Вадим Абрамчук — big drupal: issues we met
TRANSCRIPT

Big Drupal: Issues We Met
Vadym Abramchuk
Internetdevels

Project overview
Realty analytics platform
Used by professional brokers
New data imported each few hours

The technologies
PHP, MySQL, Drupal 7


The technologies
PHP, MySQL, Drupal 7
MySQL is a primary storage
Solr 5.2 as search engine
PostgreSQL + PostGIS for spatial calculations

I wanted to say “One million
nodes”but I didn’t

The facts
958769 nodes
7004555 ECK entities in 7 types
375874 custom entity type rows
MySQL database size: 4G gzipped, 66G disk space usage
Solr indexes: 91G

Importing data into Drupal

Bulk data import
Know your data
Prepare your data
Avoid direct insertions
Insert directly if you’re brave enough (or you don’t have a choice)
Watch your step

Ok, so you don’t batch
Drupal has memory leaks
Entity metadata wrapper has memory leaks
https://www.drupal.org/node/1343196
Everything has memory leaks
Avoid long-running processes
Offload processing with queues and batches

Offloading
Put your data into separate table
Add queue
Let it run in background. Queues are made to be indepent
Having small amount of data? Use batches
Need to update really fast? Think about MySQL cursors

Tuning garbage collector


Tuning garbage collector

Playing with garbage collector
gc_disable()
process your batch, then gc_collect_cycles()
gc_enable()
Not a Holy Grail, may become Pandora’s box

Living with Solr
Drupal and Solr
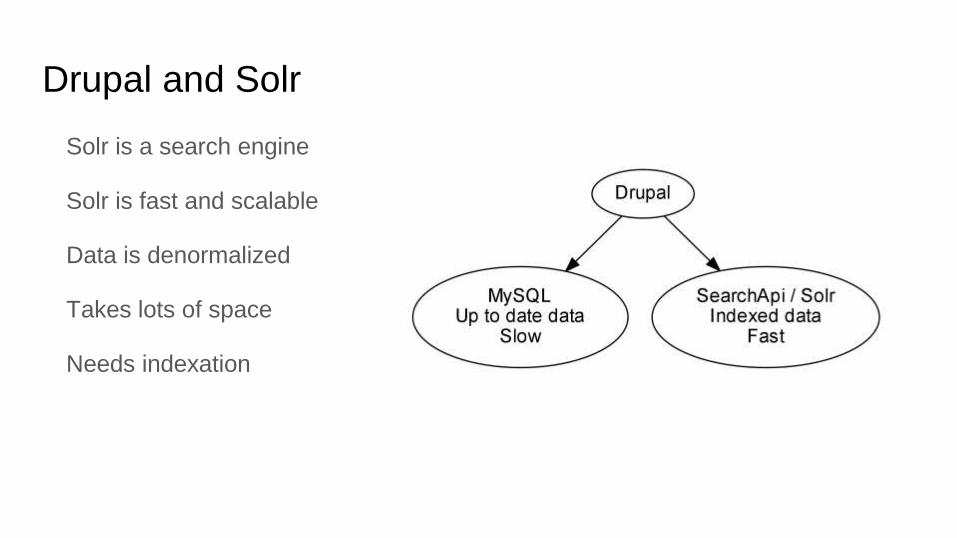
Solr is a search engine
Solr is fast and scalable
Data is denormalized
Takes lots of space
Needs indexation
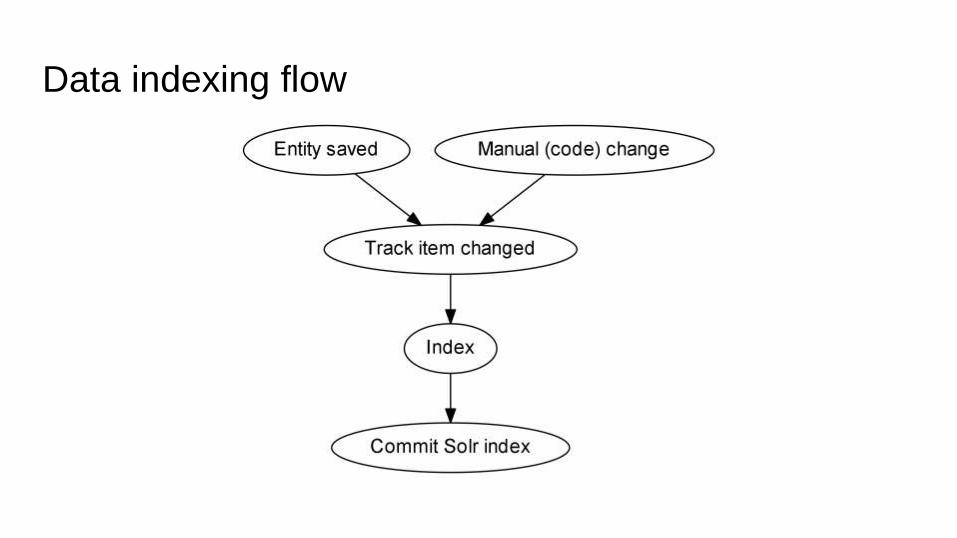
Data indexing flow

