um catÁlogo de provedores de dados para a …...um catálogo de provedores de dados para a internet...
TRANSCRIPT

EMANOEL CARLOS GOMES FERRAZ SILVA
UM CATÁLOGO DE PROVEDORES DE DADOS PARA A INTERNET DAS COISAS
Universidade Federal de Pernambuco
www.cin.ufpe.br/~posgraduacao
RECIFE
2017

1
Emanoel Carlos Gomes Ferraz Silva
Um Catálogo de Provedores de Dados para a Internet das Coisas
RECIFE
2017
Este trabalho foi apresentado ao Programa de Pós-
Graduação em Ciência da Computação do Centro de
Informática da Universidade Federal de Pernambuco
como requisito parcial para obtenção do grau de Mestre
em Ciência da Computação.
ORIENTADOR: Prof. Kiev Santos da Gama
COORIENTADORA: Profª Bernadette Farias Lóscio

Catalogação na fonte
Bibliotecária Monick Raquel Silvestre da S. Portes, CRB4-1217
S586c Silva, Emanoel Carlos Gomes Ferraz
Um catálogo de provedores de dados para a Internet das coisas / Emanoel Carlos Gomes Ferraz Silva. – 2016.
73 f.: il., fig., tab. Orientador: Kiev Santos da Gama. Dissertação (Mestrado) – Universidade Federal de Pernambuco. CIn,
Ciência da Computação, Recife, 2016. Inclui referências e apêndices.
1. Redes de computadores. 2. Qualidade de dados. 3. Internet. I. Gama, Kiev Santos da (orientador). II. Título. 004.6 CDD (23. ed.) UFPE- MEI 2017-26

3
Emanoel Carlos Gomes Ferraz Silva
Um Catálogo de Provedores de Dados para a Internet das Coisas
Dissertação de Mestrado apresentada ao Programa de Pós-Graduação em Ciência da
Computação da Universidade Federal de Pernambuco,
como requisito parcial para a obtenção do título de
Mestre em Ciência da Computação
Aprovado em: 05/09/2016.
BANCA EXAMINADORA
__________________________________________
Prof. Dr. Nelson Souto Rosa
Centro de Informática / UFPE
__________________________________________
Prof. Dr. Vanilson André de Arruda Burégio
Departamento de Estatística e Informática / UFRPE
__________________________________________
Prof. Dr. Kiev Santos da Gama
Centro de Informática / UFPE (Orientador)

4
Dedicado a minha família

5
Agradecimento
A minha família por tudo.
A Kiev Gama e Bernadette Lóscio, que tornaram tudo isso possível.
A Nelson Rosa e Vanilson Burégio pelo feedback dado ao trabalho.
Aos meus colegas de jornada, que tornaram o caminho menos difícil.
Ao Centro de Informática pela estrutura ofertada e à FACEPE pelo incentivo concedido.

6
My watch has ended.
(JOHN SNOW)

7
Resumo
Com a ascensão da Internet das Coisas (Internet of Things, IoT), bilhões de dispositivos estarão
conectados à internet do futuro produzindo, consumindo e processando dados, além de se
comunicarem uns com os outros. Através de plataformas de dados sem domínio específico,
desenvolvedores, cientistas e entusiastas poderão fazer uso destes dispositivos em suas
aplicações sem necessariamente ter conhecimento técnico de baixo nível, como os protocolos
de comunicação. Assim, descobrir e selecionar de forma eficiente os dispositivos que melhor
respondem a uma determinada necessidade se mostram como problemas relevantes a serem
investigados no paradigma da Internet das Coisas. Este trabalho auxilia mecanismos de busca
de fontes produtoras de dados, propondo uma técnica que possa, de forma objetiva, indicar
quais destas entidades são mais apropriadas, considerando como critérios os seus atributos de
qualidade. Para tanto, foram consideradas questões de interoperabilidade no formato dos dados
gerados pelos produtores de dados e dos metadados de sua descrição; escalabilidade, na técnica
proposta para o ranqueamento dos produtores de dados identificados pelo mecanismo de
seleção e, por fim, monitoramento dos indicadores de qualidade dos produtores de dados. Como
principais contribuições deste trabalho estão: (i) o uso e o monitoramento dinâmico de métricas
de qualidade na descrição dos produtores de dados, (ii) proposta de uma técnica de
ranqueamento de produtores de dados que utilize atributos de qualidade diversos e que
acompanhe as características dinâmicas dos produtores de dados (iii) a proposta do conceito de
fila dinâmica de resultados no mecanismo de busca, visando economia de processamento e
ganho de desempenho e (iv) uso do estilo arquitetural REST para a oferta dos produtores de
dados como recursos. Por fim, foi considerado um cenário de uso do aplicativo móvel Bike
Cidadão com o objetivo de avaliar a performance das contribuições propostas. A avaliação
observou, sobretudo, o tempo de resposta necessário à execução de consultas ao catálogo
utilizando, ou não, o conceito de fila dinâmica de resultados em diferentes situações, variando
a quantidade de consumidores e produtores de dados disponíveis.
Palavras-chave: Internet das Coisas. Qualidade de Contexto. Qualidade de Dados. Seleção de
Dispositivos.

8
Abstract
With the rise of the Internet of Things (IoT) billion devices will be connected to the internet of
the future producing, consuming and processing data and communicating with each other. By
way of data platforms without specific domain, developers, scientists and enthusiasts can make
use of these devices in their applications without necessarily having low-level technical
knowledge, as communication protocols. Thus, discover and select efficiently the devices best
suited to a particular need, appear as relevant issues to be investigated in the paradigm of the
Internet of Things. This work assists search engines of data producers, proposing a technique
that can objectively indicate which of these entities are more appropriate, considering as criteria
their quality attributes. Therefore, interoperability issues were considered in the data format
generated by the data producers and metadata of your description; scalability, in the proposed
technique for ranking the data producers identified by the selection mechanism and, finally,
monitoring of quality indicators of data producers. Moreover, as major contributions of this
work are: (i) using and monitoring quality metrics in the description of the data producers, (ii)
the propose of a ranking of data producers technique that makes use of quality attributes, (iii)
the suggestion of dynamic queue results by the search engine and (iv) the use of REST style for
providing data producers as resource. Finally, it was considered a use case scenario of the
mobile application Bike Cidadão in order to evaluate the performance of the proposed
contributions. The evaluation noted, above all, the response time required to perform queries to
the catalog using, or not, the concept of dynamic queue results in different situations, varying
the amount of data available to consumers and producers.
Keywords: Internet of Things. Quality of Context. Data Quality. Device Selection.

9
Lista de Figuras
2.1 Arquitetura conceitual de um sistema sensível a contexto ............................................ 20
2.2 Interdependência entre QoD, QoC e QoS ..................................................................... 21
2.3 Quantidade de citações das métricas de qualidade ........................................................ 22
2.4 Frequência de citação x Frequência de definição .......................................................... 23
2.5 Ilustração de Accuracy e Precision ............................................................................... 25
2.6 Ilustração do Cosine Vector ........................................................................................... 28
2.7 Ilustração da Distância Euclidiana ............................................................................... 29
2.8 Visão geral da proposta de GUINARD et al. (2010) .................................................... 31
2.9 Visão geral da proposta de PERERA et al. (2013) ....................................................... 32
2.10 Prioridade entre os atributos de qualidade .................................................................. 33
2.11 Visão geral do COBASEN ......................................................................................... 34
2.12 Interface da ferramenta de busca proposta por LUNARDI et al. (2015) ................... 34
3.1 Arquitetura do Waldo ................................................................................................... 37
3.2 Ilustração da Fila Dinâmica .......................................................................................... 43
3.3 Nova arquitetura do Waldo .......................................................................................... 47
3.4 Componentes do Waldo ............................................................................................... 49
4.1 Atividades de uma consulta .......................................................................................... 54
4.2 2 atributos de qualidade explícitos na estratégia de busca ........................................... 55
4.3 4 atributos de qualidade explícitos na estratégia de busca ........................................... 55
4.4 6 atributos de qualidade explícitos na estratégia de busca ........................................... 56
4.5 8 atributos de qualidade explícitos na estratégia de busca ........................................... 56
4.6 Tempo de resposta das técnicas consideradas .............................................................. 59
4.7 Comparativo do nível de qualidade dos atributos ........................................................ 60
4.8 Rotas utilizadas no experimento visualizadas no OpenStreetMap ............................... 62
4.9 Mecanismo de busca sem a estratégia de fila dinâmica ............................................... 63
4.10 Mecanismo de busca com a estratégia de fila dinâmica ............................................. 63
B.1 Níveis médios de qualidade para diferentes níveis de ρ ............................................... 74

10
Lista de Tabelas
4.1 Computadores utilizados ............................................................................................ 53
4.2 Tempos de resposta das etapas de busca em milissegundos ..................................... 57
4.3 Desempenho do Pearson Correlation e Cosine Vector em relação à técnica proposta ......... 60
A.1 Artigos considerados .................................................................................................. 71

11
Sumário
1 INTRODUÇÃO 13
1.1 Questões de Pesquisa .............................................................................................. 15
1.2 Objetivo .................................................................................................................... 15
1.3 Escopo negativo ....................................................................................................... 16
1.4 Estrutura do Trabalho ............................................................................................ 16
2 FUNDAMENTAÇÃO TEÓRICA 17
2.1 Introdução ................................................................................................................ 17
2.2 Qualidade de dados, de serviço e de contexto ....................................................... 17
2.2.1 Atualidade ................................................................................................................. 23
2.2.2 Probabilidade de corretude ...................................................................................... 24
2.2.3 Confiabilidade ........................................................................................................... 24
2.2.4 Precisão ..................................................................................................................... 24
2.2.5 Resolução .................................................................................................................. 25
2.2.6 Tempo de resposta .................................................................................................... 25
2.2.7 Completude ............................................................................................................... 26
2.3 Algoritmos de ranqueamento ................................................................................. 26
2.3.1 Pearson Correlation Coefficient ............................................................................... 27
2.3.2 Cosine Vector ............................................................................................................ 28
2.3.3 Distância Euclidiana ................................................................................................. 29
2.4 Trabalhos Relacionados ......................................................................................... 30
2.4.1 Mecanismos de busca ................................................................................................ 31
2.4.2 Limitações dos trabalhos relacionados .................................................................... 34
2.5 Resumo do capítulo ................................................................................................. 35
3 PROPOSTA 36
3.1 Motivação ................................................................................................................. 36
3.2 Visão geral do Waldo .............................................................................................. 37
3.3 Requisitos ................................................................................................................. 38
3.4 Requisitos funcionais .............................................................................................. 39
3.4.1 [RF001] O mecanismo de busca deve considerar indicadores de qualidade como
Parâmetros ......................................................................................................................... 39
3.4.2 [RF002] O mecanismo de busca deve implementar uma heurística para otimizar as

12
operações de busca ............................................................................................................. 43
3.5 Requisitos não funcionais ....................................................................................... 44
3.5.1 [RNF001] O mecanismo de busca do catálogo não deve ser comprometido pela
técnica de ranqueamento proposta .................................................................................... 44
3.5.2 [RNF002] Flexibilidade no esquema dos dados armazenados ................................ 45
3.6 Arquitetura do novo Waldo ................................................................................... 47
3.7 Implementação ........................................................................................................ 49
3.8 Resumo do capítulo ................................................................................................. 52
4 AVALIAÇÃO E ANÁLISE 53
4.1 Introdução ................................................................................................................ 53
4.2 Técnica de ranqueamento ....................................................................................... 53
4.2.1 Análise da técnica de ranqueamento ........................................................................ 57
4.3 Comparativo das técnicas ....................................................................................... 58
4.3.1 Análise do comparação das técnicas ........................................................................ 60
4.4 Fila dinâmica ........................................................................................................... 61
4.4.1 Análise da fila dinâmica ........................................................................................... 63
4.5 Resumo do capítulo ................................................................................................. 64
5 CONCLUSÃO 65
5.1 Principais Contribuições ........................................................................................ 65
5.2 Limitações ................................................................................................................ 65
5.3 Trabalhos Futuros ................................................................................................... 66
Referências 67
6 APÊNDICES 71
A Artigos considerados ............................................................................................... 71
B Escolha do parâmetro p .......................................................................................... 74
C Descrição ilustrativa de um termômetro em SensorML ..................................... 75
D Exemplo de um produtor de dados descrito em SensorML ................................ 76

13
1. Introdução
Nos últimos anos, diversas pesquisas vem sendo realizadas, na academia e na indústria, em
Internet das Coisas (PERERA et al., 2014). De acordo com GUILLEMIN; FRIESS (2009), a
Internet das Coisas tem como objetivo permitir que pessoas e coisas diversas possam ser
conectadas entre si a qualquer momento e lugar, preferencialmente usando qualquer
caminho/rede e qualquer serviço. Percebe-se que sua aplicação é bastante ampla e diversos
domínios de aplicação são beneficiados com o potencial de desenvolvimento de aplicações que
antes não eram possíveis como, por exemplo, aquelas chamadas de crowdsensing (GANTI; YE;
LEI, 2011), que é a participação da multidão, formada por pessoas comuns, equipada com seus
dispositivos usuais (como smartphones, relógios ou pulseiras inteligentes entre outros)
produzindo dados a todo o momento. De fato, segundo a CISCO (2016a,b), o ano 2015 iniciou
com 14 bilhões de dispositivos conectados à internet. Ela estima que até o ano 2020 este número
alcance a marca de 50 bilhões de dispositivos. Outras previsões, como a de Morgan Stanley
(DANOVA, 2013) preveem até 75 bilhões de dispositivos.
Os sistemas sensíveis a contexto são diretamente beneficiados com o desenvolvimento
da internet das coisas. Segundo DEY; ABOWD; SALBER (2001), contexto é qualquer
informação que pode ser usada para caracterizar a situação de entidades que são considerados
relevantes para a interação entre o usuário e uma aplicação, incluindo o próprio usuário e a
aplicação. Ou seja, sistemas cientes a contexto devem dinamicamente alterar seu status ou seu
comportamento tomando como base o contexto em que o usuário está inserido. No entanto,
dada a enorme quantidade de serviços que vem sendo ofertados pelos dispositivos utilizando a
internet das coisas, pode ser muito difícil identificar quais são aqueles que oferecem exatamente
a informação que o consumidor deseja e, o mais importante, a um nível de qualidade adequado.
De acordo com VIEIRA; TEDESCO; SALGADO (2009), ao se trabalhar com contexto,
grande aplicação da internet das coisas (PERERA et al., 2014), deve-se considerar o tratamento
de incertezas, já que os elementos contextuais podem conter inconsistências, serem ambíguos
ou incompletos. Como adiciona PERERA et al. (2014), há duas razões para os elementos
contextuais não serem totalmente confiáveis: (i) sensores não são capazes de gerar dados com
100% de acurácia, (ii) mesmo que existam sensores que produzem dados com 100% de
acurácia, os modelos de raciocínio ou processamento não são 100% acurados. Assim, vários
trabalhos propõem formas de quantificar e considerar a qualidade do contexto, dos serviços e

14
dos dados gerados pelos produtores de dados com o objetivo de selecionar aqueles resultados
que melhor atendem às suas necessidades. Para OLIVEIRA; GAMA; LÓSCIO (2015),
produtores de dados podem ser qualquer tipo de recurso, físico ou virtual, que seja capaz de
prover dados para os consumidores de dados. Os dados, neste caso, podem vir de sensores,
smartphones ou até mesmo de bases de dados abertos e aplicações da web.
Apesar do campo de pesquisa em qualidade ser bastante amplo, especificamente as
contribuições de BUCHHOLZ; KÜPPER; SCHIFFERS (2003) possuem afinidade com o
trabalho atual, uma vez que fazem uma distinção clara entre qualidade de contexto (QoC),
qualidade de serviço (QoS) e qualidade de dispositivo (QoD). Além disso, eles definem
algumas métricas de qualidade em cada uma destas categorias, como: precisão, probabilidade
de corretude, confiança, resolução e atualidade. Diversos outros trabalhos também definem
outras métricas - como: acurácia, completude, frequência, frescor, disponibilidade, tempo de
resposta entre outras - e serão discutidas posteriormente neste trabalho.
Assim, dado que as aplicações sensíveis a contexto se adaptam de acordo com a situação
do usuário e que ela precisa consumir continuamente elementos contextuais para entender a
situação contextual, faz-se necessário também que elas se adaptem às mudanças de qualidade
para que a aplicação possa reagir sempre de forma apropriada. É necessário considerar que as
fontes fornecedoras de dados são autônomas e podem mudar suas características de qualidade
a qualquer momento. Assim, surge a necessidade de desenvolver algum mecanismo que possa
lidar com o monitoramento das métricas de qualidade das fontes produtoras de dados
contextuais, ranqueá-las de acordo com a necessidade da aplicação consumidora em um
determinado momento, conseguir monitorar se os valores das métricas de qualidade irão mudar
ao longo do tempo -- permitindo que se reaja conforme a necessidade do consumidor - e
armazenar apropriadamente seus metadados de descrição. Tal mecanismo se preocupa
exatamente com o problema de seleção das melhores fontes produtoras de dados que a aplicação
espera consumir naquele determinado momento.
Alguns trabalhos disponíveis na literatura já utilizam seleção de serviços considerando
características de qualidade e utilizam técnicas como: árvores de decisão, naive bayes, cadeias
escondidas de Markov, support vector machine, KNN, redes neurais artificiais, Dempster-
Shafer, raciocínio em ontologias, regras, raciocínio fuzzy entre outras técnicas
(RANGANATHAN; AL-MUHTADI; CAMPBELL, 2004; XU; CHEUNG, 2005;
SOEDIONO, 1989; EVCHINA et al., 2015). PERERA et al. (2014) faz um comparativo entre
várias dessas técnicas, destacando os prós, contras e aplicabilidade de cada uma destas

