d2.4.1 rapp image processing module · format. a software platform to deliver smart, user...
TRANSCRIPT

Funded by the 7th
Framework Programme
of the European Union
Project Acronym: RAPP
Project Full Title: Robotic Applications for Delivering Smart User Empowering Applications
Call Identifier: FP7-ICT-2013-10
Grant Agreement: 610947
Funding Scheme: Collaborative Project
Project Duration: 36 months
Starting Date: 01/12/2013
D2.4.1 RAPP Image Processing Module
Deliverable status: Final
File Name: RAPP_D2.4.1_V1.0_13032015.pdf
Due Date: February 28, 2015
Submission Date: March 13, 2015
Dissemination Level: Public
Task Leader: 3 - WUT
Author: Włodzimierz Kasprzak, Maciej Stefańczyk, Jan Figat
© Copyright 2013-2016 The RAPP FP7 consortium The RAPP project consortium is composed of:
CERTH Centre for Research and Technology Hellas Greece
INRIA Institut National de Recherche en Informatique et en Automatique France
WUT Politechnika Warszawska Poland
SO Sigma Orionis SA France
Ortelio Ortelio LTD United Kingdom
ORMYLIA Idryma Ormylia Greece
MATIA Fundacion Instituto Gerontologico Matia - Ingema Spain
AUTH Aristotle University of Thessaloniki Greece

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 2 of 32
Disclaimer
All intellectual property rights are owned by the RAPP consortium members and are protected by the applicable laws. Except where
otherwise specified, all document contents are: “© RAPP Project - All rights reserved”. Reproduction is not authorised without prior
written agreement.
All RAPP consortium members have agreed to full publication of this document. The commercial use of any information contained in this
document may require a license from the owner of that information.
All RAPP consortium members are also committed to publish accurate and up to date information and take the greatest care to do so.
However, the RAPP consortium members cannot accept liability for any inaccuracies or omissions nor do they accept liability for any
direct, indirect, special, consequential or other losses or damages of any kind arising out of the use of this information.
Revision Control
VERSION AUTHOR DATE STATUS
0.1 Włodzimierz Kasprzak (WUT) November 25, 2014 Table of Contents, Initial Draft 0.2 Włodzimierz Kasprzak (WUT) JANUARY 20, 2015 Roles. Levels. Function spec.
0.3 Jan Figat (WUT) February 07, 2015 Function descriptions
0.4 Włodzimierz Kasprzak (WUT) February 09, 2015 Function descriptions
0.5 Maciej Stefańczyk (WUT) February 09, 2015 Function descriptions
0.8 Włodzimierz Kasprzak (WUT) February 16, 2015 Extensions and final edition
0.9 Emmanouil Tsardoulias (CERTH/ITI) February 20, 2015 Review
1.0 Włodzimierz Kasprzak (WUT) February 28, 2015 Updated, including review comments
Project Abstract
The RAPP project will provide an open-source software platform to support the creation and delivery of Robotic
Applications (RApps), which, in turn, are expected to increase the versatility and utility of robots. These applications will
enable robots to provide physical assistance to people at risk of exclusion, especially the elderly, to function as a
companion or to adopt the role of a friendly tutor for people who want to partake in the electronic feast but don’t know
where to start.
The RAPP partnership counts on seven partners in five European countries (Greece, France, United Kingdom, Spain
and Poland), including research institutes, universities, industries and SMEs, all pioneers in the fields of Assistive
Robotics, Machine Learning and Data Analysis, Motion Planning and Image Recognition, Software Development and
Integration, and Excluded People. RAPP partners are committed to identify the best ways to train and adapt robots to
serve and assist people with special needs.
To achieve these goals, over three years, the RAPP project will implement the following actions:
Provide an infrastructure for developers of robotic applications, so they can easily build and include machine
learning and personalization techniques to their applications.
Create a repository, from which robots can download Robotic Applications (RApps) and upload useful
monitoring information.
Develop a methodology for knowledge representation and reasoning in robotics and automation, which will
allow unambiguous knowledge transfer and reuse among groups of humans, robots, and other artificial
systems.
Create RApps based on adaptation to individuals and taking into account the special needs of elderly people,
while respecting their autonomy and privacy.
Validate this approach by deploying appropriate pilot cases to demonstrate the use of robots for health and
motion monitoring, and for assisting technologically illiterate people or people with mild memory loss.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 3 of 32
The RAPP project will help to enable and promote the adoption of small home robots and service robots as companions
to our lives. RAPP partners are committed to identify the best ways to train and adapt robots to serve and assist people
with special needs. Eventually, our aspired success will be to open and widen a new ‘inclusion market’ segment in
Europe.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 4 of 32
Table of Contents
Revision Control .......................................................................................................................................... 2
Project Abstract ........................................................................................................................................... 2
Table of Contents ........................................................................................................................................ 4
List of Abbreviations.................................................................................................................................. 6
Executive summary .................................................................................................................................... 7
1. Introduction ............................................................................................................................................. 8
2. Basic libraries needed for RAPP functions ................................................................................... 8 2.1 QR code recognition package.................................................................................................................................................................. 8 2.2 The OpenCV image processing library ................................................................................................................................................ 9 2.3 Robot’s own library .................................................................................................................................................................................... 9
3. Signal acquisition and low-level processing (level 1, core agent) ..................................... 10 3.1 Image capture ............................................................................................................................................................................................ 10 3.2 Set camera parameters .......................................................................................................................................................................... 11 3.3 Speech capture .......................................................................................................................................................................................... 11 3.4 Convert text to speech ............................................................................................................................................................................ 11 3.5 Play audio file ............................................................................................................................................................................................ 11 3.6 Acquire depth image ............................................................................................................................................................................... 12
4. Image segmentation and basic concept recognition .............................................................. 12 4.1 Detection and recognition of QR codes in an image .................................................................................................................... 12 4.2 RGB image segmentation (point, edge, texture features) ......................................................................................................... 14 4.3 Human detection in RGB images ........................................................................................................................................................ 18
HOG detector ............................................................................................................................................................................................................................ 20 Daimler ........................................................................................................................................................................................................................................ 20 Latent SVM ................................................................................................................................................................................................................................ 21
4.4 Face detection in RGB images (RAPP platform) ........................................................................................................................... 21 4.5 Detect hazard – lights left switched on ............................................................................................................................................ 22 4.6 Detect hazard – open door left – qr code based version ............................................................................................................ 23 4.7 Key word spotting in speech signal ................................................................................................................................................... 24 4.8 The update of a 3D environment map ............................................................................................................................................. 25
5. Selected object recognition (level 3, Rapp platform) ............................................................. 27 5.1 3D human pose detection/localization ............................................................................................................................................ 27 5.2 Face modelling and identification in an RGB image ................................................................................................................... 28 5.3 Detect Hazard – open door left – object model based version ............................................................................................... 29
6. General object modelling and recognition (level 4, external services) ........................... 30 6.1 Object modelling and model-based object recognition ............................................................................................................. 30 6.2 Speech recognition .................................................................................................................................................................................. 30
7. Conclusions ........................................................................................................................................... 31
References .................................................................................................................................................. 31

