a un máximo de 1 Km. de la media poblacional?
6. El dueño de una empresa de taxis sabe que la duración de las zapatas de los frenos con los que cuenta varía normalmente con una media de 80 000 Km. y una desviación estándar de 7 200 Km.
a) ¿En qué rango se espera que esté la duración media de 8 zapatas, con una confiabilidad del 99%?
b) ¿Cuál es la probabilidad de que la duración media de las 8 zapatas sea inferior a 83 200 Km?

118 Contrastes de hipótesis
Capítulo 9: Contrastes de hipótesis
9.1. Introducción Una hipótesis es una aseveración que se hace sobre una población. Generalmente, tal asevera-
ción se refiere al valor numérico de algún parámetro poblacional, como la media o la proporción. Por ejemplo, una hipótesis puede establecer que la tensión de ruptura promedio de un material para solda-dura es de 250 lb., o que el ensamble de una computadora promedia al menos 40 minutos, o que la proporción de piezas defectuosas en un proceso de manufactura es de menos de 0,05, o que el porcen-taje de clientes exclusivos de un banco es menor del 5%.
Una prueba o contraste de hipótesis es una prueba de la validez de la aseveración, y se lleva a cabo mediante un análisis de datos extraídos de una muestra.
9.2. Hipótesis nula e hipótesis alternativa Muchas veces se quiere investigar si un parámetro poblacional tiene una determinada caracterís-
tica o no; por ejemplo, que menos del 25% de los consumidores de detergente usan detergente Real, es decir, que la proporción de consumidores de detergente Real es menor que 0,25. Como no se conoce con exactitud cuál es esa verdadera proporción, se establece como hipótesis que es igual a 0,25, y se contrasta esta hipótesis contra la hipótesis de que dicha proporción es menor que 0,25. Para hacer este contraste se extrae una muestra de consumidores de detergente y se calcula qué proporción de la mues-tra usa detergente Real. Lógicamente, si esa proporción es mayor que 0,25, se aceptará la hipótesis ini-cial; pero, ¿cuándo se podrá afirmar que es menor? Si la proporción encontrada en la muestra es lige-ramente menor que 0,25, se podría aceptar la hipótesis inicial, pues esa pequeña diferencia puede ser consecuencia del azar, y, efectivamente la verdadera proporción puede no ser menor que 0,25. Para estar seguro de no cometer un grave error, rechazando “injustamente” la hipótesis inicial, se podría tomar la decisión de rechazarla sólo si la proporción de la muestra resulta mucho menor que 0,25, es decir, si se tiene un resultado inusual o poco probable. Pero, ¿a partir de qué valor de la proporción que se encuentre en la muestra se podrá afirmar que es mucho menor que 0,25?
En el ejemplo, a la aseveración concreta de que la proporción de consumidores de detergente Real es 0,25 (o más), se denomina hipótesis nula (H0). Se denomina hipótesis alternativa (H1), a la hipótesis que motivó la investigación, es decir, a la aseveración de que la proporción de consumidores de detergente Real es menor que 0,25. Para este ejemplo, estas hipótesis se expresan matemáticamente de la siguiente forma:
H0: p ≥ 0,25
H1: p < 0,25
9.3. Regiones de aceptación y de rechazo Definidas la hipótesis nula y la alternativa, el investigador debe precisar qué resultados del
muestreo harán que se acepte la hipótesis nula, y qué resultados harán que se rechace la hipótesis nula a favor de la hipótesis alternativa.
Se denomina región de aceptación al conjunto de los posibles resultados del muestreo que lleva-rían a aceptar H0. Se denomina región de rechazo al conjunto de los posibles resultados del muestreo que llevarían a rechazar H0, y por lo tanto a aceptar H1.

Contrastes de hipótesis
119
Para definir estas regiones se suele usar el siguiente criterio: para rechazar la hipótesis nula se tiene que dar un resultado muy poco usual en el muestreo. Por ejemplo, si la muestra está compuesta por 40 consumidores de detergente (n = 40) y si es cierto que el 25% de la población consume deter-gente Real (p = 0,25), se espera encontrar 10 consumidores de detergente Real (µ = np = 10). Si se en-cuentran 8 ó más consumidores de detergente Real, se puede aceptar H0; pero, ¿a partir de qué valor ya conviene rechazar H0? ¿7?, ¿6? Siguiendo el criterio de rechazar H0 cuando se obtiene un resultado muy poco usual, es decir, muy poco probable, se puede considerar que encontrar menos de 7 consumi-dores de detergente Real es muy poco probable (p1 = 6/40 = 0,15 parece considerablemente menor que 0,25). Concretamente:
P(X < 7) = ∑=
−
−
6
0
4075,025,0!)!40(
!40
x
xx
xx= 0,096 (calculada con Excel)
Así, el investigador puede tomar la siguiente decisión: extraer una muestra de 40 consumidores de detergente. Si hay 6 ó menos consumidores de detergente Real, rechaza H0; en caso contrario, acep-ta H0. En la figura 9.1 se representan estas regiones de aceptación y rechazo con las probabilidades bi-nomiales (barras verticales) correspondientes a, 0, 1, …, etc.
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Región de rechazo Región de aceptación
α
Figura 9.1. Regiones de aceptación y rechazo
9.4. Error tipo I y error tipo II Una vez que el investigador ha definido las regiones de aceptación y de rechazo para la hipótesis
nula, se puede llevar a cabo la prueba; pero se pueden cometer dos tipos de error:
1) Rechazar la hipótesis nula cuando es verdadera. A esto se le conoce como error tipo I, y a la probabilidad de cometerlo se le designa α.
Para el ejemplo de la proporción, este error se cometería si se rechaza la aseveración de que la proporción de consumidores de detergente Real es igual a 0,25 (ó más), es decir, si se acepta que dicha proporción es menor que 0,25, cuando realmente es 0,25. La probabilidad de cometer este error es α = P(X < 7) = 0.096 (ver figura 9.1).
2) Aceptar la hipótesis nula cuando es falsa. A esto se le conoce como error tipo II, y a la probabi-lidad de cometerlo se le designa β.
Para el ejemplo de la proporción, este error se cometería si se acepta la aseveración de que la proporción de consumidores de detergente Real es igual a 0,25, es decir, si se rechaza que dicha proporción es menor que 0,25, cuando realmente es menor que 0,25.

120 Contrastes de hipótesis
Supóngase que la verdadera proporción de consumidores de detergente Real (desconocida) es 0,12. Se cometerá el error tipo II cuando se acepte que p = 0,25, y esto ocurrirá cuando 7 ó más con-sumidores de detergente de la muestra consuman detergente Real. La probabilidad de cometer este error es:
β = P(X ≥ 7) = ∑=
−
−
40
7
4088,012,0!)!40(
!40
x
xx
xx= 0,198 (calculada con Excel)
En la figura 9.2 se representa la probabilidad de cometer el error tipo II (β ) cuando la verda-dera proporción de consumidores de detergente Real (desconocida) es 0,12. Como se ve, para la ver-dadera proporción p = 0,12 se tiene otra distribución binomial con media igual a np = 40(0,12) = 4,8.
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.18
0.20
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Región de rechazo Región de aceptación
α
β
Histograma binomial con p = 0,25
Histograma binomial con p = 0,12
Figura 9.2. Probabilidad de cometer los errores tipo I y tipo II.
Se deduce que mientras más difiera la verdadera proporción de la proporción establecida como hipótesis nula, menor es la probabilidad de cometer el error tipo II.
En una investigación, lo usual es que se defina el tamaño de la muestra y el máximo valor que se desea de α (0,10; 0,05; 0,025 ó 0,01), y luego se determinen las regiones de aceptación y rechazo.
9.5. Contrastes de hipótesis sobre proporciones Ejemplo 1:
En el ejemplo que se ha venido analizando sobre la proporción de consumidores de detergente Real, se cumple la condición de que np y nq > 5, por lo tanto la proporción de la muestra (p1 = x/n) tiene una distribución aproximadamente normal con media p y desviación estándar npq / .
Supóngase que se toma una muestra de 40 consumidores de detergente (n = 40) y se define α = 0,05. Si se encuentra que 6 consumen detergente Real, ¿se podrá afirmar que el porcentaje de consumidores de detergente Real es menor del 25%?
Las hipótesis son: H0: p ≥ 0,25 H1: p < 0,25
Es posible determinar las regiones de aceptación y rechazo en términos de x (número de consu-midores de detergente que usan detergente Real), o en términos de p1 (proporción de consumido-

Contrastes de hipótesis
121
res que usan detergente Real). Para esta segunda opción, se denomina p1* al valor que limita las regiones de aceptación y rechazo.
La variable estandarizada que le corresponde a p1* debe tener un área igual a 0,05 en la cola iz-quierda de la curva normal; este valor es z* = –1,645. Por lo tanto:
–1,645 = 40/75,025,080/125,0*1
×
+−p
Resolviendo, resulta:
p1* = 0,1249
En la figura 9.3 se representa la distribución normal de p1 y las regiones de aceptación y rechazo delimitadas por p1*.
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70
Región de rechazo Región de aceptación
α = 0,05
p 1*= 0,1249
Figura 9.3. Regiones de aceptación y rechazo para el contraste de hipótesis (de cola izquierda)
de una proporción
La proporción encontrada en la muestra es p1 = 6/40 = 0,15, que está en la región de aceptación; por lo tanto, se acepta la hipótesis nula, y se rechaza la hipótesis alternativa. En otras palabras, no se podrá afirmar que el porcentaje de consumidores de detergente Real es menor del 25%.
A partir de p1* se puede determinar con precisión las regiones de aceptación y rechazo:
40
*1249,0*1xp ==
x* = 4,996
Por lo tanto: Región de rechazo: x = 0, 1, 2, …, 4 Región de aceptación: x = 5, 6, 7, …, 40
Dividiendo cada valor x entre 40, se determinan las regiones de aceptación y rechazo de la va-riable p1:
Región de rechazo: p1 = 0; 0,025; 0,050, …; 0,100 Región de aceptación: p1 = 0,125; 0,150; …; 1.

122 Contrastes de hipótesis
El verdadero valor de α se puede determinar calculando la probabilidad de que p1 esté en la re-gión de rechazo, usando la aproximación normal:
01,2008,2
4075,025,0
25,0)40(2
11,0−≈−=
×
−+=z
α = 0,0222
¿Cuál sería la probabilidad de aceptar la hipótesis nula si el verdadero valor de p fuese 0,20?
En este caso, la hipótesis nula (H0: p ≥ 0,25) sería falsa, por lo tanto, dicha probabilidad, es de-cir, la probabilidad de que p1 esté en la región de aceptación, es β:
38,1
4080,020,0
20,0)40(2
1125,0−=
×
−−=z
β = 1 – 0,0838 = 0,9162
En la figura 9.4 se muestran las áreas que representan a α y β, incluyendo las áreas que se aña-den en cada caso.
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70
Región de rechazo Región de aceptación0,125
α
β
Figura 9.4. Representación gráfica de α y β del ejemplo 1.
Ejemplo 2:
Supóngase que un grupo de profesionales de la educación ha venido aplicando un método espe-cial para mejorar el nivel educativo de los alumnos del departamento de Piura. Se quiere investi-gar si el porcentaje de alumnos con promedio mayor de 15 es superior en Piura que en el resto del país. Para esto, se toman dos muestras: la primera, de 200 alumnos del resto del país, donde se encuentran 38 alumnos con promedio mayor de 15; la segunda, de 100 alumnos de Piura, donde se encuentran 23 alumnos con promedio mayor de 15. ¿Se podrá afirmar que dicho por-centaje es mayor en Piura, con α = 0,05?

Contrastes de hipótesis
123
Nótese que no se sabe cuáles son esas proporciones en las dos poblaciones consideradas en esta investigación; pero se sabe que si en ambos casos np y nq > 5, la diferencia de las proporciones se distribuye normalmente alrededor de la diferencia de las proporciones de las poblaciones, con una desviación estándar que se puede estimar gracias a que las muestras tomadas son grandes.
Sean px y py las proporciones de alumnos con promedio mayor de 15 en Piura y el resto del país, respectivamente.
Sean además:
Para Piura: Nx = 100 Para el resto del país: Ny = 200 p1 = 23/100 = 0,23 p2 = 38/200 = 0,19
Conviene asumir, como hipótesis nula, que las proporciones px y py son iguales. La hipótesis que motiva la investigación es que px > py. Por lo tanto, las hipótesis son:
H0: px – py = 0 H1: px – py > 0
En primer lugar se deben definir las regiones de aceptación y rechazo, considerando que esta úl-tima estará en la cola derecha. El límite entre ambas regiones (p1 – p2)* se determina de la si-guiente manera:
2007967,02033,0
1007967,02033,0
0075,00*)(645,1 21
×+
×
−−−=
pp
donde: px = py ≅ 2033,02001003823
=++
=++
yx NNyx ; qx = qy = 1 – px ; f.c. = 0075,0
)200)(100(2200100
=+
(p1 – p2)* = 0,089
La diferencia (p1 – p2) encontrada en las muestras es: 0,23 – 0,19 = 0,04 < 0,089. Por lo tanto se acepta la hipótesis nula (ver figura 9.5), es decir, no se puede afirmar que el porcentaje de alum-nos con promedio mayor de 15 es mayor en Piura que en el resto del país.
-0.20 -0.15 -0.10 -0.05 0.00 0.05 0.10 0.15 0.20
Región de rechazoRegión de aceptación (p 1 - p 2)*= 0,089
Figura 9.5. Regiones de aceptación y rechazo para el contraste de hipótesis
de cola derecha de una diferencia de dos proporciones (ejemplo 2).

124 Contrastes de hipótesis
9.6. Contrastes de hipótesis sobre medias muestrales Ejemplo 3:
El encargado de un taller ha estimado que el promedio del número de piezas producidas sema-nalmente por cada uno de los trabajadores es de 55. Se quiere saber si una modificación en el proceso productivo que se ha aplicado recientemente ha aumentado el nivel de producción. Para esto se toma una muestra de 60 trabajadores y se obtiene un promedio de 58 piezas producidas en una semana y una desviación estándar igual a 9. ¿Indica este resultado que el promedio de piezas producidas semanalmente por cada trabajador ha aumentado, es decir, es superior a 55? Considere α = 0,05.
Teniendo en cuenta el motivo de la investigación, se plantean las siguientes hipótesis:
H0 : µ = 55 H1 : µ > 55
Para definir las regiones de aceptación y rechazo se determina el valor x * que las limita:
1,645 = 60/955*−x ⇒ x * = 56,91
En la figura 9.6 se muestran las regiones de aceptación y rechazo para este problema. El prome-dio encontrado en la muestra está en la región de rechazo (58 > 56,91); por lo tanto se rechaza la hipótesis nula, es decir, se acepta la afirmación de que el promedio de piezas producidas sema-nalmente por cada trabajador es mayor de 55, como consecuencia de la modificación efectuada en el proceso.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
50 51 52 53 54 55 56 57 58 59
56,91
Región de rechazoRegión de aceptación
Figura 9.6. Regiones de aceptación y rechazo para el contraste de hipótesis de cola derecha
de una media muestral (ejemplo 3)
Ejemplo 4:
Respecto al problema anterior, ¿se hubiese llegado a la misma conclusión si la muestra extraída hubiese sido mucho más pequeña y se hubiese obtenido el mismo promedio de 58 y la misma desviación estándar igual a 9, con una muestra de 26 trabajadores? Se asume que el número de piezas producidas semanalmente por cada trabajador sigue una distribución normal.
Como la muestra es pequeña y no se conoce la desviación estándar de la población, ésta no se
x * =

Contrastes de hipótesis
125
puede estimar. Se recurre entonces a la distribución t de Student para determinar el valor x * que limita las regiones de aceptación y de rechazo.
Se plantean las mismas hipótesis del ejemplo anterior:
H0 : µ = 55 H1 : µ > 55 Además:
n = 26 nl = n – 1 = 25 (grados de libertad)
t* = 1,7081 = 126/9
55*−
−x ⇒ x * = 58,075
El promedio encontrado en la muestra está en la región de aceptación (58 < 58,075); por lo tanto se acepta la hipótesis nula, es decir, se rechaza la afirmación de que el promedio de piezas pro-ducidas semanalmente por cada trabajador es mayor de 55, como consecuencia de la modifica-ción efectuada.
Ejemplo 5:
Supóngase que, aunque no se conoce el promedio de las puntuaciones que obtienen los alumnos del cuarto año de secundaria de los departamentos de Piura y Lambayeque en una prueba de ap-titud académica, se cree que es el mismo. Sin embargo, algunos profesores sospechan que estos promedios son diferentes. Se investiga si son diferentes, y para esto se toma una muestra de 80 alumnos de Lambayeque, encontrándose un promedio de 57 puntos y 10 puntos de desviación estándar. En Piura se extrae una muestra de 70 alumnos, encontrándose un promedio de 54 pun-tos y 9 puntos de desviación estándar. Con base en estos resultados, ¿se podrá afirmar que los promedios son diferentes?
Sean:
µ x : la media de las puntuaciones en Lambayeque. µ y : la media de las puntuaciones en Piura. n x : el tamaño de la muestra de Lambayeque. ny : el tamaño de la muestra de Piura. x : la media de las puntuaciones obtenidas en la muestra de Lambayeque. y : la media de las puntuaciones obtenidas en la muestra de Piura.
Se plantean las siguientes hipótesis:
H0 : µ x – µ y = 0 H1 : µ x – µ y ≠ 0
A diferencia de los contrastes de hipótesis vistos hasta ahora, en este caso se rechazará la hipóte-sis nula cuando la diferencia de los promedios sea significativa, sin importar cuál es mayor. Se tendrán entonces dos regiones de rechazo: una en cada cola de la distribución normal, como se muestra en la figura 9.7.
En primer lugar, se determinan los valores ( yx − )* que limitan las regiones de aceptación y de rechazo. Téngase en cuenta que el área de cada cola debe ser 0,025.
709
8010
0*)(96,122
+
−−=±
yx
Se ha asumido que las varianzas de las muestras son iguales a las varianzas poblacionales, debi-do a que las muestras son suficientemente grandes (nx > 50; ny > 50).

126 Contrastes de hipótesis
-7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7
Región de rechazoRegión de rechazo Región de aceptación
α/2 = 0,025 α/2 = 0,025
-3,041 3,041
Figura 9.7. Regiones de aceptación y rechazo para el contraste de hipótesis de dos colas de una diferencia de medias (ejemplo 5)
Resolviendo:
( yx − )* = ± 3,041
La diferencia yx − encontrada en las muestras es 3; valor que cae en la región de aceptación. Por lo tanto se acepta que los promedios en ambos departamentos es el mismo. La diferencia en-contrada no es “significativa”.
Ejemplo 6:
Supóngase que, en el ejemplo 5, las muestras que se extraen de Lambayeque y Piura son peque-ñas, de tamaños 17 y 12, respectivamente, y que las medias y desviaciones estándar encontradas son las mismas. Con base en estos resultados, ¿se podrá afirmar que los promedios son diferen-tes?
En primer lugar, se asume que las puntuaciones obtenidas en Lambayeque y Piura se distribuyen normalmente, y que las desviaciones estándar de dichas puntuaciones en ambas poblaciones son iguales. (Más adelante se podrá aplicar la Prueba F para corroborar si son iguales).
Se plantean nuevamente las siguientes hipótesis:
H0 : µ x – µ y = 0 H1 : µ x – µ y ≠ 0 Las regiones de aceptación y rechazo son las mismas que las del ejemplo 5 (figura 9.7); pero con
otros límites.
Se determinan los valores ( yx − )* que limitan las regiones de aceptación y rechazo:
t*
+
−+×+×
−−=±=
121
171
212179121017
0*)(0518,222
yx
( yx − )*2 =( yx − )*2 =

Contrastes de hipótesis
127
Como se ve, el número de grados de libertad es: 17 + 12 – 2 = 27
( yx − )* = ± 7,696
La diferencia yx − encontrada en las muestras es 3, que cae en la región de aceptación. Por lo tanto se acepta que los promedios en ambos departamentos es el mismo. La diferencia encontra-da no es “significativa”.
9.7 La distribución F: comparación de varianzas. Se incluye en este capítulo la distribución F, empleada para comparar varianzas, por lo impor-
tante que es verificar si las varianzas de dos universos son iguales.
La función densidad de probabilidad de la variable F es:
( )2/)(
2
112/21
1 1)(nn
n
nFnkFFf
+−−
+=
donde n1 y n2 representan grados de libertad, y k es una constante que depende de n1 y n2.
En la figura 9.8 se representa esta función:
F
f(F)
Figura 9.8. Distribución F
Como hay dos tipos de grados de libertad, resultaría muy trabajoso tabular áreas bajo la función
F tan detalladamente como se hace con las funciones χ2 y t. En el apéndice se muestra una tabla que da los valores de F*, a partir de los cuales el área bajo la función F es 5% ó 1%, para distintas combi-naciones de n1 y n2. A estos valores se les suele denominar Fn1, n2; p (págs. 268-269).
Teorema:
Si se extraen dos muestras de tamaños N1 y N2 del mismo universo, con varianzas s12 y s2
2, el cociente s1
2 / s22 tiene una distribución F con:
n1 = N1 – 1
n2 = N2 – 1, grados de libertad.
Como la distribución F es asimétrica, y las tablas (pág.268; 269) sólo proporcionan áreas en la cola derecha, se suelen plantear las siguientes hipótesis para hacer la comparación de varianzas:
H0 : σ 12 = σ 2
2
H1 : σ 12 > σ 2
2
Así entonces, al extraer las dos muestras, conviene denominarle s12 a la mayor de las varianzas.
Cabe esperarse que el valor F* a partir del cual se rechaza la hipótesis nula, sea menor conforme aumenten los tamaños de las muestras. Así, cuando N1 y N2 tienden a infinito, F* tiende a 1; pues cuando las muestras representen casi la totalidad de sus universos, sólo se debe admitir que las varian-zas de dichos universos son iguales si lo son también las varianzas de las muestras.

128 Contrastes de hipótesis
F
f(F)
F* = 2,29
Región de aceptación Región de rechazo
Ejemplo:
Una máquina está programada para llenar recipientes con 20 onzas de líquido. El jefe de pro-ducción está pensando aumentar la velocidad de llenado; pero teme que la variabilidad aumente significativamente. Para asegurarse, toma una muestra de 16 recipientes llenados a velocidad normal, encontrando una desviación estándar de 0,020 onzas. Luego toma una muestra de 25 re-cipientes llenados a la nueva velocidad, encontrando una desviación estándar de 0,028 onzas. ¿Se podrá afirmar que con la nueva velocidad de llenado la varianza aumenta? Considere un ni-vel de significación del 5%.
Se investiga:
H0: σ 12 = σ 2
2
H1: σ 12 > σ 2
2
Sean: s1 = 0.028; N1 = 25
s2 = 0.020; N2 = 16
Para: n1 = 25 – 1 = 24
n2 = 16 – 1 = 15
Resulta: F* = 2,29
Según las muestras: 96,1)020,0()028,0(
2
2
22
21 ===
ss
F < 2.29.
Se acepta H0 y se concluye que la varianza no ha aumentado.
9.8 Contrastes de hipótesis en Excel
9.8.1 Prueba t para medias de dos muestras suponiendo varianzas iguales.
Ejemplo: En un programa de capacitación industrial algunos aprendices son instruidos con el método A, que consiste en instrucciones mecanizadas, y otros son capacitados con el método B, que entraña también la atención personal de un instructor. Se seleccionaron aleatoriamente aprendices ins-truidos con los dos métodos, encontrándose las siguientes calificaciones (la calificación máxima es 100):
Método A 68 75 69 71 73 66 68 71 71 68 Método B 72 77 79 78 70 68 77 77 72 66
¿Se puede afirmar que el método B es mejor? Considere α = 0,05.
Se trata de una prueba de hipótesis de diferencia de medias, a partir de muestras pequeñas. Co-mo el propósito es investigar si el método B es mejor, se plantea:
H0 : µ B – µ A = 0 H1 : µ B – µ A > 0
Ingresando al menú Herramientas/Análisis de datos/Prueba t para dos muestras suponiendo va-rianzas iguales se abre el cuadro de diálogo que se muestra en la figura 9.9, que en este caso ya tiene ingresados los datos del problema:

Contrastes de hipótesis
129
Figura 9.9. Cuadro de diálogo de Excel de la prueba t para la diferencia de medias
suponiendo varianzas iguales.
Cabe aclarar que los datos del método B fueron ingresados en el rango B1:K1 y los datos del método A fueron ingresados en el rango B2:K2; con lo cual Excel asignó la Variable 1 a las ca-lificaciones del método B y Variable 2 a las calificaciones del método A.
Aceptando los datos ingresados en el cuadro de diálogo, se obtiene el siguiente resultado:
Variable 1 Variable 2 Media 73.6 70 Varianza 21.156 7.333 Observaciones 10 10 Varianza agrupada 14.244 Diferencia hipotética de las medias 0 Grados de libertad 18 Estadístico t 2.133 P(T<=t) una cola 0.023 Valor crítico de t (una cola) 1.734 P(T<=t) dos colas 0.047 Valor crítico de t (dos colas) 2.101
Como se trata de una prueba de cola derecha, la región de rechazo está hacia la derecha del va-lor crítico t*. Por lo tanto se rechaza H0, pues t = 2,133 >1,734 = t*.
Se llega a la misma conclusión, que t está en la región de rechazo, observando que:
P(T <= t) = 0,023 < 0,05 = α
Por lo tanto, se rechaza H0, se acepta H1; o sea que sí se puede afirmar que el método B es mejor que el método A.
9.8.2 Prueba t para medias de dos muestras suponiendo varianzas desiguales. En este caso se procede de la misma forma que en el apartado anterior, ingresando al menú
Herramientas/Análisis de datos/Prueba t para dos muestras suponiendo varianzas desiguales.
Para saber si las varianzas de dos poblaciones son iguales o diferentes, se debe hacer la prueba F, tal como se explicó en el apartado 9.7.

130 Contrastes de hipótesis
9.8.3 Prueba z para medias de dos muestras cuando se conocen la varianzas de las poblaciones
Ejemplo:
Una encuesta de hábitos de consumo de alimentos realizada en Piura y Chiclayo revela los re-sultados que se muestran a continuación. En Piura fueron encuestadas 25 amas de casa y en Chiclayo se entrevistaron 35 amas de casa. Se conocen las desviaciones estándar de ambas po-blaciones: S/.55 para Piura y S/.65 para Chiclayo. ¿Se puede afirmar que el gasto es menor en Piura que en Chiclayo? Considere α = 0,05
364,98 316,11 392,21 443,82 439,91 466,65 270,82 368,29 370,69 386,74 434,75 325,66 345,48 295,47 363,65 361,48 447,13 375,73 361,72 359,79 Piura 287,65 331,11 341,32 274,10 351,60 514,02 370,92 312,07 317,54 316,27 370,06 377,13 263,26 337,49 369,07 479,56 386,97 382,27 310,30 325,19 375,86 449,72 401,05 468,66 471,17 366,80 324,06 367,80 384,09 501,57 250,12 363,10 327,29 452,14 434,47
Chiclayo
316,12 359,47 389,47 407,21 310,85
Se trata de una prueba de hipótesis de diferencia de medias, cuando se conocen las varianzas de las poblaciones. Como el propósito es investigar si el gasto es menor en Piura, se plantea:
H0 : µ P – µ Ch = 0 H1 : µ P – µ Ch < 0
Ingresando al menú Herramientas/Análisis de datos/Prueba z para medias de dos muestras, se abre el cuadro de diálogo que se muestra en la figura 9.10, que ya tiene ingresados los datos del problema. En este caso los datos de la Variable 1 corresponden a Piura y los de la Variable 2 a Chiclayo.
Figura 9.10. Cuadro de diálogo de Excel de la prueba z para la diferencia de
medias cuando se conocen las varianzas de las poblaciones
Aceptando los datos ingresados en el cuadro de diálogo, se obtiene el siguiente resultado.
Como se trata de una prueba de cola izquierda, la región de rechazo está hacia la izquierda del valor crítico z*.

Contrastes de hipótesis
131
Variable 1 Variable 2 Media 363.0744 370.804 Varianza (conocida) 3025 4225 Observaciones 25 35 Diferencia hipotética de las medias 0 z -0.49717 P(Z<=z) una cola 0.3095 Valor crítico de z (una cola) -1.64485 P(Z<=z) dos colas 0.6191 Valor crítico de z (dos colas) 1.95996
Por lo tanto se acepta H0, pues z = –0,49717 > –1,64485 = z*. Se llega a la misma conclusión, que z está en la región de aceptación, observando que:
P(Z <= z) = 0,3095 > 0,05 = α
O sea que no se puede afirmar que el gasto por consumo de alimentos en Piura es menor que en Chiclayo.
9.8.4 Prueba de una media cuando se conoce o no la varianza de la población Excel permite hacer pruebas de hipótesis respecto a una media, cuando se conoce la varianza de
la población y cuando se desconoce. En el segundo caso considera la desviación estándar de la mues-tra, como se expresa en el cuadro de diálogo de Excel que se muestra en la figura 9.11.
La función de Excel que se emplea es PRUEBA.Z; aunque cuando la muestra que se emplea es pequeña, se trate realmente de una prueba t.
Para ambos casos, Excel sólo considera una prueba de dos colas; sin embargo, se puede emplear esta función para pruebas de una sola cola, comparando el valor de P que da Excel (que representa el área que hay desde la media de la muestra hasta ∞), con el valor de α. Si P es menor que α, la media de la muestra está en la región de rechazo, pues α contendría a P.
En el siguiente ejemplo se hace un contraste o prueba de hipótesis de una media, de una cola, cuando se conoce la varianza de la población.
Ejemplo:
El dueño de un restaurante ha muestreado 20 clientes para averiguar si el consumo promedio por cliente es de más de S/.31, encontrando los siguientes consumos:
33,85 28,47 36,84 42,52 42,09 45,03 23,49 34,21 41,52 29,52 31,70 26,20 25,34 30,12 31,25 23,85 32,38 33,28 36,24 33,49
Si se sabe que los consumos de los clientes de este restaurante están distribuidos normalmente con una desviación estándar igual a 6,4 ¿se podrá afirmar que el consumo promedio por cliente es de más de S/.31? Considere α = 0,05
Como el propósito es investigar si el consumo promedio de los clientes del restaurante es mayor que S/. 31, se plantea:
H0 : µ = 31 H1 : µ > 31
Insertando la función PRUEBA.Z, Excel muestra el cuadro de diálogo que se muestra en la figu-ra 9.11. Nótese que en este cuadro ya se han ingresado los datos del problema, incluyendo la desviación estándar (sigma) de la población.
Haciendo clic en Aceptar, Excel devuelve el valor P = 0,07 > 0,05. Por lo tanto se rechaza H0, se acepta H1; o sea que el consumo promedio por cliente es de más de S/.31.

132 Contrastes de hipótesis
Figura 9.11. Cuadro de diálogo de Excel de la prueba z de una media
9.8.5 Comparación de varianzas Con Excel se puede realizar la prueba de comparación de varianzas utilizando la herramienta es-
tadística Prueba F para varianzas de dos muestras que se encuentra en el menú Herramientas/Análisis de datos. A continuación se resuelve un problema.
Ejemplo:
Una empresa de servicios encuesta semanalmente a sus clientes para medir y controlar su nivel de satisfacción. En una de las preguntas de la encuesta los clientes deben puntuar entre 1 y 5 la profesionalidad de los empleados que los acaban de atender. Suponga que en las últimas 16 se-manas la empresa obtuvo los siguientes promedios de la profesionalidad de sus empleados, de las encuestas hechas en las oficinas de Piura y Chiclayo:
Piura 3,37 2,98 3,59 4,01 3,97 4,19 2,62 3,40 3,93 3,06 3,22 2,82 2,76 3,10 3,19 2,65Chiclayo 2,53 3,76 3,29 2,80 2,62 3,61 2,88 3,15 2,92 2,97 3,00 2,81 3,64 2,50 3,15 3,15
¿Se puede afirmar que la variabilidad es mayor en Piura, y que por lo tanto los empleados de Piura son menos homogéneos en cuanto a la profesionalidad? Considere α = 0,05
Se plantean las siguientes hipótesis: H0 : σP
2 = σCh2
H1 : σP2 > σCh
2
Recuérdese que esta prueba es siempre de una sola cola (derecha), debido a que las tablas F sólo están tabuladas para calcular áreas en la cola derecha de la función F.
Ingresando al menú Herramientas/Análisis de datos/Prueba F para varianzas de dos muestras, se abre el cuadro de diálogo que se muestra en la figura 9.12, que ya tiene ingresados los datos del problema. En este caso los datos de la Variable 1 corresponden a Piura y los datos de la Va-riable 2 a Chiclayo.

Contrastes de hipótesis
133
Figura 9.12. Cuadro de diálogo de la prueba de comparación de varianzas
Aceptando los datos ingresados en el cuadro de diálogo, se obtiene el siguiente resultado.
Variable 1 Variable 2 Media 3.30375 3.04875 Varianza 0.257745 0.14573167 Observaciones 16 16 Grados de libertad 15 15 F 1.76862727 P(F<=f) una cola 0.14032574 Valor crítico para F (una cola) 2.40344633
Por lo tanto se acepta H0, pues F = 1,7686 < 2,4034 = F*. Se llega a la misma conclusión, que F está en la región de aceptación, observando que:
P(F <= f) = 0,1403 > 0,05 = α
O sea que no se puede afirmar que la variabilidad es mayor en Piura, es decir, que los emplea-dos de Piura son menos homogéneos en cuanto a la profesionalidad.

134 Contrastes de hipótesis
Problemas propuestos 1. En una fábrica que produce artículos en serie, el 75% son, en promedio, de óptima calidad. El jefe
de producción cree que con cierto cambio en el proceso, conseguirá aumentar dicho porcentaje en forma considerable. Para asegurarse, un día efectúa dicho cambio, pone el proceso en marcha y toma una muestra de 20 artículos, encontrando que 18 son de óptima calidad. Considerando α = 10%:
a) ¿Afirmaría usted que ese cambio hará aumentar el porcentaje de artículos de óptima calidad? Respuesta: Sí afirmaría que aumenta el % de artículos de óptima calidad. b) ¿Estaría usted completamente seguro de la respuesta que ha dado en el apartado anterior?
¿Cuál es la probabilidad de que usted esté equivocado? Respuesta: No estaría tan seguro; hay una probabilidad del 9,13% de estar equivocado. c) Suponga que el cambio efectuado sí da los resultados que esperaba el jefe de producción, pero
existe una probabilidad de 7,55% de no descubrirlo. ¿A cuánto ha aumentado el porcentaje de artículos de óptima calidad?
2. Un profesor de Estadística tiene una moneda deformada. Después de experimentar con ella, ha lle-gado a la conclusión de que si la lanza muchas veces, obtendrá el triple número de caras que de se-llos. Un grupo de alumnos cree que el profesor está equivocado, pero no están seguros si tienden a salir más caras o sellos. Otro grupo también cree que el profesor está equivocado, pero no de tal modo, pues opinan que deben salir aún más caras que sellos.
a) Determine qué regiones de aceptación y rechazo debe plantear cada grupo de alumnos, si de-ciden lanzar dicha moneda 20 veces, considerando un α = 10%.
b) Determine, para cada grupo de alumnos, para qué valores de p, β es menor del 30%.
3. El 80% de los pacientes que reciben cierto tratamiento reaccionan favorablemente. De un grupo de 15 pacientes de un hospital, 8 reaccionaron favorablemente.
a) ¿Podría aceptarse la hipótesis de que los pacientes de este hospital reaccionan menos favora-blemente a este tratamiento? Sea α = 0,05.
Respuesta: Se acepta que los pacientes de este hospital reaccionan menos favorablemente al tratamiento.
b) ¿Cuál es realmente la probabilidad de cometer el error tipo I? Respuesta: αreal = 0,0181 c) Si realmente se recuperan el 70% de los pacientes del hospital, ¿cuál es la probabilidad de
aceptar la hipótesis inicial? Repuesta: β = 0,8689
4. En una compañía que produce ciertos artículos se afirma que, en promedio, el 5% son defectuosos. El jefe de producción quiere investigar si dicho porcentaje es mayor, tomando primeramente una muestra de doce artículos. Si en la muestra se encuentran más de dos artículos defectuosos, no aceptará la afirmación inicial. En caso contrario, tomará otra muestra de doce artículos y, si el nú-mero de artículos defectuosos es 2 como máximo, aceptará la afirmación inicial.
a) Determine el valor de α Respuesta: α = 0,0388 b) Si el porcentaje de artículos defectuosos es realmente 10, ¿cuál es la probabilidad de cometer
el error tipo II? Respuesta: β = 0,7905
5. El profesor de Estadística ha informado a la Dirección de Estudios que el porcentaje de alumnos de la Universidad que llega tarde a clases es 20%. El director de estudios inició un plan de aseso-ramiento personal con el propósito de reducir ese porcentaje. Un alumno de Estadística quiere comprobar si dicho plan ha dado buenos resultados y muestrea aleatoriamente 20 alumnos, encon-trando que cinco de éstos llegaron tarde. Si considera α = 0,05, ¿a qué conclusión llegará?

Contrastes de hipótesis
135
6. Un candidato a la alcaldía afirma que por lo menos el 55% de los ciudadanos votarán por él. Se hizo una encuesta a 20 votantes para investigar su afirmación y sólo 8 dijeron que votarían por él. Sea α = 0,05.
a) ¿Se aceptará la afirmación del candidato? Respuesta: Sí se acepta b) Si en las elecciones, el mencionado candidato obtiene el 40% de los votos, ¿Cuál es la proba-
bilidad de que hayamos aceptado su afirmación? Respuesta: 0,75
7. Un peluquero afirma que por lo menos el 80% de sus clientes seguirán acudiendo a su peluquería, a pesar de un fuerte incremento que está haciendo en su tarifa. Su ayudante no está muy seguro de ello y consulta con 15 de sus clientes, tomados aleatoriamente, resultando que 11 de ellos piensan seguir acudiendo a su peluquería. Considerando α = 5%, ¿qué opina sobre la afirmación del pelu-quero?
8. Se sabe que la proporción de artículos defectuosos en un proceso de producción es de 0,15. Con el objeto de mejorar la producción, se hizo una modificación en una de las máquinas y se contrató más personal. Estas acciones dieron origen a una discusión entre dos Ingenieros de Planta. A pen-saba que la proporción de artículos defectuosos había disminuido y B por el contrario sostenía que había aumentado. Tomando una muestra de 20 artículos en un día de producción, y considerando α = 0,10:
a) Determine las regiones de aceptación y rechazo para A y B. b) Si realmente la proporción de defectuosos bajó a 0,10. ¿Quién puede cometer el error tipo II?
¿Cuál es la probabilidad de que lo cometa?
9. El jefe del centro de cómputo de un banco afirma que la probabilidad de que las digitadoras pulsen la tecla de un carácter incorrectamente, es igual a 0,001. Si en un documento de 10,000 caracteres se pulsaron erróneamente 15 teclas, ¿concluiría que dicha probabilidad es realmente mayor que 0,001? Considere α = 0,10.
10. Se ha estimado que no más del 2% de los alumnos de la UDEP provienen de Morropón. Si de una muestra de 400 alumnos, 15 son de Morropón, ¿que diría de esa estimación? Considere α = 0,10.
11. El departamento médico desea actualizar su información con respecto a los alumnos que fuman. Con base a estudios previos se cree que la proporción es del 58%. El departamento lleva a cabo una encuesta tomando una muestra aleatoria de 600 alumnos, a los cuales se les pregunta si fuman. De los 600, 367 son fumadores. ¿Afirmaría usted, tomando este resultado, que el porcentaje de alumnos que fuman ha aumentado? Considere α = 0,10.
12. Un fabricante afirma que en general el 8% de las piezas que produce son defectuosas. Un ingenie-ro industrial propone un control de calidad y afirma que así reducirá considerablemente el porcen-taje de defectuosos. El fabricante quiere comprobarlo, y escoge aleatoriamente 100 piezas, una vez que se está aplicando el control de calidad, encontrando 5 defectuosas. Con α = 0,05:
a) ¿Aceptaría la afirmación del Ingeniero? b) Si con este control de calidad, el fabricante escoge 100 piezas diarias durante 50 días, encon-
trando que sólo en ocho días se verifica su hipótesis. ¿Cuál es aproximadamente el verdadero porcentaje de piezas defectuosas?
13. En un grupo de 20 cartas están incluidos los cuatro ases. En 80 extracciones son sustitución se ob-tienen 21 ases.
a) ¿Se puede considerar este resultado fuera de lo usual? Sea α = 0,05 b) ¿Cuál es el mínimo número de ases que debo obtener para considerar el resultado como usual?
Sea α = 0,05
14. Uno de los dos candidatos a la presidencia del Club Grau afirma que al menos el 45% de los so-cios votarán por él. Si se hace una encuesta a una muestra aleatoria de 200 socios (α = 0,05)

136 Contrastes de hipótesis
a) ¿Cuántos socios del total de encuestados tendrán que afirmar que votarán por él para que se acepte su afirmación?
Respuesta: Por lo menos, 78 socios deberán afirmar que votarán por él, para que se acepte su hipótesis.
b) Si luego de las elecciones se determina que se equivocó, y que la probabilidad de aceptar su afirmación era 0,84, ¿qué porcentaje de votos obtuvo?
Respuesta: Obtuvo aproximadamente el 42% de los votos.
15. Se sabe que la proporción de artículos defectuosos en un proceso de manufactura es de 0,15. El proceso se vigila en forma periódica, tomando muestras aleatorias de tamaño 40 e inspeccionando las unidades, con el propósito de detectar un aumento de dicha proporción; en cuyo caso se detiene el proceso y se considera como "fuera de control". Si se desea que en menos del 5% de las inspec-ciones se declare que el proceso está "fuera de control", cuando realmente la proporción de artícu-los defectuosos no ha aumentado:
a) Enunciar las hipótesis nula y alternativa apropiadas. b) Determine las regiones de aceptación y rechazo. c) Suponiendo que la proporción de artículos defectuosos es 0,20, ¿en qué porcentaje de inspec-
ciones se declarará que el proceso está fuera de control? ¿Y si dicha proporción es 0,30?
16. El 5% de los productos de una fábrica son defectuosos. Se hizo una modificación del proceso de producción y se investigó una posible mejoría mediante una muestra de 120 unidades, encontrán-dose 3 defectuosas. Sea α = 0,05 ¿Podría decirse que la modificación redujo el porcentaje defec-tuoso?
Respuesta: No se redujo el porcentaje defectuoso.
17. Hay 2 candidatos a la Alcaldía para las próximas elecciones en la ciudad de Piura. Según el candi-dato A, alcanzará como mínimo el 65% de los votos. Si en las encuestas el candidato A obtiene el 56% de los votos. ¿De qué tamaño fue la muestra si los resultados fueron aceptables, a un nivel del 5%?
18. En una prueba de Estadística tomada a un grupo de 70 alumnos, 52 alumnos contestaron correcta-mente la primera pregunta y 57 alumnos contestaron correctamente la segunda pregunta. ¿Se po-drá afirmar que la segunda pregunta es más fácil? Sea α = 0,10.
19. Un fabricante afirma que las llantas que produce tienen una duración media de 50 000 Km., con una desviación estándar de 7 300 Km. Una organización de protección al consumidor selecciona una muestra de 100 de estas llantas, encontrando una duración promedio de 47 000 Km. ¿Debe dudar dicho organismo de la aseveración del fabricante? Sea α = 0,10.
20. Se ha asegurado que el peso promedio de las alumnas de la UDEP es de 54,4 Kg. Uno de los pro-fesores no cree que tal aseveración sea correcta y reúne una muestra aleatoria de 100 pesos. De ello resulta una media de 53,75 Kg. y una desviación estándar de 5,4 Kg. ¿Es esta evidencia sufi-ciente para rechazar la afirmación inicial? Sea α = 0,10.
Respuesta: No es suficiente para rechazar la afirmación inicial.
21. Suponga que las calificaciones en matemáticas de los alumnos de dos escuelas siguen distribucio-nes normales. Para investigar si tales calificaciones son significativamente mayores en una de las escuelas, se toman muestras aleatorias de 40 alumnos en ambas, encontrándose un promedio de 80 puntos y una desviación estándar de 9,5 puntos para la primera escuela, y un promedio de 75 pun-tos con una desviación estándar de 7 puntos para la segunda escuela. Considere un nivel de signi-ficancia del 5%:
a) ¿Se podrá aceptar que en una escuela se obtienen mayores calificaciones que en la otra? Respuesta: Sí se acepta. b) ¿A partir de qué valor de la diferencia entre las calificaciones de las dos muestras, se podrá
aceptar que en una escuela se obtienen mayores calificaciones que en la otra? Respuesta: A partir de 3,15.

Contrastes de hipótesis
137
22. Un laboratorista piensa modificar el proceso para producir cal viva a partir de la caliza. Hará la modificación sólo si la cal viva promedio que se obtiene por este nuevo proceso aumenta su valor con respecto al proceso actual. Con base en un experimento de laboratorio y mediante el empleo de dos muestras aleatorias de tamaño 11, una para cada proceso, se obtuvo lo siguiente: la cantidad del cal viva promedio del proceso actual fue de 24,5 con una desviación estándar de 2,2, y para el proceso propuesto fue de 28,1 con una desviación estándar de 2,6. ¿Cree usted que debe adoptarse el nuevo proceso? Haga las consideraciones y pruebas necesarias para contestar esta interrogante.
Respuesta: Debe aceptarse el nuevo proceso.
23. Se espera que dos operadores produzcan, en promedio, el mismo número de unidades terminadas en el mismo tiempo. A continuación se muestra la cantidad de unidades terminadas para ambos trabajadores, en una semana de trabajo. Considere un nivel de significancia (α) del 5%.
Operador 1 12 11 18 16 13 Operador 2 15 18 17 16 17
a) ¿Se puede discernir alguna diferencia entre los operadores? Respuesta: No hay diferencia. b) Si cree necesario, diga qué condiciones deben cumplir las variables aleatorias en estudio. Diga
además qué representan esas variables. Respuesta: σx debe ser igual a σy. X e Y representan el número de unidades terminadas por los
operadores 1 y 2 respectivamente; deben tener distribución normal. c) Si realmente hay una diferencia de una unidad entre los promedios mencionados, ¿cuál sería la
probabilidad de cometer el error tipo II? ¿En que consistiría este error? Respuesta: Aproximadamente 0,93.
24. Una compañía adquirió mil pistones de un nuevo proveedor que, aunque dando un precio más bajo que el productor anterior, garantiza la misma calidad. Al llegar el embarque, la compañía selec-cionó una muestra de 30 artículos, encontrando que el diámetro promedio es de 7,504 cm. con una desviación estándar 0,018 cm. Las especificaciones requieren que no se sobrepase un diámetro promedio de 7,500 cm. Suponiendo que se acepta un riesgo del 10% de una acusación falsa, ¿con-sideraría usted que el proveedor está cumpliendo con el acuerdo? Considere un nivel de signifi-cancia del 5%
Respuesta: El proveedor sí está cumpliendo con el acuerdo.
25. Supóngase que en una línea aérea se desea determinar si el peso promedio del equipaje que llevan los pasajeros que van de Piura a Lima es de más de 15 Kg. Se selecciona aleatoriamente una muestra de 40 pasajeros y se pesa su equipaje, encontrando una media de 16 Kg. Supóngase que se sabe que la desviación estándar de los pesos es de 2,8 Kg. ¿Debería llegarse a la conclusión de que el peso promedio del equipaje es de más de 15 Kg?
Respuesta: Sí, el peso promedio es mayor que 15.
25. El gerente de una refinería piensa modificar el proceso para producir gasolina a partir del petróleo crudo; pero hará la modificación sólo si la gasolina promedio que se obtenga por este nuevo pro-ceso (expresada como porcentaje del crudo) aumenta su valor con respecto al proceso en uso. Con base en un experimento de laboratorio y mediante el empleo de dos muestras aleatorias de tamaño 25 para cada proceso, la cantidad de gasolina promedio del proceso en uso fue de 26,34 con una desviación estándar de 2,4, y para el proceso propuesto fue de 28,8 con una desviación estándar de 2,9. El gerente piensa que los resultados proporcionados por los dos procesos son variables aleato-rias independientes normalmente distribuidas. Considere α = 0,05.
a) ¿Se podrá afirmar que las varianzas de los dos procesos son iguales? b) ¿Debe adoptarse el nuevo proceso?
26. Una organización va a probar la distancia de frenado, a una velocidad de 80 Km/h, de dos marcas distintas de automóviles. Para la primera marca se seleccionaron 10 automóviles y se probaron en un medio controlado, obteniendo las siguientes distancias (en metros): 50,8; 53,5; 48,5; 49,6; 51,1;

138 Contrastes de hipótesis
52,3; 52,7; 50,5; 57,1; 48,8. Para la segunda marca se seleccionaron 8 automóviles y se obtuvo: 40,5; 45,9; 50,1; 47,4; 46,2; 49,0; 43,3; 41,6. Con base en esta evidencia, ¿existe alguna razón para afirmar que los autos de la segunda marca tienen un mejor frenado? Considere α = 0,05.
27. Un comerciante piensa comprar a un productor una gran cantidad de material para soldar. Éste asegura al comerciante que la tensión de ruptura del material que emplea es de 250 lb., con una desviación estándar de 25 lb. El comerciante envía a uno de sus técnicos indicándole que compre el material sólo si una muestra de 64 especimenes da una tensión de ruptura promedio de por lo menos 245 lb. Pero, por error, el productor muestrea 94 especimenes. ¿Qué tensión de ruptura promedio debe tener la muestra, como mínimo, para que el técnico decida comprar el material, cumpliendo con los requerimientos del comerciante?
28. Supongamos que la estatura media de los alumnos de la UDEP es 1.70m. Un alumno que quiere investigar esto, toma una muestra aleatoria de 10 de sus compañeros, midiéndoles: 1,66; 1,82; 1,75; 1,58; 1,73; 1,72; 1,64; 1,63; 1,58 y 1,65m. ¿Se puede considerar esta muestra representativa? Considere α = 0.05
Respuesta: Sí es representativa.
29. Se quiere saber si el nivel en el primer ciclo de la Facultad de Ingeniería ha mejorado respecto al semestre pasado. Un alumno toma una muestra de 14 alumnos del primer ciclo del semestre pasa-do y calcula un promedio de notas 10,18 con desviación estándar 1,77. Luego toma una muestra de 17 alumnos del primer ciclo del semestre actual y calcula un promedio 10,77 con desviación es-tándar 2,07. Sea α = 0,05. ¿Se podrá afirmar que el nivel ha mejorado?
Respuesta: No se puede afirmar que ha mejorado.
30. Un fabricante requiere fibra de algodón con una resistencia media a la tensión de 6,50 onzas y desviación estándar 0,25 onzas. Investigó un nuevo lote de fibras mediante una muestra de 17 pie-zas y encontró una resistencia media de 6,35 onzas. Suponga que la desviación estándar no ha cambiado. ¿Se puede afirmar que la resistencia media a este lote no se ajusta a sus requerimientos? Sea α = 0,05.
31. La experiencia indica que la resistencia a la rotura del alambre comprado a cierta compañía está distribuida normalmente con una resistencia media de 100 Kg. y una desviación estándar de 5 Kg. Un comprador emplea estos alambres colocando 8 en paralelo, con el propósito de aumentar la re-sistencia a la rotura a 800 Kg. Si se toma una conexión de estos alambres y resiste 755 Kg. ¿Diría usted que los alambres de esta compañía no soportan 100 Kg? Sea α = 0,05.
32. Una muestra de 100 familias encuestadas en Lima revela que 10 familias consumen jugo de frutas envasado. ¿Con qué nivel de significancia (α) se podrá afirmar que el porcentaje de familias de Lima que consumen jugo de frutas envasado es de menos del 15%?
33. La SUNAT estima que el 25% de todas las devoluciones de impuestos contienen errores aritméti-cos. Se toma una muestra aleatoria de 20 devoluciones. Sea α = 0,10.
a) ¿Cuántas de estas devoluciones tendrían que contener errores para poder afirmar que el porcentaje de las devoluciones de impuestos que contienen errores aritméticos es mayor del 25%?
b) ¿Cuántas de estas devoluciones tendrían que contener errores aritméticos para poder afirmar que el porcentaje de las devoluciones de impuestos que contienen errores aritméticos es menor del 25%?
34. Se afirma que la media poblacional en madurez lectora en los colegios de Piura es menor que 10 (Test ABC de Filho). Se aplica este test a una muestra de 36 niños y se obtienen los resultados que se muestran. ¿Qué opina de la afirmación inicial?
18 17 7 12 15 6 7 10 9 4 2 7 20 9 10 13 11 2 16 8 3 9 4 2 19 14 15 9 8 11 10 13 10 4 10 3

La distribución ji-cuadrada 139
Capítulo 10. La distribución ji-cuadrada (χ2)
10.1 Introducción. La distribución ji-cuadrada (χ2) se usa con mucha frecuencia en investigaciones estadísticas; y
es, después de la distribución normal, la más empleada.
La más importante aplicación de esta distribución es la prueba de bondad de ajuste, donde se in-vestiga si una determinada distribución de frecuencias se ajusta a una distribución de frecuencias teó-rica, analizando qué tanto difieren las frecuencias observadas y las frecuencias esperadas, las cuales son calculadas a partir de la distribución teórica.
Otra aplicación es la prueba de independencia, donde se investiga si dos variables cualitativas son independientes.
Además, se emplea en pruebas de hipótesis respecto a la varianza de una población.
10.2 La función densidad de probabilidad ji-cuadrada. La función densidad de probabilidad ji-cuadrada es la siguiente:
1)2/(22 )(2 −−= neky χχ
donde: n = número de grados de libertad (se explica más adelante) k = constante que depende de n
Dado que n es el único parámetro de esta función, su valor determina la forma de ésta. En la fi-gura 10.1 se muestran algunas curvas de la función ji-cuadrado, donde se aprecia que la asimetría dis-minuye conforme aumenta n.
0
0.1
0.2
0.3
0.4
0.5
0.6
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
n =1
n =2
n =4n =6
n =8
Figura 10.1. Curvas ji-cuadrado para distintos grados de libertad