15
abordagens. Estas técnicas utilizadas para a seleção de serviços poderiam ser utilizadas no
contexto de seleção de produtores de dados. No entanto, considerando o cenário de internet das
coisas, onde não apenas humanos fazem requisições, mas também sistemas e dispositivos, é
necessário que sejam satisfeitos requisitos básicos como: a não exigência de interação explícita
ente consumidor e mecanismo de busca e eficiência no tempo de resposta.
Assim, o objetivo deste trabalho é auxiliar mecanismos de busca de fontes produtoras de
dados, fornecendo uma técnica que possa, de forma objetiva, indicar quais destas entidades são
mais apropriadas, considerando como critérios os seus atributos de qualidade. Seu propósito é
retirar do desenvolvedor da aplicação a tarefa de se preocupar com a seleção das melhores
fontes para a sua aplicação. Assim, pode-se elencar o conjunto de características essenciais
desse mecanismo de busca:
a) Utilizar uma técnica de ranqueamento que considere como critério os atributos de
qualidade das fontes produtoras de dados e que seja eficiente sob a perspectiva dos
resultados recomendados e do tempo de resposta necessário para o seu cálculo;
b) Disponibilizar uma interface utilizando o estilo arquitetural REST para que aplicações
façam solicitações de fontes produtoras de dados disponíveis naquele momento que
satisfaçam requisitos mínimos de qualidade;
c) Utilizar um formato de dados comum que permita uma representação apropriada das
fontes produtoras de dados, incluindo seus atributos de descrição e suas características
de qualidade;
d) Monitoramento constante das métricas de qualidade das fontes produtoras de dados;
1.1. Questões de Pesquisa
Este trabalho busca responder à seguinte questão de pesquisa:
É possível implementar uma técnica de ranqueamento de fontes produtoras de dados,
que seja eficiente, do ponto de vista dos resultados recomendados e do custo computacional
requerido pelo cálculo proposto?
1.2. Objetivo
O objetivo geral deste trabalho é propor um mecanismo de busca de fontes produtoras de dados
em internet das coisas. Os critérios básicos de seleção destas fontes são, principalmente, seus

16
atributos de qualidade, cujo monitoramento e atualização é constante. Assim, para atingir este
fim, como objetivos específicos este trabalho pretende:
a) Propor e implementar técnica de ranqueamento de fontes produtoras de dados em
internet das coisas que: (i) utilize seus indicadores de qualidade como parâmetros, (ii)
que seja viável sob a perspectiva do custo computacional e do tempo de resposta;
b) Propor, implementar e avaliar uma abordagem para economia de processamento
computacional e ganho de desempenho nas recomendações realizadas pelo mecanismo
de busca;
c) Validar a proposta utilizando o catálogo de produtores de dados Waldo, proposto por
OLIVEIRA; GAMA; LÓSCIO (2015);
1.3. Escopo negativo
De forma a complementar os objetivos elencados anteriormente, deve-se frisar que não faz parte
do escopo deste trabalho lidar com as seguintes questões:
a) Propor, implementar ou testar diferentes mecanismos de segurança entre a comunicação
dos diferentes componentes arquiteturais do catálogo Waldo. Sobretudo aqueles
adicionados por este trabalho e que dizem respeito ao seu mecanismo de busca;
b) Composição, inferência ou análise de contexto computacional;
1.4. Estrutura do Trabalho
O trabalho está organizado da seguinte forma: o Capítulo 2 apresenta todo o embasamento
teórico para o entendimento deste trabalho; o Capítulo 3 discute a proposta da técnica de
ranqueamento e sua integração ao catálogo Waldo; o Capítulo 4 apresenta a avaliação de
desempenho das técnicas propostas e, por fim, o Capítulo 5 resume o trabalho, elencando suas
principais contribuições, limitações e trabalhos futuros.

17
2. Fundamentação Teórica
2.1. Introdução
O objetivo deste capítulo é apresentar os conceitos básicos relacionados aos temas abordados
neste trabalho. Serão discutidos contexto computacional e sistemas sensíveis a contexto,
atributos de qualidade de serviço, contexto e dados e como estão relacionados a internet das
coisas e técnicas de recomendação.
2.2. Qualidade de dados, de serviço e de contexto
Ainda hoje é difícil encontrar uma definição precisa de Contexto. Como o termo pode ser
aplicado em vários domínios, \cite{brezillon2005reinforcing} conseguiram mapear cerca de
150 diferentes definições. No entanto, a definição mais utilizada até então foi dada por DEY;
ABOWD; SALBER (2001). Segundo eles, contexto é:
[...] qualquer informação que possa ser usada para caracterizar a situação de
entidades (isto é, clima, pessoa, lugar ou objeto) que são considerados relevantes
para a interação entre o usuário e uma aplicação, incluindo o próprio usuário e a
aplicação. Contexto é, tipicamente, a localização, identidade, o estado da pessoa,
grupos e objetos físicos e computacionais.
No entanto, VIEIRA; TEDESCO; SALGADO (2009) vão além e fazem uma distinção
clara entre Contexto e Elemento Contextual. Elemento contextual seria qualquer dado,
informação ou conhecimento que permite caracterizar uma entidade em um domínio. Contexto,
por sua vez, seria o conjunto de elementos contextuais instanciados que são necessários para
apoiar a tarefa atual entre um agente e uma aplicação.
DEY; ABOWD; SALBER (2001) definem seis requisitos básicos para o
desenvolvimento de um sistema sensível a contexto. São eles:
a) Separação de interesses. Como em todo middleware, é essencial que regras de negócio
da aplicação sensível a contexto não sejam implementadas na plataforma de dados. Ou
seja, quem implementa um sistema sensível a contexto não deve se preocupar como os
elementos contextuais são coletadas, bem como não deve se preocupar com
características diversas dos sensores utilizados. Dessa forma, necessário que os sistemas
sensíveis a contexto ofereçam mecanismos de abstração quem permitam utilizar
elementos contextuais sem preocupação de baixo nível.

18
b) Interpretação de contexto. Este requisito é responsável por agregar elementos
contextuais em outros de maior significado para a aplicação. Isto é necessário porque, a
princípio, os dados coletados são puramente técnicos e não tem tanto valor agregado à
aplicação. Várias técnicas são aplicadas na interpretação de contexto, mas dentre as
principais vale destacar: árvores de decisão, naive bayes, cadeias escondidas de Markov,
support vector machine, KNN, redes neurais artificiais, Dempster-Shafer, raciocínio em
ontologias, regras, raciocínio fuzzy entre outras técnicas (RANGANATHAN; AL-
MUHTADI; CAMPBELL, 2004; XU; CHEUNG, 2005; SOEDIONO, 1989;
EVCHINA et al., 2015). PERERA et al. (2014) faz um comparativo entre vária dessas
técnicas, destacando os prós, contras e aplicabilidade de cada uma destas abordagens.
c) Comunicação transparente e distribuída. PERERA et al. (2014) categoriza os
elementos contextuais em Primários e Secundários. Elemento contextual primário é
qualquer informação recuperada sem usar operações de agregação de dados. Um
elemento contextual secundário é qualquer informação que pode ser gerada a partir de
elementos contextuais primários. Dessa forma, uma mesma informação pode ser
adquirida utilizando fontes distintas. Afinal, eventualmente um elemento contextual
pode vir de um sensor, de um conjunto de sensores, de um perfil ou, até mesmo, de uma
análise histórica.
d) Disponibilidade de aquisição de contexto constante. Para DEY; ABOWD; SALBER
(2001), os componentes responsáveis por prover contexto não deve ser instanciados
quando requisitados, mas devem estar sempre em execução, independentemente da
aplicação que os utiliza.
e) Armazenamento e histórico de contexto. A todo momento os dispositivos estão
gerando dados. Se a aplicação armazena esses todos estes elementos contextuais,
posteriormente é possível estabelecer tendências e predições de situações a partir da
base histórica. No entanto isto se configura como um problema clássico de Big Data,
caracterizado pela grande variedade, volume de dados e velocidade de produção.
Bancos de dados NoSQL podem se mostrar como uma alternativa aos SGBDs
relacionais tradicionais, já que abrem mão da normalização dos dados tabulares e
investem seus recursos em flexibilidade e performance nas operações.
f) Descoberta de recurso. Dada a grande quantidade de dispositivos conectados, bem
como a ampla heterogeneidade em suas características e comportamentos, um grande

19
desafio é encontrar exatamente aqueles dispositivos que melhor respondem a
determinado problema. Vários trabalhos provem diferentes mecanismos de descoberta
em IoT utilizando informação contextual (KRAUSE; HOCHSTATTER, 2005; ZHENG
et al., 2011; ZHAO et al., 2014; WEI; JIN, 2012; RAN, 2003; BUTT, 2014; LUNARDI
et al., 2015), incluindo o atual trabalho.
Com o objetivo de facilitar o desenvolvimento de aplicações sensíveis a contexto, bem
como a integração de diferentes tecnologias em internet das coisas, diversas plataformas de
mediação de dados são propostas. Entre suas possibilidades estão o gerenciamento de
dispositivos, auxílio no armazenamento e na recuperação de dados gerados pelos dispositivos,
processamento dos dados a fim de sumarizar estatísticas e disparar alertas entre outras
características (SILVA et al., 2015). Tais plataformas, segundo ZASLAVSKY; PERERA;
GEORGAKOPOULOS (2012) podem ser classificadas como Sensor-as-a-Service, pois
encapsulam sensores físicos e virtuais em serviços, de acordo com o conceito SOA (Service
Oriented Architecture). OpenIoT1, GSN2, LSM3, Axeda4, Fi-ware5 e Octoblu6 são alguns
exemplos dessas plataformas.
Disponibilizar dispositivos como serviços se mostra como uma boa alternativa do ponto
de vista de reuso e integração de sistemas. No entanto, é importante notar que os padrões SOA
foram projetados para a integração de serviços complexos e estáticos (GUINARD et al., 2010).
Por outro lado, os dispositivos participantes da internet das coisas possuem, em sua grande
maioria, restrições em seus recursos e possuem caráter totalmente dinâmico. A restrição de
recurso está relacionada a limitações da capacidade de processamento, precisão do sensor,
armazenamento, tempo de resposta, comunicação entre outros. A característica dinâmica, por
sua vez, está relacionada à natureza autônoma dos dispositivos. Afinal eles se registram na
plataforma de dados, tornam-se disponíveis para responder a solicitações, mas podem tornar-se
indisponíveis ou mudar suas características a qualquer momento. De fato, quem desenvolve as
aplicações que consomem os dados produzidos por estes dispositivos não necessariamente
mantém controle sobre eles, pois este é um dos propósitos das plataformas de dados, permitir o
reuso dos mesmos recursos por diversos sistemas.
1 http://www.openiot.eu/ 2 https://github.com/LSIR/gsn 3 https://code.google.com/p/deri-lsm/downloads/list 4 https://www.xively.com/ 5 https://www.fiware.org/ 6 https://www.octoblu.com/

20
Basicamente as plataformas de mediação de dados possuem a arquitetura conceitual
ilustrada na Figura 2.1. Aplicações fazem uso de uma API para solicitar dispositivos específicos
à plataforma. Esta, por sua vez, retira das aplicações, e implementa, as tarefas de representação,
descoberta, busca e seleção dos dispositivos.
Figura 2.1: Arquitetura conceitual de um sistema sensível a contexto.
Fonte: Adaptado de LUNARDI et al. (2015)
No entanto, um problema evidente no âmbito de internet das coisas é: Dado que os
dispositivos ofertados são autônomos e dinâmicos, como selecionar os dispositivos que melhor
atendem à necessidade da aplicação em determinado momento? Uma estratégia possível, e
utilizada neste trabalho, é realizar o monitoramento das características destes dispositivos e,
através de uma técnica de ranqueamento proposta, sugerir os dispositivos que melhor atendem
às exigências da aplicação consumidora. Em um exemplo prático, podemos imaginar uma
cidade em que os ônibus de transporte público tem instalado sensores de temperatura externa,
umidade e poluição do ar. Um desenvolvedor que queira implementar um sistema que mostre
em tempo real o mapa de temperatura, umidade e poluição da cidade obviamente deseja apenas
aqueles dispositivos que estão disponíveis naquele momento e que possuam as melhores
características para que, dessa forma, os resultados sejam mais precisos e confiáveis. Sobre
melhores resultados alguns trabalhos propõem, o uso de métricas para quantificar a qualidade
do serviço, do contexto e dos dispositivos. Tais métricas podem ser utilizadas como parâmetros
aos critérios de seleção dos dispositivos. Uma leitura mais detalhada sobre este tema será
abordada na Seção 2.2.
De acordo com VIEIRA; TEDESCO; SALGADO (2009), ao se trabalhar com contexto
deve-se considerar o tratamento de incertezas, já que os elementos contextuais podem conter

21
inconsistências, serem ambíguos ou incompletos. De fato, MCCARTHY; BUVAC (1997)
apresenta que contexto possui dimensão infinita, não pode ser completamente modelado e há
sempre um contexto comum, acima de todos os contextos locais. Ou seja, sempre haverá um
erro inerente a cada elemento contextual capturado, por menor que seja, pois como adiciona
PERERA et al. (2014), há duas razões para os elementos contextuais não serem totalmente
confiáveis: (i) sensores não são capazes de gerar dados com 100% de acurácia, (ii) mesmo que
existam sensores que produzem dados com 100% de acurácia, os modelos de raciocínio ou
processamento não são 100% acurados. Dessa forma, vários trabalhos propõem formas de
considerar a qualidade do contexto. Da mesma forma, a qualidade do dado gerado pelos
produtores de dados (sensores, bases de dados entre outros) e serviços também podem ter sua
qualidade quantificada.
Dessa forma, visto que um dispositivo pode não ter 100% de acurácia em suas
observações, os elementos contextuais também não serão completamente acurados por conta
de limitações nos processos de raciocínio/inferência/processamento. BUCHHOLZ; KÜPPER;
SCHIFFERS (2003) definem três categorias de qualidade: QoD, QoC e QoS.
Figura 2.2: Interdependência entre QoD, QoC e QoS.
Fonte: Elaborado por BUCHHOLZ; KÜPPER; SCHIFFERS (2003)
Para eles, QoC (Quality of Context) é qualquer informação que descreve a qualidade
daquilo que é usado como elemento contextual. Assim, QoC se refere à informação e não ao
processo ou ao dispositivo que proveu esta informação. QoS, por sua vez, é qualquer
informação que descreve quão bem um serviço é executado. Por fim, QoD é qualquer
informação sobre as propriedades técnicas do dispositivo e suas capacidades. Assim, como
mostra o diagrama da Figura 2.2 os três tipos de qualidades podem intervir uns nos outros. Por
exemplo, um dispositivo defeituoso (com QoD comprometido) proverá dados incorreto, afetará

22
a qualidade do contexto observado (QoC) e o serviço que recebe este elemento contextual como
entrada processará um resultado errôneo. De fato, segundo KIM; LEE (2006), “se informações
de baixo nível tem um erro, as informações de alto nível naturalmente terão erro e mecanismos
de raciocínio simplificados causarão ou propagarão erros”.
Assim, surgem métricas de qualidade como uma tentativa de qualificar, de forma
objetiva, serviços, contextos, dados ou dispositivos. As principais métricas encontradas na
literatura são apresentadas a seguir.
Figura 2.3: Quantidade de citações das métricas de qualidade.
Fonte: Elaborado pelo Autor

23
De acordo com Figura 2.3 as métricas de qualidade que foram mais mencionadas nos
artigos mapeados (Tabela 6) foram: accuracy, precision, resolution, up-to-dateness, probability
of correctness, confidence, timeliness, trust-worthiness, completeness, frequency e freshness.
No entanto, algumas métricas foram apenas mencionadas, mas não foram definidas. Ou seja, o
trabalho não informava exatamente o que essa métrica observa, nem sua estratégia de cálculo.
A Figura 2.4 faz uma relação entre a quantidade de citações que a métrica recebeu em
relação à quantidade de definições que ela teve. Pode-se observar que as métricas com maior
quantidade de definições foram: up-to-dateness, probability of correctness, accuracy, precision
e resolution.
Figura 2.4: Frequência de citação x Frequência de definição.
Fonte: Elaborado pelo Autor
De acordo com uma seleção estruturada de artigos que foi realizada (Anexo 6.1) as
principais métricas encontradas na literatura (ver Figura 2.3).
2.2.1. Atualidade
Ao se utilizar contexto em uma aplicação, exige-se que ele reflita a atual situação de forma mais
fiel possível.
Assim, a métrica atualidade (do inglês, up-to-dateness) descreve a idade de um dado,
sendo geralmente dado através da diferença entre o tempo em que o dado foi gerado, até o

24
momento de uso atual (BUCHHOLZ; KÜPPER; SCHIFFERS, 2003; HONLE et al., 2005; XU;
CHEUNG, 2005; KAHN; STRONG; WANG, 2002; JUDD; STEENKISTE, 2003).
up-to-dateness = momentoatual – momentoobservação
Assim, essa métrica pode ser considerada como inversamente positiva, ou seja, quanto
menor o valor dado pelo cálculo da métrica, melhor é a qualidade da entidade observada. Neste
caso, quanto menor a atualidade mais recente é o dado, e portanto, melhor representa a situação
atual.
Alguns artigos abordam atualidade com outra nomenclatura, como: timeliness,
freshness e age.
2.2.2. Probabilidade de corretude
Segundo BUCHHOLZ; KÜPPER; SCHIFFERS (2003); SHEIKH; WEGDAM; SINDEREN
(2008); XU; CHEUNG (2005) e KAHN; STRONG; WANG (2002), probabilidade de corretude
(do inglês, probability of correctness) quantifica a probabilidade de que um elementos
contextual esteja correto. Geralmente seu valor é dado em porcentagem ou em níveis, como:
baixo, médio e alto.
Essa métrica é considerada diretamente positiva e é em alguns casos como: free-of-
error, confidence e certainty.
2.2.3. Confiabilidade
É muito semelhante a probabilidade de corretude, no entanto, esta métrica quantifica a
confiança na entidade que proveu o elemento contextual e não o elemento propriamente dito
(BUCHHOLZ; KÜPPER; SCHIFFERS, 2003; XU; CHEUNG, 2005; KAHN; STRONG;
WANG, 2002)
Confiabilidade (do inglês, trust-whorthiness) é diretamente positiva e em alguns casos
é definida como: trust, believability e reliability.
2.2.4. Precisão
Geralmente a definição de Precisão (do inglês, precision) é confundida com a definição de
acurácia (do inglês, accuracy). Aqui será feita uma distinção clara entre as duas definições.
(2.1)