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 5 of 32
Annex ........................................................................................................................................................... 32 Camera parameters ........................................................................................................................................................................................ 32

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 6 of 32
List of Abbreviations
ABBREVIATION DEFINITION
RAPP RAPP APPLICATION
RAPP RAPP PLATFORM
RAPP::API RAPP API
RAPP-FSM RAPP CORE AGENT
NAOQI NAOQI LIBRARY
OPENCV OPENCV IMAGE PROCESSING LIBRARY

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 7 of 32
Executive summary
The present document is a deliverable of the RAPP project, funded by the European Commission’s Directorate-General
for Communications Networks, Content & Technology (DG CONNECT), under its 7th EU Framework Programme for
Research and Technological Development (FP7).
This deliverable is directly related to the work of Task 2.4; to allow robots to perceive the indoor environment with an on-
board RGB camera and with support of a stationary depth-map scanner (e.g. like the MS-Kinect device). The goal is to
design efficient and reliable image pre-processing and segmentation, symbolic concept detection and model-based
object recognition algorithms that can be used in real-world scenarios, preferably designed for the NAO robot. The image
processing module is structured into three layers, dealing with image segmentation functions and object recognition
functions. Additionally, speech capture and speech synthesis functions, necessary for human-robot interface, are listed
here.
.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 8 of 32
1. Introduction
The aim of the second RAPP work package is to provide the basic infrastructure both for the execution of skills
downloaded to the robot from the global repository located in the cloud and to provide this repository with the information
about the environment acquired by the robot while executing its tasks.
This deliverable is directly related to the work of Task 2.4 and describes design and implementation of image processing
algorithms based on a color camera and (optionally) a depth-map scanner. Additionally, some basic functions for speech
acquisition and synthesis are defined.
The RAPP functions are structured into the following levels:
1. RAPP functions stored and executed on the robot platform – the “Core Agent” functions (in particular,
implemented for the robot NAO applied by WUT);
2. RAPP functions available (stored) at the RAPP platform - being downloaded and executed on the robot – as a
temporary “Dynamic Agent”;
3. RAPP functions available (stored) at the RAPP platform and executed on the RAPP platform
4. Wrapper functions for external services (executed in the cloud).
Appropriately to the function levels, the current document is structured as follows:
Section 2: Basic libraries. This section provides the review of the image processing algorithm and libraries –
the dependencies in our implementation of RAPP functions.
Section 3: Signal acquisition and low-level processing. This section provides a detailed description of low-
level RAPP functions for image and speech acquisition and signal processing. These functions are assumed to
be available at the robot platform (i.e. a part of the core agent).
Section 4: Image segmentation and basic concept recognition. This section provides RAPP functions for
the detection of intermediate-level concepts, like edge loops, textures and surface patches. These functions are
stored at the RAPP platform and can be downloaded for execution on the robot (i.e. as the temporary dynamic
agent).
Section 5: Selected object recognition. This section provides functions for selected object recognition
(implemented as RAPP platform services). Example models are created for typical in-room objects, like chairs,
desks, doors; and for human postures and faces.
Section 6: General object modelling and recognition. This section provides wrapper functions for general-
purpose object modelling and recognition (implemented as external services, that are running in the cloud).
2. Basic libraries needed for RAPP functions
2.1 QR code recognition package
In our implementation, the ZBar library [3] is used for the QR-code localization and for the QR-code decoding
procedures.
A QR code stands for the well-known Quick Response code which is like a bar code in matrix form. The orientation
estimation of this type of codes is based on markers, finder patterns, of three main corners detection. This type of codes
is readable from any direction by searching for unique ratio on the finder pattern - the ratio of black and white bars on
printed matter is equal to 1:1:3:1:1. A QR-code can contain a lot of useful information, usually contained in a string (text)
format.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 9 of 32
The detection of QR-codes is a relatively simple process. Firstly, the binarization of an image is performed. Next, the
finder patterns must be found – this step is implemented in the ZBar library - and the information stored in the QR code is
decoded. In order to obtain a transformation matrix from the image- to the camera coordinate system, the solvePnP
method is used.
The detection rate depends on the image resolution, printed code quality and size. Since a QR-code is a barcode and it
consists of small elements such as bars and squares, the image resolution must be chosen in accordance with the
distance between the camera and the QR-code itself.
2.2 The OpenCV image processing library
OpenCV (Open Source Computer Vision) [1] is a library of programming functions mainly aimed at real-time computer
vision. It consists of multiple modules, designed for specific vision tasks. Modules that will be useful in the project are:
- core - a compact module defining basic data structures, including the dense multi-dimensional array Mat and
basic functions used by all other modules,
- imgproc - an image processing module that includes linear and non-linear image filtering, geometrical image
transformations (resize, affine and perspective warping, generic table-based remapping), color space
conversion, histograms, and so on,
- features2d - salient feature detectors, descriptors, and descriptor matchers,
- ml – machine learning module, a set of classes and functions for statistical classification, regression, and
clustering of data,
- objdetect - detection of objects and instances of the predefined classes (for example, faces, eyes, mugs,
people, cars, and so on).
The OpenCV library is used on all image processing and object recognition levels – from image pre-processing, through
image segmentation, to object modelling, recognition and localization.
2.3 Robot’s own library
The implementation of low-level image and sound processing functions in RAPP is supported by the NAOqi library [6].
Image processing modules and dependencies in NAOqi:
ALMotion module provides methods which facilitate making the robot move. It is used for getting current
camera position in NAO space and for computing transform matrices while using NAOqi functions.
ALVideoDevice module is in charge of providing, in an efficient way, images from the video source (e.g. robot’s
cameras) to all modules processing them, such as ALFaceDetection or ALVisionRecognition.
Sound processing modules in NAOqi:
ALTextToSpeech is used for converting text to speech, i.e. provided a text, NAO can read the message.
ALMemory is a centralized memory module used to store all key information related to the hardware
configuration of the NAO robot. It provides event handling and is used for acquiring data, such as the robot’s
configuration parameters.
ALModule is used as a base class for user modules to help towards serving and advertising their methods.
Each module advertises the methods it wishes to make available to clients participating in the network to a
broker within the same process. It is used for direct method calls, which are used to provide optimal speed
without having to change the method signatures.
ALAudioRecorder is used for sound recording while using NAO microphones,
ALSoundDetection is used for sound detection by the NAO microphones,