140 La distribución ji-cuadrada
Para valores grandes de n, χ2 tiene una distribución aproximadamente normal.
La media y la varianza de la función χ2 son:
µ = n σ 2 = 2n
verificándose lo dicho anteriormente, que la función χ2 queda determinada con n.
Por tratarse de una función densidad de probabilidad, el área bajo la curva χ2 es igual a 1, y, por-ciones de esta área representan probabilidades.
Existen tablas que permiten determinar áreas bajo esta función, como la que se muestra en el apéndice (pág. 267). Esta tabla no puede ser tan detallada como la que determina áreas bajo la curva normal estandarizada; pues para ello se tendría que tabular cada curva χ2 que corresponde a cada valor posible de n. La tabla muestra los valores de χ2 correspondientes a determinadas áreas (las más em-pleadas) de la cola derecha de la curva.
Para n > 30, la curva χ2 se aproxima mucho a una curva normal, y, como sugiere E. Mode, resul-ta muy buena aproximación emplear la siguiente expresión:
122 2 −−= nz χ y usar la tabla de áreas bajo la curva normal.
10.3 Pruebas de bondad de ajuste. Una prueba de bondad de ajuste es una prueba de hipótesis donde se investiga si una variable
aleatoria tiene una distribución dada. Las hipótesis nula y alternativa que se plantean son las siguien-tes:
H0: X tiene una distribución ... (se especifica cuál). H1: X no tiene dicha distribución.
Para llevar a cabo esta prueba, se toma una muestra y se elabora una tabla de distribución de fre-cuencias. Estas frecuencias observadas (fi) se comparan con las frecuencias esperadas o teóricas (fi) que se obtienen a partir de la distribución teórica especificada en la hipótesis nula. Si la muestra, de tamaño n, tiene m frecuencias, se puede demostrar que la siguiente suma:
( )∑=
−m
i i
ii
fff
1
2
''
tiene aproximadamente una distribución χ2, con m – 1 grados de libertad, siempre que ninguna frecuencia esperada sea menor de 5.
Esto se puede comprobar de la siguiente manera: se toma una muestra de tamaño n y se calcula χ2
1, luego otra muestra de tamaño n y se calcula χ22, y así sucesivamente hasta tener la suficiente can-
tidad de valores para construir un histograma. Así, se podrá ver que el polígono de frecuencias corres-pondiente se parece mucho a la curva χ2 con m – 1 grados de libertad.
Se puede apreciar que aquella sumatoria, que se denomina χ2, da una medida de la discrepancia que hay entre las frecuencias observadas y las frecuencias esperadas; por lo que valores grandes de χ2 nos harán rechazar la hipótesis nula. Dependiendo del valor de α, se puede determinar el valor de χ2 que limita las regiones de aceptación y rechazo, lo que permitirá decidir finalmente si se acepta o re-chaza la hipótesis nula.
Para que la prueba χ2 sea confiable, es recomendable que ninguna frecuencia esperada resulte menor que 5. Esto se consigue agrupando clases vecinas o aumentando el tamaño de la muestra. Es re-comendable también que m sea un valor comprendido entre 5 y 20.
El número de grados de libertad refleja el hecho de que, en una muestra de tamaño n, tabulada con m frecuencias, existe libertad para asignar valores a m – 1 de ellas; una vez fijadas éstas, la restan-te queda determinada por la ecuación:

La distribución ji-cuadrada 141
∑=
=m
ii nf
1
Cabe señalar que, por cada medida descriptiva muestral que se emplee para estimar algún pará-metro de la población, ya sea µ o σ , se pierde un grado de libertad.
10.3.1 Distribución multinomial. A continuación se muestra un caso de prueba de bondad de ajuste de una determinada distribu-
ción multinomial. Aunque es recomendable que el número de frecuencias sea mayor que 5 y menor que 15, la prueba es confiable si todas las frecuencias teóricas resultan mucho mayores de 5, como se dijo antes.
Ejemplo:
Luego de una investigación se determinó que, aproximadamente el 50% de todos los vehículos que llegan por la avenida Loreto hacia la avenida Sánchez Cerro, hacia el norte, giran hacia la izquierda; el 20% giran a la derecha y el 30% restante siguen hacia el frente. Para verificar esto, un estudiante de Estadística fue a dicha intersección y observó que, de 80 autos, 47 giraron ha-cia la izquierda, 15 hacia la derecha y 18 siguieron de frente. ¿Son aceptables los porcentajes es-tablecidos, considerando un nivel de significancia del 5%?
H0: la cantidad de vehículos que giran en las tres direcciones establecidas siguen una distribu-ción multinomial con probabilidades 0,50; 0,20 y 0,30.
H1: no siguen dicha distribución.
Según las probabilidades establecidas, y considerando que cada frecuencia esperada es: f ’i = npi, se puede construir la siguiente tabla:
Izquierda Derecha Frente p 0,50 0,20 0,30 f 47 15 18 f ' 40 16 24
Entonces:
7875,224
)2418(16
)1615(40
)4047( 2222 =
−+
−+
−=χ
Para: α = 0,05; n = 2; el valor crítico de χ2 es: χ2* = 5,991
0
0.1
0.2
0.3
0.4
0.5
0.6
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
Región de rechazoRegión de aceptaciónχ2*=5,991
α = 0,05

142 La distribución ji-cuadrada
El valor de χ2 = 2,7875 se encuentra en la región de aceptación, es decir, se acepta H0.
Se concluye por lo tanto que la cantidad de vehículos que giran en las tres direcciones estableci-das: izquierda, derecha, de frente, siguen una distribución multinomial con probabilidades 0,50; 0,20 y 0,30. Esto equivale a afirmar que los vehículos que siguen tales direcciones están en pro-porción: 0,50; 0,20 y 0,30; o que el 50%, 20% y 30% siguen dichas direcciones.
10.3.2 Distribución de Poisson. A continuación se muestra una prueba de bondad de ajuste donde se investiga si una variable
aleatoria sigue una distribución aproximadamente de Poisson. Para poder realizar esta prueba se debe estimar el parámetro µ a partir de los datos de la muestra, "perdiéndose" de esta manera un grado de libertad.
Ejemplo:
La siguiente tabla muestra la cantidad de fallas diarias que presenta un sistema automático, du-rante 120 días consecutivos.
Fallas diarias 0 1 2 3 4 5 >5 Frecuencia 31 46 19 14 8 2 0
¿Se puede afirmar que la cantidad de fallas diarias de este sistema sigue aproximadamente una distribución de Poisson? Emplee α = 0,05.
H0: la cantidad de fallas diarias sigue una distribución de Poisson. H1: no siguen dicha distribución.
En primer lugar se estima la media de la población:
4,1120
0)5(3)4(8)3(14)2(19)1(46)0(31=
++++++=≈ xµ
Se puede determinar la varianza de la muestra a partir de la tabla de distribución de frecuencias. Este valor resulta: σ 2 = 1,59, que es aproximadamente el valor de la media, como era de espe-rarse en una distribución de Poisson.
Las frecuencias esperadas, para cada x, se calculan entonces de la siguiente manera:
f ' = nP(x)
f ' = !x
enxµµ−
⋅
En la siguiente tabla se presentan los valores de estas frecuencias esperadas o teóricas, junto con las frecuencias observadas.
Fallas diarias 0 1 2 3 4 5 >5 Frecuencia observada 31 46 19 14 8 2 0 Frecuencia esperada 29,59 41,42 29,00 13,54 4,74 1,32 0,39
En este caso, para calcular χ2 conviene agrupar las tres últimas frecuencias, consiguiendo así que todas las frecuencias teóricas sean mayores que 5.
02,645,6
)45,610(54,13
)54,1314(29
)2919(42,41
)42,4146(59,29
)59,2931( 222222 =
−+
−+
−+
−+
−=χ
Considerando que se ha tenido que estimar el parámetro µ de la distribución de Poisson, el nú-mero de grados de libertad es: nl = (m – 1) – 1.
Entonces: nl = 5 – 1 – 1 = 3

La distribución ji-cuadrada 143
El χ*2 será entonces (tabla del apéndice): 7,815.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
χ2*=7,815Región de rechazoRegión de aceptación
α = 0,05
Por lo tanto, el χ2 = 6,02 encontrado nos hace aceptar la hipótesis nula; se concluye que la can-tidad de fallas diarias sí tiene una distribución de Poisson.
10.3.3 Distribución normal. En la prueba de bondad de ajuste de una distribución normal es necesario estimar dos paráme-
tros, σ y µ ; por lo que se "pierden" dos grados de libertad. El siguiente ejemplo ilustra cómo se efec-túa una prueba de este tipo.
Ejemplo:
En un análisis de los diámetros de los pistones de bolas fabricados en un taller, se tomó una muestra de 140 pistones, cuya distribución de frecuencias se muestra en la siguiente tabla.
Límites (cm) Frecuencia 7,20 – 7,24 3 7,25 - 7,29 7 7,30 - 7,34 12 7,35 - 7,39 16 7,40 - 7,44 19 7,45 - 7,49 24 7,50 - 7,54 22 7,55 - 7,59 19 7,60 - 7,64 12 7,65 - 7,69 6
Determine si dichos diámetros se distribuyen normalmente.
H0: los diámetros de los pistones siguen una distribución normal. H1: no siguen dicha distribución.
En el capítulo 6 (pág. 94) se determinó la curva normal que más se aproxima a estos datos, cal-culándose las frecuencias esperadas para cada clase. En la siguiente tabla se muestran las fre-cuencias observadas y las frecuencias esperadas. Nótese que se ha añadido una frecuencia más.
f 3 7 12 16 19 24 22 19 12 6 0 f ' 2,06 5,20 10,47 17,22 23,22 25,34 22,49 16,30 9,65 4,58 1,80
Es necesario agrupar las dos primeras clases y las dos últimas, para conseguir que: f ' > 5. Así entonces:

144 La distribución ji-cuadrada
f 10 12 16 19 24 22 19 12 6 f ' 7,26 10,47 17,22 23,22 25,34 22,49 16,30 9,65 6,38
Por lo tanto:
+−
+−
+−
+−
+−
+−
=49,22
)49,2222(34,25
)34,2524(22,23
)22,2319(22,17
)22,1716(47,10
)47,1012(26,7
)26,710( 2222222χ
464,538,6
)38,66(65,9
)65,912(30,16
)30,1619( 222
=−
+−
+−
+
El número de grados de libertad es: n = 9 – 1 – 2 = 6.
Entonces, para α = 0.05: χ*2 = 12,59 > 5,464.
Por lo tanto se acepta la hipótesis nula; es decir, que los diámetros de los pistones sí se distribu-yen normalmente.
10.4 Pruebas de independencia: tablas de contingencia. En este tipo de pruebas se investiga si existe alguna relación entre dos variables cualitativas, ca-
da una de las cuales se clasifica en atributos.
Ejemplo
Se quiere investigar si existe alguna relación entre el desempeño en el trabajo de los empleados de una empresa y la formación académica de dichos empleados. La primera variable se clasifica en excelente, bueno y regular; y la segunda en primaria, secundaria y superior. Esta clasifica-ción se puede expresar con mucha claridad en una tabla de contingencia, como se ve a conti-nuación.
Formación Desempeño Primaria Secundaria Superior Total Muy bueno 40% Bueno 30% Regular 30% Total 10% 40% 50%
Los registros de esta empresa muestran que, en promedio, el 10%, 40% y 50% de todos los em-pleados de esta fábrica tienen formación primaria, secundaria y superior, respectivamente. Además, el 40%, 30% y 30% tienen rendimiento muy bueno, bueno y regular, respectivamente.
Para realizar la investigación se toma una muestra de 150 empleados, cumpliendo con los por-centajes antes mencionados, obteniéndose el resultado que muestra la siguiente tabla.
Formación Desempeño Primaria Secundaria Superior Total Muy bueno 8 25 27 60 Bueno 3 19 23 45 Regular 4 16 25 45 Total 15 60 75 150
Para determinar si hay alguna relación entre las dos variables se asume que ambas son indepen-dientes, y, bajo esta hipótesis (hipótesis nula), se determinan las frecuencias esperadas. La hipó-tesis alternativa expresa que dichas variables no son independientes.
H0: la formación académica y el desempeño laboral son independientes. H1: no son independientes.

La distribución ji-cuadrada 145
La probabilidad de que un empleado elegido al azar tenga formación académica X y desempeño Y, es:
P(X ∩Y) = P(X) P(Y \ X)
Pero, como se está asumiendo que X e Y son independientes:
P(X ∩ Y) = P(X) P(Y)
Las frecuencias esperadas para cada uno de los casilleros de la tabla se determinan multiplican-do el tamaño de la muestra por cada una de las probabilidades:
f '(X ∩Y) = n P(X ∩Y)
Así, por ejemplo:
P (desempeño muy bueno y formación primaria) = 0,40 × 0,10 = 0,04 f '(desempeño muy bueno y formación primaria) = 150 × 0,04 = 6
P (desempeño bueno y formación primaria) = 0,30 × 0,10 = 0,03 f '(desempeño bueno y formación primaria) = 150 × 0,03 = 4,5
En la siguiente tabla se muestran todas las frecuencias esperadas.
Formación Desempeño Primaria Secundaria Superior Total Excelente 6 24 30 60 Bueno 4,5 18 22,5 45 Regular 4,5 18 22,5 45 Total 15 60 75 150
Así como en las pruebas de bondad de ajuste, la suma:
∑ −
i
ii
fff'
)'( 2
también tiene una distribución χ2 con nl grados de libertad.
Si la tabla de contingencia tiene p filas y q columnas, el número de grados de libertad es:
nl = (p – 1)( q – 1)
ya que será necesario conocer, como mínimo, (p – 1)( q – 1) frecuencias para que el resto que-den determinadas.
Entonces:
1306,25,22
)5,2225(...18
)1819(5,4
)5,43(30
)3027(24
)2425(6
)68( 2222222 =
−++
−+
−+
−+
−+
−=χ
El número de grados de libertad es, en este caso: n = (3 – 1)(3 – 1) = 4.
Como χ2 mide la discrepancia entre las frecuencias observadas y las frecuencias esperadas, valo-res muy grandes de χ2 nos harán rechazar la hipótesis nula. El valor de χ*2, por encima del cual se rechazará la hipótesis nula, considerando un nivel de significancia del 5%, será igual a 9,488 (tabla del apéndice).
El valor de χ2 = 2,1306 < 9,488 ; por lo tanto se acepta H0, concluyéndose que en esta empresa sí hay independencia entre la formación académica y el desempeño en el trabajo.

146 La distribución ji-cuadrada
Un caso especial de las pruebas de independencia es el que emplea tablas de contingencia de 2×2. En estos casos el número de grados de libertad es igual a 1, y se suele emplear e factor de correc-ción de Yates, para corregir el error de aproximación que se comete al ajustar la distribución χ2 a la distribución que sigue la suma ∑ (fi – f 'i)2
/ f 'i.
Si una tabla de 2 × 2 tiene las siguientes frecuencias observadas:
X1 X2 Total Y1 a b a + b Y2 c d c + d Total a + c b + d n
entonces, el valor de χ 2 se puede calcular con la siguiente fórmula alternativa:
)()()()(
)2/( 22
dbdccabanbcadn
++++
−−=χ
En estas pruebas de independencia, cuanto mayor es el tamaño de la muestra, más confiables son los resultados. Cuando el número de grados de libertad es mayor que 1, se considera que una muestra es lo suficientemente grande si f 'i > 5,. Si nl es igual a 1 (tablas de 2×2), entonces se requiere que f 'i > 10.
10.5 Pruebas de hipótesis respecto a la varianza. Teorema:
Sea s2 la varianza de una muestra de tamaño n, extraída de una población con distribución nor-mal con varianza σ 2. Entonces:
2
2
σsn tiene una distribución χ2 con n – 1 grados de libertad.
Recuérdese que en la fórmula de la varianza de una muestra, s2, se emplea n en el denominador; pero cuando la muestra extraída es pequeña conviene usar n – 1 en vez de n. Sea sn-12 la varianza así definida. Entonces:
2
21)1(
σ−− nsn también tiene una distribución x2 con n – 1 grados de libertad.
Aunque no se demostrará este teorema, se puede comprobar de la siguiente manera: se toma una muestra de tamaño n y se calcula ns1
2/σ2, luego otra muestra de tamaño n y se calcula ns22/σ2, y así su-
cesivamente hasta tener la suficiente cantidad de valores para construir un histograma. Se podrá com-probar que el polígono de frecuencias correspondiente se parece mucho a la curva χ2 con m – 1 grados de libertad.
Ejemplo:
Supóngase que los pesos de las bolsas de leche que se producen en una fábrica tienen una distri-bución aproximadamente normal con una varianza igual a 0,025 l. El jefe de producción decide hacer algunos ajustes en la máquina llenadora. Una vez efectuado esto, se sospecha que la va-riabilidad de los pesos ha aumentado considerablemente, pues en una muestra de 60 bolsas se encontró una varianza de 0,032 l. ¿Indica este resultado que la variabilidad realmente ha aumen-tado? Considere α = 0.05
H0: σ 2 = 0,025 H1: σ 2 > 0,025
8,76025,0
032,0602
22 =
×==
σχ
sn

La distribución ji-cuadrada 147
n = 60 – 1 = 59
Como n > 30, se emplea la distribución normal como aproximación a la distribución χ2.
Valores muy grandes de χ2, por encima de χ2*, nos harán rechazar H0 en favor de H1.
1)59(2*2122645,1* 22 −−=−−== χχ nz
χ*2 = 77,646 < 76,8 ; entonces se acepta H0.
Se concluye que la variabilidad no ha aumentado. La varianza obtenida en la muestra no es lo suficientemente grande como para aceptar que la variabilidad ha aumentado.
10.6 La distribución ji-cuadrada en Excel Excel cuenta con algunas funciones que pueden ser útiles en las distintas pruebas de hipótesis
con la distribución ji-cuadrada. A continuación se explica lo que realiza cada una de esas funciones:
• DISTR.CHI: calcula la probabilidad de exceder un valor determinado de ji-cuadrado. Al eje-cutar esta función, Excel presenta un cuadro de diálogo donde se ingresan dos datos: el valor de ji-cuadrado y el número de grados de libertad.
• PRUEBA.CHI: calcula la probabilidad de exceder el valor de ji-cuadrado que mide la discre-pancia entre m frecuencias observadas y sus correspondientes teóricas en una prueba de bon-dad de ajuste. Esta función presenta el inconveniente que considera m – 1 grados de libertad, independientemente del número de parámetros que se hayan estimado para calcular las fre-cuencias teóricas. Al ejecutar esta función, Excel presenta un cuadro de diálogo donde se in-gresa cada rango de celdas donde están las frecuencias observadas y las teóricas.
• PRUEBA.CHI.INV: calcula el valor de ji-cuadrado para una determinada probabilidad de ex-cederlo. Excel presenta un cuadro de diálogo donde se ingresan dos datos: la probabilidad y el número de grados de libertad.

148 La distribución ji-cuadrada
Problemas propuestos. 1. Se está probando un programa informático generador de números aleatorios. Las instrucciones del
programa originan 100 dígitos entre 0 y 9 con las siguientes frecuencias:
Entero 0 1 2 3 4 5 6 7 8 9 Frecuencia 11 8 7 7 10 10 8 11 14 14
¿Existe evidencia suficiente para pensar que los dígitos no están siendo generados en forma aleato-ria? Sea α = 0,10.
2. Suponga que la Secretaría Académica de la UDEP afirma que, aproximadamente, el 40% de los alumnos estudian Ingeniería, el 20% Administración de Empresas, otro 20% Educación, el 15% Información y el 5% Derecho. Además, el 70% del alumnado proviene del departamento de Piura, el 20% de Lambayeque, el 5% de La Libertad, y el 5% restante de otros departamentos y países.
a) Se toma una muestra aleatoria de 80 alumnos, y se encuentra que 35 estudian Ingeniería, 18 Administración, 12 Educación, 12 Información y 3 Derecho. ¿Es consistente este resultado con lo que afirma la Secretaría Académica?
Respuesta: El resultado sí es consistente. b) Se desea investigar si el lugar de procedencia influye en la elección de la carrera, para lo cual
se toma una muestra de 200 alumnos. ¿Cómo debe estar constituida la muestra?
3. Suponga que la calidad de un producto ha dado una desviación estándar igual a 8,1. Una muestra de 30 unidades de dicho producto da una desviación estándar de 9,5 ¿Existe una evidencia de que la variabilidad ha aumentado? Sea α = 0,10.
4. En los primeros niveles de la Facultad de Ciencias de una Universidad, cada semestre, aproxima-damente el 38% de los alumnos de los cursos de matemáticas son repitentes. Además, el 32% de los alumnos de estos cursos suelen salir aprobados. El Director de Estudios quiere investigar si la fracción de alumnos de matemáticas que aprueban es siempre la misma, ya sea que fueran repiten-tes o no. Para esto toma una muestra aleatoria de 50 alumnos, encontrando que 9 de los repitentes están aprobados.
a) ¿Cómo debe estar compuesta la muestra de 50 alumnos? Respuesta: Repiten 19, no repiten 31, aprueban 16, no aprueban 34. b) ¿Cuál será el resultado de la investigación? Considere α = 0.10. Respuesta: La fracción de aprobados es independiente de la condición (repitentes o no)
5. Los alumnos que ingresaron a la Facultad de Ingeniería este semestre han sido clasificados en 4 grupos, según su nivel socio-económico, tal como se indica:
A B C D 12 20 31 33
a) Investigue si los alumnos que ingresan a la Facultad de Ingeniería pertenecen indistintamente a los distintos niveles.
Respuesta: No pertenecen indistintamente a los distintos niveles. b) Investigue si en la Facultad de Ingeniería la mayoría pertenece a los niveles medios (B y C). Respuesta: La mayoría no pertenece a los niveles medios.
6. El director de un colegio quiere investigar si existe mayor tendencia, por parte de los alumnos de Ingeniería, a escoger la carrera de Ingeniería Industrial. Para esto toma una muestra de 13 alumnos que encontró conversando en el tercer piso del edificio de Ingeniería y realiza una prueba χ2. Dis-cuta el método empleado.
7. La desviación estándar de los diámetros de ciertas piezas de precisión que se producen en una fá-brica es 0,0865. El jefe de control de calidad sospecha que la calidad ha bajado y que por lo tanto tiene una desviación estándar mayor. Para estar seguro de su afirmación, extrae aleatoriamente una muestra de 25 piezas y calcula la desviación estándar. ¿En que rango tendría que estar este valor para que se confirmen sus sospechas? Sea α = 0,10.

La distribución ji-cuadrada 149
8. Un profesor de una Universidad ha diseñado un test mediante el cual determinará la carrera que debe seguir un alumno promocional de secundaria, según sus aptitudes y preferencias. Según las estadísticas de los últimos años, el 39% de los alumnos que están por salir del colegio desea estu-diar Ingeniería, el 15% Medicina, el 7% Derecho, el 30% Administración de Empresas, Economía o Contabilidad, y el resto otras carreras o nada. Se toma el test a un grupo de 50 alumnos promo-cionales en Piura, obteniendo el siguiente resultado.
Ing. Med. Derecho A.E.C. Otros 25 9 3 10 3
¿Qué conclusión daría usted? Sea α = 0,10.
9. Los pagos mensuales de 204 estudiantes que trabajan parte de su tiempo se distribuyen así:
Pagos ($) Nº estudiantes 78 - 82 6 83 - 87 12 88 - 92 16 93 - 97 22 98 - 102 30
103 - 107 35 108 - 112 32 113 - 117 20 118 - 122 15 123 - 127 10 128 - 132 6
Investigue la hipótesis de que la frecuencia observada se aproxima a una distribución normal. Considere α = 0.05
10. De los 210 alumnos que ingresaron a la Facultad de Ingeniería este año, 77 desean seguir Ing. In-dustrial, 60 desean Ing. Civil y 73 desean Ing. Mecánica Eléctrica.
a) ¿Es consistente este resultado con la hipótesis de que el 40% de los alumnos seguirán Ing. In-dustrial, el 25% Ing. Civil y el 35% Ing. Mecánica eléctrica?
Respuesta: Sí es consistente, hasta para α = 0.10. b) ¿Y será consistente con la hipótesis de que los alumnos se distribuirán uniformemente en los
tres programas? Respuesta: Sí es consistente, hasta para α = 0,10.
11. Las estaturas de 200 empleados se distribuyen así:
Estaturas (en metros)
Frecuencia observada
1,51 – 1,55 9 1,56 – 1,60 20 1,61 – 1,65 45 1,66 – 1,70 55 1,71 – 1,75 43 1,76 – 1,80 17 1,81 – 1,85 11
Investigue la hipótesis de que tales estaturas se distribuyen normalmente. Considere α = 0,05.
12. Durante este año, en una fábrica que elabora artículos metálicos se han registrado 50 accidentes laborales, lo cual ha provocado retrasos en la producción. El jefe de seguridad tiene interés en sa-ber en qué días de la semana ocurren los accidentes. A partir de los siguientes datos, ¿se puede afirmar que los accidentes son igualmente probables en los cinco días de la semana?
Día de la semana Lunes Martes Miércoles Jueves Viernes Número de accidentes 12 7 8 10 13

150 Estimación puntual y de intervalo
Capítulo 11. Estimación puntual y de intervalo
11.1 Introducción Con mucha frecuencia se realizan experimentos o se toman datos con el propósito de estimar al-
gunos valores o parámetros que no son conocidos con mucha exactitud. Por ejemplo: en una fábrica de aceite se emplea una máquina que llena automáticamente las botellas con un volumen “fijo”. En la práctica, resulta que ese volumen no es “tan fijo”, y el fabricante necesita estimar periódicamente cuál es el volumen de llenado promedio. Evidentemente no le conviene que las botellas estén demasiado llenas, pues resultarían costosas; ni que les falte mucho aceite, pues puede ser demandado por los con-sumidores. Además, es importante para el fabricante determinar la variabilidad del llenado de botellas. Para ello tendrá que estimar la varianza, para luego poder realizar los ajustes necesarios, y reducir al máximo dicha varianza. En cada caso, ya sea para estimar el volumen de llenado promedio o la va-rianza del llenado, se pueden hacer dos tipos de estimaciones: puntual y de intervalo.
11.2 Estimación puntual. Se hace una estimación puntual de un parámetro, cuando se elige un valor único para dicho pa-
rámetro. Por ejemplo, se puede estimar el volumen de llenado promedio de las botellas en una fábrica de aceite, tomando una muestra y calculando la media aritmética. A este resultado se le denomina es-timado puntual.
Supóngase que una variable aleatoria X tiene una distribución que está determinada, salvo por un parámetro θ. Si se toma una muestra x1, x2, ..., xn, y se escoge una función )...,,,(ˆ 21 nxxxθ para es-timar el parámetro desconocido, a la variable aleatoria θ̂ se le denomina estimador puntual, y el va-lor que toma es el estimado puntual de θ .
Pueden existir muchos estimadores para un parámetro θ. En el caso de la media poblacional µ, podrían considerarse como estimadores: la media muestral, la mediana muestral, el valor más frecuen-te o moda.
La variable aleatoria θ̂ es un estimador no sesgado del parámetro θ si su valor esperado es igual a θ. Si los valores estimados tienden a ser muy grandes o muy pequeños, entonces θ̂ es un esti-mador sesgado. A la diferencia θ – E(θ̂ ) se le denomina sesgo.
La variable aleatoria θ̂ es un estimador eficiente del parámetro θ si la varianza de θ̂ no es ma-yor que la varianza de cualquier otro estimador de θ.
La media muestral x es un estimador no sesgado de la media del universo:
µxE =)(
La proporción p1 es un estimador no sesgado de la proporción p:
E(p1) = p
La varianza muestral sn-1 es un estimador no sesgado de σ :
E(sn-1) = σ
Se puede demostrar que s es un estimador sesgado de σ , pues E(s) resulta diferente a σ.

Estimación puntual y de intervalo 151
11.3 Estimación por intervalos. Un parámetro se puede estimar dando un intervalo dentro del cual resulte probable incluir a di-
cho parámetro. Esta probabilidad, que mide el grado de confianza de la estimación, depende del tama-ño que se le dé al intervalo. Los estimadores de intervalo siempre serán funciones de la muestra. Se podría afirmar, por ejemplo, que el promedio de llenado de las botellas en una fábrica de aceite está comprendido entre 749,2 y 751,7 ml., con una probabilidad de 0,90. Este es un intervalo de confianza del 90%. Entonces hay una probabilidad de 0,10 de que el verdadero promedio de llenado no esté en dicho intervalo.
A continuación se verá la metodología que se debe seguir para determinar intervalos de confian-za de parámetros poblacionales. Será fácil para el lector verificar que estos intervalos coinciden con la región de aceptación de las pruebas de hipótesis de dos colas.
11.3.1 Intervalo de confianza para la media poblacional. Para determinar un intervalo de confianza del 100(1 – α) % para una media poblacional, se ex-
trae primeramente una muestra, se calcula la media muestral y, si no se conoce la varianza del univer-so, la varianza muestral.
Como se vio en el capítulo 8 (pág.113), la media muestral se distribuye normalmente si la po-blación es normal o, si la población no es normal y la muestra es lo suficientemente grande (n ≥ 50). Si se conoce la varianza de la población o se estima con una muestra suficientemente grande, entonces los límites de confianza del intervalo se determinan a partir de la siguiente expresión:
nσµxz
/* −
=±
Los límites de confianza se obtienen despejando µ para cada signo del primer miembro de esta ecuación. En la figura 11.1 se representa el intervalo de confianza del 100(1 – α) %.
1 - α
α / 2 α / 2
Figura 11.1. Intervalo de confianza de la media poblacional cuando se conoce σ
Ejemplo:
Determine un intervalo de confianza del 90 % del peso de las bolsas de harina que se llenan en una máquina automática, si una muestra de 60 bolsas dio una media de 0,996 Kg. y una desvia-ción estándar de 0,03 Kg.
Para α/2 = 5% ⇒ z = ±1,645
Por lo tanto:
60/03,0
996,0*645,1 µ−=±
Despejando: µ = 0,996 ± 0,0064
–z* +z* z

152 Estimación puntual y de intervalo
Por lo tanto se puede afirmar que la media poblacional se encuentra en el siguiente intervalo, con un 90% de confianza:
0,9896 < µ < 1,0024
Si una población es normal y se desconoce la varianza de dicha población, entonces los límites de confianza del intervalo se determinan a partir de la siguiente expresión:
1/
*−
−=±
nsµxt
Los límites de confianza se obtienen despejando µ para cada signo del primer miembro de esta ecuación.
Ejemplo:
Determine un intervalo de confianza del 95 % del peso de las bolsas de harina que se llenan en una máquina automática, si una muestra de 40 bolsas dio una media de 0,996 Kg. y una desvia-ción estándar de 0,022 Kg.
Para α /2 = 2,5%; n – 1 = 39 grados de libertad ⇒ t* = ±2,0227
Por lo tanto:
39/022,0
996,00227,2 µ−=±
Despejando:
µ = 0,996 ± 0,0071
Por lo tanto se puede afirmar que la media poblacional se encuentra en el siguiente intervalo, con un 95% de confianza:
0,9889 < µ < 1,0031
11.3.2 Intervalo de confianza para la diferencia de medias. Para determinar un intervalo de confianza del 100(1 – α) % para la diferencia de las medias de
dos poblaciones, se sigue el mismo procedimiento del apartado anterior, empleando las distribuciones normal y t de Student correspondientes, según sea el caso.
y
y
x
x
yx
nσ
nσ
µµyxz
22
)()(*
+
−−−=±
+
−+
+
−−−=±
yxyx
yxxx
yx
nnnnsnsn
µµyxt
112
)()(*
22
En cada caso se llegará a determinar dos valores para la diferencia (µ x – µ y ), que son precisa-mente los límites del intervalo de confianza.
11.3.3 Intervalo de confianza para la proporción p. Dada una variable aleatoria binomial X, la proporción X/n, denominada p1, se distribuye nor-
malmente alrededor de p, con una desviación estándar igual a npq / , cuando np y nq > 5.
La variable normal estandarizada que corresponde a p1 es la siguiente:
npq
pn
pz
−±=± 2
1
*1

Estimación puntual y de intervalo 153
Se determinan los límites del intervalo de confianza del 100(1 – α) % para p, empleando la ecuación anterior, donde z toma los valores +z* y -z*. El signo que tome el factor de corrección de-penderá de lo siguiente: si los límites están incluidos en el intervalo (a ≤ p ≤ b), el factor de corrección será positivo para +z* y negativo para -z*, como se muestra en la figura 11.2a. Si los límites no están incluidos en el intervalo (a < p < b), el signo será negativo para +z* y positivo para –z*, como se muestra en la figura 11.2b.
1-α
+z*+ f.c.- f.c.
- z*
z
1-α
- z*+ f.c. - f.c.
+z*
z
Figura 11.2a. Intervalo a ≤ p ≤ b Figura 11.2b. Intervalo a < p < b
Es importante considerar que la distribución de una proporción, que es binomial, será aproxima-damente normal sólo cuando np y nq > 5. Si no se cumplen estas condiciones, debe emplearse la dis-tribución binomial para determinar los intervalos de confianza.
Ejemplo:
Una compañía de teléfonos quiere averiguar qué porcentaje de sus clientes de Piura estaría dis-puesto a suscribirse a Internet por cable. Selecciona aleatoriamente a 300 clientes y encuentra que 36 de éstos sí se suscribirían. Haga una estimación de intervalo con un 95% de confianza de la proporción de clientes que se suscribirían a Internet por cable.
Para α /2 = 2,5% ⇒ z = ±1,96
Además: p1 = 36/300 = 0,12
Se va a determinar un intervalo de confianza del tipo: a ≤ p ≤ b. Por lo tanto se plantean las si-guientes ecuaciones:
300)1()300(2
112,096,1
pp
p
−
−+=+ ;
300)1()300(2
112,096,1
pp
p
−
−−=−
De la primera ecuación resulta:
p2 – 0,2529p + 0,014616 = 0 ⇒ p = 0,08938
De la segunda ecuación resulta:
p2 – 0,246317p + 0,013826 = 0 ⇒ p = 0,15979
Por lo tanto, el intervalo de confianza del 95% es:
0,08938 ≤ p ≤ 0,15979

154 Estimación puntual y de intervalo
Si se quisiera determinar un intervalo de confianza del tipo: a < p < b, se plantearían las siguien-tes ecuaciones:
300)1()300(2
112,096,1
pp
p
−
−−=+ ;
300)1()300(2
112,096,1
pp
p
−
−+=−
De la primera ecuación resulta:
p2 – 0,246317p + 0,013826 = 0 ⇒ p = 0,08652
De la segunda ecuación resulta:
p2 – 0,2529p + 0,014616 = 0 ⇒ p = 0,16352
Por lo tanto, el intervalo de confianza del 95% es:
0,08652 < p < 0,16352
11.3.4 Intervalo de confianza para la diferencia de proporciones. Dada dos variables aleatorias binomiales X e Y, la proporción X/nx, denominada p1, se distribuye
normalmente alrededor de px, con una desviación estándar igual a xxx nqp / , cuando nx px y ny py son mayores que 5; y la proporción Y/ny, denominada p2, se distribuye normalmente alrededor de py, con una desviación estándar igual a yyy nqp / , cuando nx px y ny py son mayores que 5. Asimismo, la di-
ferencia X – Y se distribuye normalmente alrededor de px – py, con una desviación estándar igual a
y
yy
x
xx
nqp
nqp
+ .
Para determinar un intervalo de confianza del 100(1 – α) % para la diferencia de las proporcio-nes de dos poblaciones, se sigue el mismo procedimiento de los apartados anteriores, empleando la aproximación normal :
y
yy
x
xx
yx
yxyx
nqp
nqp
nnnn
ppppz
+
+±−−−
=±
.2
)()(*
21
Para poder despejar px – py de las dos ecuaciones que se planteen (una para cada signo), es nece-sario hacer las siguientes estimaciones de punto en el denominador:
x
x nxp = ;
yy n
yp =
11.3.5 Intervalo de confianza para la varianza. Recuérdese que si se extrae una muestra de tamaño n de un universo normal con varianza σ 2,
ns2/σ 2 tiene una distribución ji-cuadrada con n – 1 grados de libertad.
Recuérdese también que es equivalente emplear 221 /)1( σ−− nsn o ns2/σ 2.
Así, para determinar un intervalo de confianza del 100(1 – α) % (figura 11.3) para la varianza de una población normal, se usan las siguientes ecuaciones:
21
22
2/ σχα
ns= 2
2
22
2/1 σχ α
ns=−

Estimación puntual y de intervalo 155
De esta forma se determina el intervalo: σ1 2 < σ 2 < σ2
2
α / 2α / 2
χ2α /2χ2
1-α /2
χ2
1-α
Figura 11.3. Intervalo de confianza para la varianza
Ejemplo:
El dueño de una hamburguesería ha visto que conocer la variabilidad del número de hambur-guesas que vende diariamente es muy importante para una buena administración de su negocio. Determine un intervalo de confianza del 90% de la varianza del número de hamburguesas que vende diariamente, si a partir de los registros de las ventas del último mes (30 días) se ha calcu-lado una desviación estándar de 7,25 unidades.
Para: α /2 = 5% ; n – 1 = 29 grados de libertad.
21
22
05,02
2/)25,7(305569,42
σχχα === ⇒ 0533,372
1 =σ
22
22
95,02
2/1)25,7(307084,17
σχχ α ===− ⇒ 0467,892
2 =σ
Por lo tanto, el intervalo de confianza del 90% de la varianza es:
37,0533 < σ 2 < 89,0467
El intervalo de confianza del 90% de la desviación estándar es:
6,0871 < σ < 9,4365
11.4 Intervalo de confianza para la media en Excel Excel cuenta con la función INTERVALO.CONFIANZA dentro de las funciones que se des-
pliegan al ejecutar el icono fx o al entrar al menú Insetar/Función.
Al ejecutar esta función INTERVALO.CONFIANZA, Excel presenta el cuadro de diálogo de la figura 11.4. Al ingresar los datos, el resultado que muestra Excel es el rango que hay entre la media y los intervalos de confianza que se quieren determinar. Nótese que entre los datos que se ingresan al cuadro de diálogo de la figura 11.4 está la desviación estándar de la población y no está la media de la muestra.
A continuación se resuelve el ejemplo de la sección 11.3.1, cuyo texto se repite por comodidad.

156 Estimación puntual y de intervalo
Ejemplo:
Determine un intervalo de confianza del 90 % del peso de las bolsas de harina que se llenan en una máquina automática, si una muestra de 60 bolsas dio una media de 0,996 Kg. y una desvia-ción estándar de 0,03 Kg.
Figura 11.4. Cuadro de diálogo para determinar el intervalo de confianza de la media
El resultado que muestra Excel es : 0,00637049 ≅ 0,0064
Por lo tanto el intervalo de confianza es: 0,996 ± 0,0064; que es el mismo resultado que se obtu-vo en la sección 11.3.1.

Estimación puntual y de intervalo 157
Problemas propuestos. 1. Se hizo una encuesta antes de las elecciones municipales en la ciudad de Piura a una muestra de
100 votantes. De éstos, el 40% declaró que votarían por Gerardo Guzmán para Alcalde. Calcule el intervalo de confianza de 90% para la proporción de la ciudad que votaría por Guzmán.
Respuesta: 0,318 ≤ p ≤ 0,486
2. Haga una estimación de intervalo del porcentaje de alumnos de la Facultad de Ingeniería que tie-nen índice académico acumulado mayor que 14, con una confiabilidad del 95%, utilizando una muestra de 45 alumnos. En dicha muestra se encontró que 27 tienen índice académico acumulado mayor que 14.
3. Determine el intervalo de confianza del 95% de la cantidad promedio de dólares que tienen los cambistas del Jirón Arequipa de Piura, si se ha tomado una muestra de 10 cambistas y los resulta-dos son los siguientes, en dólares: 5 255; 1 452; 2 236; 400; 860; 1 290; 3 030; 1 620, 750; 3 600.
4. Una muestra de 60 barras de manjar blanco producidas por una empresa da los siguientes pesos (en gramos):
499,6 498,3 500,3 501,7 501,6 502,3 497,2 499,7 501,4 498,6 499,1 497,8 497,6 498,7 499,0497,2 499,3 499,5 500,2 499,5 499,6 499,5 501,7 499,9 499,8 499,3 502,6 501,1 503,1 499,1502,2 497,9 500,7 501,2 502,5 499,9 499,3 500,9 499,5 501,0 498,1 498,9 498,0 499,5 500,0500,0 499,6 502,9 497,7 499,0 496,6 501,9 498,3 499,2 501,0 500,6 501,1 500,8 498,2 498,5
Determine un intervalo de confianza del 98% de:
a) el peso promedio de las barras de manjar blanco que produce la empresa. b) la desviación estándar del peso de las barras de manjar blanco que produce la empresa.
5. Un fabricante de fármacos está preocupado por el tiempo promedio que tarda en hacer efecto una pastilla para el dolor de cabeza “tensional”. Si en una muestra de 20 pacientes se obtuvieron los siguientes tiempos (en minutos):
34,85 34,93 36,10 33,50 34,22 29,10 35,11 33,11 38,22 35,23 36,63 34,68 33,46 31,97 37,96 33,72 40,03 30,05 35,51 31,51
Determine un intervalo de confianza del 95% de:
a) el tiempo promedio que tarda dicha pastilla en hacer efecto. b) la desviación estándar del tiempo que tarda dicha pastilla en hacer efecto.
6. El jefe de un taller mecánico toma una muestra de 35 unidades producidas durante una semana, y mide una desviación estándar de 0,07 cm. del diámetro de dichas unidades. Determine un intervalo de confianza del 90% de la varianza de los diámetros de las unidades producidas en el taller.
Respuesta: 13,3232 < σ 2 < 49,5174
7. El gerente de una empresa que se dedica a la venta de automóviles ha tomado una muestra de 300 clientes de distintas empresas, encontrando que 112 compraron su auto hace 10 años o más. Calcu-le el intervalo de confianza del 95% para la proporción de personas que compraron su auto hace 10 años o más. Considere los dos tipos de intervalo.
8. En una muestra de alumnos universitarios de Lima se encontró que, de 300 mujeres y de 350 hombres entrevistados, 223 y 187 respectivamente, veían alguna telenovela. Determine el interva-lo de confianza del 95% de la diferencia entre las proporciones de universitarios mujeres y hom-bres que ven alguna telenovela.
9. En una muestra de 400 alumnos universitarios de Piura se encontró que 312 ven algún programa político los domingos en la televisión. Determine el intervalo de confianza del 95% de la propor-ción de alumnos universitarios de Piura que ven algún programa político los domingos.

158 Diseño de experimentos y análisis de varianza
Capítulo 12. Diseño de experimentos y análisis de varianza
12.1 Introducción. Para comparar las medias aritméticas de dos poblaciones, se toma una muestra de cada pobla-
ción y, mediante una prueba de hipótesis, se hace la comparación de medias, usando la distribución normal o la distribución t de Student.
En este capítulo se ve una nueva herramienta estadística, llamada análisis de varianza, que per-mite hacer una comparación de dos o más de dos medias poblacionales, a partir de muestras tomadas de dichas poblaciones.
A continuación se dan algunos ejemplos de comparaciones de medias poblaciones:
• La acción limpiadora de tres posibles fórmulas mejoradas de una marca de detergente. • Las eficiencias de tres métodos de enseñanza de programación. • La pérdida de peso de ciertas piezas mecánicas debido a la fricción, usando tres tipos de lubri-
cante. • Las alturas de cierto tipo de planta después de tres meses de sembrarlas usando distintos tipos
de riego y fertilizante. • La resistencia a la compresión de varios tipos de concreto. • El número de errores que se cometen, durante una semana, en cuatro laboratorios. • La productividad que se obtiene empleando tres procesos distintos de producción.
12.2 Diseño de experimentos.
12.2.1 Definiciones Los datos recolectados para la comparación de medias pueden proceder de encuestas o de expe-
rimentos diseñados, según sea el propósito.
Como se dijo en el capítulo 1, se denomina experimento a la reproducción controlada de un fe-nómeno cualquiera que ocurre en la naturaleza. Queda en evidencia entonces que un experimento es controlado.
Se denominan unidades experimentales a los elementos (personas u objetos) sobre los que se va a experimentar para obtener las medidas que se desea comparar. Por ejemplo, para comparar la ac-ción limpiadora de tres posibles fórmulas mejoradas de una marca de detergente, se requiera aplicar dichas fórmulas a algunas prendas de vestir (unidades experimentales); luego se comparará la limpieza de las prendas limpiadas con las distintas fórmulas.
Las unidades experimentales se dividen en grupos experimentales y, si es conveniente, en un grupo de control.
Los grupos experimentales y el grupo de control son sometidos a distintos tratamientos. Por ejemplo, las prendas de vestir se pueden dividir en tres grupos experimentales, cada uno de los cuales es sometido a una distinta fórmula mejorada (tratamientos).

Diseño de experimentos y análisis de varianza 159
El grupo de control, cuando existe, estará sometido al tratamiento habitual. Por ejemplo, un gru-po de prendas de vestir se puede someter a la fórmula limpiadora que se emplea actualmente, es decir, al tratamiento habitual.
En conclusión, todas las unidades experimentales son sometidas a distintos tratamientos, para luego medir y promediar los resultados de dichos tratamientos. En el ejemplo, existe una forma de medir la limpieza de cada prenda de vestir, y, será posible entonces, comparar las limpiezas promedio de cada grupo de prendas de vestir.
Generalmente, sobre las unidades experimentales actúan, además de los tratamientos, factores externos que influyen en los resultados del experimento. Esta acción de los factores externos suele lle-var a conclusiones erróneas, salvo que se sepan controlar.
Hay dos formas de controlar la acción de los factores externos:
• Aleatorización: se asignan aleatoriamente las unidades experimentales a los grupos experi-mentales y al grupo de control, para que cada grupo tenga la misma probabilidad de ser afec-tado por los factores externos. Por ejemplo, si se tienen 30 prendas de vestir de distinto mate-rial, se puede controlar la distinta acción limpiadora de las tres fórmulas de detergente sobre los distintos materiales, repartiendo aleatoriamente las prendas de vestir en los tres grupos.
• Formación de bloques: se forman boques de unidades experimentales en cada grupo, de tal forma que tales bloques sean homogéneos respecto a los factores externos que se desea elimi-nar. Por ejemplo, si se tienen 30 prendas de vestir de cuatro tipos de material, se pueden for-mar cuatro bloques (uno de cada tipo de material) en cada grupo. De esta manera, los tres gru-pos se verán igualmente afectados por este factor externo que es el tipo de material.
12.2.2 Diseño completamente aleatorizado Se dice que el diseño de un experimento es completamente aleatorizado cuando se asignan las
unidades experimentales a los distintos grupos en forma aleatoria.
12.2.3 Diseño aleatorizado por bloques Se dice que el diseño de un experimento es aleatorizado por bloques cuando se forman boques
de unidades experimentales en cada grupo, de tal forma que tales bloques sean homogéneos respecto a los factores externos que se desea eliminar. En cada bloque puede haber una o más unidades experi-mentales.
12.2.4 Errores en los datos de los experimentos En un experimento se pueden cometer dos tipos de error: aleatorios y no aleatorios.
• Error aleatorio o experimental: es la diferencia entre la medida obtenida del resultado de un experimento y la obtenida promediando los resultados de varios experimentos: xxe iA −=
• Error no aleatorio o sesgo: es la diferencia entre la medida obtenida promediando los resulta-dos de varios experimentos y la medida verdadera: µ−= xeN
12.3 Análisis de varianza: ANOVA El análisis de varianza, o ANOVA, compara dos o más medias de distintas poblaciones. Para es-
to extrae una muestra de cada población y analiza qué tan dispersas están las medias de dichas mues-tras, es decir, qué tanto difieren entre sí.
Para que el análisis de varianza tenga validez se requiere que las poblaciones muestreadas sean normales y que las varianzas de dichas poblaciones sean iguales. Una estimación de esta varianza co-mún, σ2, que sería también la varianza de todas las muestras, estará conformada por dos varianzas: la varianza entre las medias de las muestras y la varianza promedio dentro de las muestras.
Para entender la naturaleza del análisis de varianza, supóngase que se quiere averiguar si son

160 Diseño de experimentos y análisis de varianza
iguales o no las medias de tres poblaciones: µ 1, µ 2 y µ 3. Para esto, se extrae una muestra de cada po-blación, cuyas medidas se expresan en la figura 12.1. Se asume que el investigador sólo conoce las medias muestrales.
xxx xx x xxx xx x xxx x xx
µ1 µ2 µ3
Figura 12.1. Muestreos con medias muy diferentes
A simple vista se podría afirmar (figura 12.1) que µ 1, µ 2 y µ 3 son diferentes, pues las tres me-dias muestrales son muy diferentes (recuerde el lector que no se conocen las medias poblacionales). Analíticamente, se podría llegar a la misma conclusión calculando la varianza que hay entre las medias de las muestras. Si esta varianza es grande, indicará que las medias muestrales difieren mucho; pero, ¿cómo determinar a partir de qué valor se puede afirmar que la varianza es grande? Una forma muy práctica de hacerlo es comparándola con la varianza promedio de los datos de las muestras. Así, si la varianza que hay entre las medias de las muestras es significativamente mayor que la varianza que hay dentro de las muestras, se puede afirmar que las medias poblacionales difieren significativamente.
Supóngase ahora que se quiere averiguar si las medias de las tres poblaciones representadas en la figura 12.2 son iguales o no. Nuevamente el lector debe asumir que no conoce las medias poblacio-nales; aunque en la figura se aprecien estos valores.
xx xxx x xx xx x x x xx x xx
µ1 µ2 µ3
Figura 12.2. Muestreos con medias diferentes
Se aprecia en la figura 12.2 que las medias muestrales son diferentes; pero esta vez difieren me-nos. La varianza entre las medias muestrales es, en este caso, ligeramente mayor que la varianza pro-medio dentro de las muestras. Nuevamente se podrá afirmar que las medias poblacionales difieren sig-nificativamente.
Supóngase, finalmente, que se desea averiguar si las medias de las tres poblaciones representa-das en la figura 12.3 son iguales o no. Nuevamente el lector debe asumir que no conoce las medias poblacionales, aunque en la figura se aprecie que estos valores son iguales.
xx xxx xxx
x
x x x
x x
x
x xx
µ1 = µ2 = µ3
1x
2x
Figura 12.3. Muestreos con medias diferentes
1x 2x 3x
1x 2x 3x
1x
2x
3x

Diseño de experimentos y análisis de varianza 161
En esta última situación, la varianza entre las medias muestrales es menor que la varianza pro-medio dentro de las muestras, lo cual indica que las medias muestrales no difieren significativamente. Se concluye entonces que las medias poblacionales son iguales.
Ahora se entiende cómo un análisis de las varianzas permite probar si las medias de varias po-blaciones son iguales o no. En caso que no sean iguales, se podría probar que una de las medias pobla-cionales es la mayor (o la menor) mediante una prueba de hipótesis entre las dos con mayor (o menor) media muestral.
12.3.1 Análisis de varianza de un factor Se denomina análisis de varianza de un factor o unidireccional, al análisis que se hace cuando
los factores externos se controlan mediante un diseño completamente aleatorio del experimento. En-tonces, se considera que el único factor que actúa sobre las unidades experimentales son los tratamien-tos. En el ejemplo anterior de las distintas fórmulas nuevas de detergente que se aplican a distintos grupos de prendas de vestir, los tratamientos serán precisamente las distintas fórmulas del detergente.
Si se quiere comparar las medias de k poblaciones, se plantean las siguientes hipótesis:
H0 : µ1 = µ2 = … = µk H1 : Al menos una media es diferente
Como se dijo antes, la varianza total está conformada por dos varianzas: la varianza entre las medias de las muestras y la varianza promedio dentro de las muestras. La varianza de las medias muestrales se conoce como varianza explicada y, según el teorema del límite central, será:
n
Ex
22 σ
σ =
donde:σE2 es la varianza explicada de las poblaciones, ya que se asume que éstas tienen la mis-
ma varianza, y n es el número de datos de cada muestra.
La varianza de las medias muestrales puede ser estimada por la varianza de las medias de las k muestras:
1
)(1
2
2
−
−=∑
=
k
xxs
k
ii
x
Por lo tanto, despejando de la ecuación anterior, la varianza explicada sE2 resulta:
1
)(1
2
2
−
−≅
∑=
k
xxns
k
ii
E
En esta expresión, al numerador se le conoce como suma de los cuadrados de los tratamien-tos (SST), y el denominador representa el número de grados de libertad. A este cociente también se le llama promedio de los cuadrados de los tratamientos (PPT).
La varianza promedio dentro de las muestras se conoce como varianza no explicada o error, pues se atribuye al azar. Esta varianza constituye otra estimación de la varianza de la población.
Para estimar la varianza no explicada se calcula, en primer lugar, la varianza de cada muestra:
1
)(1
2
2
−
−
=∑
=
n
xxs
n
jiij
i
donde: xij es el j-ésimo dato de la muestra i; ix es la media de la muestra i, y n es el número de datos de la muestra.