25
Enquanto que acurácia quantifica a proximidade do valor observado com o valor real,
precisão mede a proximidade entre os valores observados (GRAY; SALBER, 2001).
Como ilustra a Figura 2.5, no primeiro alvo os resultados estão bastante próximos uns
dos outros, no entanto estão longe do valor desejado (centro do alvo), assim os valores tem uma
boa precisão, mas uma baixa acurácia. No alvo 2, os dados estão bastantes dispersos e também
longes do centro do alvo, logo há uma baixa acurácia e baixa precisão. No alvo três, os
resultados estão próximos do centro do alvo, mas dispersos entre si. Há, então, uma boa
acurácia, mas baixa precisão. Por fim, no alvo quatro, os resultados estão bastante próximos do
centro do alvo e bastante próximos entre si. Logo, há uma boa acurácia e boa precisão.
Precisão é tida como diretamente positiva e às vezes é definida como repeatability.
Figura 2.5: Ilustração de Accuracy e Precision
Fonte: Elaborado pelo Autor
2.2.5. Resolução
Resolução (do inglês, Resolution) diz respeito à granularidade do dado (GRAY; SALBER,
2001; BUCHHOLZ; KÜPPER; SCHIFFERS, 2003). Por exemplo, um termômetro que aferiu
a temperatura de um ambiente. Ora, temperatura é uma grandeza escalar, contínua. Ou seja,
cada ponto deste ambiente possui uma determinada temperatura. Assim, quanto mais
termômetros aferindo a temperatura local, maior será a resolução do dado temperatura. Afinal,
eventualmente o único termômetro do ambiente pode estar perto de um ar-condicionado e,
assim, aferir temperaturas mais baixas. De fato a temperatura está mais baixa próxima ao ar-
condicionado, mas não necessariamente reflete a temperatura de todo o ambiente.
2.2.6. Tempo de resposta
Tempo de resposta (do inglês, Response time) mede o tempo que vai desde o momento de envio
da solicitação até o total recebimento da resposta (ZHENG et al., 2011; KAHN; STRONG;

26
WANG, 2002). Tempo de resposta é inversamente positiva e em alguns casos é definida como:
latency, accessibility e rtt - route time trip.
2.2.7. Completude
Esta métrica mede o quanto de informação está disponível (ou faltando) e se ela é suficiente
para a realização de uma tarefa. KIM; LEE (2006) sugere que seja calculada como:
𝐶𝑜𝑚𝑝𝑙𝑒𝑡𝑢𝑑𝑒 =𝐴𝐷𝑇𝐷
em que: AD é quantidade de partes (que compõem o dado) estão disponíveis e TD é a
quantidade de partes que compõem completamente o dado.
Diretamente positiva, completude também foi definida como appropriate amount of
information.
Por fim, antes do contexto ser entregue ao consumidor final, é necessário identificar os
melhores provedores de elementos contextuais. Como visto acima, utilizar métricas de
qualidade nessa tarefa se mostra como uma abordagem bastante promissora. Algoritmos
utilizados em sistemas de recomendação, sobretudo aqueles que são capazes de lidar com
atributos de qualidade, serão abordados na próxima seção.
2.3. Algoritmos de ranqueamento
Como abordado anteriormente, os valores dos atributos de qualidade de entidades produtoras
de dados estão diretamente relacionados às necessidades do usuário. Ou seja, para um usuário
ou outro diferentes valores para custo, acurácia e disponibilidade, por exemplo, podem assumir
diferentes valores. Além disso, monitorar sempre estes valores e mensurar qual entidade é mais
apropriada que outra se mostra como uma tarefa desafiadora (ZHENG et al., 2011).
É importante, então, que a técnica de ranqueamento escolhida consiga lidar com a
dinamicidade inerente aos produtores de dados, já que estes podem mudar seus níveis de QoS
a todo momento. Além disso, é importante que a técnica seja leve, do ponto de vista do custo
computacional já que a recomendação de produtores de dados lida com uma quantidade cada
vez maior de candidatos a resultado. Assim, serão abordadas a seguir três técnicas apropriadas
para este cenário, segundo a literatura disponível.
(2.2)

27
2.3.1. Pearson Correlation Coefficient
A métrica Pearson Correlation mede o grau de linearidade entre duas variáveis (CHEN, 2005).
Como a similaridade entre dois itens pode ser dada pela correlação entre eles a métrica pearson
correlation vem sendo utilizada em diversos sistemas de recomendação, sobretudo aqueles
baseados na estratégia de filtragem colaborativa, que pode ser: baseado em usuário ou baseado
item (ZHENG et al., 2011). Pearson Correlation é dada pela Fórmula 2.3, sendo que sum(x, y)
é a covariância entre o conjunto de pontos x e y e σ é o desvio padrão (AMATRIAIN et al.,
2011).
𝑃𝑒𝑎𝑟𝑠𝑜𝑛(𝑥, 𝑦) = ∑(𝑥, 𝑦)
σ𝑥 . σ𝑦
O método baseado em usuário é utilizado para comparar a similaridade entre dois
usuários tomando como base os serviços requisitados ou avaliados por ambos. Assim,
considerando que I é o conjunto de itens avaliados pelos usuários a e u, a similaridade entre
eles pode ser calculada pela expressão (DESROSIERS; KARYPIS, 2011; ZHENG et al., 2011):
𝑆𝑖𝑚(𝑎, 𝑢) =∑ (𝑤𝑎,𝑖 − �̅�𝑎)(𝑤𝑢,𝑖 − �̅�𝑢)𝑖∈𝐼
√∑ (𝑤𝑎,𝑖 − �̅�𝑎)2
𝑖∈𝐼 √∑ (𝑤𝑢,𝑖 − �̅�𝑢)2
𝑖∈𝐼
Onde: ai é a avaliação dada pelo usuário a ao item i; wui é a avaliação dada pelo usuário
u ao item i; wa e wu representam as médias das avaliações dadas pelos usuários a e u.
Da mesma forma, o método baseado em item é utilizado para calcular a similaridade
entre dois itens i e j. Considerando que U é o conjunto de usuários que requisitaram ou
avaliaram determinado item i e j, a similaridade entre estes dois itens pode ser calculada pela
expressão (DESROSIERS; KARYPIS, 2011; ZHENG et al., 2011):
𝑆𝑖𝑚(𝑖, 𝑗) =∑ (𝑤𝑢,𝑖 − �̅�𝑢)(𝑤𝑢,𝑗 − �̅�𝑗)𝑢∈𝑈
√∑ (𝑤𝑢,𝑖 − �̅�𝑖)2
𝑢∈𝑈 √∑ (𝑤𝑢,𝑗 − �̅�𝑗)2
𝑢∈𝑈
Onde: wui é a avaliação dada pelo usuário u ao item i; wuj é a avaliação dada pelo usuário
u ao item j; wi e wj representam as médias das avaliações dadas aos itens i e j.
O cálculo da métrica Pearson Correlation pode considerar atributos de qualidade uma
vez que, no método de similaridade baseada em usuário, wui representa o vetor de valores QoS
do item i observado por u. Assim como, na similaridade baseada em item, wui representa o vetor
de valores de QoS do i observado por u. Como os valores do Pearson Correlation estão contidos
(2.3)
(2.4)
(2.5)

28
no intervalo [-1, 1], quanto mais próximo de -1, mais distintos são os itens avaliados. Quanto
mais próximo de 1, mais semelhantes são os itens avaliados.
2.3.2. Cosine Vector
O Cosine Vector é uma técnica bastante utilizada em cálculo de similaridade entre documentos.
Sua lógica consiste em representar entidades em um espaço vetorial multidimensional.
Considerando que uma entidade u tenha n atributos de qualidade, o espaço terá n dimensões e
cada um destes atributos de qualidade será representado por um dos eixos coordenados. Ou
seja, 𝑢 ∈ ℝ𝑛 onde ui = uj se a entidade já possui valor para o item i ou ui = 0, caso contrário
(DESROSIERS; KARYPIS, 2011). Para fins de representação, a Figura 2.6 considera três
atributos de qualidade (eixos x, y, e z) e ilustra três entidades (vetores C, D e E).
Figura 2.6: Ilustração do Cosine Vector.
Fonte: Elaborado pelo Autor
Após representar as entidades como vetores em um espaço multidimensional, a técnica
utiliza a expressão 2.6 para calcular o ângulo entre eles.
𝑆𝑖𝑚(𝑑𝑖, 𝑑𝑗) =∑ 𝑤𝑘𝑖. 𝑤𝑘𝑗𝑘
√∑ 𝑤𝑘𝑖2
𝑘 √∑ 𝑤𝑘𝑗2
𝑘
Esta técnica considera que quanto menor o ângulo entre dois vetores, mais semelhantes
eles são. Como ilustrado na Figura 2.6, o ângulo entre os vetores C e D é menor que o ângulo
entre os vetores D e E, logo os vetores C e D são mais semelhantes que D e E. Da mesma forma
os vetores C e E tem a menor similaridade neste espaço.
(2.6)
29
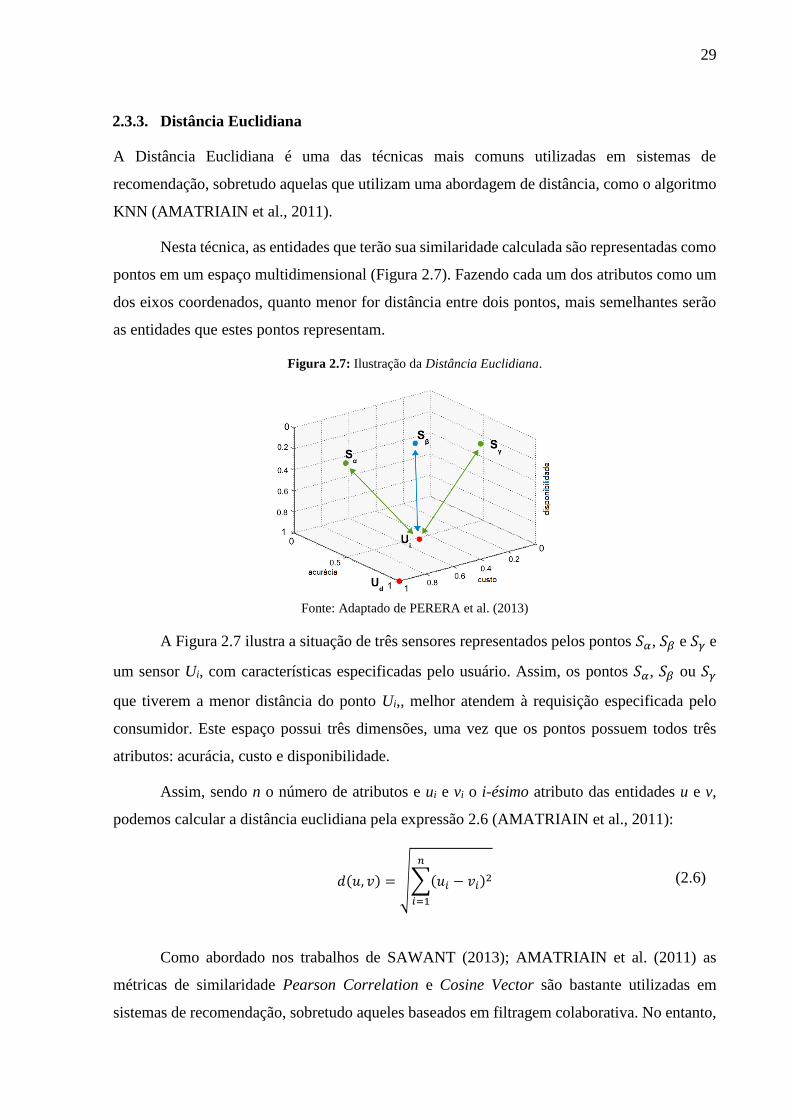
2.3.3. Distância Euclidiana
A Distância Euclidiana é uma das técnicas mais comuns utilizadas em sistemas de
recomendação, sobretudo aquelas que utilizam uma abordagem de distância, como o algoritmo
KNN (AMATRIAIN et al., 2011).
Nesta técnica, as entidades que terão sua similaridade calculada são representadas como
pontos em um espaço multidimensional (Figura 2.7). Fazendo cada um dos atributos como um
dos eixos coordenados, quanto menor for distância entre dois pontos, mais semelhantes serão
as entidades que estes pontos representam.
Figura 2.7: Ilustração da Distância Euclidiana.
Fonte: Adaptado de PERERA et al. (2013)
A Figura 2.7 ilustra a situação de três sensores representados pelos pontos 𝑆𝛼, 𝑆𝛽 e 𝑆𝛾 e
um sensor Ui, com características especificadas pelo usuário. Assim, os pontos 𝑆𝛼, 𝑆𝛽 ou 𝑆𝛾
que tiverem a menor distância do ponto Ui,, melhor atendem à requisição especificada pelo
consumidor. Este espaço possui três dimensões, uma vez que os pontos possuem todos três
atributos: acurácia, custo e disponibilidade.
Assim, sendo n o número de atributos e ui e vi o i-ésimo atributo das entidades u e v,
podemos calcular a distância euclidiana pela expressão 2.6 (AMATRIAIN et al., 2011):
𝑑(𝑢, 𝑣) = √∑(𝑢𝑖 − 𝑣𝑖)2
𝑛
𝑖=1
Como abordado nos trabalhos de SAWANT (2013); AMATRIAIN et al. (2011) as
métricas de similaridade Pearson Correlation e Cosine Vector são bastante utilizadas em
sistemas de recomendação, sobretudo aqueles baseados em filtragem colaborativa. No entanto,
(2.6)

30
uma de suas principais implicações é a necessidade de avaliações explícitas dos consumidores
sobre os resultados sugeridos.
Como em internet das coisas, não apenas humanos são consumidores, mas também
serviços e até mesmo outros dispositivos, a exigência de avaliações explícitas dos resultados se
torna inviável. Mesmo que os consumidores fossem apenas humanos, avaliar cada resultado
ainda seria uma tarefa inviável, dada a grande quantidade de resultados possíveis. De fato,
segundo ZHENG et al. (2011); ZHAO et al. (2014), outro grande problema em sistemas de
recomendação baseados em filtragem colaborativa é que a matriz itens x avaliações é muito
esparsa, ou seja, as avaliações se concentram em poucos itens. Trabalhos como ZHENG et al.
(2011); SAWANT (2013); CHEN (2005) sugerem estratégias para predição de avaliações,
aumentando a complexidade da técnica.
ZHENG et al. (2011) aplicam as métricas de similaridade Pearson Correlation e Cosine
Vector considerando as entidades a serem recomendadas como vetores de valore QoS (por
exemplo, tempo de resposta, disponibilidade entre outros). No entanto, ainda assim alguns
problemas persistem e permanecem em aberto. Estas técnicas não consideram a diferença de
prioridade entre os atributos de qualidade declarados explicitamente na estratégia de busca
sobre aqueles são declarados, mas ainda assim monitorados pelos catálogos de produtores de
dados em internet das coisas, como visto na seção 2.2. A métrica de distância euclidiana
também lida com este mesmo problema, sobretudo quando as dimensões dos dados importam.
Segundo AMATRIAIN et al. (2011), pearson correlation e cosine similarity são consideradas
as melhores escolhas para sistemas de recomendação, muito embora melhoramentos possam
ser sugeridos para cada tipo de aplicação.
Como o contexto de aplicação deste trabalho lida com entidades produtoras de dados
totalmente autônomas e dinâmicas, podendo alterar seus atributos de QoS a todo o momento, a
métrica de similaridade cosine vector se mostra mais flexível que pearson correlation e
distância euclidiana, uma vez que ela pode oferecer formas de lidar com os problemas
mencionados acima sem implicar em aumento considerável de custo computacional. A técnica
sugerida por este trabalho será melhor detalhada no capítulo 3.
2.4. Trabalhos Relacionados
Esta seção abordará alguns trabalhos disponíveis na literatura que possuem alguma afinidade
com o atual. Foram considerados trabalhos que tenham proposto algum catálogo de entidades

31
produtoras de dados, como sensores, mostrando preocupação com a descoberta, busca, seleção
e a provisão destes. Além disso considerando, se possível, a inclusão de qualidade no processo
de descoberta. Três trabalhos principais mostraram afinidade com o tema atual, cada qual com
suas peculiaridades, que serão mostradas nas seções a seguir. São eles: PERERA et al. (2013),
LUNARDI et al. (2015) e GUINARD et al. (2010).
2.4.1. Mecanismos de busca
Segundo GUINARD et al. (2010), antes que uma entidade contextual - aquela que fornece
elementos contextuais (VIEIRA; TEDESCO; SALGADO (2009)) - possa ser utilizada por uma
aplicação, um serviço de descoberta deve ser acionado para verificar se a descrição desta
entidade é compatível com a descrição fornecida na requisição de uma aplicação. Assim,
mecanismos de busca devem ser propostos com o objetivo de fornecer apenas aqueles objetos
que melhor respondem à necessidade da aplicação. No passado, vários trabalhos faziam a
recomendação de objetos baseada apenas na comparação de palavras chave, fornecidas ao
mecanismo de busca, com a descrição destes objetos. No entanto, dada a heterogeneidade e
quantidade de objetos disponíveis, outras técnicas foram sendo propostas, como a utilização de
ontologias e buscas semânticas. No entanto, para este trabalho, preferiu-se considerar que os
produtores de dados possuem características próprias, heterogêneas e não estáticas. Assim, foi
considerado incluir indicadores de qualidade na descrição dos produtores de dados e que são
verificados e atualizados a todo o tempo.
Figura 2.8: Visão geral da proposta de GUINARD et al. (2010).
Fonte: Adaptado de GUINARD et al. (2010).