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 10 of 32
ALSpeechRecognition is used for specified words recognition while using the NAO microphones.
3. Signal acquisition and low-level processing (level 1, core agent)
The functions, given in this section, are implemented as part of the Core agent and they reside on the robot (namespace
robot).
3.1 Image capture
Image robot::captureImage (Camera id)
Input:
o Id: camera identifier.
Output: image (e.g. stored RGB image)
Description: This function captures the frame from the robot’s camera. The resolution of the captured image is
set to k4VGA. The color space is set to kBGRColorSpace. The frame rate of the camera is set to 15 fps.
Note: Required by other functions that uses image from NAO camera.
Dependencies (for NAO): ALVideoDevice
Example of function implementation:
#define Camera std::string
sensor_msgs::Image rapp::nao::captureImage(Camera cameraId)
{
rapp_core_agent::GetImage srv; // ROS service for the captureImage – Core Agent service
srv.request.request=cameraId; // setting up the request for the ROS service
sensor_msgs::Image img;
if (capture_image_.call(srv))
{
img = srv.response.frame;
std::cout << "[Rapp Capture Image client] - Image captured\n";
}
else
{
//Failed to call service rapp_capture_image
std::cout<<"[ Rapp Capture Image client] - Error calling service rapp_capture_image\n";
}
return img;
}

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 11 of 32
3.2 Set camera parameters
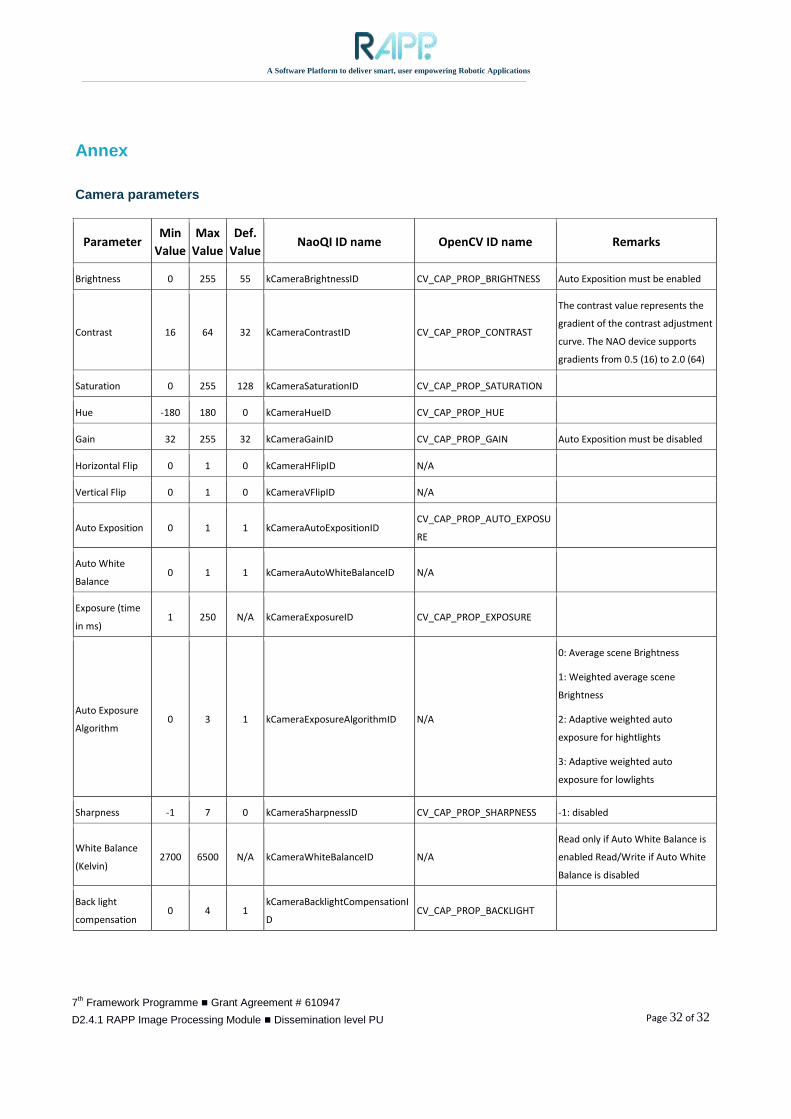
bool robot::setCameraParams (vector<Parameter>)
Input: a list of parameter-value pairs (e.g. pair<string, float>), possibly more options for other parameters (in
general: of type Parameter).
Output: result of operation – “failed/succeeded” (of type Boolean).
Description. It sets acquisition parameters of camera device (exposure time, gain, color space etc.) Required
by light checking behaviour. The most important parameters (available for cameras mounted on Nao robot) are
presented the Annex (adapted from Aldebaran documentation for software version 2.1).
Dependencies: ALVideoDevice (for Naoqi library), VideoCapture form highgui module (for OpenCV library)
3.3 Speech capture
audioFileInfo robot::captureAudio(int duration, string audioUrl)
Input: int:time duration, audioUrl: file path destination
Output: A description with fields, like bool (audio recorded), audioUrl (audio file path and name).
Description. Given time duration of the recording and the destination file path, it records the sound from the
NAO microphones by the desired time, and saves the file in the ogg extension.
Example of the audio file path: "/home/nao/recordings/microphones/rapp_email.ogg"
Note: Required by the ”email sending” behavior.
Dependencies (in Naoqi): ALAudioRecorder, ALMemory, ALModule
3.4 Convert text to speech
int robot::speak (vector<string> text)
Input: vector<string>: text
Output: success index on speak request
Description. Given a text message, the robot says the specified string of characters while using speakers.
Uses the default language.
Dependencies (in Naoqi): ALTextToSpeech, ALMemory, ALModule
3.5 Play audio file
int robot::playAudio (AudioFileInfo)
Input: audio file Info, e.g. contains audioUrl - file path destination

