add-ons to heath ’scientific computing’ · ... antworten auf verst¨andnisfragen . . . . . ....
TRANSCRIPT

Add-ons to Heath ’Scientific Computing’
Prof. Dr. Thomas Risse
23. Januar 2008

2

Inhaltsubersicht
1 Scientific Computing 11
2 Systems of Linear Equations 57
3 Linear Least Squares 133
4 Eigenvalue Problems 197
5 Nonlinear Equations 253
6 Optimization 301
7 Interpolation 359
8 Numerical Integration and Differentiation 399
9 Initial Value Problems 449
10 Boundary Value Problems 489
11 Partial Differential Equations 517
3

4 INHALTSUBERSICHT
Einleitung
Die folgenden Bemerkungen und Algorithmen sind Ausarbeitungen der Verstand-nisfragen, Ubungen und Computer-Probleme des begeisternden Buches
Michael T. Heath: Scientific Computing – An Introductory Survey;McGraw-Hill International Edition, 2nd edition 2002, ISBN 0-07-112229-Xhttp://www.cse.uiuc.edu/heath/scicomp/
Den Verstandnisfragen, Ubungen und Computer-Problemen eines jeden Kapi-tels sind eine kurze Einfuhrung in die Problemstellung und eine Vorstellung dereinschlagigen Verfahren vorangestellt.
Selbstverstandlich sind die Leser dieses Buches gehalten, zunachst selbst Antwor-ten zu finden, Ubungen durchzufuhren sowie Aufgaben zu programmieren underst dann, wenn ihre Ansatze oder Versuche scheitern, dieses Dokument zu Ratezu ziehen.
Eine ganze Reihe von interaktiven Anwendungen soll helfen, Probleme zu erkun-den. Dabei handelt es sich meist um kleine exemplarische Berechnungen, dieinteressierte Leser mit eigenen Parametern durchfuhren konnen.
Die meist numerischen Eingabe-Parameter dieser Algorithmen sind in rot-ge-rahmte Formular-Feldern, z.B. x = , einzutippen. Bei Anklicken entspre-chender Knopfe, z.B. eval , erscheinen Ausgaben in blau-gerahmten Formular-Feldern, z.B. y = f(x) = , und Ausgaben zur Kontrolle in grun-ge-rahmten Formular-Feldern, z.B. Konstante = . Dabei liefert testgenau einen Satz und tests nacheinander weitere Satze von Eingabe-Parametern.
Anmerkungen:
Die Zahlen am Rand der Antworten auf Verstandnisfragen, der Ubungsergebnisseund der Rechner-Problem-Losungen sind als Hinweise auf die einschlagigen Sei-tenzahlen der 2. Auflage zu verstehen.Bezeichner fur Vektoren und Matrizen sind durch Fettdruck hervorgehoben.Es wird nachdrucklich empfohlen, den Acrobat Reader Version 6 zu verwenden,um nicht Absturze der fruheren Versionen hinnehmen zu mussen.

Inhaltsverzeichnis
1 Scientific Computing 11
1.0.1 Approximation . . . . . . . . . . . . . . . . . . . . . . . . 11
1.0.2 Computer-Arithmetik . . . . . . . . . . . . . . . . . . . . . 14
1.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 19
1.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 22
1.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 24
1.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 28
1.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 38
1.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 48
2 Systems of Linear Equations 57
2.0.1 Lineare Systeme . . . . . . . . . . . . . . . . . . . . . . . . 57
2.0.2 Existenz und Eindeutigkeit . . . . . . . . . . . . . . . . . . 57
2.0.3 Sensitivitat und Konditionierung . . . . . . . . . . . . . . 58
2.0.4 Systeme linearer Gleichungen losen . . . . . . . . . . . . . 63
2.0.5 Spezielle Typen linearer Gleichungssysteme . . . . . . . . . 72
2.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 75
2.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 80
2.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 83
2.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 88
2.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 105
2.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 121
3 Linear Least Squares 133
5

6 INHALTSVERZEICHNIS
3.0.1 data fitting – lineare Ausgleichsrechnung . . . . . . . . . . 133
3.0.2 Existenz und Eindeutigkeit . . . . . . . . . . . . . . . . . . 135
3.0.3 Sensitivitat und Konditionierung . . . . . . . . . . . . . . 136
3.0.4 Problem-Transformationen . . . . . . . . . . . . . . . . . . 138
3.0.5 Orthogonalisierungsmethoden . . . . . . . . . . . . . . . . 140
3.0.6 Singular-Wert-Zerlegung, SVD . . . . . . . . . . . . . . . . 144
3.0.7 Anwendungen der Singular-Wert-Zerlegung . . . . . . . . . 146
3.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 150
3.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 153
3.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 157
3.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 160
3.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 171
3.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 188
4 Eigenvalue Problems 197
4.0.1 Eigenwerte, EWe und Eigenvektoren, EVen . . . . . . . . . 197
4.0.2 Existenz und Eindeutigkeit . . . . . . . . . . . . . . . . . . 198
4.0.3 Sensitivitat und Konditionierung . . . . . . . . . . . . . . 202
4.0.4 Problem-Transformationen . . . . . . . . . . . . . . . . . . 204
4.0.5 Eigenwerte und Eigenvektoren berechnen . . . . . . . . . . 205
4.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 211
4.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 214
4.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 217
4.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 221
4.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 231
4.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 241
5 Nonlinear Equations 253
5.0.1 Existenz und Eindeutigkeit . . . . . . . . . . . . . . . . . . 253
5.0.2 Sensitivitat und Konditionierung . . . . . . . . . . . . . . 254
5.0.3 Konvergenz-Raten und Abbruch-Kriterien . . . . . . . . . 254
5.0.4 nichtlineare Gleichungen in einer Unbekannten . . . . . . . 255

INHALTSVERZEICHNIS 7
5.0.5 Systeme nichtlinearer Gleichungen . . . . . . . . . . . . . . 258
5.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 260
5.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 263
5.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 265
5.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 270
5.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 277
5.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 286
6 Optimization 301
6.0.1 Optimierungsprobleme . . . . . . . . . . . . . . . . . . . . 301
6.0.2 Existenz und Eindeutigkeit . . . . . . . . . . . . . . . . . . 302
6.0.3 Sensitivitat und Kondition . . . . . . . . . . . . . . . . . . 306
6.0.4 Unrestringierte Optimierung in einer Variablen . . . . . . . 307
6.0.5 Unrestringierte Optimierung in mehreren Variablen . . . . 309
6.0.6 nichtlineare least squares Probleme . . . . . . . . . . . . . 314
6.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 316
6.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 319
6.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 321
6.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 325
6.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 335
6.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 347
7 Interpolation 359
7.0.1 Interpolation . . . . . . . . . . . . . . . . . . . . . . . . . 359
7.0.2 Existenz, Eindeutigkeit und Konditionierung . . . . . . . . 360
7.0.3 Polynomiale Interpolation . . . . . . . . . . . . . . . . . . 360
7.0.4 Interpolation mit stuckweise polynomialen Funktionen . . 365
7.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 368
7.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 370
7.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 372
7.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 374
7.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 381

8 INHALTSVERZEICHNIS
7.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 391
8 Numerical Integration and Differentiation 399
8.0.1 Integration . . . . . . . . . . . . . . . . . . . . . . . . . . 399
8.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 410
8.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 413
8.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 415
8.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 419
8.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 429
8.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 437
9 Initial Value Problems 449
9.0.1 Gewohnliche Differentialgleichungen . . . . . . . . . . . . . 449
9.0.2 Existenz, Eindeutigkeit und Konditionierung . . . . . . . . 452
9.0.3 Gewohnliche Differentialgleichungen numerisch losen . . . . 454
9.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 465
9.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 466
9.3 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 469
9.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 471
9.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 476
9.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 484
10 Boundary Value Problems 489
10.0.1 Randwert-Probleme . . . . . . . . . . . . . . . . . . . . . . 489
10.0.2 Existenz, Eindeutigkeit, Konditionierung . . . . . . . . . . 490
10.0.3 Schieß-Verfahren . . . . . . . . . . . . . . . . . . . . . . . 494
10.0.4 Finite-Differenzen-Verfahren . . . . . . . . . . . . . . . . . 496
10.0.5 Kollokationsverfahren . . . . . . . . . . . . . . . . . . . . . 497
10.0.6 Galerkin-Verfahren . . . . . . . . . . . . . . . . . . . . . . 499
10.0.7 Eigenwert-Probleme . . . . . . . . . . . . . . . . . . . . . 501
10.1 Review Questions – Verstandnisfragen . . . . . . . . . . . . . . . 503
10.2 Exercises – Ubungen . . . . . . . . . . . . . . . . . . . . . . . . . 504
10.3 Computer Problems – Rechner-Probleme . . . . . . . . . . . . . . 505

INHALTSVERZEICHNIS 9
10.4 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 507
10.5 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 510
10.6 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 514
11 Partial Differential Equations 517
11.0.1 Partielle Differentialgleichungen . . . . . . . . . . . . . . . 517
11.0.2 Zeit-abhangige partielle Differentialgleichungen . . . . . . 519
11.0.3 Zeit-unabhangige partielle Differentialgleichungen . . . . . 521
11.0.4 Direkte Verfahren fur dunn besetzte lineare Systeme . . . 521
11.0.5 Iterative Verfahren fur lineare Systeme . . . . . . . . . . . 522
11.1 Review Questions – Antworten auf Verstandnisfragen . . . . . . . 523
11.2 Exercises – Ubungsergebnisse . . . . . . . . . . . . . . . . . . . . 530
11.3 Computer Problems – Rechner-Problem-Losungen . . . . . . . . . 533
Die Kapitel werden nach und nach weiter ausgearbeitet. 23. Januar 2008

10 INHALTSVERZEICHNIS

Kapitel 1
Scientific Computing
Stichpunktartige Auflistung der Inhalte: Definitionen, Sachverhalte, Beispiele
1.0.1 ApproximationUrsachen und Auswirkungen
extern: Modelle bilden Wirklichkeit nur teilweise ab, Messungen sind prinzipiellungenau, verwendete Daten sind Fehler-behaftet.intern: mathematische Naherung (truncation/discretization), Rundungsfehler
Z.B. Die Erdoberflache A = 4π r2 mit r = 6370 km ist zu berechnen. c
absoluter und relativer Fehler
Def. absoluter Fehler = Naherung - exakter Wert Def. relativer Fehler = absoluter Fehler / exakter Wert Bem. Wenn eine Naherung x einen relativen Fehler von 10−p aufweist, dannhat x gerade p korrekte, signifikante Dezimalziffern. Def. Prazision bezeichnet die Zahl der signifikanten Stellen der Darstellung einerZahl, Genauigkeit die Zahl der korrekten signifikanten Stellen einer Naherung. Soist beispielsweise 3.258320462521 eine prazise Zahl, aber keine besonders genaueNaherung von π. Naherung = exakter Wert × (1+relativer Fehler)
computational and propagated data error
Def. totaler Fehler = computational error + propagated data errorf(x)− f(x) = (f(x)− f(x)) + (f(x)− f(x))
11

12 KAPITEL 1. SCIENTIFIC COMPUTING
Z.B. sin(π8) ≈ sin 3
8≈ 3
8= 0.375 wobei sin π
8≈ 0.3827
total error: f(x)− f(x) ≈ 0.3750− 0.3827 = −0.0077
computational error: f(x)− f(x) = 38− sin 3
8≈ 0.3750− 0.3663 = 0.0087
propagated data error: f(x)−f(x) = sin 38−sin π
8≈ 0.3663−0.3827 = −0.0164 c
truncation and rounding error
Def. computational error = truncation/discretization error + rounding errortruncation/discretization error = Fehler aufgrund approximierendem Algorith-mus bei exakter Arithmetik, z.B. endliche statt unendliche Folge, Teilsummestatt unendliche Reihe, Differenzenquotient statt Differentialquotient, Riemann-sche Summe statt Integral etc.rounding error = Fehler aufgrund Verwendung endlich-genauer Arithmetik Z.B. f ′(x) ≈ 1
h(f(x + h) − f(x)). Mit Taylor gilt f(x + h) = f(x) + h f ′(x) +h2
2f ′′(z) fur ein z ∈ [x, x+ h] und mit |f ′′(z)| < M fur z nahe x fur geeignete f .
Sei der Fehler bei der Auswertung von f durch ε beschrankt. Dann istcomputational error = truncation/discretization error + rounding error
1h(f(x+ h)− f(x))− f ′(x) < 1
2M h+ 1
h2ε
minimal, falls h = 2√
εM
. c
forward and backward error
forward error := ∆y = y − y meist schwer zu bestimmenbackward error := ∆x = x− x mit f(x) = ybackward error := wieviel data error erklart den gesamten Fehler im Ergebnis?
•x
•x
• y = f(x) = f(x)
• y = f(x)
-f
-fQ
Qs
f
6
?
∆x = x− x backward error
6
?
forward error ∆y = y − y
Z.B. y =√
2: forward error fur y = 1.4 ist |∆y| = |y−y| = |1.4−1.4141| ≈ 0.0142und daher liegt ein relative forward error von etwa 1% vor. Wegen
√1.96 = 1.4
ist backward error |∆x| = |x− x| = |1.96− 2| = 0.04 und daher liegt ein relativebackward error von 2% vor. cZ.B. Fur y = f(x) = cosx sei y = f(x) = 1− 1
2x2.

13
Dann ist der forward error ∆y = y − y = f(x)− f(x) = 1− 12x2 − cosx.
Gesucht x mit f(x) = f(x), d.h. x = arccos (f(x)) = arccos(y).
Fur x = 1 gilt y = f(x) = cos 1 ≈ 0.5403, y = f(1) = 1 − 1212 = 0.5 und
x = arccos(y) = arccos(0.5) ≈ 1.0472.forward error ∆y = y − y ≈ 0.5− 0.5403 = −0.0403backward error ∆x = x− x ≈ 1.0472− 1 = 0.0472. c
Sensitivitat und Konditionierung
Sensitivitat ist das qualitative Phanomen, daß ein Problem auf Storungen derEingabe-Daten reagiert. Konditionierung quantifiziert, wie stark ein Problemauf Storungen der Eingabe-Daten reagiert (propagated data error).
Def. Ein Problem heißt insensitiv oder gut konditioniert, well conditioned, wenneine relative Anderung der Eingabe-Daten eine vergleichbare relative Anderungder Ausgabe-Daten nach sich zieht.Ein Problem heißt sensitiv oder schlecht konditioniert, ill conditioned, wenn dierelative Anderung der Ausgabe-Daten wesentlich großer als eine relative Ande-rung der Eingabe-Daten ausfallt.
Def. cond(f)|x =∣∣∣f(x)−f(x)
f(x)
∣∣∣ / ∣∣ x−xx
∣∣ ist die Konditionszahl von f in x.
|relative forward error | = Konditionszahl × |relative backward error |
Z.B. Fur differenzierbare f : R → R giltabsolute forward error f(x+ ∆x)− f(x) ≈ f ′(x)∆x
relative forward error f(x+∆x)−f(x)f(x)
≈ f ′(x)∆xf(x)
Konditionszahl cond(f)|x ≈∣∣∣f ′(x)∆x/f(x)
∆x/x
∣∣∣ =∣∣∣x f ′(x)
f(x)
∣∣∣ c
Z.B. Fur f(x) =√x ist cond(f)|x = 1
2fur alle x > 0. c
Z.B. Berechnung der Konditionszahl cond(f) =
∣∣∣∣ f(x)−f(x)f(x)
x−xox
∣∣∣∣ ≈ ∣∣∣xf ′(x)f(x)
∣∣∣ etwa fur
f(x) = cosx in x ≈ π2≈ 1.5707963267948966. c
symbolic f(x) =symbolic f ′(x) =
get f , f ′ test eval reset
f(x) =f ′(x) =
f( ) =f( ) =
cond =
∣∣∣∆f/f∆x/x
∣∣∣= =∣∣∣xf ′(x)f(x)
∣∣∣ =

14 KAPITEL 1. SCIENTIFIC COMPUTING
1.0.2 Computer-Arithmetik
Gleitpunkt-Zahlen-Systeme
Def. F(β, p, L, U) = ±βE∑p−1
i=0di
βi : N 3 di ∈ [0, β − 1],N 3 E ∈ [L,U ]
β p L U bytes typeIEEE 754 single precision, SP 2 24 −126 127 4 floatIEEE 754 double precision, DP 2 53 −1022 1023 8 double
IEEE 754 spezifiziert daruberhinaus SP extended F(2,≥ 32,≤ −1022,≥ 1023)und DP extended F(2,≥ 64,≤ −16382,≥ 16383). Weitere Referenzen und linkss.a. http://babbage.cs.qc.edu/courses/cs341/IEEE-754references.html
David Goldberg: What every computer Scientist should know about FloatingPoint Arithmetic; www.weblearn.hs-bremen.de/risse/RST/docs/goldberg.pdf
Bem. Intel80x86 Prozessoren stellen Gleitpunkt-Zahlen intern im 80bit extendedprecision Format (IEEE 754 DP extended Format) dar.
Normalisierung
Def. F = F(β, p, L, U) ist normalisiert, wenn d0 > 0 fur jedes 0 6= x ∈ F. Die IEEE 754 Gleitpunkt-Zahlensysteme sind normalisiert.
Underflow/Overflow
Anzahl der Gleitpunkt-Zahlen ist |F(β, p, L, U)| = 2(β − 1)βp−1(U − L+ 1) + 1.
Def. Im normalisierten F = F(β, p, L, U) istunderflow level, UFL = minx : 0 < x ∈ F = βL
overflow level, OFL = max F = βU+1(1− β−p)
Runden
Def. In F = F(β, p, L, U) istrounding by chopping, round toward zero round(βE
∑∞i=0
di
βi ) = βE∑p−1
i=0di
βi
rounding to nearest, round to even round(x) = y minimiert |y − x| fur y ∈ F. IEEE 754 spezifiziert vier Rundungsarten: round to nearest (default),round towards plus infinity bzw. round towards minus infinity und round towardszero. Um diese IEEE 754 Rundungsarten umzusetzen, wird intern die Mantisseum das guard bit und das round bit erweitert und ein sticky bit verwaltet.

15
Maschinen-Genauigkeit, machine precision
Def. Fur εmach, unit roundoff, machine precision oder machine epsilon giltbei rounding by chopping, round toward zero εmach = β1−p
bei rounding to nearest, round to even εmach = 12β1−p
Fur alle x ∈ R, |x| ≤ OFL gilt∣∣∣fl(x)−x
x
∣∣∣ ≤ εmach. Meist ist 0<UFL<εmach<OFL.
In IEEE 754 mit round to nearest (default) gilt daher:
in SP ist εmach = 2−24 ≈ 5.96 · 10−8 entspricht ≈ 7 Dezimalziffernin DP ist εmach = 2−53 ≈ 1.11 · 10−16 entspricht ≈ 16 Dezimalziffern
Subnormale Gleitpunkt-Zahlen, gradual underflow
Def. Positive Zahlen kleiner als UFL = βL konnen dargestellt werden, wenn furE = L eben d0 = 0 zugelassen wird. Solche Zahlen in F heißen subnormal oderdenormalized. F weist dann gradual underflow auf. IEEE 754 verwendet gradual underflow, speichert Gleitpunkt-Zahlen fur die le-xikographische Sortierung in der Form s E+offset fraction f , wobei fur dieMantisse 1 ≤ m = 1 + f < 2 mit 0 ≤ f < 1 gilt. Wie wird die Null dargestellt?
Ausnahme-Werte
Def. IEEE 754 kennt den Ausnahme-Wert, Inf fur infinity, etwa overflow oder1/0, und den Ausnahme-Wert NaN, not a number, fur Ausdrucke der Form 0/0,0*Inf oder Inf/Inf. zur Bedeutung von 00 s.a. www.matheng4.hs-bremen.de/Folien/Buchholz.pps
JavaScript bzw. der JavaScript Interpreter in Adobe’s Acrobat Forms implemen-tiert diese Vorgaben des IEEE-Standards. Experimentiere auch mit tan π
2, hier
tan(pi/2), cot 0, hier cot(0), coth 0, hier coth(0), artanh(1), hier artanh(1),00, hier pow(0,0) usw. sowie beliebigen algebraischen Ausdrucken, namlich Sum-men, Differenzen, Produkte, Quotienten usw. in diesen Großen.
argsym = eval(argsym) = tests eval reset
Gleitpunkt-Arithmetik
Vgl. schriftliche Addition, Subtraktion, Multiplikation und Division jeweils mitanschließender Rundung auf p Ziffern und gegebenenfalls Renormalisierung. Er-gebnisse dieser Operationen angewandt auf Maschinen-Zahlen sind nicht notwen-dig wieder Maschinen-Zahlen.

16 KAPITEL 1. SCIENTIFIC COMPUTING
Z.B. Addition von x = 1.92×102, y = 6.56×100 ∈ F(10, 3, L, U) mit rounding tonearest ergibt fl(x+y) = 1.99×102 unabhangig von der letzten Ziffer von y. cZ.B. Multiplikation von x = 1.92 × 102, y = 6.56 × 100 ∈ F(10, 3, L, U) mitrounding to nearest ergibt fl(x ∗ y) = 1.26× 103 unter Vernachlassigung von dreisignifikanten Ziffern. cZ.B. Division von x = 1.0× 100, y = 3.0× 100 ∈ F(10, p, L, U) mit rounding to
nearest ergibt fl(x/y) =3.
p−1 mal︷ ︸︸ ︷3 . . . 3 ×10−1, qualitativ aber nicht quantitativ verschie-
den. cZ.B. Division von x = 1.0 × 10L, y = 2.0 × 100 ∈ F(10, p, L, U) ohne gradualunderflow ergibt fl(x/y) = fl(5.0 · 10L−1) und damit underflow. cZ.B. Addition von x = 5.0×10U , y = 6.0×10U ∈ F(10, p, L, U) ergibt fl(x+y) =fl(1.1 · 10U+1) und damit overflow. cz.H. Warum ist overflow i.a.R. gravierender als underflow? oz.H. Warum ist
∑∞n=1
1n
in Gleitpunkt-Arithmetik endlich? vgl. 1CP8. oDP x = y =pdec = x = y =
x op y =x op y =
12101−p = + − ∗ / reset | x op y−x op y
x op y| =
Idealerweise gilt x flop y = fl(x op y), was etwa in IEEE 754 gegeben ist, solangex op y im Darstellungsbereich liegt.
In F(β, p, L, U) sind bestimmte Gesetze der Arithmetik verletzt, was forwarderror analysis erschweren kann. Ein Vorteil der backward error analysis bestehtdarin, daß in der Analyse die (gewohnte) reelle Arithmetik verwendet wird.
Gleitpunkt-Addition ist nicht notwendig assoziativ, d.h. (a+ b) + c 6= a+ (b+ c)
pdec = a = b = c = eval reset(a+ b) + c = a+ (b+ c) =
Gleitpunkt-Vergleiche |<> ∈ =, 6=, <,≥, >,≤ sind nicht notwendig monoton,d.h. es gibt a, b, c mit a |<>b 6⇒ (a+ c) |<> (b+ c) fur einen Vergleichsoperator |<>pdec = a = b = c = eval reseta = = b und a+ c = = b+ c
Ausloschung, cancellation
Def. Ausloschung, cancellation tritt auf, wenn zwei Zahlen mit identischemVorzeichen und von derselben Großenordnung subtrahiert werden. Z.B. Fur 0 < ε < εmach gilt in F(β, p, L, U) eben fl(1 + ε)− fl(1− ε) = 1− 1 = 0statt exakt (1 + ε)− (1− ε) = 2ε. c

17
Bei unsicheren Argumenten kann die Differenz nur aus Rundungsfehler bestehen!
Z.B. Approximation von exp(x) fur (große) negativer Argumente x durch dieTaylor-Reihe exp(x) = ex =
∑∞i=0
1i!xi fuhrt aufgrund von Ausloschung zu kata-
strophalen Ergebnissen, vgl. 1CP9. cZ.B. Die Losungen der quadratischen Gleichung ax2 + bx+ c = 0 lauten
x1,2 = 12a(− b±
√b2 − 4ac) = 2c/(− b∓
√b2 − 4ac)
Sei beispielsweise a = 0.05010, b = −98.78 und c = 5.015. In F(10, 4) gilt dann furdie Diskriminante b2− 4ac = fl(9757− 1.005) = 9756 und fl(
√b2 − 4ac) = 98.77.
x1 x2
(−b±√b2 − 4ac)/(2a) 1972 0.09980
exakte Losung auf 10 signifikante Stellen 1971.605916 0.05077069387
2c/(−b∓√b2 − 4ac) 1003 0.05077
Exakte Losungen und berechnete Losungen weisen hier aufgrund von Ausloschungrelative Fehler in der Großenordnung von etwa 100% auf, vgl. 1CP10. cZ.B. Der Mittel- oder Erwartungswert einer Folge X = (xi)i=1,...,n ist durchx = 1
n
∑ni=1 xi definiert, ihre Standard-Abweichung σ durch die Varianz
Var(X) = σ2 =1
n− 1
n∑i=1
(xi − x)2 =1
n− 1(
n∑i=1
x2i − nx2)
Der erste Ausdruck (two pass) ist – wenn auch aufwandiger – numerisch stabilerals der zweite (one pass), vgl. 1CP12. cZ.B. Fur die lineare Gleichung ax = b sei eine Losung x berechnet. Um dieGute der Losung zu bestimmen, berechnen wir das Residuum r = b − ax. InGleitpunkt-Arithmetik gilt fl(ax) = ax(1 + δ1) fur |δ1| ≤ εmach und analog fur|δ2| ≤ εmach
fl(r) = fl(b− ax) = (b− ax(1 + δ1))(1 + δ2) = (r − axδ1)(1 + δ2)
= r(1 + δ2)− axδ1 − axδ1δ2 ≈ r(1 + δ2)− δ1b
δ1b ist von der Großenordnung von εmachb, das seinerseits von der Großenordnungvon r ist, so daß das Residuum mit einem Fehler von 100% behaftet sein kann: wirmussen das Residuum mit hoherer Prazision berechnen, um uberhaupt sinnvolleErgebnisse zu bekommen.In F(10, 3) sei beispielsweise a = 2.78, b = 3.14 und x = 1.13. Wegen fl(2.78 ×1.13) = 3.14 verschwindet das Residuum in F, obwohl exakt r = b − ax =3.14 − 3.1414 = −0.0014 gilt. Kein Wunder, sind doch b und ax fast identisch,so daß das Residuum, d.h. die Differenz nur aus Rundungsfehler besteht.
3.14 = fl(ax) = ax(1+δ1) = 3.1414(1+δ1) impliziert δ1 = −0.00143.1414
≈ −0.00044566

18 KAPITEL 1. SCIENTIFIC COMPUTING
In der folgenden Subtraktion tritt nur Ausloschung, aber kein Rundungsfehlerauf, also δ2 = 0. Fur das in F berechnete Residuum gilt dann
fl(r) = fl(b− ax) ≈ r(1 + δ2)− δ1b = r − δ1b ≈ −0.0014− (−0.0014) = 0
Generell ist das Residuum mit doppelter Genauigkeit zu berechnen. cZ.B. Der Differentialquotient f ′(x) werde approximiert durch den Differenzen-quotienten f ′(x) ≈ 1
h(f(x+ h)− f(x)). Beobachtung: je kleiner h um so großerder rounding error! und je großer h um so großer der truncation error!Sei der relative Fehler bei der Auswertung von f beschrankt durch ε. Wegen Tay-lor f(x+h)−f(x) = h f ′(x)+ 1
2h2 f ′′(z), also 1
h(f(x+h)−f(x))−f ′(x) = 12h f ′′(z)
fur ein z ∈ [x, x + h] ist dann der truncation error |12h f ′′(z)| beschrankt durch
12hM fur eine Schranke M von |f ′′(x)| in einer Umgebung von x. Der total error
ist dann beschrankt durch 2hε|f(x)|+ 1
2hM , was fur h = 2
√ε|f(x)|/M minimiert
wird. c

1.1. Review Questions – Verstandnisfragen 19
1.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Ein Problem istschlecht konditioniert, wenn dieLosung sensitiv auf kleine Anderun-gen der Eingangsdaten reagiert.
2. Richtig/Falsch? Die Verwendung ge-nauerer Arithmetik verbessert dieKonditionierung eines schlecht kon-ditionierten Problems.
3. Richtig/Falsch? Die Kondition einesProblems hangt vom Losungsalgo-rithmus ab.
4. Richtig/Falsch? Ein guter Algorith-mus produziert eine genaue Losungunabhangig von der Konditionie-rung des Problems.
5. Richtig/Falsch? Die Wahl desLosungsalgorithmus’ hat keinenEinfluß auf den propagated dataerror.
6. Richtig/Falsch? Ein stabiler Algo-rithmus fur ein gut konditioniertesProblem liefert notwendig eine ge-naue Losung.
7. Richtig/Falsch? Wenn zwei reelleZahlen als Gleitpunkt-Zahlen dar-stellbar sind, so ist auch das Ergeb-nis einer reellen arithmetischen Ope-ration auf diesen beiden Operandenals Gleitpunkt-Zahl darstellbar.
8. Richtig/Falsch? Gleitpunkt-Zahlensind gleichmaßig uber ihren Werte-bereich verteilt.
9. Richtig/Falsch? Gleitpunkt-Addition ist assoziativ, abernicht kommutativ.
10. Richtig/Falsch? In Gleitpunkt-Systemen ist underflow level, UFLdie kleinste positive Zahl ε mit1 6= 1 + ε.
11. Richtig/Falsch? Im IEEE 754 Stan-dard sind die Mantissen doppelt ge-nauer Zahlen genau doppelt so langwie die Mantissen von Zahlen miteinfacher Genauigkeit.
12. Welche drei Eigenschaften charak-terisieren ein korrekt gestelltes Pro-blem.
13. Liste drei Fehler-Quellen in wissen-schaftlichen Berechnungen.
14. Klare den Unterschied zwischentruncation (oder discretization) undrounding.
15. Klare den Unterschied zwischen ab-solutem und relativem Fehler.
16. Klare den Unterschied zwischencomputational error und propagateddata error.
17. Klare den Unterschied zwischen pre-cision und accuracy.
18. a) Was bedeutet Kondition einesProblems?
b) Beeinflußt der Losungsalgorith-mus die Kondition eines Problems?
c) Wird die Kondition eines Pro-blems durch die Genauigkeit derArithmetik beeinflußt?
19. Ein Problem habe die Konditions-zahl 1. Ist das gut oder schlecht?
20. Klare den Unterschied zwischen re-lativer und absoluter Konditions-zahl.

20 KAPITEL 1. SCIENTIFIC COMPUTING
21. Was ist ein inverses Problem? Undin welcher Beziehung stehen dieKondition eines Problems und die-jenige des inversen Problems?
22. a) Was bedeutet backward error ei-nes Rechenergebnisses?
b) Wann gilt in der backward erroranalysis ein genaherte Losung einesProblems als gut?
23. Welche der folgenden Großenwerden durch die Stabilitat desLosungsalgorithmus’ beeinflußt?
a) propagated data error
b) Genauigkeit des Ergebnisses
c) Kondition des Problems
24. a) Klare den Unterschied zwischenforward error und backward error.
b) Wie verhalten sich forward errorund backward error quantitativ zu-einander?
25. Wie sind in einem Gleitpunkt-System die Gleitpunkt-Zahlen aufdem Zahlenstrahl verteilt?
26. Was ist in Gleitpunkt-Arithmetikschadlicher: underflow oder over-flow ?
27. Welche der folgenden Gleitpunkt-Operationen auf zwei positivenGleitpunkt-Zahlen kann overflow er-zeugen?
a) Addition b) Subtraktionc) Multiplikation d) Division
28. Welche der folgenden Gleitpunkt-Operationen auf zwei positivenGleitpunkt-Zahlen kann underflowerzeugen?
a) Addition b) Subtraktionc) Multiplikation d) Division
29. Gib Grunde dafur an, Gleitpunkt-Zahlen normalisiert darzustellen.
30. Gib den maximalen relativen Feh-ler der Darstellung beliebiger reellerZahlen durch Maschinen-Zahlen an.
31. a) Wie unterscheiden sich round to-wards zero und round to nearest ?
b) Welche der beiden Rundungsre-geln ist genauer?
c) Wie wirkt sich die Rundungsregelauf εmach aus?
32. Bestimme εmach in F(2, p, L, U) mitround to nearest.
33. Ist in einem Gleitpunkt-System mitgradual underflow, also mit subnor-mal numbers, die Zahldarstellungimmer noch eindeutig?
34. Ist in einem Gleitpunkt-System dasProdukt zweier Maschinen-Zahlenwieder als Maschinen-Zahl darstell-bar?
35. Ist in einem Gleitpunkt-System derQuotient zweier Maschinen-Zahlenwieder als Maschinen-Zahl darstell-bar?
36. a) Die Gleitpunkt-Addition ist nichtnotwendig assoziativ. Beispiel?
b) Die Gleitpunkt-Multiplikation istnicht notwendig assoziativ. Bei-spiel?
37. a) Unter welchen Umstanden trittcancellation auf?
b) Impliziert cancellation, daßdas korrekte Ergebnis nicht alsMaschinen-Zahl darstellbar ist?
c) Warum ist cancellation meistensschadlich?

1.1. Review Questions – Verstandnisfragen 21
38. Gib ein Beispiel einer Zahl mit end-licher Dezimal-Darstellung und un-endlicher Binar-Darstellung.
39. Gib Beispiele fur Gleitpunkt-Operationen, die als Ergebnis Infbzw. NaN erzeugen.
40. Wie groß ist der maximale relativeFehler bei der Darstellung beliebigernicht-verschwindender reeller Zah-len x in einem Gleitpunkt-Systemzur Basis β, Prazision p und roundto nearest, x ∈ F(β, p, L, U) ?
41. Warum ist cancellation bei derSubtraktion zweier Zahlen gleicherGroßenordnung haufig schadlich,auch wenn das Ergebnis der Sub-traktion der beiden aktuellen Ope-randen exakt ist?
42. Was ist das Ergebnis der folgen-den Operationen in einem dezima-len Gleitpunkt-System mit εmach =10−5 und Exponenten zwischen -20und +20 ?
a) 1 + 10−7 b) 1 + 103
c) 1 + 107 d) 1010 + 103
e) 1010/10−15 f) 10−10 × 10−15
43. Welche der folgende Berechnungenergibt underflow in einem Gleit-punkt-System mit UFL = 10−38 ?
a) a =√b2 + c2 mit b = 1 und c =
10−25
b) a =√b2 + c2 mit b = c = 10−25
c) u = (v×w)/(y×z) mit v = 10−15
und w = 10−30 und y = 10−20 undz = 10−25
In welchen Fallen von underflow istes sinnvoll, die betroffene Große aufNull zu setzen.
44. a) Klare den Unterschied zwischenunit roundoff, εmach und underflowlevel, UFL.
b) Welche der beiden Großen hangtnur von der Anzahl der Stellen in derMantisse ab?
c) Welche der beiden Großen hangtnur von der Anzahl der Stellen imExponenten ab?
d) Welche der beiden Großen hangtnicht von der Rundungsregel ab?
e) Welche der beiden Großen wirdnicht davon beeinflußt, wenn sub-normale Zahlen zugelassen werden?
45. Seien x1 > x2 > . . . > xn > 0 gege-ben und sei s =
∑ni=1 xi zu bestim-
men. In welcher Reihenfolge solltendie xi aufsummiert werden, um denRundungsfehler zu minimieren?
46. Ist cancellation ein Beispiel fur einenRundungsfehler?
47. a) Warum konnen in Gleitpunkt-Arithmetik divergierende (unendli-che) Reihen wie etwa
∑∞k=1
1k end-
liche Reihenwerte haben?
b) Wann werden sich die n-ten Teil-summen von etwa
∑∞k=1
1k nicht
mehr andern?
48. Seien alle xi > 0 und sei der Rei-henwert der konvergenten Reihe S =∑∞
i=1 xi < ∞ in naturlicher, vor-gegebener Ordnung zu berechnen.Welches Abbruchskriterium liefertmaximale Genauigkeit bei minima-ler Anzahl von Summanden?
49. Warum ist es schwierig, den Rei-henwert einer konvergenten, alter-nierenden Reihe wie etwa ex =∑∞
i=0 xi/i! fur x < 0 in Gleitpunkt-Arithmetik genau zu berechnen?

22 KAPITEL 1. SCIENTIFIC COMPUTING
50. Die Ableitung f ′ von f : R → Rwerde durch die endliche Differenzf ′(x) ≈ 1
h(f(x + h) − f(x)) appro-ximiert. Fur h → 0 geht auch dertruncation error gegen Null. Gibzwei Großen an, die die ’Kleinheit’von h in Gleitpunkt-Systemen be-schranken.
51. Gegeben die quadratische Gleichungax2 + bx + c = 0 mit den bei-den Losungen x1,2 = 1
2a( − b ±√b2 − 4ac). Welche zwei Grunde
bereiten numerische Schwierigkeitenbei der Berechnung der Losungen?
1.2 Exercises – Ubun-
gen
1. Die durchschnittliche normaleKorper-Temperatur ist 98.6oF, wasexakt 37oC entspricht.
a) Was ist der maximale relativeFehler, angenommen, der akzep-tierte Wert ist auf ±0.05 oF genau.
b) Was ist der maximale relativeFehler, angenommen, der akzep-tierte Wert ist auf ±0.5 oC genau.
2. Was sind absolute und relative Feh-ler der Approximation von π durch
a) 3 b) 3.14 c) 22/7 d) 355/113
3. Sei a der approximierte Wert einerGroße mit exaktem Wert t. Der re-lative Fehler von a sei r.Zeige: a = t(1 + r).
4. Bestimme der propagated data errorbei der Auswertung von sinx, d.h.den Fehler aufgrund einer Storungh im Argument x.
a) Schatze den absoluten Fehler beider Auswertung von sinx ab.
b) Schatze den relativen Fehler beider Auswertung von sinx ab.
c) Schatze die Konditionszahl diesesProblems ab.
d) Fur welche Werte von x ist dasProblem hoch-sensitiv?
5. Sei f : R2 → R mit f(x, y) = x − ygegeben. Die Norm |(x, y)| = |x| +|y| messe die Große der Eingabe-Daten. Sei |x|+|y| ≈ 1 und x−y ≈ ε.Zeige: cond(f) ≈ 1
ε . Was heißt dasfur die Sensitivitat der Subtraktion?
6. Es gilt sinx =∑∞
i=0(−1)ix2i+1
(2i+1)! .
a) Bestimme forward error undbackward error der Approximationsinx ≈ x in x = 0.1, 0.5, 1.0.
b) Bestimme forward error undbackward error der Approximationsinx ≈ x− 1
6x3 in x = 0.1, 0.5, 1.0.
7. Sei F(10, p, L, U) gegeben.
a) Was sind die kleinsten Werte vonp und U und der großte Wert vonL, so daß die beiden Zahlen x =2365.27 und y = 0.0000512 exaktim normalisierten F(10, p, L, U) dar-stellbar sind?
b) Was gilt, wenn in F(10, p, L, U)gradual underflow zugelassen wird?
8. Sei x = 1.23456 und y = 1.23579 inF(10, 6, L, U) gegeben.
a) Wieviele signifikante Ziffern haty − x ?
b) Was ist der minimale Wertebe-reich fur Exponenten derart, daß x,y und y−x zugleich im normalisier-ten F darstellbar sind?
c) Ist die Differenz y−x unabhangigvom Exponenten-Wertebereich ex-akt darstellbar, wenn gradual under-flow zugelassen wird?

1.2. Exercises – Ubungen 23
9. a) Berechne die Oberflache A(r) =4πr2 der Erde mit r = 6370 km inF(10, 4, L, U).
b) Berechne A(r+1)−A(r) im Gleit-punkt-System F(10, 4, L, U).
c) Wegen d Adr = 8πr gilt ∆A(r) ≈
8πr∆r. Vergleiche mit Teil b).
d) Fuhre den Vergleich aus Teil c) inF(10, 6, L, U) durch.
e) Erlautere die Ergebnisse a) bis d)
f) Wie klein muß ∆r sein, damit dasPhanomen bei SP bzw. DP zu beob-achten ist?
10. Sei f(x) = 11−x −
11+x fur |x| 6= 1
gegeben.
a) In welchen Intervallen fur das Ar-gument x ist es schwierig, f(x) inGleitpunkt-Arithmetik genau zu be-rechnen?
b) Welcher mathematisch aquiva-lente Ausdruck fur f(x) erlaubt,f(x) fur x in den Intervallen aus a)genauer zu bestimmen?
11. Ist lnx − ln y oder ln xy fur x ≈ y
genauer? Hinweis: wo ist lnx sensi-tiv?
12. a) Kann x2 − y2 oder (x− y)(x+ y)genauer berechnet werden?
b) Fur welche x und y ergibt sichein betrachtlicher Unterschied in derGenauigkeit der beiden Ausdrucke?
13. Wie sind overflow und ’harm-ful’ underflow in der Berechnungder Euklid’schen Norm ||x|| =
(∑n
i=1 x2i )
1/2des Vektors x ∈ Rn
zu vermeiden? s.a. 1CP15, S. 26
14. Wie wird der Mittelpunkt m des In-tervalles [x, y] am besten berechnet?
a) m = 12(x+ y) = x
2 + y2
b) m = x+ 12(y − x)
15. Gib Beispiele dafur, daß die Gleit-punkt-Addition nicht assoziativ ist,
a) in F(2, 3,−1, 1)
b) in IEEE SP
16. Inwiefern unterscheiden sich die di-versen alternativen Definitionen furεmach konkret?Hinweis: verwende F(2, 3,−1, 1).
17. x und y seien benachbarte nicht-verschwindende Gleitpunkt-Zahlenin einem normalisierten Gleitpunkt-System F(β, p, L, U).
a) Was ist der minimale Abstandzwischen x und y ?
b) Was ist der maximale Abstandzwischen x und y ?
18. Wieviele normalisierte IEEE SPGleitpunkt-Zahlen gibt es?Wieviele IEEE SP Gleitpunkt-Zahlen gibt es, wenn subnormalnumbers zugelassen werden?
19. Bestimme UFL und OFL inIEEE SP. Bestimme UFL imsubnormalisierten IEEE SP.
20. Wie wird 110 in IEEE SP dargestellt,
a) bei round towards zero oder roun-ding by chopping,
b) bei round to nearest ?
21. a) Ist εmach notwendig eineMaschinen-Zahl?
b) Gibt es ein Gleitpunkt-SystemF(β, p, L, U) mit εmach < UFL ? Bei-spiel?
22. Gegeben a x2 + b x + c = 0 mita = 1.22, b = 3.34 und c = 2.28im normalisierten F=F(10, 3, L, U).
a) Bestimme den Wert der Diskrimi-nanten D = b2 − 4ac in F.

24 KAPITEL 1. SCIENTIFIC COMPUTING
b) Bestimme den exakten Wert derDiskriminanten D = b2 − 4ac.
c) Bestimme |D −D|/|D|, den rela-tiven Fehler.
23. Gegeben das normalisierte Gleit-punkt-System F(10, 3,−98, U).
a) Was ist UFL ?
b) Was ist x−y fur x = 6.87×10−97
und y = 6.81× 10−97 ?
c) Was ist x − y, wenn gradual un-derflow zugelassen ware?
24. Zu zeigen: Wenn β = 2 und1β ≤ x
y ≤ β, dann ist mit je-der Maschinen-Zahl x und jederMaschinen-Zahl y mit xy > 0 auchx− y eine Maschinen-Zahl.Gibt ein Gegenbeispiel fur β = 3.
25. Sei mpyadd(a,b,c) := a*b+c, wobeia, b und c SP-Argumente sind. DasProdukt a*b werde in DP berechnet.Auf das nicht-normalisierte Produktwerde c aufaddiert. Das Ergebniswerde in SP zuruckgegeben.Wie kann diese Instruktion verwen-det werden, um DP-Produkte zuberechnen, ohne DP-Argumente zuverwenden. Das DP-Produkt a ∗b liege dabei in zwei SP-Variablenhigh und low vor.
26. Zeige x1,2 = −b±√
b2−4ac2a und alter-
nativ x′1,2 = 2c−b∓
√b2−4ac
liefern glei-chermaßen die beiden Losungen derquadratischen Gleichung
ax2 + bx+ c = 0
27. σ2 = 1n−1
∑ni=1(xi − x)2 (two pass)
vs σ2 = 1n−1(
∑ni=1 x
2i − n x2) (one
pass)Inwiefern ist die one pass formula
zur Berechnung der Standard-Ab-weichung σ der two pass formula nu-merisch unterlegen? (vgl. 1CP12auf S. 26)
1.3 Computer Pro-
blems – Rechner-
Probleme
1. Laut Stirling’s Formel ist n! ≈ n! =√2π n (n/e)n. Schreibe ein Pro-
gramm, das absoluten und relati-ven Fehler fur beliebige n berechnet.Wie andern sich absoluter und rela-tiver Fehler, wenn n wachst?
2. Schreibe ein Programm, das εmach,UFL und OFL sowie die Anzahl derbits in Matisse und Exponent aufdem jeweiligen Rechner bestimmt.
3. Es gilt εmach ≈ |3 ∗ (4/3 − 1) − 1|naherungsweise.
a) Warum funktioniert dieser Trick?
b) Auf diversen Rechnern ausprobie-ren!
c) Funktioniert dieser Trick inF(3, p, L, U) ?
4. Es gilt e = limn→∞ (1 + 1n)
n.
Schreibe ein Programm, das (1+ 1n)n
fur n = 10k und verschiedene k er-stens per Schleife, zweitens per Ex-ponentiationsoperator und drittensper (1 + 1
n)n = en ln(1+1/n) zusam-men mit den Abweichungen berech-net. Erklare die Beobachtungen.
5. a) Wieso gilt fur f(x) = ex−1x gerade
limx→0 f(x) = 1 ?
b) Berechne f(xk) fur xk = 10−k
und k = 1, 2, . . . , 15. Klare

1.3. Computer Problems – Rechner-Probleme 25
die Beobachtungen und theoretischbegrundete Erwartungen.
c) Was passiert bei Verwendungdes aquivalenten Ausdrucks f(x) =ex−1ln(ex) ?
6. Im Intervall [a, b] sind die n+1 aqui-distanten Punkte mit Abstand h =b−an zu erzeugen.
a) Welche der beiden Berechnungs-weisen xo = a und xk = xk−1 +h furk = 1, 2, . . . , n oder x′k = a+ k h furk = 0, 1, . . . , n ist vorteilhafter?
b) Schreibe ein Programm, das denVergleich erlaubt und die Unter-schiede zeigt.
7. Schreibe ein Programm, das denDifferentialquotienten f ′(x) einerFunktion durch die (zentrierten)Differenzenquotienten approximiertund den Fehler berechnet.
a) f ′(x) ≈ f(x+h)−f(x)h fur h = 10−k
mit k = 0, 1, . . . , 16 und beispiels-weise f(x) = sinx in x = 1.
b) f ′(x) ≈ f(x+h)−f(x−h)2h fur h =
10−k mit k = 0, 1, . . . , 16 und bei-spielsweise f(x) = sinx in x = 1.
8. Betrachte die harmonische Reihe∑∞n=1
1n .
a) Zeige:∑∞
n=11n ist divergent.
b) Erlautere, warum∑∞
n=11n in
Gleitpunkt-Arithmetik endlich ist.
c) Prognostiziere, wann sich die Teil-summen in IEEE SP bzw. inIEEE DP nicht mehr andern.
d) Schreibe ein Programm, das denReihenwert in IEEE SP wie auch inIEEE DP ermittelt und dabei Fort-schritt und Laufzeit protokolliert.
9. a) Schreibe ein Programm, das dieExponential-Funktion exp(x) an-
hand ihrer Taylor-Polynome pn mitpn(x) =
∑ni=0
xi
i! approximiert.
b) Wenn in der naturlichen Rei-henfolge summiert wird, welchesAbbruch-Kriterium sollte verwendetwerden?
c) Teste das Programm fur x = ±1,±5, ±10, ±15, ±20 und vergleichedie Ergebnisse mit denen der jewei-ligen Bibliotheksfunktion exp.
d) Kann die kanonische Summationverwendet werden, um genaue Er-gebnisse auch fur negative Argu-mente zu erhalten?
e) Kann die Reihenfolge der Sum-mation so abgeandert werden, daßgenaue Ergebnisse auch fur negativeArgumente gewonnen werden?
10. Bestimme die Losungen der quadra-tischen Gleichung a x2 + b x+ c = 0per
−b±√
b2−4ac2a = x1,2 = 2c
−b∓√
b2−4ac
etwa fur Koeffizienten
a b c
6 5 −46 · 10154 5 · 10154 −4 · 10154
0 1 11 −4 3.99999
10−155 −10155 10155
11. f(x) = x3 + a x2 + b x + c hatmindestens eine reelle Nullstelle x.Schreibe ein Programm, das x be-stimmt.Per Substitution y = x + a
3 ergibtsich y3 + p y + q = 0 mit p = 1
3(3b−a2) und q = 1
27(2a3 − 9ab + 27c).Wenn die Determinante D = 1
27p3 +
14q
2 positiv ist, gibt es genau die einereelle Nullstelle
x = −a3+ 3
√− q
2 +√D+ 3
√− q
2 −√D.

26 KAPITEL 1. SCIENTIFIC COMPUTING
12. a) Schreibe ein Programm, das furx = (xi)i=1,...,n jeweils Mittelwertx und Standardabweichung σ be-stimmt. Vergleiche (1Ex27, S. 24)die two pass formula
σ2 = 1n−1
n∑i=1
(xi − x)2
mit der one pass formula
σ2 = 1n−1(
n∑i=1
x2i − nx2).
b) Fur welche Eingabe-Vektoren xergeben die beiden mathematischaquivalenten Formeln betrachtlichenumerische Unterschiede bis hin zunegativen Radikanden?
13. Sei a das Start-Kapital, r der Zins-satz und n die Anzahl der Zins-ausschuttungen (jahrlich: n = 1,halbjahrlich: n = 2, in jedem Quar-tal: n = 4, monatlich: n = 12,wochentlich: n = 56, taglich: n =365). Dann ist f(n) = a(1+ r
n)n dasaufgezinste Kapital am Jahresende.
a) Schreibe ein Programm, das f(n)erstens vermittels einer Schleife,zweitens vermittels des Exponen-tiationsoperators und drittens un-ter Verwendung von Bibliotheks-funktionen als f(n) = en ln(1+r/n)
berechnet.
b) Vergleiche die drei Ergebnisse.
14. p(x) = (1− x)6,q(x) =
∑6i=0
(6i
)(−x)i,
r(x)=∑3
i=0
(62i
)x2i−
∑3i=1
(6
2i−1
)x2i−1
oder mit Horner h(x) = (((((x −6)x + 15)x − 20)x + 15)x − 6)x + 1sind identische, nicht negative Funk-tionen mit der 6-fachen Nullstelle 1.Vergleiche p, q, r und h in etwa derUmgebung [0.995, 1.005] von 1.
15. Schreibe ein Programm, das ||x||2 =√∑ni=1 x
2i , die Euklid’sche Norm
des Vektors x = (x1, . . . , xn)T be-rechnet und dabei overflow wie auchharmful underflow vermeidet (vgl.1Ex13, S. 23). Gib Beispiele furVektoren, so daß naive und umsich-tige Berechnung signifikant unter-schiedliche Ergebnisse liefern. Wie-viel performance kostet wieviel Ge-nauigkeit?
16. Sei (xi)i=1,...,n eine Folge von nin [0, 1] gleichverteilten (Pseudo-)SP Zufallszahlen. Bestimme s =∑n
i=1 xi.
a) sa =∑n
i=1 xi bei Verwendung ei-ner DP-Variablen sa.
b) sb =∑n
i=1 xi bei Verwendung ei-ner SP-Variablen sb.
c) sc =∑n
i=1 xi bei Verwendung desfolgenden Algorithmus’ mit SP-Va-riablen s, c und t
s=x[1]; c=0;for(i=2; i<=n;i++)
y=x[i]-c; t=s+y;c=(t-s)-y; s=t;
d) sd =∑n
j=1 xij wobei xi1 ≤ xi2 ≤. . . ≤ xin
e) se =∑n
j=1 xij wobei xi1 ≥ xi2 ≥. . . ≥ xin
Vergleiche die Verfahren a) bis e).Wie und warum funktioniert c) ?Welche Rangfolge nehmen a) bis e)im Hinblick auf Genauigkeit undKosten ein?
17. Schreibe ein Programm, das die er-sten n Folgen-Elemente der Folgexk+1 = 2.25xk − 0.5xk−1 mit Start-werten x1 = 1
3 und x2 = 112 erzeugt.

1.3. Computer Problems – Rechner-Probleme 27
Verwende etwa n = 225 in SP undn = 60 in DP.Wieso ist xk = 1
341−k die exakteLosung der Differenzengleichung?Erklare die Unterschiede zwischenBeobachtung und exaktem Ergeb-nis.
18. Schreibe ein Programm, das die er-sten n Folgen-Elemente der Folgexk+1 = 111−(1130−3000/xk−1)/xk
mit x1 = 112 und x2 = 61
11 erzeugt.Verwende etwa n = 10 in SP undn = 20 in DP.Die exakte Losung der Differenzen-gleichung ist eine monoton wach-sende Folge mit limk→∞ xk = 6.Erklare die Unterschiede zwischenBeobachtung und exaktem Ergeb-nis.

28 KAPITEL 1. SCIENTIFIC COMPUTING
1.4 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Ein Problem ist schlecht konditioniert, wenn die Losungsensitiv auf kleine Anderungen der Eingangsdaten reagiert.
Ein Problem ist schlecht konditioniert, wenn die Losung (hoch-) sensitiv13/14auf kleine Anderungen der Eingangsdaten reagiert.
2. Richtig/Falsch? Verwendung genauerer Arithmetik verbessert die Kondi-tionierung eines schlecht konditionierten Problems.
Die Konditionszahl cond(f) =∣∣∣f(x)−f(x)
f(x)
∣∣∣ / ∣∣ x−xx
∣∣ ist unabhangig von f de-13/14
finiert und damit unabhangig von der bei der Implementation f von fverwendeten Arithmetik!
3. Richtig/Falsch? Die Konditionierung eines Problems hangt vom Losungs-algorithmus ab.
cond(f) ist unabhangig von f , also unabhangig vom Algorithmus, cond ist13/14Problem-inharent! ’even with exact computation the solution may be highlysensitive to pertubations in the input data’
4. Richtig/Falsch? Ein guter Algorithmus produziert eine genaue Losung un-abhangig von der Konditionierung des Problems.
Wenn ein Problem schlecht konditioniert ist, kann auch ein guter Algorith-13/14mus daran nichts andern!
5. Richtig/Falsch? Die Wahl des Losungsalgorithmus’ hat keinen Einfluß aufden propagated data error.
Wegen total error = f(x) − f(x) = (f(x) − f(x)) + (f(x) − f(x)) =6computational error + propagated data error hat die Wahl des Algorithmus’keinen Einfluß auf den propagated data error.
6. Richtig/Falsch? Ein stabiler Algorithmus fur ein gut konditioniertes Pro-blem liefert notwendig eine genaue Losung.
Ein stabiler Algorithmus fur ein gut konditioniertes System liefert eine ge-16naue Losung.
7. Richtig/Falsch? Wenn zwei reelle Zahlen als Gleitpunkt-Zahlen darstellbarsind, so ist auch das Ergebnis einer reellen arithmetischen Operation aufdiesen beiden Operanden als Gleitpunkt-Zahl darstellbar.
1 = 20 und 10 = 23 + 21 sind binar darstellbare float-Zahlen. Aber ihr22/23Quotient 0.1 = 1
10= 0.00011 ist keine binar darstellbare float-Zahl.

1.4. Review Questions – Antworten auf Verstandnisfragen 29
8. Richtig/Falsch? Gleitpunkt-Zahlen sind gleichmaßig uber ihren Wertebe-reich verteilt.
Gleitpunkt-Zahlen sind nur in den Intervallen βe[1, β] gleichmaßig verteilt: 19In der Darstellung x = ±βe
∑p−1i=0
di
βi mit ganzen 0 ≤ di ≤ β − 1 ist dieMantisse, also die Summe nicht negativ.
Induktion nach der precision p:p = 0: die moglichen d0 sind gleichverteilt in [0, β − 1] und damit sind diemoglichen x gleichverteilt in βe[0, β − 1].
p → p + 1: zwischen jedem x = ±βe∑p−1
i=0di
βi und x + dp−1+1
βi fur dp−1 <
β − 1 werden gleichverteilt weitere β Stuck y = ±βe∑p
i=0di
βi fur dp =0, 1, 2, . . . , β − 1 eingefugt.
9. Richtig/Falsch? Gleitpunkt-Addition ist assoziativ, aber nicht kommutativ.
Gleitpunkt-Addition ist nicht assoziativ (vgl. (1+ε)+ε = 1 6= 1+(ε+ε) = 231 + 2 ε, z.B. in F(10, 2,−2, 2) gilt mit ε = 0.05 = 5.0 × 10−2 zum einenfl(1 + ε) = fl(1.05) = 1 und zum anderen fl(ε + ε) = fl(0.1) = 1.0 × 10−1
sowie fl(1 + (ε+ ε)) = fl(1.1) = 1.1× 10−0), aber kommutativ.
10. Richtig/Falsch? In Gleitpunkt-Systemen ist underflow level, UFL die klein-ste positive Zahl ε mit 1 + ε 6= 1.
UFL = βL 6= min0 < f ∈ F : 1 + f 6= 1. Etwa im normalisierten 18F(2, 3,−3, 1) gilt UFL = (1.00)(2) × 2−3 = 1
8und 1 + 1
8= (1.00)(2) +fl
(0.001)(2) = (1.00)(2), also UFL < min0 < f ∈ F : 1 + f 6= 1, da UFL diekleinste positive Maschinen-Zahl ist.
11. Richtig/Falsch? Die Mantisse in IEEE DP ist genau doppelt so lang wie dieMantisse in IEEE SP.
Die Mantisse in IEEE DP hat 53 bits, die Mantisse in IEEE SP hat 24 bits: 18die DP-Mantisse ist also mehr als doppelt so lang wie die SP-Mantisse.
12. Welche drei Eigenschaften charakterisieren ein korrekt gestelltes Problem.
Ein korrekt gestelltes Problem hat eine eindeutige Losung, die stetig von 3den Eingangsdaten abhangt.
13. Liste drei Fehler-Quellen in wissenschaftlichen Berechnungen.
Fehler-Quellen in wissenschaftlichen Berechnungen sind einerseits 4
• vereinfachende Annahmen im physikalischen Modell
• Meßfehler in Eingabe-Großen
• Fehler in Eingabe-Großen aufgrund vorangegangener Berechnungen
und andererseits

30 KAPITEL 1. SCIENTIFIC COMPUTING
• vereinfachende Annahmen im mathematischen Modell(truncation oder discretization)
• Rundungsfehler in Berechnungen
14. Klare den Unterschied zwischen truncation (oder discretization) und roun-ding.
computational error = truncation error + rounding error4/5
truncation error oder discretization error := Fehler aufgrund des Algorith-mus bei exakter Arithmetik, z.B. Polynom statt Reihe, Differenz statt Dif-ferential etcrounding error := Fehler zwischen Ergebnis bei endlich genauer Arithmetikund Ergebnis bei unendlich genauer, also exakter Arithmetik bei gegebenemAlgorithmus
15. Klare den Unterschied zwischen absolutem und relativem Fehler.
absolute error := naherungsweiser Wert - exakter Wert5
relative error := naherungsweiser Wert - exakter Wertexakter Wert
16. Klare den Unterschied zwischen computational error und propagated dataerror.
computational error := Fehler aufgrund (der Wahl) des Algorithmus’6/7propagated data error := ’prinzipieller’ Fehler aufgrund fehlerhafter Ein-gabe-Daten
17. Klare den Unterschied zwischen precision und accuracy.
Prazision, precision, ist die Anzahl der Ziffern/bits in der Darstellung einer6Zahl.Genauigkeit, accuracy, ist die Anzahl der korrekten Ziffern/bits in der Ap-proximation einer Große.
18. a) Was bedeutet Kondition eines Problems?13
Die Kondition eines Problems, cond = |relativer Fehler der exakten Losung||relativer Fehler der Eingabe-Daten| =∣∣∣f(x)−f(x)
f(x)
∣∣∣ / ∣∣ x−xx
∣∣, ist die relativen Anderung der Ausgabe-Daten des Pro-
blems bezogen auf die relative Anderung der Eingabe-Daten.
b) Wird die Kondition durch den Losungsalgorithmus beeinflußt?
Die Kondition hangt nur vom Problem und nicht von dem zu seiner Losungverwendeten Algorithmus ab.
c) Wird die Kondition durch die Genauigkeit der Arithmetik beeinflußt?
Die Kondition ist wegen a) unabhangig von der Prazision der Arithmetik,z.B. single oder double.

1.4. Review Questions – Antworten auf Verstandnisfragen 31
19. Ein Problem habe die Konditionszahl 1. Ist das gut oder schlecht?
cond = 1, d.h. cond ist sicher nicht ’much larger than 1’: Das Problem ist 13/14also gut konditioniert, insensitive oder well-conditioned.Sowohl das Problem selbst wie auch das inverse Problem reagieren gutmutigauf Anderungen der Eingabe-Daten: die resultierende relative Anderungder Ausgabe-Daten entspricht der relativen Anderung der Eingabe-Daten.forward error und backward error sind betragsmaßig gleich.
20. Klare den Unterschied zwischen relativer und absoluter Konditionszahl.
Die (relative) Konditionszahl cond(f) =∣∣∣f(x)−f(x)
f(x)
∣∣∣ / ∣∣ x−xx
∣∣ ist undefiniert, 15/16
falls x oder f(x) verschwinden. In diesem Fall wird die (absolute) Konditi-
onszahl cond(f) =∣∣∣f(x)−f(x)
x−x
∣∣∣ =∣∣∆y∆x
∣∣ verwendet.
21. Was ist ein inverses Problem? Wie verhalten sich die Kondition eines Pro-blems und diejenige des inversen Problems zueinander?
Das zu y = f(x) inverse Problem ist x = f−1(y). Es gilt cond(f−1) = 14∣∣∆xx
∣∣ / ∣∣∣∆yy
∣∣∣ = 1/cond(f).
22. a) Was bedeutet backward error eines Rechenergebnisses? 11
Der ruckwartige Fehler ist definiert durch die Abweichung ∆x = x− x derEingabe-Daten mit f(x) = y, die alle Fehler im Ergebnis y erklart.
b) Wann gilt in der backward error analysis ein genaherte Losung eines 11Problems als gut?
’According to backward analysis an approximated solution to a given pro-blem is good if it is the exact solution to a ¨nearby¨ problem.’
23. Welche der folgenden Großen werden durch die Stabilitat des Losungsalgo-rithmus’ beeinflußt?
a) propagated data error 6,16
Der propagated data error f(x)− f(x) ist unabhangig von Losungsalgorith-men und deren Stabilitat.
b) Genauigkeit des Ergebnisses 16
Die Genauigkeit der berechneten Losung hangt von der Kondition des Pro-blems und von der Stabilitat des Losungsalgorithmus’ ab.
c) Kondition des Problems 16
Die Kondition eines Problems ist unabhangig von seinen Losungsalgorith-men und wird daher nicht durch deren Stabilitat beeinflußt.

32 KAPITEL 1. SCIENTIFIC COMPUTING
24. a) Klare den Unterschied zwischen forward error und backward error. 11
forward error ist die Differenz ∆y = y − y zwischen berechneter y = f(x)und echter Losung y = f(x). backward error ist der Fehler ∆x = x− x mitf(x) = y in den Eingangsdaten, der fur den beobachteten Fehler ∆y = y−yin den Ausgangsdaten verantwortlich zu machen ware.
b) Wie verhalten sich forward error und backward error quantitativ zuein-13ander?
Wegen cond = |∆y|/|∆x| sind forward error und backward error durch
|relative forward error| = cond× | relative backward error|
quantitativ miteinander verknupft.
25. Wie sind in einem Gleitpunkt-System F die Gleitpunkt-Zahlen auf demZahlenstrahl verteilt?
Maschinen-Zahlen sind jeweils in den Intervallen [βe, βe+1] und [−βe+1,−βe]19fur e = L,L+ 1, . . . , U − 1 auf dem Zahlenstrahl gleichmaßig verteilt.
26. Was ist in Gleitpunkt-Arithmetik schadlicher: underflow oder overflow ?
overflow ist ’schlimmer’ als underflow, weil 0 haufig eine gute Approxima-23tion betragsmaßig sehr kleiner Zahlen ist, wahrend betragsmaßig sehr großeZahlen eben nicht angemessen dargestellt werden konnen.
27. Welche der folgenden Gleitpunkt-Operationen auf zwei positiven Gleit-punkt-Zahlen kann overflow erzeugen?
a) Addition b) Subtraktion c) Multiplikation d) Division
overflow kann entstehen bei Addition (so ist etwa OFL+OFL > OFL)18/19Multiplikation (so ist etwa OFL∗OFL > OFL) und Division (so ist etwaOFL/UFL > OFL), nicht aber bei Subtraktion zweier positiver Gleitpunkt-Zahlen.
28. Welche der folgenden Gleitpunkt-Operationen auf zwei positiven Gleit-punkt-Zahlen kann underflow erzeugen?
a) Addition b) Subtraktion c) Multiplikation d) Division
underflow kann entstehen bei Subtraktion (so sind etwa x = 0.75 = 1.1(2)×18/192−1 und y = 0.5 = 1.0(2) × 2−1 im normalisierten F(2, 3,−1, 1) und es giltx − y = 0.25 < UFL), Multiplikation (UFL∗UFL < UFL) und Division(UFL/OFL < UFL), nicht aber bei Addition zweier positiver Gleitpunkt-Zahlen.

1.4. Review Questions – Antworten auf Verstandnisfragen 33
29. Gib Grunde dafur an, Gleitpunkt-Zahlen normalisiert darzustellen.
Gleitpunkt-Zahlensysteme sind normalisiert, weil erstens dann die Zahlen-18Darstellung eindeutig ist, weil zweitens keine Ziffern in der Mantisse ver-geudet werden und weil drittens in der Binar-Darstellung das erste Bitnotwendigerweise 1 und damit redundant ist.
30. Gib den maximalen relativen Fehler der Darstellung beliebiger reeller Zah-len durch Maschinen-Zahlen an.
Der maximale relative Fehler |fl(x)−xx
| bei der Darstellung von x ∈ R durch 20Maschinen-Zahlen fl(x) ist abhangig vom Rundungsverfahren und ist bei
rounding by chopping εmach = β1−p
rounding to nearest εmach = 12β1−p
31. a) Wie unterscheiden sich round towards zero und round to nearest ? 19
rounding by chopping oder rounding towards zero besteht im Abschneidennach der p−1sten Ziffer: fl(x) ist die x am nachsten liegende Maschinen-Zahlin Richtung der Null. rounding to nearest oder rounding to even bestimmtfl(x) als die x am nachsten liegende Maschinen-Zahl. Falls x genau zwischenzwei Maschinen-Zahlen liegt, ist die letzte Ziffer von fl(x) gerade zu setzen.
b) Welche der beiden Rundungsregeln ist genauer? 19
rounding to nearest ist genauer, aber aufwandiger zu implementieren.
c) Wie wirkt sich die Rundungsregel auf εmach aus? 19
Rounding bestimmt εmach, s. RQ 1.30
32. Bestimme εmach in F(2, p, L, U) mit round to nearest.
In F(2, p, L, U) mit round to nearest ist εmach = 1221−p = 2−p. In IEEE 20
SP mit p = 24 gilt also εmach = 2−24 ≈ 0.000000059604644775390625 und2−24 = 2−42−20 ≈ 1
1610−6 ≈ 10−7.
33. Ist in einem Gleitpunkt-System mit gradual underflow, also mit subnormalnumbers, die Zahldarstellung immer noch eindeutig?
In F(β, p, L, U) mit gradual underflow gibt es subnormal floats nur wenn 21e = L. Eindeutigkeit ist garantiert, solange do gespeichert wird. Falls inF(2, p, L, U) wie etwa in IEEE SP oder IEEE DP do nicht gespeichert wird,braucht es spezielle flags, um Subnormalitat zu signalisieren.
34. Ist in einem Gleitpunkt-System das Produkt zweier Maschinen-Zahlen wie-der als Maschinen-Zahl darstellbar?
Das Produkt zweier Maschinen-Zahlen ist nicht als Maschinen-Zahl darstell- 22bar, wenn das Produkt der Mantissen mehr nicht verschwindende Ziffernals die Prazision p hat.

34 KAPITEL 1. SCIENTIFIC COMPUTING
35. Ist in einem Gleitpunkt-System der Quotient zweier Maschinen-Zahlen wie-der als Maschinen-Zahl darstellbar?
Der Quotient zweier Maschinen-Zahlen ist nicht als Maschinen-Zahl dar-22stellbar, wenn der Quotient etwa irrational ist.
36. Sei das normalisierte F(10, 2,−2, 2) mit rounding by chopping unterstellt.
a) Die Gleitpunkt-Addition ist nicht notwendig assoziativ. Beispiel?23
Gleitpunkt-Addition ist nicht notwendig assoziativ, wie ε = 0.05 = 5.0 ×10−2 zeigt: einerseits gilt fl(1 + 0.05) = fl(1.05) = 1 und daher fl(fl(1 +
ε) + ε) = 1, wahrend andererseits fl(0.05 + 0.05) = fl(0.1) = 1.0× 10−1 und
daher fl(1 + fl(ε+ ε)) = fl(1 + 0.1) = 1.1 = 1.1× 100 gilt, so daß insgesamt(1 + ε) + ε 6= 1 + (ε+ ε) folgt.
b) Die Gleitpunkt-Multiplikation ist nicht notwendig assoziativ. Beispiel?23
Gleitpunkt-Multiplikation ist nicht notwendig assoziativ, da beispielsweisefur x = 5.0 = 5.0 × 100 ∈ F und y = 0.12 = 1.2 × 10−1 ∈ F einerseitsfl((x ∗ y) ∗ y) = fl(0.6 ∗ 0.12) = fl(0.072) = 7.2 × 10−2 und andererseits
fl(x ∗ y2) = fl(5.0 ∗ fl(0.0144)) = fl(5.0 ∗ 0.014) = 7.0 × 10−2 und somit(x ∗ y) ∗ y 6= x ∗ y2 gilt.
37. a) Unter welchen Umstanden tritt cancellation auf?24/25
cancellation tritt genau dann auf, wenn zwei Zahlen identischen Vorzeichensund identischer Großenordnung, d.h. mit identischen Exponenten und mitahnlichen Mantissen, subtrahiert werden: in der Differenz verschwindendann fuhrende Mantissenbits.
b) Impliziert cancellation, daß das korrekte Ergebnis nicht als Maschinen-25Zahl darstellbar ist?
Bei cancellation ist die Differenz darstellbar, hat aber weniger signifikanteZiffern.
c) Warum ist cancellation meist schadlich?25
Sei wieder 0 < ε < εmach. Dann gilt fl(1+ε)−fl(1+ε) = 1−1 = 0, wahrendsich exakt (1 + ε)− (1 + ε) = 2ε > 0 ergibt.
’If two nearly equal numbers are accurate only to within roundingerror, then taking their difference leaves only rounding error as aresult!’
38. Gib ein Beispiel einer Zahl mit endlicher Dezimal-Darstellung und unend-licher Binar-Darstellung.
x = 0.1(10) = 0.00011(2) hat endliche Dezimalbruchdarstellung aber unend-23liche Binarbruchdarstellung.

1.4. Review Questions – Antworten auf Verstandnisfragen 35
39. Gib Beispiele fur Gleitpunkt-Operationen, die als Ergebnis Inf bzw. NaN
erzeugen.
x/0 produziert Inf. 0/0, 0*Inf oder Inf/Inf produzieren NaN. vgl. S.15 21/22
40. Wie groß ist der maximale relative Fehler bei der Darstellung beliebigernicht-verschwindender reeller Zahlen x in einem Gleitpunkt-System zur Ba-sis β, Prazision p und round to nearest, x ∈ F(β, p, L, U) ?
Wieso ist bei rounding by chopping der maximale relative Fehler der Dar- 20stellung durch Maschinen-Zahlen gerade εmach = β1−p ?Sei x = βe
∑∞i=0
di
βi mit do 6= 0 und ganzen 0 ≤ di ≤ β − 1. Dann
ist fl(x) = βe∑p−1
i=0di
βi und |fl(x) − x| = βe∑∞
i=pdi
βi ≤ βe∑∞
i=0β−1βi =
βe β−1βp
11−1/β
= βe β−1βp
ββ−1
= βe β1−p. Also ist ≤ βe β1−p
βe = β1−p.
Bei rounding to nearest halbiert sich der relative Fehler auf εmach = 12β1−p.
41. Warum ist cancellation bei der Subtraktion zweier Zahlen gleicher Großen-ordnung haufig schadlich, auch wenn das Ergebnis der Subtraktion der bei-den aktuellen Operanden exakt ist?
Zwei Zahlen identischen Vorzeichens und identischer Großenordnung zu 25subtrahieren bedeutet, daß in der Differenz fuhrende Mantissenbits ver-schwinden: die Differenz ist darstellbar, hat aber weniger signifikante Zif-fern. Wenn die Operanden selber unsicher sind, so basieren die verbleiben-den Ziffern ausschließlich auf unsicherer Information, vgl. 1RQ37.
42. Was ist das Ergebnis der folgenden Operationen in einem dezimalen Gleit-punkt-Zahlensystem mit εmach = 10−5 und Exponenten zwischen -20 und+20 ?
Sei F(10, 6,−20, 20) und εmach = 10−5, also p = 6 und rounding by chopping 19/20und UFL = 10−20 unterstellt.
a) 1 + 10−7
fl(1 + 10−7) = fl(1.0000001) = 1
b) 1 + 103
fl(1 + 103) = fl(1001) = 1.00100× 103
c) 1 + 107
fl(1 + 107) = fl(10000001) = 1.00000× 107
d) 1010 + 103
fl(1010 + 103) = fl(1000001000) = 1.00000× 1010
e) 1010/10−15
fl(1010/10−15) = fl(1025) ⇒ overflow

36 KAPITEL 1. SCIENTIFIC COMPUTING
f) 10−10 × 10−15
fl(10−10 ∗ 10−15) = fl(10−25) ⇒ underflow
43. Welche der folgende Berechnungen ergibt underflow in einem Gleitpunkt-18/19System mit UFL = 10−38 ? In welchen Fallen von underflow ist es sinnvoll,die betroffene Große auf Null zu setzen.
a) a =√b2 + c2 mit b = 1 und c = 10−25
a =√b2 + c2 mit b = 1 und c = 10−25. c2 ⇒ underflow; c2 = 0 ist
vernunftig ⇒ a =√
1 = 1.
b) a =√b2 + c2 mit b = c = 10−25
a =√b2 + c2 mit b = c = 10−25. b2, c2 ⇒ underflow; b2 = c2 = 0 ist hier
unvernunftig, da das exakte Ergebnis a = 10−5√
2 sehr wohl darstellbar ist.
c) u = (v × w)/(y × z) mit v = 10−15 und w = 10−30 und y = 10−20 undz = 10−25
u = (v × w)/(y × z) mit v = 10−15, w = 10−30, y = 10−20 und z = 10−25.Dann ist (v × w) = 10−35 und (y × z) = 10−45 ⇒ underflow; (y × z) = 0ist hier unvernunftig, da das exakte Ergebnis u = 10−35/10−45 = 1010 sehrwohl darstellbar ist.
44. a) Klare den Unterschied zwischen unit roundoff, εmach und underflow level,18UFL.
Je nach rounding ist εmach = β1−p bzw. εmach = 12β1−p der maximale rela-
tive Fehler bei der Darstellung von reellen Zahlen durch Maschinen-Zahlen.UFL = βL ist die kleinste positive Maschinen-Zahl.
b) Welche der beiden Großen hangt nur von der Anzahl der Stellen in der20Mantisse ab?
Nur εmach hangt nur von der Anzahl der bits in der Mantisse ab.
c) Welche der beiden Großen hangt nur von der Anzahl der Stellen im18Exponenten ab?
Nur UFL hangt nur von der Anzahl der bits im Exponenten ab.
d) Welche der beiden Großen hangt nicht von der Rundungsregel ab?18
UFL hangt nicht von der Rundungsregel ab.
e) Welche der beiden Großen wird nicht davon beeinflußt, wenn subnormale21Zahlen zugelassen werden?
Nur εmach wird nicht verandert, wenn subnormal numbers zugelassen wer-den.Dann andert sich auch der relative Fehler
∣∣∣fl(x)−xx
∣∣∣ der Darstellung von x ∈ R

1.4. Review Questions – Antworten auf Verstandnisfragen 37
durch Maschinen-Zahlen fl(x) nicht, weil subnormal numbers nur die Dar-stellung betragsmaßig kleiner Zahlen verbessern, die Darstellung aller an-deren Zahlen jedoch unverandert lassen.
45. Sei x1 > x2 > . . . > xn > 0 und s =∑n
i=1 xi sei zu bestimmen. In welcherReihenfolge sollten die xi aufsummiert werden, um den Rundungsfehler zuminimieren?
Sei x1 > x2 > . . . > xn > 0 und s =∑n
i=1 xi zu bestimmen. Der rounding ?error wird minimiert, wenn s durch s = ((. . . ((xn + xn+1) + xn−2) + . . . x1)berechnet wird, weil bei s = ((. . . ((x1+x2)+x3)+. . . xn) auf immer großereTeilsummen immer kleinere Folgen-Elemente aufaddiert werden.
46. Ist cancellation ein Beispiel fur einen Rundungsfehler?
cancellation (’most significant digits are lost to cancellation’) ist keine Form 25des rounding errors (’least significant digits are lost to rounding’).
47. a) Warum konnen in Gleitpunkt-Arithmetik divergierende (unendliche) Rei- 23hen wie etwa
∑∞k=1
1k
endliche Reihenwerte haben?∑∞k=1
1k
= +∞ ist in Gleitpunkt-Arithmetik endlich, wenn Teilsummen sichnicht mehr andern und/oder 1
nunderflows, lange bevor die Teilsummen
uberlaufen.
b) Wann werden sich die n-ten Teilsummen von etwa∑∞
k=11k
nicht mehr 23andern?
Die n-ten Teilsummen sn =∑n
k=11k
von∑∞
k=11k
andern sich nicht mehr,
wenn 1n< εmachsn−1; denn dies ist aquivalent zu
∣∣∣ sn−sn−1
sn−1
∣∣∣ =1n
sn−1< εmach.
48. Seien alle xi > 0 und sei der Reihenwert der konvergenten Reihe S =∑∞i=1 xi <∞ in naturlicher, vorgegebener Ordnung zu berechnen. Welches
Abbruchskriterium liefert maximale Genauigkeit bei minimaler Anzahl vonSummanden?
Seien alle xi > 0 und sei S =∑∞
i=1 xi < ∞ in naturlicher, vorgegebener ?Ordnung zu berechnen. Wenn sich die Teilsummen nicht mehr andern,ist erstens maximale Genauigkeit erreicht und zweitens sind nicht mehrSummanden als notig gebildet und aufaddiert worden.
49. Warum ist es schwierig, den Reihenwert einer konvergenten, alternierendenReihe wie etwa ex =
∑∞i=0 xi/i! fur x < 0 in Gleitpunkt-Arithmetik genau
zu berechnen?
ex =∑∞
i=0xi
i!ist fur x < 0 wegen cancellation schlecht zu berechnen. Besser 25
ist es, ex = 1e−x zu verwenden und dabei e−x ohne cancellation zu berechnen.

38 KAPITEL 1. SCIENTIFIC COMPUTING
50. Die Ableitung f ′ von f : R → R werde durch die endliche Differenz f ′(x) ≈1h(f(x+h)−f(x)) approximiert. Fur h→ 0 geht auch der truncation errorgegen Null. Gib zwei Großen an, die die ’Kleinheit’ von h in Gleitpunkt-Systemen beschranken.
In f ′(x) ≈ f(x+h)−f(x−h)h
ist die ’Kleinheit’ von h limitiert durch fl(x+ h) 6=?fl(x − h) sowie fl(f(x + h)) 6= fl(f(x − h)) (’due to rounding’) und die
Genauigkeit von fl(f(x+ h)− f(x− h)) (’due to cancellation’).
51. Gegeben die quadratische Gleichung ax2+bx+c = 0 mit den beiden Losun-gen x1,2 = 1
2a(− b±√b2 − 4ac). Welche zwei Grunde bereiten numerische
Schwierigkeiten bei der Berechnung der Losungen?
x = −b±√
b2−4ac2a
bereitet numerische Schwierigkeiten in Form von overflow,26/27underflow und cancellation: overflow kann durch Reskalierung (Division derdrei Koeffizienten durch den betragsmaßig großten Koeffizienten) vermiedenwerden. So wird auch unnotiger underflow vermieden, wenn namlich alledrei Koeffizienten betragsmaßig sehr klein sind. Cancellation zwischen −bund der Quadratwurzel kann durch die alternative Formel x′ = 2c
−b∓√
b2−4ac
(vgl. 1Ex26) wegen der entgegengesetzten Vorzeichen vermieden werden.
1.5 Exercises – Ubungsergebnisse
1. Die durchschnittliche normale Korper-Temperatur ist 98.6oF, was exakt37oC entspricht.
Sei eine Temperatur in tFoF Grad Fahrenheit bzw. in tC
oC Grad Celsiusgemessen. Dann gilt tF = 9
5tCoC
+ 32 oF bzw. tC = 59( tF
oF− 32) oC. Fur
tC = 37 oC ist tF = 9537+32 = 66.6+32 = 98.6 oF, wahrend fur tF = 98.6 oF
eben tC = 59(98.6− 32) = 5
966.6 = 5
322.2 = 111
3= 37 oC ist.
a) Was ist der maximale relative Fehler, angenommen, der akzeptierte Wert5ist auf ±0.05 oF genau.
Angenommen, der akzeptierte Wert ist auf ±0.05 oF genau, dann ist der
maximale relative Fehler∣∣0.0598.6
∣∣ ≈ 0.0005 bzw.∣∣∣ 5
966.65−37
37
∣∣∣ ≈ 0.00075.
b) Was ist der maximale relative Fehler, angenommen, der akzeptierte Wert5ist auf ±0.5 oC genau.
Angenommen, der akzeptierte Wert ist auf ±0.5 oC genau, dann ist der
maximale relative Fehler∣∣0.5
37
∣∣ ≈ 0.0135 bzw.∣∣∣ 9
537.5+32−98.6
98.6
∣∣∣ ≈ 0.0091.
2. Was sind absolute und relative Fehler bei der Approximation von π durch
a) 3.0 b) 3.14 c) 22/7 d) 355/1135

1.5. Exercises – Ubungsergebnisse 39
symbolic expression for π isπ = abs error = π−π ≈π ≈ rel error = π−π
π≈
evalreset
3. Sei a der approximierte Wert einer Große mit exaktem Wert t. Der relativeFehler von a sei r. Zeige: a = t(1 + r).
a sei eine Approximation fur den exakten Wert t und a weise den relativen 5Fehler r auf. Dann gilt r = a−t
tund so r t = a− t sowie a = t(1+r).
4. Bestimme der propagated data error bei der Auswertung von sinx, d.h. denFehler aufgrund einer Storung h im Argument x.
a) Schatze den absoluten Fehler bei der Auswertung von sinx ab. 6/7
Der absolute Fehler ist sin(x + h) − sin x =∫ x+h
xcosu du ≈ h cosx mit
h cosx ≈ h fur |x| 1.
b) Schatze den relativen Fehler bei der Auswertung von sinx ab.
Der relative Fehler ist sin(x+h)−sin xsin x
≈ h cos xsin x
= h cotx.
c) Schatze die Konditionszahl dieses Problems ab.
cond = |∆f/f∆x/x
| ≈ |h cot xh/x
| = |x cotx|.Wegen limx→0 x cotx = limx→0
xtan x
= limx→01
1+tan2 x= 1 ist das Problem
also in 0 gut konditioniert.
d) Fur welche Werte von x ist das Problem hoch-sensitiv?
Das Problem ist hoch-sensitiv in den ubrigen Polen πZ \ 0 von cotx.
5. Sei f : R2 → R mit f(x, y) = x − y gegeben. Die Norm |(x, y)| = |x| + |y| 13messe die Große der Eingabe-Daten. Sei |x|+ |y| ≈ 1 und x− y ≈ ε.Zeige: cond(f) ≈ 1
ε. Was heißt das fur die Sensitivitat der Subtraktion?
Mit der Dreiecksungleichung laßt sich cond(f) =∣∣∣f(x,y)−f(x,y)
f(x,y)
∣∣∣ |(x,y)||(x,y)−(x,y)| =∣∣∣ (x−y)−(x−y)
x−y
∣∣∣ |x|+|y||x−x|+|y−y| =
∣∣∣ (x−x)−(y−y)|x−x|+|y−y|
∣∣∣ · ∣∣∣ |x|+|y|x−y
∣∣∣ ≤ 1 · |x|+|y||x−y| ≈1ε
abschatzen.
Die Differenz ist hochsensitiv fur x− y ≈ ε.
6. Es gilt sinx =∑∞
i=0(−1)ix2i+1
(2i+1)!.
a) Was sind forward error und backward error der Approximation sinx ≈ x 10–12in x = 0.1, 0.5, 1.0 ?
Sei f(x) = x. Fur x mit f(x) = f(x) gilt dann x = arcsin f(x) = arcsin x.

40 KAPITEL 1. SCIENTIFIC COMPUTING
Mit funf-stelliger Genauigkeit ergibt sich etwa
forward backwardx f(x) f(x) f(x)− f(x) x x− x
0.1 0.99833 10−1 0.10000 100 0.16658 10−3 0.10017 100 0.16742 10−3
0.5 0.47943 100 0.50000 100 0.20574 10−1 0.52360 100 0.23599 10−1
1.0 0.84147 100 0.10000 101 0.15853 100 0.15708 101 0.57080 100
b) Was sind forward error und backward error der Approximation sin x ≈x− 1
6x3 in x = 0.1, 0.5, 1.0 ?
Sei f(x) = x − 16x3. Fur x mit f(x) = f(x) gilt dann x = arcsin f(x) =
arcsin(x− 16x3). Mit funf-stelliger Genauigkeit ergibt sich etwa
forward backwardx f(x) f(x) f(x)− f(x) x x− x
0.1 0.99833 10−1 0.99833 10−1 −0.83313 10−9 0.99999 10−1 −0.83731 10−9
0.5 0.47943 100 0.47917 100 −0.25887 10−3 0.49971 100 −0.29496 10−3
1.0 0.84147 100 0.83333 100 −0.81377 10−2 0.98511 100 −0.14889 10−1
x =f(x) =
f(x) =
for y − y =x =
back x− x =
testseval aeval breset
7. Sei F(10, p, L, U) gegeben.
a) Was sind die kleinsten Werte von p und U und der großte Wert von16–21L, so daß die beiden Zahlen x = 2365.27 und y = 0.0000512 exakt imnormalisierten F(10, p, L, U) darstellbar sind?
normalisiert: also x = 2.36527× 103 und y = 5.12000× 10−5, so daß p = 6,L = −5 und U = 3 folgt.
b) Was gilt, wenn in F(10, p, L, U) gradual underflow zugelassen wird?
gradual underflow: also wegen x = 2365.27 wieder p = 6 und wegen y =0.00512× 10−2 eben L = −2 und U = 3.
8. Sei x = 1.23456 und y = 1.23579 in F(10, 6, L, U) gegeben.
a) Wieviele signifikante Ziffern hat y − x ?24/25
Die Differenz y − x = 0.00123 hat nur noch drei signifikante Ziffern.
b) Was ist der minimale Wertebereich fur Exponenten derart, daß x, y und18/19y − x zugleich im normalisierten F darstellbar sind?
Der minimale Exponenten-Bereich derart, daß x, y und y − x zugleichMaschinen-Zahlen sind, ist wegen y − x = 1.23 × 10−3 durch L = −3und U = 0 gegeben.

1.5. Exercises – Ubungsergebnisse 41
c) Ist die Differenz y − x unabhangig vom Wertebereich fur Exponenten21exakt darstellbar, wenn gradual underflow zugelassen wird?
Wenn gradual underflow zugelassen ist, ist wegen y − x = 0.00123 =0.00123 × 100 nur dann exakt darstellbar, wenn L = 0 gilt. Die Dar-stellbarkeit ist also nicht unabhangig vom Wertebereich fur Exponenten.
9. a) Berechne die Oberflache A(r) = 4πr2 der Erde mit r = 6370 km inF(10, 4, L, U).
Mit Erdradius r1 = 6370 km gilt in F(10, 4, L, U) fl(A(r1)) = fl(4π r21) =
fl(4 ∗ 3.141 ∗ 63702) = fl(12.564 ∗ 40 576 900) = fl(12.56 ∗ 40 570 000) =509 500 000 km2 bei rounding by chopping bzw. fl(A(r1)) = fl(4π r2
1) =fl(4 ∗ 3.141 ∗ 63702) = fl(12.564 ∗ 40 576 900) = fl(12.56 ∗ 40 580 000) =509 700 000 km2 bei rounding to nearest.
b) Berechne A(r + 1)− A(r) in F(10, 4, L, U).
Mit Erdradius r2 = 6371 km gilt in F(10, 4, L, U) fl(A(r2)) = fl(4π r22) =
fl(4 ∗ 3.141 ∗ 63712) = fl(12.564 ∗ 40 589 641) = fl(12.56 ∗ 40 580 000) =509 600 000 km2 bei rounding by chopping bzw. fl(A(r2)) = fl(4π r2
2) =fl(4 ∗ 3.141 ∗ 63712) = fl(12.564 ∗ 40 589 641) = fl(12.56 ∗ 40 590 000) =509 800 000 km2 bei rounding to nearest.Fur beide Rundungsarten ergibt sich eine Differenz von 100 000 km2.
c) Wegen d Adr
= 8πr gilt ∆A(r) ≈ 8πr∆r. Vergleiche mit Teil b). 14/15
Wegen d Adr
= d 4πr2
dr= 8 π r kann die Anderung der Flache durch 8π r∆r
approximiert werden, wenn ∆r die Anderung des Radius’ ist. Also ergibtsich fur eine Anderung des Radius’ um 1 km eine Anderung der Flachevon naherunsgweise 8πr · 1 = 25.13 ∗ 6370 = 160 078.1, also 160 000 km2
(by chopping) bzw. 160 100 km2 (to nearest) in vier-stelliger und 8πr ·1 = 25.1327 ∗ 6370 = 160 095.299, also 160 000 km2 (by chopping) bzw.160 100 km2 (to nearest) in sechs-stelliger Arithmetik.
d) Fuhre den Vergleich aus Teil c) in F(10, 6, L, U) durch.
Mit Radius r1 = 6370 km gilt in sechs-stelliger Dezimal-Arithmetik fl(A(r1)) =
fl(4π r21) = fl(4 ∗ 3.14159 ∗ 63702) = fl(12.56636 ∗ 40 576 900) = fl(12.5663 ∗
40 576 900) = 509 901 000 km2 bei rounding by chopping bzw. fl(A(r1)) =
fl(4π r21) = fl(4 ∗ 3.14159 ∗ 63702) = fl(12.56636 ∗ 40 576 900) = fl(12.5664 ∗
40 576 900) = 509 906 000 km2 bei rounding to nearest.
Mit Erdradius r2 = 6371 km gilt in sechs-stelliger Dezimal-Arithmetikfl(A(r2)) = fl(4π r2
2) = fl(4 ∗ 3.14159 ∗ 63712) = fl(12.56636 ∗ 40 589 641) =fl(12.5664 ∗ 40 589 600) = 510 065 000 km2 bei rounding by chopping bzw.fl(A(r2)) = fl(4π r2
2) = fl(4 ∗ 3.14159 ∗ 63712) = fl(12.56636 ∗ 40 589 641) =fl(12.5664 ∗ 40 589 600) = 510 065 000 km2 bei rounding to nearest.

42 KAPITEL 1. SCIENTIFIC COMPUTING
Die Differenz betragt ca. 154 000 km2 (by chopping) bzw. ca. 159 000 km2
(to nearest).
e) Erlautere die Ergebnisse a) bis d)
Zusammenfassend ergibt sich also
4-stellig 6-stelligrounding by chopping to nearest by chopping to nearest
A(r2) = A(6371) 509 600 000 509 800 000 510 065 000 510 065 000A(r1) = A(6370) 509 500 000 509 700 000 509 901 000 509 906 000A(r2)− A(r1) 100 000 100 000 154 000 159 000
8πr∆r 160 000 160 100 160 000 160 100
???f) Wie klein muß ∆r sein, damit das Phanomen bei SP bzw. DP zu beob-achten ist?
Berechne A(r2), A(r1), A(r2)−A(r1), 8πr∆r fur p = pdec1 bzw. fur p = pdec2
sowie fur die beiden Radien r1 = und r2 =pdec1 = π = pdec2 = π =
A(r2) = A(r2) =A(r1) = A(r1) =
A(r2)−A(r1) = A(r2)−A(r1) =8πr1(r2−r1) = 8πr1(r2−r1) =
evalreset
10. Sei f(x) = 11−x
− 11+x
fur −1 6= x 6= 1. Dann gilt15
y(x) = cond(f)|x ≈∣∣∣x f ′(x)
f(x)
∣∣∣ =∣∣∣x((1−x)−2+(1+x)−2)
11−x
− 11+x
∣∣∣ = 12
∣∣1+x1−x
+ 1−x1+x
∣∣ = 2|x|1−x2 .
x
y = y(x) = 2|x|/(1− x2)
1−1
a) In welchen Intervallen fur das Argument x ist es schwierig, f(x) in Gleit-punkt-Arithmetik genau zu berechnen?
Fur x nahe bei Null liegt cancelling, fur x nahe jedem der beiden Pole liegttruncation vor.

1.5. Exercises – Ubungsergebnisse 43
b) Welcher mathematisch aquivalente Ausdruck fur f(x) erlaubt, f(x) furx in den Intervallen aus a) genauer zu bestimmen?
Fur −1 6= x 6= 1 ist f mit f(x) = 1+x−(1−x)12−x2 = 2x
1−x2 nahe bei Null und nahejedem der beiden Pole besser zu berechnen.
11. Ist lnx− ln y oder ln xy
fur x ≈ y genauer? Hinweis: wo ist lnx sensitiv? 14
cond(f) = cond(ln) =∣∣∣xf ′(x)
f(x)
∣∣∣ = 1| ln x| hat Pol in 1, d.h. lnx ist bei 1 extrem
schlecht konditioniert. Damit ist lnx− ln y genauer als ln xy
fur x ≈ y.
12. a) Kann x2 − y2 oder (x− y)(x+ y) genauer berechnet werden?
Mit β = 10 und p = 2 und rounding by chopping gilt fur x = 12 = 1.2×101
und y = 11 = 1.1× 101 eben fl(x2)− fl(y2) = 1.4× 102 − 1.2× 102 = 20 6=23 = 2.3 × 101 = 0.23 · 102 = (0.1 × 101)(2.3 × 101) = fl(x − y) fl(x + y).(x − y)(x + y) ist hier sogar exakt. Aufgrund truncation beim Quadrierenweist hier x2 − y2 einen relativen Fehler von 100 3
23≈ 13 % auf.
x =y =
x−fl y =x+fl y =
x ∗fl x =y ∗fl y =
pdec = tests eval trial1 resetz1 = fl(fl(x− y) ∗ fl(x+ y)), zo =DP (x− y) ∗ (x+ y), z2 = fl(fl(x2)− fl(y2))
z1 =in DP zo =
z2 =
| z1−z0
z0| =
| z2−z0
z0| =
b) Fur welche x und y ergibt sich ein betrachtlicher Unterschied in derGenauigkeit der beiden Ausdrucke?
z.B. fur p = 2, x = 35 und y = 34 ergibt z1 = 69 das exakte Ergebnis,wahrend bei rounding to nearest fl(x2) = fl(1225) = 1200 und fl(y2) =fl(1156) = 1200 eben z2 = 0 ergibt und damit einen 100% Fehler.
13. Wie sind overflow und ’harmful underflow’ in der Euklid’schen Norm ||x|| =(∑n
i=1 x2i )
1/2von x zu vermeiden?
Sei c = |xio | = max|xi| : i = 1, 2, . . . , n. Dann gilt ||x|| = c||1cx|| =
c(∑n
i=1(xi
c)2)
1/2, so daß alle Summanden kleiner als 1 ausfallen und so
overflow vermieden ist. Zugleich wird so bei der Quadrierung betragsmaßigsehr kleiner xi harmful underflow vermieden.
14. Wie berechnet sich der Mittelpunkt m des Intervalles [x, y] am besten?
a) m = 12(x+ y) = x
2+ y
2b) m = x+ 1
2(y − x)
1erzeuge pseudzufallige x und y, bis | z2−z0z0
| ≥ 1

44 KAPITEL 1. SCIENTIFIC COMPUTING
Falls x = 6.7 und y = 6.9, so liegt fl(fl(x+y)2
) = fl(142) = 7 noch nicht einmal
in [x, y]. Falls dagegen x = −7.7 und y = 7.8, so ergibt fl(fl(x + y)/2) =fl(0.1/2) = 0.5 den exakten Mittelpunkt, wahrend sich mit rounding tonearest fl(x+ fl(fl(y− x)/2)) = fl(x+ fl(160/2)) = fl(−77 + 80) = 3 ergibt,
was einen relativen Fehler von |3−0.50.5
| = 5 oder 500% ausmacht.
x =y =
m1 =mo =m2 =
|m1−mo
mo| =
|m2−mo
mo| =
m1 = 12(x+ y), mo =DP x+ 1
2(y − x), m2 = x+ 1
2(y − x)
pdec = tests eval trial2 reset
15. Gib Beispiele dafur, daß die Gleitpunkt-Addition nicht assoziativ ist,
a) in F(2, 3,−1, 1)
In F(2, 3,−1, 1) gilt – wie gehabt – fur x = 1 und y = z = 0.001(2) einerseitsfl(x+y)+z = fl(1.001(2))+z = fl(1+z) = 1 und andererseits x+fl(y+z) =1 + fl(0.01(2)) = 1.01(2) 6= 1.
b) in IEEE SP23
In F(2, 24,−126, 127) gilt fur x = 1, y = z = 2−24 wegen fl(x + y) =
fl(1.
23 mal︷ ︸︸ ︷0 . . . 0 1) = 1 einerseits fl(fl(x + y) + z) = fl(1 + z) = 1 und wegen
fl(y+z) = fl(2−23) = 1.0×2−23 andererseits fl(x+fl(y+z)) = fl(1+2−23) =
1.
22 mal︷ ︸︸ ︷0 . . . 0 1, so daß (1 +fl x) +fl y 6= 1 +fl (x+fl y).
16. Inwiefern unterscheiden sich die diversen alternativen Definitionen fur εmach
konkret? Hinweis: verwende F(2, 3,−1, 1).
In F(2, 3,−1, 1) gilt laut Definition εmach = β1−p = 2−2 = 14
bei rounding by19/20chopping oder εmach = 1
2β1−p = 1
22−2 = 1
8bei rounding to nearest.
Die Alternative εmach = minε ∈ F : fl(1 + ε) > 1 = 1.00× 2L = 0.1(2) = 12
ist verschieden von der Definition fur εmach bei beiden Rundungsregeln.Die Alternative εmach = minε > 1 : ε ∈ F − 1 = 1.01(2) − 1 = 0.01(2) = 1
4
ist verschieden von der Definition fur εmach bei rounding to nearest.
17. x und y seien benachbarte nicht-verschwindende Gleitpunkt-Zahlen in einemnormalisierten Gleitpunkt-Zahlensystem F(β, p, L, U).
a) Was ist der minimale Abstand zwischen x und y ?16/17
Der minimale Abstand d zwischen zwei benachbarten nicht-verschwinden-
den Gleitpunkt-Zahlen ist derjenige zwischen z.B. x = 1.
p−1 mal︷ ︸︸ ︷0 . . . 0(β)×βL und
2erzeuge pseudozufallige x und y bis m 6∈ [x, y]

1.5. Exercises – Ubungsergebnisse 45
y = 1.
p−2 mal︷ ︸︸ ︷0 . . . 0 1(β) × βL und damit d = y − x = β−(p−1) βL = βL−p+1.
b) Was ist der maximale Abstand zwischen x und y ?
Der maximale Abstand D zwischen zwei benachbarten nicht-verschwinden-
den Gleitpunkt-Zahlen ist derjenige zwischen z.B. x = 1.
p−1 mal︷ ︸︸ ︷0 . . . 0(β)×βU und
y = 1.
p−2 mal︷ ︸︸ ︷0 . . . 0 1(β) × βU und damit D = y − x = β−(p−1) βU = βU−p+1.
18. Wieviele normalisierte IEEE SP Gleitpunkt-Zahlen gibt es?Wieviele IEEE SP Gleitpunkt-Zahlen gibt es, wenn subnormal numberszugelassen werden?
IEEE SP ist durch β = 2, p = 24, L = −126 und U = 127 gekennzeichnet.Falls die fuhrende 1 tatsachlich gespeichert wird, gibt es im normalisierten 18IEEE SP also 223 · (U −L+ 1) = 223 · (127 + 126 + 1) = 254 · 223 ≈ 223+8 =231 ≈ 2 ·109 positive floats und eben doppelt soviele positive floats, falls diefuhrende 1 nicht gespeichert wird.Falls die fuhrende 1 tatsachlich gespeichert wird, gibt es im subnormalisier-ten IEEE SP zusatzlich 223 − 1 positive floats.
19. Was sind UFL und OFL in IEEE SP ? Was ist UFL im subnormalisiertenIEEE SP?
Im normalisierten IEEE SP gilt OFL = βU+1(1 − β−p) = 2128(1 − 2−24) = 18/192128 − 2104 und UFL = 2L = 2−126.Im subnormalisierten IEEE SP gilt dagegen UFL = β−t+1βL = βL−p+1 =2−149.
20. Wie wird 110
in IEEE SP dargestellt,
Im IEEE SP gilt fur 110
= 0.00011(2) 19/20
a) bei round towards zero oder rounding by chopping,
bei rounding by chopping, falls die fuhrende 1 tatsachlich gespeichert wird:110 = 0.00011(2) = 1.10011(2) × 2−4 = 1.1001 1001 1001 1001 1001 100× 2−4.
b) bei round to nearest ?
bei rounding to nearest, falls die fuhrende 1 tatsachlich gespeichert wird:110
= 0.00011(2) = 1.10011(2)×2−4 = 1.1001 1001 1001 1001 1001 101×2−4.
21. a) Ist εmach notwendig eine Maschinen-Zahl? 20/21
εmach = 12β1−p ist nicht notwendig eine Maschinen-Zahl, etwa im normali-
sierten F(2, 2,−1, U) mit beliebigem U ≥ L, da dann εmach = 12β1−p = 1
4,
wahrend doch UFL = βL = 12
die kleinste positive Gleitpunkt-Zahl dar-stellt.

46 KAPITEL 1. SCIENTIFIC COMPUTING
b) Gibt es ein F(β, p, L, U) mit εmach < UFL ? Beispiel?
’In all practical floating point systems 0 < UFL < εmach < OFL.’ Aberεmach < UFL ist moglich, wie a) zeigt.
22. Gegeben a x2 + b x + c = 0 mit a = 1.22, b = 3.34 und c = 2.28 imnormalisierten F(10, 3, L, U) und rounding by chopping.
a) Was ist der berechnete Wert der Diskriminanten D = b2 − 4ac ?
Dann berechnet sich die Diskriminante D = b2 − 4 a c zu D = fl(3.342) −fl(4 ∗ 1.22 ∗ 2.28) = fl(11.1556)− fl(11.1264) = 11.1− 11.1 = 0.
b) Was ist der exakte Wert der Diskriminanten D = b2 − 4ac ?
Der exakte Wert der Diskriminanten D ist D = 11.1556−11.1264 = 0.0292.
c) Was ist der relative Fehler |D −D|/|D| ?
Der relative Fehler ist∣∣∣ D−D
D
∣∣∣ = 0.02920.0292
= 1.
23. Gegeben das normalisierte F(10, 3,−98, U).
a) Was ist UFL ?
Dann ist UFL = βL = 10−98.
b) Was ist x− y fur x = 6.87× 10−97 und y = 6.81× 10−97 ?
Sei x = 6.87× 10−97 und y = 6.81× 10−97. Dann gilt x− y = 0.06 · 10−97,was beim Renormalisieren underflow auslost.
c) Was ist x− y, wenn gradual underflow zugelassen ware?24/25
Bei gradual underflow ergibt sich x− y = 0.06 · 10−97 = 0.60× 10−98.
24. Zu zeigen: Wenn β = 2 und 1β≤ x
y≤ β, dann ist mit jeder Maschinen-Zahl
x und jeder Maschinen-Zahl y mit xy > 0 auch x− y eine Maschinen-Zahl.Gibt ein Gegenbeispiel fur β = 3.
Sei x = m2e und y = m′2e′ mit 1 ≤ m,m′ < 2 und o.B.d.A. x > y.Zunachst gilt e = e′ oder e = e′ + 1. Denn angenommen, e = e′ + nmit n > 1. Nun gilt generell 1
2< 1
m′ ≤ mm′ <
2m′ ≤ 2. Damit folgt mit
2 ≤ 2n−1 = 122n < m
m′2n = m2e′+n
m′2e′ = m2e
m′2e′ = xy≤ 2 der Widerspruch.
Falls e = e′, so ist x− y = (m−m′)2e eine Maschinen-Zahl.√
Falls e = e′+1, so ist x−y = (2m−m′)2e, wobei xy
= 2mm′ ≤ 2 eben m ≤ m′
impliziert. Falls m = m′ ist x−y = m2e Maschinen-Zahl. Falls 1 ≤ m < m′
oder m −m′ < 0 muß von der (t + 1)-bit Zahl 2 ≤ 2m mit zwei Vor- und(t− 1) Nachpunkt-Ziffern die t-bit Zahl m′ < 2 mit einer Vor- und (t− 1)Nachpunkt-Ziffern subtrahiert werden: wegen 2m−m′ = m+ (m−m′) <m < 2 hat x− y nur eine Vorpunkt-Ziffer und ist damit Maschinen-Zahl.

1.5. Exercises – Ubungsergebnisse 47
Wenn β > 2 und 1β≤ x
y≤ β, dann ist x − y nicht notwendig auch eine
Maschinen-Zahl. Sei namlich etwa β = 3, t = 3 und x = 2.21(3) × 31 =3(2 + 2
3+ 1
9) = 8 + 1
3= 25
3sowie y = 2.22(3) × 30 = 2 + 2
3+ 2
9= 26
9. Dann
ist wegen 13≤ x
y= 25
3926
= 7526≈ 2.88 ≤ 3 die Voraussetzung erfullt, obwohl
x − y = 3 + 2 + 13
+ 19
= 12.11(3) = 1.211(3) × 31 nicht mit dreiziffrigerMantisse darstellbar und somit keine Maschinen-Zahl ist.
25. Sei mpyadd(a,b,c) := a*b+c, wobei a, b und c SP-Argumente sind. DasProdukt a*b werde in DP berechnet. Auf das nicht-normalisierte Produktwerde c aufaddiert. Das Ergebnis werde in SP zuruckgegeben.Wie kann diese Instruktion verwendet werden, um DP-Produkte zu berech-nen, ohne DP-Argumente zu verwenden. Das DP Produkt a∗ b liege dabeiin zwei SP-Variablen high und low vor.
Die folgende Implementierung in C sei unterstellt.
float mpyadd(float a,b,c)
double prod=a*b;
float sum = prod+c; // ohne (Re-) Normalisierung
return sum;
Sei rounding by chopping unterstellt. Fur SP-Variablen a und b gilt
float prod = mpyadd(a,b,0);
low = mpyadd(a,b,-prod);
high= mpyadd(prod, 2pSP−pDP,0);
26. Zeige x1,2 = −b±√
b2−4ac2a
und alternativ x′1,2 = 2c−b∓
√b2−4ac
liefern gleicher-
maßen die Losungen der quadratischen Gleichung ax2 + bx + c = 0. (vgl.1RQ51)
x und x′ stimmen uberein, weil x = −b±√
b2−4ac2a
= 2c−b∓
√b2−4ac
= x′ ⇐⇒ 26/27
(− b±√b2 − 4ac)(− b∓
√b2 − 4ac) = 4ac ⇐⇒ (b2 − (b2 − 4ac)) = 4ac.
27. σ2 = 1n−1
∑ni=1(xi− x)2 (two pass) vs σ2 = 1
n−1(∑n
i=1 x2i −n x2) (one pass)
Inwiefern ist die one pass formula zur Berechnung der Standard-Abwei-chung σ der two pass formula numerisch unterlegen? (vgl. 1CP12)
’one pass formula’ ist nachteilig, weil∑n
i=1 x2i und n x2 naturgemaß groß 27
und fast gleich, so daß cancellation droht, wenn nicht aufgrund von Fehlernder Radikand sogar negativ wird (vgl. 1CP12).

48 KAPITEL 1. SCIENTIFIC COMPUTING
1.6 Computer Problems –
Rechner-Problem-Losungen
1. Laut Stirling3 s Formel ist n! ≈ n! =√
2π n (n/e)n. Schreibe ein Pro-gramm, das absoluten und relativen Fehler fur beliebige n berechnet. Wieandern sich absoluter und relativer Fehler, wenn n wachst?
n =n! =
n! =
n!− n! =
| bn!−n!n!| =
inc nreset
0 50 100 150 200−10
300
−10250
−10200
−10150
−10100
−1050
−100
−10−50
absoluter Fehler Sterling(n)−n!
0 50 100 150 200−0.08
−0.07
−0.06
−0.05
−0.04
−0.03
−0.02
−0.01
0relativer Fehler (Sterling(n)−n!)/n!
n
2. Schreibe ein Programm, das εmach, UFL und OFL sowie die Anzahl der bitsin Matisse und Exponent auf dem jeweiligen Rechner bestimmt.
Es sei unterstellt, daß β = 2 gilt.
εmach = β1−p bei rounding by chopping und εmach = 12β1−p bei rounding to
nearest. Berechne εmach – hier fur JavaScript mit seiner DP-Arithmetik.
β p L USP 2 24 −126 127DP 2 53 −1022 1023
jeweils mitrounding to nearest
Im Folgenden wird rounding to nearest unterstellt, wie etwa x = 0.045zeigt. IEEE 754 diktiert, daß x = 0.045 durch den echten Binar-Bruchfl(x) = 0.04499999999999999833466546306226518936455249786376953125
3James Stirling (1692-1770) www-history.mcs.st-andrews.ac.uk/Biographies/Stirling.html

1.6. Computer Problems – Rechner-Problem-Losungen 49
dargestellt wird. Wegen |fl(x) − 0.04| < |fl(x) − 0.05| liefert daher dieRundung von x auf eine signifikante Dezimal-Stelle 0.04 und nicht 0.05:
pdec = x = fl(x) = eval reset
double eps=1; int p=0;
do p++; eps/=beta; while (1.0+eps>1.0); // eps=beta^(-p)
double UFL=1; int L’=0; // gradual underflow!while (UFL/beta>0.0) L’--;UFL/=beta; ; // UFL=beta^(L’)
double OFL, OFL’=1, f=1; int U=0;
while (isFinite(beta*OFL’)) U++; OFL’*=beta; ; OFL=OFL’;
while (isFinite(OFL+(f/beta)*OFL’)) f/=beta; OFL+=f*OFL’; ;
p =L′ =
L = L′ + p− 1 =U =
εmach = 2−p =UFL = 2L′ =MIN VALUE =
OFL =MAX VALUE =
evalreset
3. Naherungsweise gilt εmach ≈ |3 ∗ (4/3 − 1) − 1| wobei εmach = β1−p beirounding by chopping und εmach = 1
2β1−p bei rounding to nearest.
a) Warum funktioniert dieser Trick?
Fur β = 2 gilt 13
= 0.01(2) und 43
= 1.01(2). So ist fl(43) = 1.
(p−1)/2 mal︷ ︸︸ ︷(01) . . . (01)(2)
und x = fl(43) − 1 = 0.
(p−1)/2 mal︷ ︸︸ ︷(01) . . . (01)(2) = 1.
(p−3)/2 mal︷ ︸︸ ︷(01) . . . (01)00(2) × 2−2 und 3x =
(2 + 1)x = 2x+ x = 1.
(p−3)/2 mal︷ ︸︸ ︷(01) . . . (01)00(2) × 2−1 + 1.
(p−3)/2 mal︷ ︸︸ ︷(01) . . . (01)00(2) × 2−2 =
1.
(p−3)/2 mal︷ ︸︸ ︷(01) . . . (01)00(2) × 2−10.1
(p−3)/2 mal︷ ︸︸ ︷(01) . . . (01)0(2) × 2−1 = 1.1
p−3 mal︷ ︸︸ ︷1 . . . 10(2) × 2−1 =
0.11
p−3 mal︷ ︸︸ ︷1 . . . 1(2) und damit εmach = 1− 3x = 21−p.
b) Auf diversen Rechnern ausprobieren!
Fur DP gilt p = 53 und bei rounding to nearest eben εmach = 2−p.
εmach =εmach =εmach =
test evalreset
c) Funktioniert dieser Trick in F(3, p, L, U) ?
Fur β = 3 gilt∣∣fl(3 ∗ (fl(4/3)− 1)− 1)
∣∣ =∣∣fl(3 ∗ (1.1(3) × 31 − 1)− 1)
∣∣ =∣∣fl(3 ∗ (0.1(3) × 31 − 1)∣∣ = |fl(1 − 1)| = 0, d.h. fur β = 3 funktioniert der
Trick nicht !

50 KAPITEL 1. SCIENTIFIC COMPUTING
4. Es gilt e = limn→∞ (1 + 1n)
n. Schreibe ein Programm, das (1 + 1
n)n fur
n = 10k und verschiedene k erstens per Schleife, zweitens per Exponentia-tionsoperator und drittens per (1 + 1
n)n = en ln(1+1/n) zusammen mit den
Abweichungen berechnet. Erklare die Beobachtungen.
Es gilt e = limn→∞ (1+ 1n)
n. Die Folge en = (1+ 1
n)n
ist monoton wachsendund beschrankt, und daher konvergent.s.a. www.weblearn.hs-bremen.de/risse/MAI/docs/MAI1.pdf, S.53
loop (1 + 1n)n =
pow (1 + 1n)n =
en ln(1+ 1n
) =
(1+1/n)n−ee
=(1+1/n)n−e
e=
(1+1/n)n−ee
=
Math.E = n = inc n reset
5. a) Wieso gilt fur f(x) = ex−1x
gerade limx→0 f(x) = 1 ?
Mit f(x) = ex−1x
gilt wegen de l’Hopital4 limx→0 f(x) = limx→0ex
1= 1.
b) Berechne f(xk) fur xk = 10−k und k = 1, 2, . . . , 15. Klare die Beobach-tungen und theoretisch begrundete Erwartungen.
Fur |x| 1 ist ex ≈ 1 + x und wegen der 16 Dezimal-stelligen DPGenauigkeit daher fl(ex − 1) ≈ fl(fl(1 + x) − 1) = fl(1 − 1) = 0 fur0 < x < εmach = 2−53 ≈ 10−16.
c) Was passiert bei Verwendung des aquivalenten Ausdrucks f(x) = ex−1ln(ex)
?
k =xk =
b) f(xk) =c) f(xk) =
inc kreset
6. Im Intervall [a, b] sind die n+1 aquidistanten Punkte mit Abstand h = b−an
zu erzeugen.
a) Welche der beiden Berechnungsweisen xo = a und xk = xk−1 + h furk = 1, 2, . . . , n oder x′k = a+ k h fur k = 0, 1, . . . , n ist vorteilhafter?
Fur a = 1, b = 2 und n so, daß 1 h = 1n< εmach gilt x1 = fl(1 + h) = 1
und daher xk = 1 fur alle 0 < k ≤ n, wahrend x′k dieses Phanomen nichtzeigen. Daruberhinaus laßt sich h per shift und damit besonders einfachund zuverlassig berechnen, falls n eine Zweier-Potenz ist.
b) Schreibe ein Programm, das den Vergleich erlaubt und die Unterschiedezeigt.
Fur fest vorgegebene a und b sowie n berechnet man
k =n =
a =b =
xk =x′k =
testinc kreset
4Guillaume Francoise Antoine de l’Hopital (1661-1704) www-history.mcs.st-andrews.ac.uk/Biographies/De L’Hopital.html

1.6. Computer Problems – Rechner-Problem-Losungen 51
7. Schreibe ein Programm, das den Differentialquotienten f ′(x) einer Funktiondurch die (zentrierten) Differenzenquotienten approximiert und den Fehlerberechnet.
a) f ′(x) ≈ f(x+h)−f(x)h
fur h = 10−k mit k = 0, 1, . . . , 16 und beispielsweisef(x) = sinx in x = 1.
b) f ′(x) ≈ f(x+h)−f(x−h)2h
fur h = 10−k mit k = 0, 1, . . . , 16 und beispielsweisef(x) = sinx in x = 1.
f(x) =f ′(x) =
test
get f , f ′
x = k =h =
hopt =
∆y∆x
=∆y++∆y−
2∆x=
f ′(x) =
inc kreset
8. Betrachte die harmonische Reihe∑∞
n=11n.
a) Zeige:∑∞
n=11n
ist divergent.∑∞n=1
1n
= 1 + 12+ (1
3+ 1
4) + (15+ 1
6+ 1
7+ 1
8) + . . . > 1 + 12+ (1
4+ 1
4) + (18+
18
+ 18
+ 18) + . . . = 1 + 1
2+ 1
2+ 1
2+ . . . = +∞
b) Erlautere, warum∑∞
n=11n
in Gleitpunkt-Arithmetik endlich ist. 23
In Gleitkoma-Arithmetik entsteht bei 1n
entweder underflow, oder bei denTeilsummen overflow oder aber – je nach Abbruch-Kriterium – verandernsich die Teilsummen dann nicht mehr, wenn 1
n< εmach
∑n−1k=1
1k.
c) Prognostiziere, wann sich die Teilsummen in IEEE SP bzw. in IEEE DP 23nicht mehr andern.
In IEEE DP mit εmach = 12· 2−53 ≈ 10−16 andern sich die n-ten Teil-
Summen sn =∑n
k=11k
nicht mehr, wenn 1n< 2−53sn−1. Nun ist nach
Teil a) s2m =∑2m
k=11k> (1 + m
2). Daher folgt fur n − 1 = 2m: die Teil-
Summen verandern sich sicher nicht mehr, wenn 1n
= 12m+1
≤ 10−16(1+m2) <
10−16s2m < 10−16sn−1 oder eben n(1 + 12ld(n− 1)) ≥ 1016 – a fortiori also,
wenn n ≥ 1016.
n =1n
=∑ni=1
1i
=
sec’s /106 =
next 10 next 102 next 103
next 104 next 105 next 106
next 107 next 108 reset
d) Schreibe ein Programm, das den Reihenwert in IEEE SP wie auch inIEEE DP ermittelt und dabei Fortschritt und Laufzeit protokolliert.
???
9. a) Schreibe ein Programm, das die Exponential-Funktion exp(x) anhand
ihrer Taylor-Polynome pn mit pn(x) =∑n
i=0xi
i!approximiert.

52 KAPITEL 1. SCIENTIFIC COMPUTING
Die Exponential-Funktion exp(x) werde durch die Taylor-Polynome pn mit
pn(x) =∑n
i=0xi
i!approximiert und jeweils mit der JavaScript Bibliotheks-
funktion Math.exp verglichen.
x =n =
∑ni=0
xi
i!=
1/∑n
i=0(−x)i
i!=
Math.exp(x) =
inc nreset
b) Wenn in der naturlichen Reihenfolge summiert wird, welches Abbruch-Kriterium sollte verwendet werden?
Vergleich des ersten Abbruchkriteriums A1 fl(pn(x)) = fl(pn+1(x)) mit
dem zweiten Abbruchkriterium A2 fl(|xi
i!|) < ε.
x =ε =
A1 : n = und f(x) =
Math.exp(x) =
A2 : n = und f(x) =
evalreset
c) Teste das Programm fur x = ±1, ±5, ±10, ±15, ±20 und vergleiche dieErgebnisse mit denen der jeweiligen Bibliotheksfunktion exp.
siehe a) und b)
d) Kann die kanonische Summation verwendet werden, um genaue Ergeb-nisse auch fur negative Argumente zu erhalten?
Fur x < 0 ergibt sich eine alternierende Reihe, deren numerische Nachteile(vgl. 1RQ49) durch ex = 1/e−x umgangen werden konnen (vgl. a)).
e) Kann die Reihenfolge der Summation so abgeandert werden, daß genaueErgebnisse auch fur negative Argumente gewonnen werden?
???
10. Bestimme die Losungen der quadratischen Gleichung a x2 + b x+ c = 0 per
x1,2 =−b±
√b2 − 4ac
2abzw. x′1,2 =
2c
−b∓√b2 − 4ac
u.a. fur Koeffizientena 6 6 · 10154 0 1 1 10−155
b 5 5 · 10154 1 −105 −4 −10155
c −4 −4 · 10154 1 1 3.999999 10155
.
a = b = c =x1 = −b+
√b2−4ac
2a= p(x1) =
x2 = −b−√
b2−4ac2a
= p(x2) =x′1 = 2c
−b−√
b2−4ac= p(x′1) =
x′2 = 2c−b+
√b2−4ac
= p(x′2) =
pdec = tests eval reset

1.6. Computer Problems – Rechner-Problem-Losungen 53
11. f(x) = x3 + a x2 + b x+ c hat mindestens eine reelle Nullstelle xo. Schreibeein Programm, das xo bestimmt.Per Substitution y = x+ a
3ergibt sich y3 + p y + q = 0 mit p = 1
3(3b− a2)
und q = 127
(2a3−9ab+27c). Wenn die Determinante D = 127p3+ 1
4q2 positiv
ist, gibt es genau die eine reelle Nullstelle
xo = −13a+
3
√−1
2q +
√D +
3
√−1
2q −
√D.
a = b = c = d =
p =q =
xo =f(xo) =
testseval
reset
12. a) Schreibe ein Programm, das fur x = (xi)i=1,...,n jeweils Mittelwert x undStandardabweichung σ bestimmt. Vergleiche (Ex 1.27)
die two pass formula σ2 = 1n−1
n∑i=1
(xi − x)2
mit der one pass formula σ2 = 1n−1(
n∑i=1
x2i − nx2).
b) Fur welche Eingabe-Vektoren x ergeben die beiden mathematisch aquiva-lenten Formeln betrachtliche numerische Unterschiede bis hin zu negativenRadikanden?
x =
n =x =
2pass σ2 =1pass σ2 =
testseval
reset
b) s. Teil a)
13. Wenn a das Start-Kapital, r den Zinssatz und n die Anzahl der Zins-ausschuttungen (jahrlich: n = 1, halbjahrlich: n = 2, in jedem Quartal:n = 4, monatlich: n = 12, wochentlich: n = 56, taglich: n = 365) bezeich-nen, so ist f(n) = a(1 + r
n)n das aufgezinste Kapital am Jahresende.
a) Schreibe ein Programm, das f(n) erstens vermittels einer Schleife, zwei-tens vermittels des Exponentiationsoperators und drittens unter Verwen-dung von Bibliotheksfunktionen als f(n) = en ln(1+r/n) berechnet.
mit for loop bzw. f=a*Math.pow((1+r/n),n) bzw. mit f = a en ln(1+r/n)
a =r =n =
mit for loop:
a*pow((1+r/n),n)=a*exp(n*ln(1+r/n))=
testinc nreset
b) Vergleiche jeweils die drei Ergebnisse.

54 KAPITEL 1. SCIENTIFIC COMPUTING
14. p(x) = (1 − x)6 und q(x) = x6 − 6x5 + 15x4 − 20x3 + 15x2 − 6x + 1oder r(x) = (x6 + 15x4 + 15x2 + 1)− (6x5 + 20x3 + 6x) oder mit Hornerh(x) = (((((x − 6)x + 15)x − 20)x + 15)x − 6)x + 1 sind identische, nichtnegative Funktionen mit der 6-fachen Nullstelle 1.Vergleiche p, q, r und h in etwa der Umgebung [0.995, 1.005] von 1.
Bei der Auswertung von q(x) ≈ 1− 6 + 15− 20 + 15− 6 + 1 = 0 fur x ≈ 1,von r(x) ≈ (1 + 15 + 15 + 1) − (6 + 20 + 6) = 0 fur x ≈ 1, bzw. vonh(x) ≈ (((((1−6)+15)−20)+15)−6)+1 = 0 fur x ≈ 1 spielt cancellationdie entscheidende Rolle.
n =xmin =x =
xmax =
p(x) =q(x) =r(x) =h(x) =
testnext x
reset
15. Schreibe ein Programm, das ||x||2 =√∑n
i=1 x2i , die Euklid’sche Norm des
Vektors x = (x1, . . . , xn)T berechnet und dabei overflow wie auch harmfulunderflow vermeidet (vgl. 1Ex13). Gib Beispiele fur Vektoren an, so daßnaive und umsichtige Berechnung signifikant unterschiedliche Ergebnisseliefern. Wieviel performance kostet wieviel Genauigkeit?
x =naiv ||x||2 =
scaled ||x||2 =scaled+sorted ||x||2 =
testseval
reset
16. Sei (xi)i=1,...,n eine Folge von n in [0, 1] gleichverteilten (Pseudo-) SP-Zu-fallszahlen. Bestimme s =
∑ni=1 xi.
a) sD =∑n
i=1 xi bei Verwendung einer DP-Variablen fur sD.
b) sS =∑n
i=1 xi bei Verwendung einer SP-Variablen fur sS.
c) sK =∑n
i=1 xi bei Verwendung des folgenden Algorithmus’ mit SP-Vari-ablen c, t und s fur sK
s=x[1]; c=0; // c = Korrektur-Termfor(i=2; i<=n;i++)
y=x[i]-c; // neuer Summand inkl. altem Korrektur-Termt=s+y; // temporare neue Teilsumme

1.6. Computer Problems – Rechner-Problem-Losungen 55
c=(t-s)-y; // aktualisierter Korrektur-Terms=t; // aktualisierte Teilsumme
In exakter Arithmetik berechnet der Schleifenkorpery := xi−c, t := s+y = s+xi−c, c := (t−s)−y = ((s+y)−s)−y = 0(c ist initial und so konstant Null) und schließlich s := t = s+xi−0.
Sei etwa x1 = 1, x2 = 0.05 und x3 = 0.05 mit xi ∈ F(10, 2, L, U). Dannist x1 + x2 + x3 = 1.1, wahrend in F(10, 2, L, U) eben fl(fl(s1 + s2) + x3) =fl(1 + x3) = 1 gilt. Mit Kahan’s Addition dagegen ergibt sich
init s := x1 = 1; c := 0;
i = 2 y := x2 − c = fl(1 − 0.05) = 0.05; t := s + y = fl(1 + 0.05) = 1;c := (t− s)− y = fl(fl(1− 1)− 0.05) = −0.05; s := t = 1;
i = 3 y := x3 − c = fl(0.05 + 0.05) = 0.1; t := s + y = fl(1 + 0.1) = 1.1;c := (t− s)− y = fl(fl(1.1− 1)− 0.1) = fl(0.1− 0.1) = 0; s := t = 1.1;
d) s≤ =∑n
j=1 xij wobei xi1 ≤ xi2 ≤ . . . ≤ xin
e) s≥ =∑n
j=1 xij wobei xi1 ≥ xi2 ≥ . . . ≥ xin
Vergleiche die Verfahren a) bis e). Wie und warum funktioniert c) ? WelcheRangfolge nehmen a) bis e) im Hinblick auf Genauigkeit und Kosten ein?
sD =sS =sK =
s≤ =s≥ =
n =trialreset
17. Schreibe ein Programm, das die ersten n Folgen-Elemente der Folge xk+1 =2.25xk − 0.5xk−1 mit Startwerten x1 = 1
3und x2 = 1
12erzeugt. Verwende
etwa n = 225 in SP und n = 60 in DP.Wieso ist xk = 4
34−k die exakte Losung der Differenzengleichung? Erklare
die Unterschiede zwischen Beobachtung und exaktem Ergebnis.
Sei xk+1 = a xk − b xk−1 mit vorgebenen Startwerten fur x1 und x2 undKonstanten a und b. Der Ansatz xk = rk liefert die charakteristische Glei-chung oder auxiliary equation5 r2 − a r+ b = 0 mit den beiden Losungen αund β. Dann gilt
xk = c αk + d βk
xk = (c+ k d)αk mitc = x1β−x2
α(β−α)
c = 2x1α−x2
α2
undd = x1α−x2
β(α−β)
d = x2−x1αα2
falls
α 6= βα = β
Fur xk+1 = 94xk− 1
2xk−1 hat die charakteristische Gleichung r2− 9
4r+ 1
2= 0
die beiden Nullstellen α = 2 und β = 14. Damit ist c =
13
14− 1
12
α(β−α)= 0 und
d =13
2− 112
β(α−β)= 7/12
7/16= 4
3. Insgesamt gilt also xk = dβk = 4
34−k wie behauptet.
5 Ian Anderson: A First Course in Discrete Mathematics; Springer 2001

56 KAPITEL 1. SCIENTIFIC COMPUTING
a =b =x1 =x2 =
k =xk =xk =
xk−1 =
testinc kreset
18. Schreibe ein Programm, das die ersten n Folgen-Elemente der Folge xk+1 =111 − (1130 − 3000/xk−1)/xk mit x1 = 11
2und x2 = 61
11erzeugt. Verwende
etwa n = 10 in SP und n = 20 in DP.Die exakte Losung der Differenzengleichung ist eine monoton wachsendeFolge mit limk→∞ xk = 6. Erklare die Unterschiede zwischen Beobachtungund exaktem Ergebnis.
Offensichtlich erfullt xk = 6k+5k
6k−1+5k−1 die beiden Startbedingungen, x1 =6+51+1
= 112
und x2 = 36+256+5
= 6111
, sowie die rekursive Definition
xk+1 =6k+1 + 5k+1
6k + 5k= 111−
(1130− 3000
6k−2 + 5k−2
6k−1 + 5k−1
)6k−1 + 5k−1
6k + 5k
= 111− 1130 (6k−1 + 5k−1)− 3000 (6k−2 + 5k−2)
6k + 5k
= 111− 6k−1(1130− 500) + 5k−1(1130− 600)
6k + 5k
=6k(111− 105) + 5k−1(111− 106)
6k + 5k=
6k+1 + 5k+1
6k + 5k
Nun ist limk→∞
xk = limk→∞
6k + 5k
6k−1 + 5k−1= lim
k→∞
6(1 + 5(5/6)k−1)
1 + (5/6)k−1= 6
und x = 111− (1130− 3000/x)/x ⇐⇒ x2 = 111x− 1130 + 3000/x ⇐⇒x3−111x2+1130x−3000=0=(x−6)(x2−105x+500)=(x−5)(x−6)(x−100),also hat p(x) = x3 − 111x2 + 1130x − 3000 die drei Nullstellen 5, 6 und100, die Fixpunkte von (xk) sind.
x5 6 100
y = 1125p(x)
pdec = k =x1 =x2 =
xk =xk =
xk−1 =
testinc kreset

Kapitel 2
Systems of Linear Equations
In Heath: ’Scientific Computing’ sind Vektoren grundsatzlich Spaltenvektoren.Zur Unterscheidung von Skalaren scalar sind Vektoren vector und Matrizenmatrix durch Fettdruck gekennzeichnet.
2.0.1 Lineare Systeme
Z.B. Schnitte von Geraden der Ebene, Schnitte von Ebenen im Raum, Mechanik(vgl. 2CP3), linear least squares problems (Kap. 3), Systeme nichtlinearer Glei-chungen (Kap. 5), Optimierung (Kap. 6), polynomiale Interpolation (Kap. 7),Systeme (linearer) Differentialgleichungen (Kap. 9–11)lineare physikalische Zusammenhange wie z.B. F = m a, U = R I in Netzen cEine n× n Koeffizientenmatrix A und ein Vektor b ∈ Rn der rechten Seite seiengegeben: dann ist das System Ax = b von nGleichungen in den n Unbekannten xzu losen! vgl. z.B. www.weblearn.hs-bremen.de/risse/MAI/docs/numerik.pdf
2.0.2 Existenz und Eindeutigkeit
Def. Eine n × n-Matrix A ist regular oder nicht singular (nonsingular) genaudann, wenn eine der folgenden aquivalenten Bedingungen erfullt ist:
i. Die inverse Matrix A−1 von A existiert: AA−1 = I = A−1A.
ii. det(A) 6= 0.
iii. rank(A) = n, d.h. A hat maximalen Rang.
iv. Fur jedes 0 6= z ∈ Rn gilt Az 6= 0, d.h. A annulliert kein nicht-triviales z.
57

58 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Z.B. Fur regulares A ist A−1 =
(a bc d
)−1
= 1det(A)
(d −b−c a
)mit det(A) =∣∣∣∣a b
c d
∣∣∣∣ = ad− bc. c
Folge:
falls A regular, existiert genau eine Losung
falls A singular, ist Ax = b
inkonsistent: es gibt keine Losungkonsistent mit unendlich vielen Losungen
Z.B. Schnitt von zwei Geraden in der Ebene c
2.0.3 Sensitivitat und Konditionierung
Sensitivitat zu bewerten und Konditionierung zu messen, bedeutet Anderungender Losung aufgrund von Anderungen von A und b zu bewerten und zu messen.
Anderungen/Abstande mißt man mit Hilfe von Normen!
Def. ||.|| : Rn,Cn → R heißt Norm genau dann, wenn
i. ||x|| > 0 falls x 6= 0
ii. ||γx|| = |γ| · ||x|| fur alle γ ∈ R
iii. ||x + y|| ≤ ||x||+ ||y|| (Dreiecksungleichung)
Vektor-Normen
Def. Fur x ∈ Rn oder x ∈ Cn definiert ||x||p = (∑n
i=1 |xi|p)1/pdie p-Norm auf
Rn oder Cn.
| ||x|| − ||y|| | ≤ ||x− y|| (Dreiecksungleichung, Stetigkeit)
Wichtig sind die drei in bestimmtem Sinn (s.u.) gleichwertigen Spezial-Falle:
1-Norm ||x||1 =∑n
i=1 |xi| (Manhattan- oder taxi cab Norm)
2-Norm ||x||2 = (∑n
i=1 |xi|2)1/2(Euklid’sche Norm)
∞-Norm ||x||∞ = max1≤i≤n |xi| (p→∞)
Die letzte Eigenschaft folgt aus ||x||p = |x1|(1+∑n
i=2 |xi|p/|x1|p)1/p
, falls o.B.d.A.
|x1| = max1≤i≤n |xi| und 1 < f(c) = (1 + cp)1/p < 1 + cpp→∞−→ 1 fur 0 < c < 1.

59
x
y
1
2
∞Einheitskreise bzgl. ||.||1, ||.||2 und ||.||∞
Fur die drei Normen gelten folgendeAbschatzungen
c mit||.||links ≤ c||.||oben
||.||1 ||.||2 ||.||∞||.||1
√n n
||.||2 1√n
||.||∞ 1 1
Um ||.||1 ≤√n||.||2 zu zeigen, brauchen wir die Cauchy1-Schwarz2sche Unglei-
chung |xTy|2 ≤ (xTx)(yTy) = ||xT ||22 · ||y||22 fur alle x,y ∈ Rn. Zur Herleitungstellen wir zunachst
0 ≤ (x− λy)T (x− λy) = xTx− 2λxTy + λ2yTy
fest. In dieser Ungleichung setzen wir λ = 1||y||2x
Ty und erhalten
0 ≤ xTx− 2 1||y||22
(xTy)2 + ( 1||y||22
xTy)2||y||22 = ||x||22 − 1
||y||22(xTy)2
Auflosen liefert die gewunschte Ungleichung |xTy|2 ≤ ||x||22 · ||y||22.Sei nun speziell z := (|x1|, . . . , |xn|)T ∈ Rn und y = (1, . . . , 1)T ∈ Rn gesetzt.Dann liefert die Cauchy-Schwarz’sche Ungleichung
||x||1 =n∑
i=1
1 · zi = yTz ≤ ||y||2 · ||z||2 =√n||z||2 =
√n||x||2
und damit die Abschatzung ||.||1 ≤√n||.||2.
Matrix-Normen
Def. ||A|| = maxx6=0||Ax||||x|| definiert die von der Vektor-Norm ||.|| induzierte
Matrix-Norm. Alle von p-Normen induzierten Matrix-Normen sind submultiplikative Normen:
i. ||A|| > 0 fur alle A 6= 0
ii. ||γA|| = |γ| · ||A|| fur alle γ ∈ R1 Augustin Louis Cauchy (1789-1857) www-history.mcs.st-andrews.ac.uk/Biographies/Cauchy.html
2 Hermann Amandus Schwarz (1843-1921) www-history.mcs.st-andrews.ac.uk/Biographies/Schwarz.html

60 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
iii. ||A + B|| ≤ ||A||+ ||B|| fur alle A und B
iv. ||AB|| ≤ ||A|| · ||B|| fur alle A und B
v. ||Ax|| ≤ ||A|| · ||x|| fur alle x
1-Norm ||A||1 = maxj
∑ni=1 |ai,j| (maximale absolute Spaltensumme)
2-Norm ||A||2 ist schwierig(er) zu berechnen, etwa per SVD.
∞-Norm ||A||∞ = maxi
∑nj=1 |ai,j| (maximale absolute Zeilensumme)
Konditionszahl einer Matrix
Def. cond(A) = ||A|| · ||A−1|| =(maxx6=0
||Ax||||x||
)/(minx6=0
||Ax||||x||
)ist die Kon-
ditionszahl der regularen Matrix A bzgl. der Vektor-Norm ||.||.Fur singulares A ist cond(A) = ∞ definiert.
Z.B. Fur A =
2 −1 11 0 13 −1 4
ist A−1 = 12
1 3 −1−1 5 −1−1 −1 1
. Es gilt ||A−1||1 = 4.5
sowie ||A−1||∞ = 3.5 und daher cond1(A) = ||A||1 · ||A−1||1 = 6 · 4.5 = 27 sowiecond∞(A) = ||A||∞ · ||A−1||∞ = 8 · 3.5 = 28. cZ.B. Transformationen des Einheitskreises durch verschiedene Matrizen
x
y
a1
a2
A1 =(.87 .5−.5 .87
), cond2(A1) = 1
x
y
a1
a2
A2 =(
2 00 .5
), cond2(A2) = 4

61
x
y
a1
a2
A2 =(
1.73 .25−1 .43
), cond2(A2) = 4
x
y
a1
a2
A3 =(
1.52 .91.47 .94
), cond2(A4) = 4
cEigenschaften:
i. cond(A) ≥ 1 fur jede Matrix A
ii. cond(I) = 1
iii. cond(γA) = cond(A) fur alle γ ∈ R
iv. cond(diag(d1, . . . , dn)) = (maxi |di|)/(mini |di|)
||A−1|| ist aufwandig zu berechnen. Daher sind schon wenigstens untere Schran-ken hochst willkommen: Sei Az = y. Dann gilt z = A−1y und daher
||z|| = ||A−1y|| ≤ ||A−1|| · ||y|| so daß||z||||y||
≤ ||A−1||
Z.B. Sei A =
(0.913 0.6590.457 0.330
). Mit y = (0, 1.5)T ergibt sich z = (−7780, 10780)T ,
so daß ||A−1||1 ≈ ||z||1||y||1 = 18560
1.5≈ 12373 und endlich cond1(A) = ||A||1 · ||A−1||1 ≈
1.370 · 12373 ≈ 16951 1 folgt3: cond(A,1)=1.695779527559450e+004 c
Fehler-Schranken
Sei Ax = b und Ax = b + ∆b. Setze ∆x = x− x. Dann gilt
Ax = A(x + ∆x) = Ax + A∆x = b + ∆b
Wegen Ax = b gilt also insbesondere A∆x = ∆b oder eben ∆x = A−1∆bund damit einerseits ||b|| = ||Ax|| ≤ ||A|| · ||x|| oder eben ||b||
||A|| ≤ ||x|| und
andererseits ||∆x|| = ||A−1∆b|| ≤ ||A−1|| · ||∆b||. Zusammen ergibt sich also
3 laut MATLAB

62 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
||∆x||||x|| ≤ ||A−1|| · ||∆b||/||x|| ≤ ||A−1|| · ||∆b|| · ||A||/||b|| = ||A−1|| · ||A|| ||∆b||
||b||und somit
||∆x||||x||
≤ cond(A)||∆b||||b||
Sei Ax = b und (A+E)x = b. Dann gilt ∆x = x−x = A−1(Ax−b) = −A−1Exund damit ||∆x|| ≤ ||A−1|| · ||E|| · ||x|| oder
||∆x||||x||
≤ cond(A)||E||||A||
Etwas Analysis liefert eine umfassendere Abschatzung:Definiere A(t) = A + tE und b(t) = b + t∆b. Dann sei x(t) = x + t∆x dieLosung des Systems linearer Gleichungen A(t)x(t) = b(t). Differentation nach tliefert
Ex(t) + A(t)∆x = A′(t)x(t) + A(t)x′(t) = b′(t) = ∆b
In t = 0 gilt Ex + A∆x = ∆b bzw. ∆x = A−1∆b−A−1Ex und so
||∆x|| ≤ ||A−1∆b||+ ||A−1Ex|| ≤ ||A−1|| · ||∆b||+ ||A−1|| · ||E|| · ||x||
||∆x||||x||
≤ ||A−1∆b||||x||
+ ||A−1|| · ||E|| = ||A|| · ||A−1∆b||||A|| · ||x||
+||A|| · ||A−1|| · ||E||
||A||
und wegen ||b|| = ||Ax|| ≤ ||A|| · ||x|| endlich
||∆x||||x||
≤ cond(A)
(||∆b||||b||
+||E||||A||
)Falls die Eingabe-Daten A und b in Maschinen-Genauigkeit vorliegen, gilt
||x− x||||x||
<≈ cond(A)εmach
Allerdings ist folgendes zu berucksichtigen:
• Diese Abschatzung gilt nur fur die betragsmaßig großte Komponente desLosungsvektors: der relative Fehler betragsmaßig kleinerer Komponentendes Losungsvektors kann wesentlich großer ausfallen!
• Schlechte Skalierung wie auch Fast-Singularitat zeigen sich in großen Kon-ditionszahlen. Reskalierung kann dem Einfluß der schlechten Skalierung aufdie Konditionszahl entgegenwirken, nicht aber dem der Fast-Singularitat.

63
Residuen
Def. r = b−Ax heißt Residuum zur genaherten Losung x von Ax = b. Residua als solche ergeben keinen Sinn, weil das gleichwertige lineare Gleichungs-system cAx = cb das c-fache Residuum cr = c(b−Ax) aufweist.
Def. ||r||||A||·||x|| = ||b−Ax||
||A||·||x|| heißt relatives Residuum.
||∆x|| = ||x− x|| = ||A−1(Ax− b)|| = || −A−1r|| ≤ ||A−1|| · ||r||
||∆x||||x||
≤ cond(A)||r||
||A|| · ||x||
Z.B. Sei Ax =
(0.913 0.6590.457 0.330
)(x1
x2
)=
(0.2540.127
)= b. Fur die Residuen der
beiden naherungsweisen Losungen x1 =
(−0.0827
0.5
)und x2 =
(0.999
−1.001
)gilt
||r1|| = 2.1 · 10−4 und ||r2|| = 2.4 · 10−2, obwohl x2 naher an der exakten Losung
x =
(1
−1
)liegt. Dieses Phanomen ist in der schlechten Konditionierung von A
mit cond1(A), cond2(A), cond∞(A) > 104 begrundet. c
2.0.4 Systeme linearer Gleichungen losen
Es gibt direkte und iterative Verfahren, quadratische Systeme linearer Gleichun-gen Ax = b, d.h. Systeme mit n × n Koeffizienten-Matrix A und b ∈ Rn, zulosen. Gauß4-Elimination ist das wichtigste direkte, Gauß-Seidel5 das wichtig-ste iterative Verfahren. Im Folgenden befassen wir uns vornehmlich mit (derdirekten) Gauß-Elimination.
Problem-Transformationen
Multiplikation von Ax = b mit regularer Matrix M von links MAx = Mbandert nichts an der Losung x. Fur MAz = Mb gilt namlich
z = (MA)−1Mb = A−1M−1Mb = A−1b = x
Z.B. Permutationen P, d.h. Einheitsmatrix mit vertauschten Zeilen und Spal-ten, sind regular, da P−1 = PT und PAx = Pb hat dieselbe(n) Losung(en) wieAx = b, wahrend APx = b nur die Komponenten von x vertauscht.Diagonale Skalierungen D = diag(d) mit DAx = Db andern zwar x nicht, dafur
4 Johann Carl Friedrich Gauß (1777-1855) www-history.mcs.st-andrews.ac.uk/Biographies/Gauss.html
5 Philipp Ludwig von Seidel (1821-1896) www-history.mcs.st-andrews.ac.uk/Biographies/Seidel.html

64 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
aber die numerischen Verhaltnisse.Spalten-Skalierung ADx = b andert die (physikalischen) Einheiten der Unbe-kannten und damit die Numerik des Gleichungssystems. Wenn z Losung vonADz = b ist, so ist wegen z = (AD)−1b = D−1A−1b = D−1x eben x = DzLosung von Ax = b. c
Triangulare lineare Systeme
Def. L = (`i,j) heißt untere (lower) Dreiecksmatrix ⇐⇒ `i,j = 0 fur alle i < j.U = (ui,j) heißt obere (upper) Dreiecksmatrix ⇐⇒ ui,j = 0 fur alle i > j. Ein Gleichungssystem Lx = b kann durch forward substitution gelost werden,d.h. x1 = b1/`1,1 und xi = 1
`i,i(bi −
∑i−1j=1 `i,jxj) fur i = 2, . . . , n.
function x = forward (L , b)% FORWARD(L,b) ermittelt per forward substitution die Losung x von% L*x = b fur eine untere n× n-Dreiecksmatrix L und einen n-Vektor b
n = s ize (L , 1 ) ; x = zeros (n , 1 ) ;for j = 1 : n % fur jede Spalte j
i f (L( j , j )==0)disp ( ’L i s t s i n gu l a e r ! ’ ) ;
endx ( j ) = b( j )/L( j , j ) ; % berechne xj
for i = j +1:n % eliminatiere xj in L*x=b
b( i ) = b( i )−L( i , j )∗x ( j ) ; % aktualisiere biend
end
Ein Gleichungssystem Ux = b kann durch backward substitution gelost werden,d.h. xn = bn/un,n und xi = 1
ui,i(bi −
∑nj=i+1 ui,jxj) fur i = 2, . . . , n
function x = backward (U, b)% BACKWARD(U,b) ermittelt per backward substitution die Losung x von% U*x = b fur eine obere n× n-Dreiecksmatrix U und einen n-Vektor b
n = s ize (U, 1 ) ; x = zeros (n , 1 ) ;for j = n:−1:1 % fur jede Spalte j
i f (U( j , j )==0)disp ( ’U i s t s i n gu l a e r ! ’ ) ;
endx ( j ) = b( j )/U( j , j ) ; % berechne xj
for i = 1 : j−1 % eliminatiere xj in U*x=b
b( i ) = b( i )−U( i , j )∗x ( j ) ; % aktualisiere biend
end

65
Bem. Je nach Zeilen- oder Spalten-weiser Allokation von Matrizen im Spei-cher und in Abhangigkeit von cache-Auslegung und Speicher-Organisation istdie alternative Implementierung von forward bzw. backward mit Zeilen-weisemZugriff auf L bzw. auf U vorteilhafter. Ziel ist die sogenannte LU-Faktorisierung A = LU von A.
Elementare Eliminationsmatrizen
Z.B. Mz = M
(xy
)=
(1 0
−y/x 1
)(xy
)=
(x0
)ist zu verallgemeinern! c
Elementare Eliminationsmatrizen Mk annullieren ak+1, ak+2, . . . , an von a.
Mka =
1 · · · 0 0 · · · 0...
. . ....
.... . .
...0 · · · 1 0 · · · 00 · · · −mk+1 1 · · · 0...
. . ....
.... . .
...0 · · · −mn 0 · · · 1
a1...ak
ak+1...an
=
a1...ak
0...0
mit mi =
ai
ak
=ai
pivot
• Mk ist als untere Dreiecksmatrix mit Einheitsdiagonale regular.
• Mk = I−meTk mit m = mk = m(a) = (0, . . . , 0,mk+1, . . . ,mn)T
• Lk = M−1k = I + meT
k
Gauß-Elimination und LU-Faktorisierung
Mehrfache Elimination in Ax = b uberfuhrt A in eine obere DreiecksmatrixMA, so daß das Gleichungssystem per backward substitution gelost werden kann.
MAx := Mn−1Mn−2 · · ·M1Ax = Mn−1Mn−2 · · ·M1b = Mb
Gauß-Elimination produziert so auch die LU-Faktorisierung A = LU von A.Sei U := MA und L := M−1 = (Mn−1Mn−2 · · ·M1)
−1 = M−11 M−1
2 · · ·M−1n−1 =
L1L2 · · ·Ln−1 und so
A = LU = (L1L2 · · ·Ln−1)(Mn−1Mn−2 · · ·M1A)
so daß Ax = LUx = b mit zwei substitutions gelost werden kann: erst Ly = bper forward substitution und dann Ux = y per backward substitution losen.
LU-Faktorisierung durch Gauß-Elimination (noch ohne Pivotisierung) in MAT-LAB

66 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
function [ L ,U] = LUfact (A)% LUfact(A) faktorisiert die quadratische Matrix A = L*U – ohne Pivotisierungn = s ize (A, 1 ) ; L = eye (n ) ;for k = 1 : n−1 % fur jede Spalte k
pivot = A(k , k ) ;i f ( p ivot == 0)
disp ( ’ p ivot == 0 ’ ) ; % stoppendfor i = k+1:n
L( i , k ) = A( i , k )/ p ivot ; % berechne negative Multipliziererendfor j = k+1:n
for i = k+1:nA( i , j ) = A( i , j )−L( i , k )∗A(k , j ) ;% modifiziere Untermatrix
endend
end % A ’in place’ modifiziertU = triu (A) ; % obere Dreiecksmatrix von A
% fur das Argument, fur die originale, unmodifizierte Matrix A, gilt A = LU
Losung von Ax = b per LU-Faktorisierung in MATLAB
function x = gauss (A, b)% GAUSS(A,b) lost A*x = b per LU-Faktorisierung LUfact (Gauß-Elimination),% lost L*y = b per forward substitution, dann U*x = y per backward substitution[ L ,U] = LUfact (A) ;y = forward (L , b ) ;x = backward (U, y ) ;
oder – falls LUfact auch die Matrix M der positiven Multiplizierer zuruckgibt –
function x = gauss (A, b)% GAUSS(A,b) lost A*x = b per LU-Faktorisierung LUfact (Gauß-Elimination).[ L ,U,M] = LUfact (A) ;x = backward (U,M∗b ) ;
Z.B. Gegeben das System linearer Gleichungen
Ax =
1 2 24 4 24 6 4
x1
x2
x3
=
36
10
= b
M1Ax =
1 0 0−4 1 0−4 0 1
1 2 24 4 24 6 4
x =
1 2 20 −4 −60 −2 −4
x =
3−6−2
= M1b

67
M2M1Ax=
1 0 00 1 00 −.5 1
1 2 20 −4 −60 −2 −4
x=
1 2 20 −4 −60 0 −1
x=
3−6
1
=M2M1b
wobei U = MA = M2M1A obere Dreiecksmatrix ist. Aus Ux = Mb ergibt sichper backsubstitution x = (−1, 3,−1)T . Die LU-Faktorisierung von A wird durch
L = L1L2 = M−11 M−1
2 =
1 0 04 1 04 0 1
1 0 00 1 00 0.5 1
=
1 0 04 1 04 0.5 1
A =
1 2 24 4 24 6 4
=
1 0 04 1 04 0.5 1
1 2 20 −4 −60 0 −1
= LU
geliefert. c
Pivotisierung
Def. Falls ein pivot-Element, d.h. eines der Diagonal-Elemente, im Verlaufdes Eliminationsprozesses verschwindet, vertausche die betreffende Gleichung miteiner der folgenden Gleichungen. Dieses Vorgehen heißt Pivotisierung. Z.B. Notwendigkeit der Pivotisierung und Singularitat haben nichts miteinander
zu tun. A =
(0 11 0
)ist regular, hat aber keine LU-Faktorisierung, solange
die beiden Zeilen nicht vertauscht werden. Dagegen hat die singulare Matrix
A =
(1 11 1
)=
(1 01 1
)(1 10 0
)= LU eine LU-Faktorisierung. c
Pivotisierung dient weiterhin dazu, betragsmaßig kleine pivots und damit inak-zeptable Rundungsfehler zu vermeiden:
Def. Partielle Pivotisierung beschrankt die Betrage der Multiplikatoren durch 1,indem in jeder Spalte jeweils das betragsmaßig großte Element auf oder unterhalbder Diagonalen durch Zeilenvertauschungen als pivot verwendet wird.
Z.B. Fur A =
(ε 11 1
)mit 0 < ε < εmach ist ε das pivot-Element und der
Muliplikator −1ε
in der Eliminationsmatrix M =
(1 0
−1/ε 1
)betragsmaßig groß.
So ergibt sich L =
(1 0
1/ε 1
)und fl(U) = fl
(ε 10 1− 1/ε
)=
(ε 10 −1/ε
), so daß
sich L fl(U) =
(1 0
1/ε 1
)(ε 10 −1/ε
)=
(ε 11 0
)6= A ergibt.
Vertauschen der beiden Zeilen liefert ein pivot von 1 und den Multiplikator −ε in

68 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
M =
(1 0−ε 1
)sowie L =
(1 0ε 1
)und fl(U) = fl
(1 10 1− ε
)=
(1 10 1
), so daß
L fl(U) =
(1 0ε 1
)(1 10 1
)=
(1 1ε 1
), also A mit vertauschten Zeilen, ergibt. c
Vor dem k-ten Eliminationsschritt erfolgt also eine Permutation Pk der Glei-chungen, so daß das betragsmaßig großte Element in der k-ten Spalte auf oderunterhalb der Diagonalen in der Diagonalposition zu stehen kommt.MA = U ist obere Dreiecksmatrix mit jetzt M = Mn−1Pn−1 . . .M1P1. Aller-dings ist M−1 = L jetzt nicht mehr notwendig untere Dreiecksmatrix.
P = Pn−1 . . .P1 ordnet A in PA um, so daß keine partielle Pivotisierung mehrnotwendig ware, PA = LU ware eine LU-Faktorisierung mit echter unterer Drei-ecksmatrix L und statt Ax = b ist PAx = Pb per Ly = Pb und dann perUx = y zu losen.
Gauß-Elimination mit partieller Pivotisierung
function x = gaussPP (A, b)% gaussPP(A,b) lost A * x = b mit partieller Pivotisierungn = s ize (A, 1 ) ; L = eye (n ) ;for k = 1 : n−1 % fur jede Spalte k
[ void p ] = max(abs (A(k : n , k ) ) ) ;% p = argmin|ai,k| : k ≤ i ≤ np = p+k−1; % offset berucksichtigeni f (p˜=k) % pivotisiere partiell
tmprow = A(p , : ) ; A(p , : ) = A(k , : ) ; A(k , : ) = tmprow ;tmp = b(p ) ; b(p) = b(k ) ; b (k ) = tmp ; % in b und
end % in A Zeilen p und k vertauschtpivot = A(k , k ) ;i f ( p ivot==0) % Spalte in Untermatrix schon Null
cont inue ;endfor i = k+1:n
L( i , k ) = A( i , k )/ p ivot ; % berechne negative Multipliziererendfor j = k+1:n
for i = k+1:nA( i , j ) = A( i , j )−L( i , k )∗A(k , j ) ;% modifiziere Untermatrix
endendfor i = k+1:n
b( i ) = b( i )−L( i , k )∗b(k ) ;end
end % A ’in place’ modifiziertU = triu (A) ;

69
x = backward (U, b ) ;
In der Praxis ist abzuwagen, ob nicht effizienter ist, Indizes, uber die auf A undb zugegriffen wird, zu verwalten, als die Zeilen tatsachlich zu vertauschen.
Z.B. Gegeben wieder das System linearer Gleichungen
Ax =
1 2 24 4 24 6 4
x1
x2
x3
=
36
10
= b
Vertausche erste und zweite Zeile, damit das betragsmaßig großte Element derersten Spalte in der Diagonalen zu stehen kommt (pivot-Betrag maximieren!):
P1Ax =
0 1 01 0 00 0 1
1 2 24 4 24 6 4
x1
x2
x3
=
4 4 21 2 24 6 4
x1
x2
x3
=
63
10
= P1b
M1P1Ax =
1 0 0−1
41 0
−1 0 1
4 4 21 2 24 6 4
x1
x2
x3
=
4 4 20 1 3
2
0 2 2
x1
x2
x3
=
632
4
= M1P1b
Vertausche zweite und dritte Zeile, damit das betragsmaßig großte Element derzweiten Spalte in der Diagonalen zu stehen kommt (pivot-Betrag maximieren!):
P2M1P1Ax =
1 0 00 0 10 1 0
4 4 20 1 3
2
0 2 2
x =
4 4 20 2 20 1 3
2
x =
6432
= P2M1P1b
M2P2M1P1Ax=
1 0 00 1 00 −1
21
4 4 20 2 20 1 3
2
x=
4 4 20 2 20 0 1
2
x=
64
−12
=M2P2M1P1b
Die Losung x =
−13
−1
ergibt sich aus Ux =
64
−12
wieder per backsubstitution.
L = M−1 = (M2P2M1P1)−1 = PT
1 L1PT2 L2 =
14
12
11 0 01 1 0
A =
1 2 24 4 24 6 4
=
14
12
11 0 01 1 0
4 4 20 2 20 0 1
2
= LU
L ist keine echte untere Dreiecksmatrix, sondern die Permutation einer solchen.
Mit P = P2P1 =
1 0 00 0 10 1 0
0 1 01 0 00 0 1
=
0 1 00 0 11 0 0
und Lo =
1 0 01 1 014
12
1
gilt

70 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
PA =
0 1 00 0 11 0 0
1 2 24 4 24 6 4
=
4 4 24 6 41 2 2
=
1 0 01 1 014
12
1
4 4 20 2 20 0 1
2
= LoU
cDef. Vollstandige Pivotisierung liegt vor, wenn das betragsmaßig großte Elementder gesamten jeweils verbleibenden Untermatrix in die betreffende Diagonalposi-tion durch Zeilen- und Spalten-Tausch vertauscht wird. d.h. PAQ = LU. Um Ax = b zu losen, lose zunachst Ly = Pb, dann Uz = y,um schließlich x = Qz zu erhalten.
Z.B. Gegeben das System linearer Gleichungen
Ax =
(0.913 0.6590.457 0.330
)(x1
x2
)=
(0.2540.127
)= b
Gauß-Elimination liefert in F = F(10, 4, L, U)
MAx=Ux=
(0.9130 0.6590
0 0.0002
)(x1
x2
)=
(0.25400.0001
)=Mb und x=
(−0.0827
0.5
)mit Residuum r = b−Ax vom Betrag ||r||1 = 2.1× 10−4 obwohl x = (1,−1)T .Grund ist cond(A) > 104.Bestimmung von x2 per Division zweier Großen in der Großenordnung des Run-dungsfehlers in F. Einsetzen in die erste Gleichung liefert dann x1, so daß diese’exakt’ erfullt ist, was das kleine Residuum erklart. cGauß-Elimination ist fur spezielle A auch ohne Pivotisierung numerisch stabil!
• A ist Spalten-weise diagonal dominant ⇐⇒∑n
i=1,i6=j |ai,j| < |aj,j| furj = 1, . . . , n
• A ist symmetrisch und positiv definit genau dann, wenn A = AT undxTAx > 0 fur alle x 6= 0
Implementierung
Grundsatzlich weisen alle Verfahren zur Losung von Systemen linearer Gleichun-gen fur die Gauß-Elimiation drei geschachtelte Schleifen auf:
forfor
forA( i , j ) = A( i , j )−(A( i , k )/ p ivot )∗A(k , j )
endend
end

71
Je nach Anordnung dieser drei Schleifen ergeben sich unterschiedliche Zugriffs-muster auf den Speicher (vgl. 2CP15). Daher verwundert nicht, daß die perfor-mance einer Implementierung von Problem-Große, Compiler (mit/ohne Vektori-sierung), Rechner-Architektur (multiple (virtuelle) Prozessoren, cache-Organisation,Speicher-Organisation) abhangt.
Komplexitat
Elimination:∑n−1
i=1
∑nj=i+1(1+
∑nk=i+1 1) = O(1
3n3) mit
∑n−1i=1 i
2 = 16(n−1)n(2n−
1); Auflosen:∑n
i=1
∑nj=i+1 1 = O(n2); zusammen O(1
3n3 + n2) = O(1
3n3), s.a.
2Ex22
Gauß-Jordan-Elimination
Gauß-Jordan-Elimination uberfuhrt A in Diagonalgestalt vermittels
Mka=
1 · · · 0 −m1 0 · · · 0...
. . . 0...
.... . .
...0 · · · 1 −mk−1 0 · · · 00 · · · 0 1 0 · · · 00 · · · 0 −mk+1 1 · · · 0...
. . ....
......
. . ....
0 · · · 0 −mn 0 · · · 1
a1...
ak−1
ak
ak+1...an
=
0...0ak
0...0
mit mi =
ai
ak
=ai
pivot
Die Komplexitat ist O(n3 + n) = O(n3). Anwendung z.B. Matrix-Invertierung!Allerdings kann man sich in aller Regel die gegenuber Gauß-Elimination um 50%hoheren Kosten der Invertierung immer dann sparen, wenn nicht die Inverseexplizit gebraucht wird sondern nur ein lineares Gleichungssystem zu losen ist.Anstelle beispielsweise X = A−1B als Produkt von A−1, also der Inversen von A,mit B zu berechnen, lost man besser die n linearen Gleichungssysteme AX = B.
Genauigkeit verbessern
Das System linearer Gleichungen kann schlecht skaliert sein: die Eintrage derKoeffizienten-Matrix sollten von derselben Großenordnung sein, die Unsicherheitder Eintrage sollte vergleichbar sein, jede Gleichung sollte entsprechend ihrerWichtigkeit und Unsicherhewit gewichtet sein.
Z.B. Die Koeffizienten-Matrix A in Ax =
(1 00 ε
)(x1
x2
)=
(1ε
)mit der exakten
Losung x =
(11
)hat die Konditionszahl 1/ε, ist also fur betragsmaßig kleine ε

72 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
beliebig schlecht konditioniert: kleine Anderungen der Eingabe-Daten fuhren zu
großen Anderungen in der Losung. Die rechte Seite beispielsweise um
(0−ε
)auf(
10
)abzuandern, andert die Losung von
(11
)auf
(10
).
Skalierung der zweiten Gleichung mit 1/ε macht aus dem extrem schlecht kon-ditionierten ein bestens konditioniertes Gleichungssystem. Jetzt fuhrt die Ande-rung der rechten Seite zu einer vergleichbaren Anderung der Losung. cAuch iterative refinement kann die Genauigkeit der Losung verbessern: sei xo
eine Naherung der Losung von Ax = b. Mit dem Residuum ro = b −Axo undder Losung so desselben Systems Aso = ro mit ro als neuer rechter Seite laßt sichxo zu x1 = xo + so verbessern: jezt gilt namlich
Ax1 = A(xo + so) = Axo + Aso = (b− ro)− ro = b
Das Verfahren wird wiederholt, bis etwa die Norm des Residuums ausreichendklein geworden ist. Um immer wieder das Gleichungssystem mit neuen rechtenSeiten zu losen, wird tunlichst A LU-faktorisiert, was allerdings den Speicherbe-darf verdoppelt.
2.0.5 Spezielle Typen linearer Gleichungssysteme
Bestimmte Eigenschaften der Koeffizienten-Matrix A konnen ausgenutzt werden,um Speicher- und/oder Laufzeit-Anforderungen des Losungsverfahren drastischzu reduzieren:
• A ist symmetrisch genau dann, wenn A = AT gilt.
• A ist positiv definit genau dann, wenn xTAx > 0 fur alle x 6= 0 gilt.
• A ist eine Band-Matrix mit Bandbreite β genau dann, wenn ai,j = 0 fur alle|i− j| > β gilt. Eine Band-Matrix mit Bandbreite β = 1 heißt tridiagonal.
• A ist eine dunn besetzte Matrix genau dann, wenn fast alle ai,j verschwinden.
Symmetrisch positiv definite Matrizen
Die Cholesky6-Faktorisierung A = LLT symmetrisch positiv definiter MatrizenA ist aus folgenden Grunden attraktiv:
• Alle Radikanden sind positiv: das Verfahren ist wohldefiniert.
6 Andre-Louis Cholesky (1875-1918) www-history.mcs.st-andrews.ac.uk/Biographies/Cholesky.html

73
• Pivotisierung fur numerische Stabilitat ist unnotig.
• Die Symmetrie von A halbiert in etwa den Speicherbedarf.
• Nur etwa 16n3 Multiplikationen und ahnlich viele Additionen fallen an.
function L = Cholesky (A)% CHOLESKY(A) berechnet die Cholesky-Faktorisierung A = LLT von A
n = s ize (A, 1 ) ;for k = 1 : n % fur jede Spalte k
A(k , k)=sqrt (A(k , k ) ) ;for i = k+1:n
A( i , k ) = A( i , k )/A(k , k ) ; % skaliere k-te Spalteendfor j = k+1:n
for i= j : nA( i , j ) = A( i , j )−A( i , k )∗A( j , k ) ;
endend
endL = t r i l (A) ;
Bem. Die erfolgreiche Cholesky-Faktorisierung einer symmetrischen Matrix Aist umgekehrt der Nachweise dafur, daß A positiv-definit ist.
Z.B. Die Matrix A =
3 −1 −1−1 3 −1−1 −1 3
ist symmetrisch positiv-definit. Ihre
Cholesky-Faktorisierung ergibt sich Schrittweise durch Skalieren der ersten Spaltemit
√3 ≈ 1.7321 (nur die relevanten Elemente der unteren Dreiecksmatrix sind
angegeben) zu
1.7321−0.5774 3−0.5774 −1 3
, durch Aktualisieren der zweiten und drit-
ten Spalte zu
1.7321−0.5774 2.6667−0.5774 −1.3333 2.6667
, durch Division der zweiten Spalte
durch√
2.6667 ≈ 1.6330 zu
1.7321−0.5774 1.6330−0.5774 −0.8165 2.6667
, durch Aktualisieren
der dritten Spalte zu
1.7321−0.5774 1.6330−0.5774 −0.8165 2.0000
und mit√
2 ≈ 1.4142 end-
lich zu L =
1.7321 0 0−0.5774 1.6330 0−0.5774 −0.8165 1.4142
. c

74 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Band-Matrizen
Wie bei dunn besetzten Matrizen wird eine Band-Matrix effizient gespeichert,wenn nur die von Null verschiedenen ’Parallelen’ zur Diagonalen abgelegt werden.Auch die Losungsverfahren vereinfachen sich wesentlich, wie das Beispiel einertridiagonalen Matrix A zeigt. Die LU-Faktorisierung A = LU von A
A =
b1 c1 0 · · · 0
a2 b2 c2. . .
...
0. . . . . . . . . 0
.... . . an−1 bn−1 cn−1
0 · · · 0 an bn
=
1 0 · · · · · · 0
m2 1. . . . . .
...
0. . . . . . . . . 0
.... . . mn−1 1 0
0 · · · 0 mn 1
d1 c1 0 · · · 0
0 d2 c2. . .
...
0. . . . . . . . . 0
.... . . . . . dn−1 cn−1
0 · · · · · · 0 dn
= LU
berechnet etwa folgender Algorithmus
function [M D] = LUfa c t t r i d i a g (A,B,C)% LUfact_tridiag(A,B,C) berechnet die LU-Faktorisierung der tridiagonalen% Matrix mit Sub-Diagonalen A, mit Diagonalen B und mit Super-Diagonalen C
% LUfact_tridiag berechnet Sub-Diagonale M von L und Diagonale D von Un = length (B) ; M = zeros (n , 1 ) ; D = zeros (n , 1 ) ;for i = 2 : n
M( i ) = A( i )/D( i −1);D( i ) = B( i )−M( i )∗C( i −1);
end
Um eine beliebige Band-Matrix mit Bandbreite β abzulegen, braucht es O(βn)Speicherplatz. Und die LU-Faktorisierung einer solchen Matrix kostet O(β2n).Fur β n ergeben sich beidesmal betrachtliche Einsparungen.