162 Diseño de experimentos y análisis de varianza
El promedio de las varianzas de las i muestras será la varianza no explicada:
kn
xxs
n
jiij
k
iN )1(
)(1
2
12
−
−
=∑∑
==
En esta última expresión, al numerador se le conoce como suma de los cuadrados del error (SSE), y el denominador representa el número de grados de libertad. A este cociente también se le llama promedio de los cuadrados del error (PPE).
Para determinar si la varianza explicada o varianza de los tratamientos es mayor que la varianza no explicada o varianza del error, se hace la Prueba F de comparación de varianzas. Recuérdese que si ocurre esto ( 22
NE σσ > ), se podrá afirmar que la varianza de los tratamientos es muy grande, y por lo tanto se podrá afirmar que las medias de los tratamientos difieren significativamente.
Se plantean entonces las siguientes hipótesis:
H0 : 22NE σσ =
H1 : 22NE σσ >
Como se vio en la sección 9.7, se aceptará la hipótesis nula si: *2
2
Fss
FN
E <=
Si se acepta esta hipótesis nula, (H0: 22NE σσ = ) se estaría aceptando que las medias de los trata-
mientos no difieren significativamente, es decir, que dichas medias son iguales (H0: µ1 = µ2 = … = µk).
Tabla ANOVA
Los valores que se calculan para el análisis de varianza suelen expresarse en una tabla, como se muestra en la tabla 12.1.
Tabla 12.1. Tabla ANOVA de un factor
Variaciones Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F F*
Entre muestras SST k – 1 PPT = SST / (k – 1) PPT / PPE F* Dentro de las muestras SSE (n – 1) k PPE = SSE / (n – 1) k Total SSTOT nk – 1
Ejemplo 1: Se quiere evaluar tres métodos de capacitación del personal de una fábrica. El jefe de capacita-ción selecciona 15 nuevos obreros y los distribuye aleatoriamente en los tres métodos. Una vez terminada la capacitación, los obreros comienzan a trabajar y se anota la producción semanal de cada uno de ellos. ¿Hay diferencia en la eficacia de los tres métodos de capacitación?
Producción diaria Método 1 16 17 19 13 21 Método 2 20 25 17 18 21 Método 3 19 24 16 19 17
En primer lugar, se plantean las siguientes hipótesis:
H0 : µ1 = µ2 = µ3 H1 : Al menos una media es diferente
A continuación se calculan las medias muestrales y la media de las medias muestrales:
Producción diaria x x Método 1 16 17 19 13 21 17,2 Método 2 20 25 17 18 21 20,2 Método 3 19 24 16 19 17 19
18,8

Diseño de experimentos y análisis de varianza 163
La varianza explicada sE2 resulta:
[ ]
4,112
8,2213
)8,1819()8,182,20()8,182,17(513
)8,18(5 2221
2
2 ==−
−+−+−=
−
−≅
∑=
k
ii
E
xs
La varianza no explicada sN2 resulta:
3)15(
)2,1721()2,1713()2,1719()2,1717()2,1716(3)15(
)(22222
1 1
2
2
−+−+−+−+−+−
=−
−
=∑∑
= =
k
i
n
jiij
N
xxs
3)15(
)2,2021()2,2018()2,2017()2,2025()2,2020( 22222
−+−+−+−+−+−+
4667,93)15(
)1917()1919()1916()1924()1919( 22222
=−
−+−+−+−+−+
Por lo tanto:
2042,14667,9
4,11==F
Para nlE = 2; nlN = 12 (grados de libertad), α = 0,05: F* = 3,8853 (ver apéndice).
La tabla ANOVA es entonces la siguiente:
Variaciones Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F F*
Entre muestras 22,8 2 11,4 1,2042 3,8853 Dentro de las muestras 113,6 12 9,467 Total 136,4
Resulta entonces: F < F*; por lo tanto se acepta la hipótesis nula de comparación de varianzas (H0: 22
NE σσ = ) y se acepta también la hipótesis nula de medias (H0: µ1 = µ2 = µ3).
Se puede afirmar entonces que los tres métodos de capacitación son igualmente eficientes.
12.3.2 Análisis de varianza de dos factores, sin interacción entre los factores. Se denomina análisis de varianza de dos factores o bidireccional, al análisis que se hace cuando
los factores externos se controlan mediante un diseño aleatorizado por bloques. Se consideran dos fac-tores que actúan sobre las unidades experimentales: los tratamientos y el factor externo que se desea eliminar mediante la formación de bloques.
Cabe la posibilidad de que estos dos factores interactúen uno sobre el otro. Por ejemplo, una fórmula del detergente que se va a experimentar puede actuar mejor o peor sobre determinados mate-riales de ropa. En este apartado no se va a considerar esta posibilidad de interacción entre los factores.
Ya que se están considerando dos factores que actúan sobre las unidades experimentales, se puede aprovechar esto para hacer simultáneamente dos investigaciones: comparar las medias de los k tratamientos y comparar las medias de los n bloques. Se pueden plantear entonces las siguientes hipó-tesis:
Para los tratamientos: H0 : µ1 = µ2 = … = µk H1 : Al menos una media es diferente
Para los bloques: H0 : µ1 = µ2 = … = µn H1 : Al menos una media es diferente

164 Diseño de experimentos y análisis de varianza
En este caso se considera la varianza explicada de los tratamientos y la varianza explicada de los bloques. La varianza explicada de los tratamientos sET
2 se calcula nuevamente con la expresión:
1
)(1
2
2
−
−≅
∑=
k
xxns
k
ii
ET
Al numerador se le conoce como suma de los cuadrados de los tratamientos (SST), y el de-nominador representa el número de grados de libertad. A este cociente también se le llama prome-dio de los cuadrados de los tratamientos (PPT).
La varianza explicada de los bloques sEB2 se calcula con una expresión similar. El número de
bloques es n, y el número de datos en cada bloque es k. La varianza explicada de los bloques será en-tonces:
1
)(1
2
2
−
−
≅∑
=
n
xxks
n
jj
EB
Al numerador se le conoce como suma de los cuadrados de los bloques (SSB), y el denomina-dor representa el número de grados de libertad. A este cociente también se le llama promedio de los cuadrados de los bloques (PPB).
La varianza no explicada o error es (no se demostrará):
)1()1(
)(1
2
12
−−
+−−
=∑∑
==
kn
xxxxs
n
jjiij
k
iN
En esta última expresión, al numerador se le conoce como suma de los cuadrados del error (SSE), y el denominador representa el número de grados de libertad. A este cociente también se le llama promedio de los cuadrados del error (PPE).
Para determinar si la varianza explicada o varianza de los tratamientos es mayor que la varianza no explicada o varianza del error, se hace la Prueba F de comparación de varianzas. Igualmente se podrá determinar si la varianza de los bloques es mayor que la varianza no explicada o varianza del error mediante otra Prueba F.
Se plantean entonces, independientemente, las hipótesis:
Para los tratamientos: H0 : 22NET σσ =
H1 : 22NET σσ >
Para los bloques: H0 : 22NEB σσ =
H1 : 22NEB σσ >
Se aceptará cada hipótesis nula si:
*2
2
TN
ETT F
ss
F <=
*2
2
BN
EBB F
ss
F <=
Si se acepta la primera hipótesis nula (H0: 22NET σσ = ), se estaría aceptando que las medias de los
tratamientos no difieren significativamente, es decir, que las medias de los tratamientos son iguales (H0: µ1 = µ2 = … = µk).

Diseño de experimentos y análisis de varianza 165
Igualmente, si se acepta la hipótesis nula (H0: 22NEB σσ = ), se estaría aceptando que las medias de
los bloques no difieren significativamente, es decir, que las medias de los bloques son iguales (H0: µ1 = µ2 = … = µn).
Tabla ANOVA
Los valores que se calculan para este análisis de varianza suelen expresarse en una tabla, como se muestra en la tabla 12.2.
Tabla 12.2. Tabla ANOVA de dos factores sin interacción
Variaciones Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F F*
Entre tratamientos SST k – 1 PPT = SST / (k – 1) PPT / PPE FT* Entre bloques SSB n – 1 PPB = SSB / (n – 1) PPB / PPE FB* Error SSE (n – 1) (k – 1) PPE = SSE / [(n – 1) (k – 1)] Total SSTOT nk – 1
Ejemplo 2:
El gerente de producción de una fábrica quiere evaluar tres máquinas. Para esto, asigna cinco empleados a cada máquina, distribuyéndolos de acuerdo a su nivel académico, de manera tal que cada máquina sea operada por empleados de los cinco niveles en los que se les ha clasifica-do previamente. De esta forma ninguna máquina se verá favorecida al asignarle más operarios de mayor nivel académico. En la tabla adjunta se muestra la producción diaria.
Máq. 1 Máq. 2 Máq. 3 Nivel 1 16 17 20 Nivel 2 15 20 17 Nivel 3 20 19 17 Nivel 4 19 22 23 Nivel 5 22 24 25
¿Se puede afirmar que las tres máquinas tienen la misma productividad?
En primer lugar, se plantean las siguientes hipótesis:
Para los tratamientos: H0 : µ1 = µ2 = µ3 (máquinas) H1 : Al menos una media es diferente
Para los bloques: H0 : µ1 = µ2 = µ3 = µ4 = µ5 (niveles académicos) H1 : Al menos una media es diferente
A continuación se calculan las medias de los tratamientos, de los bloques y la media total:
Máq. 1 Máq. 2 Máq. 3 jx
Nivel 1 16 17 20 17,667 Nivel 2 15 20 17 17,333 Nivel 3 20 19 17 18,667 Nivel 4 19 22 23 21,333 Nivel 5 22 24 25 23,667
ix 18,4 20,4 20,4 19,733
La varianza explicada de los tratamientos sET2 resulta:
667,62333,13
13
)733,19(53
1
2
2 ==−
−≅
∑=i
i
ET
xs

166 Diseño de experimentos y análisis de varianza
La varianza explicada de los bloques sEB2 resulta:
9,214
6,8715
)733,19(35
1
2
2 ==−
−
≅∑
=jj
EB
xs
La varianza no explicada sN2 resulta:
25,3826
)13()15(
)733,19(5
1
23
12 ==−−
+−−
=∑∑
== jjiij
iN
xxxs
En la siguiente tabla se expresan estas varianzas. El lector puede verificar fácilmente los valores de F y sus correspondientes valores críticos. Considere α = 0,05.
Variaciones Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F F*
Entre tratamientos 87,6 4 21,9 6,7385 3,8379 Entre bloques 13,3333 2 6,6667 2,0513 4,4590 Error 26 8 3,25 Total 126,9333 14
Resulta entonces: FT > FT*; por lo tanto se rechaza la hipótesis nula de comparación de varian-zas (H0: 22
NET σσ = ) y se rechaza también la hipótesis nula de medias (H0: µ1 = µ2 = µ3).
Se puede afirmar entonces que las tres máquinas no tienen la misma productividad.
Además: FB < FB*; por lo tanto se acepta la hipótesis nula de comparación de varianzas (H0: 22NEB σσ = ) y se acepta también la hipótesis nula de medias (H0: µ1 = µ2 = µ3 = µ4 = µ5).
Se puede afirmar entonces que la productividad es la misma en los distintos niveles académicos de los empleados.
12.3.3 Análisis de varianza de dos factores, con interacción entre los factores. Nuevamente se consideran dos factores que actúan sobre las unidades experimentales: los trata-
mientos y el factor externo que se desea eliminar mediante la formación de bloques; pero esta vez se considera la posibilidad de que haya interacción entre los factores.
Se podría dar el caso, por ejemplo, de que un grupo de empleados de cierto nivel académico sean más productivos que un grupo de otro nivel, si operan cierta máquina; pero con las otras máqui-nas podrían tener menor productividad. Esto indicaría que hay interacción entre el nivel académico y el tipo de máquina.
Para probar si hay interacción entre los dos factores es necesario diseñar el experimento por blo-ques con al menos dos datos para cada combinación tratamiento – bloque.
De esta manera se pueden investigar las hipótesis:
Para los tratamientos: H0 : µ1 = µ2 = … = µk H1 : Al menos una media es diferente
Para los bloques: H0 : µ1 = µ2 = … = µn H1 : Al menos una media es diferente
Para la interacción: H0 : Los factores no interactúan respecto a la variable investigada. H1 : Los factores sí interactúan respecto a la variable investigada.
En este caso se consideran tres varianzas explicadas: de los tratamientos, de los bloques y de la interacción.

Diseño de experimentos y análisis de varianza 167
Si r es el número de datos en cada combinación tratamiento – bloque, y n el número de bloques en cada muestra, el número total de datos que hay en cada muestra es nr; por lo tanto la varianza ex-plicada de los tratamientos sET
2 se calcula con la expresión:
1
)(1
2
2
−
−⋅≅
∑=
k
xxrns
k
ii
ET
Al numerador se le conoce como suma de los cuadrados de los tratamientos (SST), y el de-nominador representa el número de grados de libertad. A este cociente también se le llama prome-dio de los cuadrados de los tratamientos (PPT).
La varianza explicada de los bloques se calcula con una expresión similar. El número de blo-ques es n, y el número de datos en cada bloque es kr. La varianza explicada de los bloques será enton-ces:
1
)(1
2
2
−
−⋅
≅∑
=
n
xxrks
n
jj
EB
Al numerador se le conoce como suma de los cuadrados de los bloques (SSB), y el denomina-dor representa el número de grados de libertad. A este cociente también se le llama promedio de los cuadrados de los bloques (PPB).
Se considera que hay interacción entre los dos factores que actúan sobre las unidades experi-mentales si la diferencia entre la media de los r datos de una combinación tratamiento – bloque y la media total ( xxij − ) difiere de la suma de dos diferencias: una entre la media del tratamiento corres-
pondiente y la media total )( xxi − , y otra entre la media del bloque correspondiente y la media total )( xx j − . Así, para todas las combinaciones tratamiento – bloque, estas diferencias miden la interac-
ción entre los factores. La interacción, para cada combinación tratamiento – bloque se mide entonces con la expresión:
I = ( xxij − ) – [ )()( xxxx ji −+− ]
Simplificando, cada interacción resulta:
I = xxxx jiij +−−
La interacción total se mide con la varianza explicada de la interacción, que se calcula enton-ces con la siguiente expresión:
)1()1(
)(1 1
2
2
−−
+−−
=∑∑
= =
kn
xxxxrs
k
i
n
jjiij
EI
Al numerador se le conoce como suma de los cuadrados de la interacción (SSI), y el denomi-nador representa el número de grados de libertad. A este cociente también se le llama promedio de los cuadrados de la interacción (PPI).
La varianza no explicada o error es:
)1(
)(1 1 1
2
2
−
−
=∑∑∑
= = =
rnk
xxs
k
i
n
j
r
hijijh
N
En esta última expresión, al numerador se le conoce como suma de los cuadrados del error

168 Diseño de experimentos y análisis de varianza
(SSE), y el denominador representa el número de grados de libertad. A este cociente también se le llama promedio de los cuadrados del error (PPE).
Para determinar si cada una de las tres varianzas explicadas es mayor que la varianza no expli-cada o varianza del error, se hacen tres Pruebas F de comparación de varianzas:
Para los tratamientos: H0 : 22NET σσ =
H1 : 22NET σσ >
Para los bloques: H0 : 22NEB σσ =
H1 : 22NEB σσ >
Para la interacción: H0 : 22NEI σσ =
H1 : 22NEI σσ >
Se aceptará cada hipótesis nula si:
*2
2
TN
ETT F
ss
F <=
*2
2
BN
EBB F
ss
F <=
*2
2
IN
EII F
ss
F <=
Si se acepta la hipótesis nula (H0: 22NET σσ = ), se estaría aceptando que las medias de los trata-
mientos no difieren significativamente, es decir, que las medias de los tratamientos son iguales (H0: µ1 = µ2 = … = µk).
Si se acepta la hipótesis nula (H0: 22NEB σσ = ), se estaría aceptando que las medias de los bloques
no difieren significativamente, es decir, que las medias de los bloques son iguales (H0: µ1 = µ2 = … = µn).
Si se acepta la hipótesis nula (H0: 22NEI σσ = ), se estaría aceptando que las interacciones medidas
en cada combinación tratamiento – bloque son muy pequeñas, es decir, que no hay interacción.
Tabla ANOVA
Los valores que se calculan para este análisis de varianza se expresan en la tabla 12.3.
Tabla 12.3. Tabla ANOVA de dos factores con interacción
Variaciones Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F F*
Entre tratamientos SST k – 1 PPT = SST / (k – 1) PPT / PPE FT* Entre bloques SSB n – 1 PPB = SSB / (n – 1) PPB / PPE FB* Interacción SSI (n – 1) (k – 1) PPI = SSI / [(n – 1) (k – 1)] PPI / PPE FI* Error SSE nk (r – 1) PPE = SSE / [nk (r – 1)] Total SSTOT nk – 1
Ejemplo 3:
El gerente de producción de una fábrica quiere evaluar tres máquinas. Para esto asigna cinco empleados a cada máquina, distribuyéndolos de acuerdo a su nivel académico, de manera tal que cada máquina sea operada por empleados de los cinco niveles en que se les ha clasificado

Diseño de experimentos y análisis de varianza 169
previamente. De esta forma ninguna máquina se verá favorecida al asignarle más operarios de mayor nivel académico. Como es probable que haya interacción entre el tipo de máquina y el nivel académico de los empleados, respecto a la productividad de éstos, se consideraron dos empleados para cada combinación tipo de máquina – nivel académico. En la tabla adjunta se muestra la producción diaria.
M1 M2 M3 14 20 15 1 16 16 17 11 21 18 2 13 22 21 18 17 15 3 20 16 15 17 22 21 4 21 21 23 20 25 24 5 26 28 25
¿Se puede afirmar que las tres máquinas tienen la misma productividad?
Se plantean las siguientes hipótesis:
Para los tratamientos: H0 : µ1 = µ2 = µ3 (máquinas) H1 : Al menos una media es diferente
Para los bloques: H0 : µ1 = µ2 = µ3 = µ4 = µ5 (niveles académicos) H1 : Al menos una media es diferente
Para la interacción: H0 : No hay interacción entre el tipo de máquina y el nivel académico de los empleados, respecto a la productividad de éstos.
H1 : Sí hay interacción entre dichos factores.
A continuación se calculan las medias para cada tratamiento, para cada bloque, la media total y la media de cada combinación nivel académico – tipo de máquina (entre paréntesis):
M1 M2 M3 jx
14 20 15 (15) (18) (16) 16,333 1 16 16 17 11 21 18 (12) (21,50) (19,50) 17,667 2 13 22 21 18 17 15 (19) (16,50) (15) 16,833 3 20 16 15 17 22 21 (19) (21,50) (22) 20,833 4 21 21 23 20 25 24 (23) (26,50) (24,50) 24,667 5 26 28 25
ix 17,60 20,80 19,40 19,267

170 Diseño de experimentos y análisis de varianza
Aplicando las fórmulas recientemente descritas para calcular las tres varianzas explicadas y la varianza no explicada o error, se completa la tabla ANOVA que se muestra a continuación:
Variaciones Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F F*
Entre tratamientos 51,4667 2 25,7333 7,0182 3,6823 Entre bloques 292,2 4 73,05 19,9227 3,0556 Interacción 97,2 8 12,15 3,3136 2,6408 Error 55 15 3,6667 Total 495,8667 29
Resulta entonces: FT > FT*; por lo tanto se rechaza la hipótesis nula de comparación de varian-zas (H0: 22
NET σσ = ) y se rechaza también la hipótesis nula de medias (H0: µ1 = µ2 = µ3).
Se puede afirmar entonces que las tres máquinas no tienen la misma productividad.
Además: FB > FB*; por lo tanto se rechaza la hipótesis nula de comparación de varianzas (H0: 22NEB σσ = ) y se rechaza también la hipótesis nula de medias (H0: µ1 = µ2 = µ3 = µ4 = µ5).
Se puede afirmar entonces que la productividad no es la misma en los distintos niveles académi-cos de los empleados.
Finalmente, FI > FI*; por lo tanto se rechaza la hipótesis de que no hay interacción. Se puede afirmar entonces que el tipo de máquina y el nivel académico sí interactúan, lo cual afecta la productividad de los empleados.
12.4 Análisis de varianza en Excel
12.4.1 Análisis de varianza de un factor En este apartado se va a resolver el ejemplo 1, resuelto en el apartado 12.3.1.Por comodidad, se
repite el texto y el planteamiento de este problema.
Ejemplo 1:
Se quiere evaluar tres métodos de capacitación del personal de una fábrica. El jefe de capacita-ción selecciona 15 nuevos obreros y los distribuye aleatoriamente en los tres métodos. Una vez terminada la capacitación, los obreros comienzan a trabajar y se les anota la producción semanal de cada uno de ellos. ¿Hay diferencia de eficacia entre los tres métodos de capacitación?
Producción diaria Método 1 16 17 19 13 21 Método 2 20 25 17 18 21 Método 3 19 24 16 19 17
La hipótesis que se plantearon son:
H0 : µ1 = µ2 = µ3 H1 : Al menos una media es diferente
Ingresando al menú Herramientas/Análisis de datos/Análisis de varianza de un factor, Excel muestra el cuadro de diálogo de la figura 12.4. En este cuadro ya se han ingresado los datos del problema, que en la hoja de cálculo figuran entre las celdas A1 y E3.
Aceptando los datos ingresados en el cuadro de diálogo, Excel presenta dos tablas: la primera es un resumen de los datos del problema, incluyendo medias y varianzas; y la segunda es la tabla ANOVA del problema, como se muestra a continuación:

Diseño de experimentos y análisis de varianza 171
Figura 12.4. Cuadro de diálogo del ANOVA de un factor
La tabla ANOVA que presenta Excel tiene una columna más que la tabla ANOVA presentada en el apartado 12.3.1, con P = 0,3337; que representa la probabilidad de que se obtenga un valor de F mayor o igual a 1,2042. Lógicamente, si esta probabilidad es mayor que α; se rechazará H0.
RESUMEN Grupos Cuenta Suma Promedio Varianza
Fila 1 5 86 17.2 9.2 Fila 2 5 101 20.2 9.7 Fila 3 5 95 19 9.5
ANÁLISIS DE VARIANZA Origen de las variaciones
Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F Probabilidad Valor crítico
para F Entre grupos 22,8 2 11,4 1,2042 0,3337 3,8853 Dentro de los grupos 113,6 12 9,4667 Total 136,4 14
Resulta: F < F*; por lo tanto se acepta la hipótesis nula (H0: 22NE σσ = ) y se acepta también la
hipótesis nula (H0: µ1 = µ2 = µ3).
Se puede afirmar entonces que los tres métodos de capacitación son igualmente eficientes.
12.4.2 Análisis de varianza de dos factores, sin interacción. En este apartado se va a resolver el ejemplo 2, resuelto en el apartado 12.3.2. Por comodidad, se
repite el texto y el planteamiento de este problema.
Ejemplo 2:
El gerente de producción de una fábrica quiere evaluar tres máquinas. Para esto asigna cinco empleados a cada máquina, distribuyéndolos de acuerdo a su nivel académico, de manera tal que cada máquina sea operada por empleados de los cinco niveles en que se les ha clasificado previamente. De esta forma ninguna máquina se verá favorecida al asignarle más operarios de mayor nivel académico. En la tabla adjunta se muestra la producción diaria.

172 Diseño de experimentos y análisis de varianza
¿Se puede afirmar que las tres máquinas tienen la misma productividad?
Máq. 1 Máq. 2 Máq. 3 Nivel 1 16 17 20 Nivel 2 15 20 17 Nivel 3 20 19 17 Nivel 4 19 22 23 Nivel 5 22 24 25
En primer lugar, se plantean las siguientes hipótesis:
Para los tratamientos: H0 : µ1 = µ2 = µ3 (máquinas) H1 : Al menos una media es diferente
Para los bloques: H0 : µ1 = µ2 = µ3 = µ4 = µ5 (niveles académicos) H1 : Al menos una media es diferente
Ingresando al menú Herramientas/Análisis de datos/Análisis de varianza de dos factores con una sola muestra por grupo, Excel muestra el cuadro de diálogo de la figura 12.5. En este cua-dro ya se han ingresado los datos del problema, que están entre las celdas B2 y D6.
Figura 12.5. Cuadro de diálogo del análisis de varianza con dos factores, sin interacción.
Aceptando los datos ingresados en el cuadro de diálogo, Excel presenta dos tablas: la primera es un resumen de los datos del problema, incluyendo medias y varianzas; y la segunda es la tabla ANOVA del problema, como se muestra a continuación:
RESUMEN Cuenta Suma Promedio Varianza Fila 1 3 49 16.3333 2.3333 Fila 2 3 50 16.6667 26.3333 Fila 3 3 50 16.6667 2.3333 Fila 4 3 63 21 3 Fila 5 3 73 24.3333 6.3333
Columna 1 5 85 17 17.5 Columna 2 5 105 21 15.5 Columna 3 5 95 19 15
Como se puede ver en esta tabla y en la tabla ANOVA que se muestra a continuación, lo que Excel denomina filas corresponde a los bloques (niveles académicos) y lo que denomina colum-nas corresponde a los tratamientos (tipos de máquina).

Diseño de experimentos y análisis de varianza 173
ANÁLISIS DE VARIANZA Origen de las variaciones
Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F Probabilidad Valor crítico
para F Filas 151,3333 4 37,8333 7,4426 0,0084 3,8379 Columnas 40 2 20 3,9344 0,0646 4,4590 Error 40,6667 8 5,08333 Total 232 14
Para las filas resulta: F > F*; por lo tanto se rechaza la hipótesis nula (H0: µ1 = µ2 = µ3).
Se puede afirmar entonces que las tres máquinas no tienen la misma productividad.
Para las columnas: F < F*; por lo tanto se acepta la hipótesis nula (H0: µ1 = µ2 = µ3 = µ4 = µ5).
Se puede afirmar entonces que la productividad es la misma en los distintos niveles académicos de los empleados.
El lector debe llegar a estas mismas dos conclusiones interpretando los valores de Probabilidad, tal como se hizo en el apartado anterior.
12.4.3 Análisis de varianza de dos factores, con interacción. En este apartado se va a resolver el ejemplo 3, resuelto en el apartado 12.3.3. Por comodidad, se
repite el texto y el planteamiento de este problema.
Ejemplo 3:
El gerente de producción de una fábrica quiere evaluar tres máquinas. Para esto asigna cinco empleados a cada máquina, distribuyéndolos de acuerdo a su nivel académico, de manera tal que cada máquina sea operada por empleados de los cinco niveles en que se les ha clasificado previamente. De esta forma ninguna máquina se verá favorecida al asignarle más operarios de mayor nivel académico. Como es probable que haya interacción entre el tipo de máquina y el nivel académico de los empleados, respecto a la productividad de éstos, se consideraron dos empleados para cada combinación tipo de máquina – nivel académico. En la tabla adjunta se muestra la producción diaria.
M1 M2 M3 14 20 15 1 16 16 17 11 21 18 2 13 22 21 18 17 15 3 20 16 15 17 22 21 4 21 21 23 20 25 24 5 26 28 25
¿Se puede afirmar que las tres máquinas tienen la misma productividad?
Se plantean las siguientes hipótesis:
Para los tratamientos: H0 : µ1 = µ2 = µ3 (máquinas) H1 : Al menos una media es diferente
Para los bloques: H0 : µ1 = µ2 = µ3 = µ4 = µ5 (niveles académicos) H1 : Al menos una media es diferente

174 Diseño de experimentos y análisis de varianza
Para la interacción: H0 : No hay interacción entre el tipo de máquina y el nivel académico de los empleados, respecto a la productividad de éstos.
H1 : Sí hay interacción entre dichos factores.
Ingresando al menú Herramientas/Análisis de datos/Análisis de varianza de dos factores con varias muestras por grupo, Excel muestra el cuadro de diálogo de la figura 12.6. En este cuadro ya se han ingresado los datos del problema.
Figura 12.6. Cuadro de diálogo del análisis de varianza con dos factores, con interacción.
Hay dos particularidades en el cuadro de diálogo de Excel para este análisis que incluye la posi-ble interacción entre los factores (figura 12.6). La primera es que en el rango de entrada deben incluirse no sólo los datos (valores numéricos) sino también los títulos de las filas y columnas. A continuación se presentan los datos de este problema, tal como se escribieron en la hoja de cál-culo de Excel:
A B C D 1 M1 M2 M3 2 1 14 20 15 3 16 16 17 4 2 11 21 18 5 13 22 21 6 3 18 17 15 7 20 16 15 8 4 17 22 21 9 21 21 23 10 5 20 25 24 11 26 28 25
La segunda particularidad es la opción Fila por muestra del mismo cuadro de diálogo de la figu-ra 12.6, donde se debe indicar el número de datos que hay en cada combinación tratamiento – bloque. En este problema hay 2 datos por cada combinación.
Aceptando los datos ingresados en el cuadro de diálogo, Excel presenta dos tablas: la primera es un resumen de los datos de cada bloque y de cada tratamiento, incluyendo sus respectivas me-dias y varianzas; y la segunda es la tabla ANOVA del problema, como se muestra a continua-ción:
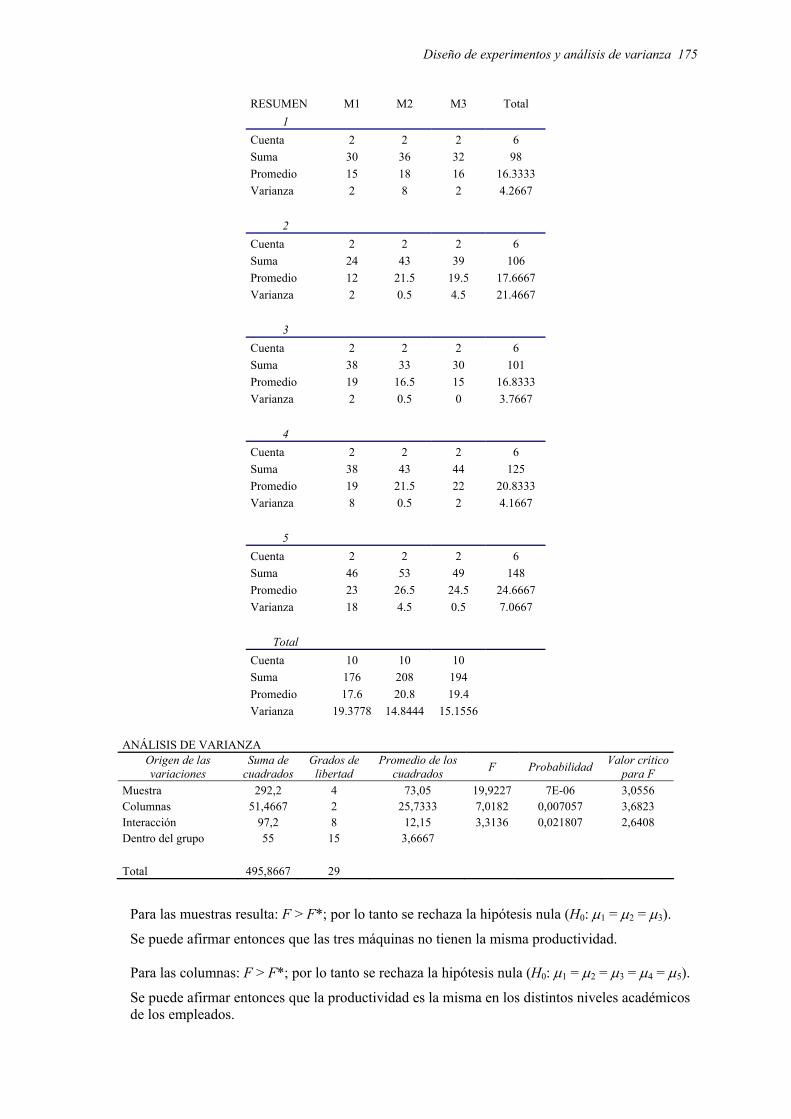
Diseño de experimentos y análisis de varianza 175
RESUMEN M1 M2 M3 Total 1
Cuenta 2 2 2 6 Suma 30 36 32 98 Promedio 15 18 16 16.3333 Varianza 2 8 2 4.2667
2 Cuenta 2 2 2 6 Suma 24 43 39 106 Promedio 12 21.5 19.5 17.6667 Varianza 2 0.5 4.5 21.4667
3 Cuenta 2 2 2 6 Suma 38 33 30 101 Promedio 19 16.5 15 16.8333 Varianza 2 0.5 0 3.7667
4 Cuenta 2 2 2 6 Suma 38 43 44 125 Promedio 19 21.5 22 20.8333 Varianza 8 0.5 2 4.1667
5 Cuenta 2 2 2 6 Suma 46 53 49 148 Promedio 23 26.5 24.5 24.6667 Varianza 18 4.5 0.5 7.0667
Total Cuenta 10 10 10 Suma 176 208 194 Promedio 17.6 20.8 19.4 Varianza 19.3778 14.8444 15.1556
ANÁLISIS DE VARIANZA
Origen de las variaciones
Suma de cuadrados
Grados de libertad
Promedio de los cuadrados F Probabilidad Valor crítico
para F Muestra 292,2 4 73,05 19,9227 7E-06 3,0556 Columnas 51,4667 2 25,7333 7,0182 0,007057 3,6823 Interacción 97,2 8 12,15 3,3136 0,021807 2,6408 Dentro del grupo 55 15 3,6667 Total 495,8667 29
Para las muestras resulta: F > F*; por lo tanto se rechaza la hipótesis nula (H0: µ1 = µ2 = µ3).
Se puede afirmar entonces que las tres máquinas no tienen la misma productividad.
Para las columnas: F > F*; por lo tanto se rechaza la hipótesis nula (H0: µ1 = µ2 = µ3 = µ4 = µ5).
Se puede afirmar entonces que la productividad es la misma en los distintos niveles académicos de los empleados.

176 Diseño de experimentos y análisis de varianza
Para la interacción: F > F*; por lo tanto se rechaza la hipótesis de que los factores interactúan.
Se puede afirmar entonces que el tipo de máquina y el nivel académico sí interactúan, lo cual afecta la productividad de los empleados.
El lector debe llegar a estas mismas tres conclusiones interpretando los valores de Probabilidad de la tabla ANOVA, tal como se hizo en el ejemplo 1.

Diseño de experimentos y análisis de varianza 177
Problemas propuestos. 1. El Departamento de Investigación de la Facultad de Agronomía de una universidad quiere investi-
gar el crecimiento de un tipo de planta sometida a uno de tres tipos de riego y a uno de cuatro fer-tilizantes. Considerando que no hay interacción entre el tipo de riego y el fertilizante, se diseñó un experimento aleatorizado por bloques, sembrando doce plantas del mismo tamaño en un terreno cuya calidad del suelo es homogénea, de tal manera que cada planta fue sometida a un tipo de rie-go y a un fertilizante. En la siguiente tabla se muestran los crecimientos de las plantas (en cm.) después de 6 meses.
Fertilizante Tipo de riego 1 2 3 4
A 52 30 38 50 B 44 55 54 45 C 36 60 35 48
Determine si el crecimiento es el mismo, independientemente del tipo de riego y del fertilizante. Considere α = 0,05.
2. Se seleccionaron muestras aleatorias independientes de tres poblaciones. Los datos se muestran a continuación, junto con la salida de la tabla ANOVA de un software. Se considera α = 0,05.
ANOVA
Fuente Suma de cuadrados GL Promedio de los cuadrados F P Entre grupos 7,726666667 2 3,863333333 2,79502 0,138739 Dentro de los grupos 8,293333333 6 1,382222222 Total 16,02 8
a) Localice varianza entre las muestras. ¿Qué tipo de variabilidad se mide con esta cantidad? b) Localice la varianza dentro de las muestras ¿Qué tipo de variabilidad se mide? c) ¿Se acepta Ho: µ1=µ2= µ3 contra la hipótesis alternativa que al menos una media poblacional
difiere de las otras dos? ¿Por qué? d) ¿A qué conclusión llega?
3. El jefe de un taller quiere investigar si el promedio de resistencia de unas láminas es el mismo pa-ra tres temperaturas y tres presiones aplicadas durante la producción. A continuación se muestran los datos obtenidos y la tabla ANOVA de Excel, incompleta. Se considera α = 0,05.
a) Complete la tabla ANOVA b) ¿A qué conclusiones puede llegar?
Temperatura Presión Baja Mediana Alta
66 83 80 86 92 121 56 82 77 81 90 106 Baja
72 88 93 81 119 121 109 98 131 136 53 74 103 64 148 127 63 73 Mediana
100 113 152 146 67 93 164 140 79 64 59 58 133 154 67 108 48 51 Alta
132 162 45 72 50 58
Muestra 1 Muestra 2 Muestra 3 2.1 4.4 1.1 3.3 2.6 0.2 0.2 3 2

178 Diseño de experimentos y análisis de varianza
ANÁLISIS DE VARIANZA
Origen de las Suma de Grados de Promedio de Valor crítico
variaciones cuadrados libertad los cuadrados F Probabilidad
para F
Muestra 0,006616254 Columnas 1,92315E-07 Interacción 39715,77778 1,07475E-16
Dentro del grupo 8187,666667
Total 58041,33333 4. Un fabricante de llantas está investigando el desgaste de tres marcas distintas. Para esto se selec-
cionaron 6 llantas de cada marca y se colocaron en 18 autos, en la misma posición. Después de re-correr 5 000 km. se tuvieron los siguientes desgastes:
Marca A 211 231 235 204 222 208 Marca B 145 168 161 134 187 125 Marca C 190 210 230 160 205 201
Diga si existe evidencia estadística para concluir que las tres marcas de llanta no difieren en la re-sistencia al desgaste. Excel proporciona la siguiente tabla ANOVA para un diseño completamente aleatorizado con un nivel de significancia (α) del 5%.
Variaciones Suma de cuadrados Grados de lib. Prom. cuadrados F Prob. F* Entre grupos 17422,86111 2 8711,43055 20,0784606 5,737E-05 3,68231667Dentro de los grupos 6508,041667 15 433,869444 Total
Respuesta: No, se afirma que las tres marcas de llanta sí difieren en la resistencia al desgaste.
5. Un profesor de matemáticas quiere investigar si el aprendizaje en un determinado tema es el mis-mo empleando cualquiera de tres métodos: A, B o C. Se escogen aleatoriamente treinta alumnos de distintos colegios, y se les distribuye también aleatoriamente en tres aulas, de tal manera que en cada una se les enseña el tema con un método. En la siguiente tabla se muestran las evaluaciones de los alumnos después de concluidas las clases.
Método A 15 16 18 11 15 14 14 13 16 14 Método B 13 18 19 15 17 16 12 15 16 18 Método C 19 17 20 14 18 16 15 15 17 18
¿Se puede afirmar que con los tres métodos se obtiene el mismo resultado? Considere α = 0,05.
Respuesta: Sí se puede afirmar que con los tres métodos se obtiene el mismo resultado
6. Cuando se hace un análisis de varianza se investiga:
a) si las varianzas de varias poblaciones difieren, para comparar eficiencias. b) si las medias de varias poblaciones difieren, lo cual se constata comparando las varianzas de
las muestras extraídas de dichas poblaciones. c) si las medias de varias muestras difieren. d) ninguna de las anteriores.
7. Cuando se hace el análisis de varianza con un solo factor, ¿la variabilidad de todos los datos de-pende de la variabilidad de los tratamientos o de la variabilidad dentro de los tratamientos?
8. Cuando se hace el análisis de varianza con dos factores que no interactúan, ¿importa si se denomi-nan indistintamente los tratamientos y los grupos?

Regresión lineal simple y correlación 179
Capítulo 13. Regresión lineal simple y correlación.
13.1 Introducción. El propósito de este capítulo es determinar la relación que existe entre dos variables X e Y, que
representan dos características de un universo, con el propósito de predecir una en términos de la otra. Se podría establecer, por ejemplo, qué relación hay entre:
• El gasto en publicidad y las ventas mensuales en una empresa. • La resistencia del cemento y el tiempo de envejecimiento. • La rapidez en una línea de producción y el porcentaje de unidades defectuosas. • Los residuos de cloro en una piscina y el número de horas después de que ha sido tratada. • La resistencia a la compresión de un suelo y la profundidad de éste. • La frecuencia de reparaciones en un auto y la edad del auto.
13.2 Regresión. En cada uno de los ejemplos dados se puede ver que existe una asociación entre una variable X,
llamada variable independiente o de predicción, y otra Y, llamada variable dependiente o variable respuesta. Evidentemente las variables de predicción serán, para cada ejemplo:
• El gasto de publicidad. • El tiempo de envejecimiento del cemento. • La rapidez en la línea de producción. • El número de horas después que ha sido tratada la piscina. • La profundidad del suelo. • La edad del auto.
En el análisis de regresión sólo se examinan variables entre las cuales la relación no es causal. En los ejemplos mencionados, no es posible establecer una relación causa-efecto entre las dos varia-bles. No sería correcto decir, por ejemplo, que las ventas mensuales y en una empresa son altas debido al alto gasto de publicidad x, pues, aunque las ventas sí dependan de la publicidad, no las causan, ya que hay muchas otras razones por las que se hacen las ventas. Tampoco se puede decir que un cemen-to tiene una resistencia y debido a que se ha envejecido un tiempo x, pues la resistencia depende de ese tiempo, pero el tiempo de envejecimiento no causa dicha resistencia. Ni se puede afirmar que en una piscina hay y partes por millón de cloro debido a que hace exactamente x horas fue tratada; esto último influye pero no es la causa. Así, en muchas otras situaciones, no se debe confundir una influencia que pueda ejercer una variable sobre otra, con causalidad. Un caso donde sí hay una relación causa-efecto es el siguiente: si a un motor se le inyecta cierto flujo de gasolina, adquirirá una velocidad determina-da. Pero esto no se puede estudiar mediante un análisis estadístico; de esto se ocupa otra ciencia.
La palabra regresión fue usada por Francis Galton (1822–1911) cuando notó que las caracterís-ticas promedio de la siguiente generación de un grupo en particular tendían hacia las características promedio de la población general, más que hacia las de la generación previa de ese grupo. A esta ten-dencia le llamó regresión hacia la media de la población.
Sean X e Y variables de predicción y respuesta, respectivamente. Según lo dicho antes, no será posible predecir con exactitud un valor de Y para ciertos valores de X; pero sí se podrá estimar un promedio de Y para todos los casos en que X tome un determinado valor x. Para poder hacer esto será

180 Regresión lineal simple y correlación
necesario tomar una serie de mediciones y1, y2, ..., yn, correspondientes a los valores x1, x2, ..., xn, y es-timar una función matemática que describa el comportamiento de la variable respuesta, dados los valo-res de la variable de predicción. Una forma muy práctica para vislumbrar qué tipo de función puede ser útil es representar todas las parejas de valores (x, y) en un sistema de coordenadas cartesianas. A este gráfico se le conoce como diagrama de dispersión. El siguiente paso es estimar aquella función empleando un método muy aceptado por todos, denominado: Método de los mínimos cuadrados. Si dicha función es lineal, se le denomina modelo lineal simple. Lineal, pues lo es en los parámetros que la determinan, y simple porque emplea una sola variable de predicción (X).
Se puede afirmar que la variable de predicción (X) no es una variable aleatoria pues sus valores son fijos o se dan previamente. La variable de predicción está controlada, y por lo tanto no existen errores de observación. En la práctica, esto último no siempre es cierto, pero tales errores resultan des-preciables. En cambio la variable respuesta (Y) sí es aleatoria pues los valores que toma no están de-terminados.
13.3 La recta de regresión de la población. Si la relación entre las variables X e Y es lineal, el modelo que más se ajusta es la recta de regre-
sión de la población, que se puede estimar mediante la recta de regresión de una muestra, por el méto-do de los mínimos cuadrados.
La recta de regresión de la población puede expresarse de la siguiente manera:
Yi = α + β Xi + εi
donde α y β son parámetros de la población y εi es la diferencia entre Yi y el valor esperado de Y, dado Xi, es decir:
εi = Yi – µ Y \ Xi
Así, se deduce:
XXY βαµ +=/
Esta ecuación es conocida como recta de regresión de Y con respecto a X. Para cada valor de X, la ordenada de la recta de regresión representa la media de un número teóricamente infinito de valo-res de Y.
El parámetro α , que es la intersección de la recta con el eje Y, expresa el valor promedio de Y que corresponde a X = 0. El parámetro β, que es la pendiente de la recta, expresa cuánto se incrementa Y por cada unidad de incremento de X.
Generalmente la distribución de Y para cada valor de X es aproximadamente normal, y la des-viación estándar σ Y / X es la misma en cada caso (homoscedasticidad), como se aprecia en la figura 13.1, donde se muestra la distribución normal de Y alrededor de µY\X, para tres valores de X. Se asume entonces que los errores tienen la misma variabilidad para todos los valores de X. Se asume también que los errores son independientes para cada valor de X.
µ Y \ X = α + β X
X
Y
x1xnx2
Figura 13.1. Suposiciones en la recta de regresión

Regresión lineal simple y correlación 181
13.4 Método de los mínimos cuadrados. A partir de los datos de una muestra es posible estimar la recta de regresión de la población, de-
terminando la recta de regresión de la muestra, por el método de los mínimos cuadrados. A esta recta se le llama también recta de mínimos cuadrados. Este método determina los parámetros de la recta minimizando la suma de los cuadrados de las diferencias entre los valores que toma la variable res-puesta (y1, y2, ..., yn) y aquellos que determina la ecuación de regresión.
En la figura 13.2 se muestra un diagrama de dispersión y una recta (y = a + bx) ajustada a dicho diagrama, donde a y b son los estimadores de los parámetros α y β.
y = a + b xy
x
*e1 = y1 - y'1
**
* * *
*
***
(x1, y1)
(xn, yn)*ei = yi - y'i
(xi, yi)
Figura 13.2. Errores de estimación de la recta de regresión
En este gráfico, las diferencias entre los valores de Y observados y los correspondientes que de-termina la ecuación de la recta Y’, están representados por:
ei = yi – y’i = yi – (a + bxi) para: i = 1, 2, ..., n.
A estas diferencias se les denomina errores de estimación. Puede decirse que ei es un estimador de εi.
El método de los mínimos cuadrados determina los parámetros de la ecuación de la recta que minimiza ∑ e2
i. Esta sumatoria será mínima cuando:
02
=∂
∂ ∑aei
02
=∂
∂ ∑bei
Despejando a y b de estas ecuaciones resulta:
( )22
2
∑∑∑ ∑ ∑∑
−
−=
ii
iiiii
xxn
yxxyxa ; ( )22 ∑∑
∑ ∑ ∑−
−=
ii
iiii
xxn
yxyxnb
El empleo de estas fórmulas debe ser simple para un estudiante universitario; aunque sí resulta engorroso. De hecho, es mucho más práctico emplear calculadoras que traen incorporadas estas fór-mulas, además de Excel u otros softwares estadísticos como SPSS, Minitab, Statistics o Statgraphics.
Ejemplo:
Se afirma que los alumnos que tienen mejores calificaciones promedio en la universidad, tienen posibilidades de conseguir mejores trabajos y por lo tanto mejores salarios iniciales. Los datos que se muestran en la siguiente tabla representan los índices académicos acumulados (I.A.A.) de

182 Regresión lineal simple y correlación
15 alumnos egresados de la Facultad de Ingeniería de una universidad y sus correspondientes sueldos iniciales (en soles).
I.A.A. 12,20 13,12 13,94 14,76 13,12 14,50 12,71 11,73 Sueldo inicial 1850 2000 2150 2250 2100 2150 1800 1900 I.A.A. 12,51 15,52 11,28 16,36 12,92 12,10 11,32 Sueldo inicial 1950 2200 1550 2300 1900 1700 1650
Empleando las fórmulas que determinan a y b, se determina la recta de mínimos cuadrados:
y = 166,8 + 136,04x
En la figura 13.3 se representan el diagrama de dispersión y la recta de mínimos cuadrados. Ésta es una estimación de la recta de regresión de la población, conformada en este ejemplo por to-dos los alumnos egresados de la Facultad de Ingeniería.
Los valores que se obtengan de Y para determinados valores de X, es decir, para determinados índices académicos acumulados, son las estimaciones de las medias de los salarios iniciales co-rrespondientes a dichos índices.
El valor que toma b (la pendiente de la recta) se interpreta de la siguiente manera: por cada pun-to que un alumno mejore su I.A.A., puede esperar que su salario mejore en 136,04 soles.
Es importante tener en cuenta que esta recta estimada puede no ser apropiada para valores de la variable de predicción que no estén comprendidos en el intervalo de la muestra, es decir, entre 11,28 y 16,36.
1400
1600
1800
2000
2200
2400
2600
11 11.5 12 12.5 13 13.5 14 14.5 15 15.5 16 16.5 17
Figura 13.3. Diagrama de dispersión y recta de mínimos cuadrados
13.5 Propiedades de la recta de mínimos cuadrados A continuación se deducen algunas propiedades de la recta de mínimos cuadrados. A partir de la
primera ecuación diferencial se puede deducir:
2(∑yi – a – bxi)(–1) = 0 ∑yi – na – b∑ xi = 0
Dividiendo entre n:
0=−− ∑∑n
xba
n
y ii

Regresión lineal simple y correlación 183
Entonces:
xbay +=
Esto indica que la recta estimada pasa por el centroide ),( yx .
Los valores de Y determinados por la recta de mínimos cuadrados deberían denominarse y’, ya que se trata de estimaciones. Para simplificar la terminología, se usará la comilla (’) sólo en las situa-ciones donde se requiera para fines de claridad.
La media de los valores de Y determinados por la recta de mínimos cuadrados puede expresarse de la siguiente manera:
E(y’) = E(a + bx) = E(a) + E(bx) = a + bE(x)
Es decir:
yxbay =+='
Dado este último resultado, se puede deducir fácilmente:
0''
')'( =−=
−=−=−= ∑∑∑ ∑∑∑ yy
ny
ny
nyyyye iiiiiii
Esto indica que la suma de los errores positivos es igual a la suma de los errores negativos, lo cual resulta útil para trazar visualmente la recta de mínimos cuadrados sobre un diagrama de disper-sión.
13.6 Medidas de variabilidad En el análisis de regresión, la variación total de los valores Y alrededor de su media Y se puede
dividir en dos partes:
• la variabilidad de los valores estimados Y’ respecto a la media Y , conocida como variación de la regresión o variación explicada, pues se explica por la relación que hay entre X e Y.
• la variabilidad de los valores Y respecto a los valores estimados Y’, conocida como variación del error o variación no explicada, pues no se explica por la relación que hay entre X e Y, si-no por otros factores.
Para medir la variación total se emplea la suma total de cuadrados (SST):
∑ −= 2)( yySST i
Para medir la variación de la regresión se emplea la suma de cuadrados de la regresión (SSR):
∑ −= 2)'( yySSR i
Para medir la variación del error se emplea la suma de cuadrados del error (SSE):
∑ −= 2)'( yySSE i
Los valores de Y que corresponden a un determinado valor de X, tienen una desviación estándar sY / X que mide la variabilidad del error que se comete al medir Y en vez de Y’:
eiii
XY sn
en
yys =
−=
−
−= ∑∑
22)'( 22
/
A sY \ X se le denomina desviación estándar del error.
El denominador es n – 2, pues se pierden 2 grados de libertad al estimar los parámetros α y β mediante los estimadores a y b.

184 Regresión lineal simple y correlación
En la figura 13.5 se expresan estas tres medidas de variabilidad y se ve claramente que:
SST = SSR + SSE
y = a + b xy
x
*y'i
yi
xi
∑ −= 2)'( yySSR i
∑ −= 2)'( yySSE i
∑ −= 2)( yySST i
Y
Figura 13.5. Medidas de variación
Se define el coeficiente de determinación como el cociente de la suma de cuadrados de la re-gresión y la suma de cuadrados total:
SSTSSRr =2
Este coeficiente de determinación mide la fracción de la variación total de Y que es explicada por la variable X. Se deduce que mientras más se acerquen los Y’ estimados a los Y observados, es de-cir, mientras más concentrado esté el diagrama de dispersión alrededor de la recta de mínimos cuadra-dos, mayor será el coeficiente de determinación, pues menor será la variación de los errores de estima-ción. Por lo tanto, el coeficiente de determinación mide la bondad del ajuste de la recta de regresión.
Ejemplo:
En el ejemplo del primer sueldo de los ingenieros recién egresados de una universidad se tiene:
X Y Y' Y –Y Y' –Y 12,20 1850 1826,48 -113,33 -136,86 13,12 2000 1951,63 36,67 -11,70 13,94 2150 2063,19 186,67 99,85 14,76 2250 2174,74 286,67 211,40 13,12 2100 1951,63 136,67 -11,70 14,50 2150 2139,37 186,67 176,03 12,71 1800 1895,86 -163,33 -67,48 11,73 1900 1762,54 -63,33 -200,79 12,51 1950 1868,65 -13,33 -94,68 15,52 2200 2278,13 236,67 314,79 11,28 1550 1701,32 -413,33 -262,01 16,36 2300 2392,40 336,67 429,07 12,92 1900 1924,43 -63,33 -38,91 12,10 1700 1812,87 -263,33 -150,46 11,32 1650 1706,76 -313,33 -256,57
Los valores de la tercera columna (Y’) corresponden a los valores estimados con la recta de re-gresión. Por lo tanto:

Regresión lineal simple y correlación 185
∑ −= 2)( yySST i = 727 333,33
∑ −= 2)'( yySSR i = 600 312,84
8254,033,33372784,3126002 ==r
Se interpreta que el 82,54% de la variación de los primeros sueldos de esa muestra de exalum-nos se puede explicar por la variabilidad de los índices académicos acumulados que tuvieron en la universidad; y por lo tanto sólo el 17,46% de la variabilidad de dichos sueldos se pueden atri-buir a otros factores.
13.7 Estimaciones de intervalo para la regresión. La recta de mínimos cuadrados proporciona el método más eficaz para estimar la media de la
variable respuesta (Y), para un valor específico de la variable de predicción (X); es decir, para estimar µY\X . Estas estimaciones, que denominamos y’, o y simplemente, son puntuales.
Pero, para distintas muestras que se extraigan, se determinarán distintas rectas de mínimos cua-drados. Si se tomaran n muestras de la población, se obtendrían n estimaciones y’ diferentes para cada valor de X. Se puede demostrar que, para cada valor que tome X, Y’ se distribuye normalmente alrede-dor de µY\X. Entonces, se podría hacer una estimación de intervalo para µY\X, de la misma forma como se hizo para µ en el capítulo 11. También se podría hacer una estimación de intervalo para Y, dado un valor de X, pues ya se ha asumido que Y se distribuye normalmente alrededor de µY\X.
Todas las estimaciones de intervalo que se puedan hacer de µY\X para distintos valores de X, se suelen expresar gráficamente mediante una banda de confianza de µY\X ; de la misma manera se pue-de graficar una banda de confianza de Y correspondiente a los intervalos de confianza de Y para de-terminados valores de X, como se puede apreciar en la figura 13.6.
Banda de confianza para µ Y/X
Banda de confianza para Y
Figura 13.6. Bandas de confianza
13.8 Correlación lineal. El objetivo del análisis de regresión es predecir la variable dependiente o respuesta Y basándose
en la variable de predicción o independiente X; en cambio, el objetivo del análisis de correlación es medir el grado de asociación que hay entre dichas variables.
Para medir el grado de asociación lineal que hay entre dos variables X e Y, se define el coefi-ciente de correlación (ρ), de tal forma que: –1 < ρ < +1.