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 12 of 32
Output: success index on playAudio request.
Description. Given a path to the existing audio file, preferable in the ogg file extension, NAO plays back the
audio file while using robot speakers.
Dependencies (in NAOqi): ALAudioPlayer, ALMemory, ALModule
3.6 RGB-D image capture
[DImage, Image] robot::captureDImage(Camera id)
Input:
o Id: camera identifier.
Output: an RGB-D image
Description: This function captures the RGB-D image from a MS-Kinect like camera. Its use is illustrated in the
Deliverable D2.3.1.
4. Image segmentation and basic concept recognition The functions, given in this section, are invoked by the Core agent and they reside on the Rapp platform (namespace
rappPlatform).
4.1 Detection and recognition of QR codes in an image
vector<QrCodeDesc> rappPlatform::robot::qrCodeDetection(Image, vector<Parameter>,
libraryFun)
Input. Image – the RGB image; vector of parameters, libraryFun() – a pointer to external function (e.g. in the
ZBar library)
Output. A vector of QR-code messages - QR-code messages, vector of coordinates vector<pair<float, float> >,
in camera coordinate system, vector of coordinates (vector<pair<float, float> >) in the robot coordinate system.
Description. Given an RGB image, it detects QR-codes. The results are: the number of detected QR-codes,
messages contained in the QR-codes, localization matrices in the camera coordinate system, localization
matrices in the robot coordinate system.
Note: This function is used for the hazard of open door detection, while using QR-codes.
Note: Zbar library is used for QR-code detection and localization in the image coordinate system.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 13 of 32
Fig. 4.1 Testing the ability of QR-code detection and recognition from different distances and orientations.
Implementation: as a RAPP platform function invoked from a dynamic agent through the API.
Dependencies:
OpenCV: modules /core/core.hpp, /imgproc/imgproc.hpp, /highgui/highgui.hpp, /calib3d/calib3d.hpp;
o functions: CreateImage, ConvertImage, solvePnP, Rodriques
Zbar - functions: set_config, scan
Naoqi library: ALMotion, ALVideoDevice;
Testing [5]
The NAO robot was placed in a predetermined distance from the wall. A five meter measuring tape was used to
determine reference distances (fig. 4.1). The accuracy of the tape was 10 mm. On both feet of the NAO robot there were
intersections marked, equally distant from the beginning of both feet. A plane perpendicular to the ground was passing
through both intersections and the point corresponding to the top camera of NAO. Any change of the position of the
robot's head relative to the feet were corrected by software. On the floor there were areas marked with known distance
from the wall. During the experiment the NAO was placed on selected areas, so that the marked line crosses each of the
marked points on the feet of the robot.
For the measurement of angular errors, a protractor has been used with a diameter of 17 cm. The test code was
attached to a rigid, flat material with perpendicular sides. Depending on the accuracy of the test for the axis of rotation,
the protractor was rigidly mounted to the wall. Then, the surface with the code was rotated every 10 degrees around one
of the selected sides.
Main results
The size of the QR-code was fixed – the best performance was for the size of 0.16 m x 0.16 m, allowing up to 25 bars of
width of the main tag (there are three main tags in the QR-code), while the highest possible camera resolution of the
NAO robot is chosen (1280 x 960 pixels).
Under above conditions, the distance from which the QR-code can be detected is: maximum distance 4.74 m, minimum
distance 0,2 m. The possible orientations are as follows:
- can be freely rotated around the depth axis (perpendicular to the image plane);
- allowed rotation around the vertical axis is about +/- 50 deg;
- allowed rotation around the horizontal axis is about +/- 50 deg.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 14 of 32
Fig. 4.2 Illustration of the localization quality, while using QR-codes
The quality of QR-code based localization is made visible by projecting a cuboidal hypothesis of a box-like object onto
the image plane. The box localization recognition results for different orientations are shown on fig. 4.2. Green lines
correspond to rear wall of the box. However the blue lines correspond to the upper and lower front lines of the box, and
violet lines correspond to the front side lines. Fig. 4.3 shows localization results for an only partially visible box.
Fig. 4.3 Illustration of the localization quality, while detecting a partially visible QR-code
4.2 RGB image segmentation (point, edge, texture features)
vector<RGBFeatures> rappPlatform::robot::detectRGBFeatures(Image,
vector<Parameter>)
Description. Given an RGB image, and the required feature (specified by a Parameter vector) it detects
selected features.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 15 of 32
Note: Some key-point detectors and descriptors are computationally expensive and eventually they should be
computed only on external machine, other (such as binary features) can be calculated on the robot platform.
Implementation: as a RAPP platform function invoked from a dynamic agent through the API.
Dependencies:
o OpenCV modules: core, imgproc, features2d, nonfree.
o OpenCV function: FeatureDetector with possible parameters:
"FAST" – FastFeatureDetector, possible parameters: threshold, nonmaxSuppression,
"STAR" – StarFeatureDetector, possible parameters: maxSize, responseThreshold,
lineThresholdProjected, lineThresholdBinarized
"SIFT" – SIFT (a nonfree module),
"SURF" – SURF (a nonfree module),
"ORB" – ORB,
"BRISK" – BRISK,
"MSER" – MSER,
"GFTT" – a GoodFeaturesToTrackDetector,
"HARRIS" – a GoodFeaturesToTrackDetector with Harris detector enabled,
"Dense" – DenseFeatureDetector,
"SimpleBlob" – SimpleBlobDetector,
o Other useful OpenCV functions: KeyPoint, Canny
Testing
To give the idea how many point features are usually detected by different available point detectors, we present fig. 4.4
with results of key-point detection in the same image by BRISK, FAST, GFTT, HARRIS, MSER, ORB and SIFT.
Fig. 4.5 presents the procedure for performance evaluation of feature detectors and descriptors. For each image of a
given pair (containing basic and distorted images) we first have detected key-points with a given detector and
subsequently extracted the associated descriptors [4]
Next, features from those two sets are compared in order to find the best match. The knowledge of the proper
(homographic) transformation between the two analysed images enables us to transform the positions of features
extracted from the distorted image into the equivalent position in basic image. We treat this as a ground truth and reject
all correspondences with difference in image positions being greater than a given parameter (here the best solution was
to fix it to the distance of 2 pixel units).
(a) From left: BRISK, FAST, GFTT
Fig. 4.4 (to be continued)