2.1. Review Questions – Verstandnisfragen 75
2.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Die Anzahl derLosungen von Ax = b fur regularesA ist unabhangig von b.
2. Richtig/Falsch? Wenn eine MatrixA eine betragsmaßig sehr kleine De-terminante det(A) hat, so ist dieMatrix ’fast singular’.
3. Richtig/Falsch? Fur jede symmetri-sche Matrix A gilt ||A||1 = ||A||∞.
4. Richtig/Falsch? A sei triangular.Falls ein Hauptdiagonal-Elementvon A verschwindet, so ist A not-wendig singular.
5. Richtig/Falsch? Eine beliebigeMatrix mit mindestens einemverschwindenden Hauptdiagonal-Element ist notwendig singular.
6. Richtig/Falsch? A sei eine m × n-Matrix mit m < n. Dann hat Ax =b immer eine Losung.
7. Richtig/Falsch? Das Produkt zweieroberer Dreiecksmatrizen ist wiedereine obere Dreiecksmatrix.
8. Richtig/Falsch? Das Produkt zweiersymmetrischer Matrizen ist wiedersymmetrisch.
9. Richtig/Falsch? Die Inverse einer re-gularen oberen Dreiecksmatrix istwieder obere Dreiecksmatrix.
10. Richtig/Falsch? Wenn die Zeilen ei-ner n×n-Matrix A l.a. sind, so sindauch die Spalten von A l.a.
11. Richtig/Falsch? A sei eine m ×n-Matrix. Das LGS Ax = b
hat eine Losung genau dann, wennrank(A) = rank([A b]), wobei[A b] die um die Spalte b erweitertem× (n+ 1)-Matrix bezeichne.
12. Richtig/Falsch? Fur eine beliebigen × n-Matrix A und eine n × n-Permutationsmatrix P gilt notwen-dig AP = PA.
13. Richtig/Falsch? Unterstellt, daßZeilen von A vertauscht werdendurfen: dann existiert die LU-Fak-torisierung A = LU, sogar fursingulare A.
14. Richtig/Falsch? In einem gut kondi-tionierten LGS ist Pivotisierung furdie Gauß-Elimination unnotig.
15. Richtig/Falsch? Singulare Matrizenhaben keine LU-Faktorisierung.
16. Richtig/Falsch? Wenn eine regulare,symmetrische Matrix A nicht po-sitiv definit ist, so hat A keineCholesky-Faktorisierung.
17. Richtig/Falsch? Eine symmetrische,positiv definite Matrix ist immer gutkonditioniert.
18. Richtig/Falsch? Die Gauß-Elimination ohne Pivotisierungschlagt fehl nur dann, wenn Aschlecht konditioniert oder singularist.
19. Richtig/Falsch? Hat man erst ein-mal A faktorisiert, so kann manAx = b fur beliebige rechte Seitenb ohne erneute Faktorisierung losen.
20. Richtig/Falsch? Wenn eine Matrixper LU-Faktorisierung und Losendes dreieckigen Gleichungssystemsexplizit zu invertieren ist, so wirddie Hauptarbeit fur die LU-Faktori-sierung erbracht.

76 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
21. Richtig/Falsch? ||x||1 ≥ ||x||∞ furalle x ∈ Rn.
22. Richtig/Falsch? Die Norm einer sin-gularen Matrix A ist notwendig 0.
23. Richtig/Falsch? A sei n×n-Matrix.Falls ||A|| = 0, dann A = 0.
24. Richtig/Falsch? Fur beliebiges Agilt ||A||1 = ||AT ||∞.
25. Richtig/Falsch? Fur beliebige Agilt cond(A) = ||A|| · ||A−1|| =cond(A−1).
26. Richtig/Falsch? Gauß-Eliminationmit partieller Pivotisierung erzieltkleine Residuen, auch wenn Aschlecht konditioniert ist.
27. Richtig/Falsch? Die Multipliziererin der Gauß-Elimination mit partiel-ler Pivotisierung sind betragsmaßigkleiner 1, so daß die Elemente derreduzierten Matrizen betragsmaßignicht wachsen konnen.
28. Kann ein System Ax = b genauzwei verschiedene Losungen haben?
29. Kann die Anzahl der Losungen vonAx = b unabhangig von b und al-lein aus A bestimmt werden?
30. Gegeben Ax = b mit quadratischerMatrix A. Was ist schwerwiegender:die Zeilen von A sind l.a. oder dieSpalten von A sind l.a.?
31. a) Genau wann ist eine Matrix sin-gular?
b) Ax = b habe zwei verschiedeneLosungen. Zeige: A ist singular.
32. Gegeben Ax = b. Welche Wirkungauf die Losung haben die folgendenAktionen?
a) Vertauschen der Zeilen von [Ab]
b) Vertauschen der Spalten von A
c) Multiplikation von Ax = b vonlinks mit einer regularen Matrix M
33. Beide Seiten von Ax = b werdenmit einem Skalar α 6= 0 multipli-ziert.
a) Andert das die exakte Losung?
b) Andert das das Residuum r = b−Ax ?
c) Andert das die Gute der Losung?
34. Beide Seiten von Ax = b werdenvon links mit einer Diagonal-MatrixD multipliziert.
a) Andert das die exakte Losung?
b) Andert das die Konditionierungdes Systems?
c) Andert das die Wahl der pivotsbei Gauß-Elimination?
35. Welche elementare Eliminati-onsmatrix annulliert die letz-ten beiden Komponenten vonx = (3, 2,−1, 4)T ?
36. a) Welche 4×4-PermutationsmatrixP vertauscht die zweite und dievierte Komponente von x ∈ R4 ?
b) Welche 4×4-Permutationsmatrixkehrt die Reihenfolge der Kompo-nenten von x ∈ R4 um?
37. A sei singular. Die Arithmetiksei exakt. Zu welchem Zeitpunktwird der Losungsprozess per Gauß-Elimination scheitern?
a) mit partieller Pivotisierung?
b) ohne Pivotisierung?
38. a) Wie unterscheiden sich partielleund vollstandige Pivotisierung?
b) Was sind jeweils Vor- und Nach-teile der beiden Pivotisierungen?

2.1. Review Questions – Verstandnisfragen 77
39. Berechne die LU-Faktorisierung von
A =
4 −8 16 5 70 −10 −3
per Gauß-Eli-
mination. Was ist das initiale pivot-Element?
a) ohne pivoting
b) mit partial pivoting
c) mit complete pivoting
40. Warum ist Pivotisierung essentiellfur numerisch stabile Implementie-rungen der Gauß-Elimination?
41. A sei schlecht konditioniert. DieLU-Faktorisierung sei per Gauß-Eli-mination mit partial pivoting durch-gefuhrt. Wo zeigt sich die schlechteKonditionierung, in L ? in U ? oderin beiden Matrizen?
42. a) Sei M =
1 0 0 00 1 0 00 m1 1 00 m2 0 1
. Be-
stimme M−1.
b) In welchem Zusammenhang tre-ten solche Matrizen M auf?
43. a) Kann jede regulare Matrix A alsA = LU, also als Produkt einerunteren Dreiecksmatrix L und eineroberen Dreiecksmatrix U geschrie-ben werden?
b) Falls ja, gib einen Algorithmusan, falls nein, gib ein Gegenbeispiel.
44. A und B seien n × n-Matrizen. Bsei regular. Berechne C = A−1Beffizient.
45. A und B seien n × n-Matrizen, Asei regular und c ∈ Rn. Berechnex = A−1Bc effizient.
46. A sei n×n-Matrix und x ∈ Rn. Ver-gleiche die Kosten der Berechnungvon
a) y = (xxT )A
b) y = x(xTA)
47. Wie aufwandig ist es, ein dreieckigesn× n-System zu losen?Wie aufwandig ist es, ein beliebigesn× n-System zu losen?
48. Wie kann die LU-FaktorisierungA = LU der regularen Matrix Agenutzt werden, um ATx = b zulosen?
49. L sei regulare untere n × n-Dreiecksmatrix, P eine n × n-Permutationsmatrix und b ∈ Rn.
a) Lose LPx = b.
b) Lose PLx = b.
50. Gibt es 0 6= x ∈ R2 mit ||x||1 =||x||∞ ?
51. Gibt es x,y ∈ R2 mit ||x||1 > ||y||1aber ||x||∞ < ||y||∞ ?
52. Welche Matrix-Norm ist einfacherzu berechnen, ||A||1 oder ||A||2 ?
53. a) Ist det(A) ein guter Indikatordafur, ob A near singular ist?
b) Falls ja, wieso? Falls nein, was istein besserer Indikator?
54. a) Wie ist die Konditionszahl einerMatrix A definiert?
b) Welche Rolle spielt die Konditi-onszahl von A fur die Genauigkeitder berechneten Losung von Ax =b ?
55. Warum ist die Bestimmung voncond(A) fur beliebiges A nicht-trivial?

78 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
56. Gib Beispiele fur 3×3-Matrizen A 6=I mit cond(A) = 1.
57. a) Bestimme cond(A) fur A =diag(4,−6, 2) in der 1-Norm ||.||1.b) Bestimme cond(A) in der ∞-Norm ||.||∞.
58. A sei eine n × n-Matrix mitcond(A) = 1. Welche der folgendenMatrizen sind dann ebenfalls ’be-stens’ konditioniert?
a) cA fur beliebiges c ∈ R
b) DA fur beliebige DiagonalmatrixD
c) PA fur beliebige Permutations-matrix P
d) BA fur beliebige regulare MatrixB
e) A−1
f) AT
59. A = 12I = diag(1
2 , . . . ,12) sei n × n-
Matrix.
a) Bestimme det(A).
b) Bestimme cond(A).
c) Welche Schlusse sind zu ziehen?
60. Sei A exakt singular, aber fl(A) seiregular. Was ist von cond(fl(A)) zuerwarten?
61. Ist A jeweils gut oder schlecht kon-ditioniert?
a) A =(
1010 00 10−10
)b) A =
(1010 00 1010
)c) A =
(10−10 0
0 10−10
)d) A =
(1 22 4
)
62. Was sind gute Indikatoren dafur,daß A fast singular ist?
a) det(A) 1 ?
b) ||A|| 1 ?
c) ||A|| 1 ?
d) cond(A) 1 ?
63. a) Was ist das Residuum der berech-neten Losung x von Ax = b ?
b) Impliziert ein kleines relatives Re-siduum die Genauigkeit der Losung?
c) Impliziert ein großes relativesResiduum die Ungenauigkeit derLosung?
64. Eine Gleitpunkt-Arithmetik habeeine Genauigkeit von 10 Dezimal-Ziffern. In Ax = b mitcond(A) = 103 seien A und b mitvoller Maschinen-Genauigkeit gege-ben. Das System werde per Gauß-Elimination mit partieller Pivotisie-rung gelost. Auf wieviel Dezimal-Ziffern genau ist die Losung?
65. In Ax = b seien A und b mit vol-ler Maschinen-Genauigkeit, namlichauf 12 Dezimal-Ziffern genau, gege-ben. Wie groß darf cond(A) werden,bevor die Losung keine signifikantenZiffern mehr aufweist?
66. Unter welchen Umstanden impli-ziert ein kleines Residuum r = b −Ax, daß x eine genaue Losung vonAx = b ist?
67. A sei n× n-Matrix und c ∈ R belie-big. Was gilt notwendigerweise?
a) ||cA|| = |c| · ||A|| ?
b) cond(cA) = cond(A) 6=|c| cond(A) ?
68. a) Was ist der wesentliche Unter-schied zwischen Gauß-Eliminationund Gauß-Jordan-Elimination?

2.1. Review Questions – Verstandnisfragen 79
b) Stelle Vor- und Nachteile vonGauß-Elimination und Gauß-Jordan-Elimination gegenuber.
69. Ordne die folgenden Verfahren, einbeliebiges n × n-System linearerGleichungen zu losen, nach Auf-wand.
a) Gauß-Jordanb) Gauß-Elimination mit partial pi-votingc) Cramer-Regeld) explizite Matrix-Inversion mitanschließender Matrix-Vektor-Mul-tiplikation
70. a) In wieviel Speicher kann eine n×n-Matrix A mit rank(A) = 1 effizi-ent gespeichert werden.
b) Wieviele arithmetische Operatio-nen sind notig, um z ∈ Rn und einen × n-Matrix A mit rank(A) = 1effizient zu multiplizieren?
71. Vergleiche Gauß-Elimination undGauß-Jordan-Elimination, umAx = b zu losen.
a) Welches Verfahren hat dieaufwandigere LU-Faktorisierung?
b) Welches Verfahren hat dieaufwandigere back-substitution?
c) Welches Verfahren hat diehoheren Gesamtkosten?
72. Fur welches Verfahren gibt es einepivoting Strategie, die garantiert,daß alle Multiplizierer betragsmaßigkleiner als 1 sind?
a) Gauß-Elimination?
b) Gauß-Jordan-Elimination?
73. Welche beiden Eigenschaften garan-tieren, daß A eine Cholesky-Fakto-risierung hat?
74. Welches sind die Vorteile derCholesky-Faktorisierung gegenuberder LU-Faktorisierung?
75. Wieviele Quadratwurzeln sind furdie Cholesky-Faktorisierung einern× n-Matrix zu berechnen?
76. Sei A = (ai,j) symmetrisch und po-sitiv definit und A = LLT mit L =(`i,j).
a) Bestimme `1,1.
b) Bestimme `n,1.
77. Was ist die Cholesky-Faktorisierung
von A =(
4 22 2
)= AT ?
78. a) Kann ein symmetrisches, indefini-tes System linearer Gleichungen beiKosten vergleichbar denen, die zurLosung eines symmetrischen, positivdefiniten Systems linearer Gleichun-gen anfallen, gelost werden?
b) Falls nein, warum? Falls ja, mitwelchem Algorithmus?
79. Warum sind Verfahren zur iterati-ven Verbesserung der Losung linea-rer Gleichungssysteme haufig ’im-practical’ zu implementieren?
80. Ax = b sei schon per LU-Faktori-sierung und back-substitution gelost.Welche zusatzlichen Kosten entste-hen bei Anderungen der Problem-stellung?
a) bei Ubergang zu neuem b ?
b) bei Ubergang zu neuem A−uvT ?
c) bei Ubergang zu vollig neuem A ?

80 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
2.2 Exercises – Ubun-
gen
1. Zeige die Aquivalenz der folgendenAussagen.
i. A−1 existiert nicht.
ii. det(A) = 0
iii. rank(A) < n
iv. es existiert z 6= 0 mit Az = 0
2. A = (ai,j) habe verschwindendeZeilen-Summen, d.h.
∑nj=1 ai,j = 0
fur i = 1, . . . , n. Zeige: A ist sin-gular.
3. A sei singulare quadratische Matrix.Zeige: Wenn Ax = b eine Losungx hat, so hat das Gleichungssystemunendlich viele Losungen.
4. a) Zeige: A =
1 1 01 2 11 3 2
ist sin-
gular.
b) Wieviele Losungen hat die Glei-chung Ax = (2, 4, 6)T = b ?
5. Was ist die Inverse der Matrix A =1 0 01 −1 01 −2 1
?
6. A sei n × n-Matrix mit A2 = 0.Zeige: A ist singular.
7. Sei A =(
1 1 + ε1− ε 1
)gegeben.
a) det(A) ?
b) Fur welche ε wird eine verschwin-dende Determinante berechnet?
c) Was ist die LU-Faktorisierung vonA ?
d) Fur welche ε wird eine singulareMatrix U berechnet?
8. A und B seien quadratische Matri-zen.
a) Zeige: (AB)T = BTAT .
b) A und B seien regular. Zeige:(AB)−1 = B−1A−1.
9. A sei regular und reell. Zeige:(A−1)T = (AT )−1, so daß A−T =(A−1)T = (AT )−1 wohldefiniert ist.A sei regular und komplex. Zeige:(A−1)H = (AH)−1, so daß A−H =(A−1)H = (AH)−1 wohldefiniert ist.
10. P sei eine Permutationsmatrix.
a) Zeige: P−1 = PT .
b) Zeige: Jede Permutation ist Pro-dukt von paarweisen Vertauschun-gen.
11. Entwirf einen Algorithmus zurLosung von Lx = b mit untererDreiecksmatrix L durch forwardsubstitution.
12. Zeige: Der dominante Term in derAnzahl der fur die Losung von Lx =b mit unterer Dreiecksmatrix Lnotigen arithmetischen Operationen(Additionen oder Multiplikationen)ist 1
2n2.
13. B sei beliebige Matrix und L1 so-wie L2 seien regulare untere Drei-ecksmatrizen geeigneter Dimension.Zeige die notwendigen Schritte zurLosung des linearen Gleichungssy-
stems Ax =[L1 0B L2
] [x1
x2
]=[
b1
b2
]= b.
14. Die elementaren Eliminationsma-trizen oder Gauß-TransformationenMk sind durch Mk =

2.2. Exercises – Ubungen 81
1 . . . 0 0 . . . 0...
. . ....
......
0 . . . 1 0 . . . 00 . . . −mk+1 1 . . . 0...
. . ....
......
0 . . . −mn 0 . . . 1
definiert. Zeige:
i. Mk ist eine untere Dreiecks-matrix mit Einheitshauptdia-gonalen und damit regular.
ii. Mit m =(0, . . . , 0,mk+1, . . . ,mn)T laßtsich Mk als Mk = I − meT
k
darstellen.
iii. Lk = I + meTk = M−1
k .
iv. Sei Mk = I − meTk , Mj =
I − teTj fur j > k. Dann gilt
MkMj = I−meTk − teT
j .
15. a) Zeige: Das Produkt zweier unte-rer Dreiecksmatrizen ist wieder eineuntere Dreiecksmatrix.
b) Zeige: Die Inverse einer unte-ren Dreiecksmatrix ist wieder untereDreiecksmatrix.
16. Sei A =(
1 ac b
).
a) Was ist die LU-Faktorisierungvon A ?
b) Unter welchen Bedingungen ist Asingular?
17. Bestimme die LU-Faktorisierung der
Matrix A =
1 −1 0−1 2 −1
0 −1 1
.
18. Zeige: A =(
0 11 0
)hat keine LU-
Faktorisierung.
19. Wende auf die reglare n× n-MatrixA folgenden Algorithmus an:
I. Scan die Spalten von A nach-einander und vertausche, wonotwendig, Zeilen so, daß injeder Spalte die Eintrage aufder Diagonalen betragsmaßigalle Eintrage auf und unter derDiagonalen dominieren. Es er-gibt sich eine Permutationsma-trix P, die A in PA uberfuhrt.
II. Fuhre jetzt Gauß-Eliminationohne pivoting durch, um PA =LU zu faktorisieren.
a) Ist der Algorithmus numerischstabil?
b) Wenn ja, warum? Wenn nein, gibein Gegenbeispiel.
20. A sei spaltenweise diagonal domi-nant, diagonal dominant by co-lumns, d.h.
∑ni=1,i6=j |ai,j | < |aj,j |
fur j = 1, . . . , n. Zeige: Wenn Gauß-Elimination mit partieller Pivotisie-rung auf A angewandt wird, wer-den keine Vertauschungen von Zei-len notwendig.
21. A,B,C seien n × n-Matrizen; Bund C seien regular. Wie ist x =B−1(2A+ I)(C−1 +A)b zu bestim-men, ohne Matrizen explizit zu in-vertieren?
22. Verifiziere: Der dominante Term inder Anzahl der fur die LU-Faktori-sierung einer n×n-Matrix per Gauß-Elimination notigen arithmetischenOperationen (Additionen oder Mul-tiplikationen) ist 1
3n3.
23. Verifiziere: Der dominante Termin der Anzahl der fur die Invertie-rung einer n × n-Matrix per Gauß-Elimination notigen arithmetischenOperationen (Additionen oder Mul-tiplikationen) ist n3.

82 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
24. Verifiziere: Der dominante Term inder Anzahl der fur die Diagonalisie-rung einer n × n-Matrix per Gauß-Jordan-Elimination notigen arith-metischen Operationen (Additionenoder Multiplikationen) ist 1
2n3.
25. a) Seien u,v ∈ Rn gegeben. Zeige:rank(uvT ) = 1.
b) A sei n×n-Matrix mit rank(A) =1. Zeige: dann existieren u und vmit A = uvT .
26. A heißt elementar ⇐⇒ A = I −uvT .
a) A sei elementar. Wann ist dannA regular?
b) A sei elementar und regular.Zeige: A−1 = I−σuvT (fur welchesσ ∈ R ?)
c) Wieso ist Mk = I−meTk elemen-
tar? fur welche u und v sowie σ ?
27. Zeige (A− uvT )−1 =A−1 +A−1u(1−vTA−1u)−1vTA−1
Sherman-Morrison7
28. Zeige (A−UVT )−1 = A−1 + A−1U(I −VTA−1U)−1VTA−1 Woodbury8
29. Zeige: ||.||1, ||.||2 und ||.||∞ sindVektor-Normen.
30. Zeige: ||.||1 und ||.||∞ sind submul-tiplikative Matrix-Normen.
31. A = AT sei positiv definit. Zeige:||x||A =
√xTAx definiert eine
7 J. Sherman, W.J. Morrison: Adjustmentof an inverse matrix corresponding to changesin the elements of a given column or a givenrow of the original matrix; Ann. Math. Statist.,20, 1949, p.621
8 M.A. Woodbury: Inverting modified ma-trices; Statist. Res. Group, Mem. Rep., No. 42,Princeton University, Princeton, N.J., 1950
Vektor-Norm, die sogenannte durchA induzierte Norm.
32. a) Zeige: ||A||max = maxi,j |ai,j | istMatrix-Norm und es gilt ||A||max =||A||∞ fur A ∈ Rmn.
b) Zeige: ||A||F =√∑
i,j a2i,j ,
die sogenannte Frobenius-Norm, istMatrix-Norm und es gilt ||A||F =||A||2 fur A ∈ Rmn.
33. Zeige oder widerlege durch ein Ge-genbeispiel: ||A−1|| = ||A||−1.
34. a) Zeige: Eine positiv definite Ma-trix ist regular.
b) Zeige: Mit A ist auch A−1 positivdefinit.
35. Sei A = BBT mit regularem B.Zeige: A ist symmetrisch und po-sitiv definit.
36. A sei symmetrisch und positiv defi-nit. Der Vergleich der entsprechen-den Matrix-Elemente liefert einenAlgorithmus fur die Cholesky-Fak-torisierung A = LLT von A.
37. B =[α aT
a A
]= BT sei positiv defi-
nit.
a) Zeige: α ist positiv und A ist po-sitiv definit.
b) Wie sieht die Cholesky-Faktori-sierung von B aus?
38. B =[A aaT α
]= BT sei positiv defi-
nit.
a) Zeige: α ist positiv und A ist po-sitiv definit.
b) Wie sieht die Cholesky-Faktori-sierung von B aus?

2.3. Computer Problems – Rechner-Probleme 83
39. Verifiziere: Der dominante Term inder Anzahl der fur die Cholesky-Faktorisierung einer symmetrischen,positiv definiten n × n-Matrix noti-gen arithmetischen Operationen(Additionen oder Multiplikationen)ist 1
6n3.
40. A sei Bandmatrix mit Bandbreite β.Die LU-Faktorisierung PA = LUsei per Gauß-Elimination mit par-tieller Pivotisierung durchgefuhrt.Zeige: Die Bandbreite der oberenDreiecksmatrix U ist maximal 2β.
41. A sei regulare, tridiagonale Matrix.
a) Zeige: A−1 ist i.A. ’dense’, alsokeine dunn besetzte Matrix (sparsematrix ).
b) Vergleiche Laufzeit und Speicher-bedarf der Losung von Ax = b perGauß-Elimination und back-substi-tution mit Laufzeit und Speicherbe-darf der Losung per expliziter Ma-trix-Invertierung.
42. a) Entwirf einen Algorithmus,der die Inverse einer n × n-Dreiecksmatrix ’in place’ berechnet.
b) Ist es moglich, die Inverse einerbeliebigen n × n-Matrix ’in place’zu berechnen? Falls nein, warum?Falls ja, skizziere einen Algorithmus.
43. Lose das komplexe Gleichungssy-stem Cz = d mit C = A + iB,d = b + i c mit reellen MatrizenA und B sowie reellen Vektoren bund c. Zeige: z = x + iy ist zu-gleich Losung des reellen linearenGleichungssystems[A −BB A
] [xy
]=[bc
].
Ist es effizient, anstelle des komple-xen n×n-Systems das reelle 2n×2n-System zu losen?
2.3 Computer Pro-
blems – Rechner-
Probleme
1. a) Gegeben sei Ax = b mit A =
110
1 2 34 5 67 8 9
und b = 110
135
.
Zeige: A ist singular. Beschreibe dieLosungsmenge von Ax = b.
b) An welcher Stelle brichtdas Losungsverfahren ’Gauß-Elimination mit partieller Pivoti-sierung’ bei Verwendung exakterArithmetik ab?
c) fl(A) ist nicht notwendig singular.Gauß-Elimination schlagt nicht not-wendig fehl. Welche Losung er-mitteln Bibliotheksroutinen? Wel-che Konditionszahl cond(A) ermit-teln Konditionsschatzer? WelcheGenauigkeit der Losung ist zu er-warten?
2. a) Gegeben sei Ax = b mit A = 2 4 −24 9 −3
−2 −1 7
und b =
28
10
.
Welche Losung ermitteln Biblio-theksroutinen?
b) Mit der LU-Faktorisierung aus a)lose Ay = c = (4, 8,−6)T .
c) Modifiziere A so, daß a1,2 = 2.Lose das modifizierte System mitb als rechter Seite per Sherman-Morrison-Verfahren.
3. Gegeben ein Gittertrager mit 8 Ver-bindungen, 13 Streben und den ein-gezeichneten Lasten in den Verbin-dungen Nr. 2, Nr. 5 und Nr. 6.

84 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
1
2
3
4
5
6
7
8
9
10
11 12
13
10 15 20
1 2
3 4
5 6
7
8
Im statischen Gleichgewicht hebensich die horizontalen und vertika-len Krafte in jeder Verbindung auf.Jeweils zwei Gleichungen fur jedeVerbindung, insgesamt also 16 Glei-chungen in 13 Kraften beschreibendiesen Zustand. Fur die eindeutigeLosbarkeit sei angenommen, daß –wie skizziert – die Verbindung Nr. 1horizontal und vertikal und die Ver-bindung Nr. 8 vertikal fixiert sind.Mit a =
√2
2 ergeben sich die Glei-chungen
Nr. 2f2 = f6
f3 = 10
Nr. 3af1 = f4 + af5
af1 + f3 + af5 = 0
Nr. 4f4 = f8
f7 = 0
Nr. 5af5 + f6 = af9 + f10
af5 + f7 + af9 = 15
Nr. 6f10 = f13
f11 = 20
Nr. 7f8 + af9 = af12
af9 + f11 + af12 = 0Nr. 8
f13 + af12 = 0
Welche Losung ermitteln allge-meine Bibliotheksroutinen? WelcheLosung ermitteln Bibliotheksrouti-nen speziell fur Band-Matrizen?
4. Schreibe ein Programm zurSchatzung von cond1(A) undcond∞(A). ||A|| ist einfach zubestimmen. Die Herausforderungliegt darin, ||A−1|| durch moglichstgroße ||z||/||y|| mit Az = y nachunten abzuschatzen.
Vergleiche die beiden Ansatze a)und b) anhand der beiden Ma-
trizen A1 =
10 −7 0−3 2 6
5 −1 5
und
A2 =
−73 78 2492 66 25
−80 37 10
Vergleiche
jeweils mit den exakten Ergebnis-sen von Bibliotheksroutinen undmit gegebenenfalls vorhandenenKonditionsschatzern.
a) Wahle y als Losung von ATy = cmit c ∈ −1,+1n. Der Vektorc der rechten Seite wird dabei wiefolgt bestimmt:Mit A = LU wird zur Losung vonATy = c erst UTv = c in v unddann LTy = v in y gelost. BeimAuflosen von UTv = c wahle da-bei ci = ±1 jeweils so, daß |vi| ma-ximiert wird. (Die schlechte Kon-ditionierung von A wird sich in Uwiderspiegeln und ein v mit großenKomponenten liefern. Das verhalt-nismaßig gut konditionierte L mitEinheitsdiagonalen wird dann ebenauch ein y mit großen Komponen-ten liefern.)
b) Schatze ||A−1|| mit pseudo-zufalligen Vektoren y nach unten ab.
5. a) Lose Ax = b mit A =21.0 67.0 88.0 73.076.0 63.0 7.0 20.00.0 85.0 56.0 54.0
19.3 43.0 32.2 29.4
und b =
141.0109.0218.093.7
mit einfacher Genauigkeit.
b) Berechne das Residuum r = b −Ax in doppelter Genauigkeit.
c) Lose das lineare Gleichungssy-stem Az = r, um die verbesserte

2.3. Computer Problems – Rechner-Probleme 85
Losung x + z zu gewinnen.
d) Iteriere Schritte b) und c).
6. Die n × n-Matrix H = (hi,j) mitden Elementen hi,j = 1
i+j−1 heißtHilbert-Matrix. Die Hilbert-Matrix
H =
1 1
2 · · · 1n
12
13 · · · 1
n+1...
......
1n
1n+1 · · · 1
2n−1
ist
symmetrisch und positiv definit. Seib = Hx ∈ Rn, wobei x =(1, . . . , 1)T ∈ Rn.Welche Losung x ermitteln Bi-bliotheksroutinen fur die Gauß-Elimination? Welche Losung x er-mitteln Bibliotheksroutinen fur dieCholesky-Faktorisierung? Berechne||r||∞ fur das Residuum r = b −Hx. Wie groß muß n werden,so daß die Losung keine signifi-kanten Ziffern enthalt? WelcheKonditionszahl cond(H) ermittelnKonditionsschatzer? Charakteri-siere cond(H) als Funktion von n.Wie verhalten sich Anzahl der kor-rekten Ziffern in den Komponentenund die Konditionszahl von H furvariierendes n ?
7. a) Gegeben sei die 5×5-Matrix A =1 0 0 0 1
−1 1 0 0 1−1 −1 1 0 1−1 −1 −1 1 1−1 −1 −1 −1 1
.
Wende auf A Gauß-Elimination mitpartieller Pivotisierung an. Waspassiert? Wende auf A Gauß-Eli-mination mit vollstandiger Pivoti-sierung an. Was passiert?
b) Lose Ax = b fur entsprechende,großere A mit bekannten Losun-gen x zu berechneten rechten Seitenb = Ax. Welche Losung x ermit-teln Bibliotheksroutinen fur Gauß-
Elimination? Wie hangen Fehler,Residuum und Konditionszahl vonder Dimension von A ab?
8. D sei Diagonal-Matrix. Ubergangvon Ax = b zu DAx = Dbverandert die Konditionierung desGleichungssystemes und kann dieGenauigkeit der Losung verbessern.Experimentiere mit pseudo-zufalli-gen Matrizen A, berechneten rech-ten Seiten b zu bekannten Losungenx und Diagonal-Matrizen D. Beob-achte dabei Fehler, Residuum undKonditionszahl cond(DA) von DA.
9. a) Lose Ax =(ε 11 1
)x =(
1 + ε2
)= b mit ε = 10−2k fur
k = 1, 2, . . . , 10 ohne Pivotisierung.Die exakte Losung x = (1, 1)T istunabhangig von ε.
b) Fur kleine ε verbessere die Losungdurch eine Iteration des iterative re-finement. Wie verhalt sich die Ge-nauigkeit der Losung fur ε→ 0 ?
10. Exakte Losung von Ax =(1 1+ε
1−ε 1
)x =
(1+(1+ε)ε
1
)=
b ist x =(
1ε
).
Welche Losung x ermitteln Biblio-theksroutinen fur Gauß-Eliminationfur ε ≈ √
εmach? Schatze cond(A)und die Genauigkeit der Losungund vergleiche mit den Fehler-Schranken. Welche Schlusse sindaus diesem Beispiel zu ziehen?
11. a) Programmiere Gauß-Eliminationohne Pivotisierung, mit partiellerPivotisierung, mit vollstandiger Pi-votisierung.
b) Erzeuge pseudo-zufallige Matri-zen, Losungen und zugehorige rechte

86 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Seiten. Vergleiche Genauigkeit, Re-sidua und performance der drei Im-plementierungen.
c) Fur welche Matrix ist vollstandigePivotisierung signifikant genauer alspartielle Pivotisierung?
12. Programmiere die Losung vontridiagonalen Gleichungssystemenohne und mit partieller Pivo-tisierung. Teste auch anhandvon positiv definiten Matrizen.Vergleiche dann Cholesky- mitLU-Faktorisierung.
13. Programmiere die Berechnung derDeterminante einer Matrix per LU-Faktorisierung. Vorzeichen? under-flow? overflow?
14. A sei m×n-Matrix und B sei n×k-Matrix. Dann ist C = AB m × k-Matrix.
a) Berechne C durchmk innere Pro-dukte, also mk Aufrufe von sdot inBLAS.
b) Berechne jede Spalte von Cals Linear-Kombination der Spaltenvon A, also durch mk Aufrufe vonsaxpy in BLAS.
Fuhre beobachtete performance Un-terschiede auf caching (Große, Or-ganisation, Schreibstrategien) undSpeicher-Organisation etc. zuruck.
15. Gauß-Elimination ohne Pivotisie-rung erfolgt in drei geschachteltenSchleifen. Es gibt sechs Anord-nungen dieser drei geschachteltenSchleifen. Vergleiche jeweils die per-formance fur genugend große Matri-zen, die auch ohne Pivotisierung tri-anguliert werden konnen.
Fuhre beobachtete performance Un-terschiede auf caching (Große, Or-
ganisation, Schreibstrategien) undSpeicher-Organisation etc. zuruck.
16. forward substitution lost Gleichungs-systeme mit unterer Dreiecksma-trix. backward substitution lost Glei-chungssysteme mit oberer Dreiecks-matrix. In beiden Fallen lassensich die beiden Schleifen vertau-schen. Vergleiche die performanceder vier moglichen Algorithmen furgenugend große Dreiecksmatrizen.
Fuhre beobachtete performance Un-terschiede auf caching (Große, Or-ganisation, Schreibstrategien) undSpeicher-Organisation etc. zuruck.
17. Ein Kragtrager ist an einem Endefest eingespannt und am anderenEnde frei. Bei vorgegebenen Lastenb an diskreten Stellen auf demTrager ergibt sich die Auslenkungx in diesen Stellen als Losung vonAx = b mit Koeffizientenmatrix
A =
9 −4 1 0 . . . . . . 0
−4 6 −4 1. . .
...
1 −4 6 −4 1. . .
...
0. . . . . . . . . . . . . . . 0
.... . . 1 −4 6 −4 1
.... . . 1 −4 5 −2
0 . . . . . . 0 1 −2 1
a) Sei n = 100 und b =(1, 1, . . . , 1)T . Vergleiche die Losun-gen per Bibliotheksroutinen furGauß-Elimination fur beliebige mitsolchen fur Band-Matrizen oderdunn besetzte Matrizen.
b) A hat eine UL-FaktorisierungA = RRT mit oberer Dreiecksma-

2.3. Computer Problems – Rechner-Probleme 87
trix R
R =
2 −2 1 0 . . . 0
0 1 −2 1. . .
......
. . . . . . . . . . . . 0...
. . . 1 −2 1...
. . . 1 −20 . . . . . . . . . 0 1
Sei n = 1000. Lose das Gleichungs-system in der UL-Faktorisierung.Vergleiche Losung mit derjenigender Bibliotheksroutinen aus a). Be-stimme cond(A). Welche Genauig-keit ist zu erwarten? Kann die Ge-nauigkeit durch iterative refinementverbessert werden?

88 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
2.4 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Die Anzahl der Losungen von Ax = b fur regulares A istunabhangig von b.
Wenn eine Matrix A regular ist, so existiert A−1 und damit hat die Glei-51chung Ax = b genau eine Losung, namlich x = A−1b, d.h. die Anzahl derLosungen ist unabhangig von b.
2. Richtig/Falsch? Wenn eine Matrix A eine betragsmaßig sehr kleine Deter-minante det(A) hat, so ist die Matrix ’fast singular’.
Entweder det(A) = 0 oder det(A) 6= 0. Multiplikation der Gleichungen mit43einer sehr kleinen Konstanten erzeugt betragsmaßig beliebig kleine Deter-minanten, ohne die Losbarkeit zu beeinflussen.
3. Richtig/Falsch? Fur jede symmetrische Matrix A gilt ||A||1 = ||A||∞.
A sei eine symmetrische Matrix. Wegen A = AT stimmt fur jedes i die i-te55Zeile mit der i-ten Spalte und damit die i-te absolute Zeilensumme mit deri-ten absoluten Spaltensumme uberein. Daher gilt ||A||1 = ||A||∞.
4. Richtig/Falsch? A sei triangular. Falls ein Hauptdiagonal-Element von Averschwindet, so ist A notwendig singular.
A sei triangular. Dann gilt det(A) =∏ai,i. Falls nun ein Diagonal-51
Element verschwindet, so folgt det(A) = 0 und damit die Singularitat vonA.
5. Richtig/Falsch? Eine beliebige Matrix mit mindestens einem verschwinden-den Hauptdiagonal-Element ist notwendig singular.
Eine Matrix mit verschwindenden Hauptdiagonal-Elementen ist nicht not-51
wendig singular, wie etwa A =
(0 11 0
)mit det(A) = −1 6= 0 zeigt.
6. Richtig/Falsch? A sei eine m × n-Matrix mit m < n. Dann hat Ax = bimmer eine Losung.
Das Gleichungssystem Ax = b mit m × n-Matrix A und m < n ist un-49/50terbestimmt. Ein solches System hat nicht notwendig eine Losung, wie dasBeispiel der m× n-Null-Matrix A = 0 und eines Vektors b 6= 0 zeigt.
7. Richtig/Falsch? Das Produkt zweier oberer Dreiecksmatrizen ist wieder eineobere Dreiecksmatrix.
Das Produkt C = (ci,j) = AB zweier oberer Dreiecksmatrizen A = (ai,j)65und B = (bi,j) ist wieder eine obere Dreiecksmatrix: Sei namlich i > j.

2.4. Review Questions – Antworten auf Verstandnisfragen 89
Dann gilt ci,j =∑n
k=1 ai,k bk,j =∑n
k=i ai,k bk,j, da A obere Dreiecksmatrixist, d.h. ai,k = 0 fur i > k. Nun ist aber auch B obere Dreiecksmatrix, d.h.bk,j = 0 fur k ≥ i > j und damit ist ci,j = 0 fur i > j.
8. Richtig/Falsch? Das Produkt zweier symmetrischer Matrizen ist wiedersymmetrisch.
Das Produkt C zweier symmetrischer Matrizen A und B ist nicht wieder 84symmetrisch, da CT = (AB)T = BTAT = BA, wie etwa C = AB =(
1 00 2
)(0 11 0
)=
(0 12 0
)6=(
0 21 0
)=
(0 11 0
)(1 00 2
)= BA = CT zeigt.
9. Richtig/Falsch? Die Inverse einer regularen oberen Dreiecksmatrix ist wie-der obere Dreiecksmatrix.
Wegen AA−1 = I = (e1, . . . , en) ist A−1(x1, . . . ,xn), wobei die xi Losun- 65gen von Axi = ei fur Einheitsspaltenvektoren ei mit (ei)j = δi,j undi = 1, 2, . . . , n sind. Da A obere Dreiecksmatrix ist, gilt fur xi mit Axi = ei
eben (xi)j = 0 fur j > i. Also ist auch A−1 obere Dreiecksmatrix.
10. Richtig/Falsch? Wenn die Zeilen einer n × n-Matrix A l.a. sind, so sindauch die Spalten von A l.a.
Die Zeilen einer n × n-Matrix A sind l.u. ⇐⇒ det(A) = 0 ⇐⇒ die 51Spalten von A sind l.u.
11. Richtig/Falsch? A sei eine m×n-Matrix. Das LGS Ax = b hat eine Losunggenau dann, wenn rank(A) = rank([A b]), wobei [A b] die um die Spalteb erweiterte m× (n+ 1)-Matrix bezeichne.
Ax = b hat eine Losung ⇐⇒ b ist eine Linearkombination der Spalten 50von A ⇐⇒ A und [A b] haben denselben Rang.
12. Richtig/Falsch? Fur eine beliebige n× n-Matrix A und eine n× n-Permu-tationsmatrix P gilt notwendig AP = PA.
Sei A eine n× n-Matrix und P eine n× n-Permutationsmatrix. Dann gilt 63/64
nicht notwendig AP = PA, wie etwa AP =
(1 00 2
)(0 11 0
)=
(0 12 0
)6=(
0 21 0
)=
(0 11 0
)(1 00 2
)= PA zeigt.
13. Richtig/Falsch? Unterstellt, daß Zeilen von A vertauscht werden durfen:dann existiert die LU-Faktorisierung A = LU, sogar fur singulare A.
Entweder gibt es im k-ten Eliminationsschritt in der k-ten Spalte ein nicht- 68verschwindendes Element, das in die Diagonal-Position vertauscht wird, sodaß Mk wohldefiniert ist. Oder sonst ist xk eben schon in der (k+1)-ten bisn-ten Gleichung eliminiert und es gibt nichts zu tun: Mk = I. Insgesamt

90 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
sind U = MA und L = M−1 also wohldefiniert und es gilt A = LU mitregularem L.
LU-Faktorisierung von A und Singularitat von A sind unabhangig: Bei-
spielsweise ist A =
(1 11 1
)=
(1 01 1
)(1 10 0
)= LU und fur A
(xy
)=
LU
(xy
)=
(12
)folgt aus L
(uv
)=
(12
)zunachst
(uv
)=
(11
). Aller-
dings kann dann U
(xy
)=
(x+ y
0
)=
(uv
)=
(11
)nicht in x und y gelost
werden.
14. Richtig/Falsch? In einem gut konditionierten LGS ist Pivotisierung fur dieGauß-Elimination unnotig.
In einem gut konditionierten LGS ist Pivotisierung fur die Gauß-Elimi-
nation notig, wie A =
(0 11 0
)mit cond(A) = 1 zeigt. A ist ’bestens’?
konditioniert, dennoch schlagt Gauß-Elimination ohne Pivotisierung fehl.
15. Richtig/Falsch? Singulare Matrizen haben keine LU-Faktorisierung.
Eine singulare Matrix A kann sehr wohl eine LU-Faktorisierung haben, wie71
A =
(1 11 1
)mit M =
(1 0−1 1
)und U = MA =
(1 0−1 1
)(1 11 1
)=(
1 10 0
)sowie L =
(1 01 1
)und daher A = LU zeigt.
16. Richtig/Falsch? Wenn eine regulare, symmetrische Matrix A nicht positivdefinit ist, so hat A keine Cholesky-Faktorisierung.
A sei regular, symmetrisch und nicht positiv definit. Dann existiert ein xo 6=850 mit xT
o Axo = 0. Angenommen A = LLT mit unterer Dreiecksmatrix L.Aus 0 = xT
o Axo = xTo LLTxo = (LTxo)
TLTxo = yTy = ||y||22 = 0, alsoy = LTxo = 0 folgt damit Axo = LLTxo = Ly = L0 = 0 fur xo 6= 0.Somit ist A singular im Widerspruch zur Annahme. Also kann A keineCholesky-Faktorisierung haben!
17. Richtig/Falsch? Eine symmetrische, positiv definite Matrix ist immer gutkonditioniert.
Eine positiv definite Matrix A = AT ist nicht immer well-conditioned (i.e.cond(A) ≈ 1), wie schon A = diag(|d1|, |d2|) zeigt. Erstens ist A = AT .
Zweitens ist A positiv definit, da zTAz =
(xy
)T(|d1| 00 |d2|
)(xy
)= |d1|x2+
|d2|y2 > 0 fur z =
(xy
)6= 0. Sei nun d1 = 10m und d2 = 10−m, dann gilt
cond(A) = cond(diag(10m, 10−m)) = max10m,10−mmin10m,10−m = 10m
10−m = 102m 1.

2.4. Review Questions – Antworten auf Verstandnisfragen 91
18. Richtig/Falsch? Die Gauß-Elimination ohne Pivotisierung schlagt fehl nurdann, wenn A schlecht konditioniert oder singular ist.
Falsch, wie das Beispiel A =
(0 11 0
)mit cond(A) = 1 und AA = I
zeigt: A ist ’bestens’ konditioniert und regular. Dennoch schlagt Gauß-Elimination ohne Pivotisierung fehl (vgl. 2RQ13).
19. Richtig/Falsch? Hat man erst einmal A faktorisiert, so kann man Ax = bfur beliebige rechte Seiten b ohne erneute Faktorisierung losen.
Hat man erst einmal A = LU faktorisiert, so kann man Ax = b fur 68beliebige rechte Seiten b ohne erneute Faktorisierung losen, einfach furgegebenes b zunachst y in Ly = b per forward substitution und dann x inUx = y per backward substitution bestimmen.
20. Richtig/Falsch? Wenn eine Matrix per LU-Faktorisierung und Losen desdreieckigen Gleichungssystems explizit zu invertieren ist, so wird die Haupt-arbeit fur die LU-Faktorisierung erbracht.
LU-Faktorisierung von A kostet 13n3 flOs. A dann explizit zu invertieren, 79
heißt Axi = ei fur i = 1, . . . , n zu losen. Dies kostet nn2 = n3 flOs.
21. Richtig/Falsch? ||x||1 ≥ ||x||∞ fur alle x ∈ Rn.
||x||1 ≥ ||x||∞ fur alle x ∈ Rn, denn es gilt ||x||1 =∑
i |xi| ≥ max|xi| : i = 53/541, . . . , n = ||x||∞.
22. Richtig/Falsch? Die Norm einer singularen Matrix A ist notwendig 0.
Die Norm ||A|| einer singularen Matrix A ist nicht notwendig 0, wie etwa 53/54
A =
(1 00 0
)mit det(A) = 0 und ||A||1 = 1 = ||A||∞ zeigt.
23. Richtig/Falsch? A sei n× n-Matrix. Falls ||A|| = 0, dann A = 0.
A sei n × n-Matrix. Wenn ||A|| = 0, dann A = 0 in Umkehrung der 54Norm-Eigenschaft Nr. 1.
24. Richtig/Falsch? Fur beliebiges A gilt ||A||1 = ||AT ||∞.
Die 1-Norm ist die maximale absolute Spalten-Summe. Die ∞-Norm ist 54die maximale absolute Zeilen-Summe. Transposition uberfuhrt Zeilen inSpalten und umgekehrt. Also gilt ||A||1 = ||AT ||∞.
25. Richtig/Falsch? Fur beliebige A gilt cond(A) = ||A||·||A−1|| = cond(A−1).
Fur jedes quadratische A gilt cond(A) = ||A|| · ||A−1|| = cond(A−1) wegen 56(A−1)−1 = A.

92 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
26. Richtig/Falsch? Gauß-Elimination mit partieller Pivotisierung erzielt kleineResiduen, auch wenn A schlecht konditioniert ist.
Gauß-Elimination mit partieller Pivotisierung erzielt kleine Residuen, auch76wenn A schlecht konditioniert ist.
27. Richtig/Falsch? Die Multiplizierer in der Gauß-Elimination mit partiellerPivotisierung sind betragsmaßig kleiner 1, so daß die Elemente der redu-zierten Matrizen betragsmaßig nicht wachsen konnen.
Falsch! Auch wenn die Multiplizierer in der Gauß-Elimination betragsmaßig76kleiner 1 sind, konnen sich die Elemente der reduzierten Matrizen im un-gunstigsten Fall verdoppeln.
28. Kann ein System Ax = b genau zwei verschiedene Losungen haben?
Ein System Ax = b kann nicht genau zwei verschiedene Losungen haben:52es hat entweder keine, eine oder unendlich viele Losungen.
29. Kann die Anzahl der Losungen von Ax = b unabhangig von b und alleinaus A bestimmt werden?
Die Anzahl der Losungen von Ax = b kann nur dann unabhangig von b52allein aus A bestimmt werden, wenn A regular ist. Dann existiert namlichzu jedem b genau eine Loung x. Ist A dagegen singular, so kann Ax = bkeine Losung oder unendlich viele Losungen haben.
30. Gegeben Ax = b mit quadratischer Matrix A. Was ist schwerwiegender:51die Zeilen von A sind l.a. oder die Spalten von A sind l.a.?
Fur quadratische Matrix A gilt: die Zeilen von A sind l.a. ⇐⇒ dieSpalten von A sind l.a. Dies laßt sich auf unterschiedliche Weise zeigen.Die Spalten von A sind l.a. ⇐⇒ die Zeilen von A sind l.a. ⇐⇒ Aist singular: Sei namlich A = (a1, . . . , an). Die Spalten von A sind l.a.⇐⇒ es existiert x 6= 0 mit Ax = 0 ⇐⇒ dim (span(A)) < n ⇐⇒dim (span(A)⊥) > 0 ⇐⇒ es existiert 0 6= y ∈ span(A)⊥ ⇐⇒ es existiert0 6= y mit y ⊥ span(A) ⇐⇒ es existiert 0 6= y mit y ⊥ ai fur i = 1, . . . , n⇐⇒ es existiert 0 6= y mit yTai = 0 fur i = 1, . . . , n ⇐⇒ es existiert0 6= y mit yTA = 0T ⇐⇒ die Zeilen von A sind l.a.die Zeilen von A sind l.a. ⇐⇒ det(A) = 0 = det(AT ) ⇐⇒ die Zeilenvon A sind l.a.Es gilt rank(A) = rank(AT ).
31. a) Genau wann ist eine Matrix singular?51/52
A ist singular ⇐⇒ A−1 existiert nicht ⇐⇒ det(A) = 0 ⇐⇒ rank(A) <n ⇐⇒ es existiert y 6= 0 mit Ay = 0.
b) Ax = b habe zwei verschiedene Losungen. Zeige: A ist singular.51/52

2.4. Review Questions – Antworten auf Verstandnisfragen 93
Angenommen Axi = b mit x1 6= x2. Sei nun z = x2 − x1. Dann giltAz = Ax1 −Ax2 = 0 mit z 6= 0, also ist A singular.
32. Gegeben Ax = b. Welche Wirkung auf die Losung haben die folgendenAktionen?
a) Vertauschen der Zeilen von [Ab] 63/64
Vertauschen der Zeilen von [Ab] vertauscht Gleichungen und andert daherdie Losung nicht.
b) Vertauschen der Spalten von A 63/64
Vertauschen der Spalten von A vertauscht die Komponenten des Losungs-vektors x entsprechend.
c) Multiplikation von Ax = b von links mit einer regularen Matrix M 63/64
Multiplikation MAx = Mb mit regularer Matrix M andert nichts, daAx = M−1MAx = M−1Mb = b.
33. Der Ubergang von Ax = b zu αAx = αb
a) Andert das die exakte Losung? 63/64
Andert die exakte Losung nicht.
b) Andert das das Residuum r = b− Ax ? 63/64
Uberfuhrt r = b−Ax in αr = αb− αAx.
c) Andert das die Gute der Losung? 63/64
Andert wegen cond(A) = cond(αA) nichts an der Gute der Losung.
34. Ubergang von Ax = b zu DAx = Db, wobei D eine Diagonal-Matrix ist,
a) Andert das die exakte Losung? 64,83/84
Andert die exakte Losung nicht, da D als Diagonal-Matrix regular ist.
b) Andert das die Konditionierung des Systems? 64,83/84
Verandert die Konditionierung des Systems, wie etwa A = I mit cond(A)
= 1 und D = diag(10m, 10−m) mit cond(DA) = cond(D) = max10m,10−mmin10m,10−m
= 10m
10−m = 102m 1 zeigt.
c) Andert das die Wahl der pivots bei Gauß-Elimination? 64,83/84
Verandert i.a.R. die Wahl der pivots bei Gauß-Elimination, außer etwa furD = I.
35. Welche elementare Eliminationsmatrix annulliert die letzten beiden Kom-ponenten von x = (3, 2,−1, 4)T ?

94 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Es gilt Mx =
1 0 0 00 1 0 00 1
21 0
0 −2 0 1
32−14
=
3200
.66/67
36. a) Welche 4× 4-Permutationsmatrix P vertauscht die zweite und die vierte63/64Komponente von x ∈ R4 ?
Es gilt Px = P
adcb
=
1 0 0 00 0 0 10 0 1 00 1 0 0
abcd
=
adcb
.
b) Welche 4 × 4-Permutationsmatrix P kehrt die Reihenfolge der Kompo-63/64nenten von x ∈ R4 um?
Es gilt Px = P
adcb
=
0 0 0 10 0 1 00 1 0 01 0 0 0
abcd
=
dcba
.
37. A sei singular. Die Arithmetik sei exakt. Zu welchem Zeitpunkt wird derLosungsprozess per Gauß-Elimination scheitern?
a) mit partieller Pivotisierung?70/71
Mit partial pivoting wird die LU-Faktorisierung erfolgreich abgeschlossen,weil das Verfahren ja unabhangig davon ist, ob A regular oder singular
ist. So gilt beispielsweise A =
1 0 00 1 00 1 0
=
1 0 00 1 00 1 1
1 0 00 1 00 0 0
=
LU. Das Losungsverfahren scheitert fur singulares A erst bei der backsubstitution.
b) ohne Pivotisierung?71
Ohne pivoting kann der Losungsprozess schon wahrend der LU-Faktorisie-
rung scheitern, wie wieder die sogar regulare Matrix A =
(0 11 0
)zeigt
(vgl. 2RQ18).
38. a) Wie unterscheiden sich partielle und vollstandige Pivotisierung?75
partial pivoting sucht nur in der aktuellen Spalte nach dem betragsmaßiggroßten Eintrag. complete pivoting sucht dagegen in der ganzen verbleiben-den Unter-Matrix nach dem betragsmaßig großten Eintrag.
b) Was sind jeweils Vor- und Nachteile der beiden Pivotisierungen?75
complete pivoting kann die Stabilitat gegenuber partial pivoting weiter ver-bessern, dauert aber auch langer.

2.4. Review Questions – Antworten auf Verstandnisfragen 95
39. Berechne die LU-Faktorisierung von A =
4 −8 16 5 70 −10 −3
per Gauß-Elimi-
nation. Was ist das initiale pivot-Element?
a) ohne pivoting 68
Multiplikationen mit −32
und 1017
Mit erstens M1A =
1 0 0−3
21 0
0 0 1
4 −8 16 5 70 −10 −3
=
4 −8 10 17 11
2
0 −10 −3
und
zweitens mit U = M2M1A =
1 0 00 1 00 10
171
4 −8 10 17 11
2
0 −10 −3
=
4 −8 10 17 11
2
0 0 417
ist dann L = M−1
1 M−12 =
1 0 032
1 00 −10
171
und A = LU.
b) mit partial pivoting 72/73
Multiplikationen mit −23
und −1517
Mit P1A =
0 1 01 0 00 0 1
4 −8 16 5 70 −10 −3
=
6 5 74 −8 10 −10 −3
und damit er-
stens M1P1A =
1 0 0−2
31 0
0 0 1
6 5 74 −8 10 −10 −3
=
6 5 70 −34
3−11
3
0 −10 −3
und
zweitens U = M2M1P1A =
1 0 00 1 00 −15
171
6 5 70 −34
3−11
3
0 −10 −3
=
6 5 70 −34
3−11
3
0 0 417
ist dann L = PT
1 M−11 M−1
2 = P1
1 0 023
1 00 15
171
=
23
1 01 0 00 15
171
und A = LU.
c) mit complete pivoting 75
Multiplikationen mit 12
und −23
P1A =
0 0 10 1 01 0 0
4 −8 16 5 70 −10 −3
=
0 −10 −36 5 74 −8 1
vertauscht erste
und letzte Zeile und P1AQ1 =
0 −10 −36 5 74 −8 1
0 1 01 0 00 0 1
=
−10 0 −35 6 7
−8 4 1
vertauscht dann noch erste und zweite Spalte und so −10 in die Diagonale.
Dann gilt M1P1AQ1 =
1 0 012
1 0−4
50 1
−10 0 −35 6 7
−8 4 1
=
−10 0 −30 6 11
2
0 4 175

96 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
und U = M2M1P1AQ1 =
1 0 00 1 00 −2
31
−10 0 −30 6 11
2
0 4 175
=
−10 0 −30 6 11
2
0 0 −415
sowie L = M−1
1 M−12 =
1 0 0−1
21 0
45
0 1
1 0 00 1 00 2
31
=
1 0 0−1
21 0
45
23
1
und
LU = P1AQ1.
40. Warum ist Pivotisierung essentiell fur numerisch stabile Implementierungender Gauß-Elimination?
Pivotisierung ist essentiell, um einerseits pivot 6= 0 zu garantieren und um70/71andererseits Multiplizierer betragsmaßig kleiner 1 sicherzustellen.
41. A sei schlecht konditioniert. Die LU-Faktorisierung sei per Gauß-Elimina-?tion mit partial pivoting durchgefuhrt. Wo zeigt sich die schlechte Kondi-tionierung, in L ? in U ? oder in beiden Metrizen?
Fur den Extrem-Fall eines singularen A mit LU-Faktorisierung A = LUist cond(L) < ∞, da L als untere Dreiecksmatrix mit Einheitsdiagonalenregular ist. Also muß sich die ’extrem’ schlechte Konditionierung in Uzeigen.
???Zunachst ist die LU-Faktorisierung eindeutig, wenn alle Diagonal-Elementevon U nicht verschwinden. Denn angenommen L1U = A = L2U
′. Mitunteren Dreiecksmatrizen L1 und L2 mit Einheitsdiagonalen sind beide Ma-trizen regular. L−1
2 L1U = U′. Wegen Ex 2.15 sind L−12 und daher auch
L = L−12 L1 untere Dreiecksmatrizen und L hat ebenfalls Einheitsdiagonale.
Aus (`i,j)(ui,j) = LU = U′ = (u′i,j) folgt fur die erste Zeile u1,1 = u′1,1,. . . , u1,n = u′1,n, falls u1,1 6= 0 fur die zweite Zeile `2,1 = 0 und u2,2 = u′2,2,. . . , u2,n = u′2,n, falls u2,2 6= 0 fur die dritte Zeile `3,1 = 0, `3,2 = 0 undu3,3 = u′3,3, . . . , u3,n = u′3,n, usw. Insgesamt folgt also L = I und U = U′.Konstruiere nun schlecht konditionierte Matrizen L und U und schließe aufdie schlechte Konditionierung von A.Allerdings Gauß-Elimination mit partial pivoting
???Betrachte etwa A = diag(d1, . . . , dn) mit |d1| ≥ |d2| ≥ . . . |dn|. Mit oderohne Pivotisierung ist die LU-Faktorisierung von A dann A = LU = IA.Die gegebenenfalls schlechte Konditionierung von A zeigt sich hier also nurin U.
Betrachte etwa A =
(0.913 0.6590.457 0.330
)mit LU-Faktorisierung A = LU =(
1 00.457/0.913 1
)(0.913 0.659
0 0.330− 0.659 ∗ 0.457/0.913
)und so naherungs-
weise A ≈(
1 00.5005 1
)(0.913 0.659
0 0.32986
)= LU mit cond1(A) ≈ 17000,

2.4. Review Questions – Antworten auf Verstandnisfragen 97
cond1(L) ≈ 1.52 und cond1(U) = ||U||1 · ||U−1||1 = 0.988.???
42. a) Sei M =
1 0 0 00 1 0 00 m1 1 00 m2 0 1
. Bestimme M−1. 67
Dann ist M−1 =
1 0 0 00 1 0 00 −m1 1 00 −m2 0 1
.
b) In welchem Zusammenhang treten solche Matrizen M auf? 67
M ist elementary elimination matrix oder auch Gauß transformation.
43. a) Kann jede regulare Matrix A als A = LU, also als Produkt einer unteren 69Dreiecksmatrix L und einer oberen Dreiecksmatrix U geschrieben werden?
A =
(0 11 0
)ist regular, da AA = I, hat aber keine LU-Faktorisierung:
A = LU = (`i,j)(ui,j) impliziert `1,1u1,1 = 0 und `1,1u1,2 = 1, also `1,1 6= 0und u1,1 = 0. Allerdings gilt `2,1u1,1 + 0 = 1 im Widerspruch zu u1,1 = 0.
b) Falls ja, gib einen Algorithmus an, falls nein, gib ein Gegenbeispiel. 73
partial pivoting erlaubt, A in eine obere Dreiecksmatrix U = MA zuuberfuhren und damit als M−1U = LU = A darzustellen.
44. A und B seien n×n-Matrizen. B sei regular. Berechne C = A−1B effizient. 79,80
Wegen AC = AA−1B = B = (b1, . . . ,bn) und Axi = bi laßt sich C alsC = (x1, . . . ,xn) darstellen. C zu berechnen, kostet 1
3n3 + n3 flOs.
???Die Uberfuhrung von A nach D per Gauß-Jordan kostet 1
2n3 flOs und die
Berechnung der xi zusatzlich n2 flOs.
45. A und B seien n × n-Matrizen, A sei regular und c ∈ Rn. Berechnex = A−1Bc effizient.
Wie in 2RQ44 sei C = A−1B. Dann gilt ACc = AA−1Bc = Bc =: b zu 79Kosten n2 flOs. x ist Losung von Ax = Bc und kostet 1
3n3 + n2 flOs.
46. A sei n×n-Matrix und x ∈ Rn. Vergleiche die Kosten der Berechnung von
a) (xxT )A
y = (xxT )A zu berechnen, kostet n2 + n3 flOs.
b) x(xTA)
y = x(xTA) zu berechnen, kostet n2 + n2 flOs.

98 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
47. Wie aufwandig ist es, ein dreieckiges n× n-System zu losen?Wie aufwandig ist es, ein beliebiges n× n-System zu losen?
Ein dreieckiges n× n-System zu losen, kostet n2 flOs.79Ein beliebiges n× n-System zu losen, kostet 1
3n3 + n2 flOs.
48. Wie kann die LU-Faktorisierung A = LU der regularen Matrix A genutztwerden, um ATx = b zu losen?
Lose ATx = b, also (LU)Tx = b bzw. UTLTx = b, wobei UT untere und65/66LT obere Dreiecksmatrix ist: per back-substitution losbar. Mit A sind auchL und U regular, d.h. det(L) 6= 0 6= det(U). Da L und U Dreiecksmatrizensind, sind alle Diagonal-Elemente von L und U von Null verschieden. Daherkann jeweils aufgelost werden!
49. L sei regulare untere Dreiecksmatrix und P eine Permutationsmatrix.
a) Lose LPx = b.65
Zur Losung von LPx = b lose Ly = b in y = Px per forward-substitutionund bestimme x = P−1y = PTy.
b) Lose PLx = b.65
Zur Losung von PLx = b lose Lx = P−1b = PTb = c per forward-substitution.
50. Gibt es 0 6= x ∈ R2 mit ||x||1 = ||x||∞ ?
Ja, etwa x = ex, denn dann gilt ||ex||1 = 1 + 0 = 1 = max1, 0 = ||ex||∞.53
51. Gibt es x,y ∈ R2 mit ||x||1 > ||y||1 aber ||x||∞ < ||y||∞ ?
Ja, etwa x = (1, 1)T und y = (1.1, 0.1)T mit ||x||1 = 1+1 = 2 > 1.1+0.1 =53||y||1 aber ||x||∞ = max1, 1 = 1 < 1.1 = max1.1, 0.1 = ||y||∞.
52. Welche Matrix-Norm ist einfacher zu berechnen, ||A||1 oder ||A||2 ?
Sicher ist ||A||1 als maximale absolute Spaltensumme einfacher zu berech-nen, da fur ||A||2 der maximale singulare Wert von A oder ebenso die55Wurzel des betragsmaßig großten EWes von A zu bestimmen ist.
53. a) Ist det(A) ein guter Indikator dafur, ob A near singular ist?56
det(A) ist kein guter Indikator dafur, ob A near singular ist, wie etwacond(αI) = 1 aber det(αI) = αn 1 fur 0 < α < 1 zeigt.
b) Falls ja, wieso? Falls nein, was ist ein besserer Indikator?56
Selbstverstandlich ist cond(A) der bessere und richtige Indikator.

2.4. Review Questions – Antworten auf Verstandnisfragen 99
54. a) Wie ist die Konditionszahl einer Matrix A definiert?56
The condition number einer Matrix A ist definiert durch cond(A) = ||A|| ·||A−1|| fur eine beliebige Matrix-Norm ||.||.b) Welche Rolle spielt die Konditionszahl von A fur die Genauigkeit der 61berechneten Losung von Ax = b ?
Die Genauigkeit der Losung von Ax = b ist gegeben durch ||x−x||||x|| ≈
cond(A)εmach.
55. Warum ist die Bestimmung von cond(A) fur beliebiges A nicht-trivial?
Die Bestimmung von cond(A) = ||A|| · ||A−1|| ist wegen der Invertierung 58/59von A−1, um ||A−1|| zu berechnen, nicht-trivial.
56. Gib Beispiele fur 3× 3-Matrizen A 6= I mit cond(A) = 1.
Beispiele fur 3 × 3-Matrizen A 6= I mit cond(A) = 1 fur zumindest ||.||1 55und ||.||∞ gibt jede Permutationsmatrix P ab, da ||P||1 = 1 = ||P||∞ undwegen P−1 = PT auch ||PT ||1 = 1 = ||PT ||∞ gilt.
57. a) Bestimme cond(A) fur A = diag(4,−6, 2) in der 1-Norm ||.||1. 57/58
Zunachst gilt A−1 = diag(14,−1
6, 1
2) sowie einerseits ||A||1 = max4, 6, 2 =
6 und andererseits ||A−1||1 = max14, 1
6, 1
2 = 1
2, so daß cond(A) = 6
2= 3
folgt.
b) Bestimme cond(A) in der ∞-Norm ||.||∞. Da fur Diagonal-Matrizen1-Norm und ∞-Norm ubereinstimmen, ist cond(A) = 3 in beiden Normen.
Da fur Diagonal-Matrizen A in jeder Norm cond(A) = max |di|/min |di| 58gilt, ergibt sich auch direkt cond(A) = 6/2 = 3.
58. A sei n× n-Matrix mit cond(A) = 1. Welche der folgenden Matrizen sinddann ebenfalls ’bestens’ konditioniert?
a) cA fur beliebiges c ∈ R 58
Dann gilt auch fur cA ebenso cond(cA) = cond(A) = 1 fur jedes c ∈ R.
b) DA fur eine beliebige Diagonal-Matrix D 58
Es gilt nicht notwendig cond(DA) = 1, wie A = I mit cond(A) = 1 und
D =
(1 00 ε
)mit cond(DA) = cond(D) = 1
εzeigt.
c) PA fur eine beliebige Permutationsmatrix P 58
Dann gilt zumindest fur ||.||1 und ||.||∞ offensichtlich ||PA|| = ||A|| =||AP||, so daß cond(PA) = ||PA|| · ||(PA)−1|| = ||A|| · ||A−1PT || = ||A|| ·||A−1|| = cond(A) = 1 folgt.
d) BA fur eine beliebige regulare Matrix B 58

100 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Es gilt nicht notwendigerweise cond(BA) = 1, wie A = I mit cond(A) = 1
und B =
(1 00 ε
)mit cond(BA) = cond(B) = 1
εzeigt.
e) A−1
cond(A−1) = cond(A) = 1.
f) AT
Mit cond(A) = 1 gilt auch cond(AT ) = 1, da fur die SVD A = UΣVT
zumindest in der 2-Norm grundsatzlich cond(A) = σmax/σmin gilt. Ein139quadratisches AT hat daher die SVD AT = VΣTUT = VΣUT mit ebendenselben SWen.
???
59. A = 12I = diag(1
2, . . . , 1
2) sei n× n-Matrix.
a) Bestimme det(A).58
det(A) = 12n = 2−n.
b) Bestimme cond(A).58
cond(A) = cond(12I) = cond(I) = 1.
c) Welche Schlusse sind zu ziehen?58
det(A) und cond(A) sind insofern unabhangig, als 0 < det(A) 1 nichtsuber die Konditionierung von A aussagt.
60. Sei A exakt singular, aber fl(A) sei regular. Was ist von cond(fl(A)) zuerwarten?
Sei A =
(3 0.110 1
3
). In F(10, 2, L, U) ist fl(A) =
(3× 100 1.0× 10−1
1.0× 101 3.3× 10−1
).
Dann ist det(A) = 0 und damit A exakt singular. Sei rounding by choppingunterstellt. Also ist det (fl(A)) = 9.9×10−1−1.0×100 = 0.9·100−1.0·100 =−0.1 · 100 = 1.0× 10−1 6= 0 und damit fl(A) in F(10, 2, L, U) regular.
Weiter ist ||fl(A)||1 = 13 und ||fl(A)−1||1 =
∣∣∣∣∣∣∣∣ 1−0.01
(0.33 −0.1−10 3
)∣∣∣∣∣∣∣∣1
= 1033
und so cond(A) = 13429, falls fl(A)−1 exakt berechnet wird, bzw.
||fl(A)−1||1 =
∣∣∣∣∣∣∣∣ 1−1.0×10−1
(0.33 −0.1−10 3
)∣∣∣∣∣∣∣∣1
=
∣∣∣∣∣∣∣∣( 3.3 −1−100 30
)∣∣∣∣∣∣∣∣1
= 103.3
und so cond(A) = 1342.9 in F(10, 2, L, U).
A =
( )fl(A) =
( )det(A) = det(fl(A)) = detfl(fl(A)) =pdec = test eval reset||fl(A)||1 =||fl(A)||∞ =
||fl(A)−1DP ||1 =
||fl(A)−1DP ||∞ =
cond1(A) =cond∞(A) =

2.4. Review Questions – Antworten auf Verstandnisfragen 101
61. Ist A jeweils gut oder schlecht konditioniert?
a) A =
(1010 00 10−10
)56,58
A =
(1010 00 10−10
)= diag(1010, 10−10), d.h. cond(A) = max1010,10−10
min1010,10−10 =
1010
10−10 = 1020, also ist A schlecht konditioniert.
b) A =
(1010 00 1010
)56,58
A =
(1010 00 1010
)= 1010I, d.h. cond(A) = cond(1010I) = cond(I) = 1.
Also ist A ’bestens’ konditioniert.
c) A =
(10−10 0
0 10−10
)56,58
A =
(10−10 0
0 10−10
)= 10−10I, d.h. cond(A) = cond(10−10I) = cond(I),
cond(A) = 1. Also ist A ’bestens’ konditioniert.
d) A =
(1 22 4
)56,58
A =
(1 22 4
)mit det(A) = 0. Also ist A singular und damit gilt Definiti-
onsgemaß cond(A) = ∞.
62. Was sind gute Indikatoren dafur, daß A fast singular ist?
a) det(A) 1 ? 58
det(A) 1 ist kein guter Indikator, wie RQ 2.53 zeigt.
b) ||A|| 1 ? 58
||A|| 1 ist kein guter Indikator, wie A = αI mit ||A|| = |α| · ||I|| 1 fur|α| 1 aber cond(A) = cond(αI) = cond(I) = 1 zeigt.
c) ||A|| 1 ? 58
||A|| 1 ist kein guter Indikator, wie A = αI mit ||A|| = |α| · ||I|| 1 fur|α| 1 aber cond(A) = cond(αI) = cond(I) = 1 zeigt.
d) cond(A) 1 ? 58
cond(A) 1 entspricht genau der Definition . . .
63. a) Was ist das Residuum der genaherten Losung x von Ax = b ? 62
Das Residuum r der genaherten Losung x von Ax = b ist r = b−Ax.
b) Impliziert ein kleines relatives Residuum die Genauigkeit der Losung? 62

102 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Nein, wenn A schlecht konditioniert ist, so hilft auch ein kleines relativesResiduum ||r||
||A||·||x|| nicht, in ||∆x||||x|| ≤ cond(A) ||r||
||A||·||x|| den relativen Fehler||∆x||||x|| klein zu halten.
A small relative residuum implies a small relative error in thesolution if and only if the coefficient matrix is well conditioned.
c) Impliziert ein großes relatives Residuum die Ungenauigkeit der Losung?63
Nein, ein großes relatives Residuum impliziert nicht die Ungenauigkeit der
Losung, wie das Beispiel Ax =
(0.913 0.6590.457 0.330
)x =
(0.2540.127
)= b mit
den beiden Naherungen x1 =
(−0.0827
0.5000
)und x2 =
(0.999
−1.001
)der ex-
akten Losung x =
(1
−1
)zeigt: Die zugehorigen Residuen sind ||r1||1 =
||b − Ax1||1 ≈ 2.1 × 10−4 sowie ||r2||1 = ||b − Ax2||1 ≈ 2.4 × 10−3.
Die zugehorigen relativen Residuen sind ||r1||1||A||1·||x1||1 ≈ 2.6 × 10−4 sowie
||r2||1||A||1·||x2||1 ≈ 8.6 × 10−4: Die im Vergleich zu x1 bessere Naherung x2 derexakten Losung hat das großere relative Residuum.
64. Eine Gleitpunkt-Arithmetik habe eine Genauigkeit von 10 Dezimal-Ziffern.In Ax = b mit cond(A) = 103 seien A und b mit voller Maschinen-61Genauigkeit gegeben. Das System werde per Gauß-Elimination mit parti-eller Pivotisierung gelost. Auf wieviel Dezimal-Ziffern ist die Losung genau?
Mit εmach = 10−10 und wegen ||∆x||||x||
<≈ cond(A)εmach = 103 · 10−10 = 10−7 ist
ein auf sieben Stellen genaues Ergebnis zu erwarten.
65. In Ax = b seien A und b mit voller Maschinen-Genauigkeit, namlich auf6112 Dezimal-Ziffern genau, gegeben. Wie groß darf cond(A) werden, bevordie Losung keine signifikanten Ziffern mehr aufweist?
Mit εmach = 10−12 und wegen ||∆x||||x||
<≈ cond(A)εmach = 10−12cond(A) sind
dann keine signifikanten Stellen mehr zu erwarten, wenn der Fehler so großwie die Losung ist, wenn also großenordnungsmaßig cond(A) = 1012 gilt.
66. Unter welchen Umstanden impliziert ein kleines Residuum r = b−Ax, daßx eine genaue Losung von Ax = b ist?
Wenn A gut konditioniert ist, impliziert ein kleines Residuum r = b−Ax,57daß x eine genaue Losung von Ax = b ist.
67. A sei n× n-Matrix und c ∈ R beliebig. Was gilt notwendigerweise?
a) ||cA|| = |c| · ||A|| ?55
||cA|| = |c| · ||A|| gilt notwendigerweise fur jede Matrix-Norm.

2.4. Review Questions – Antworten auf Verstandnisfragen 103
b) cond(cA) = cond(A) 6= |c| cond(A) ? 58
cond(cA) = cond(A) 6= |c| cond(A) fur |c| 6= 1.
68. a) Was ist der wesentliche Unterschied zwischen Gauß-Elimination und 68;79/80Gauß-Jordan-Elimination?
Gauß-Elimination uberfuhrt A in eine obere Dreiecksmatrix, Gauß-Jordan-Elimination uberfuhrt A in eine Diagonalmatrix.
b) Stelle Vor- und Nachteile von Gauß-Elimination und Gauß-Jordan-Eli- 68;79/80mination gegenuber.
Gauß-Elimination kostet mit 13n3 flOs weniger, dafur ist back-substitution
mit n2 flOs aufwandiger. Die Gauß-Jordan-Elimination kostet mit 12n3 flOs
mehr, dafur ist back-substitution mit n flOs billiger.
69. Ordne die folgenden Verfahren, ein beliebiges n × n-System linearer Glei-chungen zu losen, nach Aufwand.
a) Gauß-Jordanb) Gauß-Elimination mit partial pivotingc) Cramer-Regeld) explizite Matrix-Inversion mit anschließender Matrix-Vektor-Multiplika-tion
Der Aufwand, ein beliebiges n × n-System linearer Gleichungen zu losen,ist wie folgt angeordnet:
b) Gauß-Elimination mit partial pivoting< a) Gauß-Jordan< d) explizite Matrix-Inversion und dann Matrix-Vektor-Multiplikation< c) Cramer-Regel
70. a) In wieviel Speicher kann eine n× n-Matrix A mit rank(A) = 1 effizientgespeichert werden.
Da A = (x, α2x, . . . , αnx), kann A durch 2n− 1 floats gespeichert werden.
b) Wieviele arithmetische Operationen sind notig, um z ∈ Rn und einen× n-Matrix A mit rank(A) = 1 effizient zu multiplizieren?
Um zTA = zT (x, y2x, . . . , ynx) = (z · x)(1, y2, . . . , yn) zu berechnen, sindinsgesamt n+n−1+n−1 = 3n−2 arithmetische Operationen (Additionenund Multiplikationen) notig.
71. Vergleiche Gauß-Elimination und Gauß-Jordan-Elimination, um Ax = bzu losen.
a) Welches Verfahren hat die aufwandigere LU-Faktorisierung? 68;79/80

104 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Gauß-Jordan-Faktorisierung ist aufwandiger als Gauß-LU-Faktorisierung.
b) Welches Verfahren hat die aufwandigere back-substitution?68;79/80
back-substitution bei Gauß-Elimination ist aufwandiger als back-substitutionbei Gauß-Jordan.
c) Welches Verfahren hat die hoheren Gesamtkosten?68;79/80
Die Gesamtkosten bei Gauß-Elimination sind 13n3 + n2 flOs, bei Gauß-
Jordan-Elimination 12n3 + n flOs.
72. Fur welches Verfahren gibt es eine pivoting Strategie, die garantiert, daßalle Multiplizierer betragsmaßig kleiner als 1 sind?
a) Gauß-Elimination?72
Bei Gauß-Elimination garantiert partial pivoting, daß alle Multipliziererbetragsmaßig kleiner als 1 sind.
b) Gauß-Jordan-Elimination?80
Bei Gauß-Jordan-Elimination gibt es auch mit pivoting keine Garantiedafur, daß alle Multiplizierer betragsmaßig kleiner als 1 sind.
73. Welche beiden Eigenschaften garantieren, daß A eine Cholesky-Faktorisie-rung hat?
Wenn A symmetrisch und positiv definit, dann hat A eine Cholesky-Fak-85/86torisierung A = LLT .
74. Welches sind die Vorteile der Cholesky-Faktorisierung gegenuber der LU-Faktorisierung?
Vorteile der Cholesky-Faktorisierung gegenuber der LU-Faktorisierung sind85– numerische Stabilitat (kein pivoting notig)– Speicher-Ersparnis (statt L und U ist nur L zu speichern)– Zeit-Ersparnis (nur 1
6n3 statt 1
3n3 flOs)
75. Wieviele Quadratwurzeln sind fur die Cholesky-Faktorisierung einer n×n-Matrix zu berechnen?
Es sind n Quadratwurzeln fur die Cholesky-Faktorisierung zu berechnen:86for(j=1;j<=n;j++) ... a[j][j]=sqrt(a[j][j]); ...
76. Sei A = (ai,j) symmetrisch und positiv definit und A = LLT mit L = (`i,j).
a) Bestimme `1,1.86
Dann gilt `1,1 =√a1,1.
b) Bestimme `n,1.86
Dann gilt `n,1 = an,1/√a1,1.

2.5. Exercises – Ubungsergebnisse 105
77. Was ist die Cholesky-Faktorisierung von A =
(4 22 2
)= AT ? 86
A =
(4 22 2
)= AT ist auch positiv definit, da zTAz =
(4x+ 2y2x+ 2y
)T (xy
)=
4x2 + 2xy + 2xy + 2y2 = 2x2 + 2(x2 + 2xy + y2) = 2x2 + 2(x + y)2 > 0
fur z =
(xy
)6= 0. Also existiert die Cholesky-Faktorisierung A = LLT
mit L = (`i,j). Insbesondere ist `1,1 =√
4 = 2, `2,1 = 2`1,1
= 2 und
`2,2 =√a2,2 − l22,1 =
√2− 12 = 1, so daß L =
(2 01 1
)und A = LLT .
78. a) Kann ein symmetrisches, indefinites System linearer Gleichungen bei 87/88
87/88Kosten vergleichbar denen, die zur Losung eines symmetrischen, positivdefiniten Systems linearer Gleichungen anfallen, gelost werden?
ja, siehe Referenzen Aasen, Bunch, Parlett, Kaufman in [164] Golub/VanLoan
b) Falls moglich, mit welchem Algorithmus? Falls unmoglich, warum?
siehe Referenzen Aasen, Bunch, Parlett, Kaufman in [164] Golub/Van Loan
79. Warum sind Verfahren zur iterativen Verbesserung der Losung linearer Glei-chungssysteme haufig ’impractical’ zu implementieren?
Erstens ist der doppelte Speicherbedarf zu befriedigen und zweitens sind 84die Residuen mit doppelter Genauigkeit zu bestimmen. vgl. Example 1.17 28
80. Ax = b sei schon per LU-Faktorisierung und back-substitution gelost. Wel-che zusatzlichen Kosten entstehen bei Anderung der Problemstellung?
a) bei Ubergang zu neuem b ? 79
Bei Ubergang zu neuem b fallen nur n2 flOs fur back-substitution an.
b) bei Ubergang zu neuem A− uvT ? 82
Bei Ubergang zu neuem A− uvT fallen nur n2 flOs an.
c) bei Ubergang zu vollig neuem A ? 79
Bei Ubergang zu vollig neuem A fallen 13n3 +n2 flOs fur LU-Faktorisierung
und substitution an.
2.5 Exercises – Ubungsergebnisse
1. Zeige die Aquivalenz der folgenden Aussagen. 51
i. A−1 existiert nicht.

106 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
ii. det(A) = 0
iii. rank(A) < n
iv. es existiert z 6= 0 mit Az = 0
iv.⇒iii. Az = 0, d.h.∑n
j=1 ai,jzj = 0 fur i = 1, . . . , n oder fur A =(a1, . . . , an) eben
∑i ziai = 0, d.h. die n Spalten von A sind l.a., d.h.
rank(A) < n.
iii.⇒ii. rank(A) < n, d.h. durch Determinanten-erhaltende Zeilen- oderSpalten-Operationen laßt sich eine Null-Zeile oder Null-Spalte erzeu-gen, so daß det(A) = 0 folgt.
ii.⇒i. Sei det(A) = 0 und angenommen, daß A−1 existiert. Dann gilt1 = det(I) = det(AA−1) = det(A) · det(A−1) und damit det(A) 6= 0im Widerspruch zur Voraussetzung.
i.⇒iv. Angenommen, es gibt kein z 6= 0 mit Az = 0. Dann sind die nSpalten von A l.u. Dagegen sind die n Spalten von A und ei l.a., d.h.es gibt zi mit Azi = ei. Also ist A−1 = (z1, . . . , zn), so daß A−1 imWiderspruch zur Voraussetzung existiert.
2. A = (ai,j) habe verschwindende Zeilen-Summen, d.h.∑n
j=1 ai,j = 0 furi = 1, . . . , n. Zeige: A ist singular.∑n
j=1 ai,j = 0 fur i = 1, . . . , n oder ebenso A(1, . . . , 1)T = 0 impliziert mit512Ex1 die Singularitat von A.
3. A sei singulare quadratische Matrix. Zeige: Wenn Ax = b eine Losung xhat, so hat das Gleichungssystem unendlich viele Losungen.
A sei singular und es gebe xo mit Axo = b. Wegen der Singularitat von51A gibt es z 6= 0 mit Az = 0, also A(cz) = 0 fur alle c ∈ R. WegenA(xo + cz) = Axo + Acz = b + 0 = b sind somit alle unendlich vielenVektoren xo + cz fur c ∈ R Losungen von Ax = b.
4. a) Zeige: A =
1 1 01 2 11 3 2
ist singular.51
det(A)=det ((a1, a2, a3))=
∣∣∣∣∣∣1 1 01 2 11 3 2
∣∣∣∣∣∣=det ((a1, a2−a1, a3))=
∣∣∣∣∣∣1 0 01 1 11 2 2
∣∣∣∣∣∣=0,
so daß A singular ist.
b) Wieviele Losungen hat Ax = (2, 4, 6)T = b ?51

2.5. Exercises – Ubungsergebnisse 107
Ax =
246
ist zu
1 1 00 1 10 2 2
x1
x2
x3
=
224
mit x =
c2− cc
fur c ∈ R
aquivalent. Fur diese rechte Seite b hat Ax = b also unendlich vieleLosungen.
5. Was ist die Inverse von A =
1 0 01 −1 01 −2 1
?
Dann ist det(A) = −1 6= 0, also existiert die Inverse A−1, die per Gauß- 79/80Jordan bestimmt wird. Sei B1 = [A|I] gesetzt. Dann ist B2 = M1B1 = 1 0 0−1 1 0−1 0 1
1 0 0 1 0 01 −1 0 0 1 01 −2 1 0 0 1
=
1 0 0 1 0 00 −1 0 −1 1 00 −2 1 −1 0 1
, B3 =M2B2 =1 0 00 1 00−2 1
1 0 0 1 0 00−1 0 −1 1 00−2 1 −1 0 1
=
1 0 0 1 0 00−1 0 −1 1 00 0 1 1−2 1
und endlich B4 =DB3 =1 0 00 −1 00 0 1
1 0 0 1 0 00 −1 0 −1 1 00 0 1 1 −2 1
=
1 0 0 1 0 00 1 0 1 −1 00 0 1 1 −2 1
und es gilt
B4 = DM2M1(A|I) = (I|A−1).
6. A sei n× n-Matrix mit A2 = 0. Zeige: A ist singular.
Wenn A = 0 gilt, so ist A sicher singular. Sei also A 6= 0. Dann ist 51wenigstens eine Spalte ai 6= 0. Insbesondere gilt also Aai = 0. Also ist Asingular.
7. Sei A =
(1 1 + ε
1− ε 1
).
a) det(A) ?
det(A) = 1− (1− ε)(1 + ε) = 1− (1− ε2) = ε2.
b) Fur welche ε wird eine verschwindende Determinante berechnet?
Wenn von der Binomial-Formel kein Gebrauch gemacht wird, ergibt sichdet(A) = 0, falls fl(1 + ε) = 1 = fl(1− ε), namlich falls |ε| < β1−t = εmach.Wenn dagegen von der Binomial-Formel Gebrauch gemacht wird, ergibtsich det(A) = 0, falls fl(1− ε2) = 1, namlich falls |ε| < β(1−t)/2 =
√εmach.
c) Was ist die LU-Faktorisierung von A ?
U = M1A =
(1 0
−(1− ε) 1
)(1 1 + ε
1− ε 1
)=
(1 1 + ε0 1− (1−ε)(1+ε)
)=(
1 1 + ε0 ε2
)und L = M−1
1 =
(1 0
1− ε 1
).

108 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
d) Fur welche ε wird eine singulare Matrix U berechnet?
Ohne Ausnutzen der Assoziativitat ist det(U) = 0, falls fl(1 − ε2) = 1,namlich falls |ε| < β(1−t)/2 =
√εmach.
Mit Ausnutzen der Assoziativitat ist det(U) = 0, falls fl(ε2) = 0, namlichfalls |ε| <
√UFL.
8. A = (ai,j) und B = (bi,j) seien quadratische Matrizen.
a) Zeige: (AB)T = BTAT .84
(AB)T = BTAT , da fur jedes Element (AB)Ti,j der Produkt-Matrix (AB)T
i,j =(AB)j,i =
∑nk=1 aj,kbk,i =
∑nk=1 BT
i,kATk,j = (BTAT )i,j gilt.
b) A und B seien regular. Zeige: (AB)−1 = B−1A−1.84
Zunachst stimmen Rechtsinverse A−1r und Linksinverse A−1
l von A uberein,da A−1
l = A−1l (AA−1
r ) = (A−1l A)A−1
r = A−1r , und daher ist die Inverse, so
sie existiert, eindeutig, da B = B(AC) = (BA)C = C.Aus ABB−1A−1 = AIA−1 = AA−1 = I folgt daher (AB)−1 = B−1A−1.
9. A sei regular und reell. Zeige: (A−1)T = (AT )−1, so daß A−T = (A−1)T =(AT )−1 wohldefiniert ist.A sei regular und komplex. Zeige: (A−1)H = (AH)−1, so daß A−H =(A−1)H = (AH)−1 wohldefiniert ist.
Wegen 2Ex8 gilt dann (A−1)TAT = (AA−1)T = IT = I und wegen derEindeutigkeit der Inversen eben (A−1)T = (AT )−1, so daß A−T = (A−1)T =(AT )−1 wohldefiniert ist. Fur komplexe Matrizen A gilt ebenso A−H =(A−1)H = (AH)−1.
10. Sei P eine Permutationsmatrix, d.h. P ∈ 0, 1n2und in jeder Zeile und in
jeder Spalte von P gibt es bis auf lauter Nullen genau eine Eins.
a) Zeige: P−1 = PT .64
P−1 = PT , da (PPT )i,j =∑n
k=1 Pi,kPTk,j =
∑nk=1 Pi,kPj,k = Pi,ioPj,io , falls
die einzige Eins in der i-ten Zeile in der io-ten Spalte steht. Damit stehtdie einzige Eins in der io-ten Spalte eben genau in der i-ten Zeile und esfolgt (PP T )i,j = δi,j.
b) Zeige: Jede Permutation ist Produkt von paarweisen Vertauschungen.64
Zunachst ist jede Permutation p : [1, n] ∩ N → [1, n] ∩ N ein Produktvon Zyklen, wobei ein Zyklus (i0, i1, . . . , iz−1) von p eine Einschrankungp|i0,i1,...,iz−1 von p auf i0, i1, . . . , iz−1 mit p(ij) = ij+1 mod z fur j =0, 1, . . . , z − 1 ist. Und jeder Zyklus (i0, i1, . . . , iz−1) laßt sich als Produkt∏z−1
j=0(ij, ij+1 mod z) der Vertauschungen (ij, ij+1 mod z) darstellen.
11. Entwirf einen Algorithmus zur Losung von Lx = b mit unterer Dreiecks-matrix L durch forward substitution.

2.5. Exercises – Ubungsergebnisse 109
Algorithmus zur Losung von Lx = b per forward-substitution xi = 1`i,i
(bi− 65∑i−1j=1 xj`i,j) mit `i,i 6= 0 fur i = 1, . . . , n oder eben
for i = ( 1 : n)s = 0 . 0 ;for j = ( 1 : i −1)
s = s+x( j )∗L( i , j ) ;endx ( i ) = (b( i )−s )/L( i , i ) ;
end
12. Zeige: Der dominante Term in der Anzahl der fur die Losung von Lx = bmit unterer Dreiecksmatrix L notigen arithmetischen Operationen (Addi-tionen oder Multiplikationen) ist 1
2n2.
Die Losung von Lx = b per forward-substitution macht eine Division fur 65i = 1, eine Division und eine Multiplikation fur i = 2, usw. eine Divisionund n− 1 Multiplikationen fur i = n, also insgesamt
∑ni=1 i = 1
2n(n+ 1) =
12n2 + 1
2n Divisionen und Multiplikationen notig. Der dominierende Faktor
ist also 12n2 flOs.
13. B sei beliebige Matrix und L1 sowie L2 seien regulare untere Dreiecksmatri-zen geeigneter Dimension. Zeige die notwendigen Schritte zur Losung des
linearen Gleichungssystems Ax =
[L1 0B L2
] [x1
x2
]=
[b1
b2
]= b.
L1 sei untere n × n-Dreiecksmatrix. L2 sei untere m ×m-Dreiecksmatrix.
Das System linearer Gleichungen Ax = b sei zu losen mit A =
[L1 0B L2
],
mit m× n-Matrix B und mit (m+ n)-Vektoren x =
[x1
x2
]und b =
[b1
b2
].
Lose zunachst L1x1 = b1 und dann Bx1+L2x2 = b2 bzw. L2x2 = b2−Bx1.Wegen der Regularitat von L1 und L2 und damit det(L1) 6= 0 6= det(L2),sind alle Diagonal-Elemente von L1 und L2 von Null verschieden, so daßaufgelost weden kann.
14. Die elementaren Eliminationsmatrizen oder Gauß-Transformationen Mk
sind durch Mk =
1 . . . 0 0 . . . 0...
. . ....
......
0 . . . 1 0 . . . 00 . . . −mk+1 1 . . . 0...
. . ....
......
0 . . . −mn 0 . . . 1
definiert. Zeige:

110 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
i. Mk ist eine untere Dreiecksmatrix mit Einheitshauptdiagonalen unddamit regular.
ii. Mit m = (0, . . . , 0,mk+1, . . . ,mn)T laßt sich Mk als Mk = I − meTk
darstellen.
iii. Lk = I + meTk = M−1
k .
iv. Sei Mk = I − meTk , Mj = I − teT
j fur j > k. Dann gilt MkMj =I−meT
k − teTj .
Per Definition gilt67
i. Per Konstruktion ist Mk eine untere Dreiecksmatrix mit Einheits-hauptdiagonalen. Daher ist det(Mk) = 1 und damit ist Mk regular.
ii. Mit m = (0, . . . , 0,mk+1, . . . ,mn)T laßt sich Mk darstellen als Mk =I−(0, . . . ,0,m,0, . . . ,0) = I−meT
k , da meTk nur in der (k+1)-ten bis
n-ten Zeile und in der k-ten Spalte von Null verschieden ist: meTk hat
namlich lauter Null-Spalten, nur die k-te Spalte ist durch m ersetzt.
iii. Lk = I + meTk = M−1
k , denn MkLk = (I − meTk )(I + meT
k ) = I −meT
k meTk = I−m(eT
k m)eTk = I− (eT
k m)meTk = I− 0 ·meT
k = I.
iv. Sei Mk = I − meTk , Mj = I − teT
j fur j > k. Dann gilt MkMj =(I−meT
k )(I− teTj ) = I−meT
k − teTj + meT
k teTj = I−meT
k − teTj , da
meTk teT
j = m(eTk t)eT
j = (eTk t)meT
j = 0 ·meTj = 0, da eT
k t = 1 · tk = 0.
15. a) Zeige: Das Produkt zweier unterer Dreiecksmatrizen ist wieder eine un-65tere Dreiecksmatrix.
Das Produkt L = L1L2 zweier unterer Dreiecksmatrizen ist wieder eineuntere Dreiecksmatrix: Zu zeigen ist, daß Li,j = 0 fur alle i < j. Sei alsoi < j. Dann ist Li,j =
∑nk=1(L1)i,k(L2)k,j =
∑ik=1(L1)i,k(L2)k,j, da L1
untere Dreiecksmatrix, und Li,j =∑i
k=1(L1)i,k(L2)k,j = 0, da k ≤ i < jund daher (L2)k,j = 0, weil L2 untere Dreiecksmatrix ist.
b) Zeige: Die Inverse einer unteren Dreiecksmatrix ist wieder untere Drei-65ecksmatrix.
Die Inverse M = L−1 = (mi,j) einer unteren Dreiecksmatrix L = (`i,j) istwieder untere Dreiecksmatrix: Aus LM = I bzw.
∑nk=1 `i,kmk,j = δi,j folgt
namlich
i=1 m1,1 = 1/`1,1 und m1,j = 0 fur j = 2, . . . , n
i=2 `2,1m1,2 + l2,2m2,2 = 0 + `2,2m2,2 = 1 und m2,j = 0 fur j = 3, . . . , n
i=3∑3
k=1 l3,kmk,3 = 0 + 0 + `3,3m3,3 = 1 und m3,j = 0 fur j = 4, . . . , n
. . .
i=n-1∑n−1
k=1 `n−1,kmk,n−1 =0+. . .+0+`n−1,n−1mn−1,n−1 =1 und mn−1,n =0

2.5. Exercises – Ubungsergebnisse 111
16. Sei A =
(1 ac b
).
a) Was ist die LU-Faktorisierung von A ? 67
U = MA =
(1 0−c 1
)(1 ac b
)=
(1 a0 b− ac
)und L = M−1 =
(1 0c 1
)b) Unter welchen Bedingungen ist A singular? 51
A ist singular ⇐⇒ 0 = det(A) = b− ac = det(U) ⇐⇒ U ist singular.
17. Bestimme die LU-Faktorisierung von A =
1 −1 0−1 2 −1
0 −1 1
.
M1A =
1 0 01 1 00 0 1
1 −1 0−1 2 −1
0 −1 1
=
1 −1 00 1 −10 −1 1
und U = MA = 68/69
M2M1A =
1 0 00 1 00 1 1
1 −1 00 1 −10 −1 1
=
1 −1 00 1 −10 0 0
und L = M−1 =
M−11 M−1
2 =
1 0 0−1 1 0
0 0 1
1 0 00 1 00 −1 1
=
1 0 0−1 1 0
0 −1 1
, so daß A =
LU.
18. Zeige: A =
(0 11 0
)hat keine LU-Faktorisierung.
A =
(0 11 0
)hat keine LU-Faktorisierung. Denn angenommen A = LU = 68/69
(`i,j)(ui,j). Dann gilt `1,1u1,1 = 0 sowie `1,1u1,2 = 1 und folglich `1,1 6= 0sowie u1,1 = 0. Dann kann allerdings `2,1u1,1 = 1 nicht befriedigt werden.
19. Wende auf die regulare n× n-Matrix A folgenden Algorithmus an:
I. Scan die Spalten von A nacheinander und vertausche, wo notwendig,Zeilen so, daß in jeder Spalte die Eintrage auf der Diagonalen be-tragsmaßig alle Eintrage auf und unter der Diagonalen dominieren.Es ergibt sich eine Permutationsmatrix P, die A in PA uberfuhrt.
II. Fuhre jetzt Gauß-Elimination ohne pivoting durch, um PA = LU zufaktorisieren.
a) Ist der Algorithmus numerisch stabil?
???b) Wenn ja, warum? Wenn nein, gib ein Gegenbeispiel.???

112 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
20. A sei spaltenweise diagonal dominant, diagonal dominant by columns, d.h.(*)
∑ni=1,i6=j |ai,j| < |aj,j| fur j = 1, . . . , n (*)
Zeige: Wenn Gauß-Elimination mit partial pivoting auf A angewandt wird,werden keine Vertauschungen von Zeilen notwendig.
Es reicht zu zeigen, daß die bei der Gauß-Elimination jeweils rechts un-ten entstehenden Untermatrizen alle wieder spaltenweise diagonal dominant77sind. Es reicht zudem, dies fur den ersten Eliminationsschritt zu tun. We-gen (*) gilt |a1,1| > |ai,1| fur jedes i 6= 1. Fur die Pivotisierung mussen alsokeine Zeilen vertauscht werden. Die neue Koeffizienten-Matrix ist M1A =
1 0 · · · 0−a2,1
a1,11 0
.... . .
−an,1
a1,10 1
a1,1 a1,2 · · · a1,n
a2,1 a2,2 · · · a2,n
......
an,1 an,2 · · · an,n
=
a1,1 a1,2 · · · a1,n
0 a2,2 − a2,1
a1,1a1,2 · · · a2,n − a2,1
a1,1a1,n
......
...0 an,2 − an,1
a1,1a1,2 · · · an,n − an,1
a1,1a1,n
.
Fur jedes j = 2, . . . , n gilt dann
n∑i=2,i6=j
|(M1A)i,j| =n∑
i=2,i6=j
∣∣∣ai,j − ai,1
a1,1a1,j
∣∣∣ ≤ n∑i=2,i6=j
(|ai,j|+ |a1,j |
|a1,1| |ai,1|)
=∑i6=j
|ai,j| − |a1,j|+ |a1,j ||a1,1|
(∑i6=1
|ai,1| − |aj,1|
)wegen (*)
< |aj,j| − |a1,j|+ |a1,j ||a1,1| (|a1,1| − |aj,1|) = |aj,j| − |a1,j |
|a1,1| |aj,1|
≤∣∣∣aj,j − a1,j
a1,1aj,1
∣∣∣ = |(M1A)j,j| Dreiecksungleichung
Also ist auch die (n − 1) × (n − 1)-Untermatrix ((M1A)i,j)i,j=2,...,n spal-tenweise diagonal dominant, wie induktiv ebenso die (n − 2) × (n − 2)-Untermatrix ((M2M1A)i,j)i,j=3,...,n, usw.
21. A,B,C seien n×n-Matrizen; B und C seien regular. Wie ist x = B−1(2A+I)(C−1 + A)b fur beliebiges b ∈ Rn zu bestimmen, ohne Matrizen explizitzu invertieren?
Bx = (2A + I)(C−1 + A)b = (2AC−1 + 2A2 + C−1 + A)b. Mit Cy = b79folgt Bx = (2AC−1 + 2A2 +C−1 +A)Cy = (2A+ 2A2C+ I+AC)y = z.Lose also zunachst Cy = b und dann Bx = z.
22. Verifiziere: Der dominante Term in der Anzahl der fur die LU-Faktori-sierung einer n × n-Matrix per Gauß-Elimination notigen arithmetischenOperationen (Additionen oder Multiplikationen) ist 1
3n3.
Gemessen in Anzahl a von Multiplikationen und Divisionen ergibt sich79

2.5. Exercises – Ubungsergebnisse 113
1. Zeile von U kostet 01. Spalte von L kostet 1(n− 1) 2. Zeile von U kostet 1(n− 1)2. Spalte von L kostet 2(n− 2) 3. Zeile von U kostet 2(n− 2)3. Spalte von L kostet 3(n− 3) 4. Zeile von U kostet 3(n− 3)
......
n− 1. Spalte von L kostet (n− 1)1 n. Zeile von U kostet (n− 1)1
#MUL = 2n−1∑i=1
i(n− i) = 2nn−1∑i=1
i− 2n−1∑i=1
i2
= 2n12(n− 1)n− 21
6(n− 1)n(2n− 1) = (n−1)n
3 (3n− (2n− 1))= 1
3(n− 1)n(n+ 1).
Die Anzahl #MUL von Multiplikationen und Divisionen wird somit domi-niert von 1
3n3.
23. Verifiziere: Der dominante Term in der Anzahl der fur die Invertierung einern × n-Matrix per Gauß-Elimination notigen arithmetischen Operationen(Additionen oder Multiplikationen) ist n3.
???Die LU-Faktorisierung schlagt mit 1
3n3 flOs zu Buch. Danach erfolgt das
Auflosen von LUx = ei fur i = 1, . . . , n. Fur n-maliges Auflosen fallenweitere n · n2 = n3 flOs an, insgesamt eben 4
3n3 flOs.
???
24. Verifiziere: Der dominante Term in der Anzahl der fur die Diagonalisierungeiner n × n-Matrix per Gauß-Jordan-Elimination notigen arithmetischenOperationen (Additionen oder Multiplikationen) ist 1
2n3.
Zur Elimination von xi sei jeweils die i-te Gleichung ’normiert’, d.h. der 79/80Koeffizient von x1 ist 1. Diese großenordnungsmaßig n2 Divisionen durchdas pivot-Element sind im Folgenden nicht mitgezahlt, da sie keinen Beitragzum dominanten Term leisten.
Elimination von x1 in der 2., 3., 4., . . . , n-ten Gleichung braucht(n−1)-fach n Multiplikationen (incl. rechte Seite)
Elimination von x2 in der 1., 3., 4., . . . , n-ten Gleichung braucht(n−1)-fach n− 1 Multiplikationen (incl. rechte Seite)
Elimination von x3 in der 1., 2., 4., . . . , n-ten Gleichung braucht(n−1)-fach n− 2 Multiplikationen (incl. rechte Seite)
. . .
Elimination von xn−1 in der 1., 2., . . . , n−1-ten Gleichung braucht(n−1)-fach 2 Multiplikationen (incl. rechte Seite)

114 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
macht (n− 1)∑n−1
i=1 (n+ 1− i) = (n− 1)∑n
i=2 i = (n− 1)(12n(n+ 1)− 1) =
12n3 + . . . flOs insgesamt.
25. a) Seien u,v ∈ Rn. Zeige: rank(uvT ) = 1.81
Seien u,v ∈ Rn und vT = (v1, . . . , v). Dann ist uvT = (v1u, . . . , vnu) einen× n-Matrix und es gilt rank(uvT ) = 1.
b) A sei n × n-Matrix mit rank(A) = 1. Zeige: dann existieren u und v81mit A = uvT .
A sei n × n-Matrix mit rank(A) = 1. Dann hat A etwa einen Spal-tenvektor u, von dem alle anderen Spaltenvektoren l.a. sind, d.h. A =(v1u, v2u, . . . , vnu) mit v1 = 1, also A = uvT .
26. Matrizen A von der Form A = I− uvT heißen elementar.
a) A sei elementar. Wann ist dann A regular?67
A ist regular, wenn vTu 6= 1, s. Teil b)
b) A sei elementar und regular. Zeige: A−1 = I − σuvT (fur welches67σ ∈ R ?)
Es gilt A−1 = I− σuvT fur ein σ ∈ R, da AA−1 = (I− uvT )(I− σuvT ) =I−(σ+1)uvT +σ(uvT )2 = I−(σ+1)uvT +σu(vTu)vT = I−(σ+1)uvT +σ(vT )uuvT = I− (σ(1− vTu) + 1)uvT = I ⇐⇒ σ = −1
1−vT u.
c) Wieso ist Mk = I−meTk elementar? fur welche u und v sowie σ ?67
Selbstverstandlich ist Mk = I−meTk mit u = m und v = ek elementar und
es gilt σ = −11−vT u
= −1, da vTu = eTk m = 1 ·mk = 0, so daß sich erneut
M−1k = I− (−1)meT
k = I + meTk ergibt.
27. Zeige (A−uvT )−1 = A−1+A−1u(1−vTA−1u)−1vTA−1 Sherman-Morrison9
⇐⇒ I = A−1(A− uvT ) + A−1u(1− vTA−1u)−1vTA−1(A− uvT )82⇐⇒ I = I−A−1uvT + A−1u(1− vTA−1u)−1vT (I−A−1uvT )⇐⇒ A−1uvT = A−1u(1− vTA−1u)−1vT (I−A−1uvT )⇐⇒ uvT = u(1− vTA−1u)−1vT (I−A−1uvT ) und da (1− vTA−1u) ∈ R⇐⇒ u(1− vTA−1u)vT = uvT − uvTA−1uvT = uvT (I−A−1uvT )
√
28. Zeige (A−UVT )−1 = A−1 + A−1U(I−VTA−1U)−1VTA−1 Woodbury10
Wie 2Ex27: ersetze 1 durch I.82
29. Zeige: ||.||1, ||.||2 und ||.||∞ sind Vektor-Normen.54
9 J. Sherman, W.J. Morrison: Adjustment of an inverse matrix corresponding to changes inthe elements of a given column or a given row of the original matrix; Ann. Math. Statist., 20,1949, p621
10 M.A. Woodbury: Inverting modified matrices; Statist. Res. Group, Mem. Rep., No. 42,Princeton Univ., Princeton, N.J., 1950

2.5. Exercises – Ubungsergebnisse 115
1-Norm ||x||1 =∑
i |xi| ist Vektor-Norm, weil
i. ||x||1 > 0, wenn ein xi 6= 0, also wenn x 6= 0
ii. ||γ x||1 =∑
i |γ xi| = |γ|∑
i |xi| = |γ| · ||x||1iii. ||x + y||1 =
∑i |xi + yi| ≤
∑i |xi|+
∑i |yi| = ||x||1 + ||y||1
2-Norm ||x||2 =√∑
i x2i ist Vektor-Norm, weil
i. ||x||2 > 0, wenn ein xi 6= 0, also wenn x 6= 0
ii. ||γ x||2 =√∑
i(γ xi)2 = |γ|√∑
i x2i = |γ| · ||x||2
iii.||x + y||22 =∑
i(xi + yi)2 =
∑i x
2i + 2
∑i xiyi +
∑i y
2i
= ||x||22 + 2xTy + ||y||22 ≤ ||x||22 + 2||x||2 ||y||2 + ||y||22und damit die Dreiecksungleichung ||x+y||2 ≤ ||x||2 + ||y||2, weilzunachst die Schwarz11sche Ungleichung |xTy| ≤ ||x||2 · ||y||2 gilt.
Mit z = xT yyT y
y folgt namlich
0 ≤ ||x− z||22 = (x− z)T (x− z) = xTx− 2xTz + zTz
= xTx− 2(xTy)2
yTy+
(xTy)2
(yTy)2yTy = xTx− (xTy)2
yTy,
also 0 ≤ (xTx)(yTy) − (xTy)2 und daher |xTy| ≤ ||x||2 · ||y||2.Damit gilt
∑i xiyi = xTy ≤ |xTy| ≤ ||x||2 · ||y||2.
∞-Norm ||x||∞ = maxi |xi| ist Vektor-Norm, weil
i. ||x||∞ > 0, wenn ein xi 6= 0, also wenn x 6= 0
ii. ||γ x||∞ = maxi |γ xi| = |γ|maxi |xi| = |γ| · ||x||∞iii.||x + y||∞ = maxi |xi + yi| ≤ maxi(|xi|+ |yi|)
≤ maxi |xi|+ maxi |yi| = ||x||∞ + ||y||∞
30. Zeige: ||.||1 und ||.||∞ sind submultiplikative Matrix-Normen. 55
1-Norm ||A||1 = maxj
∑i |ai,j|, also die maximale absolute Spalten-Sum-
me, ist submultiplikative Matrix-Norm, weil
i. ||A||1 > 0, wenn ein ai,j 6= 0, also wenn A 6= 0
ii. ||γA||1 = maxj
∑i |γ ai,j| = |γ|maxj
∑i |ai,j| = |γ| · ||A||1
iii.||A + B||1 = maxj
∑i |ai,j + bi,j| ≤ maxj
∑i(|ai,j|+ |bi,j|)
≤ maxj
∑i |ai,j|+ maxj
∑i |bi,j| = ||A||1 + ||B||1
iv. Zu zeigen ||AB||1 ≤ ||A||1 · ||B||1||AB||1 = maxj
∑i |∑
k ai,kbk,j| ≤ maxj
∑i
∑k |ai,k| · |bk,j|
= maxj
∑k (∑
i |ai,k|)|bk,j| ≤ maxj
∑k (max`
∑i |ai,`|)|bk,j|
= (max`
∑i |ai,`|) · (maxj
∑k |bk,j|) = ||A||1 · ||B||1
v. Zu zeigen ||Ax||1 ≤ ||A||1 · ||x||1 mit ||x||1 =∑
i |xi|11 Hermann Amandus Schwarz (1843-1921), www-history.mcs.st-andrews.ac.uk/Biographies/Schwarz.html

116 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
||Ax||1 = ||(∑
j a1,jxj, . . . ,∑
j an,jxj)|| =∑
i
∣∣∣∑j ai,jxj
∣∣∣≤∑
i
∑j |ai,j| |xj| =
∑j (∑
i |ai,j|)|xj|≤ (max`
∑i |ai,`|)
∑j |xj| = ||A||1 · ||x||1
∞-Norm ||A||∞ = maxi
∑j |ai,j|, also die maximale absolute Zeilen-Sum-
me, ist submultiplikative Matrix-Norm, weil
i. ||A||∞ > 0, wenn ein ai,j 6= 0, also wenn A 6= 0
ii. ||γA||∞ = maxi
∑j |γ ai,j| = |γ|maxi
∑j |ai,j| = |γ| · ||A||∞
iii.||A + B||∞ = maxi
∑j |ai,j + bi,j| ≤ maxi
∑j(|ai,j|+ |bi,j|)
≤ maxi
∑j |ai,j|+ maxi
∑j |bi,j| = ||A||∞ + ||B||∞
iv. Zu zeigen ||AB||∞ ≤ ||A||∞ · ||B||∞||AB||∞ = maxi
∑j |∑
k ai,kbk,j| ≤ maxi
∑j
∑k |ai,k| · |bk,j|
= maxi
∑k |ai,k|
∑j |bk,j| ≤ maxi
∑k |ai,k|max`
∑j |b`,j|
= ||A||1 · ||B||1v. Zu zeigen ||Ax||∞ ≤ ||A||∞ · ||x||∞ mit ||x||∞ = maxi |xi|||Ax||∞ = ||(
∑j a1,jxj, . . . ,
∑j an,jxj)|| = maxi
∣∣∣∑j ai,jxj
∣∣∣≤ maxi
∑j |ai,j| |xj| ≤ maxi
∑j |ai,j|max` |x`| = ||A||∞ · ||x||∞
31. Sei A = AT positiv definit, d.h. xTAx > 0 fur alle x 6= 0. Dann definiert54||x||A =
√xTAx eine Norm, die sogenannte durch A induzierte Norm, weil
i. ||x||A =√
xTAx > 0, wenn x 6= 0, da A positiv definit.
ii. ||γ x||A =√
(γx)TAγx = |γ|√
xTAx = |γ| · ||x||Aiii.||x + y||2A = (x + y)TA(x + y) = xTAx + yTAx + xTAy + yTAy
xTAx + 2yTAx + yTA≤||x||2A + 2||x||A · ||y||A + ||y||2Ada R 3 xTAy = (xTAy)T = yTAx und da analog zur Schwarz’schenUngleichung (yTAx)2 ≤ xTAxyTAy = ||x||2A · ||y||2A gilt. Mit z =xT AyyT Ay
y folgt namlich
0 ≤ ||x− z||2A = (x− z)TA(x− z) = xTAx− 2xTAz + zTAz
= xTAx− 2(xTAy)2
yTAy+
(xTAy)2
(yTAy)2yTAy = xTAx− (xTAy)2
yTAy,
also 0 ≤ (xTAx)(yTAy)−(xTAy)2 und daher |xTAy| ≤ ||x||A ·||y||A.Damit gilt xTAy ≤ |xTAy| ≤ ||x||A · ||y||A.
32. a) Zeige: ||A||max = maxi,j |ai,j| ist Matrix-Norm und es gilt ||A||max =55||A||∞ fur A ∈ Rmn.
b) Zeige: ||A||F =√∑
i,j a2i,j, die sogenannte Frobenius12-Norm, ist Matrix-55
Norm und es gilt ||A||F = ||A||2 fur A ∈ Rmn.
12 Ferdinand Georg Frobenius (1849-1917) www-history.mcs.st-andrews.ac.uk/Biographies/Frobenius.html

2.5. Exercises – Ubungsergebnisse 117
max-Norm ||A||max = maxi,j |ai,j| ist Matrix-Norm, weil
i. ||A||max > 0, wenn ein ai,j 6= 0, also wenn A 6= 0
ii. ||γA||max = maxi,j |γ ai,j| = |γ|maxi,j |ai,j| = |γ| · ||A||max
iii.||A + B||max = maxi,j |ai,j + bi,j| ≤ maxi,j(|ai,j|+ |bi,j|)≤ maxi,j |ai,j|+ maxi,j |bi,j| = ||A||max + ||B||max
F-Norm ||A||F =√∑
i,j a2i,j ist Matrix-Norm, weil
i. ||A||F > 0, wenn ein ai,j 6= 0, also wenn A 6= 0
ii. ||γA||F =√∑
i,j(γ ai,j)2 = |γ|√∑
i,j a2i,j = |γ| · ||A||F
iii.||A + B||2F =∑
i,j(ai,j + bi,j)2 =
∑i,j a
2i,j + 2
∑i,j ai,jbi,j +
∑i,j b
2i,j
≤ ||A||2F + 2||A||F · ||B||F + ||B||2F = (||A||F + ||B||F )2
da jede m × n-Matrix mit genau einem mn-Vektor identifiziertwerden kann, so daß (
∑i,j ai,jbi,j)
2 ≤ (∑
i,j ai,j)(∑
i,j bi,j) genauwie in Ex 2.29 folgt.
33. Zeige oder widerlege durch ein Gegenbeispiel: ||A−1|| = ||A||−1.
Generell gilt ||A−1|| 6= ||A||−1, wie etwa A = diag(1, c) mit 0 < c < 1zeigt: Einerseits gilt ||A||1 = maxj
∑i |ai,j| = 1 = maxi
∑j |ai,j| = ||A||∞. 55
Fur A−1 = diag(1, 1c) gilt andererseits ||A−1||1 = maxj
∑i |(A−1)i,j| = 1
c=
maxi
∑j |(A−1)i,j| = ||A−1||∞.
In beiden Normen gilt also ||A−1|| = 1c6= 1 = ||A||−1.
34. A sei positiv definit, d.h. xTAx > 0 fur alle x 6= 0.
a) Zeige: Eine positiv definite Matrix ist regular. 84
Dann ist A regular, denn angenommen, A sei singular. Dann existiertein z 6= 0 mit Az = 0, a fortiori zTAz = zT0 = 0 im Widerspruch zurVoraussetzung, daß A positiv definit ist.
b) Zeige: Mit A ist auch A−1 positiv definit. 84
Zunachst ist wegen (xTAx)T = xTATx mit A auch AT positiv definit. Zuzeigen: mit A ist auch A−1 positiv definit. Sei x 6= 0 und x = Ay sowiexT = yTAT mit y 6= 0. Dann gilt xTA−1x = yTATA−1Ay = yTATy > 0.
35. Sei A = BBT mit regularem B. Zeige: A ist symmetrisch und positivdefinit.
Wegen AT = (BBT )T = BBT = A ist A symmetrisch. Wegen xTAx = 84xTBBTx = (BTx)T (BTx) = yTy > 0, da aufgrund der Regularitat von Bmit x 6= 0 auch BTx = y 6= 0, ist A auch positiv definit.
36. A sei symmetrisch und positiv definit. Der Vergleich der entsprechenden 85/86

118 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Matrix-Elemente liefert einen Algorithmus fur die Cholesky-FaktorisierungA = LLT von A.
Wegen A = AT spielt es keine Rolle, ob A Spalten-weise oder Zeilen-weiseausgewertet wird.
1. Spalte von A aus `1,1`1,1 = a1,1 folgt `1,1 =√a1,1 und aus `i,1`1,1 = ai,1
eben `i,1 =ai,1
`1,1fur i = 2, . . . , n.
2. Spalte von A aus `22,1 + `22,2 = a2,2 folgt `2,2 =√a2,2 − `22,1 und aus
`i,1`2,1 + `i,2 = ai,2 eben `i,2 = 1`2,2
(ai,2 − `i,1l2,1) fur i = 3, . . . , n.
. . .
n-te Spalte von A aus∑
i `2n,i = an,n folgt `n,n =
√an,n −
∑n−1i=1 `
2n,i.
37. B =
[α aT
a A
]= BT mit A = AT sei positiv definit und aT = (a1, . . . , an).
a) Zeige: α ist positiv und A ist positiv definit.85/86
B ist positiv definit. Wegen 0 < eT1 Be1 = eT
1 (α, a1, . . . , an)T = α isteinerseits α positiv. Andererseits ist weiterhin 0 < (0,xT )B(0,xT )T =
(0,xT )(α · 0 + (aTx), a1 · 0 +∑
j a1,jxj, . . . , an · 0 +∑
j an,jxj)T
= 0 +
x1
∑j a1,jxj + . . . + xn
∑j an,jxj = xTAx fur alle x 6= 0. Also ist auch A
positiv definit.
b) Wie sieht die Cholesky-Faktorisierung von B aus?85/86
Sei β =√α und b = 1
βa. Wegen xT (bbT +A)x = (bTx)T (bTx)+xTAx =
|bTx|2+xTAx > 0 fur alle x 6= 0 ist die symmetrische Matrix C = bbT +Apositiv definit mit Cholesky-Faktorisierung C = LCLT
C. Dann ist B =
LBLTB mit LB =
[β 0b LC
]Cholesky-Faktorisierung B.
38. B =
[A aaT α
]= BT
mit A = AT sei positiv definit und aT = (a1, . . . , an).
a) Zeige: α ist positiv und A ist positiv definit.85/86
B ist positiv definit. Also ist einerseits α wegen 0 < eTn+1Ben+1 = eT
n+1(aT , α)T =
α positiv. Andererseits gilt weiter 0 < (xT , 0)B(xT , 0)T = (xT , 0)(∑
j a1,jxj+
a1·0, . . . ,∑
j an,jxj+an·0, (aT ·x)+α·0)T= x1
∑j a1,jxj+. . .+xn
∑j an,jxj+
0 = xTAx fur alle x 6= 0. Also ist auch A positiv definit.
b) Wie sieht die Cholesky-Faktorisierung von B aus?85/86

2.5. Exercises – Ubungsergebnisse 119
Sei A = LALTA die Cholesky-Faktorisierung von A. Dann gilt fur die
Cholesky-Faktorisierung B = LBLTB von B eben LB =
[LA 0bT β
], wobei
LAb = a und bTb + β2 = α2 vorausgesetzt sei. LAb = a laßt sichnach b auflosen, weil LA regular ist und damit keine verschwindendenHauptdiagonal-Elemente hat. β2 = α2 − bTb > 0, weil letzter Schrittder Cholesky-Faktorisierung?
???
39. Verifiziere: Der dominante Term in der Anzahl der fur die Cholesky-Fakto-risierung einer symmetrischen, positiv definiten n×n-Matrix notigen arith-metischen Operationen (Additionen oder Multiplikationen) ist 1
6n3.
Fur die Komplexitat der Cholesky-Faktorisierung einer symmetrischen, po- 86sitiv definiten Matrix A gemessen in der Anzahl a von Multiplikationen undDivisionen ist nur der folgende Ausschnitt aus dem Algorithmus relevant.
for j = ( 1 : n)for k = ( 1 ; j−1)
for i = ( j : n )a ( i , j ) = a ( i , j )−a ( i , k )∗ a ( j , k ) ;
endend
end
Damit ist
a =n∑
j=1
j−1∑k=1
n∑i=j
1 =n∑
j=1
(j − 1)(n− (j − 1))
= nn∑
j=1
(j − 1)−n∑
j=1
(j − 1)2 = nn∑
j=2
(j − 1)−n∑
j=2
(j − 1)2
= n
n−1∑i=1
i−n−1∑i=1
i2 = 12(n− 1)n2 − 1
6(n− 1)n(2n− 1)
= 16(n− 1)n(3n− (2n− 1)) = 1
6(n− 1)n(n+ 1).
a wird somit durch 16n3 flOs dominiert.
40. A sei Bandmatrix mit Bandbreite β. Die LU-Faktorisierung PA = LU sei 88per Gauß-Elimination mit partieller Pivotisierung durchgefuhrt. Zeige: DieBandbreite der oberen Dreiecksmatrix U ist maximal 2β.
???
41. A sei regulare, tridiagonale Matrix. 88
a) Zeige: A−1 ist i.A. ’dense’, also keine dunn besetzte Matrix (sparse 85matrix ).

120 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
A−1 ist i.A. ’dense’, also keine dunn besetzte (sparse) Matrix.
Beispiel: Sei A = (ai,j) mit ai,i = (−1)i fur i = 1, . . . , n, ai,i−1 = 1 furi = 2, . . . , n und ai,j = 0 sonst. Dann ist A tridiagonal mit verschwindender,oberer Nebendiagonalen und fur A−1 = (bi,j) gilt bi,j = (−1)bi/2c+1+b(j−1)/2c
fur i > j und bi,j = 0 sonst. Also ist A−1 eine sogar vollbesetzte untereDreiecksmatrix.
i.A. . . .???
b) Vergleiche Laufzeit und Speicherbedarf der Losung von Ax = b per88/89Gauß-Elimination und back-substitution mit Laufzeit und Speicherbedarfder Losung per expliziter Matrix-Invertierung.
Die LU-Faktorisierung A = LU einer tridiagonalen n × n-Matrix kostetO(n) flOs, die nachfolgende Losung von Ly = b in y und Ux = y in xkostet jeweils O(n) flOs, zusammen also O(n) flOs.Matrix-Inversion von A kostet O(n3) flOs, Auflosen von x = A−1b kostetO(n) flOs, zusammen also O(n3) flOs.
42. a) Entwirf einen Algorithmus, der die Inverse einer n × n-Dreiecksmatrix’in place’ berechnet.
Sei A etwa obere Dreiecksmatrix. Dann ist auch A−1 obere Dreiecksmatrix(s.a. Ex 2.15 b)). Aus AA−1 = I folgt Axi = ei fur i = 1, . . . , n und A−1 =(x1, . . . ,xn). Insbesondere gilt also (A−1)i,i = 1/(A)i,i. Die Inverse A−1
kann – bis auf die Diagonale – als untere Dreiecksmatrix im Speicher-Bereichvon A ’unterhalb der Diagonalen’ abgelegt werden. Es ist zu vereinbaren,ob die Diagonale von A oder die von A−1 gespeichert wird.
b) Ist es moglich, die Inverse einer beliebigen n × n-Matrix ’in place’ zuberechnen?
Wenn A6i,6j aus A durch Streichen der i-ten Zeile und der j-ten Spalte her-vorgeht, so heißen mi,j = det(A6i,6j) Minoren sowie ci,j = (−1)i+jmi,j Kofak-toren von A. Adj(A) = (ci,j) heißt die zu A adjungierte Matrix. Dann giltA−1 = 1
det(A)Adj(AT ). Wenn nun Elemente von A, etwa erst ai,j und dann
ai′,j′ mit i 6= i′ und j 6= j′, sukzessive mit Elementen von A−1 uberschriebenwerden, so hangt i.a.R. (A−1)i′,j′ auch von dem nun nicht mehr verfugbarenai,j ab: beliebige Matrizen konnen nicht ’in place’ invertiert werden.
43. Lose das komplexe Gleichungssystem Cz = d mit C = A+ iB, d = b+ i cmit reellen Matrizen A und B sowie reellen Vektoren b und c. Zeige:z = x + iy ist zugleich Losung des reellen linearen Gleichungssystems[A −BB A
] [xy
]=
[bc
].
Ist es effizient, anstelle des komplexen n × n-Systems das reelle 2n × 2n-System zu losen?

2.6. Computer Problems – Rechner-Problem-Losungen 121
Zunachst ist Cz = (A + iB)(x + iy) = (Ax − By) + i(Ay + Bx) = b +
ic⇐⇒ Ax−By = bAy + Bx = c
. Der komplexe Losungsvektor z = x+iy ergibt sich
aus dem reellen linearen Gleichungssystem
[A −BB A
] [xy
]=
[bc
]. Dieser
Ansatz stellt allerdings keinen guten Weg zur Losung dar, da der doppelteSpeicherplatz und vermutlich auch die doppelte Zeit zur Losung benotigtwird.
2.6 Computer Problems –
Rechner-Problem-Losungen
1. a) Gegeben A = 110
1 2 34 5 67 8 9
und b = 110
135
. 51
Zeige: A ist singular. Beschreibe die Losungsmenge von Ax = b.
Die Matrix A ist singular, etwa weil det(A) = 10−3(45 + 84 + 96 − 105 −48− 72) = 0. Losungen von Ax = b mit bT = 1
10(1, 3, 5) ergeben sich aus
10Ax =
1 2 34 5 67 8 9
x =
135
⇐⇒
1 2 30 −3 −60 −6 −12
x =
1−1−2
⇐⇒
x =
1− 23(1− 6c)− 3c
13(1− 6c)c
=
13
+ c13− 2cc
fur alle c ∈ R.
b) An welcher Stelle bricht das Losungsverfahren ’Gauß-Elimination mitpartieller Pivotisierung’ bei Verwendung exakter Arithmetik ab?
partial pivoting ergibt bei Verwendung exakter Arithmetik 10Ax =
7 8 91 2 34 5 6
x =513
⇐⇒
7 8 90 2− 8/7 3− 9/70 5− 32/7 6− 36/7
x =
51− 5/73− 20/7
⇐⇒
49 56 630 6 120 3 6
x =3521
⇐⇒
7 8 90 3 60 3 6
x =
511
⇐⇒ x =
5− 83+16c−9c
71−6c
3
c
=
13
+ c13− 2cc
fur
alle c ∈ R. Abbruch bei Auflosen nach x3.
c) fl(A) ist nicht notwendig singular. Gauß-Elimination schlagt nicht not-wendig fehl. Welche Losung ermitteln Bibliotheksroutinen? Welche Kondi-tionszahl cond(A) ermitteln Konditionsschatzer? Welche Genauigkeit der

122 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Losung ist zu erwarten?
Die Matrix ist bei Verwendung endlich genauer Arithemtik nicht notwendigsingular. Etwa numerik.pdf oder numerics.pdf liefern ohne Pivotisierung
die einzige Losung x =
0.212121212121212150.5757575757575757
−0.12121212121212119
. Naherungsweise13 gilt
cond1(A) = 6.4852·1016, cond2(A) = 2.1119·1016 und cond∞(A) = 8.6469·1016.
2. a) Gegeben Ax =
2 4 −24 9 −3
−2 −1 7
x =
28
10
= b.
Welche Losung ermitteln Bibliotheksroutinen?
Dann liefert etwa numerik.pdf oder numerics.pdf die Losung xT = (−7, 4, 0).
b) Mit der LU-Faktorisierung aus a) lose Ay = c = (4, 8,−6)T .68
Erstens M1A =
1 0 0−2 1 0
1 0 1
2 4 −24 9 −3
−2 −1 7
=
2 4 −20 1 10 3 5
und zwei-
tens U = MA = M2M1A =
1 0 00 1 00 −3 1
2 4 −20 1 10 3 5
=
2 4 −20 1 10 0 2
,
so daß L = M−11 M−1
2 =
1 0 02 1 0
−1 0 1
1 0 00 1 00 3 1
=
1 0 02 1 0
−1 3 1
und
A = LU. Dann ergibt sich die Losung von Ay = c = (4, 8,−6)T ausLz = c, also z = (4, 0,−2)T , und aus Uy = z eben zu y = (−1, 1,−1)T .
c) Modifiziere A so, daß a1,2 = 2. Lose das modifizierte System mit b als51rechter Seite per Sherman-Morrison-Verfahren.
Der Ubergang von A zu A − uvT = A − 2e1eT2 setzt das ’neue’ a1,2 = 2.
Die Losung des neuen Systems (A− 2e1eT2 )x = c ergibt sich mit Sherman-
Morrison aus den folgenden drei Schritten.
1. Die Losung von Az = u = 2e1 in z ergibt sich aus Lt = 2e1, d.h.t = (2,−4, 14)T , und aus Uz = t eben zu z = (30,−11, 7)T .
2. Die Losung von Ay = c in y ergibt sich aus Lt = c, d.h. t = (4, 0,−2)T ,und aus Uy = t eben zu y = (−1, 1,−1)T .
3. Berechne Losung x = y+ vT y1−vT z
z = y+ y2
1−z2z = y+ 1
1−−11z = y+ 1
12z =
112
(−12+30, 12−11,−12+7)T = 112
(18, 1,−5)T mit (A−2e1eT2 )x = c.
13 laut MATLAB

2.6. Computer Problems – Rechner-Problem-Losungen 123
3. Gegeben ein Gittertrager mit 8 Verbindungen, 13 Streben und den einge-zeichneten Lasten in den Verbindungen Nr. 2, Nr. 5 und Nr. 6.
1
2
3
4
5
6
7
8
9
10
11 12
13
10 15 20
1 2
3 4
5 6
7
8
Im statischen Gleichgewicht heben sich die horizontalen und vertikalenKrafte in jeder Verbindung auf. Jeweils zwei Gleichungen fur jede Ver-bindung, insgesamt also 16 Gleichungen in 13 Kraften beschreiben diesenZustand. Fur die eindeutige Losbarkeit sei angenommen, daß – wie skiz-ziert – die Verbindung Nr. 1 horizontal und vertikal und die VerbindungNr. 8 vertikal fixiert sind. Mit a =
√2
2ergeben sich die Gleichungen
Nr. 2
f2 = f6
f3 = 10
Nr. 3
af1 = f4 + af5
af1 + f3 + af5 = 0
Nr. 4
f4 = f8
f7 = 0
Nr. 5
af5 + f6 = af9 + f10
af5 + f7 + af9 = 15
Nr. 6
f10 = f13
f11 = 20
Nr. 7
f8 + af9 = af12
af9 + f11 + af12 = 0Nr. 8
f13 + af12 = 0
Welche Losung ermitteln allgemeine Bibliotheksroutinen? Welche Losungermitteln Bibliotheksroutinen speziell fur Band-Matrizen?
Das den Trager beschreibende System linearer Gleichungen (mit c =√
22
)

124 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Af =
0 1 0 0 0 −1 0 0 0 0 0 0 00 0 1 0 0 0 0 0 0 0 0 0 0c 0 0 −1 −c 0 0 0 0 0 0 0 0c 0 1 0 c 0 0 0 0 0 0 0 00 0 0 1 0 0 0 −1 0 0 0 0 00 0 0 0 0 0 1 0 0 0 0 0 00 0 0 0 c 1 0 0 −c −1 0 0 00 0 0 0 c 0 1 0 c 0 0 0 00 0 0 0 0 0 0 0 0 1 0 0 −10 0 0 0 0 0 0 0 0 0 1 0 00 0 0 0 0 0 0 1 c 0 0 −c 00 0 0 0 0 0 0 0 c 0 1 c 00 0 0 0 0 0 0 0 0 0 0 c 1
f =
01000000
150
20000
lost14 f≈
−28.284320.010.0
−30.014.142120.00.0
−30.07.0711
25.020.0
−35.355325.0
.
A ist Band-Matrix mit der Bandbreite β = 5, d.h. ai,j = 0 fur |i − j| > 595...
???
4. Schreibe ein Programm zur Schatzung von cond1(A) und cond∞(A). ||A||ist einfach zu bestimmen. Die Herausforderung liegt darin, ||A−1|| durchgroße ||z||/||y|| mit Az = y nach unten abzuschatzen.Vergleiche die beiden Ansatze a) und b) anhand der beiden Matrizen
A1 =
10 −7 0−3 2 6
5 −1 5
und A2 =
−73 78 2492 66 25
−80 37 10
Vergleiche jeweils mit den exakten Ergebnissen von Bibliotheksroutinen undmit gegebenenfalls vorhandenen Konditionsschatzern.
a) Wahle y als Losung von ATy = c mit c ∈ −1,+1n. Der Vektor c derrechten Seite wird dabei wie folgt bestimmt:Mit A = LU wird zur Losung von ATy = c erst UTv = c in v und dannLTy = v in y gelost. Beim Auflosen von UTv = c wahle dabei ci = ±1jeweils so, daß |vi| maximiert wird. (Die schlechte Konditionierung von Awird sich in U widerspiegeln und ein v mit großen Komponenten liefern.Das verhaltnismaßig gut konditionierte L mit Einheitsdiagonalen wird danneben auch ein y mit großen Komponenten liefern.)
???b) Schatze ||A−1|| mit pseudo-zufalligen Vektoren y nach unten ab.
???
5. a) Lose Ax = b mit A =
21.0 67.0 88.0 73.076.0 63.0 7.0 20.00.0 85.0 56.0 54.0
19.3 43.0 32.2 29.4
und b =
141.0109.0218.093.7
mit einfacher Genauigkeit.
???b) Berechne das Residuum r = b− Ax in doppelter Genauigkeit.
???14laut MATLAB

2.6. Computer Problems – Rechner-Problem-Losungen 125
c) Lose das lineare Gleichungssystem Az = r, um die verbesserte Losungx + z zu gewinnen.
???d) Iteriere Schritte b) und c).
???
6. Die n× n-Matrix H = (hi,j) mit den Elementen hi,j = 1i+j−1
heißt Hilbert-
Matrix. Die Hilbert-Matrix H =
1 1
2· · · 1
n12
13
· · · 1n+1
......
...1n
1n+1
· · · 12n−1
ist symmetrisch
und positiv definit. Sei b = Hx ∈ Rn, wobei x = (1, . . . , 1)T ∈ Rn.Welche Losung x ermitteln Bibliotheksroutinen fur die Gauß-Elimination?Welche Losung x ermitteln Bibliotheksroutinen fur die Cholesky-Faktorisie-rung? Berechne ||r||∞ fur das Residuum r = b−Hx. Wie groß muß n wer-den, so daß die Losung keine signifikanten Ziffern enthalt? Welche Kondi-tionszahl cond(H) ermitteln Konditionsschatzer? Charakterisiere cond(H)als Funktion von n. Wie verhalten sich Anzahl der korrekten Ziffern in denKomponenten und die Konditionszahl von H fur variierendes n ?
Offensichtlich ist H symmetrisch. H ist genau dann positiv definit, wennxTHx > 0 fur jedes 0 6= x ∈ Rn. Fur beliebiges 0 6= x = (x1, x2, . . . , xn)T ∈Rn ist also
0 < xTHx = xT
∑n
j=1xj
1+j−1∑nj=1
xj
2+j−1...∑n
j=1xj
n+j−1
= xT
n∑j=1
xj
1
1+j−11
2+j−1...1
n+j−1
=n∑
i=1
n∑j=1
xixj
i+ j − 1
zu zeigen. Definiere dazu p(t) = x1 + x2t+ . . .+ xntn−1. Dann gilt
0 <
∫ 1
o
p2(t) dt =
∫ 1
o
2n−2∑k=o
tk∑
ν+µ=k0≤ν,µ≤n−1
xν+1xµ+1 dt
=2n−2∑k=o
1
k + 1
∑ν+µ=k
0≤ν,µ≤n−1
xν+1xµ+1
=2n−2∑k=o
∑ν+µ=k
0≤ν,µ≤n−1
xν+1xµ+1
ν + µ+ 1=
n∑i=1
n∑j=1
xixj
i+ j − 1
Die folgenden Graphiken zeigen das Residuum r = b−Hx der Gauß- undCholesky-Losung und cond(H) jeweils in Abhangigkeit von n.

126 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
0 2 4 6 8 10 12 14 16 18 200
0.5
1
1.5
2
2.5x 10
−15 H = hilb(n); b = H*ones(n,1); x = H\x; r = b−H*x
n
norm
(r,2
)
1/cond geschätzt = rcond ≈ 1: no warning
1/cond geschätzt = rcond ≈ eps: warning
0 2 4 6 8 10 12 14 16 18 200
1
2
3
4
5
6
7
8x 10
−16 H=hilb(n);b=H*ones(n,1); R=chol(H); y = R’ \b; x = R\y; r = b−H*x
n
norm
(r,2
)
H = hilb(n) positiv definit: CholeskyH = hilb(n) (numerisch) nicht positiv definit: Abbruch
0 2 4 6 8 10 12 14 16 18 2010
0
105
1010
1015
1020
cond(hilb(n)) und 1/rcond(hilb(n))
n
cond(hilb(n)1/rcond(hilb(n))
7. a) Gegeben A =
1 0 0 0 1
−1 1 0 0 1−1 −1 1 0 1−1 −1 −1 1 1−1 −1 −1 −1 1
. Wende auf A Gauß-Elimination
mit partial pivoting an. Was passiert?Wende auf A Gauß-Elimination mit vollstandiger Pivotisierung an. Waspassiert?
Elimination von x1
M1A =
1 0 0 0 01 1 0 0 01 0 1 0 01 0 0 1 01 0 0 0 1
A =
1 0 0 0 10 1 0 0 20 −1 1 0 20 −1 −1 1 20 −1 −1 −1 2
=
b1b1 + b2b1 + b3b1 + b4b1 + b5
= M1b
und Elimination von x2
M2M1A =
1 0 0 0 00 1 0 0 00 1 1 0 00 1 0 1 00 1 0 0 1
M1A =
1 0 0 0 10 1 0 0 20 0 1 0 40 0 −1 1 40 0 −1 −1 4
=
b1b1 + b22b1 + b2 + b32b1 + b2 + b42b1 + b2 + b5
= M2M1b
und Elimination von x3
M3M2M1A =
1 0 0 0 00 1 0 0 00 0 1 0 00 0 1 1 00 0 1 0 1
M2M1A =
1 0 0 0 10 1 0 0 20 0 1 0 40 0 0 1 80 0 0 −1 8
=
b1b1 + b22b1 + b2 + b34b1 + 2b2 + b3 + b44b1 + 2b2 + b3 + b5
= M3M2M1b
und Elimination von x4
M4M3M2M1A =
1 0 0 0 00 1 0 0 00 0 1 0 00 0 0 1 00 0 0 1 1
M3M2M1A =
1 0 0 0 10 1 0 0 20 0 1 0 40 0 0 1 80 0 0 0 16
=
b1b1 + b22b1 + b2 + b34b1 + 2b2 + b3 + b48b1 + 4b2 + 2b3 + b4 + b5
= M4M3M2M1b
liefert x =
b1/2− b2/4− b3/8− b4/16− b5/16b2/2− b3/4− b4/8− b5/8b3/2− b4/4− b5/4b4/2− b5/2b1/2 + b2/4 + b3/8 + b4/16 + b5/16
per back-substitution.
Vollstandige Pivotisierung verhindert das Wachstum (worst case 2n−1):

2.6. Computer Problems – Rechner-Problem-Losungen 127
Elimination von x1 sowie anschließendes Vertauschen von x2 und x51 0 0 0 10 1 0 0 20 −1 1 0 20 −1 −1 1 20 −1 −1 −1 2
x1
x2
x3
x4
x5
=
b1b1 + b2b1 + b3b1 + b4b1 + b5
und
1 1 0 0 00 2 0 0 10 2 1 0 −10 2 −1 1 −10 2 −1 −1 −1
x1
x5
x3
x4
x2
=
b1b1 + b2b1 + b3b1 + b4b1 + b5
und Elimination von x5 sowie anschließendes Vertauschen von x2 und x3
1 1 0 0 00 2 0 0 10 0 1 0 −20 0 −1 1 −20 0 −1 −1 −2
x1
x5
x3
x4
x2
=
b1b1 + b2b3 − b2b4 − b2b5 − b2
und
1 1 0 0 00 2 1 0 00 0 −2 0 10 0 −2 1 −10 0 −2 −1 −1
x1
x5
x2
x4
x3
=
b1b1 + b2b3 − b2b4 − b2b5 − b2
und Elimination von x2 sowie anschließendes Vertauschen von x4 und x3
1 1 0 0 00 2 1 0 00 0 −2 0 10 0 0 1 −20 0 0 −1 −2
x1
x5
x2
x4
x3
=
b1b1 + b2b3 − b2b4 − b3b5 − b3
und
1 1 0 0 00 2 1 0 00 0 −2 1 00 0 0 −2 10 0 0 −2 −1
x1
x5
x2
x3
x4
=
b1b1 + b2b3 − b2b4 − b3b5 − b3
und Elimination von x3 sowie anschließende back-substition liefern
1 1 0 0 00 2 1 0 00 0 −2 1 00 0 0 −2 10 0 0 0 −2
x1
x5
x2
x3
x4
=
b1b1 + b2b3 − b2b4 − b3b5 − b4
sowie
x1
x5
x2
x3
x4
=
b1/2− b2/4− b3/8− b4/16− b5/16b1/2 + b2/4 + b3/8 + b4/16 + b5/16b2/2− b3/4− b4/8− b5/8b3/2− b4/4− b5/4b4/2− b5/2
.
b) Lose Ax = b fur entsprechende, großere A mit bekannten Losungenx zu berechneten rechten Seiten b = Ax. Welche Losung x ermittelnBibliotheksroutinen fur Gauß-Elimination? Wie hangen Fehler, Residuumund Konditionszahl von der Dimension von A ab?
0 200 4000
200
400
600
800
1000
1200
1400
1600
1800
2000
||b−A*x||2 mit b=A*ones(n,1)
0 200 4000
50
100
150
||A\b−ones(n,1)||2
0 200 4000
20
40
60
80
100
120
140cond(A)
8. D sei Diagonal-Matrix. Ubergang von Ax = b zu DAx = Db verandertdie Konditionierung des Gleichungssystemes und kann die Genauigkeit derLosung verbessern.Experimentiere mit pseudo-zufalligen Matrizen A, berechneten rechten Sei-ten b zu bekannten Losungen x und Diagonal-Matrizen D. Beobachte dabeiFehler, Residuum und Konditionszahl cond(DA) von DA.
???

128 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
9. a) Lose Ax =
(ε 11 1
)x =
(1 + ε
2
)= b mit ε = 10−2k fur k = 1, 2, . . . , 10
ohne Pivotisierung. Die exakte Losung x = (1, 1)T ist unabhangig von ε.(ε 10 1− 1
ε
)x =
(1 + ε
2− 1+εε
)liefert x2 = 2−(1+ε)/ε
1−1/ε= 1 und x1 = 1+ε−x2
ε= 1.
k =ε = 1
102k =x =
( )inc kreset
Fur ε < εmach gilt namlich fl(1 − 1/ε) = −1/ε = fl(2 − 1/ε). Elimination
liefert daher
(ε 10 −1
ε
)x =
(1−1
ε
)und so die Losung x = (0, 1)T .
b) Fur kleine ε verbessere die Losung durch eine Iteration des iterative84refinement. Wie verhalt sich die Genauigkeit der Losung fur ε→ 0 ?
Zu jeder Losung x berechne das zugehorige Residuum r = b − Ax, loseAs = r und verbessere x durch x + s. Aus b −Ax = r = As folgt dannnamlich b = A(x + s).
k =ε = 1
102k =x =
( )r = b−Ax =
( )s =
( ) inc krefinereset
10. Exakte Losung von Ax =
(1 1+ε
1−ε 1
)x =
(1+(1+ε)ε
1
)= b ist x =54 (
1ε
).
Welche Losung x ermitteln Bibliotheksroutinen fur Gauß-Elimination furε ≈ √
εmach? Schatze cond(A) und die Genauigkeit der Losung und verglei-che mit den Fehler-Schranken. Welche Schlusse sind aus diesem Beispiel zuziehen?
Sei ε > 0. Dann gilt ||A||1 = 2 + ε = ||A||∞.
Aus A−1 = 11−(1−ε2)
(1 −1−ε
−1+ε 1
)= 1
ε2
(1 −1−ε
−1+ε 1
)folgt ||A−1||1 =
2+εε2
= ||A−1||∞ und damit cond(A) = ||A|| · ||A−1|| = (2+εε
)2.???
11. a) Programmiere Gauß-Elimination ohne Pivotisierung, mit partieller Pi-votisierung, mit vollstandiger Pivotisierung. ...
???b) Erzeuge pseudo-zufallige Matrizen, Losungen und zugehorige rechte Sei-ten. Vergleiche Genauigkeit, Residua und performance der drei Implemen-tierungen.
???c) Fur welche Matrix ist vollstandige Pivotisierung signifikant genauer alspartielle Pivotisierung?
???

2.6. Computer Problems – Rechner-Problem-Losungen 129
12. Programmiere die Losung von tridiagonalen Gleichungssystemen ohne undmit partieller Pivotisierung. Teste auch anhand von positiv definiten Ma-trizen. Vergleiche dann Cholesky- mit LU-Faktorisierung.
???
13. Programmiere die Berechnung der Determinante einer Matrix per LU-Fak-torisierung. Vorzeichen? underflow? overflow?
det(A) = det(LU) = det(L) · det(U) = det(U) =∏n
i=1 ui,i falls L untere???
Dreiecksmatrix mit Einheitsdiagonale ist.
14. A seim×n-Matrix und B sei n×k-Matrix. Dann ist C = ABm×k-Matrix.
a) Berechne C durch mk innere Produkte, also mk Aufrufe von sdot in 91BLAS.
Mit ci,j =∑n
k=1 ai,kbk,j wird C durch mk innere Produkte, also mk Aufrufevon sdot in BLAS berechnet.
b) Berechne jede Spalte von C als Linear-Kombination der Spalten von A, 91also durch mk Aufrufe von saxpy in BLAS.
Mit A = (a.,1, . . . , a.,n) = (a1, . . . , an) und C = (c.,1, . . . , c.,n) = (c1, . . . , cn)ist wegen cj = c.,j =
∑nk=1 a.,kbk,j =
∑nk=1 bk,jak jede Spalte von C eine
Linear-Kombination der Spalten von A. Also wird C durch mk Aufrufevon saxpy in BLAS berechnet.
Fuhre beobachtete performance Unterschiede auf caching (Große, Organi-sation, Schreibstrategien) und Speicher-Organisation etc. zuruck.
???
15. Gauß-Elimination ohne Pivotisierung erfolgt in drei geschachtelten Schlei-fen. Es gibt sechs Anordnungen dieser drei geschachtelten Schleifen. Ver-gleiche jeweils die performance fur genugend große Matrizen, die auch ohnePivotisierung trianguliert werden konnen.
Gauß-Elimination ohne Pivotisierung erfolgt in drei geschachtelten Schleifen
for(i=1;i<n;i++) // eliminiere i-te Unbekannte
for(j=i+1;j<=n;j++) // in der j-ten Gleichung
for(k=i;k<=n;k++) a[j][k]-=(a[j][i]/a[i][i])*a[i][k]
oder – mit derselben Funktionalitat –
for(i=1;i<n;i++) // eliminiere i-te Unbekannte
for(j=i+1;j<=n;j++) // in der j-ten Gleichung
for(k=1;k<=n;k++) a[j][k]-=(a[j][i]/a[i][i])*a[i][k]
oder – mit derselben Funktionalitat –

130 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
for(i=1;i<n;i++) // eliminiere i-te Unbekannte
for(j=1;j<=n;j++) if (i!=j) // in der j-ten Gleichung
for(k=1;k<=n;k++) a[j][k]-=(a[j][i]/a[i][i])*a[i][k]
Es gibt nun sechs Anordnungen dieser drei geschachtelten Schleifen.
Fuhre beobachtete performance Unterschiede auf caching (Große, Organi-sation, Schreibstrategien) und Speicher-Organisation etc. zuruck.
???
16. forward substitution lost Gleichungssysteme mit unterer Dreiecksmatrix.backward substitution lost Gleichungssysteme mit oberer Dreiecksmatrix.In beiden Fallen lassen sich die beiden Schleifen vertauschen. Vergleichedie performance der vier moglichen Algorithmen fur genugend große Drei-ecksmatrizen.
forward-substitution lost Gleichungssysteme mit unterer Dreiecksmatrix65
x[1]=b[1]/a[1][1];
for(i=2;i<=n;i++) // berechne x[i]
x[i]=b[i]/a[i][i];
for(j=1;j<i;j++) x[i]-=a[i][j]*x[j];
oder – mit derselben Funktionalitat –
x[1]=b[1]/a[1][1];
for(i=2;i<=n;i++) // berechne x[i]
x[i]=b[i]/a[i][i];
for(j=1;j<=n;j++) if (i!=j) x[i]-=a[i][j]*x[j];
backward-substitution lost Gleichungssysteme mit oberer Dreiecksmatrix66
x[n]=b[n]/a[n][n];
for(i=n-1;i>=1;i--) // berechne x[i]
x[i]=b[i]/a[i][i];
for(j=i+1;j<=n;j++) x[i]-=a[i][j]*x[j];
oder – mit derselben Funktionalitat –

2.6. Computer Problems – Rechner-Problem-Losungen 131
x[n]=b[n]/a[n][n];
for(i=n-1;i>=1;i--) // berechne x[i]
x[i]=b[i]/a[i][i];
for(j=1;j<=n;j++) if (i!=j) x[i]-=a[i][j]*x[j];
Die beiden Schleifen lassen sich also vertauschen.???
Fuhre beobachtete performance Unterschiede auf caching (Große, Organi-sation, Schreibstrategien) und Speicher-Organisation etc. zuruck.
17. Ein Kragtrager ist an einem Ende fest eingespannt und am anderen Endefrei. Bei vorgegebenen Lasten b an diskreten Stellen auf dem Trager ergibtsich die Auslenkung x in diesen Stellen als Losung von Ax = b mit
A =
9 −4 1 0 . . . . . . 0
−4 6 −4 1. . .
...
1 −4 6 −4 1. . .
...
0. . . . . . . . . . . . . . . 0
.... . . 1 −4 6 −4 1
.... . . 1 −4 5 −2
0 . . . . . . 0 1 −2 1
a) Sei n = 100 und b = (1, 1, . . . , 1)T . Vergleiche die Losungen per Bi-bliotheksroutinen fur Gauß-Elimination fur beliebige mit solchen fur Band-Matrizen oder dunn besetzte Matrizen.
???b) A hat eine UL-Faktorisierung A = RRT mit oberer Dreiecksmatrix R
R =
2 −2 1 0 . . . 0
0 1 −2 1. . .
......
. . . . . . . . . . . . 0...
. . . 1 −2 1...
. . . 1 −20 . . . . . . . . . 0 1
mit RT =
2 0 . . . . . . . . . 0
−2 1. . .
...
1 −2 1. . .
...
0. . . . . . . . . . . .
......
. . . 1 −2 1 00 . . . 0 1 −2 1
Zunachst ist A = (ai,j) = 0 bis auf a1,1 = 9, an−1,n−1 = 5, an,n = 1 undai,i = 6 fur i = 2, . . . , n− 2, ai,i±1 = −4 und ai,i±2 = 1 sowie R = (ri,j) = 0bis auf r1,1 = 2, ri,i = 1 fur i 6= 1, ri,i+1 = −2 und ri,i+2 = 1. Also istRT = (si,j) = 0 bis auf s1,1 = 2, si,i = 1 fur i 6= 1, si,i−1 = −2 undsi,i−2 = 1.

132 KAPITEL 2. SYSTEMS OF LINEAR EQUATIONS
Damit gilt (RRT )1,1 =∑n
k=1 r1,ksk,1 = 22+(−2)2+12 = 9, (RRT )n−1,n−1 =∑nk=1 rn−1,ksk,n−1 = 12 + (−2)2 = 5, (RRT )n,n =
∑nk=1 rn,ksk,n = 12 = 1,
(RRT )i,i =∑n
k=1 ri,ksk,i = 12 + (−2)2 + 12 = 6 fur i = 2, . . . , n − 2,(RRT )i,i+1 =
∑nk=1 ri,ksk,i+1 = 0 + 0 + (−2) · 1 + 1 · (−2) = −4 sowie
(RRT )i,i−1 = −4 und (RRT )i,i+2 =∑n
k=1 ri,ksk,i+2 = 0 + 0 + 1 · 1 + 0 =1 sowie (RRT )i,i−2 = 1. Fur |i − j| > 2 gilt schließlich (RRT )i,j =∑n
k=1 ri,ksk,j =∑i+2
k=i ri,ksk,j = 1 · si,j − 2 · si+1,j + si+2,j = 0, da fur i > j+2mit si,j = 0 auch si+1,j = 0 sowie si+2,j = 0 und fur j > i+ 2 und a fortiorij > i + 1 und j > i eben auch si+2,j = 0, si+1,j = 0 sowie si,j = 0 gilt.Insgesamt ist also A = RRT .Sei n = 1000. Lose das Gleichungssystem in der UL-Faktorisierung. Ver-gleiche Losung mit derjenigen der Bibliotheksroutinen aus a). Bestimmecond(A). Welche Genauigkeit ist zu erwarten? Kann die Genauigkeit durchiterative refinement verbessert werden?
???