32
GUINARD et al. (2010) propõem um serviço de descoberta, busca e seleção de serviços
do mundo real (sensores e atuadores) chamado RSDPP (Real World Service Discovery and
Provisioning Process), como ilustrado na Figura 2.8.
O processo tem início na etapa de Types Query, na qual o consumidor elabora sua
estratégia de consulta, definindo o serviço que ele busca, por meio de palavras chave. Serviços
web são utilizados para expandir os termos informados pelo consumidor utilizando sinônimos.
Foram utilizados repositórios de conhecimento, como o Wikipedia, e mecanismos de busca,
como: Google e Yahoo!.
A estratégia de busca do consumidor após ser “aumentada” é usada para descobrir quais
serviços descrevem tal funcionalidade, mas não ainda os dispositivos físicos em si.
Na etapa Candidate Search são localizados os dispositivos considerados candidatos a
responderem de forma adequada à solicitação realizada. Além de considerar a estratégia de
busca aumentada na etapa anterior, também é considerada informação de qualidade destes
dispositivos. Foram consideradas informações de QoS: disponibilidade e latência de rede.
Caso a etapa candidate search não encontre candidatos, então é realizada a etapa
opcional Provisioning para uma descoberta forçada de serviços.
Figura 2.9: Visão geral da proposta de PERERA et al. (2013).
Fonte: Adaptado de PERERA et al. (2013).
Outro trabalho próximo ao atual, em termos mecanismo de busca foi o proposto por
PERERA et al. (2013). O fluxo de atividades segue aquele ilustrado na Figura 2.9. Como usual,
primeiro é elaborada a estratégia de busca, no qual o consumidor informa quais atributos de

33
qualidade são apropriados à sua necessidade. Foram considerados no trabalho de PERERA et
al. (2013): disponibilidade, acurácia, reliability, tempo de resposta, frequência, sensitividade,
intervalo de medida, seletividade, precisão, latência, drift, resolução, detecção de limite, nível
de energia, tempo de vida, bateria, segurança, acessibilidade, robustez, exceção,
interoperabilidade, configurabilidade, satisfação do usuário, capacidade, throughput, custo de
transmissão de dados, custo de geração de dados, custo de consumo de dados, largura de banda
e confiança.
Figura 2.10: Prioridade entre os atributos de qualidade
Fonte: Adaptado de PERERA et al. (2013).
Como ilustrado na Figura 2.10, o consumidor além de selecionar quais atributos de
qualidade são relevantes à sua aplicação também configura o nível de prioridade que eles
possuem. Através de uma barra deslizante é possível distribuir diferentes pesos de importância
aos atributos. Na figura percebe-se que acurácia possui uma prioridade maior que custo e
energia.
Após a elaboração da busca, ela é submetida e processada utilizando SPARQL, uma vez
que os sensores são descritos através de ontologias, e são identificados os sensores candidatos
a responderem adequadamente a requisição. Por fim, estes candidatos são ranqueados após a
aplicação da técnica de distância euclidiana ponderada através da representação dos sensores
em um espaço multidimensional.
Já o trabalho de LUNARDI et al. (2015) implementa um mecanismo de busca chamado
COBASEN (COntext-BAsed Search ENgine), ilustrado pela Figura 2.11. A busca começa com
a elaboração de uma query formada por palavras chave. Há uma tabela de índice invertido que
ajuda a localizar os sensores que possuem um alto grau de similaridade com a string de busca
submetida. Os resultados são listados, como ilustrado na Figura 2.12, e o consumidor pode,
então, selecionar as opções que mais se adequam à sua necessidade, considerando as
características apresentadas.

34
Figura 2.11: Visão geral do COBASEN
Fonte: Adaptado de LUNARDI et al. (2015).
Como o COBASEN utiliza o conceito de publish-subscribe, é possível que o
consumidor configure parâmetros para que seja sempre notificado por novos resultados que
satisfaçam suas condições.
Figura 2.12: Interface da ferramenta de busca proposta por LUNARDI et al. (2015).
Fonte: Elaborado por LUNARDI et al. (2015)}
2.4.2. Limitações dos trabalhos relacionados
Observa-se que das três propostas, apenas o trabalho PERERA et al. (2013) possui uma
estratégia de busca estruturada. Os trabalhos de GUINARD et al. (2010) e LUNARDI et al.
(2015) aceitam como busca sequências de palavras chave que descrevem o fenômeno que se
quer observar, detalhes de descrição dos dispositivos ou níveis de qualidade. GUINARD et al.

35
(2010), como foi discutido, utiliza dicionários para expandir as palavras chave. No entanto, um
problema desta abordagem é o retorno de falsos sinônimos, ou sinônimos que apontam para
nenhum dispositivo. GUINARD et al. (2010) cita, por exemplo que utilizando de 5 a 10 palavras
chave sugeridas é apresentado um índice de 20% de falsos positivos, ou que aproximadamente
50% das palavras utilizadas contra o wikipedia não levam a nenhum artigo. Estes
comportamentos além de implicarem em desperdício de recurso, podem aumentar o tempo de
resposta do mecanismo de busca.
Por outro lado, observando apenas sob a perspectiva da técnica de ranqueamento
utilizada, apenas o trabalho proposto por PERERA et al. (2013) utiliza algum cálculo explícito.
LUNARDI et al. (2015) e GUINARD et al. (2010) são altamente dependentes de similaridades
entre palavras chave. LUNARDI et al. (2015), por exemplo aceita string de busca em linguagem
natural, como “available temperature device situated in Northwest silo 13”. Para lidar com essa
abordagem, a proposta de LUNARDI et al. (2015) faz uso da ferramenta de indexação Apache
Lucene.
Por fim, um aspecto negativo presente nos trabalhos de LUNARDI et al. (2015) e
PERERA et al. (2013) é que eles exigem a interação explícita de um consumidor, humano,
através de uma interface gráfica, selecionando itens manualmente e configurando valores
através de componentes gráficos. Por outro lado, assim como GUINARD et al. (2010), o
presente trabalho pretende implementar uma interface REST, através da qual os dispositivos
possam ser ofertados como recurso e acessados através de verbos HTML (GET, POST, PUT,
DELETE).
2.5. Resumo do capítulo
Este capítulo trouxe toda a fundamentação teórica necessária para a leitura do trabalho,
abordando os temas qualidade de dados, de serviço e de contexto, além de algoritmos de
ranqueamento. Por fim, foram discutidos três trabalhos relacionados à proposta do trabalho
atual. O principal objetivo deste capítulo foi ilustrar o atual estado da arte, suas oportunidades
de pesquisa e ambientar o leitor à próxima seção.

36
3. Proposta
Neste capítulo será discutida a motivação, os requisitos e a implementação das propostas
discutidas no Capítulo 1. Como forma de integração e validação a um catálogo já existente, foi
considerado o Waldo, proposto por OLIVEIRA; GAMA; LÓSCIO (2015).
3.1. Motivação
Com o paradigma da Internet das Coisas, diversos tipos de dispositivos estarão conectados
produzindo todos os tipos de dados. Sensores domésticos de temperatura ou presença,
semáforos, sensores de velocidade e câmeras de monitoramento nas cidades, sensores de
umidade e temperatura em plantações, carros autônomos, drones entre outros.
Uma categoria de produtores de dados, em especial, ganhou o nome de crowdsensing
(GANTI; YE; LEI, 2011), que é a participação da multidão, formada por pessoas comuns,
equipada com seus dispositivos usuais (como smartphones, relógios ou pulseiras inteligentes
entre outros) produzindo dados a todo o momento. A partir do crowdsensing diversos tipos de
aplicações, antes inviáveis, se tornam possíveis através da colaboração de terceiros. Um
exemplo clássico é o aplicativo Waze. Através dele motoristas podem encontrar as rotas mais
curtas para seu destino considerando a situação em tempo real do trânsito. Em contra partida,
enquanto acompanham a rota sugerida pelo aplicativo, os motoristas também contribuem
implicitamente com sua localização e velocidade para que o aplicativo verifique a situação da
sua via e utilize essa informação no cálculo de recomendação rota para outros usuários.
Outro aplicativo que faz uso do crowdsensing e que tem reação direta com a motivação
deste trabalho é o BikeCidadão (DINIZ et al., 2016). O objetivo deste aplicativo é oferecer rotas
seguras para ciclistas e motoristas, permitindo uma interação harmoniosa entre esses integrantes
do trânsito que, como se sabe, possuem potencial risco de colisão. Motoristas que utilizam o
BikeCidadão são notificados quando há aproximação de algum ciclista logo adiante, bem como
notificação de eventos diversos como acidentes, problemas no asfalto, desvios entre outros.
Ciclistas que utilizam o BikeCidadão são notificados da aproximação de veículos e dos mesmos
eventos externos do motorista (acidentes, problemas no asfalto, desvios entre outros).
Assim como o Waze, inúmeros aplicativos sensíveis a contexto podem ser
implementados utilizando uma vasta quantidade de entidades contextuais (produtores de dados)
autônomas, com características diversas e dinâmicas. Mas, como selecionar as melhores
entidades contextuais? Dado que os produtores de dados do Waze ou do BikeCidadão, por

37
exemplo, são responsáveis por fornecer os dados mais críticos para o bom funcionamento do
sistema, como selecionar aqueles que possuem as melhores características para as necessidades
da aplicação? Quais são estas características? Como descrever e entender os dados produzidos
por tantos produtores diferentes?
3.2. Visão geral do Waldo
OLIVEIRA; GAMA; LÓSCIO (2015) propuseram um catálogo de produtores de dados
chamado Waldo. O catálogo possui a arquitetura ilustrada na Figura 3.1. Seus componentes
principais são: dois repositórios para armazenamento da descrição dos produtores de dados e
vocabulários; e três módulos (Registro, Monitor e Registro de Vocabulário).
Registro é o módulo responsável por adicionar, atualizar, remover e buscar produtores
de dados. No Waldo as buscas são realizadas apenas considerando parâmetros como fenômeno
de interesse, identificador entre outros atributos em seus metadados.
Figura 3.1: Arquitetura do Waldo
Fonte: Elaborado por OLIVEIRA; GAMA; LÓSCIO (2015)
Monitor é o módulo responsável por verificar se os produtores de dados registrados
continuam ativos. Como se sabe que os indivíduos do paradigma crowdsensing são autônomos,
seu comportamento é imprevisível e podem se tornar temporariamente, ou não, indisponíveis.
Por exemplo, um usuário do BikeCidadão, discutido na Seção 3.1, por economia se desconecta
de sua rede de dados ou passa por uma localidade que não há cobertura da rede de telefonia ou
simplesmente tem a bateria do seu aparelho descarregada. Nesse caso, o Monitor de tempos em
tempos se encarrega de manter o catálogo atualizado de quem ainda está disponível e apto a ser
consultado.

38
O Módulo de Vocabulário se encarrega de administrar os termos utilizadas para a
interoperabilidade na comunicação os componentes do próprio Waldo ou do Waldo com
sistemas externos.
Apesar do trabalho de OLIVEIRA; GAMA; LÓSCIO (2015) ter demonstrado que sua
proposta é viável para o contexto de internet das coisas e cidades inteligentes ainda carece de
um mecanismo de busca mais refinado. Afinal, como dito na descrição do módulo de Registro,
as buscas são realizadas apenas por palavras chave sobre fenômenos de interesse ou atributos
específicos dos metadados de descrição dos produtores de dados, desconsiderando, por
exemplo, sua característica inata de dinamicidade.
Como visto no Capítulo introdutório, o presente trabalho propõe e implementa uma
técnica de ranqueamento de fontes produtoras de dados em internet das coisas que: (i) utilize
seus indicadores de qualidade como parâmetros, (ii) que seja viável sob a perspectiva do custo
computacional e do tempo de resposta; Propõe, implementa e avalia uma abordagem para
economia de processamento computacional e ganho de desempenho nas recomendações
realizadas pelo mecanismo de busca. Assim, o catálogo Waldo se mostra como uma boa opção
para a validação das estratégias propostas. Os requisitos adicionais, recorrentes deste trabalho,
são discutidos na Seção 3.3.
3.3. Requisitos
Como visto anteriormente, o Waldo possui um mecanismo de busca simples, reduzido a busca
por atributos básicos de descrição, como: identificador, nome, localização entre outros. No
entanto, como discutido na Seção 3.1, sobre a Motivação, em diversas situações, sobretudo em
aplicações de crowdsensing, é necessário levar em consideração a qualidade daqueles
produtores de dados nos quais estamos confiando a nossa aplicação. Dessa forma, o presente
trabalho propõe, por consequência, um mecanismo de busca mais elaborado a catálogos de
produtores de dados, que considere seus atributos de qualidade como critérios de seleção. As
implementações que pretendem atingir os objetivos elencados no Capítulo 1 serão adicionados
como módulos ao catálogo Waldo apenas para efeito de execução e de avaliação. No entanto,
as contribuições deste trabalho podem ser acopladas a qualquer outro catálogo de produtores
de dados interessado. Assim, os objetivos de pesquisa apresentados no Capítulo 1 serão
mostrados aqui como requisitos de um catálogo de produtores de dados.

39
3.4. Requisitos funcionais
Ao propor alguma estratégia de busca deve-se, primeiramente, delinear a estratégia de seleção,
ranqueamento e recomendação. Várias abordagens são propostas, até mesmo considerando
atributos de qualidade de produtores de dados, como o presente trabalho. Para citar: rede neural
com backpropagation (NWE; BAO; GANG, 2014), algoritmos genéticos (YANG; LI, 2014)
colônia de abelhas (YANG; LI, 2014), técnicas de filtragem colaborativa com pearson
correlation (ZHAO et al., 2014; LEI et al., 2012; NIU et al., 2014; ZHENG et al., 2011),
distância euclidiana (PERERA et al., 2013; ZHAO et al., 2014), AHP (YUEN; WANG, 2014)
entre outros.
No entanto, diversas dessas técnicas são complexas demais e demandam muito
processamento, resultando em um longo tempo de resposta. Por exemplo, algoritmos genéticos,
colônia de abelhas, grafos entre outros são problemas típicos de complexidade NP. Além disso,
técnicas como AHP e filtragem colaborativa exigem a interação explícita de um humano através
de uma interface gráfica. Este comportamento não é desejado, uma vez que no contexto de
internet das coisas são os próprios dispositivos que conversam uns com os outros, de forma
autônoma.
Assim, deseja-se que o mecanismo de busca seja rápido e exija o mínimo, ou nenhuma
interação explícita. Os requisitos do mecanismo de busca proposto serão discutidos a seguir.
3.4.1. [RF001] O mecanismo de busca deve considerar indicadores de qualidade como
parâmetros
Prioridade: Essencial
Descrição:
Como visto na Seção 2.2, os produtores de dados além de terem atributos de descrição
esperados, como código identificador, nome, localização, dados do proprietário entre outros,
também possuem atributos de qualidade diversos. Estes atributos devem ser considerados pelo
cálculo de ranqueamento do mecanismo de busca.
A estratégia adotada foi embasada na técnica de similaridade Cosine Vector (LOPS; DE
GEMMIS; SEMERARO, 2011). No entanto, há dois pontos de melhoria desta técnica em nosso
contexto de aplicação.
a) A técnica cosine vector não considera o tamanho dos vetores. Vamos assumir que um
dos vetores do espaço n-dimensional é o vetor ideal (vetor I). Ou seja, aquele possui o

40
valor máximo dentro do domínio de cada um dos eixos coordenados. Dessa forma, para
um vetor ser considerado ótimo (próximo ao vetor ideal I) não basta apenas que o angulo
entre eles seja o menor possível, mas também que a diferença entre a norma
(comprimento) dos vetores seja a menor possível.
b) A técnica dá a mesma prioridade para os atributos informados explicitamente na
requisição e os outros atributos também monitorados pelo catálogo, mas não
explicitados na estratégia de busca. Ou seja, considerando que o catálogo monitora as
os atributos de qualidade a1, a2, a3, a4, a5 e a6, mas a consulta realizada explicita apenas
níveis de qualidade dos atributos a1 e a2, entende-se que os atributos a1 e a2 possuem
uma relevância maior que os outros. No entanto, mesmo assim é desejável que os outros
atributos também tenham os melhores níveis possível. Por exemplo, uma requisição
solicita produtores de dados com disponibilidade acima de 95%. Sabendo que há apenas
duas opções disponíveis. Opção(1): disponibilidade = 93%, tempo de resposta =
9000ms e opção(2): disponibilidade = 92%, tempo de resposta = 500ms torna a
opção(2) muito mais desejável que a primeira.
Assim, tendo como base a técnica Cosine Vector e assumindo as duas lacunas
apresentadas acima, sugere-se a seguinte técnica de Cosine Vector melhorada:
𝑆𝑐𝑜𝑟𝑒(𝑎) =∑ 𝐼𝑘𝑖. 𝑎𝑘𝑗𝑘
√∑ 𝐼𝑘𝑖2
𝑘 √∑ 𝑎𝑘𝑗2
𝑘
∗ (𝜌 ∗‖√∑ 𝑎𝑒
2𝑘 ‖
‖√∑ 𝐼𝑒2
𝑘 ‖)+ (1 − 𝜌) ∗
(
‖√∑ 𝑎𝑖
2𝑘 ‖
‖√∑ 𝐼𝑖2
𝑘 ‖)
𝑆𝑐𝑜𝑟𝑒(𝑎) = cos (𝐼, 𝑎) ∗ (𝜌 ∗‖𝑎𝑒‖
𝐼𝑒) + (1 − 𝜌) ∗
‖𝑎𝑖‖
𝐼𝑖
Em que:
I é o vetor ideal;
a é o vetor que se deseja ranquear;
||ae|| é a norma do subvetor de a formado apenas pelos atributos de qualidade explícitos
na requisição;
||ai|| é a norma do subvetor de a formado apenas pelos atributos de qualidade implícitos
na requisição;
||Ie|| é a norma do subvetor de I formado apenas pelos atributos de qualidade explícitos
na requisição;
(3.1)