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 16 of 32
(b) From left: HARRIS, MSER, ORB
(c) SIFT
Fig. 4.4 Example images with detected features
Fig. 4.5 The quality evaluation procedure for quality evaluation of different point features.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 17 of 32
The first set of tests was performed to evaluate the quality of point descriptors (expressed by the matching success rate).
Fig. 4.6 shows a summary of the results obtained for four different-type image sets. We can observe that the best results
were obtained once again for SIFT, with the ORB detector acting on the second place.
Fig. 4.6 The quality evaluation of selected point features.
During the experiments we have also measured the time of key-point detection and descriptor extraction. In the tests, we
applied the OpenCV library (version 2.4.8) running on a PC with a quadcore Phenom II 965 processor and 4GB RAM,
under control of Ubuntu 12.0.4 OS.
The detection time per detected key-point is presented in the tab. 4.1. The FAST detector is the fastest and SIFT
detector is the slowest one. Please note that ORB detector is almost twice time faster than BRISK but almost 20 times
slower than FAST.
Tab. 4.1 Average key-point detection times (micro-seconds per key-point)
In tab. 4.2, the times of feature description generation (extraction) per detected feature are shown. T extraction time for
the SIFT descriptor was far more time-consuming then for binary descriptors.
Tab. 4.2 Average descriptor generation times (micro-seconds per key-point)
Tab. 4.3 provides complete times of feature detection plus feature description. It can be seen that FREAK with ORB
detector is a little bit slower than BRISK with ORB detector, but more than ten times faster than the SIFT with SIFT
detector.
If we analyse the quality evaluation and time measuring tests together, and observe also other results (not mentioned so
far) of mixing detectors and descriptors, then we can conclude, that with respect to both quality and speed, the best
solution is the combination of the ORB detector with the FREAK descriptor.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 18 of 32
Tab. 4.3 Average total times of key-point detection and description extraction.
4.3 Human detection in RGB images
vector<human2D> rappPlatform::robot::detectHuman2D(RGBImage ,
vector<Parameter>, vector<human2DModel>)
Description. Given an RGB image and built-in 2D models (views) of a human shape, it detects hypotheses of
human shapes in the image. The analysis is controlled by a vector of suitable parameters.
Implementation: as a RAPP platform function invoked from a dynamic agent through the API..
Dependencies in NAOqi
In the NAOqi library : weak support from the ALVisionRecognition package.
Use Choregraphe (NAO): learning an object can be done through the Teaching NAO to recognize objects.
The learned object can be recognized by using the Choregraphe Vision Reco box.
Dependencies in OpenCV: getDefaultPeopleDetector, detect, detectMultiScale
Examples:
vector<float>& detector) gpu::HOGDescriptor::getDefaultPeopleDetector
o // Returns coefficients of the classifier trained for people detection (for default window size).
C++:
o static vector<float> gpu::HOGDescriptor::getDefaultPeopleDetector()
gpu::HOGDescriptor::getPeopleDetector48x96
o // Returns coefficients of the classifier trained for people detection (for 48x96 windows).
C++:
o static vector<float> gpu::HOGDescriptor::getPeopleDetector48x96()
gpu::HOGDescriptor::getPeopleDetector64x128¶
o // Returns coefficients of the classifier trained for people detection (for 64x128 windows).
C++:
o static vector<float> gpu::HOGDescriptor::getPeopleDetector64x128()
gpu::HOGDescriptor::getPeopleDetector64x128()
gpu::HOGDescriptor::detect // Performs object detection without a multi-scale window.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 19 of 32
C++:
o void gpu::HOGDescriptor::detect(const GpuMat& img, vector<Point>& found_locations, double
hit_threshold=0, Size win_stride=Size(), Size padding=Size())
o Parameters:
o img – Source image. CV_8UC1 and CV_8UC4 types are supported for now.
o found_locations – Left-top corner points of detected objects boundaries.
o hit_threshold – Threshold for the distance between features and SVM classifying plane. Usually it
is 0 and should be specified in the detector coefficients (as the last free coefficient). But if the free
coefficient is omitted (which is allowed), you can specify it manually here.
o win_stride – Window stride. It must be a multiple of block stride.
o padding – Mock parameter to keep the CPU interface compatibility. It must be (0,0).
gpu::HOGDescriptor::detectMultiScale // Performs object detection with a multi-scale window.
C++:
o void gpu::HOGDescriptor::detectMultiScale(const GpuMat& img, vector<Rect>& found_locations,
double hit_threshold=0, Size win_stride=Size(), Size padding=Size(), double scale0=1.05,
int group_threshold=2)
o Parameters:
o img – Source image. See gpu::HOGDescriptor::detect() for type limitations.
o found_locations – Detected objects boundaries.
o hit_threshold – Threshold for the distance between features and SVM classifying plane. See
gpu::HOGDescriptor::detect() for details.
o win_stride – Window stride. It must be a multiple of block stride.
o padding – Mock parameter to keep the CPU interface compatibility. It must be (0,0).
o scale0 – Coefficient of the detection window increase.
o group_threshold – Coefficient to regulate the similarity threshold. When detected, some
objects can be covered by many rectangles. 0 means not to perform grouping. See
groupRectangles() .
Testing
So far, we have tested the people detection ability of OpenCV functions. A general approach to face and human
detection in images in the OpenCV library is based on Haar-like image features and cascade classifiers [7]. There are
functions for the training of classifiers and for classification. Even already trained classifiers, ready to use Haar-like
features, are available for the detection of:
face (front-several versions of the profile),
the entire human body,
the upper part of the body,
the lower part of the body.
In testing the human detection ability, this approach has mainly failed. The success rate for the ”entire body” and “lower
body” classifiers has been around 10 % only, while for the NAO images the detection rate is even worse.
The “upper-body” classifier provides better results as it quite reliable detects the contour of the head and shoulders (fig.
4.7). The success rate reached 50 % for our NAO test images, while for a general „outdoor” test set this rate was around
40%. But at the same time, the false positive rate was quite high.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 20 of 32
Fig. 4.7 Example of “upper-body” detection with the cascade classifier.
HOG detector Another solution in OpenCV to “entire-body” human detection is possible with the HOG detector (in the gpu-accelerated
vision module, using the CUDA library) [8]. The class (gpu::HOGDescriptor) implements the description of objects in
terms of a histogram of oriented gradients (of the image function) [9]. An SVM classifier is applied for object detection.
The typical required smallest size of an object is 48 x 96 pixel. In testing, slightly better success rate than for the “upper-
body” classifier, based on Haar-like features, has been observed (around 50% for the NAO indoor images and 50% for
outdoor images) (fig. 4.8). At the same time, the false acceptance rate is decreased.
Fig. 4.8 Example of “entire-body” detection with the HOG detector.
Daimler A second version of this classifier – so called "Daimler" – is provided. It is characterized by a nearly 100% success rate,
but with a significant number of false detections in the image (fig. 4.9). We consider to add a suitable filtering step, to
cancel the false detections, when the “Daimler” detector is a first processing step.
Fig. 4.9 False-positive” detections by the “Daimler” version of the HOG detector.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 21 of 32
Latent SVM Among the tested human detectors in OpenCV, the best one is the “Latent SVM” detector (called as “Discriminatively
Trained Part Based Models for Object Detection”) [10]. In testing, it appeared to be by far the most efficient one (fig.
4.10). It provides good results for virtually any position of a human (there has not been tested the “lying” position), under
different hand positions, even when a large part of the human posture is hidden. Good detection results have been
achieved even with structured background and low image contrast. The only difficulties appear if blurred images are
processed. For the applied test collections, the success rate was 100% (for NAO indoor images) and nearly 90% for the
outdoor test set, with very few false detections.
Fig. 4.11 “Entire-body” detections by the “Latent SVM” detector.
4.4 Face detection in RGB images (RAPP platform)
vector<Faces> rappPlatform::robot::detectFaces(Image,
vector<Parameter>, vector<FaceModel>)
o Description. Given an RGB image and possible 2D models (image descriptors, texture classes, discrete
segment groups) of a human face, it detects hypotheses of human faces in the image. The analysis is controlled
by a vector of suitable parameters. Provides a detection of all visible faces.
o Implementation: as a RAPP platform function invoked from a dynamic agent through the API.
o Dependencies: several face detectors in OpenCV; NAOqi library: ALFaceDetection.
Testing
The approach in OpenCV is based on Haar-like image features and cascade classifiers, as introduced above for the
case of human detection [7]. There are already trained classifiers available, ready to use Haar-like features, for the
detection of faces (front-several versions of the profile). Also local binary patterns have been acquired for front face
recognition.
In testing, it turned out, that the cascade classifiers allow for rapid and effective face detection, but only for front face
views (fig. 4.12, 4.13).
The NAOqi function “ALFaceDetection” also provides good results for front face detection (fig. 4.14).