Kapitel 3
Linear Least Squares
niedrig-dimensionale Approximation eines hoher-dimensionalen Sachverhaltes!
Z.B. Mittelwert, Ausgleichsgerade, ’Ausgleichsparabel’, usw.; Astronomie (Gauß),Statistik, Vermessung, etc.: Extraktion von Signalen oder Trends aus einer Meß-wertreihe clineare vs nichtlineare Probleme
Z.B. linear: Bestimme R in u(ı) = R ı aus (ı`, u`) fur ` = 1, . . . ,mnicht-linear: Bestimme τ in u(t) = uoe
−t/τ aus (ti, Ui) fur i = 1, . . . ,m Abhilfe? c
3.0.1 data fitting – lineare Ausgleichsrechnung
Def. A sei m× n-Matrix. Falls m > n, heißt Ax = b uberbestimmt. Ein uberbestimmtes System hat i.a.R. keine exakte Losung. Gesucht ist approxi-mative Losung x von Ax ∼= b, namlich die Minimierung von ||r||2 = ||b−Ax||2.Z.B. Gegeben m Meßpunkte (ti, yi) fur i = 1, . . . ,m. Gesucht sei die sogenannte
Ausgleichs/Regressionsgerade y = x2t+x1, die die Summe∑m
i=1 (yi−(x2ti+x1))2
der Fehlerquadrate (least squares) minimiert. cZ.B. Gegeben gemessene Hohen x1 = 1237, x2 = 1941 und x3 = 2417 sowie diegemessenen Hohendifferenzen x2 − x1 = 711, x3 − x1 = 1177 und x3 − x2 = 475.
Ax =
1 0 00 1 00 0 1
−1 1 0−1 0 1
0 −1 1
x1
x2
x3
∼=
123719412417711
1177475
= b lost x =
123619432416
c
Z.B. Gegeben (ti, yi) fur i = 1, . . . ,m und Modell-Funktion, d.h. eine mehrfach
133

134 KAPITEL 3. LINEAR LEAST SQUARES
parametrisierte Familie von Funktionen f(t,x) : R × Rn → R. Gesucht ist x∗
bzw. f(t,x∗), also die Funktion, die∑m
i=1 (yi−f(t,x))2
minimiert:∑m
i=1 (yi−f(t,x∗))
2= minx
∑mi=1 (yi−f(t,x))
2. c
Def. Bestimmung von f(t,x∗) heißt linear least squares Problem, falls f(t,x)vgl.3RQ10 linear in x ist, sonst non-linear least squares Problem.
Sei f(t,x) = x1φ1(t) + x2φ2(t) + . . . + xnφn(t) und A = (ai,j) sei m × n-Matrixmit ai,j = φj(ti) und b = y.
Ax ∼= b
Z.B. Gegeben (ti, yi) fur i = 1, . . . , 21 wie folgt:
t 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0y 2.9 2.7 4.8 5.3 7.1 7.6 7.7 7.6 9.4 9.0 9.6
t 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0y 10.0 10.2 9.7 8.3 8.4 9.0 8.3 6.6 6.7 4.1
Gesucht ist die Parabel, die die Summe der Fehlerquadrate minimiert. DieBasis-Funktionen φj(t) sind also gerade die j-ten Monome φj(t) = tj−1 fur j =1, 2, 3. Die Modelfunktionen f(t,x) sind die Polynome zweiten Grades f(t,x) =∑3
j=1 xjφj(t) =∑3
j=1 xjtj−1 mit zu bestimmendem Koeffizienten-Vektor x.
Ax =
1 0.0 0.01 0.5 0.251 1.0 1.0...
......
1 10.0 100.0
x1
x2
x3
∼=
2.92.74.8
...4.1
= b lost x =
2.182.67
−0.238
t
y
0 2 4 6 8 102
4
6
8
10
c

135
3.0.2 Existenz und Eindeutigkeit
Intuitiv gilt folgenderSatz Fur das linear least squares Problem Ax ∼= b existiert immer eine Losungy = Ax ∈ span(A), die ||r||2 = ||b− y||2 = ||b−Ax||2 minimiert. •Bew. Die Funktion φ(y) = ||b−y|| ist stetig und auf der unbeschrankten MengeRm coercive, d.h. lim||y||→∞ φ(y) = +∞. Dann hat φ auf der abgeschlossenen,unbeschrankten Menge span(A) ein Minimum. Da weiterhin φ auf der konvexenMenge span(A) streng konvex ist, ist das Minimum y ∈ span(A) eindeutig.
√
Aus Ax1 = y = Ax2 mit x1 6= x2 folgt fur z = x2−x1 6= 0 eben Az = 0, die Spal-ten von A sind l.a. oder m.a.W. rank(A) < n: Das linear least squares Problemhat also mehrere Losungen nur dann, wenn A Rang-defizient ist. Die Losung deslinear least squares Problems ist eindeutig, genau dann wenn rank(A) = n, d.h.wenn A maximalen Rang hat.
Normalen-Gleichungen – die analytische Sicht
Zu minimieren ist die Funktion Φ : Rn → R
Φ(x) = ||r||22 = rT r = (b−Ax)T (b−Ax) = bTb− 2xTATb + xTATAx
Notwendige Bedingung fur einen Extrem-Wert in x ist, daß alle partiellen Ablei-tungen ∂Φ/∂xi in x verschwinden, d.h. daß der Gradient ∇Φ in x verschwindet.
grad(Φ)(x) = ∇Φ(x) = 0 = 2ATAx− 2ATb d.h. ATAx = ATb
Zusatzliche hinreichende Bedingung ist, daß die (Hesse’sche) Matrix der zweitenpartiellen Ableitungen positiv definit ist: d.h. hier, daß ATA positiv definit ist. vgl. 3RQ16ATA ist positiv definit ⇐⇒ rank(A) = n.
Z.B. Gegeben seien wieder die absoluten und relativen Hohen-Messungen
Ax =
1 0 00 1 00 0 1
−1 1 0−1 0 1
0 −1 1
x1
x2
x3
∼=
123719412417711
1177475
= b
ATAx =
3 −1 −1−1 3 −1−1 −1 3
x1
x2
x3
=
−65121774069
= ATb lost x =
123619432416
mit ||r||22 = ||b−Ax||22 = 35. cOrthogonalitat – die geometrische und die algebraische Sicht

136 KAPITEL 3. LINEAR LEAST SQUARES
Fur Ax ∼= b mit m×n-Matrix A und b ∈ Rm ist i.a.R. b 6∈ span(A). Gesucht istdas y mit y = Ax ∈ span(A), das b am nachsten ist, d.h. das ||b−Ax||2 = ||r||2minimiert, d.h. b ⊥ span(A), d.h. b ⊥ ai fur i = 1, . . . , n mit A = (a1, . . . , an).
y = Ax
b r = b−Ax
span(A)
r ⊥ span(A) ⇐⇒ 0 = AT r = AT (b−Ax) ⇐⇒ ATAx = ATb
y ist also die orthogonale Projektion von b auf span(A).
Def. Eine quadratische Matrix P heißt Projektor, falls P idempotent ist, d.h.falls P2 = P. Ein n× n-Projektor P projiziert Rn auf PRn = span(P).
Def. Ein Projektor P heißt orthogonal, falls P symmetrisch ist, d.h. fallsPT = P gilt. Sei P ein orthogonaler Projektor. Dann ist P⊥ = I−P orthogonaler Projektor aufspan(P)⊥ = v : v ⊥ w fur alle w ∈ span(P), auf das sogenannte orthogonaleKomplement von span(P) und jedes v ∈ Rm ist als v = (P + (I − P))v =
Pv + P⊥v mit span(P) 3 Pv ⊥ P⊥v ∈ span(P)⊥ darstellbar.
Gegeben Ax ∼= b und ein orthogonaler Projektor P auf span(A), d.h. PA = A.
||r||22 = ||b−Ax||22 = ||P(b−Ax) + P⊥(b−Ax)||22= ||P(b−Ax)||22 + ||P⊥(b−Ax)||22 (Pythagoras)
= ||Pb−Ax||22 + ||P⊥b||22 da PA = A und P⊥A = 0
||P⊥b||22 ist unabhangig von x und daher konstant. Also ist ||r||22 minimal, wennx Losung des uberbestimmten, aber konsistenten Gleichungssystems Ax = Pbist: Multiplikation mit AT liefert ATAx = ATPb = ATPTb = (PA)Tb = ATb,also erneut das System der Normalen-Gleichungen.
Falls A maximalen Rang hat, ist ATA regular und P = A(ATA)−1AT ist sym-metrisch und idempotent, also ein Projektor auf span(A).
3.0.3 Sensitivitat und Konditionierung
Fur Sensitivitat und Konditionierung von Ax ∼= b ist die Definition cond(A) =||A|| · ||A−1|| auf nicht-quadratische Matrizen A zu verallgemeinern:

137
Def. Die n×m-Matrix A+ heißt die Pseudo-Inverse der m× n-Matrix A. Nurfur Matrizen A mit rank(A) = n ist ATA regular und A+ = (ATA)−1AT . Offensichtlich verhalt sich A+ wegen A+A = (ATA)−1ATA = I wie eine Inverseund nach dem obigen ist P = AA+ ein orthogonaler Projektor auf span(A). 3Ex32
Ax ∼= b wird gelost durch x = A+b
Def. Die Konditionszahl cond(A) einer m × n-Matrix A mit vollem Spalten-Rang, d.h. rank(A) = n ist durch cond(A) = ||A||2 · ||A+||2 definiert. Im Gegensatz zu linearen Gleichungssystemen hangt die Kondition eines leastsquares Problems Ax ∼= b auch von b ab: falls b nahe bei span(A), dann re-sultieren kleine Anderungen von b in nur kleinen Anderungen von y = Pb.Falls aber b mehr oder weniger senkrecht auf span(A) steht, dann verursachenkleine Anderungen von b relativ große Anderungen von y = Pb und damit vonx (|y| = |b| cos ∠(b, span(A)), also die zu cos′ = − sin proportionale Anderungmaximal fur π
2).
cos θ = cos ∠(b,y) =||y||2||b||2
=||Ax||2||b||2
Die Sensitivitat ist um so großer, je kleiner der Quotient, je naher θ bei π2
liegt.
Sensitivitat auf Anderungen von b
Gegeben Ax ∼= b mit rank(A) = n. Die Normalengleichungen ATA(x + ∆x) =AT (b + ∆b) bei variiertem b implizieren ATA∆x = AT∆b oder eben x =(ATA)−1AT ∆b = A+∆b. Also folgt ||∆x||2 ≤ ||A+||2 · ||∆b||2 und es gilt
||∆x||2||x||2
≤ ||A+||2||∆b||2||x||2
= cond(A)||b||2
||A||2 · ||x||2||∆b||2||b||2
≤ cond(A)||b||2||Ax||2
||∆b||2||b||2
= cond(A)1
cos θ
||∆b||2||b||2
Sensitivitat auf Anderungen von A
Fur (A + E)x ∼= b schließt man in ahnlicher Weise
||∆x||2||x||2
≤ ((cond(A))2 tan θ + cond(A))||E||2||A||2
Z.B. Gegeben sei wieder der Hohen-Datensatz
Ax =
1 0 00 1 00 0 1
−1 1 0−1 0 1
0 −1 1
x1
x2
x3
∼=
123719412417711
1177475
= b

138 KAPITEL 3. LINEAR LEAST SQUARES
Dann ist A+ = (ATA)−1AT = 14
2 1 1 −1 −1 01 2 1 1 0 −11 1 2 0 1 1
und ||A||2 = 2 sowie
||A+||2 = 1, so daß cond(A) = ||A||2 · ||A+||2 = 2 folgt. Wegen der kleinen
Konditionszahl und wegen cos θ = ||Ax||2||b||2 = ||y||2
||b||2 ≈ 0.99999868 mit θ ≈ 0.001625
ist das Problem gut konditioniert. cZ.B. Fur ε ≈ √
εmach und
A =
1 1ε −ε0 0
sowie E =
0 00 0−ε ε
gilt cond(A) = 1
εund ||E||2/||A||2 = ε.
Falls b = (1, 0, ε)T ist ||∆x||2/||x||2 = 0.5 und tan θ ≈ ε: der quadratische Term(cond(A))2 tan θ ist vernachlassigbar!Falls b = (1, 0, 1)T ist ||∆x||2/||x||2 = 0.5/ε und tan θ ≈ 1: das Problem istschlecht konditioniert. c
3.0.4 Problem-Transformationen
Es gibt mehrere Methoden, ein uberbestimmtes System Ax ∼= b in ein quadrati-sches System am besten mit dreieckiger Koeffizienten-Matrix zu transformieren.
Normalen-Gleichungen
Die Losung von linear least squares Problemen per System der Normalen-Glei-chungen, also Uberfuhrung von Ax ∼= b in das quadratische GleichungssystemATAx = ATb mit anschließender Triangulierung, kann numerisch unbefriedi-gend sein:
• wegen Rundungsfehlern bei der Berechnung von ATA und/oder ATb
Z.B. Mit A =
1 1ε 00 ε
ist fl(ATA) = fl
(1 + ε2 1
1 1 + ε2
)=
(1 11 1
)fur
0 < ε < εmach sogar singular. c
• cond(ATA) = (cond(A))2
Ziel: Uberfuhrung von linear least squares Problemen Ax ∼= b in mathematischaquivalente, aber numerisch vorteilhaftere Form

139
Augmented System
Def. Ein linear least squares Problem Ax ∼= b ist aquivalent zum (m + n) ×(m+ n) linearen Gleichungssystem, dem augmented system
r + Ax=bAT r=0
bzw.
[I A
AT 0
] [rx
]=
[b0
]dessen Losung sowohl x als auch gleich das zugehorige Residuum r liefert.
Skalieren
[αI AAT 0
] [r/αx
]=
[b0
]des augmented system
[I A
AT 0
] [rx
]=
[b0
]kann durch geeignete Gewichtung – etwa α = 0.001 maxi,j |ai,j| – die numeri-schen Schwachen der Normalen-Gleichungen ausgleichen. Zugleich konnen aberdie Kosten O((m+ n)3) abschrecken, wenn man nicht die Struktur des augmen-ted system effizient ausnutzt. MATLABs spaugment tut dies fur dunn besetzteMatrizen mit obigem α.
Orthogonale Transformationen
Def. Quadratische Matrizen Q mit QTQ = I heißen orthogonal. Wegen ||Qx||22 = (Qx)TQx = xTQTQx = xTx = ||x||22 sind orthogonale Matri-zen Norm-erhaltend und damit die Kandidaten fur Problem-Transformationen.
Wir haben Koeffizienten-Matrizen linearer Gleichungssysteme in obere Dreiecks-gestalt uberfuhrt, um das Gleichungssystem zu losen; wir verwenden die LU-Faktorisierung, um Determinanten zu berechnen. hier erlauben orthogonale Ma-trizen als Norm-erhaltende Transformationen das linear least squares Problem inobere Dreiecksgestalt zu uberfuhren, so daß es dann leicht und numerisch stabilzu losen ist.
Dreieckige linear least squares Probleme
Unser Ziel muß sein, ein linear least squares Problem Ax ∼= b mit orthogona-len Transformationen in Dreiecksgestalt zu uberfuhren. Das Problem bekommt
so die Form
[R0
]x ∼=
[c1
c2
], wo R eine obere n × n-Dreiecksmatrix ist und der
(transformierte) Vektor der rechten Seite sich aus c1 ∈ Rn und c2 ∈ Rm−n zu-sammensetzt.
Weil der zweite Summand unabhangig von x ist, ist das Residuum ||r||22 = ||c1−Rx||22 + ||c2||22 minimal, wenn Rx = c1 gilt. Fur dreieckige linear least squaresProbleme laßt sich die Losung x einfach durch back substitution bestimmen.Zudem gilt fur die minimale Summe der Fehler-Quadrate ||r||22 = ||c2||22.

140 KAPITEL 3. LINEAR LEAST SQUARES
QR-Faktorisierung
Def. Fur Ax ∼= b mit m × n-Matrix A ist eine orthogonale m × m-Matrix
Q so zu bestimmen, daß A = Q
[R0
]mit oberer Dreiecksmatrix R gilt. Diese
Darstellung von A heißt QR-Faktorisierung von A.
Wegen ||b−Ax||2 = ||b−Q
[R0
]x||2 = ||QTb−
[R0
]x||2 = ||
[c1
c2
]−[R0
]x||2 =
||c2||2 ist dann nur Rx = c1 mit c = QTb zu losen.
3.0.5 Orthogonalisierungsmethoden
QR-Faktorisierung erfolgt u.a. per
• Householder Transformationen
• Givens Rotationen
• Gram-Schmidt-Orthogonalisierung
Householder Transformation
Wie bei linearer Gleichungssysteme Eliminationsmatrizen werden bei linear leastsquares Problemen Householder Transformationen zur Triagonalisierung verwen-det.
Def. Householder Transformationen oder elementare Reflektoren sind Matrix-Transformationen H mit Matrizen der Form H = I− 2
vT vvvT fur v 6= 0.
Offensichtlich sind Householder Transformationsmatrizen H symmetrisch undwegen HTH = (I − 2
vT vvvT )
2= I − 4
vT vvvT + ( 2
vT vvvT )
2= I − 4
vT vvvT +
4(vT v)2
vvTvvT = I− 4vT v
vvT + 4vT v
vvT = I orthogonal. Sie sind damit geeigneteKandidaten fur die Triangulierung:Gegeben ein Vektor a, der so transformiert werden soll, daß alle seine Kompo-nenten bis auf die erste verschwinden, d.h. Ha = αe1. Auflosen von
Ha = (I−2
vTvvvT )a = a− 2
vTa
vTvv = αe1
nach v liefert v = vT v2vT a
(a− αe1). Der skalare Faktor kann ignoriert werden, weiler sich in H sowieso herauskurzt, also v = a − αe1. Damit H die Norm erhalt,damit also ||Ha||2 = |α| = ||a||2 gilt, muß α = ±||a||2 gelten. Um Ausloschungin v zu vermeiden, wahlen wir α = − sgn(a1)||a||2.

141
Die geometrische Interpretation der Funktionsweise der Householder Transfor-mation ist hilfreich. Um einen beliebigen Vektor a – unter Beibehaltung sei-ner Norm – in die x-Achse zu transformieren und so alle anderen Komponen-ten zu annullieren, kann a an den beiden gestrichelt dargestellten Hyperebe-nen gespiegelt werden. Nur zur Erinnerung: Derartige Hyperebenen sind durchspan()⊥ = x : vTx = 0 fur ein v 6= 0 gegeben. Das Ergebnis der Transforma-tion ist dann je nach Hyperebene entweder −||a||2e1 oder +||a||2e1.
e1
(e1)⊥
a
span(v)⊥
a− vTavTv
v
a− vTavTv
v
−||a||2e1
vTavTv
v
e1
(e1)⊥
a
span(v)⊥
a− vTavTv
v
a− vTavTv
v
||a||2e1
vTavTv
v
Die Skizze zeigt, daß v ’parallel’ zu a − αe1 liegen muß. Dabei ist je nachHyperebene α = ±||a||2. In Abschnitt 3.0.2 auf S. 136 haben wir gesehen, daßder orthogonale Projektor P auf span(v) durch P = v(vTv)vT = 1
vT vvvT und
derjenige auf span(v)⊥ durch I−P gegeben sind. Also liegt (I−P)a = a− vT avT v
v in
der Hyperebene und erst Ha = (I−2P)a = a−2vT avT v
v in der ersten Koordinaten-Achse.Prinzipiell arbeitet H = I − 2P fur jede der beiden Hyperebenen gleichwertig.Um aber bei der Berechnung von v Ausloschung zu vermeiden, wahlen wir dasVorzeichen von α so, daß Ha und a voneinander moglichst weit entfernt sind.
Z.B. Sei a = (a1, a2, a3)T = (2, 1, 2)T so zu transformieren, daß Ha = αe1 gilt.
Dann ist v = a − αe1 = (5, 1, 2)T mit α = − sgn(a1)||a||2 = −3. Zur Probe
berechnen wir Ha = a− 2vT avT v
v = (−3, 0, 0)T und verifizieren, daß H den Vektora Norm-erhaltend in ein Vielfaches von e1 transformiert, d.h. daß alle bis auf dieerste Komponente von Ha verschwinden. cUm Ha = [b1,0]T mit b1 ∈ Rk−1 fur gegebenes a = [a1, a2]
T mit a1 ∈ Rk−1 unda2 ∈ Rn−k+1 zu erzielen, wahlen wir v = [0, a2]
T − αek mit α = − sgn(ak)||a2||2.Denn dann gilt wegen α2 = ||a2||22
Ha = a−2vTa
vTvv = a− 2(||a2||22 − αak)
||a2||22 − 2αak + α2v = a− ||a2||2 + sgn(ak)ak
||a2||2 + sgn(ak)ak
v =
a1
−α0
Mit einer geegneten Reihe von Householder Transformationen konnen wir so eineMatrix Norm-erhaltend in eine obere Dreiecksmatrix uberfuhren.

142 KAPITEL 3. LINEAR LEAST SQUARES
function R = HouseholderQR (A)% HOUSEHOLDERqr(A) ermittelt die QR-Faktorisierung% von A per Householder Transformation – eigentlich in place[m, n ] = s ize (A) ;for k = 1 : n % fur jede Spalte k
alpha = −sign (A(k , k ) )∗ sqrt (A(k :m, k ) ’∗A(k :m, k ) ) ;v = [ zeros (k , 1 ) A(k :m, k ) ] ; v ( k)=v(k)−alpha ;beta = v ’∗ v ;i f (beta == 0) % wenn schon ’annulliert’,
cont inue ; % ist in dieser Spalteend % nichts zu tunfor j = k : n % wende H auf
gamma = v ’∗A( : , j ) ; % j-te Spalte anA( : , j ) = A( : , j )−(2∗gamma/beta )∗v ;
endendR = triu (A) ;end
...
Auf diese Weise setzen wir eine Folge H1, . . . , Hn von Householder Transformati-onsmatrizen ein, um die Matrix A in eine obere Dreiecksmatrix Hn . . .H2H1A =[R0
]zu uberfuhren. Mit den Hi ist auch QT = Hn . . .H2H1 und daher ebenso
Q = H1H2 . . .Hn orthogonal. Insgesamt gilt also A = Q
[R0
].
Givens Rotationen
Householder Transformationen annullieren in einem Schritt ganze (Teil-) Spalten.In bestimmten Situationen kann es gunstiger sein, individuelle Elemente zu annul-
lieren. Das leisten Rotationen der Ebene, die Givens Rotationen G =
(c s−s c
)mit dem Kosinus c und dem Sinus s des betreffenden Rotationswinkels und da-her mit c2 + s2 = 1. Wir wollen also a = (a1, a2)
T der Ebene in einen Vektor
in der ersten Koordinaten-Achse drehen, d.h. Ga =
(c s−s c
)a =
(α0
). Um c
und s zu bestimmen, schreiben wir Ga =
(a1 a2
a2 −a1
)(cs
)=
(α0
)und erhalten
c = α a1
a21+a2
2und s = α a2
a21+a2
2als Losung des linearen Gleichungssystemes in c und

143
s. Mit c2 + s2 = 1 skaliert, ergibt sich
c =a1
a21 + a2
2
und s =a2
a21 + a2
2
Skalieren durch Erweitern vermeidet unnotigen overflow oder underflow: Falls|a1| ≥ |a2| gewinnen wir c = 1/
√1 + t2 und s = c · t aus dem Tangens t = s/c =
a2/a1 und falls |a2| ≥ |a1| gewinnen wir s = 1/√
1 + τ 2 und c = s · τ aus demCotangens τ = c/s = a1/a2.
Z.B. Damit eine Givens Rotation a2 in a = [a1, a2]T = [3, 4]T annulliert, berech-
nen wir direkt den Cosinus c = a1
a21+a2
2des Drehwinkels zu c = 4
5und den Sinus
s = a2
a21+a2
2des Drehwinkels zu s = 3
5. Ebenso ergibt der Tangens t = a2
a1= 3
4die
zugehorigen Cosinus c und Sinus s zu
c =1√
1 + t2=
4
5und s = c · t =
4
5
3
4=
3
5
Die Givens Rotation G =
(c s−s c
)= 1
5
(4 3
−3 4
)annulliert wegen Ga = [5, 0]T
wie beabsichtigt a2 und erhalt dabei die Norm ||a||2 = 5 = ||Ga||2. c...
Gram-Schmidt-Orthogonalisierung
Wir als letztes Verfahren zur QR-Faktorisierung stellen wir die Gram-Schmidt-Orthogonalisierung vor. Seien zunachst zwei Vektoren a1 und a2 gegeben undzwei orthonormale Vektoren q1 und q2 gesucht, die denselben Unterraum auf-spannen wie a1 und a2. Als Erstes normalisieren wir dazu a1, indem wir q1 =a1/||a1||2 setzen. Als nachstes annullieren wir die q1-Komponente von a2, in-dem wir etwa a2 orthogonal auf span(q1) projizieren. Ein Weg ist, das linearleast squares Problem q1γ ∼= a3 zu losen, etwa anhand der Normalen-Gleichungγ = (qT
1 q1)−1(qT
1 a1) = qT1 a2. Wir erhalten dann q2 durch Normalisierung des
Residuums r = a2 − (qT1 a2)q1.
Das klassische Gram-Schmidt-Orthogonalisierungsverfahren orthogonalisiert ge-gebene Vektoren a1, a2,. . . , am schrittweise, indem jeder Vektor qk orthonormalzu jedem seiner Vorganger q1,. . . , qk−1 gemacht wird.
function Q = GSc la s s i c (A)% gsCLASSIC(A) ermittelt in Q die QR-Faktorisierung von A
% per Gram-Schmidt-Orthogonalisierung

144 KAPITEL 3. LINEAR LEAST SQUARES
[m, n ] = s ize (A) ; Q = A;for k = 1 : n % fur jede Spalte k
Q( : , k ) = A( : , k ) ;for j = 1 : k−1 %
r = Q( : , j ) ’∗A( : , k ) ; %Q( : , k ) = Q( : , k)−r∗Q( : , j ) ; %
endr = norm(Q( : , k ) ) % r = ||qk||2i f ( r==0) error % nicht l.u.Q( : , k)=Q( : , k )/ r % Normalisierung
endend
Rang-Defizienz
Z.B.
Ax =
1 1ε 00 ε
x1
x2
x3
∼=
7111177475
= b
c
Z.B. In der QR-Faktorisierung A = Q
[R0
]von A =
0.913 0.6590.780 0.5630.457 0.330
ist R =(−1.28484 −0.92744
0.0 0.00013
). R ist also fast singular: solche linear least squares
Probleme Ax ∼= b reagieren sensitiv auf Storungen in den Eingangsdaten. c
3.0.6 Singular-Wert-Zerlegung, SVD
Def. Die Singular-Wert-Zerlegung, SVD stellt eine m×n-Matrix A als ProduktA = UΣVT , wobei U eine orthogonale m ×m-Matrix, Σ = (σi,j) eine m × n-
Diagonal-Matrix σi,j =
0 i 6= jσi i = j
der singularen Werte, SWe σi ≥ 0 von A und
V eine orthogonale n× n-Matrix ist.Die singularen Werte werden ublicherweise absteigend angeordnet: σi ≥ σi+1 furi = 1, 2, . . . , n− 1. Die Spalten ui von U bzw. vi von V heißen linke bzw. rechtesingulare Vektoren, SVen zum singularen Wert σi. Bem. Der Rang einer Matrix stimmt uberein mit der Anzahl ihrer nicht ver-schwindenden singularen Werte.

145
Z.B. Die Singular-Wert-Zerlegung von A =
1 2 34 5 67 8 9
10 11 12
ist A = UΣVT
mit U =
0.141 0.825 −0.420 −0.3510.344 0.426 0.298 0.7820.547 0.028 0.664 −0.5090.750 −0.371 −0.542 0.079
, Σ =
25.5 0 00 1.29 00 0 00 0 0
und V =
0.504 0.574 0.644−0.761 −0.057 0.646
0.408 −0.816 0.408
. Wegen −a1 + 2a2 = a3 gilt rank(A) = 2 und erwar-
tungsgemaß hat A zwei verschwindende singulare Werte. cDie Singular-Wert-Zerlegung lost besonders elegant linear least squares Problemejeden Zuschnitts und jeden Ranges. Im uberbestimmten Fall (A ist m×n-Matrixmit m > n) maximalen Ranges (rank(A) = n) gilt
A = UΣVT = [U1U2]
[Σ1
0
]VT = U1Σ1V
T
fur eine m×n-Matrix U1 und eine regulare n× n-Diagonal-Matrix Σ1, die soge-nannte reduzierte Singular-Wert-Zerlegung (vgl. reduzierte QR-Faktorisierung).
x = VΣ−11 UT
1 b lost dann das linear least squares Problem Ax ∼= b, wie
ATAx == ATUΣVTVΣ−11 UT
1 b = ATb
zeigt. Im allgemeinen Fall eines linear least squares Problemes Ax ∼= b beliebigenZuschnitts und beliebigen Ranges laßt sich die Losung x durch
x =∑σi>0
uTi b
σi
vi
berechnen. Die Singular-Wert-Zerlegung erweist sich speziell fur schlecht kondi-tionierte und Rang-defiziente Probleme als hilfreich, insofern als die Vernachlassi-gung genugend kleiner SWe die Losung x weniger sensitiv auf Storungen in denDaten reagieren laßt.
Z.B. Sei wieder das linear least squares Problem Ax ∼= b mit
Ax =
1 1ε 00 ε
x1
x2
x3
∼=
7111177475
= b
gegeben. Die Singular-Wert-Zerlegung A = UΣVT−0.707 0.408 0.577−0.707 −0.408 −0.577
0.0 −0.816 0.577
1.732 0 00 1.732 00 0 0
−0.816 −0.408 −0.4080.0 0.707 −0.707
−0.577 −0.577 0.577

146 KAPITEL 3. LINEAR LEAST SQUARES
liefert die Losung
x =uT
1 b
σ1
v1 +uT
2 b
σ2
v2 =−1335
1.732
0.816−0.408−0.408
+−578
1.732
0.00.707
−0.707
=
−62979
551
c
3.0.7 Anwendungen der Singular-Wert-Zerlegung
Wir wollen einige der zahlreiche Anwendungen der Singular-Wert-Zerlegung vor-stellen.
Euklidische Norm einer Matrix Die durch die Euklidische Norm ||.||2 vonVektoren induzierte Norm ||A||2 einer Matrix A stimmt mit dem großtenSW von A uberein, d.h.
||A||2 = maxx6=0
||Ax||2/||x||2 = σmax
wie sich allerdings erst im Zusammenhang mit Eigenwerten (im Kapitel 4)und Optimierung (im Kapitel 6) herausstellen wird.
Euklidische Konditionszahl Die Konditionszahl cond2(A) einer Matrix A (beiVerwendung der Euklidischen Matrix-Norm) stimmt mit dem Verhaltnisvon großtem zu kleinstem SW uberein, d.h.
cond2(A) = ||A||2||A−1||2 = σmax/σmin
So wie die Konditionszahl einer quadratischen Matrix ihre Nahe zur Singu-laritat mißt, so mißt diese verallgemeinerte Konditionszahl beliebiger Ma-trizen deren Nahe zur Rang-Defizienz.
Bestimmung des (numerischen) Ranges einer Matrix Der Rang einer Ma-trix stimmt uberein mit der Anzahl nicht verschwindender SWe. Singular-Wert-Zerlegung bestimmt so den Rang numerisch verlaßlicher als andereVerfahren wie etwa QR-Faktorisierung mit Spalten-Pivotisierung.
Z.B. Die Singular-Wert-Zerlegung von A =
0.913 0.6590.780 0.5630.457 0.330
ist A =
UΣVT mit U =
0.7106 −0.2663 −0.65130.6071 −0.2359 0.75880.3557 0.9346 0.0060
, Σ =
(1.5846 0
0 0.0001
)und V =
(0.8108 0.5853
−0.5853 0.8108
). Je nach Schwellwert ist der (numerische)
Rang von A also 1 oder 2. c

147
Bestimmung der pseudo-inversen Matrix Losungen von linear least squa-res Problemen konnen auch mit Hilfe von pseudo-inversen Matrizen darge-stellt werden.
Def. Sei das Pseudo-Inverse σ+ eines Skalars σ durch σ+ = 1/σ fallsσ 6= 0 und 0 sonst definiert. Sei die Pseudo-Inverse Σ+ einer nicht notwen-dig quadratischen Diagonal-Matrix Σ = (σi,j) durch (σ+
j,i) definiert, also
durch Transposition von Σ und Ubergang zum Pseudo-Inversen eines je-den Matrix-Elementes. Dann ist die Pseudo-Inverse A+ einer beliebigenm× n-Matrix A durch A+ = (UΣVT )+ := VΣ+UT definiert. Die Pseudo-Inverse A+ existiert immer und fallt fur quadratische regulareMatrizen A mit der Inversen A−1 zusammen. Fur regulares A gilt namlichA−1 = (UΣVT )−1 = (V T )−1Σ−1U−1 = VΣ+UT aufgrund der Orthogona-litat von U und V sowie der Regularitat von Σ.Fur Matrizen A mit vollem Spalten-Rang gilt A+ = (ATA)−1AT (wie in 3Ex33Abschnitt 3.0.3 auf S.137 verwendet).In jedem Fall lost A+b das linear least squares Problem Ax ∼= b: WennA vollen Spalten-Rang hat, dann lost A+b = (ATA)−1ATb die Normalen-gleichungen ATAx = (ATA)(ATA)−1ATb = ATb. Anderenfalls gilt ebenATAx = ATUΣVTVΣ+UTb = ATUΣΣ+UTb = ATUUTb = ATb.
Orthonormal Basen In der Singular-Wert-Zerlegung von A = UΣVT bildendie Spalten ui von U zu SWen σi 6= 0 eine Orthonormal-Basis fur span(A)und die restlichen Spalten eine solche fur das orthogonale Komplementspan(A)⊥.Entsprechend bilden die Spalten vi von V zu SWen σi 6= 0 eine Orthonormal-Basis fur den Null-Raum null(A) = x : Ax = 0 und die restlichen Spalteneine solche fur das orthogonale Komplement null(A)⊥.
Approximation durch Matrizen kleineren Ranges Die Singular-Wert-Zer-legung von A = UΣVT laßt sich auch als
A = UΣVT = σ1E1 + σ2E2 + . . .+ σnEn
mit Ei = uivTi schreiben. Die Matrizen Ei lassen sich in m + n Speicher-
zellen speichern. Die Berechnung von Eix = ui(vTi x) braucht nur m + n
Multiplikationen. Berucksichtigung nur der großten k SWe σi erzeugt diein der Frobenius-Norm1 (die Frobenius-Norm ||A||F einer m× n-Matrix Aist die Euklidische Norm von A ∈ Rmn) beste Approximation von A durchMatrizen vom Rang k. Es gibt viele Anwendungen.
Z.B. Die Singular-Wert-Zerlegung von A =
0.913 0.6590.780 0.5630.457 0.330
ist A =
1 Ferdinand Georg Frobenius (1849-1917) www-history.mcs.st-andrews.ac.uk/Biographies/Frobenius.html

148 KAPITEL 3. LINEAR LEAST SQUARES
UΣVT mit U =
0.71058 −0.26631 −0.651270.60707 −0.23592 0.758820.35573 0.93457 0.00597
, Σ =
(1.5846 0
0 0.00011
)und V =
(0.81083 0.58528
−0.58528 0.81083
). Dann ist E1 vom Rang 1 und σ1E1 =
σ1u1vT1 = 1.58460
0.710580.607070.35573
(0.810830.58528) =
0.91298 0.659020.77999 0.563020.45706 0.32992
ist
eine sehr gute Approximation von A, weil σ2E2 nur einen vernachlassigba-ren Beitrag leistet. c
Total least squares Unser Losungsansatz von linear least squares ProblemenAx ∼= b geht stillschweigend davon aus, daß die Koeffzienten-Matrix Aexakt bekannt ist, wahrend die Elemente von b Storeinflussen wie Meß-fehlern usw. unterworfen sind. Sollen Daten-Punkte (ti, yi) durch Modell-Funktionen im Sinne eines linear least squares Problems angenahert werden,dann haben wir eben unterstellt, daß die Zeitpunkte ti exakt bestimmt wer-den konnen und nur die yi Meß-Fehler aufweisen. Unter diesen Umstandenist es gerechtfertigt, die Summe der quadratischen vertikalen Abstande zwi-schen Daten-Punkten yi und Modell-Funktion f(ti,x) zu minimieren, d.h.minimiere ||b− y||2 unter der Bedingung y ∈ span(A).Wenn allerdings alle Variablen unsicher sind, ist es sinnvoll, die Summeder quadratischen orthogonalen Abstande zwischen Daten-Punkten yi undModell-Funktion f(ti,x) zu minimieren. Dieser Ansatz heißt total leastsquares Losung. Wir suchen also die Matrix [A,y], die ||?||2 unter derBedingung y ∈ span(A) minimiert. [A,b] = UΣVT sei die Singular-Wert-Zerlegung der m× (n+ 1)-Matrix [A,b].
...
Dann ist
x = − 1
vn+1,n+1(v1,n+1, v2,n+1, . . . , vn1,n+1)
T
die Losung des total linear least squares Problems, solange σn+1 < σn undvn+1,n+1 6= 0.
Z.B. Gegeben die drei Daten-Punktet −2 −1 3y −1 3 −2
. Die Modell-
Funktion f(t, x) = xt seien Ursprungsgeraden. Gesucht ist die Steigungx, erstens als Losung des gewohnten linear least squares Problems (nurdie Ortsmessung (y), nicht aber die Zeitmessung (t) ist unsicher) Ax =−2−1
3
x ∼=
−13
−2
= b, also x = −12
etwa als Losung der Normalenglei-
chung ATAx = 14x = −7 = ATb.

149
Um zweitens die Summe der quadratischen horizontalen Abstande zu mi-nimieren (weil nur die Zeitmessung (t), nicht aber die Ortsmessung (y)unsicher ist), liefert Vertauschen von t und y das linear least squares Pro-
blem Ax =
−13
−2
x ∼=
−2−1
3
= b, also wieder x = −12
etwa als Losung
der Normalengleichung ATAx = 14x = −7 = ATb fur die Steigung derLosungsfunktion t = t(y) = −1
2y und damit per Auflosen y = −2t.
Um drittens die Summe der quadratischen Lot-Abstande zu minimieren(weil Zeitmessung (t) und Ortsmessung (y) mit Fehlern behaftet sind),
...
[A,b] = [t,y] =
−2 −1−1 3
3 −2
= UΣVT =
−0.151 0.802 0.577−0.617 −0.535 0.577
0.772 −0.267 0.577
4.583 00 2.6460 0
( 0.707 −0.707−0.707 −0.707
), so daß sich
x = − 1v2,2
v1,2 = − 1−0.707
(−0.707) = −1 ergibt.
t
y
t
y
t
y
c

150 KAPITEL 3. LINEAR LEAST SQUARES
3.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Ein linear leastsquares Problem hat immer eineLosung.
2. Richtig/Falsch? Eine Regressionsge-rade zu eine Menge von Datenpunk-ten zu finden, ist ein linear leastsquares Problem, dagegen ist eine’Regressionsparabel’ zu finden keinlinear least squares Problem.
3. Richtig/Falsch? Sei x Losung des li-near least squares Problems Ax ∼=b. Dann ist das Residuum r =b−Ax orthogonal zu span(A).
4. Richtig/Falsch? Ein uberbestimm-tes linear least squares ProblemsAx ∼= b hat immer eine eindeutigeLosung x, die die Euklid’sche Norm||r||2 des Residuums r = b−Ax mi-nimiert.
5. Richtig/Falsch? Sei x Losung des li-near least squares Problems Ax ∼=b. Wenn b ∈ span(A), dann giltr = b−Ax = 0.
6. Richtig/Falsch? Wenn r = b−Ax =0, so ist die Losung x des linear leastsquares Problems Ax ∼= b eindeu-tig.
7. Richtig/Falsch? Das Produkt einerHouseholder Transformation und ei-nerGivens Rotation ist immer eineorthogonale Matrix.
8. Richtig/Falsch? Q sei eine n ×n-Householder Transformation undx ∈ Rn beliebig. Dann gibt es eink < n, so daß die letzten k Kompo-nenten von Qx verschwinden.
9. Richtig/Falsch? Orthogonalisie-rungsverfahren zur Losung vonlinear least squares Problemen sindaufwandiger als Verfahren, das(lineare) System der Normalen-Gleichungen zu losen.
10. a) Was heißt, daß die Modell-Funktion f(t,x) linear in x ist?
b) Gib Beispiele fur in diesem Sinnlineare Modell-Funktionen f .
c) Gib Beispiele fur in diesem Sinnnichtlineare Modell-Funktionen f .
11. Gegeben das least squares ProblemAx ∼= b mit m × n-Matrix A undrank(A) < n < m. Welche Situatio-nen sind moglich?
a) Es gibt keine Losung.
b) Es gibt eine einzige Losung.
c) Es mehrere Losungen.
12. Gegeben ein uberbestimmtes leastsquares Problem Ax ∼= b. Was istschwerwiegender: die Zeilen von Asind l.a. oder die Spalten von A sindl.a.?
13. In einem uberbestimmten leastsquares Problem Ax ∼= b sei dieModell-Funktion f(t,x) = x1φ1(t)+x2φ2(t) + x3φ3(t) mit φ1(t) = 1,φ2(t) = t und φ3(t) = 1 − t. Wasist rank(A) ?
14. Gegeben das linear least squaresProblem Ax ∼= b. Was ist daszugehorige System der Normalen-Gleichungen?
15. Wieso kann das Losen des Systemsder Normalen-Gleichungen nume-risch enttauschende Ergebnisse pro-duzieren?
16. A sei m× n-Matrix. Unter welchenBedingungen fur A ist dann ATA

3.1. Review Questions – Verstandnisfragen 151
a) symmetrisch?
b) regular?
c) positiv definit?
17. Welche der folgenden Bedingungenfur eine m× n-Matrix A mit m > ngarantieren, daß die minimal resi-dual solution des linear least squa-res Problem Ax ∼= b nicht eindeutigist?
a) Die Spalten von A sind l.a..
b) Die Zeilen von A sind l.a..
c) ATA ist singular.
18. a) Kann die Gauß-Elimination mitPivotisierung verwendet werden, umdie LU-Faktorisierung von A zu be-stimmen? A = LU sei dabei m×n-Matrix, L eine m× k-Matrix, derenElemente oberhalb der Hauptdiago-nalen verschwinden, U eine k × n-Matrix, deren Elemente unterhalbder Hauptdiagonalen verschwinden,und k = minm,n.
b) Falls ja, kann so Ax ∼= b mit m >n gelost werden?
19. a) Was heißt, daß zwei Vektoren or-thogonal zueinander sind?
b) Gegeben 0 6= x ⊥ y 6= 0. Zeige:x und y sind l.u.
c) Gib Beispiele fur zueinander or-thogonale Vektoren im R2 \ 0.
d) Gib Beispiele fur zueinander nichtorthogonale Vektoren im R2 \ 0.
e) Inwiefern spielt Orthogonalitateine wichtige Rolle in linear leastsquares Problemen?
20. Ist Orthogonalitat im Rn transitiv?d.h. ist mit x ⊥ y und y ⊥ z auchx ⊥ z ?
21. Was ist ein orthogonaler Projektor?Inwiefern sind diese bedeutsam furlinear least squares Probleme?
22. a) Wieso werden HouseholderTransformationen und Givens Ro-tationen zur Losung von linear leastsquares Problemen verwendet?
b) Warum werden HouseholderTransformationen und Givens Ro-tationen nicht haufig genutzt, um’square linear problems’ zu losen?
c) Bieten orthogonale Transfor-mationen im Vergleich zu Gauß-Elimination Vorteile, um ’square li-near problems’ zu losen?
23. Welche der folgenden Matrizen sindorthogonal?
a)(
0 11 0
)b)(
1 00 −1
)c)(
2 00 1
2
)d)
√2
2
(1 1
−1 1
)24. Welche Eigenschaften hat eine belie-
bige orthogonale n× n-Matrix Q ?
a) Q ist regular.
b) Q erhalt die Euklid’sche Norm.
c) Die transponierte Matrix QT vonQ ist die inverse Matrix Q−1 von Q.
d) Die Spalten von Q sind orthonor-mal.
e) Q ist symmetrisch.
f) Q ist diagonal.
g) Die Euklid’sche Matrix-Norm||Q||2 von Q ist 1.
h) Die Euklid’sche Konditionszahlcond(Q) ist 1.
25. Welche Matrizen sind notwendig or-thogonal?
a) Permutationsmatrizen

152 KAPITEL 3. LINEAR LEAST SQUARES
b) symmetrische, positiv definiteMatrizen
c) Householder Transformationen
d) Givens Rotationen
e) regulare Matrizen
f) Diagonal-Matrizen
26. Zeige: Multiplikation eines Vek-tors mit einer orthogonalen Matrixerhalt die Euklid’sche Norm.
27. Unter welchen Bedingungen an w 6=0 ist H = I− 2wwT orthogonal?
28. Q sei orthogonal mit Qx =
Q(
11
)=(α0
)= b. Welchen Wert
hat α ?
29. Wieviele skalare Multiplikatio-nen sind notig, um eine n × n-Householder Matrix H = I − wwT
mit ||w||2 = 1 mit einem beliebigenVektor in Rn zu multiplizieren?
30. Zu jedem a existiert eine Househol-der Transformation H = I− 2
vT vvvT
mit Ha = αe1. Dabei ist v =a− αe1 und α = ±||a||2. Wie solltedas Vorzeichen gewahlt werden?
31. Vergleiche Vor- und Nachteile vonGivens Rotationen fur QR-Faktori-sierung und Householder Transfor-mationen.
32. Die zweite Komponente eines Vek-tors sei zu annullieren. Liefern Hou-seholder Transformation und GivensRotation immer dasselbe Ergebnis?
33. A sei gespeichert und kann uber-schrieben werden. Wieviel zusatzli-cher Speicherplatz ist fur die folgen-den Aufgaben erforderlich?
a) fur die LU-Faktorisierung dern × n-Matrix A durch Gauß-Elimination mit partieller Pivotisie-rung
b) fur die QR-Faktorisierung derm× n-Matrix A durch HouseholderTransformationen
34. Gegeben das linear least squaresProblem Ax ∼= b mit m× n-MatrixA und rank(A) < n ≤ m. Anwelcher Stelle bricht der jeweiligeLosungsprozess bei Verwendung ex-akter Arithmetik ab?
a) bei Cholesky Faktorisierung desSystems der Normalengleichungen
b) bei QR-Faktorisierung durchHouseholder Transformationen
35. Welche Vorteile hat das modifi-zierte gegenuber dem klassischenGram-Schmidt-Orthogonalisie-rungsverfahren?
a) geringerer Speicherbedarf?
b) kurzere Laufzeit?
c) bessere numerische Stabilitat?
36. Die QR-Faktorisierung einer m× n-Matrix mitm > n sei zu bestimmen.Wie groß muß n sein, so daß sichklassisches und modifiziertes Gram-Schmidt-Verfahren unterscheiden?
37. Warum braucht das HouseholderVerfahren weniger Speicherplatz furdie QR-Faktorisierung einer m × n-Matrix als das modifizierte Gram-Schmidt-Verfahren?
38. Wie kann die QR-Faktorisierungmit Spalten-Pivotisierung eingesetztwerden, um den Rang einer Matrixzu bestimmen?

3.2. Exercises – Ubungen 153
39. Warum kann Spalten-Pivotisierungin der modifizierten Gram-Schmidt-Orthogonalisierung, aber nicht inder klassischen Gram-Schmidt-Or-thogonalisierung eingesetzt werden?
40. Das linear least squares ProblemAx ∼= b werde einerseits anhand desSystems von Normalen-Gleichungenund andererseits vermittels des Hou-seholder QR-Verfahrens gelost. Furwelche Werte von cond(A) werdendie Verfahren jeweils scheitern?
41. A sei eine m× n-Matrix.
a) Wieviel nicht-verschwindendesingulare Werte kann A maximalhaben?
b) Sei rank(A) = k. Wie-viele nicht-verschwindende singulareWerte kann A dann maximal ha-ben?
42. Sei 0 6= a ∈ Rm aufgefasst als m×1-Matrix. Dann hat a nur einen sin-gularen Wert? welchen?
43. Drucke die Euklid’sche Konditions-zahl einer Matrix durch ihre sin-gularen Werte aus.
44. Gib zwei numerisch zuverlassigeVerfahren an, um den Rang einerMatrix zu berechnen.
45. A sei 2n× n-Matrix. Ordne die fol-genden Losungsverfahren des linearleast squares Problems Ax ∼= b nachsteigendem Aufwand.
a) QR-Faktorisierung durch House-holder Transformationen
b) Losen des Systems von Normalen-Gleichungen
c) per SVD
46. Liste Anwendungen von SVD auf.
3.2 Exercises – Ubun-
gen
1. Gegeben die Abhangigkeity = x0 + x1 t, gemessent 10 15 20y 11.60 11.85 12.25
.
a) Stelle das uberbestimmte 3 ×2-System von linearen Gleichungenauf.
b) Zum Test der Konsistenz der Da-ten bestimme x jeweils aus Paarenvon Gleichungen.
c) Stelle das System der Normalen-Gleichungen auf und vergleiche des-sen Losung mit den Ergebnissen ausb).
2. Gesucht sei die Regressionsgerade zu(0, 1), (1, 2) und (3, 3).
a) Stelle das uberbestimmte Glei-chungssystem zum gegebenen linearleast squares Problem auf.
b) Stelle das System der Normalen-Gleichungen auf.
c) Lose das linear least squares Pro-blem per Cholesky-Faktorisierung.
3. Gesucht ist die Funktion aus derFamilie f(t) = x1t + x2e
t, die dieSumme der Fehlerquadrate zu denPunkten (1, 2), (2, 3) und (3, 5) mi-nimiert.
4. Ist die Regressionsgerade zu denPunkten (0, 0), (1, 0) und (1, 1) ein-deutig?
5. Gegeben das least squares Problem
Ax ∼= b mit A =
1 01 11 21 3
. Welcher

154 KAPITEL 3. LINEAR LEAST SQUARES
der folgenden Werte des Residuumsr = b−Ax ist moglich?
a)
1111
b)
−1−1
11
c)
−1
11
−1
6. Gegeben das least squares Problem
Ax =
1 10 10 0
x =
211
= b.
a) Was ist die Euklid’sche Norm||r||2 des minimalen residualen Vek-tors dieses linear least squares Pro-blems?
b) Welche Losung hat das Problem?
7. A sei m× n-Matrix und b ∈ Rm.
a) Zeige: Zu jedem linear least squa-res Problem Ax ∼= b existiert immereine Losung x.
b) Zeige: Die Losung ist eindeutiggenau dann, wenn rank(A) = n.
8. Zeige: A sei m × n-Matrix mitrank(A) = n. Dann ist ATA po-sitiv definit.
9. Zeige: Die augmented system matrixA ist nicht positiv definit.
10. B sei quadratische, orthogonaleobere Dreiecksmatrix.
a) Zeige: B ist Diagonal-Matrix.
b) Welche Hauptdiagonalelementehat B ?
c) A sei regulare n × n-Matrix.Zeige: die QR-Faktorisierung von Aist bis auf das Vorzeichen der Haupt-diagonalelemente eindeutig, d.h. esgibt genau zwei Matrizen Q und R,so daß Q orthogonal, R obere Drei-ecksmatrix mit positiven Hauptdia-gonalelementen und A = QR.
11. Die Matrix Q =[A B0 C
]mit qua-
dratischen Unter-Matrizen A und Csei orthogonal. Zeige: Dann sindauch A und C orthogonal und es giltB = 0.
12. a) Zeige: Je zwei der folgenden Ei-genschaften einer n × n-Matrix Aimplizieren die dritte.
1. AT = A
2. ATA = I
3. A2 = I
b) Gib Beispiele fur 3× 3-Matrizen,anders als I oder Permutationsma-trizen, mit allen drei Eigenschaften.
c) Benenne eine nicht-triviale Klassevon Matrizen mit allen drei Eigen-schaften.
13. Was folgt, wenn A sowohl orthogo-nal als auch orthogonaler Projektorist?
14. Zeige: Fur v 6= 0 sind HouseholderMatrizen H = I − 2
vT vvvT symme-
trisch und orthogonal.
15. Sei a 6= 0 beliebig und v = a − αe1
mit α = ±||a||2. Zeige: Fur dieHouseholder Transformation H =I− 2
vT vvvT gilt Ha = αe1.
16. Ein beliebiger Vektor a ∈ Rn werdeals n× 1-Matrix aufgefasst.
a) Bestimme die QR-Faktorisierungvon a mit expliziter Angabe von Qund R.
b) Lose das linear least squares Pro-blems ax ∼= b fur beliebig gegebenesb.
17. Sei a = (1, 1, 1, 1)T . Gesucht ist dieHouseholder Transformation H =I − 2
vT vvvT mit Ha = αe1. Be-
stimme α und v.

3.2. Exercises – Ubungen 155
18. Bestimme die QR-Faktorisierung
von A =
1 1 11 2 41 3 91 4 16
durch Hou-
seholder Transformationen.
a) Wieviele Householder Transfor-mationen werden notwendig?
b) Wie sieht die erste Spalte von Aals Ergebnis der ersten HouseholderTransformation aus?
c) Wie sieht dann die erste Spaltevon A als Ergebnis der zweiten Hou-seholder Transformation aus?
d) Wieviele Givens Rotationen wer-den fur die QR-Faktorisierung vonA benotigt?
19. a = (a1, a2, a3)T = (2, 3, 4)T sei ge-geben.
a) Bestimme die elementary elimi-nation matrix, die die dritte Kom-ponente a3 von a annulliert.
b) Welche Householder Transforma-tion annulliert die dritte Kompo-nente a3 von a ?
c) Welche Givens Rotationen annul-lieren die dritte Komponente a3 vona ?
d) Konnen elementary eliminationmatrix und Householder Transfor-mation ubereinstimmen, die einenicht-verschwindende Komponenteeines beliebigen Vektors annullie-ren?
e) Konnen Householder Transforma-tion undGivens Rotation uberein-stimmen, die eine nicht-verschwin-dende Komponente eines beliebigenVektors annullieren?
20. Gegeben sei a = (0, a2)T .
a) Kann eineGivens Rotation a2 an-nullieren?
b) Kann eine elementary elimina-tion matrix a2 annullieren?
21. Givens Rotationen sind durch diebeiden Parameter c und s spezifi-ziert. Geht es auch mit einem Pa-rameter?
22. A sei m × n-Matrix, rank(A) = n
und A = Q[R0
]die QR-Faktori-
sierung von A, wobei Q orthogonalist und R quadratische obere Drei-ecksmatrix ist. Sei ATA = LLT dieCholesky-Faktorisierung von ATA.
a) Zeige: RTR = LLT .
b) Kann R = LT gefolgert werden?
23. Gegeben A =
1 1ε 00 ε
. In einem
floating point system ist dann ATAsingular, wenn ε <
√εmax. Zeige:
Wenn A = Q[R0
]die QR-Faktori-
sierung von A ist, dann ist R auchin Gleitpunkt-Arithmetik regular.
24. Verifiziere, daß der dominante Termin der Anzahl von fur die Losung ei-nes m × n-linear least squares Pro-blems per System von Normalen-Gleichung und Cholesky-Faktorisie-rung notigen Operationen (Multipli-kationen oder Additionen) 1
2mn2 +
16n
3 ist.
25. Verifiziere, daß der dominante Termin der Anzahl von fur die QR-Fak-torisierung einer m × n-Matrix perHouseholder Transformationen noti-gen Operationen (Multiplikationenoder Additionen) 1
2mn2 − 1
6n3 ist.
26. Sei c = cos θ und s = sin θ. Wel-chen geometrischen Effekt verursa-chen folgende orthogonale 2 × 2-Matrizen im R2 ?

156 KAPITEL 3. LINEAR LEAST SQUARES
a) G =(c s−s c
)b) H =
(−c ss c
)27. a) Q sei n×k-Matrix (n > k), deren
Spalten q1, . . .qk eine Orthonormal-Basis von S ⊂ Rn formen. Zeige:Dann ist P = QQT ein orthogonalerProjektor auf S.
b) A sei eine Matrix mit l.u. Spalten.Zeige: Dann ist P = A(ATA)−1AT
ein orthogonaler Projektor auf denSpalten-Raum S von A. Wie hangtdies mit linear least squares Proble-men zusammen?
c) P sei ein orthogonaler Projektorauf S = PRn. Zeige: Dann ist P⊥ =I−P ein orthogonaler Projektor aufdas orthogonale Komplement S⊥ =P⊥Rn von S.
d) Sei 0 6= v ∈ Rn. Was ist derorthogonale Projektor auf span(v) ?
28. a) Sei Q = (q1, . . . ,qn) im Gram-Schmidt-Verfahren zur QR-Faktori-sierung. Zeige: fur die orthogonalenProjektoren Pk = qkqT
k gilt(I−Pk)(I−Pk−1) · · · (I−P1) = I−Pk −Pk−1 − . . .−P1.
b) Zeige: das klassische Gram-Schmidt-Verfahren ist aquivalent zuqk = (I− (P1 + . . .+ Pk−1))ak.
c) Zeige: das modifizierte Gram-Schmidt-Verfahren ist aquivalent zuqk = (I−Pk−1) · · · (I−P1)ak.
d) Ein alternativer Weg, das klas-sische Verfahren numerisch zu sta-bilisieren, besteht darin, es mehr-fach anzuwenden (iterative refine-ment), d.h. qk = (I − (P1 + . . . +Pk−1)m)ak, wobei meist m = 2 aus-reicht.
Zeige: alle drei Verfahren sind ma-thematisch (wenn auch uberhauptnicht numerisch) aquivalent.
29. Sei 0 6= v ∈ Rn. Die zu v normaleHyperebene v⊥ ist der (n − 1)-di-mensionale Unterraum aller x mitvTx = 0. Die Matrix R ist ein Re-flektor, genau dann wenn Rx = −xfur x ∈ Rv und Rx = x fur alle x inder zu v normalen Hyperebene v⊥,d.h. fur alle vTx = 0.
a) Sei P der orthogonale Projektorauf die zu v normale Hyperebenev⊥. Zeige: Dann gilt R = 2P− I.
b) Zeige: R symmetrisch und ortho-gonal.
c) Zeige: Die Householder Transfor-mation H = I− 2
vT vvvT ist ein Re-
flektor.
d) Gegeben s, t ∈ Rn mit s 6= t und||s||2 = ||t||2. Zeige: Dann existiertein Reflektor R mit Rs = t.
e) Zeige: Jede orthogonale Matrix Qist Produkt von Reflektoren.
f) Visualisiere: Die Rotationen desR2 sind Produkte von je zwei Re-flektoren.
30. a) Sei 0 6= a ∈ Rm aufgefasst alsm×1-Matrix. Zeige die singular va-lue decomposition explizit auf, d.h.bestimme U, Σ und V.
b) Sei 0 6= aT ∈ Rn aufgefasst als1× n-Matrix. Zeige die singular va-lue decomposition explizit auf, d.h.bestimme U, Σ und V.
31. A sei m × n-Matrix, b ∈ Rm undx die Losung des linear least squa-res Problem Ax ∼= b minimalerEuklid’scher Norm. Zeige: x =∑
i,σi 6=0uT
i bσi
vi fur die singular va-lues σi und zugehorige singular vec-tors ui und vi.

3.3. Computer Problems – Rechner-Probleme 157
32. Zeige: die Pseudo-InverseA+ = VΣ+UT einer m × n-Matrix A = UΣVT erfullt diesogenannten Penrose-Bedingungen.
a) AA+A = A
b) A+AA+ = A+
c) (AA+)T = AA+
d) (A+A)T = A+A
33. Zeige folgende Implikationen fur diePseudo-Inverse A+ einer m × n-Matrix A.
a) Wenn m = n und A regular ist,dann gilt A+ = A−1.
b) Wenn m > n und rank(A) = nist, dann gilt A+ = (ATA)−1AT .
c) Wenn m < n und rank(A) = mist, dann gilt A+ = AT (AAT )−1.
34. a) Was ist die Pseudoinverse von
A =(
1 00 0
)?
b) Was ist die Pseudoinverse von
A =(
1 00 ε
)fur ε > 0 ?
c) Was bedeutet dies fur die Kon-dition des Problems, die Pseudoin-verse einer Matrix zu berechnen?
3.3 Computer Pro-
blems – Rechner-
Probleme
1. Gesucht sind die Polynome n-tenGrades y = pn(t) mit n = 0, 1, . . . , 5,die das linear least squares Problemzu den folgenden Daten losen.
t 0.0 1.0 2.0 3.0 4.0 5.0y 1.0 2.7 5.8 6.6 7.5 9.9
Visualisiere die Losungen. WelchesPolynom scheint den Trend der Da-ten am besten widerzuspiegeln?
2. Lose das linear least squaresProblem in x1, x2, x3, x4 zu denfolgenden Hohen-Messungen
absoluty1 y2 y3 y4
2.95 1.74 −1.45 1.32
differentiell
−y2 −y3 −y4
y1 1.23 4.45 1.61y2 3.21 0.45y3 −2.75
,
d.h. bestimme minx (∑
i(yi−xi)2 +∑i<j ((yi − yj)− (xi − xj))
2).
3. a) t(n) sei die Zeit fur die LU-Fak-torisierung von n×n-Matrizen etwaper MatLab-Routinen. Passe einPolynom dritten Grades den t(n) (nin Hunderten-Schritten wachsend)an und prognostiziere t(10000).
b) Bestimme die Anzahl ausgefuhr-ter Gleitpunkt-Operationen proSekunde, FLOPS, des eingesetztenRechen-Systems anhand etwa derMatrix-Multiplikation, bestimmedamit t(n) in flOs und vergleichemit dem laut Theorie dominantenTerm 4
3n3.
4. a) Lose Ax ∼= b mit A =0.16 0.100.17 0.112.02 1.29
und b =
0.260.283.31
.
b) Lose Ax ∼= b mit A =0.16 0.100.17 0.112.02 1.29
und b =
0.270.253.33
.
c) Begrunde die vergleichenden Be-obachtungen.
5. Die Bahn eines Planeten sei ellip-tisch und sei beschrieben durch
ay2 + bxy + cx+ dy + e = x2

158 KAPITEL 3. LINEAR LEAST SQUARES
a) Sei p = (a, b, c, d, e)T . Gemes-sen wurden folgende Bahnpunktex 1.02 0.95 0.87 0.77 0.67y 0.39 0.32 0.27 0.22 0.18x 0.56 0.44 0.30 0.16 0.01y 0.15 0.13 0.12 0.13 0.15
.
Lose das linear least squaresProblem in p = (a, b, c, d, e)T
und visualisiere Bahnpunkte underrechnete Bahn.
b) Addiere pseudo-zufallig erzeugteStorungen im Intervall (−.005, .005)zu den gemessenen Koordinatenund vergleiche die sich ergebendenLosungen und die sich ergebendeBahn mit Losungen und Bahn ausa).
c) Verwende fur a) und b) spe-ziell auf rank deficient Matrizenzugeschnittene Bibliotheksroutinen(etwa mit column pivoting). Experi-mentiere mit der vorzugebenden To-leranz.
d) Berechne mit Bibliotheksroutinendie SVD.
e) Verwende SVD, um die Losungenvon a) zu ermitteln.
f) Verwende SVD, um die Losungenvon b) zu ermitteln und mit denenvon a) zu vergleichen.
g) Formuliere das Problem als tota-les least squares Problem und losedies per SVD.
6. Entwickle ein Programm zu Be-rechnung der Pseudoinversen undvergleiche mit Bibliotheksroutinen.(Das Programm sollte als Pseudoin-verse einer regularen Matrix derenInverse berechnen.) Experimentieremit Schranken fur Null zu setzendeSWe. Was passiert fur regulare,aber extrem schlecht konditionierteMatrizen wie die Hilbert-Matrix?
7. Entwickle ein Programm zur Losungvon rank deficient linear least squa-res Problemen Ax ∼= b per SVD.
8. Seien die Modell-Funktionenf(t,x) = x1 + x2 t + x3 t
2 + . . . +xn t
n−1 und die Datenpunkte (ti, yi)mit ti = i−1
m−1 fur i = 1, . . . ,m − 1gegeben. Die Datenpunkte yi wer-den etwa durch die Setzung xj = 1fur j = 1, . . . , n erzeugt und durchyi := yi + ε(2ui − 1) fur Pseudo-Zufallszahlen ui ∈ [0, 1] gestort.In IEEE DP etwa sei m = 21,n = 12 und ε = 10−10. Gewinnenun die (bekannten) xi per Losender Normalen-Gleichungen und perQR-Faktorisierung zuruck. WelchesVerfahren ist genauer? WelchesVerfahren reagiert sensitiver aufStorungen der Daten?
9. Verwende die augmented systemVerfahren, um die least squares Pro-bleme aus CP 3.8 zu losen. Dadas augmented system zwar sym-metrisch aber nicht positiv de-finit ist, ist Cholesky-Faktorisie-rung nicht anwendbar und stattdes-sen indefinite LU-Faktorisierung zuwahlen. Experimentiere mit demParameter α und vergleiche die Er-gebnisse mit denen, gewonnen durchLosen der Normalengleichungen unddurch QR-Faktorisierung.
10. A sei die m × n-Matrix des leastsquares Problems Ax ∼= b mit m >n. Dann heißt C = σ2(ATA)−1 mitσ2 = 1
m−n ||b−Ax||22 die CovarianceMatrix des least squares ProblemsAx ∼= b fur die Losung x.
a) Sei A = Q[R0
]mit orthogona-
lem Q die QR-Faktorisierung vonA. Zeige: Dann ist (ATA)−1 =(RTR)−1.

3.3. Computer Problems – Rechner-Probleme 159
b) Entwickle ein Programm zur Be-rechnung der Kovarianz-Matrix, dasnur das schon berechnete R benutzt.(Der skalare Faktor σ2 darf ignoriertwerden.) Verifiziere, daß das Ergeb-nis mit (ATA)−1 ubereinstimmt.
11. Verwende Bibliotheksroutinen, um
die QR-Faktorisierung A = Q[R0
]einer m×n-Matrix A per Househol-der Transformationen zu berechnen.Entwickle ein Programm, das Q ex-plizit als Produkt der HouseholderTransformationen berechnet, das dieOrthogonalitat von Q verifiziert und
das A = Q[R0
]pruft.
12. a) Implementiere das klassische unddas modifizierte Gram-Schmidt-Ver-fahren, um jeweils eine orthogo-nale Matrix Q zu generieren, derenSpalten eine Orthonormal-Basis furden Spaltenraum der Hilbert-MatrixHn = (hi,j)i,j=1,...,n mit hi,j = 1
i+j−1fur n = 2, 3, . . . , 12 bilden.
b) Wiederhole a) mit HouseholderQR-Faktorisierung.
c) Wiederhole a) mit SVD.
d) Die Normalen-Gleichungen er-lauben einen weiteren Losungs-weg: mit der Cholesky-Faktorisie-rung ATA = LLT von ATAgilt I = L−1(ATA)L−T =(AL−T )T (AL−T ). Also ist Q =AL−T orthogonal mit demselbenSpaltenraum wie A.Wiederhole a) mit dem in dieserWeise gewonnenen Q.
e) Vergleiche die Ergebnisse von a),b) c) und d).
13. Sei das linear least squares Problem
Ax =
1 1 1ε 0 00 ε 00 0 ε
x1
x2
x3
∼=
1000
=
b gegeben. Beobachte insbesondereε ∼= εmach und ε ∼=
√εmach, wenn
das Problem mit einer der folgendenVerfahren gelost wird.
a) per System der Normalen-Gleichungen
b) per augmented system method
c) per Householder QR-Faktorisie-rung d) per Givens QR-Faktori-sierung e) per klassischer Gram-Schmidt-Orthogonalisierung
f) per modifizierter Gram-Schmidt-Orthogonalisierung
g) per klassischer Gram-Schmidt-Orthogonalisierung mit iterierterVerbesserung (CGS zweimal)
h) per SVD

160 KAPITEL 3. LINEAR LEAST SQUARES
3.4 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Ein linear least squares Problem hat immer eine Losung.
Ein linear least squares Problem Ax ∼= b hat immer eine Losung, da109φ(y) = ||b − y|| stetig und coercive ist und daher ein Minimum in derabgeschlossenen, unbeschrankten Menge span(A) hat.
2. Richtig/Falsch? Eine Regressionsgerade zu eine Menge von Datenpunktenzu finden, ist ein linear least squares Problem, dagegen ist eine ’Regressi-onsparabel’ zu finden kein linear least squares Problem.
Eine Gerade wie auch eine Parabel zu bestimmen, die die Summe der qua-107dratischen Abstande zu drei bzw. vier oder mehr Daten-Punkten minimie-ren, sind beides linear least squares Probleme.
3. Richtig/Falsch? Sei x Losung des linear least squares Problems Ax ∼= b.Dann ist das Residuum r = b−Ax orthogonal zu span(A).
Das Residuum r = b − Ax der Losung des linear least squares Problems111Ax ∼= b steht senkrecht auf dem Spaltenraum span(A) von A.
4. Ein uberbestimmtes linear least squares Problem Ax ∼= b hat immer genau109eine Losung x derart, daß die Norm ||r||2 des Residuums r = b − Axminimal ist.
nur richtig, wenn rank(A) = n ist. linear least squares Probleme mit Rang-defizienten Matrizen A haben mehrere Losungen, da es dann xi mit y =Axi gibt.
5. Richtig/Falsch? Sei x Losung des linear least squares Problems Ax ∼= b.Wenn b ∈ span(A), dann gilt r = b−Ax = 0.
Wenn b im Spaltenraum von A liegt, d.h. wenn es ein x mit b = Ax gibt,109so verschwindet notwendig das Residuum r = b−Ax = 0.
6. Richtig/Falsch? Wenn r = b−Ax = 0, so ist die Losung x des linear leastsquares Problems Ax ∼= b eindeutig.
Wenn das Residuum r = b − Ax = 0 verschwindet, dann ist x nicht109
notwendig eindeutig, wie etwa Ax =
[B0
] [yz
]=
[c0
]= b fur regulares B,
y = B−1c und beliebiges z zeigt.
7. Richtig/Falsch? Das Produkt einer Householder Transformation und einerGivens Rotation ist immer eine orthogonale Matrix.
Das Produkt Q = HG einer Householder Transformation H = I− 2vT v
vvT ,121–130

3.4. Review Questions – Antworten auf Verstandnisfragen 161
im ubrigen mit H = HT = H−1 da H2 = I− 4vT v
vvT + 4(vT v)2
v(vTv)vT = I−4
vT vvvT + 4
vT vvvT = I, und einer Givens Rotation G ist immer eine ortho-
gonale Matrix Q, d.h. QTQ = I, da QTQ = (HG)THG = GTHTHG =
GT IG = GTG = I, weil ja fur jede Rotation R =
(c s−s c
)gerade
R−1 = RT oder eben RTR = I und damit allgemein GTG = I gilt.
8. Richtig/Falsch? Q sei eine n× n-Householder Transformation und x ∈ Rn
beliebig. Dann gibt es ein k < n, so daß die letzten k Komponenten vonQx verschwinden.
H = I − 2vT v
vvT sei eine n × n-Householder Transformation und x ∈ Rn 121–127beliebig. Dann gibt nicht notwendig ein k < n, so daß die letzten k Kom-ponenten von Hx verschwinden, wie etwa der Fall Hx = (I− 2
xT xxxT )x =
x − 2x = −x fur ein x mit ganzlich nicht verschwindenden Komponentenzeigt.
9. Richtig/Falsch? Orthogonalisierungsverfahren zur Losung von linear leastsquares Problemen sind aufwandiger als Verfahren, das (lineare) Systemder Normalen-Gleichungen zu losen.
Fur die Losung von linear least squares Problemen sind unglucklicherweise 143/144Orthogonalisierungsverfahren signifikant aufwandiger als Verfahren, das (li-neare) System der Normalen-Gleichungen zu losen.
10. a) Was heißt, daß die Modell-Funktion f(t,x) linear in x ist? 107
Die skalare Funktion f(t,x) ist linear in x ⇐⇒ fur beliebige a, b ∈ R undx,y ∈ Rn gilt f(t, ax + by) = af(t,x) + bf(t,y) .
b) Gib Beispiele fur in diesem Sinn lineare Modell-Funktionen f . 107
Beispielsweise f(t,x) =∑n
i=1 xiti−1 ist linear in x.
c) Gib Beispiele fur in diesem Sinn nichtlineare Modell-Funktionen f . 107
Beispielsweise f(t,x) =∑n
i=1 exit ist nicht linear in x.
11. Gegeben das least squares Problem Ax ∼= b mit m × n-Matrix A undrank(A) < n < m. Welche Situationen sind moglich?
a) Es gibt keine Losung. 109
’Es gibt keine Losung’ ist falsch: es gibt immer ein y ∈ span(A), das ||b−y||minimiert!
b) Es gibt eine einzige Losung. 109
’Es gibt eine einzige Losung’ ist falsch, siehe c)
c) Es mehrere Losungen. 109

162 KAPITEL 3. LINEAR LEAST SQUARES
Es mehrere Losungen x, da fur Rang-defiziente A die Gleichung y = Axmehrere Losungen x hat.
12. Gegeben ein uberbestimmtes least squares Problem Ax ∼= b. Was istschwerwiegender: die Zeilen von A sind l.a. oder die Spalten von A sindl.a.?
Die Zeilen von A sind Vektoren im Rn. Wegenm > n sind diesem Vektorennotwendigerweise l.a.Wenn dagegen die Spalten von A l.a. sind, so ist die Losung des linear least109/110squares Problem nicht eindeutig!
13. In einem uberbestimmten least squares Problem Ax ∼= b sei die Modell-Funktion f(t,x) = x1φ1(t) + x2φ2(t) + x3φ3(t) mit φ1(t) = 1, φ2(t) = t undφ3(t) = 1− t. Was ist rank(A) ?
Das least squares Problem ist dann durch Ax =
1 t1 1 + t11 t2 1 + t2
...
x1
x2
x3
∼=
b beschrieben. Sei A = (a1, a2, a3). Wegen a3 = a1 + a2 hat die Matrix A107,109den Rang 2.
14. Gegeben das linear least squares Problem Ax ∼= b. Was ist das zugehorigeSystem der Normalen-Gleichungen?
Das lineare Gleichungssystem AATx = ATb ist das zugehorige System der110Normalen-Gleichungen.
15. Wieso kann das Losen des Systems der Normalen-Gleichungen numerischenttauschende Ergebnisse produzieren?
Losen des Systems der Normalen-Gleichungen kann numerisch enttauschen-117/118de Ergebnisse produzieren, erstens aufgrund des Informationsverlustes beider Berechnung von ATA und zweitens wegen Verschlechterung der Kon-ditionszahl cond(ATA) = cond2(A).
16. A sei m× n-Matrix. Unter welchen Bedingungen fur A ist dann ATA
a) symmetrisch?
ATA ist wegen (ATA)T = ATA notwendig symmetrisch.
b) regular?51,135
Wenn rank(A) = n, dann ist die n× n-Matrix ATA regular.Wegen c) ist B = ATA positiv definit. Sei 0 6= x EV zum EW λ von B.Wegen λ||x||22 = xTλx = xTBx > 0 hat eine positiv definite Matrix B nurpositive EWe. Insbesondere ist also 0 kein EW. Es gibt also kein z mitBz = 0. Damit ist B = ATA regular.

3.4. Review Questions – Antworten auf Verstandnisfragen 163
Das Beispiel A =
1 22 43 6
mit ATA =
(14 2828 56
)und det(ATA) = 0 zeigt,
daß die Bedingung notwendig ist.
c) positiv definit? 110
Wenn rank(A) = n, genau dann ist die n× n-Matrix ATA positiv definit.Denn: rank(A) = n ⇐⇒ Ax = (a1, . . . , an)x =
∑ni=1 xiai 6= 0 fur alle
0 6= x ∈ Rn ⇐⇒ xT (ATA)x = (Ax)TAx > 0 fur alle 0 6= x ∈ Rn ⇐⇒ATA ist positiv definit.
17. Welche der folgenden Bedingungen fur eine m × n-Matrix A mit m >n garantieren, daß die minimal residual solution des linear least squaresProblems Ax ∼= b nicht eindeutig ist?
a) Die Spalten von A sind l.a. 109
Wenn die Spalten von A l.a. sind, gibt es ein z 6= 0 mit Az = 0, d.h. mitAx = y gilt auch A(x + z) = y, so daß ||b− y||2 = ||b−Ax||2 minimal inx auch in x + z minimal ist: die Losung ist nicht eindeutig.
b) Die Zeilen von A sind l.a. 109
Die lineare Abhangigkeit der Zeilen von A sagt nichts uber die Eindeutigkeit
der Losung aus, wie A =
[I
A2
]zeigt: Da A vollen Spalten-Rang hat, ist
die Losung von Ax ∼= b eindeutig – unabhangig davon, ob Zeilen von A2
linear unabhangig sind oder nicht.
c) ATA ist singular. 109
Wenn ATA singular ist, hat das System der Normalen-Gleichungen ATAx =ATb keine oder mehrere Losungen. Da es immer eine Losung des linearleast squares Problems Ax ∼= b gibt, impliziert die Singularitat von ATAmehrere Losungen.
18. a) Kann Gauß-Elimination mit Pivotisierung verwendet werden, um dieLU-Faktorisierung von A zu bestimmen? A = LU sei dabei m×n-Matrix,L eine m × k-Matrix, deren Elemente oberhalb der Hauptdiagonalen ver-schwinden, U eine k × n-Matrix, deren Elemente unterhalb der Hauptdia-gonalen verschwinden, und k = minm,n.
???b) Falls ja, kann so Ax ∼= b mit m > n gelost werden?
Das Beispiel A =
(1 11 2
)=
(1 01 1
)(1 10 1
)= LU zeigt, daß weder
UTLTL =
(2 13 2
)noch LTLU =
(2 31 2
)notwendigerweise untere bzw.
obere Dreiecksmatrizen sind. Die LU-Faktorisierung A = LU von A liefert

164 KAPITEL 3. LINEAR LEAST SQUARES
damit keine LU-Faktorisierung von ATA = UTLTLU, die helfen wurde,das System der Normal-Gleichungen ATAx = UTLTLUx = ATb zu losen.
19. a) Was heißt, daß zwei Vektoren orthogonal zueinander sind?111
x ⊥ y ⇐⇒ (x · y) = xTy = 0
b) Gegeben 0 6= x ⊥ y 6= 0. Zeige: x und y sind l.u.111
Angenommen, x und y sind l.a. Dann ware x = λy und damit (x · y) =λ||y||2 6= 0 im Widerspruch zur Voraussetzung.
c) Gib Beispiele fur zueinander orthogonale Vektoren im R2 \ 0.111
Beispielsweise 0 6= (1, 1)T ⊥ (1,−1)T 6= 0.
d) Gib Beispiele fur zueinander nicht orthogonale Vektoren im R2 \ 0.111
Beispielsweise 0 6= x = (1, 1)T 6⊥ (1, 2)T = y 6= 0, da (x · y) = 3 6= 0.
e) Inwiefern spielt Orthogonalitat eine wichtige Rolle in linear least squares111Problemen?
Orthogonalitat spielt eine wichtige Rolle in linear least squares ProblemenAx ∼= b, insofern als das Residuum r = b−Ax der Losung des linear leastsquares Problems senkrecht auf dem Spaltenraum von A steht und genau112die orthogonalen Matrizen Q Norm-erhaltend und damit einzig geeignet119sind, das Problem, ||r||2 = ||b − Ax||2 zu minimieren, in das aquivalenteProblem, ||r||2 = ||Qb−QAx||2 zu minimieren, zu transformieren.
20. Ist Orthogonalitat im Rn transitiv? d.h. ist mit x ⊥ y und y ⊥ z auch111x ⊥ z ?
Orthogonalitat in Rn ist nicht transitiv, da etwa e1 ⊥ e2 und e2 ⊥ 2e1,111aber eben e1 6⊥ 2e1.
21. Was ist ein orthogonaler Projektor? Inwiefern sind diese bedeutsam fur111/112linear least squares Probleme?
Ein orthogonaler Projektor P ist ein symmetrischer Projektor, also idem-potent, d.h. P2 = P, und symmetrisch, d.h. PT = P.Falls A vollen Spalten-Rang hat, liefert der orthogonale Projektor P =A(ATA)−1AT auf span(A) mit y = Pb den Vektor y = Ax ∈ span(A),der b am nachsten liegt, d.h. ||b− y||2 = ||b−Ax||2 ist minimal.Alternativ sei Q eine m×n-Matrix, deren Spalten eine Orthonormal-Basisfur span(A) bilden. Dann ist Q orthogonaler Projektor auf span(Q) =span(A) und das fur geeignete Q dreieckige n×n-Gleichungssystem liefertdie Losung des linear least squares Problem Ax ∼= b.
22. a) Wieso werden Householder Transformationen und Givens Rotationen zur121,127Losung von linear least squares Problemen verwendet?

3.4. Review Questions – Antworten auf Verstandnisfragen 165
Householder Transformationen und Givens Rotationen werden zur Losungvon linear least squares Problemen verwendet, um die betreffende Ma-trix Norm-erhaltend zu triangulieren (Householder) oder zumindest Norm-erhaltend gezielt einzelne Nullen zu erzeugen (Givens).
b) Warum werden Householder Transformationen und Givens Rotationen 121,127nicht haufig genutzt, um ’square linear problems’ zu losen?
Fur m = n ist QR-Faktorisierung vermittels Householder Transformatio-nen mit mn2 − 1
3n3 = 2
3n3 doppelt so aufwandig wie LU-Faktorisierung
vermittels Gauß-Elimination mit 13n3. Noch aufwandiger als Householder
Transformationen sind Givens Rotationen. 129
c) Bieten orthogonale Transformationen im Vergleich zu Gauß-Elimination 119Vorteile, um ’square linear problems’ zu losen?
Orthogonale Transformationen sind im Gegensatz zur Gauß-EliminationNorm-erhaltend. Also keine Pivotisierung?
???
23. Welche der folgenden Matrizen sind orthogonal?
a) A =
(0 11 0
)b) A =
(1 00 −1
)c) A =
(2 00 1
2
)d) A =
√2
2
(1 1
−1 1
)a) Fur A =
(0 11 0
)gilt ATA = A2 = I, also ist A orthogonal.
b) Fur A =
(1 00 −1
)gilt ATA = A2 = I, also ist A orthogonal.
c) Fur A =
(2 00 .5
)gilt (ATA)2,2 = .25 6= I2,2, also ist A nicht orthogonal.
d) A =√
22
(1 1−1 1
)=
(c s−s c
)ist eine Rotationsmatrix und damit gilt
AT = A−1 bzw. ATA = I, also ist A orthogonal.
24. Q sei orthogonale n × n-Matrix, d.h. QTQ = I und R sei die Rotations- 89
matrix R =
(c s−s c
)mit c2 + s2 = 1, da c = cosα und s = sinα. Welche
Eigenschaften hat eine beliebige orthogonale n× n-Matrix Q ?
a) Q ist regular.
Die Spalten von Q sind orthonormal. Daher ist rank(Q) = n. Also ist Qnotwendig regular. (siehe auch c))
b) Q erhalt die Euklid’sche Norm.
Q erhalt die Euklid’sche Norm, da ||Qx||22 = (Qx)TQx = xTQTQx =xT Ix = xTx = ||x||22.c) Die transponierte Matrix QT von Q ist die inverse Matrix Q−1 von Q.

166 KAPITEL 3. LINEAR LEAST SQUARES
Wegen QTQ = I gilt QT = Q−1.
d) Die Spalten von Q sind orthonormal.
Sei Q = (q1, . . . ,qn). Aus I = QTQ = (qT1 , . . . ,q
Tn )T (q1, . . . ,qn) folgt
dann qTi qj = δi,j, also die Orthonormalitat der Spalten von Q.
e) Q ist symmetrisch.
Q ist nicht notwendig symmetrisch, wie etwa Rotationsmatrizen R zeigen.
f) Q ist diagonal.
Q ist nicht notwendig diagonal, wie etwa Rotationsmatrizen R zeigen.
g) Die Euklid’sche Matrix-Norm ||Q||2 von Q ist 1.139
Die Euklid’sche Matrix-Norm ||Q||2 von Q ist der großte SW von Q, dieWurzel des großten EW von QTQ. Wegen QTQ = I und weil 1 doppelterEW von I ist notwendig ||Q||2 = 1.
h) Die Euklid’sche Konditionszahl cond(Q) ist 1.
Wegen ||Q||2 = 1 = ||QT ||2 und wegen QT = Q−1 gilt cond(Q) = ||Q||2 ||Q−1||2 =1 in der Euklid’schen Matrix-Norm.
25. Welche Matrizen sind notwendig orthogonal?119
a) Permutationsmatrizen63/64
Fur Permutationsmatrizen P gilt P−1 = PT . Damit sind Permutationsma-trizen orthogonal.
b) symmetrische, positiv definite Matrizen84
A sei symmetrisch, d.h. AT = A, und positiv definit, d.h. xTAx > 0fur alle x 6= 0. Dann ist A nicht notwendig orthogonal, wie etwa A =diag(1, 2) zeigt: wegen (x, y)A(x, y)T = x2 + 2y2 > 0 fur (x, y)T ∈ R2 ist Apositiv definit. Allerdings ist A wegen ATA = A2 = diag(1, 2)diag(1, 2) =diag(1, 4) 6= I nicht orthogonal.
c) Householder Transformationen121ff
Householder Transformationen H = I− 2vT v
vvT sind wegen H = HT = H−1
und damit HTH = I orthogonal.
d) Givens Rotationen127ff
Givens Rotationen sind im Wesentlichen Rotationen R mit R−1 = RT unddamit orthogonal.
e) regulare Matrizen
Regulare Matrizen sind nicht notwendig orthogonal, wie etwa die MatrixA = diag(2, .5) mit ATA = diag(4, .25) 6= I zeigt.
f) Diagonal-Matrizen

3.4. Review Questions – Antworten auf Verstandnisfragen 167
Diagonal-Matrizen sind nicht notwendig orthogonal, wie etwa die MatrixA = diag(2, .5) mit ATA = diag(4, .25) 6= I zeigt.
26. Zeige: Multiplikation eines Vektors mit einer orthogonalen Matrix erhaltdie Euklid’sche Norm.
Multiplikation eines Vektors mit einer orthogonalen Matrix erhalt die Eu- 119klid’sche Norm (siehe b) in RQ 3.24).
27. Unter welchen Bedingungen an w 6= 0 ist H = I− 2wwT orthogonal?
H = I − 2wwT ist symmetrisch. H ist nun orthogonal ⇐⇒ HTH = 119, 121ffH2 = (I− 2wwT )(I− 2wwT ) = I ⇐⇒ I− 4wwT + 4wwTwwT = I ⇐⇒4wwT = 4w(wTw)wT = 4||w||2wwT .Also: wenn ||w|| = 1, genau dann ist H = I− 2wwT orthogonal.
28. Q sei orthogonal mit Qx = Q
(11
)=
(α0
)= b. Welchen Wert hat α ?
QTQ = I impliziert q21,1 + q2
2,1 = 1 und q1,1q1,2 + q2,1q2,2 = 0. Die Summeder beiden Gleichungen ist q1,1(q1,1 + q1,2) + q2,1(q2,1 + q2,2) = 1. Qx = bimpliziert nun q1,1+q1,2 = α und q2,1+q2,2 = 0 und zusammen q1,1α+q2,10 =1, also α = 1/q1,1.
29. Wieviele skalare Multiplikationen sind notig, um eine n × n-HouseholderMatrix H = I−wwT mit ||w||2 = 1 mit einem beliebigen Vektor in Rn zumultiplizieren?
Gegeben n × n-Householder Matrix H = I − wwT mit ||w||2 = 1. (Ohne 124||w||2 = 1 ist H = I − wwT keine Householder Transformation!) Dannsind je n skalare Multiplikationen fur c = wTx und fur wwTx = cw durch-zufuhren.
30. Zu jedem a existiert eine Householder Transformation H = I − 2vT v
vvT
mit Ha = αe1. Dabei ist v = a − αe1 und α = ±||a||2. Wie sollte dasVorzeichen gewahlt werden?
Fur beliebiges a existiert die Householder Transformation H = I− 2vT v
vvT 121ffmit Ha = αe1, namlich fur v = a − αe1. Dann gilt α = ±||a||2. DasVorzeichen sollte so gewahlt werden, daß Ausloschung vermieden wird.
31. Vergleiche Vor- und Nachteile von Givens Rotationen fur QR-Faktorisierungund Householder Transformationen.
Vorteil der Givens Rotationen ist die Moglichkeit, gezielt Eintrage etwa 127ffin sparlich besetzten Matrizen zu annullieren. Nachteilig im Vergleich zurHouseholder Transformation sind 50% mehr Aufwand, Speicher-Anforde-rungen und aufwandigere Implementierung.

168 KAPITEL 3. LINEAR LEAST SQUARES
32. Die zweite Komponente eines Vektors sei zu annullieren. Liefern Househol-der Transformation und Givens Rotationen immer dasselbe Ergebnis?
Gegeben a =
(a1
a2
). Um a2 zu annullieren, ist entweder die Householder121ff
Transformation H = I− 2vT v
vvT mit v = a−αe1 und α = ±||a||2, also v =(a1 − αa2
)mit 1
2||v||22 = 1
2vTv = a2
1 − a1α+ a22 = α(α− a1) und somit H =
2vT v
(vT v
2− (a1 − α)2 −(a1 − α)a2
−(a1 − α)a2vT v
2− a2
2
)= 2
vT v
(a1(α− a1) a2(α− a1)a2(α− a1) −a1(α− a1)
)=
1α
(a1 a2
a2 −a1
)= 1
±√
a21+a2
2
(a1 a2
a2 −a1
), wobei Ha = αe1 = ±||a||2e1, oder127ff
die Givens Rotation G = 1√a21+a2
2
(a1 a2
−a2 a1
), wobei Ga = ||a||2e1, zu ver-
wenden. Im R2 sind also Householder Transformation und Givens Rotationverschieden.
33. A sei gespeichert und kann uberschrieben werden. Wieviel zusatzlicherSpeicherplatz ist fur die folgenden Aufgaben erforderlich?
a) fur die LU-Faktorisierung der n × n-Matrix A durch Gauß-Eliminationmit partieller Pivotisierung
Wenn die LU-Faktorisierung der n × n-Matrix A durch Gauß-Elimination78mit partial pivoting bestimmt werden soll, dann werden L (ohne die Ein-heitsdiagonale) und U jeweils im Speicherbereich von A abgelegt. Einzusatzlicher Vektor beschreibt die Umordnung der Zeilen aufgrund von Pi-votisierung.
b) fur die QR-Faktorisierung der m×n-Matrix A durch Householder Trans-formationen
Wenn die QR-Faktorisierung der m×n-Matrix A durch Householder Trans-125formationen bestimmt werden soll, dann kann R im oberen Dreieck von Aund die Vektoren v im unteren Dreieck von A und die Diagonale in einemzusatzlichen, separaten Vektor gespeichert werden.
34. Gegeben das linear least squares Problem Ax ∼= b mit m×n-Matrix A undrank(A) < n ≤ m. An welcher Stelle stoppt der jeweilige Losungsprozessbei Verwendung exakter Arithmetik?
???a) Cholesky Faktorisierung angewandt auf das System der Normalenglei-85chungen
Fur Rang-defizientes A ist ATA nicht positiv definit (vgl. RQ 2.16 und RQ110,1353.16). Also scheitert die Cholesky-Faktorisierung von ATA, wie etwa A =

3.4. Review Questions – Antworten auf Verstandnisfragen 169
√3
3
1 21 21 2
mit singularem, nicht positiv definiten B = ATA =
(1 22 4
)zeigt: in B = LLT gilt `1,1 =
√1 = 1, `2,1 = 2/1 = 2 und `2,2 =
√4− 4
b) QR-Faktorisierung durch Householder Transformationen
35. Welche Vorteile hat das modifizierte gegenuber dem klassischen Gram-Schmidt-Orthogonalisierungsverfahren?
a) geringerer Speicherbedarf
b) kurzere Laufzeit????
c) bessere numerische Stabilitat?
36. Die QR-Faktorisierung einer m × n-Matrix mit m > n sei zu bestimmen.Wie groß muß n sein, so daß sich klassisches und modifiziertes Gram-Schmidt-Verfahren unterscheiden?
???37. Warum braucht das Householder Verfahren weniger Speicherplatz fur die
QR-Faktorisierung einer m×n-Matrix als das modifizierte Gram-Schmidt-Verfahren?
???38. Wie kann die QR-Faktorisierung mit Spalten-Pivotisierung eingesetzt wer-
den, um den Rang einer Matrix zu bestimmen? 135/136
QR-Faktorisierung mit Spalten-Pivotisierung!???
39. Warum kann Spalten-Pivotisierung in der modifizierten Gram-Schmidt-Or-thogonalisierung, aber nicht in der klassischen Gram-Schmidt-Orthogona-lisierung eingesetzt werden?
???40. Das linear least squares Problem Ax ∼= b werde einerseits anhand des
Systems von Normalen-Gleichungen und andererseits vermittels des Hou-seholder QR-Verfahrens gelost. Fur welche Werte von cond(A) werden die
???Verfahren jeweils scheitern?
???41. A sei m× n-Matrix.
a) Wieviel nicht-verschwindende singulare Werte kann A maximal haben? 137
Offensichtlich gerade k = minm,n viele, wie etwa A = I
[Σ1
0
]I mit
Σ1 =
k 0 · · · 0
0 k − 1...
.... . . 0
0 · · · 0 1
zeigt.
b) Sei rank(A) = k. Wieviele nicht-verschwindende singulare Werte kann 140

170 KAPITEL 3. LINEAR LEAST SQUARES
A dann maximal haben?
Der Rang von A stimmt uberein mit der Anzahl der nicht-verschwindendensingularen Werte von A.
42. Sei 0 6= a ∈ Rm aufgefasst als m × 1-Matrix. Dann hat a nur einen140singularen Wert? welchen?
Wegen rank(a) = 1 hat a genau einen nicht-verschwindenden SW σ. Ina = UΣVT ist hier Σ = (σ, 0, . . . , 0)T . Da orthogonale Matrizen Langenerhalten, gilt ||a||2 = ||Σ||2 und daher σ = ||a||2.
43. Drucke die Euklid’sche Konditionszahl einer Matrix durch ihre singularen139Werte aus.
Es gilt cond2(A) = σmax/σmin.
44. Gib zwei numerisch zuverlassige Verfahren an, um den Rang einer Matrixzu berechnen.
QR-Faktorisierung mit Spalten-Pivotisierung bla bla135/136
??? singular value decomposition In A = UΣVT stimmt die Anzahl der137,140 nicht-verschwindenden SW mit rank(A) uberein.
45. A sei 2n×n-Matrix. Ordne die folgenden Losungsverfahren des linear leastsquares Problems Ax ∼= b nach steigendem Aufwand.
a) QR-Faktorisierung vermittels Householder Transformationen
b) Losen des Systems von Normalen-Gleichungen
c) per SVD
Es gilt b) < a) < c), weil b)mn2 Multiplikationen fur ATA und n3/6 fur die143/144Cholesky-Faktorisierung der positiv definiten Matrix ATA braucht und weilQR-Faktorisierung vermittels Householder Transformationen mn2 − n3/3Multiplikationen braucht und weil SVD mindestens 4(mn2 + n3) Multipli-kationen braucht.
46. Liste Anwendungen von SVD auf.138–143
Singular Value Decomposition, SVD findet u.a. folgende Anwendungen.
linear least squares Probleme Gegeben Ax ∼= b mit A = UΣVT .138Dann ist x = VΣ−1
1 UT1 b Losung des linear least squares Problem,
falls A maximalen Spaltenrang hat. Allgemein ist x =∑
σ1 6=0uT
i b
σivi
fur U = (u1, . . . ,um) und V = (v1, . . . ,vn).
Euklid’sche Matrix-Norm Es gilt ||A||2 = σmax.139
Euklid’sche Matrix-Konditionszahl Es gilt cond2(A) = σmax/σmin.139

3.5. Exercises – Ubungsergebnisse 171
Rang einer Matrix Es gilt rank(A) = |σi : σi 6= 0|.140
Pseudo-Inverse einer Matrix Fur A = UΣVT ist A+ = VΣ+UT . 140
Orthonormal-Basen In A = UΣVT bilden die Spalten von U bzw. 141von V eine Orthonormal-Basis von span(A) und von span(A)⊥ bzw.eine Orthonormal-Basis von null(A) = x ∈ Rn : Ax = 0 und vonnull(A)⊥.
lower rank approximation Es gilt A = UΣVT =∑n
i=1 σiEi mit Ei = 141uiv
Ti . Mit σ1 > σ2 > . . . > σn ist
∑ki=1 σiEi die Matrix vom Rang k,
die in der Frobenius-Norm der Matrix A am nachsten liegt.
total least squares Angenommen, daß auch die Abszissen ti der Daten- 141Punkte (ti, yi) Meßfehlern unterworfen sind. Dann besteht das totalleast squares Problem darin, die Kurve f(t,x) so zu bestimmen, daßdie Summe der orthogonalen Abstande der Daten-Punkte zur Kurveminimiert wird.
3.5 Exercises – Ubungsergebnisse
1. Gegeben die Abhangigkeit y = x0+x1 t, gemessent 10 15 20y 11.60 11.85 12.25
.
a) Stelle das uberbestimmte 3× 2-System von linearen Gleichungen auf.
Das uberbestimmte 3×2-System von linearen Gleichungen ist Ax =
1 101 151 20
(x0
x1
)∼=11.60
11.8512.25
= b.
b) Zum Test der Konsistenz der Daten bestimme x jeweils aus Paaren vonGleichungen.
Zum Test der Konsistenz der Daten bestimme x aus Paaren von Gleichun-gen:(
1 101 15
)(x0
x1
)=
(11.6011.85
)liefert x =
(11.100.05
).

172 KAPITEL 3. LINEAR LEAST SQUARES(1 101 20
)(x0
x1
)=
(11.6012.25
)liefert x =
(10.9500.065
).(
1 151 20
)(x0
x1
)=
(11.8512.25
)liefert x =
(11.640.08
).
c) Stelle das System der Normalen-Gleichungen auf und vergleiche dessenLosung mit den Ergebnissen aus b).
ATAx =
(1 1 110 15 20
)1 101 151 20
x =
(3 4545 725
)x =
(35.70
538.75
)
=
(1 1 110 15 20
)11.6011.8512.25
= ATb.
Also
(3 450 50
)x =
(35.703.25
)und daher x =
(10.9250.065
).
2. Gesucht sei die Regressionsgerade zu (0, 1), (1, 2) und (3, 3).
Einschub:
Sei A die zu paarweise verschiedenen ti gehorende n × n-Vandermonde-Matrix. Dann hat A maximalen Rang. Sei namlich Az = 0, d.h. dasPolynom mit Koeffizienten z hat gerade die n Nullstellen ti. Also ist dasPolynom das Null-Polynom und somit z = 0.Weil nun mit x 6= 0 auch Ax 6= 0, gilt xTATAx = (Ax)TAx = yTy > 0fur jedes x 6= 0. Also ist ATA positiv definit.
wohin gehort das alles????
a) Stelle das uberbestimmte Gleichungssystem zum gegebenen linear least82squares Problem auf.
Ax =
1 01 11 3
(x0
x1
)∼=
123
= b ist das uberbestimmte Gleichungssystem
zum gegebenen linear least squares Problem.
b) Stelle das System der Normalen-Gleichungen auf.84

3.5. Exercises – Ubungsergebnisse 173
ATAx =
(1 1 10 1 3
)1 01 11 3
x =
(3 44 10
)x =
(611
)=
(1 1 10 1 3
)123
=
ATb ist das System der Normalen-Gleichungen.
c) Lose das linear least squares Problem per Cholesky-Faktorisierung. 61/62
ATA =
(3 44 10
)=
( √3 0
4/√
3√
10− 16/3
)(√3 4/
√3
0√
10− 16/3
)= LLT ist
die Cholesky-Faktorisierung von ATA. Damit ergibt sich zunachst y aus
Ly = ATb zu y =√
3√14
(2√
143
)und dann x aus LTx = y zu x = 1
14
(169
).
3. Gesucht ist die Funktion aus der Familie f(t) = x1t+ x2et, die die Summe
der Fehlerquadrate zu den Punkten (1, 2), (2, 3) und (3, 5) minimiert. 82
Ax =
1 e2 e2
3 e3
x ∼=
235
= b mit dem System von Normalen-Gleichungen
ATAx =
(1 2 3e e2 e3
)1 e2 e2
3 e3
x =
(14 e+ 2e2 + 3e3
e+ 2e2 + 3e3 e2 + e4 + e9
)x
=
(14 ff g
)x =
(23h
)=
(23
2e+ 3e2 + 5e3
)=
(1 2 3e e2 e3
)235
= ATb.
Damit ist x =
(2314− f
1414h−23f14g−f
14h−23f14g−f
)∼=(
1.642650.00003
).
4. Ist die Regressionsgerade zu den Punkten (0, 0), (1, 0) und (1, 1) eindeutig?109
Zum least squares Problem Ax =
1 01 11 1
x ∼=
001
= b gehort das Sy-
stem von Normalen-Gleichungen ATAx =
(1 1 10 1 1
)1 01 11 1
x =
(3 22 2
)x =
(11
)=
(1 1 10 1 1
)001
= ATb oder eben
(1 02 2
)x =
(01
)mit x =(
0.00.5
)als Losung. Die Losung ist eindeutig genau dann, wenn A vollen
Spaltenrang hat, d.h. wenn rank(A) = n. Wegen rank(A) = 2 ist hier dieRegressionsgerade zu (0, 0), (1, 0) und (1, 1) eindeutig.

174 KAPITEL 3. LINEAR LEAST SQUARES
5. Gegeben das least squares Problem Ax ∼= b mit A =
1 01 11 21 3
. Welcher
der folgenden Werte des Residuums r = b−Ax ist moglich?84
a) r =
1111
b) s =
−1−1
11
c) t =
−1
11
−1
Der Residual-Vektor ist orthogonal zum Spalten-Raum von A = (a1, a2).
a) (r · a1) = rTa1 = 4 6= 0, also r 6⊥ a1.
b) (s · a1) = sTa1 = 0 aber (s · a2) = sTa2 = 5 6= 0, also s 6⊥ a2.
c) (t · a1) = tTa1 = 0 und (t · a2) = tTa2) = 0, also steht s senkrecht aufdem Spalten-Raum von A.
6. Gegeben Ax =
1 10 10 0
x =
211
= b.
a) Was ist die Euklid’sche Norm ||r||2 des minimalen residualen Vektors88dieses linear least squares Problems?
Ax =
[R0
]x ∼=
[b1
b2
]mit b1 =
(21
)und b2 = 1 ist schon QR-faktorisiert.
Also ist die Euklid’sche Norm ||r||2 des minimalen residualen Vektors gerade||b2||2 = 1.
b) Welche Losung hat das Problem?88
Die Losung x =
(11
)von Rx = b1 ergibt sich per back substitution.
7. A sei m× n-Matrix und b ∈ Rm.
a) Zeige: Zu jedem linear least squares Problem Ax ∼= b existiert immer109eine Losung x.
Zu jedem least squares Problem Ax ∼= b existiert eine Losung x, weil einy ∈ span(A) existieren muß, das ||y − b||2 minimiert.
b) Zeige: Die Losung ist eindeutig genau dann, wenn rank(A) = n.109
Die Losung ist eindeutig genau dann, wenn A vollen Spalten-Rang hat, d.h.wenn rank(A) = n.
8. Zeige: A sei m×n-Matrix mit rank(A) = n. Dann ist ATA positiv definit.61

3.5. Exercises – Ubungsergebnisse 175
Zu zeigen yTy := xTATAx > 0 fur alle x 6= 0. Angenommen, es existiertx 6= 0 mit (Ax)TAx = 0. Dann ist Ax = 0 und mit A = (a1, . . . , an) eben∑n
i=1 xiai = 0, d.h. die Spalten von A sind l.a. und damit gilt rank(A) < nim Widerspruch zur Voraussetzung.
9. Zeige: Die augmented system matrix A ist nicht positiv definit. 87
Die augmented system matrix A =
[I A
AT 0
]mit A
[rx
]=
[b0
]ist nicht
positiv definit, da
[0x
]T
A[0x
]=
[0x
]T[Ax0
]= 0TAx + xT0 = 0 fur x 6= 0.
10. B = (bi,j) sei quadratische, orthogonale obere Dreiecksmatrix.
a) Zeige: B ist Diagonal-Matrix. 119
LU := BTB = I, also b21,1 = 1, insbesondere b1,1 6= 0, was b1,i = 0 fur i > 1impliziert. Die erste Zeile verschwindet also außerhalb der Diagonalen.Daher folgt weiter b22,2 = 1, insbesondere b2,2 6= 0, was b2,i = 0 fur i > 2impliziert. Die zweite Zeile verschwindet also außerhalb der Diagonalen.usw.
b) Welche Hauptdiagonal-Elemente hat B ?
Aus B = diag(d) und BTB = (diag(d))2
= diag(d21, . . . , d
2n) = I folgt
di = ±1 fur alle i = 1, . . . , n.
c) A sei regulare n×n-Matrix. Zeige: die QR-Faktorisierung von A ist bisauf das Vorzeichen der Hauptdiagonal-Elemente eindeutig, d.h. es gibt ge-nau zwei Matrizen Q und R, so daß Q orthogonal, R obere Dreiecksmatrixmit positiven Hauptdiagonal-Elementen und A = QR.
Angenommen, Q1R1 = A = Q2R2 mit orthogonalen Qi und oberen Drei-ecksmatrizen Ri. Mit A sind auch Ri regular und mir Ri sind auch R−1
i
obere Dreiecksmatrizen, vgl. 2RQ7 und 2RQ9. Also ist B = R1R−12 =
QT1 Q2 sowohl orthogonal als auch tringular, wegen a) diagonal und wegen
b) B = diag(d21, . . . , d
2n) mit di = ±1 fur alle i = 1, . . . , n. Wahle also B in
A = Q1R1 = Q1BR2 so, daß R1 = BR2 die einzige obere Dreiecksmatrixmit positiven Hauptdiagonal-Elementen ist. Damit ist die QR-Faktorisie-rung regularer n× n-Matrizen in diesem Sinn eindeutig.
11. Die Matrix Q =
[A B0 C
]mit quadratischen Unter-Matrizen A und C sei
orthogonal. Zeige: Dann sind auch A und C orthogonal und es gilt B = 0.89
QTQ =
[AT 0BT CT
] [A B0 C
]=
[ATA ATBBTA BTB + CTC
]=
[I 00 I
], d.h. A
ist orthogonal, also insbesondere A−1 = AT . Daher folgt B = AATB =A0 = 0 und zuletzt die Orthogonalitat von C.

176 KAPITEL 3. LINEAR LEAST SQUARES
12. a) Zeige: Je zwei der folgenden Eigenschaften einer n× n-Matrix A impli-zieren die dritte.
1. AT = A
2. ATA = I
3. A2 = I
1. Aus ATA = I folgt A−1 = AT und aus A2 = I folgt A−1 = A, zusam-men also A = A−1 = AT .
2. AT = A in A2 = I einsetzen liefert ATA = I.
3. AT = A in ATA = I einsetzen liefert A2 = I.
b) Gib Beispiele fur 3×3-Matrizen, anders als I oder Permutationsmatrizen,mit allen drei Eigenschaften.
Jede symmetrische orthogonale Matrix hat alle drei Eigenschaften, z.B. diedrei 3D-Rotationsmatrizen um 180o um jeweils die x-, y- und z-Achse.
c) Benenne eine nicht-triviale Klasse von Matrizen mit allen drei Eigen-90schaften.
Alle Householder Matrizen haben alle drei Eigenschaften (s. Ex 3.13).
13. Was folgt, wenn A sowohl orthogonal als auch orthogonaler Projektor ist?
Orthogonal, also ATA = I, und orthogonaler Projektor zu sein, also AT =A und A2 = A, impliziert A = A2 = AA = ATA = I, d.h. notwendigA = I.
14. Zeige: Fur v 6= 0 sind Householder Matrizen H = I− 2vT v
vvT symmetrischund orthogonal.
Fur v 6= 0 sind Householder Matrizen H = I − 2vT v
vvT wegen HT =90IT − 2
vT v(vvT )T = I− 2
vT vvvT = H symmetrisch und wegen HTH = H2 =
(I− 2vT v
vvT )2 = I−2 2vT v
vvT + 2vT v
2vT v
v(vTv)vT = I− 4vT v
vvT + 4vT v
vvT =I orthogonal.
15. Sei a 6= 0 beliebig und v = a − αe1 mit α = ±||a||2. Zeige: Fur dieHouseholder Transformation H = I− 2
vT vvvT gilt Ha = αe1.90
Mit H = I − 2vT v
vvT gilt dann Ha = (I − 2vT v
vvT )a = a − 2vT v
v(vTa) =
a− 2(at−αeT1 )a)
||a||22−2α(a)1+α2 (a− αe1) = a− (a− αe1) = αe1
16. Ein beliebiger Vektor a ∈ Rn werde als n× 1-Matrix aufgefasst.
a) Bestimme die QR-Faktorisierung von a mit expliziter Angabe von Q und97R.

3.5. Exercises – Ubungsergebnisse 177
Die QR-Faktorisierung von a ist a = Q
[||a||20
]mit orthogonalem Q =
(q1,q2, . . . ,qn). Notwendigerweise ist q1 = 1||a||a und QTQ = I impliziert,
daß die Vektoren q1, q2, . . . , qn ein Orthonormalsystem bilden, wie es perGram-Schmidt-Verfahren erzeugt werden kann.
b) Lose das linear least squares Problems ax ∼= b fur beliebig gegebenes b.
Die Losung des linear least squares Problems ax ∼= b ergibt sich aus denNormalen-Gleichungen (a · a)x = aTax = aT b = (a · b) zu x = (a·b)
(a·a)=
(a·b)
||a||22= (na · b) mit dem Einheitsvektor na in Richtung von a.
17. Sei a = (1, 1, 1, 1)T . Gesucht ist die Householder Transformation H =I− 2
vT vvvT mit Ha = αe1. Bestimme α und v. 90
Setze dazu v = a − αe1 mit α = ±||a||2 = ±2. Um Ausloschung zuvermeiden, wahle α = −2. Dann ist v = (3, 1, 1, 1)T und H = I− 2
12vvT =
I− 16vvT , so daß Ha = 1
6
−3 −3 −3 −3−3 5 −1 −1−3 −1 5 −1−3 −1 −1 5
1111
=
−2
000
= αe1 folgt.
18. Bestimme die QR-Faktorisierung von A =
1 1 11 2 41 3 91 4 16
= (a,b, c) durch 89,90
Householder Transformationen.
a) Wieviele Householder Transformationen werden notwendig?
Es werden maximal drei Householder Transformationen notwendig.
b) Wie sieht die erste Spalte von A als Ergebnis der ersten HouseholderTransformation aus?
H1 = I− 2vT v
vvT mit v = a−αe1 und α = ±||a||2. Da (a)1 = 1 positiv ist,wahle α = −||a||2 = −2, um generell Ausloschung zu vermeiden. Wegenv = (3, 1, 1, 1)T ist H1 = I − 2
vT vvvT = I − 2
9+1+1+1(3, 1, 1, 1)T (3, 1, 1, 1)
und H1A = 16
−3 −3 −3 −3−3 5 −1 −1−3 −1 5 −1−3 −1 −1 5
1 1 11 2 41 3 91 4 16
=
−2 −5 −15
0 0 −4/30 1 11/30 2 32/3
.
c) Wie sieht dann die erste Spalte von A als Ergebnis der zweiten House-holder Transformation aus?
Mit der zweiten Spalte
−5
012
von H1A ist v =
0012
− αe2 mit ±α =

178 KAPITEL 3. LINEAR LEAST SQUARES
||
012
||2 =√
5, also v =
0
−√
512
und H2 = I − 210
vvT , also H2H1A =
15
5 0 0 0
0 0√
5 2√
5
0√
5 4 −2
0 2√
5 −2 1
−2 −5 −15
0 0 −4/30 1 11/30 2 32/3
=
−2 −5 −15
0√
5 5√
5
0 0 −20−4√
515
0 0 10−8√
515
.
d) Wieviele Givens Rotationen werden fur die QR-Faktorisierung von Abenotigt?
Da jede Givens Rotation nur mindestens eine Null erzeugt, werden maximal3 + 2 + 1 = 6 Givens Rotationen notig.
19. a = (2, 3, 4)T sei gegeben.
a) Bestimme die elementary elimination matrix, die die dritte Komponente39a3 von a annulliert.
Die elementary elimination matrix, die die dritte Komponente (a)3 vona verschwinden laßt, ist die Matrix M = I − (0, 0,−4/3)TeT
3 mit Ma =
(I−
00
−4/3
eT2 )a =
1 0 00 1 00 −4/3 0
234
=
230
b) Welche Householder Transformation annulliert die dritte Komponente90a3 von a ?
Die Householder Transformation H = I− 2vT v
vvT mit v = a−αe2 und α =
±||a||2 = ±√
29, also v = (2, 3+√
29, 4)T und H = I− 24+9+6
√29+29+16
vvT =
I − 129+3
√29
(2, 3 +√
29, 4)T (2, 3 +√
29, 4) laßt die dritte Komponente von
a verschwinden, da Ha = a − 2vT avT v
v = a − 4+9+3√
29+1629+3
√29
v = a − v = αe2
mit ||Ha|| =√
29 = ||a||2 wie ebenso als Matrix-Transformation Ha =
129+3
√29
25+3√
29 −6−2√
29 −8−6−2
√29 −9−3
√29 −12−4
√29
−8 −12−4√
29 13+3√
29
2
34
= −87−29√
2929+3
√29
010
=αe2.
c) Welche Givens Rotationen annullieren die dritte Komponente a3 von a ?93
Zwei Givens Rotationen annullieren die dritte Komponente von a.
x bleibt fest: Mit c = a2√a22+a2
3
= 35
und s = a3√a22+a2
3
= 45
ist Ga =
15
5 0 00 3 40 −4 3
234
=
250
, wobei ||Ga||2 =√
29 = ||a||2.

3.5. Exercises – Ubungsergebnisse 179
y bleibt fest: Mit c = a1√a21+a2
3
=√
55
und s = a3√a21+a2
3
= 2√
55
ist Ga =
√5
5
1 0 2
0√
5 0−2 0 1
234
=
2√
530
, wobei ||Ga||2 =√
29 = ||a||2.
d) Konnen elementary elimination matrix und Householder Transformation 39ubereinstimmen, die eine nicht-verschwindende Komponente eines beliebi-gen Vektors annullieren?
Falls die elementary elimination matrix orthogonal und damit wie die Hou-seholder Transformation Norm-erhaltend ist, konnten elementary elimi-nation matrix und Householder Transformation ubereinstimmen. M =I−meT
k ist orthogonal ⇐⇒ MTM = I ⇐⇒ I = (I− ekmT )(I−meT
k ) =I−ekm
T−meTk +ekm
TmeTk ⇐⇒ ekm
T +meTk = ||m||22eke
Tk ⇐⇒ m = 0,
da (ekmT + meT
k )k,k = 0 = ||m||22 = (||m||22ekeTk )k,k.
e) Konnen Householder Transformation und Givens Rotation ubereinstim-men, die eine nicht-verschwindende Komponente eines beliebigen Vektorsannullieren?
Householder Transformation H und Givens Rotation G stimmen nie ube-rein, da H = HT und G 6= GT .
20. Angenommen, a2 in a =
(a1
a2
)soll perGivens Rotation annulliert werden,
wahrend aber schon a1 = 0 gilt.
a) Kann eineGivens Rotation a2 annullieren? 93
Givens Rotationen sind Norm-erhaltend. Wegen ||a|| = |a2| 6= 0 und||Ga|| = ||0|| = 0 kann also a2 perGivens Rotation nicht annulliert wer-den.
b) Kann eine elementary elimination matrix a2 annullieren? 39
Da kein x mit Ma =
(1 0x 1
)(0a2
)= 0 existiert, kann a2 auch nicht mit
elementary elimination matrices annulliert werden.
21. Givens Rotation sind durch die beiden Parameter c und s spezifiziert. Geht 127es auch mit einem Parameter?
Aus c = cosα und s = sinα ergibt sich eindeutig α = arccos c und aus αnaturlich eindeutig wieder c = cosα und s = sinα.
22. A sei m× n-Matrix, rank(A) = n und A = Q
[R0
]die QR-Faktorisierung
von A, wobei Q orthogonal und R quadratische, obere Dreiecksmatrix ist. 120Sei ATA = LLT die Cholesky-Faktorisierung von ATA.

180 KAPITEL 3. LINEAR LEAST SQUARES
a) Zeige: RTR = LLT . 85/86
QTQ = I liefert LLT = ATA = [RT ,0]QTQ
[R0
]= [RT ,0]
[R0
]= RTR.
b) Kann R = LT gefolgert werden?
Die Cholesky-Faktorisierung X = LLT positiv definiter Matrizen X isteindeutig, da sich die Elemente `i,j von L notwendigerweise aus
`i,j =
0 falls i < j√xj,j −
∑j−1k=1 `
2j,k falls i = j
(xi,j −∑j−1
k=1 `i,k`j,k)/`j,j falls i > j
ergeben. Schon triviale Beispiele wie I
[R0
]= A = −I
[−R0
]fur regulare
obere Dreiecksmatrizen R oder die Freiheit der Vorzeichen-Wahl in derHouseholder Transformation oder diejenige der Wahl der Reihenfolge vonGivens Rotationen dagegen zeigen, daß die QR-Faktorisierung nicht ein-deutig ist. Also kann nicht notwendig R = LT gelten.
23. Gegeben A =
1 1ε 00 ε
. ATA =
(1 + ε2 1
1 1 + ε2
)ist in einem floating
point system singular, wenn ε <√εmax gilt. Zeige: Wenn A = Q
[R0
]die
QR-Faktorisierung von A ist, dann ist R auch in Gleitpunkt-Arithmetikregular.89
Muß das nicht A = Q
[R0
]heißen? Welches A ist gemeint?
???
24. Verifiziere, daß der dominante Term in der Anzahl von fur die Losung eines85m × n-linear least squares Problems per System von Normalen-Gleichungund Cholesky-Faktorisierung notigen Operationen (Multiplikationen oderAdditionen) 1
2mn2 + 1
6n3 ist.
Die Bildung von ATA kostet fur jedes der n2 Elemente jeweils m flOs, alsounter Berucksichtigung der Symmetrie von ATA insgesamt 1
2mn2 flOs. Die
Cholesky-Faktorisierung einer n × n-Matrix kostet 16n3 flOs. Das System
der Normalen-Gleichungen LTLx = ATAx = ATb ist LU-faktorisiert. Esaufzulosen, kostet O(n2) flOs. Der dominante Term in der Anzahl der Ope-rationen zur Losung des Systems von Normalen-Gleichungen per Cholesky-Faktorisierung ist daher 1
2mn2 + 1
6n3.
25. Verifiziere, daß der dominante Term in der Anzahl von fur die QR-Fak-torisierung einer m× n-Matrix per Householder Transformationen notigenOperationen (Multiplikationen oder Additionen) 1
2mn2 − 1
6n3 ist.

3.5. Exercises – Ubungsergebnisse 181
for k = ( 1 : n) % n Durchlaufealpha = −sign ( a (k , k ) )∗norm( a ( ( k :m) , k ) ) ; %m−k+1 MULv = [ zeros ( 1 , ) a (??) ] ’− alpha∗eye (m) ( : , k ) ;beta = norm( v ) ; % m-k+1 MULfor j = (k : n) %n−k+1 Durchlaufe
gamma = v ’∗ a ( : , j ) ; %m− k + 1 MULa ( : , j ) = a ( : , j )−(2∗gamma/beta )∗v ; %m− k + 1 MUL
endend
124Die Anzahl #MUL der Multiplikationen ist also
#MUL =n∑
k=1
(2(m− k + 1) +n∑
j=k
2(m− k + 1))
= 2n∑
k=1
((m− k + 1) + (n− k + 1)(m− k + 1))
= 2n∑
k=1
(n− k + 2)(m− k + 1) = 2n∑
k=1
(n+ 2− k)(m+ 1− k)
= 2n∑
k=1
((n+ 2)(m+ 1)− (n+m+ 3)k + k2)
= 2n(n+ 2)(m+ 1)− (n+m+ 3)n(n+ 1) + 216n(n+ 1)(2n+ 1)
= O(2n2m− n2m− n3 + 23n3) = O(mn2 − n3/3).
26. Sei c = cos θ und s = sin θ. Welchen geometrischen Effekt verursachenfolgende orthogonale 2× 2-Matrizen im R2 ?
a) G =
(c s−s c
)G bewirkt eine Rotation um 0 mit Rotationswinkel θ.
b) H =
(−c ss c
)H laßt sich als H = GS mit S =
(−1 0
0 1
)darstellen. H ist also die Spiege-
lung S an der x-Achse gefolgt von der Rotation um 0 mit Rotationswinkelθ.
27. a) Q sei n× k-Matrix (n>k), deren Spalten q1, . . . ,qk eine Orthonormal- 111Basis von S ⊂ Rn formen. Zeige: Dann ist P = QQT ein orthogonalerProjektor auf S.
Wegen PT = P und P2 = QQTQQT = QQT = P ist P = QQT einorthogonaler Projektor auf S.

182 KAPITEL 3. LINEAR LEAST SQUARES
b) A sei eine Matrix mit l.u. Spalten. Zeige: P = A(ATA)−1AT ist ein112orthogonaler Projektor auf den Spalten-Raum S von A. Wie hangt diesmit linear least squares Problemen zusammen?
Dann ist P = A(ATA)−1AT ein Projektor auf den Spalten-Raum S von
A, weil P mit PT = A((ATA)−1)TAT = P erstens symmetrisch und weilEx 2.9
P mit P2 = A(ATA)−1ATA(ATA)−1AT = A(ATA)−1AT = P zweitensidempotent ist.
Zusammenhang zu least squares Problemen??????
c) P sei ein orthogonaler Projektor auf S = PRn. Zeige: Dann ist P⊥ = I−P ein orthogonaler Projektor auf das orthogonale Komplement S⊥ = P⊥Rn
von S.
P sei ein orthogonaler Projektor auf S = PRn. Dann ist P⊥ = I − P einorthogonaler Projektor auf das orthogonale Komplement S⊥ = P⊥Rn vonS. Wegen (P⊥)T = (I − P)T = I − P = P⊥ ist P⊥ symmetrisch. Wegen(P⊥)2 = (I − P)2 = I − 2P + P2 = I − 2P + P = I − P = P⊥ ist Pidempotent. Schließlich ist S⊥ = P⊥Rn das orthogonale Komplement vonS: mit beliebigen x = Pu ∈ S = PRn und y = P⊥v ∈ S⊥ = P⊥Rn
gilt namlich xTy = (Pu)TP⊥v = uTPT (I − P)v = uTPTv − uTPTPv =uTPTv − uTPTv = 0.
d) Sei 0 6= v ∈ Rn. Was ist der orthogonale Projektor auf span(v) ?
Sei 0 6= v ∈ Rn. Dann ist P = vvT
vT v= 1
||v||22vvT ein Projektor auf span(v) =
Rv, da P wegen PT = P symmetrisch und wegen P2 = vvT
vT vvvT
vT v= vvT
vT v= P
idempotent ist und da der Spalten-Raum von P offensichtlich Rv ist.
28. a) Sei Q=(q1, . . . ,qn) im Gram-Schmidt-Verfahren zur QR-Faktorisierung.131Zeige: fur die orthogonalen Projektoren Pk = qkq
Tk gilt
(I−Pk)(I−Pk−1) · · · (I−P1) = I−Pk −Pk−1 − . . .−P1.
Zunachst ist Pk = qkqTk fur normiertes qk orthogonaler Projektor, da wegen
P2k = qk(q
Tk qk)q
Tk = qkq
Tk = Pk idempotent und wegen PT
k = (qkqTk )T =
qkqTk = Pk symmetrisch. Fur orthonormale qi und i 6= j ist dann PiPj =
qi(qTi qj)q
Tj = 0, so daß per Induktion
∏k+1i=1 (I−Pi) = (I−Pk+1)(I−Pk −
. . .−P1) = I−Pk+1 −Pk − . . .−P1 folgt.
b) Zeige: das klassische Gram-Schmidt-Verfahren ist aquivalent zu qk =132(I− (P1 + . . .+ Pk−1))ak.
bis auf Normalisierung!???
c) Zeige: das modifizierte Gram-Schmidt-Verfahren ist aquivalent zu qk =132(I−Pk−1) · · · (I−P1)ak.
???d) Ein alternativer Weg, das klassische Verfahren numerisch zu stabilisieren,besteht darin, es mehrfach anzuwenden (iterative refinement), d.h. qk =

3.5. Exercises – Ubungsergebnisse 183
(I− (P1 + . . .+ Pk−1)m)ak, wobei meist m = 2 ausreicht.
Zeige: alle drei Verfahren sind mathematisch (wenn auch uberhaupt nichtnumerisch) aquivalent.
???
29. Sei 0 6= v ∈ Rn. Die zu v normale Hyperebene v⊥ ist der (n − 1)-dimen-sionale Unterraum aller x mit vTx = 0. Die Matrix R ist ein Reflektor,genau dann wenn Rx = −x fur x ∈ Rv und Rx = x fur alle x in der zu vnormalen Hyperebene v⊥, d.h. fur alle vTx = 0.
a) Sei P der orthogonale Projektor auf die zu v normale Hyperebene v⊥.Zeige: Dann gilt R = 2P− I.
Es gilt R = 2P − I, da fur x ∈ v⊥ eben Px = x und damit einerseitsRx = (2P − I)x = 2Px − x = 2x − x = x gilt. Andererseits ist Pv ∈ v⊥
und daher gilt 0 = vTPv = vTP2v = vTPTPv = (Pv)TPv und somitPv = 0, so daß Rx = 2Px− x = −x fur x ∈ Rv folgt.
b) Zeige: R symmetrisch und orthogonal. 89
Wegen RT = (2P − I)T = 2P − I = R ist R symmetrisch und wegenRTR = (2P− I)(2P− I) = 4P2 − 4P + I = I ist R orthogonal.
c) Zeige: Die Householder Transformation H = I− 2vT v
vvT ist ein Reflektor. 90
Fur die Householder Transformation H = I − 2vT v
vvT gilt Hv = v −2
vT vvvTv = v−2v = −v sowie Hw = w− 2
vT vvvTw = w fur alle vTw = 0.
Also ist H ein Reflektor.
d) Gegeben s, t ∈ Rn mit s 6= t und ||s||2 = ||t||2. Zeige: Dann existiert einReflektor R mit Rs = t.
Dann existiert ein Reflektor R mit Rs = t. Setze namlich v = s− t. Dannist die Householder Transformation H = I− 2
vT vvvT der gesuchte Reflektor,
da aus vTv = (sT−tT )(s−t) = ||s||22−sT t−tT s+||t||22 = 2(||s||22−sT t) undaus vT s = (sT−tT )s = ||s||22−sT t eben Hs = s− 2
2(||s||22−sT t)v(||s||22−sT t) =
s− (s− t) = t folgt.
e) Zeige: Jede orthogonale Matrix Q ist Produkt von Reflektoren. 119
Per QR-Faktorisierung laßt sich Q als Q = H1 · · ·HnR mit Househol-der Matrizen Hi und oberer Dreiecksmatrix R darstellen. Wegen QTQ =I = RTHT
n · · ·HT1 H1 · · ·HnR = RTR und ebenso RRT = I ist auch
R = (ri,j) orthogonal, d.h. R = (r1, . . . , rn) hat orthonormale Spaltenri, d.h. rT
i rj = δi,j. Aus rT1 rj = δ1,j folgt r2
1,1 = 1 und r1,j = 0 fur j > 1,aus rT
2 rj = δ2,j folgt r22,2 = 1 und r2,j = 0 fur j > 2 usw. Insgesamt kann die
Diagonal-Matrix R = diag(r) mit r = (ri,i) und ri,i ∈ ±1 fur i = 1, . . . , nalso als R =
∏rii=−1 Ri mit Ri = diag((−1)δi,1 , . . . , (−1)δi,n) dargestellt
werden.Die Housholder-Matrizen Hi sind nach Teil c) Reflektoren. Wegen etwa

184 KAPITEL 3. LINEAR LEAST SQUARES
R1 = diag(−1, 1, . . . , 1) = 2 diag(0, 1, . . . , 1)− I = 2P− I mit dem orthogo-nalen Projektor P auf span(e1)
⊥ sind wie R1 alle Ri Reflektoren. Insgesamtist also Q Produkt von Reflektoren.
f) Visualisiere: Die Rotationen des R2 sind Produkte von je zwei Reflekto-ren.
Zunachst werden nur Rotationen um den Ursprung betrachtet. Die Ro-
tation Rotδ um den Winkel δ ist durch Rotδ =
(cos δ − sin δsin δ cos δ
)gegeben.
Die Spiegelung Reflδ an der Geraden R(
cos δsin δ
)ist dann durch Reflδ =
RotδRefl0Rot−δ gegeben. Dabei ist Refl0 =
(1 00 −1
)die Spiegelung an der
x-Achse und es gilt
Reflδ = RotδRefl0Rot−δ =
(cos(2δ) sin(2δ)sin(2δ) − cos(2δ)
).
Wegen Refl0RotδRefl0 = Rot−δ gilt endlich
Rotδ = Rotδ/4Rotδ/2Rotδ/4 = Rotδ/4Refl0Rot−δ/2Refl0Rotδ/4
= Rotδ/4Refl0Rot−δ/4Rot−δ/4Refl0Rotδ/4 = Reflδ/4Refl−δ/4 .
Mit den Abkurzungen c = cos δ und s = sin δ gilt cos δ2
= (−1)ec
√1+c2
mit
ec = b |δ|2πc und sin δ
2= (−1)es
√1−c2
mit es = bπ+|δ|2π
c, so daß
Rotδ =
(c −ss c
)=
(cos(δ/2) sin(δ/2)sin(δ/2) − cos(δ/2)
)(cos(δ/2) − sin(δ/2)− sin(δ/2) − cos(δ/2)
)
=
(−1)ec
√1+c2
(−1)es
√1−c2
(−1)es
√1−c2
−(−1)ec
√1+c2
(−1)ec
√1+c2
−(−1)es
√1−c2
−(−1)es
√1−c2
−(−1)ec
√1+c2
folgt. Die folgende Skizze illustriert beispielhaft die Rotation um δ = 60o.

3.5. Exercises – Ubungsergebnisse 185
x
y
~z
Refl−δ/4(~z)
Reflδ/4( Refl−δ/4(~z))
30. a) Sei 0 6= a ∈ Rm aufgefasst als m × 1-Matrix. Zeige die singular value 137,141decomposition explizit auf, d.h. bestimme U, Σ und V.
Es sind U,Σ,V in a = UΣVT mit orthogonalen Matrizen U und V unddiagonaler Matrix Σ zu bestimmen. U hat als orthogonale m×m-Matrix
orthonormale Spalten U = (q1, . . . ,qm), Σ ist die m × 1-Matrix Σ =
[σ0
]und fur V als orthogonale 1 × 1-Matrix gilt V = 1. Aus a = UΣ =
[q1,U2]
[σ0
]und ||q1|| = 1 folgt q1 = 1
||a||2a sowie σ = ||a||2.
Sei e1, . . . , em die kanonische Basis des Rm. Falls a Vielfaches von ek tauschea gegen ek, sonst gegen e1. Mit neuer Nummerierung ist a, e2, . . . , em eineBasis des Rm, die vermittels des Gram-Schmidt-Orthogonalisierungsverfah-rens in eine Orthonormal-Basis 1
||a||2a,q2, . . . ,qm uberfuhrt werden kann. 131
Damit ist auch U = ( 1||a||2a,q2, . . . ,qm) vollstandig bestimmt.
b) Sei 0 6= a ∈ Rn aufgefasst als 1 × n-Matrix. Zeige die singular value 137,141decomposition explizit auf, d.h. bestimme U, Σ und V.
Mit Teil a) gilt a = UΣVT und damit aT = VΣTUT = (ΣU)T .
31. A sei m × n-Matrix, b ∈ Rm und x die Losung des linear least squares 138Problem Ax ∼= b minimaler Euklid’scher Norm. Zeige: x =
∑i,σi 6=0
uTi b
σivi
fur die singular values σi und zugehorige singular vectors ui und vi.
Nur falls Σ1 regular ist:
Mit A = UΣVT = [U1,U2]
[Σ1
0
]VT = U1Σ1V
T ist x = VΣ−11 UT
1 b eine
Losung des linear least squares Problem Ax ∼= b, weil x in ATAx = ATbeingesetzt die Normalengleichungen ATAx = (VΣT
1 UT1 )(U1Σ1V
T )x =VΣT
1 Σ1VT (VΣ−1
1 UT1 b) = VΣT
1 UT1 b = (U1Σ1V
T )Tb = ATb erfullt.

186 KAPITEL 3. LINEAR LEAST SQUARES
Mit U = (u1, . . . ,um) und V = (v1, . . . ,vn) laßt sich x = VΣ−11 UT
1 b =
V
σ1 0 · · · 0
0 σ2...
.... . . 0
0 · · · 0 σn
−1uT
1 b...
uTmb
=V
1σ1
0 · · · 0
0 1σ2
......
. . . 00 · · · 0 1
σn
uT
1 b...
uTmb
=V
uT
1 b
σ1...
uTmbσn
als
Σ1 singular: x = VΣ−11 UT
1 b = V
σ1 0 · · · 0
0. . .
σ?...
... 0. . . 0
0 · · · 0 0
−1
uT1 b...
uTmb
=
???
32. Zeige: die Pseudo-Inverse A+ = VΣ+UT einer m× n-Matrix A = UΣVT137,140erfullt die sogenannten Penrose-Bedingungen.
Fur die m×n-Matrix Σ und die zugehorige n×m-Matrix Σ+ gilt zunachst
Σ =
σ1 0. . .
0 σn
0 · · · 0...
...0 · · · 0
=[Σ1
0
]und Σ+ =
1σ1
0 0 · · · 0. . .
......
0 1σn
0 · · · 0
=[Σ+
1 ,0]
und daher Σ+Σ =[Σ+
1 ,0] [Σ1
0
]= I sowie ΣΣ+ =
[Σ1
0
] [Σ+
1 ,0]
=[I 00 0
].
a) AA+A = A
Wegen der Orthogonalitat von U und V mit UTU = I und VTV = I giltAA+A = UΣVT (VΣ+UT )UΣVT = UΣΣ+ΣVT = UΣVT = A.
b) A+AA+ = A+
Wie oben gilt A+AA+ = VΣ+UT (UΣVT )VΣ+UT = VΣ+ΣΣ+UT =VΣ+UT = A+.
c) (AA+)T = AA+
(AA+)T = (UΣVTVΣ+UT )T = (UΣΣ+UT )T = U(ΣΣ+)TUT = UΣΣ+UT =UΣVTVΣ+UT = AA+.
d) (A+A)T = A+A

3.5. Exercises – Ubungsergebnisse 187
(A+A)T = (VΣ+UTUΣVT )T = (VΣ+ΣVT )T = V(Σ+Σ)TVT = VΣ+ΣVT =VΣ+UTUΣVT = A+A.
33. Zeige folgende Implikationen fur die Pseudo-Inverse A+ einer m×n-MatrixA.
a) Wenn m = n und A regular ist, dann gilt A+ = A−1. 140
Mit quadratischem und regularem A = UΣVT ist auch Σ = UTAV qua-dratisch und regular. Insbesondere ist daher Σ+ = Σ−1 und es folgt ausA+A = VΣ+UTUΣVT = I = UΣVTVΣ+UT = AA+ die Behauptung.
b) Wenn m > n und rank(A) = n ist, dann gilt A+ = (ATA)−1AT .
A hat maximalen Spalten-Rang. Also sind ATA und Σ1 in A = UΣVT =
[U1,U2]
[Σ1
0
]VT regular. Es gilt (ATA)−1AT = (VΣTUTUΣVT )−1AT =
(VΣTΣVT )−1VΣTUT = V(ΣTΣ)−1VTVΣTUT = V(ΣTΣ)−1ΣTUT =
VΣ+UT = A+, da (ΣTΣ)−1ΣT =
([ΣT
1 ,0]
[Σ1
0
])−1
ΣT = Σ−21 [Σ1,0] =
[Σ−11 ,0] = Σ+.
c) Wenn m < n und rank(A) = m ist, dann gilt A+ = AT (AAT )−1.
AT hat maximalen Spalten-Rang. Also sind AAT und Σ1 in A = UΣVT =U[Σ1,0]VT regular und es gilt AT (AAT )−1 = AT (UΣVTVΣTUT )−1 =VΣTUT (UΣΣTUT )−1 = VΣTUTU(ΣΣT )−1UT = VΣT (ΣΣT )−1UT =
VΣ+UT = A+, da ΣT (ΣΣT )−1 =
[ΣT
1
0
]([Σ1,0]
[ΣT
1
0
])−1
=
[ΣT
1
0
]Σ−2
1 =[Σ−1
1
0
]= Σ+.
34. a) Was ist die Pseudoinverse von A =
(1 00 0
)?
Gesucht die EVen zu EWen von ATA = A2 = A. ex ist (normierter)EV zum EW 1 von A und ey ist (normierter) EV zum EW 0 von A (Aist singular). Damit folgt aus Σ = diag(1, 0), U = I = V und der SVDA = UΣVT von A eben A+ = VΣ+UT = Σ+ = A.
b) Was ist die Pseudoinverse von A =
(1 00 ε
)fur ε > 0 ?
Da A regular ist, stimmt A+ mit A−1 = diag(1, 1ε) uberein.
c) Was bedeutet dies fur die Kondition des Problems, die Pseudoinverseeiner Matrix zu berechnen?
???

188 KAPITEL 3. LINEAR LEAST SQUARES
3.6 Computer Problems –
Rechner-Problem-Losungen
1. Gesucht sind die Polynome n-ten Grades y = pn(t) mit n = 0, 1, . . . , 5, diedas linear least squares Problem zu den folgenden Daten losen.
t 0.0 1.0 2.0 3.0 4.0 5.0y 1.0 2.7 5.8 6.6 7.5 9.9
Visualisiere die Losungen. Welches Polynom scheint den Trend der Datenam besten widerzuspiegeln?
t
y
po(t)
t
y p1(t)
t
y p2(t)
n = 0 Ax0 =
111111
x0∼=
1.02.75.86.67.59.9
= b mit ATAx0 = (1, 1, 1, 1, 1, 1)
111111
x0 =
6x0 = (1, 1, 1, 1, 1, 1)
1.02.75.86.67.59.9
= 33.5 und somit x0 = 1633.5 = 5.583.
n = 1 Ax=
1 01 11 21 31 41 5
(x0
x1
)∼=
1.02.75.86.67.59.9
=b mit
(1 1 1 1 1 10 1 2 3 4 5
)
1 01 11 21 31 41 5
=
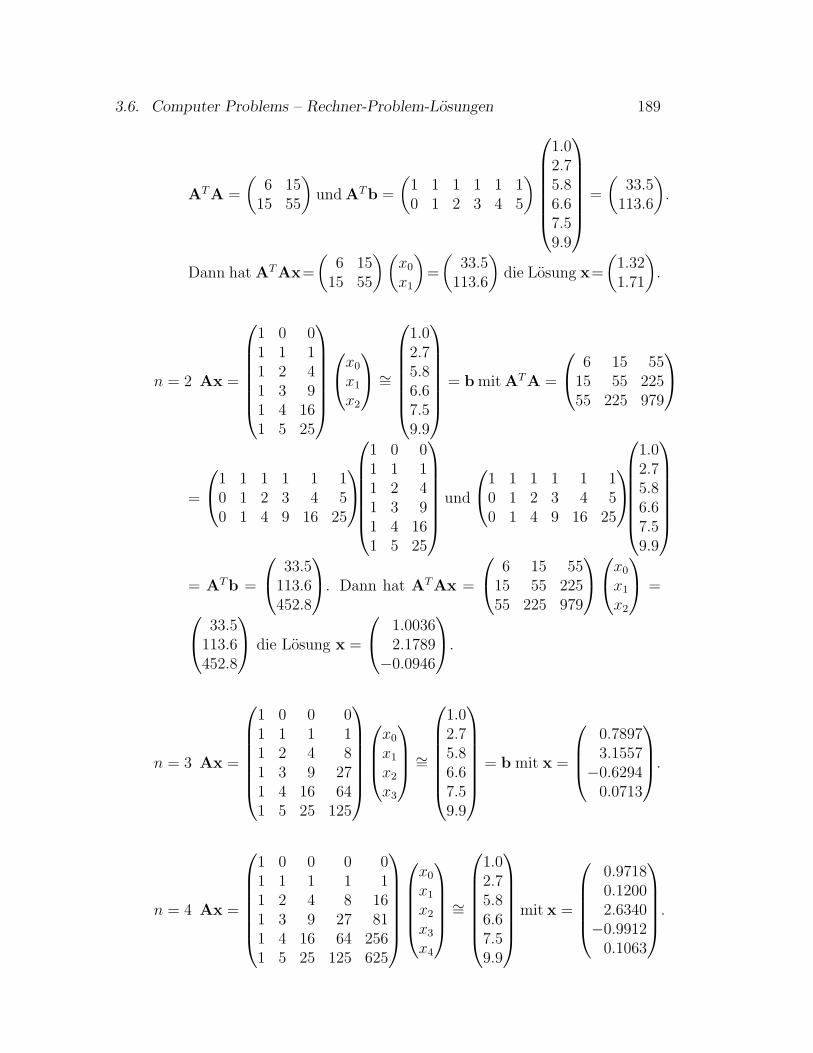
3.6. Computer Problems – Rechner-Problem-Losungen 189
ATA =
(6 15
15 55
)und ATb =
(1 1 1 1 1 10 1 2 3 4 5
)
1.02.75.86.67.59.9
=
(33.5
113.6
).
Dann hat ATAx=
(6 15
15 55
)(x0
x1
)=
(33.5
113.6
)die Losung x=
(1.321.71
).
n = 2 Ax =
1 0 01 1 11 2 41 3 91 4 161 5 25
x0
x1
x2
∼=
1.02.75.86.67.59.9
= b mit ATA =
6 15 5515 55 22555 225 979
=
1 1 1 1 1 10 1 2 3 4 50 1 4 9 16 25
1 0 01 1 11 2 41 3 91 4 161 5 25
und
1 1 1 1 1 10 1 2 3 4 50 1 4 9 16 25
1.02.75.86.67.59.9
= ATb =
33.5113.6452.8
. Dann hat ATAx =
6 15 5515 55 22555 225 979
x0
x1
x2
= 33.5113.6452.8
die Losung x =
1.00362.1789
−0.0946
.
n = 3 Ax =
1 0 0 01 1 1 11 2 4 81 3 9 271 4 16 641 5 25 125
x0
x1
x2
x3
∼=
1.02.75.86.67.59.9
= b mit x =
0.78973.1557
−0.62940.0713
.
n = 4 Ax =
1 0 0 0 01 1 1 1 11 2 4 8 161 3 9 27 811 4 16 64 2561 5 25 125 625
x0
x1
x2
x3
x4
∼=
1.02.75.86.67.59.9
mit x =
0.97180.12002.6340
−0.99120.1063
.
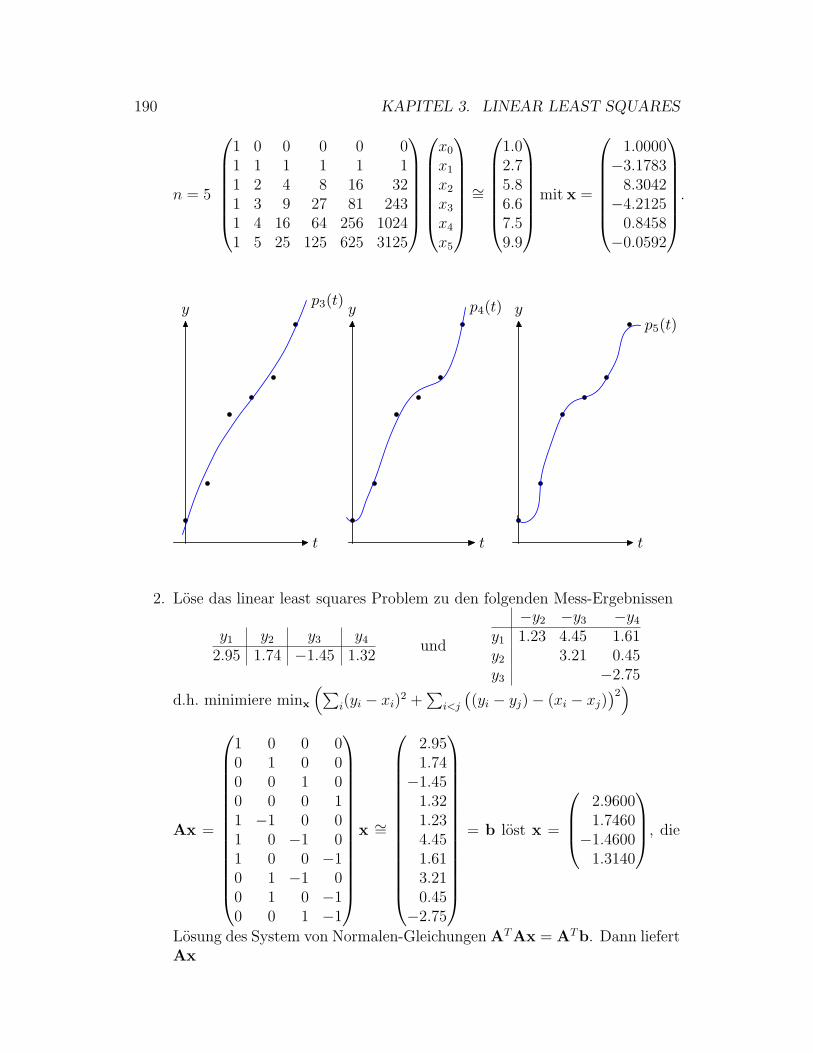
190 KAPITEL 3. LINEAR LEAST SQUARES
n = 5
1 0 0 0 0 01 1 1 1 1 11 2 4 8 16 321 3 9 27 81 2431 4 16 64 256 10241 5 25 125 625 3125
x0
x1
x2
x3
x4
x5
∼=
1.02.75.86.67.59.9
mit x =
1.0000
−3.17838.3042
−4.21250.8458
−0.0592
.
t
yp3(t)
t
y p4(t)
t
yp5(t)
2. Lose das linear least squares Problem zu den folgenden Mess-Ergebnissen
y1 y2 y3 y4
2.95 1.74 −1.45 1.32und
−y2 −y3 −y4
y1 1.23 4.45 1.61y2 3.21 0.45y3 −2.75
d.h. minimiere minx
(∑i(yi − xi)
2 +∑
i<j ((yi − yj)− (xi − xj))2)
Ax =
1 0 0 00 1 0 00 0 1 00 0 0 11 −1 0 01 0 −1 01 0 0 −10 1 −1 00 1 0 −10 0 1 −1
x ∼=
2.951.74
−1.451.321.234.451.613.210.45
−2.75
= b lost x =
2.96001.7460
−1.46001.3140
, die
Losung des System von Normalen-Gleichungen ATAx = ATb. Dann liefertAx

3.6. Computer Problems – Rechner-Problem-Losungen 191
x1 x2 x3 x4
2.96 1.746 −1.46 1.314und
−x2 −x3 −x4
x1 1.214 4.42 1.646x2 3.206 0.432x3 −2.774
3. a) t(n) sei die Zeit fur die LU-Faktorisierung von n × n-Matrizen etwaper MatLab-Routinen. Passe ein Polynom dritten Grades den t(n) (n inHunderten-Schritten wachsend) an und prognostiziere t(10000).
???b) Bestimme FLOPS des eingesetzten Rechen-Systems, d.h. die Anzahl aus-gefuhrter Gleitpunkt-Operationen pro Sekunde, anhand etwa der Matrix-Multiplikation, bestimme damit t(n) in flOs und vergleiche mit dem lautTheorie dominanten Term 4
3n3.
???
4. a) Lose Ax =
0.16 0.100.17 0.112.02 1.29
(x1
x2
)=
0.260.283.31
Dann hat ATAx = b die Losung x =
(11
).
b) Lose Ax =
0.16 0.100.17 0.112.02 1.29
(x1
x2
)=
0.270.253.33
Dann hat ATAx = b die Losung x =
(7.0089
−8.3957
).
c) Begrunde die vergleichenden Beobachtungen.
Begrundung ist die schlechte Konditionierung von ATA. Laut MatLab ist
cond(ATA) = 1.2046·106, weil ATA =
(4.1349 2.64052.6405 1.6862
)sowie (ATA)−1 =
105
(0.5994 −0.9387
−0.9387 1.4699
)und daher ||ATA||1 = 4.1349 + 2.6405 = 6.7754
sowie ||(ATA)−1||1 = 105(0.9387 + 1.4699) = 2.4086 · 105. In der 1-Normgilt also cond(ATA) = ||ATA||1 · ||(ATA)−1||1 = 6.7754 · 2.4086 · 105 =1.63192 · 106 wie ebenso in der ∞-Norm, weil ATA symmetrisch ist.
5. Die Bahn eines Planeten sei elliptisch und sei beschrieben durch
ay2 + bxy + cx+ dy + e = x2
a) Sei p = (a, b, c, d, e)T . Gemessen wurden folgende Bahnpunkte
x 1.02 0.95 0.87 0.77 0.67 0.56 0.44 0.30 0.16 0.01y 0.39 0.32 0.27 0.22 0.18 0.15 0.13 0.12 0.13 0.15
.

192 KAPITEL 3. LINEAR LEAST SQUARES
Lose das linear least squares Problem in p = (a, b, c, d, e)T und visualisiereBahnpunkte und errechnete Bahn.
Das linear least squares Problem bzgl. p = (a, b, c, d, e)T ist dann Ap =
y2 xy x y 10.1521 0.3978 1.02 0.39 10.1024 0.3040 0.95 0.32 10.0729 0.2349 0.87 0.27 10.0484 0.1694 0.77 0.22 10.0324 0.1206 0.67 0.18 10.0225 0.0840 0.56 0.15 10.0169 0.0572 0.44 0.13 10.0144 0.0360 0.30 0.12 10.0169 0.0208 0.16 0.13 10.0225 0.0015 0.01 0.15 1
abcde
∼=
x2
1.04040.90250.75690.59290.44890.31360.19360.09000.02560.0001
=b mit p=
−2.6356
0.14360.55143.2229
−0.4329
,
der Losung des Systems ATAp = ATb von Normalen-Gleichungen.
b) Addiere pseudo-zufallig erzeugte Storungen im Intervall (−.005, .005) zuden gemessenen Koordinaten und vergleiche die sich ergebenden Losungenund die sich ergebende Bahn mit Losungen und Bahn aus a).Wegen cond(ATA) ≈ 4.7394 · 105 ist ATA schlecht konditioniert.
???c) Verwende fur a) und b) speziell auf rank deficient Matrizen zugeschnit-tene Bibliotheksroutinen (etwa mit column pivoting). Experimentiere mitder vorzugebenden Toleranz.
???d) Berechne mit Bibliotheksroutinen die SVD.
???e) Verwende SVD, um die Losungen von a) zu ermitteln.
???f) Verwende SVD, um die Losungen von b) zu ermitteln und mit denen vona) zu vergleichen.
???g) Formuliere das Problem als totales least squares Problem und lose diesper SVD.
???
6. Entwickle ein Programm zu Berechnung der Pseudoinversen und vergleichemit Bibliotheksroutinen. (Das Programm sollte als Pseudoinverse einer

3.6. Computer Problems – Rechner-Problem-Losungen 193
regularen Matrix deren Inverse berechnen.) Experimentiere mit Schrankenfur Null zu setzende SWe. Was passiert fur regulare, aber extrem schlechtkonditionierte Matrizen wie die Hilbert-Matrix?
???
7. Entwickle ein Programm zur Losung von rank deficient linear least squaresProblemen Ax ∼= b per SVD.
???
8. Seien die Modell-Funktionen f(t,x) = x1 + x2 t+ x3 t2 + . . . + xn t
n−1 unddie Datenpunkte (ti, yi) mit ti = i−1
m−1fur i = 1, . . . ,m − 1 gegeben. Die
Datenpunkte yi werden etwa durch die Setzung xj = 1 fur j = 1, . . . , nerzeugt und durch yi := yi + ε(2ui − 1) fur Pseudo-Zufallszahlen ui ∈ [0, 1]gestort. In IEEE DP etwa sei m = 21, n = 12 und ε = 10−10. Gewinnenun die (bekannten) xi per Losen der Normalen-Gleichungen und per QR-Faktorisierung zuruck. Welches Verfahren ist genauer? Welches Verfahrenreagiert sensitiver auf Storungen der Daten?
???
9. Verwende das augmented system Verfahren, um die least squares Problemeaus CP 3.8 zu losen. Da das augmented system zwar symmetrisch abernicht positiv definit ist, ist Cholesky-Faktorisierung nicht anwendbar undstattdessen indefinite LU-Faktorisierung zu wahlen. Experimentiere mitdem Parameter α und vergleiche die Ergebnisse mit denen, gewonnen durchLosung der Normalengleichungen und durch QR-Faktorisierung.
???
10. A sei die m × n-Matrix des least squares Problems Ax ∼= b mit m > n.Dann heißt C = σ2(ATA)−1 mit σ2 = 1
m−n||b − Ax||22 die Covariance
Matrix des least squares Problems Ax ∼= b fur die Losung x.
a) Sei A = Q
[R0
]mit orthogonalem Q die QR-Faktorisierung von A.
Zeige: Dann ist (ATA)−1 = (RTR)−1.
ATA = [RT ,0]QTQ
[R0
]= [RT ,0]
[R0
]= RTR wegen der Orthogonalitat
von Q.
b) Entwickle ein Programm zur Berechnung der Kovarianz-Matrix, das nurdas schon berechnete R benutzt. (Der skalare Faktor σ2 darf ignoriertwerden.) Verifiziere, daß das Ergebnis mit (ATA)−1 ubereinstimmt.
???
11. Verwende Bibliotheksroutinen, um die QR-Faktorisierung A = Q
[R0
]ei-
ner m×n-Matrix A per Householder Transformationen zu berechnen. Ent-wickle ein Programm, das Q explizit als Produkt der Householder Trans-formationen berechnet, das die Orthogonalitat von Q verifiziert und das
A = Q
[R0
]pruft.
???

194 KAPITEL 3. LINEAR LEAST SQUARES
12. a) Implementiere das klassische und das modifizierte Gram-Schmidt-Ver-fahren, um jeweils eine orthogonale Matrix Q zu generieren, deren Spal-ten eine Orthonormal-Basis fur den Spaltenraum der Hilbert-Matrix Hn =(hi,j)i,j=1,...,n mit hi,j = 1
i+j−1fur n = 2, 3, . . . , 12 bilden.
???b) Wiederhole a) mit Householder QR-Faktorisierung.
??? c) Wiederhole a) mit SVD.???
d) Die Normalen-Gleichungen erlauben einen weiteren Losungsweg: mit derCholesky-Faktorisierung ATA = LLT von ATA gilt I = L−1(ATA)L−T =(AL−T )T (AL−T ). Also ist Q = AL−T orthogonal mit demselben Spalten-raum wie A.Wiederhole a) mit dem in dieser Weise gewonnenen Q.
???e) Vergleiche die Ergebnisse von a), b) c) und d).
???
13. Sei das linear least squares Problem Ax =
1 1 1ε 0 00 ε 00 0 ε
x1
x2
x3
∼=
1000
= b
gegeben. Beobachte insbesondere ε ∼= εmach und ε ∼=√εmach, wenn das
Problem mit einem der folgenden Verfahren gelost wird.
a) per System der Normalen-Gleichungen
ATAx =
1 + ε2 1 11 1 + ε2 11 1 1 + ε2
x1
x2
x3
=
111
= ATb liefert die exakte
Losung x = 13+ε2
111
per System der Normalen-Gleichungen.84
ε = set ATA reset ||b−Ax||2 = ||r||2 = =
elim x1 elim x2 comp x3 comp x2 comp x1 comp ||r||2b) per augmented system method
???c) per Householder QR-Faktorisierung
???d) per Givens QR-Faktorisierung
???e) per klassischer Gram-Schmidt-Orthogonalisierung
???f) per modifizierter Gram-Schmidt-Orthogonalisierung
???g) per klassischer Gram-Schmidt-Orthogonalisierung mit iterierter Verbes-serung (CGS zweimal)
???

3.6. Computer Problems – Rechner-Problem-Losungen 195
h) per SVD???

196 KAPITEL 3. LINEAR LEAST SQUARES

Kapitel 4
Eigenvalue Problems
4.0.1 Eigenwerte, EWe und Eigenvektoren, EVen
Eigenwerte, EWe, und Eigenvektoren, EVen, identifizieren die einfachsten Anteileder Operation linearer Transformationen.
Def. Die n× n-Matrix A stellt eine lineare Transformation des Rn dar. WennA eingeschrankt auf Rx eine simple Skalierung darstellt, d.h. wenn Ax = λx fur0 6= x ∈ Rn gilt, so heißt λ ein Eigenwert, EW von A und x 6= 0 mit Ax = λxheißt Eigenvektor, EV zum EW λ.Die Menge λ(A) = λ : es existiert 0 6= x mit Ax = λx der EWe von A heißtSpektrum von A und das Maximum ρ(A) = max|λ| : λ ∈ λ(A) der Betragevon EWen heißt Spektral-Radius von A. Bem. Daher ist nicht uberraschend, daß EWe und SWe insofern eng zusam-menhangen, als cond(A)2 = ||A||2 · ||A−1||2 = σmax/σmin fur den maximalenbzw. minimalen SW σmax bzw. σmin gilt. Dabei sind die SWe σi gerade dieDiagonal-Elemente der Diagonal-Matrix Σ in der singular value decomposition,SVD, A = UΣVT von A mit orthogonalen Matrizen U und V. Die SWe stimmenmit den nicht-negativen Quadratwurzeln der EWe von ATA uberein. Bem. Eigenfrequenzen schwingender Systeme entsprechen Eigenwerten, dieStabilitat von Strukturen ist durch Eigenwerte und Eigenvektoren bestimmt, Ei-genwerte spielen aber auch eine wichtige Rolle in der Analyse der Konvergenziterativer Verfahren oder der Stabilitat von Differentialgleichungen. Z.B. Ein schwingendes System bestehe aus den drei Massen m1, m2 und m3
sowie den drei Federn mit Federkonstanten k1, k2 und k3. Die vertikale Aus-lenkung von mi sei yi. Die von einer Feder ausgehende Ruckstellkraft k · y istder Auslenkung der an der Feder befestigten Masse entgegengerichtet. Also gilt
197

198 KAPITEL 4. EIGENVALUE PROBLEMS
m1
m2
m3
m y = F = −k y oder m y + k y = 0
Auf jede der drei Massen m1, m2 und m3 angewandt ergibt sich
m1y1 + k1y1 + k2(y1 − y2) = 0
m2y2 + k2(y2 − y1) + k3(y2 − y3) = 0
m3y3 + k3(y3 − y2) = 0
und mit y = (y1, y2, y3)T , Massen-Matrix M und Steifheitsmatrix K
My + Ky =
m1 0 00 m2 00 0 m3
y +
k1 + k2 −k2 0−k2 k2 + k3 −k3
0 −k3 k3
y = 0
Jede einzelne Masse fuhrt harmonische Schwingungen mit Eigenfrequenz ω aus,d.h. yk(t) = xke
iωt. Aus yk(t) = −ω2xkeiωt ergibt sich die algebraische Gleichung
Kx = ω2Mx oder eben Ax = λx fur A = M−1K und λ = ω2. Eigenfrequenzund Amplituden der Schwingungen der einzelnen Massen ergeben sich somit ausdem Eigenwert λ und den zugehorigen Eigenvektoren x. cBem. Idem fur komplexe Matrizen Z.B.
1. Fur A1 =
(2 00 1
)ist λ1 = 2,x1 = R
(10
)und λ2 = 1,x2 = R
(01
).
2. Fur A2 =
(2 10 1
)ist λ1 = 2,x1 = R
(10
)und λ2 = 1,x2 = R
(−11
).
3. Fur A3 =
(3 11 3
)ist λ1 = 4,x1 = R
(11
)und λ2 = 2,x2 = R
(−11
).
4. Fur A4 =
(2 00 1
)ist λ1 = 2,x1 = R
(10
)und λ2 = 1,x2 = R
(01
).
5. Fur A5 =
(0 1
−1 0
)ist λ1 = i,x1 = R
(1i
)und λ2 = −i,x2 = R
(1−i
). c
4.0.2 Existenz und Eindeutigkeit
Existenz meint Darstellung und Anzahl von EWen einer n×n-Matrix sowie derenLokalisierung in der komplexen Ebene; Eindeutigkeit meint Eigenschaften der vonEVen aufgespannten Unterraume.

199
Das charakteristische Polynom
Ax = λx ist aquivalent zu (A− λI)x = 0. Es gibt eine Losung x 6= 0 nur, wennA− λI singular ist, also wenn det(A− λI) = 0.
Def. Fur jede quadratische Matrix A heißt das Polynom p(λ) = det(A − λI)charakteristisches Polynom von A. Die Nullstellen von p heißen Eigenwerte, EWevon A.
Z.B. Fur A3 =
(3 11 3
)gilt det(A3 − λI) =
∣∣∣∣3− λ 11 3− λ
∣∣∣∣ = (3 − λ)2 − 1 mit
den beiden Nullstellen λ1 = 4 und λ2 = 2. cDer Fundamentalsatz der Algebra liefert fur p mit den Nullstellen λ1, λ2, . . . , λn−1
und λn (incl. Multiplizitat) die Darstellung
p(λ) = co + c1λ+ . . .+ cnλn = cn(λ− λ1)(λ− λ2) · . . . · (λ− λn)
Die Nullstellen/Eigenwerte sind reell oder komplex. Komplexe Eigenwerte sindpaarweise konjugiert komplex.
Zu jeder Matrix A gehort das charakteristische Polynom p(λ), dessen Nullstellenden Eigenwerten von A entsprechen. Umgekehrt gehort zu jedem Polynom p diesogenannte companion Matrix C, deren Eigenwerte gerade genau die Nullstellenvon p sind. Per Division durch cn darf o.B.d.A. cn = 1 angenommen werden.Dann ist
C =
0 0 · · · 0 −co1 0 · · · 0 −c10 1 · · · 0 −c2...
.... . .
......
0 0 · · · 1 cn−1
Die Eigenwerte von C stimmen mit den Nullstellen von p(λ) = co + c1λ + . . . +cn−1λ
n−1 + λn uberein, vgl. 5RQ35.
Abel1 zeigte 1824, daß keine geschlossene Darstellung fur die Nullstellen vonPolynomen mindestens funften Grades existiert. Daher konnen die Eigenwertevon n×n-Matrizen mit n > 4 nur naherungsweise, also iterativ berechnet werden.
Allerdings ist die Bestimmung der Eigenwerte als Nullstellen des charakteristi-schen Polynoms p aus folgenden Grunden nachteilig:
• Die Bestimmung der Determinanten von A und damit der Koeffizientenvon p ist aufwandig.
• Die Koeffizienten konnen sensitiv auf Anderungen von A reagieren.
1 Niels Henrik Abel (1802-1829) www-history.mcs.st-andrews.ac.uk/Biographies/Abel.html

200 KAPITEL 4. EIGENVALUE PROBLEMS
• Rundungsfehler bei der Bestimmung von p konnen die Genauigkeit derberechneten Nullstellen aufreiben.
• Bestimmung der Nullstellen von p als solche ist eine Herausforderung, derman typischerweise ausgerechnet mit der Berechnung der Eigenwerte dercompanion matrix C begegnet.
Z.B. Fur A =
(1 εε 1
)mit 0 < ε < εmach gilt p(λ) = det(A−λI) = (1−λ)2−ε2 =
(λ − 1 − ε)(λ − 1 + ε) mit den beiden Eigenwerten λ1 = 1 − ε und λ2 = 1 + ε.Andererseits ist fl(p(λ)) = fl(λ2 − 2λ+ 1− ε2) = λ2 − 2λ+ 1 mit der doppeltenNullstelle 1. c
Multiplizitat und Diagonalisierbarkeit
Def. Die Multiplizitat eines Eigenwertes λ von A heißt auch die algebraischeMultiplizitat. Die maximale Anzahl linear unabhangiger Eigenvektoren zu einemEigenwert λ heißt geometrische Multiplizitat von λ. Bem. geometrische Multiplizitat von λ ≤ algebraische Multiplizitat von λ. Z.B. Die n × n-Einheitsmatrix I hat den einen Eigenwert 1 mit algebraischerund geometrischer Multiplizitat n. cDef. Ein Eigenwert λ heißt defective, wenn seine geometrische Multiplizitatkleiner als seine algebraische Multiplizitat ist. Eine Matrix mit defektivem Ei-genwert heißt selbst defective.Eine nicht-defektive n× n-Matrix A hat n l.u. EV x1, . . . ,xn zu EW λ1, . . . , λn.Sei D = diag(λ1, . . . , λn) und X = (x1, . . . ,xn). Dann ist X regular und wegenAX = XD ist X−1AX = D. Ein solches A heißt diagonalisierbar.
Eigenraume und invariante Unterraume
Mit x ist auch jedes Vielfache von x ein Eigenvektor zum Eigenwert λ.
Def. Sλ = x : Ax = λx ist ein Unterraum von Rn bzw. Cn. Sλ heißt derEigenraum von λ. Def. Ein Unterraum S von Rn bzw. Cn heißt bzgl. einer n × n-Matrix Ainvariant, wenn AS ⊂ S. Bem. Die Eigenraume von A sind invariant. Fur Eigenvektoren x1, . . . ,x` vonA ist span(x1, . . . ,x`) invariant.