186 Regresión lineal simple y correlación
En la figura 13.7 se muestran tres tipos diferentes de asociación entre las variables X e Y. Se puede apreciar que el valor 1 indica una correlación perfecta entre X e Y, mientras que el signo, que coincide con el signo de la pendiente de la recta de regresión, indica si la relación es directa (+) o in-versa (–). Si r = 0, se dice que no existe ninguna relación lineal entre X e Y.
y
x
**
*
***
* *
***
y
x
*
** * *
*
*
* **
x
y
**
** **
** *
ρ = +1 ρ = -1 ρ = 0
Figura 13.7. Tipos de correlación
En el análisis de correlación no se distingue entre las dos variables; tanto X como Y son aleato-rias. Además, para una muestra, se supone que los valores que tome X, dado un valor de Y, también se distribuyen normalmente.
El coeficiente de correlación se puede estimar a partir del coeficiente de determinación, conside-rando el signo de la pendiente de la recta de regresión:
2rr ±=
También se puede obtener r a partir de la muestra que se usa para determinar los estimadores a y b, mediante la siguiente fórmula:
] )([ ])([ 2222 ∑∑∑∑
∑ ∑∑−−
−
=iiii
iiii
yynxxn
yxyxnr
Como el coeficiente de correlación es igual a la raíz cuadrada del coeficiente de determinación, se puede afirmar que r, además de medir el grado de asociación lineal entre dos variables, también mi-de la bondad del ajuste de la recta de regresión.
Ejemplo:
En el ejemplo del primer sueldo de los ingenieros recién egresados de una universidad, el coefi-ciente de correlación es:
2rr ±= = + 0,9085
Este valor indica un alto grado de asociación entre el índice académico acumulado de los alum-nos egresados de la Facultad de Ingeniería de la muestra y su primer sueldo. Un índice académi-co acumulado más alto está bastante asociado con un sueldo más alto.
Para determinar, a partir de los datos de una muestra, si efectivamente existe correlación entre las variables X e Y, se tendrá que investigar si el valor de ρ es distinto de cero:
H0: ρ = 0 ⇒ No hay correlación H1: ρ ≠ 0 ⇒ Sí hay correlación
Se emplea la siguiente variable t de Student para esta investigación:

Regresión lineal simple y correlación 187
21 2
−−
−=
nr
rt ρ
Esta variable t tiene n – 2 grados de libertad.
Ejemplo:
En el ejemplo del primer sueldo de los ingenieros recién egresados de una universidad, t es:
8392,7
2158254,01
9085,0=
−−
=t
Si α = 0,05; t* = 2,1604.
Como t > t* ⇒ Se rechaza la hipótesis nula; o sea que se puede afirmar que sí hay correlación entre el índice académico acumulado de todos los alumnos egresados de la Facultad de Ingenie-ría y su primer sueldo.
13.9 Regresión simple no lineal Hay situaciones en las que el modelo lineal no se ajusta a la relación que hay entre dos variables
X e Y. En la figura 13.8 se muestran algunos diagramas de dispersión donde la relación entre dichas variables no es lineal.
y
x
*
*
*
**
*
*
**
* *
y
x
*
x
y
*
*
**
*** *
** * *
**
*
*
**
*
**
Figura 13.8a. Relación polinomial Figura 13.8a. Relación potencial Figura 13.8a. Relación exponencial
Se dice que la regresión es polinomial si la relación entre X e Y puede expresarse de la siguien-te manera:
Y = α + β1 X + β2 X 2 + … + βn X n
Se dice que la regresión es potencial si la relación entre X e Y puede expresarse de la siguiente manera:
Y = α x β
Se dice que la regresión es exponencial si la relación entre X e Y puede expresarse de la si-guiente manera:
Y = α β x
Para estos tres casos es posible estimar la correspondiente función a partir de los datos de una muestra. Resulta muy práctico recurrir a Excel o a softwares de Estadística para determinar la función que más se ajuste a una muestra representada por un diagrama de dispersión. Comparando los coefi-cientes de determinación de los distintos ajustes que se realicen se elige la mejor opción, es decir, la función que tenga el mayor coeficiente de determinación.

188 Regresión lineal simple y correlación
13.10 Regresión lineal, no lineal y correlación en Excel
13.10.1 Diagrama de dispersión y tendencia lineal. Dada una muestra, es decir, un conjunto de parejas de valores (xi, yi), se puede elaborar un dia-
grama de dispersión con la ayuda de Excel. Para esto, primero se seleccionan las celdas donde está la muestra; luego se hace clic sobre el icono de gráficos o se selecciona el menú Insertar/Gráfico. Ex-cel muestra el cuadro de diálogo de la figura 13.9, donde ya se ha seleccionado el Tipo de gráfico de-nominado XY (Dispersión). Se elige luego el subtipo de gráfico que aparece sombreado por defecto, que es precisamente el diagrama de dispersión.
Figura 13.9. Cuadro de diálogo del asistente para gráficos de Excel
Luego se selecciona sucesivamente el botón [Siguiente >], y se va conformando el gráfico hasta darle la forma deseada.
Una vez que Excel presenta el diagrama de dispersión, se señala cualquiera de los puntos del gráfico y se hace clic con el botón derecho del mouse. Enseguida Excel muestra el cuadro de diálogo de la figura 13.10. Seleccionando Agregar línea de tendencia aparece el cuadro de diálogo que permi-te seleccionar el tipo de línea de tendencia, como se muestra en la figura 13.11.
Figura 13.10. Cuadro de diálogo del diagrama de dispersión

Regresión lineal simple y correlación 189
Figura 13.11. Cuadro de diálogo de la línea de tendencia
Una vez que se ha elegido el Tipo de línea de tendencia, se selecciona Opciones, que permite añadir la ecuación de la línea de tendencia y el coeficiente de determinación (r2).
Ejemplo:
En el ejemplo del primer sueldo de los ingenieros recién egresados de una universidad, siguien-do los pasos que se acaban de describir y eligiendo finalmente el tipo Lineal, Excel muestra fi-nalmente el gráfico de la figura 13.12., que incluye el diagrama de dispersión, la recta de regre-sión, su ecuación y el coeficiente de determinación.
y = 136.04x + 166.8R 2 = 0.8254
1400
1600
1800
2000
2200
2400
2600
11 11.5 12 12.5 13 13.5 14 14.5 15 15.5 16 16.5 17
Figura 13.12. Recta de regresión de Excel para el ejemplo.

190 Regresión lineal simple y correlación
13.10.2 Tendencia no lineal. Si la muestra no se ajusta al modelo lineal, lo cual se puede contrastar con la prueba t, tal como
se hizo en el apartado 13.6; o si, visualizando el diagrama de dispersión se sospecha que uno de los modelos no lineales se ajusta mejor a dicha muestra, conviene realizar ajustes no lineales con Excel. Comparando los coeficientes de determinación de los ajustes que se realicen, se elige la mejor opción.
Ejemplo:
Observando el diagrama de dispersión del ejemplo del primer sueldo de los ingenieros recién egresados de una universidad, se puede sospechar que el modelo lineal que más se ajusta es el polinomial de segundo orden, es decir, el parabólico. Eligiendo este tipo de modelo en el cuadro de diálogo (figura 13.11), Excel da el resultado de la figura 13.13.
y = -22.86x 2 + 761.06x - 4051.1R 2 = 0.8773
1400
1600
1800
2000
2200
2400
2600
11 11.5 12 12.5 13 13.5 14 14.5 15 15.5 16 16.5 17
Figura 13.13. Modelo polinomial de segundo orden para el ejemplo.
Como se aprecia en la figura 13.13, el coeficiente de determinación es mayor que en el ajuste li-neal (0,8733 > 0,8254); por lo tanto el ajuste polinomial de segundo orden, es decir, el ajuste pa-rabólico, describe mejor la tendencia de los sueldos de la muestra.
El lector puede verificar que ajustes polinomiales de mayor grado mejoran ligeramente (una y dos centésimas para tercer y cuarto orden) el coeficiente de determinación; pero la línea de ten-dencia prácticamente no varía, y la ecuación polinómica se complica excesivamente.
13.10.3 Regresión lineal con funciones de Excel Excel cuenta con algunas funciones que calculan individualmente algunos parámetros de la re-
gresión lineal, dentro de las funciones que se despliegan al ejecutar el icono fx o al entrar al menú Inse-tar/Función.
A continuación se explica lo que realiza cada una de esas funciones:
• COEF.DE.CORREL: calcula el coeficiente de correlación (r) de un conjunto de datos (xi, yi). Al ejecutar esta función, Excel presenta un cuadro de diálogo donde se ingresa cada rango de celdas donde está cada columna de datos. Como este coeficiente sólo mide el grado de rela-ción que hay entre X e Y, Excel no distingue entre los datos de X y los datos de Y.
• COEFICIENTE.R2: calcula el coeficiente de determinación (r2) de un conjunto de datos (xi, yi). Al ejecutar esta función, Excel presenta un cuadro de diálogo donde se ingresa cada rango de celdas donde está cada columna de datos: una para X y una para Y.

Regresión lineal simple y correlación 191
• ERROR.TIPICO.XY: calcula la desviación estándar del error (sY / X) de un conjunto de datos (xi, yi). Al ejecutar esta función, Excel presenta un cuadro de diálogo donde se ingresa cada rango de celdas donde está cada columna de datos: una para X y una para Y.
• ESTIMACION.LINEAL: calcula los parámetros a y b de la recta de regresión. Al ejecutar esta función, Excel presenta un cuadro de diálogo donde se ingresa cada rango de celdas donde es-tá cada columna de datos: una para X y una para Y; presenta además dos funciones lógicas: en la primera se define si el parámetro a (intersección de la recta con el eje Y) puede ser distinto de cero, y en la segunda se define si se desean todos los parámetros de la regresión lineal. En ambos casos conviene ingresar VERDADERO. Excel presenta los resultados en una matriz horizontal de dos celdas. Como esta función es matricial, una vez que se seleccionan las dos celdas donde Excel dará los resultados, se debe digitar control–shift–enter al final de la fórmu-la.
• INTERSECCION.EJE: calcula la intersección de la recta de regresión con el eje Y, es decir, el parámetro a. Al ejecutar esta función, Excel presenta un cuadro de diálogo donde se ingresa cada rango de celdas donde está cada columna de datos: una para X y una para Y.
• PEARSON: calcula el coeficiente de correlación (r), llamado también coeficiente de Pearson de un conjunto de datos (xi, yi). Al ejecutar esta función, Excel presenta un cuadro de diálogo donde se ingresa cada rango de celdas donde está cada columna de datos.
• PENDIENTE: calcula la pendiente de la recta de regresión, es decir, el parámetro b. Al ejecu-tar esta función, Excel presenta un cuadro de diálogo donde se ingresa cada rango de celdas donde está cada columna de datos: una para X y una para Y.
• TENDENCIA: estima algunos valores de la recta de regresión que corresponden a ciertos va-lores de X. Al ejecutar esta función, Excel presenta un cuadro de diálogo donde se ingresa ca-da rango de celdas donde está cada columna de datos: una para X y una para Y, y el rango de celdas donde están los nuevos valores de X. Excel presenta además una función lógica donde se define si el parámetro a (intersección de la recta con el eje Y) puede ser distinto de cero. Como esta función es matricial, una vez que se seleccionan las celdas donde Excel dará los valores estimados de Y, se debe digitar control–shift–enter al final de la fórmula. En la figura 13.14 se muestra la hoja de Excel donde se pueden apreciar las estimaciones hechas con esta función (sueldos de exalumnos) para algunos valores de X (índices académicos acumulados). Las llaves {} que contienen la fórmula aparecen después de digitar control–shift–enter.
Figura 13.14. Estimaciones con la función TENDENCIA

192 Regresión lineal simple y correlación
Problemas propuestos 1. Se tomaron las estaturas en cm. (X) y los pesos en Kg. (Y) de 15 alumnos de quinto de secundaria
de un colegio.
X 177 160 182 152 167 177 187 165 157 170 165 172 165 178 183 Y 74,3 68 81,6 61,2 70,7 76,2 86,7 72,6 60 71,2 63 74,6 59,2 73,5 87,8
a) Construya un diagrama de dispersión b) Asuma que hay una relación lineal entre peso y estatura y determine la ecuación de la recta de
regresión. Trace la recta sobre el diagrama de dispersión. Respuesta: y = – 61,949 + 0,786x
c) Interprete el valor de la pendiente de la recta. Respuesta: por cada centímetro más que se tenga, se espera que el peso aumente 0,786 Kg.
d) Determine el coeficiente de determinación e interprételo. Respuesta: r2 = 0,7996; el 79,96% de la variación del peso es explicada por la variación de la estatura.
e) ¿Cuánto se espera que pese otro alumno de quinto de secundaria, si mide 180 cm? Respuesta: 79,53 Kg.
2. El dueño de un restaurante quiere averiguar si existe relación entre los ingresos, en soles, que tiene durante la semana (de lunes a viernes) y los ingresos del fin de semana (sábado y domingo). A continuación se muestran los datos que recopiló durante las últimas 12 semanas.
Lunes a viernes 150 120 133 181 98 125 154 166 170 129 105 192 Sábado y domingo 320 357 390 200 330 341 245 319 236 307 285 194
a) Construya un diagrama de dispersión. b) Asuma que hay una relación lineal entre los ingresos durante la semana y el fin de semana y
determine la ecuación de la recta de regresión. Trace la recta sobre el diagrama de dispersión. c) ¿Cuánto espera ingresar un fin de semana, si durante la semana ingresó 165 soles? d) ¿Se puede afirmar que hay correlación entre ambas variables? Considere α = 0,05.
3. En un experimento sobre métodos de enseñanza de lectura se tomaron los siguientes datos a 36 ni-ños de primer grado de primaria que participaron.
Nivel de vocabulario previo a primaria
Comprensión lectora
Nivel de vocabulario previo a primaria
Comprensión lectora
28 29 22 28 27 30 18 11 14 10 7 4 23 21 12 7 24 24 9 5 14 11 8 3 14 12 27 25 18 8 24 23 14 7 24 22 10 5 17 10 5 3 12 7
14 6 18 15 30 28 14 6 18 12 18 18 15 9 17 18 20 20 10 6 16 16 16 10 8 2 12 2
a) Construya un diagrama de dispersión b) Determine la ecuación de la recta de regresión. Trace la recta sobre el diagrama de dispersión. c) Interprete el valor de la pendiente de la recta.

Regresión lineal simple y correlación 193
d) Determine el coeficiente de determinación e interprételo. e) ¿Se puede afirmar que hay correlación entre ambas variables? Considere α = 0,05
4. El encargado del laboratorio de una planta de jugos concentrados quiere determinar una ecuación
que le pronostique la concentración de azúcar según el tiempo que permanecen en el evaporador. En la siguiente tabla se muestra las medidas que tomó en su experimentación.
Tiempo (minutos) 5 10 15 20 25 30 35 40 45 50 55 Grados Brix 22 48 52 57 43 48 34 36 43 58 89
a) Construya un diagrama de dispersión. b) Asuma que hay una relación lineal entre el tiempo de evaporación y la concentración y deter-
mine la ecuación de la recta de regresión. Trace la recta sobre el diagrama de dispersión. Respuesta: y = 31,982 + 0,54x c) ¿Le parece bueno el ajuste lineal? Respuesta: No, pues se nota en el diagrama de dispersión y además el coeficiente de determi-
nación es r2 = 0,2724. d) Proponga otro tipo de ajuste y justifique si es mejor que el lineal. Respuesta: Es mejor el ajuste polinomial: y = –12,106 + 8,8726x – 0,36344x2 + 0,0043x3. Se
ajusta mucho más al diagrama de dispersión; r2 = 0,9637.
5. Una empresa de alquiler de videos quiere pronosticar cuántos videos alquilará de las películas que disponga en las próximas semanas, con base en la cantidad de videos que alquiló antes, de deter-minadas películas, y las ganancias obtenidas por dichas películas (en millones de dólares). En la siguiente tabla se muestran los datos de los que dispone.
Ganancia bruta 1,5 18,3 2,4 45,1 1,12 5,75 28,2 12,5 23,4 35,8 9,8 15,4 Videos alquilados 90 220 201 720 55 262 460 360 546 543 245 410
a) Construya un diagrama de dispersión. b) Determine la ecuación de la recta de regresión. Trace la recta sobre el diagrama de dispersión. c) ¿Le parece bueno el ajuste lineal? d) Pronostique cuántos videos alquilará de una película que tuvo una ganancia de 32 millones de
dólares.
6. En la siguiente tabla se muestra el residuo de cloro (en partes por millón) que hay en una piscina, unas horas después de haber sido tratada:
Horas 1 2 3 4 5 6 7 8 Residuo de cloro 1,80 1,75 1,64 1,52 1,44 1,38 1,27 1,10
a) Construya un diagrama de dispersión. b) Determine la ecuación de la recta de regresión. Trace la recta sobre el diagrama de dispersión. c) Determine el coeficiente de correlación e interprételo d) ¿Se puede afirmar que hay correlación entre ambas variables? Considere α = 0,05
7. En la siguiente tabla se expresa el número de bacterias por litro que se encontró en un cultivo, se-gún del número de horas que tiene dicho cultivo.
N° de horas 0 1 2 3 4 5 6 N° de bacterias 32 47 65 92 132 190 275
a) Construya un diagrama de dispersión. b) Determine la ecuación de la función potencial que más se ajuste. Trace la curva sobre el dia-
grama de dispersión. c) ¿Cuántas bacterias se espera encontrar en un cultivo después de 7 horas?
8. El encargado de hacer el inventario en un almacén debe comparar el número de unidades observa-do para cada artículo con el número que figura en el archivo (teórico). Compruebe, a partir de 10

194 Regresión lineal simple y correlación
artículos observados, si el ajuste lineal entre los valores observados y los valores teóricos es co-rrecto.
Artículo N° 1 2 3 4 5 6 7 8 9 10 Valor observado 9 14 7 29 45 109 40 238 60 170
Valor teórico 10 12 9 27 47 112 36 241 59 167

Análisis de series de tiempo 195
Capítulo 14. Análisis de series de tiempo
14.1 Introducción En cualquier diario o revista económica es fácil encontrar proyecciones futuras de algunas va-
riables económicas basándose en datos pasados. Heinz Kohler, autor de Estadística para negocios y economía, se refiere sarcásticamente a algunas proyecciones que se podrían hacer si se siguiera fiel-mente la tendencia que se ha venido dando hasta ahora. Por ejemplo, que dada la creciente participa-ción comercial japonesa, es inevitable su dominio completo de la industria aeroespacial mundial; que el gasto de salud pública absorberá todo el ingreso nacional; que nuestros nietos quedarán sepultados por un volumen exponencialmente creciente de propaganda por correo, o que estarán en quiebra por el mero interés de la deuda nacional; que la población de las cárceles incluirá toda la población del país; que la productividad laboral continuará decreciendo, llegará a cero, y se hará negativa; que las reser-vas de recursos naturales, una vez abundantes, habrán desaparecido hacia mediados del siglo XXI, y así sucesivamente.
En conclusión, es necesario ser muy prudente cuando se requiera hacer un pronóstico basándose en datos pasados, pues éste puede resultar muy disparatado; pero para muchos es necesario e inevita-ble tener que pronosticar, por ejemplo: los productores de energía eléctrica, los fabricantes de ropa, calzado o artículos deportivos, escolares; los encargados de los créditos bancarios, los encargados del presupuesto de un departamento, de toda la empresa, o de un país, etc.
14.2 Componentes de una serie de tiempo Una serie de tiempo es un conjunto de datos numéricos en orden cronológico. El análisis de se-
ries de tiempo es un procedimiento que analiza dichos datos con el propósito de explicar eventos ante-riores o pronosticar eventos futuros.
Generalmente se analizan series de tiempo de variables económicas, como las ventas mensuales de una empresa, la cantidad de unidades vendidas, el precio de un producto o de unas acciones en la bolsa de valores, las utilidades a fin de año, etc.
En este capítulo se ven los conceptos básicos del análisis de series de tiempo, suficientes para hacer un diagnóstico del comportamiento de una variable a lo largo del tiempo.
Una serie de tiempo puede tener cuatro componentes:
• Tendencial (T) • Cíclica (C) • Estacional (S) • Irregular (I)
Existen varios modelos que describen una serie de tiempo típica. Los más usados son:
• Modelo multiplicativo: y = T × C × S × I • Modelo aditivo: y = T + C + S + I • Modelos mixtos: y = T × C + S × I
y = T × C × I + S
De estos modelos, el modelo multiplicativo es el más usado, pues se adapta bien a las caracterís-ticas de muchas variables económicas y financieras.

196 Análisis de series de tiempo
A continuación se definen las componentes de una serie de tiempo, adecuándolas al modelo multiplicativo.
14.2.1 Componente tendencial (T) Generalmente se presenta como un movimiento relativamente suave de una variable, progresi-
vamente hacia arriba o hacia abajo, en un periodo prolongado (varios años).
Si los datos observados (valores de la variable que se está analizando) crecen o decrecen, se dice que la tendencia es positiva o negativa, respectivamente.
La tendencia se puede representar, si fuera el caso, mediante una línea recta (y = a + bt), con lo cual se podría afirmar, por ejemplo, que los valores de una variable (y) crecen a razón de b unidades por unidad de tiempo (t).
Por ejemplo, en la figura 14.1 se muestra la línea recta que representa la tendencia de las ventas trimestrales de un producto desde el primer trimestre de 1998 hasta el último trimestre de 2004. (Las ventas reales se muestran en la figura 14.7). Se aprecia que las ventas aumentan a razón de 7,1633 unidades por trimestre (28,65 unidades por año). A partir de este gráfico de tendencia, se hubiera pro-nosticado unas ventas trimestrales de 262 unidades para el primer trimestre de 2003; sin embargo, esto no fue así, como se ve en la figura 14.7.
0.00
50.00
100.00
150.00
200.00
250.00
300.00
350.00
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Vent
as tr
imes
tral
es
1998 1999 2000 2001 2002 2003 2004
y = 7.1633x + 119
262.27
Figura 14.1. Componente tendencial
14.2.2 Componente cíclica (C) Se detecta por las alternancias amplias de la variable en estudio (y) alrededor de la tendencia,
que duran de uno a varios años cada una, y que, por lo general, difieren en duración y amplitud de un ciclo al siguiente.
Generalmente dichas alternancias irregulares reflejan las fluctuaciones de la actividad económi-ca en general: el ciclo financiero de auge y recesión que afecta a todas las variables en la economía. En estos ciclos suelen influir fenómenos naturales importantes.
La componente cíclica se suele medir como una proporción de la tendencia. Para una mejor comprensión, en la figura 14.2 se traza la tendencia como una recta horizontal (para C = 1). La com-ponente cíclica varía alrededor de la tendencia. Por ejemplo, en el primer trimestre de 2003 la recesión hizo que las ventas sean el 87,8% de lo esperado.
En la figura 14.3 se muestra la componente Tendencial-Cíclica para las ventas. Se ve que, de las 262,27 unidades que se esperaba vender para el primer trimestre de 2003, por efecto de la componente cíclica las ventas caen a: 262,27×0,878 = 230,38 unidades.

Análisis de series de tiempo 197
0.600
0.700
0.800
0.900
1.000
1.100
1.200
1.300
1.400
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
C
1998 1999 2000 2001 2002 2003 2004
Recesión
Recuperación
Recesión Recuperación
0.878
Figura 14.2. Componente cíclica
0
50
100
150
200
250
300
350
400
450
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Vent
as tr
imes
tral
es
1998 1999 2000 2001 2002 2003 2004
TendencialTendencial-cíclica
230.38
Figura 14.3. Componente tendencial-cíclica
En conclusión, definiendo de esta forma la componente cíclica, la componente combinada Ten-dencial-Cíclica de la serie de tiempo se encuentra multiplicando (Ti× Ci) para cualquier instante.
14.2.3 Componente estacional (S) Se detecta por alternancias de la variable en estudio (y) alrededor de la componente Tendencial-
Cíclica, que se repiten en forma predecible dentro de periodos de un año, de un mes, de una semana, etc. Generalmente estas variaciones reflejan la influencia del clima y el calendario sobre la actividad económica. Se suele hablar de productos estacionales, refiriéndose a las estaciones del año, como por ejemplo: chompas, abrigos, helados, bebidas gaseosas, cerveza, carbón, kerosene, gas, panetones, adornos de Navidad, útiles escolares, etc.

198 Análisis de series de tiempo
La componente estacional se suele medir como una proporción de la componente Tendencial-Cíclica. Para una mejor comprensión, en la figura 14.4 se traza la componente Tendencial-Cíclica co-mo una recta horizontal (para S = 1). La componente estacional varía con regularidad alrededor de la componente Tendencial-Cíclica. Por ejemplo, en el primer trimestre de 2003, por efecto de la compo-nente estacional las ventas fueron el 81,7% de lo esperado.
0.7
0.8
0.9
1.0
1.1
1.2
1.3
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
S
1998 1999 2000 2001 2002 2003 2004
0.817
Figura 14.4. Componente estacional
0
50
100
150
200
250
300
350
400
450
500
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Vent
as tr
imes
tral
es
1998 1999 2000 2001 2002 2003 2004
Tendencial
Tendencial-cíclica
Tendencial-cíclica-estacional 188,32
Figura 14.5. Componente Tendencial-Cíclica-Estacional
En la figura 14.5 se muestra la componente Tendencial-Cíclica-Estacional (a trazo continuo) pa-ra las ventas. Se ve que, de las 230,38 unidades que se hubieran vendido para el primer trimestre de 2003, por efecto de la componente estacional las ventas caen a: 230,38×0,817 = 188,32 unidades.
En conclusión, definiendo de esta forma la componente estacional, la componente Tendencial-Cíclica-Estacional se encuentra multiplicando (Ti × Ci × Si) para cualquier instante.

Análisis de series de tiempo 199
14.2.4 Componente irregular o aleatoria (I) Se detecta por movimientos aleatorios de la variable en estudio alrededor de la componente
Tendencia-Cíclica-Estacional. Generalmente estos movimientos se deben a factores impredecibles y probablemente no recurrentes, como por ejemplo: modas, huelgas, desastres naturales (no cíclicos), guerras, etc.
Esta componente se expresa como una proporción de la componente Tendencial-Cíclica-Estacional que, en la figura 14.6 se muestra como una recta horizontal (para I = 1).
0.860
0.880
0.900
0.920
0.940
0.960
0.980
1.000
1.020
1.040
1.060
1.080
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
I
1998 1999 2000 2001 2002 2003 2004
0.972
Figura 14.6. Componente irregular
En la figura 14.7 se muestra la componente Tendencial-Cíclica-Estacional-Irregular, es decir, las ventas reales del producto (y). Se ve que, de las 188,32 unidades que se esperaba vender para el primer trimestre de 2003, por efecto de la componente irregular las ventas caen a: 188,32×0,972 = 183 unida-des.
0
50
100
150
200
250
300
350
400
450
500
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Vent
as tr
imes
tral
es
1998 1999 2000 2001 2002 2003 2004
183
Figura 14.7. Serie de tiempo: componente Tendencial-Cíclica-Estacional-Irregular

200 Análisis de series de tiempo
En conclusión, definiendo de esta forma la componente irregular, los valores de la variable en estudio (y) se encuentran multiplicando (Ti × Ci × Si × Ii) para cualquier instante i.
14.3 Descomposición de series de tiempo Para analizar una serie de tiempo, ya sea con el propósito de pronosticar algunos valores de la
variable en estudio o de estudiar su comportamiento pasado, es necesario conocer cada una de sus componentes; pero generalmente se dispone de un conjunto de datos a lo largo del tiempo, es decir, de una serie de tiempo con todas sus componentes, y se hace necesario descomponer dicha serie.
14.3.1 Suavización de la serie de tiempo. Para eliminar las fluctuaciones de una serie de tiempo se suelen emplear dos métodos de suavi-
zación: media móvil y suavización exponencial. Estos métodos permiten aislar algunas componentes de la serie de tiempo.
Medias móviles:
Se obtiene una serie de medias móviles calculando sucesivamente medias aritméticas de grupos sobrepuestos de M valores de una serie de tiempo.
Por ejemplo, si M = 3:
3
3212
yyyy
++= ;
3432
3yyy
y++
= ; ... 3
11 +− ++= ttt
tyyy
y
Nótese que los subíndices de las medias móviles coinciden con el subíndice central de los datos.
Cuando M es impar no hay mayor complicación en el cálculo de las medias móviles; pero si M es par, hace falta ajustar (centrar) las medias móviles obtenidas para conseguir valores de estas medias móviles en los mismos tiempos en que están los datos originales (y). En la tabla 14.1 se muestra parte de una serie de tiempo donde se calculan las medias móviles con M = 4. Como se aprecia, la media móvil de los primeros cuatro valores (132,00) se ha colocado entre los tiempos 2 y 3, la media móvil de los siguientes cuatro valores (133,25) se ha colocado entre los tiempos 3 y 4, y así sucesivamente. Para que estas medias móviles correspondan con los tiempos definidos, se calculan las medias móviles de las medias móviles, pero esta vez con M = 2. Así se obtienen las medias móviles ajustadas.
Tabla 14.1 Cáculo de medias móviles con ajuste
Tiempo Y Medias móviles (M = 4)
Medias móviles ajustadas
1 96
2 137 132,00
3 165 132,63 133,25
4 130 131,00 128,75
5 101 127,88 127,00
6 119 128,75 130,50
7 158
8 144
El principal inconveniente de este método de suavización es que no se tiene un valor suavizado correspondiente a cada valor de la serie original. Se pierden algunos valores al principio y al final de la serie. Por ejemplo, para la serie de tiempos de la tabla 14.1 se han perdido cuatro datos: dos al princi-pio y dos al final. Esta desventaja es poco notoria cuando se cuenta con una gran cantidad de datos.

Análisis de series de tiempo 201
Suavización exponencial:
Es un procedimiento que genera pronósticos auto-corregidos por medio de un mecanismo de ajuste que va corrigiendo los errores de pronóstico anteriores. Este método hace el pronóstico del si-guiente periodo fi+1 a partir del valor real actual yi y del pronóstico actual fi, empleando una constante de suavización α, de la siguiente manera:
fi+1 = α yi + (1 – α) fi
El parámetro α es un valor que está entre cero y uno, y se escoge para indicar el peso que se desee dar al valor más reciente de la serie de tiempo. Mientras mayor sea α, más peso se le da a la ex-periencia actual y menos a la pasada.
14.3.2 Aislamiento de las componentes de la serie de tiempo. El método de las medias móviles, que suele eliminar las fluctuaciones irregulares, puede elimi-
nar también la componente estacional si se emplea M igual al número estaciones (una estación puede ser una semana, un mes, o un trimestre), con lo cual las medias móviles contendrían sólo las compo-nentes cíclica y tendencial.
Se podría eliminar también la componente cíclica empleando un valor de M mayor que el núme-ro de estaciones; pero esto se dificulta por el hecho de que la duración de los ciclos que puede tener una serie de tiempos no es la misma. Si se tuviesen datos suficientes (más de 20 años) se podría redu-cir considerablemente la componente cíclica suavizando la serie de tiempo original con M igual a la duración del ciclo más duradero. De esta forma se eliminarían tres componentes: irregular, estacional y cíclica, con lo cual se obtendría la componente tendencial.
Si no se cuenta con la suficiente cantidad de datos como para emplear un valor de M muy gran-de, que es lo más probable, conviene calcular medias móviles con un valor de M mayor que el número de estaciones; así se eliminará una parte de la componente cíclica. Estas medias móviles estarán mu-cho más suavizadas, es decir, se parecerán mucho más a la tendencia. Entonces, empleando el método de los mínimos cuadrados, se puede determinar la tendencia, que puede ser una recta o una función no lineal. Esto se puede hacer con la ayuda de Excel, tal como se vio en los apartados 13.10.1 y 13.10.2.
En conclusión, para aislar las componentes tendencial y cíclica se siguen los siguientes pasos:
1. Construir una serie de medias móviles con M mayor que el número de estaciones. Por ejem-plo, si se tienen datos mensuales, M > 12; si se tienen datos trimestrales, M > 4.
2. Si la tendencia es lineal, hallar la recta de mínimos cuadrados a partir de la serie hallada. En caso contrario, hallar la línea de tendencia que mejor se ajuste a esta serie de medias móvi-les.
3. Aislar la componente cíclica (C), dividiendo los valores Ti×Ci / Ti.
Para aislar las componentes estacional e irregular se siguen los siguientes pasos.
1. Construir una serie de medias móviles con M igual al número de estaciones. Por ejemplo, si se tienen datos mensuales, M = 12; si se tienen datos trimestrales, M = 4. Esta serie conten-drá sólo las componentes Tendencial-Cíclica (T×C).
2. Aislar la componente S×I, dividiendo yi /(Ti×Ci). 3. Aislar la componente estacional (S), promediando los valores S×I de cada estación. Así, por
ejemplo, si hay cuatro estaciones (M = 4), se hallarán cuatro promedios S×I; uno para cada estación.
4. Ajustar la componente estacional (S), considerando que las M componentes estacionales de-ben promediar uno, y por lo tanto deben sumar M en vez de ∑. Para conseguirlo, cada S hallado debe multiplicarse por M/∑.
5. Aislar la componente irregular (I) dividiendo Si×Ii / Si.

202 Análisis de series de tiempo
14.4 Pronóstico Se denomina pronóstico a una afirmación que se hace sobre un evento futuro. Los pronósticos se
suelen hacer basándose en datos que se deducen del análisis de series de tiempo. Conociendo la línea de tendencia, se puede pronosticar por extrapolación (prolongando dicha línea tendencial), y cono-ciendo la componente estacional, se puede ajustar dicho pronóstico multiplicando la componente ten-dencial por la componente estacional.
En la sociedad actual es imprescindible pronosticar. Los gobernantes de un país siempre están pronosticando la inflación, el producto bruto interno, el desempleo, la recaudación de impuestos, etc., para plantear adecuadamente las políticas de gobierno. Los empresarios siempre están pronosticando las ventas, la demanda, etc., con el propósito de tomar las decisiones oportunas que los lleven a opti-mizar sus beneficios.
14.5 Análisis del comportamiento de una serie de tiempo Muchas veces conviene aislar una componente de una serie de tiempo para hacer un análisis del
comportamiento de la variable en estudio sin considerar dicha componente, ya sea la estacional, la cí-clica o la irregular. Esto permitirá evaluar el comportamiento de dicha variable sin la influencia de una u otra componente.
Una serie desestacionalizada es aquella que contiene todas las componentes excepto la estacio-nal. Sirve para sincerar los valores que toma la serie de tiempo. Por ejemplo, el gerente de una empre-sa que produce bebidas gaseosas no tendría que entusiasmarse mucho si las ventas en el verano están por encima de lo esperado por la tendencia. Para desestacionalizar una serie de tiempo basta con divi-dir cada valor de la variable en estudio entre la componente estacional: yi / Si.
14.6 Análisis de series de tiempo en Excel Aunque Excel no cuenta con una herramienta que efectúe el análisis completo de una serie de
tiempo, sí cuenta con los elementos suficientes para realizarlo paso a paso, de acuerdo al propósito que se plantee.
14.6.1 Análisis de series de tiempo con medias móviles Para calcular las medias móviles en Excel, se debe ingresar al menú Herramientas/Análisis de
datos/ Media móvil. Excel abre el cuadro de diálogo que se muestra en la figura 14.8, donde ya se han ingresado los datos para el ejemplo que se desarrolla a continuación. Excel le denomina Intervalo al valor de M que se considera al calcular las medias móviles.
Figura 14.8. Cuadro de diálogo de medias móviles

Análisis de series de tiempo 203
Una vez que se han ingresado los datos y se acepta, Excel coloca las medias móviles en una co-lumna que se inicia donde se definió el rango de salida. El único inconveniente de este resultado es que las medias móviles no las centra respecto a los datos de la serie de tiempo. El usuario debe trasla-dar estas medias móviles a la posición central. Si M es par, será necesario hallar las medias móviles ajustadas, a partir del resultado obtenido, considerando esta vez M = 2.
Con la ayuda de Excel se pueden aislar las cuatro componentes para hacer posteriormente algu-nos pronósticos o análisis de la serie de tiempos, como se muestra en el siguiente ejemplo.
Ejemplo:
Una empresa que se dedica a la elaboración de cierto accesorio para autos ha registrado las si-guientes ventas (en unidades) durante los últimos años:
Trimestre 1998 1999 2000 2001 2002 2003 2004 1 96 101 133 214 211 183 264 2 137 119 199 258 221 250 348 3 165 158 283 310 249 328 430 4 130 144 260 259 200 305 415
En primer lugar se calculan las medias móviles con M = 4 y luego las medias móviles ajustadas.
Después de ingresar los datos al cuadro de diálogo (figura 14.8), Excel da el resultado en la co-lumna D. Luego de ingresar los datos de la columna D y calcular nuevamente medias móviles, esta vez con M = 2, Excel muestra el resultado de la siguiente tabla, donde los valores de la co-lumna E han sido centrados por el usuario, pues Excel los coloca descentrados.
A B C D E 1 2
Trimestre Ventas
(Y) P.M. P.M ajustado(TC)
3 1998 1 96 4 2 137 5 3 165 132.00 132.63 6 4 130 133.25 131.00 7 1999 1 101 128.75 127.88 8 2 119 127.00 128.75 9 3 158 130.50 134.50
10 4 144 138.50 148.50 11 2000 1 133 158.50 174.13 12 2 199 189.75 204.25 13 3 283 218.75 228.88 14 4 260 239.00 246.38 15 2001 1 214 253.75 257.13 16 2 258 260.50 260.38 17 3 310 260.25 259.88 18 4 259 259.50 254.88 19 2002 1 211 250.25 242.63 20 2 221 235.00 227.63 21 3 249 220.25 216.75 22 4 200 213.25 216.88 23 2003 1 183 220.50 230.38 24 2 250 240.25 253.38 25 3 328 266.50 276.63 26 4 305 286.75 299.00 27 2004 1 264 311.25 324.00 28 2 348 336.75 350.50 29 3 430 364.25 30 4
Nótese que las medias móviles de la columna D no pueden colocarse en la posición que les co-rrespondería (sobre las líneas) pues esto no es posible en Excel.
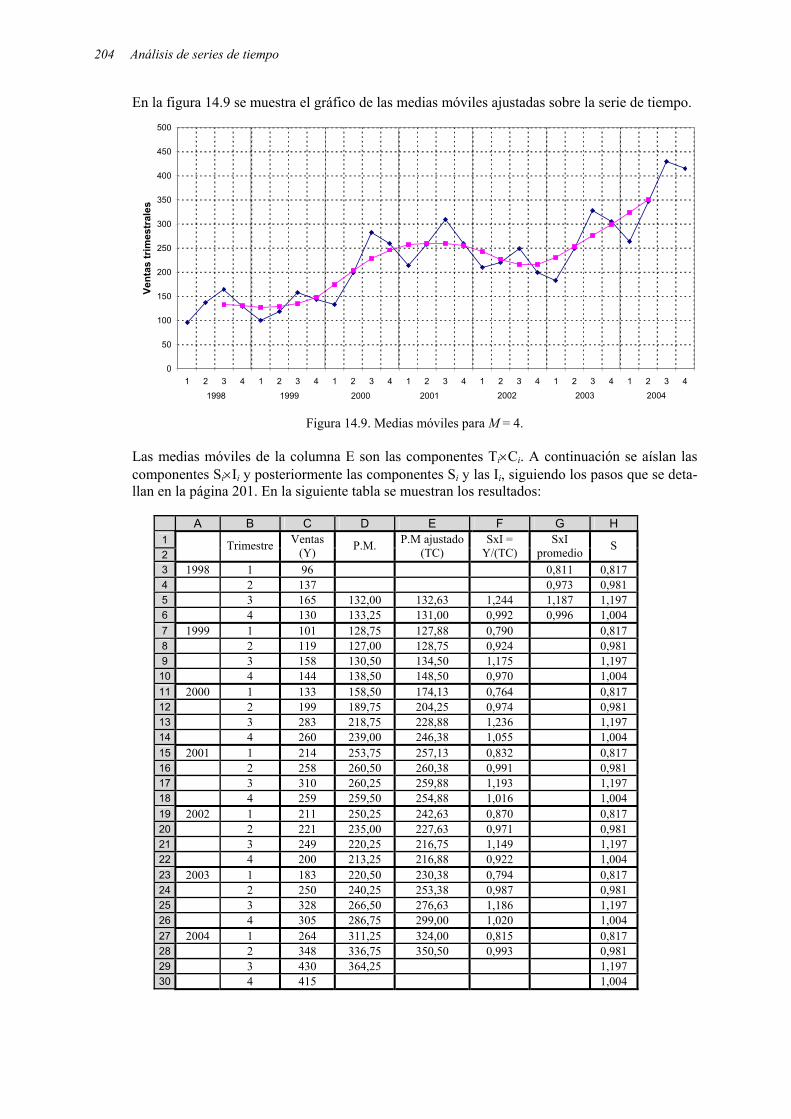
204 Análisis de series de tiempo
En la figura 14.9 se muestra el gráfico de las medias móviles ajustadas sobre la serie de tiempo.
0
50
100
150
200
250
300
350
400
450
500
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Vent
as tr
imes
tral
es
1998 1999 2000 2001 2002 2003 2004 Figura 14.9. Medias móviles para M = 4.
Las medias móviles de la columna E son las componentes Ti×Ci. A continuación se aíslan las componentes Si×Ii y posteriormente las componentes Si y las Ii, siguiendo los pasos que se deta-llan en la página 201. En la siguiente tabla se muestran los resultados:
A B C D E F G H 1 2
Trimestre Ventas
(Y) P.M. P.M ajustado(TC)
SxI = Y/(TC)
SxI promedio S
3 1998 1 96 0,811 0,817 4 2 137 0,973 0,981 5 3 165 132,00 132,63 1,244 1,187 1,197 6 4 130 133,25 131,00 0,992 0,996 1,004 7 1999 1 101 128,75 127,88 0,790 0,817 8 2 119 127,00 128,75 0,924 0,981 9 3 158 130,50 134,50 1,175 1,197
10 4 144 138,50 148,50 0,970 1,004 11 2000 1 133 158,50 174,13 0,764 0,817 12 2 199 189,75 204,25 0,974 0,981 13 3 283 218,75 228,88 1,236 1,197 14 4 260 239,00 246,38 1,055 1,004 15 2001 1 214 253,75 257,13 0,832 0,817 16 2 258 260,50 260,38 0,991 0,981 17 3 310 260,25 259,88 1,193 1,197 18 4 259 259,50 254,88 1,016 1,004 19 2002 1 211 250,25 242,63 0,870 0,817 20 2 221 235,00 227,63 0,971 0,981 21 3 249 220,25 216,75 1,149 1,197 22 4 200 213,25 216,88 0,922 1,004 23 2003 1 183 220,50 230,38 0,794 0,817 24 2 250 240,25 253,38 0,987 0,981 25 3 328 266,50 276,63 1,186 1,197 26 4 305 286,75 299,00 1,020 1,004 27 2004 1 264 311,25 324,00 0,815 0,817 28 2 348 336,75 350,50 0,993 0,981 29 3 430 364,25 1,197 30 4 415 1,004

Análisis de series de tiempo 205
Nótese que en la columna H se han repetido sucesivamente las cuatro componentes estacionales halladas en la columna G.
Como ayuda al lector, a continuación se muestran algunos ejemplos de las operaciones realiza-das para hallar S×I promedio y S:
• Para calcular la componente S×I promedio del primer trimestre del año (celda G3):
=PROMEDIO(F3,F7,F11,F15,F19,F23,F27).
• Para calcular la componente S del primer trimestre del año (celda H3):
=G3*4/SUMA(G$3:G$6)
Luego puede aislarse fácilmente la componente I, dividiendo las celdas de la columna F entre las celdas de la columna H.
Para hallar la línea de tendencia (componente tendencial) es necesario hallar promedios móviles con un valor de M suficientemente grande. Por ejemplo, para M = 9 se obtiene una serie que se ajusta mucho a una recta, como se puede apreciar en la figura 14.10. Para hallar esta recta se traza en primer lugar el diagrama de dispersión de la serie recientemente obtenida, y luego bas-tará con seleccionar cualquier punto, hacer clic con el botón derecho del mouse y ejecutar el comando Agregar línea de tendencia, como ya se ha explicado en 13.10.1
y = 7.1633x + 119
0
50
100
150
200
250
300
350
400
450
500
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
Vent
as tr
imes
tral
es
1998 1999 2000 2001 2002 2003 2004
Serie de tiempo suavizada con promedio móvil de 9 trimestres
Figura 14.10. Determinación de la recta tendencial
Si se opta por hallar media móviles con un valor de M ≠ 9, se obtendrá una recta tendencial evi-dentemente distinta; pero muy aproximada a la que se acaba de obtener. Como se trata de esti-mar la recta tendencial, las pequeñas diferencias que se obtengan entre una u otra opción care-cen de importancia.
Una vez que se ha obtenido la componente tendencial, es fácil hallar la componente cíclica, di-vidiendo las celdas de la columna E entre las celdas donde se colocan los valores Ti.
Los gráficos de las cuatro componentes de este problema corresponden a los que se muestran en las figuras 14.1; 14.2; 14.4 y 14.6. Vale la pena ver el gráfico de la componente S×I, que se muestra en la figura 14.11. Se aprecia claramente cómo la componente irregular afecta a la componente estacional. Se entiende así que para estimar las componentes estacionales de cada trimestre haya que promediar las componentes los respectivos valores de S×I de todos los tri-mestres.

206 Análisis de series de tiempo
0.600
0.700
0.800
0.900
1.000
1.100
1.200
1.300
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
SxI
1998 1999 2000 2001 2002 2003 2004
Figura 14.11. Componente S×I
14.6.2 Suavización exponencial Para hacer la suavización exponencial en Excel, se debe ingresar al menú Herramientas/Análisis
de datos/ Suavización exponencial. Excel abre el cuadro de diálogo que se muestra en la figura 14.11, donde ya se han ingresado los datos del ejemplo que viene desarrollando.
Figura 14.11. Cuadro de diálogo para la suavización exponencial
Es necesario aclarar que el factor de suavización que considera Excel es 1 – α. Además, si se marca la opción Crear gráfico, Excel traza la serie suavizada con un desfase respecto a la serie de tiempo. Es necesario entonces adelantar la serie suavizada una unidad de tiempo, como se hace en el siguiente ejemplo.
Se va a hacer la suavización exponencial del mismo problema del apartado anterior, con α = 0,5. A continuación se repite el texto para comodidad del lector.
Ejemplo:
Una empresa que se dedica a la elaboración de cierto accesorio para autos ha registrado las si-guientes ventas (en unidades) durante los últimos años:

Análisis de series de tiempo 207
Trimestre 1998 1999 2000 2001 2002 2003 2004 1 96 101 133 214 211 183 264 2 137 119 199 258 221 250 348 3 165 158 283 310 249 328 430 4 130 144 260 259 200 305 415
Entrando al menú Herramientas/Análisis de datos/ Suavización exponencial aparece el cuadro de diálogo de la figura 14.11; aceptando los datos que se han ingresado Excel da el resultado que se muestra en la figura 14.12.
96.00116.50140.75135.38118.19118.59138.30141.15137.07168.04225.52242.76228.38243.19276.59267.80239.40230.20239.60219.80201.40225.70276.85290.92277.46312.73371.37
Suavización exponencial
0
50
100
150
200
250
300
350
400
450
500
1 3 5 7 9 11 13 15 17 19 21 23 25 27
Punto de datos
Val
or RealPronóstico
Figura 14.12. Suavización exponencial con α = 0,5

208 Análisis de series de tiempo
Problemas propuestos 1. Un país registró las siguientes entradas de turistas (en millones) en el periodo 1997-2003:
1997 1998 1999 2000 2001 2002 2003 Trimestre 1 2,5 3,6 3,8 4,6 4,3 4,7 5,4 Trimestre 2 3,2 3,9 4,5 5,9 4,1 4,9 5,9 Trimestre 3 3,7 4,8 5,7 7,8 5,2 5,5 7,3 Trimestre 4 3,4 4,1 5,2 6,7 3,9 5,0 6,6
Haga un pronóstico de la entrada de turistas que se espera para los cuatro trimestres del año 2004. Sugerencia: estime la recta tendencial a partir de las medias móviles con M = 9.
Respuesta: 5,27; 5,70; 6,96; 5,92.
2. ¿Con qué componente de una serie de tiempos asociaría cada uno de los siguientes hechos? a) Un aumento en las ventas de útiles de escritorio durante el mes de marzo. b) Un incremento de la producción de mango debido a la incorporación de nueva tecnología. c) Una huelga de trabajadores del sector agrario. d) Una disminución en el volumen de construcción de viviendas durante 2 años.
3. La siguiente tabla muestra el producto bruto interno (PBI) del Perú, en miles de millones de dóla-res. Trace una recta tendencial sobre la serie de promedios móviles de 7 años y estime el producto bruto interno para los años 2003 y 2004.
Año PBI Año PBI Año PBI Año PBI 1981 25,4 1991 42,2 2001 72,3 1982 25,9 1992 41,4 2002 72,5 1983 19,9 1993 40,1
1974 12,2 1984 20,8 1994 49,5 1975 15,8 1985 18,3 1995 58,7 1976 15,5 1986 26,2 1996 61,2 1977 13,1 1987 35,7 1997 65,3 1978 11,9 1988 28,8 1998 62,8 1979 15,6 1989 33,3 1999 65,1 1980 20,2 1990 34,1 2000 72,1
4. Las ventas de un producto durante los últimos años se expresan en la siguiente tabla:
1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 1er trimestre 102 96 85 83 84 102 109 115 118 116 120 2do trimestre 111 105 94 90 89 106 119 122 126 123 131 3er trimestre 118 109 100 103 104 114 124 134 136 131 142 4to trimestre 111 99 91 97 96 107 120 127 121 120 132
Trace un gráfico de cada componente de esta serie. Haga un pronóstico para el año 2004. Sugeren-cia: estime la recta tendencial a partir de las medias móviles con M = 11
5. En la siguiente tabla se muestran las ventas del año pasado de una empresa, y las componentes de la serie de tiempo, aplicando el modelo multiplicativo. a) Determine los valores faltantes. b) ¿Cuánto varían las ventas anualmente? c) Haga un comentario breve sobre la economía del país durante el año pasado. d) ¿Qué pronóstico haría para los cuatro trimestres de este año? e) Haga un análisis de las ventas del año pasado.
Trimestre Ventas reales C.Tendencial C.Cíclica C.Estacional C.Irregular 1 65 823,00 65 000 1,126 1,173 2 42 555,00 70 000 0,937 0,984 3 85 120,50 75 000 1 4 80 000 0,955 0,579 1,020

Análisis de series de tiempo 209
6. Suponga que el CONAM (Consejo Nacional del Ambiente) ha registrado los siguientes niveles de contaminación por mercurio frente a las costas de Paita durante los últimos cuatro años.
Ene Feb Mar Abr May Jun Jul Ago Sep Oct Nov Dic 2001 0,4 0,5 0,4 1,0 0,9 1,0 0,7 0,6 0,6 0,7 0,7 0,4 2002 0,3 0,4 0,3 0,7 0,8 0,7 0,5 0,6 0,5 0,6 0,5 0,4 2003 0,2 0,2 0,3 0,5 0,6 0,5 0,5 0,4 0,5 0,3 0,3 0,2 2004 0,2 0,2 0,3 0,6 0,6 0,5 0,5 0,3 0,4 0,3 0,4 0,2
Determine la componente estacional (para los 12 meses) y dé una interpretación. Respuesta:
0,499 0,567 0,682 1,371 1,542 1,326 1,119 1,060 1,093 1,048 1,000 0,693
En diciembre, enero, febrero y marzo la contaminación baja, especialmente en enero, por efecto de la estación; probablemente en esos meses las fábricas ubicadas en el litoral operan menos, hay menos llegadas de buques, etc. En abril, mayo y junio la contaminación aumenta, especialmente en mayo, probablemente porque aumentan las actividades mencionadas.
7. El dueño de un restaurante ubicado junto a una universidad ha anotado los ingresos, en soles, du-rante los tres primeros años de funcionamiento:
Ene Feb Mar Abr May Jun Jul Ago Sep Oct Nov Dic 2002 3210 3548 5893 8251 8469 5746 6583 7360 8214 8786 7056 6415 2003 4120 4598 6155 8961 9673 6028 6740 7695 8420 8284 7654 7158 2004 5244 6828 6238 9981 10687 7452 6940 9457 9214 10426 8493 8469
Haga un pronóstico para los 6 primeros meses del año 2005.
8. Un vendedor de autos usados ha registrado las siguientes ventas (en miles de soles) durante el úl-timo año:
Mes Ene Feb Mar Abr May Jun Jul Ago Sep Oct Nov Dic Ventas 205 192 170 214 220 198 230 232 240 255 310 296 Componente estacional 0,95 0,74 0,52 0,86 0,96 1,02 1,05 1,08 1,12 1,16 1,22 1,32
Determine las ventas desestacionalizadas.
9. En la siguiente tabla se ha registrado el número de días soleados al mes que hubo en una ciudad, durante 6 años.
1996 1997 1998 1999 2000 2001 2002 Enero 30 26 14 26 25 25 25
Febrero 27 28 16 25 24 25 26 Marzo 29 28 12 18 24 16 20 Abril 27 29 16 24 26 20 21 Mayo 28 28 22 25 22 21 22 Junio 26 26 25 26 20 19 24 Julio 22 22 23 22 22 20 22
Agosto 20 20 18 20 17 18 19 Septiembre 24 24 21 24 22 23 23
Octubre 26 26 23 26 24 25 23 Noviembre 28 21 25 26 25 25 22 Diciembre 29 19 26 23 27 26 24
a) Determine las componentes estacionales. b) Trace un gráfico con la componente cíclica y coméntelo.
10. ¿Con qué componente de una serie de tiempos asociaría cada uno de los siguientes hechos? a) Un aumento en las ventas de un producto debido al cierre de la principal empresa competido-
ra.