41
||Ii|| é a norma do subvetor de I formado apenas pelos atributos de qualidade implícitos
na requisição;
ρ é um fator de ponderação. A escolha do nível deste parâmetro é descrita na Seção 6.2;
Como discutido na Seção 2.2, várias métricas de qualidade (de serviço, contexto ou
dispositivo) são propostas na literatura. Além da lista de métricas discutidas naquela Seção, há
também as métricas de qualidade apresentadas a seguir, na Tabela 3.1, que podem ser
consideradas na Equação 3.1 proposta.
Tabela 3.1: Métricas de qualidade
Nome Descrição
Acurácia
Acurácia (Accuracy) mede o quão próximo um dado observado está do valor real. Esta
métrica é diretamente positiva e está totalmente relacionada às capacidades físicas do
dispositivo que realizou a observação. Assim, geralmente é informada pelas
especificações técnicas do fabricante (GRAY; SALBER, 2001; JUDD; STEENKISTE,
2003).
Disponibilidade
Disponibilidade (availability) mede qual a parte do tempo que o serviço está disponível.
Seu cálculo é dado pela seguinte fórmula:
Disponibilidade = 1 - TaxaDeErro = Uptime
TaxaDeErro é a porcentagem de requisições que são enviadas mas não são respondidas
por qualquer falha do servidor. Dessa forma, Disponibilidade e uma métrica dada em
porcentagem.
Outra forma mais elaborada de se calcular disponibilidade é dada pela seguinte fórmula:
𝑀𝑇𝑇𝐹
𝑀𝑇𝑇𝐹 +𝑀𝑇𝑇𝑅
Em que: MTTF é o tempo médio entre falhas e MTTR é o tempo médio para reparo das
falhas. Para este trabalho foi considerada a expressão 3.2
Memória
Memória disponível informa quanto de memória o dispositivo tem disponível para uso.
Sua importância está no fato de quem um dispositivo sobrecarregado aumenta seu tempo
de resposta ou até mesmo se torna incapaz de responder a novas requisições. Geralmente
é dado em kilobytes, megabytes ou gigabytes.
Largura de
Banda
Largura de Banda é a taxa de transferência de dados por segundo. Geralmente é dado em
bits por segundo (bits/s).
Nível de bateria Nível de bateria informa qual o a carga atual de energia na bateria do dispositivo.
Normalmente o nível é dado em porcentagem.
(3.2)
(3.3)

42
Custo
Esta métrica informa o custo de consumo do dado produzido. Alguns trabalhos sugerem
outros custos, como custo de produção do dado ou custo de transmissão do dado. No
entanto, para este trabalho, resumiu-se ao custo final de acesso ao dado, que é o custo de
interesse à aplicação consumidora.
Frequência
Frequência informa qual o intervalo de tempo médio entre duas produções de dados
sequenciais e pode ser dado pela seguinte fórmula:
Frequencia(t) = qtdeMedicoes ∗ Frequencia(t − 1) + tempoMedicao
qtdeMedicoes + 1
Em que: Frequencia(t) é a frequência atual, Frequencia(t-1) é a frequência calculada
pela última vez, qtdeMedicoes é a quantidade de produção de dados realizada até o
momento e tempoMedicao é o intervalo de tempo entre a produção de dado atual e a
última realizada.
Confiabilidade
Confiabilidade é a confiança que os consumidores possuem sobre esta fonte de dado.
Muito semelhante a probability of correctness, no entanto, esta métrica quantifica a
confiança na entidade que proveu o elemento contextual e não o elemento propriamente
dito (BUCHHOLZ; KÜPPER; SCHIFFERS (2003); XU; CHEUNG (2005); KAHN;
STRONG; WANG, (2002)) Geralmente é dada por avaliações. Neste trabalho foi
considerada como um elemento presente no perfil da fonte de dado.
Resolução Resolução mede a abrangência da observação feita pelo dispositivo. Ou seja, resolução
se refere à granularidade da informação BUCHHOLZ; KÜPPER; SCHIFFERS (2003).
Tempo de
Resposta
Tempo de resposta informa o tempo médio entre o envio de uma solicitação e o
recebimento da resposta.
TR(t) = qtdeMedicoes ∗ TR(t − 1) + tempoVerificado
qtdeMedicoes + 1
Em que: TR(t) é o tempo de resposta médio que se deseja atualizar, TR(t-1) é o tempo
médio de resposta até o momento, qtdeMedicoes é a quantidade de medições recebidas
até o momento e tempoVerificado é o tempo de resposta verificado na medição atual.
Vazão
É a quantidade de produção de dados por unidade de tempo. Por ter uma relação indireta
com Frequência, pode ser calculado por:
𝑉𝑎𝑧𝑎𝑜 = unidadeDeTempo
Frequencia
Dessa forma, Vazão é dada por produção por minuto (ou qualquer unidade de tempo
conveniente).
(3.4)
(3.5)
(3.5)

43
Atualidade
Atualidade (ou Up to Dateness) é o tempo que passa desde o momento em que o dado
foi produzido até o momento em que ele é requisitado. Ou seja, é relacionado à idade do
dado.
Atualidade = momentoAtual - momentoDaProducaoDoDado
Assim, Atualidade é dado em unidades de tempo.
3.4.2. [RF002] O mecanismo de busca deve implementar uma heurística para otimizar
as operações de busca.
Prioridade: Essencial
Descrição:
Assumindo que a quantidade de produtores de dados registrados possa ser
excessivamente grande, o mecanismo de busca pode implementar heurísticas para lidar com o
trabalho do recálculo de ranqueamento a cada consulta submetida ao catálogo. De fato, no
modelo tradicional de busca o Waldo faria sempre o mesmo trabalho a cada consulta: buscar,
ranquear e entregar.
LUNARDI et al. (2015) mostra que existem duas formas de busca, no nosso caso, busca
de produtores de dados: ou por consultas realizadas por iniciativa do consumidor, ou utilizando
o padrão publish/subscribe, através do qual o consumidor é notificado a cada atualização (novo
resultado disponível). A estratégia implementada no Waldo, neste trabalho chamada de Fila
Dinâmica, é um híbrido dessas duas opções.
Figura 3.2: Ilustração da Fila dinâmica
Fonte: Elaborado pelo Autor
(3.6)

44
Como ilustrado na Figura 3.2, uma vez que uma nova requisição é submetida, os
resultados são entregues ao consumidor, uma fila é criada no catálogo e preenchida com os
mesmos resultados. Então, quando o consumidor executa sua próxima requisição, o processo
de busca e ranqueamento não é executado, mas são entregues os resultados presentes nesta fila.
No entanto, como foi discutido em seções anteriores, os produtores de dados são
autônomos e tem característica dinâmica, podendo alterar seus atributos de qualidade ou deixar
de responder a critérios da requisição como, por exemplo, estar a uma distância máxima de 200
metros da coordenada geográfica (-8.053745,-34.884442). Nesse caso, de tempo em tempo é
verificado se os resultados presentas na fila dinâmica ainda satisfazem os critérios da requisição
inicial. Se o resultado não satisfaz então é excluído da fila dinâmica. Se satisfaz, mesmo que os
níveis de qualidade ou outras restrições tenham diminuído o resultado permanece na fila.
Na situação ilustrada pela Figura 3.2, as setas azuis representam os níveis de qualidade
especificados na requisição do consumidor. Percebe-se que o consumidor explicitou níveis de
qualidade apenas para os atributos de qualidade a1 e a3. O primeiro resultado da fila atende aos
critérios. No entanto, o segundo resultado da fila deixou de atender o nível especificado para o
atributo 3. Portanto, o resultado 2 é excluído da fila dinâmica e deixa de ser recomendado como
resultado ao consumidor.
À medida que os produtores de dados na fila dinâmica deixam de atender aos requisitos
e vão sendo excluídos a fila vai sendo reduzida e, eventualmente, pode deixar de atender
satisfatoriamente a consulta inicial. Nesse momento a consulta é reenviada e a fila é novamente
populada com novos resultados.
3.5. Requisitos não funcionais
3.5.1. [RNF001] O mecanismo de busca do catálogo não deve ser comprometido pela
técnica de ranqueamento proposta
Prioridade: Essencial
Descrição: O mecanismo de busca deve lidar com a questão de performance, executando
cálculo de ranqueamento no menor tempo que for possível. Assim, é necessário que [RF001]
tenha um tempo de resposta menor ou igual às técnicas já existentes e consideradas: pearson
correlation e cosine vector.

45
3.5.2. [RNF002] Flexibilidade no esquema dos dados armazenados
Prioridade: Essencial
Descrição:
O banco de dados utilizado deve ser capaz de armazenar e manipular dados com esquemas
dinâmicos, assim como lidam os bancos de dados NoSQL. Como as descrições dos produtores
de dados são dados em formato de documentos JSON, o Waldo deve utilizar o MongoDB.
SILVA et al. (2015) verificou que das 35 plataformas de dados para IoT mais relevantes
para a indústria, 20 delas afirmam possuir algum modelo de dados, 5 não adotam algum modelo
e 10 não apresentam esta informação. Destas 20 plataformas que utilizam algum modelo,
apenas 7 adotaram algum padrão de modelo de dados proposto por algum consórcio. São elas:
Fi-ware7 que adota os padrões NGSI e SensorML, Xively8 que adota o EEML, KaaProject9 que
adota o ApacheAvro, Amee10 que adota o AMON, Zettajs11 com o Siren, Sofia212 com o
AMON e o Common Alerting Protocol (CAP) e, por fim, Prismthech13 como Object
Management Group (OMG) e o Data Distribution Service (DDS).
SILVA et al. (2015) notou que há um movimento, que caminha em direção oposta à
interoperabilidade, em que cada projeto propõe seu próprio modelo de dados, ou implementa
um modelo de dados proprietário. Assim, caso seja necessário a comunicação de objetos
diversos, destes com a plataforma de dados ou entre si, torna-se necessário a implementação de
adaptadores ou parsers para uma comunicação adequada.
No entanto, em internet das coisas, os objetos físicos devem se conectar, da forma mais
fácil possível, no mundo virtual. No entanto, considerando toda a heterogeneidade de tipos de
dispositivos, variando desde sensores de temperatura até automóveis autônomos, há a
necessidade de fazer com que esses objetos sejam entendidos uns pelos outros e permitam um
compartilhamento de informação de forma adequada. É necessário então a existência de
padrões que possam responder questões como: o que é uma coisa? como representar uma coisa?
quais seus principais atributos? como tornar sua descrição extensível a outros atributos?
7 https://www.fiware.org/ 8 https://www.xively.com 9 http://www.kaaproject.org/ 10 https://www.amee.com/ 11 http://www.zettajs.org/ 12 http://sofia2.com 13 http://www.prismtech.com/

46
Várias abordagens são propostas na literatura, considerando diferenças do ponto de vista
do formato de dado (XML, JSON, RDF entre outros), ou de seus atributos (identificador, nome,
localização, entradas, saídas, parâmetros entre outros). A seguir será abordado o padrão
SensorML, adotado neste trabalho.
Em 2014, a OGC14 adotou o SensorML como o padrão avançado para descrição de
sensores (coisas que observam), atuadores (coisas que agem) e processadores (coisas que
calculam) em Internet das Coisas15. Vários trabalhos bem referenciados utilizaram o SensorML
como padrão de modelo de dados (JIRKA; BRÖRING; STASCH, 2009; COMPTON et al.,
2012; HENSON et al., 2009), tornando-o uma opção cada vez mais consolidada para a
descrição de objetos em IoT.
O padrão SensorML define sensores, atuadores, componentes entre outros, como
processos. Todos estes processos possuem entrada, saída e métodos, podendo ser utilizados por
outras aplicações no momento de consumir as observações, como também pode prover
metadados para serviços de descoberta e identificar restrições do sistema (BOTTS et al., 2006).
Segundo OGC (2016), o principais objetivos do SensorML são:
a) Prover descrições de sensores para o catálogo de sensores
b) Prover informações que suportem a descoberta de observações
c) Dar suporte ao processamento e análise das observações dos sensores
d) Dar suporte a geolocalização de valores observados
e) Prover informações de performance e qualidade das medidas
f) Prover desde descrições gerais de componentes, até informações específicas de
configuração
g) Prover uma interface legível por máquina para stream de dados
h) Dar suporte a agregação de processos
Outros trabalhos como SSN (COMPTON et al., 2012), SEMSOS (HENSON et al.,
2009) e OSIRIS (JIRKA; BRÖRING; STASCH, 2009) utilizam ontologias sobre o SensorML
de modo a permitir a interoperabilidade semântica definida por BANDYOPADHYAY et al.
14 A OGC é um consórcio internacional que reúne, atualmente, 530 empresas, agências governamentais e
universidades e tem como principal objetivo promover soluções que façam com que informações espaciais,
complexas por natureza, e serviços se tornem mais acessíveis e úteis a todo tipo de aplicação (OGC, 2016). 15 http://www.opengeospatial.org/pressroom/pressreleases/1971

47
(2011). Por padrão, a especificação do SensorML sugere o uso das seguintes ontologias:
dicionário de termos da OGC utilizados para registro16, ontologia SWEET17, ontologia MMI18.
O código descrito na Seção 6.3 ilustra a descrição de um sensor utilizando o padrão
SensorML.
3.6. Arquitetura do novo Waldo
Para atingir aos requisitos elencados na Seção 3.3, novos módulos foram integrados à
arquitetura do Waldo. Estes módulos fazem parte da proposta da técnica de ranqueamento e,
consequentemente, do mecanismo de busca a ela relacionado. Nesta seção, todas as referências
ao Waldo dizem respeito à sua nova versão, já integrada a toda implementação proposta.
A representação básica dos novos componentes arquiteturais presentes na evolução do
catálogo Waldo está ilustrada na Figura 3.2.
Figura 3.3: Nova arquitetura do Waldo
Fonte: Elaborado pelo Autor
O Waldo possui uma interface REST, através da qual é possível enviar requisições ao
módulo Registro para inserção de produtores de dados, atualização de sua descrição, exclusão
e busca através de verbos HTTP. Através do módulo registro, também é possível buscar a
descrição dos produtores de dados e solicitar o consumo dos dados produzidos por eles.
O módulo Analisador de Consulta tem a função de validar a estrutura das requisições
recebidas. Dado que o Waldo aceita apenas requisições estruturadas, são processadas apenas
aquelas requisições que obedecem o esquema de dados definido.
16 http://www.opengis.net/def/ 17 http:// sweet.jpl.nasa.gov/2.0/ 18 http://mmisw.org/orr/

48
Uma vez que requisições de busca de produtores de dados, utilizando atributos de
qualidade como critérios, são enviadas ao módulo de registro, identifica os produtores
candidatos e solicita ao módulo Ranking para calcular a pontuação de relevância, ou score, de
cada um destes produtores utilizado a técnica descrita na Seção 3.4.1.
O módulo Distribuição tem a função de gerenciar a técnica da fila dinâmica, apresentada
na Seção 3.4.2.
Por fim, o módulo Monitor tem a tarefa de monitorar sempre os indicadores de qualidade
dos produtores de dados registrados. Além disso, é tarefa do Monitor verificar se os resultados
presentes nas filas dinâmicas do módulo de distribuição, permanecem satisfazendo as condições
das requisições de suas respectivas filas dinâmicas.
Há também três bases de dados, uma chamada Vocabulário, responsável por armazenar
os vocabulários semânticos utilizados na descrição dos produtores de dados registrados no
Waldo. Há também outra base de dados chamada de Produtores de Dados que armazena as
descrições dos produtores de dados em no formato de dados SensorML. E, por fim, uma terceira
base de dados chamada Cache. Sua função é armazenar o histórico de dados produzidos pelos
produtores de dados. A ideia que motivou o uso deste módulo foi que, dado que os dispositivos
registrados possuem restrições, não faz sentido repassar sua interface de acesso aos
consumidores. Haja visto que, caso assim fosse feito, estes dispositivos seriam sobrecarregados
por requisições. Mesmo os smartphones utilizados pela multidão (no paradigma de
crowdsensing) não seriam capazes de suportar tamanho volume de requisições. E mesmo se
fosse, ainda vinham discussões acerca do consumo de energia decorrente. Dessa forma, ao
solicitar consumo de dados dos produtores de dados ao Waldo, invés de os consumidores
receberem a interface de acesso a tais produtores, eles recebem os últimos dados destes
produtores inseridos no Cache. Assim, os consumidores lidam apenas com uma representação
“virtual” dos dispositivos físicos.
A interação entre os componentes da arquitetura do Waldo se comporta como ilustrado
na Figura 3.4. Os consumidores enviam suas requisições ao analisador de consulta (item 1 na
Figura 3.4). Ele verifica se a requisição é válida, do ponto de vista do esquema de dados. Caso
seja, ela é repassada ao módulo de registro (item 8 na Figura 3.4). Sendo operação de busca, o
módulo de registro busca os produtores de dados candidatos e repassa do módulo de
ranqueamento (item 2 na Figura 3.4). Uma vez ranqueados, são inseridos nas filas dinâmicas e
repassados ao consumidor. Sendo operações de registro, atualização e remoção o módulo de
registro interage com a base de dados que armazena a descrição dos produtores de dados.