201
Eigenschaften von Matrizen mit Blick auf Eigenwert-Probleme
Def. A = (ai,j) sei reelle oder komplexe n× n-Matrix.A heißt diagonal, wenn ai,j = 0 fur i 6= j.A heißt tridiagonal, wenn ai,j = 0 fur |i− j| > 1.A heißt obere/untere Dreiecksmatrix, wenn ai,j = 0 fur i > j bzw. i < j.A heißt obere/untere Hessenberg-Matrix, wenn ai,j = 0 fur i > j+1 bzw. i < j−1.A heißt orthogonal, wenn ATA = I = AAT .A heißt unitar, wenn AHA = I = AAH .A heißt symmetrisch, wenn A = AT .A heißt Hermite2sch, wenn A = AH .A heißt normal, wenn AHA = AAH . Bem. Eigenwerte diagonaler oder dreieckiger Matrizen sind gerade die Diagonal-Elemente. Symmetrische und Hermite’sche Matrizen haben nur reelle Eigenwerte.Normale Matrizen haben einen Satz von n orthonormalen Eigenvektoren. Sie sinddamit diagonalisierbar.
Eigenwerte lokalisieren
Wegen ||A|| = maxx6=0||Ax||||x|| ≥ maxx6=0ist EV zum EW λ
||Ax||||x|| = ||Ax||
||x|| = ||λx||||x|| = |λ|
liegen alle Eigenwerte von A im Kreis mit Radius ||A|| in der komplexen Ebene.
Satz (Gershgorin3) Die Eigenwerte von A = (ai,j) liegen in der Vereinigung dern Kreise mit Mittelpunkt ak,k und Radius
∑j 6=k |ak,j|. •
Bew. Sei x Eigenvektor zu beliebigem Eigenwert λ. Sei ||x||∞ = 1. Seix = (x1, . . . , xn)T und |xk| = 1. In der k-ten Komponente von Ax = λx ist∑n
j=1 ak,jxj = λxk oder∑
j 6=k ak,jxj = (λ− ak,k)xk, so daß mit
|λ− ak,k| = |λ− ak,k| · |xk| = |(λ− ak,k)xk| ≤∑j 6=k
|ak,j| · |xj| ≤∑j 6=k
|ak,j|
die Behauptung folgt. Angewandt auf AT ergibt sich ein entsprechendes Resultatfur die absoluten Spalten-Summen.
√
Z.B. A1 =
4.0 −.5 0.00.6 5.0 −.60.0 0.5 3.0
hat4 drei EWe, den reellen EW λ1 = 4− c130− 4
c1≈
3.1357 λ2 = 4 + c160
+ 2c1
+ i 12
√3(− c1
30+ 4
c1) ≈ 4.4322− 0.4004 i sowie die beiden
zueinander konjugiert komplexen EWe λ3 = 4 + c160
+ 2c1− i 1
2
√3( − c1
30+ 4
c1) ≈
4.4322 + 0.4004 i mit c1 =3√
4050 + 30√
16305.
2 Charles Hermite (1822-1901) www-history.mcs.st-andrews.ac.uk/Biographies/Hermite.html
3 Semyon Aranovich Gershgorin (1901-1933) www-history.mcs.st-andrews.ac.uk/Biographies/Gershgorin.html
4laut MATLAB

202 KAPITEL 4. EIGENVALUE PROBLEMS
Die Matrix A2 =
4.0 0.5 0.00.6 5.0 0.60.0 0.5 3.0
dagegen hat4 die drei reellen EWe µ1 = 4 +
c230
+ 16c2≈ 5.3499, µ2 = 4 − c2
60− 8
c2+ i 1
2
√3( c2
30− 16
c2) ≈ 2.8420 sowie µ3 =
4− c260− 8
c2− i 1
2
√3( c2
30− 16
c2) ≈ 3.8081 mit c2 =
3√
4050 + i 30√
104655.
2 3 4 5 6 7
a33 a11 a22
λ1
λ2
λ3
µ1µ2 µ3
Die EWe jeder der beiden Matrizen liegen in der Vereinigung der Kreisscheibenum 3, 4 und 5 (die gemeinsamen Diagonal-Elemente) mit Radien 0.5, 0,5 und 1.2(die Summe der Betrage der anderen Elemente in der entsprechenden Zeile vonA1 und ebenso A2). cBem. Eine Zeilen- oder Spalten-weise echt diagonal-dominante Matrix (dieDiagonal-Elemente sind betragsmaßig echt großer als die Summe der Betrage deranderen Elemente in derselben Zeile oder Spalte) ist regular, da 0 in keinemGershgorin-Kreis liegen und damit 0 kein EW sein kann.
4.0.3 Sensitivitat und Konditionierung
Es gilt, die Sensitivitat von Eigenwerten und Eigenvektoren von A auf Ande-rungen von A zu bestimmen. Soviel vorab: die Konditionszahl des Problems,Eigenwerte und Eigenvektoren von A zu bestimmen, ist verschieden von der Kon-ditionszahl, lineare Gleichungssysteme mit Koeffizienten-Matrix A zu losen. Au-ßerdem konnen Eigenwerte und Eigenvektoren unterschiedlich sensitiv auf Ande-rungen von A reagieren.
Satz (Bauer & Fike5) Sei A eine nicht-defektive n× n-Matrix mit n l.u. Eigen-vektoren x1, . . . ,xn zu Eigenwerten λ1, . . . , λn. Sei X = (x1, . . . ,xn) die Matrixdieser Eigenvektoren, E die Matrix der Storungen und µ ein beliebiger Eigenwertvon A+E. Dann gilt |µ−λk| ≤ cond2(X)||E||2 fur den µ am nachsten liegendenEigenwert λk von A. •Bew. Sei A eine nicht-defektive n × n-Matrix mit n l.u. EV x1, . . . ,xn zuEW λ1, . . . , λn. Dann ist X = (x1, . . . ,xn) regular und wegen X−1AX = D =
5 F. L. Bauer, C. T. Fike: Norms and exclusion theorems; Numer. Math., 2 (1960), pp137-144

203
diag(λ1, . . . , λn) ist A diagonalisierbar. Sei µ Eigenwert der gestorten MatrixA + E und sei F = X−1EX. Wegen
X−1(A + E)X = X−1AX + X−1EX = D + F
sind A + E und D + F ahnlich (siehe den folgenden Abschnitt) und haben somitdieselben Eigenwerte: ein Eigenwert µ mit Eigenvektor x von A + E ist wegen(D+F)X−1x = X−1(A+E)XX−1x = X−1(A+E)x = muX−1x auch Eigenwertvon D + F und entsprechend umgekehrt. Sei also v Eigenvektor zum Eigenwertµ von D + F, d.h. (D + F)v = µv oder Fv = µv − Dv = (µI − D)v) oderv = (µI−D)−1Fv. Hier ist µI−D regular, solange µ kein Eigenwert von D unddamit kein Eigenwert von A ist – E hatte also nicht alle Eigenwerte verandert.Aus ||v||2 ≤ ||(µI−D)−1||2 · ||F||2 · ||v||2 folgt ||(µI−D)−1||−1
2 ≤ ||F||2.Da (µI−D)−1 Diagonal-Matrix ist, gilt ||(µI−D)−1||2 = 1
|µ−λk|fur den Eigenwert
λk von A bzw. von D, der µ am nachsten liegt.
|µ− λk| = ||(µI−D)−1||−12 ≤ ||F||2 = ||X−1EX||2
≤ ||X−1||2 · ||E||2 · ||X||2 = cond2(X)||E||2
d.h. die absolute Konditionszahl des Eigenwert-Problems ist gerade die Konditi-onszahl des Problems, das System linearer Gleichungen zu losen, dessen Koeffi-zienten-Matrix gerade die Matrix X von Eigenvektoren ist.
√
Bem. Die Eigenwerte von A sind also sensitiv, wenn die Eigenvektoren fast l.a.sind, d.h. wenn A fast defective ist.Wenn also A normal ist, d.h. AHA = AAH , so daß die n Eigenvektoren or-thonormiert gewahlt werden konnen, dann folgt cond2(X) = 1 oder m.a.W., daßdie Eigenwerte reeller symmetrischer und Hermite’scher komplexer Matrizen gutkonditioniert sind.
Z.B. Die Matrix A =
−149 −50 −154537 180 546−27 −9 −25
hat die drei EWe λ1 = 1, λ2 = 2
und λ3 = 3. Die Matrix A ist also nicht-defektiv und daher diagonalisierbar, abernicht normal, d.h. ATA 6= AAT . Die jeweils 2-normierten rechten und linken
EVen sind die Spalten der folgenden beiden Matrizen X =
0.316 0.404 0.139−0.949 −0.909 −0.974
0.000 −0.101 0.179
und Y =
0.681 −0.676 −0.688.0.225 −0.225.−0 229.0.697 −0.701 −0.688
Wegen cond2(A) = 1289 sollten
die EWe sensitiv auf Anderungen von A reagieren. Daruber hinaus sind wegenyT
1 x1 = 0.0017, yT2 x2 = 0.0025 und yT
3 x3 = 0.0046 linke und rechte EVen fastorthogonal, was wiederum erwarten laßt, daß die EWe schlecht konditioniert sind.Und tatsachlich, wenn a2,2 zu 180.01 abgeandert wird, hat A die EWe λ1 = 1,λ2 = 2 und λ3 = 3. c

204 KAPITEL 4. EIGENVALUE PROBLEMS
Soweit die Situation fur nicht-defektive Matrizen . . .
4.0.4 Problem-Transformationen
Uberfuhre eine gegebene Matrix A durch Eigenwert-erhaltende Transformationenin Matrizen, deren Eigenwerte einfacher zu bestimmen sind.Die folgenden Transformationen erhalten EVen und transformieren die EWe.
shifts Ax = λx ist aquivalent zu (A− σI)x = (λ− σ)x, so daß die Eigenwerteverschoben werden, die Eigenvektoren dagegen erhalten bleiben.
Inversion A sei regular. Aus Ax = λx folgt λ 6= 0 und A−1x = 1λx. Die Eigen-
werte von A−1 sind also reziprok zu den Eigenwerten von A mit denselbenEigenvektoren.
Potenzen Aus Ax = λx folgt A2x = λ2x. Die Eigenwerte von A2 sind geradedie Quadrate der Eigenwerte von A. Die Eigenvektoren bleiben erhalten.
Polynome Fur ein Polynom p(t) = co + c1t + c2t2 + . . . + ckt
k sei p(A) =coI+ c1A+ c2A
2 + . . .+ ckAk definiert. Aus Ax = λx folgt p(A)x = p(λ)x.
Die Eigenwerte von p(A) ergeben sich als Bilder der Eigenwerte von Aunter der Abbildung p. Die Eigenvektoren bleiben erhalten.
Dagen erhalten Ahnlichkeitstransformationen EWe bei veranderten EVen.
Def. Eine Matrix B heißt ahnlich einer Matrix A, wenn eine regulare Matrix Tmit B = T−1AT existiert. Wegen By = λy ⇒ T−1ATy = λy ⇒ ATy = λTy ist ein EV y zum EWλ von B auch EW von A mit EV Ty. Mit y = T−1x ist umgekehrt wegenAx = λx ⇒ By = T−1ATT−1x = T−1Ax = λT−1x = λy ein EW λ mit EV xvon A auch EW von B mit EV y = T−1x.det(B − λI) = det (T−1(A − λI)T) = det(T−1) · det(A − λI) · det(T) liefertebenso, daß jeder EW von B auch EW von A ist und umgekehrt.
Bem. Ahnliche Matrizen haben notwendigerweise dieselben EWe. Aber Matri-zen mit denselben EWen sind nicht notwendigerweise ahnlich. Bem. A sei ahnlich einer Diagonal-Matrix D. Dann sind die Diagonal-Elementevon D die EWe von A und die Spalten der Matrix T mit D = T−1AT sind dieEV von A.
Z.B. Wegen AT =
(3 11 3
)(1 −11 1
)=
(1 −11 1
)(4 00 2
)= TD ist A ahnlich
der Diagonal-Matrix D = diag(4, 2). Daher sind 4 und 2 die EWe von A mit
dem EV
(11
)zum EW 4 und dem EV
(−1
1
)zum EW 2. c

205
Diagonale, Dreiecks- und Block-Dreiecksmatrizen
Die EWe einer Diagonal-Matrix sind offensichtlich gerade die Diagonal-Elemente.Leider ist nicht jede Matrix ahnlich einer Diagonal-Matrix.
Z.B. A =
(1 10 1
)kann nicht diagonalisiert werden, weil A defektiv ist: A hat
den doppelten EW 1 (algebraische Multiplizitat 2) mit dem eindimensionalenEigenraum Re1 (geometrische Multiplizitat 1). Daher kann es keine regulare 2×2-Ahnlichkeitstransformation T geben, deren Spalten durch zwei l.u. Eigenvektorengegeben sind. Insbesondere ist also A nicht ahnlich zu I, obwohl beide Matrizendieselben Eigenwerte aufweisen. c
A T B 6
n verschiedene EWe regular diagonalreell symmetrisch orthogonal reell diagonalkomplex Hermite’sch unitar reell diagonalnormal unitar diagonalreell orthogonal reell Block-dreieckig (reell Schur)beliebig unitar dreieckig (Schur)beliebig regular fast diagonal (Jordan)
4.0.5 Eigenwerte und Eigenvektoren berechnen
power-Iteration, Inverse Iteration, Rayleigh Qotient Iteration, deflation, Simul-tane Iteration, QR-Iteration, Krylov-Verfahren, Jacobi-Verfahren, Bisection oderspectrum splicing, divide and conquer, relatively robust representation
Power-Iterationen
x = i n i t ( ) ; % initialisiere x mit einem xo 6= 0for ( k=0; ; k++) % geeignetes Abbruchkriterium?
x = A∗x ; % xk+1 = Axk
end
Falls A genau einen betragsmaßig großten EW λ1 mit EV v1 hat, so konver-gieren die xk gegen ein Vielfaches von v1. Sei namlich xo =
∑nj=1 αjvj eine
6 symmetrisch ⇐⇒ AT =A, Hermite’sch ⇐⇒ A=AH , normal ⇐⇒ AHA=AAH
regular⇐⇒A−1A=I=AA−1, orthogonal⇐⇒AT A=I=AAT , unitar⇐⇒AHA=I=AAH
Block-dreieckig ⇐⇒ nur 1× 1- oder 2× 2-Blocke auf der Diagonalen,fast diagonal ⇐⇒ diagonal bis auf die obere Neben-Diagonale

206 KAPITEL 4. EIGENVALUE PROBLEMS
Linearkombination der EVen vj von A. Dann gilt
xk = Axk−1 = A2xk−2 = . . . = Akxo = Ak
n∑j=1
αjvj
=n∑
j=1
αjAkvj =
n∑j=1
αjλkjvj = λk
1
(α1v1 +
n∑j=2
αj(λj
λ1)
kvj
)
Wegen |λj
λ1| < 1 konvergiert die Summe gegen Null. Bezeichne (xk)` die `-te
Komponente von xk. Fur jedes ` konvergiert dann (xk)`
(xk−1)`gegen λ1, solange der
Nenner im Grenzwert nicht verschwindet.
Probleme der power-Iteration
• xo konnte zufalligerweise so gewahlt worden sein, daß α1 = 0 gilt. Run-dungsfehler im Verfahren produzieren aber in der Praxis entsprechendeKomponenten.
• Es gibt mehrere betragsmaßig großte EWe, z.B. ein Paar von konjugiertkomplexen Zahlen, die naturgemaß betragsmaßig gleich sind.
• Fur reelles A und reellen Start-Vektor sind auch alle xk reell und konnennicht gegen einen gegebenenfalls komplexen EV konvergieren.
Um bei |λ1| > 1 overflow oder bei |λ1| < 1 underflow zu vermeiden, werden diexk normiert, effizient in der ∞-Norm.
x = i n i t ( ) ; % initialisiere x mit einem xo 6= 0for ( k=0; ; k++) % geeignetes Abbruchkriterium?
y = A∗x ; % yk+1 = Axk
x = y/norm(y , i n f ) ; % xk+1 = yk+1/||yk+1||∞end
Dann gilt limk→∞ xk = 1||v1||∞v1 und || limk→∞ yk||∞ = || limk→∞Axk||∞ =
||A limk→∞ xk||∞ = ||A 1||v1||∞v1||∞ = 1
||v1||∞ ||λ1v1||∞ = |λ1|.
Z.B. A =
(3 11 3
)hat EV v1 =
(11
)zum EW λ1 = 4 und EV v2 =
(−1
1
)zum
EW λ2 = 2. Fur den Start-Vektor xo = e2 = 12(v1 + v2) sind die ersten paar xk

207
-1 1
1xo x1 x2 x3x4
und die beiden (normierten) EV v1 und v2 dargestellt. cDie Konvergenz-Rate hangt von |λ2
λ1| ab, wobei λ2 der betragsmaßig zweitgroßte
EW ist. Shifts σ konnen die Konvergenz-Rate umso mehr verbessern, umsokleiner |λ2−σ
λ1−σ| gegenuber |λ2
λ1| ausfallt.
Inverse Iterationen
Wegen Ax = λx ⇐⇒ x = λA−1x ⇐⇒ A−1x = 1λx ist der kleinste EW
von A zugleich das Reziproke des großten EWes von A−1. Dieser Umstand legtnahe, power iteration auf A−1 anzuwenden. Das Verfahren heißt inverse Iteration,inverse iteration.
x = i n i t ( ) ; % initialisiere x mit einem xo 6= 0for ( k=0; ; k++) % geeignetes Abbruchkriterium?
y = A\x ; % lose Ayk+1 = xk in yk+1
x = y/norm(y , i n f ) ; % normiere xk+1 = yk+1/||yk+1||∞end
shifts in Verbindung mit inverse iteration beschleunigen nicht nur die Konvergenz,sondern erlauben auch, bestimmte EWe zu bestimmen: weil der betragsmaßigkleinste EW von A − σI gerade der EW λ mit dem kleinsten Abstand zu σ ist,kann mit inverse iteration und geeigneten σ jeder EW bestimmt werden, und zwarum so schneller, je naher σ bei λ gewahlt werden konnte. Die Konvergenz-Rateist grundsatzlich linear, allerdings ist C um so kleiner, um so kleiner |λ− σ|.
Rayleigh Quotient Iteration
Angenommen, eine Naherung fur einen EV von A ist bekannt und der zugehorigeEW sei zu bestimmen. Dies kann als linear least squares Problem aufgefaßtwerden, das λ zu bestimmen, das ||Ax − λx||2 minimiert, d.h. λx ∼= Ax zulosen. Das zugehorige System der Normalengleichungen lautet xTx = xTAx mitder Losung λ = xT Ax
xT x, der sogenannte Rayleigh7-Quotient.
7 John Strutt, Lord Rayleigh (1842-1919) www-history.mcs.st-andrews.ac.uk/Biographies/Rayleigh.html

208 KAPITEL 4. EIGENVALUE PROBLEMS
Der Rayleigh-Qotient approximiert etwa in power iteration den EW besser undkann so zur Beschleunigung eingesetzt werden. Zugleich konvergiert inverse itera-tion schneller, wenn als shift eine Naherung des EWes verwendet wird. Zusammenergibt sich die sogenannte Rayleigh quotient iteration.
x = i n i t ( ) ; % initialisiere x mit einem xo 6= 0for ( k=0; ; k++) % geeignetes Abbruchkriterium?
sigma = x ’∗A∗x/(x ’∗ x ) ; % σ = xTAx/(xTx)y = (A−sigma∗eye (n ) )\ x ; % lose (A− σI)yk+1 = xk in yk+1
x = y/norm(y , i n f ) ; % normiere xk+1 = yk+1/||yk+1||∞end
Rayleigh quotient iteration ist fur nicht-defektive EWe quadratisch konvergentund fur normale Matrizen sogar kubisch konvergent. Insofern kann der hohereAufwand, in jeder Iteration ein neues Gleichungssystem losen zu mussen, gerecht-fertigt sein.
Deflation
Wenn ein EV x1 zu einem EW λ1 von A bestimmt wurde, mochte man – wie beimUbergang vom Polynom p(λ) mit einer bekannten Nullstelle λ1 zum Polynomp(λ)/(λ − λ1) mit gegenuber p um eins dekrementiertem Grad – zu einer neuenMatrix B ubergehen, die den zweiten EW λ2 von A zu bestimmen gestattet.
Sei H regulare Matrix mit Hx1 = αe1, etwa eine Householder Transforma-
tion. Dann stiftet H eine Ahnlichkeitstransformation HAH−1 =
[λ1 bT
0 B
],
weil HAH−1e1 = HA 1αx1 = Hλ1
αx1 = λ1e1, wobei B eine Matrix mit den
EWen λ2, . . . , λn ist, etwa weil det(A − λI) = (λ1 − λ) det(B − λI). WegenHAH−1αe1 = HAx1 = Hλ1x1 = λ1αe1 ist e1 EV zum EW λ1 von HAH−1,die Blockmatrix links oben ist λ1 und die Blockmatrix links unten ist der Null-Vektor. Da Ahnlichkeitstransformationen EWe erhalten, bleiben fur B nur nochgenau die EWe λ2, . . . , λn.
Wenn weiterhin y2 EV zum EW λ2 von B ist, so ist x2 = H−1
[γy2
]mit γ = bT y2
λ2−λ1
fur λ2 6= λ1 ein EV zum EW λ2 von A, weil aus By2 = λ2y2 zunachst HAx2 =
HAH−1
[γy2
]=
[λ1 bT
0 B
] [γy2
]=
[λ1γ + bTy2
By2
]=
[( λ1
λ2−λ1+ 1)bTy2
λ2y2
]= λ2
[γy2
]sowie HAx2 = λ2Hx2 und damit Ax2 = λ2x2 folgt.
Alternativ sei u1 ein Vektor mit uT1 x1 = λ1. Dann hat A−x1u
T1 einerseits wegen
Ax1 = λ1x1 und daher (A − x1uT1 )x1 = λ1x1 − λ1x1 = 0x1 den EW 0 und
andererseits wegen Axi = λixi die EWe λ2, . . . , λn.???
Der Vektor u1 kann u.a. wie folgt gewahlt werden:

209
• u1 = λ1x1, wenn A symmetrisch und x1 normalisiert, d.h. ||x1||2 = 1, dadann offensichtlich uT
1 x1 = λ1xT1 x1 = λ1||x1||22 = λ1.
• u1 = λ1y1, wenn y1 normalisierter, linker EV zum EW λ1 von A ist, d.h.wenn yT
1 A = λ1yT1 oder ATy1 = λ1y1 mit ||x1||2 = 1, da dann offensichtlich
uT1 x1 = λ1.
• u1 = A1ek, wenn x1 normalisiert, d.h. ||x1||∞ = 1 und (x1)k = 1
Auch wenn dieser Prozess schrittweise EVen und EWe zu bestimmen erlaubt, ister dennoch nicht empfehlenswert, da in jedem Schritt numerische Genauigkeitverloren gehen kann.
Simultane Iteration
Um mehrere Paare von EWen mit zugehorigen EVen zu bestimmen, kann manpower iteration zur sogenannten simultaneous iteration verallgemeinern: meh-rere power iterations werden gleichzeitig ausgefuhrt, startend mit p l.u. Start-Vektoren x
(0)1 , . . . ,x
(0)p , die die n× p-Start-Matrix Xo mit rank(Xo) = p bilden.
X = i n i t ( ) ; % initialisiere n× p-Matrix X durch Xo mit rank(Xo) = pfor ( k=0; ; k++) % geeignetes Abbruchkriterium?
X = A∗X; % Xk+1 = AXk
end
Sei So = span(Xo) und S = span(v1, . . . ,vp) der invariante Unterraum, der vonden zu den p betragsmaßig großten EWen λ1, . . . , λp gehorenden EVen v1, . . . ,vp
aufgespannt wird. Angenommen, kein Vektor in S ist orthogonal zu So. Dannformen die Spalten von Xk = AkXo eine Basis des p-dimensionalen UnterraumesSk = AkSo. Wie im ’eindimensionalen Fall’ konvergieren die Sk gegen S, wenn|λp| > |λp+1|. Daher heißt simultaneous iteration auch subspace iteration.
Wieder sind overflow und underflow durch Normierung zu vermeiden. Auch for-men die Spalten von Xk eine zunehmend schlechter konditionierte Basis von Sk.Beiden Problemen begegnet man mit Orthonormalisierung in der sogenanntenorthogonal iteration.
X = i n i t ( ) ; % initialisiere n× p-Matrix X durch Xo mit rank(Xo) = pfor ( k=0; ; k++) % geeignetes Abbruchkriterium?
Q = QRfact (X) ; % QR-Faktorisierung liefert Xk−1 = QkRk
X = A∗Q; % Xk = AQk
end
Die QR-Faktorisierung Xk−1 = Qk
[Rk
0
]= QkRk von Xk−1 ist hier in ihrer
reduzierten Form verwendet, wo Qk eine n × p-Matrix orthonormaler Spalten

210 KAPITEL 4. EIGENVALUE PROBLEMS
und Rk eine obere p× p-Dreiecksmatrix ist.Die Xk konvergieren gegen eine n × p-Matrix X, deren Spalten den invariantenUnterraum zu den p betragsmaßig großten EWen λ1, . . . , λp aufspannen. Wegen
span(Qk) = span(Xk) konvergieren die Qk gegen eine Matrix Q, deren Spalteneine orthonormale Basis fur span(X) bilden.
QR-Iteration
. . .
. . .
. . .

4.1. Review Questions – Verstandnisfragen 211
4.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Die EWe einer Ma-trix sind nicht notwendig alle ver-schieden.
2. Richtig/Falsch? Alle EWe einer re-ellen Matrix sind notwendig reell.
3. Richtig/Falsch? EVen zu einem EWsind eindeutig.
4. Richtig/Falsch? Jede n × n-Matrixhat n l.u. EVen.
5. Richtig/Falsch? Eine singulare n×n-Matrix hat keine n l.u. EVen.
6. Richtig/Falsch? Eine quadratischeMatrix ist singular genau dann,wenn einer ihrer EWe verschwindet.
7. Richtig/Falsch? Wenn alle EWe ei-ner quadratischen Matrix A ver-schwinden, gilt notwendigerweiseA = 0.
8. Richtig/Falsch? Jede komplexe,Hermite’sche Matrix A = AH hatreelle Diagonal-Elemente.
9. Richtig/Falsch? Die EWe einer kom-plexen, Hermite’schen Matrix sindreell.
10. Richtig/Falsch? Zwei Matrizen mitdenselben EWe sind ahnlich.
11. Richtig/Falsch? Zwei ahnliche Ma-trizen haben dieselben EVen.
12. Richtig/Falsch? Jede quadratischeMatrix ist ahnlich zu einer Diagonal-Matrix.
13. Richtig/Falsch? Jede quadratischeMatrix ist unitar ahnlich zu einerDreiecksmatrix.
14. Richtig/Falsch? cond(A), also dieKondition des linearen Gleichungs-systemes Ax = b, bestimmt dieKondition des EW-Problems von A.
15. Richtig/Falsch? Die EW von reel-len, symmetrischen oder komplexen,Hermite’schen Matrizen sind immergut konditioniert.
16. Richtig/Falsch? Eine symmetrischeHessenberg-Matrix ist tridiagonal.
17. Richtig/Falsch? A habe verschie-dene EWe. Dann konvergiert dieQR-Iteration von A gegen eineDiagonal-Matrix.
18. Richtig/Falsch? EWe und SWe einerquadratischen Matrix fallen zusam-men.
19. Was sind rechte und linke EVen?
20. Was ist der Spektral-Radius einerquadratischen Matrix?
21. A sei gegeben.
a) Kann ein EW zu zwei verschiede-nen EVen gehoren?
b) Kann ein EV zu zwei verschiede-nen EWen gehoren?
22. Was ist das charakteristische Poly-nom p einer quadratischen MatrixA ? Was hat p mit den EWen vonA zu tun?
23. Wie unterscheiden sich AlgebraischeMultiplizitat und Geometrische Mul-tiplizitat eines EWes?
24. Was ist ein invarianter UnterraumS einer quadratischen Matrix?

212 KAPITEL 4. EIGENVALUE PROBLEMS
25. Was sind die EWe und EVen einerdiagonalen Matrix?
26. A sei reelle n × n-Matrix. Welcheder folgenden Bedingungen garan-tiert, daß A diagonalisierbar ist, d.h.daß A einer Diagonal-Matrix ahn-lich ist?
a) A hat n verschiedene EWe.
b) A hat nur reelle EWe.
c) A ist regular.
d) A ist symmetrisch.
e) A kommutiert mit AT .
27. Welche der folgenden Klassen vonMatrizen haben nur reelle EWe?
a) reelle, symmetrische Matrizen
b) reelle, dreieckige Matrizen
c) beliebige reelle Matrizen
d) komplexe, symmetrisch Matrizen
e) komplexe, Hermite’sche Matrizen
f) komplexe, dreieckige Matrizenmit reeller Diagonalen
g) beliebige komplexe Matrizen
28. A und B seien ahnlich, d.h. B =T−1AT fur eine regulare Tranfor-mationsmatrix T. Sei y EV von B.Gib einen EV von A an.
29. Gib ein Beispiel einer nicht-diagonalisierbaren Matrix.
30. Die EWe einer Matrix sind die Null-stellen ihres charakteristischen Po-lynoms. Liefert die Nutzung die-ses Umstands ein numerisches, ge-nerell effektives Verfahren, die EWeder Matrix zu bestimmen?
31. Bevor per QR-Iteration die EWe ei-ner Matrix bestimmt werden, wirddie Matrix ublicherweise zunachstin eine gunstigere Form uberfuhrt.
Welche sind dies fur die unten ste-henden Klassen von Matrizen?
a) beliebige reelle Matrizen
b) reelle, symmetrische Matrizen
32. Eine beliebige Matrix kann per QR-Faktorisierung trianguliert werden.Die EWe einer Dreiecksmatrix sinddie Diagonal-Elemente. Konnen mitdiesem Verfahren die EWe bestimmtwerden?
33. Gauß-Jordan Elimination uberfuhrteine Matrix A in eine Diagonal-Matrix. Werden dadurch die EWevon A offenbar?
34. a) Warum konvergiert die Jacobi-Mathode zur Berechnung der EWevon reellen, symmetrischen Matri-zen nur langsam?
b) Welches Verfahren ist warumschneller?
35. Fur welche Klassen von n × n-Matrizen konnen die EWe in endlichvielen Schritten berechnet werden?
a) Diagonal-Matrizen
b) Tridiagonal-Matrizen
c) Dreiecksmatrizen
d) Hessenberg-Matrizen
e) beliebige reelle Matrizen mit ver-schiedenen EWen
f) beliebige reelle Matrizen
36. Warum wird eine Matrix Azunachst in eine Hessenberg- odereine Tridiagonal-Matrix uberfuhrt,bevor die EWe von A per QR-Iteration berechnet werden?
37. QR-Iteration werde auf A angewen-det, um die EWe von A zu berech-nen. Dann konvergiert QR-Iteration

4.1. Review Questions – Verstandnisfragen 213
gegen eine Diagonal-Matrix oder ge-gen eine Dreiecksmatrix. Welche Ei-genschaft von A bestimmt, was derFall ist?
38. Um die EWe einer Matrix A zubestimmen, wird A haufig mit ei-ner unitaren Ahnlichkeitstransfor-mation auf Hessenberg-Form redu-ziert. Warum hier aufhoren? Wareeine Dreiecksgestalt nicht noch vor-teilhafter? Wo ist der Haken diesesArguments?
39. Angenommen, ein Verfahren zur Be-rechnung aller EWe beliebiger Ma-trizen stunde zur Verfugung. Wielassen sich dann alle Nullstellen ei-nes Polynoms p bestimmen?
40. A sei regulare n× n-Matrix. Ordnea) bis d) nach ihrer Komplexitat.
a) A per Gauß-Elimination mit par-tial pivoting LU-faktorisierenb) alle EWe von A mit zugehorigenEVen bestimmenc) ein dreieckiges System Ax = bper backsubstitution losend) A invertieren
41. Gegen welchen EW konvergiertpower iteration?
42. a) A habe einen einfachen dominan-ten EW λ1. Welche Große bestimmtdie Konvergenz-Rate des power ite-ration Verfahrens zur Berechnungvon λ1 ?
b) Wie kann die Konvergenz-Rateder power-Iteration erhoht werden?
43. Ein EV x von A sei naherungsweisegegeben. Was ist die beste (leastsquares) Naherung fur den zugehori-gen EW ?
44. Liste drei Bedingungen, unter denendas power iteration Verfahren schei-tern kann.
45. Gegen welchen EV einer Matrix Akonvergiert die inverse Iteration?
46. Warum werden bei power-Iterationund inverser Iteration die Vektorenin jeder Iteration normalisiert?
47. Aus welchem ausschlaggebendenGrund werden shifts bei power-Iteration, inverser Iteration undQR-Iteration verwendet?
48. A sei beliebige quadratische Ma-trix. Welches ist das Verfahren er-ster Wahl,
a) um den kleinsten EW von A zubestimmen?
b) um den großten EW von A zubestimmen?
c) um den einem gegebenen Skalarβ am nachsten liegenden EW von Azu bestimmen?
d) um alle EWe von A zu bestim-men?
49. a) Ein EW λ einer Matrix A seinaherungsweise gegeben. Wie ge-winnt man eine gute Naherung fureinen zugehorigen EV ?
b) Ein EV x einer Matrix sei nahe-rungsweise gegeben. Wie gewinntman eine gute Naherung fur den zu-gehorigen EW ?
50. Was ist eine Krylov-Folge und wozuist sie gut?
51. Warum ist das Lanczos-Verfahrenschneller als das power iteration Ver-fahren, wenn einige wenige EWe ei-ner reellen, symmetrischen Matrixzu bestimmen sind?

214 KAPITEL 4. EIGENVALUE PROBLEMS
52. Aufgrund welcher Eigenschaft istdas Lanczos-Verfahren fur EW-Probleme großer, dunn besetzter,symmetrischer Matrizen geeignet?
53. Was bedeutet inertia einer reellen,symmetrischen Matrix?
54. a) Was bedeutet Kongruenz-Transformation einer reellen,symmetrischen Matrix?
b) Welche Eigenschaften einer Ma-trix bleiben gegebenenfalls unterKongruenz-Transformationen erhal-ten?
55. Erlautere spectrum slicing zur Be-stimmung einzelner EWe einer reel-len, symmetrischen Matrix.
56. a) Warum kann es nicht tunlich sein,das verallgemeinerte EW-ProblemAx = λBx in das klassischeEW-Problem B−1Ax = λx zuuberfuhren?
b) Welcher Ansatz ist vorzuziehen?
57. a) In welcher Beziehung stehen dieSWe einer reellenm×n-Matrix A zuden EWen der n× n-Matrix ATA ?
b) Ist es angezeigt, die SWe einerMatrix A dadurch zu bestimmen,indem man die EWe von ATA be-rechnet?
4.2 Exercises – Ubun-
gen
1. Sei A =
6 3 3 10 7 4 50 0 5 40 0 0 8
.
a) Zeige: 5 ist EW von A.
b) Gib einen EV zum EW 5 an.
2. Sei A =
1 2 −40 2 10 0 3
. Gib die EWe
von A mit zugehorigen EVen an.
3. Sei A =(
1 41 1
).
a) Gib das charakteristische Poly-nom von A an.
b) Gib die Nullstellen des charakte-ristischen Polynoms von A an.
c) Was sind die EWe von A ?
d) Was sind die EV zu den EWenvon A ?
e) Was liefert eine power-Iteration
fur den Start-Vektor x0 =(
11
)?
f) Gegen welchen EW wird diepower-Iteration konvergieren?
g) Wie schatzt der Rayleigh quotientden EW zum EV x0 ?
h) Gegen welchen EW konvergiertdie inverse Iteration?
i) Gegen welchen EW konvergiertdie inverse Iteration mit shift σ =2 ?
j) Konvergiert QR-Iteration ange-wandt auf A gegen eine dreieckigeoder tridiagonale Matrix?
4. Gib ein Beispiel einer 2 × 2-MatrixA und eines Start-Vektors x0, sodaß die power-Iteration nicht gegeneinen EV zum dominanten EW vonA konvergiert.
5. A sei n × n-Matrix. Alle Zeilen-Summen von A haben denselbenWert α.
a) Zeige: α ist ein EW von A.
b) Wie sehen die EVen zum EW αvon A aus?

4.2. Exercises – Ubungen 215
6. Zeige: A ist singular, genau dannwenn ein EW von A verschwindet.
7. A sei n× n-Matrix.
a) Zeige: A und AT haben dieselbenEWe.
b) Haben A und AT auch dieselbenEVen?
8. A sei n × n-Matrix. Zeige: A istahnlich zu einer Diagonal-Matrix ge-nau dann, wenn A einen vollstandi-gen Satz von n l.u. EVen hat.
9. a) Sei p(λ) =∑n
ν=0 cνλν Polynom
mit reellen Koeffizienten cν . Zeige:Komplexe Nullstellen treten in kon-jugiert komplexen Paaren auf, d.h.mit p(α + iβ) = 0 gilt auch p(α −iβ) = 0.
b) Verifziere, daß komplexe EWeeiner reellen Matrix A in konju-giert komplexen Paaren auftreten,anhand des Umstandes, daß x EVzum EW λ ist, wenn x EV zum EWλ ist.
10. a) Zeige: Alle EWe einer komplexen,Hermite’schen Matrix sind reell.
b) Zeige: Alle EWe einer reellen,symmetrischen Matrix sind reell.
11. Gib ein Beispiel einer komplexen,symmetrischen, nicht-Hermite’scheMatrix mit nicht-reellen EWen.
12. Zeige: EWe einer positiv definitenMatrix sind positiv.
13. Zeige: Fur den Spektral-Radiusρ(A) = max|λ| : λ ∈ λ(A) giltρ(A) ≤ ||A|| fur jede Matrix-Norm||.|| subordinate zu einer Vektor-Norm.
14. Sei A =
1 0 α4 2 06 5 3
mit α ∈ R ge-
geben.
a) Existiert α, so daß A nur reelleEWe hat?
b) Existiert α, so daß alle EWe vonA nicht-reell sind?
15. A und B seien n × n-Matrizen. Asei regular. Zeige: AB und BA sindahnlich.
16. A sei regulare n× n-Matrix.
a) In welcher Beziehung stehen dieEWe von A zu denen von A−1 ?
b) In welcher Beziehung stehen dieEVen von A zu denen von A−1 ?
17. λ sei EW von A. Zeige: λ2 ist EWvon A2.
18. A heißt nilpotent, genau dann wennAk = 0 fur ein k ∈ N.
a) Zeige: Alle EWe einer nilpotentenMatrix verschwinden.
b) Zeige: Wenn A nilpotent undnormal, d.h. AHA = AAH , dannA = 0.
19. A sei idempotent, d.h. A2 = A.Charakterisiere die EWe von A.
20. a) A sei Hermite’sche n×n-Matrix,d.h. AH = A, mit EV x zum EW λund EV y zum EW µ, wobei µ 6= λ.Zeige: yHx = 0.
b) A sei eine nicht-notwendig Her-mite’sche Matrix mit Ax = λx undyHA = µyH und µ 6= λ. Zeige:yHx = 0.
c) A sei eine nicht-notwendig Her-mite’sche Matrix mit Ax = λx undyHA = λyH fur einen einfachenEW λ. Zeige: yHx 6= 0.

216 KAPITEL 4. EIGENVALUE PROBLEMS
21. a) A sei reelle oder komplexe n×n-Matrix. Zeige: fur jeden reellen oderkomplexen Skalar λ ist Sλ = x :Ax = λx Unterraum von Rn oderCn.
b) Zeige: λ ist EW genau dann,wenn Sλ 6= 0.
22. Sei A =[B C0 D
]obere n×n-Block-
Dreiecksmatrix mit k × k-Matrix Bund (n− k)× (n− k)-Matrix D.
a) Zeige: Ein EW λ von B ist auchEW von A.
b) Zeige: Ein EW λ von D, abernicht von B, ist auch EW von A.
c) Zeige: Wenn[uv
]EV zum EW λ
von A ist, dann ist u EV zum EWλ von B oder v EV zum EW λ vonD.
d) Zeige: λ ist EW von A genaudann, wenn λ EW entweder von Boder von D ist.
23. A sei n × n-Matrix mit EWλ1, . . . , λn.
a) Zeige: det(A) =∏n
i=1 λi.
b) Die Spur trace(A) einer Matrix Aist durch trace(A) =
∑nj=1 aj,j defi-
niert. Zeige: trace(A) =∑n
j=1 λj .
24. A sei reelle n × n-Matrix mitrank(A) = 1.
a) Zeige: A = uvT fur geeignete re-elle Vektoren u 6= 0 6= v.
b) Zeige: uTv = vTu ist EW vonA.
c) Wie sehen die anderen EW von Aaus?
d) Wieviele Iterationen sind aus-zufuhren, bis power iteration genaugegen einen EV zum betragsmaßiggroßten EW konvergiert?
25. Zeige: det(I+uvT ) = 1+uTv. (Ver-wende Ex 4.23 und Ex 4.24)
26. A heißt normal, wenn AHA =AAH .
a) Zeige: Eine normale Dreiecksma-trix ist diagonal.
b) Zeige: Eine Matrix A ist ge-nau dann normal, wenn A unitardiagonalisierbar ist, d.h. wenn eseine unitare Matrix Q und eineDiagonal-Matrix D mit D =QHAQ gibt.
27. A sei n× n-Matrix mit ρ(A) < 1.
a) Zeige: I−A ist regular.
b) Zeige: (I−A)−1 =∑∞
k=0 Ak.
28. A sei reelle, symmetrische n × n-Matrix mit EWen λ1 ≤ λ2 ≤ . . . ≤λn.
a) Gegen welche EWe von Akann power-Iteration mit geeignetenshifts σ konvergieren?
b) Jeweils welche shifts σ haben dieschnellste Konvergenz zur Folge?
c) Beantworte a) und b) fur die in-verse Iteration.
29. Die komplexe, Hermite’sche n × n-Matrix C sei als C = A + iB mitReal-Teil A und Imaginar-Teil Bdargestellt. Sei die reelle 2n × 2n-
Matrix C durch C =[A −BB A
]de-
finiert und sei x + iy EV zum EWλ von C.
a) Zeige: C ist symmetrisch.
b) Zeige: λ ist EW auch von C mit
EVen[xy
]und
[−yx
].
c) Komplexe Hermite’sche EW-Probleme konnen also als reelle,symmetrische EW-Probleme gelostwerden. Ist das ein guter Ansatz?

4.3. Computer Problems – Rechner-Probleme 217
30. a) Welche EWe hat die kom-plexe, symmetrische Matrix A =(
2i 11 0
)?
b) Wieviele l.u. EVen hat A ?
c) Stelle diese Ergebnisse der Situa-tion fur reelle, symmetrische oderkomplexe, Hermite’sche Matrizengegenuber.
31. a) Zeige: fur EWe λ von orthogona-len Matrizen Q gilt |λ| = 1.
b) Bestimme die SWe einer orthogo-nalen Matrix Q.
32. a) Was sind die EWe der Househol-der Transformation H = I− 2
vT vvvT
fur beliebiges v 6= 0 ?
b) Was sind die EWe derGivens Ro-
tation G =(c s−s c
)mit c2 + s2 =
1 ?
33. Sei A eine symmetrische, tridiago-nale Matrix ohne verschwindendeElemente auf der unteren Nebendia-gonalen. Zeige: A hat verschiedeneEWe.
34. Sei A eine singulare, obereHessenberg-Matrix ohne ver-schwindende Elemente auf derunteren Nebendiagonalen. Zeige:QR-Iteration von A produziert mitnur einer Iteration einen exaktenEW. QR-Iteration konvergiert alsosehr schnell, wenn shifts verwendetwerden, die nahe genug an EWenliegen.
35. Verifiziere, daß die vom Lanczos-Verfahren schrittweise erzeugten or-thogonalen Vektoren die three termrecurrence befriedigen. So ist bei-spielsweise Aq3 ⊥ q1, so daß Aq3
nur noch relativ zu q2 und q3 or-thogonalisiert werden muß.
36. A sei m×n-Matrix. Dann ist Ax =[0 A
AT 0
] [uv
]= λ
[uv
]ein symme-
trisches EW-Problem.
a) Zeige: Wenn λ EW von A, dannist |λ| ein SW von A mit zugehori-gem linken SV u und zugehorigemrechten SV v.
b) Ist das ein guter Ansatz, die SVDvon A zu bestimmen?
4.3 Computer Pro-
blems – Rechner-
Probleme
1. a) Berechne EWe und EVen von
A =(
1 10000.001 1
).
b) Berechne die Konditionszahl derMatrix X von EVen und die absoluteKonditionszahl des EW-Problems.
c) Was sind die EWe von B =(1 10000 1
)? Wie erklaren sich die
Anderungen der EWe aus der Ande-rung von A ?
2. a) Implementiere power-Iteration,
um fur A =
2 3 210 3 23 6 1
mit x0 =
e3 den dominanten EW mit zu-gehorigem normalisierten EV zu ap-proximieren.
b) Nach deflation approximiere denbetragsmaßig zweitgroßten EW vonA per power-Iteration.
c) Verwende fur a) und b) Biblio-theksroutinen und vergleiche mitden eigenen Ergebnissen.

218 KAPITEL 4. EIGENVALUE PROBLEMS
3. a) Implementiere inverse iterationmit shift, um den normalisierten EVzu dem EW, der am nachsten zu 2
liegt, fur A =
6 2 12 3 11 1 1
zu be-
stimmen. Der Startvektor sei belie-big zu wahlen.
b) Verwende eine Bibliotheksroutinefur reelle, symmetrische Matrizenund vergleiche mit den Ergebnissenaus a).
4. Programmiere Raleigh QuotientenInteration und teste das Programmanhand der Matrix aus 4CP3.
5. a) Bestimme die EWe von A = 9 4.5 3−56 −28 −18
60 30 19
mit einer Bi-
bliotheksroutine.
b) Bestimme die EWe von A = 9 4.5 3−56 −28 −18
60 30 18.95
mit einer Bi-
bliotheksroutine. Welche relativeAnderung der EWe gegenuber a) er-gibt sich?
c) Bestimme die EWe von A = 9 4.5 3−56 −28 −18
60 30 19.05
mit einer Bi-
bliotheksroutine. Welche relativeAnderung der EWe gegenuber a) er-gibt sich?
d) Welche Schlusse uber die Kon-ditionierung des EW-Problems las-sen sich ziehen? Berechne jeweils dieKondition von A.
6. Implementiere die folgende einfacheVersion von QR-Iteration mit shiftszur Bestimmung der EWe einer be-liebigen reellen Matrix A.
doσ = an,n
QR = A− σIA = RQ + σI
until convergence
Welches Abbruch-Kriterium ist ge-eignet? Teste das Programm an-hand der Matrizen aus 4CP2 und4CP3.
7. Programmiere das Lanczos-Verfahren
8. Bestimme alle Wurzeln von p(t) =21 − 40t + 35t2 − 13t3 + t4 anhandder EWe der companion-Matrix undeiner Bibliotheksroutine. Beachte,daß die companion-Matrix schoneine Hessenberg-Matrix ist, wasdie Bibliotheksroutine gegebenen-falls ausnutzen kann. Vergleiche Ge-schwindigkeit und Genauigkeit die-ses Losungsansatzes mit Geschwin-digkeit und Genauigkeit anderer Bi-bliotheksroutinen speziell zur Null-stellenbestimmung.
9. Berechne die EWe der n×n-Hilbert-Matrix fur n ≤ 20. Wie laßtsich die Großenordnung der EWe inAbhangigkeit von n charakterisie-ren?
10. Eine singulare Matrix hat den einenEW 0. Muß aber eine fast-singulareMatrix kleine EWe haben? Untersu-che dazu n×n-Matrizen A der Form
A =
1 −1 −1 −1 −10 1 −1 −1 −10 0 1 −1 −10 0 0 1 −10 0 0 0 1
fur verschiedene n. Offensichtlichhat A nur den n-fachen EW 1.Wie verhalt sich aber σmax/σmin

4.3. Computer Problems – Rechner-Probleme 219
in Abhangigkeit von n ? WelcheSchlusse sind zu ziehen?
11. Eine symmetrische tridiagonale Ma-trix mit einem mehrfachen EW mußein verschwindendes Element aufder Neben-Diagonalen haben. Mußaber ein Paar nahe beieinanderlie-gender EWe ein kleines Elementauf der Neben-Diagonalen implizie-ren? Untersuche dazu die sym-metrischen, tridiagonalen n × n-Matrizen A mit n = 2k + 1 undk, k − 1, . . . , 1, 0, 1, . . . , k − 1, k aufder Haupt-Diagonalen und nur Ein-sen auf beiden Neben-Diagonalen.Berechne alle EWe dieser Matrizenfur verschiedene k. Treten mehrfa-che oder fast-mehrfache EWe auf?Welche Schlusse sind zu ziehen?
12. Eine Markov8-Kette beschreibtein System mit n Zustanden.Ubergange zwischen den Zustandenerfolgen zu diskreten Zeitpunkten.Die Ubergangswahrscheinlichkeitenai,j vom Zustand j in den Zustandi werden in einer n × n-MatrixA = (ai,j) zusammengefaßt. Alsogilt 0 ≤ ai,j ≤ 1 und
∑ni=1 ai,j = 1.
Bezeichne x(k)i die Wahrscheinlich-
keit dafur, daß sich das Systemnach k Zustandsubergangen imZustand i befindet, und x(0) dieinitiale Wahrscheinlichkeitsvertei-lung. Dann gilt x(k) = Akx(0). DerGleichgewichtszustand x(∞) desSystems ist durch x(∞) = A∞x(0)
mit A∞ = limk→∞Ak bestimmt.
a) Bestimme x(3).
b) Bestimme x(∞).
c) Hangt hier x(∞) von x(0) ab?
8Markov (????-19??)www-history.mcs.st-andrews.ac.uk/Biographies/Markov.html
d) Bestimme A(∞). Welchen Ranghat A(∞) ?
e) Erlautere die bisherigen Ergeb-nisse anhand der EWe und EVen vonA.
f) Ist 1 notwendig ein EW der Ma-trix der Ubergangswahrscheinlich-keiten einer Markov-Kette?
g) Ein probability distribution vectorx heißt stationar ⇐⇒ Ax = x.Wie konnen solche Vektoren anhandvon EWen und EVen von A be-stimmt werden?
h) Wie konnen solche Vektoren ohneKenntnis der EWe und EVen von Abestimmt werden?
i) Ist es in diesem speziellen Beispielmoglich, daß ein nicht-stationarerprobability distribution vector wie-derkehrt? Ist dies fur allgemeineMarkov-Ketten moglich? Falls nein,warum? falls ja, finde Beispiele.
j) Kann es mehrere stationare pro-bability distribution vectors geben?Falls nein, warum? falls ja, findeBeispiele.
k) An welches andere numerischeProblem erinnert dieses Problem?
13. Das Federn-Massen-System aus Bei-spiel 4.1 fuhrt auf das verallgemei-nerte EW-Problem Kx = λMx. Seik1 = k2 = k3 = 1 sowie m1 = 2,m2 = 3 und m3 = 4 in geeignetenEinheiten.
a) Da hier M eine Diagonal-Matrix ist, kann das verallgemei-nerte EW-Problem in ein Standard-EW-Problem uberfuhrt werden. Be-rechne alle EWe (Eigen-Frequenzen)mit zugehorigen EVen (?) unterVerwendung von power iteration, in-verse iteration, shifts oder deflation.

220 KAPITEL 4. EIGENVALUE PROBLEMS
b) Verwende Bibliotheksroutinen furverallgemeinerte EW-Probleme undvergleiche deren Ergebnisse mit deneigenen Ergebnissen.
14. a) Die Funktion exp(A) fur qua-dratische Matrizen A ist durchexp(A) =
∑∞k=0
1k!A
k spezifiziert.Schreibe ein Programm, das exp(A)berechnet.
b) Alternativ verwendet man dieEW-EV-Zerlegung A = UDU−1
von A, wo D = diag(λ1, . . . , λn)ist, λ1, . . . , λn die EWe von A unddie Spalten von U die zugehorigenEVen sind. Dann gilt exp(A) =Udiag(eλ1 , . . . , eλn)U−1. Schreibeein zweites Programm, das exp(A)auf diese Weise berechnet.
c) Anhand der beiden Matrizen
A1 =(
2 −1−1 2
)und A2 =(
−49 24−64 31
)teste die beiden Pro-
gramme und vergleiche die Ergeb-nisse mit denen von Bibliotheksrou-tinen. Welche der Methoden a) oderb) ist numerisch genauer und robu-ster? Warum?
15. Bestimme die Koeffizienten des cha-rakteristischen Polynoms.
a) Krylov-Verfahren???
b) Leverrier-Verfahren???
c) Danilevsky-Verfahren???
d) Danilevsky-Verfahren fur obereHessenberg-Matrizen
???e) Berechnung der Koeffizienten descharakteristischen Polynoms einerMatrix wie in MATLAB
???16. a) Schreibe eine Routine, die mit ei-
nerGivens Rotation eine reelle 2×2-Matrix A symmetrisiert, d.h. be-stimme c und s mit c2 + s2 = 1,
so daß A durch G =(c s−s c
)in
eine symmetrische Matrix B = GAuberfuhrt wird.
b) Schreibe eine Routine, die miteiner zweiseitigen Givens Rotationeine reelle, symmetrische 2 × 2-Matrix B diagonalisiert, d.h. be-stimme c und s mit c2 + s2 = 1,
so daß B durch G =(c s−s c
)in
eine Diagonal-Matrix D = G−1BGuberfuhrt wird.
c) Schreibe unter Verwendung vona) und b) eine Routine, die die SVDA = UΣVT einer beliebigen reellen2×2-Matrix A bestimmt. Vergleichedas Ergebnis fur beliebige MatrizenA mit demjenigen von Bibliotheks-routinen.

4.4. Review Questions – Antworten auf Verstandnisfragen 221
4.4 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Die EWe einer Matrix sind nicht notwendig alle verschie-den.
Die EWe einer Matrix sind nicht notwendig alle verschieden, z.B. hat die 159n× n-Einheitsmatrix den n-fachen EW 1.
2. Richtig/Falsch? Alle EWe einer reellen Matrix sind notwendig reell.
EWe von reellen Matrizen sind nicht notwendig wieder reell, wie die Matrix 159
A =
(0 −11 0
)mit den EWen λ1,2 = ±i zeigt.
3. Richtig/Falsch? EVen zu einem EW sind eindeutig.
EVen x zu einem EW λ sind nicht eindeutig: mit x sind auch alle Vielfachen 163in Rx wieder EVen zum EW λ.
4. Richtig/Falsch? Jede n× n-Matrix hat n l.u. EVen.
Nicht jede n × n-Matrix A hat n l.u. EVen, wie etwa A =
(1 10 1
)zeigt: 162/163
wegen det(A− λI) = (1− λ)2 hat A den doppelten EW 1 mit zugehorigen
EVen in R(
10
). Es gibt also nur den einen (l.u.) EV
(10
).
5. Richtig/Falsch? Eine singulare n× n-Matrix hat keine n l.u. EVen.
A sei singulare n × n-Matrix. Dann hat A nicht notwendig keine n l.u.
EVen, wie etwa die singulare Matrix A =
(1 22 4
)mit EW λ1 = 0 und EV
x1 =
(2
−1
)sowie EW λ2 = 5 und EV x2 =
(12
)zeigt. Es gibt also n = 2
l.u. EVen x1 und x2.
6. Richtig/Falsch? Eine quadratische Matrix ist singular genau dann, wenneiner ihrer EWe verschwindet.
A ist singular ⇐⇒ es existiert z 6= 0 mit Az=0 ⇐⇒ z ist EV zum EW 0.
7. Richtig/Falsch? Wenn alle EWe einer quadratischen Matrix A verschwin-den, gilt notwendigerweise A = 0.
Wenn alle EWe von A verschwinden, so gilt nicht notwendigerweise A = 0,
wie etwa A =
(1 1
−1 −1
)mit det(A − λI) = −(1 − λ)(1 + λ) + 1 = λ2
zeigt.

222 KAPITEL 4. EIGENVALUE PROBLEMS
8. Richtig/Falsch? Jede komplexe, Hermite’sche Matrix A = AH hat reelleDiagonal-Elemente.
A sei komplexe, Hermite9sche Matrix, d.h. AH = A. Fur die Diagonal-164Elemente ai,i von A gilt also ai,i = aH
i,i, was ai,i ∈ R impliziert.
9. Richtig/Falsch? Die EWe einer komplexen, Hermite’schen Matrix sind reell.
Alle EWe einer komplexen, Hermite’schen Matrix A = AH sind reell, weil164,173fur EVen x zum EW λ eben (xHAx)H = xHAx = xHλx = λ||x||22 gilt.Wegen (xHAx)H = xHAx ist die linke Seite und damit auch λ reell.
10. Richtig/Falsch? Zwei Matrizen mit denselben EWe sind ahnlich.
Zwei Matrizen mit denselben EWen sind nicht notwendigerweise ahnlich.171
A =
(1 10 1
)hat den doppelten EW 1 mit EVen in Re1. A ist I nicht
ahnlich, da sonst die Spalten der Transformationsmatrix T mit AT = ITaus zwei linear unabhangigen EVen von A bestehen mußten, s. 4RQ4.
11. Richtig/Falsch? Zwei ahnliche Matrizen haben dieselben EVen.
Zwei ahnliche Matrizen haben nicht notwendigerweise dieselben EVen: falls171B = T−1AT und y ein EV von Bm ist, dann ist x = Ty ein EV von A.
Etwa A =
(3 11 3
)mit EVen in R
(11
)zum EW 4 und mit EVen in R
(−1
1
)zum EW 2 ist ahnlich zu diag(4, 2) mit EVen in Re1 zum EW 4 und mitEVen in Re2 zum EW 2.
12. Richtig/Falsch? Jede quadratische Matrix ist ahnlich zu einer Diagonal-Matrix.
Nicht jede quadratische Matrix A ist ahnlich zu einer Diagonal-Matrix B,171
wie etwa A =
(1 10 1
), B =
(e 00 f
)und regulares T =
(a bc d
)mit T−1 =
1det(T)
(d −b−c a
), wobei det(T) = ad−bc 6= 0 zeigt. Aus B = T−1AT folgt
B =
(e 00 f
)= 1
det(T)
(ad+ cd− bc d2
−c2 ad− bc− cd
)und c = d = 0 und
daher det(T) = ad− bc = 0 im Widerspruch zur Regularitat von T.
13. Richtig/Falsch? Jede quadratische Matrix ist unitar ahnlich zu einer Drei-ecksmatrix.
Jede n × n-Matrix A ist unitar ahnlich zu einer Dreiecksmatrix B, d.h.171,173B = T−1AT mit unitarem T, d.h. T−1 = TH .siehe Schur Decomposition
???9 Charles Hermite (1822-1901) www-history.mcs.st-andrews.ac.uk/Biographies/Hermite.html

4.4. Review Questions – Antworten auf Verstandnisfragen 223
14. Richtig/Falsch? cond(A), also die Kondition des linearen Gleichungssyste-mes Ax = b, bestimmt die Kondition des EW-Problems von A.
Die Kondition des EW-Problems einer Matrix A stimmt nicht mit cond(A), 166-169der Kondition des linearen Gleichungssystemes Ax = b uberein.Fur nicht-defektive Matrizen A ist die absolute Konditionszahl des EW-Problemes gleich der Konditionszahl cond2(X), wobei X Matrix von n l.u.EVen ist.Die Kondition speziell des EW λ ist allgemein cond(λ) = | 1
yHx| fur normier-
ten linken EV y und normierten rechten EV x.
15. Richtig/Falsch? Die EW von reellen, symmetrischen oder komplexen, Her-mite’schen Matrizen sind immer gut konditioniert.
Die EWe von reellen, symmetrischen oder komplexen, Hermite’schen Matri- 167zen A sind bestens konditioniert, da fur solche A die n EVen xi orthonormalgewahlt werden konnen, was cond2(X) = 1 fur X = (x1, . . . ,xn) impliziert.
???
16. Richtig/Falsch? Eine symmetrische Hessenberg-Matrix ist tridiagonal.
A sei symmetrische Hessenberg-Matrix, d.h. AT = A und A ist dreieckig 163,164bis auf eine weitere nicht verschwindende Diagonale direkt neben der Haupt-Diagonalen. Wegen der Symmetrie ist A daher tridiagonal, d.h. ai,j = 0fur alle |i− j| > 1.
17. Richtig/Falsch? A habe verschiedene EWe. Dann konvergiert die QR-Iteration von A gegen eine Diagonal-Matrix.
A habe n verschiedene EWe. Dann konvergiert die QR-Iteration gegen eine 183Diagonal-Matrix.
???
18. Richtig/Falsch? EWe und SWe einer quadratischen Matrix fallen zusam-men.
A sei n × n-Matrix. In der SVD A = UΣVT von A sind U und V or- 202thogonale n× n-Matrizen und Σ = diag(σ1, . . . , σn) = diag(
√λ1, . . . ,
√λn)
ist Diagonal-Matrix mit den EW λ1, . . . , λn von ATA. Dann gilt naturlichnicht : eigenvalues and singular values are the same thing!
So ist etwa A =
(c s−s c
)mit c2+s2 = 1 orthogonal, da ATA = I = AAT . 164
Damit ist Σ = diag(1, 1), wahrend wegen det(A − λI) = (c − λ)2 + s2 =λ2 − 2cλ+ 1 aber λ1,2 = c±
√c2 − 1 = c±
√−s2 = c± is die EWe von A
sind.
19. Was sind rechte und linke EVen?
x mit Ax = λx ist rechter EV zum EW λ. 157y mit yTA = λyT ist linker EV zum EW λ.

224 KAPITEL 4. EIGENVALUE PROBLEMS
20. Was ist der Spektral-Radius ρ einer quadratischen Matrix?
ρ(A) = max|λ| : λ ∈ λ(A) = max|λ| : λ ist EW von A definiert den158Spektral-Radius einer Matrix A.
21. A sei gegeben.
a) Kann ein EW zu zwei verschiedenen EVen gehoren?
EVen sind nicht eindeutig: zu einem EW gehoren uberabzahlbar viele EVen.
b) Kann ein EV zu zwei verschiedenen EWen gehoren?
Ein EV x 6= 0 kann nicht zu zwei verschiedenen EWen λ1 6= λ2 gehoren:λ1x = Ax = λ2x impliziert namlich λ1 = λ2.
22. Was ist das charakteristische Polynom p einer quadratischen Matrix A ?Was hat p mit den EWen von A zu tun?
p(λ) = det(A − λI) definiert das charakteristische Polynom von A. Die160Nullstellen von p sind die EW von A.
23. Wie unterscheiden sich Algebraische Multiplizitat und Geometrische Multi-plizitat eines EWes?
Algebraische Multiplizitat von λ ist die Vielfachheit der Nullstelle λ des162charakteristischen Polynoms p.Geometrische Multiplizitat von λ ist die Dimension des Eigenraumes zumEW λ.
24. Was ist ein invarianter Unterraum S einer quadratischen Matrix?
Ein fur eine Matrix A invarianter Unterraum S von Rn ist ein Unterraum163S mit AS ⊂ S.
25. Was sind die EWe und EVen einer diagonalen Matrix?
Sei A = diag(d) mit d = (d1, . . . , dn). Wegen det(A− λI) =∏n
i=1(di − λ)hat A die n EWe di mit zugehorigen EVen ei fur i = 1, . . . , n.
26. A sei reelle n × n-Matrix. Welche der folgenden Bedingungen garantiert,daß A diagonalisierbar ist, d.h. daß A einer Diagonal-Matrix ahnlich ist?
a) A hat n verschiedene EWe.173 Table 4.1
Dann ist A laut Table 4.1 diagonalisierbar.
b) A hat nur reelle EWe.173 Table 4.1
A hat nur reelle EWe. Dann ist A nicht notwendig diagonalisierbar, wie
etwa A =
(1 10 1
)aus 4RQ12 mit dem doppelten reellen EW 1 zeigt.
c) A ist regular.173 Table 4.1

4.4. Review Questions – Antworten auf Verstandnisfragen 225
Eine regulare Matrix A ist nicht notwendig diagonalisierbar, wie etwa A =(1 10 1
)aus 4RQ12 mit det(A) = 1 zeigt.
d) A ist symmetrisch. 173 Table 4.1
In einer symmetrisch Matrix A konnen per Jacobi10-Verfahren alle Ele-mente außerhalb der Diagonalen annulliert werden. Daher ist A also dia-gonalisierbar.
e) A kommutiert mit AT . 173 Table 4.1
A kommutiert mit AT , d.h. AAT = ATA. Da A reell, ist A sogar normal,d.h. AH = A. Dann ist A laut Table 4.1 diagonalisierbar.
27. Welche der folgenden Klassen von Matrizen A haben nur reelle EWe?
a) reelle, symmetrische Matrizen
A sei reell und symmetrisch, also AH = A, so daß fur EV x zum EW λeben R 3 (xHAx)H = xHAx = xHλx = λ||x||22 und daher λ ∈ R folgt.
b) reelle, dreieckige Matrizen
A sei reell und dreieckig. Dann gilt det(A − λI) =∏n
i=1(ai,i − λ). A hatalso die n reellen EWe a1,1, a2,2, . . . , an,n.
c) beliebige reelle Matrizen
A sei beliebig reell. Fur beispielsweise A =
(1 −21 −1
)gilt det(A − λI) =
−(1−λ2)+2 = λ2 +1. Daher hat A die beiden imaginaren EWe λ1,2 = ±i.d) komplexe, symmetrisch Matrizen
A sei komplex und symmetrisch. Fur etwa A =
(0 ii 0
)gilt det(A−λI) =
λ2 + 1. Daher hat A die beiden imaginaren EWe λ1,2 = ±i.e) komplexe, Hermite’sche Matrizen
A sei komplex und Hermite’sch, d.h. AH = A, so daß fur EV x zum EWλ eben R 3 (xHAx)H = xHAx = xHλx = λ||x||22 und daher λ ∈ R folgt.
f) komplexe, dreieckige Matrizen mit reeller Diagonalen
A sei komplex und dreieckig mit reeller Diagonale. Wie in b) gilt danndet(A− λI) =
∏ni=1(ai,i − λ). A hat also n reelle EWe a1,1, a2,2, . . . , an,n.
g) beliebige komplexe Matrizen
A sei beliebig komplex. Fur etwa A =
(i 10 −i
)gilt det(A−λI) = −(−1−
λ2) = λ2 + 1. Daher hat A die beiden imaginaren EWe λ1,2 = ±i.10 Carl Gustav Jacob Jacobi (1804-1851) www-history.mcs.st-andrews.ac.uk/Biographies/Jacobi.html

226 KAPITEL 4. EIGENVALUE PROBLEMS
28. A und B seien ahnlich, d.h. B = T−1AT fur eine regulare Tranformati-onsmatrix T. Sei y EV von B. Gib einen EV von A an.
Sei y EV zum EW λ von B. Wegen TBy = ATy = λTy ist Ty EV zum170EW λ von A.
29. Gib ein Beispiel einer nicht-diagonalisierbaren Matrix.
Etwa A =
(1 10 1
)ist eine nicht-diagonalisierbare Matrix (vgl. 4RQ12).171
30. Die EWe einer Matrix sind die Nullstellen ihres charakteristischen Poly-noms. Liefert die Nutzung dieses Umstands ein numerisches, generell effek-tives Verfahren, die EWe der Matrix zu bestimmen?
Es ist aufwandig und numerisch nicht empfehlenswert, zur Bestimmung162der EWe einer Matrix A die Nullstellen des charakteristischen Polynoms pzu bestimmen: die Koeffizienten von p sind aufwandig zu bestimmen, dieKoeffizienten konnen sensitiv auf Anderungen von A reagieren, Rundungs-fehler bei der Bestimmung von p kann die Genauigkeit der zu berechnendenNullstellen aufreiben, die Approximation der Nullstellen selbst ist fur n > 4alles andere als trivial.
31. Bevor per QR-Iteration die EWe einer Matrix bestimmt werden, wird dieMatrix ublicherweise zunachst in eine gunstigere Form uberfuhrt. Welchesind dies fur die unten stehenden Klassen von Matrizen?
a) beliebige reelle Matrizen187,188
Eine beliebige Matrix wird zunachst in Hessenberg-Form uberfuhrt.
b) reelle, symmetrische Matrizen173,188
Eine reelle, symmetrische Matrix wird zunachst in Tridiagonal-Form uberfuhrt.
???
32. Eine beliebige Matrix kann per QR-Faktorisierung trianguliert werden. DieEWe einer Dreiecksmatrix sind die Diagonal-Elemente. Konnen mit diesemVerfahren die EWe bestimmt werden?
Nein, weil die QR-Faktorisierung als solche keine Ahnlichkeitstransforma-
tion ist: so hat z.B. A = QR =√
22
(1 1−1 1
)(1 10 1
)=
√2
2
(1 2−1 0
)die
beiden EWe λ1,2 = 12(1± i
√7) und R nur den EW 1.
33. Gauß-Jordan Elimination uberfuhrt eine Matrix A in eine Diagonal-Matrix.Werden dadurch die EWe von A offenbar?
Nein, weil die Gauß-Jordan Elimination keine Ahnlichkeitstransformation
ist: so wird z.B. A =
(1 12 3
)mit den beiden EWen λ1,2 = 2±
√3 in M1A =79/80

4.4. Review Questions – Antworten auf Verstandnisfragen 227(1 0−2 1
)(1 12 3
)=
(1 10 1
)und dann in M2M1A =
(1 −10 1
)(1 10 1
)=(
1 00 1
)mit dem EW 1 uberfuhrt: Gauß-Jordan Elimination erhalt keine
EWe.
34. a) Warum konvergiert die Jacobi-Mathode zur Berechnung der EWe von 194reellen, symmetrischen Matrizen nur langsam?
Die Jacobi11-Mathode zur Berechnung der EWe von reellen, symmetrischenMatrizen konvergiert langsam, weil annullierte Elemente sich wieder andernkonnen und daher gegebenenfalls erneut annulliert werden mussen.
b) Welches Verfahren ist warum schneller? 194
Die QR-Iteration kann so ausgelegt werden, daß einmal erzeugte Nullenauch erhalten bleiben.
35. Fur welche Klassen von n × n-Matrizen konnen die EWe in endlich vielenSchritten berechnet werden?
a) Diagonal-Matrizen 171
Die EWe von Diagonal-Matrizen sind die Diagonal-Elemente selbst.
b) Tridiagonal-Matrizen
A sei tridiagonal.???
c) Dreiecksmatrizen 171
Die EWe von dreieckigen Matrizen sind die Diagonal-Elemente selbst.
d) Hessenberg-Matrizen
A sei Hessenberg-Matrix.???
e) beliebige reelle Matrizen mit verschiedenen EWen
A sei reelle Matrix mit n verschiedenen EWen.???
f) beliebige reelle Matrizen 161
Die EWe einer beliebigen reellen Matrix konnen nicht nicht in endlich vie-len Schritten berechnet werden, da sonst anhand der EWe der companionmatrix die Nullstellen von Polynomen beliebigen Grades, also insbesonderevom Grad großer 4, in endlich vielen Schritten bestimmt werden konnen –im Widerspruch zum Ergebnis von Abel.
36. Warum wird eine Matrix A zunachst in eine Hessenberg- oder eine Tridia-gonal-Matrix uberfuhrt, bevor die EWe von A per QR-Iteration berechnetwerden?

228 KAPITEL 4. EIGENVALUE PROBLEMS
Wenn die EWe von A per QR-Iteration berechnet werden sollen, kann man 187Arbeit sparen, indem A zunachst vereinfacht wird, d.h. soweit als moglichdreieckig, d.h. Hessenberg, oder – falls A symmetrisch ist – (tri?) diagonal.Dann kann namlich erstens eine QR-Iteration schneller ausgefuhrt werden.Auch werden zweitens weniger Iterationen notwendig, weil die Matrix schonfast dreieckig oder fast diagonal ist.
37. QR-Iteration werde auf A angewendet, um die EWe von A zu berechnen.QR-Iteration konvergiert dann gegen eine Diagonal-Matrix oder gegen eineDreiecksmatrix. Welche Eigenschaft von A bestimmt, was der Fall ist?
Falls die Betrage der EWe alle verschieden sind, so konvergiert (Ak) der QR-183Iteration fur beliebige A gegen eine Dreiecksmatrix und fur symmetrische Agegen eine Diagonal-Matrix. Die Diagonale enthalt dabei Approximationender EWe.
38. Um die EWe einer Matrix A zu bestimmen, wird A haufig mit einer uni-taren Ahnlichkeitstransformation auf Hessenberg-Form reduziert. Warumhier aufhoren? Ware eine Dreiecksgestalt nicht noch vorteilhafter? Wobefindet sich der Haken dieses Arguments?
???
39. Angenommen, ein Verfahren zur Berechnung aller EWe beliebiger Matrizensteht zur Verfugung. Wie lassen sich dann alle Nullstellen eines Polynoms161p bestimmen?
Die Eigenwerte der companion matrix von p sind die Nullstellen von p.
40. A sei regulare n× n-Matrix. Ordne a) bis d) nach ihrer Komplexitat.
a) A per Gauß-Elimination mit partial pivoting LU-faktorisierenb) alle EWe von A mit zugehorigen EVen bestimmenc) ein dreieckiges System Ax = b per backsubstitution losend) A invertieren
a) Die LU-Faktorisierung per Gauß-Elimination mit partial pivoting kostet7913n3 flOs.
b) Alle EWe mit zugehorigen EVen zu bestimmen, ist i.d.R. nur approxi-161mativ moglich.c) Ein dreieckiges System Ax = b per backsubstitution zu losen, kostet79n2 flOs.d) A zu invertieren, kostet n3 flOs.80
Insgesamt gilt also c) < a) < d) < b)
41. Gegen welchen EW konvergiert power iteration?
Das power iteration Verfahren konvergiert gegen ein Vielfaches des EVs zum173/174
11 Carl Gustav Jacob Jacobi (1804-1851) www-history.mcs.st-andrews.ac.uk/Biographies/Jacobi.html

4.4. Review Questions – Antworten auf Verstandnisfragen 229
betragsmaßig großten EW.
42. a) A habe einen einfachen dominanten EW λ1. Welche Große bestimmt die 176Konvergenz-Rate des power iteration Verfahrens zur Berechnung von λ1 ?
Die Konvergenzgeschwindigkeit hangt von |λ1/λ2|, dem Verhaltnis von be-tragsmaßig großtem zu betragsmaßig zweitgroßtem EW ab.
b) Wie kann die Konvergenz-Rate der power-Iteration erhoht werden? 176,178/179
Die Konvergenz-Rate kann durch shifts (lineare Konvergenz mit verbesser-tem C = |λ1/λ2|) und durch Raleigh quotient iteration (mindestens qua-dratisch fur nicht-defektive EWe, kubisch fur normale Matrizen) verbessertwerden.
43. Ein EV x von A sei naherungsweise gegeben. Was ist die beste Naherung(least squares) fur den zugehorigen EW ?
Der Rayleigh-Quotient λ = xT AxxT x
ist als Losung des linear least squares 178Problems Ax ∼= λx die beste Naherung des zugehorigen EWes.
44. Liste drei Bedingungen, unter denen das power iteration Verfahren scheiternkann.
Das power iteration Verfahren schlagt fehl, wenn der Start-Vektor keine 174/175Komponente eines EVs zum dominanten EW enthalt, wenn die Matrix nurkomplexe EWe hat und/oder wenn die Matrix mehrere betragsmaßig großteEWe hat.
45. Gegen welchen EV einer Matrix A konvergiert die inverse Iteration?
Die inverse Iteration konvergiert gegen einen EV zum betragsmaßig klein- 176/177sten EW von A.
46. Warum werden bei power-Iteration und inverser Iteration die Vektoren injeder Iteration normalisiert?
Die yk = Axk−1 in power-Iteration bzw. yk mit Ayk = xk−1 in inverser 175,177Iteration werden normalisiert, um overflow und underflow zu vermeiden.
47. Aus welchem ausschlaggebenden Grund werden shifts bei power-Iteration,inverser Iteration und QR-Iteration verwendet?
Shifts werden hauptsachlich zur Beschleunigung der Konvergenz verwendet.176,177,184
48. A sei beliebige quadratische Matrix. Welches ist das Verfahren erster Wahl,
a) um den kleinsten EW von A zu bestimmen? 176/177
Inverse Iteration bestimmt den betragsmaßig kleinsten EW von A.

230 KAPITEL 4. EIGENVALUE PROBLEMS
b) um den großten EW von A zu bestimmen? 175
Power-Iteration bestimmt den betragsmaßig großsten EW von A.
c) um den einem gegebenen Skalar β am nachsten liegenden EW von A zu177bestimmen?
Inverse Iteration mit shift β bestimmt den β am nachsten liegenden EWvon A.
d) um alle EWe von A zu bestimmen?182-188
Simultane oder QR-Iteration bestimmt alle EWe von A.
49. a) Ein EW λ einer Matrix A sei naherungsweise gegeben. Wie gewinnt177man eine gute Naherung fur einen zugehorigen EV ?
Inverse Iteration mit shift λ bestimmt einen EV zum λ am nachsten liegen-den EW von A.
b) Ein EV x einer Matrix sei naherungsweise gegeben. Wie gewinnt man178eine gute Naherung fur den zugehorigen EW ?
Der Raleigh-Quotient λ = xT AxxT x
ist als Losung von xλ = Ax die besteNaherung fur den zugehorigen EW.
50. Was ist eine Krylov-Folge und wozu ist sie gut?
xk = Axk−1 ist die Krylov-Folge zum Start-Vektor xo. Krylov-Folgen dienen188/189dazu, A in eine ahnliche Hessenberg-Matrix zu uberfuhren.
51. Warum ist das Lanczos-Verfahren schneller als das power iteration Ver-fahren, wenn einige wenige EWe einer reellen, symmetrischen Matrix zubestimmen sind?
???52. Aufgrund welcher Eigenschaft ist das Lanczos-Verfahren fur EW-Probleme
großer, dunn besetzter, symmetrischer Matrizen geeignet?
???53. Was bedeutet inertia einer reellen, symmetrischen Matrix?
Inertia einer reellen, symmetrischen Matrix A ist das Tripel der Anzahlen195positiver, negativer und verschwindender EWe von A.
54. a) Was bedeutet Kongruenz-Transformation einer reellen, symmetrischen196Matrix?
Eine Kongruenz-Transformation einer reellen, symmetrischen Matrix Auberfuhrt A in SAST fur eine regulare Matrix S.
b) Welche Eigenschaften einer Matrix bleiben gegebenenfalls unter Kongru-196enz-Transformationen erhalten?
Kongruenz-Transformationen A → SAST erhalten die inertia reeller, sym-metrischer Matrizen.

4.5. Exercises – Ubungsergebnisse 231
55. Erlautere spectrum slicing zur Bestimmung einzelner EWe einer reellen, 195/196symmetrischen Matrix.
???
56. a) Warum kann es nicht tunlich sein, das verallgemeinerte EW-Problem 201Ax = λBx in das klassische EW-Problem B−1Ax = λx zu uberfuhren?
Die Uberfuhrung geht durch Rundungsfehler beim Invertieren und bei derProdukt-Bildung zu Lasten der Genauigkeit. Zudem geht fur symmetrischeA und B Symmetrie verloren.
b) Welcher Ansatz ist vorzuziehen? 201
Cholesky-Faktorisierung oder der QZ-Algorithmus eignen sich fur verallge-meinerte EW-Probleme.
57. a) In welcher Beziehung stehen die SWe einer reellen m × n-Matrix A zu 202den EWen der n× n-Matrix ATA ?
SWe von A sind die nicht-negativen Quadratwurzeln der EWe von ATA.
b) Ist es angezeigt, die SWe einer Matrix A dadurch zu bestimmen, indem 202man die EWe von ATA berechnet?
Nein, da schon die Produkt-Bildung ATA mit einem Verlust an Genauigkeiteinhergeht.
4.5 Exercises – Ubungsergebnisse
1. Sei A =
6 3 3 10 7 4 50 0 5 40 0 0 8
.
a) Zeige: 5 ist EW von A. 160
5 ist EW von A, weil det(A− 5I) = (6− 5)(7− 5)(5− 5)(8− 5) = 0.
b) Gib einen EV zum EW 5 an. 160
Per backsubstitution ergeben sich die EVen zum EW 5 in R(3,−2, 1, 0)T .
2. Sei A =
1 2 −40 2 10 0 3
. Gib die EWe von A mit zugehorigen EVen an.
det(A− λI) = (1− λ)(2− λ)(3− λ) = 0 fur die drei einfachen EW λ1 = 1, 160λ2 = 2 und λ3 = 3. Die EVen zum EW 1 liegen in Re1, die zum EW 2 inR(2, 1, 0)T und die zum EW 3 in R(−1, 1, 1)T

232 KAPITEL 4. EIGENVALUE PROBLEMS
3. Sei A =
(1 41 1
).
a) Gib das charakteristische Polynom von A an.160
det(A−λI) = (1−λ)2−4 = λ2−2λ−3 ist das charakteristische Polynom.
b) Gib die Nullstellen des charakteristischen Polynoms von A an.160
det(A− λI) hat die beiden einfachen NS λ1 = 3 und λ2 = −1.
c) Was sind die EWe von A ?160
Wegen b) sind λ1 = 3 und λ2 = −1 die beiden EWe von A.
d) Was sind die EV zu den EWen von A ?157
x1 =
(21
)ist EV zum EW λ1 = 3, x2 =
(2
−1
)ist EV zum EW λ2 = −1.
e) Was liefert eine power-Iteration fur den Start-Vektor x0 =
(11
)?173
Mit Start-Vektor x0 =
(11
)ist x1 = Ax0 =
(52
).
f) Gegen welchen EW wird die power-Iteration konvergieren?174
Die Folge (xk) mit xk = Akx0 konvergiert gegen einen EV zum dominantenEW λ1 = 3.
g) Wie schatzt der Rayleigh quotient den EW zum EV x0 ?178
Der Rayleigh quotient schatzt den EW zum EV x0 zu λ = xT AxxT x
= (1,1)(5,2)T
2=
72
= 3.5.
h) Gegen welchen EW konvergiert die inverse Iteration?176
Die inverse Iteration konvergiert gegen den betragsmaßig kleinsten EW vonA, also gegen λ2 = −1.
i) Gegen welchen EW konvergiert die inverse Iteration mit shift σ = 2 ?177
Inverse Iteration mit shift σ = 2, also fur A − σI, konvergiert gegen denEW von A, der 2 am nachsten liegt, also gegen λ1 = 3.
j) Konvergiert QR-Iteration angewandt auf A gegen eine dreieckige oder183tridiagonale Matrix?
QR-Iteration konvergiert gegen eine Dreiecksmatrix, da A nicht symme-trisch ist.
4. Gib ein Beispiel einer 2 × 2-Matrix A und eines Start-Vektors x0, so daßdie power-Iteration nicht gegen einen EV zum dominanten EW von A kon-vergiert.
Jede reelle Matrix A mit ausschließlich komplexen Eigenwerten stellt ein174

4.5. Exercises – Ubungsergebnisse 233
gesuchtes Beispiel dar, da xk = Akx0 ∈ Rn fur x0 ∈ Rn. Etwa A =(0 1
−1 0
)hat die beiden EWe λ1,2 = ±i mit jeweils komplexen EVen. Sei
x0 = (1, . . . , 1)T . Dann ist Akx0 ∈ ±e1,±e2 ⊂ R2.
5. A sei n× n-Matrix. Alle Zeilen-Summen von A haben denselben Wert α.
a) Zeige: α ist ein EW von A. 157
α ist ein EW von A, da mit x = (1, . . . , 1)T eben Ax = αx gilt.
b) Wie sehen die EVen zum EW α von A aus? 157
EVen zum EW α von A sind Rx.
6. Zeige: A ist singular, genau dann wenn ein EW von A verschwindet.
A ist singular ⇐⇒ es existiert z 6= 0 mit Az=0 ⇐⇒ z ist EV zum EW 0. 157
7. A sei n× n-Matrix.
a) Zeige: A und AT haben dieselben EWe. 160
Wegen det(A− λI) = det(AT − λI) haben A und AT dieselben EWe.
b) Haben A und AT auch dieselben EVen? 157
Sei A =
(1 41 1
). EVen von AT zum EW λ1 = 3 sind xAT
1 = R(
12
),
verschieden von den EVen von A zum EW λ1 = 3, namlich xA1 = R
(21
).
8. A sei n × n-Matrix. Zeige: A ist ahnlich zu einer Diagonal-Matrix genaudann, wenn A einen vollstandigen Satz von n l.u. EVen hat.
Zuvor: D = diag(d) sei n×n-Diagonal-Matrix. Dann sind die Elemente von 170d = (d1, . . . , dn)T die EWe von D und ei ist EV zum EW di fur i = 1, . . . , n.
A sei n × n-Matrix. A ist ahnlich zu einer Diagonal-Matrix D = diag(d) 170⇐⇒ es existiert eine regulare Matrix T mit D = T−1AT, d.h. fur jedenEV ei zum EW di von D ist xi = Tei ein EV von A zum selben EW di,d.h. T = (x1, . . . ,xn) ⇐⇒ da T regular, ist rank(T) = n, insbesonderesind also die Spalten-Vektoren xi von T, die zugleich EVen von A sind, l.u.und umgekehrt.
9. a) Sei p(λ) =∑n
ν=0 cνλν ein Polynom mit reellen Koeffizienten cν . Zeige:
Komplexe Nullstellen treten in konjugiert komplexen Paaren auf, d.h. mitp(α+ iβ) = 0 gilt auch p(α− iβ) = 0.
Da Konjugieren eine lineare Operation ist, gilt p(λ) = p(λ) fur Polynome pmit reellen Koeffizienten. Also ist mit λ auch λ ein EW.
b) Verifziere, daß komplexe EWe einer reellen Matrix A in konjugiert kom-

234 KAPITEL 4. EIGENVALUE PROBLEMS
plexen Paaren auftreten, anhand des Umstandes, daß x EV zum EW λ ist,wenn x EV zum EW λ ist.
Fur reelles A folgt aus Ax = λx durch Konjugieren eben Ax = λx.
10. a) Zeige: Alle EWe einer komplexen, Hermite’schen Matrix sind reell.157
Alle EWe einer komplexen, Hermite’schen Matrix A = AH sind reell, weilfur EVen x zum EW λ aus R 3 (xHAx)H = xHAx = xHλx = λ||x||22 ebenλ ∈ R folgt.
b) Zeige: Alle EWe einer reellen, symmetrischen Matrix sind reell.157
Alle EWe einer reellen, symmetrischen Matrix A = AT sind reell, weil furEVen x zum EW λ aus R 3 (xHAx)H = xHAx = xHλx = λ||x||22 ebenλ ∈ R folgt.
11. Gib ein Beispiel einer komplexen, symmetrischen, nicht-Hermite’sche Ma-trix mit nicht-reellen EWen.
Etwa A =
(0 ii 0
)mit AH =
(0 −i−i 0
)ist eine komplexe, symmetrische,160
nicht-Hermite’sche Matrix mit det(A − λI) = λ2 + 1 und daher mit denbeiden imaginaren EWen λ1,2 = ±i.
12. Zeige: EWe einer positiv definiten Matrix sind positiv.
Die EWe einer positiv definiten Matrix A sind positiv, weil fur EVen x 6= 0157zum EW λ eben 0 < xTAx = xTλx = λ||x||22 und damit λ > 0 gilt.
13. Zeige: Fur den Spektral-Radius ρ(A) = max|λ| : λ ∈ λ(A) gilt ρ(A) ≤||A|| fur jede Matrix-Norm ||.|| subordinate zu einer Vektor-Norm.
Fur den Spektral-Radius ρ(A) = max|λ| : λ ∈ λ(A) gilt ρ(A) ≤ ||A||158fur jede Matrix-Norm ||.|| subordinate zu einer Vektor-Norm, d.h. ||A|| =
maxx6=0||Ax||||x|| , weil namlich ||A|| = maxx6=0
||Ax||||x|| ≥ max06=x ist EV
||Ax||||x|| =
max06=x ist EV zum EW λ|λ|·||x||||x|| = maxλ ist EW |λ| = ρ(A).
14. Sei A =
1 0 α4 2 06 5 3
mit α ∈ R gegeben.
a) Existiert ein α ∈ R, so daß A nur reelle EWe hat?160
Mit α = 0 ist A untere Dreiecksmatrix mit det(A−λI) = (1−λ)(2−λ)(3−λ)und daher mit den drei reellen EWen 1, 2 und 3.
b) Existiert ein α ∈ R, so daß alle EWe von A nicht-reell sind?
A hat maximal drei EW. Diese konnen nicht alle komplex sein, da komplexeEWe in konjugiert komplexen Paaren auftreten (s. 4Ex9).

4.5. Exercises – Ubungsergebnisse 235
15. A und B seien n × n-Matrizen. A sei regular. Zeige: AB und BA sindahnlich.
AB und BA ahnlich, da mit der Ahnlichkeitstransformationsmatrix A−1 170eben AB = A(BA)A−1 gilt.
16. A sei regulare n× n-Matrix.
a) In welcher Beziehung stehen die EWe von A zu denen von A−1 ? 169
Wenn λ EW von A und x EV zum EW λ ist, so ist wegen Ax = λx ⇐⇒x = λA−1x ⇐⇒ A−1x = 1
λx eben x EV zum EW 1
λvon A−1.
b) In welcher Beziehung stehen die EVen von A zu denen von A−1 ? 169
Wegen a) sind die EVen zum EW λ von A gerade die EVen zum EW 1λ
vonA−1.
17. λ sei EW von A. Zeige: λ2 ist EW von A2.
Aus Ax = λx. folgt A2x = Aλx = λ2x. Damit ist λ2 EW von A2. 169
18. A heißt nilpotent ⇐⇒ Ak = 0 fur ein k ∈ N.
a) Zeige: Alle EWe einer nilpotenten Matrix verschwinden. 169
Angenommen, x 6= 0 ist EV zum EW λ 6= 0 von A. Dann ergibt sich derWiderspruch aus 0 = 0x = Akx = λkx 6= 0.
b) Zeige: Wenn A nilpotent und normal, d.h. AHA = AAH , dann A = 0.
Wegen a) verschwinden alle EWe von A. Da A normal ist, ist A (sogarunitar) ahnlich zu einer Diagonal-Matrix D = diag(d) mit denselben EWen.Also ist d = 0 und damit D = 0 = THAT, was A = 0 impliziert.
19. A sei idempotent, d.h. A2 = A. Charakterisiere die EWe von A.
Sei λ ein EW von A mit zugehorigem EV x 6= 0. Dann folgt aus λx =Ax = A2x = λ2x eben λ2 = λ und somit λ = 0 oder λ = 1.
20. a) A sei Hermite’sche n × n-Matrix, d.h. AH = A, mit EV x zum EW λund EV y zum EW µ, wobei µ 6= λ. Zeige: yHx = 0.
Da alle EWe einer Hermite’schen Matrix A reell sind (vgl. 4Ex10 a)),
folgt aus µyHx = (xHµy)H = (xHAy)H = (xHAHy)H = (yHAx)HH=
(yHλx)HH= (λxHy)H = λyHx eben (λ− µ)yHx = 0 und damit yHx = 0,
falls λ 6= µ.
b) A sei eine nicht-notwendig Hermite’sche n×n-Matrix mit Ax = λx undyHA = µyH und µ 6= λ. Zeige: yHx = 0.
Aus µyHx = yAx = yλx = λyHx folgt wieder (λ− µ)yHx = 0 und damityHx = 0, falls λ 6= µ.

236 KAPITEL 4. EIGENVALUE PROBLEMS
c) A sei eine nicht-notwendig Hermite’sche n×n-Matrix mit Ax = λx undyHA = λyH fur einen einfachen EW λ. Zeige: yHx 6= 0.
???
21. a) A sei reelle oder komplexe n × n-Matrix. Zeige: fur jeden reellen oder163komplexen Skalar λ ist Sλ = x : Ax = λx Unterraum von Rn oder Cn.
Fur beliebige x1,x2 ∈ Sλ und Skalare c1 und c2 ist auch c1x1 + c2x2 ∈ Sλ,da A(c1x1 + c2x2) = c1Ax1 + c2Ax2 = c1λx1 + c2λx2 = λ(c1x1 + c2x2).
b) Zeige: λ ist EW genau dann, wenn Sλ 6= 0.163
λ ist EW ⇐⇒ es existiert x 6= 0 mit Ax = λx ⇐⇒ Sλ 6= 0.
22. Sei A =
[B C0 D
]obere n × n-Block-Dreiecksmatrix mit k × k-Matrix B
und (n− k)× (n− k)-Matrix D.
a) Zeige: Ein EW λ von B ist auch EW von A.
Denn Bu = λu impliziert A
[u0
]=
[B C0 D
] [u0
]=
[Bu0
]=
[λu0
]= λ
[u0
].
b) Zeige: Ein EW λ von D, aber nicht von B, ist auch EW von A.
Sei Dv = λv. Da λ kein EW von B ist, existiert u mit (B− λI)u = −Cv.
Dann gilt A
[uv
]=
[B C0 D
] [uv
]=
[Bu + Cv
Dv
]=
[λuλv
]= λ
[uv
].
c) Zeige: Wenn
[uv
]EV zum EW λ von A ist, dann ist u EV zum EW λ
von B oder v EV zum EW λ von D.
Sei A
[uv
]=
[B C0 D
] [uv
]=
[Bu + Cv
Dv
]= λ
[uv
]. Falls nun λ EW von D
ist, so ist v 6= 0 und alles gezeigt. Sonst ist notwendigerweise mit v = 0eben Bu + Cv = λu, also u EV zum EW λ von B.
d) Zeige: λ ist EW von A genau dann, wenn λ EW entweder von B odervon D ist.
Wenn λ EW von A ist, folgt die Behauptung aus c).Wenn λ EW von B oder von D ist, folgt die Behauptung aus a) und b).
23. A sei n× n-Matrix mit EW λ1, . . . , λn.
a) Zeige: det(A) =∏n
i=1 λi.160
Das charakteristische Polynom p(λ) =∏n
i=1(λ − λi) = det(A− λI) ausge-wertet in 0 ist p(0) =
∏ni=1 λi = det(A).
b) Die Spur trace(A) einer Matrix A ist durch trace(A) =∑n
j=1 aj,j defi-160niert. Zeige: trace(A) =
∑nj=1 λj.

4.5. Exercises – Ubungsergebnisse 237
Mit A = (a1, . . . , an) ist
p(λ) =n∏
i=1
(λ− λi) = (−λ)n + (n∑
i=1
λi)(−λ)n−1 + . . .+ c1(−λ) + co
= det(A− λI) = det(a1 − λe1, . . . , an − λen)
=n∑
k=0
(−λ)k∑
fur genau k der bi gilt bi = ei
sonst n− k der bi = ai
det(b1, . . . ,bn)
Vergleich der Koeffizienten von (−λ)n−1 liefert
n∑i=1
λi =∑
fur genau eines der bi gilt bi = ai
wahrend fur alle anderen bi = ei gilt
det(b1, . . . ,bn)
=∑n
k=1, mit bj=δj,kak+(1−δj,k)ej fur j=1,...,n det(b1, . . . ,bn)
= det(a1, e2, ..., en) + det(e1, a2, e3, ..., en) +
+ . . .+ det(e1, e2, ..., en−2, an−1, en) + det(e1, e2, ..., en−1, an)
=n∑
j=1
aj,j = trace(A)
24. A sei reelle n× n-Matrix mit rank(A) = 1.
a) Zeige: A = uvT fur reelle Vektoren u 6= 0 6= v.
In A = (a1, . . . , an) sind alle ai von etwa a1 l.a. Also gilt ai = via1 =: viufur i = 2, . . . , n. Mit v1 = 1 ist also A = uvT .
b) Zeige: uTv = vTu ist EW von A.
Wegen Au = uvTu = u(vTu) = (uTv)u ist u EV zum EW uTv.
c) Wie sehen die anderen EWe von A aus?
Sei v⊥ = span(w2, . . . ,wn). Wegen Awi = uvTwi = 0u = 0 ist 0 EW vonA. Falls u ⊥ v ist 0 n-facher EW, sonst n− 1 EW von A.
d) Wieviele Iterationen sind auszufuhren, bis power iteration genau gegeneinen EV zum betragsmaßig großten EW konvergiert?
Wegen span(v,w2, . . . ,wn) = Rn kann jeder Start-Vektor xo als xo = α1v+∑nj=2 αjwj dargestellt werden. Dann gilt x1 = Axo = uvTxo = α1u(vTv).
Wegen x2 = Ax1 = uvTx1 = α1u(vTu)(vTv) ist x2 Vielfaches des EVs uzum EW uTv.
25. Zeige: det(I + uvT ) = 1 + uTv. Verwende 4Ex23 und 4Ex24.
Sei A = uvT mit EWen λ1 = uTv und λ2 = . . . = λn = 0. Fur σ = −1 hat 160dann A + I = A − σI die EWe µ1 = uTv − σ = uTv + 1 und µ2 = . . . =µn = 0− σ = 1. Damit folgt det(I + uvT ) =
∏nj=1 µj = 1 + uTv.

238 KAPITEL 4. EIGENVALUE PROBLEMS
26. A heißt normal ⇐⇒ AHA = AAH .
a) Zeige: Eine normale Dreiecksmatrix ist diagonal.164
Sei A = (ai,j) normale, obere Dreiecksmatrix. Aus |a1,1|2 = a1,1a1,1 =(AHA)1,1 = (AAH)1,1 =
∑nk=1 a1,k(A
H)k,1 =∑n
k=1 a1,ka1,k =∑n
k=1 |a1,k|2folgt a1,k = 0 fur k = 2, . . . , n. Aus |a2,2|2 = (AH)2,1a1,2 + a2,2a2,2 =(AHA)2,2 = (AAH)2,2 =
∑nk=2 a2,k(A
H)k,2 =∑n
k=2 a2,ka2,k =∑n
k=2 |a2,k|2folgt a2,k = 0 fur k = 3, . . . , n usw. Aus |ai,i|2 =
∑n`=i(A
H)i,`(A)`,i =(AHA)i,i = (AAH)i,i =
∑nk=i ai,k(A
H)k,i =∑n
k=i ai,kai,k =∑n
k=i |ai,k|2folgt per Induktion ai,k = 0 fur k = i, . . . , n. Also ist A diagonal.
b) Zeige: Eine Matrix A ist genau dann normal, wenn A unitar diagona-171lisierbar ist, d.h. wenn es eine unitare Matrix Q und eine Diagonal-MatrixD mit D = QHAQ gibt.
Sei A unitar diagonalisierbar ist, d.h. es existiere eine unitare Matrix Q undeine Diagonal-Matrix D = diag(d1, . . . , dn) mit D = QHAQ. Zunachst giltalso QD = AQ und DQH = QHA. Dann folgt AHA = AHQQHA =(QHA)HQHA = (DQH)HDQH = QDHQDH = diag(|d1|2, . . . , |dn|2) =QDDHQH = QD(DQ)H = AQ(AQ)H = AQQHAH = AAH .Sei nun A normal. Wie jede Matrix ist auch A unitar ahnlich zu einerDreiecksmatrix T, d.h. T = QHAQ fur unitares Q (Schur decomposition).Wegen TTH = QHAQ(QHAQ)H = QHAQQHAHQ = QHAAHQ =QHAHAQ = QHAHQQHAQ = (QHAQ)HQHAQ = THT ist T normaleDreiecksmatrix und damit laut a) diagonal.
27. A sei n× n-Matrix mit ρ(A) < 1.
a) Zeige: I−A ist regular.158
Wegen ρ(A) < 1 ist 1 kein EW von A und somit p(1) = det(A − I) 6= 0.Also ist mit A− I auch I−A regular.
b) Zeige: (I−A)−1 =∑∞
k=0 Ak.
Aus (I −A)∑∞
k=0 Ak =∑∞
k=0 Ak −∑∞
k=0 Ak+1 =∑∞
k=0 Ak −∑∞
k=1 Ak =A0 = I folgt die Behauptung (I−A)−1 =
∑∞k=0 Ak.
28. A sei reelle, symmetrische n× n-Matrix mit EWen λ1 ≤ λ2 ≤ . . . ≤ λn.
a) Gegen welche EWe von A kann power-Iteration mit geeigneten shifts σ176konvergieren?
Erstens konvergiert power-Iteration von A gegen den betragsmaßig großtenEW, also λ1 oder λn. Zweitens hat A − σI die EWe λ1 − σ ≤ λ2 − σ ≤. . . ≤ λn−σ. power-Iteration mit shifts σ kann also – ja nach σ – nur gegendie extremen EWe von A, d.h. gegen λ1 und λn konvergieren.
b) Jeweils welche shifts σ haben die schnellste Konvergenz zur Folge?176

4.5. Exercises – Ubungsergebnisse 239
Konvergenz ist am schnellsten, wenn shift σ so gewahlt wird, daß |λ2−σλ1−σ
|verschwindet, d.h. wenn σ = λ2 gewahlt wird. I.a.R. ist λ2 allerdings
???unbekannt.
c) Beantworte a) und b) fur die inverse Iteration. 176/177
Inverse Iteration mit shifts σ kann jeden EW von A approximieren. Dabeiist die Konvergenz umso schneller, je naher σ an einem EW λj liegt.
29. Die komplexe, Hermite’sche n× n-Matrix C sei als C = A + iB mit Real-Teil A und Imaginar-Teil B dargestellt. Sei x + iy EV zum EW λ von C.
Die reelle 2n× 2n-Matrix C sei durch C =
[A −BB A
]definiert und
a) Zeige: C ist symmetrisch.
C ist Hermite’sch, d.h. CH = (A + iB)H = AT − iBT = A + iB = C⇐⇒ AT = A und −BT = B ⇐⇒ C ist symmetrisch.
b) Zeige: λ ist EW auch von C mit (reellen) EVen
[xy
]und
[−yx
].
C
[xy
]=
[A −BB A
][xy
]=
[Ax−ByBx + Ay
]=
[<((A + iB)(x + iy))=((A + iB)(x + iy))
]=
[λxλy
]= λ
[xy
],
C
[−yx
]=
[A −BB A
][−yx
]=
[−Ay −Bx−By + Ax
]=
[−=((A + iB)(x + iy))<((A + iB)(x + iy))
]=
[−λyλx
]= λ
[−yx
].
c) Komplexe Hermite’sche EW-Probleme konnen also als reelle, symmetri-sche EW-Probleme gelost werden. Ist das ein brauchbarer Ansatz?
Nein, dagegen spricht der doppelte Speicherplatz fur C wie auch der Um-
stand, daß zur Berechnung von C
[xy
]fur etwa power-Iteration offensicht-
lich 2n(2n−1) reelle Additionen aufgewendet werden mussen, wahrend zurgleichwertigen Berechnung von Cz nur n(n − 1) komplexe, also 2n(n − 1)reelle Additionen durchgefuhrt werden mussen.
30. a) Welche EWe hat die komplexe, symmetrische Matrix A =
(2i 11 0
)? 160
Wegen p(λ) = −(2i− λ)λ− 1 = λ2− 2iλ− 1 = (λ− i)2 ist i doppelter EWvon A.
b) Wieviele l.u. EVen hat A ? 162
Etwa (i, 1)T ist einziger EV zum EW i. Die geometrische ist also echtkleiner als die algebraische Multiplizitat des EWes i.
c) Stelle das Ergebnis der Situation fur reelle, symmetrische oder komplexe,Hermite’sche Matrizen gegenuber.
Reelle, symmetrische oder komplexe, Hermite’sche Matrizen haben nur re-elle EWe (s. 4Ex10).
???

240 KAPITEL 4. EIGENVALUE PROBLEMS
31. a) Zeige: fur EWe λ von orthogonalen Matrizen Q gilt |λ| = 1.164
Sei x EV zum EW λ von Q mit Q−1 = QT . Dann folgt aus |λ|2 · ||x||22 =(λx)T (λx) = (Qx)T (Qx) = xTQTQx = xTx = ||x||22 eben |λ| = 1.
b) Bestimme die SWe einer orthogonalen Matrix Q.202
Die Matrix Q mit SVD Q = UΣVT und orthogonalen Matrizen U undV sowie diagonaler Matrix Σ ist orthogonal, d.h. QQT = I = QTQ.Aus I = QQT = UΣVTVΣTUT = UΣΣTUT = UΣ2UT folgt Σ2 =UTUΣ2UTU = UT IU = I. Die Diagonal-Matrix Σ der SWe ist alsoidempotent, d.h. die SWe sind ±1. Andererseits sind die SWe von Q die
???nicht-negativen Quadratwurzeln der EWe von QTQ = I, also SWe +1.
202
32. a) Was sind die EWe der Householder Transformation H = I− 2vT v
vvT fur121beliebiges v 6= 0 ?
Wegen Hx = x− 2vT v
vvTx = x−2vT xvT v
v = λx ⇐⇒ (1−λ)x = 2vT xvT v
v ⇐⇒λ = −1 und x = v oder λ = 1 und vTx = 0, d.h. v ⊥ x. Dabei ist −1einfacher EW und 1 ist EW mit der Vielfachheit n− 1.
b) Was sind die EWe derGivens Rotation G =
(c s−s c
)mit c2 + s2 = 1 ?127
Wegen p(λ) = (c− λ)2 + s2 = λ2 − 2cλ+ c2 + s2 = λ2 − 2cλ+ 1 hat G diebeiden konjugiert komplexen EWe λ1,2 = c±
√c2 − 1 = c± i s.
33. Sei A eine symmetrische, tridiagonale Matrix ohne verschwindende Ele-?mente auf der unteren Nebendiagonalen. Zeige: A hat verschiedene EWe.
???
34. Sei A eine singulare, obere Hessenberg-Matrix ohne verschwindende Ele-?mente auf der unteren Nebendiagonalen. Zeige: QR-Iteration von A pro-duziert mit nur einer Iteration einen exakten EW. QR-Iteration konvergiertalso sehr schnell, wenn shifts verwendet werden, die nahe genug an EWenliegen.
???
35. Verifiziere, daß die vom Lanczos-Verfahren schrittweise erzeugten orthogo-nalen Vektoren die three term recurrence befriedigen. So ist beispielsweiseAq3 ⊥ q1, so daß Aq3 nur noch relativ zu q2 und q3 orthogonalisiertwerden muß.191
???
36. A sei m× n-Matrix. Dann ist Ax =
[0 A
AT 0
] [uv
]= λ
[uv
]ein symmetri-
sches EW-Problem.
a) Zeige: Wenn λ EW von A, dann ist |λ| ein SW von A mit zugehorigem202linken SV u und zugehorigem rechten SV v.

4.6. Computer Problems – Rechner-Problem-Losungen 241
Die SWe von A sind die nicht-negativen Quadratwurzeln der EWe vonATA. Wegen Ax = λx gilt Av = λu sowie ATu = λv und damit ATAv =λATu = λ2v, so daß λ2 EW von ATA und damit |λ| ein SW von A ist.Insbesondere ist v EV zum EW λ2 von ATA. Wegen AATu = λAv = λ2uist u EV zum EW λ2 von AAT .In der SVD A = UΣVT von A sind die Spalten von U und V orthonormaleEV von AAT bzw. von ATA. Damit ist gezeigt, daß bis auf Normalisierungu linker SV und v rechter SV von A ist.
b) Ist das ein brauchbarer Ansatz, die SVD von A zu bestimmen?
???
4.6 Computer Problems –
Rechner-Problem-Losungen
Verfahren zur Bestimmung von EVen und EWen
< tests > reset σ = power inverse
A=
xo =
k = xk =
EWe von A: λ1 = , λ2 = , λ3 = .
λ− σ1
λ−σ
= ist EW vonA− σI
(A− σI)−1 ⇐⇒ λ = ist EW von A
||(A− σI)xk − λxk||∞ = k = 0 step cont
1. a) Berechne EWe und EVen von A =
(1 10000.001 1
). 160
Wegen p(λ) = (1 − λ)2 − 1 = λ2 − 2λ = λ(λ − 2) hat A die beiden EWe
λ1 = 0 mit EV
(1000−1
)und λ2 = 2 mit EV
(1000
1
). Die Matrix A hat
also zwei einfache EWe.
b) Berechne die Konditionszahl der Matrix X von EVen und die absolute 167Konditionszahl des EW-Problems.
Die singular value decomposition, SVD von X =
(1000 1000−1 1
)ist X =

242 KAPITEL 4. EIGENVALUE PROBLEMS
UΣVT =
(−1 0
0 1
)√2
(1000 0
0 1
)√
22
(−1 −1−1 1
)mit orthogonalen Matri-
zen U und V und der Diagonal-Matrix Σ = diag(σ1, σ2) =√
2diag(1000, 1)der SWe. Daher ist cond2(X) = σmax/σmin = 1000 die absolute Konditions-zahl des EW-Problems.
x1 =
(1000−1
)und y1 =
(−1
1000
)sind rechte und linke EVen zum EW
λ1 = 0. Damit ist die absolute Konditionszahl des einfachen EWs λ1 ge-rade 1
cos ∠(x1,y1)= ||x1||2·||y1||2
|yT1 x1|
=√
1000001·√
10000012000
= 10000012000
≈ 500.
x2 =
(1000
1
)und y2 =
(1
1000
)sind rechte und linke EVen zum EW
λ2 = 2. Damit ist die absolute Konditionszahl des einfachen EWs λ2 ge-rade 1
cos ∠(x2,y2)= ||x2||2·||y2||2
|yT2 x2|
=√
1000001·√
10000012000
= 10000012000
≈ 500.
c) Was sind die EWe von B =
(1 10000 1
)? Wie erklaren sich die Ande-168
rungen der EWe aus der Anderung von A ?
Wegen p(λ) = (1−λ)2 hat B den doppelten EW λ = 1 mit Eigenraum Re1.
(Also ist B defektiv.) B = A + E mit E =
(0 0
−0.001 0
)mit SVD E =
UΣVT =
(0 11 0
)(0.001 00 0
)(−1 0
0 1
)und daher ||E||2 = σmax = 0.001.
Allerdings |∆λ| <≈
1cos ∠(xi,yi)
||E||2 = 500 · 0.001 = 0.5???
2. a) Implementiere power-Iteration, um fur A =
2 3 210 3 23 6 1
mit x0 =
001
173
den dominanten EW mit zugehorigem normalisierten EV zu approximieren.
Mit der power-Iteration auf S. 241 ergibt sich fast genau der exakte EVx1 = (0.5, 1, 0.75)T zum exakten EW λ1 = 11.
b) Nach deflation approximiere den betragsmaßig zweitgroßten EW von A179per power-Iteration.
Sei A = (a1, a2, a3). Dann annulliert die Householder Transformation H =
I − 2vvT
vT vmit v = x1 − αe1 = (0.5 +
√29/4, 1, 3/4)T mit α = −||x1||2 =
−√
29/4 alle nicht-Diagonal-Elemente von x1. Es gilt HAH−1 =
[11 bT
0 B
]mit B = 1
(−29+2√
29)2
(3 (−1131 + 200
√29) 6 (−58 + 31
√29)
−3 (−696 + 169√
29) −4 (348 + 5√
29)
). B hat
die beiden EWe λ2 = −2 und λ3 = −3.
c) Verwende fur a) und b) Bibliotheksroutinen und vergleiche mit den ei-genen Ergebnissen.

4.6. Computer Problems – Rechner-Problem-Losungen 243
MATLABs function eig berechnet die in ||.||2 normierten EVen zu EWenx1/||x1||2 ≈ (0.3714, 0.7428, 0.5571)T zum EW λ1 = 11 undx2/||x2||2 ≈ (0.1826, 0.3651,−0.9129)T zum EW λ2 = −2 sowiex3/||x3||2 ≈ (0,−0.5547, 0.8321)T zum EW λ3 = −3.
3. a) Implementiere inverse iteration mit shift, um den normalisierten EV zu 176/177
dem EW, der am nachsten zu 2 liegt, fur A =
6 2 12 3 11 1 1
zu bestimmen.
Der Startvektor sei beliebig zu wahlen.
Mit der inverse-Iteration auf S. 241 ergibt sich???
b) Verwende eine Bibliotheksroutine fur reelle, symmetrische Matrizen undvergleiche mit den Ergebnissen aus a).
MATLABs function eig berechnet die in ||.||2 normierten EVen zu EWenx1/||x1||2 ≈ (0.8664, 0.4531, 0.2098)T zum EW λ1 = 7.2880 undx2/||x2||2 ≈ (−0.4974, 0.8196, 0.2843)T zum EW λ2 = 2.1331 sowiex3/||x3||2 ≈ (−0.0432,−0.3507, 0.9355)T zum EW λ3 = 0.5789.
4. Programmiere Raleigh Quotienten Interation und teste das Programm an- 178hand der Matrix aus 4CP3.
Mit der Raleigh quotienten interation auf S. 241 ergibt sich???
5. a) Bestimme die EWe von A =
9 4.5 3−56 −28 −18
60 30 19
mit einer Bibliotheks-
routine.
MATLABs function eig berechnet die drei exakten EWe λ1 = 1 mit EVx1 = (1,−4, 10/3)T , λ2 = 0 mit EV x2 = (1,−2, 0)T und λ3 = −1 mit EVx3 = (0, 1,−3/2)T sowie cond(A) ≈ 1.4 · 1017.
b) Bestimme die EWe von A =
9 4.5 3−56 −28 −18
60 30 18.95
mit einer Bibliotheks-
routine. Welche relative Anderung der EWe gegenuber a) ergibt sich?
MATLABs function eig berechnet die drei exakten EWe λ1 = 0.2, λ2 = 0und λ3 = −0.25 sowie cond(A) ≈ 1.1 · 1017.
c) Bestimme die EWe von A =
9 4.5 3−56 −28 −18
60 30 19.05
mit einer Bibliotheks-
routine. Welche relative Anderung der EWe gegenuber a) ergibt sich?
MATLABs function eig berechnet die drei EWe λ1 = 1.4216, λ2 = 0 undλ3 = −1.3716 sowie cond(A) ≈ 1.8 · 1017.

244 KAPITEL 4. EIGENVALUE PROBLEMS
d) Welche Schlusse uber die Konditionierung des EW-Problems lassen sichziehen? Berechne jeweils die Kondition von A.
???
6. Implementiere die folgende einfache Version von QR-Iteration mit shifts zurBestimmung der EWe einer beliebigen reellen Matrix A.
do
σ = an,n
QR = A− σIA = RQ + σI
until convergence
Welches Abbruch-Kriterium ist geeignet? Teste das Programm anhand derMatrizen aus 4CP2 und 4CP3.
???
7. Programmiere das Lanczos-Verfahren???
8. Bestimme alle Wurzeln von p(t) = 21 − 40t + 35t2 − 13t3 + t4 anhand derEWe der companion-Matrix und einer Bibliotheksroutine. Beachte, daß diecompanion-Matrix schon eine Hessenberg-Matrix ist, was die Bibliotheks-routine gegebenenfalls ausnutzen kann. Vergleiche Geschwindigkeit undGenauigkeit dieses Losungsansatzes mit Geschwindigkeit und Genauigkeitanderer Bibliotheksroutinen speziell zur Nullstellenbestimmung.
C =
0 0 0 241 0 0−400 1 0 350 0 1−13
ist die companion-Matrix zum Polynom p. MATLAB’s
Funktion eig liefert die EWe λ1,2 = 0.68390383629460±0.94097688618921i,λ3 = 1.80476989206217 und λ4 = 9.82742243534863 der companion-Matrixin weitgehender Ubereinstimmung mit dem Ergebnis von MATLAB’s Funk-tion roots (bis auf λ3 = 1.80476989206218) zur Bestimmung der Nullstel-len von p. Die Laufzeiten von eig und von roots unterscheiden sich nichtmeßbar.
Die folgenden Graphiken zeigen durchschnittliche Laufzeit und durchschnitt-liche Genauigkeit der Bestimmung der (reellen) Wurzeln von Polynomensteigenden Grades: die ’exakten’ Nullstellen der Polynome sind pseudo-zufallig erzeugt; die Koeffizienten eines jeden Polynoms p werden aus demProdukt seiner Linear-Faktoren berechnet. Die Genauigkeit der Ergebnissevon roots(p) bzw. eig(C) fur die companion-Matrix C von p wird anhandder relativen Abstande von den generierten Nullstellen gemessen.

4.6. Computer Problems – Rechner-Problem-Losungen 245
5 10 15 200
0.5
1
1.5x 10
−3 mittlere Laufzeiten von roots bzw. eig für Polynome vom Grad n
n
Zeit für roots(p)Zeit für eig(C)
5 10 15 2010
−15
10−10
10−5
100
105
1010
1015
mittlere Genauigkeit von roots bzw. eig für Polynome vom Grad n
n
norm(roots(p)−ns)norm(eig(C)−ns)
9. Berechne die EWe der n × n-Hilbert-Matrix fur n ≤ 20. Wie laßt sich dieGroßenordnung der EWe in Abhangigkeit von n charakterisieren?
Da die Hilbert-Matrizen Hn positiv definit (s. 2CP6) sind, sind alle EWepositiv (s. 2CP6).
2 4 6 8 10 12 14 16 18 200
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
EWe von hilb(n) in blauminimaler Abstand der EWe von hilb(n) in rot
n
Vermutung λ < 2 fur alle EWe λ von H und limn→∞ ρ(Hn) = 2???
10. Eine singulare Matrix hat den einen EW 0. Muß aber eine fast-singulareMatrix kleine EWe haben? Untersuche dazu n× n-Matrizen A der Form
A =
1 −1 −1 −1 −10 1 −1 −1 −10 0 1 −1 −10 0 0 1 −10 0 0 0 1
fur verschiedene n. Offensichtlich hat A nur den n-fachen EW 1. Wieverhalt sich aber σmax/σmin in Abhangigkeit von n ? Welche Schlusse sindzu ziehen?
???

246 KAPITEL 4. EIGENVALUE PROBLEMS
0 10 200
0.05
0.1
0.15
0.2
0.25
0.3
0.35
n
σmin = σmin(n)
0 10 200
2
4
6
8
10
12
n
σmax = σmax(n)
0 10 200
0.5
1
1.5
2
2.5
3
3.5
4
4.5x 10
6
n
σmax(n)/σmin(n)
11. Eine symmetrische tridiagonale Matrix mit einem mehrfachen EW mußein verschwindendes Element auf der Neben-Diagonalen haben. Muß aberein Paar nahe beieinanderliegender EWe ein kleines Element auf der Neben-Diagonalen implizieren? Untersuche dazu die symmetrischen, tridiagonalenn×n-Matrizen A mit n = 2k+1 und k, k−1, . . . , 1, 0, 1, . . . , k−1, k auf derHaupt-Diagonalen und nur Einsen auf beiden Neben-Diagonalen. Berechnealle EWe dieser Matrizen fur verschiedene k. Treten mehrfache oder fast-mehrfache EWe auf? Welche Schlusse sind zu ziehen?
???
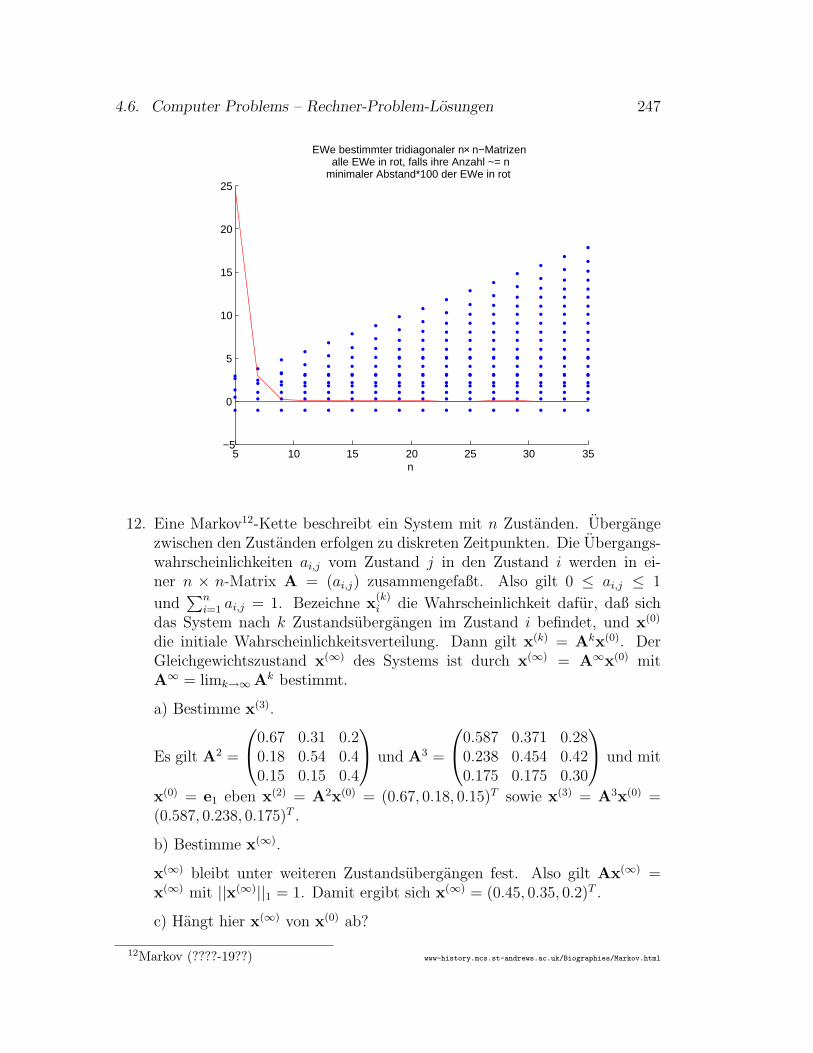
4.6. Computer Problems – Rechner-Problem-Losungen 247
5 10 15 20 25 30 35−5
0
5
10
15
20
25
EWe bestimmter tridiagonaler n× n−Matrizenalle EWe in rot, falls ihre Anzahl ~= n
minimaler Abstand*100 der EWe in rot
n
12. Eine Markov12-Kette beschreibt ein System mit n Zustanden. Ubergangezwischen den Zustanden erfolgen zu diskreten Zeitpunkten. Die Ubergangs-wahrscheinlichkeiten ai,j vom Zustand j in den Zustand i werden in ei-ner n × n-Matrix A = (ai,j) zusammengefaßt. Also gilt 0 ≤ ai,j ≤ 1
und∑n
i=1 ai,j = 1. Bezeichne x(k)i die Wahrscheinlichkeit dafur, daß sich
das System nach k Zustandsubergangen im Zustand i befindet, und x(0)
die initiale Wahrscheinlichkeitsverteilung. Dann gilt x(k) = Akx(0). DerGleichgewichtszustand x(∞) des Systems ist durch x(∞) = A∞x(0) mitA∞ = limk→∞Ak bestimmt.
a) Bestimme x(3).
Es gilt A2 =
0.67 0.31 0.20.18 0.54 0.40.15 0.15 0.4
und A3 =
0.587 0.371 0.280.238 0.454 0.420.175 0.175 0.30
und mit
x(0) = e1 eben x(2) = A2x(0) = (0.67, 0.18, 0.15)T sowie x(3) = A3x(0) =(0.587, 0.238, 0.175)T .
b) Bestimme x(∞).
x(∞) bleibt unter weiteren Zustandsubergangen fest. Also gilt Ax(∞) =x(∞) mit ||x(∞)||1 = 1. Damit ergibt sich x(∞) = (0.45, 0.35, 0.2)T .
c) Hangt hier x(∞) von x(0) ab?
12Markov (????-19??) www-history.mcs.st-andrews.ac.uk/Biographies/Markov.html

248 KAPITEL 4. EIGENVALUE PROBLEMS
Hier hangt x(∞) nicht von x(0) ab, da dieses System mit nicht verschwin-dender Wahrscheinlichkeit von jedem (initialen) Zustand in jeden anderenZustand ubergehen kann.
d) Bestimme A∞. Welchen Rang hat A∞ ?
Wegen AA∞ = A∞ und wegen des Umstandes, daß A∞ selbst wieder eineUbergangsmatrix mit 0 ≤ (A∞)i,j ≤ 1 und
∑ni=1(A
∞)i,j = 1 ist, bildetx(∞) die identischen Spalten von A∞. Damit hat A∞ den Rang 1.
e) Erlautere die bisherigen Ergebnisse anhand der EWe und EVen von A.
Wegen Ax(∞) = x(∞) ist x(∞) 1-normierter EV zum EW 1. Weiterhin gilt
A∞ = x(∞)T (1, . . . , 1).
f) Ist 1 notwendig ein EW der Matrix der Ubergangswahrscheinlichkeiteneiner Markov-Kette?
Wegen 4Ex5 a) hat AT den EW 1. Wegen 4Ex7 a) haben A und AT
dieselben EWe. Also hat A notwendig den EW 1.
g) Ein probability distribution vector x heißt stationar ⇐⇒ Ax = x.Wie konnen solche Vektoren anhand von EWen und EVen von A bestimmtwerden?
Jeder stationare probability distribution vector ist ein 1-normierter EV zumEW 1 von A. Solche EVen werden am besten per inverse Iteration mit shiftσ = 1 bestimmt.
h) Wie konnen solche Vektoren ohne Kenntnis der EWe und EVen von Abestimmt werden?
Lose (A− I)x = 0 mit ||x||1 = 1.???
i) Ist es in diesem speziellen Beispiel moglich, daß ein nicht-stationarerprobability distribution vector wiederkehrt? Ist dies fur allgemeine Markov-Ketten moglich? Falls nein, warum? falls ja, finde Beispiele.
Wenn ein nicht-stationarer probability distribution vector x wiederkehrt, giltAkx = x fur ein k > 1. Hier ????
???
Beispielsweise in der durch A =
0 1 01 0 00 0 1
beschriebenen Markov-Kette
alterniert das System zwischen den beiden ersten Zustanden, falls x(0) ∈e1, e2, und verharrt im dritten Zustand, falls x(0) = e3. Wegen p(λ) =det(A−λI) = (λ2−1)(1−λ) hat A den einfachen EW−1 und den doppeltenEW 1.Allgemeiner, wenn A eine k-te Einheitswurzel λ 6= 1 als EW mit EV x hat,so ist dieses x mit ||x||1 = 1 wiederkehrender nicht-stationarer probabilitydistribution vector, da aus Ax = λx eben Akx = λkx = x folgt.
???

4.6. Computer Problems – Rechner-Problem-Losungen 249
j) Kann es mehrere stationare probability distribution vectors geben? Fallsnein, warum? falls ja, finde Beispiele.
Beispielsweise die durch A =
0 1 01 0 00 0 1
beschriebene Markov-Kette hat
mehrere stationare probability distribution vectors, etwa (e1 +e2)/2 und e3.
k) An welches andere numerische Problem erinnert dieses Problem?
???13. Das Federn-Massen-System aus Beispiel 4.1 fuhrt auf das verallgemeinerte
EW-Problem Kx = λMx. Sei k1 = k2 = k3 = 1 sowie m1 = 2, m2 = 3 undm3 = 4 in geeigneten Einheiten.
a) Da hier M eine Diagonal-Matrix ist, kann das verallgemeinerte EW-Problem in ein Standard-EW-Problem uberfuhrt werden. Berechne alleEWe (Eigen-Frequenzen) mit zugehorigen EVen (?) unter Verwendung vonpower iteration, inverse iteration, shifts oder deflation.
Laut Vorgaben ist K =
k1 + k2 −k2 0−k2 k2 + k3 −k3
0 −k3 k3
=
2 −1 0−1 2 −1
0 −1 1
und
M = diag(2, 3, 4). Grundsatzlich ist Kx = λMx aquivalent zu Ax :=
M−1Kx = diag(2, 3, 4)−1Kx = diag(12, 1
3, 1
4)Kx = 1
12
12 −6 0−4 8 −4
0 −3 3
x =
λx. power iteration auf S. 241 ergibt den betragsmaßig großten ’exakten’13
EW λ1 = 1.300542842820 mit ’exaktem’ 13 EV x1 =
1.−0.60108568564062
0.1430416878637
.
Einfache power iteration mit shift σ = 1 liefert den betragsmaßig klein-sten ’exakten’13 EW λ2 = 0.05733449491640 mit ’exaktem’ 13 EV x2 =0.4087674876074
0.770662020334401.
.???
b) Verwende Bibliotheksroutinen fur verallgemeinerte EW-Probleme undvergleiche deren Ergebnisse mit den eigenen Ergebnissen.
MATLAB’s Funktion eig lost auch verallgemeinerte EW-Probleme. Hierstimmen die Ergebnisse exakt mit denen von eig angewandt auf das aqui-valente Standard-EW-Problem uberein.
14. a) Die Funktion exp(A) fur quadratische Matrizen A ist durch exp(A) =∑∞k=0
1k!Ak spezifiziert. Schreibe ein Programm, das exp(A) berechnet.
???b) Alternativ verwendet man die EW-EV-Zerlegung A = UDU−1 von A,
13 d.h. die angegebenen Stellen stimmen mit denen der von MATLAB’s Funktion eig symbo-

250 KAPITEL 4. EIGENVALUE PROBLEMS
wo D = diag(λ1, . . . , λn) ist, λ1, . . . , λn die EWe von A und die Spalten vonU die zugehorigen EVen sind. Dann gilt exp(A) = Udiag(eλ1 , . . . , eλn)U−1.Schreibe ein zweites Programm, das exp(A) auf diese Weise berechnet.
???
c) Anhand der beiden Matrizen A1 =
(2 −1
−1 2
)und A2 =
(−49 24−64 31
)teste die beiden Programme und vergleiche die Ergebnisse mit denen vonBibliotheksroutinen. Welche der Methoden a) oder b) ist numerisch genauerund robuster? Warum?
???15. Bestimme die Koeffizienten des charakteristischen Polynoms.
a) Krylov-Verfahren???
b) Leverrier-Verfahren???
c) Danilevsky-Verfahren???
d) Danilevsky-Verfahren fur obere Hessenberg-Matrizen???
e) Berechnung der Koeffizienten des charakteristischen Polynoms einer Ma-trix wie in MATLAB
???16. a) Schreibe eine Routine, die mit einerGivens Rotation eine reelle 2 × 2-193
Matrix A symmetrisiert, d.h. bestimme c und s mit c2 + s2 = 1, so daß
A durch G =
(c s−s c
)in eine symmetrische Matrix B = GA uberfuhrt
wird.
Symmetrie von GA=
(c s−s c
)(a1,1 a1,2
a2,1 a2,2
)=
(ca1,1 + sa2,1 ca1,2 + sa2,2
ca2,1 − sa1,1 ca2,2 − sa1,2
)impliziert ca1,2 + sa2,2 = ca2,1 − sa1,1 bzw. t = s
c= a2,1−a1,2
a1,1+a2,2und damit
c = 1/√
1 + t2 und s = ct.
b) Schreibe eine Routine, die mit einer zweiseitigen Givens Rotation eine193reelle, symmetrische 2× 2-Matrix B diagonalisiert, d.h. bestimme c und s
mit c2 + s2 = 1, so daß B durch G =
(c s−s c
)in eine Diagonal-Matrix
D = G−1BG uberfuhrt wird.
Diagonalitat der Matrix D = G−1BG =
(c −ss c
)(b1,1 b1,2
b1,2 b2,2
)(c s−s c
)=(
c2b1,1 − 2csb1,2 + s2b2,2 (c2 − s2)b1,2 + cs(b1,1 − b2,2)(c2 − s2)b1,2 + cs(b1,1 − b2,2) s2b1,1 + 2csb1,2 + c2b2,2
)impliziert die
quadratische Gleichung t2 + t b2,2−b1,1
b1,2− 1 = 0 mit den beiden Losungen
t = sc
= b1,1−b2,2
2b1,2± 1
2b1,2
√(b1,1 − b2,2)2 + 4b21,2 und damit c = 1/
√1 + t2 und
s = ct.
c) Schreibe unter Verwendung von a) und b) eine Routine, die die SVD A =193
lisch berechneten und in doppelt genaue Gleitpunkt-Zahlen konvertierten EWe/EVen uberein!

4.6. Computer Problems – Rechner-Problem-Losungen 251
UΣVT einer beliebigen reellen 2 × 2-Matrix A bestimmt. Vergleiche dasErgebnis fur beliebige Matrizen A mit demjenigen von Bibliotheksroutinen.
Wegen a) gibt es eineGivens Rotation G1 mit G1A = B und wegen b) gibtes eineGivens Rotation G2 mit G−1
2 BG2 = D =: Σ. Zusammen ergibt sichdie SVD A = G−1
1 B = G−11 G2DG−1
2 =: UΣVT von A.
A =
( )test rand reset
c1 = s1 = symm
B = G1A =
( )c2 = s2 = diag+ diag–
D = G−12 BG2 =
( )

252 KAPITEL 4. EIGENVALUE PROBLEMS

Kapitel 5
Nonlinear Equations
Def. Losungen von nichtlinearen Gleichungen f(x) = 0 oder von Systemenf(x) = 0 nichtlinearer Gleichungen sind die Nullstellen von f oder f . Ziel: Verfahren zur Losung von f(x) = 0 oder f(x) = 0
5.0.1 Existenz und Eindeutigkeit
Z.B. Die nichtlineare Vektor-wertige Funktion f(z) =
(x2 − y + γ−x+ y2 + γ
)= 0 hat
x
y
γ = 0.5
x
y
γ = 0.25
x
y
γ = −0.5
x
y
γ = −1
je nach Parameter γ keine, eine, zwei oder vier Losungen. cZ.B. Etwa f(x) = sinx = 0 hat unendlich viele Nullstellen. cFur gewisse Skalar-wertige, stetige Funktionen f garantiert der Zwischenwert-satz Losungen: falls f auf [a, b] stetig und falls [a, b] eine Klammer, d.h. fallssgn (f(a)) 6= sgn (f(b)), dann existiert x ∈ [a, b] mit f(x) = 0.
Die Verallgemeinerung is usually impractical to apply !f(a) ≤ 0 und f(b) ≥ 0 ⇐⇒ (x−z)f(x) ≥ 0 in x = a und x = b fur ein z ∈ (a, b)
253

254 KAPITEL 5. NONLINEAR EQUATIONS
Sei f : Rn → Rn stetig auf offenem, beschrankten S ⊂ Rn und (x− z)T f(x) ≥ 0fur z ∈ S und x ∈ ∂S. Dann existiert x∗ ∈ S mit f(x∗) = 0.
Satz (Inverse Function Theorem) Wenn f stetig differenzierbar und die Jacobi1-
Matrix Jf (x) = (∂fi(x)∂xj
)i,j
in x∗ regular ist, dann ist f in einer Umgebung von
f(x∗) invertierbar, d.h. f(x) = y ist losbar fur alle y in dieser Umgebung. •leider nur eine lokale Eigenschaft, ...
Def. Eine Funktion g : Rn → Rn heißt contractive auf S ⊂ Rn genau dann,wenn ein 0 < γ < 1 mit ||g(y)− g(z)|| ≤ γ||y − z|| fur alle y, z ∈ S existiert. Satz (Contraction Mapping Theorem) Wenn g auf S ⊂ Rn contractive undg(S) ⊂ S, dann hat g genau einen Fixpunkt x ∈ S, d.h. g(x) = x. •Fixpunkte x von g sind Nullstellen von f(x) = x− g(x).
Def. Eine differenzierbare Funktion f hat in x∗ eine Nullstelle der Vielfachheitm, wenn f(x∗) = f ′(x∗) = . . . = f (m−1)(x∗) = 0 aber f (n)(x∗) 6= 0. Z.B. p(x) = (x− 1)2 ≥ 0 hat in 1 eine doppelte Nullstelle und keine Klammer,q(x) = (x− 1)3 hat in 1 eine Nullstelle der Vielfachheit 3. c
5.0.2 Sensitivitat und Konditionierung
Nullstellenbestimmung ist das zur Funktionsauswertung inverse Problem!
f nahe einer Nullstelle x∗ auswerten: cond(f)|x∗ = |f ′(x∗)|Nullstelle x∗ von f bestimmen: cond(f(x∗) = 0) = 1/|f ′(x∗)| (abs. Kond.-Zahl)
f nahe einer Nullstelle x∗ auswerten: cond(f)|x∗ = ||Jf (x∗)||
Nullstelle x∗ von f bestimmen: cond(f(x∗) = 0) = ||J−1f (x∗)|| (abs. Kond.-Zahl)
Z.B. Das System nichtlinearer Gleichungen f(z) =
(x2 − y + γ−x+ y2 + γ
)= 0 fur
γ = 14
lost einzig x∗ = 12(1, 1)T . Die Jacobi-Matrix J−1
f (x∗) =
(2x −1−1 2y
)ist in
x∗ singular. Fur 0 γ < 14
gibt es zwei, fur 14< γ 1 gibt es keine Losung. c
5.0.3 Konvergenz-Raten und Abbruch-Kriterien
Def. Sei ek = xk − x∗. Dann konvergiert xk gegen x∗ mit Konvergenz-Rater genau dann, wenn limk→∞ xk = x∗ und limk→∞
||ek+1||||ek||r
= C fur eine positiveKonstante C.
Mit r = 1 und C < 1 konvergiert xk linear gegen x∗.Mit 1 < r < 2 konvergiert xk super-linear gegen x∗.
1 Carl Gustav Jacob Jacobi (1804-1851) www-history.mcs.st-andrews.ac.uk/Biographies/Jacobi.html

255
Mit r = 2 konvergiert xk quadratisch gegen x∗. linear
super-linearquadratisch
⇐⇒
festesteigendedoppelte
Anzahl von korrekten Ziffern pro Iteration!
5.0.4 nichtlineare Gleichungen in einer Unbekannten
Sei stetiges f : R ⊃ D → R gegeben. Gesucht x∗ mit f(x∗) = 0.
Intervall-Halbierung
f sei stetig auf [a, b] mit f(a)f(b) < 0 und tol eine vorgegebene Toleranz.
while ( ( b−a)> t o l )m = a+(b−a ) / 2 ; %m = xk mit k = Nr. der Abarbeitung etwa dieser Zuweisungi f ( sign ( f ( a))==sign ( f (m) ) ) a = m;else b = m;end
end
Fixpunkt-Verfahren
Zu g : R → R suche Fixpunkt x∗ mit g(x∗) = x∗, d.h. Schnitt des Graphens vong mit der Hauptdiagonalen.
x = i n i t ( g ) ; % initialisiere xo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?x = g (x ) ; % xk+1 = g(xk);
end
Wenn |g′(x∗)| < 1, so ist xk+1 = g(xk) (lokal) konvergent mit lim xk = x∗ = g(x∗).Bew. Sei ek+1 = xk+1−x∗ = g(xk)−g(x∗) = g′(z)(xk−x∗) fur ein z zwischen xk
und x∗ wegen des Zwischenwertsatzes, also ek+1 = g′(z)ek. Falls nun |g′(x∗)| < 1,gibt es eine Umgebung U von x∗ mit |g′(z)| ≤ C < 1 fur z ∈ U und daher
|ek+1| ≤ C|ek| ≤ C2|ek−1| ≤ . . . ≤ Ck|eo|
Also konvergiert ek → 0 und damit xk → x∗.√
Zu einem Nullstellen-Problem f(x) = 0 stiften mehrere Funktionen g aquivalenteFixpunkt-Probleme g(x) = x !
Z.B. f(x) = x2 − x − 2 = 0 hat einfache Nullstellen in x∗ = −1 und x∗ = 2.Aquivalente Fixpunkt-Probleme zu x∗ = 2 stiften g1(x) = x2−2, g2(x) =
√x+ 2,

256 KAPITEL 5. NONLINEAR EQUATIONS
x
y
1 2 3
1
2
3
y = x
g1(x) = x2 − 2
g2(x) =√x+ 2
g3(x) = 1 + 2/x
g4(x) = (x2 + 2)/(2x− 1)
g3(x) = 1 + 2x
oder g4(x) = x2+22x−1
mit vollig unterschiedlichem Verhalten vonxk+1 = gi(xk) fur i = 1, 2, 3, 4.
x
y
1 2 3
1
2
3
y = x
g1(x) = x2 − 2x
y
1 2 3
1
2
3
y = x
g2(x) =√x+ 2
x
y
1 2 3
1
2
3
y = x
g3(x) = 1 + 2/x
x
y
1 2 3
1
2
3
y = x
g4(x) = (x2 + 2)/(2x− 1)
Hinweis: check |g′i(x∗)| c
Newton2-Verfahren
f sei differenzierbar
2Isaac Newton (1642-1727) www-history.mcs.st-andrews.ac.uk/Biographies/Newton.html

257
x
y = f(x)
x∗
xkxk+1
x = i n i t ( f ) ; % initialisiere xo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?x = x−f ( x )/ df ( x ) ; % xk+1 = xk − f(xk)/f
′(xk)end
Mit dem zu f(x∗) = 0 aquivalenten Fixpunkt-Problem g(x) = x − f(x)f ′(x)
gilt
g′(x∗) = 0 und wegen ek+1 = xk+1 − x∗ = g(xk) − g(x∗) = 12g′′(zk)(xk − x∗)2 fur
ein zk zwischen xk und x∗ eben limk→∞|ek+1||ek|2
= 12limk→∞
|g′′(zk)|·|ek|2|ek|2
= 12|g′′(x∗)|.
Sekanten-Verfahren
Approximation des Differentialquotienten durch den Differenzenquotienten
x
y = f(x)
x∗
xk−1xkxk+1
x0 = i n i t 0 ( f ) ; % initialisiere xo
x1 = i n i t 1 ( f ) ; % initialisiere x1
for ( k=1; ; k++) % geeignetes Abbruchkriterium?tmp = x1 ; % xk+1 = xk − f(xk)(xk − xk−1)/(f(xk)− f(xk−1))x1 = x1−f ( x1 )∗ ( x1−x0 )/ ( f ( x1)− f ( x0 ) ) ;x0 = tmp ;
end
Das Sekanten-Verfahren ist i.d.R. superlinear konvergent (r = 1+√
52
≈ 1.618). 233

258 KAPITEL 5. NONLINEAR EQUATIONS
5.0.5 Systeme nichtlinearer Gleichungen
Verallgemeinerungen einiger Verfahren sind moglich.
Fixpunkt-Verfahren
Gesucht Fixpunkt x∗ von g : Rn → Rn, d.h. g(x∗) = x∗.
x = i n i t ( g ) ; % initialisiere Vektor x mit xo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?x = g (x ) ; % xk+1 = g(xk)
end
xk+1 = g(xk) konvergiert gegen Fixpunkt x∗, wenn ρ(Jg(x∗)) < 1 gilt, dabei
ist ρ(A) = max|λ| : Ax = λx fur x 6= 0, d.h. der maximale Betrag derEigenwerte, EWe von A, der Spektral-Radius ρ(A) einer Matrix A.
Wegen ρ(A) ≤ ||A||mussen die EWe von A dann nicht explizit bestimmt werden,wenn ||A|| < 1.
Newton-Verfahren
Die Folge xk+1 = xk − (Jf (xk))−1
f(xk) konvergiert gegen eine Nullstelle x∗ von
f , falls ρ(Jg(x∗)) < 1 fur g(x) = x− (Jf (x))
−1f(x).
Wegen xk+1 = xk − (Jf (xk))−1
f(xk) ⇐⇒ (Jf (xk))−1
f(xk) = xk − xk+1 ⇐⇒−f(xk) = Jf (xk)(xk+1−xk) ⇐⇒ Jf (xk)sk = −f(xk) fur sk = xk+1−xk brauchtdie Jacobi-Matrix nicht explizit invertiert zu werden.
f sei differenzierbar und Jf (x) sei regular in einer Umgebung von x∗.
x = i n i t ( f ) ; % initialisiere Vektor x mit xo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?s = Jacobi ( f , x )\ f ( x ) ; % Lose Jf (xk)sk = −f(xk) in sk
x = x+s ; % xk+1 = xk + sk
end
Das verallgemeinerte Newton-Verfahren ist lokal quadratisch konvergent.
Sekanten-Verfahren
Wenn die Jacobi-Matrix aber nun nicht bekannt, nicht regular, zu aufwandig zubestimmen und auszuwerten ist, dann ist Broyden’s secant updating Verfahreneinzusetzen.

259
x = i n i t x ( f ) ; % initialisiere Vektor x mit xo
B =in i tB ( f ) ; % initialisiere Matrix B mit Bo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?s = B\(− f ( x ) ) ; % Lose Bksk = −f(xk) in sk
y = f (x+s)− f ( x ) ; % yk = f(xk+1)− f(xk)x = x+s ; % xk+1 = xk + sk
B = B+((y−B∗ s )∗ s ’ ) / ( s ’∗ s ) ; % Bk+1 = Bk + (yk −Bksk)sTk /(s
Tk sk)
end
. . .
Robuste Newton-ahnliche Verfahren
Das Newton-Verfahren ist lokal konvergent. Konvergenz ist also nur gegeben,wenn der Startwert nahe genug an der (unbekannten) Nullstelle liegt. Fur Funk-tionen mehrerer Veriabler kann es nun leider keine hybride Methode geben, diewie im Fall von Funktionen einer Variabler etwa Interval-Halbierung und Newton-Verfahren kombinieren und so Konvergenz garantieren.
Ein Verfahren ist das gedampfte Newton-Verfahren, das mit xk+1 = xk +αksk dieVeranderung sk der Naherungen mit αk wichtet. Man wahlt αk dabei etwa so, daß||f(xk)||2 monoton abnimmt. Man kann sogar ||f(xk +αksk)||2 in αk minimieren.Sobald die xk genugend nah an x∗ liegt, wahlt man αk = 1 und geht damit zumklassischen Newton-Verfahren uber. Allerdings kann es passieren, daß man soauch in einem lokalen Minimum von f landet. . . .
Andere Verfahren aktualiseren in jeder Iteration eine trust region . . .

260 KAPITEL 5. NONLINEAR EQUATIONS
5.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Ein kleines Resi-duum ||f(x)|| garantiert eine genaueLosung eines Systems von nichtli-nearen Gleichungen f(x) = 0.
2. Richtig/Falsch? Das Newton-Ver-fahren ist ein Fixpunkt-Verfahren.
3. Richtig/Falsch? Wenn ein iterativesVerfahren zur Losung einer nicht-li-nearen Gleichung mehr als ein bitGenauigkeit pro Iterationsschritt ge-winnt, so heißt die Konvergenz-Ratesuperlinear.
4. Richtig/Falsch? Ein superlinearesVerfahren braucht immer wenigerIterationen als ein lineares Verfah-ren, um die Losung eines nichtlinea-ren Problems mit gegebener Genau-igkeit zu bestimmen.
5. Das nichtlineare Problem f(x) =0 sei schlecht konditioniert undwerde mit einem iterativen Verfah-ren gelost. Welche Abbruchbedin-gung ist vorzuziehen: ’das Resi-duum |f(xk)| ist klein genug’ oder’der Abstand |xk − xk−1| der Nahe-rungen ist klein genug’ ?
6. a) Was bedeutet eine Klammer,bracket, fur eine nichtlineare Funk-tion f : R → R ?
b) Was haben derartige Klammernmit der Bestimmung von Nullstellenzu tun?
7. Warum ist bei der Bestimmung vonNullstellen die absolute statt der re-lativen Konditionszahl zu verwen-den, wenn die Sensitivitat zu beur-teilen ist?
8. a) Wie ist die Konvergenzrate r ei-nes iterativen Verfahrens definiert?
b) Kann es ein kubisch konvergentesVerfahren (r = 3) zur Bestimmungvon Nullstellen geben?
c) Falls nein, warum? Falls ja, in-wiefern?
9. Welche Konvergenz-Rate r liegt beifolgenden Fehlern in aufeinander fol-genden Iterationen vor?
a) 10−2, 10−4, 10−8, 10−16, 10−32, 10−64, . . .
b) 10−2, 10−4, 10−6, 10−8, 10−10, 10−12, . . .
10. Welche Bedingung garantiert, daßper Intervall-Halbierung eine Null-stelle einer stetigen, nichtlinearenFunktion f im Intervall [a, b] gefun-den wird?
11. a) Die Intervall-Halbierung zur Be-stimmung einer Nullstelle einer ste-tigen, nichtlinearen Funktion fstarte mit einem initialen Intervallder Lange 1. Wie lang ist das dieNullstelle enthaltende Intervall nachsechs Iterationen?
b) Hangt die Antwort in a) von derspeziellen Funktion f ab?
c) Intervall-Halbierung starte miteiner Klammer, bracket, [a, b], d.h.mit einem Vorzeichen-Wechself(a) f(b) < 0 von f . Hangt dieKonvergenz-Rate des Verfahrensder Intervall-Halbierung davon ab,ob die gesuchte Nullstelle einfachoder mehrfach ist?
12. Intervall-Halbierung starte mit ei-ner Klammer, bracket, [a, b] fur dieFunktion f . Wieviele Iterationenwerden notwendig, um die Lange derKlammer unter eine gegebene Tole-ranz tol zu drucken?

5.1. Review Questions – Verstandnisfragen 261
13. Was bedeutet eine quadratischeKonvergenz-Rate fur ein iterativesVerfahren?
14. Welche Konvergenz-Rate r hat einiteratives Verfahren, das den Fehleralle zwei Iterationen quadriert?
15. a) Was bedeutet, daß x∗ eine mehr-fache Nullstelle von f ist?
b) Wie beeinflußt eine mehrfacheNullstelle die Konvergenz-Rate derIntervall-Halbierung?
c) Wie beeinflußt eine mehrfacheNullstelle die Konvergenz-Rate desNewton-Verfahrens?
16. Welche der folgenden Phanomenekonnen auftreten, wenn eine nicht-lineare Gleichung per Newton-Ver-fahren gelost werden soll?
a) lineare Konvergenz
b) quadratische Konvergenz
c) keine Konvergenz
17. Welche Konvergenz-Raten ergebensich, wenn die Nullstelle x =2 folgender nichtlinearer Gleichun-gen per Newton-Verfahren bestimmtwerden soll?
a) f(x) = (x− 1)(x− 2)2 = 0
b) f(x) = (x− 1)2(x− 2) = 0
18. a) Was ist ein Fixpunkt einer Funk-tion g(x) ?
b) Gegeben die nichtlineare Glei-chung f(x) = 0. Wie laßt sich einaquivalentes Fixpunkt-Problem fin-den, d.h. eine Funktion g, deren Fix-punkt eine Losung von f(x) = 0 ist?
c) Welche Funktion resultiert kon-kret aus obigem Ansatz?
19. Eine eindimensionale nichtlineareGleichung f(x) = 0 sei perSekanten-Verfahren zu losen.
a) Wieviele Startwerte werdenbenotigt?
b) Wieviele Auswertungen von fwerden pro Iteration notig?
20. g : R → R sei glatte Funktion mitFixpunkt x∗.
a) Unter welcher Bedingung istxk+1 = g(xk) lokal-konvergent ge-gen x∗ ?
b) Was ist die Konvergenz-Rate?
c) Unter welcher zusatzlichen Bedin-gung ist die Konvergenz-Rate qua-dratisch?
d) Ist das Newton-Verfahren zur Be-stimmung der Nullstelle einer glat-ten Funktion f ein Beispiel fur einFixpunkt-Verfahren? Falls ja, furwelches g ? falls nein, wieso nicht?
21. Ist f(a) f(b) < 0 ein geeigneter Testfur Vorzeichenwechsel?
22. g : R → R sei glatte Funktion mitFixpunkt x∗.
a) Unter welcher Bedingung konver-giert xk+1 = g(xk) quadratisch ge-gen x∗, wenn nur xo nahe genug anx∗ gewahlt wurde?
b) Zeige: das Newton-Verfahrenkonvergiert quadratisch gegen eineeinfache Nullstelle x∗ einer glattenFunktion f : R → R, wenn nur xo
nahe genug an x∗ gewahlt wurde.
23. Welche Vorteile und Nachteile hatdas Sekanten-Verfahren gegenuberder Intervall-Halbierung, wenn ein-fache Nullstellen von nichtlinearenFunktionen zu bestimmen sind?

262 KAPITEL 5. NONLINEAR EQUATIONS
24. Welche Vorteile und Nachteile hatdas Sekanten-Verfahren gegenuberdem Newton-Verfahren, wenn eineeinfache Nullstelle einer nicht-line-aren Funktion zu bestimmen ist?
25. Das Sekanten-Verfahren interpolierteine gegebene Funktion linear inzwei Punkten. Interpolation derFunktion in mehreren Punktendurch ein Polynom hoheren Gra-des konnte die Konvergenz-Rate desVerfahrens verbessern.
a) Aus welchen drei Grunden funk-tioniert dieser Ansatz nicht gut?
b) Welcher alternative Ansatz furdas Problem umgeht die obigenSchwierigkeiten?
26. Wieviele Auswertungen der Funtionoder ihrer Ableitung fallen pro Itera-tion an, wenn eine nichtlineare Glei-chung gelost werden soll?
a) per Newton-Verfahren b) perSekanten-Verfahren
27. Ordne die folgenden Verfahren zurBestimmung einer einfachen Null-stelle einer nichtlinearen Funktionnach steigender Konvergenz-Rate.
a) Intervall-Halbierung
b) Newton-Verfahren c) Sekanten-Verfahren
28. Wieviele bits an Genauigkeit derLosung einer nichtlinearen Glei-chung werden pro Iteration gewon-nen
a) per Intervall-Halbierung?
b) per Newton-Verfahren?
29. Die nichtlineare Gleichung f(x) =0 sei zu losen. Der Kosten furdie Auswertung von f und f ′ seien
in etwa gleich. Vergleiche die Ko-sten des Newton-Verfahrens pro Ite-ration mit den Kosten des Sekanten-Verfahrens pro Iteration.
30. Was heißt inverse Interpolation?Inwiefern ist inverse Interpolationnutzlich, um eine nichtlineare Glei-chung zu losen?
31. Per Fixpunkt-Verfahren g(x) = xwerde die Losung x∗ der nichtlinea-ren Gleichung f(x) = 0 bestimmt.Ergibt sich die bessere Konvergenz-Rate fur eine waagerechte Tangentevon g in x∗ oder fur eine waagerechteTangente von f in x∗ ?
32. Entwirf eine abgesicherte Variantedes Sekanten-Verfahrens zur Losungeiner nichtlinearen Gleichung, dasauch fur Startwerte weit weg von derLosung sicher konvergiert.
33. Fur welchen Typ von Funktionen istgebrochen lineare Interpolation dasgeeignete Verfahren zur Nullstellen-bestimmung?
34. Jedes der folgenden Verfahren zurLosung einer nichtlineare Glei-chung hat asymptotisch dieselbeKonvergenz-Rate. In welchen Si-tuationen sind die Verfahren jeweilsbesonders geeignet?
a) regulare quadratische Interpola-tion
b) inverse quadratische Interpola-tion
c) gebrochen lineare Interpolation
35. Wie lassen sich alle Nullstellen ei-nes Polynoms bestimmen? Verglei-che Vor- und Nachteile verschiede-ner Verfahren.