210 Análisis de series de tiempo
b) Una disminución en las ventas de un producto debido a la globalización. c) Un aumento en las ventas de un producto debido a una crisis petrolera durante 2 años. d) Una disminución en las ventas de un producto debido al cierre de la frontera con un país veci-
no durante un mes, por un problema limítrofe.

Herramientas estadísticas para mejorar la calidad de los procesos
211
Capítulo 15. Herramientas estadísticas para mejorar la calidad de los procesos
15.1 Mejora de la calidad
15.1.1 Definiciones Aunque existen muchas definiciones de calidad, quizás la más simple y certera sea: “Calidad es
lo que el cliente define como tal”.
La calidad es un objeto móvil; siempre hay que estarla buscando. Nunca se podrá afirmar que ya se ha conseguido la máxima calidad posible, pues los clientes siempre están cambiando de parecer, de gusto, etc. Por lo tanto siempre hay que estar averiguando qué tan satisfechos están los clientes con el producto o servicio que se les brinda. Se concluye entonces que para conseguir la calidad se debe estar en un proceso de mejora continua.
La calidad siempre se asocia con los defectos; si hay muy pocos defectos se dice que hay cali-dad. Como los defectos siempre estarán presentes, se intenta disminuirlos; y para esto es fundamental preguntarse: ¿por qué ocurren los defectos?
Los defectos ocurren por una causa fundamental: la variabilidad en las personas, en los mate-riales, en las máquinas y herramientas, en el medio ambiente, en la inspección, etc.
Para disminuir los defectos hay que buscar las causas. Éstas pueden ser:
• Causas asignables: cuando se les puede atribuir a alguien o a algo (personas, materiales, máquinas, herramientas, medio ambiente, inspectores, etc).
• Causas no asignables: cuando la variabilidad se debe al azar. Se dice que es una variabili-dad inherente a las personas, materiales, máquinas, herramientas, medio ambiente, inspecto-res, etc. Generalmente es imposible evitar estas causas de forma económica.
A la determinación de las causas de los defectos en un proceso se le llama diagnóstico. Para hacer un buen diagnóstico se puede recurrir a la intuición de un experto, a la experimentación o al aná-lisis estadístico de los datos. Aunque la última opción es generalmente la más acertada, no siempre es aprovechada porque los encargados de tomar las decisiones en las empresas no creen en su efectivi-dad.
Para poder creer que las herramientas estadísticas son efectivas es necesario aceptar que siempre hay variabilidad, y que esta variabilidad siempre es posible medirla, y más si se debe a causas asigna-bles. Así, evitando las causas asignables, se disminuye la variabilidad, y por lo tanto los defectos.
15.1.2 Breve historia de la calidad Desde finales del siglo XIX, la gestión de la calidad ha pasado por cuatro grandes etapas:
• Inspección de la calidad. • Control de la calidad. • Aseguramiento de la calidad. • Gestión de la calidad total.
La gestión de la calidad ha ido evolucionando hacia una visión cada vez más global. Las etapas

Herramientas estadísticas para mejorar la calidad de los procesos
212
más recientes abarcan las anteriores; de esta manera, por ejemplo, el aseguramiento de la calidad abar-ca el control de la calidad y la gestión de la calidad total abarca también el aseguramiento de la cali-dad.
Tradicionalmente la palabra calidad ha estado asociada a la calidad del producto. El objetivo que se perseguía era evitar que un producto defectuoso llegara al cliente. Para ello se efectuaba una ins-pección al 100% de todos los productos, separando los productos buenos de los defectuosos. La cali-dad era un problema de los inspectores.
Al aumentar los volúmenes de producción, la inspección masiva era cada vez más difícil, costo-sa y menos fiable. Se pasó de inspeccionar el 100 % de los productos terminados a controlar los proce-sos. Así, Shewart (1931) propuso el Control estadístico de procesos, CEP.
Pero esta forma de entender la calidad era reactiva, no prevenía los errores; únicamente los de-tectaba cuando ya habían aparecido. Entonces los especialistas centraron sus esfuerzos en diseñar mé-todos de trabajo que permitieran evitar los errores antes de que éstos ocurrieran. Éste es el enfoque del aseguramiento de la calidad, que pretende proporcionar a los clientes la confianza de que un produc-to o servicio satisface los requisitos de calidad. Pero este enfoque, aunque ya es proactivo, está limita-do al ámbito interno de la empresa.
La gestión de la calidad total, además de garantizar que los productos o servicios satisfacen los requisitos de la calidad, pretende involucrar a todos los miembros de la organización en la mejora de todos los procesos. Este sistema de gestión de la calidad ha sido mejorado por Seis Sigma, que se ha preocupado por mejorar continuamente el nivel de satisfacción de los clientes, entre otras cosas.
A continuación se presentan las herramientas estadísticas básicas más empleadas para el mejo-ramiento de la calidad de los procesos, ya sean productivos o de servicio.
15.2 Interpretación de histogramas y medición de la capacidad de un proceso
15.2.1 Interpretación de histogramas. A continuación se muestran diversos tipos de histogramas:
Histograma general: la media del histograma está en el centro del rango de datos. La frecuencia es mayor en el centro y dismi-nuye gradualmente hacia los extremos, ajustándose a una distri-bución normal. Se presenta en casi todos los casos en que se re-presenta una medida en un proceso productivo.
Histograma con sesgo positivo o negativo: tie-ne forma asimétrica. La media del histograma está a la izquierda (o derecha) y la frecuencia disminuye lentamente hacia la derecha (o iz-quierda). Se presenta cuando el límite inferior (o superior) se controla teóricamente o por un valor de especificación; o cuando no se presentan va-lores inferiores (o superiores) a cierto límite.
Histograma con precipicio: es similar al tipo con sesgo, pero con un descenso más brusco hacia un lado. Este tipo se presenta frecuentemente cuando se ha hecho una inspección al 100% y se han separado elementos que no cumplen con el límite inferior o superior de especificación del producto.
Histograma multimodal: hace zigzag sobre la forma general. Se presenta cuando no se ha elegido correctamente la longitud de clase y el número de clases, ya sea porque el número de datos no es suficiente para trazar el histograma (n < 50) o se han conside-rado muchas clases para el número de datos que hay.
Sesgo positivo Sesgo negativo
General
Precipicio
Multimodal

Herramientas estadísticas para mejorar la calidad de los procesos
213
Histograma bimodal: se ven dos histogramas generales, uno junto al otro. Se presenta cuando se mezclan dos distribuciones con medias muy diferentes; por ejemplo cuando en el proceso hay dos turnos, o dos máquinas, o dos operarios, etc. que traba-jan de manera distinta.
Histograma con pico aislado: hay un pequeño pico, aislado de un histograma de tipo general. Se presenta cuando se incluye una pequeña cantidad de datos con una distribución diferente, ya sea por una anormalidad en el proceso, por error de medición o por inclusión de datos de otro proceso.
Histograma planicie: las frecuencias forman una planicie. Se presenta cuando se mezclan varios histogramas que tienen que tienen medias diferentes y distribuciones diferentes, de tal mane-ra que el conjunto forma la planicie.
15.2.2 Capacidad de un proceso Se denominan especificaciones de un producto al rango de medidas dentro del cual se dice que
el producto es conforme. Por ejemplo, las especificaciones del diámetro de los pistones que se fabrican en un taller son: 5,000 ± 0,005 cm. A la media que se especifica se le llama valor nominal, y a la me-dida entre la media y los límites de especificación (LEI y LES) se le denomina tolerancia. En este ejemplo, la tolerancia es ± 0,005 cm.
Si se conocen las especificaciones de un producto, es posible medir si el proceso es capaz de cumplir con dichas especificaciones.
Si se cuenta con un histograma, se pueden trazar dos líneas verticales sobre éste, correspondien-tes a las medidas de las especificaciones. Así se podrá observar si el histograma se encuentra razona-blemente entre dichos límites. En la figura 15.1 se describen dos casos típicos donde se cumplen las especificaciones del producto. En el primer histograma se ve que el proceso es capaz de cumplir con las especificaciones con holgura; pero en el segundo las cumple ajustadamente.
LEI LES LEI LES Figura 15.1. Procesos capaces de cumplir con las especificaciones
En la figura 15.2 se describen dos casos típicos donde no se cumplen las especificaciones del producto.
LEI LES LEI LES Figura 15.2. Procesos no capaces de cumplir con las especificaciones
Bimodal
Pico aislado
Planicie

Herramientas estadísticas para mejorar la calidad de los procesos
214
En el primer caso se ve que el proceso no es capaz de cumplir con las especificaciones porque está descentrado. En el segundo caso tampoco cumple con las especificaciones, pero esta vez porque el proceso tiene mucha variabilidad.
Si se conocen la media y la desviación estándar de un conjunto de datos obtenidos en un proce-so, se puede calcular el índice de capacidad del proceso:
σ6
LEILESC p−
=
Como se ve, un índice de capacidad exactamente igual a 1 (segundo caso de la figura 15.1) indi-cará que el proceso es capaz, pero que está a punto de no serlo.
Si la media del conjunto de datos no coincide con el punto medio de los límites de especifica-ción, es decir, si el proceso está descentrado respecto a las especificaciones, conviene emplear el si-guiente índice de capacidad:
σ6
2)( dLEILESC pk
−−=
En la figura 15.3 se aprecia que d representa la distancia entre la media del conjunto de datos y el centro de los límites de especificación:
2
LEILESxd +−=
En general, siempre conviene emplear esta última fórmula para calcular el índice de capacidad, pues cuando el proceso no está descentrado d es igual a 0.
LEI LESx
d
6σ Figura 15.3. Medición de la capacidad de un proceso
A continuación se presenta una interpretación de los valores que puede tomar el índice de capa-cidad de un proceso:
Si: 0 <Cpk < 1 ⇒ Proceso inadecuado Si: 1 <Cpk < 1,33 ⇒ Proceso adecuado Si: 1,33 <Cpk < ∞ ⇒ Proceso satisfactorio
Ejemplo:
En una planta procesadora de conservas de pescado, dos empleados A y B están llenando latas de conserva de dos tipos: en filetes y en trozos. El peso neto de las latas muestreadas durante 20 días se muestra en la siguiente tabla. Cada día se escogieron aleatoriamente 10 latas y se registró su peso. El peso neto nominal es de 200 g. y la tolerancia es de ± 5 g.
A continuación se muestran los nueve posibles histogramas que se pueden trazar, para que el lector los analice y dé sus conclusiones.

Herramientas estadísticas para mejorar la calidad de los procesos
215
Día Empleado En filete En trozos 1 A 198,55 197,08 199,37 200,91 200,80 201,60 195,72 201,43 203,65 200,35 2 A 198,65 200,64 197,37 194,96 196,46 196,23 197,53 202,21 194,17 204,05 3 B 197,84 195,82 198,15 198,39 197,20 198,45 198,51 201,16 194,55 198,74 4 B 199,45 197,27 200,19 198,72 196,23 201,96 200,30 199,22 198,08 199,03 5 A 202,07 193,18 198,36 196,58 199,81 200,35 201,88 196,81 200,66 201,47 6 A 200,67 196,77 195,49 198,43 200,14 196,83 197,73 201,73 195,04 199,51 7 B 195,92 197,43 197,00 199,04 194,52 202,29 196,39 200,60 197,21 202,14 8 B 195,19 199,19 196,09 197,08 193,02 200,14 199,70 201,06 198,36 198,36 9 A 197,23 197,35 197,13 197,33 200,04 199,48 197,59 200,76 200,02 201,61 10 A 196,94 198,74 199,86 199,21 197,63 201,83 199,73 201,76 202,82 202,32 11 B 199,44 199,12 196,50 198,05 193,62 197,67 197,20 202,23 197,23 201,93 12 B 199,95 199,08 201,27 195,31 201,17 200,96 199,17 196,84 199,47 199,11 13 A 198,11 197,53 199,50 197,42 196,34 200,24 199,67 201,80 197,60 202,83 14 A 199,93 199,32 197,46 200,86 198,53 197,74 197,77 204,66 201,16 201,40 15 B 198,36 196,32 198,21 200,27 192,77 194,09 200,96 202,82 200,21 202,18 16 B 196,36 199,83 198,83 196,06 197,02 198,18 200,27 199,60 203,33 202,95 17 A 200,20 199,68 200,04 201,45 199,46 199,88 201,78 201,19 201,37 199,79 18 A 198,50 200,56 199,22 200,71 198,78 197,83 200,61 200,77 198,33 200,81 19 B 198,13 199,80 199,82 198,53 198,34 196,95 201,99 203,08 202,86 202,68 20 B 198,15 199,13 198,65 194,25 200,88 200,32 201,00 201,49 201,44 200,49
0
5
10
15
20
25
30
35
40
193 194 195 196 197 198 199 200 201 202 203 204 205 206 Figura 15.4. Histograma total
0
5
10
15
20
25
193 194 195 196 197 198 199 200 201 202 203 204 205 206
Figura 15.5. Histograma del empleado A.

Herramientas estadísticas para mejorar la calidad de los procesos
216
0
2
4
6
8
10
12
14
16
18
20
193 194 195 196 197 198 199 200 201 202 203 204 205 206 Figura 15.6. Histograma del empleado B.
0
5
10
15
20
25
193 194 195 196 197 198 199 200 201 202 203 204 205 206 Figura 15.7. Histograma de la conserva en filete.
0
5
10
15
20
25
193 194 195 196 197 198 199 200 201 202 203 204 205 206 Figura 15.8. Histograma de la conserva en trozos.

Herramientas estadísticas para mejorar la calidad de los procesos
217
0
2
4
6
8
10
12
193 194 195 196 197 198 199 200 201 202 203 204 205 206 Figura 15.9. Histograma de empleado A – conserva en filete.
0
2
4
6
8
10
12
14
193 194 195 196 197 198 199 200 201 202 203 204 205 206 Figura 15.10. Histograma de empleado B – conserva en filete.
0
2
4
6
8
10
12
14
16
193 194 195 196 197 198 199 200 201 202 203 204 205 206
Figura 15.11. Histograma de empleado A – conserva en trozos.

Herramientas estadísticas para mejorar la calidad de los procesos
218
0
2
4
6
8
10
12
193 194 195 196 197 198 199 200 201 202 203 204 205 206
Figura 15.12. Histograma de empleado B – conserva en trozos.
15.3 Gráficos de control
15.3.1 Definiciones Un gráfico de control está conformado por una línea central, que suele medir un promedio, dos
límites de control, uno por encima y otro por debajo de la línea central, y una serie de valores caracte-rísticos registrados en el gráfico que representa el estado del proceso. Si todos los valores se encuen-tran dentro de los límites de control, y no se presenta ninguna situación atípica (se explicará más ade-lante), se dice que el proceso está bajo control; en caso contrario se dice que el proceso está fuera de control. En la figuras 15.13 y 15.14 se muestran estas dos situaciones.
Figura 15.13. Gráfico de control de un proceso bajo control
Figura 15.14. Gráfico de control de un proceso fuera de control
Límite de control superior
Límite de control inferior
Línea Central
Límite de control superior
Línea Central
Límite de control inferior

Herramientas estadísticas para mejorar la calidad de los procesos
219
15.3.2 Tipos de gráficos de control Gráficos de control de variables: se aplican a características que se pueden medir. General-
mente los datos provienen de una población que se puede describir con una distribución normal.
Ventajas principales: la mayoría de los procesos son medibles, la medición proporciona más in-formación que un atributo, emplea muestras más pequeñas, la acción correctiva es rápida, etc.
Gráficos de control de atributos: se emplean cuando es posible establecer la ausencia o exis-tencia de una característica de calidad. Generalmente se asocian con distribuciones discretas, como la binomial o Poisson. Proporcionan menos información que los gráficos de control de variables.
Ventajas principales: los datos por atributos existen en todos los procesos y se pueden obtener de manera rápida y económica, un gráfico puede controlar varias características, son fáciles de cons-truir e interpretar, etc.
Como desventaja importante se puede decir que el proceso de decisión es más lento.
En la tabla 15.1 se presentan los tipos de gráficos de control y las fórmulas para determinar los límites de control. Estas fórmulas han sido deducidas asumiendo que casi el 100% de los datos se en-cuentran entre el valor medio ± 3 veces la desviación estándar correspondiente.
Tabla 15.1. Gráficos de control de variables: fórmulas para calcular los límites de control.
Tipo de gráfico de control Límites de control
Media ( x )
LCS = RAx 2+
LCI = RAx 2−
LCS = sAx 3+
LCI = sAx 3−
Mediana (M) LCS = RAM 215,1+
LCI = RAM 215,1−
Rango (R) LCS = RD4
LCI = RD3
Desviación estándar (s) LCS = sB4
LCI = sB3
De
vari
able
s
Individual (con rango móvil, Rm) LCS = mREx 2+
LCI = mREx 2−
Proporción de unidades defectuosas (p) LCS = nppp /)1(3 −+
LCI = nppp /)1(3 −−
Número de unidades defectuosas (np) LCS = )1(3 ppnpn −+
LCI = )1(3 ppnpn −−
Número de defectos (c) LCS = cc 3+
LCI = cc 3− De
atri
buto
s
Número de defectos por unidad (u) LCS = nuu /3+
LCI = nuu /3−
Los valores de los coeficientes A2, A3, D3, D4, B3, B4, E2 se encuentran en el apéndice (pág. 270).
15.3.3 Interpretación de los gráficos de control. Para que un gráfico de control sea correctamente interpretado es recomendable que esté confor-
mado por lo menos por 20 puntos.

Herramientas estadísticas para mejorar la calidad de los procesos
220
Una vez que ya se ha instalado un gráfico de control, es decir, una vez que ya se han determina-do la línea central y los límites de control superior e inferior, se podrá afirmar que el proceso está fuera de control en las siguientes situaciones:
Si hay al menos un punto más allá de los límites de control. Racha: si hay 7 puntos consecutivos a un lado de la línea central, ó si 10 de 11 puntos con-secutivos están a un lado de la línea central, ó 12 de 14, ó 16 de 20.
Tendencia: si hay 6 puntos consecutivos ascendentes o descendentes. Acercamiento a los límites de control: si 2 de 3 puntos consecutivos está comprendidos en-tre 2σ y 3σ.
Acercamiento a la línea central: si la gran mayoría de los puntos están entre –1,5σ y +1,5σ. Esto se debe generalmente a que las muestras se han tomado en forma inapropiada, ya que es poco probable que el proceso haya mejorado tan rápidamente.
Periodicidad: si hay tendencia ascendente y descendente para casi el mismo intervalo.
Estos criterios deben aplicarse con cierta flexibilidad, dependiendo de las circunstancias. En la figura 15.15 se muestran algunas de las situaciones mencionadas.
Figura 15.15. Situaciones de procesos fuera de control
15.3.4 Elaboración de los gráficos de control. Ahora que ya se sabe interpretar los gráficos de control, se verá cómo elaborarlos. Una vez que
ya se ha decidido qué tipo de gráfico se va a trazar, se requiere tomar una serie de muestras, anotar los datos y calcular la medida central y los límites de control.
En los gráficos de control de variables es recomendable determinar, en primer lugar, los límites de control de las medidas de variabilidad, pues suelen ser los primeros en ser violados cuando un pro-ceso se sale de control.
Existen diferentes criterios para aceptar o rechazar los límites de control. Debe tenerse en cuenta que si se presenta alguna de las situaciones mencionadas en el apartado anterior (racha, tendencia, etc.), se deben buscar las causas asignables que deforman el proceso, ya que está fuera de control, y corregirlo. Una vez que se hagan las correcciones oportunas, se intentará instalar el gráfico de control.
Si no hay racha, tendencia, etc, se suele emplear el siguiente criterio:
Si todos los puntos que se han determinado a partir de las muestras están dentro de los lími-tes de control, se instala el gráfico de control.
Si uno o dos puntos están fuera de los límites de control, se eliminan dichos puntos y se re-calcula la medida central y los límites de control. Si ahora todos los puntos quedan dentro de los límites de control, se instala el gráfico de control; en caso contrario, se deben buscar las causas asignables que deforman el proceso y corregirlo. Una vez que se hagan las correccio-nes oportunas, se vuelven a tomar muestras y se calcula la medida central y los límites de control.
Si tres o más puntos están fuera de los límites de control, se deben buscar las causas asigna-
Racha: siete puntos
Tendencia positiva: seis puntos
Acercamiento al límite de control superior: dos de tres puntos

Herramientas estadísticas para mejorar la calidad de los procesos
221
bles que deforman el proceso y corregirlo. Una vez que se hagan las correcciones oportunas, se vuelven a tomar muestras y se calcula la medida central y los límites de control.
Este criterio sólo se usa para instalar los gráficos de control, es decir, para establecer el valor central y los límites de control. Luego, cuando ya se esté controlando el proceso, un punto fuera de los límites de control indicará que el proceso está fuera de control.
Si un proceso está bajo control, no necesariamente hace lo que supuestamente tiene que hacer. Que esté bajo control significa que trabaja bien y da un servicio consistente, de acuerdo a sus posibili-dades. Una vez que un proceso está bajo control ya conviene determinar qué tan capaz es.
A continuación se muestran algunos ejemplos de elaboración de gráficos de control.
Ejemplo 1: *
Los datos de la siguiente tabla muestran los resultados de la medición de temperatura de proce-samiento de 20 lotes continuos. Las temperaturas fueron tomadas cada 15 minutos durante 20 horas de proceso. Elabore los gráficos de control Media-Rango.
Muestra T1 T2 T3 T4 Media Rango1 65 66 67 68 66,50 3 2 65 66 67 67 66,25 2 3 68 65 67 64 66,00 4 4 67 66 68 67 67,00 2 5 67 66 66 67 66,50 1 6 67 67 66 68 67,00 2 7 68 64 67 68 66,75 4 8 67 66 67 67 66,75 1 9 66 68 66 66 66,50 2 10 66 67 67 67 66,75 1 11 66 68 67 67 67,00 2 12 66 66 67 67 66,50 1 13 65 67 65 67 66,00 2 14 68 66 65 67 66,50 3 15 66 67 67 67 66,75 1 16 65 67 67 66 66,25 2 17 67 67 66 66 66,50 1 18 67 67 68 67 67,25 1 19 67 67 68 68 67,50 1 20 68 67 67 67 67,25 1
Total 1333,50 37
Para trazar los gráficos de control se siguen los siguientes pasos:
Paso 1: Calcule la media y el rango de cada muestra.
∑=
=n
kki x
nx
1
1 mínmáx ii xxR −=
Paso 2: Grafique las medias y los rangos por separado.
Paso 3: Calcule la media de las medias ( )x y la media de los rangos ( )R
675,6650,13332011
1∑
=
=×==m
jjx
mx ; 85,137
2011
1∑
=
=×==m
jjR
mR
Paso 4: Calcule los límites de control del gráfico de rangos.
2,485,1282,24 =×=×= RDLCS R
085,103 =×=×= RDLCI R
Sobre el gráfico de rangos trazado en el paso 2 (figura 15.16), trace líneas horizontales que re-presenten los límites de control recién calculados. Verifique que no haya ningún punto más allá

Herramientas estadísticas para mejorar la calidad de los procesos
222
de los límites de control. En este caso no hay.
Paso 5: Calcule los límites de control del gráfico de medias.
02,6885,1729,0675,662 =×+=×+= RAxLCS x 33,6585,1729,0675,662 =×−=×−= RAxLCI x
Sobre el gráfico de medias trazado en el paso 2 (figura 15.17), trace líneas horizontales que re-presenten los límites de control que acaba de calcular. Verifique que no haya ningún punto más allá de los límites de control. En este caso no hay.
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Ran
go
LCS = 4,2
LCI = 0
Media = 1,85
Figura 15.16. Gráfico de control de rangos del ejemplo 1.
64.5
65
65.5
66
66.5
67
67.5
68
68.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Tem
pera
tura
med
ia
LCS = 68,02
LCI = 65,33
Media = 66,675
Figura 15.17. Gráfico de control de medias del ejemplo 1.
Como se ve, el proceso está bajo control, y se pueden instalar ambos gráficos de control. Vale la pena comentar que hubo un descenso en la variabilidad a lo largo del periodo en que se tomaron las muestras, como se ve en el gráfico de control de rangos. Esto, aunque sea positivo, no deja de llamar la atención pues no es un signo de aleatoriedad. Valdría la pena verificar si esto vuel-ve a ocurrir en la siguiente toma de datos.

Herramientas estadísticas para mejorar la calidad de los procesos
223
Ejemplo 2: *
Se quiere controlar las ventas diarias de un grupo de vendedores de una empresa grande. Para esto, durante 20 días se extrajeron aleatoriamente registros de ventas de tres vendedores. En la siguiente tabla se muestran estos datos. Elabore los gráficos de control Mediana-Rango.
Muestra V1 V2 V3 Mediana Rango1 133 138 148 138 15 2 147 131 131 131 16 3 134 128 145 134 17 4 134 143 147 143 13 5 128 128 143 128 15 6 143 137 134 137 9 7 133 129 129 129 4 8 124 127 130 127 6 9 128 125 126 126 23 10 134 151 146 146 17 11 147 135 128 135 19 12 123 140 127 127 17 13 130 126 129 129 4 14 122 128 134 128 12 15 144 124 141 141 20 16 124 124 135 124 11 17 135 125 128 128 10 18 130 136 134 134 6 19 125 123 121 123 4 20 125 128 125 125 3
Total 2633 241
Este caso de ventas es propicio para controlarlo mediante las medianas de las muestras, pues en caso que un vendedor tenga una venta atípica, ya sea muy alta o muy baja respecto a las demás ventas de la muestra, la mediana no registrará ese cambio brusco. Si se controlaran las medias, en cambio, una venta alta atípica de un vendedor podría hacer pensar que las ventas en general han subido.
Para trazar los gráficos de control se siguen los siguientes pasos:
Paso 1: Calcule la mediana y el rango de cada muestra.
Paso 2: Grafique las medianas y los rangos por separado.
Paso 3: Calcule la media de las medianas ( )M y la media de los rangos ( )R .
65,13126332011
1
=×== ∑=
m
jjM
mM ; 05,12241
2011
1
=×== ∑=
m
jjR
mR
Paso 4: Calcule los límites de control del gráfico de rangos
02,3105,12574,24 =×=×= RDLCS R 005,1203 =×=×= RDLCI R
Sobre el gráfico de rangos trazado en el paso 2, trace líneas horizontales que representen los lí-mites de control que acaba de calcular. En este caso no hay ningún punto más allá de los límites de control.
Paso 5: Calcule los límites de control del gráfico de medianas.
83,14505,12023,115,165,13115,1 2 =××+=×+= RAMLCS M
47,11705,12023,115,165,13115,1 2 =××−=×−= RAMLCI M
Sobre el gráfico de medianas trazado en el paso 2, trace líneas horizontales que representen los

Herramientas estadísticas para mejorar la calidad de los procesos
224
límites de control que acaba de calcular. Verifique que no haya ningún punto más allá de los lí-mites de control. En este caso hay un punto (el décimo) que está ligeramente por encima del lí-mite de control superior. Por lo tanto aún no se puede instalar el gráfico de control de medianas.
Paso 6: Elimine el punto que está fuera de los límites y recalcule la media de las medianas, el rango medio y los límites de control.
76,14479,11023,115,189,13015,1 2 =××+=×+= RAMLCSM
02,11779,11023,115,189,13015,1 2 =××−=×−= RAMLCI M
En las figuras 15.18 y 15.19 se muestran los gráficos de control de rangos y de medianas des-pués de ejecutar el paso 6, donde se ha eliminado el décimo punto.
0
5
10
15
20
25
30
35
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Ran
go
LCS = 31.02
LCI = 0
Media = 12.05
Figura 15.18. Gráfico de control de rangos del ejemplo 2.
110
115
120
125
130
135
140
145
150
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Med
iana
LCS = 145.83
LCI = 117.47
131.65
Figura 15.19. Gráfico de control de medianas del ejemplo 2.

Herramientas estadísticas para mejorar la calidad de los procesos
225
Ahora no hay ningún punto fuera de los nuevos límites de control, y no se observa ninguna irre-gularidad, por lo que se pueden instalar ambos gráficos para controlar las ventas diarias. Quizá valdría la pena verificar una posible tendencia de las ventas diarias a disminuir.
Ejemplo 3: *
Un vehículo de una empresa de transportes realiza un viaje diario llevando mercadería desde una fábrica hasta un almacén. Con el propósito de controlar la calidad del servicio se tomaron los tiempos de viaje durante 20 días. En la siguiente tabla se muestran estos tiempos en minutos. Elabore un gráfico de control individual con rango móvil.
Muestra Tiempo Rango móvil Muestra Tiempo Rango móvil 1 63 11 68 5 2 64 1 12 64 4 3 65 1 13 64 0 4 65 0 14 64 0 5 66 1 15 63 1 6 65 1 16 63 0 7 65 0 17 65 2 8 67 2 18 62 3 9 67 0 19 63 1 10 63 4 20 66 3 Total 1292 29
Es evidente que, si se quiere hacer un control diario de los tiempos de viaje, sólo se podrá tomar un dato cada día, y no quedará más remedio que emplear un gráfico de control individual. Si se quisiera hacer control cada tres días, sí se podría usar un gráfico de control de medias.
Para trazar estos gráficos de control se siguen los siguientes pasos:
Paso 1: Calcule el rango móvil entre cada par de mediciones consecutivas (valores absolutos).
Paso 2: Grafique los valores individuales y los rangos móviles por separado.
Paso 3: Calcule la media de los valores individuales ( )x y el rango móvil promedio ( )mR
∑=
=×==20
1
6,641292201
201
jjxx ∑
=
=×==20
2
53,129191
191
jjRR
Paso 4: Calcule los límites de control del gráfico de rangos móviles. Nótese que para el cálcu-lo de los rangos móviles se han agrupado dos valores individuales (éste es el tamaño de la mues-tra). Se podrían calcular rangos móviles agrupando tres o más valores individuales.
00,553,1267,34 =×=×= mR RDLCSm
053,103 =×=×= mR RDLCIm
Sobre el gráfico de rangos móviles trazado en el paso 2 (figura 15.20), trace líneas horizontales que representen los límites de control que acaba de calcular. En este caso no hay ningún punto más allá de los límites de control ni otra irregularidad.
Paso 5: Calcule los límites de control del gráfico de control de valores individuales.
67,6853,1660,26,642 =×+=×+= mx RExLCS
53,6053,1660,26,642 =×−=×−= RExLCI x
Sobre el gráfico de valores individuales trazado en el paso 2 (figura 15.21), trace líneas horizon-tales que representen los límites de control que acaba de calcular. Verifique que no haya ningún punto más allá de los límites de control. En este caso no hay; pero se aprecia una racha desde el punto 3 hasta el punto 9, por lo que se concluye que el proceso está fuera de control. Habría que

Herramientas estadísticas para mejorar la calidad de los procesos
226
investigar cuáles son las causas (asignables) para así mejorar el proceso. Luego se deberán to-mar más datos para intentar instalar estos gráficos de control.
0
1
2
3
4
5
6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Ran
go m
óvil
LCS = 5.00
LCI = 0
Media = 1.53
Figura 15.20. Gráfico de control de rango móvil del ejemplo 3.
56
58
60
62
64
66
68
70
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Val
ores
indi
vidu
ales
LCS = 68,67
LCI = 60,53
Media = 64,6
Figura 15.21. Gráfico de control de valores individuales del ejemplo 3.
Ejemplo 4: *
Se ha inspeccionado 22 lotes semanales de envases plásticos. Los lotes son de tamaño variable y en cada uno se ha registrado el número de unidades defectuosas, como se muestra en la siguien-te tabla. Elabore un gráfico de proporción de unidades defectuosas.
Paso 1: Calcule la proporción defectuosa para cada lote.
Paso 2: Grafique la proporción defectuosa.
Paso 3: Calcule la media de la proporción defectuosa y la media del tamaño de la muestra.

Herramientas estadísticas para mejorar la calidad de los procesos
227
073,0163101183
==p ; 36,74122
16310==n
Semana Tamaño de lote
Unidades defectuosas
Proporcióndefectuosa Semana Tamaño
de lote Unidades
defectuosasProporción defectuosa
1 724 48 0,066 12 739 50 0,068 2 763 83 0,109 13 723 47 0,065 3 748 70 0,094 14 748 57 0,076 4 748 85 0,114 15 770 51 0,066 5 724 45 0,062 16 756 71 0,094 6 727 56 0,077 17 719 53 0,074 7 726 48 0,066 18 757 34 0,045 8 719 67 0,093 19 760 29 0,038 9 759 37 0,049 20 742 37 0,050
10 745 52 0,070 21 726 50 0,069 11 736 47 0,064 22 751 66 0,088 Total 16310 1183 0,073
Paso 4: Calcule los límites de control
102,036,741/)073,01(073,03073,0/)1(3 =−+=−+= npppLCS p
044,036,741/)073,01(073,03073,0/)1(3 =−−=−−= npppLCI p
Sobre el gráfico de proporción defectuosa trazado en el paso 2 (figura 15.22), trace líneas hori-zontales que representen los límites de control que acaba de calcular. Verifique que no haya nin-gún punto más allá de los límites de control. En este caso se encuentran tres puntos fuera de los límites. Se concluye que el proceso está fuera de control. Conviene investigar cuáles son las causas (asignables) para mejorar el proceso. Luego se deberán tomar más datos para intentar ins-talar este gráfico de control.
0.030
0.040
0.050
0.060
0.070
0.080
0.090
0.100
0.110
0.120
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
Prop
orci
ón d
efec
tuos
a
LCS = 0,102
LCI = 0,044
Media = 0,073
Figura 15.22. Gráfico de control de proporciones defectuosas del ejemplo 4.
Ejemplo 5: *
En la siguiente tabla se muestra el número de tardanzas registradas durante 15 días en una em-presa de vigilancia conformada por 400 trabajadores. El gerente ha tomado datos para ver si está dando resultado el programa de factor humano que está implantando. Elabore un gráfico de uni-dades defectuosas. (Pase por alto el hecho de que sólo haya 15 datos).

Herramientas estadísticas para mejorar la calidad de los procesos
228
Día Tardanzas Día Tardanzas Día Tardanzas1 1 6 0 11 2 2 3 7 1 12 0 3 0 8 0 13 1 4 7 9 8 14 0 5 2 10 5 15 3 Total 33
Paso 1: Grafique el número de unidades defectuosas.
Paso 2: Calcule la media de unidades defectuosas y la media de las fracciones defectuosas.
2,21533
==pn ; 0055,015
400/33==p
Paso 3: Calcule los límites de control.
6,6)0055,01(2,232,2)1(3 =−+=−+= ppnpnLCSnp
0)0055,01(2,232,2)1(3 =−−=−−= ppnpnLCI np
El límite inferior saldría negativo, por lo que toma el valor cero.
Sobre el gráfico de unidades defectuosas trazado en el paso 1 (figura 15.23), trace líneas hori-zontales que representen los límites de control que acaba de calcular. Verifique que no haya nin-gún punto más allá de los límites de control.
0
1
2
3
4
5
6
7
8
9
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Uni
dade
s def
ectu
osas
LCS = 6,6
LCI = 0
Media = 2.2
Figura 15.23. Gráfico de control de unidades defectuosas del ejemplo 5.
En este caso se encuentran dos puntos por encima de los límites; por lo tanto aún no se puede instalar este gráfico de control.
Paso 4: Elimine los dos puntos que están fuera de los límites y recalcule la media de unidades defectuosas, la media de las fracciones defectuosas y los límites de control.
385,11318
==pn ; 0035,013
400/18==p
25,6)0035,01(385,13385,1)1(3 =−+=−+= ppnpnLCSnp
0)0035,01(2,23385,1)1(3 =−−=−−= ppnpnLCI np

Herramientas estadísticas para mejorar la calidad de los procesos
229
0
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10 11 12 13
Uni
dade
s def
ectu
osas
LCS = 6,25
Media = 1,385
LCI = 0
Figura 15.24. Gráfico de control de unidades defectuosas (corregido) del ejemplo 5.
Ya no hay ningún punto fuera de los nuevos límites de control, y, como se ve en el gráfico de la figura 15.24, no hay ninguna irregularidad, por lo que se puede instalar este gráfico de control.
Ejemplo 6: *
En la siguiente tabla se muestran los resultados de una prueba realizada en muestras de papel impermeable de tamaño A4. Para determinar su impermeabilidad se ha utilizado el método de la tinta, de tal manera que cada mancha es considerada un defecto. Elabore un gráfico de control de número de defectos.
Muestra Defectos Muestra Defectos Muestra Defectos 1 8 10 7 19 7 2 9 11 6 20 8 3 5 12 4 21 18 4 8 13 7 22 6 5 5 14 6 23 9 6 9 15 14 24 10 7 9 16 6 25 5 8 11 17 4 9 8 18 11 Total 200
Paso 1: Grafique el número de defectos.
Paso 2: Calcule la media de defectos por muestra.
825
200==c
Paso 3: Calcule los límites de control.
5,168383 =+=+= ccLCSc 08383 =−=−= ccLCI c
El límite inferior saldría negativo, por lo que toma el valor cero.
Sobre el gráfico de número de defectos trazado en el paso 1 (figura 15.25), trace líneas horizon-tales que representen los límites de control que acaba de calcular. Verifique que no haya ningún punto más allá de los límites de control. En este caso se encuentra un punto por encima del lími-te superior; por lo tanto aún no se puede instalar este gráfico de control.
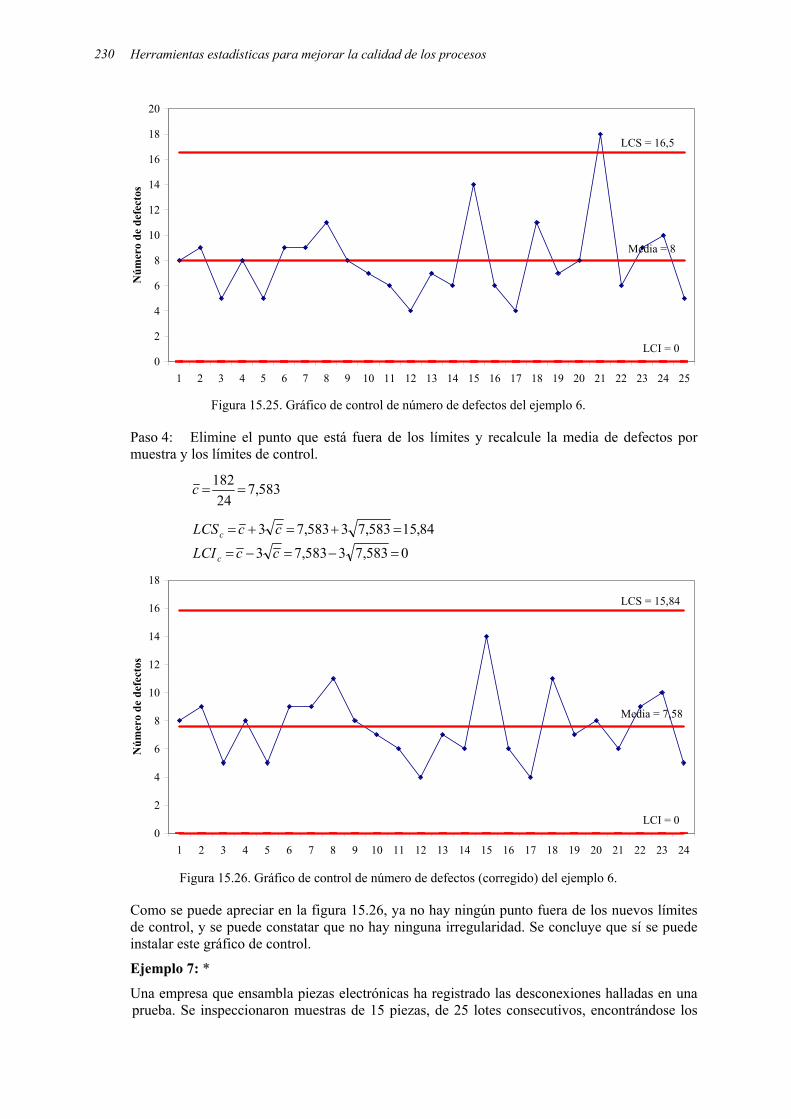
Herramientas estadísticas para mejorar la calidad de los procesos
230
0
2
4
6
8
10
12
14
16
18
20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Núm
ero
de d
efec
tos
LCS = 16,5
LCI = 0
Media = 8
Figura 15.25. Gráfico de control de número de defectos del ejemplo 6.
Paso 4: Elimine el punto que está fuera de los límites y recalcule la media de defectos por muestra y los límites de control.
583,724
182==c
84,15583,73583,73 =+=+= ccLCSc 0583,73583,73 =−=−= ccLCI c
0
2
4
6
8
10
12
14
16
18
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Núm
ero
de d
efec
tos
LCS = 15,84
LCI = 0
Media = 7,58
Figura 15.26. Gráfico de control de número de defectos (corregido) del ejemplo 6.
Como se puede apreciar en la figura 15.26, ya no hay ningún punto fuera de los nuevos límites de control, y se puede constatar que no hay ninguna irregularidad. Se concluye que sí se puede instalar este gráfico de control.
Ejemplo 7: *
Una empresa que ensambla piezas electrónicas ha registrado las desconexiones halladas en una prueba. Se inspeccionaron muestras de 15 piezas, de 25 lotes consecutivos, encontrándose los

Herramientas estadísticas para mejorar la calidad de los procesos
231
números de defectos que se muestran en la siguiente tabla. Elabore un gráfico de control de de-fectos por unidad.
Muestra Defectos Defectos por unidad Muestra Defectos Defectos
por unidad Muestra Defectos Defectos por unidad
1 17 1,13 10 18 1,20 19 23 1,53 2 14 0,93 11 25 1,67 20 22 1,47 3 6 0,40 12 5 0,33 21 9 0,60 4 23 1,53 13 8 0,53 22 15 1,00 5 5 0,33 14 11 0,73 23 20 1,33 6 7 0,47 15 18 1,20 24 7 0,47 7 10 0,67 16 13 0,87 25 24 1,60 8 19 1,27 17 22 1,47 9 29 1,93 18 6 0,40 Total 376
Si se emplease un gráfico de control de número de defectos como en el ejemplo 6, se tendría el inconveniente que el número de defectos en cada pieza es muy bajo o cero, es decir, se tendría que controlar una variable que toma valores cero, uno o dos. Mucho más práctico resulta contro-lar una variable que toma valores mayores, o valores promedio.
Paso 1: Grafique el número de defectos por unidad.
Paso 2: Calcule la media de defectos por unidad para el total de muestra.
003,11525
376=
×=µ
Paso 3: Calcule los límites de control
77,115/003,13003,1/3 =+=+= nµµLCS µ
23,015/033,13003,1/3 =−=−= nµµLCI µ
Sobre el gráfico de número de defectos trazado en el paso 1 (figura 15.27), trace líneas horizon-tales que representen los límites de control que acaba de calcular. Verifique que no haya ningún punto más allá de los límites de control.
0
0.5
1
1.5
2
2.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Núm
ero
de d
efec
tos p
or u
nida
d
LCS = 1,77
LCI = 0,23
Media = 1,003
Figura 15.27. Gráfico de control de defectos por unidad del ejemplo 7.
En este caso se encuentra un punto por encima del límite superior; por lo tanto aún no se puede instalar este gráfico de control.

Herramientas estadísticas para mejorar la calidad de los procesos
232
Paso 4: Elimine el punto que está fuera de los límites y recalcule la media de defectos por uni-dad y los límites de control.
964,01524
347=
×=µ
72,115/964,03964,0/3 =+=+= nµµLCS µ
20,015/964,03964,0/3 =−=+= nµµLCI µ
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Núm
ero
de d
efec
tos p
or u
nida
d
LCS = 1,72
LCI = 0,20
Media = 0,964
Figura 15.28. Gráfico de control de defectos por unidad (corregido) del ejemplo 7.
Como se aprecia en la figura 15.28, ya no hay ningún punto fuera de los nuevos límites de con-trol, y se puede constatar que no hay ninguna irregularidad. Se concluye que se puede instalar este gráfico de control.
(*) Ejemplos extraídos del curso de Herramientas Estadísticas para el mejoramiento de procesos dictado por el Ing. Federico Salvador en la Sociedad Nacional de Industrias del Perú.
15.4 Muestreo de aceptación Es el proceso de evaluación o inspección de una muestra extraída de un lote de productos, con el
propósito de juzgar la calidad del lote completo y tomar la decisión de aceptarlo o rechazarlo.
Las ventajas del muestreo de aceptación respecto a la inspección del lote completo son:
• Es más económico inspeccionar una parte del lote, a pesar del costo del diseño y administra-ción de los planes de muestreo.
• Es menos complejo y menos costoso administrar grupos pequeños de inspectores. • Existe menor daño a los productos, si es el caso. • Se dispone del lote más rápidamente. • Se minimiza el problema de la monotonía y de los errores de inspección, que suelen aumen-
tar cuando se inspecciona el 100% del lote. • El rechazo de los lotes no conformantes tiende a apremiar a las organizaciones a que bus-
quen medidas preventivas.
Las desventajas del muestreo de aceptación son:
• Trae consigo dos riesgos: cometer el error tipo I y cometer el error tipo II.

Herramientas estadísticas para mejorar la calidad de los procesos
233
• Mayores costos administrativos. • Menor información sobre el producto.
Conviene usar el muestreo de aceptación en las siguientes situaciones:
• Cuando el costo de la inspección es alto respecto al costo del daño que resulta al aceptar productos defectuosos.
• Cuando la inspección es muy monótona y/o causa errores de inspección. • Cuando la inspección es destructiva.
Evidentemente no vale la pena usar el muestreo de aceptación cuando el fabricante tiene una certificación de calidad.
Es importante conocer los límites del muestreo de aceptación. Una manera práctica de hacerlo es aclarando lo que no hace:
• No proporciona estimaciones depuradas de la calidad de un lote. • No proporciona juicios sobre el producto rechazado respecto a si es adecuado para el uso.
15.4.1 Análisis económico de la inspección. Para evaluar lotes de productos se cuenta con las siguientes alternativas:
No inspeccionar: no conviene inspeccionar ninguna unidad de un lote cuando laboratorios califi-cados han hecho inspecciones anteriores sobre el mismo lote, ya sea en otras divisiones de la misma empresa o en la empresa del proveedor.
Muestreo pequeño: conviene inspeccionar muestras pequeñas cuando un proceso es inherente-mente uniforme y cuando se puede preservar el orden de la producción. Por ejemplo, en algunas ope-raciones de impresión, las placas se hacen de manera que tengan un alto grado de estabilidad. Como resultado de esto, las impresiones sucesivas hechas con estas placas tienen un alto grado de uniformi-dad para ciertas características dimensionales. Para tales características, si la primera y la última uni-dad del lote están correctas, todo el resto estará también correcto, aun para lotes de miles de unidades. Además, conviene inspeccionar muestras pequeñas cuando el producto es homogéneo debido a su fluidez (gases y líquidos) o debido a operaciones anteriores de mezclado. Una vez comprobado el hecho de la homogeneidad, el muestreo que se necesita es mínimo.
Muestreo: conviene inspeccionar muestras grandes cuando la información sobre la calidad de un lote debe derivarse únicamente a partir del muestreo. El tamaño de la muestra depende principalmente de dos variables: el porcentaje tolerable de productos defectuosos y los riesgos que se está dispuesto a correr. El muestreo suele ser la mejor alternativa cuando se alternan lotes de alta y baja calidad, o cuando el proceso de producción está fuera de control.
Inspeccionar todo el lote: Conviene inspeccionar el 100% de un lote cuando los resultados del muestreo indican que el nivel actual de defectos es demasiado alto para que el lote se envíe a los clien-tes o cuando la inspección es muy barata y rápida (automática).
Para determinar cuál de estas alternativas de inspección es la que conviene en determinadas si-tuaciones, es necesario estimar los costos que genera la inspección. Sean:
N = el número de artículos del lote. n = el número de artículos de la muestra. p = la proporción de artículos defectuosos del lote. D = el costo de los daños en que se incurre si un artículo defectuoso pasa la inspección. I = el costo por inspeccionar un artículo. Pa = la probabilidad de que un lote sea aceptado por el plan de muestreo.
Los costos esperados para cada alternativa de inspección serán entonces:
– Por no inspeccionar: NpD – Por muestrear: nI + (N – n)pDPa + (N – n)(1 – Pa)I – Por inspeccionar el 100%: NI

Herramientas estadísticas para mejorar la calidad de los procesos
234
Lógicamente, se escogería la alternativa que dé el menor costo.
Se asume que el costo por reemplazar un artículo defectuoso encontrado en la inspección lo cu-bre el fabricante, o que resulta muy pequeño comparado con el daño o inconveniente causado por el defecto.
15.4.2 Riesgos del muestreo. El muestreo siempre involucra el riesgo de que la muestra no refleje el contenido del lote. Evi-
dentemente, mientras más grande sea la muestra, menor será este riesgo; pero las muestras grandes suelen ser costosas en tiempo y dinero. Los riesgos que se corre con el muestreo son dos:
• Rechazar un lote “bueno”, es decir, rechazar un lote que sí cumple la norma de calidad. A este riesgo se le llama riesgo del productor, pues quien resulta perjudicado ante este error es
el productor. También se le conoce como error tipo I. A la probabilidad de cometer el error ti-po I se le denomina α.
• Aceptar un lote “malo”, es decir, aceptar un lote que no cumple la norma de calidad. A este riesgo se le llama riesgo del consumidor, pues quien resulta perjudicado ante este error
es el consumidor. También se le conoce como error tipo II. A la probabilidad de cometer el error tipo II se le denomina β.
Que un lote cumple la norma de calidad significa que el porcentaje de unidades defectuosas es menor o igual al que especifica el productor.
Ejemplo:
Un productor asegura que el porcentaje de unidades defectuosas en su fábrica no supera el 2%. Un cliente toma una muestra de 300 unidades para decidir si acepta un lote muy grande del pro-ductor. ¿Qué porcentaje de unidades defectuosas tendría que encontrar en la muestra para re-chazar el lote? Considere α = 5%.
H0: p ≤ 0,02
H1: p > 0,02
p = 0,02 p1*
Región de aceptación Región de rechazo
Para determinar el límite entre las regiones de aceptación y rechazo:
30098,002,0
)300(2102,0*
645,1*1
×
−−==
pz
p1* = 0,035 = 3,5% ⇒ x* = 300(0,035) = 10,5
P1

Herramientas estadísticas para mejorar la calidad de los procesos
235
Por lo tanto, se rechazará el lote cuando en la muestra haya 11 ó más unidades defectuosas, es decir, cuando el porcentaje de unidades defectuosas sea 11/300 = 3,66% ó más.
Si realmente el lote tuviese un 5% de unidades defectuosas. ¿Cuál sería la probabilidad de acep-tar el lote? (Se dice que un lote con esta característica no está cumpliendo con la norma de cali-dad, o que no es conformante).
Se aceptará ese lote cuando el porcentaje de unidades defectuosas de la muestra “caiga” en la región de aceptación:
192,1
30095,005,0
)300(2105,0
30010
−=×
+−=z ⇒ β = 0,1170
La probabilidad de aceptar el lote con 5% de unidades defectuosas (creyendo que tiene 2% de unidades defectuosas) será 0,1170.
15.4.3 Plan de muestreo Un plan de muestreo es un conjunto de lineamientos específicos elaborados para examinar un lo-
te de productos, con el propósito de aceptarlo o rechazarlo. Esta decisión dependerá de la calidad de la muestra tomada.
Para definir un plan de muestreo se emplean los siguientes parámetros:
n = tamaño de la muestra. c = número de aceptación, es decir, el máximo de artículos defectuosos permitido en la mues-
tra para aceptar el lote. N = tamaño del lote.
15.4.4 Curva característica de operación (Curva CO) Es una curva que muestra, para un plan de muestreo determinado y para valores hipotéticos de la
proporción de artículos defectuosos, la probabilidad de que el lote sea aceptado.
Curva CO ideal:
Si se diseñara un plan de muestreo ideal, se eliminarían los riesgos del fabricante y del consumi-dor. Esto sólo sería posible si se inspeccionase el 100% del lote, es decir, si n = N.
Supóngase que se decide aceptar un lote si éste cumple con lo especificado por el productor, es decir, si son defectuosos p0 % de los artículos o menos; y rechazar el lote en caso contrario. En la figu-ra 15.29 se muestra la curva CO ideal para esta situación.
p0
1
p
PA
15.29 Curva característica de operación ideal
Como se ve en la figura 15.29, sólo se aceptará un lote si el porcentaje de artículos defectuosos es 1% ó menos. Por lo tanto, la probabilidad (Pa) de aceptar un lote con 1% ó menos de artículos de-

Herramientas estadísticas para mejorar la calidad de los procesos
236
fectuosos es 1. En cambio, la probabilidad (Pa) de aceptar un lote con más del 1% de artículos defec-tuosos es 0.
Curva CO real:
Cuando un lote sí cumple la norma de calidad, es decir, cuando se cumple la hipótesis nula, cabe la posibilidad de que sea rechazado. La probabilidad de que esto ocurra (α) es cero si p = 0; pero α comienza a aumentar conforme aumenta p. Por lo tanto, Pa comienza a disminuir desde 1, tal como se muestra en la figura 15.30.
p0 = NCA
1
PA
α
NCL
β = 0,10
Figura 15.30. Curva característica de operación
En la curva CO real se identifican dos puntos característicos:
• NCA: Nivel de calidad aceptable. Es el máximo valor de p que se debería aceptar, es decir, el máximo valor de p que anuncia
el fabricante. La probabilidad de rechazar este nivel de calidad es α. • NCL: Nivel de calidad límite. Es el nivel de calidad que sería mejor no aceptar. La probabilidad de aceptar este nivel es β,
y suele establecerse en 0,10. Trazo de la curva CO:
Para trazar la curva CO de un plan de muestreo se calculan algunos pares de valores Pa , p.
Para calcular Pa , en caso que el lote sea lo suficientemente grande (N >> n) como para asumir que el porcentaje de artículos defectuosos se mantiene constante a medida que se extrae cada unidad de la muestra, se puede usar la fórmula de probabilidad binomial:
∑=
−
=≤=
c
x
xnxa qp
xn
cxPP0
)(
Si n es grande y p muy pequeño, puede resultar buena la aproximación de las probabilidades bi-nomiales a probabilidades de Poisson. En el apéndice se presenta una tabla con probabilidades Pa (de Poisson) para determinados valores de np y c (página 271).
Si np>5 y nq>5; se puede aproximar la distribución binomial a la distribución normal.
Forma de la curva CO:
En un plan de muestreo es importante que los riesgos de muestreo sean lo menor posible, es de-cir, que se consigan los valores típicos de α y β : 0,05 y 0,10, respectivamente, para el NCA que anun-cia el productor y para un valor de NCL que no perjudique al consumidor.
Si se aumenta el número de aceptación c en un plan de muestreo, manteniendo constante el valor de n, lógicamente aumentará la probabilidad de aceptación, como se muestra en la figura 15.31.