49
Figura 3.4: Componentes do Waldo
Fonte: Elaborado pelo Autor
O módulo monitor (item 6 na Figura 3.4) envia requisições de tempos em tempos aos
produtores e atualiza seus atributos de qualidade, se for o caso. Além disso, responde a
requisições realizadas pelo módulo de distribuição (item 5 na Figura 3.4). As requisições feitas
pelo módulo de distribuição tem o objetivo de verificar se os resultados de ainda obedecem aos
requisitos da requisição que sua respectiva fila dinâmica.
Como ilustrado no item 4 (da Figura 3.4), os produtores de dados possuem uma
representação “virtual”, que é apresentada aos consumidores. Os consumidores não acessam os
produtores de dados propriamente ditos, mas acessam sua representação no Waldo. Os dados
dos produtores são sempre armazenados em um cache. Assim, quando se solicita o consumo de
dados dos produtores, não se consome diretamente nos dispositivos, mas sim nos resultados
armazenados localmente no catálogo Waldo.
3.7. Implementação
O serviço REST de acesso ao Waldo foi implementado utilizando o framework Jersey versão
2.22.2. Através dele é possível ter acesso a requisições através de requisições HTTP, como
ilustrado nos Códigos 3.1, 3.2, 3.3 e 3.4.

50
A operação de registro inserem um produtor de dados no catálogo Waldo. Para tanto, a
descrição em SensorML do produtor de dados é enviada, através de uma requisição HTTP PUT
para o endereço do Código 3.1.
Código 3.1: URL para registro
A operação atualizar modifica a descrição de um produtor de dados já registrado. A
nova descrição é enviada, através de uma requisição HTTP POST para o endereço do Código
3.2:
Código 3.2: URL para atualização
A operação remover exclui um produtor de dados cadastrado no catálogo Waldo++.
Para tanto, basta informar o identificador do produtor de dados através de uma requisição HTTP
DELETE para o endereço do Código 3.3:
Código 3.3: URL para registro
Esta operação deve receber uma requisição estruturada e retornar os melhores
produtores de dados que a atendem. A consulta estruturada deve ser enviada, através de uma
requisição HTTP GET para o endereço do Código 3.4:
Código 3.4: URL para busca
A requisição deve ser formulada no formato de dados JSON e estruturada obedecendo
o esquema do Código 3.5. Um exemplo de requisição é ilustrado no Código 3.6.
A requisição acima é realizada por um consumidor de código identificador id igual a
“$57ba2c2c7ebf021a0c789a07$”, em busca de produtores que produzam dado de temperatura
(fenômeno descrito em uma ontologia, através do caminho http://linkedgeodata.org/page/onto
logy/Temperature). Tais produtores devem estar localizados a uma distância máxima de 200
metros da coordenada geográfica (-8.053745, -34.884442). Além disso, seus atributos de
qualidade devem ser: disponibilidade maior que 90% e tempo de resposta menor que 9000
milissegundos.
http://[endereço do servidor]:[porta]/basic-catalog/rest/waldopp/dataproducer
http://[endereço do servidor]:[porta]/basic-catalog/rest/waldopp/dataproducer
http://[endereço do servidor]:[porta]/basic-catalog/rest/waldopp/dataproducer
http://[endereço do servidor]:[porta]/basic-catalog/rest/waldopp/dataproducer

51
Código 3.5: Esquema das requisições
Código 3.6: Exemplo de uma requisição
Para gerenciar o monitoramento permanente, realizado pelo módulo Monitor, foi
utilizado o RabbitMQ. RabbitMQ é um message broker que implementa o protocolo AMQP e,
através dele, é possível dar suporte a serviços de mensageria.
No Waldo, como visto anteriormente, de tempos em tempos o módulo Monitor verifica
o status dos produtores de dados registrados com o objetivo de recalcular seus indicadores de
qualidade. Para isso, um processo paralelo chamado
BasicCatalogMonitorScheduleQuality agenda em uma fila do rabbitMQ chamada
TASK, tarefas de verificação de status. Por outro lado, processos paralelos chamados
BasicCatalogMonitorQualityTask ouvem permanentemente a fila TASK e uma vez que
uma nova tarefa é agendada, algum processo BasicCatalogMonitorQualityTask retira o
agendamento da fila e o processa, indo até o produtor de dados, verificando seu atual status e
recalculando seus indicadores de qualidade.
{ "idConsumer": "String", "phenomenon": "String", "qos": [ "type": "tripla", "minimum": 1 ], "location": { "latitude": "String", "longitude": "String", "radius": "String" } }, "tripla": ["String", "String", int]
{ "idConsumer": "57ba2c2c7ebf021a0c789a07", "phenomenon": "http://linkedgeodata.org/page/ontology/Temperature", "qos": [ ["availability", "gt", 80], ["responseTime", "lt", 9000] ], "location": { "latitude": "-8.053745", "longitude": "-34.884442", "radius": "200" } }

52
Sobre o modelo de dados utilizado na descrição dos produtores de dados no Waldo, foi
utilizada a especificação SensorML, descrito anteriormente na Seção 3.5.2. Além disso, foi
utilizado a especificação Observations & Measurements (O&M), como esquema para o formato
dos dados na Seção 6.4) ilustra um produtor de dados registrado no Waldo. Além disso o código
no Código 3.7 ilustra um dado gerado por um produtor de dados.
Código 3.7 Exemplo de uma produção de dado em O&M
O servidor de aplicação utilizado foi o Glassfish versão 4.1.1 e a linguagem de
programação utilizada em toda a implementação foi o Java 1.8.0\_91.
3.8. Resumo do capítulo
Neste capítulo foram apresentados detalhes da arquitetura e implementação dos novos módulos
do Waldo, no que diz respeito ao mecanismo de busca e ao conceito de fila dinâmica. Foi
apresentado também detalhes das tecnologias utilizadas no desenvolvimento, como:
Glasshfish, Jersey, RabbitMQ, Java e MongoDB, além das especificações SensorML e O&M.
{ "idConsumer": "57ba2c2c7ebf021a0c789a07", "phenomenon": "http://linkedgeodata.org/page/ontology/Temperature", "qos": [ ["availability", "gt", 80], ["responseTime", "lt", 9000] ], "location": { "latitude": "-8.053745", "longitude": "-34.884442", "radius": "200" } }

53
4. AVALIAÇÃO E ANÁLISE
4.1. Introdução
Este capítulo apresenta uma avaliação quantitativa e qualitativa da técnica de ranqueamento
sugerida, bem como da sua integração ao catálogo de produtores de dados Waldo. Para executar
todos os experimento foram utilizados os computadores descritos na Tabela 4.1 Detalhes sobre
os experimentos realizados serão descritos nas seções a seguir. A metodologia seguiu
basicamente a abordagem de avaliação de performance proposta por JAIN (1990), que consiste
em: definir bem os objetivos do estudo, selecionar as métricas de performance, parâmetros,
fatores e seus respectivos valores. Além disso, selecionar a técnica de avaliação, planejar e, por
fim, executar o experimento, analisar, interpretar e apresentar os dados coletados.
Tabela 4.1 Computadores utilizados
Nome Configuração
Wi5.A Intel Core i5-5200U CPU @ 2.20GHz 6.00 RAM Windows 8.1 64 bits
Wi7.A Intel Core i7-2600 CPU @ 3.40 GHz 8.00 RAM Windows 8.1 64 bits
Wi7.B Intel Core i7-2600 CPU @ 3.40 GHz 8.00 RAM Windows 8.1 64 bits
4.2. Técnica de ranqueamento
O primeiro aspecto a ser observado na técnica de ranqueamento sugerida é verificar se ela
implica em uma perda de desempenho do mecanismo de busca do catálogo ao qual ela foi
agregada. Ou seja, se o tempo de resposta da técnica torna-a inviável ou não. Assim, para este
experimento foi mensurado o tempo gasto em diversas atividades de um processo de consulta
(como ilustrado na Figura 4.1 com o objetivo de responder a seguinte pergunta: a técnica de
ranqueamento proposta é viável do ponto de vista computacional?
O tempo de resposta, de cada etapa da busca, foi considerado como métrica. Assim,
validar consulta é o tempo gasto para verificar se uma consulta submetida é válida, ou seja, se
ela obedece ao esquema de consulta ilustrado no Código 3.5. Filtrar e consultar o banco de
dados é o tempo gasto para transformar a consulta submetida em uma consulta válida ao
MongoDB, dado que as consultas ao MongoDB são realizadas por meio de um DBObject. Além
disso, é somado o tempo da consulta propriamente dita ao MongoDB, ou seja, submeter o
critério de busca, por meio do DBObject e receber a lista de resultados. Por fim, Calcular
ranking é o tempo gasto para calcular e indexar cada resultado com seu ranking.

54
Tabela 4.1 Atividades de uma consulta
Fonte: Elaborado pelo Autor
Como parâmetros do experimento, foram considerados a quantidade de atributos
explícitos na estratégia de busca, bem como a quantidade de produtores de dados candidatos,
retornados pela consulta ao MongoDB. Assim, quatro cenários foram simulados: (i) 2 atributos
de qualidade explícitos na estratégia de busca e variação da quantidade de produtores
candidatos, (ii) 4 atributos de qualidade explícitos na estratégia de busca e variação da
quantidade de produtores candidatos, (iii) 4 atributos de qualidade explícitos na estratégia de
busca e variação da quantidade de produtores candidatos, (iv) 8 atributos de qualidade explícitos
na estratégia de busca e variação da quantidade de produtores candidatos. Cada cenário variou
a quantidade de produtores de dados candidatos em 1000, 3000, 5000, 7000, 9000 e 10000 e os
níveis dos atributos de qualidade obedeceram uma distribuição normal.
Muito embora o cenário da internet das coisas considere que milhões, ou até bilhões, de
dispositivos estejam conectados à rede em breve, deve-se considerar que ao submeter uma
requisição de busca ao catálogo, o consumidor está interessado em resolver apenas um
problema em específico. Logo, apenas produtores de dados que são capazes de observar
determinado fenômeno f, que estejam a um raio de no máximo m metros de um local de interesse
e que possuam um conjunto a de níveis mínimos de indicadores qualidade são úteis ao
consumidor. Assim, em uma aplicação como o BikeCidadão, por exemplo, o aplicativo que
previne o motorista de ciclistas logo adiante, certamente não encontrará milhares de ciclistas à
frente, pois se trata de um fenômeno e um local específico. Ou seja, os valores 1000, 3000,
5000, 7000, 9000 e 10000 nãos e trata do universo de produtores de dados conectados à internet
das coisas, mas sim os produtores de dados candidatos. Ou seja, aqueles que já satisfazem todas
as condições iniciais e participarão da recomendação.
O ambiente de simulação utilizou as duas máquinas descritas em na Tabela 4.1 sendo o
catálogo Waldo++, com a técnica de ranqueamento implementada, executado em Wi5.A,
recebendo requisições de Wi7.A. Além disso, cada cenário foi executado 32 vezes, mantendo
as mesmas métricas, parâmetros e níveis. Dessas 32 medidas, a maior e a menor foram excluídas
e as outras 30 tiveram a média calculada. Os dados coletados são discutidos a seguir.

55
Figura 4.2: 2 atributos de qualidade explícitos na estratégia de busca
Fonte: Elaborado pelo Autor
No primeiro cenário, onde foram considerados 2 atributos de qualidade explícitos na
estratégia de busca e variação da quantidade de produtores candidatos, as médias do tempo de
ranqueamento para 1000, 3000, 5000, 7000, 9000 e 10000 produtores de dados candidatos
foram, respectivamente, 58.75ms, 141.30ms, 236.85ms, 338.34ms, 474.89ms e 579.64ms.
Figura 4.3: 4 atributos de qualidade explícitos na estratégia de busca
Fonte: Elaborado pelo Autor
No segundo cenário, onde foram considerados 4 atributos de qualidade explícitos na
estratégia de busca e variação da quantidade de produtores candidatos, as médias do tempo de
ranqueamento para 1000, 3000, 5000, 7000, 9000 e 10000 produtores de dados candidatos
foram, respectivamente, 62.17ms, 139ms, 403.47ms, 371.48ms, 563.55ms e 603.75ms.

56
Figura 4.4: 6 atributos de qualidade explícitos na estratégia de busca
Fonte: Elaborado pelo Autor
No terceiro cenário, onde foram considerados 6 atributos de qualidade explícitos na
estratégia de busca e variação da quantidade de produtores candidatos, as médias do tempo de
ranqueamento para 1000, 3000, 5000, 7000, 9000 e 10000 produtores de dados candidatos
foram, respectivamente, 78.79ms, 151.68ms, 425.72ms, 369.65ms, 562.17ms e588.37ms.
Figura 4.5: 8 atributos de qualidade explícitos na estratégia de busca
Fonte: Elaborado pelo Autor
No quarto cenário, onde foram considerados 8 atributos de qualidade explícitos na
estratégia de busca e variação da quantidade de produtores candidatos, as médias do tempo de
ranqueamento para 1000, 3000, 5000, 7000, 9000 e 10000 produtores de dados candidatos
foram, respectivamente, 71.41ms, 149.41ms, 439.17ms, 457.86ms, 576.33ms e 697.03ms.
No entanto, é necessário notar que, por menor que seja o tempo necessário para calcular
o ranking dos produtores de dados, é necessário saber qual o impacto que esse tempo tem em

57
todo o processo de busca. Ou seja, quanto mais o tempo gasto pelo ranqueamento tende ao
tempo gasto no processo de busca, menos eficiente é a técnica proposta, considerando a métrica
escolhida para o experimento. Assim, a Tabela 4.2 compara o tempo de ranqueamento com os
tempos de cada etapa do processo de busca. Para cada cenário é destacado o tempo das etapas
de validação, filtragem e ranqueamento. Dessa forma, é possível ter uma imagem objetiva do
impacto da técnica de ranqueamento no processo de busca até então implementado no catálogo
Waldo.
#Candidatos Validação Filtragem Ranking Total % do tempo total
Cenário 1
1000
3000
5000
7000
9000
10000
0.1724
0.242
0.250
2.896
0.928
0.250
188.4828
1011.212
1499.964
3159.241
2656.857
2615.429
58.7586
141.303
236.857
338.344
474.892
579.642
247.4138
1152.758
1737.071
3500.483
3132.679
3195.321
23.7491
12.257
13.635
9.665
15.159
18.140
Cenário 2
1000
3000
5000
7000
9000
10000
0.357
0.321
0.434
0.259
0.310
0.172
217.50
960.821
1277.957
3083.370
2492.276
2694.172
62.178
139.000
403.478
371.481
563.551
603.758
280.035
1100.143
1681.870
3455.111
3056.138
3298.103
22.203
12.634
23.989
10.751
18.440
18.306
Cenário 3
1000
3000
5000
7000
9000
10000
0.344
0.275
0.413
0.379
0.241
0.333
232.655
995.724
1536.103
3323.897
2674.621
2916.778
78.793
151.689
425.724
369.655
562.172
588.370
311.7931
1147.690
1962.241
3693.931
3237.034
3505.481
25.270
13.216
21.695
10.007
17.366
16.784
Cenário 4
1000
3000
5000
7000
9000
10000
0.344
0.448
0.428
2.833
0.300
0.533
234.103
1089.897
1520.464
3395.600
2742.700
3372.633
71.413
149.413
439.178
457.866
576.333
697.033
305.861
1239.759
1960.071
3856.300
3319.333
4070.200
23.348
12.058
22.406
11.873
17.362
17.125
Tabela 4.2: Tempos de resposta das etapas de busca em milissegundos
Segundo os dados da Tabela 4.2 (coluna % do tempo total), nota-se que, em média, a
técnica de ranqueamento consome 23.25% do processo total de busca no catálogo Waldo,
considerando que há 1000 produtores de dados candidatos. Para 3000 candidatos, o tempo gasto
pela técnica de ranqueamento é de, em média, 12.25%. Para 5000, 7000, 9000 e 10000
candidatos, o tempo médio de ranqueamento é de 19%, 10%, 16.75% e 17.25% do tempo total
do processo de busca.
4.2.1. Análise da técnica de ranqueamento
Como visto através dos gráficos ilustrados nas Figuras 4.2 a 4.5, o crescimento do tempo de
ranqueamento se dá de forma praticamente linear. No entanto, para 5000 produtores de dados,

58
nota-se um distúrbio no tempo de resposta. Tal fato se deve à forma de funcionamento do
sistema de armazenamento do MongoDB, pois ele pré-aloca o espaço destinado ao
armazenamento dos documentos e índices19. Para que seja evitada a fragmentação dos arquivos,
uma primeira partição (chamada de .0) possui 64MB. Quando este espaço está prestes a ser
preenchido (aproximadamente 70%), é criada uma partição (chamada .1) com 128MB. Da
mesma forma é criada a partição .2 com 256MB e assim sucessivamente, até 2GB. Uma vez
que se alcance 2GB, as próximas partições são alocadas com 2GB.
Com 5000 produtores de dados registrados tem-se, apenas com dados puros, 40.880.000
bytes. Adicionalmente, deve-se somar espaço reservado ao próprio MongoDB, mais os índices
e cabeçalhos dos documentos. Assim, não apenas para 5000 produtores de dados, mas também
para toda a quantidade de produtores cujo espaço total ocupado no armazenamento esteja
próximo ao limite das partições, este fenômeno irá ocorrer. Não se trata, portanto, de uma
limitação da técnica de ranqueamento, mas sim do próprio MongoDB.
Para se ter uma visão objetiva de que o tempo de resposta não implica em perda de
desempenho do processo de busca do catálogo, foi discriminado na Tabela 4.2 o tempo gasto
em cada etapa do processo de busca. Nela pode-se perceber que o impacto que a técnica de
ranqueamento incide sobre o processo de busca não aumenta à medida que cresce o número de
produtores de dados candidatos. De fato, para o cenário 1 a técnica representou em média
15,43416% do tempo total de busca e nos cenários 2, 3 e 4 foram respectivamente de 17,7205%,
16,8896% e 17,362%.
4.3. Comparativo das técnicas
Uma segunda verificação a ser feita é uma comparação do tempo de resposta da técnica proposta
frente às técnicas correlatas à aplicação existentes na literatura. Como visto na Seção 2.3 as
técnicas Pearson Correlation (DESROSIERS; KARYPIS, 2011; ZHENG et al., 2011) e Cosine
Vector (DESROSIERS; KARYPIS, 2011) são as principais técnicas aplicadas atualmente,
considerando recomendação de objetos da internet das coisas, baseada em atributos de
qualidade e computacionalmente viáveis.
Assim, para esta avaliação o tempo de resposta foi considerado como métrica. Os
parâmetros do experimento foram a quantidade de atributos explícitos na estratégia de busca e
a quantidade de produtores de dados candidatos. A quantidade de produtores candidatos variou
19 Mais em: https://blog.serverdensity.com/mongodb-monitoring-watch-your-storage/

59
em 1000, 3000, 5000, 7000, 9000 e 10000 e o número de atributos de qualidade explícitos foi
fixado em 2. Por fim, o ambiente de simulação implementou o catálogo na máquina Wi5.A,
recebendo requisições da máquina Wi7.A (Tabela 4.1). O cenário foi executado 32 vezes,
mantendo as métricas, os parâmetros e seus respectivos níveis. Após desconsiderar o maior e o
menor valor, a média foi calculada com as 30 medidas restantes. Os dados coletados estão
ilustrados a seguir.
Figura 4.6: Tempo de resposta das técnicas consideradas.
Fonte: Elaborado pelo Autor
Como ilustrado na Figura 4.6, bem como na Tabela 4.2, o tempo médio da técnica
proposta para calcular o ranqueamento de 1000, 3000, 5000, 7000 e 10000 produtores de dados
candidatos ao resultado da busca foram, respectivamente, 58.75862ms, 141.303ms,
236.8571ms, 338.3448ms, 474.8929ms e 579.6429ms.
A técnica cosine vector, por sua vez, calculou o ranking para 1000, 3000, 5000, 7000,
9000 e 10000 produtores de dados candidatos em 48.06667ms, 100.5ms, 253.3667ms,
254.7857ms, 505.5556ms e 530.3929ms, respectivamente. Já a técnica pearson correlation
realizou as mesmas tarefas em 310.6ms, 1271.31ms, 2486.667ms, 2227.345ms, 4132.483ms e
5661.286ms.
Além de comparar o tempo de resposta das três técnicas consideradas por este trabalho
(técnica proposta, pearson correlation e cosine vector), também foram analisadas as respostas
e seus respectivos níveis de qualidade em seus atributos. Para esta análise a máquina Wi5.A
recebeu requisições da máquina Wi7.A (Tabela 4.1). Para cada técnica de ranqueamento foram
executados 30 consultas. Em cada uma dessas consultas, foram separados os dez melhores
resultados e a média de seus atributos de qualidade foi calculada. Por fim, foi calculada a média
dessas 30 médias anteriores (ver Figura 4.7).