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 22 of 32
Fig. 4.12 Illustration of face detection results
Fig. 4.13 “No detection”-case for profile views.
Fig. 4.14 Example of face detection by a dedicated NAOqi function.
4.5 Detect hazard – lights left switched on
int rappPlatform::robot::lightCheck( Image )
o Description. It checks, whether light is turned on. Provided image must be acquired by looking directly at light
source (e.g. lamp).
o Input: color image (e.g. cv::Mat)
o Output: confidence ratio of light being turned on (0 – turned off, 100 – turned on).

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 23 of 32
o Implementation: a RAPP platform function invoked by the dynamic agent.
o Dependencies: OpenCV modules - core, imgproc.
Testing
Sample images (taken at exposure of 1ms) present a lamp that is turned on (left) and turned off (right) (fig. 4.15). Final
result for image is computed by comparison of average brightness of eight surrounding regions (red) with central region
(blue). In the case of looking at the lamp central region will be much brighter than surrounding (light left switched on). In
case of looking through the door into other room central column will be brighter than border ones for light left switched
on.
Fig. 4.15 Images with a lamp switched on (left image) and switched off (right image)
4.6 Detect hazard – open door left – qr code based version
HazardDesc rappPlatform::robot::openDoorDetection(vector<QrCodeDesc>,
EnvMap, RobotPos)
o Input: a vector of messages < string >: QR-code messages, vector of coordinates vector<pair<float, float> >: in
camera coordinate system. Environment map with locations of QR codes. Own position of the robot on the map.
o Output: if hazard detected gives a description of it.
o Description: Given previously detected QR-code message and localization matrices in the robot coordinate
system, it detects open doors while comparing rotation of the QR-code the with the QR-code on the stable
object, such as “wall” (fig. 4.16). In result, the position of detected hazard is given with the QR-code message
corresponding to the object with is open, such as “entrance door”.
Note. The robot needs to find the QR-codes first with the qrCodeLocalization() function.
o Implementation: as a RAPP platform function invoked by the dynamic agent.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 24 of 32
(a) (b)
Fig. 4.16 Illustration of open door detection based on two QR-codes evaluation: (a) closed door – both QR-codes have
the same orientation, (b) open door detection by differently orientated RR-codes.
Testing
Some results of open door detection are shown on fig. 4.17. In fig (b) the orientations of two QR-codes differ by 2.7
angular degrees only, while in fig. (c) – by 37.4 deg. In fig. (d) the problem of partial code visibility is illustrated. A QR-
code can eventually be recognized by an error repairing step but all the three finder markers must be visible.
(a) closed door (b) minimum opening (c) maximum opening (d) partial code visibility
Fig. 4.17 Different cases of open door detection
Limitations:
- The minimal difference, between the compared codes, of angle values, at which the door opening can be
detected is ~3o, due to the angular error of QR-code detection, which is about 2-3% .
- Both QR-codes should be readable allowing their identification.
4.7 Key word spotting in speech signal
vector<WordDesc> rappPlatform::robot::wordSpotting(AudioFileDesc, WordDictionary)
o Input: current audio file. It works for a small dictionary of words.
o Output: detected words.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 25 of 32
o Description. Given small database of recognized words (for example: [Alarm, E-mail, Hazard, Exit] ). It
recognizes the words included in the database and returns the word, which was detected with the highest
probability. Note: User should speak clearly into the microphone located on the front of the robot head.
o Dependencies. Naoqi: ALSoundDetection, ALSpeechRecognition, ALMemory, ALModule
Testing.
The distance from the microphone to the user need to be limited – the optimal distance is up to 1m. As there is no
speaker separation ability, only one person should talk at the same time
4.8 The update of a 3D environment map
Map rappPlatform::robot::updateMap(Map current, DImage newDImage, Transform t,
vector<Parameter> param)
Description
Let us assume, that we are moving an MS-Kinect-like camera around the room. The goal is to create a 3D environment
map. A depth image (or dually – a point cloud) is captured and need to be registered against the previously acquired
images, already combined into a single cloud of points, playing the role of a partial 3D map. A common approach to the
problem of registration of two point clouds is illustrated on Fig. 4.18 [2].
The cloud newly obtained from the sensor is aligned against previous point cloud (or a map – a combination of previously
registered point clouds) to establish the change in sensor position (this process is called visual odometry). To increase
accuracy and efficiency, the procedure starts by extracting key points from both clouds, followed by matching the
keypoints obtained from a keypoint descriptor (e.g. SIFT, SURF for RGB image or FPFH, SHOT for depth data). The
initial transformation obtained in such fashion is then fine-tuned using the Iterative Closest Point algorithm (usually
operating on the dense clouds).
Fig. 4.18 Block diagram of the procedure for registration of two point clouds
Up to now, there have been proposed several systems for cloud registration and occupancy map computation using
RGB-D sensors. The most successful ones are:
RGB-D Mapping (Peter Henry, Univ. of Washington, Seattle)
KinectFusion (Microsoft Research, UK) and Kintinuous (MIT)
RGB-D SLAM (Univ. Freiburg, TU Munchen)
Fast Visual Odometry and Mapping from RGB-D Data (The City University of New York)
For the last three methods there are available implementations in ROS or PCL. An example of testing our
implementation of the “updateMap” function, using KinectFusion implementation, is given in fig. 4.19(a).