Herramientas estadísticas para mejorar la calidad de los procesos
237
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 0.55 0.60
Prob
abili
dad
de a
cept
ació
n
c = 0 c = 1 c = 2 c = 3 c = 4 c = 5
Figura 15.30. Curvas CO para n constante
Si se aumenta el tamaño de la muestra n en un plan de muestreo, manteniendo constante el valor de c, lógicamente disminuirá la probabilidad de aceptación, como se muestra en la figura 15.31.
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40
Prob
abili
dad
de a
cept
ació
n
n = 60n = 50
n = 40n = 30
n = 20
Figura 15.30. Curvas CO para c constante
En conclusión, para elegir un buen plan de muestreo se debe escoger una adecuada combinación del número de aceptación c y del tamaño de la muestra n. Dado un valor de NCA y definido un valor de β, se debe elegir un plan de muestreo que haga que α y NCL sean tan pequeños como se desee.

Herramientas estadísticas para mejorar la calidad de los procesos
238
Problemas propuestos. 1. Una empresa de manufactura recibe componentes de un proveedor, cuyas dimensiones ha repre-
sentado mediante el histograma de la siguiente figura:
LEi LEs
Según se aprecia, el proveedor sólo envía los componentes que cumplen con las especificaciones
establecidas, descartando los defectuosos. ¿Qué ventajas puede tener la empresa si exige a su pro-veedor que centre el proceso?
a) Ninguna, pues lo que importa es que cumpla con las especificaciones. b) Puede exigir precios más bajos a su proveedor. c) Puede ahorrarse los costos de inspección. d) Todas las respuestas anteriores son correctas, excepto (a). e) No se puede saber, pues faltan datos.
2. Suponga que usted es el gerente de una empresa que fabrica discos metálicos recubiertos con plás-tico. El jefe de producción tiene una muestra que fue extraída durante 3 días de producción. En la siguiente figura se muestra el histograma que representa dicha muestra. ¿Qué le diría al jefe de producción?
Espesor del recubrimiento(milésimas de pulgada)
2
4
12 20 28 36 44
3. Una empresa, que quiere analizar las ventas de sus productos en esta campaña navideña, ha toma-do datos de las ventas (en soles) realizadas en sus dos tiendas durante este mes de diciembre. Para hacer un mejor análisis, ha construido el siguiente histograma:
¿Qué comentarios puede hacer al respecto?
4. Un fabricante de un compuesto está preocupado por la densidad de su producto. Análisis previos han demostrado que dicho compuesto tiene las características requeridas sólo si la densidad se en-cuentra entre 5,40 g/cm2 y 6,02 g/cm2. Si una muestra de 100 piezas da un promedio de 5,69 g. y una desviación estándar de 0,1 g. ¿Se puede afirmar que su proceso es capaz? ¿Qué recomendaría al jefe de producción?
Respuesta: no es capaz, pues cpk = 0,967. Convendría centrar el proceso, y más aún, reducir la va-riabilidad del proceso.
Venta

Herramientas estadísticas para mejorar la calidad de los procesos
239
5. Se afirma que un proceso cuya tolerancia es de ±45 mm. no es capaz, a pesar de que la desviación estándar es igual a 13,11 mm. ¿Es posible esto?
6. ¿Cómo cree que debería ser el histograma de la longitud de los trozos de madera de desecho en un taller de carpintería?
Respuesta: con sesgo positivo; esto revelaría que se desechan pocos trozos grandes.
7. Explique qué implicaría calcular el índice de capacidad de un proceso si se emplea 8σ en vez de 6σ.
Respuesta: Empleando 8σ se mediría un índice de capacidad menor; por lo tanto se estaría siendo más estricto al valorar qué tan capaz es un proceso.
8. Las especificaciones para cierta dimensión de un producto elaborado mediante un proceso son: 3,000 ± 0,006 pulgadas. Una muestra grande indica un promedio de 2,998 pulgadas y una desvia-ción estándar de 0,002 pulgadas. Suponga que se puede ajustar el proceso, con un gasto de $750, para cambiar el promedio a la especificación nominal, es decir, a 3,000 pulgadas. Cada producto fuera de los límites de especificación significa una pérdida de $5.
a) Determine en cuánto mejora el índice de capacidad del proceso si se hace el ajuste especifica-do. Respuesta: mejora en 0,3333
b) Si se hace el ajuste del proceso para producir un lote de 10 000 unidades, ¿se lograría un aho-rro?
Respuesta: Sí, se espera ahorrar $254,10.
9. Conteste verdadero (V) o falso (F).
a) El muestreo de aceptación determina si un proceso funciona correctamente. b) Un proceso productivo que está bajo control suele generar histogramas simétricos. c) Si se van obteniendo puntos fuera de los límites de control, es casi seguro que no se cumpla
con los límites de especificación. d) Para detectar posibles fallas en un proceso conviene emplear los gráficos de control en lugar
de estudiar la capacidad del proceso. e) β es la probabilidad Pa cuando la proporción de productos defectuosos es indeseable. f) α es la probabilidad (1 – Pa) cuando la proporción de productos defectuosos no corresponde
con la especificada por el productor.
10. Se observa que el gráfico de medias aritméticas de un proceso ha estado bajo control. Si el rango disminuye repentina y significativamente, entonces la media:
a) siempre aumentará. b) se mantendrá igual. c) siempre disminuirá. d) ocasionalmente hay una indicación de fuera de control para cualquiera de los límites. e) ninguno de los anteriores.
11. En la siguiente tabla se presentan medidas extraídas de 13 lotes producidos sucesivamente. De ca-da lote se ha extraído una muestra de 5 medidas. Trace los gráficos de control de media, mediana y de rangos, y comente los resultados obtenidos.
Lote N° 1 2 3 4 5 6 7 8 9 10 11 12 13
47 19 13 29 28 40 15 25 37 23 28 31 22 32 37 31 29 12 35 30 44 37 45 44 25 37 44 31 24 42 45 11 12 32 26 26 40 24 19 35 25 46 59 36 38 33 11 20 37 31 32 47
Valores medidos
20 34 44 38 25 33 26 38 35 32 18 22 14

Herramientas estadísticas para mejorar la calidad de los procesos
240
12. Se desea controlar el proceso de llenado de bolsitas con cocoa, mediante gráficos de control me-dia–desviación estándar, para lo cual se han tomado muestras de seis bolsitas durante 20 horas consecutivas, como se muestra en la siguiente tabla. Determine si se pueden instalar dichos gráfi-cos de control.
Hora 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
74,86 74,84 73,82 75,15 74,79 75,18 75,46 74,91 76,49 74,45 75,93 75,03 74,70 75,40 74,27 74,44 74,69 75,41 74,44 75,1276,31 74,95 73,91 74,67 75,87 74,79 74,09 74,78 74,40 75,25 74,34 74,51 75,26 74,17 75,50 74,83 73,71 75,40 75,05 75,0876,08 75,60 76,62 74,87 74,35 74,82 75,27 74,95 75,37 75,28 73,62 75,56 74,74 74,78 75,68 74,37 75,80 74,57 75,21 74,4475,84 74,96 74,90 74,93 75,17 74,55 75,11 76,32 75,29 75,25 74,93 75,15 75,94 74,01 75,03 74,77 75,09 74,43 74,21 73,9474,78 75,16 75,63 73,90 75,46 76,17 75,31 75,03 75,48 74,36 75,84 74,89 75,38 74,16 74,68 74,09 74,36 74,79 73,43 75,4174,94 74,65 73,73 74,77 75,52 74,95 75,87 74,76 75,43 75,40 75,58 76,14 74,73 74,95 74,32 74,32 75,63 75,67 74,17 75,99
Respuesta: no se pueden instalar, pues hay una racha de 9 puntos en el gráfico de medias.
13. Una biblioteca universitaria considera que ordenará entre 200 y 400 libros cada mes. Se han ras-treado las órdenes de los últimos 23 meses, con los siguientes resultados:
1 2 3 4 5 6 7 8 9 10 11 12 275 335 336 363 319 400 376 245 240 300 210 363 13 14 15 16 17 18 19 20 21 22 23 368 325 400 491 500 400 175 297 170 271 250
a) ¿El proceso de órdenes se encuentra bajo control? b) ¿El proceso de órdenes cumple con las especificaciones?
14. El jefe de una biblioteca universitaria quiere medir y controlar el nivel de satisfacción de los alum-nos usuarios respecto a la rapidez con que se les entrega los libros para préstamo. Para esto ha en-cuestado diariamente a 10 alumnos que salían de la biblioteca con algún libro prestado, durante 22 días del mes pasado, pidiéndoles que escojan una alternativa para la siguiente afirmación:
“Usted considera que la rapidez con que se le ha entregado el libro que ha solicitado es”:
1) Muy baja. 2) Baja. 3) Ni baja ni alta. 4) Alta. 5) Muy alta.
A cada una de estas respuestas se les da el puntaje 1, 2, 3, 4, 5, respectivamente. De esta manera, un promedio alto indicará un alto nivel de satisfacción de los usuarios.
En la siguiente tabla se muestran los promedios de los puntajes obtenidos durante los 22 días.
Días 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 3 1 2 1 3 2 1 1 1 1 1 2 1 1 1 1 1 1 1 2 1 2 4 1 1 3 1 1 1 1 2 1 2 1 2 1 1 2 3 2 1 2 1 2 2 2 2 3 1 2 2 4 5 2 2 2 3 1 1 1 4 1 3 1 3 5 1 3 1 1 3 1 3 1 1 1 1 1 3 3 3 3 1 4 2 2 2 4 2 3 2 1 1 1 2 1 3 1 1 1 2 5 2 1 1 3 1 1 1 1 1 3 3 1 3 1 2 4 5 2 2 2 2 1 4 1 3 2 1 1 1 1 2 2 1 1 3 1 1 3 2 2 2 3 3 1 1 1 4 1 2 1 2 2 3 4 2 2 1 2 3 1 2 1 1 2 4 1 1 2 5 3 2 1 2 3 1 2 1 1 4 2 2 2 1 1 3 1 1 2 4 4 3 4 1 1 3 1 2 1 3 1 2 2 4 3 2 1 1 5 1 2 2 2 1 2 2 1 2 1
Determine si se pueden instalar gráficos de control media–rango.
15. Una distribuidora recibe diariamente paquetes de 400 tuercas de un fabricante, que luego vende a ferreterías locales. El porcentaje de tuercas defectuosas es, en promedio, 2,75%.
a) ¿En qué rango puede considerarse estadísticamente aceptable la variación del porcentaje de tuercas defectuosas?

Herramientas estadísticas para mejorar la calidad de los procesos
241
b) ¿En qué rango puede considerarse estadísticamente aceptable la variación del número de tuer-cas defectuosas?
16. ¿Qué haría si, luego de tomar datos para instalar un gráfico de control de una variable de calidad:
a) tres puntos se encuentran fuera de los límites de control? b) dos puntos se encuentran fuera de los límites de control? c) hay una racha?
17. ¿Por qué es más pequeña la distancia entre los límites de control de un gráfico de control de me-dias, que la distancia entre los límites de especificación?
18. ¿Cuándo conviene instalar un gráfico de control de proporción de unidades defectuosas en vez de número de unidades defectuosas? ¿Cuándo conviene instalar un gráfico de control de número de defectos en vez de número de defectos por unidad?
19. Se toman muestras de n = 8 de un proceso de manufactura a intervalos regulares. Se mide cierta característica de calidad (distribuida normalmente) y se calculan los valores de x y R para cada muestra. Después de 50 muestras se tiene:
100050
1
=∑=i
ix ; 25050
1
=∑=i
iR
a) Calcule los límites de control para los gráficos de control de medias y de rangos. Respuesta: LC x = 20 ± 1,865; LCIR = 0,68; LCSR = 9,32.
b) Si los límites de especificación son: 21 ± 5,0. ¿Cuál es su conclusión acerca de la capacidad del proceso?
Respuesta: el proceso no es capaz, pues cpk = 0,785.
20. Un plan de muestreo n = 25; c = 0 para un lote muy grande implica un alto riesgo para un produc-tor que afirma que tiene un máximo de 2% de productos defectuosos.
a) Explique por qué y determine dicho riesgo. b) ¿Qué porcentaje de defectuosos tendría que afirmar que tiene el productor para que su riesgo
no supere el 10%?
21. Una empresa recibe lotes de 1 000 productos, los cuales se pueden inspeccionar a $0,70/unidad. Si acepta material defectuoso, se incurre en un costo de $14 /unidad. Se propone un plan de muestreo n = 75; c = 2. Si el porcentaje de productos defectuosos es aproximadamente 2,2%, ¿se justifica el plan de muestreo?
22. Defina un plan de muestreo con n = 100 para un lote muy grande enviado por un productor que afirma que p = 0,02; tratando que el riesgo del productor no supere el 10% y el nivel de calidad límite sea el menor posible. Determine además el nivel de calidad límite. Considere el valor usual de β = 0,10.
Respuesta: n = 100; c = 4; NCL = 0,0797.
23. Un fabricante vende su producto en lotes grandes a un cliente que utiliza un plan de muestreo n = 180, c = 2. Si un lote es rechazado se regresará al fabricante, quien ha decidido arriesgarse y en-viar el mismo lote rechazado al cliente, sin revisarlo, con la esperanza de que la segunda vez el muestreo lo lleve a aceptar el lote. ¿Cuál es la probabilidad de que esto ocurra, es decir, de que un lote sea rechazado y luego aceptado, si p = 0,02?
24. ¿Cómo influye la pendiente de la curva CO en la protección para el productor y para el consumi-dor?
25. Se establece el siguiente plan de muestreo: n = 250; c = 5.
a) Determine NCA si el riesgo del productor es 0,025. Respuesta: 0,88% b) Determine NCA si el riesgo del productor es 0,05. Respuesta: 1,04%

Herramientas estadísticas para mejorar la calidad de los procesos
242
26. La probabilidad de aceptar un producto con un nivel de calidad aceptable se define como:
a) NCA b) α c) β d) 1 – α e) 1 – β
27. Defina un plan de muestreo con n > 100 para un lote muy grande enviado por un fabricante que afirma que p = 3%, tratando que el riego del productor esté entre el 5% y el 10% y el nivel de cali-dad límite no supere el 9%.
28. Para calificar la bondad de un plan de muestreo debe tenerse en cuenta:
a) NCA y c b) NCA c) NCA y NCL d) NCL y β
29. Un fabricante nacional de equipo de navegación compra partes de una compañía alemana, en lotes de 5 000 unidades. El fabricante planea un muestreo de 50 piezas por lote.
a) Construya la curva CO para c = 0; 2 y 5. b) Determine α y NCL en cada caso, si NCA = 0,02 y β = 0,10.
30. Determine Pa para un plan de muestreo n = 110; c = 3 para lotes muy grandes con:
a) 1% de productos defectuosos. Respuesta: 0,974
b) 2% de productos defectuosos. Respuesta: 0,580 c) 5% de productos defectuosos. Respuesta: 0,058208

Teoría de decisiones 243
Capítulo 16. Teoría de decisiones.
16.1 Introducción. En todas las empresas, fábricas, tiendas, etc., se toman decisiones continuamente. Se tiene que
decidir, por ejemplo:
• Cuántas horas-hombre contratar el próximo mes. • Cuánto gastar en publicidad de un producto el próximo año. • Cuántas mochilas comprar para la campaña escolar. • Si conviene introducir un nuevo producto en el mercado. • Si conviene comprar una máquina para elaborar un componente de un producto final, o seguir
comprando el componente a un proveedor. • Si conviene reemplazar o reconstruir un equipo.
En cada uno de estos ejemplos se ve que son posibles dos o más cursos de acción. Generalmente las decisiones se toman con base en la intuición de personas expertas; pero existe el peligro de equivo-carse por no hacer un análisis profundo de las decisiones posibles y sus consecuencias.
16.2 Definiciones
16.2.1 Decisor Es un ente individual o colectivo capaz de tomar decisiones. Se asocia al decisor un conjunto de
decisiones posibles {ai}.
16.2.2 Alternativas de decisión Es el conjunto de decisiones o acciones {ai} entre las cuales el decisor debe elegir una.
16.3 Estados de la naturaleza Son las circunstancias que influyen en el beneficio que va a recibir el decisor y sobre los cuales
él no puede influir. A los distintos estados de la naturaleza se les denomina {bj}.
Según el conocimiento que se tenga de los posibles estados de la naturaleza, se puede tener:
16.3.1 Ambiente de certeza Cuando el decisor conoce perfectamente el estado de la naturaleza para la decisión que tome.
16.3.2 Ambiente de riesgo Cuando no se dispone de información perfecta como el caso anterior, pero se conocen las proba-
bilidades de ocurrencia de los diferentes estados de la naturaleza. En este capítulo se analizarán situa-ciones de este tipo.
16.3.3 Ambiente de incertidumbre Cuando no se dispone de ninguna información sobre las probabilidades con que pueden ocurrir
los estados de la naturaleza. El decisor debe elaborar un criterio que dependerá mucho de su criterio particular.

244 Teoría de decisiones
16.3.4 Ambiente de competencia Cuando influyen causas promovidas por otro decisor, pudiendo sus decisiones influir negativa-
mente en el beneficio. Esto significa que lo que suponga un beneficio para un decisor, será un perjui-cio para el otro. La teoría de juegos, que es parte de la Investigación de Operaciones, se encarga de analizar situaciones como ésta.
16.4 Consecuencias Son los resultados asociados a cada acción. Dependen de la decisión que tome el decisor y del
estado de la naturaleza que se presente. No está demás aclarar que un estado de la naturaleza se pre-sentará después de que el decidor haya escogido una acción.
A los resultados se les suele cuantificar con un valor (vij), que representa el costo o beneficio que se obtiene cuando se toma la decisión i y ocurre el estado de la naturaleza j.
En la siguiente tabla se pueden identificar los conceptos ya explicados:
Estados de la naturaleza b1 b2 … … bn
a1 v11 v12 v1n a2 v21 v22 V2n ... ...
Alternativas de decisión
am vm1 vm2 vmn
16.5 Criterios de decisión Para una mejor comprensión de los criterios de decisión que se pueden adoptar, se aplicará cada
uno de éstos al ejemplo 1. El lector debe decidir cuál de los criterios le conviene emplear, lo cual de-penderá de la situación específica que se presente y de su nivel de aversión al riesgo.
Ejemplo 1: Diariamente, un vendedor de periódicos (se puede suponer cualquier producto perecedero) debe decidir cuántos periódicos comprar. Cada periódico lo compra a S/.2 y lo vende a S/.2.50. Los periódicos que no vende durante el día los pierde. Por experiencia, ha encontrado que puede vender entre 6 y 10 periódicos, con la misma probabilidad de ocurrencia. ¿Cuántos periódicos le conviene comprar cada día?
En la siguiente tabla se representan los posibles beneficios de este problema de decisión, que se calculan fácilmente a partir de los datos:
Posible demanda 6 7 8 9 10
6 3 3 3 3 3 7 1 3,50 3,50 3,50 3,50 8 -1 1,50 4 4 4 9 -3 -0,50 2 4,50 4,50
Posible pedido
10 -5 -2,50 0 2,50 5
16.5.1 Criterio Maximin Es un criterio muy pesimista. Elige la acción que maximiza el peor resultado; es decir, de los
peores resultados de cada acción posible, se escoge el mejor. Así se asegura que, en el peor de los ca-sos, el resultado sea lo mejor posible.
Aplicando este criterio al ejemplo 1, habría que escoger el mayor beneficio entre los menores de cada pedido posible: 3, 1, -1, -3 y -5. El mayor es 3; por lo tanto se pedirían 6 periódicos.

Teoría de decisiones 245
16.5.2 Criterio Maximax Es un criterio muy optimista. Elige la acción que determina el mejor resultado entre los mejores
de cada acción posible.
Aplicando este criterio al ejemplo 1, habría que escoger el mayor beneficio entre los siguientes: 3; 3,50; 4; 4,50; 5. El mayor es 5; por lo tanto se pedirían 10 periódicos.
16.5.3 Criterio realista Es un criterio que se sitúa entre el optimismo del criterio maximax y el pesimismo del criterio
maximin. El decisor debe elegir un coeficiente de optimismo (α) comprendido entre 0 y 1. Así, para cada acción posible, la medida de realismo será:
r = α (beneficio máximo) + (1 – α) (beneficio mínimo)
Como se trata de obtener el máximo beneficio posible, el decisor elegirá el mayor valor de r.
Aplicando este criterio al ejemplo 1, para α = 0,6:
r6 = 0,6 (3) + (1 – 0,6) (3) = 3 ⇐ mínimo r7 = 0,6 (3,50) + (1 – 0,6) (1) = 2,50 r8 = 0,6 (4) + (1 – 0,6) (-1) = 2 r9 = 0,6 (4,50) + (1 – 0,6) (-3) =1,50 r10 = 0,6 (5) + (1 – 0,6) (-5) =1
Por lo tanto, se decide comprar 6 periódicos.
16.5.4 Criterio minimax del costo de oportunidad Elige la acción que minimiza el mayor costo de oportunidad posible. El costo de oportunidad es
lo que se podría haber ganado adicionalmente si se hubiese elegido la mejor acción posible. Por ejem-plo, si se piden 6 periódicos y la demanda es de 8 periódicos, la ganancia es de S/.3; pero, siendo la demanda de 8 periódicos, si hubiese pedido 8 la ganancia hubiera sido S/.4. El costo de oportunidad es: 4 – 3 = S/.1.
En resumen, este criterio trata de minimizar lo que se deja de ganar.
Para el ejemplo 1, la matriz de costos de oportunidad se puede calcular fácilmente:
Posible demanda 6 7 8 9 10
6 0 0,50 1 1,50 2 7 2 0 0,50 1 1,50 8 4 2 0 0,50 1 9 6 4 2 0 0,50
Posible pedido
10 8 6 4 2 0 Aplicando este criterio, habría que escoger el menor costo entre los siguientes: 2 ,2 ,4 ,6 ,8; por
lo tanto pediría 6 ó 7 periódicos; pues en ambos casos el costo es mínimo: S/.2.
16.5.5 Criterio del valor esperado (de Bayes) Elige la acción que produce la máxima ganancia esperada. Para el ejemplo 1, las ganancias espe-
radas para cada acción posible son:
G6 = 0,2(3) + 0,2(3) + 0,2(3) + 0,2(3) + 0,2(3) = 3 G7 = 0,2(1) + 0,2(3,50) + 0,2(3,50) + 0,2(3,50) + 0,2(3,50) = 3 G8 = 2,50 G9 = 1,50 G10 = 0
Aplicando este criterio, pediría 6 ó 7 periódicos.

246 Teoría de decisiones
16.5.6 Criterio del costo de oportunidad esperado Elige la acción que produce el mínimo costo de oportunidad esperado. Para el ejemplo 1, los
costos de oportunidad esperados son:
C6 = 0,2(0) + 0,2(0.50) + 0,2(1) + 0,2(1,50) + 0,2(2) = 1 C7 = 1 C8 = 1,50 C9 = 2,50 C10 = 4
Aplicando este criterio, pediría 6 ó 7 periódicos.
16.5.7 Criterio de máxima verosimilitud Elige el estado de la naturaleza que tiene la mayor probabilidad de ocurrencia, y, después, asu-
miendo que ocurrirá dicho estado, elige la acción que da el mayor beneficio.
En el ejemplo 1 no se puede aplicar este criterio, pues todos los estados de la naturaleza tienen la misma probabilidad de ocurrencia.
16.6 Árboles de decisión Las tablas de decisión elaboradas en el apartado anterior son muy útiles para representar pro-
blemas de una sola etapa. Existen problemas con dos o más etapas, en donde hay una sucesión de ac-ciones y eventos, que conviene representar mediante árboles para poder hacer un mejor análisis.
A continuación se resuelve el ejemplo 2 empleando un árbol de decisión que se dibuja expresa-mente para esa situación.
En los árboles se suele seguir el siguiente convenio tácito: las acciones posibles se ramifican a partir de un cuadrado, y los estados de la naturaleza a partir de un círculo (ver figura 16.1).
Ejemplo 2:
Una editorial está considerando lanzar una revista mensual con artículos e información de inte-rés para economistas y empresarios. Con base en su experiencia pasada y en sus percepciones, el gerente de la editorial ha estimado las siguientes ganancias anuales (en soles), considerando tres niveles distintos de demanda de su revista.
Si no edita la revista Si edita la revistaDemanda baja 0 –150 000 Demanda regular 0 50 000 Demanda alta 0 200 000
El gerente estima además que las probabilidades de estos tres niveles de demanda son:
P(baja) = 0,5; P(regular) = 0,2; P(alta) = 0,3
Además, el gerente pronostica que la competencia para su revista será muy grande, por lo que piensa en la posibilidad de hacer un sondeo de mercado sobre la aceptación que tendrá su revis-ta. Suponga que este sondeo, que le costaría S/.5 000 a la editorial, sólo indicará si el diagnósti-co es favorable o si es desfavorable, con lo que se decidirá si editar o no la revista. Con base en experiencias previas en relación a otras publicaciones, el gerente ha establecido las siguientes probabilidades condicionales, dadas las posibles demandas:
P(diagnóstico favorable \ demanda baja) = 0,10 P(diagnóstico favorable \ demanda regular) = 0,60 P(diagnóstico favorable \ demanda pobre) = 0,90 ¿Cuál es la mejor decisión para la editorial?
En la siguiente tabla se introducen las probabilidades dadas y se calculan las probabilidades condicionales, procediendo tal como se explicó en 1.7.4 y 1.7.5.
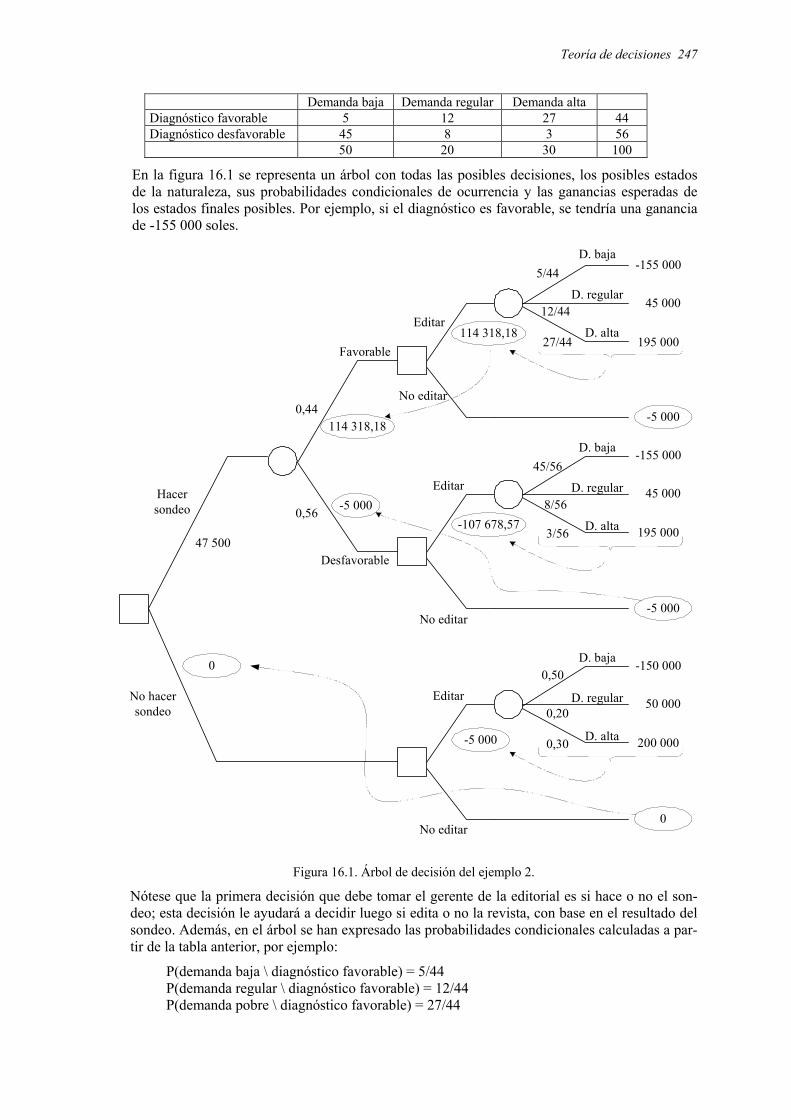
Teoría de decisiones 247
Demanda baja Demanda regular Demanda alta Diagnóstico favorable 5 12 27 44 Diagnóstico desfavorable 45 8 3 56 50 20 30 100
En la figura 16.1 se representa un árbol con todas las posibles decisiones, los posibles estados de la naturaleza, sus probabilidades condicionales de ocurrencia y las ganancias esperadas de los estados finales posibles. Por ejemplo, si el diagnóstico es favorable, se tendría una ganancia de -155 000 soles.
Hacersondeo
No hacersondeo
Favorable
Desfavorable
Editar
No editar
D. baja
D. regular
D. alta
D. baja
D. regular
D. alta
D. baja
D. regular
D. alta
Editar
No editar
Editar
No editar
27/44
5/44
12/44
3/56
45/56
8/56
-155 000
45 000
195 000
0,44
0,56
47 500
-155 000
45 000
195 000
-150 000
50 000
200 000
0,50
0,20
0,30
114 318,18
-5 000
-107 678,57
-5 000
-5 000
114 318,18
-5 000
0
0
Figura 16.1. Árbol de decisión del ejemplo 2.
Nótese que la primera decisión que debe tomar el gerente de la editorial es si hace o no el son-deo; esta decisión le ayudará a decidir luego si edita o no la revista, con base en el resultado del sondeo. Además, en el árbol se han expresado las probabilidades condicionales calculadas a par-tir de la tabla anterior, por ejemplo:
P(demanda baja \ diagnóstico favorable) = 5/44 P(demanda regular \ diagnóstico favorable) = 12/44 P(demanda pobre \ diagnóstico favorable) = 27/44

248 Teoría de decisiones
Una vez expresadas las probabilidades en el árbol, resulta fácil calcular las ganancias esperadas para cada decisión, utilizando el criterio de Bayes. Con base en estas ganancias esperadas se de-cide si editar o no editar, escogiendo la acción que dé la mayor ganancia. Por ejemplo, si el re-sultado del sondeo es favorable, por editar la revista se espera ganar 114 318,18 soles y por no editarla se espera perder 5 000 soles. Evidentemente se elige editarla. Siguiendo este mismo pro-cedimiento se elige no editar la revista para el caso en que el diagnóstico sea desfavorable, con una pérdida esperada de 5 000 soles. Como se conoce la probabilidad de que el sondeo dé un diagnóstico favorable y que dé un diagnóstico desfavorable, aplicando el criterio de Bayes se calcula la ganancia que se espera tener si se hace sondeo, que resulta 47 500. Siguiendo este mismo procedimiento se llega a obtener la ganancia esperada si no se hace sondeo: cero.
Por lo tanto se decide hacer el sondeo, pues reporta mayor ganancia esperada. Si el sondeo da un diagnóstico favorable, convendrá editar la revista; y si el diagnóstico es desfavorable, convendrá no editarla.

Teoría de decisiones 249
Problemas propuestos 1. Un fabricante de discos está considerando varios métodos alternativos de expandir su producción
para adecuar una demanda creciente. A continuación se muestra una tabla de beneficios (en miles de dólares) que le ha elaborado un consultor de empresas para los próximos 5 años. Diga qué deci-sión tomaría siguiendo cada uno de los criterios: maximin, maximax, minimax del costo de opor-tunidad, Bayes, costo de oportunidad esperado y máxima verosimilitud.
Demanda DECISIÓN POSIBLE Alta Moderada Baja Nula Expandir 500 250 -250 -450 Construir nueva planta 700 300 -400 -800 Subcontratar 300 150 -10 -100 PROBABILIDAD 0,25 0,40 0,30 0,05
2. El propietario de un terreno ha recibido una oferta de una compañía para explorar su terreno pues es muy probable que haya petróleo. La oferta es de $450 000, con la posibilidad de recibir $500 000 más si encuentran petróleo y les cede los derechos de explotación. El propietario del terreno piensa en la posibilidad de explorar él mismo, y ha averiguado que le costaría $100 000, los cuales los perdería si no encuentra petróleo; pero si encuentra, sus ingresos serían de $1 300 000. Un ex-perto ha estimado que la probabilidad de que haya petróleo es 0,6.
a) Diga qué decisión aconsejaría al propietario siguiendo cada uno de los siguientes criterios: maximin, maximax, minimax del costo de oportunidad, Bayes, costo de oportunidad esperado, máxima verosimilitud.
b) Supóngase que existe la posibilidad de realizar una prueba para estimar mejor la probabilidad de que haya petróleo, con un costo de $20 000. La empresa que realiza estas pruebas acepta que el 20% de las veces indica que no hay petróleo cuando sí hay; y que cuando no hay petró-leo, la prueba lo indica el 90% de las veces. ¿Qué aconsejaría usted al propietario?
3. Daniel puede usar su lancha durante el verano para la pesca o puede alquilarla para recreación a los veraneantes de La Punta, a $100 diarios. Cuando el clima es bueno, la alquila un promedio de 80 días; pero cuando el clima no es bueno, sólo la alquila un promedio de 55 días. Daniel ha calcu-lado que por cada día de alquiler tiene unos gastos de $25. Cuando el clima es bueno, las utilida-des de la pesca son en promedio $6 200. Cuando el clima no es bueno, la pesca le da un promedio de $3 100 de utilidad. Para este verano, Daniel ha averiguado en un reporte meteorológico gratuito que la probabilidad de tener buen clima es 0,70. Su amigo Alejo, que dirige un servicio privado de pronóstico meteorológico afirma que en el 80% de las temporadas que hubo buen clima pronosticó buen clima y en el 90% de las temporadas en que hubo mal clima pronosticó mal clima. ¿Cuánto pagaría a Alejo por el pronóstico meteorológico para la temporada?
Respuesta: Pagaría menos de $81,25.
4. Fernando, un joven ingeniero, quiere construir un edificio con 10, 20 ó 30 habitaciones para alqui-lar a estudiantes de la UDEP, para lo cual debe decidir cuánto invertir. En las urbanizaciones veci-nas a la UDEP ya hay edificios con habitaciones para estudiantes, por lo que Fernando no está muy seguro de qué tan fuerte será la demanda para su proyecto. Si fuese conservador y construye pocas habitaciones, perdería utilidades potenciales si la demanda resulta ser alta. Por otra parte, re-sultaría poco rentable tener muchas habitaciones sin alquilar. En la siguiente tabla se muestran las posibles utilidades anuales (en dólares), sobre la base de tres niveles de demanda.
Demanda baja Demanda mediana Demanda alta Construir 10 5000 5000 5000 Construir 20 0 10000 10000 Construir 30 – 6000 4000 15000 Probabilidad 0,2 0,5 0,3

250 Teoría de decisiones
Para reducir la incertidumbre sobre el número de habitaciones que debe construir, Fernando puede realizar una encuesta que dará como resultado una de las tres medidas de demanda: baja, mediana o alta. Esta encuesta se la puede realizar una pequeña empresa consultora de Piura, (ECP) que pre-senta el siguiente historial:
La empresa consultora pronosticó Cuando la demanda resultó Demanda baja Demanda mediana Demanda alta
Baja 0,7 0,2 0,1 Mediana 0,3 0,4 0,3
Alta 0,1 0,3 0,6
El costo de la encuesta depende de la confiabilidad y del máximo error muestral que se fije, y de-be discutirse. ¿Qué decisión debe tomar Fernando?
Respuesta: debe solicitar la encuesta a ECP, sólo si ésta cobra menos de 1 970 dólares. Si ECP pronostica demanda baja, le conviene construir 10 habitaciones (espera ganar 5 000 dólares); si pronostica demanda mediana, le conviene construir 20 habitaciones (espera ganar 7 000 dólares); y si pronostica demanda alta, le conviene construir 30 habitaciones (espera ganar 9 600 dólares).
5. En un taller de manufactura se está considerando la posibilidad de inspeccionar pequeñas muestras extraídas de unos lotes de artículos que le llegan de un proveedor, con el propósito de determinar si se acepta o se rechaza cada lote. En el pasado le han llegado tres tipos de lotes de artículos de dicho proveedor: A, B y C, que contenían 90%, 80% y 70% de artículos de óptima calidad, respec-tivamente. Estos porcentajes han ocurrido en el 50%, 30% y 20% de los casos, respectivamente. Debido a las características del proceso de manufactura, se puede tomar una muestra de sólo 2 ar-tículos de cada lote. Esta inspección tendría un costo de $5. Un detallado análisis de “costos de oportunidad” (expresan lo que se deja de ganar) ha permitido elaborar la siguiente tabla:
Acción Tipo de lote
Rechazar el lote Aceptar el lote A $200 $0 B $0 $100 C $0 $200
Como resultado del muestreo de cada lote, se puede tener: 0, 1 ó 2 artículos de óptima calidad. Se-gún el resultado del muestreo, el jefe del taller decidirá si acepta o rechaza el lote ¿Qué decisión debe tomarse?
Respuesta: Le conviene hacer la inspección, con un costo esperado de $62,78. Si en la muestra los dos artículos son de óptima calidad, conviene aceptar el lote; en caso contrario, conviene rechazar-lo.
6. Una empresa comercializadora debe clasificar los lotes de cierta fruta que le llegan de un agricul-tor, en uno de dos tipos: A o B. Para hacer esta clasificación tiene dos posibilidades: una simple inspección ocular, sin costo alguno, o una revisión de una muestra de 10 unidades, que le costaría $10. Generalmente, de los lotes que le han llegado, el 70% han sido tipo A y el 30% de tipo B. Además, haciendo esta revisión de 10 unidades, cuando le han llegado lotes tipo A los ha clasifi-cado bien en el 90% de los casos, y cuando le han llegado lotes tipo B los ha clasificado bien en el 80% de los casos. Las utilidades que ha tenido con estos dos tipos de lote, según como los clasifi-có, se resumen en la siguiente tabla. ¿Qué debe hacer la empresa comercializadora para lograr el máximo beneficio?
Clasificación del lote de frutas Tipo del lote de frutas Tipo A Tipo B
A $460 $380 B $290 $370

Teoría de decisiones 251
7. Christian, un joven ingeniero de sistemas ha desarrollado un novedoso software que puede vender a una conocida empresa de desarrollo de softwares, a $20 000. También lo puede comercializar él mismo, con estos posibles resultados: que no tenga aceptación, lo cual significaría una pérdida de $5 200; que sí tenga aceptación, que significaría una utilidad de $52 000. Un compañero, experto en este tipo de negocios, estima que las probabilidades de aceptación y rechazo del software son 0,6 y 0,4. Christian se entera que podría pedirle a una empresa consultora un pronóstico sobre la posible reacción del mercado, a un costo de $1 000. El gerente de la empresa consultora afirma que cuando ha hecho este tipo de pronósticos ha acertado en el 90% de los casos en que el produc-to no fue aceptado, y en el 80% de los casos en que el producto fue aceptado. ¿Qué le aconsejaría usted a Christian?
8. El propietario de un terreno ha hecho un contrato por 30 días con una inmobiliaria para su venta, estipulando un precio de $25 000. La inmobiliaria cobra el 4% de comisión sobre lo vendido. Además, ha estimado que necesitaría gastar $800 para efectuar la venta en el plazo estipulado. La probabilidad de vender el terreno en el tiempo estipulado es 0,7. Diga si a la inmobiliaria le con-viene aceptar la oferta para la venta del terreno siguiendo los siguientes criterios:
a) Maximin; b) Maximax; c) Realista (α = 0.8); d) Bayes; e) Mínimax del costo de oportunidad; f) Costo de oportunidad esperado; g) Máxima verosimilitud.
9. El propietario del terreno del problema 8 le ha ofrecido a la inmobiliaria, en caso que venda el te-rreno durante esos 30 días, una de dos propiedades que tiene: una casa en la Urbanización Santa María del Pinar a $50 000 y otra en la Urbanización Los Geranios a $100 000, ambas por 90 días. La inmobiliaria ha estimado que los gastos que necesitaría hacer para efectuar las ventas de las ca-sas de Santa María del Pinar y Los Geranios en el plazo estipulado ascienden a $200 y $400, res-pectivamente. Además, ha estimado que las probabilidades de vender dichas casas en el tiempo es-tipulado son 0,6 y 0,5; respectivamente. ¿Qué le aconsejaría a la inmobiliaria?
Respuesta: Le aconsejaría aceptar el terreno (espera ganar $1 020). Si vende el terreno, le aconse-jaría aceptar la casa de Los Geranios (espera ganar $1 800).

252 Apéndice
Apéndice
Las tablas estadísticas que se incluyen en este apéndice han sido elaboradas con la ayuda de Excel.

Apéndice
253
Tabla de probabilidades binomiales acumulativas ∑=
−
n
kx
xnx qpxn
p n k 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,0975 0,1900 0,2775 0,3600 0,4375 0,5100 0,5775 0,6400 0,6975 0,7500 2 2 0,0025 0,0100 0,0225 0,0400 0,0625 0,0900 0,1225 0,1600 0,2025 0,2500
0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50 1 0,1426 0,2710 0,3859 0,4880 0,5781 0,6570 0,7254 0,7840 0,8336 0,8750 2 0,0073 0,0280 0,0608 0,1040 0,1563 0,2160 0,2818 0,3520 0,4253 0,5000
3
3 0,0001 0,0010 0,0034 0,0080 0,0156 0,0270 0,0429 0,0640 0,0911 0,1250 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,1855 0,3439 0,4780 0,5904 0,6836 0,7599 0,8215 0,8704 0,9085 0,9375 2 0,0140 0,0523 0,1095 0,1808 0,2617 0,3483 0,4370 0,5248 0,6090 0,6875 3 0,0005 0,0037 0,0120 0,0272 0,0508 0,0837 0,1265 0,1792 0,2415 0,3125
4
4 0,0000 0,0001 0,0005 0,0016 0,0039 0,0081 0,0150 0,0256 0,0410 0,0625 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,2262 0,4095 0,5563 0,6723 0,7627 0,8319 0,8840 0,9222 0,9497 0,9688 2 0,0226 0,0815 0,1648 0,2627 0,3672 0,4718 0,5716 0,6630 0,7438 0,8125 3 0,0012 0,0086 0,0266 0,0579 0,1035 0,1631 0,2352 0,3174 0,4069 0,5000 4 0,0000 0,0005 0,0022 0,0067 0,0156 0,0308 0,0540 0,0870 0,1312 0,1875
5
5 0,0000 0,0000 0,0001 0,0003 0,0010 0,0024 0,0053 0,0102 0,0185 0,0313 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,2649 0,4686 0,6229 0,7379 0,8220 0,8824 0,9246 0,9533 0,9723 0,9844 2 0,0328 0,1143 0,2235 0,3446 0,4661 0,5798 0,6809 0,7667 0,8364 0,8906 3 0,0022 0,0158 0,0473 0,0989 0,1694 0,2557 0,3529 0,4557 0,5585 0,6563 4 0,0001 0,0013 0,0059 0,0170 0,0376 0,0705 0,1174 0,1792 0,2553 0,3438 5 0,0000 0,0001 0,0004 0,0016 0,0046 0,0109 0,0223 0,0410 0,0692 0,1094
6
6 0,0000 0,0000 0,0000 0,0001 0,0002 0,0007 0,0018 0,0041 0,0083 0,0156 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,3017 0,5217 0,6794 0,7903 0,8665 0,9176 0,9510 0,9720 0,9848 0,9922 2 0,0444 0,1497 0,2834 0,4233 0,5551 0,6706 0,7662 0,8414 0,8976 0,9375 3 0,0038 0,0257 0,0738 0,1480 0,2436 0,3529 0,4677 0,5801 0,6836 0,7734 4 0,0002 0,0027 0,0121 0,0333 0,0706 0,1260 0,1998 0,2898 0,3917 0,5000 5 0,0000 0,0002 0,0012 0,0047 0,0129 0,0288 0,0556 0,0963 0,1529 0,2266 6 0,0000 0,0000 0,0001 0,0004 0,0013 0,0038 0,0090 0,0188 0,0357 0,0625
7
7 0,0000 0,0000 0,0000 0,0000 0,0001 0,0002 0,0006 0,0016 0,0037 0,0078 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,3366 0,5695 0,7275 0,8322 0,8999 0,9424 0,9681 0,9832 0,9916 0,9961 2 0,0572 0,1869 0,3428 0,4967 0,6329 0,7447 0,8309 0,8936 0,9368 0,9648 3 0,0058 0,0381 0,1052 0,2031 0,3215 0,4482 0,5722 0,6846 0,7799 0,8555 4 0,0004 0,0050 0,0214 0,0563 0,1138 0,1941 0,2936 0,4059 0,5230 0,6367 5 0,0000 0,0004 0,0029 0,0104 0,0273 0,0580 0,1061 0,1737 0,2604 0,3633 6 0,0000 0,0000 0,0002 0,0012 0,0042 0,0113 0,0253 0,0498 0,0885 0,1445 7 0,0000 0,0000 0,0000 0,0001 0,0004 0,0013 0,0036 0,0085 0,0181 0,0352
8
8 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0002 0,0007 0,0017 0,0039 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,3698 0,6126 0,7684 0,8658 0,9249 0,9596 0,9793 0,9899 0,9954 0,9980 2 0,0712 0,2252 0,4005 0,5638 0,6997 0,8040 0,8789 0,9295 0,9615 0,9805 3 0,0084 0,0530 0,1409 0,2618 0,3993 0,5372 0,6627 0,7682 0,8505 0,9102 4 0,0006 0,0083 0,0339 0,0856 0,1657 0,2703 0,3911 0,5174 0,6386 0,7461 5 0,0000 0,0009 0,0056 0,0196 0,0489 0,0988 0,1717 0,2666 0,3786 0,5000 6 0,0000 0,0001 0,0006 0,0031 0,0100 0,0253 0,0536 0,0994 0,1658 0,2539 7 0,0000 0,0000 0,0000 0,0003 0,0013 0,0043 0,0112 0,0250 0,0498 0,0898 8 0,0000 0,0000 0,0000 0,0000 0,0001 0,0004 0,0014 0,0038 0,0091 0,0195
9
9 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0003 0,0008 0,0020

254 Apéndice
p n k 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,4013 0,6513 0,8031 0,8926 0,9437 0,9718 0,9865 0,9940 0,9975 0,9990 2 0,0861 0,2639 0,4557 0,6242 0,7560 0,8507 0,9140 0,9536 0,9767 0,9893 3 0,0115 0,0702 0,1798 0,3222 0,4744 0,6172 0,7384 0,8327 0,9004 0,9453 4 0,0010 0,0128 0,0500 0,1209 0,2241 0,3504 0,4862 0,6177 0,7340 0,8281 5 0,0001 0,0016 0,0099 0,0328 0,0781 0,1503 0,2485 0,3669 0,4956 0,6230 6 0,0000 0,0001 0,0014 0,0064 0,0197 0,0473 0,0949 0,1662 0,2616 0,3770 7 0,0000 0,0000 0,0001 0,0009 0,0035 0,0106 0,0260 0,0548 0,1020 0,1719 8 0,0000 0,0000 0,0000 0,0001 0,0004 0,0016 0,0048 0,0123 0,0274 0,0547 9 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0005 0,0017 0,0045 0,0107
10
10 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0003 0,0010 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,4312 0,6862 0,8327 0,9141 0,9578 0,9802 0,9912 0,9964 0,9986 0,9995 2 0,1019 0,3026 0,5078 0,6779 0,8029 0,8870 0,9394 0,9698 0,9861 0,9941 3 0,0152 0,0896 0,2212 0,3826 0,5448 0,6873 0,7999 0,8811 0,9348 0,9673 4 0,0016 0,0185 0,0694 0,1611 0,2867 0,4304 0,5744 0,7037 0,8089 0,8867 5 0,0001 0,0028 0,0159 0,0504 0,1146 0,2103 0,3317 0,4672 0,6029 0,7256 6 0,0000 0,0003 0,0027 0,0117 0,0343 0,0782 0,1487 0,2465 0,3669 0,5000 7 0,0000 0,0000 0,0003 0,0020 0,0076 0,0216 0,0501 0,0994 0,1738 0,2744 8 0,0000 0,0000 0,0000 0,0002 0,0012 0,0043 0,0122 0,0293 0,0610 0,1133 9 0,0000 0,0000 0,0000 0,0000 0,0001 0,0006 0,0020 0,0059 0,0148 0,0327 10 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0007 0,0022 0,0059
11
11 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0005 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,4596 0,7176 0,8578 0,9313 0,9683 0,9862 0,9943 0,9978 0,9992 0,9998 2 0,1184 0,3410 0,5565 0,7251 0,8416 0,9150 0,9576 0,9804 0,9917 0,9968 3 0,0196 0,1109 0,2642 0,4417 0,6093 0,7472 0,8487 0,9166 0,9579 0,9807 4 0,0022 0,0256 0,0922 0,2054 0,3512 0,5075 0,6533 0,7747 0,8655 0,9270 5 0,0002 0,0043 0,0239 0,0726 0,1576 0,2763 0,4167 0,5618 0,6956 0,8062 6 0,0000 0,0005 0,0046 0,0194 0,0544 0,1178 0,2127 0,3348 0,4731 0,6128 7 0,0000 0,0001 0,0007 0,0039 0,0143 0,0386 0,0846 0,1582 0,2607 0,3872 8 0,0000 0,0000 0,0001 0,0006 0,0028 0,0095 0,0255 0,0573 0,1117 0,1938 9 0,0000 0,0000 0,0000 0,0001 0,0004 0,0017 0,0056 0,0153 0,0356 0,0730 10 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0008 0,0028 0,0079 0,0193 11 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0003 0,0011 0,0032
12
12 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0002 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,4867 0,7458 0,8791 0,9450 0,9762 0,9903 0,9963 0,9987 0,9996 0,9999 2 0,1354 0,3787 0,6017 0,7664 0,8733 0,9363 0,9704 0,9874 0,9951 0,9983 3 0,0245 0,1339 0,3080 0,4983 0,6674 0,7975 0,8868 0,9421 0,9731 0,9888 4 0,0031 0,0342 0,1180 0,2527 0,4157 0,5794 0,7217 0,8314 0,9071 0,9539 5 0,0003 0,0065 0,0342 0,0991 0,2060 0,3457 0,4995 0,6470 0,7721 0,8666 6 0,0000 0,0009 0,0075 0,0300 0,0802 0,1654 0,2841 0,4256 0,5732 0,7095 7 0,0000 0,0001 0,0013 0,0070 0,0243 0,0624 0,1295 0,2288 0,3563 0,5000 8 0,0000 0,0000 0,0002 0,0012 0,0056 0,0182 0,0462 0,0977 0,1788 0,2905 9 0,0000 0,0000 0,0000 0,0002 0,0010 0,0040 0,0126 0,0321 0,0698 0,1334 10 0,0000 0,0000 0,0000 0,0000 0,0001 0,0007 0,0025 0,0078 0,0203 0,0461 11 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0003 0,0013 0,0041 0,0112 12 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0005 0,0017
13
13 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001

