dynamic bayesian networks for meeting structuring alfred dielmann, steve renals (university of...
TRANSCRIPT

Dynamic Bayesian Networks for Meeting Structuring
Alfred Dielmann, Steve Renals
(University of Sheffield)
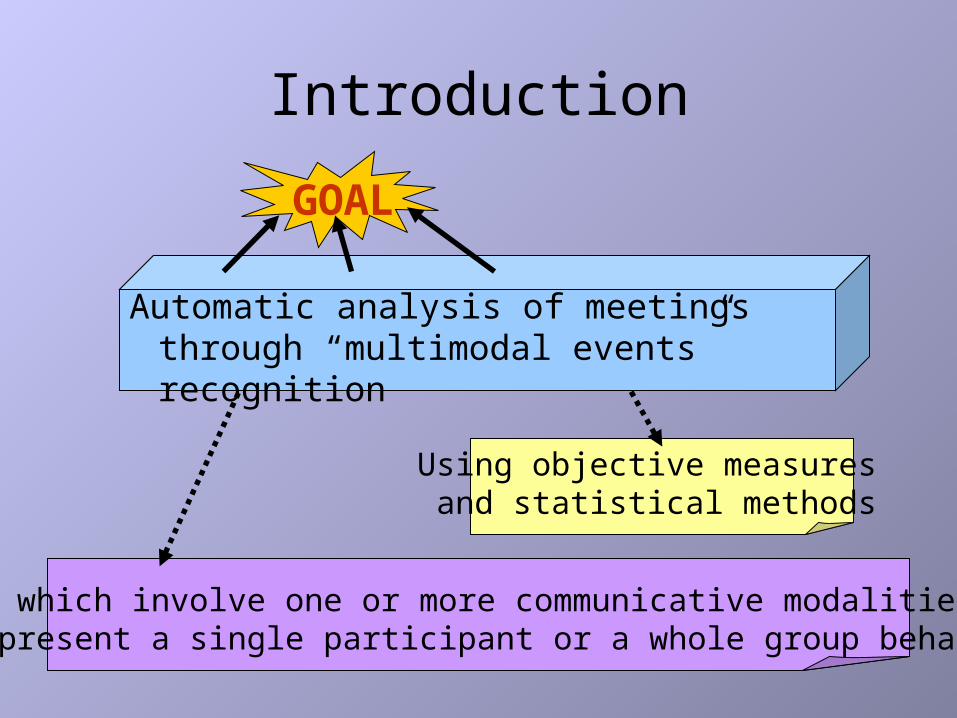
Introduction
Automatic analysis of meetings through “multimodal events” recognition
GOAL
events which involve one or more communicative modalities, and represent a single participant or a whole group behaviour
Using objective measures and statistical methods

Multimodal Recognition
Meeting Room
Audio Video ………
“Multimodal Events” Recognition
Feature Extraction
KnowledgeDatabase
………
Signal Pre-processing
Models
Specialised Recognition Systems (Speech,Video,Gestures)
Information Retrieval

Group Actions1. The machine observes group behaviours through
objective measures (“external observer”)
2. Results of this analysis are “structured” into a sequence of symbols (“coding system”)
– Exhaustive (covering the entire meeting duration)– Mutually exclusive (non overlapping symbols)We used the coding system adopted by the “IDIAP
framework”, composed by 5 “meeting actions”:• Monologue / Dialogue / Note taking / Presentation /
Presentation at the whiteboard
derived from different comunicative modalities

Corpus• 60 meetings (30x2 set) collected in the “IDIAP Smart Meeting
Room”:– 30 meetings are used for the training– 23 meetings are used for the testing– 7 meetings will be used for the results validation
• 4 participants per meeting• 5 hours of multi-channel Audio-Visual recordings:
– 3 fixed cameras– 4 lapel microphones + 8 element circular microphones array
• Meeting agendas are generated “a priori” and strictly followed, in order to have an average of 5 “meeting actions” for each meeting
• Available for public distributionhttp://mmm.idiap.ch/

Features (1)
Mic. Array
Lapel Mic.
SpeakerTurns
Beam-forming
Rate Of Speech …..
Pitch baseline Energy
Prosody and Acoustic
Only features derived from audio are currently used...
Dimensionreduction

Features (2)Speaker Turns
L1 L2 L3 L4
t-3
t-2
t-1
t
0.1 0.4 0.6 0.3
0.3 0.5 0.5 0.3
0.2 0.4 0.7 0.2
0.2 0.3 0.7 0.1
i
j
k
Location based “Speech activities”(SRP-PHAT beamforming)Kindly provided by IDIAP
Speaker Turns Features
Li(t)*Lj(t-1)*Lk(t-2)

Features (3)
RMS Energy
Pitch
Rate Of Speech
Mask F
eatures using “Speech activity”Mic. Array Beam-forming
Pitchextractor
Filters (*)
MRATE
(*) Histogram, median and interpolating filter
Lapel Mic.