60
A Figura 4.7 ilustra o nível de cada atributo de qualidade em cada uma das técnicas
consideradas por este trabalho.
Figura 4.7: Comparativo do nível de qualidade dos atributos.
Fonte: Elaborado pelo Autor
Do gráfico da Figura 4.7 pode-se extrair as diferenças de níveis dada por cada técnica
de ranqueamento para cada um dos atributos ilustradas na Tabela 4.3. Os valores negativos
significam que a técnica teve um nível médio menor que a técnica proposta por este trabalho.
Os valores positivos significam que a técnica teve um desempenho melhor que a técnica
proposta por este trabalho.
Tabela 4.3: Desempenho do Pearson Correlation e Cosine Vector em relação à técnica proposta
a1 a2 a3 a4 a5 a6 a7 a8 a9 a10 a11 a12
Cosine Vector -0.05 -2.35 -7.72 -0.33 2.30 -36.86 -16.50 1.58 -13.11 -52.78 -27.53 -66.57
Pearson -2.31 -2.28 -12.35 -0.46 4.82 -27.01 -41.94 0.61 -36.27 -13.07 21.95 -36.56
4.3.1. Análise do comparação das técnicas
Sobre o desempenho da técnicas sob a perspectiva quantitativa, considerando o tempo de
resposta como métrica, podemos observar que a técnica de recomendação proposta se mostra
bastante semelhante à técnica cosine vector, enquanto que estas duas são dramaticamente mais
eficientes que a técnica pearson correlation. À medida que a quantidade de produtores de dados
a serem ranqueados aumenta, o tempo de resposta da técnica de ranqueamento proposta e do
cosine vector cresce de forma praticamente linear e com baixa inclinação. Por outro lado, o
tempo de reposta da técnica pearson correlation cresce obedecendo uma curva, se acentuando
à medida que o número de produtores de dados a serem ranqueados aumenta.

61
Apesar do tempo de resposta da técnica de ranqueamento proposta ser bastante
semelhante ao cosine vector, a Figura 4.7 evidencia diferenças entre essas duas técnicas sob
uma perspectiva qualitativa. Nela, percebe-se que a técnica proposta supera o cosine vector em
todos os atributos de qualidade, exceto apenas em a5 e a8.
A Tabela 4.3 explicita o quão próximo (ou distante) estão os níveis de qualidade
recomendados por cada técnica. Nos dois atributos em que a técnica cosine vector se mostrou
melhor, a diferença foi de apenas 2.3% e 1.58%. Por outro lado, além de a técnica recomendada
ser melhor que o cosine vector em todos os outros atributos de qualidade, a diferença entre elas
chegou a níveis notáveis como 66.57% para a12 e 52.78% para a10.
Comparando com pearson correlation a técnica recomendada também se mostrou
melhor em todos os atributos, exceto em apenas dois (a5 e a8). Nos outros atributos, a técnica
proposta não apenas superou o pearson correlation, como também a superou em níveis
consideráveis, como 44.91% para a7 e 36.56% para a12.
Outro aspecto interessante a ser destacado foi o comportamento da técnica de
ranqueamento proposta para atributos inversamente positivos. Como visto na Seção 2.2,
atributos inversamente positivos são aqueles que, quanto menor o valor dado pelo cálculo da
métrica, melhor é a qualidade da entidade observada. Por exemplo, quanto menor a idade de
um dado, mais recente ele é e, portanto, melhor representa o contexto atual. Exatamente os
atributos de qualidade a6, a7 e a12 foram aqueles em que a técnica de recomendação proposta
teve os maiores níveis sobre as técnicas pearson correlation e cosine vector.
4.4. Fila dinâmica
Como visto na Seção 3.4.2, foi implementado no catálogo uma estratégia chamada de fila
dinâmica. Seu objetivo é eliminar o recalculo de ranqueamento a cada busca solicitada ao
catálogo. Assim, o consumidor recebe como resultados produtores de dados em uma lista de
resultados mantida a partir de uma consulta realizada anteriormente. O catálogo, por sua vez,
trata de observar essa lista de tempos em tempos e retirar aqueles resultados que deixam de
satisfazer as condições iniciais. Uma vez que essa lista deixa de satisfazer o contrato inicial de
quantidade de resultados e qualidade, a fila é preenchida novamente.
Assim, foi executado um experimento com o objetivo de analisar o comportamento da
fila dinâmica enquanto que o catálogo lida com requisições de busca e de atualização de
metadados dos produtores de dados. Para tal fim, foi modelado um cenário em que ciclistas

62
pedalam pela cidade enquanto que fornecem dados de sua rota ao catálogo, se comportando
então como produtores de dados. As informações repassadas são, basicamente, a coordenada
geográfica e seu timestamp.
Figura 4.8: Rotas utilizadas no experimento visualizadas no OpenStreetMap.
Fonte: Elaborado pelo Autor
Por outro lado, consumidores pesquisam quais rotas possuem ciclistas naquele exato
momento. Aplicativos como, por exemplo, o BikeCidadão (DINIZ et al., 2016), que oferece
rotas seguras para ciclistas e motoristas, permitindo uma interação harmoniosa entre esses
integrantes do trânsito que, como se sabe, possuem potencial risco de colisão. As rotas
utilizadas neste experimento (Figura 4.8) são reais, percorridas na cidade Recife, Pernambuco,
e foram extraídas da plataforma de compartilhamento de rotas de ciclistas Strava20.
O tempo de resposta foi considerado como métrica e a quantidade de consumidores
simultâneos do catálogo e a quantidade de ciclistas simultâneos foram considerados como
parâmetros. O ambiente de simulação utilizou três máquinas descritas na Tabela 4.1, sendo o
catálogo Waldo executado em Wi5.A, com monitor da fila dinâmica executado em Wi7.B. As
requisições foram submetidas ao catálogo por Wi7.A.
A quantidade de consumidores enviando requisições de busca de produtores de dados
ao catálogo variou em 100, 200, 300, 400 e 500, com requisições a cada 5 segundos. A
quantidade de ciclistas simultâneos foi fixada em 100, gerando dados a cada 3 segundos. A
Figura 4.9 ilustra o tempo de resposta do catálogo para buscas por ciclistas realizadas por
diferentes quantidades de consumidores simultâneos.
20 http://www.strava.com

63
Figura 4.9: Mecanismo de busca sem a estratégia de fila dinâmica
Fonte: Elaborado pelo Autor
A Figura 4.10, por sua vez, ilustra o tempo de resposta das requisições de busca ao
catálogo com a estratégia da fila dinâmica implementada.
Figura 4.10: Mecanismo de busca com a estratégia de fila dinâmica
Fonte: Elaborado pelo Autor
4.4.1. Análise da fila dinâmica
Como evidenciado nas Figuras 4.9 e 4.10, a estratégia da fila dinâmica diminui
consideravelmente o tempo de resposta de uma requisição de busca ao catálogo. Sem
implementar a estratégia de fila dinâmica, o catálogo respondeu às requisições de 100, 200,
300, 400 e 500 consumidores simultâneos em uma média, respectivamente, de 987ms, 1860ms,
2869ms, 3909ms e 4739ms. Já com a estratégia de fila dinâmica implementada o tempos médios
foram de, respectivamente, 26ms, 49ms, 74ms, 114ms e 163ms.
A grande vantagem da técnica é, além de diminuir o tempo de espera do consumidor,
liberar processamento do catálogo para atender a novas requisições. Aumentando assim, a
vazão de requisições processadas por unidade de tempo.

64
4.5. Resumo do capítulo
Neste capítulo a técnica de ranqueamento proposta por este trabalho foi confrontada com as
técnicas cosine vector e pearson correlation, observando seus respectivos comportamentos em
diferentes configurações. Além de observar os tempos de resposta e os níveis de qualidade
recomendados, também foi analisada a viabilidade da estratégia da fila dinâmica.

65
5. CONCLUSÃO
No cenário de Internet das Coisas, a quantidade e a heterogeneidade de dispositivos que
produzem dados aumenta a cada momento. Sabe-se que estas entidades que produzem dados
são autônomas e que seus metadados e seus indicadores de qualidade podem mudar
constantemente. Por exemplo, produtores de dados em aplicações de crowdsensing estão a todo
o momento mudando sua posição geográfica e alterando suas características de qualidade pois,
se dado produtor de dados está disponível agora, pode fica indisponível a qualquer momento.
Seja essa indisponibilidade provocada por problemas na cobertura da rede, ou por ação do
próprio detentor do dispositivo. Assim, um problema emergente é como selecionar os
dispositivos que melhor atendem à necessidade de um determinado consumidor, considerando
que estes dispositivos são autônomos e tão dinâmicos.
Este trabalho propôs uma técnica de ranqueamento que considera a característica
dinâmica da qualidade dos produtores de dados em internet das coisas, sendo ela viável do
ponto de vista computacional e facilmente acoplável em catálogos de produtores de dados.
Além disso, foi proposta e analisada a estratégia de fila dinâmica, que tem por objetivo reduzir
o custo do recalculo de ranqueamento a cada solicitação de busca enviada ao catálogo. Tanto a
técnica de ranqueamento, quanto a estratégia de fila dinâmica foi implementada no catálogo de
produtores de dados Waldo, sugerido por (OLIVEIRA; GAMA; LÓSCIO, 2015).
5.1. Principais Contribuições
As principais contribuições deste trabalho foram:
a) Propor uma técnica de ranqueamento que considere a dinamicidade dos atributos de
qualidade dos produtores de dados e que seja facilmente acoplada em catálogos de
entidades produtoras de dados;
b) Eliminar do desenvolvedor a tarefa de filtrar quais dos resultados retornados pelo
mecanismo de busca do catálogo melhor atendem à sua necessidade;
c) Por meio da estratégia de fila dinâmica, ofertar aos consumidores, com eficiência de
tempo, resultados sempre atualizados que correspondem às suas expectativas;
5.2. Limitações
As principais limitações deste trabalho foram:

66
a) Não foram consideradas mecanismos de segurança entre a comunicação do catálogo
com o monitor de QoS dos produtores de dados;
b) Apenas o MongoDB foi utilizado como banco de dados;
c) Apenas o Jersey foi considerado como framework para a implementação da interface
REST do catálogo Waldo, assim os tempos de resposta, utilizados na etapa de análise
de desempenho, estão diretamente atrelados a esta ferramenta;
d) Apesar de todos os metadados em SensorML serem armazenados em manipulados no
formato JSON, originalmente eles são criados no formato XML. Sendo sempre
necessário a sua conversão para JSON após sua criação;
5.3. Trabalhos Futuros
Para uma continuidade deste trabalho, propõe-se:
a) Criar alguma mecanismo de intersecção de requisições. Eventualmente algum
consumidor pode submeter uma requisição de busca cujos requisitos sejam um
subconjunto de uma requisição já submetida e que tem uma fila de resultados ativa.
Assim, como uma segunda estratégia de se evitar a execução de todo o processo de
busca, essa fila já disponível pode, de pronto, já ser recomendada a este consumidor.
Como se trata de um sub conjunto de uma outra requisição, o consumidor terá resultados
com níveis maiores ou iguais a aqueles exigidos inicialmente;
b) Entender o comportamento do MongoDB frente a outros bancos de dados NoSql
baseados em memória, haja visto que custo computacional para acessar o disco no
processo de busca se mostrou bastante alto. Fato verificável na diferença de tempo de
resposta com a estratégia e sem a estratégia de fila dinâmica;
c) Entender se a estratégia da fila dinâmica ocasiona algum impacto, positivo ou negativo,
na qualidade dos resultados recomendados;

67
Referências
AMATRIAIN, X. et al. Data mining methods for recommender systems. In: Recommender
Systems Handbook. [S.l.]: Springer, 2011. p.39–71.
BANDYOPADHYAY, S. et al. Role of middleware for internet of things: a study. International
Journal of Computer Science and Engineering Survey, [S.l.], v.2, n.3, p.94–105, 2011.
BOTTS, M. et al. OGC® sensor web enablement: overview and high level architecture. In:
INTERNATIONAL CONFERENCE ON GEOSENSOR NETWORKS. Anais. . . [S.l.: s.n.],
2006. p.175–190.
BRÉZILLON, P.; MENDES DE ARAUJO, R. Reinforcing shared context to improve
collaboration. Revue d’intelligence artificielle, [S.l.], v.19, n.3, p.537–556, 2005.
BUCHHOLZ, T.; KÜPPER, A.; SCHIFFERS, M. Quality of Context: what it is and why we
need it. Proceedings of the workshop of the HP OpenView University Association, [S.l.],
p.1–14, 2003.
BUTT, T. Provision of adaptive and context aware service discovery for the Internet of
Things. 2014.
CHEN, A. Context-aware collaborative filtering system: predicting the user’s preferences in
ubiquitous computing. Proceedings of ACM CHI 2005 Conference on Human Factors in
Computing Systems, [S.l.], v.2, p.1110–1111, 2005.
CISCO. The Internet of Everything is the New Economy. [Online. Acessado em 25 jul
2016].
CISCO. How Many Internet Connections are in the World? Right. Now. [Online. Acessado
em 25 jul 2016].
COMPTON, M. et al. The SSN ontology of the W3C semantic sensor network incubator group.
Web Semantics: Science, Services and Agents on the World Wide Web, [S.l.], v.17,
p.25–32, 2012.
DANOVA, T. Morgan Stanley: 75 billion devices will be connected to the internet of things by
2020. [Online. Acessado em 25 jul 2016].
DESROSIERS, C.; KARYPIS, G. A comprehensive survey of neighborhood-based
recommendation methods. In: Recommender systems handbook. [S.l.]: Springer, 2011.
p.107–144.
DEY, A. K.; ABOWD, G. D.; SALBER, D. A conceptual framework and a toolkit for supporting
the rapid prototyping of context-aware applications. Human-computer interaction, [S.l.], v.16,
n.2, p.97–166, 2001.
DINIZ, H. et al. A Reference Architecture for Mobile Crowdsensing Platforms. In: Anais. . .
[S.l.: s.n.], 2016.
EVCHINA, Y. et al. Context-aware knowledge-based middleware for selective information
delivery in data-intensive monitoring systems. Engineering Applications of Artificial
Intelligence, [S.l.], v.43, p.111–126, 2015.