5.2. Exercises – Ubungen 263
36. Laßt sich Intervall-Halbierung da-hingehend verallgemeinern, daß dasVerfahren Nullstellen von Funktio-nen mehrerer Veranderlicher be-stimmt?
37. Wie oft sind skalarer Funktionenpro Iteration auszuwerten, wennper Newton-Verfahren eine n-dimensionale nichtlineare Gleichunggelost werden soll?
38. Aufgrund welcher der folgendenFaktoren ist das updating secant-Verfahren dem Newton-Verfahrenvorzuziehen, um Systeme nichtlinea-rer Gleichungen zu losen?
a) Geringerer Aufwand pro Iteration
b) hohere Konvergenz-Rate
c) großere Robustheit weit weg vonder Losung
d) Wegfall der Notwendigkeit, Ab-leitungen zu berechnen
39. Wieso ist das updating secant-Verfahren trotz geringerer Konver-genz-Rate haufig effizienter als dasNewton-Verfahren, wenn Systemenichtlinearer Gleichungen zu losensind?
5.2 Exercises – Ubun-
gen
1. Gegeben die nichtlineare Gleichungf(x) = x2 − 2 = 0.
a) Welche Naherung x1 liefert dasNewton-Verfahren bei dem Start-wert xo = 1 in der ersten Iteration?
b) Welche Naherung x2 liefert dasSekanten-Verfahren bei den Start-werten xo = 1 und x1 = 2 in derersten Iteration?
2. Wie sehen die Iterationen desNewton-Verfahrens fur die folgen-den nichtlinearen Gleichungen aus?
a) x3 − 2x− 5 = 0
b) e−x = x
c) x sinx = 1
3. Per Newton-Verfahren werde dieQuadratwurzel berechnet. DieStartwerte werden per lookup tablebereitgestellt.
a) Wie sehen dann die Iterationendes Newton-Verfahrens zur Losungvon f(x) = x2 − y = 0 fur y > 0aus?
b) Angenommen, der Startwert seiauf 4 bits genau. Wieviele Iteratio-nen werden notig, um 24 bit (SP)bzw. um 53 bit (DP) Genauigkeit zuerreichen?
4. Ein Prozessor ohne Gleitpunkt-Division approximiere diese Divisionper Newton-Verfahren. Wie wirdf(x) = 1/x−y = 0 fur y 6= 0 gelost?
5. a) Zeige: xk+1 = xk−1f(xk)−xkf(xk−1)f(xk)−f(xk−1)
ist aquivalent zum Sekanten-Verfahren.
b) Welche Vor- und Nachteile erge-ben sich im Vergleich zur Iterations-formelxk+1 = xk − f(xk)
xk−xk−1
f(xk)−f(xk−1) ?
6. Die nichtlineare Gleichungf(x) = x2 − y = 0 fur y > 0 werdeper Fixpunkt-Iterationsverfahrenxk+1 = gi(xk) gelost. Welches lokaleKonvergenzverhalten xk → √
y iny = 3 haben die Verfahren fur diefolgenden beiden Funktionen gi ?
a) g1(x) = y + x− x2
b) g2(x) = 1 + x− x2/y

264 KAPITEL 5. NONLINEAR EQUATIONS
c) Welches Fixpunkt-Iterationsverfahren realisiert dasNewton-Verfahren?
7. Fur die Euler3sche Gamma-Funktion Γ(x) sind Γ(1
2) =√π,
Γ(1) = 1 und Γ(1.5) = 12
√π be-
kannt. Bestimme die Naherung derLosung von Γ(x) = 1.5 nach einemIterationsschritt der folgenden dreiVerfahren.
a) quadratische Interpolation
b) inverse quadratische Interpola-tion
c) gebrochen lineare Interpolation
8. Untersuche Existenz und Eindeutig-keit der Losungen des Systems vonnichtlinearen Gleichungen f(z) =(x2 − y + γ−x+ y2 + γ
)= 0 fur γ =
0.5, 0.25,−0.5,−1.
9. Wie sehen die Iterationen imNewton-Verfahren zur Losung derfolgenden Systeme von nichtlinearenGleichungen aus?
a)x2 + y2 = 1x2 − y = 0
b)x2 + x y3 = 93x2y − y3 = 4
c)x+ y − 2x y = 0
x2 − y2 − 2x+ 2y = −1
d)x3 − y2 = 0x+ x2y = 2
e)2 sinx+ cos y − 5x = 0
4 cosx+ 2 sin y − 5y = 0
10. Fuhre eine Iteration des Newton-Verfahrens zur Losung des Sy-stems zweier nichtlinearer Gleichun-
3 Leonhard Euler (1707-1783)www-history.mcs.st-andrews.ac.uk/Biographies/Euler.html
genx2 − y2 = 0
2x y = 1mit Startwert zo =(
01
)aus.
11. Per Sekanten-Verfahren werde dienichtlineare Gleichung f(x) = 0gelost. Zeige: falls in einer Itera-tion xk = x∗ oder xk−1 = x∗ (abernicht beides zugleich) gilt, so giltauch xk+1 = x∗.
12. Im Newton-Verfahren zur Losungvon f(x) = 0 muß in jeder Itera-tion die Ableitung f ′ ausgewertetwerden. Angenommen, f ′(x) werdedurch die Konstante d ersetzt. Be-trachte also xk+1 = xk − f(xk)/d.
a) Unter welchen Bedingungen and ist dieses Verfahren lokal konver-gent?
b) Welche Konvergenz-Rate hat dasVerfahren im Allgemeinen?
c) Gibt es ein d, fur das das Verfah-ren quadratisch konvergent ist?
13. Fur welche Startwerte und warumwird das Newton-Verfahren zur
Losung des Systemesx− 1 = 0
x y − 1 = 0von nichtlinearen Gleichungen gege-benenfalls scheitern?
14. Zeige: Wenn x∗ Fixpunkt von gmit g′(x∗) = 0 ist, dann ist dieKonvergenz-Rate von xk+1 = g(xk)mindestens quadratisch, wenn dasFixpunkt-Iterationsverfahren nurnahe genug an x∗ gestartet wird.
15. Verifiziere: in der gebrochen linea-ren Interpolation ist die Anderungh des Parameters c gegeben durch
h = (a−c)(b−c)(fa−fb)fc
(a−c)(fc−fb)fa−(b−c)(fc−fa)fb

5.3. Computer Problems – Rechner-Probleme 265
5.3 Computer Pro-
blems – Rechner-
Probleme
1. a) Wieviele Nullstellen hat die Funk-tion f(x) = sin(10x)− x ?
b) Verwende Bibliotheksroutinenoder selbst entwickelte Programme,um alle Nullstellen zu bestimmen.
2. f(x) = x2 − 3x + 2 hat die beidenNullstellen x1,2 = 3
2 ±12 . Die fol-
genden Funktionen gi(x) spezifizie-ren aquivalente Fixpunkt-Probleme.
g1(x) = 13(x2 + 2) g2(x) =
√3x− 2
g3(x) = 3− 2x g4(x) = x2−2
2x−3
a) Untersuche die Konvergenz derFixpunkt-Probleme gi im Fixpunkt2.
b) Verifiziere die theoretischen Er-gebnisse aus a) praktisch.
3. Implementiere Intervall-Halbierung,Sekanten- und Newton-Verfahrenzur Losung nichtlinearer Gleichun-gen. Teste die Programme anhandder folgenden Probleme und verglei-che erwartete und augenscheinlicheKonvergenz-Rate.
a) x3 − 2x− 5 = 0
b) e−x − x = 0
c) x sinx− 1 = 0
d) x3 − 3x2 + 3x− 1 = 0
4. Implementiere das invers-quadratische und das gebrochen-lineare Interpolationsverfahren zurLosung nichtlinearer Gleichungen.Teste die Programme anhand derProbleme aus CP 5.3 und vergleicheerwartete und augenscheinlicheKonvergenz-Rate.
a) f(x) = x3 − 2x− 5 = 0
b) f(x) = e−x − x = 0
c) f(x) = x sinx− 1 = 0
d) f(x) = x3 − 3x2 + 3x− 1 = (x−1)3 = 0
5. Die Funktion f(x) =(((x− 0.5) + x)− 0.5
)+ x werde
wie angegeben – also nicht verein-facht – ausgewertet. Gibt es einfl(x) mit fl(f(x)) = 0 ? WelchesErgebnis liefern die Verfahren zurLosung nichtlinearer Gleichungen?
6. Berechne die ersten Iterationen desNewton-Verfahrens fur die angege-benen Funktionen und Startwerte.Welche Konvergenz-Rate scheint an-fangs vorzuliegen? Was ist die(asymptotische) Konvergenz-Rate?Erlautere die Beobachtungen.
a) f(x) = x2 − 1 = 0 mit xo = 106
b) f(x) = (x− 1)4 = 0 mit xo = 10
7. a) Wie verhalt sich das Newton-Ver-fahren bei der Losung der nichtlinea-ren Gleichung f(x) = x5−x3−4x =0 mit Startwert xo = 1 ?
b) Was sind die reellen Nullstellenvon f und gegebenenfalls ihre Be-sonderheiten?
8. Bestimme die kleinste positive Null-stelle von f(x) = 1
1+e−2x +cosx. Untersuche folgende aquiva-lente Fixpunkt-Probleme mit Funk-tionen gi und xo = 3 theoretischund praktisch auf Konvergenz undKonvergenz-Rate.
a) xk+1 =arccos −11+exp(−2xk) =g1(xk)
b) xk+1 = 12 ln −1
1+1/ cos xk= g2(xk)
c) per Newton-Verfahren

266 KAPITEL 5. NONLINEAR EQUATIONS
9. Laut Kepler4 hangt die mittlere An-omalie M eines elliptischen Orbitsder Exzentrizitat e mit 0 < e < 1per M = E − e sin(E) von der ex-zentrischen Anomalie E ab.
a) Zeige: g(E) = M + e sin(E) spe-zifiziert ein aquivalentes, lokal kon-vergentes Fixpunkt-Problem.
b) Lose das Fixpunkt-Problem ausa) fur M = 1 und e = 0.5.
c) Lose per Newton-Verfahren d)Verwende Bibliotheksroutinen.
10. Die kritische Lange5 x eines Brenn-stabes ist durch cotx = x2−1
2x gege-ben. Bestimme die kleinste positiveLosung.
11. Die Eigen-Frequenzen x eines nur aneiner Seite eingespannten, gleichfor-migen Stabes von Einheitslange sindLosungen der nichtlinearen Glei-chung6 tanx tanhx = −1. Be-stimme die kleinste positive Losung.
12. y = 1k ln ( cosh(t
√gk)) ist die ver-
tikale Strecke, die ein Fallschirm-Springer in t Sekunden zuruck-legt. Dabei ist g ≈ 9.8065m/sec2
die Erdbeschleunigung und k =0.00341m−1 eine Konstante fur denLuftwiderstand. In welcher Zeit falltder Fallschirmspringer 1km?
13. Das Kugel-Volumen ist V = 43πr
3
und das einer Kugel-Kappe derHohe h ist V = π
3h2(3r − h). Wie
4 vgl. z.B. www.bruce-shapiro.com/pair/KeplersEquation.pdf
5 vgl. z.B. www.mathcs.emory.edu/~nagy/courses/fall04/hw5.pdf
6 vgl. z.B. www.vibrationdata.com/Newrap.pdf oder auchhttp://personalpages.umist.ac.uk/staff/shuguang.li/download/MoSSII Exam 04.pdf
weit (relativ zu r) taucht eine Kugelmit einem (relativ zu Wasser) spe-zifischen Gewicht von 0.4 in Wasserein?
14. Die van der Waals Gleichung
(p+ a/v2)(v − b) = RT
setzt Druck p, Volumen v und Tem-peratur T eines Gases in Bezie-hung. Dabei sind R = 0.082054die universelle Gas-Konstante sowiea und b Stoff-Konstanten, beispiels-weise fur Kohlendioxid a = 3.592und b = 0.04267. Bestimme v furT = 300o K und p = 1, 10, 100 atm.Vergleiche die Losung mit derjeni-gen der Gleichung pv = RT furideale Gase, aus der auch Startwertegewonnen werden konnen.
15. Falls man das Kapital a bei einerZinsrate r/Jahr aufgenommen hat,muß man nach n Jahren insgesamta(1 + r)n zuruckzahlen. Wenn manpro Jahr p tilgt, reduziert sich dietotale Ruckzahlung um∑n−1
i=0 p(1 + r)i = pr((1 + r)n − 1).
a) Wie lang dauert die ganzliche Til-gung fur a = 100 000, p = 10 000und r = 0.06 ?
b) Fur welche Zinsrate r dauert fura = 100 000 und p = 10 000 dieganzliche Tilgung 20 Jahre?
c) Wieviel muß jahrlich getilgt wer-den, wie groß ist also p, damit a =100 000 plus Zinsen bei r = 0.06 in20 Jahren ganzlich getilgt werden?
16. a) Programmiere das Newton-Ver-fahren zur Bestimmung der n-tenWurzeln von f(x) = xn − y = 0 furgegebenes n und y.
b) Programmiere das Muller-Verfah-ren, d.h. schrittweise quadratische

5.3. Computer Problems – Rechner-Probleme 267
Interpolation, zur Bestimmung dern-ten Wurzeln von f(x) = xn−y = 0fur gegebenes n und y.
17. Die Nullstellen des kubischen Po-lynoms p(x) = x3 + ax2 + bx + cgenugen der nichtlinearen Gleichung
−(x1 + x2 + x3) = ax1x2 + x2x3 + x1x3 = b
−x1x2x3 = c
von Vieta7. Programmiere dasNewton-Verfahren zur Bestimmungder drei gegebenenfalls komplexenNullstellen von p und vergleiche mitBibliotheksroutinen.
18. a) Programmiere das Newton-Ver-fahren zur Losung des Systemesnicht-linearer Gleichungen
(x+3)(y3−7) + 18 = 0sin(yex − 1) = 0
mit Start-Vektor zo =(−0.5
1.4
).
b) Programmiere das Broyden-Ver-fahren zur Losung der nichtlinea-ren Gleichung aus a) mit demselbenStart-Vektor zo.
c) Vergleiche die Konvergenz-Ratender beiden Verfahren anhand des re-lativen Fehlers angesichts der exak-ten Losung z∗ = (0, 1)T .
19. Biologische Reinigung basiert aufBakterien, die giftige Abfalle ver-stoffwechseln. Im Gleichgewicht giltfur die Dichte x der Bakterien undfur die Konzentration y der Nahr-stoffe
γxy − x(1 + y) = 0−x2 + (δ − y)(1 + y) = 0
7 Francois Viete (1540-1603)www-history.mcs.st-andrews.ac.uk/Biographies/Viete.html
fur System-Konstanten γ und δ.Lose das nichtlineare Gleichungssy-stem fur typische Werte wie γ = 5und δ = 1. Es gibt Losungen mitx > 0 und x = 0.
20. a) In der Quanten-Mechanik ist derGrund-Zustand (x, y) eines Partikelsin a spherical well durch die nichtli-neare Gleichung
x/ tan(x) = −yx2 + y2 = s2
fur eine Konstante s, typisch s = 3.5beschrieben. Bestimme (x, y).
b) Der erste angeregte Zustand(x, y) eines Partikels ist durch dienichtlineare Gleichung
(x tan(x))−1 − x−2 = y−1 + y−2
x2 + y2 = s2
beschrieben. Bestimme (x, y).
21. Lorenz stellte ein einfaches Systemvon gewohnlichen Differentialglei-chungen fur die buoyant Konvek-tion in Flussigkeiten und Gasen auf,um die Zirkulation in der Atmo-sphare zu beschreiben. Im Gleich-gewicht gilt fur die Geschwindigkeitx der Konvektion, den Temperatur-Gradienten y und fur den Warme-Fluß z die nichtlineare Gleichung
σ ∗ (y − x) = 0rx− y − xz = 0
xy − bz = 0
wobei σ die Prandtl-Zahl, r dieRaleigh-Zahl und b eine Konstanteist. Typische Werte sind σ = 10,r = 28 und b = 8/3.
22. a) Lose die nichtlineare Gleichung
x1 = − 181 cosx1 + 1
9x22 + 1
3 sinx3
x2 = 13 sinx1 + 1
3 cosx3
x3 = −19 cosx1 + 1
3x2 + 16 sinx3

268 KAPITEL 5. NONLINEAR EQUATIONS
per offensichtlichem Fixpunkt-Ver-fahren.
b) Welche Konstante C fur die li-neare Konvergenz im Fixpunkt er-gibt sich? Vergleiche C mit der be-obachteten Konstanten.
c) Lose das System per Newton-Ver-fahren und vergleiche die Konver-genzrate mit der des Fixpunkt-Ver-fahrens.
23. Lose die nichtlineare Gleichung
16x4 + 16y4 + z4 = 16x2 + y2 + z2 = 3
x3 − y = 0
mit Start-Vektor
xo
yo
zo
=
111
per
Newton-Verfahren. Vergleiche Er-gebnisse und Konvergenzraten mitdenen von Bibliotheksroutinen.
24. Lose die nichtlineare Gleichung
w1 + w2 = 2w1x1 + w2x2 = 0w1x
21 + w2x
22 = 2
3w1x
31 + w2x
32 = 0
in den Unbekannten w1, x1, x1 undx2 (Gauß-Quadratur). Wieviele ver-schiedene Losungen lassen sich fin-den?
25. Lose die nichtlineare Gleichung
sinx+ y2 + ln z = 33x+ 2y − z3 = 0x2 + y2 + z3 = 6
in den Unbekannten x, y und z.Neben komplexen Losungen solltensich mindestens vier reelle Losungenfinden lassen.
26. Ein Modell fur die Verbrennungvon Propan-Gas in Luft fuhrt aufdas folgende System nichtlinearerGleichungen
x1 + x4 = 32x1 + 2x10++x2 + x4 + x7 + x8 + x9
= R+10
2x2 + 2x5 + x6 + x7 = 82x3 + x5 = 4R
x1x5 − 0.193x2x4 = 0x6√x2 − 0.002597
√x2x4S = 0
x7√x4 − 0.003448
√x1x4S = 0
x4x8 − 0.00001799x2S = 0x4x9 − 0.0002155
√x3S = 0
x24(x10 − 0.00003846S) = 0
mit R = 4.056734 und S =∑10
i=1 xi.Lose das System mit Hilfe vonBibliotheksroutinen. Ersetze ge-gebenenfalls negative Radikandendurch deren Betrag.
27. Die folgenden nichtlinearen Glei-chungen zu losen, kann uber-raschende Probleme aufwerfen.Verifiziere die ermittelten Losun-gen, erlautere Abweichungen,vergleiche ermittelte und erwarteteKonvergenz-Raten.
a)x1 + x2(x2(5− x2)− 2) = 13x1 + x2(x2(1 + x2)− 14) = 29
mit Start-Vektor xo = (15,−2)T
b)x2
1 + x22 + x2
3 = 5x1 + x2 = 1x1 + x3 = 3
mit Start-
Vektor xo = (1+√
32 , 1−
√3
2 ,√
3)T
c)
x1 + 10x2 = 0√5(x3 − x4) = 0(x2 − x3)2 = 0√
10(x1 − x4)2 = 0
mit Start-
Vektor xo = (1, 2, 1, 1)T
d)x1 = 0
10x1/(x1 + 0.1) + 2x22 = 0
mit
Start-Vektor xo = (1.8, 0)T

5.3. Computer Problems – Rechner-Probleme 269
e)104x1x2 = 1
e−x1 + e−x2 = 1.0001mit
Start-Vektor xo = (0, 1)T
28. Matrizen konnen per Newton-Ver-fahren invertiert werden. Seinamlich die Abbildung F : Rn×n →Rn×n durch F(X) = I−AX fur n×n-Matrizen X definiert. Dann giltF(X) = 0 ⇐⇒ X = A−1. WegenF′(X) = −A lautet das Newton-Verfahren
Xk+1 = Xk − (F′(Xk))−1
F(Xk)
= Xk + A−1(I−AXk)
Da aber A−1 ja gerade unbekanntist, verwendet man die NaherungXk. Die Iteration lautet somitXk+1 = Xk + Xk(I−AXk).
a) Fur die Residuumsmatrix Rk =I−AXk und die Fehler-Matrix Ek =A−1 − Xk zeige: Rk+1 = R2
k undEk+1 = EkAEk. Folgere, daß dieKonvergenz quadratisch ist, obwohleine Naherung fur A−1 verwendetwird.
b) Programmiere die Matrix-Inversion mit Hilfe dieses Itera-tionsverfahrens mit Start-MatrixXo = 1
||A||1·||A||∞AT . Teste das Pro-gramm mit Pseudo-Zufallsmatrizenund vergleiche Genauigkeit undEffizienz mit Standard-Verfahrenwie LU-Faktorisierung oder Gauß-Jordan-Elimination.
29. Per Newton-Verfahren konnenEWe und zugehorige EVen nahe-rungsweise bestimmt werden. Seinamlich f : Rn+1 → Rn+1 durch
f(x, λ) =[Ax−λxxTx−1
]fur x ∈ Rn und
λ ∈ R definiert.Dann ist f(x, λ) = 0 genau dann,wenn λ ein EW mit zugehorigem
normalisierten EV x ist. We-
gen Jf (x, λ) =[A− λI −x
2xT 0
]lautet die Newton Iteration[xk+1
λk+1
]=
[xk
λk
]+[sk
δk
]wobei[
sk
δk
]das lineare Gleichungssy-
stem[A− λkI −xk
2xTk 0
] [sk
δk
]=
−[Axk − λkxk
xTk xk − 1
]lost. Program-
miere dieses Newton-Verfahren mit
Start-Vektor[xo
λo
]wobei xT
o x = 1
und λo = xTo Ax. Teste das Pro-
gramm mit Pseudo-Zufallsmatrizenund vergleiche Genauigkeit undEffizienz mit Standard-Verfahrenzur Bestimmung von Paaren vonEW und EV wie etwa des powerVerfahrens.

270 KAPITEL 5. NONLINEAR EQUATIONS
5.4 Review Questions –
Antworten auf Verstandnisfragen
1. Ein kleines Residuum ||f(x)|| garantiert keine genaue Losung eines Systems223/224von nichtlinearen Gleichungen f(x) = 0, wie etwa p(x) = εx(x2−3x+3) mitder einzigen (einfachen) reellen NS 0 und dem Minimum (1, ε) zeigt: dasResiduum an der Stelle 1 kann je nach ε beliebig klein ausfallen, wahrendfur den Fehler |x− x∗| = |x− 0| ≈ 1 gilt.
2. Das Newton-Verfahren zu f(x) = 0 ist ein Fixpunkt-Verfahren, namlich230mit g(x) = x− f(x)/f ′(x).
3. Wenn ein iteratives Verfahren zur Losung einer nichtlinearen Gleichung223mehr als ein bit Genauigkeit pro Iterationsschritt gewinnt, so ist die Konver-genz-Rate nicht notwendig superlinear, wie etwa ek = 2−2k zeigt: in jedemIterationsschritt werden genau zwei bit Genauigkeit gewonnen. Allerdingsgilt limk→∞
|ek+1||ek|
= 14
und damit ist das Verfahren linear.
4. Ein superlineares Verfahren braucht nur asymptotisch immer weniger Ite-223rationen als ein lineares Verfahren, um die Losung eines nichtlinearen Pro-blems mit gegebenen Genauigkeit zu bestimmen. Zur Abschatzung derAnzahl benotigter Iterationen sind namlich r sowie Clinear und Csuperlinear
notig.
5. Das nichtlineare Problem f(x) = 0 sei schlecht konditioniert und werde mit221–223einem iterativen Verfahren gelost. Welche Abbruchbedingung ist vorzuzie-hen: ’das Residuum |(xk)| ist klein genug’ oder ’der Abstand |xk − xk−1|der Naherungen ist klein genug’ ?
Die Nullstellen-Bestimmung ist genau dann schlecht konditioniert, wenn1
|f ′(x∗| 1 oder eben |f ′(x∗)| 1. Wegen f(x) ≈ f(x∗) + f ′(x∗) (x− x∗) =
f ′(x∗) (x − x∗) folgt daher aus kleinem Residuum |f(x)| noch lange nicht,daß auch |x− x∗| klein ist, d.h. daß x nahe bei x∗ ist.
6. a) Eine Klammer, bracket, einer nichtlinearen Funktion f : R → R ist ein219Intervall [a, b] mit Vorzeichenwechsel von f , d.h. mit f(a) f(b) < 0.
b) Der Zwischenwertsatz garantiert fur stetige Funktionen f die Existenz(mindestens) einer Nullstelle in der Klammer.
7. Bei der Bestimmung von Nullstellen ist die absolute statt der relativen Kon-221ditionszahl zu verwenden, weil die relative Konditionszahl wegen f(x∗) = 0nicht definiert ist.
8. a) Die Konvergenzrate r eines iterativen Verfahrens ist definiert durch223

5.4. Review Questions – Antworten auf Verstandnisfragen 271
limk→∞|ek+1||ek|r
= C fur eine Konstante C.
b) Kann es ein kubisch konvergentes Verfahren (r = 3) zur Bestimmung 233von Nullstellen geben?
???c) Falls nein, warum? Falls ja, inwiefern?
???9. Welche Konvergenz-Rate r liegt bei folgenden Fehlern in aufeinander fol- 223
genden Iterationen vor?
a) 10−2, 10−4, 10−8, 10−16, 10−32, 10−64, . . ., d.h. ek = 10−2kund damit ist
wegen limk→∞|ek+1||ek|2
= limk→∞10−2k+1
10−2·2k = 1 die Konvergenz-Rate quadra-tisch.
b) 10−2, 10−4, 10−6, 10−8, 10−10, 10−12, . . ., d.h. ek = 10−2k und damit ist
wegen limk→∞|ek+1||ek|
= limk→∞10−2k+2
10−2k = 14
die Konvergenz-Rate linear.
10. f(a) f(b) < 0 garantiert, daß per Intervall-Halbierung eine Nullstelle einer 224stetigen, nichtlinearen Funktion f im Intervall [a, b] gefunden wird.
11. a) Die Intervall-Halbierung zur Bestimmung einer Nullstelle einer stetigen, 226nichtlinearen Funktion f starte mit einem initialen Intervall der Lange 1,d.h. [a, a+ 1]. Die Intervall-Lange nach k Iterationen ist (b− a)2−k. Nachsechs Iterationen hat die Klammer eine Lange von 2−6.
b) Offensichtlich hangt (b− a)2−k nicht von der speziellen Funktion f ab. 226
c) Die Konvergenz-Rate der Intervall-Halbierung hangt nicht davon ab, ob 226die gesuchte Nullstelle einfach oder mehrfach ist (regardless of the functioninvolved), da nur das Vorzeichen der Funktionswerte berucksichtigt wird.
12. Intervall-Halbierung starte mit einer Klammer, bracket, [a, b] fur die Funk- 226tion f . Wegen (b − a)2−k = tol oder eben 2k = b−a
tolwerden k = dld b−a
tole
Iterationen notwendig, um die Lange der Klammer unter die gegebene To-leranz tol zu drucken.
13. Quadratische Konvergenz-Rate bedeutet fur ein iteratives Verfahren, daß 223limk→∞
|ek+1||ek|2
= C oder eben daß jede Iteration die Anzahl der exaktenStellen verdoppelt.
14. Wenn ein iteratives Verfahren den Fehler alle zwei Iterationen quadriert,
gilt ek+2 = e2k und damit ek+1 = e√
2k , so daß das Verfahren die Konvergenz-
Rate r =√
2 hat.
15. a) f hat in x∗ eine Nullstelle der Multiplizitat m genau dann, wenn dieTaylor-Reihenentwicklung f(x) =
∑∞i=m f
(i)(x∗)(x− x∗)i/i! von f nur Mo-nome (x− x∗)i vom Grad mindetens m enthalt.

272 KAPITEL 5. NONLINEAR EQUATIONS
b) Die Multiplizitat der Nullstelle beeinflußt die Konvergenz-Rate der In-tervall-Halbierung nicht, vgl. RQ 5.11 b).
c) Fur m-fache Nullstellen ist die Konvergenz-Rate des Newton-Verfahrens231linear mit der Konstanten C = 1− 1
m.
16. Welche der folgenden Phanomene konnen auftreten, wenn eine nichtlineareGleichung per Newton-Verfahren gelost werden soll?
a) Lineare Konvergenz liegt fur mehrfache Nullstellen vor, vg. RQ 5.15 c).231
b) Quadratische Konvergenz liegt fur einfache Nullstellen vor.231
c) Das Verfahren divergiert fur f(x∗)=0, wenn fur das zugehorige Fixpunkt-227Verfahren g(x) = x eben |g(x∗)| > 1 gilt.
17. Welche Konvergenz-Raten ergeben sich, wenn die Nullstelle x = 2 folgender231nichtlinearer Gleichungen per Newton-Verfahren bestimmt werden soll?
a) Fur f(x) = (x − 1)(x − 2)2 = 0 ist 2 eine doppelte Nullstelle. DasNewton-Verfahren konvergiert linear.
b) Fur f(x) = (x − 1)2(x − 2) = 0 ist 2 eine einfache Nullstelle. DasNewton-Verfahren konvergiert quadratisch.
18. a) x∗ mit g(x∗) = x∗ ist ein Fixpunkt einer Funktion g.
b) Gegeben die nichtlineare Gleichung f(x) = 0. Jede Funktion g mitg(x∗) = x∗ ⇐⇒ f(x∗) = 0 liefert ein ein aquivalentes Fixpunkt-Problem,wenngleich mit unterschiedlicher Konvergenz oder sogar Divergenz.
c) Fur das Newton-Verfahren liefert g(x) = x− f(x)/f ′(x) das zu f(x) = 0aquivalente Fixpunkt-Problem.
19. Eine eindimensionale nichtlineare Gleichung f(x) = 0 sei per Sekanten-232Verfahren zu losen.
a) Dann werden zwei Startwerte xo und x1 benotigt.
b) Dann wird in jeder Iteration eine Auswertung f(xk) von f notig.
20. g : R → R sei glatte Funktion mit Fixpunkt x∗.227
a) |g(x∗)| < 1 garantiert die lokale Konvergenz von xk+1 = g(xk) gegen x∗.228
b) Falls g′(x∗) 6= 0 ist das Verfahren linear-konvergent mit |g′(x)| ≤ C < 1in einer Umgebung von x∗.
c) Falls g′(x∗) = 0 ist die Konvergenz-Rate (mindestens) quadratisch.
d) Das Newton-Verfahren zur Losung von f(x) = 0 fur glatte Funktio-nen f ist ein Beispiel eines Fixpunkt-Verfahrens, namlich mit g(x) = x −f(x)/f ′(x) und g′ = 1− f ′2−f f ′′
f ′2= f f ′′
f ′2, so daß g′(x∗) = 0 wegen f(x∗) = 0.

5.4. Review Questions – Antworten auf Verstandnisfragen 273
21. Wegen moglichen overflows/underflows ist f(a) f(b) < 0 kein geeigneter225Test fur Vorzeichenwechsel. Außerdem ist dieser Test wegen der Gleit-punkt-Multiplikation teuer.
22. g : R → R sei glatte Funktion mit Fixpunkt x∗. 227
a) Falls g′(x∗) = 0, so konvergiert xk+1 = g(xk) quadratisch gegen x∗, wennnur xo nahe genug an x∗ gewahlt wird.
b) Das Newton-Verfahren konvergiert quadratisch gegen eine einfache Null-stelle x∗ einer glatten Funktion f : R → R, wenn nur xo nahe genug an x∗
gewahlt wurde. siehe RQ 5.20 d)
23. x∗ sei eine einfache Nullstelle von f . Dann ist das Sekanten-Verfahren 233super-linear konvergent (r = 1
2(1 +
√5)), wahrend Intervall-Halbierung nur
linear konvergent ist. Allerdings ist im Gegensatz zur Intervall-Halbierungdas Sekanten-Verfahren nicht sicher. 236
24. Im Gegensatz zum Newton-Verfahren muß im Sekanten-Verfahren keineAbleitung bekannt sein und ausgewertet werden. Allerdings gilt fur dieKonvergenz-Raten rsecant = 1
2(1 +
√5) ≈ 1.6.18 < 2 = rNewton. 233
25. Das Sekanten-Verfahren interpoliert eine gegebene Funktion linear in zweiPunkten. Interpolation der Funktion in mehreren Punkten durch ein Po-lynom hoheren Grades konnte die Konvergenz-Rate des Verfahrens verbes-sern.
a) Dieser Ansatz ist problematisch, weil erstens mehr Startwerte gebraucht 233werden, weil zweitens Nullstellen von Polynomen hoheren Grades schwierigoder garnicht zu berechnen sind, weil drittens komplexe Nullstellen auftre-ten konnen und weil viertens schwer zu entscheiden ist, welche der Nullstel-len fur die nachste Iteration weiterverwendet werden soll.
b) Inverse Interpolation umgeht obigen Schwierigkeiten.
26. Wieviele Auswertungen der Funtion oder ihrer Ableitung fallen pro Itera-tion an, wenn eine nichtlineare Gleichung gelost werden soll?
a) Im Newton-Verfahren mussen f und f ′ pro Iteration ausgewertet werden. 230
b) Im Sekanten-Verfahren muß nur f einmal pro Iteration ausgewertet wer- 232den.
27. Ordne die folgenden Verfahren zur Bestimmung einer einfachen Nullstelleeiner nichtlinearen Funktion nach steigender Konvergenz-Rate.
a) Intervall-Halbierung
b) Newton-Verfahren c) Sekanten-Verfahren

274 KAPITEL 5. NONLINEAR EQUATIONS
Fur einfache Nullstellen gilt rbisection = 1 < rsecant = 12(1 +
√5) ≈ 1.6.18 <
2 = rNewton.
28. Wieviele bits an Genauigkeit der Losung einer nichtlinearen Gleichung wer-den pro Iteration gewonnen?
a) Intervall-Halbierung ist linear konvergent: man gewinnt 1 bit Genauig-226keit pro Iteration.
b) Fur einfache Nullstellen ist das Newton-Verfahren quadratisch konver-231gent: mit jeder Iteration verdoppelt man die Anzahl der korrekten bits.
29. Die nichtlineare Gleichung f(x) = 0 sei zu losen. Der Kosten fur die Aus-wertung von f und f ′ seien in etwa gleich. Pro Iteration sind dann dieKosten des Newton-Verfahrens (Auswertung von f und f ′) doppelt so hochwie die Kosten des Sekanten-Verfahrens (Auswertung von f).
30. Inverse Interpolation interpoliert f inv(y) polynomial. Inverse Interpolation233ist nutzlich, um eine nichtlineare Gleichung zu losen, weil sie die Problemepolynomialer Interpolation umgeht, vgl. RQ 5.25.
31. Per Fixpunkt-Verfahren g(x) = x werde die Losung x∗ der nichtlinearen228/229Gleichung f(x) = 0 bestimmt. Falls g′(x∗) = 0, falls also g eine waagerechteTangente in x∗ hat, so hat das Fixpunkt-Verfahren mindestens quadratischeKonvergenz.Falls f ′(x∗) = 0, falls also f eine waagerechte Tangente in x∗ hat, so ist x∗
mehrfache Nullstelle. Dann ist das Newton-Verfahren, ein Fixpunkt-Ver-fahren, nur noch linear-konvergent.
32. Entwirf eine abgesicherte Variante des Sekanten-Verfahrens zur Losung ei-236ner nichtlinearen Gleichung, das auch fur Startwerte weit weg von derLosung sicher konvergiert.
f sei stetig auf [a, b] mit f(a)f(b) < 0 und tol eine vorgegebene Toleranz.
while ((b-a)>tol)
m = b− f(b)(b− a)/(f(b)− f(a)); // m = Sekanten-Nullstelle// m = xk+1 mit k = Nr. der Abarbeitung etwa dieser Zuweisungif ((m<=a)||(b<=m)) m=a+(b-a)/2;
// falls m nicht in Klammer, wahle doch Intervall-Mitteif (sign(f(a))==sign(f(m))) a=m;
else b=m;
33. Gebrochen lineare Interpolation ist fur Funktionen mit horizontaler oder235vertikaler Asymptote bei rfractional ≈ 1.839 das geeignete Verfahren zur Null-stellenbestimmung.

5.4. Review Questions – Antworten auf Verstandnisfragen 275
34. Jedes der folgenden Verfahren zur Losung einer nichtlineare Gleichung hatasymptotisch dieselbe Konvergenz-Rate r ≈ 1.839. In welchen Situationensind die Verfahren jeweils besonders geeignet?
a) regulare quadratische Interpolation: Muller-Verfahren 233???b) Inverse quadratische Interpolation:
233/234
???c) gebrochen lineare Interpolation: siehe RQ 5.33
23535. Wie lassen sich alle Nullstellen eines Polynoms p vom Grad n bestimmen?236/237Vergleiche Vor- und Nachteile verschiedener Verfahren.
• repeat
bestimme Nullstelle x∗ per Newton oder per Muller-Verfahrenp(x) = p(x)/(x− x∗) // reduziere p um den Linearfaktor x− x∗
until alle Nullstellen bestimmt
Allerdings findet Newton – wenn uberhaupt – nur reelle Nullstellen!
• Bilde die sogenannte companion matrix C des in der Form pn(λ) =λn+c1λ
n−1+. . .+cn−1λ1+cn gegebenen Polynoms pn mit Koeffizienten-
Vektor c = (cn, . . . , c1)T . Die zugehorige companion matrix C = Cn =
(e2, . . . , en,−c) ist dann eine n× n-Matrix.Behauptung: Die EWe von C sind die Nullstellen von p, oder m.a.W.und praziser, det(C − λI) = (−1)npn(λ).Im Induktionsanfang mit n = 2 gilt fur die companion matrix C =(
0 −c21 −c1
)mit det(C − λI) =
(−λ −c21 −λ− c1
)= λ2 + c1λ − −c2 =
p2(λ) = (−1)2p2(λ).√
Im Induktionsschritt sei det(Cn−λIn) = (−1)npn(λ) vorausgesetzt. Esist det(Cn+1 − λIn+1) = (−1)n+1pn+1(λ) zu zeigen.Die Entwicklung nach der ersten Spalte liefert det(Cn+1 − λIn+1) =∣∣∣∣∣∣∣∣∣∣∣∣
−λ 0 · · · 0 −cn+1
1 −λ . . ....
...
0 1. . . 0 −c3
.... . . . . . −λ −c2
0 · · · 0 1 −λ−c1
∣∣∣∣∣∣∣∣∣∣∣∣=
−λ det(Cn − λIn)
−1 ·
∣∣∣∣∣∣∣∣∣∣∣∣
0 · · · · · · 0 −cn+1
1 0... −cn−1
0 1. . . 0
......
. . . . . . 0 −c20 · · · 0 1 −λ−c1
∣∣∣∣∣∣∣∣∣∣∣∣.
Induktionsvoraussetzung und Entwicklung nach der ersten Zeile liefern
det(Cn+1−λIn+1)=(−1)n+1λ pn(λ) + (−1)1+ncn+1 det(In−1)=(−1)n+1(λn+1+c1λn+...+cn−1λ
2+cnλ)+(−1)n+1cn+1
=(−1)n+1 pn+1(λ).
und damit den Induktionsschritt.√

276 KAPITEL 5. NONLINEAR EQUATIONS
Also konnen zur Ermittelung der Nullstellen von p genauso die EWeder zugehorigen companion matrix mit Bibliotheksroutinen bestimmtwerden.
• Verfahren von Laguerre, Bairstow, Jenkins oder Traub8237
36. Laßt sich Intervall-Halbierung dahingehend verallgemeinern, daß das Ver-219,237fahren Nullstellen von Funktionen mehrerer Veranderlicher bestimmt?
Fur stetige skalare Funktionen f : Rn ⊃ D → R, D zusammenhangend,mit a,b ∈ D und f(a) f(b) < 0 gibt es eine stetige Kurve p : [0, 1] → Dmit p(0) = a und p(1) = b. Dann ist f p : [0, 1] → R stetig. KlassischeIntervall-Halbierung liefert dann eine Nullstelle x∗ = p(x∗) von f in D.
Eine Verallgemeinerung auf Vektor-wertige Funktionen f : Rn → Rm ist219’usually impractical to apply’ !
37. Wenn per Newton-Verfahren eine n-dimensionale nichtlineare Gleichung240gelost werden soll, so sind pro Iteration n2 skalare Funktionen fur die Be-stimmung der Jacobi9-Matrix auszuwerten und dann ist jeweils das Systemlinearer Gleichungen zu losen.
38. Aufgrund welcher der folgenden Faktoren ist das updating secant-Verfahrendem Newton-Verfahren vorzuziehen, um Systeme nichtlinearer Gleichungenzu losen?
a) Geringerer Aufwand pro Iteration, da erstens keine Ableitungen auszu-240werten sind und da zweitens Jacobi-Matrix und LU-Faktorisierung aktua-lisiert werden konnen anstatt beide erneut zu berechnen.
b) nicht wegen hoherer Konvergenz-Rate: asymptotisch ist das Sekanten-241Verfahren nur superlinear, das Newton-Verfahren dagegen quadratisch kon-vergent.
c) großere Robustheit weit weg von der Losung
??? d) naturlich entfallt die Notwendigkeit, Ableitungen zu berechnen, da dieJacobi-Matrix kontinuierlich approximiert wird.
39. Wenn Systeme nichtlinearer Gleichungen zu losen sind, ist trotz geringerer240/241Konvergenz-Rate das updating secant-Verfahren haufig effizienter als dasNewton-Verfahren, weil keine Ableitung berechnet werden mussen und weildie LU-Faktorisierung aktualisiert werden kann anstatt sie erneut zu be-rechnen.
8 M.A. Jenkins, J.F. Traub: Zeros of a Complex Polynomial; Comm. ACM, 15, p97–99,1972M.A. Jenkins, J.F. Traub: Zeros of a Real Polynomial; ACM Trans. Math. Software, 1 p178–189, 1975J.F. Traub: Iterative Methods for the Solution of Equations; Prentice-Hall 1964
9 Carl Gustav Jacob Jacobi (1804-1851) www-history.mcs.st-andrews.ac.uk/Biographies/Jacobi.html

5.5. Exercises – Ubungsergebnisse 277
5.5 Exercises – Ubungsergebnisse
Fixpunkt-Verfahren zur Losung von g(v) = g(
xyz
) =
g1(v)g2(v)g3(v)
= v, d.h.
zur Losung der drei nichtlinearen Gleichungen g1(v) = x, g2(v) = y und g3(v) = zin v, den drei Unbekannten x, y und z
Newton-Verfahren zur Losung von f(v) = f(
xyz
) =
f1(v)f2(v)f3(v)
= 0, d.h. zur
Losung dreier nichtlinearer Gleichungen in v, den drei Unbekannten x, y und z
g(v)f(v)
=
=v0
< tests > get f , Jf (z)
Jf (v)=
vo =
0@xo
yo
zo
1A=
k = k = 0Fix contNewton cont
reset
||g(vk)−vk||2 =
||f(vk)||2 =
vk =
0@xk
yk
zk
1A=
g(vk)f(vk)
=
1. Gegeben die nichtlineare Gleichung f(x) = x2 − 2 = 0.
a) Wegen f ′(x) = 2x liefert das Newton-Verfahren bei dem Startwert xo = 1 230im ersten Schritt x1 = xo − f(xo)/f
′(xo) = 1−−1/2 = 1.5.
b) Das Sekanten-Verfahren liefert bei den Startwerten xo = 1 und x1 = 2 232im ersten Schritt x2 = x1 − f(x1)
x1−xo
f(x1)−f(xo)= 2− 2 2−1
2−−1= 4
3.
2. Wie sehen die Iterationen des Newton-Verfahrens fur die folgenden nichtli- 230neare Gleichungen aus?
a) Fur f(x) = x3 − 2x − 5 = 0 ist f ′(x) = 3x2 − 2 und daher xk+1 =
xk − f(xk)/f′(xk) = xk −
x3k−2xk−5
3x2k−2
=2x3
k+5
3x2k−2
.
b) Fur f(x) = e−x − x = 0 ist f ′(x) = −e−x − 1 und daher xk+1 =
xk − f(xk)/f′(xk) = xk + e−xk−xk
e−xk+1.
c) Fur f(x) = x sin x− 1 = 0 ist f ′(x) = sinx + x cosx und daher xk+1 =xk − f(xk)/f
′(xk) = xk − xk sin xk−1sin xk+xk cos xk

278 KAPITEL 5. NONLINEAR EQUATIONS
3. Per Newton-Verfahren werde die Quadratwurzel berechnet. Die Startwertewerden per lookup table bereitgestellt.
a) xk+1 = xk−x2
k−y
2xksind die Iterationen des Newton-Verfahrens zur Losung230
von f(x) = x2 − y = 0 fur y > 0.
b) Angenommen, der Startwert sei auf 4 bits genau. Wieviele Iterationenwerden notig, um 24 bit (SP) bzw. um 53 bit (DP) Genauigkeit zu errei-chen?
√y ist eine einfache Nullstelle von f . Also konvergiert das Newton-Verfah-
ren quadratisch, d.h. mit jeder Iteration verdoppelt sich die Anzahl nk derkorrekten bits. Es gilt also nk = no 2k und damit speziell nk = 4 · 2k =2k+2 = 24 ⇐⇒ k+ 2 = dld(24)e = 5, also k = 3 bzw. nk = 4 · 2k = 2k+2 =53 ⇐⇒ k + 2 = dld(53)e = 6, also k = 4.
xo =xk =√2 =
ek(10)=
k = test step resetxo(2)
=√2(2) =xk(2)
=
4. Ein Prozessor ohne Gleitpunkt-Division approximiere diese Division per230Newton-Verfahren. Wie wird f(x) = 1/x− y = 0 fur y 6= 0 gelost?
Zu f(x) = 1/x − y ist f ′(x) = − 1x2 und daher xk+1 = xk − f(x)
f ′(x)= xk −
1/xk−y
−1/x2k
= xk + x2k(
1xk− y) = xk + xk(1− xk y) ohne Divisionen.
5. a) Zeige: xk+1 = xk−1f(xk)−xkf(xk−1)
f(xk)−f(xk−1)ist aquivalent zur Sekanten-Verfahren.232
xk+1 = xk − f(xk)xk − xk−1
f(xk)− f(xk−1)
=xk(f(xk)− f(xk−1))− f(xk)(xk − xk−1)
f(xk)− f(xk−1)
=xk−1f(xk)− xkf(xk−1)
f(xk)− f(xk−1)
b) Welche Vor- und Nachteile ergeben sich im Vergleich zur Iterationsformel248xk+1 = xk − f(xk)
xk−xk−1
f(xk)−f(xk−1)?
Formel Rechen-Aufwand
xk − f(xk)xk−xk−1
f(xk)−f(xk−1)3ADDs/SUBs 1MULs 1DIVs 2 eval f
xk−1f(xk)−xkf(xk−1)
f(xk)−f(xk−1)2ADDs/SUBs 2MULs 1DIVs 2 eval f

5.5. Exercises – Ubungsergebnisse 279
xk−1 =xk =
fl(xk−1) =fl(xk) =
f(xk−1) =f(xk) =
fl(f(xk−1)) =fl(f(xk)) =
testsreset
pdec =eval
mit ∆x = xk − xk−1, ∆f = f(xk)− f(xk−1) vergleiche yDP = xk − f(xk)∆x∆f
mit y1 =fl(xk − fl
(f(xk)fl(
fl(∆x)fl(∆f))
))vs
y2 =fl(
fl(fl(xk−1∗f(xk))−fl(xk∗f(xk−1)))fl(∆f)
)dx =
fl(dx) =df =
fl(df) =dx/df =
fl(fl(dx)/fl(df)) =
trial10
trial11
y1 =in DP yDP1 =
∣∣∣y1−yDP1
yDP1
∣∣∣ =
y2 =in DP yDP2 =
∣∣∣y2−yDP2
yDP2
∣∣∣ =
Numerik????
6. Die nichtlineare Gleichung f(x) = x2−y = 0 fur y > 0 werde per Fixpunkt-Iterationsverfahren xk+1 = gi(xk) gelost. Welches lokale Konvergenzver-halten xk →
√y in y = 3 haben die Verfahren fur die folgenden beiden
Funktionen gi ?
a) Fur g1(x) = y+ x− x2 gilt g1(x) = x ⇐⇒ y+ x− x2 = x ⇐⇒ f(x) =x2 − y = 0 und g′1(x) = 1 − 2x, insbesondere also |g′1(
√3)| = |1 − 2
√3| ≈
2.4641 und damit |g′1(√
3)| 6< 1, so daß xk+1 = g1(xk) nicht lokal konvergentgegen
√3 ist.
b) Fur g2(x) = 1 + x − x2/y gilt g2(x) = x ⇐⇒ 1 + x − x2/y =x ⇐⇒ f(x) = x2 − y = 0 und g′2(x) = 1− 2x/y, insbesondere |g′2(
√3)| =
|1 − 23
√3| ≈ 0.1547 und damit |g′2(
√3)| < 1, so daß xk+1 = g2(xk) lokal
konvergent gegen√
3 ist.
c) Das Newton-Verfahren realisiert ein Fixpunkt-Iterationsverfahren, nam-lich gNewton(x) = x − f(x)/f ′(x), da gNewton(x) = x ⇐⇒ f(x)/f ′(x) =
0 ⇐⇒ f(x) = 0 und hier gNewton(x) = x − x2−y2x
= x2+y2x
, so daß
g′Newton(x) = x2−y2x2 und insbesondere g′Newton(
√y) = 0 und damit die quadra-
tische Konvergenz folgt.
7. Fur die Euler12sche Gamma-Funktion Γ(x) sind Γ(12) =
√π, Γ(1) = 1 und
10Berechnet y = xk+1 fur pseudozufallig erzeugte xk−1 und xk mit xk−1 < xk sowie f(xk−1)und f(xk) mit f(xk−1) f(xk) < 0, bis der relative Fehler |(yi − yDP )/yDP | > 0.5.
11Berechnet y = xk+1 fur pseudozufallig erzeugte xk−1 und xk mit xk−1xk > 0 sowie f(xk−1)und f(xk) mit f(xk−1) f(xk) < 0, bis der relative Fehler |(yi − yDP )/yDP | > 0.5.
12 Leonhard Euler (1707-1783) www-history.mcs.st-andrews.ac.uk/Biographies/Euler.html

280 KAPITEL 5. NONLINEAR EQUATIONS
Γ(1.5) = 12
√π bekannt. Bestimme die Naherung der Losung von Γ(x) = 1.5
nach einem Iterationsschritt der folgenden drei Verfahren.
1 2 3 4 5
5
10
15
20
25
30
mit Γ(n+ 1) = n!
und Γ(0.59533) ≈ 1.5
und Γ(2.66277) ≈ 1.5
a) Quadratische Interpolation bestimmt die Parabel p(x) mit p(12) = Γ(1
2) =233 √
π, p(1) = Γ(1) = 1 und p(32) = Γ(3
2) = 1
2
√π. Per Koeffizienten-Vergleich
oder als Legendre-Polynom p(x) =∑3
i=1 Γ(xi)∏
j 6=ix−xj
xi−xjergibt sich
p(x) = Γ(12)
(x−1)(x− 32)
( 12−1)( 1
2− 3
2)+ Γ(1)
(x− 12)(x− 3
2)
(1− 12)(1− 3
2)+ Γ(3
2)
(x− 12)(x−1)
( 32− 1
2)( 3
2−1)
= 2√π(x− 1)(x− 3
2)− 4(x− 1
2)(x− 3
2) +
√π(x− 1
2)(x− 1)
=√π(x− 1)(3x− 7
2)− (2x− 1)(2x− 3)
= (3√π − 4)x2 + (8− 13
2
√π)x+ 7
2
√π − 3
Gesucht ist nun x1 mit p(x1) = 1.5, d.h. die Nullstelle x1 = −16−13√
π12√
π−16±√
(16−13√
π)2
(12√
π−16)2−
72
√π− 9
2
3√
π−4= −16−13
√π
12√
π−16±√
(16−13√
π)2
(12√
π−16)2− 14
√π−18
12√
π−16= −16−13
√π
12√
π−16±
√(16−13
√π)2−(14
√π−18)(12
√π−16)
12√
π−16≈ 0.63446 von p(x)− 1.5 in [0.5, 1].
b) Die inverse quadratische Interpolation bestimmt die Parabel x = q(y) mit233/234q(Γ(1
2)) = q(
√π) = 1
2, q(Γ(1)) = q(1) = 1 und q(Γ(3
2)) = q(1
2
√π) = 3
2. Per
Koeffizienten-Vergleich oder als Legendre-Polynom q(y)=∑3
i=1 xi
∏j 6=i
y−yj
yi−yj
ergibt sich
q(y) = 12
(y−Γ(1))(y−Γ( 32))
(Γ( 12)−Γ(1))(Γ( 1
2)−Γ( 3
2))
+(y−Γ( 1
2))(y−Γ( 3
2))
(Γ(1)−Γ( 12))(Γ(1)−Γ( 3
2))
+ 32
(y−Γ( 12))(y−Γ(1))
(Γ( 32)−Γ( 1
2))(Γ( 3
2)−Γ(1))
= 12
(y−1)(y− 12
√π)
(√
π−1)(√
π− 12
√π)
+(y−
√π)(y− 1
2
√π)
(1−√
π)(1− 12
√π)
+ 32
(y−√
π)(y−1)
( 12
√π−
√π)( 1
2
√π−1)
Mit q(0) = x1 ≈ 9.13986 liegt der x-Achsen-Abschnitt von q(y) allerdingsweit außerhalb von etwa [0.5, 1].
c) Fur die gebrochene lineare Interpolation liefert das System linearer Glei-235chungen1 afa −fa
1 bfb −fb
1 cfc −fc
uvw
=
1 12
√π −
√π
1 1 · 1 −11 3
212
√π −1
2
√π
uvw
= 12
123
=
abc

5.5. Exercises – Ubungsergebnisse 281
die Losung u = −12
7−4√
π−3+2
√π, v = − 1√
π4−3
√π
−3+2√
πund w = − 1
2√
π8−5
√π
−3+2√
π. Die
Nullstelle von φ(x) = x−uv x−w
ist also u ≈ 0.08238.
x
y
0.5 1 1.5
1
1.5
p(x)
p(x)− 1.5
x
y
0.5 1 1.5
1
1.5
q(x)
x
y
0.5 1 1.5
1
1.5
φ(x)
8. Untersuche Existenz und Eindeutigkeit der Losungen des Systems von nicht-
linearen Gleichungen f(z) =
(x2 − y + γ−x+ y2 + γ
)= 0 fur γ=0.5, 0.25,−0.5,−1.
γ = 12: Das System
x2 − y + 12
= 0−x+ y2 + 1
2= 0
hat keine reelle Losung: Subtraktion
liefert x2−y2 +x−y = (x+y)(x−y)+(x−y) = (x+y+1)(x−y) = 0.Falls x + y + 1 = 0 oder y = −x − 1, ergibt Einsetzen in die erste
Gleichung x2 + x + 32
= 0 mit Losung x1,2 = −12±√
14− 3
2∈ C \ R.
Falls x = y, ergibt Einsetzen in die erste Gleichung x2−x+ 12
= 0 mit
Losung x1,2 = 12±√
14− 1
2∈ C \ R.
γ = 14: Das System
x2 − y + 14
= 0−x+ y2 + 1
4= 0
hat genau eine reelle Losung: Sub-
traktion liefert x2−y2+x−y = (x+y+1)(x−y) = 0. Falls x+y+1 = 0oder y = −x−1, ergibt Einsetzen in die erste Gleichung x2 +x+ 5
4= 0
mit Losung x1,2 = −12±√
14− 5
4∈ C\R. Falls x = y, ergibt Einsetzen
in die erste Gleichung x2 − x + 14
= (x − 12)2 = 0 mit der einzigen
Losung x1,2 = 12
= y1,2, d.h. z = 12(1, 1)T .
γ = −12: Das System
x2 − y − 12
= 0−x+ y2 − 1
2= 0
hat zwei reelle Losungen: Subtrak-
tion liefert x2− y2 +x− y = (x+ y+1)(x− y) = 0. Falls x+ y+1 = 0oder y = −x−1, ergibt Einsetzen in die erste Gleichung x2 +x+ 1
2= 0
mit Losung x1,2 = −12±√
14− 1
2∈ C \ R. Falls x = y, ergibt Einset-
zen in die erste Gleichung x2 − x − 12
= 0 mit den beiden Losungen
x1,2 = 12±√
14
+ 12
= 12(1±
√3) = y1,2, d.h. z1,2 = 1
2(1±
√3)(1, 1)T .

282 KAPITEL 5. NONLINEAR EQUATIONS
γ = −1: Das Systemx2 − y − 1 = 0
−x+ y2 − 1 = 0hat vier reelle Losungen: Subtrak-
tion liefert x2−y2+x−y = (x+y+1)(x−y) = 0. Falls x+y+1 = 0 odery = −x−1, ergibt Einsetzen in die erste Gleichung x2+x = x(x+1) = 0mit den Losungen z1 = (0,−1)T und z2 = (−1, 0)T . Falls x = y, ergibtEinsetzen in die erste Gleichung x2−x−1 = 0 mit den beiden Losungen
x3,4 = 12±√
14
+ 1 = 12(1±
√5) = y3,4, d.h. z3,4 = 1
2(1±
√5)(1, 1)T .
9. Wie sehen die Iterationen im Newton-Verfahren zur Losung der folgendenSysteme von nichtlinearen Gleichungen aus?
a) Das System f(z) =
(x2 + y2 − 1x2 − y
)= 0 hat zwei reelle Losungen: Ein-
setzen von y = x2 in die erste Gleichung liefert y2 + y − 1 = 0 mit den
beiden Losungen y1,2 = −12±√
14
+ 1 = 12(−1 ±
√5). Da nur y1 =
12(−1 +
√5) > 0, gibt es nur zwei reelle Losungen, d.h. z∗1,2 = (±√y1, y1)
T ,
also z∗1 ≈(
0.78615137775742330.6180339887498949
)und z∗2 ≈
(−0.7861513777574233
0.6180339887498949
).
Die Jacobi-Matrix ist Jf (z) =
(2x 2y2x −1
). Mit etwa dem Start-Vektor zo =(
11
)liefert das Newton-Verfahren eine Naherung
(0.78615137775742330.6180339887498948
)der Losung z∗1 und wegen Symmetrie von Einheitskreis und Normal-Parabelentsprechend auch der Losung z∗2.
b) Das System f(z) =
(x2 + x y3 − 93x2y − y3 − 4
)= 0 hat die vier reellen Losungen13
z∗1≈(−0.901266−2.086590
), z∗2≈
(−3.001620
0.148108
), z∗3≈
(2.998370.14843
)und z∗4≈
(1.336361.75424
).
Die Jacobi-Matrix ist Jf (z) =
(2x+ y3 3xy2
6xy 3x2 − 3y2
). Mit beispielsweise
dem Start-Vektor zo =
(11
)liefert das Newton-Verfahren eine Naherung(
1.3363553772171671.7542351976516994
)der Losung z∗4.
c) Das System f(z) =
(x+ y − 2x y
x2 + y2 − 2x+ 2y + 1
)= 0 hat die beiden reellen
Losungen13 z∗1 =
(0.215761
−0.379541
)und z∗2 =
(0.39098
−1.79315
).
Mit Jacobi-Matrix ist Jf (z) =
(1− 2y 1− 2x2x− 2 2y + 2
)und etwa Start-Vektor
13laut Mathematica

5.5. Exercises – Ubungsergebnisse 283(10
)liefert das Newton-Verfahren eine Naherung
(0.21576091563162217
−0.37954125153315116
)der Losung z∗1 und mit etwa dem Start-Vektor zo =
(0
−2
)eine Naherung
der Losung z∗2.
d) Das System f(z) =
(x3 − y2
x+ x2y − 2
)= 0 hat genau die eine reelle Lo-
sung14 z∗1 =
(11
).
Mit Jacobi-Matrix Jf (z) =
(3x2 −2y
1 + 2xy x2
)und etwa dem Start-Vektor
zo =
(2121
)liefert das Newton-Verfahren die exakte Losung z∗ =
(11
)in
12 Iterationen.
e) Das System f(z) =
(2 sin x+ cos y − 5x4 cos x+ 2 sin y − 5y
)= 0 hat genau eine reelle
Losung14.
Mit der Jacobi-Matrix ist Jf (z) =
(2 cos x− 5 − sin y−4 sin x 2 cos y − 5
)und beispiels-
weise dem Start-Vektor
(11
)liefert das Newton-Verfahren eine Naherung(
0.13297631622010451.1595936390158170
)zumindest einer Losung z∗.
10. Fuhre eine Iteration des Newton-Verfahrens zur Losung des Systems zweier 238/239
nichtlinearer Gleichungenx2 − y2 = 0
2x y = 1mit Startwert zo =
(01
)aus.
Zunachst ist x2 = y2, d.h. |x| = |y|, und wegen xy = 12
ist sgn(x) = sgn(y).
Aus |xy| = |x| · |y| = |x|2 = 12
folgt x = y = ±12
√2, d.h. die beiden
Losungen lauten z∗1,2 = ±12
√2
(11
).
Wegen f(z) =
(x2 − y2
2x y − 1
)= 0 ist Jf (z) =
(2x −2y2y 2x
). Fur zo =
(01
)ist
Jf (zo) =
(0 −22 0
)und f(z0) = −
(11
). Dann ist so = 1
2
(1
−1
)Losung von
Jf (zo)so = −f(z0) und damit ist z1 = zo + so = 12
(11
).
Nun ist Jf (z1) =
(1 −11 1
)und f(z1) = −1
2
(01
)und s1 = 1
4
(1
−1
)Losung
von Jf (z1)s1 = −f(z1) und damit z2 = z1 + s1 = 14
(11
), z3 = 19
24
(11
), usw.
14laut MATLAB

284 KAPITEL 5. NONLINEAR EQUATIONS
11. Per Sekanten-Verfahren werde die nichtlineare Gleichung f(x) = 0 gelost.Zeige: falls in einer Iteration xk = x∗ oder xk−1 = x∗ (aber nicht beides232zugleich) gilt, so gilt auch xk+1 = x∗.
Wegen Ex 5.5 gilt xk+1 = xk−1f(xk)−xkf(xk−1)
f(xk)−f(xk−1). Falls einerseits xk = x∗,
dann ist xk+1 = 0−x∗ f(xk−1
0−f(xk−1)= x∗. Falls andererseits xk−1 = x∗, dann ist
xk+1 = x∗ f(xk)−0f(xk)−0
= x∗. Falls dagegen xk = x∗ = xk−1, dann verschwindetder Nenner und xk+1 ist nicht definiert.
12. Im Newton-Verfahren zur Losung von f(x) = 0 muß in jeder Iteration dieAbleitung f ′ ausgewertet werden. Angenommen, f ′(x) werde durch die230Konstante d ersetzt. Betrachte also xk+1 = xk − f(xk)/d.
a) Falls d = f ′(x∗), so ist dieses Verfahren lokal konvergent: Zunachst istein Fixpunkt x∗ von g(x) = x−f(x)/d Nullstelle von f , weil g(x) = x ⇐⇒x − f(x)/d = x ⇐⇒ f(x) = 0 solange d 6= 0. Die Konvergenz-Rate istlinear, solange C = |g′(x∗| = |1 − f ′(x∗)/d| < 1, d.h. 0 < f ′(x∗)/d < 2oder 0 < f ′(x∗) < 2d, falls f ′(x∗) und d positiv, bzw. 0 > f ′(x∗) > 2d, fallsf ′(x∗) und d negativ sind.
b) Im Allgemeinen ist das Verfahren linear konvergent mit C = |g′(x∗)| =|1− f ′(x∗)/d|.c) Das Verfahren ist quadratisch konvergent, wenn zufallig d = f ′(x∗) gilt.
13. Fur welche Startwerte und warum wird das Newton-Verfahren zur Losung239
des Systemesx− 1 = 0
x y − 1 = 0von nichtlinearen Gleichungen gegebenenfalls
scheitern?
Nur z∗ =
(11
)lost das System f(z) =
(x− 1xy − 1
)= 0 mit Jf (z) =
(1 0y x
).
Da die Jacobi-Matrix Jf (z) in allen Startwerten zo =
(0yo
)singular ist,
muß das Newton-Verfahren fur diese Startwerte scheitern. Fur alle anderen
Startwerte zo =
(xo
yo
)mit xo 6= 0 konvergiert das Newton-Verfahren in
zwei Iterationen gegen die Losung z∗ =
(11
).
1. Iteration: Wegen (Jf (zo))−1
= 1xo
(xo 0−yo 1
)und−f(zo) =
(1− xo
1− xoyo
)gilt so =
(1− xo
(1− yo)/xo
)und daher z1 = zo +so =
(1
yo + (1− yo)/xo
).
2. Iteration: Wegen (Jf (z1))−1
= 1x1
(x1 0−y1 1
)=
(1 0−y1 1
)und−f(z1) =

5.5. Exercises – Ubungsergebnisse 285(1− x1
1− x1y1
)=
(0
1− y1
)gilt s1 = −(Jf (z1))
−1f(z1) =
(0
1− y1
)und
daher z2 = z1 + s1 =
(11
)= z∗.
14. Zeige: Wenn x∗ Fixpunkt von g mit g′(x∗) = 0 ist, dann ist die Konvergenz- 229Rate von xk+1 = g(xk) mindestens quadratisch, wenn das Fixpunkt-Itera-tionsverfahren nur nahe genug an x∗ gestartet wird.
Wegen Taylor ist g(xk)−x∗ = g(xk)−g(x∗) = 12g′′(zk) (xk−x∗)2 = 1
2g′′(zk) e
2k
fur ein zk zwischen x∗ und xk und ek = xk − x∗. Daher gilt fur |g′′(z)| ≤ Cnahe bei x∗
|ek+1| = |g(xk)− x∗| = 12|g′′(zk)| · |ek|2 ≤ C |ek|2
so daß limk→∞|ek+1||ek|2
= 12|g′′(x∗)| und damit – falls g′′(x∗) 6= 0 – die quadra-
tische Konvergenz folgt.
15. Verifiziere, daß die Anderung h des Parameters c in der gebrochen linearen 235Interpolation durch
h =(a− c)(b− c)(fa − fb)fc
(a− c)(fc − fb)fa − (b− c)(fc − fa)fb
gegeben ist.
Fur A =
1 afa −fa
1 bfb −fb
1 cfc −fc
gilt u = 1det(A)
∣∣∣∣∣∣a afa −fa
b bfb −fb
c cfc −fc
∣∣∣∣∣∣ = det(A1)det(A)
, wobei
det(A) = afafc + bfafb + cfbfc − afafb − bfbfc − cfafc = afa(fc − fb) +bfb(fa − fc) + cfc(fb − fa) = afa(fc − fb) − bfb(fc − fa) + cfbfc − cfafc +(cfafb− cfafb) = (a− c)fa(fc− fb)− (b− c)fb(fc− fa) mit dem Nenner vonh ubereinstimmt. Damit bleibt u = c+ h oder gleichbedeutend det(A1) =c det(A) + (a− c)(b− c)(fa − fb)fc zu zeigen.
det(A1) = ab(fa − fb)fc + ac(fc − fa)fb + bc(fb − fc)fa
= abfafc − abfbfc + acfbfc − acfafb + bcfafb − bcfafc
= acfafc + bcfafb + c2fbfc − acfafb − bcfbfc − c2fafc++abfafc − abfbfc − acfafc + acfbfc − bcfafc + bcfbfc + c2fafc − c2fbfc
= c det(A) + (a− c)(b− c)(fa − fb)fc
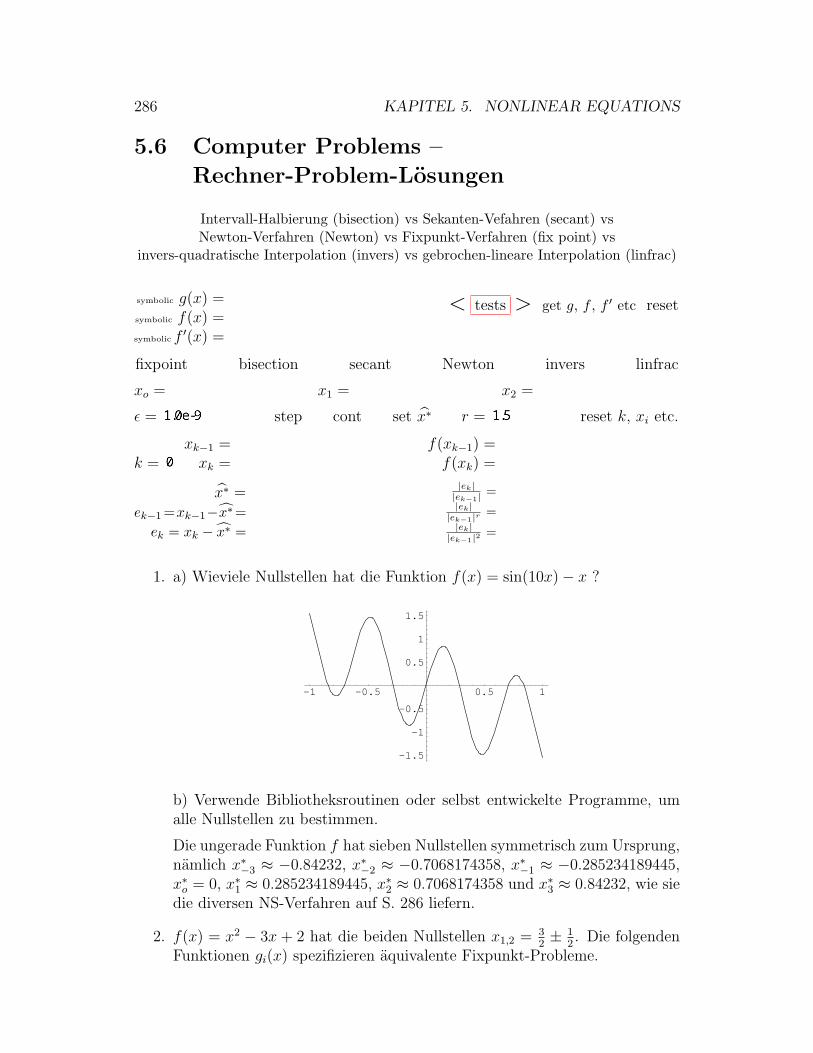
286 KAPITEL 5. NONLINEAR EQUATIONS
5.6 Computer Problems –
Rechner-Problem-Losungen
Intervall-Halbierung (bisection) vs Sekanten-Vefahren (secant) vsNewton-Verfahren (Newton) vs Fixpunkt-Verfahren (fix point) vs
invers-quadratische Interpolation (invers) vs gebrochen-lineare Interpolation (linfrac)
symbolic g(x) =symbolic f(x) =symbolic f ′(x) =
< tests > get g, f , f ′ etc reset
fixpoint bisection secant Newton invers linfrac
xo = x1 = x2 =
ε = step cont set x∗ r = reset k, xi etc.
xk−1 =k = xk =
f(xk−1) =f(xk) =
x∗ =ek−1 =xk−1−x∗=ek = xk − x∗ =
|ek||ek−1| =|ek|
|ek−1|r =|ek|
|ek−1|2 =
1. a) Wieviele Nullstellen hat die Funktion f(x) = sin(10x)− x ?
-1 -0.5 0.5 1
-1.5
-1
-0.5
0.5
1
1.5
b) Verwende Bibliotheksroutinen oder selbst entwickelte Programme, umalle Nullstellen zu bestimmen.
Die ungerade Funktion f hat sieben Nullstellen symmetrisch zum Ursprung,namlich x∗−3 ≈ −0.84232, x∗−2 ≈ −0.7068174358, x∗−1 ≈ −0.285234189445,x∗o = 0, x∗1 ≈ 0.285234189445, x∗2 ≈ 0.7068174358 und x∗3 ≈ 0.84232, wie siedie diversen NS-Verfahren auf S. 286 liefern.
2. f(x) = x2 − 3x + 2 hat die beiden Nullstellen x1,2 = 32± 1
2. Die folgenden
Funktionen gi(x) spezifizieren aquivalente Fixpunkt-Probleme.

5.6. Computer Problems – Rechner-Problem-Losungen 287
g1(x) = 13(x2 + 2) g2(x) =
√3x− 2 g3(x) = 3− 2
xg4(x) = x2−2
2x−3
a) Untersuche die Konvergenz der Fixpunkt-Probleme gi im Fixpunkt 2.226
g1(x) = x ⇐⇒ 13(x2 + 2) = x ⇐⇒ f(x) = 0 und mit g′1(x) = 2
3x
gilt |g′1(2)| = 43> 1 und |g′1(1)| = 2
3< 1, so daß xk+1 = g1(xk) fur jeden
Startpunkt xo > 2 divergiert, fur −2 < xo < 2 gegen den Fixpunkt 1konvergiert und fur xo < −2 wieder divergiert. Fur den Fixpunkt 2 istek = xk − 2 also keine Nullfolge.
g2(x) = x ⇐⇒√
3x− 2 = x ⇐⇒ 3x − 2 = x2 ⇐⇒ f(x) = 0 undmit g′2(x) = 3
2√
3x−2gilt |g′2(2)| = 3
4< 1, so daß xk+1 = g2(xk) lokal linear
konvergent mit C = 43
ist.
g3(x) = x ⇐⇒ 3 − 2x
= x ⇐⇒ f(x) = 0 und mit g′3(x) = 2x2 gilt
|g′3(2)| = 12< 1, so daß xk+1 = g3(xk) lokal linear konvergent mit C = 1
2ist.
g4(x) = x ⇐⇒ x2−22x−3
= x ⇐⇒ x2 − 2 = x(2x − 3) = 2x2 − 3x ⇐⇒f(x) = 0 und mit g′4(x) = 2x2−3x+2
(2x−3)2und g′′4(x) = 2
(2x−3)3gilt |g′4(2)| = 0, so
daß xk+1 = g1(xk) lokal quadratisch konvergent mit C = 1 = 12|g′′4(2)| ist.
b) Verifiziere die theoretischen Ergebnisse aus a) praktisch.
Verwende dazu etwa die diversen NS-Verfahren auf S. 286.
3. Implementiere Intervall-Halbierung, Sekanten- und Newton-Verfahren zurLosung nichtlinearer Gleichungen. Teste die Programme anhand der fol-genden Probleme und vergleiche erwartete und augenscheinliche Konver-genz-Rate.
a) f(x) = x3 − 2x− 5 = 0 mit f ′(x) = 3x2 − 2 hat zwei Extrema in ±√
23,
namlich ein Maximum in −√
23
mit f( −√
23) = 4
3
√23− 5 ≈ −3.911 < 0.
Wegen f(3) = 16 hat f genau eine reelle Nullstelle x∗ ∈ (√
23, 3) ≈ (0.8, 3),
namlich x∗ ≈ 2.09455 etwa per diverser NS-Verfahren auf S. 286.
b) f(x) = e−x−x = 0 ist wegen f ′(x) = −e−x−1 < −1 < 0 monoton fallendund hat wegen f(0) = 1 > 0 und f(1) = 1
e− 1 < 0 genau eine Nullstelle in
(0, 1), namlich x∗ ≈ 0.567 per diverser NS-Verfahren auf S. 286.
c) f(x) = x sin x − 1 = 0 hat unendlich viele Nullstellen, etwa als erstepositive in (0, π
2), namlich x∗ ≈ 1.114 per diverser NS-Verfahren auf S. 286.
d) f(x) = x3 − 3x2 + 3x− 1 = (x− 1)3 = 0 hat in 1 die einzige, im ubrigendreifache Nullstelle, vgl. etwa diverse NS-Verfahren auf S. 286.
4. Implementiere das invers-quadratische und das gebrochen-lineare Interpola-tionsverfahren zur Losung nichtlinearer Gleichungen. Teste die Programmeanhand der Probleme aus CP 5.3 und vergleiche erwartete und augenschein-liche Konvergenz-Rate.

288 KAPITEL 5. NONLINEAR EQUATIONS
a) f(x) = x3 − 2x− 5 = 0
b) f(x) = e−x − x = 0
c) f(x) = x sin x− 1 = 0
d) f(x) = x3 − 3x2 + 3x− 1 = (x− 1)3 = 0
5. Die Funktion f(x) =(((x− 0.5) + x)− 0.5
)+x werde wie angegeben, also
nicht vereinfacht, ausgewertet. Gibt es ein fl(x) mit fl(f(x)) = 0 ? WelchesErgebnis liefern die Verfahren zur Losung nichtlinearer Gleichungen?
Verwende die diversen NS-Verfahren auf S. 286.???
6. Berechne die ersten Iterationen des Newton-Verfahrens fur die angegebe-nen Funktionen und Startwerte. Welche Konvergenz-Rate scheint anfangsvorzuliegen? Was ist die (asymptotische) Konvergenz-Rate? Erlautere dieBeobachtungen.
a) f(x) = x2 − 1 = 0 mit xo = 106
scheinbar lineare Konvergenz mit C = 12
fur k <≈ 15 laut Newton-Verfahren
auf S. 286.
b) f(x) = (x− 1)4 = 0 mit xo = 10
scheinbar lineare Konvergenz mit C = 34
fur k <≈ 30 laut Newton-Verfahren
auf S. 286.
7. a) Wie verhalt sich das Newton-Verfahren bei der Losung der nichtlinearenGleichung f(x) = x5 − x3 − 4x = 0 mit Startwert xo = 1 ?
f ′(x)=5x4−2x2−4 und daher xk+1 =xk−x5
k−x3k−4xk
5x4k−3x2
k−4=
5x5k−3x3
k−4xk−x5k+x3
k+4xk
5x4k−3x2
k−4
=4x5
k−2x3k
5x4k−3x2
k−4= 2x3
k2x2
k−1
5x4k−3x2
k−4, sodaß mit xo =1 eben x1 =−1 und x2 =1 folgt.
-2 -1 1 2
-15
-10
-5
5
10
15
Der Graph zeigt die Gefahr dieses Oszillierens, das Newton-Verfahren aufS. 286 demonstriert sie.
b) Was sind die reellen Nullstellen von f und gegebenenfalls ihre Besonder-heiten?

5.6. Computer Problems – Rechner-Problem-Losungen 289
Wegen f(x) = x(x4−x2−4) = x(z2−z−4) fur z = x2 und z1,2 = 12(1±
√17)
hat f die drei reellen Nullstellen x1 = 0 und x2,3 = ±√
12(1 +
√17) ≈
±1.60048518 (vgl. Newton-Verfahren auf S. 286).
8. Bestimme die kleinste positive Nullstelle von f(x) = 11+e−2x + cos x. Un-
tersuche folgende aquivalente Fixpunkt-Probleme mit Funktionen gi undxo = 3 theoretisch und praktisch auf Konvergenz und Konvergenz-Rate.
Zunachst ist f(x) = h(x)+cosx mit h(x) = 11+e−2x = 1
1+(e−x)2. h ist Punkt-
symmetrisch zu (0, 12) mit h(0) = 1
2und h′(x) = 2e−2x
(1+e−2x)2mit h′(0) = 1
2.
Endlich hat h die Asymptoten y = 0 und y = 1 und es gilt 0 < h′(x) ≤ 12.
−6 −4 −2 0 2 4 6−1
−0.5
0
0.5
1
1.5
2
x
h(x) = 1/(1+exp(−2*x))
−6 −4 −2 0 2 4 6−1
−0.5
0
0.5
1
1.5
2
x
f(x) = cos(x)+h(x) = cos(x)+1/(1+exp(−2*x))
3.05 3.1 3.15 3.2 3.25
−2
−1
0
1
2
3
4
x 10−3
x
f(x) = cos(x)+1/(1+exp(−2*x)) nahe x1* ≈ 3.0764 und x2
* ≈ 3.1992
x1 x2xmin
f(x) = cos(x)+1/(1+exp(−2*x))
Taylor−Polynom 2. Grades von f um xmin≈ 3.1378
x∗1 ≈ 3.0764211637927588 ist15 die kleinste positive Nullstelle von f .
a) xk+1 = arccos −11+exp(−2xk)
= g1(xk)
Wegen g1(x) = arccos −11+exp(−2x)
= x ⇐⇒ −11+exp(−2x)
= cosx ⇐⇒f(x) = 0 ist g1(x) = x ein aquivalentes Fixpunkt-Problem. Wegen g′1(x) =
−1q1−( −1
1+exp(−2x))2
−2 exp(−2x)(1+exp(−2x))2
= 2 exp(−x)
(1+exp(−2x))√
2+exp(−2x)gilt g′1(3) ≈ 0.0702:
das Fixpunkt-Verfahren ist lokal konvergent mit C ≈ 0.07. vgl. Fixpunkt-Verfahren auf S. 286
0 1 2 3 4 50
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
x
y
f(x) = cos(x)+1/(1+exp(−2x)) y = xg1(x) = acos(−1/(1+exp(−2x)))
−4 −2 0 2 4 6
−3
−2
−1
0
1
2
3
4
5
6
x
y
f(x) = cos(x)+1/(1+exp(−2x)) y = xg2(x) = 0.5*log(−1/(1+1/cos(x)))
b) xk+1 = 12ln −1
1+1/ cos xk= g2(xk)
15 laut MATLAB

290 KAPITEL 5. NONLINEAR EQUATIONS
Wegen g2(x) = 12ln −1
1+1/ cos x= x ⇐⇒ −1
1+1/ cos x= e2x ⇐⇒ 1/ cosx =
−1− e−2x ⇐⇒ f(x) = 0 ist g2(x) = x ein aquivalentes Fixpunkt-Problem.
Mit g′2(x) = 12
1+1/ cos x−1
sin x/ cos2 x(1+1/ cos x)2
= −12
sin xcos2 x+cos x
= −12
tan x1+cos x
gilt g′2(3) ≈7.112: das Fixpunkt-Verfahren ist nicht konvergent. vgl. Fixpunkt-Verfah-ren auf S. 286
c) Newton-Verfahren Fur den Start-Wert xo = 3 konvergiert das Newton-Verfahren in wenigen Schritten gegen die erste positive Nullstelle x∗1 – derlinken des Nullstellen-k xk f(xk) f ′(xk) xk+1 = xk − f(xk)
f ′(xk)
0 3.00000000000000 0.00753488024292 −0.13618698947715 3.055327460221041 3.05532746022104 0.00150435140505 −0.08173967831024 3.073731635967092 3.07373163596709 0.00016733979094 −0.06354938458539 3.076364860380313 3.07636486038031 0.00000342980195 −0.06094426773038 3.076421138059524 3.07642113805952 0.00000000156686 −0.06088858450394 3.076421163792755 3.07642116379275 0.00000000000000 −0.06088855904247 3.07642116379276
Paares16 x∗1 ≈ 3.0764 und x∗2 ≈ 3.1992 nahe dem ersten positiven Minimum
(xmin1 , f(xmin1)) ≈ (3.1378,−0.00187). Fur etwa xo = 3.3 konvergiert dasNewton-Verfahren gegen x∗2. vgl. Fixpunkt-Verfahren auf S. 286
9. Laut Kepler17 hangt die mittlere Anomalie M eines elliptischen Orbits derExzentrizitat e mit 0 < e < 1 per M = E − e sin(E) von der exzentrischenAnomalie E ab.
a) Zeige: g(E) = M + e sin(E) spezifiziert ein aquivalentes, lokal konver-gentes Fixpunkt-Problem.
g(E) = E ⇐⇒ M+e sin(E) = E ⇐⇒ f(E) := M−E+e sin(E) = 0 undes gilt g′(E) = e cos(E) mit |g′(E)| < 1 fur alle E, so daß das Fixpunkt-Problem lokal konvergent ist.
b) Lose das Fixpunkt-Problem aus a) fur M = 1 und e = 0.5.
Das Fixpunkt-Verfahren auf S. 286 liefert E∗ ≈ 1.4987011335178484 mitlinearer Konvergenz und C ≈ 0.036.
c) Lose g(E) = 1 + 0.5 sin(E) = 0 per Newton-Verfahren.
Das Newton-Verfahren auf S. 286 liefert E∗ ≈ 1.4987011335178482 mitscheinbar linearer Konvergenz und C ≈ 0.069.
d) Verwende eine Bibliotheksroutine.
MATLAB liefert fzero(@(E)(E-0.5*sin(E)-1),1) = 1.49870113351785
sowie solve(’E-0.5*sin(E)-1’) = 1.498701133517848314.
16 auch per MATLAB’s fzero17 vgl. z.B. http://www.bruce-shapiro.com/pair/KeplersEquation.pdf

5.6. Computer Problems – Rechner-Problem-Losungen 291
10. Die kritische Lange18 x eines Brennstabes ist durch cotx = (x2 − 1)/(2x)gegeben. Bestimme die kleinste positive Losung.
Etwa das Newton-Verfahren auf S. 286 liefert x∗ ≈ 1.3065423741888 mitscheinbar linearer Konvergenz und C ≈ 0.085.
11. Die Eigen-Frequenzen x eines nur an einer Seite eingespannten, gleichformi-gen Stabes von Einheitslange sind Losungen der nichtlinearen Gleichung19
tan x tanh x = −1. Bestimme die kleinste positive Losung.
z.B. per Newton der diversen NS-Verfahren auf S. 286
f(x) = 1+tanx tanh x ist gerade mit f(0) = 1 und Polstellen in π2Z ≈ 1.57Z
und f(x) ≥ 1 fur |x| < π2. Die kleinste positive Nullstelle liegt also in
(12π, 3
2π) ≈ (1.57, 4.71). Mit einem Startwert xo = 1.6 liefert etwa das
Newton-Verfahren auf S. 286 x∗ ≈ 2.347 mit quadratischer Konvergenzund C ≈ 0.06361.
12. y = 1k
ln ( cosh(t√gk)) ist die vertikale Strecke, die ein Fallschirm-Springer
in t Sekunden zurucklegt. Dabei ist g ≈ 9.8065m/sec2 die Erdbeschleu-nigung und k = 0.00341m−1 eine Konstante fur den Luftwiderstand. Inwelcher Zeit fallt der Fallschirmspringer 1km?
Fur f(t) = 1k
ln ( cosh(t√gk))−1000 liefert etwa das Newton-Verfahren auf
S. 286 t∗ ≈ 22.43644483sec.
13. Das Kugel-Volumen ist V = 43πr3 und das einer Kugel-Kappe der Hohe h
ist V = π3h2(3r − h). Wie weit (relativ zu r) taucht eine Kugel mit einem
(relativ zu Wasser) spezifischen Gewicht von 0.4 in Wasser ein?
Die Kugel verdrangt die Menge Wassers G= π3h2(3r−h), die ihrem Gewicht
G = 0.4 43πr3 entspricht, d.h. π
3h2(3r − h) = 0.4 4
3πr3 ⇐⇒ 3 h2
r2 − h3
r3 =1.6 ⇐⇒ p(H) = p(h
r) = H3 − 3H2 + 1.6 = 0. Wegen p′(H) = 3H(H − 2)
hat p das lokales Maximum (0, p(0)) = (0, 1.6) und das lokale Minimum
(2, p(2)) = (2,−2.4). p hat also drei Nullstellen H1, H2 und H3 mit H1 < 0,0 < H2 < 2 und 2 < H3. Wegen p(1) = −0.4 gilt fur die relevante NullstelleH2 ∈ (0, 1). Mit einem der Verfahren auf S. 286 ergibt sich naherungsweiseH2 ≈ 0.8659. Die SubstitutionH = y+1 uberfuhrtH3−3H2+1.6 = 0 in dieNormalform y3−3y−0.4 = 0 = y3+3y+2q mit p = −1 und q = −0.2 sowienegativer Diskriminante D = p3 + q2 = −1 + 1
25= −24
25(casus irreduzibilis)
und drei analytisch aus P = sgn(q)√|p| = −1 und β = 1
3arccos q
P 3 =13arccos 1
5zu bestimmenden Nullstellen y1 = −2P cos β ≈ 1.7952 und y2 =
2P cos(β + π/3) ≈ −0.1341 sowie y3 = 2P cos(β − π/3) ≈ −1.661. Auchanalytisch ergibt sich also H2 = y2 + 1 ≈ 0.8659.
18 vgl. z.B. http://www.mathcs.emory.edu/~nagy/courses/fall04/hw5.pdf19 vgl. z.B. www.vibrationdata.com/Newrap.pdf,
http://personalpages.umist.ac.uk/staff/shuguang.li/download/MoSSII Exam 04.pdf
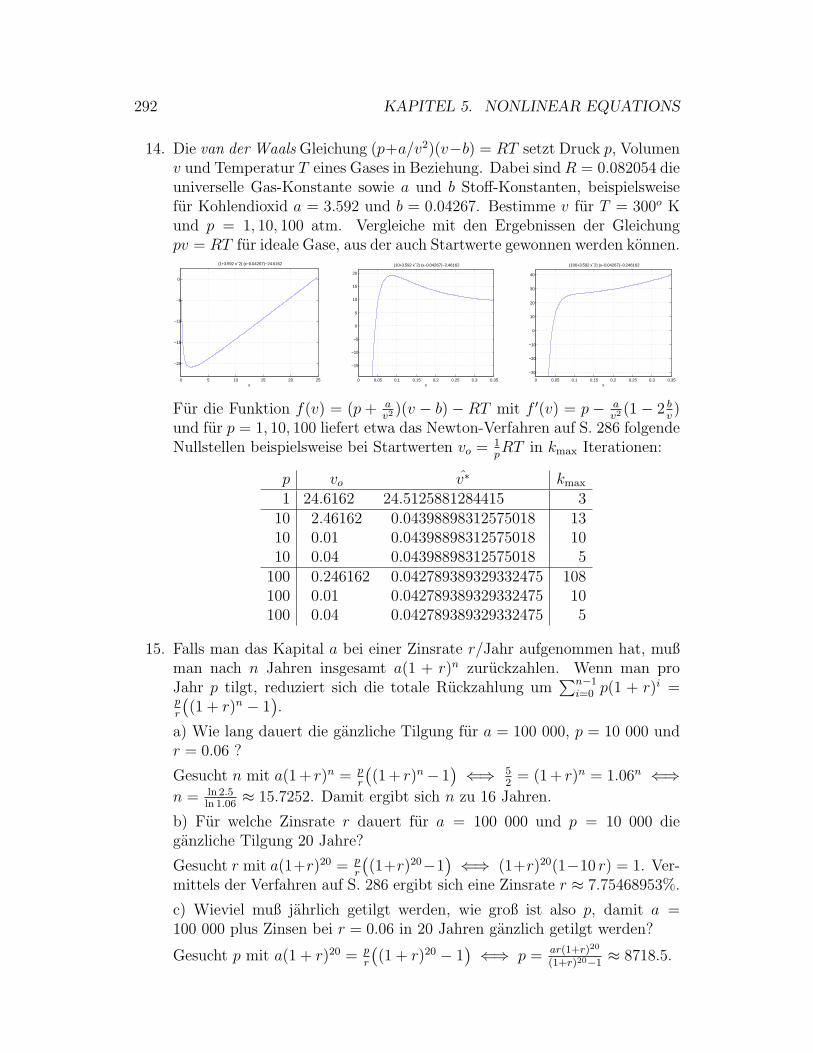
292 KAPITEL 5. NONLINEAR EQUATIONS
14. Die van der Waals Gleichung (p+a/v2)(v−b) = RT setzt Druck p, Volumenv und Temperatur T eines Gases in Beziehung. Dabei sind R = 0.082054 dieuniverselle Gas-Konstante sowie a und b Stoff-Konstanten, beispielsweisefur Kohlendioxid a = 3.592 und b = 0.04267. Bestimme v fur T = 300o Kund p = 1, 10, 100 atm. Vergleiche mit den Ergebnissen der Gleichungpv = RT fur ideale Gase, aus der auch Startwerte gewonnen werden konnen.
0 5 10 15 20 25
−20
−15
−10
−5
0
x
(1+3.592 x−2) (x−0.04267)−24.6162
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35
−15
−10
−5
0
5
10
15
20
x
(10+3.592 x−2) (x−0.04267)−2.46162
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35
−30
−20
−10
0
10
20
30
40
x
(100+3.592 x−2) (x−0.04267)−0.246162
Fur die Funktion f(v) = (p + av2 )(v − b) − RT mit f ′(v) = p − a
v2 (1 − 2 bv)
und fur p = 1, 10, 100 liefert etwa das Newton-Verfahren auf S. 286 folgendeNullstellen beispielsweise bei Startwerten vo = 1
pRT in kmax Iterationen:
p vo v∗ kmax
1 24.6162 24.5125881284415 310 2.46162 0.04398898312575018 1310 0.01 0.04398898312575018 1010 0.04 0.04398898312575018 5
100 0.246162 0.042789389329332475 108100 0.01 0.042789389329332475 10100 0.04 0.042789389329332475 5
15. Falls man das Kapital a bei einer Zinsrate r/Jahr aufgenommen hat, mußman nach n Jahren insgesamt a(1 + r)n zuruckzahlen. Wenn man proJahr p tilgt, reduziert sich die totale Ruckzahlung um
∑n−1i=0 p(1 + r)i =
pr((1 + r)n − 1).
a) Wie lang dauert die ganzliche Tilgung fur a = 100 000, p = 10 000 undr = 0.06 ?
Gesucht n mit a(1 + r)n = pr((1 + r)n− 1) ⇐⇒ 5
2= (1 + r)n = 1.06n ⇐⇒
n = ln 2.5ln 1.06
≈ 15.7252. Damit ergibt sich n zu 16 Jahren.
b) Fur welche Zinsrate r dauert fur a = 100 000 und p = 10 000 dieganzliche Tilgung 20 Jahre?
Gesucht r mit a(1+r)20 = pr((1+r)20−1) ⇐⇒ (1+r)20(1−10 r) = 1. Ver-
mittels der Verfahren auf S. 286 ergibt sich eine Zinsrate r ≈ 7.75468953%.
c) Wieviel muß jahrlich getilgt werden, wie groß ist also p, damit a =100 000 plus Zinsen bei r = 0.06 in 20 Jahren ganzlich getilgt werden?
Gesucht p mit a(1 + r)20 = pr((1 + r)20 − 1) ⇐⇒ p = ar(1+r)20
(1+r)20−1≈ 8718.5.

5.6. Computer Problems – Rechner-Problem-Losungen 293
16. a) Programmiere das Newton-Verfahren zur Bestimmung der n-ten Wurzelnvon f(x) = xn − y = 0 fur gegebenes n und y.
???b) Programmiere das Muller-Verfahren, i.e. schrittweise quadratische In-terpolation, zur Bestimmung der n-ten Wurzeln von f(x) = xn − y = 0 furgegebenes n und y.
???
17. Die Nullstellen des kubischen Polynoms p(x) = x3 + ax2 + bx + c genugen
dem nichtlinearen Gleichungssystem−(x1 + x2 + x3) = a
x1x2 + x2x3 + x1x3 = b−x1x2x3 = c
von Vieta20.
Programmiere das Newton-Verfahren zur Bestimmung der drei gegebenen-falls komplexen Nullstellen von p und vergleiche mit Bibliotheksroutinen.
???
18. a) Programmiere das Newton-Verfahren zur Losung des Systemes nicht-line-
arer Gleichungen(x+3)(y3−7) + 18 = 0
sin(yex − 1) = 0mit Start-Vektor zo =
(−0.5
1.4
).
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
0
2
4
6
8
10
x
(1+2 π)/exp(x)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
−8
−7
−6
−5
−4
−3
−2
−1
0
x
(1−2 π)/exp(x)
Das Newton-Verfahren auf S. 286 mit Start-Vektor zo = (1, 1)T liefert invielen Schritten oszillierend (x∗, y∗) ≈ (−8.9699147790 · 10−7, 1.0000005),obwohl offensichtlich z∗ = (0, 1)T eine exakte Losung ist. Dabei ist Jf (z) =(
y3 − 7 3(x+ 3)y2
yex cos(yex) ex cos(yex)
)und daher Jf (z
∗) = Jf (
(01
)) =
(−6 9
cos 1 cos 1
)regular mit cond(Jf (z
∗)) ≈ 14.4391.
Mit anderen, zufalligen Start-Vektoren ergeben sich weitere Losungen, nam-
lich als die Schnittpunkte der Graphen y = 3
√7− 18
x+3und y = (1+πZ)e−x.
Beispielsweise fur den Start-Vektor zo = (0.1, 1.4)T ist die Jacobi-Matrixnach drei Schritten singular!
???b) Programmiere das Broyden-Verfahren zur Losung des Systemes nichtli-nearer Gleichungen aus a) mit demselben Start-Vektor zo.
???20 Francois Viete (1540-1603) www-history.mcs.st-andrews.ac.uk/Biographies/Viete.html

294 KAPITEL 5. NONLINEAR EQUATIONS
c) Vergleiche die Konvergenz-Raten der beiden Verfahren anhand des rela-tiven Fehlers angesichts der exakten Losung z∗ = (0, 1)T .
???
19. Biologische Reinigung basiert auf Bakterien, die giftige Abfalle verstoff-wechseln. Im Gleichgewicht gilt fur die Dichte x der Bakterien und fur
die Konzentration y der Nahrstoffeγxy − x(1 + y) = 0
−x2 + (δ − y)(1 + y) = 0fur System-
Konstanten γ und δ. Lose das nichtlineare Gleichungssystem fur typischeWerte wie γ = 5 und δ = 1. Es gibt Losungen mit x > 0 und x = 0.
Das Newton-Verfahren auf S. 277 mit Start-Vektor (xo, yo) = (1, 1) liefert ineinem Schritt eine exakte Losung (x∗1, y
∗1) = (0, 1). Mit anderen, zufalligen
Start-Vektoren ergibt sich eine weitere exakte Losung (x∗2, y∗2) = 1
4(15, 1).
20. a) In der Quanten-Mechanik ist der Grund-Zustand (x, y) eines Partikels in
a spherical well durch die beiden nichtlinearen Gleichungenx/ tan(x) = −yx2 + y2 = s2
fur eine Konstante s, typisch s = 3.5 beschrieben. Bestimme (x, y).
In wenigen Schritten liefert das Newton-Verfahren auf S. 277 fur f(z) =
f(
(xy
)) =
(x/ tan(x) + yx2 + y2 − s2
)= 0 mit Start-Vektor
(xo
yo
)=
(22
)die eine
Losung z∗ =
(x∗
y∗
)=
(2.38994694380975202.5569813463876554
)mit ||f(z∗)||2 ≈ 8.88 · 10−16.
b) Der erste angeregte Zustand (x, y) eines Partikels ist durch die bei-
den nichtlinearen Gleichungen(x tan(x))−1 − x−2 = y−1 + y−2
x2 + y2 = s2 beschrie-
ben. Bestimme (x, y).
In wenigen Schritten liefert das Newton-Verfahren auf S. 277 fur f(z) =
f(
(xy
)) =
(1
x tan x− 1
x2 − 1y− 1
y2
x2 + y2 − s2
)= 0 mit Start-Vektor
(xo
yo
)=
(−3
1
)die
Losung z∗ =
(x∗
y∗
)=
(−3.440284995343989−0.643769485771894
)mit ||f(z∗)||2 ≈ 4.44 · 10−16.
21. Lorenz21 beschreibt die Konvektion in kompressiblen Flussigkeiten und Ga-sen. Im Gleichgewicht erfullen Geschwindigkeit x der Konvektion, Gradienty der Temperatur und Warme-Fluß z das System nichtlinearer Gleichungen
σ(y − x) = 0 1
rx− y − xz = 0 2
xy − bz = 0 3
21 vgl. z.B. Bernd Simeon: Numerik gewohnlicher Differentialgleichungen, S.27 in S.17-28enthalten in http://www-m2.ma.tum.de/~simeon/numerik3/aktuell.pdf

5.6. Computer Problems – Rechner-Problem-Losungen 295
mit der Prandtl-Zahl σ, typisch σ = 10, der Rayleigh-Zahl r, typisch r =28 und einer Stoffkonstanten b, typisch b = 8/3. Bestimme x, y und zvermittels des Newton-Verfahrens.
Wegen 1 ist x = y, wegen 3 ist z = 1bxy = 1
bx2 und wegen 2 gilt dann
1bx3 + x(1 − r) = 0 mit den drei Nullstellen u1 = 0 und u2,3 = ±6
√2. So
ergeben sich die Losungen x∗1 = 0 sowie x∗2,3 = (±6√
2,±6√
2, 72/(8/3)) ≈(±8.485,±8.485, 27)T . Das Newton-Verfahren auf S. 277 liefert fur etwaden Start-Vektor xo = (1, 1, 1)T gerade x∗1, fur etwa den Start-Vektor xo =(10, 10, 10)T gerade x∗2 und fur etwa den Start-Vektor xo = −(10, 10, 10)T
gerade x∗3.
22. a) Lose die Gleichungx = − 1
81cosx+ 1
9y2 + 1
3sin z
y = 13sin x+ 1
3cos z
z = −19cosx+ 1
3y + 1
6sin z
per offensichtlichem
Fixpunkt-Verfahren.
v :=
xyz
=
− 181
cosx+ 19y2 + 1
3sin z
13sin x+ 1
3cos z
−19cosx+ 1
3y + 1
6sin z
=: g(
xyz
) ⇐⇒ g(v) = v.
Die Losungen der vorliegenden Gleichung sind genau die Fixpunkte von g.Das Fixpunkt-Verfahren auf S. 277 approximiert in vielen Iterationen einen
exakten Fixpunkt v∗ = (0, 13, 0)
Tvon g.
b) Welche Konstante C fur die lineare Konvergenz im Fixpunkt ergibt sich?Vergleiche C mit der beobachteten Konstanten.
???c) Lose das System per Newton-Verfahren und vergleiche die Konvergenz-rate mit der des Fixpunkt-Verfahrens.
Das Newton-Verfahren auf S. 277 liefert fur etwa den Start-Vektor vo =(1, 1, 1)T in wenigen Schritten die nicht weiter zu verbessernde Naherung
v∗ =
−9.461553154305885 · 10−79
0.33333333333419152.8360588041149905 · 10−13
fur die exakte Losung v∗ = (0, 13, 0)
T.
23. Lose16x4 + 16y4 + z4 = 16
x2 + y2 + z2 = 3x3 − y = 0
mit Start-Vektor
xo
yo
zo
=
111
per Newton-
Verfahren. Vergleiche Ergebnisse und Konvergenzraten mit denen von Bi-bliotheksroutinen.
Das Newton-Verfahren auf S. 277 mit Start-Vektor (1, 1, 1)T liefert in sechs
Schritten eine exakte22 Losung
x∗y∗z∗
=
0.87796576027429800.67675697051782871.3308554116212266
. MAT-
22 im Rahmen der Rechengenauigkeit

296 KAPITEL 5. NONLINEAR EQUATIONS
LAB ermittelt neben einer Reihe von komplexen folgende vier reelle Losun-genabc
,
ab−c
,
−a−bc
,
−a−b−c
fura = 0.87796576027429791346207160175342b = 0.67675697051782859866956374244554c = 1.33085541162122676349943760954810
24. Lose
w1x01 + w2x
02 = 2
w1x1 + w2x2 = 0w1x
21 + w2x
22 = 2
3
w1x31 + w2x
32 = 0
in vier Unbekannten, den Knoten x1 und x2 und
den Gewichten w1 und w2 (vgl. Gauß-Quadratur auf S. 406). Wievieleverschiedene Losungen lassen sich finden?
Mit den Setzungen w1 = 2−w2 und x = w2, y = x1 und z = x2 ergibt sich
das aquivalente Gleichungssystem(2− x)y + xz= 0
(2− x)y2 + xz2 − 2/3 = 0(2− x)y3 + xz3 = 0
. Das Newton-
Verfahren auf S. 277 liefert fur Start-Vektoren (3,±2,∓1)T die Naherungen11
±0.5773502691896257∓0.5773502691896257
fur die exakten Losungen
w∗1w∗2x∗1x∗2
=
11
±1/√
3
∓1/√
3
mit 1/
√3 ≈ 0.57735026918962576.
25. Losesin x+ y2 + ln z = 3
3x+ 2y − z3 = 0x2 + y2 + z3 = 6
in den Unbekannten x, y und z. Neben kom-
plexen Losungen sollten sich mindestens vier reelle Losungen finden lassen.
Fur f(v) =
sin x+ y2 + ln z − 33x+ 2y − z3
x2 + y2 + z3 − 6
liefert das Newton-Verfahren auf S. 277
mit Start-Vektoren vo folgende Nullstellen v∗ mit Residuen f(v∗) und derenNorm ||f(v∗)||2.

5.6. Computer Problems – Rechner-Problem-Losungen 297
vo v∗ f(v∗) ||f(v∗)||2111
0.24226692932745841.52718160623487261.5338982536491128
000
0−111
−1.14558173137896052.01826950327160000.8500487671649247
10−16
8.8817841970012522.2204460492503138.881784197001252
≈ 1.3 · 10−15
1−1
1
0.9641314243431404−1.3347658671694178
1.4871269768022113
10−16
4.4408920985006264.440892098500626
0
≈ 6.3 · 10−16
−0.1−1.0
0.1
−0.06100862661181374−2.4486992540785715
0.053122365184783346
10−16
8.881784197001252−0.11221492485224971
8.881784197001252
≈ 1.2 · 10−15
wobei die letzte Nullstelle von MATLABs fminsearch nahegelegt wird,wenn man diese Funktion mit geeigneten Startwerten auf das Argument
h(x, y, z) = ( sin x+ y2 + ln z − 3)2+ (3x+ 2y − z3)
2+ (x2 + y2 + z3 − 6)
2
anwendet.Wir eliminieren die Unbekannte z aus den drei Gleichungen und erhalten
3x+ 2y + x2 + y2 = 63 sin x+ 3y2 + ln(3x+ 2y) = 9
3 sin x+ 3y2 + ln(6− x2 − y2) = 9
Wegen 6 = 3x + 2y + x2 + y2 = (x + 1.5)2 − 1.52 + 2y + y2 ist die ersteOrtskurve symmetrisch zu x = −1.5. Selbstverstandlich sind eigentlich nurzwei der dargestellten drei Ortskurven notig.
−5 −4 −3 −2 −1 0 1 2 3
−3
−2
−1
0
1
2
3
x
y
5CP25
1
2
3
4
3*x+x2+y2+2y = 6
3*sin(x)+3*y2+log(3*x+2y) = 9
3*sin(x)+3*y2+log(6−x2−2y) = 9
3*x+2y = 0
x2+y2 = 6
−0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
−2.6
−2.4
−2.2
−2
−1.8
−1.6
−1.4
x
y
5CP25 3
4
3*x+x2+y2+2y = 6
3*sin(x)+3*y2+log(3*x+2y) = 9
3*sin(x)+3*y2+log(6−x2−2y) = 9
3*x+2y = 0
x2+y2 = 6
Der Schnitt des Inneren des Kreises x2 + y2 ≤ 6 mit dem durch 3x+2y ≥ 0spezifizierten Teil der x-y-Ebene markiert den Bereich z3 > 0 und damitden Bereich der reellen Losungen/Nullstellen, die in den Definitionsbereichvon f fallen. Die gemeinsamen Schnittpunkte (x∗i , y
∗i ) der drei Ortkurven
sind die Projektionen der Losungen v∗i in die x-y-Ebene. Die naherungs-weise ermittelte Graphik legt neben den drei zufallig ermittelten Losungenv∗1, v∗2 und v∗3 die weitere Losung v∗4 nahe, die das Newton-Verfahren mitgeeigneten Startwerten auch approximiert.

298 KAPITEL 5. NONLINEAR EQUATIONS
26. Ein Modell fur die Verbrennung von Propan-Gas in Luft fuhrt auf dasfolgende System nichtlinearer Gleichungen
x1 + x4 = 32x1 + x2 + x4 + x7 + x8 + x9 + 2x10 = R + 10
2x2 + 2x5 + x6 + x7 = 82x3 + x5 = 4R
x1x5 − 0.193x2x4 = 0x6√x2 − 0.002597
√x2x4S = 0
x7√x4 − 0.003448
√x1x4S = 0
x4x8 − 0.00001799x2S = 0x4x9 − 0.0002155
√x3S = 0
x24(x10 − 0.00003846S) = 0
mitR = 4.056734
S =∑10
i=1 xi
Lose das System mit Hilfe von Bibliotheksroutinen. Ersetze gegebenenfallsnegative Radikanden durch deren Betrag.
???27. Die folgenden Systeme nichtlinearer Gleichungen zu losen, kann uberra-
schende Probleme aufwerfen. Verifiziere die ermittelten Losungen, erlautereAbweichungen, vergleiche ermittelte und erwartete Konvergenz-Raten.
a)x+ y(y(5− y)− 2) = 13x+ y(y(1 + y)− 14) = 29
mit Start-Vektor zo =
(xo
yo
)=
(15−2
)Subtraktion der beiden Gleichungen eliminiert x und liefert y3−2y2−6y−8 = 0 mit den Losungen y1 = 4, y2,3 = −1± i sowie die zugehorigen x1 = 5,x2,3 = 13 ± 14i. Die nichtlineare Gleichung hat also die eine reelle Losungz1 = (5, 4)T und die beiden komplexen Losungen z2,3 = (13±14i,−1±i)T =(13,−1)T ± i(14, 1)T .
Das Newton-Verfahren auf S.277 konvergiert in 43 Iterationen gegen z1.Konvergenz-Rate?
???
b)x2 + y2 + z2 = 5
x+ y = 1x+ z = 3
mit Start-Vektor
xo
yo
zo
=
12(1 +
√3)
12(1−
√3)√
3
Quadrieren der beiden letzten Gleichungen und jeweilige Subtraktion vonder ersten liefert z2 = 2xy+4 sowie y2 = 2xz−4. In die erste Gleichung ein-gesetzt ergibt sich 3x2−8x+5 = 0 mit den beiden Losungen x1,2 = (4±1)/3.Der Schnitt dieser Kugel mit den beiden Ebenen besteht aus den bei-den Punkten v∗1 = 1
3(5,−2, 4)T und v∗2 = 1
3(3, 0, 6)T . Fur den Start-
Vektor vo =
xo
yo
zo
=
12(1 +
√3)
12(1−
√3)√
3
ist Jf (vo) =
2xo 2yo 2zo
1 1 01 0 1
wegen
det (Jf (vo)) = det
1 +√
3 1−√
3 2√
31 1 01 0 1
= det
√3 −√
3 2√
31 1 01 0 1
=

5.6. Computer Problems – Rechner-Problem-Losungen 299
det
−√3 −√
3 2√
31 1 00 0 1
= 0 singular, wahrend Jf (vo) fast singular ist,
wie cond(Jf (vo)) ≈ 8.98 · 1016 zeigt. Deshalb ist die erste Naherung v1 desNewton-Verfahrens extrem weit von der einen Losung v∗1 entfernt. Immer-hin konvergiert das Newton-Verfahren auf S.277 auch bei diesem Startwertin vielen Iterationen gegen v∗1.
c)
x1 + 10x2 = 0√5(x3 − x4) = 0(x2 − x3)
2 = 0√10(x1 − x4)
2 = 0
mit Start-Vektor
xo1
xo2
xo3
xo4
=
1211
Aufgrund der zweiten bis vierten Gleichung gilt x1 = x2 = x3 = x4 undaufgrund der ersten Gleichung daher x∗1 = x∗2 = x∗3 = x∗4 = 0.
???
d)x = 0
10x/(x+ 0.1) + 2y2 = 0mit Start-Vektor
(xo
yo
)=
(1.80
)Selbstverstandlich ist die einzige exakte Losung x∗ = y∗ = 0.
Schon in der ersten Iteration ist Jf (zo) =
(1 01
(xo+0.1)20
)singular, so daß
das Newton-Verfahren auf S.277 scheitern muß.???
e)104xy = 1
e−x + e−y = 1.0001mit Start-Vektor
(xo
yo
)=
(01
)Wegen der ersten Gleichung liegt jede Losung z∗ = (x∗, y∗)T entweder im1. oder 3. Quadranten, wegen der zweiten Gleichung kann z∗ aber nichtim dritten Quadranten liegen, so daß x∗, y∗ > 0 folgt. Beide Ortskur-ven sind symmetrisch zur Hauptdiagonalen, d.h. mit23 z∗1 = (x∗, y∗)T ≈(9.106, 0.1098 · 10−4)T ist z∗2 = (y∗, x∗)T die andere Losung.
Das Newton-Verfahren auf S.277 konvergiert in 13 Iterationen gegen z∗2 =(0.000010981593296997291, 9.106146739867256)T = (x∗, y∗)T und mit demStart-Vektor (1, 0)T eben gegen z∗1 = (y∗, x∗).
???
28. Matrizen konnen per Newton-Verfahren invertiert werden. Sei namlich dieAbbildung F : Rn×n → Rn×n durch F(X) = I−AX fur n× n-Matrizen Xdefiniert. Dann gilt F(X) = 0 ⇐⇒ X = A−1. Wegen F′(X) = −A lautetdas Newton-Verfahren
Xk+1 = Xk − (F′(Xk))−1
F(Xk) = Xk + A−1(I−AXk)
Da aber A−1 ja gerade unbekannt ist, verwendet man die Naherung Xk.Die Iteration lautet somit Xk+1 = Xk + Xk(I−AXk).
a) Fur die Residuumsmatrix Rk = I − AXk und die Fehler-Matrix Ek =
23laut MATLAB

300 KAPITEL 5. NONLINEAR EQUATIONS
A−1−Xk zeige: Rk+1 = R2k und Ek+1 = EkAEk. Folgere, daß die Konver-
genz quadratisch ist, obwohl A−1 durch Xk nur angenahert wird.
Es gilt Rk+1 = I−AXk+1 = I−A(2Xk−XkAXk) = (I−AXk)2 = R2
k undEk+1 = A−1 −Xk+1 = A−1 − 2Xk + XkAXk = (I −XkA)(A−1 −Xk) =(A−1 − Xk)A(A−1 − Xk) = EkAEk. Fur jede submultiplikative Matrix-
Norm ||.|| gilt nun limk→∞||Ek+1||||Ek||2
= limk→∞||EkAEk||||Ek||2
≤ limk→∞||Ek||2·||A||||Ek||2
=
||A||. Also ist die Folge Xk mindestens quadratisch konvergent.
b) Programmiere die Matrix-Inversion mit Hilfe dieses Iterationsverfahrensmit Start-Matrix Xo = 1
||A||1·||A||∞AT . Teste das Programm mit Pseudo-Zufallsmatrizen und vergleiche Genauigkeit und Effizienz mit Standard-Verfahren wie LU-Faktorisierung oder Gauß-Jordan-Elimination.
???
29. Per Newton-Verfahren konnen EWe und zugehorige EVen naherungsweise
bestimmt werden. Sei namlich f : Rn+1 → Rn+1 durch f(x, λ) =
[Ax−λxxTx−1
]fur x ∈ Rn und λ ∈ R definiert.Dann ist f(x, λ) = 0 genau dann, wenn λ ein EW mit zugehorigem nor-
malisierten EV x ist. Wegen Jf (x, λ) =
[A− λI −x
2xT 0
]lautet die New-
ton Iteration
[xk+1
λk+1
]=
[xk
λk
]+
[sk
δk
]wobei
[sk
δk
]das lineare Gleichungssy-
stem
[A− λkI −xk
2xTk 0
] [sk
δk
]= −
[Axk − λkxk
xTk xk − 1
]lost. Programmiere dieses
Newton-Verfahren mit Start-Vektor
[xo
λo
]wobei xT
o x = 1 und λo = xTo Ax.
Teste das Programm mit Pseudo-Zufallsmatrizen und vergleiche Genauig-keit und Effizienz mit Standard-Verfahren zur Bestimmung von Paaren vonEW und EV wie etwa des power Verfahrens.
???

Kapitel 6
Optimization
6.0.1 Optimierungsprobleme
Minimiere/maximiere Zielgroße unter Randbedingungen
Z.B. Eine Masse m hangt an zwei Federn mit Federkonstanten k1 bzw. k2 undRuhelangen L1 bzw. L2. Der Abstand der Aufhangungen der Federn betragt D.
x
y
0 D
m
Die potentielle Energie des Gesamtsystems (unter Vernachlassigung des Gewich-tes der Federn) ist
V (x, y) = 12k1(√x2 + y2 − L1)
2+ 1
2k2(√
(D − x)2 + y2 − L2)2 −mgy
Das System befindet sich im Gleichgewicht genau dann, wenn V (x, y) minimalist. cDef. Allgemein: gegeben f : Rn → R und S ⊂ Rn. Gesucht x∗ ∈ S mitf(x∗) = minf(x) : x ∈ S. x∗ heißt hier Minimum von f . Die Menge S istdurch die Randbedingungen spezifiziert. Bem. Minima von f sind Maxima von −f und umgekehrt. Speziell stetige Optimierungsprobleme haben folgende Form:
301

302 KAPITEL 6. OPTIMIZATION
Def. Gegeben seien stetige Funktionen f : Rn → R, g : Rn → Rm undh : Rn → Rp. Dann ist x∗ mit f(x∗) = minf(x) : g(x) = 0,h(x) ≤ 0 gesucht.Das Optimierungsproblem wird ein linear programming Problem genannt, fallsdie Funktionen f , g und h linear oder affin sind, sonst handelt es sich um einnonlinear programming Problem. Z.B. Radius x1 und Hohe x2 eines Zylinders seien so zu bestimmen, daß seineOberflache f(x) = f(x1, x2) bei festem Volumen V minimiert wird, d.h. x∗ mit
f(x∗) = minxf(x) = min
x2πx1(x1 + x2) wobei g(x1, x2) = πx2
1x2 − V = 0
zu bestimmen, stellt ein nichtlineares Optimierungsproblem dar. cMan unterscheidet lokale und globale Minima:
x
y = f1(x)
x
y = f2(x)
x
y = f3(x)
x
y = f4(x)
x
y = f5(x)
f1(x) = x hat auf R kein Minimum, f2(x) = x2 hat auf R in 0 ein lokalesMinimum, das zugleich globales Minimum ist, f3(x) = x3− 3x hat auf R in 1 einlokales Minimum und kein globales Minimum, f4(x) = 3x4 − 4x3 − 12x2 hat aufR in −1 ein lokales und in 2 ein globales Minimum, wahrend f5(x) = sin x auf Rin 3
2π + 2πZ lauter lokale Minima, aber kein globales Minimum hat.
Bem. I.a.R. nutzen die einschlagigen iterativen Verfahren lokale Eigenschaftenwie Ableitungen oder Taylor-Reihenentwicklungen und konnen daher nur lokaleMinima finden! Als Abhilfe bleibt nur die Variation der Startwerte in S. Dagegenfinden Verfahren fur lineare, allgemeiner konvexe Probleme globale Minima! Bem. Hier keine diskreten Probleme: s. integer programming
6.0.2 Existenz und Eindeutigkeit
Def. Eine auf einer unbeschrankten Menge S stetige Funktion f : Rn ⊃ S → Rmit lim||x||→∞ f(x) = +∞ heißt coercive. Satz Eine auf einer unbeschrankten, abgeschlossenen Menge S coercive Funktionf hat ein globales Minimum in S. •Z.B. f(x) = x2 ist auf R coercive mit globalem Minimum in 0.f(x) = x3 ist auf R nicht coercive. f hat in R kein globales Minimum.f(x) = ex ist auf R nicht coercive. f hat in R kein globales Minimum.

303
f(x, y) = x4 − 4xy + y4 ist auf R2 coercive, weil f(x, y) = (x4 + y4)(1 − 4xyx4+y4 ),
wobei lim||(x,y)||→∞4xy
x4+y4 = 0. f hat ein globales Minimum in −(
11
).
f(x, y) = ax+ by + c mit (a, b, c)T 6= 0 ist auf R2 nicht coercive, weil f(x, y) = cauf der unbeschrankten Menge ax+ by = 0. f hat kein globales Minimum. cDef. Fur f : Rn ⊃ S → R heißt Lc = x ∈ S : f(x) ≤ c sublevel set. Bem. Eine stetige Funktion f : Rn ⊃ S → R mit einem unbeschrankten,abgeschlossenen Lc 6= ∅ hat ein globales Minimum in S. Bem. Sei S unbeschrankt. Dann ist f coercive auf S genau dann, wenn alleLc 6= ∅ beschrankt sind.
Konvexitat
Def. S ⊂ Rn heißt konvex genau dann, wenn mit x,y ∈ S auch die verbindendeStrecke in S liegt, d.h. auch αx + (1− α)y ∈ S fur alle α ∈ [0, 1]. Def. f : Rn ⊃ S → R heißt konvex bzw. strikt konvex auf einer konvexenMenge S genau dann, wenn f(αx + (1 − α)y) ≤ αf(x) + (1 − α)f(y) bzw.
f(αx + (1− α)y) < αf(x) + (1− α)f(y) fur alle α ∈ [0, 1] und alle x,y ∈ S. Bem. Der zugehorige Abschnitt des Graphens einer konvexen Funktion liegtunterhalb jeder Sehne. Bem. Sei f konvex auf konvexem S. Dann ist erstens f im Inneren von Sstetig, zweitens ist jedes Lc konvex, drittens ist jedes lokale Minimum von f inS zugleich globales Minimum von f in S. Fur strikt konvexes f ist ein lokalesMinimum sogar das einzige globale Minimum von f in S.
Optimalitat ohne Nebenbedingungen
Def. f : Rn → R differenzierbar. Dann heißt gradf = ∇f : Rn → Rn mitgradf(x) = ∇f(x) = (∂f(x)
∂x1, . . . , ∂f(x)
∂x1)T Gradient von f in x.
Bem. Die Taylor-Entwicklung von f um x liefert fur jedes s ∈ Rn
f(x + s) = f(x) +∇f(x + αs)T s
bei geeignetem α = α(s) ∈ (0, 1). Sei nun f stetig differenzierbar und∇f(x) 6= 0.Fur s = −β∇f(x) mit 0 < β 1 zeigt sich, daß f in Richtung s abnimmt, da we-gen der Stetigkeit von ∇f(x) mit ∇f(x)T s = −β∇f(x)T∇f(x) = −β||∇f(x)||22auch ∇f(x + αs)T s negativ ist. Da dieses Verhalten von f in der Umgebungeines Minimums x∗ nicht moglich ist, muß in Minima zwangslaufig ∇f(x∗) = 0gelten. (Dieselbe Argumentation fur s = β∇f(x) zeigt, daß auch in Maxima x∗
zwangslaufig ∇f(x∗) = 0 gilt.)

304 KAPITEL 6. OPTIMIZATION
Def. f : Rn → R sei differenzierbar. Dann heißt x∗ mit ∇f(x∗) = 0 kritischer,stationarer oder Gleichgewichtspunkt von f . Satz Sei x∗ lokales Minimum von f . Dann ist notwendig ∇f(x∗) = 0 und damitx∗ ein kritischer Punkt von f . •Z.B. Im Beispiel der an zwei Federn aufgehangten Masse ist die potentielle Ener-gie notwendigerweise in einem kritischen Punkt minimal, d.h. ∇V (x, y) = 0.In der Mechanik gilt fur die Kraft F(x, y) = −∇V (x, y). Wenn daher die ausFeder-Kraften und Gravitation resultierende Kraft verschwindet, ist die potenti-elle Energie minimal und das System befindet sich im Gleichgewicht. Aufgrunddieser physikalischen Interpretation heißen kritsche Punkte auch stationare oderGleichgewichtspunkte. cDef. f : Rn → R sei zweimal differenzierbar. Dann heißt Hf : Rn → Rn×n mit
Hf (x) =(
∂2f(x)∂xi∂xj
)i,j
Hesse1sche Matrix von f in x.
Bem. Die Hesse’sche Matrix Hf von f ist gerade die Jacobi2sche Matrix
J∇f (x) = ∂ (∇f)i
∂xj(x) von ∇f in x. Falls die zweiten Ableitungen stetig sind,
ist wegen ∂2f(x)∂xi∂xj
= ∂2f(x)∂xj∂xi
die Hesse’sche Matrix symmetrisch.
Satz f : Rn → R sei zweimal differenzierbar und x∗ ein kritischer Punkt von f ,d.h. ∇f(x∗) = 0. Dann sind folgende vier Falle zu unterscheiden:
i. wenn Hf (x∗) positiv definit ist, dann ist x∗ ein Minimum von f .
ii. wenn Hf (x∗) negativ definit ist, dann ist x∗ ein Maximum von f .
iii. wenn Hf (x∗) indefinit ist, dann ist x∗ ein Sattelpunkt von f .
iv. wenn Hf (x∗) singular ist, dann ist f ’pathologisch’. •
Bem. f : Rn ⊃ S → R sei zweimal stetig differenzierbar auf konvexem S. Wennnun Hf (x) in einem x ∈ S positiv definit ist, dann ist f in einer Nachbarschaftvon x konvex.Wenn Hf (x) in jedem x ∈ S positiv definit ist, dann ist f auf ganz S konvex. Hf (x) ist positiv definit ⇐⇒ Hf (x) hat Cholesky-Faktorisierung ⇐⇒ dieAnzahl der negativen und verschwindenden EWe von Hf (x), ausgewiesen durchdie inertia von Hf (x), bestimmt aus Hf (x) = LDLT -Faktorisierung von Hf (x),ist Null ⇐⇒ alle EWe von Hf (x) sind positiv.
Z.B. Fur f : Rn → R mit f(x) = 2x31 + 3x2
1 + 12x1x2 + 3x22 − 6x2 + 6 gilt
∇f(x) =
(6x2
1 + 6x1 + 12x2
12x1 + 6x2 − 6
). Die Losungen des Systems nichtlinearer Glei-
1Ludwig Otto Hesse (1811-1874) www-history.mcs.st-andrews.ac.uk/Biographies/Hesse.html
2 Carl Gustav Jacob Jacobi (1804-1851) www-history.mcs.st-andrews.ac.uk/Biographies/Jacobi.html

305
chungen ∇f(x) = 0 ergeben sich aus x21 − 3x1 + 2 = 0 zu x∗1 =
(1
−1
)und
x∗2 =
(2
−3
). Die Hesse-Matrix Hf (x) =
(12x1 + 6 12
12 6
)ist erwartungsgemaß
symmetrisch und es gilt Hf (x∗1) =
(18 1212 6
)sowie Hf (x
∗2) =
(30 1212 6
). Hf (x
∗1)
mit EWen 12 + 6√
5 ≈ 25 und 12 − 6√
5 ≈ −1.4 ist nicht nicht positiv definit,wahrend Hf (x
∗2) mit EWen 18 + 12
√2 ≈ 35 und 18 − 12
√2 ≈ 1 positiv definit
ist. Also hat f in x∗1 einen Sattelpunkt und in x∗2 ein lokales Minimum. c
Optimalitat mit Nebenbedingungen
Def. 0 6= s heißt feasible direction in x∗ ∈ S genau dann, wenn x∗ + αs ∈ S furalle α ∈ [0, r] und ein geeignetes r > 0. Bem. Wenn f ein lokales Minimum in x∗ ∈ S hat, dann ist wegen Taylornotwendigerweise ∇f(x∗)Tx ≥ 0 in jeder feasible direction in x∗ ∈ S.Wenn x∗ im Innern von S liegt, so ist jedes s feasible direction, sowohl s als auch−s, so daß in lokalen Minima wieder notwendigerweise ∇f(x∗) = 0 gilt.Wieder wegen Taylor folgt sTHf (x
∗)s ≥ 0 fur jede feasible direction s in in x∗ ∈ S,d.h. Hf (x
∗) ist positiv semidefinit in jeder feasible direction. Def. Gegeben das (nichtlineare) Optimierungsproblem, ein x∗ mit f(x∗) =minf(x) : g(x) = 0 fur f : Rn → R und g : Rn → Rm mit m < n zu suchen.Dann liegt notwendig −∇f(x∗) in dem von den Nebenbedingungsnormalen auf-gespannten Raum, d.h. −∇f(x∗) = JT
g (x∗)λ∗ fur die Jacobi-Matrix JTg (x∗) von
g in x und geeignetes λ∗ ∈ Rm. Diese Vektoren λ∗ ∈ Rm heißen Lagrange3
Multiplikatoren und geben Anlaß, die Lagrange-Funktion L : Rn+m → R mitL(x, λ) = f(x) + λTg(x) zu definieren.
Bem. Es gilt ∇L(x, λ) =
[∇xL(x, λ)∇λL(x, λ)
]=
[∇f(x) + JT
g (x)λg(x)
]. Die Hesse-
Matrix der Lagrange-Funktion ist HL(x, λ) =
[B(x, λ) Jg(x)Jg(x) 0
], wobei B(x, λ) =
∇x,xL(x, λ) = Hf (x) +∑m
i=1 λiHgi(x). Gesucht ist also ein kritischer Punkt der
Lagrange-Funktion und damit eine Losung des Systems von n+m nichtlinearen
Gleichungen ∇L(x, λ) =
[∇f(x) + JT
g (x)λg(x)
]= 0 in n+m Unbekannten.
Wann ist nun ein kritischer Punkt der Lagrange-Funktion ein restringiertes Mi-nimum von f ? Hinreichend ist, daß B(x∗, λ∗) auf dem Tangential-Raum derBedingung, d.h. auf dem Null-Raum v : Jg(x
∗)v = 0 von Jg(x∗), dem Raum
der Vektoren orthogonal zu den Zeilen von Jg(x∗), positiv definit ist. Eine sol-
che Basis konnen wir durch orthogonale Faktorisierungen von JTg (x∗) gewinnen.
3 Joseph Louis Lagrange (1736-1813) www-history.mcs.st-andrews.ac.uk/Biographies/Lagrange.html

306 KAPITEL 6. OPTIMIZATION
Wenn nun die Spalten einer Matrix Z eine Basis dieses Null-Raumes bilden, dannbleibt also verifizieren, ob ZTBZ positiv definit ist. Z.B. Die Oberflache eines Zylinders mit gegebenem Volumen V sei zu mi-nimieren. Wir haben also das restringierte Optimierungsproblem f(x1, x2) =2πx1(x1 + x2) unter der Nebenbedingung g(x1, x2) = πx2
1x2 − V = 0 zu losen,wo jeweils x1 den Radius und x2 die Hohe bezeichnet. Der Gradient von f ist
gradf(x) = ∇f(x) = 2π(2x1 + x2, x1)T, die Jacobi-Matrix von g ist Jg(x) =
(∂g(x)∂xj
)i,j
= π(2x1x2, x21). Nullstellen des Gradienten der Lagrange-Funktion
L(x, λ) = f(x) + λTg(x), also Losungen des Systems nichtlinearer Gleichungen
∇L(x, λ) =
(∇f(x) + JT
g (x)λg(x)
)= π
2(2x1 + x2) + 2x1x2λ2x1 + x2
1λπx2
1x2 − V
= 0
gewinnen wir etwa mit den Methoden des vorangehenden Kapitels. Fur bei-spielsweise V = 1000cm3 ergibt sich die Losung naherungsweise zu x∗1 = 5.4cm,x∗2 = 10.8cm und λ∗ = −0.37. An dieser Stelle ist
Hf (x∗) =
(2 11 0
), Hg(x
∗) = 2π
(x2 x1
x1 0
), B(x∗, λ∗) = 2π
(2 + x∗2λ 1 + x∗1λ1 + x∗1λ 0
)Erwartunsgemaß ist B(x∗, λ∗) nicht positiv definit – die Matrix hat den negativenEW ≈ −15.2 und den positiven EW ≈ 2.5. Die Matrix Jg(x
∗) = (369, 92.3) hatden eindimensionalen Null-Raum z = (−0.2430.970)T . zTBv = 2.23 ist in derTat positiv, so daß sich x∗ als Minimum von f unter der Bedingung g(x) = 0heraustellt. c. . . Nebenbedingungen mit Ungleichungen . . .
6.0.3 Sensitivitat und Kondition
Das Minimum einer Funktion zu bestimmen, ist offensichtlich untrennbar damitverbunden, (nichtlineare) Gleichungen zu losen. Grundsatzlich ist aber ein Opti-mierungsproblem inharent sensitiver als die Bestimmung von Nullstellen.Die absolute Kondition der Bestimmung der einfachen Nullstelle x∗ einer Funk-tion f : R → R ist 1/|f ′(x∗)|, d.h. fur eine Naherung x mit |f(x)| ≤ ε der exaktenNullstelle x∗ gilt fur den absoluten Fehler |x− x∗| ≤ ε/|f ′(x∗)|.Laut Taylor-Entwicklung von f im Minimum x∗
f(x) = f(x∗+h) = f(x∗)+hf ′(x∗)+ h2
2f ′′(x∗)+O(h3) = f(x∗)+ h2
2f ′′(x∗)+O(h3)
folgt aus f(x) ≈ f(x∗) + 12h2 f ′′(x∗) eben h2 ≈ 2(f(x) − f(x∗))/f ′′(x∗), falls
f ′′(x∗) 6= 0. Damit ist fur |f(x) − f(x∗)| ≤ ε der absolute Fehler |x − x∗| =|h| ≤
√2ε/|f ′′(x∗)|. Falls also beispielsweise ε = εmach und |f ′′(x∗)| ≈ 1, so liegt

307
der absolute Fehler großenordnungsmaßig bei√εmach, die Losung hat nur halb so
viele korrekte Ziffern wie die Maschinen-Genauigkeit.
...
Laut Taylor-Entwicklung einer differenzierbaren Funktion f : Rn → R gilt
f(x) = f(x∗+hs) = f(x∗) +∇f(x∗)T s + 12h2sTHf (x
∗)s +O(h3)
mit |h| = ||x − x∗|| und ||s|| = 1. In einem Minimum x∗ ist ∇f(x∗) = 0 undHf (x
∗) positiv definit, so daß h2 ≈ 2(f(x) − f(x∗))/(sTHf (x∗)s) folgt. Fur ein
x mit |f(x)− f(x∗)| ≤ ε kann der absolute Fehler abgeschatzt werden durch
||x− x∗||2 <≈
2ε
sTHf (x∗)s≤ 2ε
λmin
wobei λmin der kleinste EW von Hf (x∗) ist.
...
6.0.4 Unrestringierte Optimierung in einer Variablen
Def. Eine Funktion f : R → R heißt auf [a, b] unimodal genau dann, wenn esgenau ein Minimum x∗ ∈ [a, b] von f derart gibt, daß f links von x∗ monotonfallend und rechts von x∗ monoton wachsend ist.
golden section search
Bem. golden section search zur Bestimmung des Minimums entspricht Intervall-Halbierung zur Bestimmung der Nullstelle einer Funktion. f sei auf auf [a, b] unimodal und a < x1 < x2 < b.Falls f(x1) < f(x2), dann x∗ 6∈ (x2, b], also x∗ ∈ [a, x2].Falls f(x1) > f(x2), dann x∗ 6∈ [a, x1), also x∗ ∈ [x1, b].
Iteration per golden section search: die Intervall-Lange schrumpft in jeder Itera-tion um denselben Faktor4 τ = 1
2(√
5−1), wenn x1 und x2 relativ zum jeweiligenIntervall die festen Positionen 1− τ ≈ 0.382 und τ ≈ 0.618 haben.
4 vgl. Dirk Stegmann: Der Goldene Schnitt – Mathematische Betrachtungen zu einemantiken Thema, welches bis heute aktuell geblieben ist; www.uni-hildesheim.de/~stegmann/goldschn.pdf

308 KAPITEL 6. OPTIMIZATION
a bx1 x2
↑ ↑a bx1 x2
τ
↓ ↓
a bx1 x2
1−τ
Falls f(x1) > f(x2), also beim Ubergang [aneu, bneu] = [x1, b] gilt
a+ τ(b− a) = x2 = xneu1 = aneu + (1− τ)(bneu − aneu)
= x1 + (1− τ)(b− x1) = (1− τ)b+ τ(a+ (1− τ)(b− a))= (1− τ)(b− a) + (1− τ)a+ τa+ τ(1− τ)(b− a)
so daß sich τ als positive Losung von τ 2 + τ − 1 = 0 zu τ = (√
5− 1)/2 ergibt –wie ebenso im Fall f(x1) < f(x2), also beim Ubergang [aneu, bneu] = [a, x2].
tau = ( sqrt (5)−1)/2;x1 = a+(1−tau )∗ ( b−a ) ; y1=f ( x1 ) ; % init x1 und y1
x2 = a+tau ∗(b−a ) ; y2=f ( x2 ) ; % init x2 und y2
while (b−a>t o l ) do % geeignetes Abbruchkriterium?i f ( y1>y2 ) % Minimum in [x1, b]
a = x1 ; x1 = x2 ; y1 = y2 ;x2 = a+tau ∗(b−a ) ; y2 = f ( x2 ) ;
else % Minimum in [a, x2]b = x2 ; x2 = x1 ; y2 = y1 ;x1 = a+(1−tau )∗ ( b−a ) ; y1 = f ( x1 ) ;
endend
golden section search ist linear konvergent mit C = τ , garantierte Konvergenzallerdings nur fur unimodale Funktionen!
Z.B. f(x) = 12−xe−x2
hat ein Minimum in 12
√2. Vgl. Minimierungsverfahren c
successive parabolic interpolation
successive parabolic interpolation startet mit drei Argumenten u, v und w undFunktionswerten fu = f(u), fv = f(v) und fw = f(w). Dann ist y = p(x) =fu
x−vu−v
x−wu−w
+fvx−uv−u
x−wv−w
+fwx−uw−u
x−vw−v
die Parabel durch (u, fu), (v, fv) und (w, fw).

309
Wegen p′(x) = (2x−v−w) fu
(u−v)(u−w)+ (2x−u−w) fv
(v−u)(v−w)+ (2x−u−v) fw
(w−u)(w−v)hat p gegebenenfalls das
Extremum x∗ = 12
(v2−w2) fu+(w2−u2) fv+(u2−v2) fw
(v−w) fu+(w−u) fv+(u−v) fw.
Der nachsten Iterationsschritt basiert dann auf den drei Punkten (w, fw), (v, fv)und (v − p/q, f(v − p/q)) mit
p = (v − u)2(fv − fw)− (v − w)2(fv − fu)
q = 2((v − u)(fv − fw)− (v − w)(fv − fu))
successive parabolic interpolation ist lokal super-linear konvergent mit Konver-genz-Rate r ≈ 1.324. Vgl. Minimierungsverfahren
Newton-Verfahren
Wenn die zu minimierende Funktion f wird durch ihre ’Taylor-Parabel’ f(x+h) ≈f(x) + f ′(x)h+ 1
2f ′′(x)h2 approximiert wird, hat diese quadratische Funktion in
h ihr Minimum in h = −f ′(x)/f ′′(x). Dies legt das Newton-Verfahren nahe:
x = i n i t ( f ) ; % initialisiere xo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?x = x−df ( x )/ ddf ( x ) ; % xk+1 = xk − f ′(xk)/f
′′(xk)end
Wie das Newton-Verfahren zu Bestimmung einer Nullstelle ist auch dieses Ver-fahren lokal quadratisch konvergent, solange xo nahe genug einem Minimum x∗
von f gewahlt wurde.
Z.B. Fur f(x) = 12−xe−x2
gilt f ′(x) = (2x2−1)e−x2und f ′′(x) = 2x(3−2x2)e−x2
.
f hat ein Minimum in 12
√2. Vgl. Minimierungsverfahren c
abgesicherte Verfahren
Wie bei den Verfahren zur Nullstellen-Bestimmung gibt es auch Kombinationenlangsam aber sicher konvergierender Verfahren mit schnell aber unsicher konver-gierenden Verfahren, etwa golden section search mit successive parabolic interpo-lation.
6.0.5 Unrestringierte Optimierung in mehreren Variablen
Es ist nicht uberraschend, daß die Verfahren zur mehrdimensionalen, unrestrin-gierten Optimierung viel mit der eindimensionalen restringierten Optimierungund dem Losen von Systemen nichtlinearer Gleichungen gemein haben.

310 KAPITEL 6. OPTIMIZATION
direkte Suche
Das Verfahren von Nelder und Mead5 approximiert ein Minimum einer Funktionf : Rn → R, indem in einem Iterationsschritt die Funktionswerte von n+ 1 nichtpaarweise kollinearen Punkten, d.h. eines Simplexes im Rn, berechnet werden undder Punkt mit dem großten, also ungunstigsten Funktionswert nach bestimmtenRegeln gegen einen Punkt auf der Verbindungsstrecke zum Schwerpunkt der n+1Punkte ausgetauscht wird.
steepest descent
Funktionswerte fallen am starksten in Richtung des negativen Gradienten ab.Man sucht also am besten in dieser Richtung nach Minima.
Def. Definiere φ : R → R durch φ(α) = f(x + αs). Die Suche nach einemMinimum von φ heißt dann line search. Das steepest descent-Verfahren fuhrt nun iterativ line searches jeweils in Richtungdes negativen Gradienten durch.
x = i n i t ( f ) ; % initialisiere xo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?s = grad ( f , x ) ; % sk = ∇f(xk)alpha = minimize ( f ( x+alpha∗ s ) ) ; % α∗k = argminαf(xk + αsk)x = x+alpha∗ s ; % xk+1 = xk + α∗ksk
end
Das steepest descent-Verfahren ist nur linear konvergent.
Z.B. Die Funktion f(z) = f(x, y) = 12x2+ 5
2y2 sei zu minimieren. Es gilt∇f(z) =
∇f(x, y) =
(x5y
). Im Start-Vektor zo =
(51
)gilt ∇f(zo) =
(55
)= −so. Dann
nimmt φ(α) = f(zo +αso) = 12(5− 5α)2 + 5
2(1− 5α)2 ein Minimum in α∗ = 1
3an.
Damit ist z1 = zo + α∗so usw.
x
y
f(x, y) = 15
f(x, y) = 20/3
f(x, y) = 80/27
f(x, y) = 320/243
5 J. A. Nelder, R. Mead: A Simplex Method for Function Minimization; Comput. J. 7,308-313, 1965

311
Die Graphik illustriert die beiden folgenden, allgemeinen Sachverhalte: Unterder Voraussetzung ∂ f
∂y(xo, yo) 6= 0 sichert der Satz uber implizite Funktionen fur
f(x, y) − c = 0 die Existenz einer Funktion y = g(x) mit yo = g(xo), so daßlokal f(x, g(x)) − c = 0 und g′(x) = −∂ f
∂x (x, g(x))/∂ f∂y (x, g(x)) gilt. Damit ist( ∂ f
∂y(zo)
−∂ f∂x
(zo)
)ein Richtungsvektor der Tangente in zo =
(xo
yo
)an eine Isohypse
oder Hohenlinie f(x, y) = c. Zum einen steht also der Gradient ∇f(zo) in zo
senkrecht auf der Tangente und damit auch senkrecht auf der Isohypse.Weiterhin ist das Minimum α∗ von φ(α) = f(zo + αs) erst recht ein kritischerPunkt von φ, d.h. φ′(α∗) = ∇f(z∗)T s = 0 mit z∗ = zo +α∗s. Daher ist die Rich-
tung
( ∂ f∂y
(z∗)
−∂ f∂x
(z∗)
)der Tangenten in z∗ an die zum Minimum c∗ = f(z∗) gehorige
Isohypse f(x, y) = c∗ kollinear6 zu s. Zum anderen ist also s ein Richtungsvektorder Tangente an die Isohypse f(x, y) = c∗ in z∗. Der Vektor s ist in z∗ tangentialzu f(x, y) = c∗. cBem. Allgemein steht der Gradient in xo senkrecht auf der zu f(xo) gehorigenIsohypse f(x) = c = f(xo), wo doch fur jede Kurve r(t) ⊂ Lc = x : f(x) = c ineinem level set Lc, eben in einer Isohypse, f(r(t)) = c und damit 0 = d
dtf(r(t)) =(
gradf(r(t)))T
r(t) gilt. ???
Newton-Verfahren
Wie im Fall einer Variablen wird eine Funktion f = f(x) mehrerer Variabler auchhier durch ihr quadratisches Taylor-Polynom approximiert:
f(x + s) ≈ f(x) +∇f(x)T s + 12sTHf (x)s
mit Gradient ∇f(x) = grad(f)(x) = ( ∂ f∂x1
(x), . . . , ∂ f∂xn
(x))T
und Hesse-Matrix
Hf (x) = ( ∂2 f∂xi∂xj
(x))i,j
. Minimum s∗ des quadratischen Taylor-Polynoms in s
sind erst recht kritische Punkte, d.h. ∇f(x) + Hf (x)s = 0, und damit Losungenvon Hf (x)s = −∇f(x). Dies legt das Newton-Verfahren zur Approximation desMinimums einer Funktion f mehrerer Variabler nahe:
x = i n i t ( f ) ; % initialisiere xo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?s = Hesse ( f , x)\(−grad ( f , x ) ) ; % sk lost Hf (xk)sk = −∇f(xk)x = x+s ; % xk+1 = xk + sk
end
6 Sei zur Abkurzung (gx, gy)T := ∇f(z∗) und (sx, sy)T = s gesetzt. Aus ∇f(z∗)T s = 0folgt dann gxsx + gysy = 0 oder gleichermaßen −gxsx = gysy wie auch −gx/sy = β = gy/sx.Also gilt −gx = (gy/sx)sy = βsy sowie gy = (−gx/sy)sx = βsx. Damit sind s und (gy,−gx)T
kollinear.

312 KAPITEL 6. OPTIMIZATION
Das Newton-Verfahren ist lokal quadratisch konvergent.
. . . trust region . . .
Nahe einem Minimum ist die Hesse-Matrix positiv definit, so daß die GleichungHf (xk)sk = −∇f(xk) in sk effizienter per Cholesky-Faktorisierung gelost werdenkann.
. . . falls (∇f(xk))Tsk < 0, direction of negative curvature . . .
. . . positive Definitheit erzwingen, d.h. Hf +µI fur geeignetes µ statt Hf verwen-den, kombiniert Newton-Verfahren und steepest descent . . .
Quasi-Newton-Verfahren
Das Newton-Verfahren ist aufwandig: In jeder Iteration fallen fur die Berechnungder Hesse-Matrix bis zu n2 Funktionsauswertungen an. Die Losung des linearenGleichungssystems schlagt dann noch einmal mit O(n3) skalaren Operationen zuBuche. Die sogenannten Quasi-Newton-Verfahren reduzieren diesen Aufwand, in-dem sie in jeder Iteration die Hesse-Matrix Hf (xk) durch eine regulare Matrix Bk
approximieren und gegebenenfalls zugleich line search durchfuhren. Die nachsteApproximation des Minimums wird aus
xk+1 = xk − αkB−1k ∇f(xk)
gewonnen. Zu den Quasi-Newton-Verfahren gehoren etwa Sekanten aktualisie-rende Verfahren, finite-Differenzen-Verfahren, oder periodic reevaluation.
Sekanten aktualisierende Verfahren
Das BFGS-Verfahren, benannt nach den Autoren7 Broyden, Fletcher, Goldfarbund Shanno, ist eines der verbreitetsten Sekanten aktualisierenden Verfahren,dessen Effizienz auf zwei Aspekten beruht: die Naherung Bk der Hesse-Matrixist erstens symmetrisch, so daß sich der Aufwand der Losung des linearen Glei-chungssystems halbiert (sonst konnte man ja auch die Nullstelle des Gradientenper Broyden-Verfahren bestimmen), und zweitens positiv definit, so daß die Nahe-rung xk in die richtige Richtung aktualisiert wird.Das BFGS-Verfahren arbeitet mit schrittweise verbesserten Naherungen Bk derHesse-Matrix Hf (xk) von f in xk, haufig durch Bo = I initialisiert. Im ubrigen
7 C.G. Broyden: Quasi-Newton methods and their application to function minimization;Math. Comp. 21 (1967) 368-381R. Fletcher: A new approach to variable metric algorithms; Computer J. 13 (1970) 317-322D. Goldfarb: A family of variable metric methods derived by variational means; Math. Comp.24 (1970) 23-26D.F. Shanno: Conditioning of quasi-Newton methods for function minimization; Maths. Comp.24 (1970) 647-656

313
wird in Implementierungen des BGFS-Verfahrens nicht Bk sondern eine Faktori-sierung von Bk aktualisiert, um so den Aufwand von O(n3) auf O(n2) zu drucken.
x = i n i t x ( f ) ; % initialisiere xo
B = in i tB ( f ) ; % initialisiere Bo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?g = grad ( f , x ) ; % gk = ∇f(xk)s = H\(−g ) ; % sk lost Bksk = −∇f(xk) = −gk
x = x+s ; % xk+1 = xk + sk
y = grad ( f , x)−g ; % yk = ∇f(xk+1)−∇f(xk)B = update (B, y , s ) ; % Bk+1 = Bk + yky
Tk /(y
Tk sk)−Bksks
Tk Bk/(s
Tk Bksk)
end
Das BFGS-Verfahren ist super-linear konvergent. Wenn zusatzlich line searchdurchgefuhrt wird, konvergiert es angewandt auf quadratische Funktionen in nVariablen in n Iterationen gegen die exakte Losung.
Konjugierte-Gradienten-Verfahren
Konjugierte-Gradienten-Verfahren vermeiden, Verbesserungen mehrfach in die-selbe Richtung vorzunehmen, indem die Suchrichtungen konjugiert, d.h. orthogo-nal im Sinn von xTHfy, gewahlt werden.
x = i n i t x ( f ) ; % initialisiere xo
g = grad ( f , x ) ;s = −g ; % initiale Suchrichtungfor ( k=0; ; k++) % geeignetes Abbruchkriterium?
a = fminsearch (@( a ) f ( x+a∗ s ) , 1 ) ; % minimiere f(x + αs) in αx = x+a∗ s ; % xk+1 = xk + αksk
gg = grad ( f , x ) ; % gk+1 = ∇f(xk+1)b = gg ’∗ gg /(g ’∗ g ) ; % Fletcher & Reevesg = gg ; s = −g+b∗ s ;% modifiziere Richtung
end
Eine i.a.R. effizientere Alternative zu βk+1 =gT
k+1gk+1
gTk gk
(Fletcher & Reeves)8 ist
etwa βk+1 = (gk+1−gk)T gk+1
gTk gk
(Polak & Ribiere)9.
Anwendungen etwa Neuronale-Netze, PID-Regler . . .
8 R. Fletcher, C.M. Reeves: Function minimization by conjugate gradients; The ComputerJournal 1964 Vol 7, No 2, 149-154
9 E. Polak, G. Ribiere: Notes sur la convergence de methodes. de directions conjugattes;Revue Francaise d’Informatique de Recherche Operationelle, 16-R1, 35-43 (1969)

314 KAPITEL 6. OPTIMIZATION
Abbrechende Newton-Verfahren
Anstatt das Gleichungssystem Bksk = −∇f(xk) tatsachlich zu losen, laßt sichviel Zeit und Speicher sparen, indem weder die Hesse-Matrix oder geeignete Nahe-rungen berechnet werden, sondern die Losung direkt etwa durch finite DifferenzenBkv = 1
h(∇f(xk + hv)−∇f(xk)) approximiert wird.
. . .
6.0.6 nichtlineare least squares Probleme
Ein nichtlineares least-squares-Problem liegt vor, wenn Modell-Funktionen f(t,x) :Rn+1 → R wieder einer Reihe von m Daten-Punkten (ti, yi) fur i = 1, . . . ,m imleast squares Sinn angpasst werden sollen und wenn f eben nicht linear von xabhangt. Wir definieren die sogenannte Residual-Funktion r : Rn → Rm durchr = (ri) mit ri = yi − f(ti,x) fur i = 1, . . . ,m. Dann besteht also die Aufgabedarin, die Zielfunktion φ(x) = 1
2r(x)T r(x) = 1
2||r(x)||22 zu minimieren.
Der Gradient ∇φ(x) der Zielfunktion ist JT (x)r(x), wobei J(x) die Jacobi-Matrix von r(x) bezeichnet, und die Hesse-Matrix Hφ(x) von φ ist JT (x)J(x) +∑m
i=1 ri(x)Hri(x), wobei Hri
(x) die Hesse-Matrix der Komponenten-Funktionri(x) bezeichnet.Wenn in xk die k-te Approximation des Minimums in einem Newton-Verfahrenvorliegt, dann ist xk+1 = xk+sk, wobei sk Losung des linearen Gleichungssystems(
JT (xk)J(xk) +m∑
i=1
ri(xk)Hri(xk)
)sk = JT (x)r(xk) = ∇φ(xk)
ist. Die aufwandige Auswertung der Hesse-Matrizen Hri(x) entfallt, wenn man
das Problem vereinfacht.
Gauß-Newton-Verfahren
Nahe des Minimums x∗ sollten die Komponenten-Funktionen ri der Residual-Funktion r betragsmaßig klein ausfallen. Damit sollten die Terme ri(xk)Hri
(xk)vernachlassigbar sein. Der entsprechende Schritt im obigen Newton-Verfahrenwird damit auf JT (xk)J(xk)sk = −JT (xk)r(xk) reduziert. Dieser Schritt lost alsogerade das lineare least squares Problem J(xk)sk
∼= −r(xk).
x = i n i t ( f ) ; % initialisiere xo
for ( k=0; ; k++) % geeignetes Abbruchkriterium?r = r e s i d u a l ( x ) ; % rk = r(xk)J = jacob ian (x ) ; % Jk = J(xk) Jacobi-Matrix von r in xk
s = (J ’∗ J)\(−J ’∗ r ) ; % sk lost JT (xk)J(xk)sk = −JT (xk)r(xk)

315
x = x+s ; % xk+1 = xk + sk
end
Z.B. Gegeben die vier Daten-Punktet 0.0 1.0 2.0 3.0y 2.0 0.7 0.3 0.1
und die Familie
von Modell-Funktionen f(t,x) = x1ex2t fur x ∈ R2. Die Jacobi-Matrix J(x) der
Residual-Funktion r(x) = (yi−x1ex2ti)
i=1,2,3,4ist J(x) =
(∂ri(x)∂xj
)i=1,2,3,4;j=1,2
mit
∂ri(x)∂x1
= −x1ex2ti und ∂ri(x)
∂x2= −x1tie
x2ti fur i = 1, 2, 3, 4. Fur den Start-Vektor
xo = (1, 0)T liefert dann das Gauß-Newton-Verfahren die folgenden Naherungenfur das Minimum x∗.
k xTk ||r(xk)||22
0 1.000 0.000 2.3901 1.690 −0.610 0.2122 1.975 −0.930 0.0073 1.994 −1.004 0.0024 1.995 −1.009 0.0026 1.995 −1.010 0.002
Obige MATLAB-Implementierung liefert ubrigens x∗ = ()T . c. . .

316 KAPITEL 6. OPTIMIZATION
6.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Die Minima einernichtlinearen Funktion sind inharentweniger genau bestimmbar als ihreNullstellen.
2. Richtig/Falsch? Eine auf [a, b] uni-modale Funktion hat genau ein Mi-nimum x∗ ∈ [a, b].
3. Richtig/Falsch? Wenn das Mini-mum einer (unimodalen) Funktionper golden section search bestimmtwird, wird in jedem Schritt ge-nau das Argument mit dem großtenFunktionswert verworfen.
4. Richtig/Falsch? Wenn das Minimumeiner Funktion mehrerer Variablerbestimmt werden soll, ist das stee-pest descent Verfahren i.a.R. schnel-ler konvergent als das Newton-Ver-fahren.
5. Richtig/Falsch? Die Losung eines li-near programming Problems liegt ineiner der Ecken der feasible region S.
6. Richtig/Falsch? In jedem Schritt er-zeugt das Simplex-Verfahren feasiblepoints als Naherungen der Losungeines linear programming Problems.
7. f sei unimodal auf [a, b]. Fur a <x1 < x2 < b gelte f(x1) = 1.232und f(x2) = 3.576. Welche Aussa-gen treffen zu?
i. Das Minimum von f liegt in[x1, b].
ii. Das Minimum von f liegt in[a, x2].
iii. Ohne Kenntnis von f(a) undf(b) ist die Frage nicht zu be-antworten.
8. a) f sei unimodal auf [0, 1]. Inwelchen beiden Punkten wird f imersten Schritt der golden sectionsearch ausgewertet?
b) Warum werden genau diese bei-den Punkte verwendet?
9. f sei monoton auf [a, b]. Istdann golden section search konver-gent? gegebenenfalls gegen welchenPunkt?
10. f sei unimodal auf [a, b] und fur a <x1 < x2 < b gelte f(x1) < f(x2).
a) Was ist das kurzeste Intervall, indem das Minimum liegen muß?
b) In welchem Intervall muß das Mi-nimum liegen, wenn f(x1) = f(x2)gilt?
11. Fuhre Nachteile und Vorteile vongolden section search im Vergleichzu successive parabolic interpolationan.
12. a) Warum ist lineare Interpolationeiner Funktion f : R → R nicht sinn-voll, um ein Minimum von f zu be-stimmen?
b) Warum verwendet man inversequadratische Interpolation zur Be-stimmung von Nullstellen von Funk-tionen f : R → R und (regulare)quadratische Interpolation zur Be-stimmung von Minima solcher Funk-tionen?
13. successive parabolic interpolationund Newton-Verfahren passen beideder zu minimierenden Funktion eineParabel an, deren Minimum denPunkt der nachsten Iteration ergibt.

6.1. Review Questions – Verstandnisfragen 317
a) Wie unterscheiden sich die beidenVerfahren in der Wahl des quadrati-schen Polynoms?
b) Wie unterscheiden sich dieKonvergenz-Raten der beiden Ver-fahren?
14. Warum minimiert das Newton-Ver-fahren eine quadratisches Polynomin einer Iteration, wahrend dasNewton-Verfahren eine quadratischeGleichung nicht in einer Iterationlosen kann?
15. f : R → R sei zu minimieren. Wel-ches Verfahren hat i.a.R. die ange-gebene Konvergenz-Rate?
a) linear aber nicht super-linear kon-vergent
b) super-linear aber nicht quadra-tisch konvergent
c) quadratisch konvergent
16. f : Rn → R sei zu minimieren. Wel-ches Verfahren hat i.a.R. die ange-gebene Konvergenz-Rate?
a) linear aber nicht super-linear
b) super-linear aber nicht quadra-tisch
c) quadratisch
17. Welche der folgenden Verfahren sindi.a.R. super-linear konvergent?
a) successive parabolic interpolationzur Bestimmung der Minima einerFunktion
b) golden section search zur Bestim-mung der Minima einer Funktion
c) Intervall-Halbierung zur Bestim-mung der Nullstellen einer Funktion
d) Sekanten aktualisierende Verfah-ren zur Bestimmung der Minima ei-ner Funktion von n Veranderlichen
e) steepest descent Verfahren zur Be-stimmung der Minima einer Funk-tion von n Veranderlichen
18. a) Was ist die initiale ’Such-Richtung’ des conjugate gradientVerfahrens zur Bestimmung derMinima einer Funktion von nVeranderlichen?
b) Unter welchen Bedingungen gehtdas BFGS-Verfahren in derselbeninitialen ’Such-Richtung’ vor?
19. Eine quadratische Funktion von nVeranderlichen sei zu minimieren.In maximal wievielen Schritten kon-vergieren die folgenden Verfahrengegen das exakte Ergebnis bei belie-bigen Startwerten?
a) conjugate gradient Verfahren
b) Newton-Verfahren c) BFGS-Ver-fahren mit exact line search
20. a) Was ist ein kritischer Punkt ei-ner nichtlinearen differenzierbarenFunktion f : Rn → R ?
b) Sind kritische Punkte immer Mi-nima oder Maxima?
c) Wie ist der Typ eines kritischenPunktes x∗ zu bestimmen?
21. Sei f : R2 → R eine Funktionzweier Variabler. Welche geometri-sche Bedeutung haben Lange undRichtung des Gradienten ∇f(x) =
(∂f(x)∂x1
, ∂f(x)∂x2
)T
von f in x ?
22. a) Sei f : Rn → R eine Funktion vonn Variablen. Wie heißt die Jacobi-Matrix des Gradienten ∇f(x) von fin x ?
b) Welche Eigenschaft hat diese Ma-trix, wenn f zweimal stetig differen-zierbar ist?

318 KAPITEL 6. OPTIMIZATION
c) Welche zusatzliche Eigenschaftbesitzt diese Matrix nahe lokaler Mi-nima?
23. Das steepest descent Verfahren isti.a.R. langsam, aber sicher konver-gent. Wann scheitert es? Wann istes schnell konvergent?
24. Eine Funktion in n Variablen sei perNewton-Verfahren zu minimieren.
a) Unter welchen Bedingungen istline search vorteilhaft?
b) Unter welchen Bedingungen istline search abtraglich?
25. Viele iterative Verfahren zur Losungmehrdimensionaler nichtlinearerProbleme ersetzen das nichtlinearedurch eine Folge linearer Probleme,die auf Matrix-Faktorisierungen be-ruhen. Welches ist jeweils die besteFaktorisierung fur die folgendenProbleme? (Um Komplikationenauszuschließen, sei unterstellt, daßdie Verfahren nahe genug an derLosung gestartet werden.)
a) fur das Newton-Verfahren zurLosung eines Systems von nichtli-nearen Gleichungen,
b) fur das Newton-Verfahren, eineFunktion mehrerer Veranderlicherzu minimieren,
c) Gauß-Newton-Verfahren zurLosung eines nichtlinearen leastsquares Problems.
26. Sei f : Rn → Rn gegeben. Be-kanntermaßen ist ||f(x)|| = 0 ⇐⇒f(x) = 0 Ist analog dazu, ||f(x)||zu minimieren, aquivalent dazu,das System nichtlinearer Gleichun-gen f(x) = 0 zu losen?
27. a) Warum wird im steepest descent-Verfahren zur Minimierung einer
Funktion mehrerer Veranderlichergrundsatzlich ein line search para-meter eingesetzt?
b) Warum konnte man im Newton-Verfahren zur Minimierung einerFunktion mehrerer Veranderlichereinen line search parameter einset-zen?
c) Worin sollte der Nutzen des linesearch parameters im Newton-Ver-fahren zur Minimierung einer Funk-tion mehrerer Veranderlicher beste-hen, wenn ein Minimum approxi-miert wird?
28. Wie kann man effizient testen, obeine symmetrische Matrix A positivdefinit ist oder nicht?
29. Warum wird nicht einfach dasBroyden-Verfahren eingesetzt, umeine Funktion mehrerer Veranderli-cher mit einem secant updating Ver-fahren zu minimieren, d.h. um eineNullstelle des Gradienten zu finden?
30. Auf welches Verfahren reduziert sichdie erste Iteration des BFGS-Ver-fahren, wenn die Naherung Bo derHesse-Matrix initialisiert wird
a) durch die Einheitsmatrix I ?
b) durch die exakte Hesse-MatrixHf (xo) im Start-Vektor?
31. Eine Funktion mehrerer Veranderli-cher sei mit secant updating Verfah-ren zu minimieren. Warum ist esvorteilhafter, die Faktorisierung derapproximierten Jacobi- oder Hesse-Matrizen als diese Matrizen selbstzu aktualisieren?
32. Eine Funktion mehrerer Verander-licher mit dunn besetzter Hesse-Matrix sei zu minimieren. Istdann ein secant updating wie das

6.2. Exercises – Ubungen 319
BFGS-Verfahren oder das conjugategradient-Verfahren vorteilhafter?
33. Wie unterscheiden sich conjugategradient-Verfahren und truncatedNewton-Verfahren, wenn das conju-gate gradient-Verfahren im Newton-Verfahren verwendet wird, um daslineare Gleichungssystem zu losen?
34. Fur welchen Typ nichtlinearerleast squares Probleme konver-giert das Gauß-Newton-Verfahrenquadratisch?
35. Fur welchen Typ nichtlinearer leastsquares Probleme konvergiert dasGauß-Newton-Verfahren sehr lang-sam oder garnicht?
36. Fur welche beiden Klassen von leastsquares Problemen ist die Appro-ximation der Hesse-Matrix durchdas Gauß-Newton-Verfahren in derLosung exakt?
37. Das Levenberg-Marquardt-Verfahren weist gegenuber demGauß-Newton-Verfahren einenzusatzlichen Term auf. Interpre-tiere diesen Term algebraisch odergeometrisch.
38. Was sind Lagrange-Multiplikatorenund welche Bedeutung haben siefur restringierte Optimierungspro-bleme.
39. Eine Funktion f : Rn → R sei unterder Bedingung g(x) = 0 fur gegebe-nes g : Rn → Rm zu minimieren.
a) Wie sieht die Lagrange-Funktionfur dieses Problem aus?
b) Wie sieht die notwendige Bedin-gung fur ein Minimum von f unterder Bedingung g(x) = 0 aus?
40. Erlautere der Unterschied zwischenrange space und null space Verfah-ren fur die Losung von restringiertenOptimierungsproblemen.
41. Was versteht man unter active setstrategy zur Losung von Optimie-rungsproblemen mit Ungleichungs-bedingungen?
42. a) Konnen Algorithmen mit ei-ner Komplexitat, die polynomialvon der Große der Eingabe-Datenabhangt, beliebig gegebene linearprogramming problems losen?
b) Hangt die Komplexitat desSimplex-Verfahrens polynomial vomUmfang der Eingabe-Daten ab?
6.2 Exercises – Ubun-
gen
1. Welche der folgenden Funktionen istcoercive ?
a) f(x, y) = x+ y + 2
b) f(x, y) = x2 + y2 + 2
c) f(x, y) = x2−2xy+y2 = (x−y)2
d) f(x, y) = x4 − 2xy + y4
2. Welche der folgenden Funktionensind konvex, strikt konvex oder nichtkonvex?
a) f(x) = x2
b) f(x) = x3
c) f(x) = e−x
d) f(x) = |x|
3. Untersuche anhand der Kriterien er-ster und zweiter Ordnung, ob 0 einMinimum der folgenden Funktionenist.
a) f(x) = x2

320 KAPITEL 6. OPTIMIZATION
b) f(x) = x3
c) f(x) = x4
d) f(x) = −x4
4. Bestimme kritische Punkte, Mi-nima, Maxima sowie Wendepunkteund gegebenenfalls globale Extremader folgenden Funktionen.
a) f(x) = x3 + 6x2 − 15x+ 2
b) f(x) = 2x3 − 25x2 − 12x+ 15
c) f(x) = 3x3 + 7x2 − 15x− 3
d) f(x) = x2ex
5. Bestimme kritische Punkte, Mi-nima, Maxima sowie Sattelpunkteund gegebenenfalls globale Extremader folgenden Funktionen.
a) f(x, y) = x2 − 4xy + y2
b) f(x, y) = x4 − 4xy + y4
c) f(x, y) = 2x3−3x2−6xy(x−y−1)
d) f(x, y) = (x−y)4 +x2−y2−2x+2y + 1
6. Bestimme und klassifiziere diekritischen Punkte der Lagrange-Funktion folgender restringierterOptimierungsprobleme.
a) f(x, y) = x2 + y2 wobei g(x, y) =x+ y − 1 = 0
b) f(x, y) = x3 + y3 wobei g(x, y) =x+ y − 1 = 0
c) f(x, y) = 2x + y wobei g(x, y) =x2 + y2 − 1 = 0
d) f(x, y) = x2 + y2 wobei g(x, y) =x y2 − 1 = 0
7. Zeige: v∗ = (2.5, 1.5,−1)T istMinimum der Funktion f(v) =f(x, y, z) = x2 − 2x + y2 − z2 + 4z,wobei g(v) = g(x, y, z) = x − y +2z − 2 = 0.
8. Sei f : R2 → R durch f(z) =f(x, y) = 1
2(x2 − y)2 + 12(1− x)2 ge-
geben.
a) In welchem Punkt nimmt f einMinimum an?
b) Fuhre eine Iteration des Newton-Verfahrens mit zo = (2, 2)T durch.
c) In welcher Hinsicht ist dies ein gu-ter Schritt?
d) In welcher Hinsicht ist dies einschlechter Schritt?
9. Sei f : Rn → R durch f(x) =12x
TAx − xTb + c gegeben, wobeiA eine symmetrische, positiv defi-nite n×n-Matrix, b ∈ Rn und c ∈ Rist.
a) Zeige: Das Newton-Vefahren kon-vergiert in einem Schritt fur jedenStart-Vektor xo.
b) Sei x∗ das Minimum und derStart-Vektor xo so gewahlt, daß xo−x∗ ein EV von A ist. Was passiertdann, wenn man das steepest descentVerfahren einsetzt?
10. a) Zeige: Eine stetige, auf Rn coer-cive Funktion f : Rn → R hat einglobales Minimum in Rn. (Hinweis:Sei M = f(0) in der Definition voncoercive. Betrachte die abgeschlos-sene, beschrankte Menge x ∈ Rn :||x|| ≤ r.)b) Verallgemeinere das obige Resul-tat auf Funktionen, die auf beliebi-gen abgeschlossenen, beschranktenMengen S ⊂ Rn coercive sind.
11. Zeige: Wenn eine stetige Funktionf : Rn ⊃ S → R ein nicht-leeres, ab-geschlossenes und beschranktes sub-level set Lγ = x ∈ S : f(x) ≤ γhat, dann hat f ein globales Mini-mum auf S.