Gestures and Actions …
Features (4)
VideoOther blob positions …
Participants Motion featuresImage Processing
Audio. ASR Transcripts
We’d like to integrate other features…..
… Everything that could be automaticallyextracted from a recorded meeting …
Other …

Given a set of examples, EM learning algorithms(ie: Baum-Welch) could be used to train CPTs
Dynamic Bayesian Networks (1)Bayesian Networks are a convenient graphical way to describe
statistical (in)dependencies among random variables
C S
L
A F Direct Acyclic Graph
Conditional Probability Tables
Given a set of known evidence nodes, theprobability of other nodes can be computed
through inference O

Dynamic Bayesian Networks (2)DBN are an extension of BNs with random variables that evolves in time:• Instancing a static BN for each temporal slice t• Explicating temporal dependences between variables
C S
L
O
C S
L
O
C S
L
O
……..
t=0 t=+1 t=T

Dynamic Bayesian Networks (3)
Hidden Markov Models, Kalman Filter Models and other state-space models are just a special case of DBNs :
Q0
Y0
Qt
Yt
Qt+1
Yt+1
…. ….
t=0 t t+1
Representation of an HMMas an instance of a DBN

Dynamic Bayesian Networks (4)Representing HMMs in terms of DBNs makes easy
to create variations on the basic theme ….
Q0
Y0
Qt
Yt
Qt+1
Yt+1
….
Z0 Zt Zt+1….
X0 Xt Xt+1….
Factorial HMMs Coupled HMMs
Q0
Y0
Qt
Yt
…. Qt
Yt
Z0
V0
Zt
Vt
…. Zt
Vt

Dynamic Bayesian Networks (5)Use of DBN and BN present some advantages:
• Intuitive way to represent models graphically, with a standard notation
• Unified theory for a huge number of models• Connecting different models in a structured view
• Making easier to study new models
• Unified set of instruments (ie: GMTK) to work with them (training, inference, decoding)
• Maximizes resources reuse
• Minimizes “setup” time

First Model (1)“Early integration” of features and modelling through a
2-level Hidden Markov Model
S0
Y0
St
Yt
St+1
Yt+1
…. ….
A0 At At+1…. ….
ST
YT
AT
HiddenMeeting Actions
ObservableFeaturesVector
HiddenSub-states

First Model (2)The main idea behind this model is to decompose each
“meeting action” in a sequence of “sub actions” or substates(Note that different actions are free to share the same sub-state)
S0
Y0
St
Yt
….
A0 At….The structure is composed by two Ergodic HMM chains:•The top chain links sub-states {St} with “actions” {At}
•The lower one maps directly the feature vectors {Yt} into a sub-state {St}

First Model (3)• The sequence of actions {At} is known a priori
• The sequence {St} is determined during the training process,and the meaning of each substate is unknown
S0
Y0
St
Yt
….
A0 At….•The cardinality of {St} is one of the model’s parameters
•The mapping of observable features {Yt} into hidden sub-states {St} is obtained through Gaussian Mixture Models

Second Model (1)Multistream processing of features through two parallel and
independent Hidden Markov Models
S01
Y01
St1
Yt1
St+11
Yt+11
…. ….
A0 At At+1…. ….
ST1
YT1
AT Meeting Actions
ProsodicFeatures
HiddenSub-states
S02
Y02
St2
Yt2
St+12
Yt+12
…. …. ST2
YT2
Speaker Turns Features
C0
E0
C0
E0
C0
E0
C0….….
Enable Transitions
ActionCounter

Second Model (2)Each features-group (or modality) Ym, is mapped into an
independent HMM chain, therefore every group is evaluated independently and mapped into an hidden sub-state {St
n}
S01
Y01
St1
Yt1
….
A0 At….
S02
Y02
St2
Yt2
….
As in the previous model, there is another HMM layer (A), witch represents “meeting actions”
The whole sub-state {St
1 x St2 x … St
n} is
mapped into an action {At}

Second Model (3)It is a variable-duration HMM with explicit enable node:
• At represents “meeting actions” as usual• Ct counts “meeting actions”• Et is a binary indicator variable that enables states changes
inside the node At
A0 At At+1…. ….
C0
E0
C0
E0
C0
E0
….…. Ct
…
1
1
2
2
2
…
Et
…
0
1
0
0
0
…
At
…
8
8
5
5
5
…

Second Model (4)• Training: when {At} changes {Ct} is
incremented and is set on for a single frame {Et} (At ,Et and Ct are part of the training dataset)
Ct
…
1
1
2
2
2
…
Et
…
0
1
0
0
0
…
At
…
8
8
5
5
5
…
• Decoding: {At} is free to change only if {Et} is high, andthen according to {Ct} state
Behaviours of {Et} and {Ct} learnedduring the training phase are then
exploited during the decoding

ResultsUsing the two models previously described, results
obtained using only audio derived features:
Corr. Sub. Del. Ins. AER
First Model 93.2 2.3 4.5 4.5 11.4
Second Model 94.7 1.5 3.8 0.8 6.1
Equivalent to the Word Error Ratemeasure, used to evaluate speechrecogniser performances
100Sub Ins Del
AERTotalActionsNumber
The second model reduces effectively both the number of Substitutions and the number of Insertions

Conclusions
• A new approach has been proposed
• Achieved results seem to be promising, and in the future we’d like to:– Validate them with the remaining part of the test-set
(or eventually an independent test-set)– Integrate other features:
• video, ASR transcripts, Xtalk, ….
– Try new experiments with existing models– Develop new DBNs based models


Multimodal Recognition (2)
• Raw Audio• Raw Video• Acoustic Features• Visual Features• Automatic Speech
Recognition• Video Understanding• Gesture Recognition• Eye Gaze Tracking• Emotion Detection• ….
Fusion of different recognisersat an early stage, generatinghybrid recognisers (like AVSR)
Knowledge sources: Approaches:
Integration of recognisers outputs through an “high level”recogniser
A standalone hi-level recogniseroperating on low level raw data