68
GANTI, R. K.; YE, F.; LEI, H. Mobile crowdsensing: current state and future challenges. IEEE
Communications Magazine, [S.l.], v.49, n.11, p.32–39, 2011.
GRAY, P.; SALBER, D. Modelling and using sensed context information in the design of
interactive applications. Engineering for Human-Computer Interaction, [S.l.], n.1,
p.317–335, 2001.
GUILLEMIN, P.; FRIESS, P. Internet of things strategic research roadmap. [Online.
Acessado em 25 jul 2016].
GUINARD, D. et al. Interacting with the SOA-based internet of things: discovery, query,
selection, and on-demand provisioning of web services. IEEE Transactions on Services
Computing, [S.l.], v.3, n.3, p.223–235, 2010.
HENSON, C. A. et al. SemSOS: semantic sensor observation service. In: COLLABORATIVE
TECHNOLOGIES AND SYSTEMS, 2009. CTS’09. INTERNATIONAL SYMPOSIUM ON.
Anais... [S.l.: s.n.], 2009. p.44–53.
HONLE, N. et al. Benefits of integrating meta data into a context model. In: PERVASIVE
COMPUTING AND COMMUNICATIONS WORKSHOPS, 2005. PERCOM 2005
WORKSHOPS. THIRD IEEE INTERNATIONAL CONFERENCE ON. Anais... [S.l.: s.n.],
2005. p.25–29.
JAIN, R. The art of computer systems performance analysis: techniques for experimental
design, measurement, simulation, and modeling. [S.l.]: John Wiley & Sons, 1990.
JIRKA, S.; BRÖRING, A.; STASCH, C. Discovery mechanisms for the sensor web. Sensors,
[S.l.], v.9, n.4, p.2661–2681, 2009.
JUDD, G.; STEENKISTE, P. Providing Contextual Information to Pervasive Computing
Applications. International Conference on Pervasive Computing and Communications,
[S.l.], p.133, 2003.
KAHN, B. K.; STRONG, D. M.; WANG, R. Y. Information Quality Benchmarks: product and
service performance. Commun. ACM, [S.l.], v.45, n.4, p.184–192, 2002.
KIM, Y.; LEE, K. A Quality Measurement Method of Context Information in Ubiquitous
Environments. 2006 International Conference on Hybrid Information Technology, [S.l.],
v.2, p.576–581, 2006.
KRAUSE, M.; HOCHSTATTER, I. Challenges in modelling and using quality of context (QoC).
Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), [S.l.], v.3744 LNCS, p.324–333, 2005.
LEI, J. et al. Using Physical–level Context Awareness to Improve Service Ranking in Wireless
Sensor Network. Journal of Networks, [S.l.], v.7, n.6, p.926–934, 2012.
LIU, Z.; XU, X. S-ABC-A Service-Oriented Artificial Bee Colony Algorithm for Global
Optimal Services Selection in Concurrent Requests Environment. In: WEB SERVICES (ICWS),
2014 IEEE INTERNATIONAL CONFERENCE ON. Anais... [S.l.: s.n.], 2014. p.503–509.
LOPS, P.; DE GEMMIS, M.; SEMERARO, G. Content-based recommender systems: state of
the art and trends. In: Recommender systems handbook. [S.l.]: Springer, 2011. p.73–105.

69
LUNARDI, W. T. et al. Context-based search engine for industrial IoT: discovery, search,
selection, and usage of devices. IEEE International Conference on Emerging Technologies
and Factory Automation, ETFA, [S.l.], v.2015-October, n.July 2016, 2015.
MCCARTHY, J.; BUVAC, S. Formalizing context. 1997.
NIU, W. et al. Context-aware service ranking in wireless sensor networks. Journal of network
and systems management, [S.l.], v.22, n.1, p.50–74, 2014.
NWE, N. H. W.; BAO, J.-m.; GANG, C. Flexible user-centric service selection algorithm for
Internet of Things services. The Journal of China Universities of Posts and
Telecommunications, [S.l.], v.21, p.64–70, 2014.
OGC. Open Geospatial Consortium. [Online. Acessado em 25 jul 2016].
OLIVEIRA, M. I. S.; GAMA, K. S. da; LÓSCIO, B. F. Waldo: serviço para publicação e
descoberta de produtores de dados para middleware de cidades inteligentes. XI Simpósio
Brasileiro de Sistemas de Informação, [S.l.], 2015.
PERERA, C. et al. Sensor Search Techniques for Sensing as a Service Architecture for the
Internet of Things. IEEE 14th International Conference on Mobili Data Management,
[S.l.], 2013.
PERERA, C. et al. Context-aware sensor search, selection and ranking model for internet of
things middleware. Proceedings - IEEE International Conference on Mobile Data
Management, [S.l.], v.1, p.314–322, 2013.
PERERA, C. et al. Context aware computing for the internet of things: a survey. IEEE
Communications Surveys & Tutorials, [S.l.], v.16, n.1, p.414–454, 2014.
RAN, S. A model for web services discovery with QoS. SIGecom Exch., [S.l.], v.4, n.1, p.1–10,
2003.
RANGANATHAN, A.; AL-MUHTADI, J.; CAMPBELL, R. H. Reasoning about uncertain
contexts in pervasive computing environments. IEEE Pervasive Computing, [S.l.], v.3,
p.62–70, 2004.
SAWANT, S. Collaborative Filtering using Weighted BiPartite Graph Projection – A
Recommendation System for Yelp. 2013.
SHEIKH, K.; WEGDAM, M.; SINDEREN, M. van. Quality-of-context and its use for protecting
privacy in context aware systems. Journal of Software, [S.l.], v.3, n.3, p.83–93, 2008.
SILVA, E. C. G. F. et al. Um Survey sobre Plataformas de mediação de Dados para Internet das
Coisas. SEMISH – Seminário Integrado de Software e Hardware, [S.l.], 2015.
SOEDIONO, B. Managing Context Data for Smart Spaces. Journal of Chemical Information
and Modeling, [S.l.], v.53, n.October, p.160, 1989.
VIEIRA, V.; TEDESCO, P.; SALGADO, A. C. Modelos e Processos para o desenvolvimento de
Sistemas Sensíveis ao Contexto. André Ponce de Leon F. de Carvalho, Tomasz
Kowaltowski.(Org.). Jornadas de Atualização em Informática, [S.l.], p.381–431, 2009.

70
VIG, J. R. Introduction to quartz frequency standards. [S.l.]: DTIC Document, 1992.
WEI, Q.; JIN, Z. Service discovery for internet of things: a context-awareness perspective. In:
FOURTH ASIA-PACIFIC SYMPOSIUM ON INTERNETWARE. Proceedings... [S.l.: s.n.],
2012. p.25.
XU, C.; CHEUNG, S.-C. Inconsistency detection and resolution for context-aware middleware
support. ACM SIGSOFT Software Engineering Notes, [S.l.], v.30, n.5, p.336–345, 2005.
YANG, Z.; LI, D. IoT Information Service Composition Driven by User Requirement. In:
COMPUTATIONAL SCIENCE AND ENGINEERING (CSE), 2014 IEEE 17TH
INTERNATIONAL CONFERENCE ON. Anais... [S.l.: s.n.], 2014. p.1509–1513.
YUEN, K. K. F.; WANG, W. Towards a ranking approach for sensor services using primitive
cognitive network process. In: CYBER TECHNOLOGY IN AUTOMATION, CONTROL,
AND INTELLIGENT SYSTEMS (CYBER), 2014 IEEE 4TH ANNUAL INTERNATIONAL
CONFERENCE ON. Anais... [S.l.: s.n.], 2014. p.344–348.
ZASLAVSKY, A.; PERERA, C.; GEORGAKOPOULOS, D. Sensing as a Service and Big Data.
Proceedings of the International Conference on Advances in Cloud Computing (ACC-2012), [S.l.], p.21–29, 2012.
ZHAO, S. et al. A Feedback corrected Collaborative Filtering for Personalized Real world
Service Recommendation. 2014. 356–369p. v.9, n.3.
ZHENG, Z. et al. QoS-Aware Web Service Recommendation by Collaborative Filtering. Ieee
Transactions on Services Computing, [S.l.], v.4, n.2, p.140–152, 2011.

71
Apêndices
A. Artigos considerados
Os dados ilustrados nas Figuras 2.3 e 2.4 foram retirados dos artigos elencados na Tabela A.1.
Tabela A.1: Artigos considerados
Título Métricas
A survey on context-aware systems Confidence
Quality of Context: What It Is And Why We Need It Precision, Probability of correctness,
Trustworthiness, Resolution, Up-to-dateness
Managing Context Data for Smart Spaces Accuracy
Modelling and Using Sensed Context Information in the
Design of Interactive Applications
Information quality: coverage, resolution,
accuracy, repeatability, frequency, timeliness;
sensor source:, reliability, intrusiveness, security
or privacy, cost
Modeling Context Information in Pervasive Computing
Systems
Coverage, resolution, accuracy, repeatability,
frequency, timeliness, for future: trust, data
quality, cost
Benefits of Integrating Meta Data into a Context Model Reliability, precision, consistency, age, access
control
A Quality Measurement Method of Context Information
in Ubiquitous Environments
Accuracy, completeness, representation
consistency, access security and up-to-dateness.
Information quality: Probability of correctness
(Free-of-Error), Up-to-dateness (Timeliness),
Trust-worthiness (Believability), Accessibility,
Completeness, Concise Representation,
Consistent Representation, Ease of
Manipulation„ Appropriate Amount of
Information, Interpretability, Objectivity,
Relevancy,
Reputation, Value-Added, Understandability,
Security; QoC Parameters: Resolution,
Precision, Probability of correctness (Free-
ofError), Up-to-dateness (Timeliness),
Trustworthiness (Believability)

72
Challenges in Modelling and Using Quality of Context
(QoC)
The most important QoC-parameters have
been listed as precision, probability of
correctness, trust-worthiness, resolution and up-
todateness.
Categorization and Modelling of Quality in Context
Information
Related works: freshness and confidence
accuracy and confidence coverage, resolution,
accuracy, repeatability, frequency and timeliness
A Layered Model for User Context Management with
Controlled Aging and Imperfection Handling
Aging funcions
Quality-of-Context and its use for Protecting Privacy in
Context Aware Systems
Precision, probability of correctness and upto-
dateness, trustworthiness, freshness, confidence
Precision, freshnes, spatial resolution,
temporal resolution, probability of correctness
A Context Quality Model for Ubiquitous Applications Related: precision, probability of correctness„
trust-worthiness, resolution and up-to-dateness
- accuracy, completeness, representation
consistency, access security and up-to-dateness
Context for Ubiquitous Data Management Accuracy, confidence, update time, sample
interval - accuracy, time, energy cost
Inconsistency Detection and Resolution for
ContextAware Middleware Support
certainty, freshness
A Feedback-corrected Collaborative Filtering for
Personalized Real-world Service Recommendation
RTT (route trip time)
Context-aware Sensor Search, Selection and Ranking
Model for Internet of Things Middleware
Availability, accuracy, reliability, response
time, frequency, sensitivity, measurement
range, selectivity, precision, latency, drift,
resolution, detection limit, operating power
range,
system (sensor) lifetime, battery life, security,
accessibility, robustness, exception handling,
interoperability, configurability, user satisfaction
rating, capacity, throughput, cost of data
transmission, cost of data generation, data
ownership cost, bandwidth, and trust.
QoS-Aware Web Service Recommendation by
Collaborative Filtering
Response time failure rate

73
Adaptive and Context-aware Service Discovery for the
Internet of Things
Battery consumed
Retrieving Monitoring and Accounting Information
From Constrained Devices in Internet-of-Things
Applications
Remaining battery level, operational status of
the device, available memory and the uptime
at which the metering process has been
performed.
Information Quality Benchmarks: Product and Service
Performance
Accessibility, apropriate amount of informatio,
believability, completeness, concise
representation, ease of manipulation, freee-of-
error,
interpretability, objectivity, relevancy,
reputation, security, timeliness,
understandability,
value-added
A Flexible Framework for Representations of Entities in
the Internet of Things
Time, Bandwidth latency, Other
Providing Contextual Information to Pervasive
Computing Applications
Accuracy, confidence, update time, sample
interval

74
B. Escolha do parâmetro ρ
Para a escolha de um nível ideal para o parâmetro ρ da técnica de ranqueamento proposta e
discutida na Seção 3.4.1, foram executadas consultas ao catálogo Waldo utilizando, como
critérios de busca, 2 atributos de qualidade, variando o nível do parâmetro ρ da técnica de
ranqueamento em: 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8 e 0.9. Em cada um destes cenários foram
realizadas 32 execuções. Para gerar o gráfico da Figura B.1 em cada cenário foram excluídos o
maior e o menor valor de cada atributo de qualidade e a média das 30 medidas restantes foi
calculada.
Figura B.1. Níveis médios de qualidade para diferentes níveis de ρ.
Fonte: Elaborado pelo Autor
Como visto no gráfico da Figura B.1, o cenário que possui um comportamento mais apropriado,
ou seja, que retorna resultados com maiores níveis de qualidade é aquele em que ρ = 0.8. Assim,
esse valor foi fixado na técnica de ranqueamento proposta e discutida na Seção 3.4.1.

75
C. Descrição ilustrativa de um termômetro em SensorML
Código C.1: Exemplo de descrição em SensorML
<?xml version="1.0" encoding="UTF-8"?> <sml:PhysicalComponent gml:id="MY_SENSOR" xmlns:sml="http://www.opengis.net/sensorml/2.0" xmlns:swe="http://www.opengis.net/swe/2.0" xmlns:gml="http://www.opengis.net/gml/3.2" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xlink="http://www.w3.org/1999/xlink" xsi:schemaLocation="http://www.opengis.net/sensorml/2.0 http://schemas.opengis.net/sensorml/2.0/sensorML.xsd"> <!-- ================================================= --> <!-- System Description --> <!-- ================================================= --> <gml:description>simple thermometer with time tag</gml:description> <gml:identifier codeSpace="uid">urn:meteofrance:stations:76455</gml:identifier> <!-- metadata deleted for brevity sake --> <!-- ================================================= --> <!-- Observed Property = Output --> <!-- ================================================= --> <sml:outputs> <sml:OutputList> <sml:output name="temp"> <sml:DataInterface> <sml:data> <swe:DataStream> <!-- describe output --> <swe:elementType name="temperature"> <swe:Quantity definition="http://mmisw.org/ont/cf/parameter/air_temperature"> <swe:uom code="Cel"/> </swe:Quantity> </swe:elementType> <!-- simple text encoding --> <swe:encoding> <swe:TextEncoding tokenSeparator="," blockSeparator=" "/> </swe:encoding> <!-- reference the values at a RESTful resource --> <!-- returns latest measurement or continues to send new values
through open http pipe --> <swe:values xlink:href="http://myServer.com:4563/sensor/02080"/> </swe:DataStream> </sml:data> </sml:DataInterface> </sml:output> </sml:OutputList> </sml:outputs> <!-- ================================================= --> <!-- Station Location --> <!-- ================================================= --> <sml:position> <gml:Point gml:id="stationLocation" srsName="http://www.opengis.net/def/crs/EPSG/0/4326"> <gml:coordinates>47.8 88.56</gml:coordinates> </gml:Point> </sml:position> </sml:PhysicalComponent>

76
D. Exemplo de um produtor de dados descrito em SensorML
{ "_id" : ObjectId("57bd5cf40d9c3d45a4dad6f6"), "sml:PhysicalComponent" : { "@xmlns" : { "xlink" : "http://www.w3.org/1999/xlink", "sml" : "http://www.opengis.net/sensorml/2.0", "swe" : "http://www.opengis.net/swe/2.0", "gml" : "http://www.opengis.net/gml/3.2", "gco" : "http://www.isotc211.org/2005/gco", "gmd" : "http://www.isotc211.org/2005/gmd" }, "@gml:id" : "dp:1472027892766", "@definition" : "http://linkedgeodata.org/page/ontology/Bike", "gml:description" : { "#CONTENT#" : "Some Bike Data Producer" }, "sml:characteristics" : [ { "@name" : "Bike Attributes", "sml:CharacteristicList" : { "swe:label" : { "#CONTENT#" : "Bike Attributes" }, "swe:description" : { "#CONTENT#" : "Bike Attributes" }, "sml:characteristic" : { "@name" : "Manufacturer", "swe:Text" : { "swe:label" : { "#CONTENT#" : "Manufacturer" }, "swe:description" : { "#CONTENT#" : "Manufacturer" }, "swe:value" : { "#CONTENT#" : "FastBike" } } } } }, { "@name" : "QoS Attributes", "sml:CharacteristicList" : { "swe:label" : { "#CONTENT#" : "QoS Attributes" }, "swe:description" : { "#CONTENT#" : "QoS Attributes" }, "sml:characteristic" : [ { "@name" : "qos:availability", "swe:Quantity" : { "@id" : "id:availability", "@definition" : "def:availability", "swe:identifier" : { "#CONTENT#" : "identifier:availability" }, "swe:label" : { "#CONTENT#" : "availability" }, "swe:description" : { "#CONTENT#" : "The avalilability of the DataProducer over time" }, "swe:uom" : { "@code" : "%"

77
}, "swe:value" : { "#CONTENT#" : "96.7744416493853" } } } ] } } ], "sml:outputs" : { "sml:OutputList" : { "sml:output" : { "@name" : "BusSpeed", "swe:DataRecord" : { "swe:label" : { "#CONTENT#" : "Velocity" }, "swe:description" : { "#CONTENT#" : "Bike Status Speed" }, "swe:field" : { "@name" : "Speed", "swe:Quantity" : { "swe:identifier" : { "#CONTENT#" : "http://linkedgeodata.org/page/ontology/Velocity" }, "swe:label" : { "#CONTENT#" : "Speed" }, "swe:description" : { "#CONTENT#" : "Speed measured by device" }, "swe:uom" : { "@code" : "m/s" } } } } } } }, "sml:position" : [ { "swe:Vector" : { "@referenceFrame" : "", "swe:coordinate" : { "@name" : "Latitude", "swe:Quantity" : { "@definition" : "http://sensorml.com/ont/swe/property/Latitude", "swe:uom" : { "@code" : "deg" }, "swe:value" : { "#CONTENT#" : "-8.053281213075282" } } } } }, { "swe:Vector" : { "@referenceFrame" : "", "swe:coordinate" : { "@name" : "Longitude", "swe:Quantity" : { "@definition" : "http://sensorml.com/ont/swe/property/Longitude", "swe:uom" : { "@code" : "deg" }, "swe:value" : { "#CONTENT#" : "-34.88426136527068" } }

78
} } }, { "swe:Vector" : { "@referenceFrame" : "", "swe:coordinate" : { "@name" : "Altitude", "swe:Quantity" : { "@definition" : "http://sensorml.com/ont/swe/property/Altitude", "swe:uom" : { "@code" : "m" }, "swe:value" : { "#CONTENT#" : "9.0" } } } } } ] }, "_type" : "BIKE" }
Código D.1. Exemplo de descrição de um produtor de dados em SensorML