6.3. Computer Problems – Rechner-Probleme 321
12. a) Zeige: Ein lokales Minimum x ei-ner konvexen Funktion f auf einerkonvexen Menge S ⊂ Rn ist ein glo-bales Minimum. (Hinweis: Ange-nommen, x ist kein globales Mini-mum. Sei y ∈ S mit f(y) < f(x).Betrachte dann die Strecke von xnach y.)
b) Zeige: Ein lokales Minimum x ei-ner strikt konvexen Funktion f aufeiner konvexen Menge S ⊂ Rn istdas einzige globale Minimum. (Hin-weis: Angenommen, es gibt zwei Mi-nima x und y. Betrachte wieder dieStrecke von x nach y.)
13. Eine Funktion f : Rn → R heißtquasi-konvex bzw. strikt quasi-konvex auf einer konvexen MengeS ⊂ Rn, wenn f(αx + (1 − α)y) ≤maxf(x), f(y) bzw. f(αx + (1 −α)y) < maxf(x), f(y) fur allex,y ∈ S, x 6= y und alle α ∈ (0, 1)gilt.
14. Zeige: Die Hesse-Matrix derLagrange-Funktion ist nicht positivdefinit.
15. Sei f(z) = f(x, y) = x2 + y2 un-ter der Bedingung g(z) = g(x, y) =x+ y − 1 = 0 zu minimieren. Zeige:fur die zρ der penalty method giltlimρ→∞ zρ = z∗.
16. Die Funktion f(z) = f(x, y) = x2 +y2 sei unter der Bedingung g(z) =g(x, y) = y2 − (x− 1)3 = 0 zu mini-mieren.
a) Warum scheitert die Anwendungvon Lagrange-Multiplikatoren?
b) Wende die penalty methodan, d.h. lose min(x,y) φρ(x, y) mitφρ(x, y) = f(x, y) + 1
2ρg2(x, y).
Finde einen geschlossenen Ausdruck
fur die Losung und fuhre denGrenzubergang ρ→∞ durch.
17. Lose das linear programming Pro-blem, f(x, y) = −3x− 2y unter denBedingungen 5x + y ≤ 6, 3x + 4y ≤6, 4x+ 3y ≤ 6, x ≥ 0, y ≥ 0.
a) Wieviele Ecken hat die feasibleRegion?
b) Berechne das Minimum der Funk-tionswerte f(zk) in den Ecken zk derfeasible Region, da die Losung in ei-ner der Ecken angenommen wird.
c) Bestimme die Losung graphisch.
18. Wie ist das linear programming Pro-blem aus Ex 6.17 in der Standard-Form darzustellen?
6.3 Computer Pro-
blems – Rechner-
Probleme
1. a) f(x) = x2− 2x+ 2 = 1 + (x− 1)2
hat ein globales Minimum in x∗ = 1.Fur welchen Bereich gilt fl(f(x)) =f(x∗) ? Wie erklart sich diesesPhanomen?
b) f(x) = 0.5−xe−x2hat ein globa-
les Minimum in x∗ = 12
√2. Fur wel-
chen Bereich gilt fl(f(x)) = f(x∗) ?Wie erklart sich dieses Phanomen?
2. Sei f : R → R durch f(x) =0.5 x = 0(1− cosx)/x2 x 6= 0
gegeben.
a) Zeige per l’Hospital, daß f in 0stetig ist.
b) Zeige: f hat ein lokales Maximumin 0.
c) Verwende eigene oder Biblio-theksroutinen, um das Minimum 0

322 KAPITEL 6. OPTIMIZATION
der auf [−2π, 2π] unimodalen Funk-tion −f zu approximieren.
d) Welche andere Formulierung vonf gestattet, das Minimum besserzu berechnen? (Hinweis: Verwendeeine Formulierung mit doppeltenWinkeln.)
3. Verwende eigene oder Bibliotheks-routinen, um ein Minimum der fol-genden, laut Graph auf [0, 3] unimo-dalen Funktion f zu approximieren.
a) f(x) = x4 − 14x3 + 60x2 − 70x
b) f(x) = 12x
2 − sinx
c) f(x) = x2 + 4 cosx
d) f(x) = Γ(x) =∫∞o tx−1e−t dt,
d.h. die Euler’sche Gamma-Funktion mit Γ(n + 1) = n!fur n ∈ No und Γ(x) > 0
4. Untersuche nicht-unimodale Funk-tionen mit Bibliotheksroutinen.Werden globale Minima, lokaleMinima gefunden? Wann scheiternBibliotheksroutinen?
5. Der Wasserstrahl verlasse eine Feu-erwehrspritze unter dem Winkel αmit Geschwindigkeit v und treffeden Brandherd in der Hohe h beieinem horizontalen Abstand x vomStrahlrohr. Dann gilt mit der Gravi-tationskonstanten g = 9.8065 m/s2
g2v2 cos2 α
x2 − x tanα+ h = 0
Interpretiere die beiden Wurzelndieser Gleichung. Bestimme denmaximalen Abstand mit zugehori-gem Winkel der Spritze fur v =20 m/s und h = 13.5 m.
6. Programmiere und teste ausgiebigein eigenes line search Verfahren,das minf(xo +αs) : α ∈ R fur die
Parameter Start-Vektor xo, Such-Richtung s, Ziel-Funktion f und To-leranz ε liefert.
7. Sei f : R2 → R definiert durchf(x, y) = 2x3−3x2−6xy(x−y−1).
a) Bestimme alle kritischen Punktevon f analytisch.
b) Klassifiziere analytisch alle kri-tischen Punkte von f als Minima,Maxima, Sattelpunkte oder ’patho-logisch’.
c) Verifiziere die Ergebnisse aus b)durch ein Kontur-Diagramm.
d) Bestimme Minima von f und−f mit Bibliotheksroutinen. Expe-rimentiere mit verschiedenen Start-Vektoren. Vergleiche Aufwand undKonvergenz, d.h. Kosten und Nut-zen der verschiedenen Verfahren.
8. Sei f : R2 → R durch f(x, y) =2x2 − 1.05x4 + 1
6x6 + xy + y2 defi-
niert. Finde und klassifiziere kriti-sche Punkte von f . Bestimme dasglobale Minimum von f .
9. f(x, y) = 100(y − x2)2 + (1 −x)2 definiert f : R2 → R,die Rosenbrock10-Funktion. MitStart-Vektoren (−1, 1)T , (0, 1)T und(2, 1)T bestimme ihre Minima per
a) steepest descent
b) Newton-Verfahren c) gedampf-tem Newton-Verfahren, d.h.Newton-Verfahren mit line search
10. A sei reelle, symmetrische n × n-Matrix mit EWen λ1 ≤ . . . ≤ λn.Zeige: Die kritischen Punkte desRayleigh-Quotienten sind EVen von
10 Eric W. Weisstein: ”Rosenbrock Func-tion.” From MathWorld – A Wolfram Web Re-source. http://mathworld.wolfram.com/RosenbrockFunction.html

6.3. Computer Problems – Rechner-Probleme 323
A und es gilt λ1 = minx6=0xT AxxT x
so-wie λn = maxx6=0
xT AxxT x
, wobei dieExtrema in den zugehorigen EVenangenommen werden. Daher lassensich λ1 und λn und die zugehorigenEVen als Losung von Optimierungs-problemen bestimmen.
a) Fur A =
6 2 12 3 11 1 1
bestimme
extreme EWe und die zugehorigenEVen. Ist die Losung eindeutig?
b) Wegen λ1 = minxT x=1xT AxxT x
und λn = maxxT x=1xT AxxT x
kann derTeil a) auch als restringiertes Op-timierungsproblem gelost werden.Welche Bedeutung haben hier dieLagrange-Multiplikatoren?
11. Programmiere das BFGS-Verfahrenunter folgenden Vorgaben: in je-der Iteration wird B faktorisiertoder eine Faktorisierung von B wirdaktualisiert; Bo wird mit I odermit einer Approximation der Hesse-Matrix durch endliche Differenzeninitialisiert; die Robustheit des Ver-fahrens wird durch line search ver-bessert. Teste das Verfahren anhandder Probleme dieses Abschnittes.
12. Programmiere das conjugategradient-Verfahren, wobei βk+1
anhand der Formeln wahlweisevon Fletcher-Reeves oder vonPolak-Ribiere berechnet wird.
13. Finde mit eigenen oder mit Biblio-theksroutinen least squares-Losun-gen zu folgenden uberbestimmtenSystemen nichtlinearer Gleichungen.
a)x2
1 + x22=2
(x1 − 2)2 + x22=2
(x1 − 1)2 + x22=9
b)x2
1 + x22 + x1x2=0
sin2 x1=0cos2 x2=0
14. Unterstellt, daß die Alkohol-Konzentration y im Blut exponen-tiell mit der Zeit t abfallt, sind dieModell-Funktionen f(t,x) = x1 e
x2 t
an die Meßwerte anzupassen:t 0.5 1. 1.5 2.00 2.50 3.00 3.5 4.00y 6.8 3. 1.5 0.75 0.48 0.25 0.2 0.15
.
a) Lose das nichtlineare least squa-res Problem entweder mit einer Bi-bliotheksroutine oder mit einer ei-genen, etwa Gauß-Newton basiertenRoutine.
b) Logarithmieren uberfuhrt dasProblem in ein linear least squa-res Problem: die Modell-Funktionensind lnx1 + x2 t den Meßwerten(ti, lnyi) anzupassen. Stimmt dieLosung mit derjenigen des nichtli-nearen least squares Problems ube-rein? Warum?
15. Eine Population P von Bak-terien wachse geometrischmit Wachstumsrate r, d.h.Pk = r Pk−1. Die folgenden Popu-lationsgroßen wurden beobachtet:k 1 2 3 4
Pk/109 0.19 0.36 0.69 1.30k 5 6 7 8
Pk/109 2.50 4.70 8.50 14.0
a) Lose das nichtlineare least squa-res Problem und bestimme Po undr.
b) Lose das durch Logarithmie-ren entstehende lineare least squa-res Problem und bestimme Po undr. Vergleiche die Ergebnisse mit a).
16. Die Michaelis-Menten-Gleichung be-schreibt die Kinetik von Enzym-Re-aktionen. Mit der initialen Ge-schwindigkeit vo und maximalen

324 KAPITEL 6. OPTIMIZATION
Geschwindigkeit V , der Michaelis-Konstanten Km und der Konzen-tration S im Substrat gilt vo =
V1+Km/S . Ublicherweise wird vo furverschiedene Konzentrationen S ge-messen. Aus den Daten werdendann V und Km gewonnen.
a) Folgende Werte-Paare (S, vo)S 2.5 5.0 10.0 15.0 20.0vo .024 .036 .053 .060 .064wurden gewonnen. Lose das nicht-lineare least squares Problem undbestimme V und Km, entwedermit einer Bibliotheksroutine odereinem selbst programmierten, etwaGauß-Newton-basierten Verfahren.
b) Das nichtlineare least squa-res Problem kann durch Trans-formation der Michaelis-Menten-Gleichung umgangen werden:Lineweaver und Burke verwenden1vo
= 1V + Km
V1S und losen das entste-
hende lineare least squares Problemin 1
voals Funktion von 1
S , um 1V und
KmV zu bestimmen. Dixon dagegen
stellt Svo
= KmV + 1
V S als Funktionvon S dar, um zunachst Km
V und 1V
zu bestimmen. Endlich verwendenEadie und Hofstee die Darstellungvon vo = V −Km
voS als Funktion von
voS , um V und Km zu bestimmen.

6.4. Review Questions – Antworten auf Verstandnisfragen 325
6.4 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Die Minima einer nichtlinearen Funktion sind inharent we- 269/270niger genau bestimmbar als ihre Nullstellen.
Ja, fur |f(x)| ≤ ε und etwa |f ′(x∗)| ≈ 1 ist der absolute Fehler derNullstellen-Bestimmung |x − x∗| ≤ ε, wahrend fur |f(x) − f(x∗)| ≤ ε undetwa |f ′′(x∗)| ≈ 1 der absolute Fehler der Bestimmung des Minimums mit|x− x∗| ≤
√2ε wesentlich großer ausfallt.
2. Richtig/Falsch? Eine auf [a, b] unimodale Funktion hat genau ein Minimum 270x∗ ∈ [a, b].
Laut Definition ist eine Funktion f unimodal auf [a, b] genau dann, wennes ein Minimum x∗ ∈ [a, b] von f auf [a, b] gibt, so daß f links von x∗ striktmonton fallend und rechts von x∗ strikt monoton wachsend ist.
3. Richtig/Falsch? Wenn das Minimum einer (unimodalen) Funktion per gol- 270/271den section search bestimmt wird, wird in jedem Schritt genau das Argu-ment mit dem großten Funktionswert verworfen.
f sei unimodal. Im golden section search Verfahren wird f an den beidenStellen x1 und x2 ausgewertet.Falls f(x1) > f(x2) und damit x∗ ∈ [x1, b], ubernimmt x2 mit f(x2) dieRolle von x1 mit f(x1), d.h. x1 mit großerem Funktionswert f(x1) wirdverworfen zugunsten eines neuen x2 = a+ τ(b− a) mit (neuem) f(x2).Falls f(x1) < f(x2) und damit x∗ ∈ [a, x2], ubernimmt x1 mit f(x1) dieRolle von x2 mit f(x2), d.h. x2 mit großerem Funktionswert f(x2) wirdverworfen zugunsten eines neuen x1 = a+(1−τ)(b−a) mit (neuem) f(x1).
4. Richtig/Falsch? Wenn das Minimum einer Funktion mehrerer Variabler be- 277,278stimmt werden soll, ist das steepest descent Verfahren i.a.R. schneller kon-vergent als das Newton-Verfahren.
Das steepest descent Verfahren ist linear konvergent, wahrend das Newton-Verfahren (lokal!) quadratisch konvergent ist.
5. Richtig/Falsch? Die Losung eines linear programming Problems liegt in ei- 293/294ner der Ecken der feasible region S.
Mit x,y ∈ S gilt Ax = b = Ay sowie x,y ≥ 0 und damitA(αx + (1− α)y) = αAx + (1− α)Ay = αb + (1− α)Ab = b
sowie αx+(1−α)y ≥ 0. Also folgt αx+(1−α)y ∈ S. Damit ist die feasiblereagion S ein konvexes Polyeder. Die (konvexe) Ziel-Funktion f(x) = cTxmit f(αx + (1− α)y) = αcTx + (1− α)cTy = αf(x) + (1− α)f(y) bildetStrecken in S auf Strecken (Intervalle) in R ab. Damit konnen Minima von

326 KAPITEL 6. OPTIMIZATION
f nur auf dem Rand ∂S (Vereinigung von Ebenen-Ausschnitten) von S undmit demselben Argument nur in den Ecken von S angenommen werden.
6. Richtig/Falsch? In jedem Schritt erzeugt das Simplex-Verfahren feasible293/294points als Naherungen der Losung eines linear programming Problems.
In der Start-Phase bestimmt das Simplex-Verfahren gerade einen feasiblepoint. Danach identifiziert das Simplex-Verfahren schrittweise weitere fea-sible points mit jeweils kleinerem Wert der Ziel-Funktion.
7. f sei unimodal auf [a, b]. Fur a < x1 < x2 < b gelte f(x1) = 1.232 und270f(x2) = 3.576. Welche Aussagen treffen zu?
i. Das Minimum von f liegt in [x1, b].
ii. Das Minimum von f liegt in [a, x2].
iii. Ohne Kenntnis von f(a) und f(b) ist die Frage nicht zu beantworten.
Das Minimum liegt in [a, x2]. Falls namlich x∗ ∈ (x2, b], ware x1 < x2 < x∗
mit f(x1) < f(x2) im Widerspruch zur Unimodalitat von f .
8. a) f sei unimodal auf [0, 1]. In welchen beiden Punkten wird f im ersten271Schritt der golden section search ausgewertet?
f wird in x1 = 1− τ ≈ 0.382 und x2 = τ ≈ 0.618 ausgewertet.
b) Warum werden genau diese beiden Punkte verwendet?271
Erstens reduziert sich die Lange der Intervalle in jedem Schritt um denFaktor τ , ganz gleich, ob als nachstes Intervall [0, τ ] oder [1 − τ, 1] ver-
wendet wird, und zweitens bleibt die Position der beiden Punkte x(n)1 und
x(n)2 relativ zum Intervall [a(n), b(n)] im n-ten Schritt konstant: im nachsten
Schritt befindet sich 1 − τ = τ 2 ∈ [0, τ ] in Position τ relativ zu [0, τ ] undτ = 1− τ + τ − τ 2 = (1− τ) + (1− τ)τ ∈ [1− τ, 1] in Position 1− τ relativzu [1− τ, 1].
9. f sei monoton auf [a, b]. Ist dann golden section search konvergent? gege-271benenfalls gegen welchen Punkt?
Sei f etwa strikt monoton wachsend. Dann gilt fur alle a < x1 < x2 < bimmer f(x1) < f(x2).
Nach Initialsierung von u.a. x(0)1 = a+(1− τ)(b−a) und x
(0)2 = a+ τ(b−a)
mit a(0) = a und b(0) = b gilt im ersten Schritt von golden section search
b(1) = x(0)2 = a+ τ(b− a) und
x(1)2 = x
(0)1 = a+ (1− τ)(b− a) sowie
x(1)1 = a(1) + (1− τ)(b(1) − a(1))
= a+ (1− τ)(a+ τ(b− a)− a) = a+ (1− τ)τ(b− a).Im zweiten Schritt von golden section search ergibt sich

6.4. Review Questions – Antworten auf Verstandnisfragen 327
b(2) = x(1)2 = a+ (1− τ)(b− a) und
x(2)2 = x
(1)1 = a+ (1− τ)τ(b− a) sowie
x(2)1 = a(2) + (1− τ)(b(2) − a(2))
= a+ (1− τ)(a+ (1− τ)(b− a)− a) = a+ (1− τ)2(b− a).Im dritten Schritt von golden section search ergibt sich
b(3) = x(2)2 = a+ (1− τ)τ(b− a) und
x(3)2 = x
(2)1 = a+ (1− τ)2(b− a) sowie
x(3)1 = a(3) + (1− τ)(b(3) − a(3))
= a+ (1− τ)(a+ (1− τ)τ(b− a)− a) = a+ (1− τ)2τ(b− a).Allgemein gilt im 2n-ten Schritt von golden section search
b(2n) = x(2n−1)2 = a+ (1− τ)n(b− a) und
x(2n)2 = x
(2n−1)1 = a+ (1− τ)nτ(b− a) sowie
x(2n)1 = a(2n) + (1− τ)(b(2n) − a(2n))
= a+ (1− τ)(a+ (1− τ)n(b− a)− a) = a+ (1− τ)n+1(b− a).Allgemein gilt im 2n+ 1-ten Schritt von golden section search
b(2n+1) = x(2n)2 = a+ (1− τ)nτ(b− a) und
x(2n+1)2 = x
(2n)1 = a+ (1− τ)n+1(b− a) sowie
x(2n+1)1 = a(2n+1) + (1− τ)(b(2n+1) − a(2n+1))
= a+ (1− τ)(a+ (1− τ)nτ(b− a)− a) = a+ (1− τ)n+1τ(b− a).
Wegen a = a(n) < x(n)1 < x
(n)2 < b(n) n→∞→ b konvergiert golden section search
im Fall strikt monoton wachsender Funktionen f gegen f(a) und im Fallstrikt monoton fallender Funktionen f gegen f(b).
10. f sei unimodal auf [a, b] und fur a < x1 < x2 < b gelte f(x1) < f(x2). 271
a) Was ist das kurzeste Intervall, in dem das Minimum liegen muß?
Da f unimodal ist, muß das Minimum x∗ in [a, x2] liegen. Falls namlichx∗ ∈ (x2, b], wurde x1 < x2 < x∗ mit f(x1) < f(x2) im Widerspruch zurUnimodalitat von f gelten.
b) In welchem Intervall muß das Minimum liegen, wenn f(x1) = f(x2) gilt?
Wegen der strikten Monotonie links und rechts des Minimums x∗, folgt ausf(x1) = f(x2) notwendig x∗ ∈ (x1, x2).
11. Fuhre Nachteile und Vorteile von golden section search im Vergleich zu 271,273successive parabolic interpolation an.
golden section search ist nur linear, dafur aber sicher konvergent. successiveparabolic interpolation ist super-linear, dafur aber unsicher konvergent.
12. a) Warum ist lineare Interpolation einer Funktion f : R → R nicht sinnvoll,um ein Minimum von f zu bestimmen?
Geraden haben kein Minimum!

328 KAPITEL 6. OPTIMIZATION
b) Warum verwendet man inverse quadratische Interpolation zur Bestim-233,mung von Nullstellen von Funktionen f : R → R und (regulare) quadrati-sche Interpolation zur Bestimmung von Minima solcher Funktionen?
Inverse quadratische Interpolation umgeht die Probleme (regularer) qua-dratischer Interpolation bei der Bestimmung von Nullstellen: die interpo-lierende Parabel hat moglicherweise uberhaupt keine reellen Nullstellen, dieNullstellen sind fur Polynome hoheren Grades – falls uberhaupt – aufwandigzu bestimmen, und es ist unklar, welche Nullstelle von diesen aufwandig be-rechneten Nullstellen im nachsten Schritt weiter verwendet werden soll.(Regulare) quadratische Interpolation interpoliert die Funktion durch einquadratisches Polynom, dessen Extremum sich einfach und eindeutig be-stimmen und bei der nachsten Iteration verwenden laßt.
13. successive parabolic interpolation und Newton-Verfahren passen beide derzu minimierenden Funktion eine Parabel an, deren Minimum den Punktder nachsten Iteration ergibt.
a) Wie unterscheiden sich die beiden Verfahren in der Wahl des quadrati-273,275schen Polynoms?
Das successive parabolic interpolation Verfahren verwendet das Minimumder die drei Punkte interpolierenden Parabel, wahrend das Newton-Verfah-ren die zu minimierende Funktion selbst durch ihre Taylor-Parabel appro-ximiert.
b) Wie unterscheiden sich die Konvergenz-Raten der beiden Verfahren?273,275
successive parabolic interpolation konvergiert lokal super-linear, wahrendNewton-Verfahren lokal quadratisch konvergiert.
14. Warum minimiert das Newton-Verfahren eine quadratisches Polynom in275einer Iteration, wahrend das Newton-Verfahren eine quadratische Gleichungnicht in einer Iteration losen kann?
Das quadratische Polynom f(x) = ax2 + bx + c mit f ′(x) = 2ax + b undf ′′(x) = 2a hat fur a > 0 ein Minimum in x∗ = − b
2a. Fur beliebiges xo
liefert die erste Iteration mit x1 = xo − f ′(xo)/f′′(xo) = xo − 2axo+b
2a=
xo − xo − b2a
= x∗ das exakte Minimum: da das Newton-Verfahren dieFunktion durch ihr Taylor-Polynom approximiert, fallen hier Funktion undihre Approximation zusammen.Dagegen findet das Newton-Verfahren eine Nullstelle von beispielsweisef(x) = x2−2 fur xo ∈ Q nur in unendlich vielen Schritten: da das Newton-Verfahren die Funktion durch Tangenten approximiert, fallen hier quadra-tische Funktion und Tangente nie zusammen.
15. f : R → R sei zu minimieren. Welches Verfahren hat i.a.R. die angegebeneKonvergenz-Rate?

6.4. Review Questions – Antworten auf Verstandnisfragen 329
a) linear aber nicht super-linear konvergent 271
Das golden section search Verfahren ist linear aber nicht super-linear kon-vergent.
b) super-linear aber nicht quadratisch konvergent 273
successive parabolic interpolation ist super-linear aber nicht quadratischkonvergent.
c) quadratisch konvergent 275
Das Newton-Verfahren ist quadratisch konvergent.
16. f : Rn → R sei zu minimieren. Welches Verfahren hat i.a.R. die angegebeneKonvergenz-Rate?
a) linear aber nicht super-linear 277
Das steepest descent Verfahren ist linear aber nicht super-linear konvergent.
b) super-linear aber nicht quadratisch
Sekanten aktualisierende Verfahren sind i.A. super-linear aber nicht qua-dratisch konvergent.
c) quadratisch 278
Das Newton-Verfahren ist lokal quadratisch konvergent.
17. Welche der folgenden Verfahren sind i.a.R. super-linear konvergent?
a) successive parabolic interpolation zur Bestimmung der Minima einer Funk- 273tion
successive parabolic interpolation ist super-linear konvergent mit Konver-genz-Rate r ≈ 1.324.
b) golden section search zur Bestimmung der Minima einer Funktion 271
Angewandt auf unimodale Funktionen ist golden section search linear kon-vergent mit C ≈ 0.618.
c) Intervall-Halbierung zur Bestimmung der Nullstellen einer Funktion 226
Intervall-Halbierung ist linear konvergent mit C = 12.
d) Sekanten aktualisierende Verfahren zur Bestimmung der Minima einer 282Funktion von n Veranderlichen
Das BFGS-Verfahren ist i.a.R. super-linear konvergent.
e) steepest descent Verfahren zur Bestimmung der Minima einer Funktion 277von n Veranderlichen
Das steepest descent Verfahren ist linear-konvergent.

330 KAPITEL 6. OPTIMIZATION
18. a) Was ist die initiale ’Such-Richtung’ des conjugate gradient Verfahrens 283zur Bestimmung der Minima einer Funktion von n Veranderlichen?
Wegen der Initialisierung so = −∇f(xo) ist die initiale ’Such-Richtung’ desconjugate gradient Verfahrens gerade die des negativen Gradienten von fin xo.
b) Unter welchen Bedingungen geht das BFGS-Verfahren in derselben in-itialen ’Such-Richtung’ vor?
Wenn die Naherung Bo der Hesse-Matrix durch Bo = I initialisiert wird, soist so = −∇f(xo), so daß die initiale ’Such-Richtung’ des BFGS-Verfahrengerade die des negativen Gradienten von f in xo ist.
19. Eine quadratische Funktion von n Veranderlichen sei zu minimieren. Inmaximal wievielen Schritten konvergieren die folgenden Verfahren gegendas exakte Ergebnis bei beliebigen Startwerten?
a) conjugate gradient Verfahren284
Angewandt auf solche Funktionen erzielt das conjugate gradient Verfahrendas exakte Minimum in maximal n Schritten.
b) Newton-Verfahren278-281
Fur f(x) = 12xTAx − xTb + c mit positiv definitem A = AT = Hf (0)
konvergiert das Newton-Verfahren in einem Schritt gegen das Minimum:Wegen ∇f(x) = Ax−b ist zunachst die Losung x∗ von Ax = b kritischerPunkt. x∗ ist Minimum, da Hf (x
∗) = 12(A + AT ) = A positiv definit ist.
Bei Start mit xo ist so = x∗−xo Losung von Hf (xo)so = Aso = −∇f(xo) =−(Axo − b) = b−Axo = A(x∗ − xo), so daß x1 = xo + so = x∗ folgt.
c) BFGS-Verfahren mit exact line search282
Angewandt auf solche Funktionen erzielt das BFGS-Verfahren das exakteMinimum in maximal n Schritten.
20. a) Was ist ein kritischer Punkt einer nichtlinearen differenzierbaren Funk-262tion f : Rn → R ?
Ein Punkt Rn 3 x∗ mit ∇f(x∗) = 0 ist kritischer Punkt von f : Rn → R.
b) Sind kritische Punkte immer Minima oder Maxima?263
Die fur ein Extremum notwendige Bedingung ∇f(x∗) = 0 ist nicht hin-reichend! Kritische Punkte konnen auch Sattelpunkte oder Singularitatensein. Zur Unterscheidung sind Kriterien zweiter Ordnung anzulegen.
c) Wie ist der Typ eines kritischen Punktes x∗ zu bestimmen?263
Charakterisiere dazu die Hesse’sche Matrix Hf (x∗) von f . Wenn Hf (x
∗)positiv definit, dann ist x∗ ein Minimum. Wenn Hf (x
∗) negativ definit,dann ist x∗ ein Maximum.

6.4. Review Questions – Antworten auf Verstandnisfragen 331
21. Sei f : R2 → R eine Funktion zweier Variabler. Welche geometrische Bedeu- 262tung haben Lange und Richtung des Gradienten ∇f(x) = (∂f(x)
∂x1, ∂f(x)
∂x2)
T
von f in x ?
Aufgrund der Kettenregel fur Funktionen mehrerer Veranderlicher gilt furdie Richtungsableitung ∂f
∂s(x) von f in Richtung eines Richtungsvektors s
∂f
∂s(x) =
d f(x + ts)
dt
∣∣∣∣t=0
= ∇f(x)T s = ||∇f(x)||2 ||s||2 cos ∠(∇f(x), s)
Die Richtungsableitung ist also genau dann betragsmaßig maximal, wenns und ∇f(x) kollinear sind, und verschwindet, wenn s ⊥ ∇f(x). ∇f(x)ist also die Richtung der großten Veranderung von f in x und |∇f(x)| istgerade die betragsmaßig maximale Richtungsableitung.
22. a) Sei f : Rn → R eine Funktion von n Variablen. Wie heißt die Jacobi-Matrix des Gradienten ∇f(x) von f in x ?
Die Jacobi-Matrix J∇f (x) =(
∂ (∇f)i
∂xj(x))
i,jdes Gradienten ∇f(x) von f in
x ist die sogenannte Hesse-Matrix Hf = (∂2 f(x)∂xi∂xj
)i,j
der zweiten Ableitungen
von f in x.
b) Welche Eigenschaft hat diese Matrix, wenn f zweimal stetig differenzier- 263bar ist?
Laut Schwarz11 gilt ∂2 f(x)∂xi∂xj
= ∂2 f(x)∂xj∂xi
fur zweimal stetig differenzierbare Funk-
tionen f . Daher ist die Hesse-Matrix solcher Funktionen symmetrisch.
c) Welche zusatzliche Eigenschaft besitzt diese Matrix nahe lokaler Minima? 263
Nahe lokaler Minima ist die Hesse-Matrix positiv definit.
23. Das steepest descent Verfahren ist i.a.R. langsam, aber sicher konvergent. 277Wann scheitert es? Wann ist es schnell konvergent?
Das Verfahren kann scheitern, insofern als sich ohne Gegenmaßnahmen eineunendliche Schleife ergibt, sobald ∇f(xk) = 0.Das Verfahren findet ein Minimum in einer weiteren Iteration, falls derGradient orthogonal zur Suchrichtung ist.
24. Eine Funktion in n Variablen sei per Newton-Verfahren zu minimieren.
a) Unter welchen Bedingungen ist line search vorteilhaft? 279/280
Wenn der Start-Vektor weit entfernt von jedem Minimum gewahlt wurde,kann line search zu Anfang des Verfahrens insofern vorteilhaft sein, alsdadurch das gedampfte Newton-Verfahren robuster wird.
b) Unter welchen Bedingungen ist line search abtraglich? 279/280
???11 Hermann Amandus Schwarz (1843-1921) www-history.mcs.st-andrews.ac.uk/Biographies/Schwarz.html

332 KAPITEL 6. OPTIMIZATION
25. Viele iterative Verfahren zur Losung mehrdimensionaler nichtlinearer Pro-bleme ersetzen das nichtlineare durch eine Folge linearer Probleme, die aufMatrix-Faktorisierungen beruhen. Welches ist jeweils die beste Faktorisie-rung fur die folgenden Probleme? (Um Komplikationen auszuschließen, seiunterstellt, daß die Verfahren nahe genug an der Losung gestartet werden.)
a) fur das Newton-Verfahren zur Losung eines Systems von nichtlinearen240Gleichungen,
LU-Faktorisierung von Jf (xk)
b) fur das Newton-Verfahren, eine Funktion mehrerer Veranderlicher zu280minimieren,
Cholesky-Faktorisierung von Hf (xk), da Hf (xk) fur xk nahe der Losung x∗
positiv definit ist.
c) Gauß-Newton-Verfahren zur Losung eines nichtlinearen least squares Pro-285/286blems.
orthogonale Faktorisierung von J(xk) = Jr(xk), wobei r : Rn → Rm dieResidual-Funktion mit (r)i(x) = yi − f(ti,x) bezeichnet.
26. Sei f : Rn → Rn gegeben. Bekanntermaßen ist ||f(x)|| = 0 ⇐⇒ f(x) = 0Ist analog dazu, ||f(x)|| zu minimieren, aquivalent dazu, das System nicht-linearer Gleichungen f(x) = 0 zu losen?
Nur wenn sich bei der Minimierung von ||f(x)|| herausstellt, daß das Mi-nimum minx ||f(x)|| verschwindet, ist dies gleichbedeutend mit f(x) = 0.Falls minx ||f(x)|| > 0, hat f(x) = 0 keine Losung.Umgekehrt folgt aus f(x) = 0 immer minx ||f(x)|| = 0.
27. a) Warum wird im steepest descent-Verfahren zur Minimierung einer Funk-276/277,279 tion mehrerer Veranderlicher grundsatzlich ein line search parameter einge-
setzt?
line search parameter ist sinnvoll, weil der Gradient nur die Richtung aufdas Minimum, nicht aber die Schrittweite vorgibt.
b) Warum konnte man im Newton-Verfahren zur Minimierung einer Funk-280tion mehrerer Veranderlicher einen line search parameter einsetzen?
Der Einsatz eines line search parameters kann sinnvoll sein, um das Verfah-ren robuster zu machen, wenn es fern vom Minimum gestartet wird.
c) Worin sollte der Nutzen des line search parameters im Newton-Verfahrenzur Minimierung einer Funktion mehrerer Veranderlicher bestehen, wennein Minimum approximiert wird?
???
28. Wie kann man effizient testen, ob eine symmetrische Matrix A positiv de-263finit ist oder nicht?

6.4. Review Questions – Antworten auf Verstandnisfragen 333
Am einfachsten ist es, eine Cholesky-Faktorisierung zu versuchen. A ist po-sitiv definit genau dann, wenn diese gelingt. Alternativ berechnet man dieinertia von A, indem man A in die Form A = LDLT zu faktorisieren ver-sucht. A ist positiv definit genau dann, wenn die Anzahl verschwindenderoder negativer EWe verschwindet. Letztendlich (und am aufwandigsten)kann man alle EWe berechnen. A ist positiv definit genau dann, wennjeder EW positiv ist.
29. Warum wird nicht einfach das Broyden-Verfahren eingesetzt, um eine Funk- 281tion mehrerer Veranderlicher mit einem secant updating Verfahren zu mini-mieren, d.h. um eine Nullstelle des Gradienten zu finden?
Das Broyden-Verfahren erhalt die Symmetrie der Hesse-Matrix nicht, wasgoßenordnungsmaßig Speicherbedarf und Laufzeit verdoppelt.
30. Auf welches Verfahren reduziert sich die erste Iteration des BFGS-Verfah-rens, wenn die Naherung Bo der Hesse-Matrix initialisiert wird
a) durch die Einheitsmatrix I ? 282
Mit Boso = Iso = −∇f(xo) erfolgt der erste Schritt in Richtung des naga-tiven Gradienten, d.h. in Richtung des steepest descent.
b) durch die exakte Hesse-Matrix Hf (xo) im Start-Vektor? 282
Mit Boso = Hf (xo)so = −∇f(xo) stimmt der erste Schritt des BFGS-Ver-fahrens mit dem ersten Schritt des Newton-Vefahrens uberein.
31. Eine Funktion mehrerer Veranderlicher sei mit secant updating Verfahren zuminimieren. Warum ist es vorteilhafter, die Faktorisierung der approximier-ten Jacobi- oder Hesse-Matrizen als diese Matrizen selbst zu aktualisieren?
???
32. Eine Funktion mehrerer Veranderlicher mit dunn besetzter Hesse-Matrixsei zu minimieren. Ist dann ein secant updating wie das BFGS-Verfahrenoder das conjugate gradient-Verfahren vorteilhafter?
???
33. Wie unterscheiden sich conjugate gradient-Verfahren und truncated Newton-Verfahren, wenn das conjugate gradient-Verfahren im Newton-Verfahrenverwendet wird, um das lineare Gleichungssystem zu losen?
???
34. Fur welchen Typ nichtlinearer least squares Probleme konvergiert das Gauß-Newton-Verfahren quadratisch?
???
35. Fur welchen Typ nichtlinearer least squares Probleme konvergiert das Gauß-Newton-Verfahren sehr langsam oder garnicht?
???
36. Fur welche beiden Klassen von least squares Problemen ist die Approxi-mation der Hesse-Matrix durch das Gauß-Newton-Verfahren in der Losungexakt?
???

334 KAPITEL 6. OPTIMIZATION
37. Das Levenberg-Marquardt-Verfahren weist gegenuber dem Gauß-Newton-Verfahren einen zusatzlichen Term auf. Interpretiere diesen Term algebra-isch oder geometrisch.
???
38. Was sind Lagrange-Multiplikatoren und welche Bedeutung haben sie furrestringierte Optimierungsprobleme.
???
39. Eine Funktion f : Rn → R sei unter der Bedingung g(x) = 0 fur gegebenesg : Rn → Rm zu minimieren.
a) Wie sieht die Lagrange-Funktion fur dieses Problem aus?265
Die Lagrange-Funktion L : Rn × Rm → R mit L(x, λ) = f(x) + λTg(x)
hat den kritischen Punkt
[x∗
λ∗
]genau dann, wenn x∗ kritischer Punkt fur f
unter der Bedingung g(x) = 0 ist.
b) Wie sieht die notwendige Bedingung fur ein Minimum von f unter der265Bedingung g(x) = 0 aus?
Die notwendige Bedingung ist ∇L(x, λ) =
[∇f(x) + JT
g (x)λg(x)
]= 0.
40. Erlautere der Unterschied zwischen range space und null space Verfahrenfur die Losung von restringierten Optimierungsproblemen.
???
41. Was versteht man unter active set strategy zur Losung von Optimierungs-291problemen mit Ungleichungsbedingungen?
???
42. a) Konnen Algorithmen mit einer Komplexitat, die polynomial von derGroße der Eingabe-Daten abhangt, beliebig gegebene linear programmingproblems losen?
???
b) Hangt die Komplexitat des Simplex-Verfahrens polynomial vom Umfangder Eingabe-Daten ab?
Fur f : Rn → R mit f(x) = cTx und gegebenem c ∈ Rn unter der Be-dingung Ax = b fur gegebene m × n-Matrix A und b ∈ Rm muß dasSimplex-Verfahren im ungunstigsten Fall
(nm
)Ecken untersuchen. Seine
Komplexitat ist also nicht polynomial.

6.5. Exercises – Ubungsergebnisse 335
6.5 Exercises – Ubungsergebnisse
Verfahren fur eindimensionale unrestringierte Optimierungsprobleme:golden section search, successive parabolic interpolation und Newton-Verfahren
f(x) =f ′(x) =f ′′(x) =
x∗ =
< tests >reset
get f, f ′, f ′′, x∗
a = u = v = xo = b = w =golden parabolic Newton
a = u =x1 =
v = xk =x2 =
b = w =x∗ =
f(a) = f(u) =f(x1) =
f(v) = f(xk) =f(x2) =
f(b) = f(w) =f(x∗) =
n = #12
n =k =
stepε=
cont
1. Welche der folgenden Funktionen ist coercive ? 259
a) f(x, y) = x+ y + 2
f ist nicht coercive, da f(x,−x) = 2 fur alle x ∈ R, insbesondere also furx→∞, so daß lim||(x,−x)T ||→∞ f(x,−x) = 2.
b) f(x, y) = x2 + y2 + 2
f ist coercive, da mit√x2 + y2 = ||(x, y)T || → ∞ notwendig x2+y2 → +∞
und damit auch f(x, y) → +∞ gilt.
c) f(x, y) = x2 − 2xy + y2 = (x− y)2
f ist nicht coercive, da f(x, x) = 0 fur alle x ∈ R ist (vgl. a)).
d) f(x, y) = x4 − 2xy + y4
f ist coercive, da f(x, y) = (x4+y4)(1− 2xyx4+y4 ) wobei lim||(x,−x)T ||→∞
2xyx4+y4 =
0, so daß lim||(x,y)T ||→∞ f(x, y) = lim||(x,y)T ||→∞(x4 + y4) = +∞ folgt.
2. Welche der folgenden Funktionen sind konvex, strikt konvex oder nicht 260konvex?
a) f(x) = x2
f ist strikt konvex, da f(αx+(1−α)y) = (αx+(1−α)y)2
= (αx)2+2α(1−α)xy+((1−α)y)
2= αx2−α(1−α)x2+2α(1−α)xy+(1−α)y2−α(1−α)y2 =
12n ist die Gesamtzahl der Auswertungen von f , f ′ oder f ′′.

336 KAPITEL 6. OPTIMIZATION
αx2+(1−α)y2−α(1−α)(x2−2xy+y2) = αx2+(1−α)y2−α(1−α)(x−y)2 <αx2 + (1− α)y2 = αf(x) + (1− α)f(y) fur alle α ∈ (0, 1).
b) f(x) = x3
f ist nicht konvex, da etwa 0 = f(0) = f(13(−2) + 2
3(1)) 6< −2 = −8
3+ 2
3=
13f(−2) + 2
3f(1).
c) f(x) = e−x
f ist strikt konvex, da allgemein fur jede zweimal differenzierbare Funktionf mit f ′′(x) > 0 – zur Abkurzung sei hier z = (1−α)x+αy gesetzt – unterzweimaliger Anwendung des Mittelwertsatzes der Differentialrechnung
(1−α)f(x) + αf(y)− f(z) = (1−α) (f(x)− f(z)) + α (f(y)− f(z))
= (1−α)f ′(z1)(x− z) + αf ′(z2)(y − z) mit x ≤ z1 ≤ z ≤ z2 ≤ y
= (1−α)αf ′(z1)(x− y) + αf ′(z2)(1−α)(y − x)
= (1−α)α(y − x)(f ′(z2)− f ′(z1))= (1−α)α(y − x)f ′′(zo)(z2 − z1) > 0 mit z1 ≤ zo ≤ z2
gilt. Wegen f ′′(x) = (e−x)′′
= e−x > 0 ist f also strikt konvex.
d) f(x) = |x|f ist konvex, da f(αx+ (1− α)y) = |αx+ (1− α)y| ≤ α|x|+ (1− α)|y| =αf(x) + (1 − α)f(y) fur alle α ∈ [0, 1], aber nicht strikt konvex, da jaf(αx+ (1−α)y) = αx+ (1−α)y = αf(x) + (1−α)f(y) fur alle α ∈ [0, 1]und positive x und y gilt.
3. Untersuche anhand der Kriterien erster und zweiter Ordnung, ob 0 ein262,263Minimum der folgenden Funktionen ist.
a) f(x) = x2
f(x) = x2 hat in 0 ein Minimum, da f ′(0) = 2x|x=0 = 0 und f ′′(0) =2|x=0 = 2 > 0. Wegen f(x) ≥ 0 fur alle x ∈ R ist 0 globales Minimum.
b) f(x) = x3
Fur f(x) = x3 ist 0 wegen f ′(0) = 3x2|x=0 = 0 kritischer Punkt. Wegenf ′′(0) = 6x|x=0 = 0 ist die Hesse’sche Matrix aber singular. Da f eineungerade Funktion und 0 Nullstelle von f ist, kann 0 kein Minimum sein.
c) f(x) = x4
Fur f(x) = x4 ist 0 wegen f ′(0) = 4x3|x=0 = 0 kritischer Punkt. Wegenf ′′(0) = 12x2|x=0 = 0 ist die Hesse’sche Matrix aber singular. Da f(x) ≥ 0fur alle x ∈ R gilt und 0 einzige Nullstelle von f ist, ist 0 globales Minimumvon f .
d) f(x) = −x4
Wie in c) folgt, daß 0 globales Maximum von f ist.
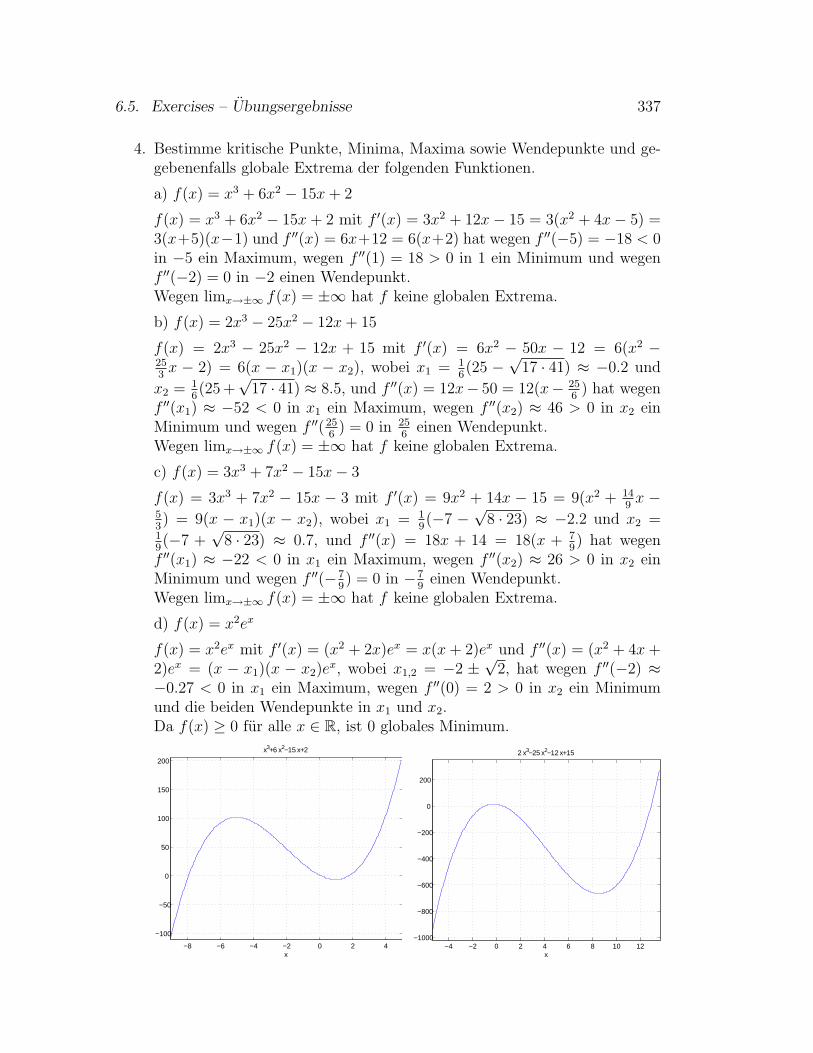
6.5. Exercises – Ubungsergebnisse 337
4. Bestimme kritische Punkte, Minima, Maxima sowie Wendepunkte und ge-gebenenfalls globale Extrema der folgenden Funktionen.
a) f(x) = x3 + 6x2 − 15x+ 2
f(x) = x3 + 6x2 − 15x+ 2 mit f ′(x) = 3x2 + 12x− 15 = 3(x2 + 4x− 5) =3(x+5)(x−1) und f ′′(x) = 6x+12 = 6(x+2) hat wegen f ′′(−5) = −18 < 0in −5 ein Maximum, wegen f ′′(1) = 18 > 0 in 1 ein Minimum und wegenf ′′(−2) = 0 in −2 einen Wendepunkt.Wegen limx→±∞ f(x) = ±∞ hat f keine globalen Extrema.
b) f(x) = 2x3 − 25x2 − 12x+ 15
f(x) = 2x3 − 25x2 − 12x + 15 mit f ′(x) = 6x2 − 50x − 12 = 6(x2 −253x − 2) = 6(x − x1)(x − x2), wobei x1 = 1
6(25 −
√17 · 41) ≈ −0.2 und
x2 = 16(25 +
√17 · 41) ≈ 8.5, und f ′′(x) = 12x− 50 = 12(x− 25
6) hat wegen
f ′′(x1) ≈ −52 < 0 in x1 ein Maximum, wegen f ′′(x2) ≈ 46 > 0 in x2 einMinimum und wegen f ′′(25
6) = 0 in 25
6einen Wendepunkt.
Wegen limx→±∞ f(x) = ±∞ hat f keine globalen Extrema.
c) f(x) = 3x3 + 7x2 − 15x− 3
f(x) = 3x3 + 7x2 − 15x − 3 mit f ′(x) = 9x2 + 14x − 15 = 9(x2 + 149x −
53) = 9(x − x1)(x − x2), wobei x1 = 1
9(−7 −
√8 · 23) ≈ −2.2 und x2 =
19(−7 +
√8 · 23) ≈ 0.7, und f ′′(x) = 18x + 14 = 18(x + 7
9) hat wegen
f ′′(x1) ≈ −22 < 0 in x1 ein Maximum, wegen f ′′(x2) ≈ 26 > 0 in x2 einMinimum und wegen f ′′(−7
9) = 0 in −7
9einen Wendepunkt.
Wegen limx→±∞ f(x) = ±∞ hat f keine globalen Extrema.
d) f(x) = x2ex
f(x) = x2ex mit f ′(x) = (x2 + 2x)ex = x(x+ 2)ex und f ′′(x) = (x2 + 4x+2)ex = (x − x1)(x − x2)e
x, wobei x1,2 = −2 ±√
2, hat wegen f ′′(−2) ≈−0.27 < 0 in x1 ein Maximum, wegen f ′′(0) = 2 > 0 in x2 ein Minimumund die beiden Wendepunkte in x1 und x2.Da f(x) ≥ 0 fur alle x ∈ R, ist 0 globales Minimum.
−8 −6 −4 −2 0 2 4
−100
−50
0
50
100
150
200
x
x3+6 x2−15 x+2
−4 −2 0 2 4 6 8 10 12−1000
−800
−600
−400
−200
0
200
x
2 x3−25 x2−12 x+15

338 KAPITEL 6. OPTIMIZATION
−4 −3 −2 −1 0 1 2 3
−40
−20
0
20
40
60
x
3 x3+7 x2−15 x−3
−7 −6 −5 −4 −3 −2 −1 0 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
x
x x exp(x)
5. Bestimme kritische Punkte, Minima, Maxima sowie Sattelpunkte und ge-263gebenenfalls globale Extrema der folgenden Funktionen.
a) f(x, y) = x2 − 4xy + y2
f(x, y) = x2 − 4xy + y2 hat wegen ∇f(x, y) =
(2x− 4y2y − 4x
)nur den einen
kritischen Punkt 0. Nun ist Hf (x, y) =
(2 −4
−4 2
)indefinit, da Hf wegen
det(H − λI) = λ2 − 4λ − 12 = (λ + 2)(λ − 6) einen negativen und einenpositiven EW hat. Also ist 0 ein Sattelpunkt.Wegen limx→±∞ f(x, x) = limx→±∞−2x2 = −∞ und limx→±∞ f(x,−x) =limx→±∞ 6x2 = +∞ hat f keine globalen Extrema.
b) f(x, y) = x4 − 4xy + y4
f(x, y) = x4 − 4xy + y4 hat wegen ∇f(x, y) = 4
(x3 − yy3 − x
)nur die beiden
kritischen Punkte x∗1 =
(1
−1
)und x∗2 =
(−1
1
). Nun ist Hf (x, y) =
4
(3x2 −1−1 3y2
), speziell also Hf (x
∗1) = Hf (x
∗2) =
(12 −4−4 12
)= H. Wegen
det(H−λI) = λ2−24λ+128 = (λ−8)(λ−16) ist H positiv definit. Dahersind x∗1 und x∗2 die einzigen Minima und wegen f(x∗1) = 6 = f(x∗2) zugleichglobale Minima.
c) f(x, y) = 2x3 − 3x2 − 6xy(x− y − 1)
Fur f ist ∇f(x, y) = 6
(x2 − x− 2xy + y2 + y
2xy − x2 + x
)= 0 ⇐⇒ x2 − x− 2xy +
y2+y = 0 und 2xy−x2+x = 0. Addition liefert y(y+1) = 0 und so die vier
kritischen Punkte x∗1 =
(00
), x∗2 =
(10
), x∗3 = −
(01
)und x∗4 = −
(11
).
Weiter ist Hf (x, y) = 6
(2x− 2y − 1 2y − 2x+ 12y − 2x+ 1 2x
).

6.5. Exercises – Ubungsergebnisse 339
x∗1 ist ein Sattelpunkt, da Hf (0, 0) =
(−6 6
6 0
)mit det(Hf (0, 0) − λI) =
λ2 + 6λ − 36 = (λ − 3(−1 −√
5))(λ − 3(−1 +√
5)) einen positiven undeinen negativen EW hat und somit indefinit ist.
x∗2 ist ein Minimum, da Hf (1, 0) =
(6 −6
−6 12
)mit det(Hf (1, 0) − λI) =
λ2 − 18λ + 36 = (λ − 3(3 −√
5))(λ − 3(3 +√
5)) zwei positive EWe hatund somit positiv definit ist.
x∗3 ist ein Sattelpunkt, da Hf (0,−1) =
(6 −6
−6 0
)mit det(Hf (1, 0)−λI) =
λ2 − 6λ− 36 = (λ− 3(1−√
5))(λ− 3(1 +√
5)) einen positiven und einennegativen EW hat und somit indefinit ist.
x∗4 ist ein Maximum, da H=Hf (−1,−1)=
(−6 6
6 −12
)mit det(H−λI) =
λ2 + 18λ+ 36=(λ− 3(−3−√
5))(λ− 3(−3 +√
5)) zwei negative EWe hatund somit negativ definit ist.Wegen limx→±∞ f(x, y) = limx→±∞(2x3 + 3x2) = ±∞ hat f keine globalenExtrema.
d) f(x, y) = (x− y)4 + x2 − y2 − 2x+ 2y + 1
Fur f ist ∇f(x, y) =
(4(x− y)3 + 2x− 2−4(x− y)3 − 2y + 2
)= 0 ⇐⇒ 2(x−y)3 +x−1 =
0 und −2(x − y)3 − y + 1 = 0. Addition liefert x = y und Einsetzenx = 1 = y. Daher ist x∗ = (1, 1)T der einzige kritische Punkt. Weiter
ist Hf (x, y) =
(12(x− y)2 + 2 −12(x− y)2
−12(x− y)2 12(x− y)2 − 2
)und speziell Hf (x
∗) =(2 00 −2
). Wegen der beiden EWe ±2 ist Hf (x
∗) indefinit. Daher ist x∗
ein Sattelpunkt.Da f außer einem Sattelpunkt keine weiteren kritischen Punkte hat, hat fauch keine globalen Extrema. (Zum einen hat f kein globales Maximum,weil etwa limx→±∞ f(2x, x) = limx→±∞(x4 + 3x2− 2x+ 1) = +∞ gilt; zumanderen hat f auch kein globales Minimum, weil etwa limx→+∞ f(x, x+1) =limx→+∞ (1 + x2− (x+ 1)2 + 2x− 2(x+ 1) + 1) = limx→+∞(3− 2x) = −∞gilt.)
6. Bestimme und klassifiziere die kritischen Punkte der Lagrange-Funktion 265/266folgender restringierter Optimierungsprobleme.
a) f(x, y) = x2 + y2 wobei g(x, y) = x+ y − 1 = 0
Zunachst gilt y = 1−x und daher f(x, 1−x) = x2+(1−x)2 = 2x2−2x+1 =2(x2 − x+ 1
2) mit Minimum fur x∗ = 1
2und somit y∗ = 1
2.
Standardmaßig ergibt sich ∇f(x, y) =
(∂f/∂x∂f/∂y
)=
(2x2y
)und Jg(x, y) =

340 KAPITEL 6. OPTIMIZATION
(1, 1). Dann ist ∇L(x, y, λ) =
(∇f(x, y) + JT
g (x, y)λg(x, y)
)=
2x+ λ2y + λx+ y − 1
=
0 mit der Losung x∗ = y∗ = 12
und λ∗ = −1. Weiterhin ist Hf (x, y) =(2 00 2
)= 2 I und Hg(x, y) = 0. Damit ist B(x, y, λ) = Hf (x, y) +
λHg(x, y) = 2 I = B(x∗, y∗, λ∗) sogar positiv definit und z∗ = (x∗, y∗)T =(0.5, 0.5)T ist bedingtes Minimum von f .Der Null-Raum von Jg(x, y) wird etwa von zo = (−1, 1)T aufgespannt.Auch wegen zT
o B(x∗, y∗, λ∗)zo = 2zTo zo = 2||zo||22 > 0 ist z∗ bedingtes Mini-
mum von f .
b) f(x, y) = x3 + y3 wobei g(x, y) = x+ y − 1 = 0
Zunachst gilt y = 1−x und daher f(x, 1−x) = x3 +(1−x)3 = 1−3x+3x2
mit Minimum x∗ = 12
und somit y∗ = 12.
Standardmaßig ergibt sich ∇f(x, y) =
(∂f/∂x∂f/∂y
)=
(3x2
3y2
)und Jg(x, y) =
(1, 1). Dann ist ∇L(x, y, λ) =
(∇f(x, y) + JT
g (x, y)λg(x, y)
)=
3x2 + λ3y2 + λx+ y − 1
=
0 mit der Losung x∗ = y∗ = 12
und λ∗ = −34. Weiterhin ist Hf (x, y) =(
6x 00 6y
)und Hg(x, y) = 0 sowie B(x, y, λ) = Hf (x, y) + λHg(x, y) =
6
(x 00 y
). Insbesondere ist also B(x∗, y∗, λ∗) = 3 I positiv definit und z∗ =
(x∗, y∗)T = (0.5, 0.5)T ist bedingtes Minimum von f .Der Null-Raum von Jg(x, y) wird etwa von zo = (−1, 1)T aufgespannt.Auch wegen zT
o B(x∗, y∗, λ∗)zo = 3zTo zo = 3||zo||22 > 0 ist z∗ bedingtes
Minimum von f .
c) f(x, y) = 2x+ y wobei g(x, y) = x2 + y2 − 1 = 0
Zunachst gilt y = ±√
1− x2 und daher f(x,±√
1− x2) = 2x ±√
1− x2
mit kritischen Punkten x∗ = ±25
√5 und somit y∗ = ±1
5
√5.
Standardmaßig ergibt sich ∇f(x, y) =
(∂f/∂x∂f/∂y
)=
(21
)und Jg(x, y) =
(2x, 2y). Dann ist∇L(x, y, λ) =
(∇f(x, y) + JT
g (x, y)λg(x, y)
)=
2 + 2xλ1 + 2yλ
x2 + y2 − 1
.
Aus ∇L(x, y, λ) = 0, insbesondere also aus2y + 2xyλ = 0x+ 2xyλ = 0
folgt x = 2y
sowie y∗1,2 = ±15
√5 und x∗1,2 = ±2
5
√5 und λ∗1,2 = ∓1
2
√5. Weiterhin ist
Hf (x, y) = 0 und Hg(x, y) = 2 I sowie B(x, y, λ) = Hf (x, y) + λHg(x, y) =2λ I. Insbesondere ist also B(x∗1, y
∗1, λ
∗1) = −2
5
√5 I negativ definit und da-

6.5. Exercises – Ubungsergebnisse 341
mit z∗1 = (x∗1, y∗1)
T ein Maximum. Dagegen ist B(x∗2, y∗2, λ
∗2) = 2
5
√5 I positiv
definit und damit z∗2 = (x∗2, y∗2)
T ein Minimum.
d) f(x, y) = x2 + y2 wobei g(x, y) = x y2 − 1 = 0
Zunachst gilt x = y−2 und daher hat f(y−2, y) = y−4 + y2 die beiden kriti-schen Punkte z∗1,2 = (x∗, y∗1,2)
T mit x∗ = 13√2
= 12
3√
4 und y∗1,2 = ± 6√
2.
Standardmaßig ergibt sich ∇f(x, y) =
(∂f/∂x∂f/∂y
)=
(2x2y
)und Jg(x, y) =
(y2, 2xy). Dann ist∇L(x, y, λ) =
(∇f(x, y) + JT
g (x, y)λg(x, y)
)=
2x+ y2λ2y + 2xyλx y2 − 1
.
Aus ∇L(x, y, λ) = 0 folgt x∗ = 12
3√
4 und y∗ = ± 6√
2 sowie λ∗ = − 3√
2. Wei-
terhin ist Hf (x, y) = 2 I und Hg(x, y) =
(0 2y2y 2x
)sowie B(x, y, λ) =
Hf (x, y) + λHg(x, y) =
(2 2yλ
2yλ 2 + 2xλ
). Speziell hat B(x∗, y∗1,2, λ
∗) =(2 ∓2
√2
∓2√
2 0
)die beiden EWe λ1,2 = 1 ± 3 und ist damit indefinit, so
daß es sich bei z∗1,2 = (x∗, y∗1,2)T um Sattelpunkte handelt.
7. Zeige: v∗ = (2.5, 1.5,−1)T ist Minimum der Funktion f(v) = f(x, y, z) =x2 − 2x+ y2 − z2 + 4z, wobei g(v) = g(x, y, z) = x− y + 2z − 2 = 0.
Mit ∇f(v) =
∂f∂x∂f∂y∂f∂z
=
2x− 22y
4− 2z
und Jg(v) =(
∂g∂x, ∂g
∂y, ∂g
∂z
)= (1,−1, 2)
hat ∇L(x, y, z, λ) =
(∇f + JT
g λg(v)
)=
2x− 2 + λ2y − λ4− 2z + 2λx− y + 2z − 2
= 0 die Losung
λ∗ = −3 und v∗ = (x∗, y∗, z∗)T = (5/2,−3/2,−1)T . Der kritische Punktv∗ ist zu klassifizieren. In B(x, y, z, λ) = B(v, λ) = Hf (v) + λHg(v) ist
Hf (v) =
∂2f
∂x∂x∂2f∂x∂y
∂2f∂x∂z
∂2f∂y∂x
∂2f∂y∂y
∂2f∂y∂z
∂2f∂z∂x
∂2f∂z∂y
∂2f∂z∂z
= diag(2, 2,−2) und Hg(v) = 0. Also gilt
B(v, λ) = diag(2, 2,−2). Der Null-Raum (Jg(v∗)) = v : Jg(v
∗)v = 0von Jg(x, y, z) = (1,−1, 2) = Jg(x
∗, y∗, z∗) wird von etwa n1 = (1, 1, 0)T
und n2 = (2, 0,−1)T aufgespannt. Mit der Matrix Z = (n1,n2) der Basis-
Vektoren ist ZTBZ = ZTB(v∗, λ∗)Z =
(4 44 6
)mit den beiden positiven
EWen 5±√
17 positiv definit. Also ist v∗ ein Minimum.
8. Sei f : R2 → R durch f(z) = f(x, y) = 12(x2 − y)2 + 1
2(1− x)2 gegeben.

342 KAPITEL 6. OPTIMIZATION
a) In welchem Punkt nimmt f ein Minimum an?
Wegen f(x, y) ≥ 0 nimmt f in z∗ = (1, 1)T mit f(z∗) = 0 ein Minimum an.
b) Fuhre eine Iteration des Newton-Verfahrens mit zo = (2, 2)T durch.
Zunachst ist ∇f(z) = ∇f(x, y) =
((x2 − y)2x+ x− 1
y − x2
)und Hf (z) =
Hf (x, y) =
(6x2 − 2y + 1 −2x
−2x 1
). Losung von Hf (zo)so =
(21 −4−4 1
)so =(
−92
)= −∇f(zo) ist so =
(−0.2
1.2
)und damit z1 = zo + so =
(1.83.2
).
c) In welcher Hinsicht ist dies ein guter Schritt?
??? d) In welcher Hinsicht ist dies ein schlechter Schritt?
??? 9. Sei f : Rn → R durch f(x) = 12xTAx − xTb + c gegeben, wobei A eine
symmetrische, positiv definite n× n-Matrix, b ∈ Rn und c ∈ R ist.
a) Zeige: Das Newton-Vefahren konvergiert in einem Schritt fur jeden Start-Vektor xo.
Wegen ∇f(x) = Ax−b ist zunachst die Losung x∗ von Ax = b kritischerPunkt. x∗ ist Minimum, da Hf (x
∗) = 12(A + AT ) = A positiv definit ist.
Bei Start mit xo ist so = x∗−xo Losung von Hf (xo)so = Aso = −∇f(xo) =−(Axo − b) = b−Axo = A(x∗ − xo), so daß x1 = xo + so = x∗ folgt.
b) Sei x∗ das Minimum und der Start-Vektor xo so gewahlt, daß xo−x∗ einEV von A ist. Was passiert dann, wenn man das steepest descent Verfahreneinsetzt?
Sei 0 6= xo − x∗ ein EV zum EW λ von A, d.h. A(xo − x∗) = λ(xo − x∗).Wegen Ax∗ = b aus a) gilt also Axo − b = λ(xo − x∗).Wegen ∇f(x) = Ax − b ist in der ersten Iteration das αo zu bestimmen,das g(α) = f(xo + αso) = f(xo − α∇f(xo)) = f(xo − α(Axo − b)) =
f(xo − αλ(xo − x∗)) minimiert. Dann ergibt sich die nachste Naherung x1
zu x1 = xo +αoso = xo−αo∇f(xo) = xo−αo(Axo−b) = xo−αo∇f(xo) =xo − αoλ(xo − x∗). Da A positiv definit ist, gilt λ 6= 0.
Mit λ 6= 0 ist d gdα
= −∇f(xo − αλ(xo − x∗))Tλ(xo − x∗) = −(Axo −
αλA(xo−x∗)−b)Tλ(xo−x∗) = −(λ(xo−x∗)−αλ2(xo−x∗))
Tλ(xo−x∗) =
−λ(1−αλ)(xo−x∗)Tλ(xo−x∗) = −λ2(1−αλ)||xo−x∗||22 = 0 ⇐⇒ αo = 1λ.
Damit folgt x1 = xo + αoso = xo − 1λλ(xo − x∗) = x∗.
10. a) Zeige: Eine stetige, auf Rn coercive Funktion f : Rn → R hat ein globales259Minimum in Rn. (Hinweis: Sei M = f(0) in der Definition von coercive.Betrachte die abgeschlossene, beschrankte Menge x ∈ Rn : ||x|| ≤ r.)Laut Definition gibt es zu M = f(0) ein r, so daß f(x) ≥ M fur allex 6∈ B = x : ||x|| ≤ r. Auf der abgeschlossenen und beschrankten Menge

6.5. Exercises – Ubungsergebnisse 343
B 6= ∅ hat f ein Minimum x∗. Also gilt erstens f(x∗) ≤ f(x) fur allex ∈ B. Da zweitens f(x∗) ≤ M ≤ f(x) fur alle ubrigen x 6∈ B gilt, ist x∗
ein globales Minimum.
b) Verallgemeinere das obige Resultat auf Funktionen, die auf beliebigen 259abgeschlossenen, beschrankten Mengen S ⊂ Rn coercive sind.
Fur f : Rn ⊃ S → R mit beliebigem xo ∈ S gibt es laut Definition zuM = 2 f(xo) ein r, so daß f(x) ≥M fur alle x ∈ S\B = x ∈ S : ||x|| > rmit B = x : ||x|| ≤ r. Nun ist xo ∈ S ∩ B, da sich sonst aus xo ∈ S \ Bder Widerspruch f(xo) = 1
2M 6≥ M ergibt. Auf der abgeschlossenen und
beschrankten Menge S ∩ B 6= ∅ hat f ein Minimum x∗. Also gilt erstensf(x∗) ≤ f(x) fur alle x ∈ S ∩ B. Da zweitens f(x∗) ≤ f(xo) < M ≤ f(x)fur alle ubrigen x ∈ S \B gilt, ist x∗ ein globales Minimum.
11. Zeige: Wenn eine stetige Funktion f : Rn ⊃ S → R ein nicht-leeres, ab- 260geschlossenes und beschranktes sublevel set Lγ = x ∈ S : f(x) ≤ γ hat,dann hat f ein globales Minimum auf S.
Die stetige Funktion f hat auf der abgeschlossenen und beschrankten MengeLγ 6= ∅ ein Minimum x∗. Also gilt erstens f(x∗) ≤ f(x) ≤ γ fur alle x ∈ Lγ
und zweitens f(x∗) ≤ γ < f(x) fur alle x 6∈ Lγ. Damit ist x∗ ein globalesMinimum.
12. a) Zeige: Ein lokales Minimum x einer konvexen Funktion f auf einer kon- 261vexen Menge S ⊂ Rn ist ein globales Minimum. (Hinweis: Angenommen,x ist kein globales Minimum. Sei y ∈ S mit f(y) < f(x). Betrachte danndie Strecke von x nach y.)
Angenommen, x ist kein globales Minimum. Dann existiert ein y ∈ S mitf(y) < f(x). Aufgrund der Konvexitat von f gilt f(αx + (1 − α)y) ≤αf(x) + (1 − α)f(y). Damit liegen in jeder Umgebung des Minimumsx Punkte αx + (1 − α)y ∈ S mit kleinerem Funktionswert als f(x) imWiderspruch zur Voraussetzung.
b) Zeige: Ein lokales Minimum x einer strikt konvexen Funktion f auf 261einer konvexen Menge S ⊂ Rn ist das einzige globale Minimum. (Hinweis:Angenommen, es gibt zwei Minima x und y. Betrachte wieder die Streckevon x nach y.)
Angenommen, es gibt zwei (lokale) Minima x ∈ S und y ∈ S. Sei o.B.d.A.wie oben f(y) < f(x). Dann liegen wegen der strikten Konvexitat von fin jeder Umgebung von x wieder Punkte αx + (1− α)y ∈ S mit kleineremFunktionswert als f(x) im Widerspruch zur Voraussetzung.
13. Eine Funktion f : Rn → R heißt quasi-konvex bzw. strikt quasi-konvex auf 270einer konvexen Menge S ⊂ Rn, wenn f(αx+ (1−α)y) ≤ maxf(x), f(y)

344 KAPITEL 6. OPTIMIZATION
bzw. f(αx + (1 − α)y) < maxf(x), f(y) fur alle x,y ∈ S, x 6= y undalle α ∈ (0, 1) gilt.
Sei f : R → R gegeben mit Minimum auf [a, b]. Zeige: f ist unimodal aufauf [a, b] genau dann, wenn f strikt quasi-konvex auf [a, b] ist.
Sei x∗ Minimum von f auf [a, b] und f unimodal auf [a, b]. Um zu zeigen,daß f strikt quasi-konvex auf [a, b], sind fur beliebige x1, x2 ∈ [a, b] mito.B.d.A. x1 < x2 und z = αx1 +(1−α)x2 fur beliebige α ∈ (0, 1) vier Fallezu unterscheiden:
i x1 < z < x2 < x∗ impliziert f(z) < f(x1) ≤ maxf(x1), f(x2)ii x1 < z < x∗ < x2 impliziert f(z) < f(x1) ≤ maxf(x1), f(x2)iii x1 < x∗ < z < x2 impliziert f(z) < f(x2) ≤ maxf(x1), f(x2)iv x∗ < x1 < z < x2 impliziert f(z) < f(x2) ≤ maxf(x1), f(x2)
Sei nun f strikt quasi-konvex auf [a, b]. Dann ist f unimodal auf [a, b],i weil f links von x∗ strikt monoton fallend ist: fur x1 < x2 < x∗ ist
x2 = αx1 + (1−α)x∗ fur geeignetes α ∈ (0, 1). Laut Voraussetzunggilt f(x∗) ≤ f(x2) < maxf(x1), f(x∗) und damit f(x2) < f(x1).
ii weil f rechts von x∗ strikt monoton wachsend ist: fur x∗ < x1 < x2
ist x1 = αx∗+(1−α)x2 fur geeignetes α ∈ (0, 1). Laut Voraussetzunggilt f(x∗) ≤ f(x1) < maxf(x∗), f(x2) und damit f(x1) < f(x2).
14. Zeige: Die Hesse-Matrix der Lagrange-Funktion ist nicht positiv definit.265???
15. Sei f(z) = f(x, y) = x2+y2 unter der Bedingung g(z) = g(x, y) = x+y−1 =2910 zu minimieren. Zeige, daß fur die zρ der penalty method limρ→∞ zρ = z∗
gilt.
Fur φρ(z) = φρ(x, y) = f(x, y) + ρ2g2(x, y) = x2 + y2 + ρ
2(x + y − 1)2 ist
∇φρ(x, y) =
((2 + ρ)x+ ρy − ρ(2 + ρ)y + ρx− ρ
)= 0 nur fur z∗ρ =
(x∗ρy∗ρ
)= 1
2ρ
1+ρ
(11
)und
es gilt limρ→∞ zρ = 12
(11
)= z∗. Im Grenzubergang ergibt aich also das
schon in Ex 6.6 a) ermittelte bedingte Minimum von f .
16. Die Funktion f(z) = f(x, y) = x2 + y2 sei unter der Bedingung g(z) =g(x, y) = y2 − (x− 1)3 = 0 zu minimieren.
a) Warum scheitert die Anwendung von Lagrange-Multiplikatoren?265/266
∇L(z, λ) =
[∇f(z) + JT
g (z)λg(z)
]=
2x− 3(x− 1)2λ2y + 2yλ
y2 − (x− 1)3
= 0 hat keine (reel-
len) Losungen: falls namlich λ = −1, so hat 2x+3(x−1)2 = 3(x2− 43x+1) =
3(x− x1)(x− x2) nur die beiden komplexen Nullstellen x1,2 = 13(2± i
√5).
Aus λ 6= −1 folgt dagegen y = 0 sowie x = 1 im Widerspruch zu 2x = 0.Dasselbe ergibt sich, wenn man g in f einsetzt. Dann ist namlich h(x) =

6.5. Exercises – Ubungsergebnisse 345
f(x, (x−1)3/2) = x2+(x−1)3 zu minimieren. Wegen h′(x) = 2x+3(x−1)2 =3(x2 − 4
3x+ 1) = 3(x− x1)(x− x2) mit x1,2 = 1
3(2± i
√5) hat h aber kein
Minimum.
b) Wende die penalty method an, d.h. lose min(x,y) φρ(x, y) mit φρ(x, y) =f(x, y) + 1
2ρg2(x, y). Finde einen geschlossenen Ausdruck fur die Losung
und fuhre den Grenzubergang ρ→∞ durch.
Fur φρ(z) = φρ(x, y) = x2+y2+ ρ2(y
4−2(x−1)3y2+(x−1)6) ist∇φρ(x, y) =(2x+ 3ρ(x− 1)5 − 3ρ(x− 1)2y2
2y + 2ρy3 − 2ρ(x− 1)3y
)= 0 ⇐⇒ 2x+ 3ρ(x− 1)5 − 3ρ(x− 1)2y2 = 0
y(1 + ρy2 − ρ(x− 1)3) = 0.
Falls y 6= 0 ... Falls dagegen y = 0???
17. Lose das linear programming Problem, f(x, y) = −3x − 2y unter den Be-dingungen 5x+ y ≤ 6, 3x+ 4y ≤ 6, 4x+ 3y ≤ 6, x ≥ 0, y ≥ 0.
a) Wieviele Ecken hat die feasible Region? 293/294
Zunachst wird das linear programming Problem durch Einfuhrung soge-nannter Schlupf-Variablen u, v und w in die Standard-Form uberfuhrt:f(z) = cTz mit c = (−3,−2, 0, 0, 0)T und z = (x, y, u, v, w)T unter der
Bedingung Az =
5 1 1 0 03 4 0 1 04 3 0 0 1
z =
666
= b und z ≥ 0. Dann ist A
eine m×n-Matrix, und c sowie z sind Vektoren im Rn mit m = 3 < 5 = n.Die feasible region im Rn hat somit maximal
(nm
)=(53
)= 10 Ecken: wahle
namlich je n − m = 2 nonbasic variables, setze diese Null und lose dieGleichkeitsrandbedingungen. Falls die Losung z ≥ 0, ist z eine Ecke.
1. Losung der Form z = (0, 0, ∗, ∗, ∗)T ist Ecke z1 = (0, 0, 6, 6, 6)T .2. Losung der Form z = (0, ∗, 0, ∗, ∗)T ist z = 6(0, 1, 0,−3,−2)T , keine Ecke.3. Losung der Form z = (0, ∗, ∗, 0, ∗)T ist Ecke z2 = 1
2(0, 3, 9, 0, 3)T .
4. Losung der Form z = (0, ∗, ∗, ∗, 0)T ist z = (0, 2, 6,−2, 0)T , keine Ecke.5. Losung der Form z = (∗, 0, 0, ∗, ∗)T ist Ecke z3 = 6
5(1, 0, 0, 2, 1)T .
6. Losung der Form z = (∗, 0, ∗, 0, ∗)T ist z = (2, 0,−4, 0,−2)T , keine Ecke.7. Losung der Form z = (∗, 0, ∗, ∗, 0)T ist z = 1
2(4, 0,−3, 3, 0)T , keine Ecke.
8. Losung der Form z = (∗, ∗, 0, 0, ∗)T ist z = 617
(3, 2, 0, 0,−1)T , keine Ecke.9. Losung der Form z = (∗, ∗, 0, ∗, 0)T ist Ecke z4 = 6
11(2, 1, 0, 1, 0)T .
10. Losung der Form z = (∗, ∗, ∗, 0, 0)T ist Ecke z5 = 67(1, 1, 1, 0, 0)T .
b) Berechne das Minimum der Funktionswerte f(zk) in den Ecken zk der 293feasible Region, da die Losung in einer der Ecken angenommen wird.
Wegen f(z1) = f(0, 0) = 0, f(z2) = f(0, 1.5) = −3, f(z3) = f(1.2, 0) =−4.2, f(z4) = f(12
11, 6
11) = −48
11≈ −4.36 und f(z5) = f(6
7, 6
7) = −30
7≈
−4.29 nimmt f das zulassige Minimum in z4 an.
c) Bestimme die Losung graphisch. 295

346 KAPITEL 6. OPTIMIZATION
x
y
5x+ y = 6
3x+ 4y = 6
4x+ 3y = 6
f(z) = f(x, y)
= −3x− 2y = d
d∗ = − 4811
d=d∗+3 d=d∗ d=d∗−3
18. Wie ist das linear programming Problem aus Ex 6.17 in der Standard-Form293darzustellen?
Es ist f(z) = f(x, y) = cTz mit c = −(
32
)und z =
(xy
)unter der
Bedingung Az ≤ b und z ≥ 0 mit Az =
5 13 44 3
z ≤
666
= b zu
minimieren. Die Standard-Form findet sich in Ex 6.17 a).

6.6. Computer Problems – Rechner-Problem-Losungen 347
6.6 Computer Problems –
Rechner-Problem-Losungen
Verfahren fur mehrdimensionale unrestringierte Optimierungsprobleme:steepest descent, Newton-Verfahren und gedampftes Newton-Verfahren
f(x) = f(x, y, z) =
< tests > get f , ∇f , Hf etc reset
x∗=
x∗y∗z∗
=
xo =
xo
yo
zo
=
∇f(x)=
∂f∂x∂f∂y∂f∂z
=
Hf (x) =
∂2f∂x2
∂2f∂x∂y
∂2f∂x∂z
∂2f∂x∂y
∂2f∂y2
∂2f∂y∂z
∂2f∂x∂z
∂2f∂y∂z
∂2f∂2z
=
Hf (x) =
Nelder-Mead steep. desc.13 Newton BFGS conj. grad. truncated
k = xk =
xk
yk
zk
=
ε =step cont
reset k, xk etc.
f(xk) =???
1. a) f(x) = x2−2x+2 = 1+(x−1)2 hat ein globales Minimum in x∗ = 1. Furwelchen Bereich gilt fl(f(x)) = f(x∗) ? Wie erklart sich dieses Phanomen?
Fur |ε| < √εmach gilt ja fl(f(1 + ε)) = fl
(fl((1 + ε)2)− 2(1 + ε) + 2
)=
fl(1 + 2ε− 2ε) = 1.
b) f(x) = 0.5−xe−x2hat ein globales Minimum in x∗ = 1
2
√2. Fur welchen
Bereich gilt fl(f(x)) = f(x∗) ? Wie erklart sich dieses Phanomen?
Wegen f(x) = 12− xe−x2
, f ′(x) = e−x2
(2x2−1) und f ′′(x) = e−x2
(6x−4x3)gilt fur die Taylor-Entwicklung von f um x∗ = 1
2
√2 eben f(x) ≈ f(x∗) +
f ′(x∗) (x − x∗) + 12f ′′(x∗) (x − x∗)2 = 1
2−
√2
2√
e+ 1
22√
2√e(x − x∗)2 fur x ≈ x∗
bzw. f(x∗ + ε) ≈ 12−
√2
2√
e+
√2√eε2 ≈ 0.071118 + 0.85776ε2 fur |ε| 1.
???
13line search per golden section search mit tolerance = ε

348 KAPITEL 6. OPTIMIZATION
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
1
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
x
x2−2 x+2
−2.5 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
0.5−x exp(−x2)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 20
0.2
0.4
0.6
0.8
1
x
g(x) = 1/2−x exp(−x2)
1/2−x*exp(−x2)
1/2−1/2*exp(−1/2)*2(1/2)+exp(−1/2)*2(1/2)*(x−1/2*2(1/2))2
???f(x) =x∗ =
tests resetget f , x∗
x∗ =x =
f(x∗) =f(x) =
evalε=
min14
max15
2. Sei f : R → R durch f(x) =
0.5 x = 0(1− cosx)/x2 x 6= 0
gegeben.
a) Zeige per l’Hospital, daß f in 0 stetig ist.
Wegen limx→01−cos x
x2 = limx→0sin x2x
= 12limx→0
cos x1
= 12
stellt f die stetigeErganzung von (1− cosx)/x2 in 0 dar.
b) Zeige: f hat ein lokales Maximum in 0.
Wegen f ′(x) = (x2 sin x− (1−cosx)2x)x−4 = (x sin x−2+2 cos x)x−3 und
f ′(0) = limx→0sin x+x cos x−2 sin x
3x2 = limx→0x cos x−sin x
3x2 = limx→0cos x−x sin x−cos x
6x
= limx→0−x sin x
6x= limx→0
− sin x−x cos x6
= 0 ist 0 kritischer Punkt von f .Wegen f ′′(x) = (x2 cosx − 4x sin x − 6 cos x + 6)/x4 und damit f ′′(0) =limx→0
2 sin x−2x cos x−x2 sin x4x3 = limx→0
−x2 cos x12x2 = −1
12< 0 ist 0 ein Maximum.
c) Verwende eigene oder Bibliotheksroutinen, um das Minimum 0 der auf[−2π, 2π] unimodalen Funktion −f zu approximieren.
Vgl. Minimierungsverfahren fur Funktionen einer Variablen auf S. 335
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
−0.04
−0.035
−0.03
−0.025
−0.02
−0.015
−0.01
−0.005
0
x
(1−cos(x))/x2−0.5
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1
x 10−3
−6
−5
−4
−3
−2
−1
0
1
2
3x 10
−8
x
(1−cos(x))/x2 = f(x) = 2*(sin(x/2)/x)2
−0.5+2*(sin(x/2)/x)2
−0.5+(1−cos(x))/x2
14bestimme minx : f(x) = f(x∗) per Binar-Suche bis |x1 − x2| < ε15bestimmt maxx : f(x) = f(x∗) per Binar-Suche bis |x1 − x2| < ε

6.6. Computer Problems – Rechner-Problem-Losungen 349
d) Welche andere Formulierung von f gestattet, das Minimum besser zu be-rechnen? (Hinweis: Verwende eine Formulierung mit doppelten Winkeln.)
Es gilt f(x) = (1 − cosx)x−2 = 2x−2 sin2(x/2) = 2( 1xsin x
2)2
mit f ′(x) =
2x−2 sin x2cos x
2−4x−3 sin2 x
2und f ′′(x) = x−2(1−2 sin2 x
2)−8x−3 cos x2sin x
2+
12x−4 sin2 x2. Vgl. Minimierungsverfahren fur Funktionen einer Variablen
auf S. 335
3. Verwende eigene oder Bibliotheksroutinen, um ein Minimum der folgenden,laut Graph auf [0, 3] unimodalen Funktion f zu approximieren.
a) f(x) = x4 − 14x3 + 60x2 − 70x
Wegen f ′(x) = 4x3 − 42x2 + 120x − 70 = 4(x3 − 212x2 + 30x − 35
2) hat als
einzige16 reelle Nullstelle x∗ = −18
3√
217 + 8√
22105 + 1118
13√
217+8√
22105+
78≈ 0.7129 Vgl. Minimierungsverfahren fur Funktionen einer Variablen auf
S. 335
b) f(x) = 12x2 − sin x
f ′(x) = x − cosx hat als einzige16 Nullstelle x∗ ≈ 0.739. Wegen f ′′(x) =1 + sin x und π
6< x∗ < π
4ist speziell f ′′(x∗) > 1.5 und damit x∗ ein
Minimum. Vgl. Minimierungsverfahren fur Funktionen einer Variablen aufS. 335
c) f(x) = x2 + 4 cosx
f ′(x) = 2x−4 sin x hat die beiden16 Nullstellen xo = 0 und x1≈ 1.895494267im Intervall [0, 3]. Da f ′′(x) = 2 − 4 cos x, ist xo wegen f ′′(xo) = −2 einMaximum. Wegen π
2< x1 < π ist cos x1 < 0, so daß x1 wegen f ′′(x1) = 2−
4 cos x1 > 2 ein Minimum ist. Vgl. Minimierungsverfahren fur Funktioneneiner Variablen auf S. 335
d) f(x) = Γ(x) =∫∞
otx−1e−t dt, d.h. die Euler’sche Gamma-Funktion mit
Γ(n+ 1) = n! fur n ∈ No und Γ(x) > 0
Mit der sogenannten Digamma-Funktion17 Ψ(x) = ddx
ln(Γ(x)) = Γ′(x)Γ(x)
gilt
f ′(x) = Γ′(x) = Γ(x)Ψ(x) =∫∞
otx−1e−t ln t dt mit der einzigen positiven
Nullstelle x∗≈ 1.46163214496836234126265954232572132846819620400644.Vgl. Minimierungsverfahren fur Funktionen einer Variablen auf S. 335
4. Untersuche nicht-unimodale Funktionen mit Bibliotheksroutinen. Werdenglobale Minima, lokale Minima gefunden? Wann scheitern Bibliotheksrou-tinen?
s.a. Minimierungsverfahren fur Funktionen einer Variablen auf S. 335
5. Der Wasserstrahl verlasse eine Feuerwehrspritze unter dem Winkel α mit
16laut MATLAB17vgl. etwa http://numbers.computation.free.fr/Constants/Miscellaneous/gammaFunction.html

350 KAPITEL 6. OPTIMIZATION
Geschwindigkeit v und treffe den Brandherd in der Hohe h bei einem ho-rizontalen Abstand x vom Strahlrohr. Dann gilt mit der Gravitationskon-stanten g = 9.8065 m/s2
g2v2 cos2 α
x2 − x tanα+ h = 0
Interpretiere die beiden Wurzeln dieser Gleichung. Bestimme den maxi-malen Abstand mit zugehorigem Winkel der Spritze fur v = 20 m/s undh = 13.5 m.
Aus z(t) =
(x(t)y(t)
)=
(0−g
)folgt z(t) =
(vx
−gt+vy
)und z(t) =
(vxt
−g2t2+vyt
)mit v =
(vx
vy
)= v
(cosαsinα
). Der Wasserstrahl beschreibt daher die be-
kannte Wurf-Parabel h = y(x) = −g2(
xvx
)2+ vy
vxx = −g
21
v2 cos2 αx2 + x tanα.
Die beiden Nullstellen x1,2 = v2 cos2 α tan αg (1±
√1− 2gh
v2 cos2 α tan2 α) der Para-
bel −g2
1v2 cos2 α
x2+x tanα−h = 0 sind die Stellen, an denen der Wasserstrahldie Hohe h erreicht.
Es ist also F (x) = v cosx(v sin x+√v2 sin2 x− 2gh)/g zu maximieren oder
eben f(x) = −v cosx(v sin x+√v2 sin2 x− 2gh)/g zu minimieren. Fur die
gegebenen g, h sowie v und fur 54.5o=0.951 < x < 2.19=125.5o ist der Radi-
kant positiv und f reellwertig mit Minimum z∗ =
(1.044142895746638
−11.62860696730266
),
vgl. Minimierungsverfahren fur Funktionen einer Variablen auf S. 335.
6. Programmiere und teste ausgiebig ein eigenes line search Verfahren, dasminf(xo +αs) : α ∈ R fur die Parameter Start-Vektor xo, Such-Richtungs, Ziel-Funktion f und Toleranz ε liefert.
s.a. Minimierungsverfahren fur Funktionen einer Variablen auf S. 335
7. Sei f : R2 → R definiert durch f(x, y) = 2x3 − 3x2 − 6xy(x− y − 1).
a) Bestimme alle kritischen Punkte von f analytisch.262
∇f(x, y) =
(6x2 − 6x− 12xy + 6y2 + 6y
−6x2 + 12xy + 6x
)= 6
((x− y)2 − x+ y(−x+ 2y + 1)x
)= 0
legt nahe, zwei Falle zu unterscheiden:
x 6= 0: aus x = 2y+1 und (x−y)2−(x−y) = (y+1)2−(y+1) = (y+1)y = 0
ergeben sich die kritischen Punkte z∗1 =
(−1−1
)und z∗2 =
(10
).
x = 0: aus y(y + 1) = 0 ergeben sich die restlichen zwei kritischen Punkte
z∗3 =
(00
)und z∗4 =
(0−1
).
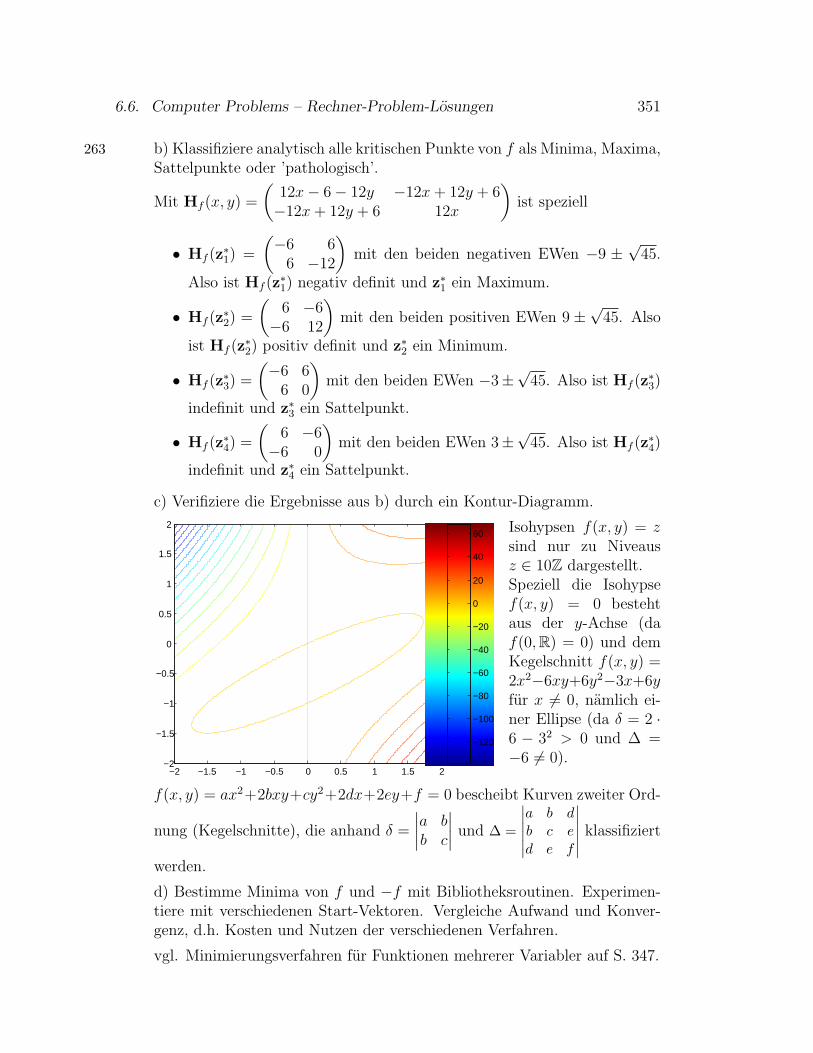
6.6. Computer Problems – Rechner-Problem-Losungen 351
b) Klassifiziere analytisch alle kritischen Punkte von f als Minima, Maxima,263Sattelpunkte oder ’pathologisch’.
Mit Hf (x, y) =
(12x− 6− 12y −12x+ 12y + 6−12x+ 12y + 6 12x
)ist speziell
• Hf (z∗1) =
(−6 6
6 −12
)mit den beiden negativen EWen −9 ±
√45.
Also ist Hf (z∗1) negativ definit und z∗1 ein Maximum.
• Hf (z∗2) =
(6 −6
−6 12
)mit den beiden positiven EWen 9 ±
√45. Also
ist Hf (z∗2) positiv definit und z∗2 ein Minimum.
• Hf (z∗3) =
(−6 6
6 0
)mit den beiden EWen −3±
√45. Also ist Hf (z
∗3)
indefinit und z∗3 ein Sattelpunkt.
• Hf (z∗4) =
(6 −6
−6 0
)mit den beiden EWen 3±
√45. Also ist Hf (z
∗4)
indefinit und z∗4 ein Sattelpunkt.
c) Verifiziere die Ergebnisse aus b) durch ein Kontur-Diagramm.
−2 −1.5 −1 −0.5 0 0.5 1 1.5 2−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
−120
−100
−80
−60
−40
−20
0
20
40
60 Isohypsen f(x, y) = zsind nur zu Niveausz ∈ 10Z dargestellt.Speziell die Isohypsef(x, y) = 0 bestehtaus der y-Achse (daf(0,R) = 0) und demKegelschnitt f(x, y) =2x2−6xy+6y2−3x+6yfur x 6= 0, namlich ei-ner Ellipse (da δ = 2 ·6 − 32 > 0 und ∆ =−6 6= 0).
f(x, y) = ax2+2bxy+cy2+2dx+2ey+f = 0 bescheibt Kurven zweiter Ord-
nung (Kegelschnitte), die anhand δ =
∣∣∣∣a bb c
∣∣∣∣ und ∆ =
∣∣∣∣∣∣a b db c ed e f
∣∣∣∣∣∣ klassifiziert
werden.
d) Bestimme Minima von f und −f mit Bibliotheksroutinen. Experimen-tiere mit verschiedenen Start-Vektoren. Vergleiche Aufwand und Konver-genz, d.h. Kosten und Nutzen der verschiedenen Verfahren.
vgl. Minimierungsverfahren fur Funktionen mehrerer Variabler auf S. 347.

352 KAPITEL 6. OPTIMIZATION
8. Sei f : R2 → R durch f(x, y) = 2x2−1.05x4 + 16x6 +xy+y2 definiert. Finde
und klassifiziere kritische Punkte von f . Bestimme das globale Minimumvon f .
∇f(x, y) =
(4x− 21
5x3 + x5 + yx+ 2y
)= 0 ⇐⇒ x(x4 − 21
5x2 + 7
2)
y = −x/2 . Fur
x = 0 ergibt sich der kritische Punkt z∗o = 0. Fur x 6= 0 folgt mit u = x2
aus u2 − 215u+ 7
2= 0 eben u1,2 = 2.1±
√0.91. Wegen u1,2 > 0 ergeben sich
vier weitere kritische Punkte z1,2 = ±√u1
(−10.5
)und z3,4 = ±√u2
(−10.5
).
Mit Hf (x, y) =
(5x4 − 63
5x2 + 4 1
1 2
)und u1 ≈ 3 sowie u2 ≈ 1.2 ist speziell
• Hf (z∗o) =
(4 11 2
)mit den beiden positiven EWen 3 ±
√2. Also ist
Hf (z∗o) positiv definit. z∗o ist ein Minimum.
• Hf (z∗1,2) =
(8.4u1 − 13.5 1
1 2
)mit den beiden positiven EWen λ1 ≈
1.9 und λ2 ≈ 12.25. Also ist Hf (z∗1) positiv definit. z∗1,2 sind Minima.
• Hf (z∗3,4) =
(8.4u2 − 13.5 1
1 2
)mit den beiden EWen λ1 ≈ −4 und
λ2 ≈ 2.1656. Also ist Hf (z∗3,4) indefinit. z∗3,4 sind Sattelpunkte.
vgl. Minimierungsverfahren fur Funktionen mehrerer Variabler auf S. 347.
9. f(x, y) = 100(y − x2)2 + (1 − x)2 definiert f : R2 → R, die Rosenbrock18-Funktion. Mit Start-Vektoren (−1, 1)T , (0, 1)T und (2, 1)T bestimme ihreMinima per
a) steepest descent
b) Newton-Verfahren c) gedampftem Newton-Verfahren, d.h. Newton-Ver-fahren mit line search
Zunachst gilt f(x, y) ≥ 0 und f(x, y) = 0 ⇐⇒ x = 1 = y. Daher ist
z∗ =
(11
)einziges und damit globales Minimum von f .
∇f(x, y) =
(−400(y − x2)x− 2(1− x)
200(y − x2)
)= 0 impliziert y = x2 und da-
mit x = 1 = y. Damit ist z∗ einziger kritischer Punkt von f . Die
Hesse-Matrix Hf (x, y) =
(−400y + 1200x2 + 2 −400x
−400x 200
)von f in z∗ ist
Hf (z∗) =
(802 −400
−400 200
)mit den beiden positiven EWen λ1,2 = 501 ±
18 Eric W. Weisstein: ”Rosenbrock Function.” From MathWorld – A Wolfram Web Resource.http://mathworld.wolfram.com/RosenbrockFunction.html

6.6. Computer Problems – Rechner-Problem-Losungen 353
√250601, namlich λ1 ≈ 0.4 und λ2 ≈ 1001.6. Hf (z
∗) ist also positiv de-finit und damit ist z∗ ein Minimum. Ubrigens ist Hf (z
∗) fast singular, da(800 −400
−400 200
)nahe bei Hf (x, y) liegt und singular ist.
vgl. Minimierungsverfahren fur Funktionen mehrerer Variabler auf S. 347.
0.5
1
1.5
0.5
1
1.50
100
200
300
400
x
Rosenbrock(x,y) = 100*(y−x2)2+(1−x)2
y
50
100
150
200
250
300
x
y
Rosenbrock(x,y) = 100*(y−x2)2+(1−x)2
0.5 1 1.50.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
1.5
100
150
200
250
10. A sei reelle, symmetrische n × n-Matrix mit EWen λ1 ≤ . . . ≤ λn. Zeige:Die kritischen Punkte des Rayleigh-Quotienten sind EVen von A und esgilt λ1 = minx6=0
xT AxxT x
sowie λn = maxx6=0xT AxxT x
, wobei die Extrema in denzugehorigen EVen angenommen werden. Daher lassen sich λ1 und λn unddie zugehorigen EVen als Losung von Optimierungsproblemen bestimmen.
Zunachst sind die kritischen Punkte des Rayleigh-Quotienten r(x) = xT AxxT x
als Funktion r : Rn → R zu bestimmen. Es gilt allgemein
∇(f g)(x) = ∇(f)(x) g(x) + f(x)∇(g)(x) fur f, g : Rn → R
∇(φ f)(x) = φ′(f(x))∇(f)(x) fur φ : R → R, f : Rn → R
und speziell mit ∇(xTAx)(x) = (A+AT )x = 2Ax und ∇(xTx)(x) = 2x
∇r(x) = ∇(xT AxxT x )(x) = ∇( 1
xT x)(x) xTAx + 1xT x
∇(xTAx)(x)
= −1(xT x)2
∇(xTx)(x) xTAx + 2xT x
Ax
= −2 xT Ax(xT x)2
x + 2xT x
Ax = 2xT x(Ax− xT Ax
xT xx) = 0
x∗ ist also kritischer Punkt von xT AxxT x
genau dann, wenn x∗ EV zum EWx∗T Ax∗
x∗T x∗von A ist.
a) Fur A =
6 2 12 3 11 1 1
bestimme extreme EWe und die zugehorigen EVen.
Ist die Losung eindeutig?

354 KAPITEL 6. OPTIMIZATION
A hat19 die drei EWe λ1 ≈ 0.5789, λ2 ≈ 2.1331 und λ3 ≈ 7.288, namlich1/6
(1412+108 i√
107)2/3
+148+203√
1412+108 i√
107
3√
1412+108 i√
107
1/12−(1412+108 i
√107)
2/3−148+40
3√
1412+108 i√
107+i√
3(1412+108 i√
107)2/3
−148 i√
3
3√
1412+108 i√
107
−1/12(1412+108 i
√107)
2/3+148−40
3√
1412+108 i√
107+i√
3(1412+108 i√
107)2/3
−148 i√
3
3√
1412+108 i√
107
b) Wegen λ1 = minxT x=1
xT AxxT x
und λn = maxxT x=1xT AxxT x
kann der Teil a)auch als restringiertes Optimierungsproblem gelost werden. Welche Bedeu-tung haben hier die Lagrange-Multiplikatoren?
???
11. Programmiere das BFGS-Verfahren unter folgenden Vorgaben: in jeder Ite-282ration wird B faktorisiert oder eine Faktorisierung von B wird aktualisiert;Bo wird mit I oder mit einer Approximation der Hesse-Matrix durch endli-che Differenzen initialisiert; die Robustheit des Verfahrens wird durch linesearch verbessert. Teste das Verfahren anhand der Probleme dieses Ab-schnittes.
vgl. Minimierungsverfahren fur Funktionen mehrerer Variabler auf S. 347.
12. Programmiere das conjugate gradient-Verfahren, wobei βk+1 anhand der283Formeln wahlweise von Fletcher-Reeves oder von Polak-Ribiere berechnetwird.
vgl. Minimierungsverfahren fur Funktionen mehrerer Variabler auf S. 347.
13. Finde mit eigenen oder mit Bibliotheksroutinen least squares-Losungen zufolgenden uberbestimmten Systemen nichtlinearer Gleichungen.
a) x21 + x2
2 = 2, (x1 − 2)2 + x22 = 2, (x1 − 1)2 + x2
2 = 9285
Gesucht ist eine least squares-Losung x fur y = f(t,x) = f(t, x1, x2) mit
f(1, x1, x2) = x21 + x2
2
f(2, x1, x2) = (x1 − 2)2 + x22
f(3, x1, x2) = (x1 − 1)2 + x22
und Dateny1 = 2 = f(1,x)y2 = 2 = f(2,x)y3 = 9 = f(3,x)
,
d.h. die quadratische Euklidische Norm des Residuums r(x) mit ri(x) =yi − f(i,x) fur i = 1, 2, 3 oder eben die Funktion
φ(x) = ||r(x)||22 = (x21+x2
2−2)2+((x1−2)2+x2
2−2)2+((x1−1)2+x2
2−9)2
ist zu minimieren. Funf kritische Punkte ergeben sich20 aus
∇φ(x) = ∇||r||22(x) =
(12x3
1 + 12x1x22 + 8x1 − 36x2
1 + 16− 12x22
12x21x2 + 12x3
2 − 32x2 − 24x1x2
)= 0
19 laut MATLAB20 laut MATLAB

6.6. Computer Problems – Rechner-Problem-Losungen 355
zu x∗1 =
(10
)mit φ(x∗1) = 249/3, x∗2,3 =
(1± 1
3
√21
0
)mit φ(x∗2,3) = 200/3
und x∗4,5 =
(1
±13
√33
)mit φ(x∗4,5) = 128/3.
x
y
vgl. Minimierungsverfahren fur Funktionen mehrerer Variabler auf S. 347.
b) x21 + x2
2 + x1x2 = 0, sin2 x1 = 0, cos2 x2 = 0 285
Wegen x2 + xy + y2 = 0 = (y − c1x)(y − c2x) mit c1 = −12± i
2
√3 und
c2 = −12∓ i
2
√3, also mit c1 + c2 = −1 und c1c2 = 1, entspricht der
Kegelschnitt x2+xy+y2 = 0 imaginaren Geraden mit Schnitt im Ursprung.Dasselbe Vorgehen wie in a) fuhrt auf
φ(x) = ||r(x)||22 = (x21 + x2
2 + x1x2)2+ ( sin2 x1)
2+ ( cos2 x2)
2
mit
∇φ(x) =
(2(x2
1 + x22 + x1x2)(2x1 + x2) + 4 sin3(x1) cos(x1)
2(x21 + x2
2 + x1x2)(x1 + 2x2)− 4 cos3(x2) sin(x2)
)= 0
???
14. Unterstellt, daß die Alkohol-Konzentration y im Blut exponentiell mit derZeit t abfallt, sind die Modell-Funktionen f(t,x) = x1 e
x2 t an die Meßwertet 0.50 1.00 1.50 2.00 2.50 3.00 3.50 4.00y 6.80 3.00 1.50 0.75 0.48 0.25 0.20 0.15
anzupassen.
a) Lose das nichtlineare least squares Problem entweder mit einer Biblio- 285theksroutine oder mit einer eigenen, etwa Gauß-Newton basierten Routine.
Mit der Residual-Funktion r : R2 → R8 mit (r)i = yi−f(ti,x) = yi−x1 ex2 ti
fur i = 1, 2, . . . , 8 ist die Zielfunktion φ(x) = 12r(x)T r(x) = 1
2||r(x)||22 =
12
∑8i=1 (yi− x1 e
x2 ti)2
etwa vermittels der Gauß-Newton Methode zu mini-mieren. Ein Minimum wird in x1 = 14.37666 und x2 = −1.5139 angenom-men. vgl. Minimierungsverfahren fur Funktionen mehrerer Variabler aufS. 347.
b) Logarithmieren uberfuhrt das Problem in ein linear least squares Pro-

356 KAPITEL 6. OPTIMIZATION
blem: die Modell-Funktionen sind lnx1 + x2 t den Meßwerten (ti, lnyi) an-zupassen. Stimmt die Losung mit derjenigen des nichtlinearen least squaresProblems uberein? Warum?
Das linear least squares Problem Ax = [1, t]v ∼= (ln yi)i = b bestehtdarin, die Gerade v1 +v2t zu bestimmen, die die quadratische Norm ||r||22 =∑8
i=1(ln yi−v1−v2ti)2 des Residual-Vektor r = b−Av minimiert. v ergibt
sich als Losung des Systems der Normalen-Gleichungen
(8 1818 51
)(v1
v2
)=
ATAv = ATb = 12
(2 ln y1 + 2 ln y2 + . . .+ 2 ln y8
1 ln y1 + 2 ln y2 + . . .+ 8 ln y8
)≈(−1.2467−17.125
)zu
v ≈(
2.15573−1.09663
). Damit hat das originare Problem die Losung y(t) =
ev1 ev2 t ≈ 8.63419 e−1.09663 t. Schließlich wird ja auch eine andere Zielfunk-tion als im nichtlinearen least squares Problem aus a) minimiert.
t
y
t
ln y
t
y
15. Eine Population P von Bakterien wachse geometrisch mit Wachstumsrater, d.h. Pk = r Pk−1. Die folgenden Populationsgroßen wurden beobachtet:
k 1 2 3 4 5 6 7 8Pk/109 0.19 0.36 0.69 1.30 2.50 4.70 8.50 14.0
a) Lose das nichtlineare least squares Problem und bestimme Po und r.
??? b) Lose das durch Logarithmieren entstehende lineare least squares Problemund bestimme Po und r. Vergleiche die Ergebnisse mit a).
???
16. Die Michaelis-Menten-Gleichung21 beschreibt die Kinetik von Enzym-Reak-tionen. Mit der initialen Geschwindigkeit vo und maximalen Geschwindig-keit V , der Michaelis-Konstanten Km und der Konzentration S im Substrat
21 Leonor Michaelis (1875-1947), Maud Leonora Menten (1879-1960) (1913) Hintergrund, s.http://de.wikipedia.org/wiki/Michaelis-Menten-Theorie, Geschichte, s. www.chemieunterricht.de/dc2/rk/mm-histo.htm

6.6. Computer Problems – Rechner-Problem-Losungen 357
gilt vo = V1+Km/S
. Ublicherweise wird vo fur verschiedene KonzentrationenS gemessen. Aus den Daten werden dann V und Km gewonnen.
a) Gemessen wurdeS 2.5 5.0 10.0 15.0 20.0vo 0.024 0.036 0.053 0.060 0.064
. Lose das nicht-
lineare least squares Problem und bestimme V und Km, entweder mit einerBibliotheksroutine oder einem selbst programmierten, etwa Gauß-Newton-basierten Verfahren.
???b) Das nichtlineare least squares Problem kann durch Transformation derMichaelis-Menten-Gleichung umgangen werden:Lineweaver und Burke22 verwenden 1
vo= 1
V+ Km
V1S
und losen das entste-
hende lineare least squares Problem in 1vo
als Funktion von 1S, um 1
Vund
Km
Vzu bestimmen. Dixon23 dagegen stellt S
vo= Km
V+ 1
VS als Funktion von
S dar, um zunachst Km
Vund 1
Vzu bestimmen. Endlich verwenden Eadie
und Hofstee24 die Darstellung von vo = V −Kmvo
Sals Funktion von vo
S, um
V und Km zu bestimmen.???
...
22 H. Lineweaver, D. Burk (1934)www.vs-c.de/vsengine/vlu/vsc/de/ch/8/bc/vlu/michaelis menten gleichung.vlu/Page/vsc/de/ch/8/bc/kinetik/lineweaver burk.vscml.html
23 H.B.F. Dixon M. Dixon, E.C. Webb: Enzymes, Academic Press, Inc., New York, NY, 196424 Eadie und Hofstee www.biologie.de/biowiki/Enzymkinetik#Eadie-Hofstee-Diagramm

358 KAPITEL 6. OPTIMIZATION

Kapitel 7
Interpolation
Gegeben Daten-Punkte, etwa Meß-Punkte (ti, yi)i=1,...,m, die eine funktionaleAbhangigkeit y = y(t) widerspiegeln. Dann kann man daran interessiert sein,
• die Daten-Punkte durch eine Funktion zu visualisieren, deren Graph durchdiese Datenpunkte verlauft,
• Werte (t, y) zwischen den (gemessenen) Daten-Punkten zu erheben,
• Werte (t, y) außerhalb der (gemessenen) Daten-Punkte zu prognostizieren,
• Indikatoren aus den (gemessenen) Daten-Punkten abzuleiten.
In jedem Fall ist eine geeignete Funktion f mit f(ti) = yi fur i = 1, . . . ,m zubestimmen.
7.0.1 Interpolation
Def. Gegeben m Daten-Punkte (ti, yi) ∈ R2 mit t1 < t2 < . . . < tm. Dann heißteine Funktion f : [t1, tm] → R mit f(ti) = yi fur i = 1, . . . ,m eine Interpolierende(Funktion). Anwendungen bestehen beispielsweise darin,
• glatte Kurve durch n Datenpunkte zu zeichnen,
• Tabellen-Eintrage zu interpolieren,
• tabellierte Funktionen zu differenzieren und zu integrieren,
• mathematische Funktionen schnell und einfach auszuwerten,
359

360 KAPITEL 7. INTERPOLATION
• komplizierte Funktionen durch einfache Funktionen zu ersetzen.
Ubliche Bedingungen fur Interpolation sind etwa die Folgenden:
• Die Interpolierende ist aus einer gegebenen Familie von Funktionen zu be-stimmen.
• Die Interpolierende weist zwischen den Daten-Punkten ein bestimmtes Ver-halten auf.
• Die Interpolierende erhalt gewisse Eigenschaften der Daten-Punkte wieetwa Monotonie, Konvexitat oder Periodizitat.
• Entweder interessiert die einfache Bestimmung der Koeffizienten der Inter-polierenden oder aber die einfache Auswertung der Interpolierenden.
• Asthetische oder andere Anforderungen z.B. beim Zeichnen sind zu erfullen.
Gangige Funktionsfamilien fur Interpolierende sind etwa
• Polynome,
• stuckweise polynomiale Funktionen (z.B. in generativer Computer-Grafik),
• trigonometrische Funktionen (vgl. Fourier-Reihen),
• gebrochen rationale Funktionen (vgl. gebrochen lineare Interpolation zurLosung nichtlinearer Gleichungen).
7.0.2 Existenz, Eindeutigkeit und Konditionierung
Wenn die Interpolierende f in spanφ1, . . . , φn zu bestimmen ist, wenn f alsoals Linearkombination der Basis-Vektoren φj darzustellen ist, dann sind Koeffizi-enten x mit f(t) =
∑nj=1 xj φj(t) gesucht, so daß f(ti) =
∑nj=1 xj φj(ti) = yi fur
i = 1, . . . ,m, d.h. x ist Losung von Ax = y mit A = (ai,j) = (φj(ti)).
Fur n = m und regulares A ist das Gleichungssystem eindeutig losbar.
Die Wahl der Basis-Funktionen beeinflußt entscheidend die Kondition von A.
7.0.3 Polynomiale Interpolation
Polynome lassen sich beispielsweise unter Verwendung der Monom-Basis, derLagrange-Basis oder der Newton-Basis darstellen, was – wie sich zeigt – unter-schiedlichen Aufwand bei unterschiedlicher Kondition fur die Berechnung des in-

361
terpolierenden Polynoms und unterschiedlichen Aufwand fur etwa seine Auswer-tung, Differentation oder Integration nach sich zieht: je aufwandiger die Berech-nung umso weniger aufwandig die Auswertung, Differentation und Integrationund umgekehrt.
Interpolation mit Monom-Basis
Die Monom-Basis-Funktionen sind φj(t) = tj−1 fur j = 1, . . . , n. Ein Polynomp(t) =
∑nj=1 xjφj(t) =
∑nj=1 xjt
j−1 interpoliert die n Daten-Punkte (ti, yi) furi = 1, . . . , n, falls p(ti) = yi fur i = 1, . . . , n gilt, oder gleichbedeutend vektoriell
Ax =
1 t1 · · · tn−1
1
1 t2 · · · tn−12
......
...1 tn · · · tn−1
n
x1
x2...xn
=
y1
y2...yn
= y
A heißt Vandermonde1-Matrix. Solche Matrizen sind regular, falls die ti paar-weise verschieden sind: Sei namlich Az = 0. Dann hat das Polynom vom Gradn − 1 mit dem Koeffizienten-Vektor z genau n Nullstellen – und zwar in den(ti)i=1,...,n. Daher ist das Polynom das Null-Polynom mit z = 0. Also ist Aregular.
Polynome, die als Linearkombination der Monome dargestellt sind, werden effi-zient per Horner ausgewertet. Dieselbe Idee laßt sich auf die Bestimmung derVandermonde-Matrix anwenden.
ai,j = φj(ti) = tj−1i = tiφj−1(ti) = tiai,j−1 fur j = 2, . . . , n
Allerdings ist A fur die meisten (ti)i=1,...,n schlecht konditioniert, was auch daranzu erkennen ist, daß die Basis-Monome φn fur wachsendes n immer weniger un-terscheidbar werden (die Spalten der Vandermonde-Matrix werden fast l.a.).
x
y
0.5 1
0.5
1to
t1
t2
t3
1 Alexandre-Theophile Vandermonde (1735-1796)www-history.mcs.st-andrews.ac.uk/Biographies/Vandermonde.html
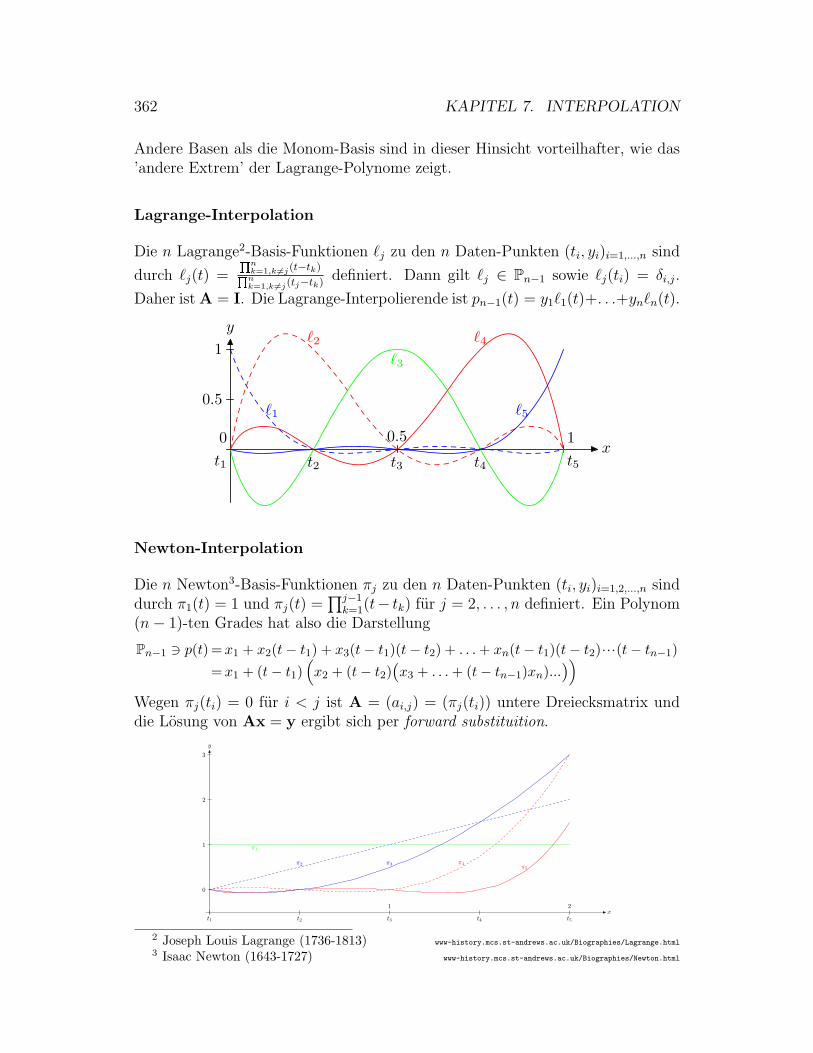
362 KAPITEL 7. INTERPOLATION
Andere Basen als die Monom-Basis sind in dieser Hinsicht vorteilhafter, wie das’andere Extrem’ der Lagrange-Polynome zeigt.
Lagrange-Interpolation
Die n Lagrange2-Basis-Funktionen `j zu den n Daten-Punkten (ti, yi)i=1,...,n sind
durch `j(t) =Qn
k=1,k 6=j(t−tk)Qnk=1,k 6=j(tj−tk)
definiert. Dann gilt `j ∈ Pn−1 sowie `j(ti) = δi,j.
Daher ist A = I. Die Lagrange-Interpolierende ist pn−1(t) = y1`1(t)+. . .+yn`n(t).
x
y
0 0.5 1t1 t2 t3 t4 t5
0.5
1
`1
`2
`3
`4
`5
Newton-Interpolation
Die n Newton3-Basis-Funktionen πj zu den n Daten-Punkten (ti, yi)i=1,2,...,n sinddurch π1(t) = 1 und πj(t) =
∏j−1k=1(t− tk) fur j = 2, . . . , n definiert. Ein Polynom
(n− 1)-ten Grades hat also die Darstellung
Pn−1 3 p(t) =x1 + x2(t− t1) + x3(t− t1)(t− t2) + . . .+ xn(t− t1)(t− t2)···(t− tn−1)=x1 + (t− t1)
(x2 + (t− t2)(x3 + . . .+ (t− tn−1)xn)...)
)Wegen πj(ti) = 0 fur i < j ist A = (ai,j) = (πj(ti)) untere Dreiecksmatrix unddie Losung von Ax = y ergibt sich per forward substituition.
x
y
1 2
t1 t2 t3 t4 t5
0
1
2
3
π1
π2 π3 π4π5
2 Joseph Louis Lagrange (1736-1813) www-history.mcs.st-andrews.ac.uk/Biographies/Lagrange.html
3 Isaac Newton (1643-1727) www-history.mcs.st-andrews.ac.uk/Biographies/Newton.html

363
Newton-Polynome werden effizient per Horner ausgewertet. Zudem lassen sichNewton-Polynome inkrementell berechnen: Wenn pj(t) ein Polynom von Gradj−1 ist, das j Daten-Punkte (ti, yi)i=1,...,j interpoliert, so ist pj+1(t) ein Polynomvon Grad j, das insgesamt j + 1 Daten-Punkte (ti, yi)i=1,...,j+1, also die j − 1Datenpunkte von pj und einen weiteren Datenpunkt (tj+1, yj+1) interpoliert, wenn
pj+1(t) = pj(t) + xj+1πj+1(t) wobei xj+1 =yj+1−pj(j+1)
πj+1(tj+1).
Orthogonale Polynome
Def. Fur Polynome p, q ∈ Pn−1 und auf [a, b] nicht-negative Gewichtsfunktion
w definiert (p, q) =∫ b
ap(t)q(t)w(t) dt ein Skalarprodukt auf Pn−1. Entsprechend
heißen p und q orthogonal genau dann, wenn (p, q) = 0 gilt, und (pi)i heißenorthonormal genau dann, wenn (pi, qj) = δi,j fur alle i und j gilt. Fur [a, b] = [−1, 1] mit der Gewichtsfunktion w ≡ 1 und bei Skalierung Pj(1) = 1erhalt man per Gram-Schmidt-Orthogonalisierungsverfahren aus den Monomendie Legendre4-Polynome
P0(t) = 1, P1(t) = t, P2(t) = 12(3t2 − 1), P3(t) = 1
2(5t3 − 3t)
P4(t) = 18(35t4 − 30t2 + 3), P5(t) = 1
8(63t5 − 70t3 + 15t), . . .
x−1 1
y
Po
P1
P2
P3
P4P5
Weitere orthogonale Polynom-Basen sind in folgender Tabelle zusammengestellt.
Polynome Symbol Intervall Gewichtsfunktion w(t)Legendre4 Pk [−1, 1] 1Chebyshev5, 1.Art Tk [−1, 1] (1− t2)−1/2
Chebyshev5, 2.Art Uk [−1, 1] (1− t2)1/2
Jacobi6 Jk [−1, 1] (1− t)α(1 + t)β, α, β > −1Laguerre7 Lk [0,∞) e−t
Hermite8 Hk (−∞,∞) e−t2
4 Adrien-Marie Legendre (1752-1833) www-history.mcs.st-andrews.ac.uk/Biographies/Legendre.html
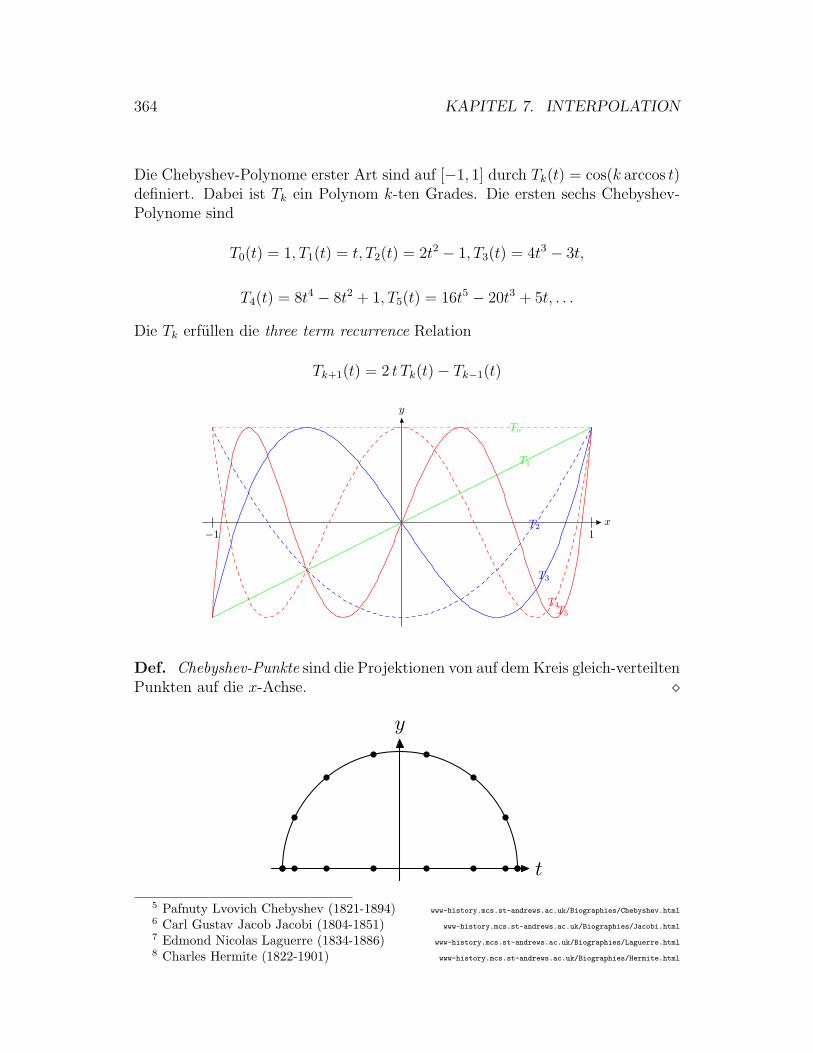
364 KAPITEL 7. INTERPOLATION
Die Chebyshev-Polynome erster Art sind auf [−1, 1] durch Tk(t) = cos(k arccos t)definiert. Dabei ist Tk ein Polynom k-ten Grades. Die ersten sechs Chebyshev-Polynome sind
T0(t) = 1, T1(t) = t, T2(t) = 2t2 − 1, T3(t) = 4t3 − 3t,
T4(t) = 8t4 − 8t2 + 1, T5(t) = 16t5 − 20t3 + 5t, . . .
Die Tk erfullen die three term recurrence Relation
Tk+1(t) = 2 t Tk(t)− Tk−1(t)
x−1 1
y
To
T1
T2
T3
T4T5
Def. Chebyshev-Punkte sind die Projektionen von auf dem Kreis gleich-verteiltenPunkten auf die x-Achse.
t
y
5 Pafnuty Lvovich Chebyshev (1821-1894) www-history.mcs.st-andrews.ac.uk/Biographies/Chebyshev.html
6 Carl Gustav Jacob Jacobi (1804-1851) www-history.mcs.st-andrews.ac.uk/Biographies/Jacobi.html
7 Edmond Nicolas Laguerre (1834-1886) www-history.mcs.st-andrews.ac.uk/Biographies/Laguerre.html
8 Charles Hermite (1822-1901) www-history.mcs.st-andrews.ac.uk/Biographies/Hermite.html

365
Interpolation stetiger Funktionen
Die Runge9-Funktion f(t) = 11+25t2
veranschaulicht, was bei der polynomialenInterpolation in aquidistanten Daten-Punkten passieren kann.
x−1 1
y
1
2
p5 p10
7.0.4 Interpolation mit stuckweise polynomialen Funktio-nen
Je mehr Daten-Punkte wir durch ein einziges Polynom interpolieren wollen, umsohoher ist dessen Grad und umso mehr meist unerwunschte Extremwerte liegenzwischen den Daten-Punkten, d.h. umso mehr storende Oszillationen treten auf.Abhilfe schafft stuckweise polynomiale Interpolation, d.h. die Interpolierende be-steht aus fur jedes Teilintervall (ti, ti+1) verschiedenen Polynomen, die in denDaten-Punkten nur geeignete zusammenzusetzen sind.
kubische Hermite-Interpolation
Die kubische Hermite10-Interpolierende ist stuckweise kubisch polynomial mitstetiger erster Ableitung. Bei insgesamtmDaten-Punkten hat die Interpolierende4(m − 1) Koeffizienten oder Freiheitsgrade. Jedes kubische Polynom soll zweiDatenpunkte interpolieren, was 2(m− 1) Freiheitsgrade aufzehrt. Die Forderungeiner stetigen Ableitung kostet weitere m − 2 Freiheitgrade. Es bleiben also4(m−1)−2(m−1)−(m−2) = m Freiheitsgrade, mit denen weitere Anforderungenan die Interpolierende wie z.B. Monotonie oder Konvexitat o.a. befriedigt werdenkonnen.
9 Carle David Tolme Runge (1856-1927) www-history.mcs.st-andrews.ac.uk/Biographies/Runge.html
10 Charles Hermite (1822-1901) www-history.mcs.st-andrews.ac.uk/Biographies/Hermite.html

366 KAPITEL 7. INTERPOLATION
kubische Spline-Interpolation
Def. Ein Spline ist eine Funktion, stuckweise polynomial vom Grad k, die k−1-fach stetig differenzierbar ist. Der Graph beispielsweise eines linearen Splines ist ein Polygonzug. Ein kubischerSpline ist zweimal stetig differenzierbar.Allgemein kostet die Interpolation 2(m − 1) Freiheitsgrade und die zweimaligestetige Differenzierbarkeit weitere 2(m−2) Freiheitsgrade eines kubischer Splines.Es bleiben genau zwei Freiheitsgrade, mit denen etwa folgende Anforderungenbefriedigt werden konnen:
• vorgegebene Steigungen in den beiden Endpunkten t1 und tm,
• verschwindende zweite Ableitungen in den beiden Endpunkten t1 und tm(sogenannter naturlicher Spline),
• not-a-knot Bedingung11, d.h. Stetigkeit sogar die dritten Ableitungen in t2und tm−1,
• Ubereinstimmung der ersten und zweiten Ableitungen in den beiden End-punkten t1 und tm (periodischer Spline).
B-Spline-Interpolation
Def. B-Splines bilden eine Basis fur Splines gegebenen Grades. Der einfacheren Darstellung halber gehen wir von unendlich vielen Daten-Punktenoder Knoten . . . < t−2 < t−1 < t0 < t1 < t2 < . . . aus, spezifizieren Wichtungs-funktionen vi,k(t) = t−ti
ti+k−tiund definieren B-Splines rekursiv durch
Bi,0(t) = χ[ti,ti+1)(t) und Bi,k(t) = vi,k(t)Bi,k−1(t) + (1−vi+1,k(t))Bi+1,k−1(t)
Da Bi,0 stuckweise konstant ist und die Wichtungsfunktionen vi,k linear sind, sinddie Bi,2 stuckweise quadratisch, die Bi,k stuckweise polynomial vom Grad k.
y
0
.5
1
tti ti+1 ti+2 ti+3ti+3 ti+4
Bi,0 Bi,1
Bi,2Bi,3
11 vgl. Funktion csapi in MATLABs Spline Toolbox

367
Die Basis-Funktionen Bi,k(t) haben folgende Eigenschaften (vgl. 7Ex16):
1. Bi,k(t) = 0 sowohl fur alle t < ti als auch fur alle ti+k+1 < t.
2. Bi,k(t) > 0 fur ti < t < ti+k+1 (zusammen also beschrankter, lokaler Trager)
3.∑∞
i=−∞Bi,k(t) = 1 fur alle t (die B.,k bilden eine Zerlegung der Eins)
4. Bi,k(t) ist k − 1-fach stetig differenzierbar fur k ≥ 1.
5. Die Funktionen B1−k,k, . . . , Bn−1,k sind auf [t1, tn] linear unabhangig.
6. Die Funktionen B1−k,k, . . . , Bn−1,k spannen den Raum aller Splines vomGrad k mit den Knoten (ti)i auf.

368 KAPITEL 7. INTERPOLATION
7.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Es gibt beliebigviele mathematische Funktionen,die einen gegebenen Satz von Daten-Punkten interpolieren.
2. Richtig/Falsch? Wenn fur f exaktf(ti) = yi fur i = 1, . . . ,m gilt, dannsind die Koeffizienten in der Darstel-lung von f als Linearkombinationder Basis-Vektoren wohlbestimmt.
3. Richtig/Falsch? Wenn das einenSatz von Daten-Punkten interpolie-rende Polynom eindeutig ist, dannist auch seine Darstellung eindeutig.
4. Richtig/Falsch? Wenn eine stetigeFunktion f in n + 1 auf [a, b] aqui-distanten Punkten durch Polynomepn interpoliert wird, dann konvergie-ren diese Polynome pn immer gegenf fur n→∞.
5. Was ist der grundsatzliche Unter-schied zwischen Interpolation undApproximation?
6. Nenne Beispiele fur Anwendungenvon Interpolation.
7. Beispielsweise welche numerischenVerfahren basieren auf Interpola-tion?
8. Konnen zwei Polynome dieselbenDaten-Punkte interpolieren?
9. Welche Kriterien bestimmen dieWahl der Basis-Funktionen fur In-terpolation?
10. Interpolieren bedeutet Ax = y zulosen. Welche Elemente von A ver-schwinden bei Verwendung der
a) Monom-Basis?
b) Lagrange-Basis?
c) Newton-Basis?
11. a) Ist Interpolation ein angemesse-nes Verfahren, um eine Funktionverrauschten Daten anzupassen?
b) Falls ja, wieso? falls nein, welcheAlternativen bieten sich?
12. a) Welche Rangfolge hat der Auf-wand, die m Daten-Punkte inter-polierende Funktion zu bestimmen,bei Verwendung von jeweils Monom-, Lagrange- und Newton-Basis?
b) Welche Rangfolge hat die Kondi-tion von A = (φj(ti)) bei Verwen-dung von Monom-, Lagrange- undNewton-Basis?
c) Welche Rangfolge hat bei Ver-wendung von jeweils Monom-,Lagrange- und Newton-Basis derAufwand, die interpolierendeFunktion auszuwerten?
13. a) Was ist eine Vandermonde-Matrix?
b) In welchem Zusammenhang tre-ten Vandermonde-Matrizen auf?
c) Warum sind Vandermonde-Matrizen großer Ordnung haufigschlecht konditioniert?
14. Gegeben die n Daten-Punkte (ti, yi)fur i = 1, . . . , n. Um die Koeffizien-ten des interpolierenden Polynomszu bestimmen, ist das n× n-Systemlinearer Gleichungen Ax = y zulosen.
a) Wie sehen die Elemente von Abei Verwendung der Monom-Basisφj(t) = tj , also 1, t, t2, . . . aus?
b) Wie andert sich cond(A), wenn nwachst?

7.1. Review Questions – Verstandnisfragen 369
c) Wie beeinflußt dieser Umstanddie Genauigkeit, mit der das Poly-nom die Daten-Punkte interpoliert?
15. Das Lagrange-Polynom interpolieredie n Daten-Punkte (ti, yi)i=1,...,n.
a) Welchen Grad haben dieLagrange-Basis-Funktionen `j(t) ?
b) Welche Funktionen g(t) ergibtg(t) =
∑nj=1 `j(t) ?
16. Inwiefern ist Lagrange-Interpolationvorteilhaft, inwiefern nachteil-haft verglichen mit Polynom-Interpolation bei Verwendung derMonom-Basis?
17. Gemessen in der Anzahl der Ad-ditionen und Multiplikationen, wieaufwandig ist es, ein Polynom perHorner auszuwerten?
18. Warum ist die Interpolation mit Po-lynomen hohen Grades haufig unbe-friedigend?
19. a) Wovon hangt der Fehler vornehm-lich ab, wenn eine stetige Funk-tion durch ein Polynom interpoliertwird?
b) Unter welchen Bedingungen wirdbei großer Anzahl von Daten-Punkten der Fehler dennoch groß?
20. Wie sollten die Abszissen der Daten-Punkte in einem gegebenen Inter-vall gewahlt sein, damit die inter-polierenden Polynome gegen einegenugend glatte Funktion konvergie-ren, wenn die Anzahl der Daten-Punkte wachst.
21. Was heißt, daß zwei Polynome p undq auf [a, b] orthogonal sind?
22. a) Was bedeutet Taylor-Polynom ei-ner Funktion f ?
b) Inwiefern interpoliert das Taylor-Polynom pn−1 eine gegebene Funk-tion f ?
23. Worin besteht der entscheidendeVorteil von stuckweise polynomia-ler Interpolation gegenuber der In-terpolation mit einem einzigen Po-lynom?
24. a) Wie unterscheidet sich Hermite-Interpolation von gewohnlicher In-terpolation?
b) Wie unterscheidet sich einekubische Spline-Interpolierendevon einer kubischen Hermite-Interpolierenden?
25. Soll man sich fur Hermite-Interpolation oder fur kubischeSpline-Interpolation entscheiden,
a) wenn die Interpolierendemoglichst glatt sein soll?
b) wenn die Interpolierende Mono-tonie der Daten erhalten soll?
26. a) Wie oft ist eine kubische Hermite-Interpolierende stetig differenzier-bar?
b) Wie oft ist eine kubische Spline-Interpolierende stetig differenzier-bar?
27. Die Stetigkeits- und Glattheitsan-forderungen an kubische Spline-In-terpolierende lassen zwei Freiheits-grade. Gib Beispiele fur zusatzlicheAnforderungen an kubische Spline-Interpolierende.
28. a) Wieviele Parameter sind notwen-dig, um ein stuckweise kubisches Po-lynom mit n Knoten zu spezifizie-ren?
b) Welches System linearer Glei-chungen entsteht bei Verwendungnaturlicher kubischer Splines?

370 KAPITEL 7. INTERPOLATION
29. Welche der folgenden n Daten-Punkte interpolierenden Funktionenist eindeutig?
a) Polynome vom Grad n− 1
b) kubische Hermite-Polynome
c) kubische Spline-Polynome
30. Welcher Typ von interpolierendenFunktionen kann grundsatzlich Mo-notonie eines Satzes von n Daten-Punkten erhalten?
a) Polynome vom Grad n− 1
b) kubische Hermite-Polynome
c) kubische Spline-Polynome
31. Inwiefern ist es vorteilhaft, wenn dieinterpolierenden Basis-Funktionenlokalisiert sind, d.h. wenn derKoeffizient zu einer jeden Basis-Funktion nur von einigen wenigenDaten-Punkten abhangt?
7.2 Exercises – Ubun-
gen
1. Gegeben die drei Daten-Punkte(−1, 1), (0, 0) und (1, 1). Bestimmedie interpolierende Parabel p = p(t)
a) als Linearkombination derMonom-Basis,
b) als Linearkombination derLagrange-Basis,
c) als Linearkombination derNewton-Basis.
2. Wie ist p(t) = 5t3 − 3t2 + 7t− 2 furdie Auswertung per Horner darzu-stellen?
3. Programmiere einen Algorithmus,der ein vorzugebendes Polynom p(t)in einem vorzugebenden Argument
auswertet. Das Polynom p ist gege-ben als
a) Linearkombination p(t) =∑gradj=0 xjt
j von Monomen tj
b) Linearkombination p(t) =∑n−1j=0 xjπj(t) von Newton-Basis-
Funktionen πj zu Abszizzenti, i = 1, . . . , n
4. Wieviele Multiplikationen sind aus-zufuhren, um ein Polynom p ∈ Pn−1
in t auszuwerten? Dabei sei das Po-lynom gegeben
a) als Linearkombination von Mono-men
b) als Linearkombination vonLagrange-Basis-Funktionen
c) als Linearkombination vonNewton-Basis-Funktionen
5. Gegeben seien die Daten-Punktet 1 2 3 4y 11 29 65 125
.
a) Bestimme die polynomiale In-terpolierende als Linearkombinationvon Monomen.
b) Bestimme die Lagrange-Interpolierende und prufe dieUbereinstimmung mit a).
6. Wende die Fehlerabschatzung
maxt∈[t1,tn]
|f(t)− pn−1(t)| ≤14nMhn
mit M = maxt∈[t1,tn] |f (n)(t)| undh = maxi=2,...,n(ti−ti−1) auf die Ap-proximation von f(t) = sin t durchein Polynom p4 vierten Grades an,das f in funf in [0, π/2] aquidistan-ten Punkten interpoliert. WievieleDaten-Punkte sind notwendig, umden maximalen Fehler unter 10−10
zu drucken?

7.2. Exercises – Ubungen 371
7. Wende die Fehlerabschatzung
maxt∈[t1,tn]
|f(t)− pn−1(t)| ≤14nMhn
mit M = maxt∈[t1,tn] |f (n)(t)| undh = maxi=2,...,n(ti − ti−1) auf dieRunge-Funktion f(t) = 1
1+25 t2an.
Bringe Fehlerabschatzung und Be-obachtung in Einklang.
8. Vergleiche den Aufwand, eineVandermonde-Matrix A = (ai,j) perai,j = φj(ti) = tj−1
i = tiφj−1(ti) =tiai,j−1 fur j = 2, . . . , n induktiv zuerzeugen, mit demjenigen, die Ma-trix durch direkte Exponentiationzu erzeugen.
9. Zeige: Verfahren und Formeln furdie inverse quadratische Interpola-tion
Mit u = fbfc, v = fb
fa, w = fa
fcund p =
v w(u − w)(c − b) − v(1 − u)(b − a)sowie q = (u − 1)(v − 1)(w − 1) istb+p/q der Abschnitt g(0) des inversquadratischen Polynoms g(y).
ergeben sich als Resultat einerLagrange-Interpolation.
10. a) Zu (Abszissen von) Daten-Punkten t1 < t2 < . . . < tn sei dieFunktion π(t) =
∏ni=1(t − ti) defi-
niert. Zeige π′(tj) =∏n
i=1,i6=j(tj −ti).
b) Zeige mit a), daß fur dieLagrange-Basis-Funktionen `j(t) =
π(t)(t−tj)π′(t)
gilt.
11. Zeige: Wenn eine Funktion f in denDaten-Punkten (ti, yi)i=1,...,n durchdas zugehorige Newton-Polynom in-terpoliert wird, so ist xj =f [t1, t2, . . . , tj ] der Koeffizient der j-ten Newton Basis-Funktion πj .
12. a) Zeige: die ersten sechs Legendre-Polynome sind paarweise orthogo-nal.
b) Zeige: die ersten sechs Legendre-Polynome erfullen die three termsrecurrence relation.
c) Stelle die die ersten sechs Mo-nome 1, t, . . . , t5 als Linearkombi-nationen der ersten sechs Legendre-Polynome dar.
13. a) Zeige: die Chebyshev-Polynomeerster Art erfullen die three terms re-currence relation.
b) Verifiziere: fur die ersten sechsChebyshev-Polynome erster Art giltTo(t) = 1, T1(t) = t, T2(t) = 2t2− 1,T3(t) = 4t3−3t, T4(t) = 8t4−8t2+1und T5(t) = 16t5 − 20t3 + 5t.
c) Verifiziere: Nullstellen von Tk
sind tni = cos ((2i − 1) π2k) fur i =
1, . . . , k. Extrema (einschließlich derEndpunkte des Definitionsbereiches[−1, 1]) von Tk sind tei = cos (iπk )fur i = 0, 1, . . . , k.
14. Wie sind die Chebyshev-Punkte imIntervall [−1, 1] auf ein beliebiges In-tervall [a, b] zu transformieren?
15. Die n Daten-Punkte (ti, yi)i=1,2,...,n
seien stuckweise durch quadratischePolynome zu interpolieren.
a) Fur welches maximale n ist die In-terpolierende einmal stetig differen-zierbar?
b) Fur welches maximale n ist dieInterpolierende zweimal stetig diffe-renzierbar?
16. Verifiziere die Eigenschaften der B-Spline Funktionen Bk
i , die rekursivdurch Bo
i = χ[ti,ti+1) und Bki (t) =
vki (t)Bk−1
i (t) + (1− vki+1(t))B
k−1i+1 (t)

372 KAPITEL 7. INTERPOLATION
mit vki (t) = (t − ti)/(ti+k − ti) defi-
niert sind.
7.3 Computer Pro-
blems – Rechner-
Probleme
1. a) Programmiere die Auswertungeines Polynoms in der Horner-Darstellung (neben dem Argumentt sind die Koeffizienten in der Formx0, x1, . . . durch Kommata getrennteinzugeben).
b) Erweitere das Programm um dieAuswertung von p′ in t und die Be-rechnung von
∫ ba p(t) dt.
2. a) Programmiere die Bestimmungdes n Daten-Punkte (ti, yi)i=1,2,...,n
interpolierenden Newton-Polynomsund seine Auswertung.
b) Programmiere die Bestimmungdes neuen interpolierenden Newton-Polynoms wenn ein Daten-Punktzur Menge der Daten-Punkte hinzu-gefugt wird.
c) Programmiere eine rekursive Ver-sion von a) unter der Verwendungvon b).
3. a) Verwende eine Bibliotheksrou-tine oder eigenes Programm, umdie drei Daten-Punkte (−2,−27),(0,−1) und (1, 0) durch einen kubi-schen Spline zu interpolieren.
b) Visualisiere den sich ergebendennaturlichen kubischen Spline zusa-men mit den Daten-Punkten sowieseine erste und zweite Ableitung.Verifiziere, daß die entsprechendenAnforderungen erfullt sind.
4. Bestimme die polynomiale Interpo-lierende und die kubische Spline-Interpolierende der Runge-Funktionf(t) = 1
1+25t2fur n = 11 und n = 21
aquidistante Daten-Punkte im In-tervall [−1, 1]. Vergleiche anhandder Funktionsgraphen.
5. Gegeben die sechs Daten-Punkteti 0.0 0.5 1.0 6.0 7.0 9.0yi 0.0 1.6 2.0 2.0 1.5 0.0
.
a) Bestimme das diese sechs Daten-Punkte interpolierende Polynomp5(t) = pMonom(t) = pLagrange(t) =pNewton(t) funften Grades. StelleDaten-Punkte und Funktionsgraphdar.
b) Bestimme einen interpolierendenkubischen Spline.
c) Welche Interpolierende erscheintangemessener? Wie erklart sich dasVerhalten der Interpolierenden zwi-schen den Datenpunkten?
d) Konnte stuckweise lineare Inter-polation fur diese Daten-Punkte ge-eigneter sein?
6. Die neun Daten-Punktet 0 1 4 9 16 25 36 49 64y 0 1 2 3 4 5 6 7 8sind Daten-Punkte der Wurzel-Funktion.
a) Vergleiche die polynomiale Inter-polierende achten Grades mit Bi-bliotheksfunktionen fur sqrt.
b) Vergleiche kubische Spline-Interpolierende mit der Bibliotheks-funktionen sqrt.
c) Welche der Interpolierenden istauf [0, 64] am genauesten?
d) Welche der Interpolierenden istauf [0, 1] am genauesten?
7. Die Gamma-Funktion ist durchΓ(x) =
∫∞o tx−1e−t dt definiert. Fur

7.3. Computer Problems – Rechner-Probleme 373
n ∈ N gilt Γ(n) = (n − 1)!.Eine die funf Daten-Punkteti 1 2 3 4 5yi 1 1 2 6 24
interpolie-
rende Funktion approximiert dieGamma-Funktion.
a) Vergleiche die polynomiale Inter-polierende vierten Grades mit einerBibliotheksfunktion gamma.
b) Vergleiche die kubische Spline-Interpolierende mit einer Biblio-theksfunktionen gamma.
c) Welche der Interpolierenden istauf [0, 5] am genauesten?
d) Welche der Interpolierenden istauf [0, 1] am genauesten?
8. Gegeben die Daten der Entwicklungder Bevolkerung der USA.
Jahr Bevolkerung1900 762121681910 922284961920 1060215371930 1232026241940 1321645691950 1513257981960 1793231751970 2033020311980 226542199
Die polynomiale Interpolierendeachten Grades ist eindeutig be-stimmt und kann als Linearkombi-nation folgender Basen dargestelltwerden:
1. φj(t) = tj−1
2. φj(t) = (t− 1900)j−1
3. φj(t) = (t− 1940)j−1
4. φj(t) = ((t− 1940)/40)j−1
a) Erzeuge fur jeder der vier Ba-sen die zugehorigen Vandermonde-Matrizen, bestimme (mit Biblio-theksroutinen) und vergleiche deren
Konditionszahlen. Erlautere die Er-gebnisse.
b) Verwende die Basis, fur die A ambesten konditioniert ist, und visuali-siere Daten-Punkte und die polyno-mial Interpolierende.
c) Berechne mit Bibliotheksroutinenund visualisiere die monotone kubi-sche Hermitesche Interpolierende.
d) Berechne und visualisiere eine ku-bische Spline Interpolierende.
e) Unter Verwendung der poly-nomialen, kubischen Hermiteschenund der kubischen Spline Interpolie-renden extrapoliere die Entwicklungder US-Population. Wie zutreffendist die jeweilige Prognose gemessenam Ergebnis von 248 709 873 derVolkszahlung von 1990?
f) Berechne die Lagrange-Interpolierende fur dieselbenDaten-Punkte und werte diese wie-der fur jedes Jahre von 1900 bis 1980aus. Vergleiche die Laufzeit mitderjenigen fur die Auswertung perHorner und fur die Auswertung derkubischen Spline Interpolierenden.
g) Bestimme das die neun Daten-Punkten interpolierende Newton-Polynom p achten Grades. Be-stimme dann das zusatzlich den Da-tenpunkt zu 1990 interpolierendeNewton-Polynom q neunten Gradesunter Verwendung von p. Zeichne pund q fur 1900 ≤ t ≤ 1990.
h) Runde die Bevalkerungszahlenauf eine Million und berechne erneutdie polynomiale Interpolierende ach-ten Grades unter Verwendung derBasis aus b). Vergleiche die Ergeb-nisse und erlautere die Beobachtun-gen.

374 KAPITEL 7. INTERPOLATION
7.4 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Es gibt beliebig viele mathematische Funktionen, die einengegebenen Satz von Daten-Punkten interpolieren.
Die Daten-Punkte (ti, yi) fur i = 1, . . . ,m mit paarweise verschiedenen tiseien gegeben. Dann gibt es genau ein Polynom p ∈ Pm−1, das diese Daten-Punkte interpoliert. Beispielsweise die Polynome qc ∈ c tm + Pm−1 ⊂ Pm,die diesem Daten-Punkte interpolieren, stellen eine ein-parametrige Familie(qc) fur c ∈ R interpolierender Funktionen dar.
2. Richtig/Falsch? Wenn fur f exakt f(ti) = yi fur i = 1, . . . ,m gilt, dann313sind die Koeffizienten in der Darstellung von f als Linearkombination derBasis-Vektoren wohlbestimmt.
Die Koeffizienten xi in f(t) =∑n
j=1 xjφj(t) sind dann wohlbestimmt, wenn
n = m gilt und die Matrix A = (ai,j) = (φj(ti)) regular ist.
3. Richtig/Falsch? Wenn das einen Satz von Daten-Punkten interpolierendePolynom eindeutig ist, dann ist auch seine Darstellung eindeutig.313,316,317
Das Polynom kann als Linearkombination etwa von Monomen, Lagrange-oder von Newton-Basis-Funktionen dargestellt werden.
4. Richtig/Falsch? Wenn eine stetige Funktion f in n+1 auf [a, b] aquidistan-325ten Punkten durch Polynome pn interpoliert wird, dann konvergieren diesePolynome pn immer gegen f fur n→∞.
Falsch, wie das Gegenbeispiel der Runge’schen Funktion f(t) = 11+25 t2
zeigt.
5. Was ist der grundsatzliche Unterschied zwischen Interpolation und Appro-ximation?311
Interpolation ist die Bestimmung derjenigen Funktion f = f(t) = f(t,p∗)einer mehr-parametrigen Familie von Funktionen f(t,p), die Daten-Punkte(ti, yi)i=1,...,n interpoliert, d.h. f(ti,p
∗) = yi fur i = 1, . . . , n.Bei verrauschten Daten-Punkten ist Interpolation ungeeignet.Approximation ist die Bestimmung derjenigen Funktion f = f(t,p∗) auseiner mehr-parametrigen Familie von Funktionen f(t,p), die eine Ziel-Funktion minimiert. Beispiele sind least squares Probleme, Approxima-tion von Funktionen durch ihre Taylor-Polynome, durch ihre Chebyshev-Approximation12 oder ihre minimax-Approximation13.
6. Nenne Beispiele fur Anwendungen von Interpolation.310
12 f ≈∑cjTj mit den Chebyshev-Polynomen Tj erster Art
13 Beispielsweise minimiert das Minimax-Polynom die maximale Abweichung von f .

7.4. Review Questions – Antworten auf Verstandnisfragen 375
Beispiele sind Zeichnen glatter Kurven, Interpolation in Tafeln, Differenta-tion und Integration tabulierter Funktionen, Auswertung mathematischerFunktionen oder das Ersetzen komplizierter Funktionen durch einfachere.
7. Beispielsweise welche numerischen Verfahren basieren auf Interpolation? 312
Inverse Interpolation und linear gebrochene Interpolation zur Losung nicht-linearer Gleichungen in einer Unbekannten sind Beispiele fur Verfahren, dieauf Interpolation basieren.
8. Konnen zwei Polynome dieselben Daten-Punkte interpolieren?
Beispielsweise interpolieren p(t) = t wie auch q(t) = t3 die drei Daten-Punkte (t1, y1) = (−1,−1), (t2, y2) = (0, 0) und (t3, y3) = (1, 1). Weil dasSystem linearer Gleichungen Ax = (tj−1
i )i=1,2,3;j=1,2,3,4x = y unterbestimmtist, gibt es sogar unendlich viele interpolierende kubische Polynome.
9. Welche Kriterien bestimmen die Wahl der Basis-Funktionen fur Interpola-tion? 313
A = (φj(ti)) soll nicht nur regular sondern auch gut konditioniert sein.Das System linearer Gleichungen Ax = y soll einfach zu losen sein, dieinterpolierende Funktion soll leicht auszuwerten sein.
10. Interpolieren bedeutet Ax = y zu losen. Welche Elemente von A ver-schwinden bei Verwendung der
a) Monom-Basis? 314
Die Vandermonde-Matrix A = (tji) =
1 t1 · · · tn−1
1
1 t2 · · · tn−12
......
. . ....
1 tn · · · tn−1n
kann hochstens
in einer Zeile n−1 Nullen (fur ti = 0) aufweisen, alle anderen Eintrage sindvon Null verschieden.
b) Lagrange-Basis? 316
Wegen `j(ti) = δi,j gilt fur die Lagrange-Basis A = I.
c) Newton-Basis? 318
Wegen πj(ti) = 0 fur i < j ist A fur die Newton-Basis eine untere Dreiecks-matrix.
11. a) Ist Interpolation ein angemessenes Verfahren, um eine Funktion ver- 311rauschten Daten anzupassen?
Interpolation ist ungeeignet, weil es sinnlos ist, f dadurch zu bestimmen,daß f verrauschte Daten-Punkte (ti, yi)i=1,...,n interpoliert, d.h. zu fordern,daß exakt f(ti) = yi fur alle i = 1, . . . , n gilt.

376 KAPITEL 7. INTERPOLATION
b) Falls ja, wieso? falls nein, welche Alternativen bieten sich?311
Bei verrauschten Daten sind etwa least squares oder total least squares Ver-fahren, Chebyshev- oder minmax-Approximation angemessen.
12. a) Welche Rangfolge hat der Aufwand, die m Daten-Punkte interpolierende315,316,318Funktion zu bestimmen, bei Verwendung von jeweils Monom-, Lagrange-und Newton-Basis?
Wegen A = I kostet die Bestimmung der Lagrange-Koeffizienten am wenig-sten. Um die Newton-Koeffizienten zu bestimmen, ist Ax = y mit untererDreiecksmatrix A per forward substitution und Aufwand O(n2) zu losen.Der Aufwand, Ax = y fur beliebiges regulares A zu losen, ist propor-tional zu O(n3). Daher ist die Bestimmung der Monom-Koeffizienten amaufwandigsten.
b) Welche Rangfolge hat die Kondition von A = (φj(ti)) bei Verwendung315,317,318von jeweils Monom-, Lagrange- und Newton-Basis?
Es gilt cond(AMonom) > cond(ANewton) > cond(ALagrange).
c) Welche Rangfolge hat bei Verwendung von jeweils Monom-, Lagrange-315,317,318und Newton-Basis der Aufwand, die interpolierende Funktion auszuwerten?
Die Auswertung eines Polynoms (n− 1)-ten Grades kostet je nach Basis
Basis Linearkombination∑
FADD FMUL FADD FMUL FADD FMULMonom-Basis, Horner n− 2 n− 1 1 n− 1 n− 1Newton-Basis, Horner n− 1 n− 2 n− 1 1 2n−2 n− 1
Lagrange-Basis14 n 2n−1 n− 1 n 2n−1 3n−1
13. a) Was ist eine Vandermonde-Matrix?314
Eine Matrix der Form
1 t1 · · · tn−1
1
1 t2 · · · tn−12
......
. . ....
1 tn · · · tn−1n
heißt Vandermonde-Matrix.
b) In welchem Zusammenhang treten Vandermonde-Matrizen auf?314
14 wobei die Lagrange-Basis-Funktionen `j(t) =∏n
k=1,k 6=j(t− tk)/∏n
k=1,k 6=j(tj − tk) furj = 1, . . . , n wie folgt ausgewertet werden: die Zahler werden fur t 6= tj per Division des einmalzu berechnenden Produktes
∏nk=1(t− tk) durch (t− tj) bestimmt und die n konstanten Nenner
sind als vorab berechnet angenommen. Divisionen werden wie Multiplikationen gezahlt.

7.4. Review Questions – Antworten auf Verstandnisfragen 377
Fur die Vandermonde-Matrix A =
1 t1 · · · tn−1
1
1 t2 · · · tn−12
......
. . ....
1 tn · · · tn−1n
zu den Daten-
Punkten (ti, yi) fur i = 1, . . . , n liefert die Losung von Ax = y die in-terpolierende Funktion als Linearkombination der Monome φj(t) = tj.
c) Warum sind Vandermonde-Matrizen großer Ordnung haufig schlecht kon- 315ditioniert?
Je hoher der Grad, um so weniger unterscheidbar sind die Monome φj(t) =tj etwa im Einheitsintervall [0, 1].
14. Gegeben die n Daten-Punkte (ti, yi) fur i = 1, . . . , n. Um die Koeffizientendes interpolierenden Polynoms zu bestimmen, ist das n×n-System linearerGleichungen Ax = y zu losen.
a) Wie sehen die Elemente von A bei Verwendung der Monom-Basis φj(t) = 314tj, also 1, t, t2, . . . aus?
A = (φj(ti)) ist eine Vandermonde-Matrix A =
1 t1 · · · tn−1
1
1 t2 · · · tn−12
......
. . ....
1 tn · · · tn−1n
.
b) Wie andert sich cond(A), wenn n wachst? 315
Fur die meisten Satze von Daten-Punkten wachst die Kondition von Aeponentiell, wenn n wachst.
c) Wie beeinflußt dieser Umstand die Genauigkeit, mit der das Polynom 315die Daten-Punkte interpoliert?
Mit partial pivoting wird das Polynom die Daten-Punkte zuverlassig in-terpolieren. Nur sind die Koeffzienten schlecht konditioniert, d.h. kleineFehler in den Eingangsdaten ti und yi ziehen große Fehler in den Koeffizi-enten nach sich.
15. Das Lagrange-Polynom interpoliere die n Daten-Punkte (ti, yi)i=1,...,n.
a) Welchen Grad haben die Lagrange-Basis-Funktionen `j(t) ? 316
Wegen `j(t) =Qn
k=1,k 6=j(t−tk)Qnk=1,k 6=j(tj−tk)
hat jedes Polynom `j(t) den Grad n− 1.
b) Welche Funktionen g(t) ergibt g(t) =∑n
j=1 `j(t) ? 316
Wegen `j(ti) = δi,j gilt g(ti) = 1 fur i = 1, . . . , n. Damit gilt notwendiger-weise g(t) ≡ 1.
16. Inwiefern ist Lagrange-Interpolation vorteilhaft, inwiefern nachteilhaft ver-

378 KAPITEL 7. INTERPOLATION
glichen mit Polynom-Interpolation bei Verwendung der Monom-Basis?
Vorteilhaft ist, daß die Koeffizienten des Lagrange-Polynoms auf einfachsteWeise und bestens konditioniert zu bestimmen sind (A = I). Nachteilig ist,daß das Lagrange-Polynom aufwandig auszuwerten, zu differenzieren undzu integrieren ist.
17. Gemessen in der Anzahl der Additionen und Multiplikationen, wie aufwan-316dig ist es, ein Polynom per Horner auszuwerten?
Ein Polynom pn−1(t) = x1 + x2t + . . . + xntn−1 vom Grad n − 1 laßt sich
per Horner als pn−1(t) = x1 + t(x2 + t(x3 + t(. . . (xn−1 +xnt))...)) darstellen:eine Auswertung kostet dann n Additionen und n Multiplikationen.
18. Warum ist die Interpolation mit Polynomen hohen Grades haufig unbefrie-digend?
Ein Polynom n-ten Grades ist aufwandig auszuwerten, seine Koeffizientensind schlecht konditioniert, es hat n − 1 Extrema oder Wendepunkte undkann damit zwischen den Daten-Punkten stark oszillieren: die Absicht, einegenugend glatte Kurve durch die Daten-Punkte zu legen, wird konterkariert.
19. a) Wovon hangt der Fehler vornehmlich ab, wenn eine stetige Funktion324,325durch ein Polynom interpoliert wird?
Der Fehler hangt von der zu approximierenden Funktion und von der Wahlder Daten-Punkte ab. Wegen f(t) − pn−1(t) = 1
n!f (n)(t∗)
∏ni=1(t − ti) fur
t1 < t2 < . . . < tn und ein t∗ ∈ (t1, tn) laßt sich der Fehler |f(t) − pn−1(t)|abschatzen durch
maxt∈[t1,tn]
|f(t)− pn−1(t)| ≤ 14nMhn mit M = maxt∈[t1,tn] |f (n)(t)|
und h = maxi=2,...,n(ti − ti−1)
Wo moglich, verbessern Chebyshev-Punkte (ti) statt aquidistanten (ti) dieApproximation von f durch pn−1 insofern, als der Fehler gleichmaßig aufdas gesamte Intervall verteilt ist.
b) Unter welchen Bedingungen wird bei großer Anzahl von Daten-Punkten324,325der Fehler dennoch groß?
vgl. Runge’sche Funktion
20. Wie sollten die Abszissen der Daten-Punkte in einem gegebenen Intervall324gewahlt sein, damit die interpolierenden Polynome gegen eine genugendglatte Funktion konvergieren, wenn die Anzahl der Daten-Punkte wachst.
Wahle die Abszissen der Daten-Punkte als Chebyshev-Punkte, i.e. die Pro-jektionen auf dem oberen Halbkreis gleichverteilter Punkte auf die x-Achse.

7.4. Review Questions – Antworten auf Verstandnisfragen 379
21. Was heißt, daß zwei Polynome p und q auf [a, b] orthogonal sind?321
Gegeben eine auf [a, b] nicht-negative Gewichtsfunktion w. Dann heißen p
und q auf [a, b] orthogonal, p ⊥ q, genau dann, wenn∫ b
ap(t)q(t)w(t) dt = 0
22. a) Was bedeutet Taylor-Polynom einer Funktion f ? 325/326
Taylor-Polynome pn−1(t) =∑n−1
i=0f (i)(to)
i!(t−to)i sind die Anfange der Taylor-
Reihen-Entwicklung f(t) =∑∞
i=0f (i)(to)
i!(t− to)
i einer Funktion f um einenEntwicklungspunkt to.
b) Inwiefern interpoliert das Taylor-Polynom pn−1 eine gegebene Funktion 326f ?
Das Taylor-Polynom pn−1 und seine Ableitungen stimmen im Entwicklungs-
punkt to mit f und seine Ableitungen uberein, d.h. f (i)(to) = p(i)n−1(to) fur
i = 0, 1, . . . , n− 1.
23. Worin besteht der entscheidende Vorteil von stuckweise polynomialer In- 326terpolation gegenuber der Interpolation mit einem einzigen Polynom?
Stuckweise polynomiale Interpolation eliminiert exzessive Oszillationen zwi-schen den Daten-Punkten und bietet Konvergenz gegen eine gegebene Funk-tion bei wachsender Anzahl der Daten-Punkte unabhangig von der spezi-ellen Wahl der Abszissen dieser Daten-Punkte. Zudem wirken sich Ande-rungen der Daten-Punkte naturgemaß nur lokal, also gerade nicht auf diegesamte interpolierende Funktion aus.
24. a) Wie unterscheidet sich Hermite-Interpolation von gewohnlicher Interpo- 327lation?
Die Hermite-Interpolierende interpoliert nicht nur gegebene Daten-Punkte,ihre Ableitungen weisen auch in den Abszissen der Daten-Punkte vorgege-bene Werte auf.
b) Wie unterscheidet sich eine kubische Spline-Interpolierende von einer 327kubischen Hermite-Interpolierenden?
???
25. Soll man sich fur Hermite-Interpolation oder fur kubische Spline-Interpola-tion entscheiden,
a) wenn die Interpolierende moglichst glatt sein soll? 327
Eine kubische Spline-Interpolierende hat stetige zweite Ableitungen, einekubische Hermite-Interpolierenden dagegen hat nur stetige erste Ableitun-gen.
b) wenn die Interpolierende Monotonie der Daten erhalten soll? 329
Nur kubische Hermite-Interpolierende weisen genugend Freiheitsgrade auf,um Monotonie der Daten erhalten zu konnen.