Why indexing is slow
Search API indexation is single threaded
Uses entity metadata wrappers
You can run multiple indexation processes, one per each index
Items are not locked, multiple workers at same index will do the same
Indexation via drush does not use batch and is slow due to memory leaks

Faster indexing
Index in parallel
One daemon to rule them all
Pool of workers
Daemon maintains list of items to index
Fully utilizes hardware
Needs special Solr configuration due to autocommit
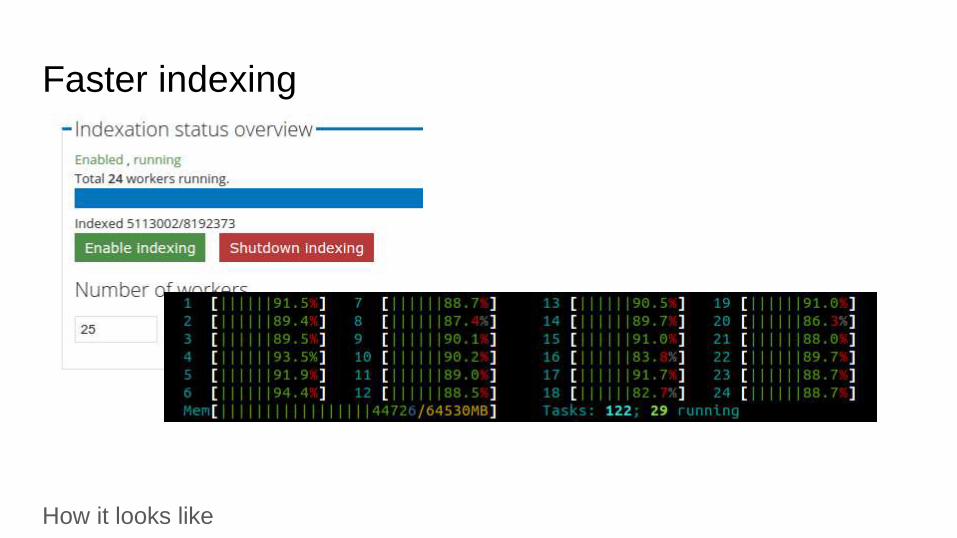
Faster indexing
How it looks like

Search API Views integration
Make a view like you always do, but for Search API items
Solr returns results set
Views fields handlers loads corresponding entities with entity_load (sic!)
https://www.drupal.org/node/2028337
Database is queried anyway but load is much less
Entity properties are rendered as entity properties
Use Search API processors to avoid loading entity and running getters

Caching

Cache backends
Database is slow
Memcache is faster
Redis is even faster
Redis caching module locks Redis by running LUA script inside serverlocal keys = redis.call("KEYS", ARGV[1])
for i, k in ipairs(keys) do
redis.call("DEL", k)
end
return 1

So useful useless cache
Field cache litters the cache storage
Use entitycache module with memcached
Large amount of cache entries kills Redis

Solr-oriented caching
Solr has an index version
Changed during Solr commit
May be used for cache key
That’s all folks!
Thanks for your time everyone
Reach me if you have some questions
Reach me right now if you have some answers ;)