Apéndice
255
p n k 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,5123 0,7712 0,8972 0,9560 0,9822 0,9932 0,9976 0,9992 0,9998 0,9999 2 0,1530 0,4154 0,6433 0,8021 0,8990 0,9525 0,9795 0,9919 0,9971 0,9991 3 0,0301 0,1584 0,3521 0,5519 0,7189 0,8392 0,9161 0,9602 0,9830 0,9935 4 0,0042 0,0441 0,1465 0,3018 0,4787 0,6448 0,7795 0,8757 0,9368 0,9713 5 0,0004 0,0092 0,0467 0,1298 0,2585 0,4158 0,5773 0,7207 0,8328 0,9102 6 0,0000 0,0015 0,0115 0,0439 0,1117 0,2195 0,3595 0,5141 0,6627 0,7880 7 0,0000 0,0002 0,0022 0,0116 0,0383 0,0933 0,1836 0,3075 0,4539 0,6047 8 0,0000 0,0000 0,0003 0,0024 0,0103 0,0315 0,0753 0,1501 0,2586 0,3953 9 0,0000 0,0000 0,0000 0,0004 0,0022 0,0083 0,0243 0,0583 0,1189 0,2120 10 0,0000 0,0000 0,0000 0,0000 0,0003 0,0017 0,0060 0,0175 0,0426 0,0898 11 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0011 0,0039 0,0114 0,0287 12 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0006 0,0022 0,0065 13 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0003 0,0009
14
14 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,5367 0,7941 0,9126 0,9648 0,9866 0,9953 0,9984 0,9995 0,9999 1,0000 2 0,1710 0,4510 0,6814 0,8329 0,9198 0,9647 0,9858 0,9948 0,9983 0,9995 3 0,0362 0,1841 0,3958 0,6020 0,7639 0,8732 0,9383 0,9729 0,9893 0,9963 4 0,0055 0,0556 0,1773 0,3518 0,5387 0,7031 0,8273 0,9095 0,9576 0,9824 5 0,0006 0,0127 0,0617 0,1642 0,3135 0,4845 0,6481 0,7827 0,8796 0,9408 6 0,0001 0,0022 0,0168 0,0611 0,1484 0,2784 0,4357 0,5968 0,7392 0,8491 7 0,0000 0,0003 0,0036 0,0181 0,0566 0,1311 0,2452 0,3902 0,5478 0,6964 8 0,0000 0,0000 0,0006 0,0042 0,0173 0,0500 0,1132 0,2131 0,3465 0,5000 9 0,0000 0,0000 0,0001 0,0008 0,0042 0,0152 0,0422 0,0950 0,1818 0,3036 10 0,0000 0,0000 0,0000 0,0001 0,0008 0,0037 0,0124 0,0338 0,0769 0,1509 11 0,0000 0,0000 0,0000 0,0000 0,0001 0,0007 0,0028 0,0093 0,0255 0,0592 12 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0005 0,0019 0,0063 0,0176 13 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0003 0,0011 0,0037 14 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0005
15
15 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,5599 0,8147 0,9257 0,9719 0,9900 0,9967 0,9990 0,9997 0,9999 1,0000 2 0,1892 0,4853 0,7161 0,8593 0,9365 0,9739 0,9902 0,9967 0,9990 0,9997 3 0,0429 0,2108 0,4386 0,6482 0,8029 0,9006 0,9549 0,9817 0,9934 0,9979 4 0,0070 0,0684 0,2101 0,4019 0,5950 0,7541 0,8661 0,9349 0,9719 0,9894 5 0,0009 0,0170 0,0791 0,2018 0,3698 0,5501 0,7108 0,8334 0,9147 0,9616 6 0,0001 0,0033 0,0235 0,0817 0,1897 0,3402 0,5100 0,6712 0,8024 0,8949 7 0,0000 0,0005 0,0056 0,0267 0,0796 0,1753 0,3119 0,4728 0,6340 0,7728 8 0,0000 0,0001 0,0011 0,0070 0,0271 0,0744 0,1594 0,2839 0,4371 0,5982 9 0,0000 0,0000 0,0002 0,0015 0,0075 0,0257 0,0671 0,1423 0,2559 0,4018 10 0,0000 0,0000 0,0000 0,0002 0,0016 0,0071 0,0229 0,0583 0,1241 0,2272 11 0,0000 0,0000 0,0000 0,0000 0,0003 0,0016 0,0062 0,0191 0,0486 0,1051 12 0,0000 0,0000 0,0000 0,0000 0,0000 0,0003 0,0013 0,0049 0,0149 0,0384 13 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0009 0,0035 0,0106 14 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0006 0,0021 15 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0003
16
16 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000

256 Apéndice
p n k 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,5819 0,8332 0,9369 0,9775 0,9925 0,9977 0,9993 0,9998 1,0000 1,0000 2 0,2078 0,5182 0,7475 0,8818 0,9499 0,9807 0,9933 0,9979 0,9994 0,9999 3 0,0503 0,2382 0,4802 0,6904 0,8363 0,9226 0,9673 0,9877 0,9959 0,9988 4 0,0088 0,0826 0,2444 0,4511 0,6470 0,7981 0,8972 0,9536 0,9816 0,9936 5 0,0012 0,0221 0,0987 0,2418 0,4261 0,6113 0,7652 0,8740 0,9404 0,9755 6 0,0001 0,0047 0,0319 0,1057 0,2347 0,4032 0,5803 0,7361 0,8529 0,9283 7 0,0000 0,0008 0,0083 0,0377 0,1071 0,2248 0,3812 0,5522 0,7098 0,8338 8 0,0000 0,0001 0,0017 0,0109 0,0402 0,1046 0,2128 0,3595 0,5257 0,6855 9 0,0000 0,0000 0,0003 0,0026 0,0124 0,0403 0,0994 0,1989 0,3374 0,5000 10 0,0000 0,0000 0,0000 0,0005 0,0031 0,0127 0,0383 0,0919 0,1834 0,3145 11 0,0000 0,0000 0,0000 0,0001 0,0006 0,0032 0,0120 0,0348 0,0826 0,1662 12 0,0000 0,0000 0,0000 0,0000 0,0001 0,0007 0,0030 0,0106 0,0301 0,0717 13 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0006 0,0025 0,0086 0,0245 14 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0005 0,0019 0,0064 15 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0003 0,0012 16 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001
17
17 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,6028 0,8499 0,9464 0,9820 0,9944 0,9984 0,9996 0,9999 1,0000 1,0000 2 0,2265 0,5497 0,7759 0,9009 0,9605 0,9858 0,9954 0,9987 0,9997 0,9999 3 0,0581 0,2662 0,5203 0,7287 0,8647 0,9400 0,9764 0,9918 0,9975 0,9993 4 0,0109 0,0982 0,2798 0,4990 0,6943 0,8354 0,9217 0,9672 0,9880 0,9962 5 0,0015 0,0282 0,1206 0,2836 0,4813 0,6673 0,8114 0,9058 0,9589 0,9846 6 0,0002 0,0064 0,0419 0,1329 0,2825 0,4656 0,6450 0,7912 0,8923 0,9519 7 0,0000 0,0012 0,0118 0,0513 0,1390 0,2783 0,4509 0,6257 0,7742 0,8811 8 0,0000 0,0002 0,0027 0,0163 0,0569 0,1407 0,2717 0,4366 0,6085 0,7597 9 0,0000 0,0000 0,0005 0,0043 0,0193 0,0596 0,1391 0,2632 0,4222 0,5927 10 0,0000 0,0000 0,0001 0,0009 0,0054 0,0210 0,0597 0,1347 0,2527 0,4073 11 0,0000 0,0000 0,0000 0,0002 0,0012 0,0061 0,0212 0,0576 0,1280 0,2403 12 0,0000 0,0000 0,0000 0,0000 0,0002 0,0014 0,0062 0,0203 0,0537 0,1189 13 0,0000 0,0000 0,0000 0,0000 0,0000 0,0003 0,0014 0,0058 0,0183 0,0481 14 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0003 0,0013 0,0049 0,0154 15 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0010 0,0038 16 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0007 17 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001
18
18 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000

Apéndice
257
p n k 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,6226 0,8649 0,9544 0,9856 0,9958 0,9989 0,9997 0,9999 1,0000 1,0000 2 0,2453 0,5797 0,8015 0,9171 0,9690 0,9896 0,9969 0,9992 0,9998 1,0000 3 0,0665 0,2946 0,5587 0,7631 0,8887 0,9538 0,9830 0,9945 0,9985 0,9996 4 0,0132 0,1150 0,3159 0,5449 0,7369 0,8668 0,9409 0,9770 0,9923 0,9978 5 0,0020 0,0352 0,1444 0,3267 0,5346 0,7178 0,8500 0,9304 0,9720 0,9904 6 0,0002 0,0086 0,0537 0,1631 0,3322 0,5261 0,7032 0,8371 0,9223 0,9682 7 0,0000 0,0017 0,0163 0,0676 0,1749 0,3345 0,5188 0,6919 0,8273 0,9165 8 0,0000 0,0003 0,0041 0,0233 0,0775 0,1820 0,3344 0,5122 0,6831 0,8204 9 0,0000 0,0000 0,0008 0,0067 0,0287 0,0839 0,1855 0,3325 0,5060 0,6762 10 0,0000 0,0000 0,0001 0,0016 0,0089 0,0326 0,0875 0,1861 0,3290 0,5000 11 0,0000 0,0000 0,0000 0,0003 0,0023 0,0105 0,0347 0,0885 0,1841 0,3238 12 0,0000 0,0000 0,0000 0,0000 0,0005 0,0028 0,0114 0,0352 0,0871 0,1796 13 0,0000 0,0000 0,0000 0,0000 0,0001 0,0006 0,0031 0,0116 0,0342 0,0835 14 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0007 0,0031 0,0109 0,0318 15 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0006 0,0028 0,0096 16 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0005 0,0022 17 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0004 18 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
19
19 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,05 0,10 0,15 0,20 0,25 0,30 0,35 0,40 0,45 0,50
1 0,6415 0,8784 0,9612 0,9885 0,9968 0,9992 0,9998 1,0000 1,0000 1,0000 2 0,2642 0,6083 0,8244 0,9308 0,9757 0,9924 0,9979 0,9995 0,9999 1,0000 3 0,0755 0,3231 0,5951 0,7939 0,9087 0,9645 0,9879 0,9964 0,9991 0,9998 4 0,0159 0,1330 0,3523 0,5886 0,7748 0,8929 0,9556 0,9840 0,9951 0,9987 5 0,0026 0,0432 0,1702 0,3704 0,5852 0,7625 0,8818 0,9490 0,9811 0,9941 6 0,0003 0,0113 0,0673 0,1958 0,3828 0,5836 0,7546 0,8744 0,9447 0,9793 7 0,0000 0,0024 0,0219 0,0867 0,2142 0,3920 0,5834 0,7500 0,8701 0,9423 8 0,0000 0,0004 0,0059 0,0321 0,1018 0,2277 0,3990 0,5841 0,7480 0,8684 9 0,0000 0,0001 0,0013 0,0100 0,0409 0,1133 0,2376 0,4044 0,5857 0,7483 10 0,0000 0,0000 0,0002 0,0026 0,0139 0,0480 0,1218 0,2447 0,4086 0,5881 11 0,0000 0,0000 0,0000 0,0006 0,0039 0,0171 0,0532 0,1275 0,2493 0,4119 12 0,0000 0,0000 0,0000 0,0001 0,0009 0,0051 0,0196 0,0565 0,1308 0,2517 13 0,0000 0,0000 0,0000 0,0000 0,0002 0,0013 0,0060 0,0210 0,0580 0,1316 14 0,0000 0,0000 0,0000 0,0000 0,0000 0,0003 0,0015 0,0065 0,0214 0,0577 15 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0003 0,0016 0,0064 0,0207 16 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0003 0,0015 0,0059 17 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0003 0,0013 18 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 19 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
20
20 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000

258 Apéndice
Tabla de probabilidades acumulativas de Poisson ∑=
−i
x
x
xe
0 !µµ
µ i 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 0 0,9048 0,8187 0,7408 0,6703 0,6065 0,5488 0,4966 0,4493 0,4066 0,36791 0,9953 0,9825 0,9631 0,9384 0,9098 0,8781 0,8442 0,8088 0,7725 0,73582 0,9998 0,9989 0,9964 0,9921 0,9856 0,9769 0,9659 0,9526 0,9371 0,91973 1,0000 0,9999 0,9997 0,9992 0,9982 0,9966 0,9942 0,9909 0,9865 0,98104 1,0000 1,0000 1,0000 0,9999 0,9998 0,9996 0,9992 0,9986 0,9977 0,99635 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,9998 0,9997 0,99946 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,99997 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 µ i 1,1 1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0 0 0,3329 0,3012 0,2725 0,2466 0,2231 0,2019 0,1827 0,1653 0,1496 0,13531 0,6990 0,6626 0,6268 0,5918 0,5578 0,5249 0,4932 0,4628 0,4337 0,40602 0,9004 0,8795 0,8571 0,8335 0,8088 0,7834 0,7572 0,7306 0,7037 0,67673 0,9743 0,9662 0,9569 0,9463 0,9344 0,9212 0,9068 0,8913 0,8747 0,85714 0,9946 0,9923 0,9893 0,9857 0,9814 0,9763 0,9704 0,9636 0,9559 0,94735 0,9990 0,9985 0,9978 0,9968 0,9955 0,9940 0,9920 0,9896 0,9868 0,98346 0,9999 0,9997 0,9996 0,9994 0,9991 0,9987 0,9981 0,9974 0,9966 0,99557 1,0000 1,0000 0,9999 0,9999 0,9998 0,9997 0,9996 0,9994 0,9992 0,99898 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,9999 0,9998 0,99989 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 µ i 2,1 2,2 2,3 2,4 2,5 2,6 2,7 2,8 2,9 3,0 0 0,1225 0,1108 0,1003 0,0907 0,0821 0,0743 0,0672 0,0608 0,0550 0,04981 0,3796 0,3546 0,3309 0,3084 0,2873 0,2674 0,2487 0,2311 0,2146 0,19912 0,6496 0,6227 0,5960 0,5697 0,5438 0,5184 0,4936 0,4695 0,4460 0,42323 0,8386 0,8194 0,7993 0,7787 0,7576 0,7360 0,7141 0,6919 0,6696 0,64724 0,9379 0,9275 0,9162 0,9041 0,8912 0,8774 0,8629 0,8477 0,8318 0,81535 0,9796 0,9751 0,9700 0,9643 0,9580 0,9510 0,9433 0,9349 0,9258 0,91616 0,9941 0,9925 0,9906 0,9884 0,9858 0,9828 0,9794 0,9756 0,9713 0,96657 0,9985 0,9980 0,9974 0,9967 0,9958 0,9947 0,9934 0,9919 0,9901 0,98818 0,9997 0,9995 0,9994 0,9991 0,9989 0,9985 0,9981 0,9976 0,9969 0,99629 0,9999 0,9999 0,9999 0,9998 0,9997 0,9996 0,9995 0,9993 0,9991 0,9989
10 1,0000 1,0000 1,0000 1,0000 0,9999 0,9999 0,9999 0,9998 0,9998 0,999711 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,999912 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

Apéndice
259
µ i 3,1 3,2 3,3 3,4 3,5 3,6 3,7 3,8 3,9 4,0 0 0,0450 0,0408 0,0369 0,0334 0,0302 0,0273 0,0247 0,0224 0,0202 0,01831 0,1847 0,1712 0,1586 0,1468 0,1359 0,1257 0,1162 0,1074 0,0992 0,09162 0,4012 0,3799 0,3594 0,3397 0,3208 0,3027 0,2854 0,2689 0,2531 0,23813 0,6248 0,6025 0,5803 0,5584 0,5366 0,5152 0,4942 0,4735 0,4532 0,43354 0,7982 0,7806 0,7626 0,7442 0,7254 0,7064 0,6872 0,6678 0,6484 0,62885 0,9057 0,8946 0,8829 0,8705 0,8576 0,8441 0,8301 0,8156 0,8006 0,78516 0,9612 0,9554 0,9490 0,9421 0,9347 0,9267 0,9182 0,9091 0,8995 0,88937 0,9858 0,9832 0,9802 0,9769 0,9733 0,9692 0,9648 0,9599 0,9546 0,94898 0,9953 0,9943 0,9931 0,9917 0,9901 0,9883 0,9863 0,9840 0,9815 0,97869 0,9986 0,9982 0,9978 0,9973 0,9967 0,9960 0,9952 0,9942 0,9931 0,9919
10 0,9996 0,9995 0,9994 0,9992 0,9990 0,9987 0,9984 0,9981 0,9977 0,997211 0,9999 0,9999 0,9998 0,9998 0,9997 0,9996 0,9995 0,9994 0,9993 0,999112 1,0000 1,0000 1,0000 0,9999 0,9999 0,9999 0,9999 0,9998 0,9998 0,999713 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,999914 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
µ i 4,1 4,2 4,3 4,4 4,5 4,6 4,7 4,8 4,9 5,0 0 0,0166 0,0150 0,0136 0,0123 0,0111 0,0101 0,0091 0,0082 0,0074 0,00671 0,0845 0,0780 0,0719 0,0663 0,0611 0,0563 0,0518 0,0477 0,0439 0,04042 0,2238 0,2102 0,1974 0,1851 0,1736 0,1626 0,1523 0,1425 0,1333 0,12473 0,4142 0,3954 0,3772 0,3594 0,3423 0,3257 0,3097 0,2942 0,2793 0,26504 0,6093 0,5898 0,5704 0,5512 0,5321 0,5132 0,4946 0,4763 0,4582 0,44055 0,7693 0,7531 0,7367 0,7199 0,7029 0,6858 0,6684 0,6510 0,6335 0,61606 0,8786 0,8675 0,8558 0,8436 0,8311 0,8180 0,8046 0,7908 0,7767 0,76227 0,9427 0,9361 0,9290 0,9214 0,9134 0,9049 0,8960 0,8867 0,8769 0,86668 0,9755 0,9721 0,9683 0,9642 0,9597 0,9549 0,9497 0,9442 0,9382 0,93199 0,9905 0,9889 0,9871 0,9851 0,9829 0,9805 0,9778 0,9749 0,9717 0,9682
10 0,9966 0,9959 0,9952 0,9943 0,9933 0,9922 0,9910 0,9896 0,9880 0,986311 0,9989 0,9986 0,9983 0,9980 0,9976 0,9971 0,9966 0,9960 0,9953 0,994512 0,9997 0,9996 0,9995 0,9993 0,9992 0,9990 0,9988 0,9986 0,9983 0,998013 0,9999 0,9999 0,9998 0,9998 0,9997 0,9997 0,9996 0,9995 0,9994 0,999314 1,0000 1,0000 1,0000 0,9999 0,9999 0,9999 0,9999 0,9999 0,9998 0,999815 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,999916 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

260 Apéndice
µ i 5,1 5,2 5,3 5,4 5,5 5,6 5,7 5,8 5,9 6,0 0 0,0061 0,0055 0,0050 0,0045 0,0041 0,0037 0,0033 0,0030 0,0027 0,00251 0,0372 0,0342 0,0314 0,0289 0,0266 0,0244 0,0224 0,0206 0,0189 0,01742 0,1165 0,1088 0,1016 0,0948 0,0884 0,0824 0,0768 0,0715 0,0666 0,06203 0,2513 0,2381 0,2254 0,2133 0,2017 0,1906 0,1800 0,1700 0,1604 0,15124 0,4231 0,4061 0,3895 0,3733 0,3575 0,3422 0,3272 0,3127 0,2987 0,28515 0,5984 0,5809 0,5635 0,5461 0,5289 0,5119 0,4950 0,4783 0,4619 0,44576 0,7474 0,7324 0,7171 0,7017 0,6860 0,6703 0,6544 0,6384 0,6224 0,60637 0,8560 0,8449 0,8335 0,8217 0,8095 0,7970 0,7841 0,7710 0,7576 0,74408 0,9252 0,9181 0,9106 0,9027 0,8944 0,8857 0,8766 0,8672 0,8574 0,84729 0,9644 0,9603 0,9559 0,9512 0,9462 0,9409 0,9352 0,9292 0,9228 0,9161
10 0,9844 0,9823 0,9800 0,9775 0,9747 0,9718 0,9686 0,9651 0,9614 0,957411 0,9937 0,9927 0,9916 0,9904 0,9890 0,9875 0,9859 0,9841 0,9821 0,979912 0,9976 0,9972 0,9967 0,9962 0,9955 0,9949 0,9941 0,9932 0,9922 0,991213 0,9992 0,9990 0,9988 0,9986 0,9983 0,9980 0,9977 0,9973 0,9969 0,996414 0,9997 0,9997 0,9996 0,9995 0,9994 0,9993 0,9991 0,9990 0,9988 0,998615 0,9999 0,9999 0,9999 0,9998 0,9998 0,9998 0,9997 0,9996 0,9996 0,999516 1,0000 1,0000 1,0000 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,999817 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,999918 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
µ i 6,1 6,2 6,3 6,4 6,5 6,6 6,7 6,8 6,9 7,0 0 0,0022 0,0020 0,0018 0,0017 0,0015 0,0014 0,0012 0,0011 0,0010 0,00091 0,0159 0,0146 0,0134 0,0123 0,0113 0,0103 0,0095 0,0087 0,0080 0,00732 0,0577 0,0536 0,0498 0,0463 0,0430 0,0400 0,0371 0,0344 0,0320 0,02963 0,1425 0,1342 0,1264 0,1189 0,1118 0,1052 0,0988 0,0928 0,0871 0,08184 0,2719 0,2592 0,2469 0,2351 0,2237 0,2127 0,2022 0,1920 0,1823 0,17305 0,4298 0,4141 0,3988 0,3837 0,3690 0,3547 0,3406 0,3270 0,3137 0,30076 0,5902 0,5742 0,5582 0,5423 0,5265 0,5108 0,4953 0,4799 0,4647 0,44977 0,7301 0,7160 0,7017 0,6873 0,6728 0,6581 0,6433 0,6285 0,6136 0,59878 0,8367 0,8259 0,8148 0,8033 0,7916 0,7796 0,7673 0,7548 0,7420 0,72919 0,9090 0,9016 0,8939 0,8858 0,8774 0,8686 0,8596 0,8502 0,8405 0,8305
10 0,9531 0,9486 0,9437 0,9386 0,9332 0,9274 0,9214 0,9151 0,9084 0,901511 0,9776 0,9750 0,9723 0,9693 0,9661 0,9627 0,9591 0,9552 0,9510 0,946712 0,9900 0,9887 0,9873 0,9857 0,9840 0,9821 0,9801 0,9779 0,9755 0,973013 0,9958 0,9952 0,9945 0,9937 0,9929 0,9920 0,9909 0,9898 0,9885 0,987214 0,9984 0,9981 0,9978 0,9974 0,9970 0,9966 0,9961 0,9956 0,9950 0,994315 0,9994 0,9993 0,9992 0,9990 0,9988 0,9986 0,9984 0,9982 0,9979 0,997616 0,9998 0,9997 0,9997 0,9996 0,9996 0,9995 0,9994 0,9993 0,9992 0,999017 0,9999 0,9999 0,9999 0,9999 0,9998 0,9998 0,9998 0,9997 0,9997 0,999618 1,0000 1,0000 1,0000 1,0000 0,9999 0,9999 0,9999 0,9999 0,9999 0,999919 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,000020 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

Apéndice
261
µ i 7,1 7,2 7,3 7,4 7,5 7,6 7,7 7,8 7,9 8,0 0 0,0008 0,0007 0,0007 0,0006 0,0006 0,0005 0,0005 0,0004 0,0004 0,00031 0,0067 0,0061 0,0056 0,0051 0,0047 0,0043 0,0039 0,0036 0,0033 0,00302 0,0275 0,0255 0,0236 0,0219 0,0203 0,0188 0,0174 0,0161 0,0149 0,01383 0,0767 0,0719 0,0674 0,0632 0,0591 0,0554 0,0518 0,0485 0,0453 0,04244 0,1641 0,1555 0,1473 0,1395 0,1321 0,1249 0,1181 0,1117 0,1055 0,09965 0,2881 0,2759 0,2640 0,2526 0,2414 0,2307 0,2203 0,2103 0,2006 0,19126 0,4349 0,4204 0,4060 0,3920 0,3782 0,3646 0,3514 0,3384 0,3257 0,31347 0,5838 0,5689 0,5541 0,5393 0,5246 0,5100 0,4956 0,4812 0,4670 0,45308 0,7160 0,7027 0,6892 0,6757 0,6620 0,6482 0,6343 0,6204 0,6065 0,59259 0,8202 0,8096 0,7988 0,7877 0,7764 0,7649 0,7531 0,7411 0,7290 0,7166
10 0,8942 0,8867 0,8788 0,8707 0,8622 0,8535 0,8445 0,8352 0,8257 0,815911 0,9420 0,9371 0,9319 0,9265 0,9208 0,9148 0,9085 0,9020 0,8952 0,888112 0,9703 0,9673 0,9642 0,9609 0,9573 0,9536 0,9496 0,9454 0,9409 0,936213 0,9857 0,9841 0,9824 0,9805 0,9784 0,9762 0,9739 0,9714 0,9687 0,965814 0,9935 0,9927 0,9918 0,9908 0,9897 0,9886 0,9873 0,9859 0,9844 0,982715 0,9972 0,9969 0,9964 0,9959 0,9954 0,9948 0,9941 0,9934 0,9926 0,991816 0,9989 0,9987 0,9985 0,9983 0,9980 0,9978 0,9974 0,9971 0,9967 0,996317 0,9996 0,9995 0,9994 0,9993 0,9992 0,9991 0,9989 0,9988 0,9986 0,998418 0,9998 0,9998 0,9998 0,9997 0,9997 0,9996 0,9996 0,9995 0,9994 0,999319 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9998 0,9998 0,9998 0,999720 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,9999 0,9999 0,999921 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000
µ i 8,1 8,2 8,3 8,4 8,5 8,6 8,7 8,8 8,9 9,0 0 0,0003 0,0003 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0001 0,00011 0,0028 0,0025 0,0023 0,0021 0,0019 0,0018 0,0016 0,0015 0,0014 0,00122 0,0127 0,0118 0,0109 0,0100 0,0093 0,0086 0,0079 0,0073 0,0068 0,00623 0,0396 0,0370 0,0346 0,0323 0,0301 0,0281 0,0262 0,0244 0,0228 0,02124 0,0940 0,0887 0,0837 0,0789 0,0744 0,0701 0,0660 0,0621 0,0584 0,05505 0,1822 0,1736 0,1653 0,1573 0,1496 0,1422 0,1352 0,1284 0,1219 0,11576 0,3013 0,2896 0,2781 0,2670 0,2562 0,2457 0,2355 0,2256 0,2160 0,20687 0,4391 0,4254 0,4119 0,3987 0,3856 0,3728 0,3602 0,3478 0,3357 0,32398 0,5786 0,5647 0,5507 0,5369 0,5231 0,5094 0,4958 0,4823 0,4689 0,45579 0,7041 0,6915 0,6788 0,6659 0,6530 0,6400 0,6269 0,6137 0,6006 0,5874
10 0,8058 0,7955 0,7850 0,7743 0,7634 0,7522 0,7409 0,7294 0,7178 0,706011 0,8807 0,8731 0,8652 0,8571 0,8487 0,8400 0,8311 0,8220 0,8126 0,803012 0,9313 0,9261 0,9207 0,9150 0,9091 0,9029 0,8965 0,8898 0,8829 0,875813 0,9628 0,9595 0,9561 0,9524 0,9486 0,9445 0,9403 0,9358 0,9311 0,926114 0,9810 0,9791 0,9771 0,9749 0,9726 0,9701 0,9675 0,9647 0,9617 0,958515 0,9908 0,9898 0,9887 0,9875 0,9862 0,9848 0,9832 0,9816 0,9798 0,978016 0,9958 0,9953 0,9947 0,9941 0,9934 0,9926 0,9918 0,9909 0,9899 0,988917 0,9982 0,9979 0,9977 0,9973 0,9970 0,9966 0,9962 0,9957 0,9952 0,994718 0,9992 0,9991 0,9990 0,9989 0,9987 0,9985 0,9983 0,9981 0,9978 0,997619 0,9997 0,9997 0,9996 0,9995 0,9995 0,9994 0,9993 0,9992 0,9991 0,998920 0,9999 0,9999 0,9998 0,9998 0,9998 0,9998 0,9997 0,9997 0,9996 0,999621 1,0000 1,0000 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9998 0,999822 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,999923 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

262 Apéndice
µ i 9,1 9,2 9,3 9,4 9,5 9,6 9,7 9,8 9,9 10,0 0 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,00001 0,0011 0,0010 0,0009 0,0009 0,0008 0,0007 0,0007 0,0006 0,0005 0,00052 0,0058 0,0053 0,0049 0,0045 0,0042 0,0038 0,0035 0,0033 0,0030 0,00283 0,0198 0,0184 0,0172 0,0160 0,0149 0,0138 0,0129 0,0120 0,0111 0,01034 0,0517 0,0486 0,0456 0,0429 0,0403 0,0378 0,0355 0,0333 0,0312 0,02935 0,1098 0,1041 0,0986 0,0935 0,0885 0,0838 0,0793 0,0750 0,0710 0,06716 0,1978 0,1892 0,1808 0,1727 0,1649 0,1574 0,1502 0,1433 0,1366 0,13017 0,3123 0,3010 0,2900 0,2792 0,2687 0,2584 0,2485 0,2388 0,2294 0,22028 0,4426 0,4296 0,4168 0,4042 0,3918 0,3796 0,3676 0,3558 0,3442 0,33289 0,5742 0,5611 0,5479 0,5349 0,5218 0,5089 0,4960 0,4832 0,4705 0,4579
10 0,6941 0,6820 0,6699 0,6576 0,6453 0,6329 0,6205 0,6080 0,5955 0,583011 0,7932 0,7832 0,7730 0,7626 0,7520 0,7412 0,7303 0,7193 0,7081 0,696812 0,8684 0,8607 0,8529 0,8448 0,8364 0,8279 0,8191 0,8101 0,8009 0,791613 0,9210 0,9156 0,9100 0,9042 0,8981 0,8919 0,8853 0,8786 0,8716 0,864514 0,9552 0,9517 0,9480 0,9441 0,9400 0,9357 0,9312 0,9265 0,9216 0,916515 0,9760 0,9738 0,9715 0,9691 0,9665 0,9638 0,9609 0,9579 0,9546 0,951316 0,9878 0,9865 0,9852 0,9838 0,9823 0,9806 0,9789 0,9770 0,9751 0,973017 0,9941 0,9934 0,9927 0,9919 0,9911 0,9902 0,9892 0,9881 0,9870 0,985718 0,9973 0,9969 0,9966 0,9962 0,9957 0,9952 0,9947 0,9941 0,9935 0,992819 0,9988 0,9986 0,9985 0,9983 0,9980 0,9978 0,9975 0,9972 0,9969 0,996520 0,9995 0,9994 0,9993 0,9992 0,9991 0,9990 0,9989 0,9987 0,9986 0,998421 0,9998 0,9998 0,9997 0,9997 0,9996 0,9996 0,9995 0,9995 0,9994 0,999322 0,9999 0,9999 0,9999 0,9999 0,9999 0,9998 0,9998 0,9998 0,9997 0,999723 1,0000 1,0000 1,0000 1,0000 0,9999 0,9999 0,9999 0,9999 0,9999 0,999924 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,000025 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

Apéndice
263
µ i 11 12 13 14 15 16 17 18 19 20 0 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,00001 0,0002 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,00002 0,0012 0,0005 0,0002 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,00003 0,0049 0,0023 0,0011 0,0005 0,0002 0,0001 0,0000 0,0000 0,0000 0,00004 0,0151 0,0076 0,0037 0,0018 0,0009 0,0004 0,0002 0,0001 0,0000 0,00005 0,0375 0,0203 0,0107 0,0055 0,0028 0,0014 0,0007 0,0003 0,0002 0,00016 0,0786 0,0458 0,0259 0,0142 0,0076 0,0040 0,0021 0,0010 0,0005 0,00037 0,1432 0,0895 0,0540 0,0316 0,0180 0,0100 0,0054 0,0029 0,0015 0,00088 0,2320 0,1550 0,0998 0,0621 0,0374 0,0220 0,0126 0,0071 0,0039 0,00219 0,3405 0,2424 0,1658 0,1094 0,0699 0,0433 0,0261 0,0154 0,0089 0,0050
10 0,4599 0,3472 0,2517 0,1757 0,1185 0,0774 0,0491 0,0304 0,0183 0,010811 0,5793 0,4616 0,3532 0,2600 0,1848 0,1270 0,0847 0,0549 0,0347 0,021412 0,6887 0,5760 0,4631 0,3585 0,2676 0,1931 0,1350 0,0917 0,0606 0,039013 0,7813 0,6815 0,5730 0,4644 0,3632 0,2745 0,2009 0,1426 0,0984 0,066114 0,8540 0,7720 0,6751 0,5704 0,4657 0,3675 0,2808 0,2081 0,1497 0,104915 0,9074 0,8444 0,7636 0,6694 0,5681 0,4667 0,3715 0,2867 0,2148 0,156516 0,9441 0,8987 0,8355 0,7559 0,6641 0,5660 0,4677 0,3751 0,2920 0,221117 0,9678 0,9370 0,8905 0,8272 0,7489 0,6593 0,5640 0,4686 0,3784 0,297018 0,9823 0,9626 0,9302 0,8826 0,8195 0,7423 0,6550 0,5622 0,4695 0,381419 0,9907 0,9787 0,9573 0,9235 0,8752 0,8122 0,7363 0,6509 0,5606 0,470320 0,9953 0,9884 0,9750 0,9521 0,9170 0,8682 0,8055 0,7307 0,6472 0,559121 0,9977 0,9939 0,9859 0,9712 0,9469 0,9108 0,8615 0,7991 0,7255 0,643722 0,9990 0,9970 0,9924 0,9833 0,9673 0,9418 0,9047 0,8551 0,7931 0,720623 0,9995 0,9985 0,9960 0,9907 0,9805 0,9633 0,9367 0,8989 0,8490 0,787524 0,9998 0,9993 0,9980 0,9950 0,9888 0,9777 0,9594 0,9317 0,8933 0,843225 0,9999 0,9997 0,9990 0,9974 0,9938 0,9869 0,9748 0,9554 0,9269 0,887826 1,0000 0,9999 0,9995 0,9987 0,9967 0,9925 0,9848 0,9718 0,9514 0,922127 1,0000 0,9999 0,9998 0,9994 0,9983 0,9959 0,9912 0,9827 0,9687 0,947528 1,0000 1,0000 0,9999 0,9997 0,9991 0,9978 0,9950 0,9897 0,9805 0,965729 1,0000 1,0000 1,0000 0,9999 0,9996 0,9989 0,9973 0,9941 0,9882 0,978230 1,0000 1,0000 1,0000 0,9999 0,9998 0,9994 0,9986 0,9967 0,9930 0,986531 1,0000 1,0000 1,0000 1,0000 0,9999 0,9997 0,9993 0,9982 0,9960 0,991932 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,9996 0,9990 0,9978 0,995333 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,9998 0,9995 0,9988 0,997334 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,9998 0,9994 0,998535 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,9997 0,999236 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,9998 0,999637 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,9999 0,999838 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,999939 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 0,999940 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

264 Apéndice
z
Tabla de áreas bajo la curva normal estandarizada
z 0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09 0 0,500000 0,496011 0,492022 0,488033 0,484047 0,480061 0,476078 0,472097 0,468119 0,464144
0,1 0,460172 0,456205 0,452242 0,448283 0,444330 0,440382 0,436441 0,432505 0,428576 0,4246550,2 0,420740 0,416834 0,412936 0,409046 0,405165 0,401294 0,397432 0,393580 0,389739 0,3859080,3 0,382089 0,378281 0,374484 0,370700 0,366928 0,363169 0,359424 0,355691 0,351973 0,3482680,4 0,344578 0,340903 0,337243 0,333598 0,329969 0,326355 0,322758 0,319178 0,315614 0,3120670,5 0,308538 0,305026 0,301532 0,298056 0,294598 0,291160 0,287740 0,284339 0,280957 0,2775950,6 0,274253 0,270931 0,267629 0,264347 0,261086 0,257846 0,254627 0,251429 0,248252 0,2450970,7 0,241964 0,238852 0,235762 0,232695 0,229650 0,226627 0,223627 0,220650 0,217695 0,2147640,8 0,211855 0,208970 0,206108 0,203269 0,200454 0,197662 0,194894 0,192150 0,189430 0,1867330,9 0,184060 0,181411 0,178786 0,176186 0,173609 0,171056 0,168528 0,166023 0,163543 0,161087
1 0,158655 0,156248 0,153864 0,151505 0,149170 0,146859 0,144572 0,142310 0,140071 0,1378571,1 0,135666 0,133500 0,131357 0,129238 0,127143 0,125072 0,123024 0,121001 0,119000 0,1170231,2 0,115070 0,113140 0,111233 0,109349 0,107488 0,105650 0,103835 0,102042 0,100273 0,0985251,3 0,096801 0,095098 0,093418 0,091759 0,090123 0,088508 0,086915 0,085344 0,083793 0,0822641,4 0,080757 0,079270 0,077804 0,076359 0,074934 0,073529 0,072145 0,070781 0,069437 0,0681121,5 0,066807 0,065522 0,064256 0,063008 0,061780 0,060571 0,059380 0,058208 0,057053 0,0559171,6 0,054799 0,053699 0,052616 0,051551 0,050503 0,049471 0,048457 0,047460 0,046479 0,0455141,7 0,044565 0,043633 0,042716 0,041815 0,040929 0,040059 0,039204 0,038364 0,037538 0,0367271,8 0,035930 0,035148 0,034379 0,033625 0,032884 0,032157 0,031443 0,030742 0,030054 0,0293791,9 0,028716 0,028067 0,027429 0,026803 0,026190 0,025588 0,024998 0,024419 0,023852 0,023295
2 0,022750 0,022216 0,021692 0,021178 0,020675 0,020182 0,019699 0,019226 0,018763 0,0183092,1 0,017864 0,017429 0,017003 0,016586 0,016177 0,015778 0,015386 0,015003 0,014629 0,0142622,2 0,013903 0,013553 0,013209 0,012874 0,012545 0,012224 0,011911 0,011604 0,011304 0,0110112,3 0,010724 0,010444 0,010170 0,009903 0,009642 0,009387 0,009137 0,008894 0,008656 0,0084242,4 0,008198 0,007976 0,007760 0,007549 0,007344 0,007143 0,006947 0,006756 0,006569 0,0063872,5 0,006210 0,006037 0,005868 0,005703 0,005543 0,005386 0,005234 0,005085 0,004940 0,0047992,6 0,004661 0,004527 0,004397 0,004269 0,004145 0,004025 0,003907 0,003793 0,003681 0,0035732,7 0,003467 0,003364 0,003264 0,003167 0,003072 0,002980 0,002890 0,002803 0,002718 0,0026352,8 0,002555 0,002477 0,002401 0,002327 0,002256 0,002186 0,002118 0,002052 0,001988 0,0019262,9 0,001866 0,001807 0,001750 0,001695 0,001641 0,001589 0,001538 0,001489 0,001441 0,001395
3 0,001350 0,001306 0,001264 0,001223 0,001183 0,001144 0,001107 0,001070 0,001035 0,0010013,1 0,000968 0,000936 0,000904 0,000874 0,000845 0,000816 0,000789 0,000762 0,000736 0,0007113,2 0,000687 0,000664 0,000641 0,000619 0,000598 0,000577 0,000557 0,000538 0,000519 0,0005013,3 0,000483 0,000467 0,000450 0,000434 0,000419 0,000404 0,000390 0,000376 0,000362 0,0003503,4 0,000337 0,000325 0,000313 0,000302 0,000291 0,000280 0,000270 0,000260 0,000251 0,0002423,5 0,000233 0,000224 0,000216 0,000208 0,000200 0,000193 0,000185 0,000179 0,000172 0,0001653,6 0,000159 0,000153 0,000147 0,000142 0,000136 0,000131 0,000126 0,000121 0,000117 0,0001123,7 0,000108 0,000104 0,000100 0,000096 0,000092 0,000088 0,000085 0,000082 0,000078 0,0000753,8 0,000072 0,000070 0,000067 0,000064 0,000062 0,000059 0,000057 0,000054 0,000052 0,0000503,9 0,000048 0,000046 0,000044 0,000042 0,000041 0,000039 0,000037 0,000036 0,000034 0,000033
4 0,000032 0,000030 0,000029 0,000028 0,000027 0,000026 0,000025 0,000024 0,000023 0,0000224,1 0,000021 0,000020 0,000019 0,000018 0,000017 0,000017 0,000016 0,000015 0,000015 0,0000144,2 0,000013 0,000013 0,000012 0,000012 0,000011 0,000011 0,000010 0,000010 0,000009 0,0000094,3 0,000009 0,000008 0,000008 0,000007 0,000007 0,000007 0,000007 0,000006 0,000006 0,0000064,4 0,000005 0,000005 0,000005 0,000005 0,000005 0,000004 0,000004 0,000004 0,000004 0,0000044,5 0,000003 0,000003 0,000003 0,000003 0,000003 0,000003 0,000003 0,000002 0,000002 0,0000024,6 0,000002 0,000002 0,000002 0,000002 0,000002 0,000002 0,000002 0,000002 0,000001 0,0000014,7 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,0000014,8 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,000001 0,0000014,9 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000 0,000000

Apéndice
265
z
φ(z)
Tabla de ordenadas de la curva normal estandarizada
z 0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09 0 0,398942 0,398922 0,398862 0,398763 0,398623 0,398444 0,398225 0,397966 0,397668 0,397330
0,1 0,396953 0,396536 0,396080 0,395585 0,395052 0,394479 0,393868 0,393219 0,392531 0,3918060,2 0,391043 0,390242 0,389404 0,388529 0,387617 0,386668 0,385683 0,384663 0,383606 0,3825150,3 0,381388 0,380226 0,379031 0,377801 0,376537 0,375240 0,373911 0,372548 0,371154 0,3697280,4 0,368270 0,366782 0,365263 0,363714 0,362135 0,360527 0,358890 0,357225 0,355533 0,3538120,5 0,352065 0,350292 0,348493 0,346668 0,344818 0,342944 0,341046 0,339124 0,337180 0,3352130,6 0,333225 0,331215 0,329184 0,327133 0,325062 0,322972 0,320864 0,318737 0,316593 0,3144320,7 0,312254 0,310060 0,307851 0,305627 0,303389 0,301137 0,298872 0,296595 0,294305 0,2920040,8 0,289692 0,287369 0,285036 0,282694 0,280344 0,277985 0,275618 0,273244 0,270864 0,2684770,9 0,266085 0,263688 0,261286 0,258881 0,256471 0,254059 0,251644 0,249228 0,246809 0,244390
1 0,241971 0,239551 0,237132 0,234714 0,232297 0,229882 0,227470 0,225060 0,222653 0,2202511,1 0,217852 0,215458 0,213069 0,210686 0,208308 0,205936 0,203571 0,201214 0,198863 0,1965201,2 0,194186 0,191860 0,189543 0,187235 0,184937 0,182649 0,180371 0,178104 0,175847 0,1736021,3 0,171369 0,169147 0,166937 0,164740 0,162555 0,160383 0,158225 0,156080 0,153948 0,1518311,4 0,149727 0,147639 0,145564 0,143505 0,141460 0,139431 0,137417 0,135418 0,133435 0,1314681,5 0,129518 0,127583 0,125665 0,123763 0,121878 0,120009 0,118157 0,116323 0,114505 0,1127041,6 0,110921 0,109155 0,107406 0,105675 0,103961 0,102265 0,100586 0,098925 0,097282 0,0956571,7 0,094049 0,092459 0,090887 0,089333 0,087796 0,086277 0,084776 0,083293 0,081828 0,0803801,8 0,078950 0,077538 0,076143 0,074766 0,073407 0,072065 0,070740 0,069433 0,068144 0,0668711,9 0,065616 0,064378 0,063157 0,061952 0,060765 0,059595 0,058441 0,057304 0,056183 0,055079
2 0,053991 0,052919 0,051864 0,050824 0,049800 0,048792 0,047800 0,046823 0,045861 0,0449152,1 0,043984 0,043067 0,042166 0,041280 0,040408 0,039550 0,038707 0,037878 0,037063 0,0362622,2 0,035475 0,034701 0,033941 0,033194 0,032460 0,031740 0,031032 0,030337 0,029655 0,0289852,3 0,028327 0,027682 0,027048 0,026426 0,025817 0,025218 0,024631 0,024056 0,023491 0,0229372,4 0,022395 0,021862 0,021341 0,020829 0,020328 0,019837 0,019356 0,018885 0,018423 0,0179712,5 0,017528 0,017095 0,016670 0,016254 0,015848 0,015449 0,015060 0,014678 0,014305 0,0139402,6 0,013583 0,013234 0,012892 0,012558 0,012232 0,011912 0,011600 0,011295 0,010997 0,0107062,7 0,010421 0,010143 0,009871 0,009606 0,009347 0,009094 0,008846 0,008605 0,008370 0,0081402,8 0,007915 0,007697 0,007483 0,007274 0,007071 0,006873 0,006679 0,006491 0,006307 0,0061272,9 0,005953 0,005782 0,005616 0,005454 0,005296 0,005143 0,004993 0,004847 0,004705 0,004567
3 0,004432 0,004301 0,004173 0,004049 0,003928 0,003810 0,003695 0,003584 0,003475 0,0033703,1 0,003267 0,003167 0,003070 0,002975 0,002884 0,002794 0,002707 0,002623 0,002541 0,0024613,2 0,002384 0,002309 0,002236 0,002165 0,002096 0,002029 0,001964 0,001901 0,001840 0,0017803,3 0,001723 0,001667 0,001612 0,001560 0,001508 0,001459 0,001411 0,001364 0,001319 0,0012753,4 0,001232 0,001191 0,001151 0,001112 0,001075 0,001038 0,001003 0,000969 0,000936 0,0009043,5 0,000873 0,000843 0,000814 0,000785 0,000758 0,000732 0,000706 0,000681 0,000657 0,0006343,6 0,000612 0,000590 0,000569 0,000549 0,000529 0,000510 0,000492 0,000474 0,000457 0,0004413,7 0,000425 0,000409 0,000394 0,000380 0,000366 0,000353 0,000340 0,000327 0,000315 0,0003033,8 0,000292 0,000281 0,000271 0,000260 0,000251 0,000241 0,000232 0,000223 0,000215 0,0002073,9 0,000199 0,000191 0,000184 0,000177 0,000170 0,000163 0,000157 0,000151 0,000145 0,000139
4 0,000134 0,000129 0,000124 0,000119 0,000114 0,000109 0,000105 0,000101 0,000097 0,0000934,1 0,000089 0,000086 0,000082 0,000079 0,000076 0,000073 0,000070 0,000067 0,000064 0,0000614,2 0,000059 0,000057 0,000054 0,000052 0,000050 0,000048 0,000046 0,000044 0,000042 0,0000404,3 0,000039 0,000037 0,000035 0,000034 0,000032 0,000031 0,000030 0,000028 0,000027 0,0000264,4 0,000025 0,000024 0,000023 0,000022 0,000021 0,000020 0,000019 0,000018 0,000017 0,0000174,5 0,000016 0,000015 0,000015 0,000014 0,000013 0,000013 0,000012 0,000012 0,000011 0,0000114,6 0,000010 0,000010 0,000009 0,000009 0,000008 0,000008 0,000008 0,000007 0,000007 0,0000074,7 0,000006 0,000006 0,000006 0,000006 0,000005 0,000005 0,000005 0,000005 0,000004 0,0000044,8 0,000004 0,000004 0,000004 0,000003 0,000003 0,000003 0,000003 0,000003 0,000003 0,0000034,9 0,000002 0,000002 0,000002 0,000002 0,000002 0,000002 0,000002 0,000002 0,000002 0,000002

266 Apéndice
Tabla de valores de t de Student Área de la cola derecha 0,45 0,40 0,35 0,20 0,15 0,10 0,05 0,025 0,01 0,005 1 0,1584 0,3249 0,5095 1,3764 1,9626 3,0777 6,3137 12,7062 31,8210 63,6559 2 0,1421 0,2887 0,4447 1,0607 1,3862 1,8856 2,9200 4,3027 6,9645 9,9250 3 0,1366 0,2767 0,4242 0,9785 1,2498 1,6377 2,3534 3,1824 4,5407 5,8408 4 0,1338 0,2707 0,4142 0,9410 1,1896 1,5332 2,1318 2,7765 3,7469 4,6041 5 0,1322 0,2672 0,4082 0,9195 1,1558 1,4759 2,0150 2,5706 3,3649 4,0321 6 0,1311 0,2648 0,4043 0,9057 1,1342 1,4398 1,9432 2,4469 3,1427 3,7074 7 0,1303 0,2632 0,4015 0,8960 1,1192 1,4149 1,8946 2,3646 2,9979 3,4995 8 0,1297 0,2619 0,3995 0,8889 1,1081 1,3968 1,8595 2,3060 2,8965 3,3554 9 0,1293 0,2610 0,3979 0,8834 1,0997 1,3830 1,8331 2,2622 2,8214 3,2498
10 0,1289 0,2602 0,3966 0,8791 1,0931 1,3722 1,8125 2,2281 2,7638 3,1693 11 0,1286 0,2596 0,3956 0,8755 1,0877 1,3634 1,7959 2,2010 2,7181 3,1058 12 0,1283 0,2590 0,3947 0,8726 1,0832 1,3562 1,7823 2,1788 2,6810 3,0545 13 0,1281 0,2586 0,3940 0,8702 1,0795 1,3502 1,7709 2,1604 2,6503 3,0123 14 0,1280 0,2582 0,3933 0,8681 1,0763 1,3450 1,7613 2,1448 2,6245 2,9768 15 0,1278 0,2579 0,3928 0,8662 1,0735 1,3406 1,7531 2,1315 2,6025 2,9467 16 0,1277 0,2576 0,3923 0,8647 1,0711 1,3368 1,7459 2,1199 2,5835 2,9208 17 0,1276 0,2573 0,3919 0,8633 1,0690 1,3334 1,7396 2,1098 2,5669 2,8982 18 0,1274 0,2571 0,3915 0,8620 1,0672 1,3304 1,7341 2,1009 2,5524 2,8784 19 0,1274 0,2569 0,3912 0,8610 1,0655 1,3277 1,7291 2,0930 2,5395 2,8609 20 0,1273 0,2567 0,3909 0,8600 1,0640 1,3253 1,7247 2,0860 2,5280 2,8453 21 0,1272 0,2566 0,3906 0,8591 1,0627 1,3232 1,7207 2,0796 2,5176 2,8314 22 0,1271 0,2564 0,3904 0,8583 1,0614 1,3212 1,7171 2,0739 2,5083 2,8188 23 0,1271 0,2563 0,3902 0,8575 1,0603 1,3195 1,7139 2,0687 2,4999 2,8073 24 0,1270 0,2562 0,3900 0,8569 1,0593 1,3178 1,7109 2,0639 2,4922 2,7970 25 0,1269 0,2561 0,3898 0,8562 1,0584 1,3163 1,7081 2,0595 2,4851 2,7874 26 0,1269 0,2560 0,3896 0,8557 1,0575 1,3150 1,7056 2,0555 2,4786 2,7787 27 0,1268 0,2559 0,3894 0,8551 1,0567 1,3137 1,7033 2,0518 2,4727 2,7707 28 0,1268 0,2558 0,3893 0,8546 1,0560 1,3125 1,7011 2,0484 2,4671 2,7633 29 0,1268 0,2557 0,3892 0,8542 1,0553 1,3114 1,6991 2,0452 2,4620 2,7564 30 0,1267 0,2556 0,3890 0,8538 1,0547 1,3104 1,6973 2,0423 2,4573 2,7500 31 0,1267 0,2555 0,3889 0,8534 1,0541 1,3095 1,6955 2,0395 2,4528 2,7440 32 0,1267 0,2555 0,3888 0,8530 1,0535 1,3086 1,6939 2,0369 2,4487 2,7385 33 0,1266 0,2554 0,3887 0,8526 1,0530 1,3077 1,6924 2,0345 2,4448 2,7333 34 0,1266 0,2553 0,3886 0,8523 1,0525 1,3070 1,6909 2,0322 2,4411 2,7284 35 0,1266 0,2553 0,3885 0,8520 1,0520 1,3062 1,6896 2,0301 2,4377 2,7238 36 0,1266 0,2552 0,3884 0,8517 1,0516 1,3055 1,6883 2,0281 2,4345 2,7195 37 0,1265 0,2552 0,3883 0,8514 1,0512 1,3049 1,6871 2,0262 2,4314 2,7154 38 0,1265 0,2551 0,3882 0,8512 1,0508 1,3042 1,6860 2,0244 2,4286 2,7116 39 0,1265 0,2551 0,3882 0,8509 1,0504 1,3036 1,6849 2,0227 2,4258 2,7079 40 0,1265 0,2550 0,3881 0,8507 1,0500 1,3031 1,6839 2,0211 2,4233 2,7045 41 0,1264 0,2550 0,3880 0,8505 1,0497 1,3025 1,6829 2,0195 2,4208 2,7012 42 0,1264 0,2550 0,3880 0,8503 1,0494 1,3020 1,6820 2,0181 2,4185 2,6981 43 0,1264 0,2549 0,3879 0,8501 1,0491 1,3016 1,6811 2,0167 2,4163 2,6951 44 0,1264 0,2549 0,3878 0,8499 1,0488 1,3011 1,6802 2,0154 2,4141 2,6923 45 0,1264 0,2549 0,3878 0,8497 1,0485 1,3007 1,6794 2,0141 2,4121 2,6896 46 0,1264 0,2548 0,3877 0,8495 1,0482 1,3002 1,6787 2,0129 2,4102 2,6870 47 0,1263 0,2548 0,3877 0,8493 1,0480 1,2998 1,6779 2,0117 2,4083 2,6846 48 0,1263 0,2548 0,3876 0,8492 1,0478 1,2994 1,6772 2,0106 2,4066 2,6822 49 0,1263 0,2547 0,3876 0,8490 1,0475 1,2991 1,6766 2,0096 2,4049 2,6800 50 0,1263 0,2547 0,3875 0,8489 1,0473 1,2987 1,6759 2,0086 2,4033 2,6778 60 0,1262 0,2545 0,3872 0,8477 1,0455 1,2958 1,6706 2,0003 2,3901 2,6603 ∞ 0,1257 0,2533 0,3853 0,8416 1,0364 1,2816 1,6449 1,9600 2,3264 2,5759