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 26 of 32
A 3D map, that provides a three-dimensional representation of environment, can be efficiently represented in several
ways:
Voxel map - 3D space is divided into small cubes;
Surface map representation - the space is modelled as surface elements, so called surfels [11];
MLS (Multi-level surface) Map - contains a list of obstacles (occupied voxels) associated with each element
of a 2D grid (e.g. related to the ground).
Octal trees (octrees) - constitute an effective implementation of the voxel map using the binary tree
structure .
A visualization of a surface map is illustrated on fig. 4.19(b).
(a) the room image with corresponding point features (b) visualization of a 3D surface map
Fig. 4.19 A 3D map of a “desktop in a room”, created by registering point clouds obtained from many viewpoints.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 27 of 32
5. Selected object recognition (level 3, Rapp platform)
These functions are being developed with the project, but they will take the form of services provided by the RAPP
platform (namespace rappPlatform::ImageProc).
5.1 3D human pose detection/localization
vector<Human3D> rappPlatform::ImageProc::detectHuman3D(Human2D, RobotState,
vector<Parameter>, vector<Constraint>, vector<Human3DModel>)
o Description. Given a previously detected 2D human object in the image and possible 3D models of a human,
eventually constrained by background knowledge, under the knowledge of robot’s current state (e.g. camera to
floor orientation and distance) it generates hypotheses of human’s 3D pose (location and orientation) in 3D
space. The analysis is controlled by a vector of suitable parameters.
o Implementation: as a RAPP platform service
o Dependencies: NaoQi library, OpenCv, open-source packages.
Note. This function is under development. The image region, corresponding to the 2D human object, detected earlier, is
segmented into boundary elements first and a skeletonization procedure is applied next, while a circle detector
completes the image detection step of the humand3D recognition procedure (fig. 5.1).
Fig. 5.1 Intermediate results of human posture recognition
An example of expected image recognition results, expected to be provided by such a function, is shown on fig. 5.1.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 28 of 32
Fig. 5.2 Human body posture recognition [D.Michel, I.Oikonomidis, A.A.Argyros: Body posture recognition and skeleton
estimation. ICS-FORTH - the Institute of Computer Science (ICS) of the Foundation for Research and Technology -
Hellas (FORTH)]
5.2 Face modelling and identification in an RGB image
vector<FaceDesc> rappPlatform::ImageProc::learnFace(Image, vector<Parameter>,
vector<Face>)
o Implementation: as a RAPP platform service
o Description. Given detected faces, recognize those faces which are known by the robot.
Note 1. The robot needs to learn a face with the learnFace() function before he can recognize it. To make NAO
not only detect but also recognize people, a learning stage is necessary. One needs to teach the robot a new
face to recognize. The robot will communicate if the process will be successful. Learning faces can also be
done by the Choregraphe Learn Face box. The learning stage is an intelligent process in which NAO checks
that the face is correctly exposed in 3 consecutive images. This process can be performed multiple times for a
particular person.
o Note 2. ALFaceDetection is based on a face detection/recognition solution provided by OKI with an upper
layer improving recognition results. More information about this module can be find in NAOqi documentation.
When learning someone’s face, the person is supposed to face the camera and to keep a neutral face, for
better recognition of emotion in the future. In order to get a more robust output, NAO checks first that he
recognises the same person in 2 consecutive images from the camera before outputting the name.
o Dependencies (Naoqi library): ALFaceDetection
o Limitations. The learning stage can only be accomplished with one face in the field of view at a time.
FaceId rappPlatform::ImageProc::recognizeFace(Image, vector<Parameter>, vector<Faces>,
vector<FaceDesc>)
o Implementation: as a RAPP platform service.

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 29 of 32
o Description: It detects people's face and recognize those which are known by the robot. This function will use
face recognition module from NAOqi library. This function will be similar to the Choregraphe Face Reco box
but it will be used without the Choregraphe.
o Note. The robot needs to learn a face with the learnFace() function, which can be run from Choreographe
Learn Face box, before he can recognize it. Recognition is less robust then detection regarding tilt, rotation and
maximal distance.
o Limitations for face detection:
o Size range for the detected faces:
Minimum: ~45 pixels in a QVGA image,
Maximum: ~160 pixels in a QVGA image.
o Tilt: +/- 20 deg (0 deg corresponding to a face facing the camera)
o Rotation in image plane: +/- 20 deg
5.3 Detect Hazard – open door left – object model based version
HazardDesc rappPlatform::imageProc::openDoorDetection(Image, EnvMap, RobotState)
o Implementation: as a RAPP platform service.
o Description. Two possible scenarios can be taken into consideration (fig. 5.3). The first one is based on a
single image - it requires to acquire a bottom part of the door, with (possibly) both right and left frame visible. By
analysing vertical (blue) and horizontal (red) lines decision about door opening angle is taken. If horizontal lines
are almost parallel to each other, doors are closed. If the lines between frames (vertical) have different angle to
those to the left and right of the frame, doors are treated as opened.
Another approach is based on many images taken from different angles, while still looking directly at the door.
On each image feature points are calculated and then compared with features from other pictures. If door are
closed, then on all of the images set of features should be almost identical. If door are left open, a lot of features
will differ because of the parts of other room being hidden or visible from different angles.
Fig. 5.3 Illustration of model-based open door detection