380 KAPITEL 7. INTERPOLATION
26. a) Wie oft ist eine kubische Hermite-Interpolierende stetig differenzierbar?327
Ein stuckweise kubisches Polynom mit n Knoten hat 4(n−1) Freiheitsgrade.Wenn es n Datenpunkte interpoliert, bleiben 2(n−1) Freiheitsgrade. Wennseine erste Ableitung stetig sein soll, d.h. wenn es glatt sein soll, n Frei-heitsgrade, mit denen keine hohere stetige Differenzierbarkeit zu erreichenist.
b) Wie oft ist eine kubische Spline-Interpolierende stetig differenzierbar?327
Eine kubische Spline-Interpolierende hat stetige zweite Ableitungen.
27. Die Stetigkeits- und Glattheitsanforderungen an kubische Spline-Interpo-327lierende lassen zwei Freiheitsgrade. Gib Beispiele fur zusatzliche Anforde-rungen an kubische Spline-Interpolierende.
• vorgegebene Steigungen in Anfangs- und Endpunkt• verschwindende zweite Ableitungen in Anfangs- und Endpunkt (natural)• not-a-knot-Bedingungen• Ubereinstimmende erste und zweite Ableitungen in Anfangs- und Endpunkt(Periodizitat)
28. a) Wieviele Parameter sind notwendig, um ein stuckweise kubisches Poly-327nom mit n Knoten zu spezifizieren?
Jedes der n−1 kubischen Polynome hat vier Koeffizienten, so daß insgesamt4(n− 1) Parameter zu spezifizieren sind.
b) Welches System linearer Gleichungen entsteht bei Verwendung naturli-327cher kubischer Splines?
Der naturliche kubische Spline p auf t1 < t2 < . . . < tn bestehe aus den ku-bischen Polynomen pi auf [ti−1, ti] fur i = 2, . . . , n, die folgende Anfordungenerfullen mussen (Anzahl resultierender Gleichungen in zweiter Spalte):
pi(ti−1) = yi−1 und pi(ti) = yi, d.h. pi interpoliert (ti−1, yi−1) und (ti, yi) : 2(n-1)p′i(ti−1) = p′i−1(ti−1) fur i = 3, . . . , n, d.h. stetige erste Ableitungen : n-2p′′i (ti−1) = p′′i−1(ti−1) fur i = 3, . . . , n, d.h. stetige zweite Ableitungen : n-2p′′2(t1) = 0 und p′′n(tn) = 0, d.h. naturlicher kubischer Spline : 2
Gesamtzahl Gleichungen : 4(n-1)
Sei pi(t) = ait3+bit
2+cit+di. Dann besteht das System in den Unbekanntenai, bi, ci und di aus den linearen Gleichungen
pi(ti−1) = ait3i−1 + bit
2i−1 + citi−1 + di = yi−1 fur i = 2, . . . , n
pi(ti) = ait3i + bit
2i + citi + di = yi fur i = 2, . . . , n
p′i(ti−1) = 3ait2i−1 + 2biti−1 + ci = 3ai−1t
2i−1 + 2bi−1ti−1 + ci−1 = p′i−1(ti−1),
p′′i (ti−1) = 6aiti−1 + 2bi = 6ai−1ti−1 + 2bi−1 = p′′i−1(ti−1) fur i = 3, . . . , np′′2(t1) = 6a2t1 + 2b2 = 0 und p′′n(tn) = 6antn + 2bn = 0

7.5. Exercises – Ubungsergebnisse 381
29. Welche der folgenden n Daten-Punkte interpolierenden Funktionen ist ein-deutig?
a) Polynome vom Grad n− 1 314
Die Koeffizienten-Matrix des zugehorigen Gleichungssystemes ist eine (re-gulare) n×n-Vandermonde-Matrix. Daher ist die interpolierende Funktioneindeutig.
b) kubische Hermite-Polynome 327
n Datenpunkte interpolierende kubische Hermite-Polynome haben n Frei-heitsgrade und sind daher nicht eindeutig.
c) kubische Spline-Polynome 327
n Datenpunkte interpolierende kubische Spline-Polynome haben zwei Frei-heitsgrade und sind daher nicht eindeutig.
30. Welcher Typ von interpolierenden Funktionen kann grundsatzlich Monoto-nie eines Satzes von n Daten-Punkten erhalten?
a) Polynome vom Grad n− 1 314
Das interpolierende Polynom ist eindeutig. Wenn das Polynom mindestensein Extremum zwischen den Daten-Punkten aufweist, kann es nicht mono-ton sein.
b) kubische Hermite-Polynome 329
Kubische Hermite-Interpolierende weisen genugend Freiheitsgrade auf, umMonotonie der Daten erhalten zu konnen.
c) kubische Spline-Polynome 327
Aufgrund der hoheren Anforderungen an Glattheit haben kubische Spline-Polynome zuwenig Freiheitsgrade, um Monotonie der Daten erhalten zukonnen.
31. Inwiefern ist es vorteilhaft, wenn die interpolierenden Basis-Funktionen lo- 331kalisiert sind, d.h. wenn der Koeffizient zu einer jeden Basis-Funktion nurvon einigen wenigen Daten-Punkten abhangt?
Anderung eines Daten-Punktes andert dann auch nur einige wenige Koeff-zienten lokalisierter Basis-Funktionen, so daß sich die interpolierende Funk-tion nicht uberall sondern nur lokal andert.
7.5 Exercises – Ubungsergebnisse
1. Gegeben die drei Daten-Punkte (−1, 1), (0, 0) und (1, 1). Bestimme dieinterpolierende Parabel p = p(t)

382 KAPITEL 7. INTERPOLATION
a) als Linearkombination der Monom-Basis.314
Die Losung von Ax =
1 −1 11 0 01 1 1
x =
101
= y ist x =
001
, d.h.
p(t) = 0 + 0 · t+ t2 = t2.
b) als Linearkombination der Lagrange-Basis.316
Es gilt p(t) = 1 · `1(t) + 0 · `2(t) + 1 · `3(t) = (t−0)(t−1)(−1−0)(−1−1)
+ (t−−1)(t−0)(1−−1)(1−0)
=12t(t− 1) + 1
2t(t+ 1) = t2.
c) als Linearkombination der Newton-Basis.318
Die Losung von Ax =
1 0 01 1 01 2 2
x =
101
= y ist x =
1−1
1
, d.h.
p(t) = 1−1(t−−1)+1(t−−1)(t−0) = 1−(t+1)+(t+1)t = 1+(t+1)(t−1) =t2.
2. Wie ist p(t) = 5t3−3t2+7t−2 fur die Auswertung per Horner darzustellen?316
p(t) = 5t3 − 3t2 + 7t− 2 = ((5t− 3)t+ 7)t− 2
3. Programmiere einen Algorithmus, der ein vorzugebendes Polynom p(t) ineinem vorzugebenden Argument auswertet. Das Polynom p ist gegeben als
a) Linearkombination p(t) =∑grad
j=0 xjtj von Monomen tj (die Koeffizienten316
sind in der Form x0, x1, . . . durch Kommata getrennt einzugeben)
x = tests
grad = t =p(t) =p′(t) =
a = b =∫ b
ap(t) dt =
evalreset
b) Linearkombination p(t) =∑n−1
j=0 xjπj(t) von Newton-Basis-Funktionen318πj zu Abszizzen ti, i = 1, . . . , n (die Koeffizienten sind in der Form t1, . . . , tnbzw. x1, x2, . . . durch Kommata getrennt einzugeben)
???
4. Wieviele Multiplikationen sind auszufuhren, um ein Polynom p ∈ Pn−1 in tauszuwerten? Dabei sei das Polynom gegeben
a) als Linearkombination von Monomen316
Mit p(t) = x1 + t(x2 + t(x3 + t(. . . (xn−1 + xnt) . . .) sind n Multiplikationennotwendig, um p in t auszuwerten.
b) als Linearkombination von Lagrange-Basis-Funktionen316
In p(t)=y1`1(t)+ . . .+yn`n(t) mit `j(t)=Qn
k=1,k 6=j(t−tk)Qnk=1,k 6=j(tj−tk)
=cj∏n
k=1,k 6=j(t− tk)seien die Konstanten cj = 1Qn
k=1,k 6=j(tj−tk)vorberechnet. Dann sind zur Aus-

7.5. Exercises – Ubungsergebnisse 383
wertung jeder Lagrange-Basis-Funktion n−2 und damit insgesamt n(n−2)Multiplikationen auszufuhren.
c) als Linearkombination von Newton-Basis-Funktionen 318
Mit p(t) = x1π1(t) + . . . + xnπn(t) und πj(t) =∏j−1
k=1(t − tk) sind zurAuswertung von xjπj in t jeweils j−1 Multiplikationen und daher insgesamt∑n
j=2(j − 1) =∑n−1
j=1 j = 12(n− 1)n Multiplikationen auszufuhren.
5. Gegeben die Daten-Punktet 1 2 3 4y 11 29 65 125
.
a) Bestimme die polynomiale Interpolierende als Linearkombination von 314Monomen.
Das interpolierenden kubische Polynom p(t) = x1 + x2t + x3t2 + x4t
3 istp(t) = 5 + 2t + 3t2 + t3, da sich seine Koeffizienten x als Losung von
Ax =
1 1 1 11 2 4 81 3 9 271 4 16 64
x =
112965
125
= y zu x =
5231
ergeben.
b) Bestimme die Lagrange-Interpolierende und prufe die Ubereinstimmung 316mit a).
Lagrange-Interpolierende ist p(t) = 11`1(t)+29`2(t)+65`3(t)+125`4(t) mit
`1(t) = (t−2)(t−3)(t−4)(1−2)(1−3)(1−4)
= (t−2)(t−3)(t−4)−6
, `2(t) = (t−1)(t−3)(t−4)(2−1)(2−3)(2−4)
= (t−1)(t−3)(t−4)2
`3(t) = (t−1)(t−2)(t−4)(3−1)(3−2)(3−4)
= (t−1)(t−2)(t−4)−2
, `4(t) = (t−1)(t−2)(t−3)(4−1)(4−2)(4−3)
= (t−1)(t−2)(t−3)6
p(t) = (11−6
(t−2)+ 292(t−1))(t−3)(t−4)+(65
−2(t−4)+ 125
6(t−3))(t−1)(t−2)
= −22t+44+174t−17412
(t2 − 7t+ 12) + −390t+1560+250t−75012
(t2 − 3t+ 2)
= −152t−13012
(t2 − 7t+ 12) + −140t+81012
(t2 − 3t+ 2)
= 112
(152t3 − 1194t2 + 2734t− 1560− 140t3 + 1230t2 − 2710t+ 1620)
= 112
(12t3 + 36t2 + 24t+ 60) = t3 + 3t2 + 2t+ 5
6. Wende die Fehlerabschatzung maxt∈[t1,tn] |f(t)−pn−1(t)| ≤ 14nMhn mitM = 324
maxt∈[t1,tn] |f (n)(t)| und h = maxi=2,...,n(ti−ti−1) auf die Approximation vonf(t) = sin t durch ein funf in [0, π/2] aquidistante Punkte interpolierendesPolynom p4 vierten Grades an. Wieviele Daten-Punkte sind notwendig, umden maximalen Fehler unter 10−10 zu drucken?
???
7. Wende die Fehlerabschatzung maxt∈[t1,tn] |f(t)−pn−1(t)| ≤ 14nMhn mitM = 324
maxt∈[t1,tn] |f (n)(t)| und h = maxi=2,...,n(ti − ti−1) auf die Runge-Funktionf(t) = 1
1+25 t2an. Bringe Fehlerabschatzung und Beobachtung in Einklang.
???

384 KAPITEL 7. INTERPOLATION
8. Vergleiche den Aufwand, eine Vandermonde-Matrix A = (ai,j) per ai,j = 316φj(ti) = tj−1
i = tiφj−1(ti) = tiai,j−1 fur j = 2, . . . , n induktiv zu erzeugen,mit demjenigen, die Matrix durch direkte Exponentiation zu erzeugen.
Die induktive Berechnung erfordert Zeilen-weise n− 1 (nur n− 2, wenn derEintrag in der zweiten Spalte initialisiert und nicht durch eine Multiplika-tion aus der Eins der ersten Spalte gewonnen wird), also insgesamt (n−1)n(bzw. (n− 2)n) Multiplikationen.Direkte Exponentiation erfordert Zeilen-weise
∑n−2j=1 j = 1
2(n − 2)(n − 1),
also insgesamt 12(n− 2)(n− 1)n Multiplikationen.
9. Zeige: Verfahren und Formeln fur die inverse quadratische Interpolation234
Mit u = fb/fc, v = fb/fa, w = fa/fc undp = v w(u−w)(c− b)− v(1− u)(b− a) sowie q = (u− 1)(v − 1)(w− 1)ist b+ p/q Abschnitt g(0) des invers quadratischen Polynoms g(y)
ergeben sich als Resultat einer Lagrange-Interpolation.316
Die die Daten-Punkte (fa, a), (fb, b) und (fc, c) interpolierende Parabel g(y)
in y ist durch g(y) = a (y−fb)(y−fc)(fa−fb)(fa−fc)
+ b (y−fa)(y−fc)(fb−fa)(fb−fc)
+ c (y−fa)(y−fb)(fc−fa)(fc−fb)
gege-
ben – mit Abschnitt g(0) = a fb fc
(fa−fb)(fa−fc)+ fa b fc
(fb−fa)(fb−fc)+ fa fb c
(fc−fa)(fc−fb)=
−a(u−1)v+b(w−1)+c u(v−1)w(u−1)(v−1)(w−1)
. Die Behauptung g(0) = b+ p/q folgt aus Koeffizi-entenvergleich in a, b und c in
−a(u− 1)v + b(w − 1) + c u(v − 1)w = b(u− 1)(v − 1)(w − 1) + v w(u− w)(c− b)− v(1− u)(b− a)
namlich −(u− 1)v = −v(1− u)(−1) fur a und w− 1 = (u− 1)(v − 1)(w−1)−v w(u−w)−v(u−1) wegen u = v w fur b sowie u(v−1)w = v w(u−w)wieder wegen u = v w fur c zeigt, daß g(0) = b+ p/q gilt.
10. a) Zu (Abszissen von) Daten-Punkten t1 < t2 < . . . < tn sei die Funktionπ(t) =
∏ni=1(t− ti) definiert. Zeige π′(tj) =
∏ni=1,i6=j(tj − ti).
Aus π′(t) =∑n
k=1
∏ni=1,i6=k(t − ti) folgt π′(tj) =
∏ni=1,i6=j(t − ti), da alle
anderen Summanden verschwinden.
b) Zeige mit a), daß fur die Lagrange-Basis-Funktionen `j(t) = π(t)(t−tj)π′(t)
gilt.
Sei gj(t) = π(t)(t−tj)π′(t)
. Fur alle i 6= j gilt gj(ti) = π(ti)(ti−tj)π′(ti)
= 0, da der
Zahler verschwindet. In tj laßt sich gj(tj) =π(tj)
(tj−tj)π′(tj)= 1 durch 1 stetig
erganzen, da Zahler und Nenner formal ubereinstimmen. Somit stimmendie Polynome gj und `j in n Argumenten und damit uberall uberein.
11. Zeige: Wenn eine Funktion f in den Daten-Punkten (ti, yi)i=1,...,n durch das320

7.5. Exercises – Ubungsergebnisse 385
zugehorige Newton-Polynom interpoliert wird, so ist xj = f [t1, t2, . . . , tj]der Koeffizient der j-ten Newton Basis-Funktion πj fur j = 1, . . . , n.
Zunachst gilt f [t1, . . . , tk] =∑k
j=1yjQk
i=1,i6=j(tj−ti), weil erstens der Indukti-
onsanfang f [t1] = y1 und zweitens der Induktionsschritt
f [t1, t2, . . . , tk+1] =f [t2, t3, . . . , tk+1]− f [t1, t2, . . . , tk]
tk+1 − t1
=k+1∑j=2
yj/(tk+1 − t1)∏k+1i=2,i6=j(tj − ti)
−k∑
j=1
yj/(tk+1 − t1)∏ki=1,i6=j(tj − ti)
=k∑
j=2
yj/(tk+1 − t1)∏k+1i=2,i6=j(tj − ti)
+yk+1∏k
i=1(tk+1 − ti)
+y1∏k+1
i=2 (t1 − ti)−
k∑j=2
yj/(tk+1 − t1)∏ki=1,i6=j(tj − ti)
=k∑
j=2
yj/(tk+1 − t1)
(tj − tk+1)∏k
i=2,i6=j(tj − ti)+
yk+1∏ki=1(tk+1 − ti)
+y1∏k+1
i=2 (t1 − ti)−
k∑j=2
yj/(tk+1 − t1)
(tj − t1)∏k
i=2,i6=j(tj − ti)
=∑
j=1,k+1
yj∏k+1i=1,i6=j(tj − ti)
+k∑
j=2
yj(tj−t1)−(tj−tk+1)
tk+1−t1∏k+1i=1,i6=j(tj − ti)
=k+1∑j=1
yj∏k+1i=1,i6=j(tj − ti)
zutrifft. Insbesondere ist also f [t1, . . . , tj] unabhangig von der Reihen-folge der Argumente. Ebenso zeigt man die Behauptung xj = f [t1, . . . , tj]per Induktion: Der Induktionsanfang ist durch x1 = y1 = f [t1] sicher-gestellt. Der Induktionsschritt basiert auf der inkrementellen Berechnungxj+1 = (yj+1 − pj(tj+1))/πj+1(tj+1) von xj+1 vermittels des die ersten jDatenpunkte interpolierenden Polynoms pj vom Grad j − 1. Mit der In-duktionsvorausetzung pj(t) =
∑jk=1 f [t1, . . . , tk] πk(t) und der Abkurzung
ci =Pj
k=i f [t1,...,tk] πk(tj+1)Qjk=1(tj+1−tk)
folgt
xj+1 =yj+1 − pj(tj+1)
πj+1(tj+1)=f [tj+1]−
∑jk=1 f [t1, . . . , tk] πk(tj+1)∏jk=1(tj+1 − tk)
=f [tj+1]− f [t1]
(tj+1 − t1)∏j
k=2(tj+1 − tk)− c2 =
f [t1, tj+1]∏jk=2(tj+1 − tk)
− c2

386 KAPITEL 7. INTERPOLATION
=f [t1, tj+1]− f [t2, t1]
(tj+1 − t2)∏j
k=3(tj+1 − tk)− c3 =
f [t2, t1, tj+1]∏jk=3(tj+1 − tk)
− c3
=f [ti−1, ti−2, . . . , t1, tj+1]∏j
k=i(tj+1 − tk)− ci fur i = 1, . . . , j
=f [tj−1, tj−2, . . . , t1, tj+1]
tj+1 − tj− f [tj, tj−1, . . . , t1]
tj+1 − tj= f [tj, tj−1, . . . , t1, tj+1] = f [tj+1, tj, . . . , t1] = f [t1, . . . , tj+1]
Alternativ kann man zeigen, daß x mit xk =∑k
j=1yjQk
i=1,i6=j(tj−ti)Losung von
Ax = (πj(ti))i,jx = y ist.
12. a) Zeige: die ersten sechs Legendre-Polynome sind paarweise orthogonal.321
Die ersten sechs Legendre-Polynome sind Po(t) = 1, P1(t) = t, P2(t) =12(3t2 − 1), P3(t) = 1
2(5t3 − 3t), P4(t) = 1
8(35t4 − 30t2 + 3) und P5(t) =
18(63t5 − 70t3 + 15t). Die Legendre-Polynome P2n sind gerade Funktionen,
die Legendre-Polynome P2n+1 sind ungerade Funktionen. Nun definiert(p, q) =
∫ 1
−1p(t)q(t) dt ein Skalar-Produkt. Wenn i + j ungerade ist, ist
auch der Integrand ungerade und daher (Pi, Pj) = 0. Die ubrigen Fallesind
(Po, P2) = 12
∫ 1
−1(3t2 − 1) dt = 1
2(t3 − t)|1−1 = 1
2(0− 0) = 0.
(Po, P4) = 18
∫ 1
−1(35t4− 30t2 + 3) dt = 1
8(7t5 − 10t3 + 3t)|1−1 = 1
8(0− 0) = 0.
(P1, P3) = 12
∫ 1
−1t(5t3 − 3t) dt = 1
2(t5 − t3)|1−1 = 1
2(0− 0) = 0.
(P1, P5) = 18
∫ 1
−1t(63t5− 70t3 + 15t) dt = 1
8(9t7−14t5+5t3)|1−1 = 1
8(0− 0) =
0.
(P2, P4) = 12
18
∫ 1
−1(3t2−1)(35t4−30t2 +3) dt = 1
16
∫ 1
−1(105t6−125t4 +39t2−
3) dt = 116
(15t7 − 25t5 + 13t3 − 3t)|1−1 = 12(0− 0) = 0.
(P3, P5) = 12
18
∫ 1
−1(5t3 − 3t)(63t5 − 70t3 + 15t) dt = 1
16
∫ 1
−1(315t8 − 539t6 −
285t4 − 45t2) dt = 1112
(35t9 − 77t7 + 57t5 − 15t3)|1−1 = 12(0− 0) = 0.
b) Zeige: die ersten sechs Legendre-Polynome erfullen die three terms re-321currence relation.
Zeige also (k + 1)Pk+1(t) = (2k + 1)t Pk(t)− kPk−1(t) fur k = 1, 2, 3, 4.
k = 1: 2P2(t) = 3 t P1(t)− Po(t) ⇐⇒ 212(3t2 − 1) = 3 t t− 1
√
k = 2: 3P2(t) = 5tP2(t) − 2P1(t) ⇐⇒ 32(5t3 − 3t) = 5
2t(3t2 − 1) − 2t =
12(15t2 − 5t− 4t)
√
k = 3: 4P4(t) = 7 t P3(t)− 3P2(t) ⇐⇒ 12(35t4− 30t2 + 3) = 7
2t(5t3− 3t)−
32(3t2 − 1) = 1
2(35t4 − 21t2 − 9t2 + 3)
√

7.5. Exercises – Ubungsergebnisse 387
k = 4: 5P5(t) = 9 t P4(t) − 4P3(t) ⇐⇒ 58(63t5 − 70t3 + 15t) = 9
8t(35t4 −
30t2 + 3)− 2(5t3 − 3t) = 18(315t5 − 270t3 − 80t3 + 27t+ 48t)
√
c) Stelle die die ersten sechs Monome 1, t, . . . , t5 als Linearkombinationen 321der ersten sechs Legendre-Polynome dar.
mo(t) = 1 = Po(t), m1(t) = t = P1(t), m2(t) = t2 = 23P2(t) + 1
3Po(t),
m3(t) = t3 = 25P3(t) + 3
5P1(t), m4(t) = t4 = 8
35P4(t) + 6
725P2(t) + 6
21Po(t)
und m5(t) = t5 = 836P5(t) + 10
925P3(t) + 2
3P1(t)
13. a) Zeige: die Chebyshev-Polynome erster Art erfullen die three terms re- 322/323currence relation.
Zeige also Tk+1(t) = 2 t Tk(t) − Tk−1(t) fur k > 0. Aus 2 cosx cos y =cos(x+y)+cos(x−y) folgt 2 cosϕ cos(kϕ) = cos ((k+1)ϕ)+cos ((k−1)ϕ)und daher mit ϕ = arccos t bzw. cosϕ = t eben 2 t cos(k arccos t) =cos ((k+1) arccos t)+cos ((k−1) arccos t), d.h. 2 t Tk(t) = Tk+1(t)+Tk−1(t).
b) Verifiziere: fur die ersten sechs Chebyshev-Polynome erster Art gilt 323To(t) = 1, T1(t) = t, T2(t) = 2t2 − 1, T3(t) = 4t3 − 3t, T4(t) = 8t4 − 8t2 + 1und T5(t) = 16t5 − 20t3 + 5t.
Es gilt To(t) = cos(0 arccos t) = 1, T1(t) = cos(arccos t) = t,T2(t) = cos(2 arccos t) = 2 cos2(arccos t)− 1 = 2t2 − 1,T3(t) = cos(3 arccos t) = 4 cos3(arccos t)− 3 cos(arccos t) = 4t3 − 3t,T4(t) = cos(4 arccos t) = 1−8 cos2(arccos t)+8 cos4(arccos t) = 8t4−8t2+1 undT5(t) = cos(5 arccos t) = 5 cos(arccos t)−20 cos3(arccos t)+16 cos5(arccos t)= 16t5 − 20t3 + 5t.
c) Verifiziere: Nullstellen von Tk sind tni= cos ((2i− 1) π
2k) fur i = 1, . . . , k. 323Extrema (einschließlich der Endpunkte des Definitionsbereiches [−1, 1]) vonTk sind tei
= cos (iπk ) fur i = 0, 1, . . . , k.
Tk(tni) = cos
(k arccos cos ((2i− 1) π
2k))
= cos ((2i − 1)π2) = 0 und fur
einen kritischen Punkt t∗ gilt T ′k(t∗) = k√
1−t∗2sin(k arccos t∗) = 0 ⇐⇒
k arccos t∗ = iπ ⇐⇒ t∗ = tei= cos iπ
kfur i = 0, 1, . . . , k. Mit T ′′k (t) =
k√1−t2
3 (t sin(k arccos t)−k√
1−t2 cos(k arccos t)) gilt T ′′k (tei) = −k2
1−t2ei
cos(iπ)
= −k2
1−t2ei
(−1)i, so daß jedes teifur i = 1, k − 1 tatsachlich Extremum ist.
Zusammen mit Tk(tei) = cos (k arccos(cos iπ
k)) = cos(iπ) = (−1)i ist so
auch die equi-alternation Eigenschaft verifiziert.
14. Wie sind die Chebyshev-Punkte im Intervall [−1, 1] auf ein beliebiges In- 324tervall [a, b] zu transformieren?
Die n+ 1 Chebyshev-Punkte im Intervall [−1, 1] sind die Projektionen vonn + 1 auf dem oberen Einheitshalbkreis gleichverteilten Punkten, namlich

388 KAPITEL 7. INTERPOLATION
pi = ej iπ/n fur i = 0, 1, . . . , n, auf die x-Achse. Damit sind xi = cos(iπ/n)die n+1 Chebyshev-Punkte in [−1, 1] und xi = 1
2(a+ b)(1+cos(iπ/n)) die
n+ 1 Chebyshev-Punkte im Intervall [a, b].
15. Die n Daten-Punkte (ti, yi)i=1,2,...,n seien stuckweise durch quadratische Po-lynome zu interpolieren.
a) Fur welches maximale n ist die Interpolierende einmal stetig differenzier-326bar?
Fur i = 1, . . . , n− 1 interpoliere die Parabel pi(t) die beiden Daten-Punkte(ti, yi) und (ti+1, yi+1). Dann erlaubt der verbleibende Freiheitsgrad, dieSteigung von pi in ti vorzugeben. Damit ist die erste Parabel p1 durchbeliebige Vorgabe von p′1(t1) = y′1, die zweite Parabel durch Vorgabe vonp′2(t2) = p′1(t2) usw. eindeutig bestimmt
b) Fur welches maximale n ist die Interpolierende zweimal stetig differen-326zierbar?
p2 ist durch p1 eindeutig bestimmt. Nun kann y′1 so gewahlt werden, daßp′′2(t2) = p′′1(t2) gilt und damit die Interpolierende von maximal drei Daten-Punkten zweimal stetig differenzierbar ist.
16. Verifiziere die Eigenschaften der B-Spline Funktionen Bki , die rekursiv durch330
Bki (t) = vk
i (t)Bk−1i (t) + (1− vk
i+1(t))Bk−1i+1 (t)
mit Boi = χ[ti,ti+1) und vk
i (t) = (t− ti)/(ti+k − ti) definiert sind.
Die Rekursion ist aufzulosen, um die Eigenschaften Nr. 4 und Nr. 5 nach-zuweisen. Sei zur Abkurzung vk
i = (1− vki ) gesetzt. Dann gilt (*)
Bki =
k∑j=0
uki,jB
0i+j mit uk
i,j =∑
j mal v in wκ = vκı oder wκ = vκ
ı , wojedes v inkrementiert ı, beginnend bei i
wkwk−1 · · ·w1
Dabei ist beispielsweise u3i,2 = v3
i v2i+1v
1i+2 + v3
i+1v2i+1v
1i+2 + v3
i+1v2i+2v
1i+2.
Induktionsanfang k = 1: wegen u1i,0 = v1
i und u1i,1 = v1
i+1 stimmt (*)mit der Rekursion B1
i = u1i,0B
0i + u1
i,1B0i+1 = v1
iB0i + (1 − v1
i+1)B0i+1 = B1
i
uberein.√
Induktionsschritt k > 0: wegen vki u
k−1i,0 = uk
i,0, vki u
k−1i,1 + vk
i+1uk−1i+1,0 = uk
i,1,
. . . , vki u
k−1i,k−1 + vk
i+1uk−1i+1,k−1 = uk
i,k−1 und vki+1u
k−1i+1,k−1 = uk
i,k gilt
Bki =
k∑j=0
uki,jB
0i+j = vk
i Bk−1i + (1− vk
i+1)Bk−1i+1
= vki (u
k−1i,0 B0
i + . . .+ uk−1i,k−1B
0i+k−1)

7.5. Exercises – Ubungsergebnisse 389
+vki+1(u
k−1i+1,0B
0i+1 + . . .+ uk−1
i+1,k−1B0i+k)
= vki u
k−1i,0 B0
i + (vki u
k−1i,1 + vk
i+1uk−1i+1,0)B
0i+1
+ . . .+ (vki u
k−1i,k−1 + vk
i+1uk−1i+1,k−1)B
0i+k−1 + vk
i+1uk−1i+1,k−1B
0i+k
= uki,0B
0i + uk
i,1B0i+1 + . . .+ uk
i,kB0i+k =
k∑j=0
uki,jB
0i+j = Bk
i
Also stimmt (*) mit der Rekursion Bki = vk
i Bk−1i + (1− vk
i+1)Bk−1i+1 uberein.
i. Fur den Trager T (Bki ) = t : Bk
i (t) 6= 0 von Bki gilt T (Bk
i ) =(ti, ti+k+1).M.a.W. verschwinden nur die B-Spline-Basis-Funktionen B0
i , B1i−1, B
1i ,
B2i−2,...,B
2i , . . .Bk
i−k,...,Bki nicht in t ∈ (ti, ti+1).
Wegen T (Boi ) = (ti, ti+1), T (B1
i ) = (ti, ti+2) usw. gilt fur den Tragervon Bk
i allgemein T (Bki ) = (ti, ti+k+1).
ii. Fur ti < t < ti+k+1 gilt Bki (t) > 0,d.h. auf dem Trager ist Bk
i (t) positiv.Induktionsanfang k = 0: fur t ∈ (ti, ti+1) gilt B0
i (t) = 1 > 0.Induktionsschritt k > 0: zunacht gilt vk
i (t) = t−titi+k−ti
> 0 fur t > ti
und 1 − vki+1(t) = 1 − t−ti+1
ti+1+k−ti+1= ti+1+k−t
ti+1+k−ti+1> 0 fur t < ti+1+k.
Aus der Induktionsvoraussetzung Bk−1i (t) > 0 fur ti < t < ti+k und
Bk−1i+1 (t) > 0 fur ti+1 < t < ti+1+k folgt somit Bk
i (t) = vki (t)Bk−1
i (t) +(1− vk
i+1(t))Bk−1i+1 (t) > 0 fur alle ti < t < ti+k+1.
iii. Fur alle t ∈ R gilt∑∞
i=−∞Bki (t) = 1, wie man per Induktion sieht:
Induktionsanfang: mit t ∈ [tio , tio+1) gilt∑∞
i=−∞Bki (t) = B0
io(t) =1.Induktionsschritt: mit t ∈ [tio , tio+1) gilt
∞∑i=−∞
Bki (t) =
io∑i=io−k−1
Bki (t) =
io∑i=io−k
(vki B
k−1i + (1− vk
i+1)Bk−1i+1 )(t)
=io∑
i=io−k
(vki B
k−1i )(t) +
io∑i=io−k
((1− vki+1)B
k−1i+1 )(t)
=io∑
i=io−k+1
(vki B
k−1i )(t) +
io−1∑i=io−k
((1− vki+1)B
k−1i+1 )(t)
=io∑
i=io−k+1
(vki B
k−1i )(t) +
io∑i=io−k+1
((1− vki )Bk−1
i )(t)
=io∑
i=io−k+1
Bk−1i (t) =
∞∑i=−∞
Bk−1i (t) = 1

390 KAPITEL 7. INTERPOLATION
Die Bki (t) bilden eine sogenannte Zerlegung der Eins, mit etwa der
Folge, daß fur endlich viele Punkte pi die Kurve p(t) =∑∞
i=−∞Bki (t)pi
in der konvexen Hulle der pi verlauft – und zwar fur beliebige Knoten-Vektoren (ti).
iv. Fur k ≥ 1 ist Bki (k− 1)-fach stetig differenzierbar, d.h. alle Ableitun-
gen Bki = Bk
i(0)
, Bki′= Bk
i(1)
, . . . , Bki
(k−1)existieren und sind stetig.
Induktionsanfang: Wegen B1i (t) = v1
i (t)B0i (t)+ (1− v1
i+1(t))B0i+1(t)
ist B1i stuckweise stetig. Es bleibt, die Stetigkeit in den Knoten ti, ti+1
und ti+2 zu zeigen.• In ti, also am linken Rand des Tragers T (B1
i ) = [ti, ti+2) von B1i gilt
B1i (ti) = v1
i (ti)B0i (ti) = v1
i (ti) = ti−titi+1−ti
= 0.√
• In ti+1, also im Knoten im Trager T (B1i ) = [ti, ti+2) von B1
i , giltlim
t→t−i+1
B1i (t) = lim
t→t−i+1
v1i (t)B
0i (t) = v1
i (ti+1) limt→t+i+1
B0i (t) = 1 · 1 = 1 =
1− tti+1−ti+1
ti+2−ti= ((1− v1
i+1)B0i+1)(ti+1) = B1
i (ti+1) = limt→t+i+1
B1i (t).
√
• In ti+2, also am rechten Rand des Tragers T (B1i ) gilt lim
t→t−i+2
B1i (t) =
limt→t−i+2
((1−v1i+1)B
0i+1)(t) = 1− v1
i+1(ti+2) limt→t−i+2
B0i+1(t) = 1−1·1 = 0.
√
Induktionsschritt:???
v. Die B-Spline-Basis-Funktionen (Bki )i=1−k,...,n−1
sind auf [t1, tn] linear
unabhangig. Es reicht, die lineare Unabhangigkeit auf jedem Intervall(ti, ti+1) zu zeigen. In jedem solchen Intervall ist Bk
i einfach ein Poly-nom vom Grad k.Induktionsanfang: Die (B0
i )i=1,...,n−1sind auf [t1, tn] linear unab-
hangig, da ihre Trager disjunkt sind.Induktionsschritt: Angenommen,
∑n−1i=1−k ciB
ki (t) = 0 auf [t1, tn].
Dann gilt 0 =∑n−1
i=1−k ciBki (t) =
∑n−1i=1−k ci(v
ki B
k−1i +(1−vk
i+1)Bk−1i+1 )(t)
=∑n−1
i=1−k ci(vki B
k−1i )(t) +
∑n−1i=1−k ci((1− vk
i+1)Bk−1i+1 )(t) =
???
vi. Die B-Spline-Basis-Funktionen Bk1−k, B
k1−k+1, . . . , B
kn−1 spannen den
Raum aller Splines vom Grad k mit Knoten t1, t2, . . . , tn auf.Ein Spline s(t) vom Grad k mit Knoten t1, t2, . . . , tn ist stuckweisepolynomial vom Grad k, (k − 1)-fach stetig differenzierbar und inter-poliert die Daten-Punkte (ti, yi)i=1,...,n. Wegen der dritten Eigenschaftist ein Spline s(t) als Linear-Kombination s(t) =
∑∞i=−∞ yiB
ki (t) der
B-Spline-Basis-Funktionen Bki darstellbar. Die Darstellung ist wegen
der linearen Unabhangigkeit der Bki (funfte Eigenschaft) eindeutig.

7.6. Computer Problems – Rechner-Problem-Losungen 391
7.6 Computer Problems –
Rechner-Problem-Losungen
1. a) Programmiere die Auswertung eines Polynoms in der Horner-Darstellung 316(neben dem Argument t sind die Koeffizienten in der Form x0, x1, . . . durchKommata getrennt einzugeben).
s. Polynom-Auswertung per Horner
b) Erweitere das Programm um die Auswertung von p′ in t und die Berech- 316nung von
∫ b
ap(t) dt.
s. Polynom-Auswertung per Horner
2. a) Programmiere die Bestimmung des n Daten-Punkte (ti, yi)i=1,2,...,n inter- 318polierenden Newton-Polynoms und seine Auswertung.
b) Programmiere die Bestimmung des neuen interpolierenden Newton-Polynomswenn ein Daten-Punkt zur Menge der Daten-Punkte hinzugefugt wird.
c) Programmiere eine rekursive Version von a) unter der Verwendung vonb).
3. a) Verwende eine Bibliotheksroutine oder eigenes Programm, um die drei 327,328Daten-Punkte (−2,−27), (0,−1) und (1, 0) durch einen kubischen Splinezu interpolieren.
Es sind die beiden kubischen Polynome p1(t) = α1 + α2t+ α3t2 + α4t
3 undp2(t) = β1 + β2t+ β3t
2 + β4t3 zu bestimmen, deren Koeffizienten
1 t1 t21 t31 0 0 0 01 t2 t22 t32 0 0 0 00 0 0 0 1 t2 t22 t320 0 0 0 1 t3 t23 t330 1 2t2 3t22 0 −1 −2t2 −3t220 0 2 6t2 0 0 −2 −6t20 0 2 6t1 0 0 0 00 0 0 0 0 0 2 6t3
α1
α2
α3
α4
β1
β2
β3
β4
=
y1
y2
y2
y3
0000
losen, namlich p1(t) = −1 + 5t− 6t2 − t3 und p2(t) = −1 + 5t− 6t2 + 2t3. CP7 3.m

392 KAPITEL 7. INTERPOLATION
−2 −1.5 −1 −0.5 0 0.5 1−30
−25
−20
−15
−10
−5
0
5
p1(t) für t∈[−2,0] in blau; p2(t) für t∈[0,1] in rot
b) Visualisiere den sich ergebenden naturlichen kubischen Spline zusamenmit den Daten-Punkten sowie seine erste und zweite Ableitung. Verifiziere,daß die entsprechenden Anforderungen erfullt sind.
Es gilt p′1(t) = 5−12t−3t2 und p′2(t) = 5−12t+6t2 sowie p′′1(t) = −12−6tCP7 3.m
und p′′2(t) = −12 + 12t.
−2 −1.5 −1 −0.5 0 0.5 1−30
−25
−20
−15
−10
−5
0
5
10
15
20
p1’(t) für t∈[−2,0] in blau; p2’(t) für t∈[0,1] in rot
−2 −1.5 −1 −0.5 0 0.5 1−30
−25
−20
−15
−10
−5
0
5
p1’’(t) für t∈[−2,0] in blau; p2’’(t) für t∈[0,1] in rot
4. Bestimme die polynomiale Interpolierende und die kubische Spline-Inter-314,327polierende der Runge-Funktion f(t) = 1
1+25t2fur n = 11 und n = 21 aqui-
distante Daten-Punkte im Intervall [−1, 1]. Vergleiche anhand der Funkti-onsgraphen.
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1−0.5
0
0.5
1
1.5
2
n = 11 äquidistante Datenpunkte in schwarzRunge f(t) für t∈[−1,1] in blau; Interpolierende pn−1(t) für t∈[−1,1] in rot
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1−60
−50
−40
−30
−20
−10
0
10
n = 21 äquidistante Datenpunkte in schwarzRunge f(t) für t∈[−1,1] in blau; Interpolierende pn−1(t) für t∈[−1,1] in rot
CP7 4.m

7.6. Computer Problems – Rechner-Problem-Losungen 393
5. Gegeben die sechs Daten-Punkteti 0.0 0.5 1.0 6.0 7.0 9.0yi 0.0 1.6 2.0 2.0 1.5 0.0
.
a) Bestimme das diese sechs Daten-Punkte interpolierende Polynom p5(t) = 313,316,318pMonom(t) = pLagrange(t) = pNewton(t) funften Grades. Stelle Daten-Punkteund Funktionsgraph dar.
0 1 2 3 4 5 6 7 8 9−0.5
0
0.5
1
1.5
2
2.5
Datenpunkte in schwarz; polynomiale Interpolierende in rot;kubische Spline Interpolierende stückweise in blau/grün
stückweise lineare Interpolierende in magenta
b) Bestimme einen interpolierenden kubischen Spline. 327
Bestimme etwa eine stuckweise kubisch polynomiale, zweifach stetig diffe-renzierbare Funktion pSpline(t). Dann sind funf kubische Polynome p1(t) =α1 +α2t+α3t
2 +α4t3, . . . , p5(t) = ε1 + ε2t+ ε3t
2 + ε4t3 mit jeweils vier Ko-
effizienten zu bestimmen. Wenn die Steigung y′1 von p1 in t1 etwa durch dieSteigung y′1 = y2−y1
t2−t1der Geraden durch die ersten beiden und die Steigung
y′6 von p5 in t6 etwa durch die Steigung y′6 = y6−y5
t6−t5der Geraden durch die
letzten beiden Datenpunkte vorgegeben werden, ist folgendes System vonzwanzig linearen Gleichungen in zwanzig Unbekannten zu losen.
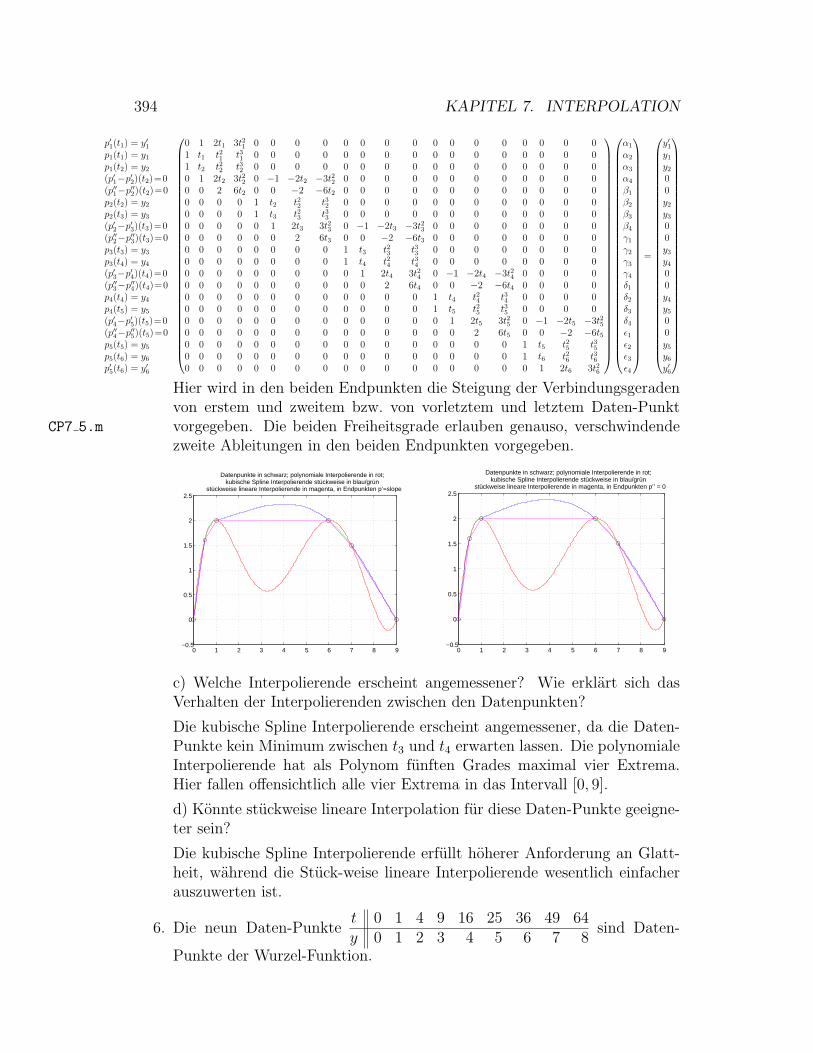
394 KAPITEL 7. INTERPOLATION
p′1(t1) = y′1p1(t1) = y1
p1(t2) = y2
(p′1−p′2)(t2)=0(p′′1−p′′2)(t2)=0p2(t2) = y2
p2(t3) = y3
(p′2−p′3)(t3)=0(p′′2−p′′3)(t3)=0p3(t3) = y3
p3(t4) = y4
(p′3−p′4)(t4)=0(p′′3−p′′4)(t4)=0p4(t4) = y4
p4(t5) = y5
(p′4−p′5)(t5)=0(p′′4−p′′5)(t5)=0p5(t5) = y5
p5(t6) = y6
p′5(t6) = y′6
0 1 2t1 3t21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 01 t1 t21 t31 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 01 t2 t22 t32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 1 2t2 3t22 0 −1 −2t2 −3t22 0 0 0 0 0 0 0 0 0 0 0 00 0 2 6t2 0 0 −2 −6t2 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 1 t2 t22 t32 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 1 t3 t23 t33 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 1 2t3 3t23 0 −1 −2t3 −3t23 0 0 0 0 0 0 0 00 0 0 0 0 0 2 6t3 0 0 −2 −6t3 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 1 t3 t23 t33 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 1 t4 t24 t34 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 1 2t4 3t24 0 −1 −2t4 −3t24 0 0 0 00 0 0 0 0 0 0 0 0 0 2 6t4 0 0 −2 −6t4 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 1 t4 t24 t34 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 1 t5 t25 t35 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 1 2t5 3t25 0 −1 −2t5 −3t250 0 0 0 0 0 0 0 0 0 0 0 0 0 2 6t5 0 0 −2 −6t50 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 t5 t25 t350 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 t6 t26 t360 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2t6 3t26
α1
α2
α3
α4
β1
β2
β3
β4
γ1
γ2
γ3
γ4
δ1δ2δ3δ4ε1ε2ε3ε4
=
y′1y1
y2
00y2
y3
00y3
y4
00y4
y5
00y5
y6
y′6
Hier wird in den beiden Endpunkten die Steigung der Verbindungsgeradenvon erstem und zweitem bzw. von vorletztem und letztem Daten-Punktvorgegeben. Die beiden Freiheitsgrade erlauben genauso, verschwindendeCP7 5.m
zweite Ableitungen in den beiden Endpunkten vorgegeben.
0 1 2 3 4 5 6 7 8 9−0.5
0
0.5
1
1.5
2
2.5
Datenpunkte in schwarz; polynomiale Interpolierende in rot;kubische Spline Interpolierende stückweise in blau/grün
stückweise lineare Interpolierende in magenta, in Endpunkten p’=slope
0 1 2 3 4 5 6 7 8 9−0.5
0
0.5
1
1.5
2
2.5
Datenpunkte in schwarz; polynomiale Interpolierende in rot;kubische Spline Interpolierende stückweise in blau/grün
stückweise lineare Interpolierende in magenta, in Endpunkten p’’ = 0
c) Welche Interpolierende erscheint angemessener? Wie erklart sich dasVerhalten der Interpolierenden zwischen den Datenpunkten?
Die kubische Spline Interpolierende erscheint angemessener, da die Daten-Punkte kein Minimum zwischen t3 und t4 erwarten lassen. Die polynomialeInterpolierende hat als Polynom funften Grades maximal vier Extrema.Hier fallen offensichtlich alle vier Extrema in das Intervall [0, 9].
d) Konnte stuckweise lineare Interpolation fur diese Daten-Punkte geeigne-ter sein?
Die kubische Spline Interpolierende erfullt hoherer Anforderung an Glatt-heit, wahrend die Stuck-weise lineare Interpolierende wesentlich einfacherauszuwerten ist.
6. Die neun Daten-Punktet 0 1 4 9 16 25 36 49 64y 0 1 2 3 4 5 6 7 8
sind Daten-
Punkte der Wurzel-Funktion.

7.6. Computer Problems – Rechner-Problem-Losungen 395
a) Vergleiche die polynomiale Interpolierende achten Grades mit Biblio- 314,316,318theksfunktionen fur sqrt.
t10 20 30 40 50 60
y
2
4
b) Vergleiche kubische Spline-Interpolierende mit der Bibliotheksfunktionensqrt.
???
c) Welche der Interpolierenden ist auf [0, 64] am genauesten?
???d) Welche der Interpolierenden ist auf [0, 1] am genauesten?
???
7. Die Gamma-Funktion ist durch Γ(x) =∫∞
otx−1e−t dt definiert. Fur n ∈
N gilt Γ(n) = (n − 1)!. Eine die funf Daten-Punkteti 1 2 3 4 5yi 1 1 2 6 24
interpolierende Funktion approximiert die Gamma-Funktion.
a) Vergleiche die polynomiale Interpolierende vierten Grades mit einer Bi-bliotheksfunktion gamma.

396 KAPITEL 7. INTERPOLATION
0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.50
10
20
30
40
50
60
b) Vergleiche die kubische Spline-Interpolierende mit einer Bibliotheksfunk-tionen gamma.
???c) Welche der Interpolierenden ist auf [0, 5] am genauesten?
??? d) Welche der Interpolierenden ist auf [0, 1] am genauesten?
???8. Gegeben die Daten der Entwicklung der Bevolkerung der USA.
Jahr Bevolkerung1900 762121681910 922284961920 1060215371930 1232026241940 1321645691950 1513257981960 1793231751970 2033020311980 226542199
Die polynomiale Interpolierende achten Grades ist eindeutig bestimmt undkann als Linearkombination folgender Basen dargestellt werden:
1. φj(t) = tj−1
2. φj(t) = (t− 1900)j−1
3. φj(t) = (t− 1940)j−1
4. φj(t) = ((t− 1940)/40)j−1
a) Erzeuge fur jeder der vier Basen die zugehorigen Vandermonde-Matrizen,bestimme (mit Bibliotheksroutinen) und vergleiche deren Konditionszahlen.Erlautere die Ergebnisse.

7.6. Computer Problems – Rechner-Problem-Losungen 397
Basis cond(A) 15
φj(t) = tj−1 3.7591e+ 036φj(t) = (t− 1900)j−1 6.1103e+ 015φj(t) = (t− 1940)j−1 9.3155e+ 012φj(t) = ((t− 1940)/40)j−1 1.6054e+ 003
CP7 8.m
b) Verwende die Basis, fur die A am besten konditioniert ist, und visuali-siere Daten-Punkte und die polynomial Interpolierende.
1900 1910 1920 1930 1940 1950 1960 1970 19800.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
2.2
2.4x 10
8 Entwicklung der US−Bevölkerung
c) Berechne mit Bibliotheksroutinen und visualisiere die monotone kubischeHermitesche Interpolierende.
???d) Berechne und visualisiere eine kubische Spline Interpolierende.
???e) Unter Verwendung der polynomialen, kubischen Hermiteschen und derkubischen Spline Interpolierenden extrapoliere die Entwicklung der US-Population. Wie zutreffend ist die jeweilige Prognose gemessen am Ergebnisvon 248 709 873 der Volkszahlung von 1990?
???f) Berechne die Lagrange-Interpolierende fur dieselben Daten-Punkte undwerte diese wieder fur jedes Jahre von 1900 bis 1980 aus. Vergleiche dieLaufzeit mit derjenigen fur die Auswertung per Horner und fur die Auswer-tung der kubischen Spline Interpolierenden.
???g) Bestimme das die neun Daten-Punkten interpolierende Newton-Polynomp achten Grades. Bestimme dann das zusatzlich den Datenpunkt zu 1990interpolierende Newton-Polynom q neunten Grades unter Verwendung vonp. Zeichne p und q fur 1900 ≤ t ≤ 1990.
???h) Runde die Bevalkerungszahlen auf eine Million und berechne erneut diepolynomiale Interpolierende achten Grades unter Verwendung der Basis ausb). Vergleiche die Ergebnisse und erlautere die Beobachtungen.
???

398 KAPITEL 7. INTERPOLATION

Kapitel 8
Numerical Integration andDifferentiation
8.0.1 Integration
Riemann1-Integral
I(f) =
∫ b
a
f(x) dx = limn→∞
max ∆i → 0
Rn(f) mit Rn(f) =n∑
i=1
f(ξi)∆xi
wobei a = x1 < x2 < . . . < xn+1 = b, ξi ∈ [xi, xi+1] und ∆i = xi+1 − xi.
Anwendungen sind
• Integral-Transformationen wie Fourier2-, Laplace3- oder Hankel4-Transfor-mationen
• Funktionen der Physik mit Integral-Darstellung wie Gamma-, Beta-, Bes-sel5- oder Fehler-Funktionen sowie Fresnel6- oder elliptische Integrale
• FEM und boundary elements Methoden fur partielle Differentialgleichungen
• Integral-Gleichungen, Variationsrechnung
• Wahrscheinlichkeitsrechnung und Statistik mit Wahrscheinlichkeitsdichtenund Verteilungsfunktionen, Erwartungswerten und Momenten
1 Bernhard Riemann (1826-1866) www-history.mcs.st-andrews.ac.uk/Biographies/Riemann.html
2 Jean Baptiste Joseph Fourier (1768-1830) www-history.mcs.st-andrews.ac.uk/Biographies/Fourier.html
3 Pierre-Simon Laplace (1749-1827) www-history.mcs.st-andrews.ac.uk/Biographies/Laplace.html
4 Hermann Hankel (1839-1873) www-history.mcs.st-andrews.ac.uk/Biographies/Hankel.html
5 Friedrich Wilhelm Bessel (1784-1846) www-history.mcs.st-andrews.ac.uk/Biographies/Bessel.html
6 Augustin Jean Fresnel (1788-1827) www-history.mcs.st-andrews.ac.uk/Biographies/Fresnel.html
399

400 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
• physikalische Großen wie z.B. das Potential, die als Integral gegeben sind.
Existenz, Eindeutigkeit und Konditionierung
Das Riemann-Integral I(f) =∫ b
af(x) dx existiert genau dann, wenn f : R → R
auf [a, b] beschrankt und dort fast uberall stetig ist. Die Eindeutigkeit von I(f)ist durch die Definition selbst garantiert.
Bezuglich der sogenannten ∞-Norm ||f ||∞ = maxx∈[a,b] |f(x)| gilt∣∣∣I(f)−I(f)∣∣∣ =
∣∣∣∣∫ b
a
f(x) dx−∫ b
a
f(x) dx
∣∣∣∣ ≤ ∫ b
a
∣∣∣f(x)−f(x)∣∣∣ dx ≤ (b−a)||f−f ||∞
d.h. die absolute Konditionszahl des Integrals bei Anderungen des Integrandenist hochstens (b− a). Da diese Schranke fur f = f + c mit beliebiger Konstante cangenommen wird, ist die absolute Konditionszahl des Integrals bei Anderungendes Integranden gleich (b− a). Wegen
cond =
∣∣∣I(f)− I(f)∣∣∣ / |I(f)|
||f − f ||∞/||f ||∞≤ (b− a)||f ||∞
|I(f)|
ist die (relative) Konditionszahl des Integrals bei Anderungen des Integrandenimmer großer als 1 und kann fur kleine |I(f)| beliebig groß werden, ohne daß ||||∞klein sein mußte. Falls I(f) = 0 verwendet man die absolute Konditionszahl.
Generell sind Integrations- oder Quadratur-Probleme gut kondioniert, was nichtuberrascht, da Integration als Summationsvorgang glattend wirkt und kleineAnderungen im Integranden dampft.
Wegen∣∣∣∫ b
af(x) dx−
∫ b
af(x) dx
∣∣∣ =∣∣∣∫ b
bf(x) dx
∣∣∣ ≤ (b − b) maxx∈[b,b] |f(x)| und
analog fur Anderungen von a ist die absolute Konditionszahl des Integrals beiAnderungen des Integrationsbereichs typischerweise moderat, solange die Inte-grationsgrenzen nicht mit Singularitaten von f zusammenfallen.
Numerische Quadratur
Fur viele Funktionen wie f(x) = e−x2/2 konnen die Stammfunktionen∫e−x2/2 dx
nicht geschlossen angegeben werden. Bestimmte Integrale wie eben∫ b
ae−x2/2 dx
sind daher nur approximativ zu bestimmen.
Im Unterschied zu der Integration von Differentialgleichungen heißt die Appro-ximation von bestimmten Integralen numerische Quadratur7. Eine n-Knoten
7 vgl. Quadratur des Kreises durch die antiken griechischen Mathematiker

401
Quadratur-Regel approximiert das Integral I(f) durch gewichtete Summen
I(f) ≈n∑
i=1
wif(xi)
der Ordinaten der Funktion, ausgewertet in den n Knoten a ≤ x1 < x2 < . . . <xn−1 < xn ≤ b. Eine n-Knoten Quadratur-Regel heißt offen, wenn a < x1 undxn < b, bzw. geschlossen, wenn a = x1 und xn = b gilt.
Quadratur-Regeln ergeben sich aus polynomialer Interpolation oder durch Koeffi-zienten-Vergleich. Interpolierende Quadratur-Regeln interpolieren den Integran-den in den Knoten durch etwa das Lagrange-Polynom p(x) =
∑ni=1 yi`i(x) und ap-
proximieren das Integral I(f) durch das Integral∑n
i=1 yiwi =∑n
i=1 yi
∫ b
a`i(x) dx
dieses Polynoms.
Alternativ kann man Quadratur-Regeln aus der Forderung ableiten, daß die er-sten n Basis-Funktionen exakt integriert werden. Diese Forderung fuhrt auf einSystem linearer Gleichungen in den Gewichten wi, beispielsweise fur die Monom-Basis
w1 · 1 + w2 · 1 + . . .+ wn · 1 =∫ b
a1 dx = b− a
w1 · x1 + w2 · x2 + . . .+ wn · xn =∫ b
ax dx = 1
2(b2 − a2)
w1 · x21 + w2 · x2
2 + . . .+ wn · x2n =
∫ b
ax2 dx = 1
3(b3 − a3)
... =...
w1 · xn−11 + w2 · xn−1
2 + . . .+ wn · xn−1n =
∫ b
axn−1 dx = 1
n(bn − an)
oder gleichwertig mit einer Vandermonde8-Matrix A vektoriell geschrieben
Aw =
1 1 · · · 1x1 x2 · · · xn...
.... . .
...xn−1
1 xn−12 · · · xn−1
n
w1
w2...wn
=
(b− a)
(b2 − a2)/2...
(bn − an)/n
= b
Fur paarweise verschiedene Knoten ist die Vandermonde-Matrix A regular, sodaß die Losung w = (wi)i=1,...,n eindeutig bestimmt ist und die Gewichte wi mit
den Integralen∫ b
a`i(x) dx ubereinstimmen.
Z.B. Fur die 3-Punkte Quadratur Q3(f) = w1f(x1) + w2f(x2) + w3f(x3) =w1f(a) + w2f(m) + w3f(b) mit m = (a+ b)/2 ergeben sich die Gewichte wi aus
Aw =
1 1 1a m ba2 m2 b2
w1
w2
w3
=
(b− a)(b2 − a2)/2(b3 − a3)/3
zu
w1
w2
w3
= b−a6
141
.
8 Alexandre-Theophile Vandermonde (1735-1796)www-history.mcs.st-andrews.ac.uk/Biographies/Vandermonde.html

402 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
Die 3-Punkte Quadratur Q3(f) = b−a6 (f(a)+4f(m)+f(b)) ist als Simpson9-Regel
bekannt. cGemaß ihrer Konstruktion und der Linearitat der Integration integrieren inter-polierende n-Punkt-Quadraturen Qn alle Polynome mit maximalem Grad n − 1exakt.
Def. Der Grad einer Quadratur-Regel Q ist der maximale Grad der Polynome,die durch Q exakt integriert werden. Umgekehrt muß jede QuadraturQmindestens vom Grad n−1 interpolierend sein,weil sie alle Monome xk fur k = 0, 1, . . . , n−1 exakt integriert, d.h. die Momenten-Gleichungen erfullt, so daß Q(f) =
∑ni=1wif(xi) =
∑ni=1 f(xi)
∫ b
a`i(x) dx =∫ b
a
∑ni=1 f(xi)`i(x) dx = Q(p), wobei das Lagrange-Polynom p die Funktion f in
xi fur i = 1, . . . , n interpoliert.
Sei Qn interpolierende Quadratur vom Grad n− 1 und pn−1 das die Funktion fin den Knoten xi fur i = 1, . . . , n interpolierende Polynom vom Grad n− 1. Mit324
||f − pn−1||∞ ≤ 14nhn||f (n)||∞ fur h = maxxi+1 − xi : i = 1, 2, . . . , n− 1
also der ’Gute’ der Interpolation, laßt sich der Fehler von Qn abschatzen durch
|I(f)−Qn(f)| = |I(f)− I(pn−1)| = |I(f − pn−1)| ≤ (b− a)||f − pn−1||∞≤ b−a
4nhn ||f (n)||∞ ≤ 1
4hn+1 ||f (n)||∞
(Naturlich lassen sich fur spezielle Quadraturen bessere Abschatzungen herlei-ten.) Wenn sich ||f (n)||∞ gut benimmt, also etwa beschrankt ist, folgt erwar-tungsgemaß Qn(f) −→ I(f) fur n→∞.
...
Def. Eine Quadratur-Regel Q heißt progressiv, wenn die Knoten von Qn eineTelmenge der Knoten von Qm fur alle m > n bilden: die einmal berechnetenFunktionswerte in den Knoten vonQn konnen zur Berechnung der Funktionswertein den Knoten von Qm wiederverwendet werden. ...
Um die Stabilitat einer n-Punkt Quadratur Qn(f) =∑n
i=1wif(xi) zu bewerten,
betrachte eine Fehler-behaftetete Version f einer Funktion f .
|Qn(f)−Qn(f)| = |Qn(f − f)| =
∣∣∣∣∣n∑
i=1
wi(f(xi)− f(xi))
∣∣∣∣∣≤
n∑i=1
|wi|∣∣∣f(xi)− f(xi)
∣∣∣ ≤ ||f − f ||∞n∑
i=1
|wi|
...9 Thomas Simpson (1710-1761) www-history.mcs.st-andrews.ac.uk/Biographies/Simpson.html

403
Newton-Cotes-Quadratur
Quadraturen mit n aquidistanten Knoten heißen n-Punkt-Newton10-Cotes11-Qua-draturen.Die Knoten einer offenen Newton-Cotes-Quadratur sind xi = a+ i
n+1(b− a) und
diejenigen einer geschlossenen Newton-Cotes-Quadratur sind xi = a+ i−1n−1
(b− a)fur i = 1, 2, . . . , n.
Def. Sei m = 12(a+ b). Die offene 1-Punkt Newton-Cotes-Quadratur M(f)
M(f) = (b− a)f(m)
heißt Mittelpunkt-Regel. Die geschlossene 2-Punkt Newton-Cotes-Quadratur T (f)
T (f) = 12(b− a)(f(a) + f(b))
heißt Trapez-Regel. Die geschlossene 3-Punkt Newton-Cotes-Quadratur S(f)
S(f) = 16(b− a)(f(a) + 4f(m) + f(b)) = 2
3M(f) + 1
3T (f)
heißt Simpson12-Regel. Z.B. Fur f(x) = e−x2
wird I(f) =∫ 1
of(x) dx ≈ 0.746824 approximiert durch
I(f) =∫ 1
of(x) dx ≈ 0.746824
M(f) = 1 · e−0.5·0.5 = e−1/4 ≈ 0.778801T (f) = 1
2(e0 + e−1) = 1
2(1 + 1/e) ≈ 0.683940
S(f) = 16(e
0 + 4 e−0.5·0.5 + e−1) ≈ 0.747180
x
y
00.5 1
1 f
M
T S
cIntegration der Taylor-Reihenentwicklung von f um m = 1
2(a+ b)
f(x) = f(m)+f ′(m)(x−m)+ f ′′(m)2!
(x−m)2+ f ′′′(m)3!
(x−m)3+ f (4)(m)4!
(x−m)4+. . .
10 Isaac Newton (1643-1727) www-history.mcs.st-andrews.ac.uk/Biographies/Newton.html
11 Roger Cotes (1682-1716) www-history.mcs.st-andrews.ac.uk/Biographies/Cotes.html
12 Thomas Simpson (1710-1761) www-history.mcs.st-andrews.ac.uk/Biographies/Simpson.html

404 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
liefert – alle Terme ungerader Ordnung verschwinden –
I(f) = (b−a)f(m)+ f ′′(m)24
(b−a)3+ f (4)(m)1920
(b−a)5+. . . = M(f)+E(f)+F (f)+. . .
E(f) bzw. F (f) sind dabei die Terme von I(f), in denen (b− a) in dritter bzw.in funfter Potenz vorkommt. Auswerten der Taylor-Reihenentwicklung von f umm in a und b und Addition
f(a) = f(m)− f ′(m)12(b− a)+f ′′(m)
2!(b−a)2
22 − f ′′′(m)3!
(b−a)3
23 +f (4)(m)4!
(b−a)4
24 − . . .
f(b) = f(m) + f ′(m)12(b− a)+f ′′(m)
2!(b−a)2
22 + f ′′′(m)3!
(b−a)3
23 +f (4)(m)4!
(b−a)4
24 + . . .
f(a) + f(b) = 2f(m) +2f ′′(m)2!
(b−a)2
22 +2f (4)(m)4!
(b−a)4
24 + 0 + . . .
liefern
T (f) = 12(f(a) + f(b))(b− a)
=M(f) + 0 + f ′′(m)2!
(b−a)3
22 + 0 + f (4)(m)4!
(b−a)5
24 + . . . = M(f) + 13E(f) + . . .
und damit die Abschatzung fur den Fehler I(f) − M(f) = E(f) + . . . derMittelpunkt-Regel
E(f) ≈ 13(T (f)−M(f))
solange (b−a)5 (b−a)3 gilt und sich f (4) ’wohlverhalt’. Wir konnen also denFehler einer Quadratur-Regel bei der Berechnung des unbekannten, exakten Inte-grals I(f) unter Verwendung der Ergebnisse zweier Quadratur-Regeln abschatzenund damit Abbruchkriterien implementieren.
Zusammen ergibt sich
• Die Mittelpunkt-Regel ist doppelt so genau wie die Trapez-Regel.
• Der Fehler der Mittelpunkt- wie auch derjenige der Trapez-Regel laßt sichjeweils durch Vielfache der Differenz T (f)−M(f) abschatzen.
• Wegen E(f) ∼ (b−a)3 vermindert sich der Fehler um den Faktor 1/8, wennwir die Intervall-Lange halbieren.
Um den Fehler I(f)− S(f) der Simpson-Regel S(f)
I(f) = 23I(f) + 1
3I(f) = 2
3M(f) + 1
3T (f)− 2
3F (f) + . . . = S(f)− 2
3F (f) + . . .
abschatzen zu konnen, brauchen wir F (f), das wir aus den drei Gleichungen
I = M + E + F + . . .I = T − 2E − 4F + . . .I = S − 2
3F + . . .
⇐⇒
2I = 2M + 2E + 2F + . . .I =T − 2E − 4F + . . .
−3I = 3S − 2F + . . .0 = 2M + T + 3S − 4F + . . .
gewinnen. Wie oben konnen wir den Fehler I(f)−S(f) ≈ −23F (f) der Simpson-
Regel unter Verwendung der Ergebnisse zweier Quadratur-Regeln abschatzen.
F (f) ≈ 2M(f)+T (f)+3S(f)4
= 2M(f)+T (f)+2M(f)+T (f)4
= M(f) + 12T (f)

405
• Der Fehler der Simpson-Regel laßt sich durch Vielfache der Summe M(f)+12T (f) abschatzen.
• Wegen F (f) ∼ (b − a)5 vermindert sich der Fehler um den Faktor 1/32,wenn wir die Intervall-Lange halbieren.
Z.B. Fur f(x) = x2 wird I(f) =∫ 1
ox2 dx = 1
3approximiert durch
M(f) = 1 · (12)
2= 1
4T (f) = 1
2(0 + 1) = 1
2S(f) = 2
3M(f) + 1
3T (f) = 1
3
Wegen grad(Simpson) = 3 ist S(f) fur das Monom zweiten Grades exakt. cWenn beispielsweise eine Konstante per Mittelpunkt-Regel (1-Punkt) eine lineareFunktion oder eine quadratisches Polynom per Simpson-Regel (3-Punkt) ein ku-bisches Polynom interpoliert, dann heben sich wegen der Symmetrie der ’positive’und der ’negative’ Fehler gegenseitig auf.
a bma bm
Dieser Umstand gilt allgemein (s. 8RQ21). Also hat die n-Punkt Newton-Cotes-Quadratur den Grad n − 1, falls n gerade, und den Grad n, falls n ungeradeist.
So einfach die n-Punkt Newton-Cotes-Quadratur auch ist, was die Bestimmungder aquidistanten Knoten und die Berechnung der Gewichte angeht, so schlechtist es um ihre Konditionierung bestellt: die Umstand, daß nicht notwendigerweise||f−pn−1||∞ → 0 fur n→∞ gilt, spiegelt sich darin wider, daß negative Gewichtefur n ≥ 11 auftreten, wahrend limn→∞
∑ni=1 |wi| = ∞ gilt. Fur die Newton-
Cotes-Quadratur spricht ihre Progressivitat, gegen die Newton-Cotes-Quadraturspricht der Umstand, daß sie nicht den maximal moglichen Grad aufweist.
Clenshaw-Curtis-Quadratur
Anstelle von aquidistanten Knoten verwendet Clenshaw-Curtis-Quadratur13 dievon der Interpolation her bekannten Chebyshev-Punkte als Knoten, die wieder 324vom Intervall [−1, 1] auf das Intervall [a, b] zu transformieren sind.
13 Gisela Engeln-Mullges, Frank Uhlig: Numerical Algorithms with C; Springer, Ber-lin 1996 ISBN 3-540-60530-4, bieten C-Quellen auch zu diesem Quadratur-Verfahren vgl.http://www.fz-juelich.de/zam/docs/tki/tki html/t0187/

406 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
t
y
Weil bei Verwendung der Chebyshev-Punkte die Interpolierende fur n→∞ gegenjede ausreichend glatte Funktion konvergiert, sollte der Fehler dieser Quadraturkleiner als derjenige der Newton-Cotes-Quadratur ausfallen. Weitere Vorteilesind
• Die Gewichte der Clenshaw-Curtis-Quadratur sind fur jedes n immer po-sitiv, so daß die Quadratur stabil und genauer als die Newton-Cotes-Qua-dratur arbeitet.
• Die Gewichte mussen nicht explizit berechnet und daher auch nicht ta-buliert werden: die Interpolierende kann als Linearkombination der Che-bychev-Polynome dargestellt werden und in geschlossener Form integriertwerden.
• Wenn die Anzahl der Chebychev-Punkte von n auf 2n− 1 gesteigert wird,mussen nur n−1 neue Punkte mit ihren Funktionswerten berechnet werden:diese praktische Form der Clenshaw-Curtis-Quadratur ist progressiv.
Trotz aller dieser Vorteile bleibt als Wehrmutstropfen: der Grad der n-PunkteClenshaw-Curtis-Quadratur ist nur n− 1 und damit suboptimal.
Gauß-Quadratur
Gauß-Quadratur Gn maximiert den Grad der Quadratur, indem sie die n zusatz-lichen Freiheitsgrade der Position der Knoten x1, x2, . . . , xn nutzt, so daßGrad(Gn) = 2n− 1 folgt.
Z.B. Gewichte und Knoten von G2 fur das Intergrationsintervall [−1, 1] erfullen
w1 + w2 =∫ 1
−11 dx = 2
w1x1 + w2x2 =∫ 1
−1x dx = 0
w1x21 + w2x
22 =
∫ 1
−1x2 dx = 2
3
w1x31 + w2x
32 =
∫ 1
−1x3 dx = 0
⇒(w1 + w2)(x1 + x2) = 2(x1 + x2) = w1x2 + w2x1
(w1x1 + w2x2)(x1 + x2) = 0 = 23
+ 2x1x2
(w1x21 + w2x
22)(x1 + x2) = 2
3(x1 + x2) = x1x2(w1x1 + w2x2) = 0
Wegen x1 + x2 = 0 gilt x1 = −x2 und wegen x1x2 = −13
eben x1,2 = ∓13
√3 sowie
wegen w1 + w2 = 2 und w1x2 + w2x1 = 0, d.h. w1 = w2 eben w1 = 1 = w2. vgl.5CP24 auf S. ?? c

407
Alternativ kann die Gauß-Quadratur auch uber orthogonale Polynome hergeleitetwerden: Sei p ein Polynom vom Grad n mit∫ b
a
p(x)xk dx = 0 fur k = 0, 1, . . . , n− 1
d.h. p ⊥ xk fur k = 0, 1, . . . , n− 1 oder ebenso p ⊥ P≤n−1. Dann gilt (s. 8Ex9)
i. Alle n Nullstellen von p sind einfach und reell und liegen in (a, b).
ii. Die n-Punkt interpolierende Quadratur Qn, deren Knoten die n Nullstellenvon p sind, hat den Grad 2n− 1 und stimmt deshalb mit Gn uberein.
Die Legendre-Polynome sind per Konstruktion Polynome mit der gefordertenEigenschaft.
...
Progressive Gauß-Quadratur
Gauß-Quadratur-Regeln sind nicht progressiv: n-Punkt Gauß-Quadratur und m-Punkt Gauß-Quadratur haben fur n 6= m keine Knoten gemein. Eine gute Mi-schung zwischen Genauigkeit und Effizienz stellen sogenannte Gauß-Kronrod14-Paare (Gn, K2n+1) dar, wo die n-Punkt Gauß-Quadratur Gn kombiniert wirdmit der 2n+ 1-Punkt Kronrod-Quadratur, die optimal so gewahlt wird, daß alleKnoten von Gn wiederverwendet werden.
Das Gauß-Kronrod-Paar (G7, K15) ...
...
Zusammengesetzte Quadratur
Def. Partition des Integrationsintervalles [a, b] in k meist gleichlange Teilinter-valle [a, x1] = [xo, x1], [x1, x2], . . . , [xk−1, xk] = [xk−1, b] und Anwendung einereinfachen Quadratur Qn auf jedes dieser Teilintervalle macht aus Qn die soge-nannte zusammengesetzte Quadratur Ck mit Ck(f) =
∑kj=1Qn(f, xj−1, xj).
Z.B. xj = a + j h mit h = b−ak
fur j = 0, 1, . . . , k spezifizieren k gleichlangeTeilintervalle [xj−1, xj] und machen aus der Mittelpunkt-Regel M(f) die zusam-mengesetzte Mittelpunkt-Regel Mk(f) mit
Mk(f) =∑k
j=1M(f, xj−1, xj) =∑k
j=1(xj −xj−1)f(xj−1+xj
2 ) = h∑k
j=1 f(xj−1+xj
2 )
14 Alexander Semenovich Kronrod (1921-1986) s.a.E.M. Landis, I.M. Yaglom: Remembering A.S. Kronrod www-sccm.stanford.edu/pub/sccm/sccm00-01.ps.gz

408 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
und aus der Trapez-Regel T (f) die zusammengesetzte Trapez-Regel Tk(f) mit
Tk(f) =∑k
j=1 T (f, xj−1, xj) =∑k
j=1(xj − xj−1)f(xj−1)+f(xj)
2
= h2(∑k−1
j=o f(xj) +∑k
j=1 f(xj)) = h2(f(a)+2f(x1)+. . .+2f(xk−1)+f(b)).
(zusammengesetzte Simpson-Regel Sk(f) siehe 8Ex11 und 8CP1) cSatz Wenn grad(Qn) ≥ 0, wenn also die unterliegende Quadratur Qn wenigstensKonstanten exakt integriert, dann gilt fur Ck, die zusammengesetzte, auf Qn
basierende Quadratur limk→∞Ck(f) = I(f). •Bew. Sei Ck(f) =
∑kj=1
∑ni=1wif(xi,j), wobei xi,j der i-te Knoten im j-ten
Teilintervall ist. Dann gilt
Ck(f) =∑k
j=1
∑ni=1wif(xi,j) =
∑ni=1wi
∑kj=1 f(xi,j) = 1
h
∑ni=1wi
∑kj=1 h f(xi,j)
und, wenn die letzte Summe als Riemann’sche Summe aufgefaßt wird, eben
limk→∞
Ck(f) =1
h
n∑i=1
wi limk→∞
k∑j=1
h f(xi,j) = I(f)1
h
n∑i=1
wi = I(f)
Grundsatzlich erreichen zusammengesetzte Quadraturen also jede beliebig großeGenauigkeit, wenn auch nicht auf effizienteste Weise, so daß nur ein Kompromißaus geeignetem n und nicht zu großem k beiden Zielen gerecht werden kann.
√
Adaptive Quadratur
Wo sich der Integrand wenig andert, sind wenige Knoten ausreichend; wo derIntegrand sich stark andert, sind mehr Knoten notwendig, um dieselbe Genau-igkeit der Quadratur zu erreichen. Die Idee ist also, Knoten in Abhangigkeitvom Integranden zu verwenden. Die Auswahl der Knoten wird dabei von einerFehler-Schatzung aufgrund zweier Quadraturen gesteuert.Starte mit [a, b]. Berechne Qn1(f) und Qn2(f). Falls |Qn1(f)−Qn2(f)| > tol un-terteile [a, b] in zwei oder mehrere Teilintervalle und wende auf jedes Teilintervalldasselbe Verfahren an.
. . .
function adaptquad ( f , a , b , t o l )I1 = Qn1( f , a , b ) ; % I1 = Qn1(f)I2 = Qn2( f , a , b ) ; % I2 = Qn2(f)m = a+(b−a ) / 2 ; % midpointi f ( (m<=a ) | | ( b<=m)) % no more machine numbers in (a, b)
return I2 ;endi f (abs ( I2−I1)< t o l ) % in actual interval tolerance is met

409
return I2 ;else
return adaptquad ( f , a ,m, t o l )+adaptquad ( f ,m, b , t o l ) ;end

410 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
8.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Ein bestimmtes In-tegral zu berechnen, ist ein gut-konditioniertes Problem.
2. Richtig/Falsch? Die Trapez-Regelist grundsatzlich genauer als dieMittelpunkt-Regel, weil der Graddes in der Trapez-Regel verwendetenPolynoms um eins hoher ist als der-jenige des in der Mittelpunkt-Regelverwendeten Polynoms.
3. Richtig/Falsch? Der Grad einerQuadratur-Regel stimmt ubereinmit dem Grad des Polynoms, aufdem die Quadratur-Regel basiert.
4. Richtig/Falsch? Der Grad der n-Punkt Newton-Cotes-Regel ist n−1.
5. Richtig/Falsch? Gauß-Quadratur-Regeln verschiedenen Grades habenkeine Punkte gemeinsam.
6. An welche notwendigen und hin-reichenden Bedingungen ist dieExistenz des Riemann-Integralsgeknupft?
7. a) Unter welchen Bedingungen rea-giert ein bestimmtes Integral sensi-tiv auf kleine Anderungen des Inte-granden?
b) Unter welchen Bedingungen rea-giert ein bestimmtes Integral sensi-tiv auf kleine Anderungen der Inte-grationsgrenzen?
8. Wie unterscheiden sich offene undgeschlossene Quadratur-Regeln?
9. Wie heißen zwei Verfahren zurBestimmung der Gewichte in ei-ner Quadratur-Regel mit gegebenenPunkten?
10. Wie laßt sich der Fehler einerQuadratur-Regel abschatzen, ohneAbleitungen des Integranden be-rechnen zu mussen?
11. a) Wie unterscheidet sich diePlatzierung von Knoten beiNewton-Cotes- und Clenshaw-Curtis-Quadratur?
b) Welches der beiden Verfahrenwird wohl bei derselben Knoten-Anzahl genauer sein?
12. a) Wie unterscheidet sich die Plat-zierung von Knoten bei Newton-Cotes- und Gauß-Quadratur?
b) Welches der beiden Verfahrenwird wohl bei derselben Knoten-Anzahl genauer sein?
13. a) Was ist der hochste Grad einer inaquidistanten Daten-Punkten poly-nomial interpolierenden Quadratur-Regel?
b) Was ist der hochste Gradeiner optimal platzierte Daten-Punkten polynomial interpolieren-den Quadratur-Regel?
14. a) Wird fur n → ∞ die Newton-Cotes-Quadratur das Integral∫ 1−1 f(x) dx der Runge-Funktionf(x) = 1
1+25x2 gut approxmieren?
b) Wird fur n → ∞ die Clenshaw-Curtis-Quadratur das Integral∫ 1−1 f(x) dx der Runge-Funktionf(x) = 1
1+25x2 gut approxmieren?
15. a) Was ist der Grad der Simpson-Regel?
b) Was ist der Grad der Gauß-Quadratur?

8.1. Review Questions – Verstandnisfragen 411
16. a) Welche Eigenschaft charakteri-siert die Newton-Cotes-Quadraturbei gegebener Anzahl von Daten-Punkten?
b) Welche Eigenschaft charakteri-siert die Gauß-Quadratur bei gege-bener Anzahl von Daten-Punkten?
17. a) Wieso integriert die Mittelpunkt-Regel, die auf einem Polynom null-ten Grades basiert, Polynome vomGrad eins exakt?
b) Ist die Mittelpunkt-Regel eineGauß-Quadratur-Regel?
18. Sei∫ ba f(x) dx =
∑ni=1wif(xi) ex-
akt fur alle konstanten Funktionen.Was impliziert dieser Umstand furdie Gewichte wi oder fur die Knotenxi ?
19. Warum ist es wichtig, daß alle Ge-wichte einer Quadratur-Regel posi-tiv sind?
20. Der Integrand weise am Rand desIntegrationsbereiches eine integrier-bare Singularitat auf. Ist danneine geschlossene Newton-Cotes-Quadratur oder Gauß-Quadraturvorteilhafter?
21. Welchen Grad haben die folgendenQuadratur-Regeln?
a) n-Punkt Newton-Cotes-Quadratur fur ungerades n,
b) n-Punkt Newton-Cotes-Quadratur fur gerades n,
c) n-Punkt Gauß-Quadratur.
d) Worin ist der Unterschied von a)und b) begrundet?
e) Worin ist der Unterschied von b)und c) begrundet?
22. Weisen jeweils Newton-Cotes-Quadratur oder Gauß-Quadraturdie folgenden Eigenschaften auf?
a) einfach zu berechnende Knotenund Gewichte,
b) einfach auf ein beliebiges Intervall[a, b] anzuwenden,
c) ist genauer bei derselben Knoten-Anzahl,
d) hat den maximalen Grad fur festeKnoten-Anzahl,
e) mit einfach wiederzuverwenden-den Knoten.
23. Welche Beziehung besteht zwischenGauß-Quadratur und orthogonalenPolynomen?
24. a) Was ist eine progressiveQuadratur-Regel?
b) Inwiefern ist Progressivitat wich-tig?
25. a) Welchen Vorteil hat es, ein Gauß-Kronrod-Paar wie etwa G7 undK15 anstatt zwei Gauß-Quadratur-Regeln wie G7 und G15 zu benut-zen, um ein Integral zu approximie-ren und den Fehler abzuschatzen?
b) Wieviele Auswertungen des Inte-granden sind notig, um G7 und K15
in einem gegebenen Intervall zu be-stimmen?
26. Ordne die folgenden Quadratur-Regeln nach ihrem Grad bei festerKnoten-Anzahl.
a) Newton-Cotes
b) Gauß
c) Kronrod
27. a) Was ist eine zusammengesetzteQuadratur-Regel?

412 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
b) Warum ist eine zusammenge-setzte Quadratur-Regel einer einfa-chen Quadratur-Regel vorzuziehen,wenn hohe Genauigkeit erzielt wer-den soll?
c) Um welchen Faktor wird der Feh-ler reduziert, wenn die Schrittweiteh in der zusammengesetzten Trapez-Regel halbiert wird?
28. a) Beschreibe adaptive Integration.
b) Wie konnen die notwendigenFehler-Abschatzungen gewonnenwerden?
c) Unter welchen Bedingungen kannadaptive Integration scheitern?
d) Unter welchen Bedingungen kannadaptive Integration extrem ineffizi-ent sein?
29. Ein Integrand weise im Intergrati-onsintervall bekannte Unstetigkeits-stellen auf. Wie ist der Integrandam besten adaptiv zu integrieren?
30. Wie integriert man am besten ta-bellierte Daten, d.h. Funktionen, dienur in diskreten (Meß-) Punkten be-kannt sind?
31. a) Wie ist ein Integrand uber ein un-beschranktes Integrationsintervallmit Standard-Quadratur-Regeln zuintegrieren?
b) Welche Vorsichtsmaßnahmensind zu treffen, um die Qualitat desErgebnisses zu sichern?
32. Wie lassen sich Doppel-Integraleuber rechteckige Integrationsberei-che mit Standard-Quadratur-Regelnberechnen?
33. Warum ist Monte-Carlo-Integrationfur einfache ’eindimensionale’ Inte-grale
∫ ba f(x) dx ungeeignet?
34. Warum ist Monte-Carlo-Integrationin hoheren Dimensionen effektiverals andere Quadraturen?
35. Erlautere, warum Integralgleichun-gen erster Art mit glatten Kernenimmer schlecht konditioniert sind.
36. Wie kann eine Quadratur-Regel zurLosung von Integral-Gleichungenbenutzt werden? Welches Problemtritt dabei auf?
37. Eine Integral-Gleichung erster Artsei durch numerische Quadratur zulosen. Wird die Losung immer ver-bessert, wenn entweder der Gradder Quadratur-Regel erhoht oder dieSchritt-Weite vermindert wird?
38. Beschreibe drei Ansatze, einschlecht konditioniertes System li-nearer Gleichungen, das die Losungeiner Integral-Gleichung erster Artapproximiert, zu losen.
39. a) Die Ableitung einer Funktion, dienur in diskreten Punkten bekanntist, sei zu approximieren. Ist es rat-sam, die Daten-Punkte zu interpo-lieren und die Interpolierende zu dif-ferenzieren?
b) Eine Funktion, die nur in diskre-ten Punkten bekannt ist, sei zu in-tegrieren. Ist es ratsam, die Daten-Punkte zu interpolieren und die In-terpolierende zu integrieren?
40. Ist Integration oder Differentationinharent besser konditioniert?
41. a) Wie kann die Ableitung ei-ner Funktion, die nur in diskretenDaten-Punkten bekannt ist, am be-sten approximiert werden?
b) Was ist zu tun, wenn die Daten-Punkte verrauscht sind?

8.2. Exercises – Ubungen 413
42. Gib zwei Methoden an, die Ab-leitungen einer gegebenen Funktiondurch finite Differenzen zu approxi-mieren.
43. Wie funktioniert und worauf basiertautomatische Differentation?
44. a) Erlautere die Richardson-Extrapolation.
b) Produziert Richardson-Extrapolation genauere Ergebnisseals die Werte, die sie verwendet?
c) Bedeutet die Extrapolation hinzur Schrittweite 0, daß das Ergebnisexakt ist?
45. Was bedeutet Romberg-Integration?
8.2 Exercises – Ubun-
gen
1. a) Approximiere∫ 1o x
3 dx durchMittelpunkt- und Trapez-Regel.
b) Verwende die Differenz der Er-gebnisse aus a), um den Fehlerjeweils der Mittelpunkt- und derTrapez-Regel abzuschatzen.
c) Kombiniere die Ergebnisse aus a),um das Ergebnis der Simpson-Regelzu erhalten.
d) Steht zu erwarten, daß die Ap-proximation per Simpson-Regel ex-akt ist?
2. a) Approximiere∫ 1o x
3 dx durchdie zusammengesetzte Mittelpunkt-Regel mit den Schrittweiten h = 0.5und h = 1.
b) Verbessere die Ergebnisse aus a)durch Richardson-Extrapolation.
3. Sei Q(f) =∑n
i=1wif(xi) eine po-lynomial interpolierende Quadraturauf dem Intervall [0, 1]. Ist damit∑n
i=1wi = 1 impliziert?
4. Fur I(f) = M(f)+E(f)+F (f)+. . .zeige
I(f) = T (f)− 2E(f)− 4F (f) + . . .
sowie
E(f) ≈ 13(T (f)−M(f))
Zeige: die ungeraden Terme in bei-den Entwicklungen verschwinden.
5. a) f sei zweimal stetig-differenzier-bar mit f ′′(x) ≥ 0 auf [a, b]. Zeigedie Klammer-Eigenschaft
Mk(f) ≤ I(f) =∫ b
af(x) dx ≤ Tk(f)
b) f sei konvex auf [a, b]. Zeige dieKlammer-Eigenschaft von Mk undTk.
6. Fur gegebene Knoten x1, x2, . . . , xn
sei Q(f) =∑n
i=1wif(xi) eine inter-polierende Quadratur. Zeige:wi =
∫ ba `i(x) dx fur i = 1, 2, . . . , n,
wobei `i die i-te Lagrange-Basis-Funktion bezeichne.
7. Bestimme die offene 2-Punkt-Newton-Cotes-Quadratur R fur dasIntervall [a, b]. Welche Knoten,welche Gewichte und welchen Gradhat R ?
8. a) Was ist das großte n der-art, daß alle Gewichte der ge-schlossenen n-Punkt-Newton-Cotes-Quadratur positiv sind?
b) Was ist das kleinste n derart, daßmindestes eines der Gewichte der ge-schlossenen n-Punkt-Newton-Cotes-Quadratur negativ ist?

414 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
c) Was ist das großte n derart, daßalle Gewichte der offenen n-Punkt-Newton-Cotes-Quadratur positivsind?
d) Was ist das kleinste n derart,daß mindestes eines der Gewichteder offenen n-Punkt-Newton-Cotes-Quadratur negativ ist?
9. Sei p ein reelles Polynom mitgrad(p) = n und
∫ ba p(x)x
k dx = 0fur alle k = 0, 1, . . . , n− 1.
a) Zeige: die n Nullstellen von p sindeinfach, reell und liegen in (a, b).(Hinweis: betrachte das Polynomq(x) = (x− x1)(x− x2) · · · (x− xk),wobei die xi fur i = 1, . . . , k die Null-stellen von p in (a, b) sind.)
b) Zeige: die n-Punkt interpolie-rende Quadratur, deren Knoten dieNullstellen von p sind, hat den Grad2n−1. (Hinweis: fur ein Polynom fbetrachte Quotient und Rest bei derDivision von f durch p.)
10. Um Multiplikationen zu sparen, ha-ben in der Chebyshev-Quadratur dieOrdinaten aller Knoten dasselbe Ge-wicht w.
a) Bestimme mit der Methodeder unbestimmten Koeffizienten Ge-wicht w und Knoten xi einer 3-Punkte Chebyshev-Quadratur Q auf[−1, 1].
b) Was ist der Grad dieserChebyshev-Quadratur-Regel Q ?
11. a) Sei m = a+b2 gesetzt. I(f) =∫ b
a f(x) dx werde vermittels der auf[a,m] und [m, b] zusammengesetztenTrapez-Regel oder alternativ ver-mittels der Simpson-Regel auf [a, b]approximiert. Welches Verfahren istgenauer?
b) Sei m = a+b2 gesetzt. I(f) =∫ b
a f(x) dx werde vermittels der auf[a,m] und [m, b] zusammengesetz-ten Simpson-Regel oder alterna-tiv vermittels der (geschlossenen)5-Punkte Newton-Cotes-Regel auf[a, b] approximiert. Welches Verfah-ren ist genauer?
c) Sei m = a+b2 gesetzt. I(f) =∫ b
a f(x) dx werde vermittels der auf[a,m] und [m, b] zusammengesetztenQuadratur Qn oder alternativ ver-mittels der (2n−1)-Punkte Newton-Cotes-Quadratur Q2n−1 auf [a, b]approximiert. Welches Verfahren istgenauer?
12. forward difference f ′(x) ≈ 1h(f(x +
h) − f(x)) und backward differencef ′(x) ≈ 1
h(f(x) − f(x − h)) sindbeide Approximationen erster Ord-nung fur die Ableitung f ′(x) einerFunktion f in x. Welche Ordnunghat das arithmetische Mittel dieserbeiden Naherungen?
13. Aus der Taylor-Entwicklung einergenugend glatten Funktion f leiteeine einseitige Approximation vonf ′(x) unter Verwendung von f(x),f(x+ h) und f(x+ 2h) her.
14. Fur h = 0.2 sei die forward diffe-rence f ′(x) ≈ 1
h(f(x+ h)− f(x)) =−0.8333 und fur h = 0.1 die for-ward difference f ′(x) ≈ 1
h(f(x+h)−f(x)) = −0.9091. Verbessere dieNaherung fur f ′(x) per Richardson-Extrapolation.
15. Archimedes approximierte π mit
pn < π < qn
durch den Umfang pn = n sin πn des
dem Kreis mit Durchmesser 1 ein-beschriebenen regelmaßigen n-Eckes

8.3. Computer Problems – Rechner-Probleme 415
und durch den Umfang qn = n tan πn
des diesem Kreis umbeschriebenenregelmaßigen n-Eckes.
a) Zeige fur h = 1/n jeweils
pn = ao + a1h2 + a2h
4 + . . .
qn = bo + b1h2 + b2h
4 + . . .
Welche Werte haben ao und bo ?
b) Verbessere die Naherungen furπ per Richardson-Extrapolation ausp6 = 3.0000 und p12 = 3.1058 bzw.aus q6 = 3.4641 und q12 = 3.2154.
8.3 Computer Pro-
blems – Rechner-
Probleme
1. Wegen∫ 1o
4 dx1+x2 = π liefern
Quadratur-Verfahren Naherun-gen fur π.
Zunachst ist∫ 1o
4 dx1+x2 = 4 arctan 1 =
π.
a) Verwende zusammengesetzteMittelpunkt-, Trapez- und Simpson-Regel fur verschiedene Schrittweitenh zur Approximation von π.Charakterisiere den Fehler inAbhangigkeit von h. Vergleichedie jeweils erzielten Genauigkeiten.Was passiert, wenn h immer weiterverkleinert wird?
b) Implementiere Romberg-Integration und wende diesewie in Teil a) an.
c) Wende Bibliotheksroutinen furadaptive Integration auf das Pro-blem an. Wie verlaßlich sind derenFehlerabschatzungen? Stelle gra-phisch dar, wo die Bibliotheksrou-tine die Knoten etabliert.
d) Implementiere Monte-Carlo-Integration und wende diese wiein Teil a) an. Charakterisiere denFehler als Funktion der Anzahl dersamples, d.h. der Auswertungen desIntegranden.
2. Fuhre dieselben numerischen Qua-draturen fur das kompliziertere In-tegral
∫ 1o
√x lnx dx = −4
9 durch.
3. Approximiere folgende Integralevermittels numerischer Quadratur-Verfahren. Vergleiche Effizienz undGenauigkeit. Stelle graphisch dar,wo adaptive IntegrationsverfahrenKnoten etablieren.
a)∫ 1−1 cosx dx
b)∫ 1−1
dx1+100x2
c)∫ 1−1
√|x| dx
4. ’Verifiziere’ oder falsifiziere folgendeAussagen vermittels numerischerQuadratur.
a)∫ 1o
√x3 dx = 0.4
b)∫ 1o
dx1+10x2 = 0.4
c)∫ 1o
e−9x2+e−1024(x−0.25)2
√π
dx = 0.2
d) 1π
∫ 10o
50 dx1+2500x2 = 0.5
e)∫ 100−9
dx√|x|
= 26
f)∫ 10o 25e−25x dx = 1
g)∫ 1o lnx dx = −1
5. Vergleiche Genauigkeit und Auf-wand der Integration stuckweise de-finierter Funktionen per adaptiverQuadratur, nicht adaptiver Quadra-tur und deren Anwendung auf die je-weiligen Teil-Integrationsintervalle.
a) f(x) = χ[0.3,1] fur x ∈ [0, 1]
b) f(x) = χ[0,e−2)(x) 1x+2 fur x ∈
[0, 1]

416 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
c) f(x) = χ[−1,0)(x) ex +χ[0,2](x) e1−x
d) f(x) = χ[−1,1/2)(x)e10x +χ[1/2,3/2](x) e10(1−x)
e) f(x) = χ[0,1/2)(x) sin(πx) +χ[1/2,1](x) sin2(πx)
6. a) Berechne Ik = 1e
∫ 1o x
kex dx furk = 0, 1, . . . , 20 per adaptiver Qua-dratur.
b) Verifiziere Ik = 1 − k Ik−1 mitIo = 1− 1/e (vorwarts rekursiv).
c) Erzeuge Ik anhand Ik−1 = (1 −Ik)/k (ruckwarts rekursiv) mit In =0 fur ein n > 20.
d) Vergleiche Genauigkeit, Stabi-litat und Aufwand der drei Metho-den und erlautere die Ergebnisse.
7. Ein Ellipsoid entsteht durchRotation einer Ellipse umeine ihrer Symmetrie-Achsen.Die Oberflache des Ellipso-ids ist dann gegeben durchI(f) = 4π
√α∫ 1/
√β
o
√1−Kx2 dx,
wobei hier β = 100 gesetzt seiund α = (3 − 2
√2)/β sowie
K = β√
1− αβ gelten. Verwendeeine adaptive Quadratur, visuali-siere die verwendeten Knoten undvergleiche mit dem exakten Ergeb-nis I(f) = π
√α/K(π+sin(2θ)−2θ)
mit θ = arccos√K/β.
8. Die Intensitat von an einer geradenKante gestreutem Licht ist durch diebeiden Fresnel-Integrale
C(x) =∫ x
ocos (π
2 t2) dt
S(x) =∫ x
osin (π
2 t2) dt
beschrieben. Ermittele und visuali-siere C(x) und S(x) fur x ∈ [0, 5]
vermittels einer adaptiven Quadra-tur und vergleiche mit den Er-gebnissen spezieller Bibliotheksrou-tinen zur Bestimmung von Fresnel-Integralen.
9. Die Periode eines Pendels ist durchein vollstandiges elliptisches Integralerster Art K(x) =
∫ π/2o
dθ√1−x2 sin2 θ
bestimmt. Ermittele und visuali-siere K(x) fur x ∈ [0, 1] vermit-tels einer adaptiven Quadratur undvergleiche mit dem Ergebnis speziel-ler Bibliotheksroutinen zur Bestim-mung derartiger Integrale.
10. Die Gamma-Funktion ist fur x >0 durch Γ(x) =
∫∞o tx−1e−t dt
definiert. Berechne die Gamma-Funktion auf jede der folgendenWeisen fur 1 ≤ x ≤ 10 undvergleiche die Ergebnisse mit Bi-bliotheksroutinen fur die Gamma-Funktion sowie mit den Funktions-werten Γ(n) = (n− 1)! der Gamma-Funktion in naturlichen Argumen-ten.
a) Programmiere die Approximationder Gamma-Funktion per zusam-mengesetzter Trapez- oder Simpson-Regel bei geeignet begrenztem In-tegrationsintervall. Untersuche denfalligen Kompromiss zwischen Ge-nauigkeit und Effizienz.
b) Gauss-Laguerre
11. Planck’s Theorie der Strahlung einesschwarzen Korpers fuhrt auf das In-tegral
∫∞o
x3 dxex−1 . Der Integrand ist
proportional der Planck brightnessin Abhangigkeit von der Frequenzbei fester Temperatur. Berechnedas Integral vermittels der Metho-den des vorigen Computer-Problemsund vergleiche wieder Genauigkeitund Effizienz.

8.3. Computer Problems – Rechner-Probleme 417
12. Berechne∫∞−∞ e−x2
cosx dx
a) per zusammengesetzter Integra-tion
b) adaptiv
c) per Gauß-Hermite
13. Angenommen, in der Ebenesei elektrische Ladung inG = [−1, 1] × [−1, 1] ⊂ R2
gleichmaßig verteilt. Dann ist daselektrostatische Potential Φ(x, y)in Punkten (x, y) 6∈ G durchΦ(x, y) =
∫ 1−1
∫ 1−1
dx dy√(x−x)2+(y−y)2
gegeben. Berechne und visualisiereΦ(x, y) fur 2 ≤ x, y ≤ 10.
14. Berechne∫∫
G e−xy dx dy fur fol-
gende Integrationsbereiche G
a) Q = [0, 1]× [0, 1] ⊂ R2, Einheits-quadrat der Ebene
b) V = (x, y) : x2 + y2 ≤ 1, x ≥0, y ≥ 0 ⊂ R2, Vierteleinheitskreisim ersten Quadranten der Ebene
15. a) Programmiere eine automatischeQuadratur unter Verwendung derzusammengesetzten Simpson-Regel.Dabei werde k solange erhoht,bis der Fehler genugend klein ist.Schatze dabei den Fehler durch Ver-gleich mit der jeweils vorangehendenIteration. Welche Datenstruktur er-laubt, die vorher berechneten Funk-tionswerte wiederzuverwenden?
b) Programmiere eine adaptiveQuadratur unter Verwendung derzusammengesetzten Simpson-Regel.Verfeinere dabei nur die Teilinter-valle, in denen der Fehler noch nichtgenugend klein ist. Welche Da-tenstruktur erlaubt, daruber Buchzu fuhren, in welchen Teilintervallendie Quadratur abgeschlossen ist?
Vergleiche die Effizienz der ad-aptiven mit derjenigen der nicht-adaptiven Quadratur anhand der In-tegrale aus den vorangehenden Pro-blemen.
16. Finde einen Integranden, fur deneine adaptive Quadratur volligfalsche Ergebnisse liefert. Gibt eseinen derartigen glatten Integran-den?
17. a) Lose die Integralglei-chung
∫ 1o
√s2 + t2u(t) dt =
13(√s2 + 1
3 − s3) im Intervall[0, 1], indem das Integral per zusam-mengesetzter Simpson-Quadraturund n aquidistanten tj approximiertwird. Verwende dieselben tj furdie Naherungen si. Lose das sichergebende lineare GleichungssystemAx = y per Gauß mit partiellerPivotisierung. Experimentieremit verschiedenen Werten vonn = 3, 4, . . . , 15. Vergleiche dieErgebnisse mit der exakten Losungu(t) = t. Fur welchen Wert von nergeben sich die besten Ergebnisse?Warum?
b) Berechne fur jedes n die Kon-ditionszahl cond(A). WelcheAbhangigkeit besteht?
c) Wiederhole a), lose allerdingsAx = y per SVD und setze da-bei genugend kleine SingularwerteNull. Bewerte den jeweiligen Fehlerin Abhangigkeit von der Schwelle.
d) Wiederhole a), lose allerdingsAx = y per Regularisierung. Ex-perimentiere mit dem Regularisie-rungsparameter µ. Welches µ ist op-timal? Stelle die Ortskurve Normder Losung Norm des Residuums inAbhangigkeit von µ graphisch dar.Legt diese Kurve einen optimalen

418 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
Wert fur µ nahe?
e) Wiederhole a), lose allerdingsAx = y per Optimierung von ||y −Ax||22. Vergleiche erneut mit der ex-akten Losung.
f) Wiederhole e) unter der zusatzli-chen Bedingung einer monoton wa-chesenden Losung, d.h. 0 ≤ x1 ≤x2 ≤ . . . ≤ xn. Welcher Unterschiedergibt sich?
18. Gegeben die Daten-Punktet 0.0 1.0 2.0 3.0 4.0 5.0y 1.0 2.7 5.8 6.6 7.5 9.9aus 3CP1.
a) Bestimme das linear least squaresProblem-Polynom vom Grad n =0, 1, . . . , 5 und seine jeweiligen Ab-leitungen in den sechs Datenpunk-ten.
b) Bestimme den die Daten-Punkteinterpolierenden kubischen Splineund seine jeweiligen Ableitungen inden sechs Datenpunkten.
c) Wiederhole b) mit unterschiedli-chem Glattheitsgrad.
d) Bestimme das die Daten-Punkteinterpolierende kubische monotoineHermite-Polynom und seine jeweili-gen Ableitungen in den sechs Daten-punkten.

8.4. Review Questions – Antworten auf Verstandnisfragen 419
8.4 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Ein bestimmtes Integral zu berechnen, ist ein gut-konditi- 341/342oniertes Problem.
Integration, d.h. Mittelwert-Bildung ist gut konditioniert, was Anderun-gen des Integranden angeht und was Anderungen der Integrationsgrenzenangeht, solange diese nicht gerade mit Singularitaten des Integranden zu-sammenfallen.
2. Richtig/Falsch? Die Trapez-Regel ist grundsatzlich genauer als die Mittel- 348punkt-Regel, weil der Grad des in der Trapez-Regel verwendeten Polynomsum eins hoher ist als derjenige des in der Mittelpunkt-Regel verwendetenPolynoms.
Wenn (b− a)5 (b− a)3 und f (4) sich gutmutig verhalt, so ist die Mittel-punkt-Regel doppelt so genau wie die Trapez-Regel.
3. Richtig/Falsch? Der Grad einer Quadratur-Regel stimmt uberein mit dem 344Grad des Polynoms, auf dem die Quadratur-Regel basiert.
Falsch, wie schon die Mittelpunkt-Regel zeigt: das verwendete Polynom hatden Grad 0, die Mittelpunkt-Regel hat den Grad 1.
4. Richtig/Falsch? Die n-Punkt Newton-Cotes-Regel hat den Grad n− 1. 346,349
Grad(n-Punkt Newton-Cotes-Regel) =
n− 1 falls n geraden falls n ungerade
.
5. Richtig/Falsch? Gauß-Quadratur-Regeln verschiedenen Grades haben keine 353Punkte gemeinsam.
Gn und Gm haben außer den Mittelpunkt (a + b)/2 fur ungerades n undungerades m keinen Punkt gemeinsam.
6. An welche notwendigen und hinreichenden Bedingungen ist die Existenz 341des Riemann-Integrals geknupft?
Das Riemann-Integral existiert genau dann, wenn f auf [a, b] beschranktund fast uberall stetig ist.
7. a) Unter welchen Bedingungen reagiert ein bestimmtes Integral sensitiv auf 341/342kleine Anderungen des Integranden?
Wegen |I(f)−I(f)|/|I(f)|||f−f ||/||f || ≤ ||f ||
|I(f)|(b−a) kann der relative Fehler fur betragsmaßig
kleine I(f) sehr groß werden.
b) Unter welchen Bedingungen reagiert ein bestimmtes Integral sensitiv auf 342

420 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
kleine Anderungen der Integrationsgrenzen?
Nahe Singularitaten des Integranden bewirken kleine Anderungen der In-tegrationsgrenze große Anderungen des Integrals.
8. Wie unterscheiden sich offene und geschlossene Quadratur-Regeln?343
Eine Quadratur-Regel mit a < x1 < x2 < . . . < xn < b heißt offen. EineQuadratur-Regel mit a = x1 < x2 < . . . < xn = b heißt geschlossen.
9. Wie heißen zwei Verfahren zur Bestimmung der Gewichte in einer Quadra-343tur-Regel mit gegebenen Punkten?
Interpolierende Quadratur bestimmt das Integral eines die Daten-Punkteinterpolierenden Polynoms. Die Methode der unbestimmten Koeffizientenbestimmt das Integral durch die Forderung, daß die Quadratur-Regel npolynomiale Basis-Funktionen exakt integriert.
10. Wie laßt sich der Fehler einer Quadratur-Regel abschatzen, ohne Ableitun-347/348gen des Integranden berechnen zu mussen?
In der Entwicklung der der Mittelpunkt-Regel I(f) = M(f)+E(f)+F (f)+. . . bzw. der Trapez-Regel I(f) = T (f)− 2E(f)− 4F (f) + . . . gilt E(f) ≈13(T (f) −M(f)). Der Fehler E(f) der Mittelpunkt-Regel bzw. der Fehler−2E(f) der Trapez-Regel kann somut durch Vielfache der Differenz T (f)−M(f) abgeschatzt werden.
11. a) Wie unterscheidet sich die Platzierung von Knoten bei Newton-Cotes-346und Clenshaw-Curtis-Quadratur?
Die Newton-Cotes-Quadratur verwendet aquidistante Daten-Punkte, wah-rend die Clenshaw-Curtis-Quadratur Chebyshev-Punkte verwendet.
b) Welches der beiden Verfahren wird wohl bei derselben Knoten-Anzahl350/351genauer sein?
Die Clenshaw-Curtis-Quadratur ist wesentlich genauer, weil der maximaleFehler uber das Intervall [a, b] bei Verwendung der Chebyshev-Punkte sehrviel kleiner als bei Verwendung aquidistanter Punkte ausfallt.
12. a) Wie unterscheidet sich die Platzierung von Knoten bei Newton-Cotes-351/352und Gauß-Quadratur?
Gauß-Quadratur optimiert auch die Platzierung der Daten-Punkte.
b) Welches der beiden Verfahren wird wohl bei derselben Knoten-Anzahl353genauer sein?
Da der Grad der Gauß-Quadratur mit 2n − 1 fast doppelt so hoch ist wieder Grad der Newton-Cotes-Quadratur, ist die Gauß-Quadratur wesentlichgenauer.

8.4. Review Questions – Antworten auf Verstandnisfragen 421
13. a) Was ist der hochste Grad einer in aquidistanten Daten-Punkten polyno- 344mial interpolierenden Quadratur-Regel?
In aquidistanten Daten-Punkten polynomial interpolierende Quadratur-Re-geln sind Newton-Cotes-Quadraturen mit Grad n − 1, falls n gerade, undmit Grad n, falls n ungerade.
b) Was ist der hochste Grad einer optimal platzierte Daten-Punkten poly- 351nomial interpolierenden Quadratur-Regel?
Der Grad der Gauß-Quadratur ist 2n− 1.
14. a) Wird fur n → ∞ die Newton-Cotes-Quadratur das Integral∫ 1
−1f(x) dx 346
der Runge-Funktion f(x) = 11+25x2 gut approxmieren?
Die Approximation durch Newton-Cotes-Quadratur ist vermutlich schlecht,weil ||pn − f || fur das interpolierende Polynom pn beliebig groß wird, wennn→∞.
b) Wird fur n→∞ die Clenshaw-Curtis-Quadratur das Integral∫ 1
−1f(x) dx 350/351
der Runge-Funktion f(x) = 11+25x2 gut approxmieren?
Fur die Clenshaw-Curtis-Quadratur CC(f) gilt |I(f) − CCn(f)| → 0 furn→∞ und fur jeden Integranden f , insbesondere also auch fur die Runge-Funktion.
15. a) Was ist der Grad der Simpson-Regel? 349
Die Simpson-Quadratur ist eine 3-Punkt Newton-Cotes-Quadratur und hatdaher den Grad 3.
b) Was ist der Grad der Gauß-Quadratur? 351
Der Grad der Gauß-Quadratur ist 2n− 1.
16. a) Welche Eigenschaft charakterisiert die Newton-Cotes-Quadratur bei ge- 346gebener Anzahl von Daten-Punkten?
Die Daten-Punkte sind aquidistant.
b) Welche Eigenschaft charakterisiert die Gauß-Quadratur bei gegebener 346Anzahl von Daten-Punkten?
Die Gauß-Quadratur optimiert die Platzierung der Daten-Punkte.
17. a) Wieso integriert die Mittelpunkt-Regel, die auf einem Polynom nullten 349Grades basiert, Polynome vom Grad eins exakt?
Fur f(x) = cx+ d gilt∫ b
af(x) dx =
∫ b
a(cx+ d) dx = c
2(b2− a2) + d(b− a) =
(b− a)(ca+b2
+ d) = (b− a)f(a+b2 ).
b) Ist die Mittelpunkt-Regel eine Gauß-Quadratur-Regel? 349

422 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
Die Mittelpunkt-Regel ist eine 1-Punkt Gauß-Quadratur-Regel: Die Forde-rung, daß
∫ b
af(x) dx ≈ w1f(x1) fur Polynome von hochstens erstem Grad
exakt ist, bedeutet fur die beiden Basis-Monome
b− a =
∫ b
a
1 dx = w1 · 1 ⇐⇒ w1 = b− a
(b− a) b+a2
= 12(b2 − a2) =
∫ b
a
x dx = w1x1 = (b− a)x1 ⇐⇒ x1 = a+b2
zusammen also∫ b
af(x) dx ≈M(f) = (b− a) f(a+b
2 ).
18. Sei∫ b
af(x) dx =
∑ni=1wif(xi) exakt fur alle konstanten Funktionen. Was343
impliziert dieser Umstand fur die Gewichte wi oder fur die Knoten xi ?
(b − a) =∫ b
a1 dx =
∑ni=1wi · 1 impliziert
∑ni=1wi = b − a fur beliebige
Knoten xi.
19. Warum ist wichtig, daß alle Gewichte einer Quadratur-Regel positiv sind?350
Positive und negative Gewichte haben Ausloschung und damit numerischeInstabilitat zur Folge.
20. Der Integrand weise am Rand des Integrationsbereiches eine integrierbare346,351Singularitat auf. Ist dann eine geschlossene Newton-Cotes-Quadratur oderGauß-Quadratur vorteilhafter?
Wie jede offene Quadratur ist die Gauß-Quadratur vorzuziehen, da so dieAuswertung des Integranden in der Singularitat vermieden wird, vgl. z.B.8CP4 g).
21. Welchen Grad haben die folgenden Quadratur-Regeln?
a) n-Punkt Newton-Cotes-Quadratur fur ungerades n,349
Die n-Punkt Newton-Cotes-Quadratur fur ungerades n hat den Grad n.
b) n-Punkt Newton-Cotes-Quadratur fur gerades n,349
Die n-Punkt Newton-Cotes-Quadratur fur gerades n hat den Grad n− 1.
c) n-Punkt Gauß-Quadratur.351
Die n-Punkt Gauß-Quadratur hat den Grad 2n− 1.
d) Worin ist der Unterschied von a) und b) begrundet?349
Sei n = 2ν + 1 ungerade, p ∈ Pn und sei q2ν ∈ P2ν das Polynom, das p inxi = a+(i−1) b−a
2νfur i = 1, 2, . . . , n interpoliert. Dann hat r = p−q2ν ∈ Pn
genau die n Nullstellen xi fur i = 1, 2, . . . , n. Damit laßt sich r darstellenals r(x) = c
∏ni=1(x − xi) oder mit h = b−a
2νund m = (a + b)/2 auch als
r(x) = c∏ν
i=1(x−m+ ih)(x−m)∏ν
i=1(x−m− ih). Wegen

8.4. Review Questions – Antworten auf Verstandnisfragen 423
r(m+x) = c∏ν
i=1(x+ih)(x)∏ν
i=1(x−ih) = −c∏ν
i=1(−x+ih)(−x)∏ν
i=1(−x−ih) = −r(m−x)
ist r = p− q2ν also ungerade bzgl. m = (a+ b)/2. Integration liefert∫ b
a
r(x) dx = (∫ m
a
+
∫ b
m)r(x) dx = −
∫ o
m−a
r(m−u) du+∫ b−m
o
r(m+u) du = 0
so daß sich negative und positive Fehler kompensieren. Wegen∫ b
a
p(x) dx =
∫ b
a
q2ν dx =n∑
i=1
wiq2ν(xi) =n∑
i=1
wip(xi)
ist die Quadratur also auch fur jedes p ∈ Pn exakt. Somit ist ihr Grad n.
e) Worin ist der Unterschied von b) und c) begrundet? 351
Der fast doppelt so hohe Grad der Gauß-Quadratur resultiert aus denzusatzlichen n Freiheitsgraden, auch die Position der Knoten zu optimieren.
22. Weisen jeweils Newton-Cotes-Quadratur oder Gauß-Quadratur die folgen-den Eigenschaften auf?
a) einfach zu berechnende Knoten und Gewichte, 343,351
Fur die Newton-Cotes-Quadratur sind mit xi = a+ in+1
(b− a) die Knotensehr einfach und die Gewichte w als Losung des Systems linearer Glei-chungen Aw = ((bi − ai)/i))
i=1,...,nmit Vandermonde-Matrix A einfach zu
berechnen. Fur die Gauß-Quadratur ist dagegen ein System nicht-linearerGleichungen zu losen.
b) einfach auf ein beliebiges Intervall [a, b] anzuwenden,343,352/353Wegen a) ist die Newton-Cotes-Quadratur auch einfach auf ein beliebi-
ges Intervall [a, b] anzuwenden. Fur die Gauß-Quadratur dagegen ist dasIntegral zunachst auf den Standard-Integrationsbereich [−1, 1] zu transfor-mieren.
c) ist genauer bei derselben Knoten-Anzahl, 343,351
Die Newton-Cotes-Quadratur hat den Grad n − 1 oder n, wahrend dieGauß-Quadratur den Grad 2n− 1 hat.
d) hat den maximalen Grad fur feste Knoten-Anzahl, 343,351
Gauß-Quadratur hat mit 2n − 1 den maximalen Grad, weil alle 2n − 1Freiheitsgrade genutzt werden.
e) mit einfach wiederzuverwendenden Knoten. 343,353
Newton-Cotes-Quadratur ist progressiv: Bei Verdopppelung von n konnenalle schon berechneten Funktionswerte wiederverwendet werden. Gauß-Quadratur ist dagegen nicht progressiv: gegebenenfalls mit Ausnahme des

424 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
Mittelpunktes a+b2
habenGm undGn furm 6= n keine gemeinsamen Knoten,was in der Version der progressiven Gauß-Quadratur mit einem niedrigerenGrad erkauft wird.
23. Welche Beziehung besteht zwischen Gauß-Quadratur und orthogonalen Po-352lynomen?
Sei p ∈ Pn mit∫ b
ap(x)xk dx = 0 fur k = 0, 1, . . . , n − 1, d.h. p ⊥ xk fur
k = 0, 1, . . . , n − 1. Dann sind erstens alle n Nullstellen von p reell undeinfach und liegen in (a, b) und zweitens hat die n-Punkt Quadratur-Regel,deren Knoten gerade die Nullstellen von p sind, den Grad 2n−1 und stimmtdaher mit der Gauß-Quadratur uberein (vgl. 8Ex9).
24. a) Was ist eine progressive Quadratur-Regel?345
Eine Quadratur-Regel Qn heißt progressiv, wenn die Knoten von Qn auchKnoten von Qm fur alle m > n sind.
b) Inwiefern ist Progressivitat wichtig?345
Progressivitat erlaubt eben, einmal berechnete Funktionswerte wiederzu-verwenden, so daß die Kosten fur Quadratur sinken.
25. a) Welchen Vorteil hat es, ein Gauß-Kronrod-Paar wie etwa G7 und K15354anstatt zwei Gauß-Quadratur-Regeln wie G7 und G15 zu benutzen, um einIntegral zu approximieren und den Fehler abzuschatzen?
Gauß-Kronrod-Paare wie G7 und K15 sind progressiv: die fur G7 berechne-ten Funktionswerte werden fur K15 wiederverwendet. Dagegen haben G7
und G15 nur den Mittelpunkt als Knoten gemein.
b) Wieviele Auswertungen des Integranden sind notig, um G7 und K15 in354einem gegebenen Intervall zu bestimmen?
Fur G7 sind sieben und fur K15 weitere, zusatzliche acht Auswertungennotig.
26. Ordne die folgenden Quadratur-Regeln nach ihrem Grad bei fester Knoten-Anzahl.
a) Newton-Cotes349
b) Gauß351
c) Kronrod354
Grad(Newton-Cotes) ∈ n−1, n < Grad(Kronrod) ≈ 3n+12
< Grad(Gauß)= 2n− 1 fur n Knoten.
27. a) Was ist eine zusammengesetzte Quadratur-Regel?355
Sei Q = Q(f, a, b) ≈∫ b
af(x) dx eine einfache Quadratur-Regel. Dann liefert
eine typischerweise aquidistante Unterteilung xj = a+jh mit h = (b−a)/k

8.4. Review Questions – Antworten auf Verstandnisfragen 425
fur j = 0, 1, . . . , k des Intergrationsintervalls und Anwendung von Q aufjedes Teilintervall (xj−1, xj) die zusammengesetzte Quadratur-Regel Qk =
Qk(f, a, b) =∑k
j=1Q(f, xj−1, xj).
b) Warum ist eine zusammengesetzte Quadratur-Regel einer einfachen Qua- 355/356dratur-Regel vorzuziehen, wenn hohe Genauigkeit erzielt werden soll?
Die Quadratur Qn weise den Grad mindestens 0 auf. Sei Ck die zusam-mengesetzte Quadratur (Qn angewandt auf k Teil-Intervalle). Dann giltlimk→∞Ck(f) = I(f). Mit zusammengesetzter Quadratur lassen sich alsobeliebig hohe Genauigkeiten erreichen.
c) Um welchen Faktor wird der Fehler reduziert, wenn die Schrittweite h in 355der zusammengesetzten Trapez-Regel halbiert wird?
Zunachst ist I(f) = T (f) − 2E(f) − 4F (f) + . . . mit E(f) proportionalzu h3, d.h. E(f) = O(h3). Zugleich bedeutet die Halbierung von h eineVerdoppelung der Anzahl der Teilintervalle: der Fehler wird also um denFaktor 21
8= 1
4reduziert.
28. a) Beschreibe adaptive Integration. 356/357
function aq = adptquad ( f , a , b )i f ( error (Q1, f , a , b)> t o l ) && ( error (Q2, f , a , b)> t o l )
aq = adptquad ( f , a , ( a+b)/2)+adptquad ( f , ( a+b)/2 , b ) ;else
i f ( error (Q1, f , a , b)<error (Q2, f , a , b ) )aq = Q1( f , a , b ) ;
elseaq = Q2( f , a , b ) ;
endend
b) Wie konnen die notwendigen Fehler-Abschatzungen gewonnen werden? 357
Fehler konnen entweder durch Verwendung zweier Quadratur-Regeln wieetwa (M,T ) oder wie (G7, K15) oder durch Verwendung einer zusammen-gesetzten Quadratur fur zwei verschiedene Unterteilungen des Integrations-intervalles gewonnen werden.
c) Unter welchen Bedingungen kann adaptive Integration scheitern? 358
Auswerten des Integranden ın nur endlich vielen Punkten kann dazu fuhren,daß entscheidende Beitrage des Integranden zum Integral unberucksichtigtbleiben.
d) Unter welchen Bedingungen kann adaptive Integration extrem ineffizient 359sein?

426 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
Wenn der Integrand Unstetigkeiten aufweist, versucht adaptive Quadratur,die Unstetigkeiten durch Polynome zu approximieren, und wertet dazu denIntegranden unsinnig oft aus.
29. Ein Integrand weise im Intergrationsintervall bekannte Unstetigkeitsstellen359auf. Wie ist der Integrand am besten adaptiv zu integrieren?
Am besten ist, das Integrationsintervall in den Unstetigkeitsstellen in Teil-intervalle aufzubrechen und jeweils separat zu integrieren.
30. Wie integriert man am besten tabellierte Daten, d.h. Funktionen, die nur359in diskreten (Meß-) Punkten bekannt sind?
Tabellierte Funktionen werden stuckweise integriert, etwa per zusammenge-setzter Trapez-Regel, oder man integriert etwa die kubische Hermite- oderdie kubischer Spline-Interpolierende.
31. a) Wie ist ein Integrand uber ein unbeschranktes Integrationsintervall mit360Standard-Quadratur-Regeln zu integrieren?
Entweder wird das unbeschrankte Integrationsintervall so durch ein be-schranktes Integrationsintervall ersetzt, daß der Fehler zu tolerieren ist,oder eine geeignete Transformation der Integrationsvariablen uberfuhrt dasuneigentliche in ein eigentliches Integral.
b) Welche Vorsichtsmaßnahmen sind zu treffen, um die Qualitat des Ergeb-360nisses zu sichern?
Das beschrankte Integrationsintervall darf nicht so groß ausfallen, daß derIntegrand nicht mehr representativ abgetastet und ausgewertet wird. BeiTransformationen durfen beispielsweise keine Singularitaten entstehen.
32. Wie lassen sich Doppel-Integrale uber rechteckige Integrationsbereiche mit361Standard-Quadratur-Regeln berechnen?
Doppel-Integrale uber rechteckige Integrationsbereiche lassen sich per suk-zessiver Anwendung einer Quadratur-Regel auf das Ergebnis der Anwen-dung einer Quadratur-Regel auf das ’innere’ Integral berechnen.
33. Warum ist Monte-Carlo-Integration fur einfache ’eindimensionale’ Integrale361/362 ∫ b
af(x) dx ungeeignet?
Die Monte-Carlo-Integration fur∫ b
af(x) dx konvergiert mit Fehler O( 1√
n)
schlecht im Vergleich zu etwa der zusammengesetzten Mittelpunkt- oderTrapez-Regel mit Fehler O( 1
n2 ).
34. Warum ist Monte-Carlo-Integration in hoheren Dimensionen effektiver als362andere Quadraturen?

8.4. Review Questions – Antworten auf Verstandnisfragen 427
Die Konvergenz-Rate O( 1√n) der Monte-Carlo-Integration ist unabhangig
von der Dimension des Integrationsbereiches und kann daruberhinaus durchimportance sampling oder stratified sampling verbessert werden.
35. Erlautere, warum Integralgleichungen erster Art mit glatten Kernen immer 362/363schlecht konditioniert sind.∫ b
aK(s, t)u(t) dt = f(s) in u(t) zu losen, kann hochfrequente Artefakte in
der Losung u(t) erzeugen, wie das Lemma von Riemann15-Lebesgue16
limn→∞
∫K(s, t) sin(nt) dt = 0 fur glatte Kerne K(s, t)
nahelegt: beliebig hochfrequente Anteile von u haben beliebig kleine Aus-wirkungen auf f . Daher ist das Problem, solche Integralgleichungen zulosen, schlecht konditioniert.
36. Wie kann eine Quadratur-Regel zur Losung von Integral-Gleichungen be- 363nutzt werden? Welches Problem tritt dabei auf?
Eine Quadratur-Regel angewandt in diskreten Punkten si, i = 1, . . . , nuberfuhrt die Integral-Gleichung
n∑j=1
wjK(si, tj)u(tj) ≈∫ b
a
K(s, t)u(t) dt = f(si)
in ein System linearer Gleichungen Ax = y mit A = (wjK(si, tj))i,jund
x = (u(tj))jsowie y = (f(si))i
. Die Losung x liefert also die diskret
approximierten Funktionswerte u(tj).
Da es im Allgemeinen Funktionen uo 6= 0 mit∫ b
aK(s, t)uo(t) dt = 0 fur alle
s gibt, wird bei besserer Approximation des Integrals die Losung immererratischer.
???
37. Eine Integral-Gleichung erster Art sei durch numerische Quadratur zu losen. 364Wird die Losung immer verbessert, wenn entweder der Grad der Quadratur-Regel erhoht oder die Schritt-Weite vermindert wird?
wie 8RQ36????
38. Beschreibe drei Ansatze, ein schlecht konditioniertes System linearer Glei- 364chungen, das die Losung einer Integral-Gleichung erster Art approximiert,zu losen.
1. Stelle A per SVD dar und streiche die betragsmaßig kleinsten SWe.

428 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
2. Minimiere ||y−Ax||22 + µ||x||22 (Regularisierung), wobei µ das Gewichtder Norm von x gegenuber der Norm des Residuums y −Ax ist.
???3. Minimiere ||y−Ax|| unter etwa physikalisch sinnvollen Nebenbedingun-
gen.
39. a) Die Ableitung einer Funktion, die nur in diskreten Punkten bekannt ist,365sei zu approximieren. Ist es ratsam, die Daten-Punkte zu interpolieren unddie Interpolierende zu differenzieren?
Die Interpolierende und damit auch ihre Ableitung reagiert sehr sensitivauf Anderungen der Daten-Punkte!
b) Eine Funktion, die nur in diskreten Punkten bekannt ist, sei zu integrie-359ren. Ist es ratsam, die Daten-Punkte zu interpolieren und die Interpolie-rende zu integrieren?
Gegeben die Daten-Punkte (ti, yi)i=1,...,m der Funktion f . Dann liefert die
zusammengesetzte Trapez-Regel I(f) ≈ T (f) =∑m
i=2(ti − ti−1)f(ti−1)+f(ti)
2.
Noch besser wird I(f) approximiert, wenn man die Hermite’sche kubischeoder die kubische spline Interpolierende integriert.
???
40. Ist Integration oder Differentation inharent besser konditioniert?341/342,365 Integration ist sicher besser konditioniert als Differentation: Integration
mittelt Storungen des Integranden heraus, wahrend Differentation als lo-kale Operation sensitiv auf Anderung der zu differenzierenden Funktionreagiert.Grundsatzlich ist Differentation als Inverse der gut konditionierten Integra-tion schlecht konditioniert.
41. a) Wie kann die Ableitung einer Funktion, die nur in diskreten Daten-367Punkten bekannt ist, am besten approximiert werden?
Das interpolierende Polynom kann als Lagrange-Polynom, als Newton-Poly-nom oder als Linearkombination von Monomen gewonnen werden. Dieletzte Darstellung ist am einfachsten zu differenzieren.
b) Was ist zu tun, wenn die Daten-Punkte verrauscht sind????
Naheliegend ist, ein geeignetes least squares Problem zu losen und dieLosung zu differenzieren.
42. Gib zwei Methoden an, die Ableitungen einer gegebenen Funktion durch366/367finite Differenzen zu approximieren.
Entweder druckt man die bekannten Funktionswerte f(xi) durch die Taylor-Entwicklung von f um x aus und gewinnt dadurch Naherungen fur f ′(x)
15 Bernhard Riemann (1826-1866) www-history.mcs.st-andrews.ac.uk/Biographies/Riemann.html
16 Henri Leon Lebesgue (1875-1941) www-history.mcs.st-andrews.ac.uk/Biographies/Lebesgue.html

8.5. Exercises – Ubungsergebnisse 429
oder man interpoliert f in den bekannten Daten-Punkten (xi, f(xi)) durchein Polynom p und nahert f ′(x) durch p′(x) an.
43. Wie funktioniert und worauf basiert automatische Differentation? 368
Funktion gegeben als algebraischer Ausdruck in den elementaren Funktio-nen werden durch wiederholte Anwendung der Differentationsregeln (Linea-ritat, Produkt- und Kettenregel) symbolisch abgeleitet.
44. a) Erlautere die Richardson-Extrapolation. 369
Die Idee ist, limh→0 F (h) = F (0) aus wenigen Auswertungen einer FunktionF (h) zu approximieren. Dabei sei F (h) = ao + a1h
p + O(hr) fur h → 0und p, q ∈ N mit p < r. Zwei Werte F (h) und F (h/q) fur ein q ∈ N seienbekannt. Aus
F (h) = ao + a1hp +O(hr) und F (h/q) = ao + a1q
−php +O(hr)
folgt F (h)− F (h/q) = a1(1− q−p)hp +O(hr) und damit
ao = F (h) +F (h/q)− F (h)
1− q−p+O(hr)
b) Produziert Richardson-Extrapolation genauere Ergebnisse als die Werte, 369die sie verwendet?
Die Genauigkeit von F (h) und F (h/q) ist O(h?), wahrend die von ao ebenO(hr) betragt.
???c) Bedeutet die Extrapolation hin zur Schrittweite 0, daß das Ergebnis 369exakt ist?
Das Ergebnis ist grundsatzlich immer noch Ergebnis einer Approximation!
45. Was bedeutet Romberg-Integration? 370/371
Romberg-Integration ist die sukzessive Anwendung der Richardson-Extra-polation auf etwa die zusammengesetzte Trapez-Regel.
???
8.5 Exercises – Ubungsergebnisse
1. a) Approximiere∫ 1
ox3 dx durch Mittelpunkt- und Trapez-Regel. 346
Einerseits ist 14
=∫ 1
ox3 dx ≈ M(f) = (b − a)f(a+b
2 ) = 1 · 0.53 = 18
und
andererseits 14
=∫ 1
ox3 dx ≈ T (f) = (b− a)f(a)+f(b)
2= 1 · 1
2= 1
2.
b) Verwende die Differenz der Ergebnisse aus a), um den Fehler jeweils der 347/348Mittelpunkt- und der Trapez-Regel abzuschatzen.

430 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
Aus I(f) = M(f) +E(f) + F (f) + . . . mit E(f) ≈ 13(T (f)−M(f)) ergibt
sich der Fehler der Mittelpunkt-Regel 18
korrekt als der Fehler E(f) =13(1
2− 1
8) = 1
8erster Naherung.
Aus I(f) = T (f)− 2E(f)− 4F (f) + . . . ergibt sich der Fehler der Trapez-Regel −1
4korrekt als der Fehler −2E(f) = −1
4erster Naherung.
c) Kombiniere die Ergebnisse aus a), um das Ergebnis der Simpson-Regel347/348zu erhalten.
Wegen S(f) = 23M(f) + 1
3T (f) = 2
318
+ 13
12
= 14
liefert die Simpson-RegelS(f) = b−a
6 (f(a) + 4f(a+b2
) + f(b)) = 16(0 + 4 · 0.53 + 1) = 1
632
= 14
sogardas exakte Ergebnis.
d) Steht zu erwarten, daß die Approximation per Simpson-Regel exakt ist?349
Die Simpson-Regel hat als 3-Punkt Newton-Cotes-Quadratur den Grad 3und ist daher fur kubische Polynome exakt.
2. a) Approximiere∫ 1
ox3 dx durch die zusammengesetzte Mittelpunkt-Regel355
mit den Schrittweiten h = 0.5 und h = 1.
Da allgemein Mk(f) = b−ak
∑kj=1 f(
xj−1+xj
2 ) = b−ak
∑kj=1 f(
a+(j−1)h+a+jh2 ) =
b−ak
∑kj=1 f(a + (2j − 1)h
2) gilt, ist M2 = 12(0.253 + 0.753) = 7
32= 0.21875
und M1 = M(f) = 18
= 0.125.
b) Verbessere die Ergebnisse aus a) durch Richardson-Extrapolation.356,369/370 Fur die Mittelpunkt-Regel M(f) gilt F (h) := M(f)(h) = ao +a1h+O(h2).
Also ist ao = F (h)+ F (h)−F (h/2)2−1−1
+O(h2). Richardson-Extrapolation verbes-
sert somit M(1) = 18
und M(1/2) = 732
zu ao = 18
+ 1/8−7/322−1−1
= 18
+ −3/32−1/2
=516
= 0.3125.
3. Sei Q(f) =∑n
i=1wif(xi) eine polynomial interpolierende Quadratur aufdem Intervall [0, 1]. Ist damit
∑ni=1wi = 1 impliziert?
Aus der ersten Momenten-Gleichung 1 =∫ 1
o1 dx =
∑ni=1wi · 1 fur das
Monom xo = 1 folgt∑n
i=1wi = 1.
4. Fur I(f) = M(f)+E(f)+F (f)+. . . zeige I(f) = T (f)−2E(f)−4F (f)+. . .347/348sowie E(f) ≈ 1
3(T (f)−M(f)).Zeige, daß die ungeraden Terme in beiden Entwicklungen verschwinden.
Aus der Taylor-Entwicklung von f um m = a+b2
f(x) = f(m) + f ′(m)(x−m) + 12f ′′(m)(x−m)2 + 1
3!f ′′′(m)(x−m)3 + . . .
folgt (aus Symmetriegrunden gilt∫ b
a(x−m)2n−1 dx = 0 fur alle n ∈ N)
I(f) = f(m)∫ b
adx+ f ′(m)
1
∫ b
a(x−m) dx+ f ′′(m)
2
∫ b
a(x−m)2 dx+ f ′′′(m)
3!
∫ b
a(x−m)3 dx+ . . .
= f(m)(b− a) +0+ 124f ′′(m)(b− a)3 +0+ 1
1920f (4)(m)(b− a)5 + . . .
= M(f) + E(f) + F (f) + . . .

8.5. Exercises – Ubungsergebnisse 431
Die Taylor-Entwicklung von f um m = a+b2
ausgewertet in b und a liefert
f(b) = f(m) + f ′(m)(b−m) + 12f ′′(m)(b−m)2 + 1
3!f ′′′(m)(b−m)3 + . . .
f(a) = f(m) + f ′(m)(a−m) + 12f ′′(m)(a−m)2 + 1
3!f ′′′(m)(a−m)3 + . . .
f(a) + f(b) = 2f(m) + 212f ′′(m) (b−a)2
22 + 2 14!f (4)(m) (b−a)4
24 + . . .
aufgelost nach f(m) eben
f(m) = 12(f(a) + f(b))− 1
2f ′′(m)
(b− a)2
22− 1
4!f (4)(m)
(b− a)4
24− . . .
und eingesetzt endlich
I(f) = T (f) − 112f ′′(m)(b− a)3 − 4
1920f (4)(m)(b− a)5 − . . .
= T (f) −2E(f) −4F (f) − . . .
sowie
T (f) = I(f) + 2E(f) + 4F (f) + . . .M(f) = I(f)− E(f)− F (f)− . . .
T (f)−M(f) = 3E(f) + 5F (f) + . . . ⇒ E(f) ≈ 13(T (f)−M(f)).
5. a) f sei zweimal stetig-differenzierbar mit f ′′(x) ≥ 0 auf [a, b]. Zeige dieKlammer-Eigenschaft
Mk(f) ≤ I(f) =
∫ b
a
f(x) dx ≤ Tk(f)
Sei f(x) = f(m)+f ′(m) (x−m)+ 12f ′′(z) (x−m)2 fur jeweils ein z zwischen
x und m die Taylor-Entwicklung von f um m. Daher gilt
I(f) =
∫ b
a
f(x) dx =
∫ b
a(f(m) + f ′(m) (x−m) + 1
2f ′′(z) (x−m)2) dx
≥∫ b
a(f(m) + f ′(m) (x−m)) dx = (b− a)f(m) = M(f)
und damit allgemein
Mk(f) =k∑
i=1
M(f, xi−1, xi) ≤k∑
i=1
∫ xi
xi−1
f(x) dx =
∫ b
a
f(x) dx = I(f)
Eine Funktion f mit f ′′ ≥ 0 auf [a, b] ist auf [a, b] konvex (vgl. 6Ex2).Daher gilt
I(f) =
∫ b
a
f(x) dx = (b− a)
∫ 1
o
f((1− u)a+ ub) du
≤ (b− a)
∫ 1
o((1− u)f(a) + uf(b)) du = (b− a)
f(a) + f(b)
2= T (f)

432 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
und damit allgemein
I(f) =
∫ b
a
f(x) dx =k∑
i=1
∫ xi
xi−1
f(x) dx ≤k∑
i=1
T (f, xi−1, xi) = Tk(f)
b) f sei konvex auf [a, b]. Zeige die Klammer-Eigenschaft von Mk und Tk.
Wegen a) bleibt nur Mk ≤ I(f) zu zeigen. Aus f(m) = f((1−u)x+uy) ≤(1− u)f(x) + u f(y) folgt
M(f) = (b−a)f(m) =
∫ b
a
f(m) dx ≤∫ b
a
(1−u)f(x) dx+
∫ b
a
u f(y) dy = I(f)
und damit wie in a) Mk ≤ I(f).???
6. Gegeben seien die Knoten x1, x2, . . . , xn. Q(f) =∑n
i=1wif(xi) sei eine343interpolierende Quadratur. Zeige: wi =
∫ b
a`i(x) dx fur i = 1, 2, . . . , n,
wobei `i die i-te Lagrange-Basis-Funktion bezeichne.
Q ist interpolierende Quadratur. Also giltQ(f)=∫ b
ap(x) dx=
∑ni=1wif(xi),
wobei p den Integranden f in den Knoten xi interpoliert, d.h. p(x) =∑ni=1 f(xi)`i(x). Daher folgt Q(f) =
∫ b
ap(x) dx =
∑ni=1 f(xi)
∫ b
a`i(x) dx
und somit wi =∫ b
a`i(x) dx.
7. Bestimme die offene 2-Punkt-Newton-Cotes-Quadratur R fur das Intervall346[a, b]. Welche Knoten, welche Gewichte und welchen Grad hat R ?
R hat die beiden Knoten x1 = a+ 13(b− a) und x2 = a+ 2
3(b− a). Sei yi =
f(xi). Dann integriert R(f) die Gerade g(x) durch (x1, y1) und (x2, y2), d.h.
R(f) =∫ b
ag(x) dx =
∫ b
a (y1 + y2−y1
x2−x1(x − x1)) dx = y1+y2
2(b − a). Somit gilt
w1 = b−a2
= w2. Wegen R(f) = M(f) fur alle Polynome f mit grad(f) ≤ 1
ist grad(R) ≥ 1. Wegen 13
=∫ 1
ox2 dx 6= 1
2((1/3)2 + (2/3)2) · 1 = 518
ist Rnicht exakt fur f(x) = x2 und daher ist grad(R) = 1.
8. a) Was ist das großte n derart, daß alle Gewichte der geschlossenen n-Punkt-Newton-Cotes-Quadratur positiv sind?
???b) Was ist das kleinste n derart, daß mindestes eines der Gewichte dergeschlossenen n-Punkt-Newton-Cotes-Quadratur negativ ist?
???c) Was ist das großte n derart, daß alle Gewichte der offenen n-Punkt-Newton-Cotes-Quadratur positiv sind?
???d) Was ist das kleinste n derart, daß mindestes eines der Gewichte deroffenen n-Punkt-Newton-Cotes-Quadratur negativ ist?
???

8.5. Exercises – Ubungsergebnisse 433
9. Sei p ein reelles Polynom mit grad(p) = n und∫ b
ap(x)xk dx = 0 fur alle
k = 0, 1, . . . , n− 1.
a) Zeige: die n Nullstellen von p sind einfach, reell und liegen in (a, b).352(Hinweis: betrachte das Polynom q(x) = (x−x1)(x−x2) · · · (x−xk), wobeidie xi fur i = 1, . . . , k die Nullstellen von p in (a, b) sind.)
Angenommen, grad(q) = k < n. Aus∫ b
ap(x)xk dx = 0 fur alle k =
0, 1, . . . , n−1 folgt also speziell∫ b
ap(x)q(x) dx = 0. Fur q(x) =
∏kj=1(x−xj)
mit den Nullstellen (xj)j=1,...,k von p in (a, b) und p(x) = q(x)∏n
j=k+1(x−xj)mit den anderen, moglicherweise komplexen Nullstellen (xj)j=k+1,...,n 6∈(a, b) von p gilt also∫ b
a
p(x)q(x) dx =
∫ b
a
k∏j=1
(x− xj)2
n∏j=k+1
(x− xj) dx = 0
Je nach Lage der anderen reellen Nullstellen gilt fur den Integranden pq 6= 0auf (a, b) entweder p(x)q(x) ≥ 0 oder p(x)q(x) ≤ 0, was im Widerspruch zu∫ b
ap(x)q(x) dx = 0 steht. Also gilt grad(q) = n und alle Nullstellen von p
sind einfach und liegen in (a, b).
b) Zeige: die n-Punkt interpolierende Quadratur, deren Knoten die Null- 352stellen von p sind, hat den Grad 2n − 1. (Hinweis: fur ein Polynom fbetrachte Quotient und Rest bei der Division von f durch p.)
Ein Polynom f mit grad(f) ≤ 2n− 1 laßt sich eindeutig als f = qp+ r mitgrad(r) < n und daher grad(q) ≤ n−1 darstellen. Sei Q die interpolierendeQuadratur mit den Nullstellen xi von p als Knoten. Also ist grad(Q) ≥ n−1.Insbesondere ist Q fur r exakt und es gilt
I(f) =
∫ b
a
q(x)p(x) dx+
∫ b
a
r(x) dx =
∫ b
a
r(x) dx =n∑
i=1
wir(xi) =n∑
i=1
wif(xi)
weil erstens aus∫ b
ap(x)xk dx=0 fur k=0, 1, . . . , n−1 eben
∫ b
aq(x)p(x) dx=0
folgt und weil zweitens f(xi) = q(xi)p(xi) + r(xi) = r(xi) gilt. Also ist Qexakt fur jedes f mit grad(f) ≤ 2n− 1.
10. Um Multiplikationen zu sparen, haben in der Chebyshev-Quadratur die Or-dinaten aller Knoten dasselbe Gewicht w.
a) Bestimme mit der Methode der unbestimmten Koeffizienten Gewicht w 343und Knoten xi einer 3-Punkte Chebyshev-Quadratur Q auf [−1, 1].
Die vier Unbekannten erfullen folgende vier nichtlineare Gleichungen∫ 1
−1
1 dx = 2 = w(1 + 1 + 1) ⇒ w = 23

434 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION∫ 1
−1
x dx = 0 = 23(x1 + x2 + x3) ⇒ x1 + x2 + x3 = 0∫ 1
−1
x2 dx = 23
= 23(x
21 + x2
2 + x23) ⇒ x2
1 + x22 + x2
3 = 1∫ 1
−1
x3 dx = 0 = 23(x
31 + x3
2 + x33) ⇒ x3
1 + x32 + x3
3 = 0
so daß etwa x2 = −(x1 +x3) und 0 = x31− (x3
1 +3x21x3 +3x1x
23 +x3
3)+x33 =
3x1x3(x1 + x3) und damit fur x1 6= 0 6= x3 eben x1 + x3 = 0 und damit
x2 = 0 folgt und sich 2x21 = 1 und so x1 = −1
2
√2 sowie x3 = 1
2
√2 ergibt.
b) Was ist der Grad dieser Chebyshev-Quadratur-Regel Q ?343
grad(Q) ≥ 3 da fur p(x) = c3x3 + c2x
2 + c1x+ co einerseits∫ 1
−1
p(x) dx =
∫ 1
−1(c2x2 + co) dx = 2co + 2
3c2
und andererseits fur Q(f) = w∑3
i=1 f(xi) eben
Q(p) = 23(p(x1) + co + p(x3)) = 2co + 2
32c2x
23 = 2co + 2
3c2
gilt. Aus∫ 1
−1x4 dx = 2
56= 4
314
= 23(x
41 + 0 + x4
3) folgt endlich grad(Q) = 3.
11. a) Sei m = a+b2
gesetzt. I(f) =∫ b
af(x) dx werde vermittels der auf [a,m]346,355
und [m, b] zusammengesetzten Trapez-Regel oder alternativ vermittels derSimpson-Regel auf [a, b] approximiert. Welches Verfahren ist genauer?
Die zusammengesetzte Trapez-Regel T2 liefert I(f) =∫ b
af(x) dx ≈ T2(f)
= m−a2 (f(m) + f(a)) + b−m
2 (f(b) + f(m)) = b−a4 (f(a) + 2f(m) + f(b)) =
12((b− a) f(m) + (b− a)f(a)+f(b)
2 ) = 12(M(f) + T (f)) = T2(f).
Die Abschatzungen aus 8Ex4 liefern347
I(f) = M(f) + E(f) + F (f) + . . .I(f) = M(f) + E(f) + F (f) + . . .
I(f) = 12(I(f) + I(f)) = 1
2(M(f) + T (f))− 12E(f)− 3
2F (f)− . . .
= T2(f)− 12E(f)− 3
2F (f)− . . .
Die Simpson-Regel S liefert I(f) =∫ b
af(x) dx ≈ b−a
6 (f(a)+4f(m)+f(b)),wobei wegen I(f) = S(f)− 2
3F (f)− . . . gilt und sich damit S genauer als348
T2 herausstellt.

8.5. Exercises – Ubungsergebnisse 435
f(x) =a = b = I(f) =
tests reset
get f , I(f)
T2(f) = |T2(f)−I(f)||I(f)| =
S(f) = |S(f)−I(f)||I(f)| =
S2(f) = |S2(f)−I(f)||I(f)| =
Q5(f) = |Q5(f)−I(f)||I(f)| =
eval
b) Sei m = a+b2
gesetzt. I(f) =∫ b
af(x) dx werde vermittels der auf [a,m] 346,355
und [m, b] zusammengesetzten Simpson-Regel oder alternativ vermittels der(geschlossenen) 5-Punkte Newton-Cotes-Regel auf [a, b] approximiert. Wel-ches Verfahren ist genauer?
Die zusammengesetzte Simpson-Regel S2 liefert
I(f) ≈S2(f)= m−a
6 (f(a) + 4f(m1) + f(m)) + b−m6 (f(m) + 4f(m2) + f(b))
= b−a12 (f(a) + 4f(m1) + 2f(m) + 4f(m2) + f(b))
wobei m1 = a + 14(b − a) = 3a+b
4und m1 = a + 3
4(b − a) = a+3b
4. Wie in
8Ex4 folgt aus der Taylor-Reihenentwicklung von f um m in a, mi und b
f(a) = f(m) + f ′(m)(a−m) + f ′′(m)2
(a−m)2 + f ′′′(m)6
(a−m)3 + f (4)(m)24
(a−m)4 + . . .
f(m1) = f(m) + f ′(m)(m1−m) + f ′′(m)2
(m1−m)2 + f ′′′(m)6
(m1−m)3 + f (4)(m)24
(m1−m)4 + . . .
f(m2) = f(m) + f ′(m)(m2−m) + f ′′(m)2
(m2−m)2 + f ′′′(m)6
(m2−m)3 + f (4)(m)24
(m2−m)4 + . . .
f(b) = f(m) + f ′(m)(b−m) + f ′′(m)2
(b−m)2 + f ′′′(m)6
(b−m)3 + f (4)(m)24
(b−m)4 + . . .
daß in S2(f) = M(f) + f ′′(m)24
(b − a)3 + 5 f (4)(m)9216
(b − a)5 + . . . wieder alleTerme ungerader Ordnung verschwinden und daß mit
I(f) = M(f) + E(f) + F (f) + . . . = M(f) + f ′′(m)24
(b− a)3 + f (4)(m)1920
(b− a)5 + . . .
= S2(f) + f (4)(m)( 11920
− 59216)(b− a)5 + . . . = S2(f)− f (4)(m)
46070(b− a)5 + . . .
eben I(f) = S2(f)− 124F (f)+ . . . gilt, wahrend I(f) = S(f)− 2
3F (f)+ . . ..
Die Gewichte w der 5-Punkte Newton-Cotes-Regel Q5 ergeben sich alsLosung von
Aw=
1 1 1 1 1a m1 m m2 ba2 m2
1 m2 m22 b2
a3 m31 m3 m3
2 b3
a4 m41 m4 m4
2 b4
w1
w2
w3
w4
w5
=
b− a
(b2 − a2)/2(b3 − a3)/3(b4 − a4)/4(b5 − a5)/5
zu w=b−a90
73212327
.
I(f)=∫ b
af(x) dx ≈ Q5(f)=w1f(a)+w2f(m1)+w3f(m)+w4f(m2)+w5f(b).
Die allgemeine Abschatzung |I(f)−Q5(f)| ≤ 14(
b−a5 )
6||f (5)||∞ ist durch 344
Q5(f) = b−a90 (7 f(a) + 32 f(m1) + 12 f(m) + 32 f(m2) + 7 f(b))
= M(f) + f ′′(m)24
(b− a)3 + f (4)(m)1920
(b− a)5 + . . .

436 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
– wieder verschwinden alle Terme ungerader Ordnung – zu
I(f) = M(f) + f ′′(m)24
(b− a)3 + f (4)(m)1920
(b− a)5
= Q5(f)
zu verbessern. Q5 ist genauer als S2.
c) Sei m = a+b2
gesetzt. I(f) =∫ b
af(x) dx werde vermittels der auf [a,m]346,355
und [m, b] zusammengesetzten Quadratur Qn oder alternativ vermittels der(2n − 1)-Punkte Newton-Cotes-Quadratur Q2n−1 auf [a, b] approximiert.Welches Verfahren ist genauer?
Vermutlich Q2n−1???
12. forward difference f ′(x) ≈ 1h(f(x + h) − f(x)) und backward difference
f ′(x) ≈ 1h(f(x) − f(x − h)) sind beide Approximationen erster Ordnung366
fur die Ableitung f ′(x) einer Funktion f in x. Welche Ordnung hat dasarithmetische Mittel dieser beiden Naherungen?
Wegen
f ′(x) ≈ 12
(f(x+h)−f(x)
h+ f(x)−f(x−h)
h
)= 1
2h(f(x+ h)− f(x− h))
ist das Mittel aus forward difference und backward difference gerade diecentered difference, die eine Approximation zweiter Ordnung darstellt.
13. Aus der Taylor-Entwicklung einer genugend glatten Funktion f leite eine367einseitige Approximation von f ′(x) unter Verwendung von f(x), f(x + h)und f(x+ 2h) her.
Das quadratische Polynom p interpoliere f in x, x+h und x+2h. Dann giltp(t) = f(x) (t−x−h)(t−x−2h)
2h2 −f(x+h) (t−x)(t−x−2h)h2 +f(x+2h) (t−x)(t−x−h)
2h2 sowie
p′(t) = f(x) (t−x−h)+(t−x−2h)2h2 −f(x+h) (t−x)+(t−x−2h)
h2 +f(x+2h) (t−x)+(t−x−h)2h2
und endlich fur t = x ausgewertet
f ′(x) ≈ p′(x) = f(x)−3h
2h2− f(x+ h)
−2h
h2+ f(x+ 2h)
−h2h2
= 12h(− 3f(x) + 4f(x+ h)− f(x+ 2h))
14. Fur h = 0.2 sei die forward difference f ′(x) ≈ 1h(f(x+h)−f(x)) = −0.8333369
und fur h = 0.1 die forward difference f ′(x) ≈ 1h(f(x+h)−f(x)) = −0.9091.
Verbessere die Naherung fur f ′(x) per Richardson-Extrapolation.
Fur die forward difference F (h) = ao + a1h + O(h2) gilt ao = F (h) +??? F (h)−F (h/2)
2−1−1+ O(h2) = −0.8333 + −0.8333+0.9091
−1/2= −0.8333 − 2 · 0.0758 =
−0.8333− 0.1516 = 0.9849.

8.6. Computer Problems – Rechner-Problem-Losungen 437
15. Archimedes17 approximierte pn < π < qn durch den Umfang pn = n sin πn
des dem Kreis mit Durchmesser 1 einbeschriebenen regelmaßigen n-Eckesund durch den Umfang qn = n tan π
ndes diesem Kreis umbeschriebenen
regelmaßigen n-Eckes.
a) Zeige, daß pn = ao + a1h2 + a2h
4 + . . . und qn = bo + b1h2 + b2h
4 + . . .fur h = 1/n gilt. Welche Werte haben ao und bo ?
Jedes der n Dreiecke des einbeschriebenen bzw. umbeschriebenen regelmaßi-gen n-Eckes hat den Innenwinkel 2π
n. Damit gilt fur den n-Eck-Umfang
π/nr
sumπ/n
r
sein
pn = n sein = n sin πn
bzw. qn = n sum = n tan πn
und mit h = 1n
eben
pn = sin(πh)h
=∑∞
i=0(−1)i(πh)2i+1
(2i+1)!= 1
h(πh1!− π3h3
3!± . . . ) = π− π3
3!h2 + π5
5!h4∓ . . .
und damit ao = π bzw. mit tan x = x+ 13x3 + 2
15x5 + 17
315x7 + 62
2835x9 + . . .
qn = tan(πh)h
= 1h(πh+ 1
3(πh)3 + 2
15(πh)5 + . . . ) = π + π3
3h2 + 2π5
15h4 + . . .
und damit bo = π.
b) Verbessere die Naherungen fur π per Richardson-Extrapolation aus p6 = 3693.0000 und p12 = 3.1058 bzw. aus q6 = 3.4641 und q12 = 3.2154.
???
8.6 Computer Problems –
Rechner-Problem-Losungen
Quadratur-Verfahren wie zusammengesetzte Mittelpunkt-, Trapez- undSimpson-Regel, sowie Romberg- und Monte-Carlo-Integration
f(x) = < tests >a = b = I(f) = get f , I(f) reset
17Archimedes (287-212 ) www-history.mcs.st-andrews.ac.uk/Biographies/Archimedes.html

438 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
Q k Q(f) |Q(f)− I(f)|/|I(f)| #f 18
Mk
RMk19
Tk
RTk20
Sk
MCk21
set k k = h = inc k ε = MonteCarlo22
1. Wegen∫ 1
o4 dx1+x2 = π liefern Quadratur-Verfahren Naherungen fur π.
Zunachst ist∫ 1
o4 dx1+x2 = 4 arctan 1 = π.
a) Verwende zusammengesetzte Mittelpunkt-, Trapez- und Simpson-Regelfur verschiedene Schrittweiten h zur Approximation von π. Charakterisiereden Fehler in Abhangigkeit von h. Vergleiche die jeweils erzielten Genau-igkeiten. Was passiert, wenn h immer weiter verkleinert wird?
vgl. Quadratur-Verfahren auf S. 437 auf S. 437
b) Implementiere Romberg-Integration und wende diese wie in Teil a) an.
vgl. Quadratur-Verfahren auf S. 437
c) Wende Bibliotheksroutinen fur adaptive Integration auf das Problem an.Wie verlaßlich sind deren Fehlerabschatzungen? Stelle graphisch dar, wodie Bibliotheksroutine die Knoten etabliert.
???vgl. Quadratur-Verfahren auf S. 437
d) Implementiere Monte-Carlo-Integration und wende diese wie in Teil a)an. Charakterisiere den Fehler als Funktion der Anzahl der samples, d.h.der Auswertungen des Integranden.
vgl. Quadratur-Verfahren auf S. 437
2. Fuhre dieselben numerischen Quadraturen fur das kompliziertere Integral∫ 1
o
√x lnx dx = −4
9durch.
Es gilt∫ 1
o
√x lnx dx = 2
3x3/2 lnx
∣∣1o− 2
3
∫ 1
ox3/2x−1 dx = 0 − 4
9x5/2
∣∣1o
= −49.
Wie auch die Visualisierung nahelegt, laßt sich der Integrand in 0 stetig
18 Fur Romberg-Integration ist #f nur eine naive obere Grenze der Anzahl der Funktions-auswertungen: die mehrfache Verwendung eines Funktionswertes wird nicht berucksichtigt.
19 RMk bezeichnet die Romberg-Integration basierend auf der Mittelpunkt-Regel.20 RTk bezeichnet die Romberg-Integration basierend auf der Trapez-Regel.21 MCk bezeichnet die Monte-Carlo-Integration mit k Auswertungen von f .22 MonteCarlo: berechne MCk(f) fur k = d1/ε2e, d.h. 1√
k≤ ε.

8.6. Computer Problems – Rechner-Problem-Losungen 439
durch limx→0+
√x lnx = limx→0+
ln xx−1/2 = limx→0+
1/x
−x−3/2/2= limx→0+
1/x
−x−3/2/2=
limx→0+ −2x1/2 = 0 erganzen.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1−0.8
−0.7
−0.6
−0.5
−0.4
−0.3
−0.2
−0.1
0
x
sqrt(x) log(x)
vgl. Quadratur-Verfahren auf S. 437
3. Approximiere folgende Integrale vermittels numerischer Quadratur-Verfah-ren. Vergleiche Effizienz und Genauigkeit. Stelle graphisch dar, wo adaptiveIntegrationsverfahren Knoten etablieren.
a)∫ 1
−1cosx dx
Zunachst ist∫ 1
−1cosx dx = sinx|1−1 = 2 sin 1.
???b)∫ 1
−1dx
1+100x2
Zunachst ist∫ 1
−1dx
1+100x2 = 110
∫ 10
−10du
1+u2 = arctan(u)|10−10 = 5 arctan 10.
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
1/(1+100 x2)
???c)∫ 1
−1
√|x| dx
Zunachst ist∫ 1
−1
√|x| dx = 2
∫ 1
o
√x dx = 22
3x3/2
∣∣1o
= 43.

440 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
−1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
sqrt(abs(x))
???
4. ’Verifiziere’ oder falsifiziere folgende Aussagen vermittels numerischer Qua-dratur.
a)∫ 1
o
√x3 dx = 0.4
Zunachst gilt∫ 1
o
√x3 dx = 2
5x5/2
∣∣1o
= 25
= 0.4.
Da der Integrand f(x) = x3/2 wegen f ′′(x) = 34x−1/2 > 0 fur x ∈ (0, 1]
konvex ist, bilden Mk und Tk erwartungsgemaß eine Klammer fur I(f), vgl.8Ex5 b). vgl. Quadratur-Verfahren auf S. 437
b)∫ 1
odx
1+10x2 = 0.4356
Wegen∫ 1
odx
1+10x2 = 1√10
∫ √10
odu
1+u2 = 1√10
arctan√
10 ≈ 0.39987600505576615
gilt I(f) 6= 0.4.I(f) = M(f)+E(f)+. . . mit E(f) ≈ 1
3(T (f)−M(f)) = 13(
611− 2
7) = 20231
≈0.08658 und der Umstand, daß Halbieren der Schrittweite den Fehlers derMittelpunkt-Regel um den Faktor 1/4 reduziert, liefern
|I(f)−M2(f)| ≈ 14E(f) ≈ 0.04 fur M2(f) ≈ 0.38
|I(f)−M4(f)| ≈ 116E(f) ≈ 0.0054 fur M4(f) ≈ 0.3999486
|I(f)−M8(f)| ≈ 164E(f) ≈ 0.0014 fur M8(f) ≈ 0.399983
|I(f)−M16(f)| ≈ 1256E(f) ≈ 0.00034 fur M16(f) ≈ 0.399983
|I(f)−M32(f)| ≈ 11024
E(f) ≈ 0.000085 fur M32(f) ≈ 0.39988
so daß I(f) = 0.4 ausgeschlossen ist. vgl. Quadratur-Verfahren auf S. 437
c) 1√π
∫ 1
o (e−9x2+ e−1024(x−0.25)2)dx = 0.2
Zunachst gilt 1√π
∫ 1
o (e−9x2+e−1024(x−0.25)2)dx ≈ 0.1979129849171669 ≈ 0.2,
vgl. tabellierte Verteilungsfunktion der Standard-Normalverteilung F (x) =1√2π
∫ x
−∞ e−u2/2 duvgl. Quadratur-Verfahren auf S. 437
???d) 1
π
∫ 10
o50 dx
1+2500x2 = 0.5

8.6. Computer Problems – Rechner-Problem-Losungen 441
Es gilt 1π
∫ 10
o50 dx
1+2500x2 = 1π
∫ 500
odu
1+u2 = 1π
arctanu∣∣500
o= 1
πarctan 500 ≈
0.4993633810764567 wahrend 1π
arctan 500 ≈ 1π
arctan∞ = 1π
π2
= 0.5.Alle Masse der Funktion ist um 0 verteilt: vgl. Quadratur-Verfahren auf
???S. 437
e)∫ 100
−9dx√|x|
= 26
Zunachst gilt∫ 100
−9dx√|x|
= (∫ 9
o+∫ 100
o ) dx√x
= 2√x|9o + 2
√x|100o = 6+20 = 26.
Es handelt sich um ein uneigentliches Integral, da der Integrand eine Sin-gularitat in 0, also im Inneren des Integrationsintervalls [−9, 100] aufweist.vgl. Quadratur-Verfahren auf S. 437
???f)∫ 10
o25e−25x dx = 1
Zunachst gilt∫ 10
o25e−25x dx =
∫ 250
oe−u du = − e−u|250
o = 1− e−250 ≈ 1.vgl. Quadratur-Verfahren auf S. 437
???g)∫ 1
olnx dx = −1
Zunachst gilt∫ 1
olnx dx = −x− x lnx|1o = −1.
Es handelt sich um ein uneigentliches Integral, da der Integrand eine Sin-gularitat in 0, also am linken Rand des Integrationsintervalls [0, 1] aufweist.vgl. Quadratur-Verfahren auf S. 437
???
5. Vergleiche Genauigkeit und Aufwand der Integration stuckweise definierterFunktionen per adaptiver Quadratur, nicht adaptiver Quadratur und derenAnwendung auf die jeweiligen Teil-Integrationsintervalle.
a) f(x) = χ[0.3,1] fur x ∈ [0, 1]
Zunachst gilt I(f) = 0.7vgl. Quadratur-Verfahren auf S. 437
???b) f(x) = χ[0,e−2)(x)
1x+2
fur x ∈ [0, 1]
Zunachst gilt I(f) =∫ e−2
odx
x+2= ln(x+ 2)|e−2
o = 1−ln 2 ≈ 0.3068528194400547.vgl. Quadratur-Verfahren auf S. 437
???c) f(x) = χ[−1,0)(x) e
x + χ[0,2](x) e1−x
Zunachst gilt I(f) = ex|o−1 − e1−x|2o = 1− 2e
+ e.vgl. Quadratur-Verfahren auf S. 437
???d) f(x) = χ[−1,1/2)(x)e
10x + χ[1/2,3/2](x) e10(1−x)
Zunachst gilt I(f) = 0.1e10x|1/2−1 − 0.1e10(1−x)
∣∣3/2
1/2= 1
10(2e5 − e−10 − e−5).
vgl. Quadratur-Verfahren auf S. 437???
e) f(x) = χ[0,1/2)(x) sin(πx) + χ[1/2,1](x) sin2(πx)
Zunachst gilt I(f) = − 1π
cos(πx)|1/2o + 1
π12
(u− sinu cosu)|ππ/2 = 1π
+ 14.
vgl. Quadratur-Verfahren auf S. 437???