Apéndice
267
Tabla de valores de ji-cuadrado
P(Área de la cola derecha bajo la función ji-cuadrada) n 0,99 0,98 0,95 0,90 0,50 0,10 0,05 0,025 0,02 0,01 1 0,0002 0,0006 0,0039 0,0158 0,4549 2,7055 3,8415 5,0239 5,4119 6,6349 2 0,0201 0,0404 0,1026 0,2107 1,3863 4,6052 5,9915 7,3778 7,8241 9,2104 3 0,1148 0,1848 0,3518 0,5844 2,3660 6,2514 7,8147 9,3484 9,8374 11,3449 4 0,2971 0,4294 0,7107 1,0636 3,3567 7,7794 9,4877 11,1433 11,6678 13,2767 5 0,5543 0,7519 1,1455 1,6103 4,3515 9,2363 11,0705 12,8325 13,3882 15,0863 6 0,8721 1,1344 1,6354 2,2041 5,3481 10,6446 12,5916 14,4494 15,0332 16,8119 7 1,2390 1,5643 2,1673 2,8331 6,3458 12,0170 14,0671 16,0128 16,6224 18,4753 8 1,6465 2,0325 2,7326 3,4895 7,3441 13,3616 15,5073 17,5345 18,1682 20,0902 9 2,0879 2,5324 3,3251 4,1682 8,3428 14,6837 16,9190 19,0228 19,6790 21,6660
10 2,5582 3,0591 3,9403 4,8652 9,3418 15,9872 18,3070 20,4832 21,1608 23,2093
11 3,0535 3,6087 4,5748 5,5778 10,3410 17,2750 19,6752 21,9200 22,6179 24,7250 12 3,5706 4,1783 5,2260 6,3038 11,3403 18,5493 21,0261 23,3367 24,0539 26,2170 13 4,1069 4,7654 5,8919 7,0415 12,3398 19,8119 22,3620 24,7356 25,4715 27,6882 14 4,6604 5,3682 6,5706 7,7895 13,3393 21,0641 23,6848 26,1189 26,8727 29,1412 15 5,2294 5,9849 7,2609 8,5468 14,3389 22,3071 24,9958 27,4884 28,2595 30,5780 16 5,8122 6,6142 7,9616 9,3122 15,3385 23,5418 26,2962 28,8453 29,6332 31,9999 17 6,4077 7,2550 8,6718 10,0852 16,3382 24,7690 27,5871 30,1910 30,9950 33,4087 18 7,0149 7,9062 9,3904 10,8649 17,3379 25,9894 28,8693 31,5264 32,3462 34,8052 19 7,6327 8,5670 10,1170 11,6509 18,3376 27,2036 30,1435 32,8523 33,6874 36,1908 20 8,2604 9,2367 10,8508 12,4426 19,3374 28,4120 31,4104 34,1696 35,0196 37,5663
21 8,8972 9,9145 11,5913 13,2396 20,3372 29,6151 32,6706 35,4789 36,3434 38,9322 22 9,5425 10,6000 12,3380 14,0415 21,3370 30,8133 33,9245 36,7807 37,6595 40,2894 23 10,1957 11,2926 13,0905 14,8480 22,3369 32,0069 35,1725 38,0756 38,9683 41,6383 24 10,8563 11,9918 13,8484 15,6587 23,3367 33,1962 36,4150 39,3641 40,2703 42,9798 25 11,5240 12,6973 14,6114 16,4734 24,3366 34,3816 37,6525 40,6465 41,5660 44,3140 26 12,1982 13,4086 15,3792 17,2919 25,3365 35,5632 38,8851 41,9231 42,8558 45,6416 27 12,8785 14,1254 16,1514 18,1139 26,3363 36,7412 40,1133 43,1945 44,1399 46,9628 28 13,5647 14,8475 16,9279 18,9392 27,3362 37,9159 41,3372 44,4608 45,4188 48,2782 29 14,2564 15,5745 17,7084 19,7677 28,3361 39,0875 42,5569 45,7223 46,6926 49,5878 30 14,9535 16,3062 18,4927 20,5992 29,3360 40,2560 43,7730 46,9792 47,9618 50,8922
Para n > 30 conviene emplear el ajuste normal: 122 2 −−= nz χ
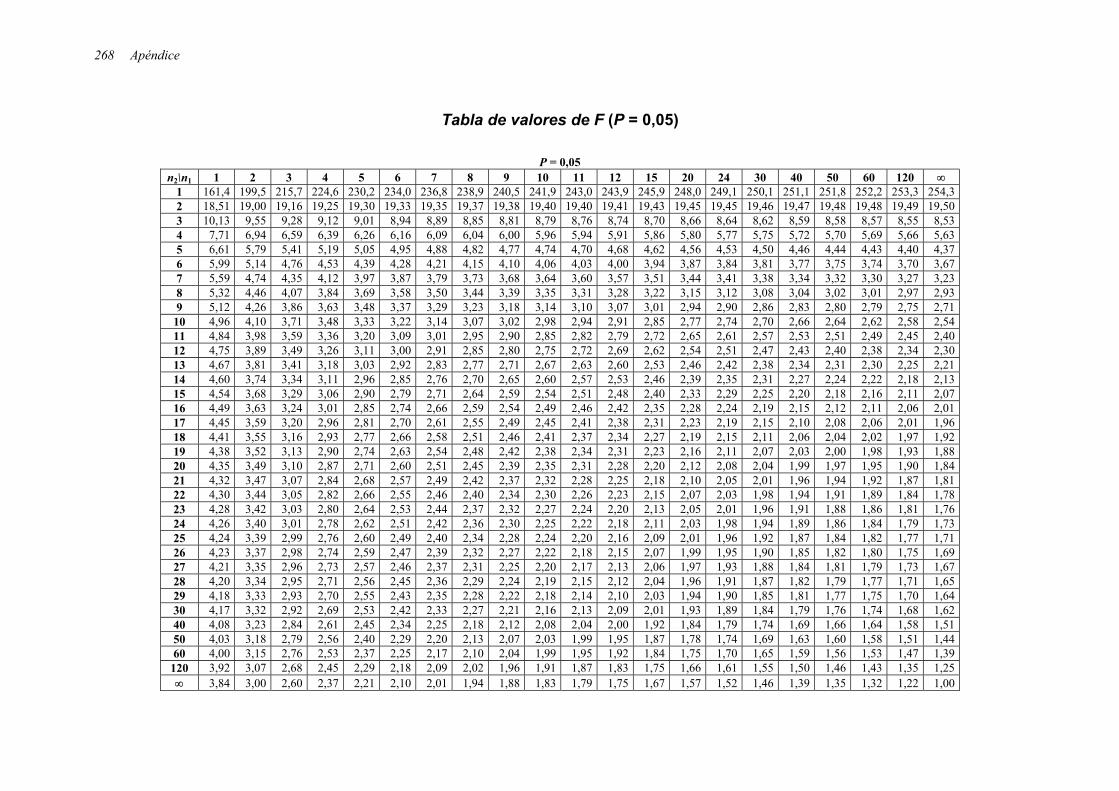
268 Apéndice
Tabla de valores de F (P = 0,05)
P = 0,05 n2\n1 1 2 3 4 5 6 7 8 9 10 11 12 15 20 24 30 40 50 60 120 ∞
1 161,4 199,5 215,7 224,6 230,2 234,0 236,8 238,9 240,5 241,9 243,0 243,9 245,9 248,0 249,1 250,1 251,1 251,8 252,2 253,3 254,32 18,51 19,00 19,16 19,25 19,30 19,33 19,35 19,37 19,38 19,40 19,40 19,41 19,43 19,45 19,45 19,46 19,47 19,48 19,48 19,49 19,503 10,13 9,55 9,28 9,12 9,01 8,94 8,89 8,85 8,81 8,79 8,76 8,74 8,70 8,66 8,64 8,62 8,59 8,58 8,57 8,55 8,534 7,71 6,94 6,59 6,39 6,26 6,16 6,09 6,04 6,00 5,96 5,94 5,91 5,86 5,80 5,77 5,75 5,72 5,70 5,69 5,66 5,635 6,61 5,79 5,41 5,19 5,05 4,95 4,88 4,82 4,77 4,74 4,70 4,68 4,62 4,56 4,53 4,50 4,46 4,44 4,43 4,40 4,376 5,99 5,14 4,76 4,53 4,39 4,28 4,21 4,15 4,10 4,06 4,03 4,00 3,94 3,87 3,84 3,81 3,77 3,75 3,74 3,70 3,677 5,59 4,74 4,35 4,12 3,97 3,87 3,79 3,73 3,68 3,64 3,60 3,57 3,51 3,44 3,41 3,38 3,34 3,32 3,30 3,27 3,238 5,32 4,46 4,07 3,84 3,69 3,58 3,50 3,44 3,39 3,35 3,31 3,28 3,22 3,15 3,12 3,08 3,04 3,02 3,01 2,97 2,939 5,12 4,26 3,86 3,63 3,48 3,37 3,29 3,23 3,18 3,14 3,10 3,07 3,01 2,94 2,90 2,86 2,83 2,80 2,79 2,75 2,71
10 4,96 4,10 3,71 3,48 3,33 3,22 3,14 3,07 3,02 2,98 2,94 2,91 2,85 2,77 2,74 2,70 2,66 2,64 2,62 2,58 2,5411 4,84 3,98 3,59 3,36 3,20 3,09 3,01 2,95 2,90 2,85 2,82 2,79 2,72 2,65 2,61 2,57 2,53 2,51 2,49 2,45 2,4012 4,75 3,89 3,49 3,26 3,11 3,00 2,91 2,85 2,80 2,75 2,72 2,69 2,62 2,54 2,51 2,47 2,43 2,40 2,38 2,34 2,3013 4,67 3,81 3,41 3,18 3,03 2,92 2,83 2,77 2,71 2,67 2,63 2,60 2,53 2,46 2,42 2,38 2,34 2,31 2,30 2,25 2,2114 4,60 3,74 3,34 3,11 2,96 2,85 2,76 2,70 2,65 2,60 2,57 2,53 2,46 2,39 2,35 2,31 2,27 2,24 2,22 2,18 2,1315 4,54 3,68 3,29 3,06 2,90 2,79 2,71 2,64 2,59 2,54 2,51 2,48 2,40 2,33 2,29 2,25 2,20 2,18 2,16 2,11 2,0716 4,49 3,63 3,24 3,01 2,85 2,74 2,66 2,59 2,54 2,49 2,46 2,42 2,35 2,28 2,24 2,19 2,15 2,12 2,11 2,06 2,0117 4,45 3,59 3,20 2,96 2,81 2,70 2,61 2,55 2,49 2,45 2,41 2,38 2,31 2,23 2,19 2,15 2,10 2,08 2,06 2,01 1,9618 4,41 3,55 3,16 2,93 2,77 2,66 2,58 2,51 2,46 2,41 2,37 2,34 2,27 2,19 2,15 2,11 2,06 2,04 2,02 1,97 1,9219 4,38 3,52 3,13 2,90 2,74 2,63 2,54 2,48 2,42 2,38 2,34 2,31 2,23 2,16 2,11 2,07 2,03 2,00 1,98 1,93 1,8820 4,35 3,49 3,10 2,87 2,71 2,60 2,51 2,45 2,39 2,35 2,31 2,28 2,20 2,12 2,08 2,04 1,99 1,97 1,95 1,90 1,8421 4,32 3,47 3,07 2,84 2,68 2,57 2,49 2,42 2,37 2,32 2,28 2,25 2,18 2,10 2,05 2,01 1,96 1,94 1,92 1,87 1,8122 4,30 3,44 3,05 2,82 2,66 2,55 2,46 2,40 2,34 2,30 2,26 2,23 2,15 2,07 2,03 1,98 1,94 1,91 1,89 1,84 1,7823 4,28 3,42 3,03 2,80 2,64 2,53 2,44 2,37 2,32 2,27 2,24 2,20 2,13 2,05 2,01 1,96 1,91 1,88 1,86 1,81 1,7624 4,26 3,40 3,01 2,78 2,62 2,51 2,42 2,36 2,30 2,25 2,22 2,18 2,11 2,03 1,98 1,94 1,89 1,86 1,84 1,79 1,7325 4,24 3,39 2,99 2,76 2,60 2,49 2,40 2,34 2,28 2,24 2,20 2,16 2,09 2,01 1,96 1,92 1,87 1,84 1,82 1,77 1,7126 4,23 3,37 2,98 2,74 2,59 2,47 2,39 2,32 2,27 2,22 2,18 2,15 2,07 1,99 1,95 1,90 1,85 1,82 1,80 1,75 1,6927 4,21 3,35 2,96 2,73 2,57 2,46 2,37 2,31 2,25 2,20 2,17 2,13 2,06 1,97 1,93 1,88 1,84 1,81 1,79 1,73 1,6728 4,20 3,34 2,95 2,71 2,56 2,45 2,36 2,29 2,24 2,19 2,15 2,12 2,04 1,96 1,91 1,87 1,82 1,79 1,77 1,71 1,6529 4,18 3,33 2,93 2,70 2,55 2,43 2,35 2,28 2,22 2,18 2,14 2,10 2,03 1,94 1,90 1,85 1,81 1,77 1,75 1,70 1,6430 4,17 3,32 2,92 2,69 2,53 2,42 2,33 2,27 2,21 2,16 2,13 2,09 2,01 1,93 1,89 1,84 1,79 1,76 1,74 1,68 1,6240 4,08 3,23 2,84 2,61 2,45 2,34 2,25 2,18 2,12 2,08 2,04 2,00 1,92 1,84 1,79 1,74 1,69 1,66 1,64 1,58 1,5150 4,03 3,18 2,79 2,56 2,40 2,29 2,20 2,13 2,07 2,03 1,99 1,95 1,87 1,78 1,74 1,69 1,63 1,60 1,58 1,51 1,4460 4,00 3,15 2,76 2,53 2,37 2,25 2,17 2,10 2,04 1,99 1,95 1,92 1,84 1,75 1,70 1,65 1,59 1,56 1,53 1,47 1,39120 3,92 3,07 2,68 2,45 2,29 2,18 2,09 2,02 1,96 1,91 1,87 1,83 1,75 1,66 1,61 1,55 1,50 1,46 1,43 1,35 1,25∞ 3,84 3,00 2,60 2,37 2,21 2,10 2,01 1,94 1,88 1,83 1,79 1,75 1,67 1,57 1,52 1,46 1,39 1,35 1,32 1,22 1,00

Apéndice
269
Tabla de valores de F (P = 0,01)
P = 0,01 n2\n1 1 2 3 4 5 6 7 8 9 10 11 12 15 20 24 30 40 50 60 120 ∞
1 4052,2 4999,3 5403,5 5624,3 5764,0 5859,0 5928,3 5981,0 6022,4 6055,9 6083,4 6106,7 6157,0 6208,7 6234,3 6260,4 6286,4 6302,3 6313,0 6339,5 6365,6 2 98,50 99,00 99,16 99,25 99,30 99,33 99,36 99,38 99,39 99,40 99,41 99,42 99,43 99,45 99,46 99,47 99,48 99,48 99,48 99,49 99,50 3 34,12 30,82 29,46 28,71 28,24 27,91 27,67 27,49 27,34 27,23 27,13 27,05 26,87 26,69 26,60 26,50 26,41 26,35 26,32 26,22 26,13 4 21,20 18,00 16,69 15,98 15,52 15,21 14,98 14,80 14,66 14,55 14,45 14,37 14,20 14,02 13,93 13,84 13,75 13,69 13,65 13,56 13,46 5 16,26 13,27 12,06 11,39 10,97 10,67 10,46 10,29 10,16 10,05 9,96 9,89 9,72 9,55 9,47 9,38 9,29 9,24 9,20 9,11 9,02 6 13,75 10,92 9,78 9,15 8,75 8,47 8,26 8,10 7,98 7,87 7,79 7,72 7,56 7,40 7,31 7,23 7,14 7,09 7,06 6,97 6,88 7 12,25 9,55 8,45 7,85 7,46 7,19 6,99 6,84 6,72 6,62 6,54 6,47 6,31 6,16 6,07 5,99 5,91 5,86 5,82 5,74 5,65 8 11,26 8,65 7,59 7,01 6,63 6,37 6,18 6,03 5,91 5,81 5,73 5,67 5,52 5,36 5,28 5,20 5,12 5,07 5,03 4,95 4,86 9 10,56 8,02 6,99 6,42 6,06 5,80 5,61 5,47 5,35 5,26 5,18 5,11 4,96 4,81 4,73 4,65 4,57 4,52 4,48 4,40 4,31
10 10,04 7,56 6,55 5,99 5,64 5,39 5,20 5,06 4,94 4,85 4,77 4,71 4,56 4,41 4,33 4,25 4,17 4,12 4,08 4,00 3,91 11 9,65 7,21 6,22 5,67 5,32 5,07 4,89 4,74 4,63 4,54 4,46 4,40 4,25 4,10 4,02 3,94 3,86 3,81 3,78 3,69 3,60 12 9,33 6,93 5,95 5,41 5,06 4,82 4,64 4,50 4,39 4,30 4,22 4,16 4,01 3,86 3,78 3,70 3,62 3,57 3,54 3,45 3,36 13 9,07 6,70 5,74 5,21 4,86 4,62 4,44 4,30 4,19 4,10 4,02 3,96 3,82 3,66 3,59 3,51 3,43 3,38 3,34 3,25 3,17 14 8,86 6,51 5,56 5,04 4,69 4,46 4,28 4,14 4,03 3,94 3,86 3,80 3,66 3,51 3,43 3,35 3,27 3,22 3,18 3,09 3,00 15 8,68 6,36 5,42 4,89 4,56 4,32 4,14 4,00 3,89 3,80 3,73 3,67 3,52 3,37 3,29 3,21 3,13 3,08 3,05 2,96 2,87 16 8,53 6,23 5,29 4,77 4,44 4,20 4,03 3,89 3,78 3,69 3,62 3,55 3,41 3,26 3,18 3,10 3,02 2,97 2,93 2,84 2,75 17 8,40 6,11 5,19 4,67 4,34 4,10 3,93 3,79 3,68 3,59 3,52 3,46 3,31 3,16 3,08 3,00 2,92 2,87 2,83 2,75 2,65 18 8,29 6,01 5,09 4,58 4,25 4,01 3,84 3,71 3,60 3,51 3,43 3,37 3,23 3,08 3,00 2,92 2,84 2,78 2,75 2,66 2,57 19 8,18 5,93 5,01 4,50 4,17 3,94 3,77 3,63 3,52 3,43 3,36 3,30 3,15 3,00 2,92 2,84 2,76 2,71 2,67 2,58 2,49 20 8,10 5,85 4,94 4,43 4,10 3,87 3,70 3,56 3,46 3,37 3,29 3,23 3,09 2,94 2,86 2,78 2,69 2,64 2,61 2,52 2,42 21 8,02 5,78 4,87 4,37 4,04 3,81 3,64 3,51 3,40 3,31 3,24 3,17 3,03 2,88 2,80 2,72 2,64 2,58 2,55 2,46 2,36 22 7,95 5,72 4,82 4,31 3,99 3,76 3,59 3,45 3,35 3,26 3,18 3,12 2,98 2,83 2,75 2,67 2,58 2,53 2,50 2,40 2,31 23 7,88 5,66 4,76 4,26 3,94 3,71 3,54 3,41 3,30 3,21 3,14 3,07 2,93 2,78 2,70 2,62 2,54 2,48 2,45 2,35 2,26 24 7,82 5,61 4,72 4,22 3,90 3,67 3,50 3,36 3,26 3,17 3,09 3,03 2,89 2,74 2,66 2,58 2,49 2,44 2,40 2,31 2,21 25 7,77 5,57 4,68 4,18 3,85 3,63 3,46 3,32 3,22 3,13 3,06 2,99 2,85 2,70 2,62 2,54 2,45 2,40 2,36 2,27 2,17 26 7,72 5,53 4,64 4,14 3,82 3,59 3,42 3,29 3,18 3,09 3,02 2,96 2,81 2,66 2,58 2,50 2,42 2,36 2,33 2,23 2,13 27 7,68 5,49 4,60 4,11 3,78 3,56 3,39 3,26 3,15 3,06 2,99 2,93 2,78 2,63 2,55 2,47 2,38 2,33 2,29 2,20 2,10 28 7,64 5,45 4,57 4,07 3,75 3,53 3,36 3,23 3,12 3,03 2,96 2,90 2,75 2,60 2,52 2,44 2,35 2,30 2,26 2,17 2,06 29 7,60 5,42 4,54 4,04 3,73 3,50 3,33 3,20 3,09 3,00 2,93 2,87 2,73 2,57 2,49 2,41 2,33 2,27 2,23 2,14 2,03 30 7,56 5,39 4,51 4,02 3,70 3,47 3,30 3,17 3,07 2,98 2,91 2,84 2,70 2,55 2,47 2,39 2,30 2,25 2,21 2,11 2,01 40 7,31 5,18 4,31 3,83 3,51 3,29 3,12 2,99 2,89 2,80 2,73 2,66 2,52 2,37 2,29 2,20 2,11 2,06 2,02 1,92 1,80 50 7,17 5,06 4,20 3,72 3,41 3,19 3,02 2,89 2,78 2,70 2,63 2,56 2,42 2,27 2,18 2,10 2,01 1,95 1,91 1,80 1,68 60 7,08 4,98 4,13 3,65 3,34 3,12 2,95 2,82 2,72 2,63 2,56 2,50 2,35 2,20 2,12 2,03 1,94 1,88 1,84 1,73 1,60 120 6,85 4,79 3,95 3,48 3,17 2,96 2,79 2,66 2,56 2,47 2,40 2,34 2,19 2,03 1,95 1,86 1,76 1,70 1,66 1,53 1,38 ∞ 6,64 4,61 3,78 3,32 3,02 2,80 2,64 2,51 2,41 2,32 2,25 2,18 2,04 1,88 1,79 1,70 1,59 1,52 1,47 1,32 1,01

270 Apéndice
Tabla de factores para el cálculo de límites de control
Tamaño de la muestra A2 A3 E2 B3 B4 D3 D4
2 1,880 2,659 2,660 0,000 3,267 0,000 3,267 3 1,023 1,954 1,772 0,000 2,568 0,000 2,574 4 0,729 1,628 1,457 0,000 2,266 0,000 2,282 5 0,557 1,427 1,290 0,000 2,089 0,000 2,114 6 0,483 1,287 1,184 0,030 1,970 0,000 2,004 7 0,419 1,182 1,109 0,118 1,882 0,076 1,924 8 0,373 1,099 1,054 0,185 1,815 0,136 1,864 9 0,337 1,032 1,010 0,239 1,761 0,184 1,816
10 0,308 0,975 0,975 0,284 1,716 0,223 1,777 11 0,285 0,927 0,946 0,321 1,679 0,256 1,744 12 0,266 0,886 0,921 0,354 1,646 0,283 1,717 13 0,249 0,850 0,899 0,382 1,618 0,307 1,693 14 0,235 0,817 0,881 0,406 1,594 0,328 1,672 15 0,223 0,789 0,864 0,428 1,572 0,347 1,653 16 0,212 0,763 0,448 1,552 0,363 1,637 17 0,203 0,739 0,466 1,534 0,378 1,622 18 0,194 0,718 0,482 1,518 0,391 1,608 19 0,187 0,698 0,497 1,503 0,403 1,597 20 0,180 0,680 0,510 1,490 0,415 1,585 21 0,173 0,663 0,523 1,477 0,425 1,575 22 0,167 0,647 0,534 1,466 0,434 1,566 23 0,162 0,633 0,545 1,455 0,443 1,557 24 0,157 0,619 0,555 1,445 0,451 1,548 25 0,153 0,606 0,565 1,435 0,459 1,541
Tabla extraída del curso de Herramientas Estadísticas para el mejoramiento de procesos dictado por el Ing. Federico Salvador en la Sociedad Nacional de Industrias del Perú.

Apéndice 271
Tabla de probabilidades de aceptación (Pa) np \ c 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 0,01 0,990 1,000 0,02 0,980 1,000 0,03 0,970 1,000 0,04 0,961 0,999 1,000 0,05 0,951 0,999 1,000 0,06 0,942 0,998 1,000 0,07 0,932 0,998 1,000 0,08 0,923 0,997 1,000 0,09 0,914 0,996 1,000 0,10 0,905 0,995 1,000 0,15 0,861 0,990 0,999 1,000 0,20 0,819 0,982 0,999 1,000 0,25 0,779 0,974 0,998 1,000 0,30 0,741 0,963 0,996 1,000 0,35 0,705 0,951 0,994 1,000 0,40 0,670 0,938 0,992 0,999 1,000 0,45 0,638 0,925 0,989 0,999 1,000 0,50 0,607 0,910 0,986 0,998 1,000 0,55 0,577 0,894 0,982 0,998 1,000 0,60 0,549 0,878 0,977 0,997 1,000 0,65 0,522 0,861 0,972 0,996 0,999 1,000 0,70 0,497 0,844 0,966 0,994 0,999 1,000 0,75 0,472 0,827 0,959 0,993 0,999 1,000 0,80 0,449 0,809 0,953 0,991 0,999 1,000 0,85 0,427 0,791 0,945 0,989 0,998 1,000 0,90 0,407 0,772 0,937 0,987 0,998 1,000 0,95 0,387 0,754 0,929 0,984 0,997 1,000 1,00 0,368 0,736 0,920 0,981 0,996 0,999 1,000 1,10 0,333 0,699 0,900 0,974 0,995 0,999 1,000 1,20 0,301 0,663 0,879 0,966 0,992 0,998 1,000 1,30 0,273 0,627 0,857 0,957 0,989 0,998 1,000 1,40 0,247 0,592 0,833 0,946 0,986 0,997 0,999 1,000 1,50 0,223 0,558 0,809 0,934 0,981 0,996 0,999 1,000 1,60 0,202 0,525 0,783 0,921 0,976 0,994 0,999 1,000 1,70 0,183 0,493 0,757 0,907 0,970 0,992 0,998 1,000 1,80 0,165 0,463 0,731 0,891 0,964 0,990 0,997 0,999 1,000 1,90 0,150 0,434 0,704 0,875 0,956 0,987 0,997 0,999 1,000 2,00 0,135 0,406 0,677 0,857 0,947 0,983 0,995 0,999 1,000 2,10 0,122 0,380 0,650 0,839 0,938 0,980 0,994 0,999 1,000 2,20 0,111 0,355 0,623 0,819 0,928 0,975 0,993 0,998 1,000 2,30 0,100 0,331 0,596 0,799 0,916 0,970 0,991 0,997 0,999 1,000 2,40 0,091 0,308 0,570 0,779 0,904 0,964 0,988 0,997 0,999 1,000 2,50 0,082 0,287 0,544 0,758 0,891 0,958 0,986 0,996 0,999 1,000 2,60 0,074 0,267 0,518 0,736 0,877 0,951 0,983 0,995 0,999 1,000 2,70 0,067 0,249 0,494 0,714 0,863 0,943 0,979 0,993 0,998 0,999 1,000 2,80 0,061 0,231 0,469 0,692 0,848 0,935 0,976 0,992 0,998 0,999 1,000 2,90 0,055 0,215 0,446 0,670 0,832 0,926 0,971 0,990 0,997 0,999 1,000 3,00 0,050 0,199 0,423 0,647 0,815 0,916 0,966 0,988 0,996 0,999 1,000 3,10 0,045 0,185 0,401 0,625 0,798 0,906 0,961 0,986 0,995 0,999 1,000 3,20 0,041 0,171 0,380 0,603 0,781 0,895 0,955 0,983 0,994 0,998 1,000 3,30 0,037 0,159 0,359 0,580 0,763 0,883 0,949 0,980 0,993 0,998 0,999 1,000 3,40 0,033 0,147 0,340 0,558 0,744 0,871 0,942 0,977 0,992 0,997 0,999 1,000 3,50 0,030 0,136 0,321 0,537 0,725 0,858 0,935 0,973 0,990 0,997 0,999 1,000 3,60 0,027 0,126 0,303 0,515 0,706 0,844 0,927 0,969 0,988 0,996 0,999 1,000 3,70 0,025 0,116 0,285 0,494 0,687 0,830 0,918 0,965 0,986 0,995 0,998 1,000 3,80 0,022 0,107 0,269 0,473 0,668 0,816 0,909 0,960 0,984 0,994 0,998 0,999 1,000 3,90 0,020 0,099 0,253 0,453 0,648 0,801 0,899 0,955 0,981 0,993 0,998 0,999 1,000 4,00 0,018 0,092 0,238 0,433 0,629 0,785 0,889 0,949 0,979 0,992 0,997 0,999 1,000 4,10 0,017 0,085 0,224 0,414 0,609 0,769 0,879 0,943 0,976 0,990 0,997 0,999 1,000 4,20 0,015 0,078 0,210 0,395 0,590 0,753 0,867 0,936 0,972 0,989 0,996 0,999 1,000 4,30 0,014 0,072 0,197 0,377 0,570 0,737 0,856 0,929 0,968 0,987 0,995 0,998 0,999 1,000 4,40 0,012 0,066 0,185 0,359 0,551 0,720 0,844 0,921 0,964 0,985 0,994 0,998 0,999 1,000 4,50 0,011 0,061 0,174 0,342 0,532 0,703 0,831 0,913 0,960 0,983 0,993 0,998 0,999 1,000 4,60 0,010 0,056 0,163 0,326 0,513 0,686 0,818 0,905 0,955 0,980 0,992 0,997 0,999 1,000 4,70 0,009 0,052 0,152 0,310 0,495 0,668 0,805 0,896 0,950 0,978 0,991 0,997 0,999 1,000 4,80 0,008 0,048 0,143 0,294 0,476 0,651 0,791 0,887 0,944 0,975 0,990 0,996 0,999 1,000 4,90 0,007 0,044 0,133 0,279 0,458 0,634 0,777 0,877 0,938 0,972 0,988 0,995 0,998 0,999 1,0005,00 0,007 0,040 0,125 0,265 0,440 0,616 0,762 0,867 0,932 0,968 0,986 0,995 0,998 0,999 1,000

272 Apéndice

Índice i
ÍNDICE CAPÍTULO 1. PROBABILIDADES................................................................................................................... 1
1.1 MODELOS MATEMÁTICOS ..................................................................................................................... 1 1.1.1 Definiciones: ................................................................................................................................... 1 1.1.2 Características de un fenómeno probabilístico: ............................................................................. 1
1.2 PERMUTACIONES Y COMBINACIONES.................................................................................................... 2 1.2.1 Teoremas relativos a permutaciones y combinaciones ................................................................... 2
1.3 EXPERIMENTOS Y EVENTOS .................................................................................................................. 7 1.4 ESPACIO MUESTRA................................................................................................................................ 7 1.5 VARIABLE ALEATORIA.......................................................................................................................... 7 1.6 PROBABILIDAD ..................................................................................................................................... 9
1.6.1. Probabilidad a priori:..................................................................................................................... 9 1.6.2. Probabilidad experimental............................................................................................................ 10 1.6.3 Probabilidad subjetiva .................................................................................................................. 11
1.7 TEOREMAS DE PROBABILIDAD. ........................................................................................................... 11 1.7.1 Suma de probabilidades:............................................................................................................... 11 1.7.2 Probabilidad condicional y regla de la multiplicación: ............................................................... 14 1.7.3 Eventos independientes ................................................................................................................. 16 1.7.4 Teorema de suma y multiplicación: particiones............................................................................ 17 1.7.5 Teorema de Bayes ......................................................................................................................... 21
PROBLEMAS PROPUESTOS. ................................................................................................................................ 23 CAPÍTULO 2. INTRODUCCIÓN A LA ESTADÍSTICA .............................................................................. 34
2.1 DEFINICIÓN DE ESTADÍSTICA.............................................................................................................. 34 2.2 DEFINICIÓN DE ALGUNOS TÉRMINOS BÁSICOS .................................................................................... 34
2.2.1 Universo o población:................................................................................................................... 34 2.2.2 Muestra ......................................................................................................................................... 34
2.3 ESTADÍSTICA DESCRIPTIVA E INFERENCIAL......................................................................................... 35 2.4 IMPORTANCIA DE LA ESTADÍSTICA ..................................................................................................... 35
CAPÍTULO 3. ESTADÍSTICA DESCRIPTIVA ............................................................................................. 37 3.1 INTRODUCCIÓN................................................................................................................................... 37 3.2 MEDIDAS DESCRIPTIVAS ..................................................................................................................... 37
3.2.1 Media aritmética ........................................................................................................................... 37 3.2.2 La mediana.................................................................................................................................... 38 3.2.3 La moda......................................................................................................................................... 38 3.2.4 La amplitud ................................................................................................................................... 39 3.2.5 La desviación media...................................................................................................................... 39 3.2.6 La varianza ................................................................................................................................... 39 3.2.7 La desviación estándar.................................................................................................................. 39 3.2.8 El coeficiente de variación............................................................................................................ 39 3.2.9 Los cuartiles .................................................................................................................................. 40 3.2.10 Los percentiles.......................................................................................................................... 40 3.2.11 Coeficiente de asimetría ........................................................................................................... 40 3.2.12 Curtosis .................................................................................................................................... 41
3.3 EXACTITUD Y PRECISIÓN .................................................................................................................... 41 3.4 MEDIDAS DESCRIPTIVAS EN EXCEL .................................................................................................... 42 3.5 REPRESENTACIONES DE DATOS........................................................................................................... 44
3.5.1 Distribución de frecuencias: diagrama de barras ........................................................................ 44 3.5.2 Representaciones tallo-hoja .......................................................................................................... 45 3.5.3 Diagrama de caja-bigote.................................................................................................................... 45
3.6 DISTRIBUCIONES DE FRECUENCIAS AGRUPADAS................................................................................. 46 3.6.1 Agrupación de datos...................................................................................................................... 46 3.6.2 Histograma, polígono de frecuencias y ojiva................................................................................ 48 3.6.3 Cálculo de algunas medidas descriptivas. .................................................................................... 50
3.7 TABLAS Y GRÁFICAS PARA LA REPRESENTACIÓN DE DATOS EN EXCEL ............................................... 50 3.7.1 Tabla y gráfico de distribución de frecuencias no agrupadas ...................................................... 50 3.7.2 Tabla de distribución de frecuencias agrupadas e histogramas en Excel .................................... 50
PROBLEMAS PROPUESTOS. ................................................................................................................................ 54

ii Índice
CAPÍTULO 4. FUNCIÓN DE PROBABILIDAD........................................................................................... 58 4.1 DEFINICIÓN DE FUNCIÓN DE PROBABILIDAD. ...................................................................................... 58 4.2 LA FUNCIÓN DE DISTRIBUCIÓN (ACUMULATIVA). ............................................................................... 59 4.3 EL VALOR ESPERADO DE UNA VARIABLE ALEATORIA DISCRETA. ........................................................ 59 4.4 VARIANZA Y DESVIACIÓN ESTÁNDAR DE UNA VARIABLE ALEATORIA DISCRETA ................................ 60 4.5 TEOREMAS SOBRE EL VALOR ESPERADO Y LA VARIANZA.................................................................... 61 4.6 LA DESIGUALDAD DE TCHEBYCHEFF. ................................................................................................. 62 4.7 LA FUNCIÓN BIVARIANTE DE PROBABILIDAD. ..................................................................................... 63
4.7.1 Definición de función bivariante de probabilidad. ....................................................................... 63 4.7.2 El valor esperado de funciones de dos variables. ......................................................................... 64 4.7.3 Varianza y covarianza de dos variables aleatorias....................................................................... 64
4.8 DISTRIBUCIONES DE PROBABILIDAD EN EXCEL................................................................................... 65 PROBLEMAS PROPUESTOS. ................................................................................................................................ 68
CAPÍTULO 5. DISTRIBUCIONES DISCRETAS DE PROBABILIDAD.................................................... 71 5.1 LA DISTRIBUCIÓN UNIFORME DISCRETA.............................................................................................. 71 5.2 LA DISTRIBUCIÓN BINOMIAL............................................................................................................... 71
5.2.1 Probabilidad binomial .................................................................................................................. 71 5.2.2 La función binomial de probabilidad. ........................................................................................... 72 5.2.3 El valor esperado y la varianza .................................................................................................... 73 5.2.4 Cálculo de probabilidades binomiales acumulativas.................................................................... 74 5.2.5 La proporción muestral como estimación de la proporción poblacional. .................................... 76 5.2.6 La distribución binomial en Excel................................................................................................. 76
5.3 LA DISTRIBUCIÓN BINOMIAL NEGATIVA.............................................................................................. 76 5.4 LA DISTRIBUCIÓN DE POISSON. ........................................................................................................... 77
5.4.1 La función de probabilidad de Poisson......................................................................................... 77 5.4.2 El valor esperado y la varianza. ................................................................................................... 78 5.4.3 Cálculo de probabilidades acumulativas de Poisson.................................................................... 79 5.4.4 Aproximación de la distribución binomial a la distribución de Poisson. ..................................... 80 5.4.5 La distribución de Poisson en Excel ............................................................................................. 80
5.5 LA DISTRIBUCIÓN HIPERGEOMÉTRICA................................................................................................. 81 5.5.1 La probabilidad hipergeométrica ................................................................................................. 81 5.5.2 La distribución hipergeométrica ................................................................................................... 82 5.5.2 La media y la varianza .................................................................................................................. 82
PROBLEMAS PROPUESTOS. ................................................................................................................................ 83 CAPÍTULO 6. DISTRIBUCIONES CONTINUAS DE PROBABILIDAD................................................... 86
6.1 LA FUNCIÓN DENSIDAD DE PROBABILIDAD. ........................................................................................ 86 6.1.1 Introducción .................................................................................................................................. 86 6.1.2 La función densidad de probabilidad............................................................................................ 86 6.1.3 La media y la varianza. ................................................................................................................. 87
6.2 LA DISTRIBUCIÓN NORMAL................................................................................................................. 87 6.2.1 La función densidad normal de probabilidad ............................................................................... 87 6.2.2 La forma estandarizada. ............................................................................................................... 89 6.2.3 Áreas bajo la curva normal........................................................................................................... 90 6.2.4 Ordenadas de la curva normal...................................................................................................... 90 6.2.5 Propiedades de la curva normal. .................................................................................................. 91 6.2.6 Aproximación a la distribución binomial...................................................................................... 92 6.2.7 Ajuste de la curva normal. ............................................................................................................ 94
6.3 LA DISTRIBUCIÓN UNIFORME CONTINUA............................................................................................. 96 PROBLEMAS PROPUESTOS. ................................................................................................................................ 98
CAPÍTULO 7. DISTRIBUCIONES DE PROPORCIONES......................................................................... 101 7.1 LA DISTRIBUCIÓN MULTINOMIAL...................................................................................................... 101 7.2 LA DISTRIBUCIÓN DE UNA PROPORCIÓN............................................................................................ 101 7.3 DETERMINACIÓN DEL TAMAÑO DE UNA MUESTRA EN POBLACIONES INFINITAS ................................ 103
7.3.1 Determinación del tamaño de una muestra para estimar una proporción de una población infinita 103 7.3.2 Determinación del tamaño de una muestra estratificada para estimar proporciones de los estratos de una población infinita................................................................................................................................ 106

Índice iii
7.4 DETERMINACIÓN DEL TAMAÑO DE UNA MUESTRA EN POBLACIONES FINITAS ................................... 109 7.5 LA DISTRIBUCIÓN DE LA DIFERENCIA DE DOS PROPORCIONES. .......................................................... 109 PROBLEMAS PROPUESTOS. .............................................................................................................................. 111
CAPÍTULO 8: DISTRIBUCIÓN DE LAS MEDIAS MUESTRALES ........................................................ 113 8.1 INTRODUCCIÓN................................................................................................................................. 113 8.2 DISTRIBUCIÓN DE LA MEDIA MUESTRAL ........................................................................................... 113 8.3. DISTRIBUCIÓN DE LA DIFERENCIA DE LAS MEDIAS MUESTRALES ...................................................... 114 8.4. LA DISTRIBUCIÓN T DE STUDENT: APLICACIONES A LAS MEDIAS POBLACIONALES ........................... 115
8.4.1 La distribución t de Student ........................................................................................................ 115 8.4.2 Distribución t de la media muestral ............................................................................................ 115 8.4.3 Distribución t de la diferencia de las medias muestrales............................................................ 116
PROBLEMAS PROPUESTOS ............................................................................................................................... 117 CAPÍTULO 9: CONTRASTES DE HIPÓTESIS .......................................................................................... 118
9.1. INTRODUCCIÓN................................................................................................................................. 118 9.2. HIPÓTESIS NULA E HIPÓTESIS ALTERNATIVA..................................................................................... 118 9.3. REGIONES DE ACEPTACIÓN Y DE RECHAZO ....................................................................................... 118 9.4. ERROR TIPO I Y ERROR TIPO II........................................................................................................... 119 9.5. CONTRASTES DE HIPÓTESIS SOBRE PROPORCIONES ........................................................................... 120 9.6. CONTRASTES DE HIPÓTESIS SOBRE MEDIAS MUESTRALES ................................................................. 124 9.7 LA DISTRIBUCIÓN F: COMPARACIÓN DE VARIANZAS. ........................................................................ 127 9.8 CONTRASTES DE HIPÓTESIS EN EXCEL ............................................................................................. 128
9.8.1 Prueba t para medias de dos muestras suponiendo varianzas iguales. ...................................... 128 9.8.2 Prueba t para medias de dos muestras suponiendo varianzas desiguales. ................................. 129 9.8.3 Prueba z para medias de dos muestras cuando se conocen la varianzas de las poblaciones..... 130 9.8.4 Prueba de una media cuando se conoce o no la varianza de la población................................. 131 9.8.5 Comparación de varianzas.......................................................................................................... 132
PROBLEMAS PROPUESTOS ............................................................................................................................... 134
CAPÍTULO 10. LA DISTRIBUCIÓN JI-CUADRADA (χ2)........................................................................ 139 10.1 INTRODUCCIÓN. ................................................................................................................................ 139 10.2 LA FUNCIÓN DENSIDAD DE PROBABILIDAD JI-CUADRADA................................................................. 139 10.3 PRUEBAS DE BONDAD DE AJUSTE. ..................................................................................................... 140
10.3.1 Distribución multinomial................................................................................................................ 141 10.3.2 Distribución de Poisson.................................................................................................................. 142 10.3.3 Distribución normal. ...................................................................................................................... 143
10.4 PRUEBAS DE INDEPENDENCIA: TABLAS DE CONTINGENCIA. .............................................................. 144 10.5 PRUEBAS DE HIPÓTESIS RESPECTO A LA VARIANZA........................................................................... 146 10.6 LA DISTRIBUCIÓN JI-CUADRADA EN EXCEL ...................................................................................... 147 PROBLEMAS PROPUESTOS. .............................................................................................................................. 148
CAPÍTULO 11. ESTIMACIÓN PUNTUAL Y DE INTERVALO............................................................... 150 11.1 INTRODUCCIÓN................................................................................................................................. 150 11.2 ESTIMACIÓN PUNTUAL...................................................................................................................... 150 11.3 ESTIMACIÓN POR INTERVALOS.......................................................................................................... 151
11.3.1 Intervalo de confianza para la media poblacional. ........................................................................ 151 11.3.2 Intervalo de confianza para la diferencia de medias...................................................................... 152 11.3.3 Intervalo de confianza para la proporción p.................................................................................. 152 11.3.4 Intervalo de confianza para la diferencia de proporciones............................................................ 154 11.3.5 Intervalo de confianza para la varianza......................................................................................... 154
11.4 INTERVALO DE CONFIANZA PARA LA MEDIA EN EXCEL..................................................................... 155 PROBLEMAS PROPUESTOS. .............................................................................................................................. 157
CAPÍTULO 12. DISEÑO DE EXPERIMENTOS Y ANÁLISIS DE VARIANZA ..................................... 158 12.1 INTRODUCCIÓN. ................................................................................................................................ 158 12.2 DISEÑO DE EXPERIMENTOS. .............................................................................................................. 158
12.2.1 Definiciones.................................................................................................................................... 158 12.2.2 Diseño completamente aleatorizado............................................................................................... 159 12.2.3 Diseño aleatorizado por bloques.................................................................................................... 159

iv Índice
12.2.4 Errores en los datos de los experimentos ....................................................................................... 159 12.3 ANÁLISIS DE VARIANZA: ANOVA.................................................................................................... 159
12.3.1 Análisis de varianza de un factor ................................................................................................... 161 12.3.2 Análisis de varianza de dos factores, sin interacción entre los factores. ....................................... 163 12.3.3 Análisis de varianza de dos factores, con interacción entre los factores. ...................................... 166
12.4 ANÁLISIS DE VARIANZA EN EXCEL ................................................................................................... 170 12.4.1 Análisis de varianza de un factor ................................................................................................... 170 12.4.2 Análisis de varianza de dos factores, sin interacción..................................................................... 171 12.4.3 Análisis de varianza de dos factores, con interacción.................................................................... 173
PROBLEMAS PROPUESTOS. .............................................................................................................................. 177 CAPÍTULO 13. REGRESIÓN LINEAL SIMPLE Y CORRELACIÓN. .................................................... 179
13.1 INTRODUCCIÓN. ................................................................................................................................ 179 13.2 REGRESIÓN. ...................................................................................................................................... 179 13.3 LA RECTA DE REGRESIÓN DE LA POBLACIÓN..................................................................................... 180 13.4 MÉTODO DE LOS MÍNIMOS CUADRADOS............................................................................................ 181 13.5 PROPIEDADES DE LA RECTA DE MÍNIMOS CUADRADOS...................................................................... 182 13.6 MEDIDAS DE VARIABILIDAD ............................................................................................................. 183 13.7 ESTIMACIONES DE INTERVALO PARA LA REGRESIÓN......................................................................... 185 13.8 CORRELACIÓN LINEAL. ..................................................................................................................... 185 13.9 REGRESIÓN SIMPLE NO LINEAL ......................................................................................................... 187 13.10 REGRESIÓN LINEAL, NO LINEAL Y CORRELACIÓN EN EXCEL ............................................................. 188
13.10.1 Diagrama de dispersión y tendencia lineal. ................................................................................. 188 13.10.2 Tendencia no lineal. ..................................................................................................................... 190 13.10.3 Regresión lineal con funciones de Excel ...................................................................................... 190
PROBLEMAS PROPUESTOS ............................................................................................................................... 192 CAPÍTULO 14. ANÁLISIS DE SERIES DE TIEMPO................................................................................. 195
14.1 INTRODUCCIÓN................................................................................................................................. 195 14.2 COMPONENTES DE UNA SERIE DE TIEMPO ......................................................................................... 195
14.2.1 Componente tendencial (T)............................................................................................................. 196 14.2.2 Componente cíclica (C) .................................................................................................................. 196 14.2.3 Componente estacional (S) ............................................................................................................. 197 14.2.4 Componente irregular o aleatoria (I)............................................................................................. 199
14.3 DESCOMPOSICIÓN DE SERIES DE TIEMPO........................................................................................... 200 14.3.1 Suavización de la serie de tiempo................................................................................................... 200 14.3.2 Aislamiento de las componentes de la serie de tiempo................................................................... 201
14.4 PRONÓSTICO ..................................................................................................................................... 202 14.5 ANÁLISIS DEL COMPORTAMIENTO DE UNA SERIE DE TIEMPO............................................................. 202 14.6 ANÁLISIS DE SERIES DE TIEMPO EN EXCEL........................................................................................ 202
14.6.1 Análisis de series de tiempo con medias móviles............................................................................ 202 14.6.2 Suavización exponencial................................................................................................................. 206
PROBLEMAS PROPUESTOS ............................................................................................................................... 208 CAPÍTULO 15. HERRAMIENTAS ESTADÍSTICAS PARA MEJORAR LA CALIDAD DE LOS PROCESOS....................................................................................................................................................... 211
15.1 MEJORA DE LA CALIDAD................................................................................................................... 211 15.1.1 Definiciones.................................................................................................................................... 211 15.1.2 Breve historia de la calidad............................................................................................................ 211
15.2 INTERPRETACIÓN DE HISTOGRAMAS Y MEDICIÓN DE LA CAPACIDAD DE UN PROCESO....................... 212 15.2.1 Interpretación de histogramas........................................................................................................ 212 15.2.2 Capacidad de un proceso ............................................................................................................... 213
15.3 GRÁFICOS DE CONTROL .................................................................................................................... 218 15.3.1 Definiciones.................................................................................................................................... 218 15.3.2 Tipos de gráficos de control ........................................................................................................... 219 15.3.3 Interpretación de los gráficos de control. ...................................................................................... 219 15.3.4 Elaboración de los gráficos de control........................................................................................... 220
15.4 MUESTREO DE ACEPTACIÓN.............................................................................................................. 232 15.4.1 Análisis económico de la inspección. ............................................................................................. 233 15.4.2 Riesgos del muestreo. ..................................................................................................................... 234

Índice v
15.4.3 Plan de muestreo ............................................................................................................................ 235 15.4.4 Curva característica de operación (Curva CO) ............................................................................. 235
PROBLEMAS PROPUESTOS. .............................................................................................................................. 238 CAPÍTULO 16. TEORÍA DE DECISIONES................................................................................................. 243
16.1 INTRODUCCIÓN. ................................................................................................................................ 243 16.2 DEFINICIONES................................................................................................................................... 243
16.2.1 Decisor ........................................................................................................................................... 243 16.2.2 Alternativas de decisión.................................................................................................................. 243
16.3 ESTADOS DE LA NATURALEZA .......................................................................................................... 243 16.3.1 Ambiente de certeza........................................................................................................................ 243 16.3.2 Ambiente de riesgo ......................................................................................................................... 243 16.3.3 Ambiente de incertidumbre............................................................................................................. 243 16.3.4 Ambiente de competencia ............................................................................................................... 244
16.4 CONSECUENCIAS............................................................................................................................... 244 16.5 CRITERIOS DE DECISIÓN ................................................................................................................... 244
16.5.1 Criterio Maximin ............................................................................................................................ 244 16.5.2 Criterio Maximax ........................................................................................................................... 245 16.5.3 Criterio realista .............................................................................................................................. 245 16.5.4 Criterio minimax del costo de oportunidad.................................................................................... 245 16.5.5 Criterio del valor esperado (Bayes) ............................................................................................... 245 16.5.6 Criterio del costo de oportunidad esperado ................................................................................... 246 16.5.7 Criterio de máxima verosimilitud................................................................................................... 246
16.6 ÁRBOLES DE DECISIÓN...................................................................................................................... 246 PROBLEMAS PROPUESTOS ............................................................................................................................... 249
APÉNDICE........................................................................................................................................................ 252 TABLA DE PROBABILIDADES BINOMIALES ACUMULATIVAS............................................................................. 253 TABLA DE PROBABILIDADES ACUMULATIVAS DE POISSON.............................................................................. 258 TABLA DE ÁREAS BAJO LA CURVA NORMAL ESTANDARIZADA......................................................................... 264 TABLA DE ORDENADAS DE LA CURVA NORMAL ESTANDARIZADA ................................................................... 265 TABLA DE VALORES DE T DE STUDENT............................................................................................................ 266 TABLA DE VALORES DE JI-CUADRADO............................................................................................................. 267 TABLA DE VALORES DE F (P = 0,05)................................................................................................................ 268 TABLA DE VALORES DE F (P = 0,01)................................................................................................................ 269 TABLA DE FACTORES PARA EL CÁLCULO DE LÍMITES DE CONTROL.................................................................. 270 TABLA DE PROBABILIDADES DE ACEPTACIÓN (PA).......................................................................................... 271


Prólogo En las últimas décadas ha cobrado especial importancia el análisis estadístico de datos para mejorar la calidad de todo tipo de procesos, y para mejorar finalmente el nivel de satisfacción de los clientes, ya sea que éstos adquieran un determinado producto o reciban un servicio. Grandes empresas transnacio-nales están implementando sistemas de gestión de la calidad, que presentan como principales argu-mentos las herramientas estadísticas. Quienes necesiten hacer análisis de datos deben conocer un mínimo de herramientas estadísticas bási-cas para abordar con éxito un problema real. Más importante que saber usar dichas herramientas, es saber cuáles son las apropiadas para cada situación. En este libro se pone especial énfasis en los con-ceptos, con el propósito de capacitar al lector para que sepa elegir con criterio las herramientas estadís-ticas que le resuelvan los problemas que aborde en su vida profesional. El rápido desarrollo que están alcanzando las computadoras personales ha ocasionado que en las últi-mas décadas hayan aparecido en el mercado mundial una gran cantidad de softwares estadísticos. Sin embargo, éstos no serán nada útiles si los usuarios no tienen los conocimientos mínimos de Estadísti-ca. En casi todos los capítulos de este libro se explica, con ejemplos, el uso de las herramientas estadísti-cas de Microsoft Excel para análisis de datos, casi desconocidas por la gran mayoría de usuarios de Excel. Se explica además cómo emplear las principales funciones estadísticas de este software. La gran ventaja de Excel sobre los softwares de Estadística como Statgraphics, Statistics, Minitab, SPSS, etc, es evidente: Excel está prácticamente al alcance de todos y requiere muy poca capacitación para su empleo. A esto se suma la gran versatilidad que se puede lograr siendo un buen usuario de Excel. Aunque éste es un libro de Estadística básica, que puede ser tomado como texto para carreras profe-sionales de Ingeniería, Administración de Empresas y Economía, incluye al final algunos capítulos de Estadística Aplicada, con algunas herramientas básicas para el mejoramiento de la calidad en procesos de diversa índole. Quiero agradecer a Susana Vegas y a Eduardo Sánchez, por sus comentarios constructivos durante el desarrollo de este libro, y a Don Rafael Estartús, por revisarlo tan cuidadosamente. El buen ambiente de trabajo que comparto con mis amigos del Área de Ingeniería Industrial y el Área de Sistemas, ha contribuido a que haya podido escribir este libro. Éstos últimos han conseguido que sea un buen usua-rio de las computadoras personales y especialmente de Excel, tan importantes en el análisis estadístico. Finalmente agradezco a mis padres, Zoila y Augusto, a mi esposa, Careen, y a mi hijo, César, por su constante apoyo y por el tiempo que me cedieron para que pudiera escribir este libro. Se lo dedico a ellos.
César Angulo Bustíos. Agosto de 2005.