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 30 of 32
6. General object modelling and recognition (level 4, external services) These functions are not going to be developed within of this project. They are wrapper functions for calls to external
services, through the RAPP platform.
6.1 Object modelling and model-based object recognition
ObjectModel extern::ImageProc::learnObject(vector<Image>, vector<Parameter>)
vector<ObjectDesc> extern::imageProc::objectRecognition(Image,
vector<ObjectModel>)
o Description. A wrapper function for external service call. It scans the provided image and detects whether any
known object (from object database or knowledge base) is visible.
o Input: color image (e.g. cv::Mat)
o Output: detected objects (vector<ObjectDesc>)
o Implementation: external service invoked by the RAPP platform (e.g. with capability of object recognition in
RGB images [12], or RGB-D images [13]).
6.2 Speech recognition
vector<WordDesc> extern::speechProc::speechRecognition(AudioFileDesc,
vector<Parameter> WordDictionary)
Input: current audio file with speech signal, parameters and dictionary of words.
Output: the recognized sentence, as a sequence of written words.
Implementation: external service, invoked by the RAPP platform (e.g. with similar capability as the resources
of the Kaldi project [14]).

A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 31 of 32
7. Conclusions
Four levels of RAPP functions have been specified, dealing with image and speech acquisition/synthesis, and image
processing. The results of a particular implementation of these functions (at level 1 and 2) for the NAO robot are also
shown. There are tests under way, with various available libraries for image analysis, that are assumed to be used in
implementations of RAPP functions at levels 3 and 4.
References
[1] OpenCV library. http://docs.opencv.org/
[2] A. Wilkowski, T. Kornuta, W. Kasprzak: Point-based object recognition in RGB-D images. Intelligent Systems’2014
(IEEE Int. Conference on Intelligent Systems). Series: Advances in Intelligent Systems and Computing, vol. 323 (2015),
pp. 593-604, Springer International Publishing Switzerland, 2015. DOI: 10.1007/978-3-319-11310-4_51
[3] ZBar bar code reader. http://zbar.sourceforge.net/
[4] J. Figat, T. Kornuta, W. Kasprzak: Performance Evaluation of Binary Descriptors of Local Features. Lecture Notes in
Computer Science, vol. 8671 (2014), pp. 187-194 Springer International Publishing Switzerland, 2014 (ISSN 0302-9743),
DOI 10.1007/978-3-319-11331-9_23
[5] J. Figat, W. Kasprzak: NAO-mark vs QR-code recognition by Nao robot vision, AUTOMATION 2015, Advances in
Intelligent Systems and Computing, Springer International Publisher, 2015, (in print)
[6] NAO software 1.14.5 documentation. http://doc.aldebaran.com/1-14/dev/tools/naoqi.html
[7] http://docs.opencv.org/modules/objdetect/doc/cascade_classification.html
[8] http://docs.opencv.org/modules/gpu/doc/object_detection.html
[9] N. Dalal, B. Triggs: Histograms of Oriented Gradients for Human Detection, 2005 IEEE Comput. Soc. Conf. Comput.
Vis. Pattern Recognition, vol. 1, pp. 886–893, 2005.
[10] http://docs.opencv.org/modules/objdetect/doc/latent_svm.html
[11] A. Wilkowski, T. Kornuta, M. Stefańczyk, W. Kasprzak: Efficient generation of 3D surfel maps using RGB-D sensors,
AMCS (submitted), 18 pages.
[12] [Felzenszwalb10] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan, Object detection with
discriminatively trained part-based models, IEEE Trans. Pattern Anal. Mach. Intell., vol. 32(9), 2010,1627–1645.
[13] J. Prankl, M. Zillich, A. Richtsfeld, T. Mörwald, and M. Vincze M. Segmentation of unknown objects in indoor
environments. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012, pp. 4791-4796.
[14] D. Povey et al. The Kaldi Speech Recognition Toolkit. IEEE 2011 Workshop on Automatic Speech Recognition and
Understanding, Hilton Waikoloa Village, Big Island, Hawaii, US, IEEE Catalog No. CFP11SRW-USB.
http://kaldi.sourceforge.net/about.html
A Software Platform to deliver smart, user empowering Robotic Applications
7th Framework Programme Grant Agreement # 610947
D2.4.1 RAPP Image Processing Module Dissemination level PU Page 32 of 32
Annex
Camera parameters
Parameter Min
Value
Max
Value
Def.
Value NaoQI ID name OpenCV ID name Remarks
Brightness 0 255 55 kCameraBrightnessID CV_CAP_PROP_BRIGHTNESS Auto Exposition must be enabled
Contrast 16 64 32 kCameraContrastID CV_CAP_PROP_CONTRAST
The contrast value represents the
gradient of the contrast adjustment
curve. The NAO device supports
gradients from 0.5 (16) to 2.0 (64)
Saturation 0 255 128 kCameraSaturationID CV_CAP_PROP_SATURATION
Hue -180 180 0 kCameraHueID CV_CAP_PROP_HUE
Gain 32 255 32 kCameraGainID CV_CAP_PROP_GAIN Auto Exposition must be disabled
Horizontal Flip 0 1 0 kCameraHFlipID N/A
Vertical Flip 0 1 0 kCameraVFlipID N/A
Auto Exposition 0 1 1 kCameraAutoExpositionID CV_CAP_PROP_AUTO_EXPOSU
RE
Auto White
Balance 0 1 1 kCameraAutoWhiteBalanceID N/A
Exposure (time
in ms) 1 250 N/A kCameraExposureID CV_CAP_PROP_EXPOSURE
Auto Exposure
Algorithm 0 3 1 kCameraExposureAlgorithmID N/A
0: Average scene Brightness
1: Weighted average scene
Brightness
2: Adaptive weighted auto
exposure for hightlights
3: Adaptive weighted auto
exposure for lowlights
Sharpness -1 7 0 kCameraSharpnessID CV_CAP_PROP_SHARPNESS -1: disabled
White Balance
(Kelvin) 2700 6500 N/A kCameraWhiteBalanceID N/A
Read only if Auto White Balance is
enabled Read/Write if Auto White
Balance is disabled
Back light
compensation 0 4 1
kCameraBacklightCompensationI
D CV_CAP_PROP_BACKLIGHT