442 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
6. a) Berechne Ik = 1e
∫ 1
oxkex dx fur k = 0, 1, . . . , 20 per adaptiver Quadratur.
??? vgl. Quadratur-Verfahren auf S. 437
b) Verifiziere Ik = 1− k Ik−1 mit Io = 1− 1/e (vorwarts rekursiv).
Ik = 1e
∫ 1
oxkex dx = 1
e( xkex∣∣1o− k
∫ 1
oxk−1ex dx) = 1 − k Ik−1 und Io =
1e
∫ 1
oex dx = 1
e(e − 1) = 1 − 1/e. Ik ist von der Form Ik = ak − (−1)kk!/e
mit ak = 1− k ak−1, wobei ao = 1. Dann gilt ak = 1− k!(k−1)!
+ k!(k−2)!
∓ . . .+(−1)k k!
2!= 1+
∑k−1i=2 (−1)k−i k!
i!=: bk und wegen ak = 1+(−1)kk!
∑k−1i=0 (−1)i 1
i!
eben ak ≈ (−1)k k!e
fur große k. Allerdings fuhrt wie bei der Auswertungder Taylor-Entwicklung von e−x Ausloschung zu numerischer Instabilitat.
k = ak = Ik =bk = k!
e=
inc kreset
c) Erzeuge Ik anhand Ik−1 = (1− Ik)/k (ruckwarts rekursiv) mit In = 0 furein n > 20.
???d) Vergleiche Genauigkeit, Stabilitat und Aufwand der drei Methoden underlautere die Ergebnisse.
???
7. Ein Ellipsoid entsteht durch Rotation einer Ellipse um eine ihrer Symmetrie-Achsen. Die Oberflache des Ellipsoids ist dann gegeben durch I(f) =
4π√α∫ 1/
√β
o
√1−Kx2 dx, wobei hier β = 100 gesetzt sei und α = (3 −
2√
2)/β sowie K = β√
1− αβ gelten. Verwende eine adaptive Quadra-tur, visualisiere die verwendeten Knoten und vergleiche mit dem exaktenErgebnis I(f) = π
√α/K(π + sin(2θ)− 2θ) mit θ = arccos
√K/β.
???
Mit x2
a2 + y2
b2= 1 und y = f(x) = ± b
a
√a2 − x2 ergibt sich durch Rotation
des Graphens von f um die x-Achse die Ober- oder Mantelflache Mx desEllipsoids zu
Mx = 2π
∫ a
−a
f(x)√
1 + f ′2(x) dx = 4π
∫ a
o
ba
√a2 − x2
√1 + ( b
a−x√
a2−x2 )2 dx
= 4π ba
∫ a
o
√a2 − x2 + ( b
ax)2 dx = 4πb
∫ a
o
√1− a2−b2
a4 x2 dx
= 4π b a2√
a2−b2
∫ √a2−b2/a
o
√1−u2 du = 2π b a2
√a2−b2
(u√
1−u2 + arcsinu)∣∣∣√a2−b2/a
o
= 2π b a2√
a2−b2(√
a2−b2
aba
+ arcsin√
a2−b2
a ) = 2π b(b+ a2√
a2−b2arcsin
√a2−b2
a )
???
8. Die Intensitat von an einer geraden Kante gestreutem Licht ist durch dieFresnel23-Integrale

8.6. Computer Problems – Rechner-Problem-Losungen 443
C(x) =
∫ x
o
cos (π2t2) dt und S(x) =
∫ x
o
sin (π2t2) dt
beschrieben. Ermittele und visualisiere C(x) und S(x) fur x ∈ [0, 5] ver-mittels einer adaptiven Quadratur und vergleiche mit den Ergebnissen spe-zieller Bibliotheksroutinen zur Bestimmung von Fresnel-Integralen.
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
x
C(x
)
Fresnel−Integral C(x) = ∫0x f(t) dt mit f(t) = cos(π t2/2)
C(x) = quad(f,0,x) (adaptive Simpson)C(x) = quadl(f,0,x) (adaptive Lobatto)C(x) = mfun(’FresnelC’,x) (Bibliothek)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
x
S(x
)
Fresnel−Integral S(x) = ∫0x g(t) dt mit g(t) = sin(π t2/2)
S(x) = quad(g,0,x) (adaptive Simpson)S(x) = quadl(g,0,x) (adaptive Lobatto)S(x) = mfun(’FresnelS’,x) (Bibliothek)
Um die Unterschiede der von MATLAB/Maple approximierten Ergebnisseuberhaupt sichtbar zu machen, sind die Bibliotheksfunktionen hier in zehn-mal so vielen Argumenten wie die durch quad und quadl gewonnenen Qua-draturen dargestellt.
9. Die Periode eines Pendels ist durch ein vollstandiges elliptisches Integral
erster Art K(x) =∫ π/2
odθ√
1−x2 sin2 θbestimmt. Ermittele und visualisiere
K(x) fur x ∈ [0, 1] vermittels einer adaptiven Quadratur und vergleichemit dem Ergebnis spezieller Bibliotheksroutinen zur Bestimmung derartigerIntegrale.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 11.4
1.6
1.8
2
2.2
2.4
2.6
2.8
3
3.2
3.4
x
K(x
)
vollständiges elliptisches Integral 1. Art K(x) = ∫0π/2 f(t) dt mit f(t) = (1−x2 sin2 t)−1/2
K(x) = quad(f,0,pi/2) (adpative Simpson)K(x) = quadl(f,0,pi/2) (adpative Lobatto)
K(x) = ellipke(x2) (Bibliotheksfunktion)
23Augustin Jean Fresnel (1788-1827) www-history.mcs.st-andrews.ac.uk/Biographies/Fresnel.html

444 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
Um die Unterschiede der von MATLAB/Maple approximierten Ergebnisseuberhaupt sichtbar zu machen, sind die Bibliotheksfunktionen hier in zehn-mal so vielen Argumenten wie die durch quad und quadl gewonnenen Qua-draturen dargestellt.
10. Die Gamma-Funktion ist fur x > 0 durch Γ(x) =∫∞
otx−1e−t dt definiert.
Berechne die Gamma-Funktion auf jede der folgenden Weisen fur 1 ≤ x ≤10 und vergleiche die Ergebnisse mit Bibliotheksroutinen fur die Gamma-Funktion sowie mit den Funktionswerten Γ(n) = (n − 1)! der Gamma-Funktion in naturlichen Argumenten.
a) Programmiere die Approximation der Gamma-Funktion per zusammen-gesetzter Trapez- oder Simpson-Regel bei geeignet begrenztem Integrati-onsintervall. Untersuche den falligen Kompromiss zwischen Genauigkeitund Effizienz.
???
b) Gauss-Laguerre
???
11. Planck24s Theorie der Strahlung eines schwarzen Korpers fuhrt auf dasIntegral
∫∞o
x3 dxex−1
. Der Integrand ist proportional der Planck brightness25
in Abhangigkeit von der Frequenz bei fester Temperatur. Berechne dasIntegral vermittels der Methoden des vorigen Computer-Problems und ver-gleiche wieder Genauigkeit und Effizienz.
???
12. Berechne das Integral∫∞−∞ e−x2
cosx dx
a) per zusammengesetzter Integration
???b) adaptiv
???c) per Gauß-Hermite
???
13. Angenommen, in der Ebene sei elektrische Ladung in G = [−1, 1]×[−1, 1] ⊂R2 gleichmaßig verteilt. Dann ist das elektrostatische Potential Φ(x, y) in
Punkten (x, y) 6∈ G durch Φ(x, y) =∫ 1
−1
∫ 1
−1dx dy√
(x−x)2+(y−y)2gegeben. Be-
rechne und visualisiere Φ(x, y) fur 2 ≤ x, y ≤ 10.
24 Max Karl Ernst Ludwig Planck (1858-1947) www-history.mcs.st-and.ac.uk/Biographies/Planck.html
25http://scienceworld.wolfram.com/physics/PlanckLaw.html

8.6. Computer Problems – Rechner-Problem-Losungen 445
24
68
10
2
4
6
8
100
0.5
1
1.5
x
elektrostatisches Potential Φ(x,y)
y
Φ(x
,y)
0.4
0.6
0.8
1
1.2
1.4
14. Berechne∫∫
Ge−xy dx dy fur folgende Integrationsbereiche G
a) Q = [0, 1]× [0, 1] ⊂ R2, Einheitsquadrat der Ebene∫∫Qe−xy dx dy =
∫ 1
o (∫ 1
oe−xy dx)dy =
∫ 1
o ( − 1ye−xy
∣∣∣1o)dy =
∫ 1
o1y(1−e
−y)dy =∫ 1
o
∑∞i=1
−(−y)i−1
i!dy =
∑∞i=1
(−1)i
i!
∫ 1
oyi−1 dy =
∑∞i=1
(−1)i
i!1i
ist eine alternie-rende Reihe
∑∞i=1(−1)iai mit monoton fallenden ai, so daß fur n ∈ N die
Reihenreste |∑∞
i=n(−1)iai| durch an abgeschatzt werden konnen. Allerdingsherrscht Ausloschung.
an = 1n!
1n<
∑n−1i=1
(−1)i
i!1i
= eval reset
Es gilt26∫ 1
o1y(1− e−y)dy ≈ 0.79659959950650 per quad (adaptive Simpson)∫ 1
o1y(1− e−y)dy ≈ 0.79659959929706 per quadl (adaptive Lobatto)∫∫
Qe−xy dx dy ≈ 0.79659959971595 per dblquad (double quad)
b) V = (x, y) : x2 + y2 ≤ 1, x ≥ 0, y ≥ 0 ⊂ R2, Vierteleinheitskreis imersten Quadranten der Ebene∫∫
Ve−xy dx dy =
∫ 1
o (∫ √1−x2
oexp(−xy) dy) dx =
∫ 1
o− 1
xexp(−xy)
∣∣√1−x2
odx =∫ 1
o1x(1− e−x
√1−x2
) dx ist (vermutlich) nicht geschlossen losbar. Es gilt26∫ 1
o1x(1− e−x
√1−x2
) dx ≈ 0.67516339245048 mit quad (Simpson)∫ 1
o1x(1− e−x
√1−x2
) dx ≈ 0.67516700418406 mit quadl (Lobatto)∫∫Ve−xy dx dy ≈ 0.67516169138522 mit dblquad (double quad)
15. a) Programmiere eine automatische Quadratur unter Verwendung der zu-sammengesetzten Simpson-Regel. Dabei werde k solange erhoht, bis derFehler genugend klein ist. Schatze dabei den Fehler durch Vergleich mitder jeweils vorangehenden Iteration. Welche Datenstruktur erlaubt, dievorher berechneten Funktionswerte wiederzuverwenden?

446 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION
???b) Programmiere eine adaptive Quadratur unter Verwendung der zusam-mengesetzten Simpson-Regel. Verfeinere dabei nur die Teilintervalle, indenen der Fehler noch nicht genugend klein ist. Welche Datenstruktur er-laubt, daruber Buch zu fuhren, in welchen Teilintervallen die Quadraturabgeschlossen ist?Vergleiche die Effizienz der adaptiven mit derjenigen der nicht-adaptivenQuadratur anhand der Integrale aus den vorangehenden Problemen.
???16. Finde einen Integranden, fur den eine adaptive Quadratur vollig falsche
Ergebnisse liefert. Gibt es einen derartigen glatten Integranden?
???17. a) Lose die Integralgleichung
∫ 1
o
√s2 + t2u(t) dt = 1
3(√s2 + 1
3 − s3) im In-tervall [0, 1], indem das Integral per zusammengesetzter Simpson-Quadraturund n aquidistanten tj approximiert wird. Verwende dieselben tj fur dieNaherungen si. Lose das sich ergebende lineare Gleichungssystem Ax = yper Gauß mit partieller Pivotisierung. Experimentiere mit verschiedenenWerten von n = 3, 4, . . . , 15. Vergleiche die Ergebnisse mit der exaktenLosung u(t) = t. Fur welchen Wert von n ergeben sich die besten Ergeb-nisse? Warum?
??? b) Berechne fur jedes n die Konditionszahl cond(A). Welche Abhangigkeitbesteht?
??? c) Wiederhole a), lose allerdings Ax = y per SVD und setze dabei genugendkleine Singularwerte Null. Bewerte den jeweiligen Fehler in Abhangigkeitvon der Schwelle.
??? d) Wiederhole a), lose allerdings Ax = y per Regularisierung. Experimen-tiere mit dem Regularisierungsparameter µ. Welches µ ist optimal? Stelledie Ortskurve Norm der Losung Norm des Residuums in Abhangigkeit vonµ graphisch dar. Legt diese Kurve einen optimalen Wert fur µ nahe?
??? e) Wiederhole a), lose allerdings Ax = y per Optimierung von ||y−Ax||22.Vergleiche erneut mit der exakten Losung.
??? f) Wiederhole e) unter der zusatzlichen Bedingung einer monoton wache-senden Losung, d.h. 0 ≤ x1 ≤ x2 ≤ . . . ≤ xn. Welcher Unterschied ergibtsich?
???
18. Gegeben die Daten-Punktet 0.0 1.0 2.0 3.0 4.0 5.0y 1.0 2.7 5.8 6.6 7.5 9.9
aus 3CP1.
a) Bestimme das linear least squares Problem-Polynom vom Grad n =0, 1, . . . , 5 und seine jeweiligen Ableitungen in den sechs Datenpunkten.
???26laut MATLAB

8.6. Computer Problems – Rechner-Problem-Losungen 447
b) Bestimme den die Daten-Punkte interpolierenden kubischen Spline undseine jeweiligen Ableitungen in den sechs Datenpunkten.
???c) Wiederhole b) mit unterschiedlichem Glattheitsgrad.
???d) Bestimme das die Daten-Punkte interpolierende kubische monotoineHermite-Polynom und seine jeweiligen Ableitungen in den sechs Daten-punkten.
???

448 KAPITEL 8. NUMERICAL INTEGRATION AND DIFFERENTIATION

Kapitel 9
Initial Value Problems forOrdinary Differential Equations
9.0.1 Gewohnliche Differentialgleichungen
Alle etwa Zeit-anhangigen Vorgange in Physik, Chemie, Biologie usw. werdendurch Differentialgleichungen beschrieben: der Zustand y(t) z.Zt. t eines Sy-stems sei durch die Funktion y = y(t) : R → Rn gegeben. Differentialgleichungenbeschreiben nun den Zusammenhang zwischen y und seinen Ableitungen. Dif-ferentialgleichungen zu losen oder gleichbedeutend zu integrieren, bedeutet, ausdiesen Gleichungen die unbekannte Funktion y(t) zu ermitteln.
Z.B. Laut Newton1 gilt F = ma, d.h. in einer Dimension gilt fur die Kraft F
F = F (t, y, y) = m y
Falls F die Kraft aufgrund der Gravitation ist, so gilt F = −mg mit der Erdbe-schleunigung g ≈ 9.82m/sec2. Die Losung dieser gewohnlichen Differentialglei-chung ist y = y(t) = −1
2gt2+c1t+co mit Konstanten co = y(0) und c1 = y′(0), die
die anfangliche Position und die anfangliche Geschwindigkeit des Massepunkteswiderspiegeln. cBem. Wie schon bei Gleichungen und Systemen von Gleichungen werden Im Fol-genden die Begriffe Differentialgleichung und Systeme von Differentialgleichungengleichbedeutend gebraucht. Def. Wenn eine Funktion y = y(t) einer einzigen Variablen t als Losung ei-ner Differentialgleichung gesucht ist, so heißt die zugehorige Differentialgleichunggewohnlich sonst partiell.Wenn y(k) die hochste Ableitung ist, die in einer gewohnlichen Differentialglei-chung auftritt, so heißt k Ordnung der Differentialgleichung.
1 Isaac Newton (1643-1727) www-history.mcs.st-andrews.ac.uk/Biographies/Newton.html
449

450 KAPITEL 9. INITIAL VALUE PROBLEMS
Gewohnliche Differentialgleichungen der Ordnung k konnen immer implizit als
f(t,y,y′, . . . ,y(k)) = 0
dargestellt werden. Falls nach y(k) aufgelost werden kann, gilt
y(k) = f(t,y,y′, . . . ,y(k−1))
Die Differentialgleichung heißt dann explizit. Im Folgenden werden nur explizite gewohnliche Differentialgleichungen ersterOrdnung betrachtet. Explizite gewohnliche Differentialgleichungen k-ter Ord-nung konnen namlich durch u1(t) = y(t), u2(t) = y′(t), . . . , uk(t) = y(k−1)(t) aufDifferentialgleichungen erster Ordnung zuruckgefuhrt werden:
u′ =
u′1u′2...
u′k−1
u′k
=
u2
u3...
uk
f(t,u1,u2, . . . ,uk)
= g(t,u)
Z.B. Mit u1(t) = y(t) und u2(t) = y′(t) wird aus F = ma das System
u′ =
(u′1u′2
)=
(u2
F/m
)von zwei Differentialgleichungen erster Ordnung. cIm Folgenden werden also nur Systeme expliziter Differentialgleichungen ersterOrdnung betrachtet:
y′ =
y′1(t)...
y′n(t)
=
f1(t,y)...
fn(t,y)
= f(t,y) mit f : Rn+1 → Rn
Z.B. Fur jedes konstante c ∈ Rn lost y(t) = c die Differentialgleichung y′ =f(t,y) = 0. Fur jedes konstante c ∈ Rn lost y(t) = tb + c die Differentialglei-chung y′ = f(t,y) = b fur festes b ∈ Rn. cDef. Die gewohnliche Differentialgleichung heißt autonom, wenn f nicht explizitvon t abhangt: y′ = f(y). Eine nicht-autonome Differentialgleichung y′ = f(t,y)kann durch eine zusatzliche Variable yn+1 = t in das autonome System gewohn-licher Differentialgleichungen(
y′
y′n+1
)=
(f(yn+1,y)
1
)

451
uberfuhrt werden.Ein System gewohnlicher Differentialgleichungen f(t,y) = A(t)y + b(t) heißtlinear. Falls A nicht von t abhangt, hat das System konstante Koeffizienten. Einlineares System mit b = 0 heißt homogen, sonst inhomogen. Z.B. Gegeben die Konzentrationen y1(t), y2(t) und y3(t) dreier chemischer Stoffe.Die Ubergangsrate 1 → 2 ist proportional zu y1, die Ubergangsrate 2 → 3 istproportional zu y2. Die Stoffkonzentrationen y(t) sind dann durch das System
y′ =
y′1y′2y′3
=
−k1y1
k1y1 − k2y2
k2y2
=
−k1 0 0k1 −k2 00 k2 0
y1
y2
y3
= Ay
linearer, homogener Differentialgleichungen mit konstanten Koeffizienten beschrie-ben. Falls sich das System im Massenaustausch mit seiner Umgebung befindet,ist das beschreibende Differentialgleichungssystem nicht mehr homogen. cZ.B. y1 sei eine Beute-Population, y2 eine Jager-Population. Dann beschreibtdas System autonomer, nichtlinearer Differentialgleichungen
y′ =
(y′1y′2
)=
(α1y1 − β1y1y2
−α2y2 + β2y1y2
)= f(y)
wie sich die beiden Populationen in der Zeit entwickeln (Schweine-Zyklus). DieDifferentialgleichung haben unabhangig Volterra2 und Lotka3 entdeckt. cEine Differentialgleichung y′ = f(t,y) hat i.d.R. unendlich viele Losungen. Vor-gabe einer sogenannten Anfangsbedingung y(to) = yo selektiert aus der Losungs-schar eine spezielle oder partikulare Losung. Die Differentialgleichung y′ = f(t,y)mit y(to) = yo heißt ein Anfangswert-Problem oder eine Anfangswertaufgabe.
Z.B. Fur jedes c ∈ R ist y(t) = c et eine Losung der Differentialgleichung y′ = y.Beispielsweise die Anfangsbedingung y(0) = yo wird durch y(t) = yoe
t befriedigt.Die Anfangsbedingung macht die Losung eindeutig. cIntegration uberfuhrt das Anfangswert-Problem y′ = f(t,y) mit y(to) = yo indie aquivalente Integralgleichung
y(t) = yo +
∫ t
to
f(s,y(s)) ds
die – wenn uberhaupt – nur von eher theoretischem Nutzen ist, aber immerhindie Bezeichnung Integration fur das Losen von Differentialgleichungen erklart.Falls f nicht von y abhangt, kann die Losung y(t) = yo +
∫ t
tof(s) ds analytisch
bestimmt oder numerisch angenahert werden.
2 Vito Volterra (1860-1940) www-history.mcs.st-andrews.ac.uk/Biographies/Volterra.html
3 Alfred James Lotka (1880-1949) http://de.wikipedia.org/wiki/Alfred James Lotka

452 KAPITEL 9. INITIAL VALUE PROBLEMS
9.0.2 Existenz, Eindeutigkeit und Konditionierung
Satz Wenn f : Rn+1 → Rn Lipschitz4-stetig auf einer geschlossenen und be-schrankten Menge D = [a, b]×Ω ⊂ Rn+1 ist, d.h. wenn es eine Konstante L gibt,so daß ||f(t, y) − f(t,y)|| ≤ ||y − y|| fur alle t ∈ [a, b] und y, y ∈ Ω gilt, danngibt es zu jedem inneren Punkt (to,yo) in D ein to enthaltendes Teilintervall von[a, b], so daß das Anfangswert-Problem y′ = f(t,y) mit y(to) = yo eine eindeutigeLosung hat, die zudem stetig auf den Rand von D fortgesetzt werden kann.Wenn f differenzierbar ist, so ist f erst recht Lipschitz-stetig mit Lipschitz-Konstanten L = max(t,y)∈D ||Jf (t,y)||. Dabei ist Jf (t,y) die Jacobi-Matrix von
f in (t,y), d.h. (Jf (t,y))i,j
= (∂fi(t,y)∂(y)j
). •
Sei y(t) die Losung der Differentialgleichung y′ = f(t, y) mit ’gestorter’ Anfangs-bedingung y(to) = yo. Dann kann man zeigen, daß fur jedes t ≥ to
||y(t)− y(t)|| ≤ eL(t−to)||yo − y||
gilt. Wenn zusatzlich auch eine ’gestorte’ Differentialgleichung y′ = f(t, y) vor-liegt, kann man zeigen, daß fur jedes t ≥ to
||y(t)− y(t)|| ≤ eL(t−to)||yo − y||+ eL(t−to)−1L
||f − f ||
mit ||f − f || = max(t,y)∈D ||f(t,y) − f(t,y)|| gilt. Die Losung hangt also stetigvon den Eingangsdaten yo und f ab: das Problem ist gut-gestellt (well-posed).Allerdings wird die Schranke im schlechtesten Fall angenommen, so daß wegeneL(t−to) die Losung fur große t sehr sensitiv auf Storungen der Eingangsdatenreagieren kann.
Def. Eine gewohnliche Differentialgleichung y′ = f(t,y) mit y(to) = yo heißtstabil, wenn es zu jedem ε > 0 ein δ > 0 gibt, so daß eine Funktion y(t), die dieDifferrentialgleichung lost, d.h. y′ = f(t, y), und die die Anfangsbedingung nichtzu schlecht befriedigt, d.h. ||y(to)−y(to)|| < δ, auch im ε-Schlauch um die echteLosung y liegt, d.h. ||y(t)− y(t)|| < ε fur alle t ≥ to. Eine stabile Losung heißtasymptotisch stabil, wenn sogar ||y(t)− y(t)|| → 0 fur t→∞ gilt. Z.B. Die Losungen der Differentialgleichung y′ = b fur konstantes b sind offen-sichtlich stabil aber nicht asymptotisch stabil.
4 Rudolf Otto Sigismund Lipschitz (1832-1903) www-history.mcs.st-andrews.ac.uk/Biographies/Lipschitz.html

453
t
y
Lsungen von y′ = b
t
y
Lsungen von y′ = y
Die Losung y(t) = yoeλt der Differentialgleichung y′ = λ y fur konstantes λ mit
Anfangsbedingung y(0) = yo ist fur λ > 0 nicht stabil, fur λ < 0 dagegen sogarasymptotisch stabil. Fur komplexes λ = a + i b ∈ C sind die Loungen fur a > 0nicht stabil, fur a < 0 asymptotisch stabil. Fur a = 0 sind die oszillierendenLosungen stabil, aber nicht asymptotisch stabil. cZ.B. Gegeben ein System y′ = Ay von linearen Differentialgleichungen mit kon-stanten Koeffizienten und Anfangsbedingung y(0) = yo. Die n×n-Matrix A habedie EVen vi zu den EWen λi fur i = 1, 2, . . . , n. Angenommen, A ist diagonali-sierbar und die EVen sind l.u. Dann ist yo als Linearkombination yo =
∑ni=1 αivi
darstellbar. Offensichtlich ist y(t) =∑n
i=1 αivieλit Losung des Anfangswert-Pro-
blems. Wie im skalaren Fall gehoren zu EWen λi mit <(λi) > 0 exponentiellwachsende Losungen, mit <(λi) < 0 exponentiell abfallende Losungen und mit<(λi) = 0 oszillierende Losungen. Zusammengenommen sind die Losungen desAnfangswert-Problems also asymptotisch stabil, wenn alle <(λi) < 0, stabil, wennalle <(λi) ≤ 0, und instabil, wenn es einen EW mit positivem Realteil gibt. cZ.B. Gegeben die inhomogene, lineare Differentialgleichung y′ = Ay + b =(y′1y′2
)=
(3 2−2 −2
)(y1
y2
)+
(et
2et
). Dann hat A die EWe λ1 = −1 mit zugehori-
gen EVen v1 = R(−12
)und λ2 = 2 mit zugehorigen EVen v2 = R
(−21
). Also
ist yhom(t) = c1v1 e−t + c2v2 e
2t die zwei-parametrige Losungsgesamtheit der zu-gehorigen homogenen, lineare Differentialgleichung.Variation der Konstanten, also der Ansatz c1 = c1(t) und c2 = c2(t) liefert nuneine partikulare oder spezielle Losung der inhomogenen Differentialgleichung. Fury = c1v1 e
−t + c2v2 e2t gilt dann y′ = (c′1 − c1)v1 e
−t + (c′2 + 2c2)v2 e2t. In die
inhomogene Differentialgleichung eingesetzt, impliziert
y′ = (c′1 − c1)v1 e−t + (c′2 + 2c2)v2 e
2t = c1Av1 e−t + c2Av2 e
2t + b
= −c1v1 e−t + 2c2v2 e
2t + b
c′1v1 e−t + c′2v2 e
2t = b und damit das, fur festes t lineare Gleichungssystem−1 c′1e
−t − 2 c′2e2t = et
+2 c′1e−t + 1 c′2e
2t = 2et mit c′2 = −43e−t und damit c2(t) = 4
3e−t + C2 sowie c′1 =

454 KAPITEL 9. INITIAL VALUE PROBLEMS
53e2t und damit c1(t) = 5
6e2t + C1. Also ist
yinhom(t) = (56e2t + C1)v1 e
−t + (43e−t + C2)v2 e
2t
die Losungsgesamtheit der inhomogenen Differentialgleichung. Die KonstantenC1 und C2 sind aus der Anfangsbedingung zu bestimmen. cDie Untersuchung der EWe einer linearen Differentialgleichung y′ = Ay mitkonstanten Koeffizienten erlaubt also, die Stabilitat aller Losungen zu beurteilen.Falls die Koeffizienten A = A(t) variabel sind, lassen sich solche Aussagen nichtgenerell sondern nur uber eher kurze Zeitspannen machen.Der Schwierigkeit, die Stabilitat beliebiger Differentialgleichungen y′ = f(t,y)zu untersuchen, begegnet man durch lokale Linearisierung, indem man die dieFunktion f durch den Anfang ihrer Taylor-Entwicklung approximiert:
z′ = Jf (t,y(t))z
wobei wieder Jf (t,y) fur die Jacobi-Matrix (Jf (t,y))i,j
= (∂fi(t,y)∂yj
) von f bzgl.
y steht. Falls die Differentialgleichung autonom ist, hat ihre Linearisierung kon-stante Koeffizienten, sonst eben variable Koeffizienten – mit den oben beschriebe-nen Konsequenzen. In jedem Fall wird die Jacobi-Matrix nur fur eine bestimmteLosung berechnet, so daß die Untersuchung der EWe nur in t und y lokal be-schrankte Aussagen erlaubt.
9.0.3 Gewohnliche Differentialgleichungen numerisch losen
Es gibt eine Reihe etablierter Verfahren, um Differentialgleichungen zu losen, bei-spielsweise Trennen der Veranderlichen, Potenz- oder Fourier-Reihen-Ansatze,Laplace-Transformation usw. Allerdings erweisen sich diese Methoden, die jaLosungen in geschlossener Form liefern, in der Praxis meist als unbrauchbar.Klassisches Beispiel ist etwa die Differentialgleichung y′ = e−t2/2. Wie nicht an-ders zu erwarten, bleibt nur, sich mit Approximationen an die exakte Losungenund als weitere bittere Pille damit zu begnugen, daß wir die Losung auch nur indiskreten Punkten annahern. Anders als etwa bei Interpolationsproblemen ge-winnen wir also nur Naherungen der exakten Losung nur in diskreten Punkten.Der Losungsprozess basiert also auf endlich dimensionaler Approximation, aufDiskretisierung. Wir ersetzen die Differentialgleichung durch algebraische Glei-chungen, deren Losungen die exakte Losung der Differentialgleichung approximie-ren. Wir approximieren die Losung in diskreten Punkten des Argumentbereiches,indem wir mit der Anfangsbedingung beginnend unter Verwendung der schonermittelten Naherungen von einem diskreten Punkt zum nachsten Punkt fort-schreiten. Aufgrund der Diskretisierungsfehler liegt dabei der nachste genaherteWert der Losung auf der exakten Losung eines anderen Anfangswertproblems.Stabilitat oder Instabilitat der Losung ist eine Ursache dafur, ob die Fehler mitder Zeit wachsen oder nicht.

455
Das Euler-Verfahren
Aus der Anfangsbedingung yo = y(to) und der Differentialgleichung y′ = f(t,y)ergibt sich eine Naherung y1 fur die Losung in t1 = to + ho mit Inkrement ho.Iteration solcher Schritte liefert das Euler5-Verfahren
yk+1 = yk + hkf(tk,yk) mit tk+1 = tk + hk
und zwar gleichermaßen per
• Taylor-Entwicklung y(t + h) = y(t) + hy′(t) + 12h2y′′(t) + . . . in t, so daß
in erster Naherung yk+1 = y(tk+1) = y(tk + hk) ≈ y(tk) + hkf(tk,y(tk)) =yk + hkf(tk,yk) gilt,
• Approximation durch numerische Differentation (d.h. endliche Differenzen)y′(tk) = f(tk,yk) ≈ 1
hk(yk+1 − yk), so daß Auflosen yk+1 = yk + hkf(tk,yk)
liefert,
• polynomiale Interpolation: das Hermite-Polynom ersten Grades p(h) =yk +hf(tk,yk) interpoliert den Wert der Losung in tk mit der vorgegebenenSteigung f(tk,yk). Auswertung von p in hk liefert wieder y(tk+1) ≈ yk+1 =p(hk) = yk + hf(tk,yk).
• numerische Quadratur von yk+1 = yk +∫ tk+1
tkf(s,y(s)) ds durch die ’Qua-
dratur-Regel’∫ b
ag(s) ds ≈ (b−a)g(a), so daß yk+1 = yk+(tk+1−tk)f(tk,yk)
folgt,
• Methode der unbestimmten Koeffizienten: ein lineare Vorhersage von yk+1
aufgrund der Kenntnis von yk und y′k = f(tk,yk) hat die Form yk+1 =αyk + βy′k. Mit zwei Freiheitsgraden kann die Vorhersage fur die erstenbeiden Monome exakt sein. Fur y(t) = (1, . . . , 1)T =: e mit y′ = 0 folgtdann aus yk+1 = e = αe + β0 sofort α = 1; und fur y(t) = te mit y′ = efolgt dann aus yk+1 = tk+1e = (tk + β)e sofort β = hk, zusammen alsowieder yk+1 = yk + hky
′k.
Z.B. Gegeben die beiden Anfangswert-Probleme y′ = y bzw. y′ = −y mity(to) = y(0) = yo = 1. Das Euler-Verfahren liefert dann folgende Naherungswertefur die exakte Losung y(t) = et bzw. y(t) = e−t.
5 Leonhard Euler (1707-1783) www-history.mcs.st-andrews.ac.uk/Biographies/Euler.html

456 KAPITEL 9. INITIAL VALUE PROBLEMS
tt1 t2 t3 t4 t5
yk yk
0.0 1.000000.5 1.500001.0 2.250001.5 3.375002.0 5.062502.5 7.59375
k yk
0.0 1.000000.5 0.500001.0 0.250001.5 0.125002.0 0.062502.5 0.03125
tt1 t2 t3 t4 t5
y
Offensichtlich ist die Losung von y′ = y instabil, diejenige von y′ = −y asympto-tisch stabil. cDas Euler-Verfahren ist Beispiel eines Ein-Schritt-Verfahrens
yk+1 = yk + hkφ(tk,yk, hk)
d.h. die approximierte Losung yk+1 im nachsten Argument tk+1 hangt nur vomaktuellen Argument tk, der approximierten Losung yk in tk und der Schrittweitehk ab, wahrend sie bei Mehr-Schritt-Verfahren von den approximierten Losungenin mehreren Argumenten abhangt.
Genauigkeit und Stabilitat
Wie alle Verfahren, die Ableitungen durch endliche Differenzen approximieren,weisen numerische Verfahren zur Losung von gewohnlichen Differentialgleichun-gen grundsatzlich zwei Arten von Fehlern auf,
Rundungsfehler aufgrund der beschrankten Genauigkeit der Gleitpunkt-Arith-metik
Diskretisierungsfehler (truncation error) aufgrund eben dieser Approxi-mation des Differential- durch den Differenzen-Quotienten.
Diese Fehler sind nicht unabhangig (vgl. Beispiel in 1.0.2 auf Seite 18), im Allge-meinen ist aber der Diskretisierungsfehler so dominant, daß der Rundungsfehler

457
vernachlassigt werden kann.Man unterscheidet
globalen Fehler ek = yk − y(tk), also die Abweichung der berechneten von derexakten Losung y in tk, die durch den Punkt (to,yo) verlauft, und
lokalen Fehler `k = yk − uk−1(tk), also die Abweichung der berechneten vonder exakten Losung uk−1 in tk, die durch den vorigen Punkt (tk−1,yk−1)verlauft.
Der lokale Fehler fur Ein-Schritt-Verfahren ergibt sich aus
yk = yk−1 + hk−1φ(tk−1,yk−1, hk−1) = uk−1(tk−1) + hk−1φ(tk−1,uk−1(tk−1), hk−1)
gerade zu dem Fehler von uk−1 in der endlichen Differenzen-Gleichung. Derglobale Fehler dagegen ist kleiner bzw. großer als die Summe der lokalen Fehler,falls die Losungen der Differentialgleichung konvergieren bzw. divergieren (vgl.y′ = −y bzw. y′ = y).
...
Def. Die Genauigkeit eines Verfahrens ist von der Ordnung p, wenn `k =O(hp+1
k ). Dann gilt fur den lokalen Fehler relativ zur Schrittweite `k/hk = O(hpk)
und – wie man zeigen kann – fur den globalen Fehler ek = O(hp) fur die durch-schnittliche Schrittweite h. Def. Analog zur Stabilitat einer Differentialgleichung heißt ein numerischesLosungsverfahren stabil, wenn bei kleinen Anderungen die berechnete Losungsich nicht unbeschrankt von der exakten Losung entfernt. Z.B. Gegeben y′ = λy fur festes λ ∈ C mit y(0) = yo und exakter Losungy(t) = yoe
λt. Das Euler-Verfahren mit fester Schrittweite h liefert yk+1 = yk +hλyk = (1 + hλ)yk und damit yk = (1 + hλ)kyo. Die Große (1 + hλ) heißtWachstumsfaktor. Wenn <(λ) < 0, dann geht die exakte Losung gegen 0 furt → ∞. Wenn |1 + hλ| < 1, dann konvergieren auch die yk gegen 0 fur k → ∞.Falls andererseits |1+hλ| > 1, dann wachsen die yk uber jede Schranke, und zwarunabhangig vom Vorzeichen von <(λ). Das Euler-Verfahren kann also instabilsein, auch wenn die exakte Losung stabil ist.Das Euler-Verfahren ist stabil, wenn |1+hλ| < 1, wenn also hλ in der Kreisscheibemit Radius 1 um −1 ∈ C liegt. Beispielsweise fur R 3 λ < 0 ist das Euler-Ver-fahren stabil, wenn h ≤ −2/λ. Aus der Taylor-Entwicklung
ehλ = 1 + hλ+ 12(hλ)2 + 1
6(hλ)3 + . . .
und tk = k h sowie uk−1(t) = yk−1e−λ(k−1)h eλt = yk−1e
λ(t−(k−1)h) folgt
`k = yk − uk−1(tk) = (1 + hλ)kyo − yk−1eλh = (1 + hλ)kyo − (1 + hλ)k−1yoe
λh
= −(1 + hλ)k−1yo(12(hλ)2 + 1
6(hλ)3 + . . . ) = −yo(1
2(hλ)2 + . . . = O(h2)

458 KAPITEL 9. INITIAL VALUE PROBLEMS
was zeigt, daß das Euler-Verfahren ein Verfahren erster Ordnung ist. c...
Implizite Verfahren
Zur Approximation von y in tk+1 verwendet das Euler-Verfahren nur Informationbis zum Zeitpunkt tk. Solche Verfahren heißen explizit.
Def. Ein Verfahren, das zur Approximation von y in tk+1 auch Information zumZeitpunkt tk+1 verwendet, heißt implizit. Das einfachste Beispiel eines impliziten Verfahrens ist das backward-Euler-Ver-fahren:
yk+1 = yk + hk f(tk+1,yk+1)
das man erhalt, wenn man die ’Quadratur-Regel’∫ b
ag(s) ds ≈ (b − a)g(b) auf
yk+1 = yk +∫ tk+1
tkf(s,y(s)) ds anwendet.
Implizite Verfahren machen notwendig, yk+1 als Losung von i.a.R. nichtlinea-ren Gleichungen mit einem der Verfahren aus Kapitel 5 zu ermitteln. (GuteStartwerte fur diese iterativen Verfahren konnen etwa mit dem expliziten Euler-Verfahren gewonnen werden.) Dafur vergroßern implizite Verfahren i.a.R. denStabilitatsbereich.
Z.B. Gegeben das Anfangswert-Problem y′ = −y3 mit y(0) = 1. Das backwardEuler-Verfahren mit der Schrittweite h = 0.5 liefert y1 aus y1 = yo +h f(t1, y1) =1 − 0.5 y3
1. Diese nichtlineare Gleichung kann etwa per Newton-Verfahren gelostwerden. Als Startwert kann man yo verwenden. Das explizite Euler-Verfahrenliefert mit y1 = yo − 0.5y3
o = 0.5 aber einen vermutlich besseren Startwert. DasNewton-Verfahren konvergiert dann gegen y1 ≈ 0.7709. cZur Untersuchung von Stabilitat und Genauigkeit des backward Euler-Verfahrenswerde wieder das skalare Anfangswert-Problem y′ = λy mit y(0) = 1 verwendet.
Aus yk+1 = yk + hλyk+1 oder gleichermaßen (1− hλ)yk+1 = yk folgt
yk =
(1
1− hλ
)k
yo
Das backward Euler-Verfahren ist also stabil, wenn |1/(1 − hλ)| < 1 fur jedes???
h > 0 und <(λ) < 0.
Der Wachstumsfaktor 11−hλ
= 1 + hλ + (hλ)2 + . . . stimmt mit der Taylor-
Entwicklung von ehλ in den ersten beiden Termen uberein, so daß die Genauigkeitdes backward Euler-Verfahrens von erster Ordnung ist.
Def. Ein Verfahren heißt unbedingt stabil, wenn es bei der Berechnung einerstabilen Losung fur jede positive Schrittweite stabil ist.

459
Das backward Euler-Verfahren ist unbedingt stabil.
...
Der ’Mittelwert’ von Euler- und backward Euler-Verfahren liefert das Trapez-Verfahren
yk+1 = yk + 12hk(f(tk,yk) + f(tk+1,yk+1))
das sich auch per Quadratur anhand der Trapez-Regel ergibt:
yk+1 − yk =
∫ tk+1
tk
f(s,y(s)) ds ≈ 12(tk+1 − tk)(f(tk,yk) + f(tk+1,yk+1))
Das Trapez-Verfahren auf y′ = λy angewandt liefert
yk+1 = yk + h2(λyk + λyk+1) bzw. yk = (1+hλ/2
1−hλ/2)kyo
Wenn <(λ) < 0 und damit die Losung stabil ist, dann ist der Wachstumsfaktor
|1+hλ/21−hλ/2
| < 1 fur jedes h > 0 und damit das Trapez-Verfahren unbedingt stabil.
Daruberhinaus stimmt der Wachstumsfaktor 1+hλ/21−hλ/2
= 1+hλ+ 12(hλ)2 + 1
4(hλ)3 +
. . . in den ersten drei Termen mit der Taylor-Entwicklung von ehλ uberein, so daßdie Genauigkeit des Trapez-Verfahrens von zweiter Ordnung ist.
...
Steifheit
Gut oder schlecht konditioniert zu sein, ist ein qualitatives Merkmal von linea-ren Gleichungssystemen bzw. von deren Koeffizienten-Matrizen. Vergleichbar istSteifheit ein qualitatives Merkmal von Differentialgleichungen.
Wenn eine sich langsam verandernde stabile Losung von sich schnell veranderndenstabilen Losungen umgeben ist, heißt eine solche Differentialgleichung steif.
t
h 2h 3h 4h 5h
y
Steife Differentialgleichungen beschreiben beispielsweise physikalische Prozesse,deren Komponenten sich in unterschiedlichen zeitlichen Großenordnungen veran-dern oder deren Zeit-Skala klein im Vergleich zum Beobachtungszeitraum ist.

460 KAPITEL 9. INITIAL VALUE PROBLEMS
Def. Eine stabile Differentialgleichung y′ = f(t,y) heißt steif, wenn ihre Jacobi-Matrix Jf EWe stark unterschiedlicher Großenordnung hat. Eine steife Differentialgleichung hat also zugleich etwa stark gedampfte Losungen(EWe mit verhaltnismaßig großen negativen Realteilen) oder schnell oszillierendeLosungen (EWe mit verhaltnismaßig großen Imaginarteilen)
...
Steifheit ist also ein qualitatives Konzept, das vom Stabilitatsbereich des verwen-deten Losungsverfahrens, von der geforderten Genauigkeit, vom Beobachtungs-zeitraum und naturlich von der Differentialgleichung selbst abhangt.
Betrachte wieder y′ = λy mit y(a) = ya uber das Intervall t ∈ [a, b]. Dann istdieses Anfangswert-Problem steif, wenn (b−a)<(λ) 1, weil die Anforderungenan h unter Stabilitatsgeswichtpunkten verhaltnismaßig hoch sind.
Def. Eine Differentialgleichung y′ = f(t,y) fur den Geltungsbereich [a, b] istnahe einer Losung y(t) steif, wenn
(b− a) minj<λj 1
fur die EWe λj der Jacobi-Matrix Jf (t,y(t)). Einige numerische Verfahren sind angewandt auf steife Differentialgleichungensehr ineffizient, weil die sich schnell verandernden Anteile der Losung sehr kleineSchrittweiten erzwingen.
Stabilitat wird durch die sich schnell verandernden Anteile der Losung,Genauigkeit die sich langsam verandernden Anteile der Losung be-stimmt!
Beispielsweise das Euler-Verfahren ist wegen seines kleinen Stabiltatsbereichesfur steife Differentialgleichungen extrem ungeeignet. Wegen seiner unbedingtenStabilitat ist dagegen das implizite backward Euler-Verfahren geeignet. SteifeDifferentialgleichungen sind also nicht per se schwieriger zu losen; wir mussennur geeignete, typischerweise implizite Verfahren einsetzen.
Z.B. Die lineare, inhomogene Differentialgleichung y′ = −100y+ 100t+ 101 hatdie Losungsgesamtheit y(t) = 1 + t+ c e−100t fur c ∈ R. Daher hat das Anfangs-wert-Problem y′ = −100y + 100t + 101 mit y(0) = 1 die Losung y(t) = 1 + t.Fur solche affinen Losungen ist das Euler-Verfahren exakt. Allerdings reagiert
???es aufgrund von Diskretisierungs- und Rundungsfehlern außerst empfindlich aufAnderungen des Anfangswertes. Sei die Schrittweite h = 0.1.
t 0.0 0.1 0.2 0.3 0.4exakte Losung 1.00 1.10 1.20 1.30 1.4Euler-Losung 0.99 1.19 0.39 8.59 −64.2Euler-Losung 1.01 1.01 2.01 −5.99 67.0

461
Die Jacobi-Matrix ist Jf = −100, so daß das Stabilitatskriterium fur das Euler-Verfahren eine Schrittweite h < 0.02 fordert.
Das backward Euler-Verfahren dagegen reagiert außerst unempfindlich auf Ande-rungen des Anfangswertes.
t 0.0 0.1 0.2 0.3 0.4exakte Losung 1.00 1.10 1.20 1.30 1.40
backward Euler-Losung 0.00 1.01 1.19 1.30 1.40backward Euler-Losung 2.00 1.19 1.21 1.30 1.40
Dieses Verhalten paßt auch mit der unbedingten Stabilitat des backward Euler-Verfahren zusammen. c...
Taylor-Reihen-Verfahren
Das Euler-Verfahren verwendet nur das Taylor-Polynom erster Ordnung. Ver-wendet man beispielsweise das Taylor-Polynom zweiter Ordnung, ergibt sich einVerfahren zweiter Ordnng
yk+1 = yk + hky′k + 1
2h2
ky′′k
wobei sich die hoheren Ableitungen per Kettenregel aus der Differentialgleichungberechnen lassen.
y′′ = ft(t,y) + fy(t,y)y′ = ft(t,y) + fy(t,y) f(t,y)
Z.B. Gegeben y′(t) = f(t, y) = −2ty2 mit y(0) = 1 und zweiter Ableitungy′′ = ft(t, y) + fy(t, y) f(t, y) = −2y2 + (−4ty)(−2ty2) = 2y2(4t2y − 1). Mitto = 0, t1 = 0.25 und h = 0.25 ergibt der erste Schritt
y1 = yo + hy′o + 12h2y′′o = 1 + 0 + h2
2(−2) = 1− 0.0625
und der zweite Schritt
y2 = y1 + hy′1 + 12h2y′′1 = 0.9375− 0.1099− 0.0421 = 0.7856
Die exakte Losung y(t) = 11+t2
liefert zum Vergleich y(t1) = 0.9412 und y(t2) =0.8. c
Runge-Kutta-Verfahren
Runge6-Kutta7-Verfahren ahneln Taylor-Reihen-Verfahren mit dem Unterschied,daß sie hohere Ableitungen durch endliche Differenzen, die Werte von f zwischen
6 Carle David Tolme Runge (1856-1927) www-history.mcs.st-andrews.ac.uk/Biographies/Runge.html
7 Martin Wilhelm Kutta (1867-1944) www-history.mcs.st-andrews.ac.uk/Biographies/Kutta.html

462 KAPITEL 9. INITIAL VALUE PROBLEMS
tk und tk+1 verwenden, approximieren. Alternativ lassen sich Runge-Kutta-Ver-fahrenen auch als numerische Quadratur-Verfahren fur
yk+1 − yk =
∫ tk+1
tk
f(t,y(t)) dt
auffassen, wobei die unbekannte Funktion y(t) in [tk, tk+1] geeignet zu approxi-mieren ist.
Taylor-Entwicklung von f = f(t,y) in y′′ = ft + fy f liefert
f(t+ h,y + hf) = f + hft + hfyf +O(h2)
und so
ft + fy f =f(t+ h,y + hf)− f(t,y)
h+O(h2)
Aus dem Taylor-Reihen-Verfahren zweiter Ordnung des vorigen Abschnittes wirdso das Heun8-Verfahren
yk+1 = yk + hkf(tk,yk) +h2
k
2
f(tk + hk,yk + hkf(tk,yk))− f(tk,yk)
hk
= yk + 12hk
(f(tk,yk) + f(tk + hk,yk + hkf(tk,yk))
)= yk + 1
2hk(k1 + k2) mit k1 = f(tk,yk) und k2 = f(tk + hk,yk + hkk1)
Das Heun-Verfahren ergibt sich ebenso bei Anwendung des Trapez-Verfahrens aufdas Intervall (tk, tk+1) mit der ’Vorhersage’ von y(tk+1) durch yk + hkk1 anhanddes Euler-Verfahrens wie folgt:
yk+1 = yk +
∫ tk+1
tk
f(s,y(s)) ds
≈ 12hk(f(tk,yk) + f(tk+1,yk+1))
≈ 12hk(k1 + f(tk+1,yk + hkk1))
Z.B. Gegeben wieder y′ = f(t, y) = −2ty2 mit y(0) = 1. Mit Schrittweite h =0.25 ergibt sich k1 = f(to, yo) = 0 und k2 = f(to + h, yo + h k1) = −21
412 = −0.5,
so daß im ersten Schritt
y1 = yo + h2(k1 + k2) = 1 + 1
8(−0.5) = 15
16= 0.9375
und fur t2 = 0.5 wegen k1 = f(t1, y1) = −214y2
1 ≈ 0.4395 und k2 = f(t1 + h, y1 +h k1)− 21
2(y1 + 1
2k1)
2 ≈ −0.685 im zweiten Schritt
y2 = y1 + h2(k1 + k2) = 0.9375 +
1
8(−1.1245) ≈ 0.7969
8 Karl Heun (1859-1929) in Ermangelung einer Biographiehttp://zmath.u-strasbg.fr/math-cgi-bin/zmen/ZMATH/en/full.html?first=1&maxdocs=3&type=pdf&an=0847.34006&format=complete

463
folgt. Fur die exakte Losung y(t) = 11+t2
gilt zum Vergleich y(14) ≈ 0.9412 und
y(12) = 0.8. c
Das klassische Runge-Kutta-Verfahren, gegeben durch
yk+1 = yk + 16hk(k1+2k2+2k3+k4) mit
k1 = f(tk,yk)k2 = f(tk + hk/2,yk + hkk1/2)k3 = f(tk + hk/2,yk + hkk2/2)k4 = f(tk + hk,yk + hkk3)
ist ein Verfahren vierter Ordnung mit vielen Vorteilen: Das Runge-Kutta-Verfah-ren braucht zur Berechnung von yk+1 keine Information vor tk und gehort damitzu den sogenannten selbst-startenden Verfahren, bei denen sich die Schrittweiteleicht dynamisch anpassen laßt. Fehler-Abschatzungen gewinnt man wie bei Qua-dratur durch Vergleich mit anderen Verfahren.
...
Extrapolationsverfahren
Extrapolationsverfahren sind vergleichbar der Richardson-Extrapolation fur nu-merische Differentation und Quadratur: Integration im Intervall [tk, tk+1] perEinschritt-Verfahren fur verschiedene Schrittweiten hi liefert eine diskrete Ap-proximation einer Funktion Y(h) mit Y(0) = yk+1. Wenn nun ein Polynom odereine rationale Funktion diese diskreten Daten-Punkte interpoliert, ergibt sich eineApproximation Y(0) fur Y(0). Extrapolationsverfahren konnen sehr genau sein,allerdings auf Kosten von Effizienz und Flexibilitat.
Mehrschritt-Verfahren
Mehrschritt-Verfahren verwenden Informationen an mehr als einer Stelle tk, umyk+1 zu approximieren. Lineare Mehrschritt-Verfahren sind von der Form
yk+1 =m∑
i=1
αiyk+1−i + h
m∑i=0
βif(tk+1−i,yk+1−i)
Wenn βo = 0, so ist das Verfahren explizit, sonst implizit. Die Paramater αi undβi lassen sich durch polynomiale Interpolation bestimmen. Adams9-Verfahreninterpolieren y′ = f durch ein Polynom p und integrieren
yk+1 = yk +
∫ tk+1
tk
f(s,y(s)) ds ≈ yk +
∫ tk+1
tk
p(s) ds
9 John Couch Adams (1819-1892) www-history.mcs.st-andrews.ac.uk/Biographies/Adams.html

464 KAPITEL 9. INITIAL VALUE PROBLEMS
BDF-Verfahren, backward differentiation formula, dagegen interpolieren die Losungy in m vorherigen Zeit-Punkten, differenzieren das Interpolationspolynom undgewinnen yk+1 aus dem Ansatz y′k+1 = f(tk+1,yk+1).
...
Mehrwerte-Verfahren
...

9.1. Review Questions – Verstandnisfragen 465
9.1 Review Questions
– Verstandnisfra-
gen
1. Richtig/Falsch? Wenn die Losungeiner gewohnlichen Differentialglei-chung fur t → ∞ unbeschrankt ist,ist sie notwendig instabil.
2. Richtig/Falsch? Der globale Fehlereiner numerischen Losung wachstnur, wenn die gesuchte Losung in-stabil ist.
3. Richtig/Falsch? Rundungs- undDiskretisierungsfehler in der nume-rischen Losung einer gewohnlichenDifferentialgleichung sind un-abhangig.
4. Richtig/Falsch? Wenn man ein An-fangswert-Problem einer gewohn-lichen Differentialgleichung nume-risch lost, dann fallt der globale Feh-ler immer großer als die Summe derlokalen Fehler aus.
5. Richtig/Falsch? Implizite Verfahrensind immer stabil, wenn sie eine sta-bile Losung einer gewohnlichen Dif-ferentialgleichung approximieren.
6. Richtig/Falsch? Wenn es gilt, einestabile Losung einer gewohnlichenDifferentialgleichung zu approximie-ren, kann man bei Einsatz einesunconditionally stabilen Verfahrensmit beliebig großen Schrittweitenjede beliebige Genauigkeit erzielen.
7. Richtig/Falsch? Steife gewohnli-che Differentialgleichungen sindgrundsatzlich schwierig undaufwandig zu losen.
8. a) Bestimmt eine Differentialglei-chung eine eindeutige Losung?
b) Falls ja, warum? falls nein, wasmacht die Losung eindeutig?
9. a) Was ist eine Differentialgleichungerster Ordnung?
b) Warum werden Differentialglei-chungen hoherer Ordnung in derRegel vor der numerischen Losungzunachst in solche erster Ordnungtransformiert?
10. a) Erlautere den Unterschied zwi-schen stabilen und instabilen Losun-gen.
b) Benenne ein mathematisches Kri-terium fur Stabilitat bzw. Instabi-litat.
c) Konnen sich Stabilitat bzw. Insta-bilitat mit der Zeit andern?
11. Welche der folgenden Typengewohnlicher Differentialgleichun-gen erster Ordnung haben stabileLosungen?
a) Differentialgleichungen, derenLosungen gegeneinander konvergie-ren,
b) Differentialgleichungen, derenJacobi-Matrix nur EWe mit negati-ven Realteilen aufweist,
c) steife Differentialgleichungen,
d) Differentialgleichungen, derenLosungen exponentiell abklingen.
12. Untersuche, ob die folgenden Diffe-rentialgleichungen instabile, stabileoder asymptotisch stabile Losungenhaben.
a) y′ = y + t
b) y′ = y − t
c) y′ = t− y
d) y′ = 1

466 KAPITEL 9. INITIAL VALUE PROBLEMS
13. Wie unterscheidet sich eine typischenumerische Losung einer gewohnli-chen Differentialgleichung von ihreranalytischen Losung?
14. a) Wie approximiert das Euler-Ver-fahren die Losung einer gewohn-lichen Differentialgleichung ersterOrdnung?
b) Leite das Euler-Verfahren her.
15. Ist der Rundungsfehler oder der Dis-kretisierungsfehler in der numeri-schen Losung gewohnlicher Differen-tialgleichungen dominant?
16. Erlautere den Unterschied zwischenglobalem und lokalem Fehler.
17. Unter welchen Bedingungen fallt derglobale Fehler i.a.R. kleiner als dieSumme der lokalen Fehler aus?
18. a) Definiere das Fehlerwachstumoder den Wachstumsfaktor fur Ein-schrittverfahren.
b) Hangt der Wachstumsfaktor vonder Differentialgleichung, vom spe-ziellen Einschrittverfahren oder vonbeidem ab?
c) Wie groß ist der Wachstumsfaktorfur einen Schritt des Euler-Verfah-rens?
d) Welches ist daher der Stabilitats-bereich des Euler-Verfahrens?
19. a) Erlautere den wesentlichen Unter-schied zwischen expliziten und im-pliziten Verfahren zur approximati-ven Losung von gewohnlichen Diffe-rentialgleichungen.
b) Vergleiche explizite und impliziteVerfahren.
c) Benenne Beispiele fur expliziteund implizite Verfahren.
20. Implizite Methoden erfordern dieiterative Losung von i.a.R. nichtli-nearen Gleichungen. Was ist ein gu-ter Startwert fur die Iteration?
21. Kann ein numerisches Verfahren fureine stabile Losung instabil sein?
22. Wann ist die Genauigkeit eines Ver-fahrens von der Ordnung p ?
23. a) Was ist die maximale Ord-nung der Genauigkeit eines linea-ren, unbedingt stabilen Mehrschritt-Verfahrens?
b) Gib Beispiele linearer, unbedingtstabiler Mehrschritt-Verfahren mitmaximaler Ordnung der Genauig-keit.
24. Vergleiche die Stabilitatsbereichedes Euler-Verfahrens und des back-ward Euler-Verfahrens angewandtauf skalare gewohnliche Differential-gleichungen.
25. Was beschrankt die Schrittweite desbackward Euler-Verfahrens starker:Stabilitat oder Genauigkeit?
26. Welche der folgenden Verfahren an-gewandt auf eine stabile gewohnli-che Differentialgleichung sind unbe-dingt stabil?
a) Euler-Verfahren?
b) backward Euler-Verfahren?
c) Trapez-Verfahren?
9.2 Exercises – Ubun-
gen
1. Schreibe die folgenden Differential-gleichungen jeweils als aquivalente(Systeme von) Differentialgleichun-gen erster Ordnung.

9.2. Exercises – Ubungen 467
a) y′′ = t+ y + y′
b) y′′′ = y′′ + ty
c) y′′′ = y′′ − 2y′ + y − t+ 1
2. Schreibe die folgenden (beruhmten)Differentialgleichungen als aquiva-lente (Systeme von) Differentialglei-chungen erster Ordnung.
a) Van der Pol-Gleichung y′′ =y′(1− y2)− y
b) Blasius-Gleichung y′′′ = −yy′′
c) Newtons Bewegungsgleichun-gen fur das Zwei-Korper-Problemy′′1 = −GMy1(y2
1 + y22)−3/2
y′′2 = −GMy2(y21 + y2
2)−3/2
3. Sind die Losungen vony′1 = −y1 + y2
y′2 = −2y2stabil?
4. Gegeben y′ = −5y mit y(0) = 1.Lose numerisch mit Schrittweite h =0.5.
a) Sind alle Losungen stabil?
b) Ist das Euler-Verfahren fur dieseSchrittweite stabil?
c) Berechne die Losung naherungs-weise in t = 0.5 per Euler-Verfahren.
d) Ist das backward Euler-Verfahrenfur diese Schrittweite stabil?
e) Berechne die Losung naherungs-weise in t = 0.5 per backward Euler-Verfahren.
5. Fur y′ = −y mit y(0) = 1 berechney1 bei h = 1 per
a) Euler-Verfahren,
b) backward Euler-Verfahren.
6. Zeige: Wenn fur y′ = −y3 mity(0) = 1 die Approximation y1 furh = 0.5 per backward Euler-Ver-fahren bestimmt wird, so ist dieFix-Punkt-Iteration zur Losung von
y1 = yo + hf(h, y1) konvergent. Mitwelcher Konvergenz-Rate?
7. Gegeben sei das Anfangswert-Pro-blem y′′ = y mit y(0) = 1 undy′(0) = 2.
Es handelt sich um eine homogenelineare Differentialgleichung zweiterOrdnung mit konstanten Koeffizien-ten. Das charakteristische Polynomist p(b) = b2 − 1 mit einfachen Null-stellen ±1. Die Losungsgesamtheitist daher y(t) = c1e
t + c2e−t und
y(t) = 32e
t−12e−t erfullt die Anfangs-
bedingungen.
a) Bestimme die aquivalente Diffe-rentialgleichung erster Ordnung.
b) Was sind dann die aquivalentenAnfangsbedingungen?
c) Sind die Losungen stabil?
d) Berechne y1 mit der Schrittweiteh = 0.5 per Euler-Verfahren.
e) Ist das Euler-Verfahren (un-abhangig von der Stabilitat derLosung) fur diese Schrittweite sta-bil?
f) Ist das backward Euler-Verfahren(unabhangig von der Stabilitat derLosung) fur diese Schrittweite sta-bil?
8. Gegeben sei das Anfangswert-Pro-blem y′ = −y2 mit y(0) = 1. Be-rechne y1 fur die Schrittweite h =0.1 per backward Euler-Verfahren.
a) Gib die nichtlineare algebraischeGleichung fur y1 an.
b) Bestimme die Newton-Iterationzur Losung dieser Gleichung.
c) Welchen Startwert fur dieNewton-Iteration generiert dasEuler-Verfahren?

468 KAPITEL 9. INITIAL VALUE PROBLEMS
d) Unter Verwendung dieses Start-wertes berechne mit einer Newton-Iteration eine Naherung fur y1.
9. Gegeben drei Methoden zur Losunggewohnlicher Differentialgleichun-gen.
(i) yk+1 = yk + h2(f(tk, yk) +
f(tk+1, yk + h f(tk, yk)))(ii) yk+1 = yk + h
2(3f(tk, yk) −f(tk−1, yk−1))
(iii) yk+1 = yk + h2(f(tk, yk) +
f(tk+1, yk+1))
Welche Verfahren sind
a) in 2. Ordnung genau,
b) Einschritt-Verfahren,
c) implizite Verfahren,
d) selbst-startend,
e) unbedingt stabil,
f) Verfahren vom Runge-Kutta-Typ,
g) gut zur Losung steifer Differenti-algleichungen geeignet.
10. Verwende wieder die skalare Diffe-rentialgleichung y′ = λy, um Sta-bilitat und Genauigkeit des Heun-Verfahrens zu bestimmen. Zeige,daß die Genauigkeit des Heun-Verfahrens von zweiter Ordnung ist,und bestimme seinen Stabilitatsbe-reich in der komplexen Ebene.
11. Vermittels der Mittelpunkt-Regelfur das Intervall [tk, tk+1] gewinntman das implizite Mittelpunkt-Verfahren
yk+1 = yk + hkf(tk + hk2 ,
yk+yk+1
2 )
zur Losung der Differentialgleichungy′ = f(t,y) mit y(to) = yo. Be-stimme die Ordnung der Genauig-keit und den Stabilitatsbereich die-ses Verfahrens.
12. Die Approximation y′ ≈ 12(yk+1 −
yk−1) der Ableitung durch die zen-trierten Differenzen liefert das zwei-schrittige, sogenannte leap frog-Verfahren yk+1 = yk−1 + 2f(tk,yk)zur Losung der Differentialgleichungy′ = f(t,y) mit y(to) = yo. Be-stimme die Ordnung der Genauig-keit und den Stabilitatsbereich die-ses Verfahrens.
13. A sei eine der Einfachkeit halberdiagonalisierbare n×n-Matrix. Wielauten die Losungen der linearenDifferenzen-Gleichung xk+1 = Axk
bzw. der Differentialgleichung y′ =Ay ? Welche Eigenschaft der Ma-trix A garantiert, daß die Losun-gen der beiden Gleichungen fur je-den Startvektor xo bzw. yo be-schrankt bleiben?
14. Gegeben die skalare, lineare, ho-mogene Differentialgleichung k-terOrdnung
f(t, u, u′, . . . , u(k)) =k∑
j=0
cju(j) = 0
mit konstanten Koeffizienten cj undck = 1. Gib Kriterien fur Sta-bilitat bzw. asymptotische Stabi-litat dieser Differentialgleichung an.Hinweis: Transformiere die Differen-tialgleichung in ein System y′ =Ay von Differentialgleichungen er-ster Ordnung und nutze den Um-stand, daß A eine companion matrixist.

9.3. Computer Problems – Rechner-Problem-Losungen 469
9.3 Computer Pro-
blems –
Rechner-Problem-
Losungen
1. a) Verwende Bibliotheks-routinen, um die Volterra-Lotka Differentialgleichungder Beute-Jager-Populationen
y′ =(y1(α1 − β1y2)y2(−α2 + β2y1)
)fur
t ∈ [0, 25] sowie fur Konstantenα1 = 1, β1 = 0.1, α2 = 0.5 undβ2 = 0.02 zu losen. Anfangs seiy1(0) = 100 und y2(0) = 10. Vi-sualisiere die Losung y(t) sowie dieparametrisierte Kurve (y1(t), y2(t)),das sogenannte Phasen-Portraitoder Phasen-Diagramm. Erklaredie Beobachtungen fur verschiedeneAnfangsbedingungen. Gibt es nicht-triviale Anfangsbedingungen so, daßeine der Populationen schlußendlichausstirbt? Gibt es Anfangsbedin-gungen so, daß sich das Systemvon Anfang an nicht andert? Hin-weis: Derartige stationare Zustandekonnen bestimmt werden, ohne dieDifferentialgleichung zu losen.
b) Fuhre die Untersuchun-gen des Teils a) diesmalmit dem Leslie-Gower-Modell
y′ =(
y1(α1 − β1y2)y2(α2 − β2y2/y1)
)mit Kon-
stanten α1 = 1, β1 = 0.1, α2 = 0.5und β2 = 10 durch. WelcheUnterschiede sind zu beobachten?
2. Das Kermack-McKendrick-Modellbeschreibt den Verlauf einerEpidemie in einer Populationanhand der Differentialgleichung
y′ =
−c y1y2
c y1y2 − d y2
d y2
, wo y1 die
noch nicht infizierten Mitglieder,y2 die sich mit der Infektionsrate cinfizierenden Mitglieder und y3 dieMitglieder der Population bezeich-net, die mit der Rate d der Infektiondurch Isolierung, Tod, Heilung oderImmunisierung entzogen werden.Verwende Bilbliotheksroutinen,um die Differentialgleichung furdie Konstanten c = 1 und d = 5sowie die Anfangsbedingungeny1(0) = 95, y2(0) = 5 und y3(0) = 0zu losen. Visualisiere die Losungen.Gibt es Parameter-Satze, fur diedie Epidemie sich nicht ausweitetbzw. fur die die Infektion die ganzePopulation ausloscht?
3. Gegeben y′ = −200 t y2 mit zweiverschiedenen Anfangsbedingungeny(0) = 1 und y(−3) = 1/901. Expe-rimentiere mit Bibliotheksroutinen,die die Schrittweite automatisch an-passen. Untersuche und erlauteredie Schrittweiten und erklare dasVerhalten der verwendeten Verfah-ren. Vergleiche die Effizienz der Ver-fahren bei gegebener Genauigkeit.
4. Die Differentialgleichung
y′ =
−k1 0 0k1 −k2 00 k2 0
y1
y2
y3
=
Ay beschreibt die Reaktionskine-matik dreier Stoffe (vgl. Beispiel aufS. 451).
a) Wie sieht die Jacobi-Matrix aus?Welche EWe hat die Jacobi-Matrix?Wenn die Ubergangsraten als kon-stant und positiv angenommen wer-den, sind dann die Losungen stabil?Unter welchen Bedingungen ist dieDifferentialgleichung steif?

470 KAPITEL 9. INITIAL VALUE PROBLEMS
b) Lose die Differentialgleichung furdie Anfangsbedingung yi(0) = 1 furi = 1, 2, 3 und fur Ubergangsra-ten k1 = 1 und k2 = 10, 100, 1000numerisch mit Runge-Kutta-Verfah-ren, Adams-Verfahren und Verfah-ren, die speziell fur die Losungsteifer Differentialgleichungen ent-wickelt wurden.
5. Gegeben das folgende Modell derReaktionskinetik dreier chemischerStoffe
y′1 =αy1 + βy2y3
y′2 =αy1 − βy2y3 − γy22
y′3 = γy22
, y(0) = ex
fur Stoff-Konstanten α = 4 · 10−2,β = 104 und γ = 3 · 107. Integrieredie Differentialgleichung fur t ∈[0, 5] unter Verwendung von Biblio-theksroutinen fur steife und nicht-steife Differentialgleichungen. Un-tersuche die Effizienz der verschiede-nen Methoden in Abhangigkeit vonder gewahlten Toleranz.

9.4. Review Questions – Antworten auf Verstandnisfragen 471
9.4 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Wenn die Losung einer gewohnlichen Differentialgleichungfur t→∞ unbeschrankt ist, ist sie notwendig instabil.
Die Losungen sind nicht notwendig instabil, wie das Beispiel y′ = c zeigt: 388Losungen sind die Geraden y(t) = c t + b fur b ∈ R. Diese Losungen sindunbeschrankt und stabil, wenn auch nicht asymptotisch stabil.
2. Richtig/Falsch? Der globale Fehler einer numerischen Losung wachst nur,wenn die gesuchte Losung instabil ist.
Der globale Fehler kann auch fur stabile Losungen wachsen, wie das Beispiel 394der per Euler-Verfahren bestimmten Losung von y′ = −y mit y(0) = 1zeigt: der globale Fehler ek = yk − y(tk) = (1− h)k − e−kh mit ek+1 − ek =(1 − h)k(1 − h − 1) − e−kh(e−h − 1) = −h(1 − h)k + e−kh(1 − e−h) > 0???wachst, obwohl die Losung stabil ist.
3. Richtig/Falsch? Rundungs- und Diskretisierungsfehler in der numerischenLosung einer gewohnlichen Differentialgleichung sind unabhangig.
Falsch, da Rundungs- und Diskretisierungsfehler insofern abhangig sind, als 354Verringern der Schrittweite den Diskretisierungsfehler verkleinert, gleichzei-tig aber i.a.R. den Rundungsfehler vergroßert.
4. Richtig/Falsch? Wenn man ein Anfangswert-Problem einer gewohnlichenDifferentialgleichung numerisch lost, dann fallt der globale Fehler immergroßer als die Summe der lokalen Fehler aus.
Falsch, wie das Beispiel y′ = −y mit y(0) = 1 und Losung y(t) = e−t 396/397zeigt: Bei fester Schrittweite h gilt yk+1 = (1 − h)yk und damit yk =(1 − h)k. Daher ist der globale Fehler ek = yk − y(kh) = (1 − h)k − e−kh.Im lokalen Fehler `k = yk−uk−1(kh) ist uk−1(t) die Losung u(t) = c e−t derDifferentialgleichung durch ((k−1)h, yk−1), d.h. uk−1(t) = yk−1e
−(t−(k−1)h),
so daß `k = (1− h)k − (1− h)k−1e−h = (1− h)k−1(1− h− e−h) folgt. Die
Summe∑k
i=1 `i = (1− h− e−h)∑k−1
i=0 (1− h)i = 1−h−e−h
1−(1−h) (1− (1− h)k) der
lokalen Fehler ist asymptotisch (e−h + h− 1)/h > 0 fur h > 0, wahrend derglobale Fehler ek asymptotisch verschwindet, wenn nur 0 < 1− h < 1.
5. Richtig/Falsch? Implizite Verfahren sind immer stabil, wenn sie eine stabileLosung einer gewohnlichen Differentialgleichung approximieren. 400
Das backward Euler-Verfahren ist ein implizites Verfahren, das unbedingtstabil ist. Allgemein sind aber nicht alle impliziten Verfahren notwendiger-weise unbedingt stabil. 401
???

472 KAPITEL 9. INITIAL VALUE PROBLEMS
stable solution388stable method396
6. Richtig/Falsch? Wenn es gilt, eine stabile Losung einer gewohnlichen Diffe-rentialgleichung zu approximieren, kann man bei Einsatz eines unconditio-nally stabilen Verfahrens mit beliebig großen Schrittweiten jede beliebigeGenauigkeit erzielen.
???7. Richtig/Falsch? Steife gewohnliche Differentialgleichungen sind grundsatz-
lich schwierig und aufwandig zu losen.402
Steife gewohnliche Differentialgleichungen sind nicht grundsatzlich aufwandi-ger zu losen: man muß nur geeignete, typischerweise implizite Verfahreneinsetzen.
8. a) Bestimmt eine Differentialgleichung eine eindeutige Losung?386
Nein, eine gewohnliche Differentialgleichung n-ter Ordnung hat eine n-parametrige Familie von Losungen.
b) Falls ja, warum? falls nein, was macht die Losung eindeutig?386
Erst n Anfangsbedingungen selektieren aus der n-parametrigen Familie dieeindeutige Losung.
9. a) Was ist eine Differentialgleichung erster Ordnung?383
Laut Definition kommt in der Differentialgleichung nur die erste Ableitungy′ vor: die Differentialgleichung hat die Form f(t,y,y′) = 0.
b) Warum werden Differentialgleichungen hoherer Ordnung in der Regel vor384der numerischen Losung zunachst in solche erster Ordnung transformiert?
Die klassischen numerischen Losungsverfahren losen Differentialgleichungenerster Ordnung.
10. a) Erlautere den Unterschied zwischen stabilen und instabilen Losungen.388
Stabile Losungen reagieren zahm auf Storungen der Anfangsbedingungen.Dagegen laßt sich der Abstand instabiler Losungen zu verschiedenen An-fangsbedingungen nicht beschranken.
b) Benenne ein mathematisches Kriterium fur Stabilitat bzw. Instabilitat.389/390
Eine Losung y mit y′ = f(t,y) und y(to) = yo ist genau dann stabil, wennes fur jedes y mit y′ = f(t, y) und zu jedem ε > 0 ein δ > 0 derart gibt,daß ||y(to)− y(to)|| < δ eben ||y(t)− y(t)|| < ε fur alle t ≥ to impliziert.Beispielsweise sind lineare Differentialgleichungen mit konstanten Koeffizi-enten, d.h. y′ = Ay + b stabil, wenn alle EWe von A negative Realteilehaben.
c) Konnen sich Stabilitat bzw. Instabilitat mit der Zeit andern?390

9.4. Review Questions – Antworten auf Verstandnisfragen 473
Stabilitat bzw. Instabilitat einer linearen Differentialgleichung hangen vonden EWen der Jacobi-Matrix ab, die sich ihrerseits fur nicht konstanteKoeffizienten mit der Zeit andert.
11. Welche der folgenden Typen gewohnlicher Differentialgleichungen ersterOrdnung haben stabile Losungen?
a) Differentialgleichungen, deren Losungen gegeneinander konvergieren, 388
Wenn die Losungen fur verschiedene Anfangswerte gegeneinander konver-gieren, sind sie asymptotisch stabil und damit erst recht stabil.
b) Differentialgleichungen, deren Jacobi-Matrix nur EWe mit negativen Re- 387,390alteilen aufweist,
???c) steife Differentialgleichungen, 401Die Tatsache, daß die Betrage der EWe der Jacobi-Matrix Jf einer steifenDifferentialgleichung sich um Großenordnungen unterscheiden, laßt keineAussagen uber das Vorzeichen der Realteile der EWe und damit uber die(lokale) Stabilitat der Losung zu.
d) Differentialgleichungen, deren Losungen exponentiell abklingen.
Wenn die Losungen exponentiell abklingen, sind sie asymptotisch stabil unddamit erst recht stabil.
12. Untersuche, ob die folgenden Differentialgleichungen instabile, stabile oderasymptotisch stabile Losungen haben.
a) y′ = y + t
Die Losungen sind y = cet − 1− t fur c ∈ R und damit instabil.
b) y′ = y − t
Die Losungen sind y = cet + 1 + t fur c ∈ R und damit instabil.
c) y′ = t− y
Die Losungen sind y = ce−t−1+t fur c ∈ R und damit asymptotisch stabil.
d) y′ = 1
Die Losungen sind y(t) = t+ c fur c ∈ R und damit stabil.
13. Wie unterscheidet sich eine typische numerische Losung einer gewohnlichenDifferentialgleichung von ihrer analytischen Losung?
Numerische Losungen sind nur fur diskrete Argumente zu ermitteln.
14. a) Wie approximiert das Euler-Verfahren die Losung einer gewohnlichen 391Differentialgleichung erster Ordnung?
Die Losung wird schrittweise ermittelt: fur ermitteltes yk ergibt sich yk+1
per Approximation von y durch die Parallele zur Tangente in yk.

474 KAPITEL 9. INITIAL VALUE PROBLEMS
b) Leite das Euler-Verfahren her.391/392
s. Euler-Verfahren auf S.455
15. Ist der Rundungsfehler oder der Diskretisierungsfehler in der numerischenLosung gewohnlicher Differentialgleichungen dominant?
I.a.R. ist der Diskretisierungsfehler dominant.394
16. Erlautere den Unterschied zwischen globalem und lokalem Fehler.394
Der globale Fehler ist die Differenz ek = yk−y(tk) zwischen approximierterLosung yk und exakter Losung y in tk.Der lokale Fehler ist die Differenz `k = yk−uk−1(tk) zwischen approximier-ter Losung yk und exakter Losung uk−1, die durch (tk−1,yk−1) verlauft,ausgewertet in tk.
17. Unter welchen Bedingungen (is likely) fallt der globale Fehler kleiner als die???
Summe der lokalen Fehler aus?
???18. a) Definiere das Fehlerwachstum oder den Wachstumsfaktor fur Einschritt-397
verfahren.
Wegen ek+1 = (I+hkJf )ek +`k heißt (I+hkJf ) (Fehler-) Wachstumsfaktor.
b) Hangt der Wachstumsfaktor von der Differentialgleichung, vom speziellen398Einschrittverfahren oder von beidem ab?
Der Wachstumsfaktor hangt von Jf und damit von der Differentialglei-chung, von der speziellen Form und damit vom Einschrittverfahren undvon der Schrittweite ab.
???c) Wie groß ist der Wachstumsfaktor fur einen Schritt des Euler-Verfahrens?
??? d) Welches ist daher der Stabilitatsbereich des Euler-Verfahrens?
???19. a) Erlautere den wesentlichen Unterschied zwischen expliziten und impli-
398ziten Verfahren zur approximativen Losung von gewohnlichen Differential-gleichungen.
Zur Berechnung von yk+1 verwenden explizite Verfahren ausschließlich schonberechnete yk, wahrend implizite Verfahren auch Informationen z.Zt. tk+1
nutzen.
b) Vergleiche explizite und implizite Verfahren.398
Explizite Verfahren berechnen yk+1 explizit und damit einfach. ImpliziteVerfahren berechnen yk+1 als Losung einer impliziten, i.a.R. nichtlinearenGleichung und damit aufwandig. Implizite Verfahren weisen dafur aber deni.a.R. großeren Stabilitatsbereich auf.
c) Benenne Beispiele fur explizite und implizite Verfahren.398

9.4. Review Questions – Antworten auf Verstandnisfragen 475
Das Euler-Verfahren ist ein explizites, das backward Euler-Verfahren einimplizites Verfahren.
20. Implizite Methoden erfordern die iterative Losung von i.a.R. nichtlinearenGleichungen. Was ist ein guter Startwert fur die Iteration?
Explizite Verfahren oder einfach die letzte Approximation yk liefern geeig- 398/399nete Startwerte.
21. Kann ein numerisches Verfahren fur eine stabile Losung instabil sein?
Das Euler-Verfahren, beispielsweise angewandt auf y′ = λy mit y(0) = yo,liefert yk = (1 + hλ)kyo. Falls |1 + hλ| > 1, wachst yk uber jede Schranke. 396Das Verfahren ist also instabil, unabhangig vom Vorzeichen von <(λ) unddamit unabhangig von der Stabilitat der Losung.
22. Wann ist die Genauigkeit eines Verfahrens von der Ordnung p ?
Die Genauigkeit eines Verfahrens ist von der Ordnung p genau dann, wenn 395/396`k = O(hp+1
k ). Damit gilt `k/hk = O(hpk) und gewohnlich ek = O(hp) fur
die durchschnittliche Schrittweite h.
23. a) Was ist die maximale Ordnung der Genauigkeit eines linearen, unbedingtstabilen Mehrschritt-Verfahrens?
???b) Gib Beispiele linearer, unbedingt stabiler Mehrschritt-Verfahren mit ma-ximaler Ordnung der Genauigkeit.
???
24. Vergleiche die Stabilitatsbereiche des Euler-Verfahrens und des backwardEuler-Verfahrens angewandt auf skalare gewohnliche Differentialgleichun-gen.
???25. Was beschrankt die Schrittweite des backward Euler-Verfahrens starker:
Stabilitat oder Genauigkeit?
???26. Welche der folgenden Verfahren angewandt auf eine stabile gewohnliche
Differentialgleichung sind unbedingt stabil?
a) Euler-Verfahren?
???b) backward Euler-Verfahren?
400Das backward Euler-Verfahren ist unbedingt stabil.
c) Trapez-Verfahren? 400/401
Das Trapez-Verfahren ist unbedingt stabil, wenn die EWe von hJf negativeRealteile haben.

476 KAPITEL 9. INITIAL VALUE PROBLEMS
9.5 Exercises – Ubungsergebnisse
1. Schreibe die folgenden Differentialgleichungen jeweils als aquivalente (Sy-steme von) Differentialgleichungen erster Ordnung.
a) y′′ = t+ y + y′384
Mity1 = yy2 = y′
gilty′1 = y2
y′2 = t+ y1 + y2oder
(y′1y′2
)=
(0 11 1
)(y1
y2
)+
(0t
).
Es liegt also eine inhomogene, lineare Differentialgleichung mit konstantenKoeffizienten vor, deren Koeffzientenmatrix die beiden EWe λ1,2 = 1
2(1 ±389/390
√5) hat. Etwa vi =
(1λi
)ist EV zum EW λi fur i = 1, 2. Damit hat die
homogene Differentialgleichung die zwei-dimensionale Losungsgesamtheityhom = c1v1e
λ1t + c2v2eλ2t fur c1, c2 ∈ R. Etwa ys = (1, λi)
T ist einespezielle oder partikulare Losung der inhomogenen Differentialgleichung mitLosungsgesamtheit ys + yhom.
b) y′′′ = y′′ + ty384
Mity1 = yy2 = y′
y3 = y′′gilt
y′1 = y2
y′2 = y3
y′3 = ty1 + y3
oder
y′1y′2y′3
=
0 1 00 0 1t 0 1
y1
y2
y3
. Es liegt
also eine homogene, lineare Differentialgleichung mit variablen Koeffizientenvor.385
c) y′′′ = y′′ − 2y′ + y − t+ 1384
Mity1 = yy2 = y′
y3 = y′′gilt
y′1 = y2
y′2 = y3
y′3 = 1− t+ y1 − 2y2 + y3
oder eben gleichbedeutendy′1y′2y′3
=
0 1 00 0 11 −2 1
y1
y2
y3
+
00
1− t
. Es liegt also eine inhomogene,
lineare Differentialgleichung mit konstanten Koeffizienten vor, deren Ko-389/390
effzientenmatrix den negativen EW λ1 = −16
(100+12√
69)2/3+4−23√
100+12√
693√
100+12√
69
und zwei konjugiert komplexe EWe λ2 und λ3 mit positivem Realteil hat.Mit jeweils zugehorigen EVen v1, v2 und v3 ergibt sich die Losungsge-samtheit yhom =
∑3i=1 civie
λit der homogenen Differentialgleichung undmit ys = (1 + t, 1, 0)T die Losungsgesamtheit ys + yhom der inhomogenenDifferentialgleichung.
2. Schreibe die folgenden (beruhmten) Differentialgleichungen als aquivalente(Systeme von) Differentialgleichungen erster Ordnung.
a) Van der Pol10-Gleichung11 y′′ = y′(1− y2)− y 12

9.5. Exercises – Ubungsergebnisse 477
Mity1 = yy2 = y′
gilty′1 = y2
y′2 = y2(1− y21)− y1
oder
(y′1y′2
)=
(0 1−1 1− y2
1
)(y1
y2
).
b) Blasius13-Gleichung14 y′′′ = −yy′′
Mity1 = yy2 = y′
y3 = y′′gilt
y′1 = y2
y′2 = y3
y′3 = −y1y3
oder
y′1y′2y′3
=
0 1 00 0 10 0 −y1
y1
y2
y3
.
c) Newton15s Bewegungsgleichungen16 fur das Zwei-Korper-Problem
y′′ =
(y′′1y′′2
)= −GM 1√
y21 + y2
2
3
(y1
y2
)= −GM 1
|y|3y
Allgemein gilt mr = F = −GmMr/|r|3 fur die Gravitationskraft zwischenzwei Massen m und M . G = 6.67428 · 10−11 m3/(kg sec2) ist dabei dieGravitationskonstante. Wenn die eine Masse – z.B. die Erde – im Ursprungsehr viel großer als die andere Masse – z.B. ein Satellit – ist, dann durfenwir annehmen, daß die Erde unbewegt im Ursprung verbleibt, wahrend diePosition r = (y1, y2)
T des Satelliten durch die Differentialgleichung17 mitgeeigneten Anfangsbedingungen beschrieben ist.
Mit
y′1 = y3
y′2 = y4
y′3 = −GMy1
(y21+y2
2)3/2
y′4 = −GMy2
(y21+y2
2)3/2
gilt
y′1y′2y′3y′4
=
0 0 1 00 0 0 1
−GM(y2
1+y22)3/2 0 0 0
0 −GM(y2
1+y22)3/2 0 0
y1
y2
y3
y4
.
10 Balthasar van der Pol (1889-1959) www.ieee.org/organizations/history center/legacies/vanderpol.html
11 vgl. z.B. Bernd Simeon: Numerik gewohnlicher Differentialgleichungen; Skriptum WS2003/04, TU Munchen http://www-m2.ma.tum.de/~simeon/numerik3/aktuell.pdf
12 Eine allgemeine geschlossene Losung ist nicht bekannt!13 W.H. Hager: Heinrich Blasius – A life in research and education; Experiments in Fluids
34 (2003) 566-571 http://www.ces.clemson.edu/~jabhiji/ME304/Blasius.pdf
14 Heinrich Blasius: Grenzschichten in Flussigkeiten mit kleiner Reibung; Z. Math. Phys.1908 56 1-37 (Engl. transl. NACA-TM-1256) http://mathworld.wolfram.com/BlasiusDifferentialEquation.html
15 Isaac Newton (1642-1727) www-history.mcs.st-andrews.ac.uk/Biographies/Newton.html
16 Nach Newton ist die Gravitationskraft F zwischen zwei Korpern proportional zu jeder derbeiden Massen m1 und m2, indirekt proportional zum Quadrat des Abstandes r der beidenMassen und auf den jeweils anderen Korper gerichtet: F ≈ m1m2
|r|2r|r|
17 Eine allgemeine geschlossene Losung ist nicht bekannt!

478 KAPITEL 9. INITIAL VALUE PROBLEMS
−10 −5 0 5 10 15−20
0
20
40
60
80
100
120
3. Sind die Losungen vony′1 = −y1 + y2
y′2 = −2y2stabil?
Wegen y′ =
(y′1y′2
)=
(−1 10 −2
)(y1
y2
)= Ay liegt eine lineare Differential-390
gleichung mit konstanten Koeffizienten vor. A hat die beiden EWe λ1 = −1und λ2 = −2. Da alle EWe negativ sind, sind die Losungen sogar asympto-tisch stabil.
4. Gegeben y′ = −5y mit y(0) = 1. Lose numerisch mit Schrittweite h = 0.5.
a) Sind alle Losungen stabil?388
Die Losung y(t) = yoe−5t klingt ab und ist damit sogar asymptotisch stabil.
b) Ist das Euler-Verfahren fur diese Schrittweite stabil?397/398?
Das Euler-Verfahren ist (fur stabile Losungen) stabil, falls |1 + hλ| < 1.Wegen |1 + hλ| = |1 − 5/2| = 1.5 > 1 ist das Euler-Verfahren fur dieseDifferentialgleichung und diese Schrittweite nicht stabil.
c) Berechne die Losung naherungsweise in t = 0.5 per Euler-Verfahren.391
Mit yo = 1 und h = 0.5 gilt y(0.5) ≈ y1 = (1− 5h)yo = −1.5.
d) Ist das backward Euler-Verfahren fur diese Schrittweite stabil?
Das backward Euler-Verfahren ist (fur stabile Losungen) stabil, falls |1/(1−hλ)| < 1. Wegen |1/(1 − hλ)| = |1/(1 + 5/2)| = 2/7 < 1 ist das backwardEuler-Verfahren fur diese Differentialgleichung und diese Schrittweite stabil.
e) Berechne die Losung naherungsweise in t = 0.5 per backward Euler-Ver-fahren.
Die Differentialgleichung lautet y′ = f(t, y) = −5y, so daß sich ’ruckwarts’aus y1 = yo + h f(h, y1) = yo − 5h y1 eben y1 = 1
1+5h= 2
7ergibt.
5. Fur y′ = −y mit y(0) = 1 berechne y1 bei h = 1 per
a) Euler-Verfahren,391

9.5. Exercises – Ubungsergebnisse 479
y1 = (1 + hλ)yo = (1− 1) · 1 = 0 ≈ 1e
per Euler-Verfahren.
b) backward Euler-Verfahren. 399
y1 = 11−hλ
yo = 12≈ 1
eper backward Euler-Verfahren.
6. Zeige: Wenn fur y′ = −y3 mit y(0) = 1 die Approximation y1 fur h = 0.5per backward Euler-Verfahren bestimmt wird, so ist die Fix-Punkt-Iteration 399zur Losung von y1 = yo + hf(h, y1) konvergent. Mit welcher Konvergenz-Rate?
Es ist y1 = 1−0.5y31 per Fix-Punkt-Iteration zu losen, d.h. zunachst ist eine
Funktion g gesucht, deren Fixpunkt mit der (einzigen reellen) Nullstelle xo
von f(x) = 1 − x − 0.5x3 ubereinstimmt. Wegen f(0) = 1 und f(45) =
15− 1
264125
= 25−32125
= −7125
liegt xo in (0, 0.8). Fur die naheliegende Funktiong(x) = 1− 0.5x3 gilt g(x) = x ⇐⇒ f(x) = 0 und |g′(x)| = |3
2x2| < 3
21625
=2425< 1 fur x ∈ (0, 0.8). Also ist die Fix-Punkt-Iteration linear-konvergent
mit Konvergenz-Rate C = |g′(xo)| < 2425
. Es gilt18 ubrigens xo ≈ 0.77.
7. Gegeben sei das Anfangswert-Problem y′′ = y mit y(0) = 1 und y′(0) = 2.
Es handelt sich um eine homogene lineare Differentialgleichung zweiterOrdnung mit konstanten Koeffizienten. Das charakteristische Polynom istp(b) = b2−1 mit einfachen Nullstellen ±1. Die Losungsgesamtheit ist dahery(t) = c1e
t + c2e−t und y(t) = 3
2et − 1
2e−t erfullt die Anfangsbedingungen.
a) Bestimme die aquivalente Differentialgleichung erster Ordnung. 384
Mit y1 = y und y2 = y′1 = y′ ist y′ =
(y′1y′2
)=
(y2
y1
)=
(0 11 0
)(y1
y2
)= Ay
die aquivalente Differentialgleichung erster Ordnung.
b) Was sind dann die aquivalenten Anfangsbedingungen? 384
Mit y1 = y und y2 = y′1 = y′ sind y1(0) = 1 und y2(0) = 2 die aquivalentenAnfangsbedingungen.
c) Sind die Losungen stabil? 389/390
Es handelt sich um eine lineare Differentialgleichung y′ = Ay =
(0 11 0
)y
mit konstanten Koeffizienten. Die Koeffizienten-Matrix A hat die beiden
EWe λ1 = 1 mit EV v1 =
(11
)und λ2 = −1 mit EV v2 =
(1−1
). Wegen
yo = 32v1 − 1
2v2 wird das Anfangswert-Problem von y = 3
2v1e
t − 12v2e
−t
gelost. Die Losungen sind daher nicht stabil.
d) Berechne y1 mit der Schrittweite h = 0.5 per Euler-Verfahren. 391
18 laut MATLAB

480 KAPITEL 9. INITIAL VALUE PROBLEMS
Das Euler-Verfahren liefert y1 = yo+hAyo = (I+hA)yo = 12
(2 11 2
)(12
)=(
22.5
)≈ 3
2
(√e√e
)− 1
2
(1/√e
−1/√e
)≈(
2.172.78
).
e) Ist das Euler-Verfahren (unabhangig von der Stabilitat der Losung) fur397diese Schrittweite stabil?
Wegen y′ = f(t,y) = Ay ist die Jacobi-Matrix Jf = ( ∂fi
∂yj) von f bzgl. y
gerade A. Das Verfahren ist also stabil, wenn ρ(I + hJf ) = ρ(I + hA) < 1,d.h. wenn die EWe von hA liegen in dem Kreis mit Radius 1 um −1 ∈ C,d.h. die EWe von A liegen in dem Kreis mit Radius 1/h = 2 um −1 ∈ C,
???f) Ist das backward Euler-Verfahren (unabhangig von der Stabilitat der399Losung) fur diese Schrittweite stabil?
???
8. Gegeben sei das Anfangswert-Problem y′ = −y2 mit y(0) = 1. Berechne y1
fur die Schrittweite h = 0.1 per backward Euler-Verfahren.
Es handelt sich um eine nichtlineare Differentialgleichung erster Ordnung.Trennen der Veranderlichen liefert dy
y2 = −dt bzw. −y−1 + Cy = −t + Ct
und Auflosen y = y(t) = 1t+c
. Die Anfangsbedingung wird durch y(t) = 11+t
bedient.
a) Gib die nichtlineare algebraische Gleichung fur y1 an.399
Wegen y′ = f(t, y) = −y2 und yk+1 = yk + f(tk+1, yk+1) gilt hier y1 = yo +
hf(h, y1) = 1+0.1−y21. Ubrigens sind y11,2 = −1
2±√
14
+ 4.44
= −12± 1
2
√5.4
die Losungen von y21 + y1 − 1.1 = 0.
b) Bestimme die Newton-Iteration zur Losung dieser Gleichung.399
Es ist eine Nullstelle von f(x) = x2 + x− 1.1 zu bestimmen. Starte mit xo
und berechne iterativ xk+1 = xk − f(xk)f ′(xk)
= xk −x2
k+xk−1.1
2xk+1.
c) Welchen Startwert fur die Newton-Iteration generiert das Euler-Verfah-391ren?
Das Euler-Verfahren generiert y1 = yo + hf(0, yo) = 1 − 0.1 · 12 = 0.9 alsStartwert xo.
d) Unter Verwendung dieses Startwertes berechne mit einer Newton-Itera-tion eine Naherung fur y1.
x1 = xo − x2o+xo−1.12xo+1
= 0.9− 0.92+0.9−1.12·0.9+1
= 0.9− 0.81−0.21.8+1
= 0.9− 0.612.8
≈ 0.68,
wahrend exakt y(h) = 11+h
= 11.1
= 1011≈ 0.9 gilt.
9. Gegeben drei Methoden zur Losung gewohnlicher Differentialgleichungen.
(i) yk+1 = yk + h2
(f(tk, yk) + f(tk+1, yk + h f(tk, yk))
)

9.5. Exercises – Ubungsergebnisse 481
(ii) yk+1 = yk + h2(3f(tk, yk)− f(tk−1, yk−1))
(iii) yk+1 = yk + h2(f(tk, yk) + f(tk+1, yk+1))
Welche Verfahren sind
a) in 2. Ordnung genau, 395
(i)???
(ii) ist (per Konstruktion) in 2. Ordnung genau,408
(iii) ist die Trapez-Regel und per Konstruktion in 2. Ordnung genau.408
b) Einschritt-Verfahren, 407
(i) und (iii) sind Einschritt-Verfahren, da sie nur Informationen zum voran-gehenden und zu keinem fruheren Zeitpunkt nutzen??? , wahrend (ii) ein
???Mehrschritt-Verfahren ist, weil es yk (z.Zt. tk) und yk−1 (z.Zt. tk−1) zurBerechnung von yk+1 verwendet.
c) implizite Verfahren,
(i) und (ii) sind explizite Verfahren, (iii) ist ein implizites Verfahren, dayk+1 implizit gegeben ist.
d) selbst-startend, 406
(i) und (iii) sind im Gegensatz zu (ii) selbst-startende Verfahren, die keineInformation zu Zeitpunkten vor tk verwenden.
e) unbedingt stabil,
(i)???
(ii)???(iii) ist als Trapez-Regel unbedingt stabil.
400f) Verfahren vom Runge-Kutta-Typ,
(i) ist das Heun-Verfahren und damit vom Runge-Kutta-Typ, 405(ii)
???(iii) ist vom Runge-Kutta-Typ, weil die Trapez-Regel
∫ b
ag(x) dx ≈ (b − 405
a)12(g(a) + g(b)) auf yk+1 − yk =
∫ tk+1
tkf(t,y(t)) dt angewendet yk+1 =
yk + h2(f(tk,yk) + f(tk+1,yk+1)) liefert.
g) gut zur Losung steifer Differentialgleichungen geeignet.
???10. Verwende wieder die skalare Differentialgleichung y′ = λy, um Stabilitat
und Genauigkeit des Heun-Verfahrens zu bestimmen. Zeige, daß die Genau-igkeit des Heun-Verfahrens von zweiter Ordnung ist, und bestimme seinenStabilitatsbereich in der komplexen Ebene.
Das Heun-Verfahren ist durch yk+1 = yk + hk
2(k1 + k2) mit k1 = f(tk,yk) 405
und k2 = f(tk +hk,yk +hkk1) gegeben, fur die Differentialgleichung y′ = λyalso yk+1 = yk + hk
2(k1 + k2) = yk + hk
2 (λyk +λ(yk +hkλyk)) = yk +hkλyk +

482 KAPITEL 9. INITIAL VALUE PROBLEMS
12h2
kλ2yk ≈ y(tk + hk) = y(tk) + hky
′(tk) + 12h2
ky′′(tk). Also ist das Heun-
Verfahren ein Taylor-Reihen-Verfahren zweiter Ordnung und damit seineGenauigkeit von zweiter Ordnung. Dies sieht man auch explizit daran,daß `k+1 = yk+1 − uk(tk+1) = yk + hkλyk + 1
2h2
kλ2yk − yke
λ(tk+hk−tk) =yk + hkλyk + 1
2h2
kλ2yk − yk(1 + λhk + 1
2λ2h2
k + O(h3k)) = O(h3
k), weil doch
uk(t) = ykeλ(t−tk) die Losung der Differentialgleichung ist. die durch (tk, yk)
verlauft.
−2 −1.5 −1 −0.5 0−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
x=ℜ(hλ)
y=ℑ
(hλ)
|1+z+z2/2|=1 und |1+z|=1 für z=hλ Fur feste Schrittweite h liefert dasHeun-Verfahren die Rekursion yk+1 =yk + hλyk + 1
2h2λ2yk = yk(1 + hλ + h2λ2/2)
und damit die naherungsweisen Losungen
yk = yo(1 + hλ + 12h2λ2))
kmit Wachstums-
faktor 1 + hλ+ 12h2λ2.
Die Graphik zeigt den umfassende-ren, Stadion-formigen Stabilitatsbereich∣∣1 + hλ+ 1
2h2λ2
∣∣ ≤ 1 fur x = h<(λ) undy = h=(λ) des Heun-Verfahrens sowie denkleineren, Kreis-formigen des Euler-Verfah-rens.
11. Vermittels der Mittelpunkt-Regel fur das Intervall [tk, tk+1] gewinnt mandas implizite Mittelpunkt-Verfahren
yk+1 = yk + hkf(tk + hk/2, (yk + yk+1)/2)
zur Losung der Differentialgleichung y′ = f(t,y) mit y(to) = yo. Bestimmedie Ordnung der Genauigkeit und den Stabilitatsbereich dieses Verfahrens.
Aus y(tk+1) = y(tk) +∫ tk+1
tkf(s,y(s)) ds ergibt sich mit der Mittelpunkt-
Regel das Mittelpunkt-Verfahren
y(tk+1) ≈ yk+1 = yk +hkf(tk + hk
2,y(tk + hk
2)) ≈ yk +hkf(tk + hk
2, yk+yk+1
2 )
Angewandt auf die skalare Differentialgleichung y′ = λy ergibt sich beifester Schrittweite h die Rekursion yk+1 = yk + hλyk+yk+1
2bzw. yk+1 =
1+hλ1−hλ/2
yk und damit yk = ( 1+hλ1−hλ/2)
kyo mit Wachstumsfaktor 1+hλ
1−hλ/2.
−4 −3 −2 −1 0−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
x=ℜ(hλ)
y=ℑ
(hλ)
Stabilitätsbereich des Mittelpunkt−, Heun− und Euler−Verfahrens|1+z|=|1−z/2| und |1+z+z2/2|=1 und |1+z|=1 für z=hλ Die Graphik zeigt den großen,
Kreis-formigen Stabilitatsbereich|1 + hλ| ≤ |1 − hλ/2| fur x =h<(λ) und y = h=(λ) desMittelpunkt-, den Stadion-formi-gen des Heun-Verfahrens sowieden kleineren, Kreis-formigen desEuler-Verfahrens.

9.5. Exercises – Ubungsergebnisse 483
12. Die Approximation y′ ≈ 12(yk+1 − yk−1) der Ableitung durch die zentrier- 366
ten Differenzen liefert das zweischrittige, sogenannte leap frog-Verfahrenyk+1 = yk−1 + 2f(tk,yk) zur Losung der Differentialgleichung y′ = f(t,y)mit y(to) = yo. Bestimme die Ordnung der Genauigkeit und den Stabi-litatsbereich dieses Verfahrens.
???
13. A sei eine der Einfachkeit halber diagonalisierbare n × n-Matrix. Wielauten die Losungen der linearen Differenzen-Gleichung xk+1 = Axk bzw.der Differentialgleichung y′ = Ay ? Welche Eigenschaft der Matrix Agarantiert, daß die Losungen der beiden Gleichungen fur jeden Startvektorxo bzw. yo beschrankt bleiben?
Die Losung der Differenzengleichung ist xk = Akxo, diejenige der Diffe-rentialgleichung y(t) =
∑ni=1 civie
λit wobei vi EV zum EW λi ist und∑ni=1 civi = yo gilt.
???
14. Gegeben die skalare, lineare, homogene Differentialgleichung k-ter Ordnung
f(t, u, u′, . . . , u(k)) = u(k) + ck−1u(k−1) + . . .+ c1u
′ + cou = 0
mit konstanten Koeffizienten cj und ck = 1. Gib Kriterien fur Stabilitatbzw. asymptotische Stabilitat dieser Differentialgleichung an. Hinweis:Transformiere die Differentialgleichung in ein System y′ = Ay von Dif-ferentialgleichungen erster Ordnung und nutze den Umstand, daß A einecompanion matrix ist.
Das aquivalente System von Differentialgleichungen erster Ordnung lautet 384
y′ =
y′1y′2...
y′k−1
y′k
=
y2
y3...yk
w
=
0 1 0 · · · 00 0 1 · · · 0...
. . . . . . . . ....
0 · · · 0 0 1−co −c1 · · · −ck−2 −ck−1
y1
y2...
yk−1
yk
= Ay
wobei y1 = u und zur Abkurzung w = −ck−1yk− . . .−c1y2−coy1 gesetzt ist.Damit ist die Koeffizienten-Matrix A eine companion matrix. Das charak-teristische Polynom det(A−λI) ist mit dem charakteristischen Polynom derDifferentialgleichung k-ter Ordnung in u identisch. Die EWe von A stim-men mit den Nullstellen dieses Polynoms uberein. f(t, u, u′, . . . , u(k)) = 0ist also stabil bzw. asymptotisch stabil, wenn <(λi) ≤ 0 bzw. <(λi) < 0 furalle k EWe λi von A.

484 KAPITEL 9. INITIAL VALUE PROBLEMS
9.6 Computer Problems –
Rechner-Problem-Losungen
1. a) Verwende Bibliotheksroutinen, um die Volterra-Lotka Differentialglei-387/388
chung der Beute-Jager-Populationen y′ =
(y1(α1 − β1y2)y2(−α2 + β2y1)
)fur t ∈ [0, 25]
sowie fur Konstanten α1 = 1, β1 = 0.1, α2 = 0.5 und β2 = 0.02 zu losen.Anfangs sei y1(0) = 100 und y2(0) = 10. Visualisiere die Losung y(t) so-wie die parametrisierte Kurve (y1(t), y2(t)), das sogenannte Phasen-Portraitoder Phasen-Diagramm. Erklare die Beobachtungen fur verschiedene An-fangsbedingungen. Gibt es nicht-triviale Anfangsbedingungen so, daß eineder Populationen schlußendlich ausstirbt? Gibt es Anfangsbedingungen so,daß sich das System von Anfang an nicht andert? Hinweis: Derartige sta-tionare Zustande konnen bestimmt werden, ohne die Differentialgleichungzu losen.
Die Beobachtungen sind auch als ’Schweine-Zyklus’ bekannt.
0 5 10 15 20 250
20
40
60
80
100
120Volterra−Lotka: Jäger−Beute−System mit ode45
t
Pop
ulat
ione
n
BeuteJäger
0 20 40 60 80 100 1200
5
10
15
20
25
30
Volterra−Lotka: Phasen−Diagramm z(t)=(y1(t),y2(t)) für 0 <= t <= 25
y1(t)
y 2(t)
Das Phasen-Diagramm fur diese Parameter zeigt einen nahezu periodischenVerlauf.
Die Differentialgleichung ist autonom, weil f(t,y) =
(y1(α1 − β1y2)y2(−α2 + β2y1)
)384
nicht explizit von t abhangt. Daher bestimmen die EWen der Jacobi-MatrixJf = (∂fi(t,y)
∂yj) von f bzgl. y Stabilitat oder Instabilitat der Differential-390
gleichung. Die Jacobi-Matrix Jf =
(α1 − β1y2 −β1y1
β2y2 −α2 + β2y1
)hat die EWe
???
Fur eine konstante Losung gilt y′ =
(y1(α1 − β1y2)y2(−α2 + β2y1)
)= 0. Aus y1(0) 6= 0
und y2(0) 6= 0 folgt daher y1(0) = α2/β2 = 25 und y2(0) = α1/β1 = 10.
b) Fuhre die Untersuchungen des Teils a) diesmal mit dem Leslie-Gower-

9.6. Computer Problems – Rechner-Problem-Losungen 485
Modell19 y′ =
(y1(α1 − β1y2)
y2(α2 − β2y2/y1)
)mit Konstanten α1 = 1, β1 = 0.1, α2 =
0.5 und β2 = 10 durch. Welche Unterschiede sind zu beobachten?
Offensichtlich strebt das System einem Gleichgewichtszustand zu.
0 5 10 15 20 250
50
100
150
200
250
300Leslie−Gower: Jäger−Beute−System mit ode45
t
Pop
ulat
ione
n
BeuteJäger
100 120 140 160 180 200 220 240 2607
7.5
8
8.5
9
9.5
10
10.5
11
11.5
Leslie−Gower: Phasen−Diagramm z(t)=(y1(t),y2(t)) für 0 <= t <= 25
y1(t)
y 2(t)
Die Differentialgleichung ist wie diejenige aus Teil a) autonom.???
Wie in Teil a) ergibt sich diesmal das stationare System und damit derGleichgewichtszustand fur y2(0) = α1
β1= 10 und y1(0) = α1
β1
β2
α2= 200.
2. Das Kermack-McKendrick-Modell20 beschreibt den Verlauf einer Epidemie
in einer Population anhand der Differentialgleichung y′ =
−c y1y2
c y1y2 − d y2
d y2
,
wo y1 die noch nicht infizierten Mitglieder, y2 die sich mit der Infektions-rate c infizierenden Mitglieder und y3 die Mitglieder der Population be-zeichnet, die mit der Rate d der Infektion durch Isolierung, Tod, Heilungoder Immunisierung entzogen werden. Verwende Bilbliotheksroutinen, umdie Differentialgleichung fur die Konstanten c = 1 und d = 5 sowie dieAnfangsbedingungen y1(0) = 95, y2(0) = 5 und y3(0) = 0 zu losen. Visua-lisiere die Losungen. Gibt es Parameter-Satze, fur die die Epidemie sichnicht ausweitet bzw. fur die die Infektion die ganze Population ausloscht?
20 W.O. Kermack, A.G. McKendrick: A Contribution to the Mathematical Theory of Epi-demics; Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathe-matical and Physical Character, Vol. 115, No. 772 (Aug. 1, 1927) , pp. 700-721dies.: Contributions to the Mathematical Theory of Epidemics. II. The Problem of Endemicity;a.a.O., Vol. 138, No. 834 (Oct. 1, 1932) , pp. 55-83dies.: Contributions to the Mathematical Theory of Epidemics. III. Further Studies of theProblem of Endemicity; a.a.O., Vol. 141, No. 843 (Jul. 3, 1933) , pp. 94-122

486 KAPITEL 9. INITIAL VALUE PROBLEMS
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
10
20
30
40
50
60
70
80
90
100Kermack−McKendrick: Population mit Epidemie per ode45
t
Pop
ulat
ione
n y 1, y
2, y3
unter Risikoinfiziertentzogen
Wenn y′2 < 0, d.h. wenn c y1(t) < d fur alle t, dann breitet sich die Epidemienicht aus. Die Differentialgleichung ist autonom und hat die Jacobi-Matrix
Jf =
−cy2 −cy1 0cy2 cy1 − d 00 d 0
mit den drei EWen 0 und 12(c(y1 − y2) − d ±
|c(y1 + y2)− d|).???
3. Gegeben y′ = −200 t y2 mit zwei verschiedenen Anfangsbedingungen y(0) =1 und y(−3) = 1/901. Experimentiere mit Bibliotheksroutinen, die dieSchrittweite automatisch anpassen. Untersuche und erlautere die Schritt-weiten und erklare das Verhalten der verwendeten Verfahren. Vergleichedie Effizienz der Verfahren bei gegebener Genauigkeit.
Die Losungsgesamtheit der Differentialgleichung ergibt sich durch Trennender Variablen zu y(t) = 1
c+100 t2. Dann ist y(t) = 1
1+100 t2spezielle Losung zu
jeder der beiden Anfangsbedingungen y(0) = 1 wie auch fur y(−3) = 1/901.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
t
y’ = −200 t y2 mit y(0)=1 per ode45 und ode23
y
exakte Lösungode45−Lösungode23−Lösungode45−Schrittweitenode23−Schrittweiten
−3 −2.5 −2 −1.5 −1 −0.5 0 0.5 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
t
y’ = −200 t y2 mit y(−3)=1/901 per ode45 und ode23
y
exakte Lösungode45−Lösungode23−Lösungode45−Schrittweitenode23−Schrittweiten
4. Die Differentialgleichung y′ =
−k1 0 0k1 −k2 00 k2 0
y1
y2
y3
= Ay beschreibt
die Reaktionskinematik dreier Stoffe (vgl. Beispiel auf S. 451).

9.6. Computer Problems – Rechner-Problem-Losungen 487
a) Wie sieht die Jacobi-Matrix aus? Welche EWe hat die Jacobi-Matrix?Wenn die Ubergangsraten als konstant und positiv angenommen werden,sind dann die Losungen stabil? Unter welchen Bedingungen ist die Diffe-rentialgleichung steif?
Die Jacobi-Matrix Jf (y) =(
∂fi(t,y)∂yj
)i,j
von f(t,y) = Ay ist Jf = A. Da
A untere Dreiecksmatrix ist, hat A die drei EWe λ1 = −k1, λ2 = −k2 undλ3 = 0. Damit gilt <(λi) ≤ 0 fur i = 1, 2, 3. Die Losungen sind also stabil,aber wegen λ3 = 0 nicht asymptotisch stabil. Die Differentialgleichung iststeif, wenn sich die Großenordnungen der EWe, d.h. diejenigen von k1 undk2 wesentlich unterscheiden.
b) Lose die Differentialgleichung fur die Anfangsbedingung yi(0) = 1 furi = 1, 2, 3 und fur Ubergangsraten k1 = 1 und k2 = 10, 100, 1000 numerischmit Runge-Kutta-Verfahren, Adams-Verfahren und Verfahren, die speziellfur die Losung steifer Differentialgleichungen entwickelt wurden.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.5
1
1.5
2
2.5
3
t
y 1,y2,y
3 und
Mas
senb
ilanz
−A
bwei
chun
gen
Reaktionskinetik für k2=10 per ode45, ode23 und ode113
ode45−Lösungode23−Lösungode113−Lösung
ode45: 1013(y1+y2+y3−3)
ode23: 1013(y1+y2+y3−3)
ode113: 1013(y1+y2+y3−3)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.5
1
1.5
2
2.5
3
t
y 1,y2,y
3 und
Mas
senb
ilanz
−A
bwei
chun
gen
Reaktionskinetik für k2=10 per ode15s, ode23s und ode23t
ode15s−Lösungode23s−Lösungode23t−Lösung
ode15s: 1013*(y1+y2+y3−3)
ode23s: 1013*(y1+y2+y3−3)
ode23t: 1013*(y1+y2+y3−3)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.5
1
1.5
2
2.5
3
t
y 1,y2,y
3 und
Mas
senb
ilanz
−A
bwei
chun
gen
Reaktionskinetik für k2=100 per ode45, ode23 und ode113
ode45−Lösungode23−Lösungode113−Lösung
ode45: 1013(y1+y2+y3−3)
ode23: 1013(y1+y2+y3−3)
ode113: 1013(y1+y2+y3−3)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.5
1
1.5
2
2.5
3
t
y 1,y2,y
3 und
Mas
senb
ilanz
−A
bwei
chun
gen
Reaktionskinetik für k2=100 per ode15s, ode23s und ode23t
ode15s−Lösungode23s−Lösungode23t−Lösung
ode15s: 1013(y1+y2+y3−3)
ode23s: 1013(y1+y2+y3−3)
ode23t: 1013(y1+y2+y3−3)
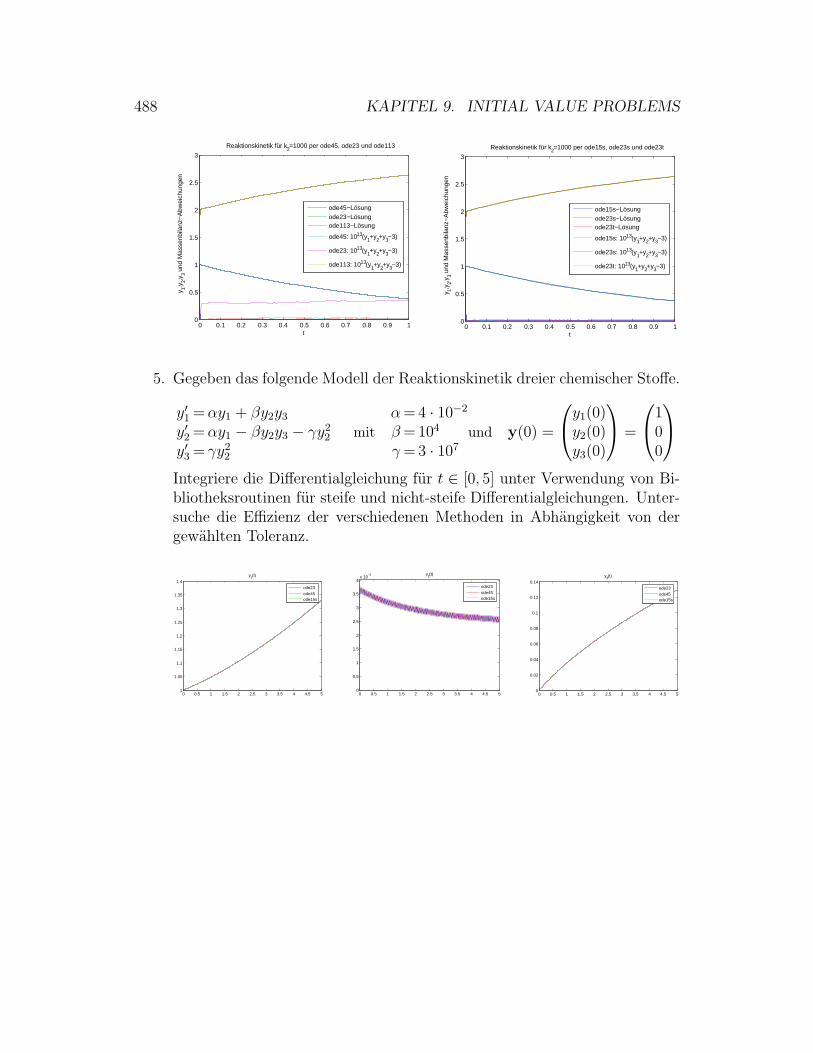
488 KAPITEL 9. INITIAL VALUE PROBLEMS
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.5
1
1.5
2
2.5
3
t
y 1,y2,y
3 und
Mas
senb
ilanz
−A
bwei
chun
gen
Reaktionskinetik für k2=1000 per ode45, ode23 und ode113
ode45−Lösungode23−Lösungode113−Lösung
ode45: 1013(y1+y2+y3−3)
ode23: 1013(y1+y2+y3−3)
ode113: 1013(y1+y2+y3−3)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.5
1
1.5
2
2.5
3
t
y 1,y2,y
3 und
Mas
senb
ilanz
−A
bwei
chun
gen
Reaktionskinetik für k2=1000 per ode15s, ode23s und ode23t
ode15s−Lösungode23s−Lösungode23t−Lösung
ode15s: 1013(y1+y2+y3−3)
ode23s: 1013(y1+y2+y3−3)
ode23t: 1013(y1+y2+y3−3)
5. Gegeben das folgende Modell der Reaktionskinetik dreier chemischer Stoffe.
y′1 =αy1 + βy2y3
y′2 =αy1 − βy2y3 − γy22
y′3 = γy22
mitα= 4 · 10−2
β= 104
γ= 3 · 107
und y(0) =
y1(0)y2(0)y3(0)
=
100
Integriere die Differentialgleichung fur t ∈ [0, 5] unter Verwendung von Bi-bliotheksroutinen fur steife und nicht-steife Differentialgleichungen. Unter-suche die Effizienz der verschiedenen Methoden in Abhangigkeit von dergewahlten Toleranz.
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 51
1.05
1.1
1.15
1.2
1.25
1.3
1.35
1.4
y1(t)
ode23ode45ode15s
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
0.5
1
1.5
2
2.5
3
3.5
4x 10
−5 y2(t)
ode23ode45ode15s
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
0.02
0.04
0.06
0.08
0.1
0.12
0.14
y3(t)
ode23ode45ode15s

Kapitel 10
Boundary Value Problems forOrdinary Differential Equations
10.0.1 Randwert-Probleme
Die Losung einer Differentialgleichung enthalt freie Integrationskonstanten. Erstweitere (Neben-) Bedingungen an die Losung, die Werte der Losung oder ihrerAbleitungen vorgeben, machen die Losung eindeutig. Wenn alle diese Bedingun-gen Werte in ein und demselben Punkt, etwa to, vorgeben, handelt es sich umein Anfangswert-Problem. Wenn dagegen die Bedingungen Vorgaben in mehrals einem Punkt machen, spricht man von einem Randwert-Problem, boundaryvalue problem. Wenn Vorgaben in genau zwei Punkten, typischerweise in denRandpunkten eines Intervalles, existieren, ist ein sogenanntes 2-Punkte Rand-wert-Problem zu losen.
Z.B. Newton F = ma fuhrt auf Differentialgleichungen zweiter Ordnung. IhreLosung weist zwei Integrationskonstanten auf. Es konnen also zwei Bedingungenan die Losung bedient werden. In einem Anfangswert-Problem werden etwa Po-sition und Geschwindigkeit in einem Startpunkt vorgegeben. Wenn Bedingungenwie Position oder Geschwindigkeit in einem initialen und einem abschließenden(Zeit-) Punkt aufgestellt sind, liegt ein Randwert-Problem vor. cWie im Beispiel hat allgemein eine Differentialgleichung k-ter Ordnung mit kNebenbedingungen eine eindeutige Losung. Wie im vorangegangenen Kapitelgezeigt, konnen wir jede Differentialgleichung k-ter Ordnung in ein System vonDifferentialgleichungen erster Ordnung transformieren.
Def. Ein gewohnliches 2-Punkte Randwert-Problem erster Ordnung hat allge-mein die Form
y′ = f(t,y) fur a < t < b mit Randbedingung(en) g(y(a),y(b)) = 0
wobei f : Rn+1 → Rn und g : R2n → Rn. Die Randbedingungen heißen separiert,
489

490 KAPITEL 10. BOUNDARY VALUE PROBLEMS
wenn jede Komponente von g nur von Losungswerten in einem und nicht inbeiden Randpunkten abhangt. Randbedingungen von der Form g(y(a),y(b)) =Bay(a) + Bby(b)− c = 0 fur n× n-Matrizen Ba und Bb und fur c ∈ Rn heißenlinear. Ein Randwert-Problem heißt linear, wenn sowohl die Differentialgleichungy′ = f(t,y) als auch die Randbedingung linear sind. Z.B. Das gewohnliche 2-Punkte Randwert-Problem zweiter Ordnungu′′ = f(t, u, u′) fur a < t < b mit Randbedingungen u(a) = α und u(b) = βist aquivalent zum System gewohnlicher Differentialgleichungen erster Ordnung(y′1y′2
)=
(y2
f(t, y1, y2)
)fur a < t < b mit separierter linearer Randbedingung
Bay(a) + Bby(b) =
(1 00 0
)(y1(a)y2(a)
)+
(0 01 0
)(y1(b)y2(b)
)=
(αβ
). c
Viele einschlagige physikalische Probleme haben genau diese Form, beispielsweise
• Biegen eines Balkens unter Last
• Potential zwischen zwei flachen Elektroden
• Temperatur-Verteilung in einer homogenen Wand mit festen Außentempe-raturen
• Konzentration (im Gleichgewicht) von Schadstoffen in porosem Erdboden
Auch die eindimensionale Poisson1-Gleichung, deren zweidimensionale Versionwir im nachsten Kapitel behandeln, hat obige Form.
10.0.2 Existenz, Eindeutigkeit, Konditionierung
Bei Anfangswert-Problemen liegt volle Information uber einen Anfangszustandvor, so daß unter geeigneten Bedingungen die Existenz genau einer exaktenLosung in einem kleinen Teilintervall garantiert ist und diese auf genau eineglobale Losung fortgesetzt werden kann. Genau diesen Umstand machen sich jaauch die Verfahren zur Losung von Anfangswert-Problemen zu Nutze.Im Gegensatz dazu gibt es bei Randwert-Problemen keinen Zeitpunkt, in demder Zustand vollstandig bekannt ist. Ein Fortschreiten von einer Losung zu ei-nem Zeitpunkt zu der zu einem ’benachbarten’ Zeitpunkt – von einer lokalen zueiner globalen Losung – ist daher nicht moglich. Daher uberrascht uns nicht, daßExistenz und Eindeutigkeit der Losung eines Randwert-Problems viel diffizilerals bei Anfangswert-Problemen zu garantieren sind.
1 Simeon Denis Poisson (1781-1840) www-history.mcs.st-andrews.ac.uk/Biographies/Poisson.html

491
Randwert-Probleme mussen keine Losungen haben und Losungen von Randwert-Problemen mussen auch nicht notwendig eindeutig sein, wie das folgende Beispielzeigt.
Z.B. Gegeben das 2-Punkte Randwert-Problem u′′ = −u fur 0 < t < b mitRandwert-Bedingungen u(0) = 0 und u(b) = β. Losungen des Anfangswert-Pro-blems u′′ = −u mit u(0) = 0 sind die Funktionen u(t) = c sin t fur alle c ∈ R.Falls nun b ein Vielfaches von π ist, so verschwindet c sin b fur alle c ∈ R. Wennalso β = 0, wenn das Verschwinden der Losung in b also gerade von der Randwert-Bedingung gefordert wird, so gibt es unendlich viele Losungen. Wenn dagegenβ 6= 0, so existiert keine Losung des Randwert-Problems. cBetrachten wir das allgemeine gewohnliche zwei-Punkte Randwert-Problem er-ster Ordnung y′ = f(t,y) fur a < t < b mit Randbedingungen g(y(a),y(b)) = 0und sei y(t,x) die Losung des Anfangswert-Problems y′ = f(t,y) mit y(a) =x. Eine solche Losung y(t,x) ist eine Losung des Randwert-Problems, wenng(x,y(b,x)) = 0. Die Losbarkeit des Randwert-Problems fallt hier also mit der
Losbarkeit der nichtlinearen algebraischen Gleichung h(x) = g(x,y(b,x)) = 0zusammen. Wie wir in Kapitel 5 gesehen haben, laßt sich die Losbarkeit nichtli-nearer Gleichungen und damit eben auch die Losbarkeit von Randwert-Problemenallgemein nicht vorhersagen.
Im Fall von linearen Randwert-Problemen dagegen konnen wir leicht Bedingun-gen fur Existenz und Eindeutigkeit aufstellen: Sei yi(t) die Losung des linearen,homogenen Anfangswert-Problems y′ = A(t)y mit Anfangsbedingung y(a) = ei.Hier ist ei der i-te kanonische Basis-Vektor, d.h. die i-te Spalte der Einheitsma-trix. Sei weiter Y(t) = (y1(t), . . . ,yn(t)). Die Matrix Y heißt ubrigens funda-mentale Losungsmatrix des Anfangswert-Problems y′ = A(t)y mit y(a) = ei.Dann hat das lineare Randwert-Problem
y′ = A(t)y + b(t) fur a < t < b
mit stetigen A(t) und b(t) und Anfangsbedingungen Bay(a) + Bby(b) − c = 0eine eindeutige Losung genau dann, wenn Q := BaY(a) + BbY(b) regular ist.
Z.B. Das gewohnliche zwei-Punkte Randwert-Problem zweiter Ordnung des vo-rigen Beispiels ist aquivalent zum linearen Randwert-Problem erster Ordnung(y′1y′2
)=
(0 1
−1 0
)(y1
y2
)fur 0 < t < b mit separierter linearer Randbedingung
B0y(0) + Bby(b) =
(1 00 0
)(y1(0)y2(0)
)+
(0 01 0
)(y1(b)y2(b)
)=
(0β
). Die funda-
mentale Losungsmatrix ist Y(t) =
(cos t sin t
− sin t cos t
)und Q =
(1 00 0
)(1 00 1
)+(
0 01 0
)(cos b sin b
− sin b cos b
)=
(1 0
cos b sin b
)ist regular genau dann, wenn b ein
Vielfaches von π ist. c

492 KAPITEL 10. BOUNDARY VALUE PROBLEMS
Wenn also obiges Q regular ist, dann ist
y(t) = Y(t)Q−1
(c−BbY(b)
∫ b
a
Y−1(s)b(s) ds
)+ Y(t)
∫ t
a
Y−1(s)b(s) ds
die eindeutige Losung des allgemeinen gewohnlichen zwei-Punkte Randwert-Pro-blems, weil y(t) wegen Y′ = A(t)Y und
y′(t) =
(Y(t)Q−1
(c−BbY(b)
∫ b
a
Y−1(s)b(s) ds
)+ Y(t)
∫ t
a
Y−1(s)b(s) ds
)′= Y′(t)Q−1
(c−BbY(b)
∫ b
a
Y−1(s)b(s) ds
)+Y′(t)
∫ t
a
Y−1(s)b(s) ds+ Y(t)Y−1(t)b(t)
= A(t)Y(t)Q−1
(c−BbY(b)
∫ b
a
Y−1(s)b(s) ds
)+A(t)Y(t)
∫ t
a
Y−1(s)b(s) ds+ b(t)
= A(t)y(t) + b(t)
die Differentialgleichung lost und weil y(t) wegen
Bay(a) + Bby(b) = BaY(a)Q−1
(c−BbY(b)
∫ b
a
Y−1(s)b(s) ds
)+BbY(b)Q−1
(c−BbY(b)
∫ b
a
Y−1(s)b(s) ds
)+BbY(b)
∫ b
a
Y−1(s)b(s) ds
= c
auch die Randbedingung befriedigt. Um nun die Kondition eines Randwert-Problems zu bestimmen, reskalieren wir die fundamentale Losungsmatrix unddefinieren zunachst
Φ(t) = Y(t)Q−1
und dann die Green2-Funktion
G(t, s) =
Φ(t)BaΦ(a)Φ−1(s) falls a ≤ s ≤ t−Φ(t)BbΦ(b)Φ−1(s) falls t < s ≤ b
so daß sich die eindeutige Losung des Randwert-Problems kompakt als
Y(t) = Y(t)Q−1
(c−BbY(b)
∫ b
a
Y−1(s)b(s) ds
)+ Y(t)
∫ t
a
Y−1(s)b(s) ds
2 George Green (1793-1841) www-history.mcs.st-andrews.ac.uk/Biographies/Green.html

493
= Φ(t)c−Y(t)Q−1BbY(b)
(∫ t
a
Y−1(s)b(s) ds+
∫ b
t
Y−1(s)b(s) ds
)+Y(t)Q−1(BaY(a) + BbY(b))
∫ t
a
Y−1(s)b(s) ds
= Φ(t)c−Y(t)Q−1BbY(b)
∫ b
t
Q−1QY−1(s)b(s) ds
+Y(t)Q−1BaY(a)
∫ t
a
Q−1QY−1(s)b(s) ds
= Φ(t)c +
∫ t
a
Φ(t)BaΦ(a)Φ−1(s) ds−∫ b
t
Φ(t)BbΦ(b)Φ−1(s) ds
= Φ(t)c +
∫ b
a
G(t, s) ds
darstellen und sich die Losung y(t) durch
||y||∞ = ||Φ(t)c +
∫ b
a
G(t, s) ds||∞ ≤ ||Φ(t)c||∞ + ||∫ b
a
G(t, s) ds||∞
≤ κ
(|c|+
∫ b
a
|b(s)| ds)
mit κ = max(||Φ||∞, ||G||∞)
beschranken laßt.Gegeben das teilweise gestorte Randwert-Problem y′ = A(t)y+b(t) fur a < t < bund mit teilweise gestorter Randbedingung Bay(a) + Bby(b) = c. Dann lost die’gestorte’ Losung z(t) := y(t)− y(t) das Randwert-Problem
z′ = A(t)z + ∆b(t) fur a < t < b mit ∆b(t) := b(t)− b(t)
und mit Randbedingung Bay(a) + Bby(b) = ∆c := c− c, so daß wir die Abwei-chung z in der Losung des Randwert-Problems durch
||z||∞ ≤ κ
(|∆c|+
∫ b
a
|∆b(s)| ds)
abschatzen konnen. Die Große κ = max(||Φ||∞, ||G||∞) ist also die absolute Kon-ditionszahl des Randwert-Problems bzgl. Storungen in den inhomogenen Termenvon Differentialgleichung und Randbedingung. Ahnliche, wenn auch komplizier-tere Verhaltnisse liegen vor, wenn auch A(t) sowie Ba und Bb gestort sind.
. . .
Z.B. Das Anfangswert-Problem y′ =
(y′1y′2
)=
(λ 00 −λ
)(y1
y2
)= Ay mit y(0) =
yo hat die Losung y(t) mit y1(t) = (yo)1eλt und y2(t) = (yo)2e
−λt. Fur <(λ) 6= 0ist also immer eine Losung instabil.
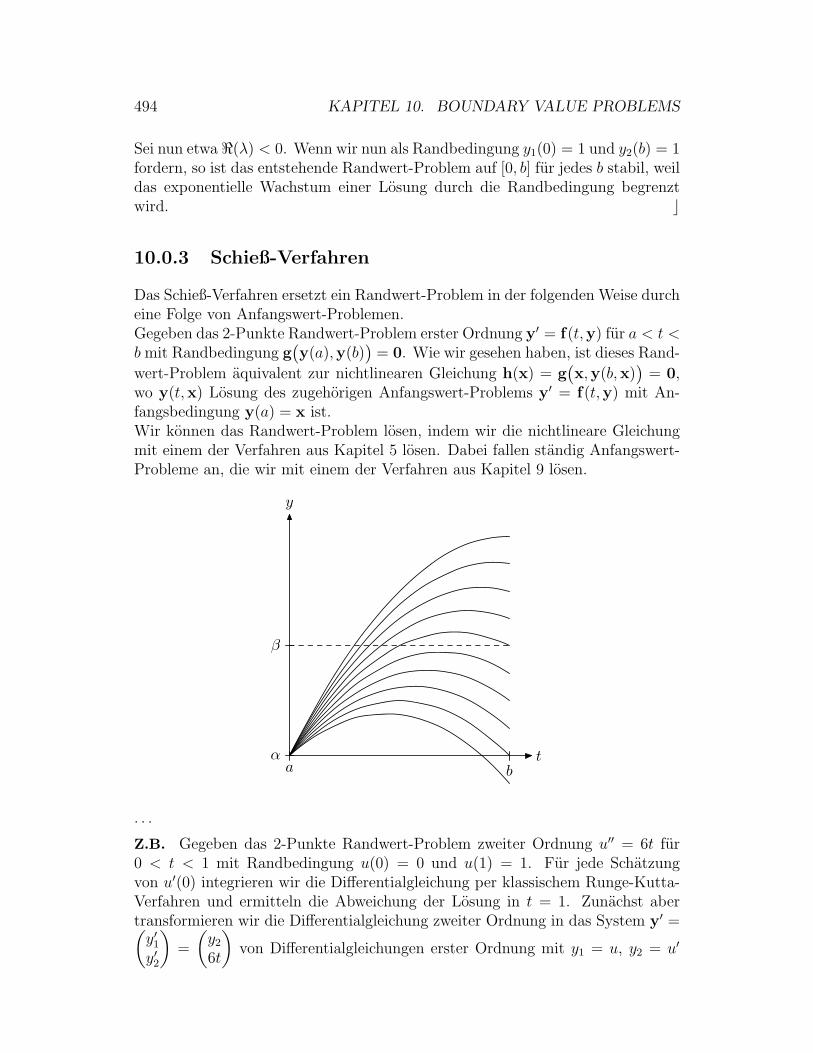
494 KAPITEL 10. BOUNDARY VALUE PROBLEMS
Sei nun etwa <(λ) < 0. Wenn wir nun als Randbedingung y1(0) = 1 und y2(b) = 1fordern, so ist das entstehende Randwert-Problem auf [0, b] fur jedes b stabil, weildas exponentielle Wachstum einer Losung durch die Randbedingung begrenztwird. c
10.0.3 Schieß-Verfahren
Das Schieß-Verfahren ersetzt ein Randwert-Problem in der folgenden Weise durcheine Folge von Anfangswert-Problemen.Gegeben das 2-Punkte Randwert-Problem erster Ordnung y′ = f(t,y) fur a < t <b mit Randbedingung g(y(a),y(b)) = 0. Wie wir gesehen haben, ist dieses Rand-
wert-Problem aquivalent zur nichtlinearen Gleichung h(x) = g(x,y(b,x)) = 0,wo y(t,x) Losung des zugehorigen Anfangswert-Problems y′ = f(t,y) mit An-fangsbedingung y(a) = x ist.Wir konnen das Randwert-Problem losen, indem wir die nichtlineare Gleichungmit einem der Verfahren aus Kapitel 5 losen. Dabei fallen standig Anfangswert-Probleme an, die wir mit einem der Verfahren aus Kapitel 9 losen.
t
y
a bα
β
. . .
Z.B. Gegeben das 2-Punkte Randwert-Problem zweiter Ordnung u′′ = 6t fur0 < t < 1 mit Randbedingung u(0) = 0 und u(1) = 1. Fur jede Schatzungvon u′(0) integrieren wir die Differentialgleichung per klassischem Runge-Kutta-Verfahren und ermitteln die Abweichung der Losung in t = 1. Zunachst abertransformieren wir die Differentialgleichung zweiter Ordnung in das System y′ =(y′1y′2
)=
(y2
6t
)von Differentialgleichungen erster Ordnung mit y1 = u, y2 = u′
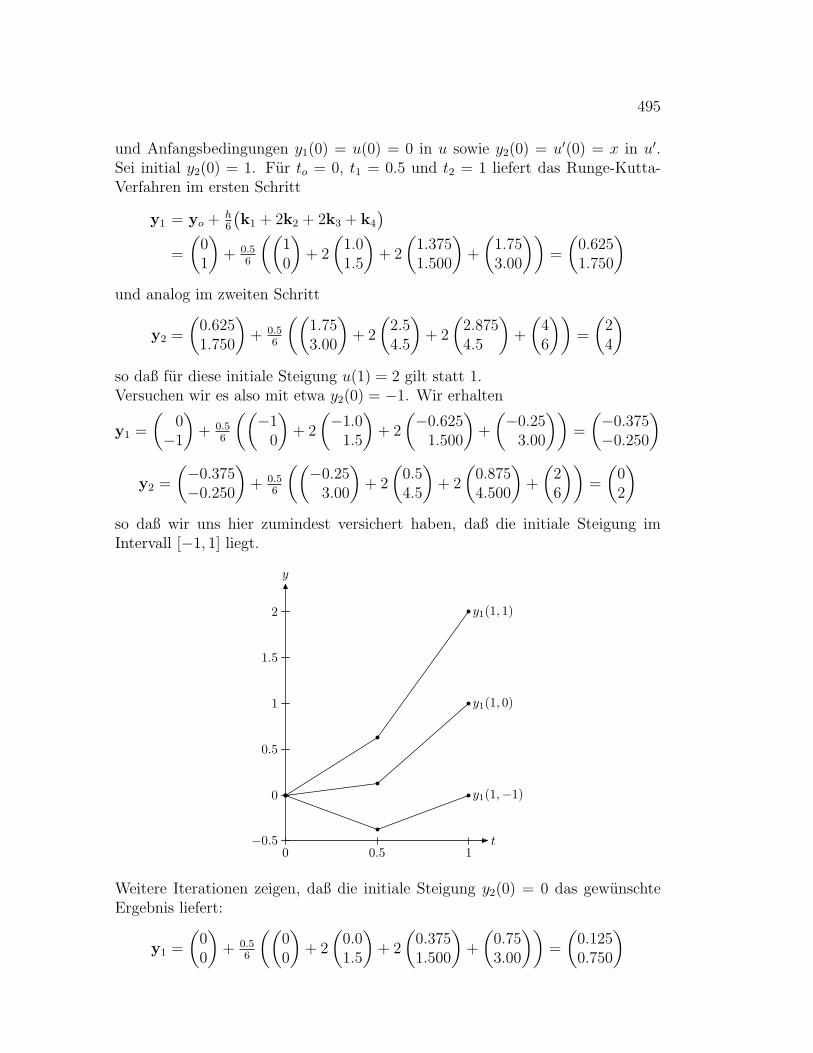
495
und Anfangsbedingungen y1(0) = u(0) = 0 in u sowie y2(0) = u′(0) = x in u′.Sei initial y2(0) = 1. Fur to = 0, t1 = 0.5 und t2 = 1 liefert das Runge-Kutta-Verfahren im ersten Schritt
y1 = yo + h6(k1 + 2k2 + 2k3 + k4)
=
(01
)+ 0.5
6
((10
)+ 2
(1.01.5
)+ 2
(1.3751.500
)+
(1.753.00
))=
(0.6251.750
)und analog im zweiten Schritt
y2 =
(0.6251.750
)+ 0.5
6
((1.753.00
)+ 2
(2.54.5
)+ 2
(2.8754.5
)+
(46
))=
(24
)so daß fur diese initiale Steigung u(1) = 2 gilt statt 1.Versuchen wir es also mit etwa y2(0) = −1. Wir erhalten
y1 =
(0
−1
)+ 0.5
6
((−1
0
)+ 2
(−1.0
1.5
)+ 2
(−0.625
1.500
)+
(−0.25
3.00
))=
(−0.375−0.250
)
y2 =
(−0.375−0.250
)+ 0.5
6
((−0.25
3.00
)+ 2
(0.54.5
)+ 2
(0.8754.500
)+
(26
))=
(02
)so daß wir uns hier zumindest versichert haben, daß die initiale Steigung imIntervall [−1, 1] liegt.
t
y
0 0.5 1−0.5
0
0.5
1
1.5
2 y1(1, 1)
y1(1,−1)
y1(1, 0)
Weitere Iterationen zeigen, daß die initiale Steigung y2(0) = 0 das gewunschteErgebnis liefert:
y1 =
(00
)+ 0.5
6
((00
)+ 2
(0.01.5
)+ 2
(0.3751.500
)+
(0.753.00
))=
(0.1250.750
)

496 KAPITEL 10. BOUNDARY VALUE PROBLEMS
y2 =
(0.1250.750
)+ 0.5
6
((0.753.00
)+ 2
(1.54.5
)+ 2
(1.8754.500
)+
(36
))=
(13
)Die obige Darstellung zeigt y1(t, 1), y1(t,−1) und y1(t, 0) fur t = 0, 0.5, 1. cFur das Schieß-Verfahren spricht, daß wir es mit vorhandener Software einfachimplementieren konnen; dagegen spricht, daß das Schieß-Verfahren Stabilitat oderInstabilitat des zugehorigen Anfangswert-Problems erbt: dieses kann instabilsein, obwohl das Randwert-Problem stabil ist. Die (schlechte) Konditionierungdes Anfangswert-Problems kann die Konvergenz des Losungsverfahren der nicht-linearen Gleichung gefahrden. Daruberhinaus kann fur bestimmte Schatzungenvon y(a) = x die Losung des Anfangswert-Problems etwa wegen eines Pols in
???b nur fur Teile des Intervalls [a, b] existieren. Abhilfe schafft in gewissem Maßmultiple shooting, d.h. das Intervall [a, b] in Teilintervalle zu unterteilen und dasSchieß-Verfahren in jedem Teilintervall separat durchzufuhren. Die Forderungnach Stetigkeit in den Stoßstellen liefert dabei die Randbedingungen fur die ein-zelnen Randwert-Probleme.
10.0.4 Finite-Differenzen-Verfahren
Das Schieß-Verfahren lost ein Randwert-Problem, indem es die zugehorige Dif-ferentialgleichung fur verschiedene Anfangsbedingungen lost, bis die Randbedin-gung erfullt ist. Das Finite-Differenzen-Verfahren dagegen befriedigt die Rand-bedingung von Anfang an und lost iteriert solange, bis die zugehorige Differenti-algleichung annahernd erfullt ist. Dazu wird die Differentialgleichung durch finiteDifferenzen in Systeme algebraischer Gleichungen uberfuhrt, deren Losungen dieLosung der Differentialgleichung approximieren.
Konkret unterteilt das Finite-Differenzen-Verfahren das Integrationsintervall [a, b]durch Gitterpunkte und ersetzt die Ableitungen in der Differentialgleichung durchApproximationen durch finite Differenzen. Fur ein skalares 2-Punkte Rand-wert-Problem zweiter Ordnung u′′ = f(t, u, u′) fur a < t < b mit Randbe-dingung u(a) = α und u(b) = β fuhren wir also Gitter-Punkte ti = a + ihmit i = 0, 1, . . . , n + 1 und h = b−a
n+1ein und bestimmen Naherungslosungen
yi ≈ u(ti). Wenn die Randbedingung grundsatzlich immer erfullt sein soll, mußyo = u(a) = α und yn+1 = u(b) = β gelten. In der Differentialgleichung ersetzenwir
u′(ti) ≈yi+1 − yi−1
2hund u′(ti) ≈
yi+1 − 2yi + yi−1
h2
(der Fehler beider finite Differenzen Approximationen ist O(h2), wie wir in Ka-pitel 8 gesehen haben) und erhalten das System algebraischer Gleichungen
yi+1 − 2yi + yi−1
h2= f(ti, yi,
yi+1 − yi−1
2h) fur i = 1, . . . , n

497
dessen Losung yi die Losung des Randwert-Problems in allen Gitter-Punktengleichzeitig annahert.
. . .
Z.B. Betrachten wir wieder das Randwert-Problem u′′ = 6t fur 0 < t < 1 mitRandbedingung u(0) = 0 und u(1) = 1. Fur n = 1 und h = 0.5 erhalten wirdrei Gitterpunkte to = 0, t1 = 0.5 und t2 = 1. Aufgrund der Randbedingung giltyo = u(to) = 0 und y2 = u(t2) = 1. Wir suchen also y1 ≈ u(t1).
yi+1 − 2yi + yi−1
h2= f(ti, yi,
yi+1 − yi−1
2h) fur i = 1, . . . , n
reduziert sich auf die einzige Gleichung 1−2y1+00.52 = 6t1 oder 4 − 8y1 = 3 und
damit u(0.5) ≈ y1 = 18, was im ubrigen auch mit y(0.5, 0) des Schieß-Verfahrens
ubereinstimmt. cSelbstverstandlich werden wir typischerweise wesentlich mehr Gitter-Punkte brau-chen, um eine akzeptable Genauigkeit zu erzielen. Die Erwartung, daß yi → u(ti)konvergiert, wenn man nur die Anzahl der Gitter-Punkte uber jede Schranke stei-gert, bedingt auch, daß die finiten Differenzen konsistent (d.h. der Diskretisie-rungsfehler geht mit h gegen Null) und stabil (d.h. die Wirkung kleiner Storungenbleibt beschrankt) sind.
10.0.5 Kollokationsverfahren
. . .
Fur ein skalares 2-Punkte Randwert-Problem zweiter Ordnung u′′ = f(t, u, u′)fur a < t < b mit Randbedingung u(a) = α und u(b) = β suchen wir eineNaherungslosung v der Form
u(t) ≈ v(t,x) =n∑
i=1
xiφi(t)
mit auf [a, b] definierten Basis-Funktionen φi. Ubliche Basis-Funktionen sindPolynome, B-Splines oder trigonometrische Funktionen. Wenn die Randbedin-gungen homogen sind, d.h. falls α = 0 = β, und wenn die Basis-Funktionen dieseRandbedingungen sowieso schon erfullen, so erfullt praktischerweise auch jedeLinear-Kombination der Basis-Funktionen die Randbedingungen. Sonst bestim-men wir eben x so, daß v(t,x) auch gleich die Randbedingung erfullt.
Wir definieren dazu n sogenannte Kollokationspunkte a = t1 < t2 < . . . < tn = bund bestimmen x so, daß v(t,x) in t1 und tn die Randbedingung und in jedeminneren Kollokationspunkt die Differentialgleichung erfullt. Am einfachsten legenwir Kollokationspunkte aquidistant fest. Allerdings sind im Fall von polynomia-len Basis-Funktionen Chebychev-Punkte die bessere Wahl, wie wir im Kapitel 7

498 KAPITEL 10. BOUNDARY VALUE PROBLEMS
gesehen haben.Auf jeden Fall konnen wir v(t,x) analytisch differenzieren. In die Differential-gleichung eingesetzt, erhalten wir ein System von n algebraischen Gleichungen
v(t1,x) = αv′′(ti,x) = f(ti, v(ti,x), v′(ti,x)) fur i = 2, . . . , n− 1v(tn,x) = β
Das Gleichungssystem ist wie f linear oder nichtlinear.
Z.B. Betrachten wir wieder das Randwert-Problem u′′ = 6t fur 0 < t < 1 mitRandbedingung u(0) = 0 und u(1) = 1. Fur n = 3 erhalten wir drei aquidistanteKollokationspunkte t1 = 0, t2 = 0.5 und t3 = 1. Wenn wir als Basis-Funktionendie ersten drei Monome wahlen, hat die Losung die Form v(t,x) = x1 +x2t+x3t
2
mit Ableitungen v′(t,x) = x2 + 2x3t und v′′(t,x) = 2x3. Randbedingungen undErfulltsein der Differentialgleichung in t2 liefern
x1 + x2t1 + x3t21 = v(t1,x) = 0 ⇒ x1 = 0
2x3 = v′′(t2,x) = f(t2, v(t2,x), v′(t2,x)) = 6t2 = 3 ⇒ x3 = 1.5x2 + 1.5 = x2t3 + x3t
23 = v(t3,x) = 1 ⇒ x2 = −0.5
Also ist v(t,x) = −0.5t+1.5t2 mit u(0.5) ≈ v(0.5,x) = −0.5·0.5+1.5·0.25 = 0.125
t
y
0 0.5 10
0.5
1
u(t)v(t,x)
in Ubereinstimmung mit den Ergebnissen von Schieß-Verfahren und Finite-Dif-ferenzen-Verfahren. c. . .

499
10.0.6 Galerkin-Verfahren
Die Losung eines Randwert-Problems, die das Kollokationsverfahren erzeugt,erfullt die Differentialgleichung in den inneren Kollokationspunkten, d.h. das Re-siduum in diesen Punkten verschwindet. Wir konnten daher bestrebt sein, eingeeignetes Residuum uber den gesamten Integrationsbereich zu minimieren.Betrachten wir beispielsweise die skalare, eindimensionale Poisson3-Gleichungu′′ = f(t) fur a < t < b mit homogenen Randbedingungen u(a) = 0 = u(b)und approximieren die Losung durch eine Linearkombination u(t) ≈ v(t,x) =∑n
i=1 xiφi(t) von Basis-Funktionen. Wir definieren das Residuum durch
r(t,x) = v′′(t,x)− f(t) =n∑
i=1
xiφ′′i (t)− f(t)
Wie bei einem linear least squares Problem minimieren wir
F (x) = 12
∫ b
a
r2(t,x) dt
indem wir die Nullstellen des Gradienten gradF bestimmen:
0 =∂F
∂xi
=
∫ b
a
r(t,x)∂r
∂xi
dt =
∫ b
a
r(t,x)φ′′i (t) dt
=
∫ b
a
(n∑
j=1
xiφ′′j (t)− f(t)
)φ′′i (t) dt
=n∑
j=1
(∫ b
a
φ′′j (t)φ′′i (t) dt
)xj −
∫ b
a
f(t)φ′′i (t) dt
Wenn wir nun ai,j =∫ b
aφ′′j (t)φ
′′i (t) dt und bi =
∫ b
af(t)φ′′i (t) dt setzen, so entpuppt
sich x als Losung der linearen Gleichung Ax = b mit A = (ai,j) und b = (bi).Die Integrale in den Definitionen von A bzw. b konnen wir dabei analytisch odernumerisch bestimmen.
Verallgemeinernd nehmen wir an, daß es n Test- oder Gewichtungsfunktionenwi(t) orthogonal zum Residuum r(t,x) = v′′(t,x) − f(t) =
∑nj=1 xjφ
′′j (t) − f(t)
gibt, d.h.∫ b
ar(t,x)wi(t) dt = 0 fur alle i = 1, . . . , n, so daß fur i = 1, . . . , n
0 =
∫ b
a
r(t,x)wi(t) dt =
∫ b
a(v′′(t,x)− f(t))wi(t) dt
=
∫ b
a
(n∑
j=1
xjφ′′j (t)− f(t)
)wi(t) dt =
n∑j=1
xj
∫ b
a
φ′′j (t)wi(t) dt−∫ b
a
f(t)wi(t) dt
3 Simeon Denis Poisson (1781-1840) www-history.mcs.st-andrews.ac.uk/Biographies/Poisson.html

500 KAPITEL 10. BOUNDARY VALUE PROBLEMS
gilt. Wir konnen diese n Gleichungen als System Ax = b linearer Gleichungenmit A = (ai,j)i,j=1,...,n
wobei ai,j =∫ b
aφ′′j (t)wi(t) dt und b = (bi)i=1,...,n
wobei
bi =∫ b
af(t)wi(t) dt schreiben.
Obige Formulierung als linear least squares Problem stellt sich mit wi = φ′′i alsSpezialfall des allgemeinen Falles heraus. Ebenso konnen wir das Kollokationsver-fahren mit wi = δ(t− ti) als Spezialfall auffassen, wobei δ(t) die Dirac4-Funktion
(eigentlich eine Distribution) mit δ(s) = 0 fur s 6= 0 und∫ b
af(t)δ(t− s) dt = f(s)
bezeichnet.
Die Matrix A dieses Ansatzes mit gewichtetem Residuum ist im Allgemeinennicht symmetrisch. Außerdem sind zweite Ableitungen der Basis-Funktionen in-volviert. Beidem hilft das Galerkin5-Verfahren ab, indem als Wichtungsfunktio-nen die Basis-Funktionen gewahlt werden, d.h. wi = φi. Die Orthogonalitatsbe-dingung lautet dann
0 =
∫ b
a
r(t,x)φi(t) dt =
∫ b
a(v′′(t,x)− f(t))φi(t) dt fur i = 1, . . . , n
Partielle Integration liefert∫ b
a
v′′(t,x)φi(t) dt = v(t,x)′(t)φi(t)|ba −∫ b
a
v′(t,x)φ′i(t) dt
Wenn wir annehmen, daß die Basis-Funktionen homogene Randbedingungen be-friedigen, d.h. φi(a) = 0 = φi(b) fur i = 1, . . . , n, dann schreiben sich dieOrthogonalitatsbedingungen einfach als
−∫ b
a
v′(t,x)φ′i(t) dt =
∫ b
a
f(t)φi(t) dt fur i = 1, . . . , n
−∫ b
a
v′(t,x)φ′i(t) dt = −∫ b
a
n∑j=1
xjφ′j(t)φ
′i(t) dt
= −n∑
j=1
(∫ b
a
φ′j(t)φ′i(t) dt
)xj =
∫ b
a
f(t)φi(t) dt
Mit A = (ai,j)i,j=1,...,nwobei ai,j = −
∫ b
aφ′j(t)φ
′i(t) dt und b = (bi)i=1,...,n
wobei
bi =∫ b
af(t)φi(t) dt ergibt sich also x wieder als Losung der linearen Gleichung
Ax = b. Diesmal ist A allerdings symmetrisch und es sind nur erste Ableitungender Basis-Funktionen involviert.
4 Paul Adrien Maurice Dirac (1902-1984) www-history.mcs.st-andrews.ac.uk/Biographies/Dirac.html
5 Boris Grigorievich Galerkin (1871-1945) www-history.mcs.st-andrews.ac.uk/Biographies/Galerkin.html
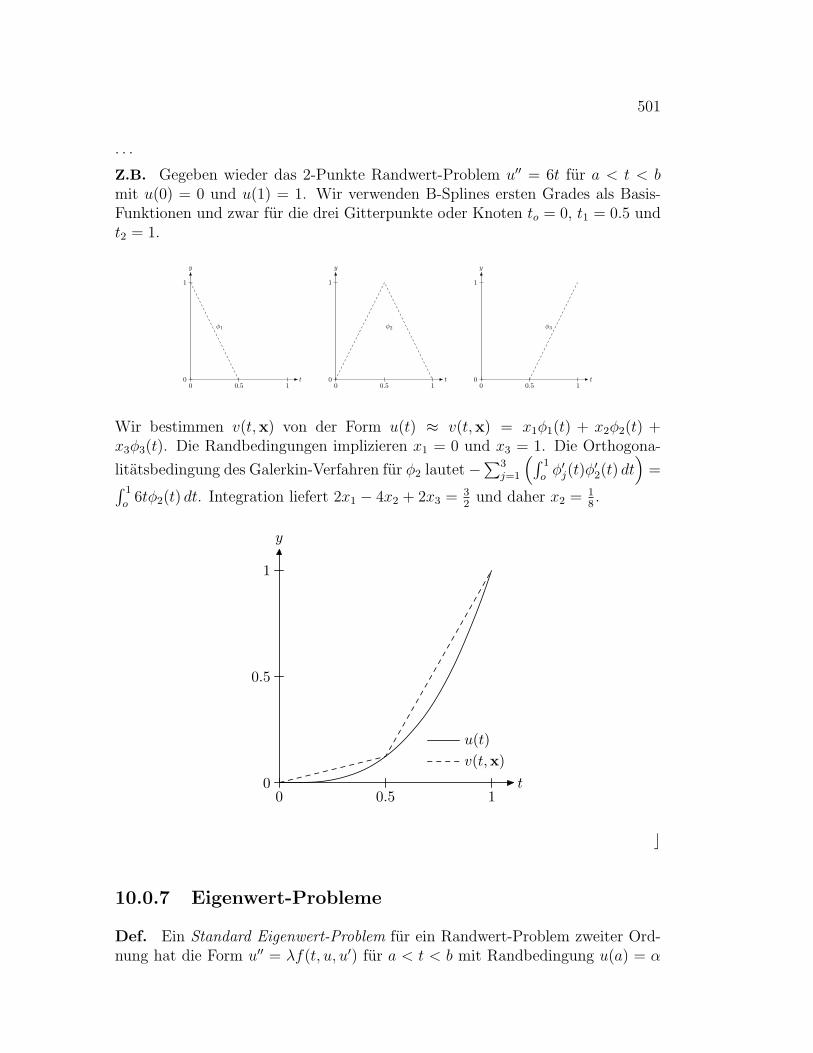
501
. . .
Z.B. Gegeben wieder das 2-Punkte Randwert-Problem u′′ = 6t fur a < t < bmit u(0) = 0 und u(1) = 1. Wir verwenden B-Splines ersten Grades als Basis-Funktionen und zwar fur die drei Gitterpunkte oder Knoten to = 0, t1 = 0.5 undt2 = 1.
t
y
0 0.5 10
1
φ1
t
y
0 0.5 10
1
φ2
t
y
0 0.5 10
1
φ3
Wir bestimmen v(t,x) von der Form u(t) ≈ v(t,x) = x1φ1(t) + x2φ2(t) +x3φ3(t). Die Randbedingungen implizieren x1 = 0 und x3 = 1. Die Orthogona-
litatsbedingung des Galerkin-Verfahren fur φ2 lautet−∑3
j=1
(∫ 1
oφ′j(t)φ
′2(t) dt
)=∫ 1
o6tφ2(t) dt. Integration liefert 2x1 − 4x2 + 2x3 = 3
2und daher x2 = 1
8.
t
y
0 0.5 10
0.5
1
u(t)v(t,x)
c
10.0.7 Eigenwert-Probleme
Def. Ein Standard Eigenwert-Problem fur ein Randwert-Problem zweiter Ord-nung hat die Form u′′ = λf(t, u, u′) fur a < t < b mit Randbedingung u(a) = α

502 KAPITEL 10. BOUNDARY VALUE PROBLEMS
und u(b) = β. Gesucht sind u(t) und der Skalar λ. Die Losung u(t) heißt Eigen-funktion des 2-Punkte Randwert-Problems. Der ggfls. komplexe Skalar λ heißtEigenwert des 2-Punkte Randwert-Problems. Es gibt ubrigens verallgemeinerte Eigenwert-Probleme zu Randwert-Problemenvon hoherer Ordnung, in impliziter Form, mit verallgemeinerten Randbedingun-gen oder mit nichtlinearer Abhangigkeit von λ.
Betrachten wir hier beispielsweise das lineare 2-Punkte Randwert-Problem zwei-ter Ordnung u′′ = λg(t)u fur a < t < b mit homogenen Randbedingungenu(a) = 0 = u(b). Wenn wir wieder Gitter-Punkte ti = a+ih fur i = 0, 1, . . . , n+1mit h = b−a
n+1definieren und die zweiten Ableitungen durch die kanonischen finiten
Differenzen approximieren, erhalten wir das System algebraischer Gleichungen
yo =u(to)=0yi+1 − 2yi + yi−1
h2=λgiyi fur i = 1, 2, . . . , n yn+1 =u(tn+1)=0
wobei yi ≈ u(ti) und zur Abkurzung gi = g(ti) gesetzt ist. Angenommen, gi 6= 0fur alle i = 1, . . . , n. Dann konnen wir die i-te Gleichung durch gi dividieren underhalten das algebraische EW-Problem Ay = λy. Dabei ist A tridiagonal mit
A =
−2/g1 1/g1 0 · · · 0
1/g2 −2/g2 1/g2. . .
...
0. . . . . . . . . 0
.... . . 1/gn−1 −2/gn−1 1/gn−1
0 · · · 0 1/gn −2/gn
Wir konnen das Problem mit einem der Verfahren aus Kapitel 4 oder als verall-gemeinertes EW-Problem losen.

10.1. Review Questions – Verstandnisfragen 503
10.1 Review Questi-
ons – Verstand-
nisfragen
1. Welches spezifische Merkmal un-terscheidet Randwert-Probleme vonAnfangswert-Problemen?
2. Was sind separierte Randwert-Bedingungen?
3. Hat ein Randwert-Problem zu einergewohnlichen Differentialgleichungimmer eine eindeutige Losung?
4. Ist die Stabilitat eines Randwert-Problems immer dieselbe wie die deszugehorigen Anfangswert-Problemszur selben Differentialgleichung?
5. Wie kann ein Verfahren zur Nullstel-lenbestimmung von Funktionen ei-ner Veranderlichen verwendet wer-den, um das 2-Punkte Randwert-Problem u′′ = f(t, u, u′) mit u(a) =α und u(b) = β zu losen?
6. Das Schieß-Verfahren und Finite-Differenzen-Verfahren sind zwei ite-rative Verfahren zur Losung nicht-lineare Randwert-Probleme. Daseine Verfahren erfullt die zugehorigeDifferentialgleichung in jedem Ite-rationsschritt und die Randwert-Bedingungen nur bei Konvergenz,das andere Verfahren dagegen erfulltdie Randwert-Bedingungen in jedemIterationsschritt und die Differen-tialgleichung nur bei Konvergenz.Welches ist welches Verfahren?
7. a) Fur welche Typen von zwei-Punkt Randwert-Problemen ist dasmehrfaches Schieß-Verfahren ver-mutlich effektiver als das gewohnli-che Schieß-Verfahren?
b) Welche Nachteile weist das mehr-faches Schieß-Verfahren gegenuberdem gewohnlichen Schieß-Verfahrenauf?
8. Welche Eigenschaft von f be-stimmt, ob das Finite-Differenzen-Verfahren ein Randwert-Problem inein System linearer Gleichungenuberfuhrt?
9. Das Finite-Differenzen-Verfahrenwie auch finite Elemente Verfahrenuberfuhren Randwert-Probleme inSysteme algebraischer Gleichun-gen. Wieso fallt der Aufwand, diesich ergebenden linearen Gleich-gungssysteme zu losen, gewohnlichwesentlich geringer als aus O(n3) ?
10. Das Finite-Differenzen-Verfahrenwie auch das Kollokationsverfah-ren fuhren beide auf algebraischeGleichungen, deren Losungen sichjedoch in Bedeutung und Gebrauchunterscheiden.
a) Wie unterscheiden sich die Losun-gen der algebraischen Gleichungenin den beiden Verfahren?
b) Wie unterscheidet sich die Naturder Losungen der beiden Verfahren?
11. Warum ist es vorteilhaft, wenndie im Kollokationsverfahren oderim Galerkin-Verfahren verwendetenBasis-Funktionen einen beschrank-ten Trager haben?
12. Welche Bedingungen mussen dienaherungsweisen Losungen des Kol-lokationsverfahrens erfullen?
13. Ein 2-Punkte Randwert-Problem zueiner linearen Differentialgleichungzweiter Ordnung werde mit demFinite-Differenzen-Verfahren gelost,das standardmaßig die Ableitungen

504 KAPITEL 10. BOUNDARY VALUE PROBLEMS
durch zentrierte finite Differenzenapproximiert. Von welcher Artist die Koeffizienten-Matrix des sichergebenden Systems linearer Glei-chungen?
14. Ein 2-Punkte Randwert-Problem imIntervall [a, b] werde mit dem Schieß-Verfahren gelost. Wenn nun dieLosungen der Differentialgleichungauf einem Teilintervall instabil sind,reagiert die sich ergebende Folgevon Anfangswert-Problemen sensi-tiv auf die Anfangsbedingungen, sodaß es schwierig wird, die Randwert-Bedingung in b zu erfullen.
a) Wie kann man mit der schlechtenKonditionierung fertig werden?
b) Wie beeinflußt dies die zu losendenichtlineare algebraische Gleichung?
15. Ein 2-Punkt Randwert-Problemwerde mit Hilfe des Kollokati-onsverfahrens gelost. Stimmendann die Funktionswerte dernaherungsweisen Losung in denKollokationspunkten immer mitdenen der exakten Losung uberein?
10.2 Exercises –
Ubungen
1. Gegeben das 2-Punkt Randwert-Problem u′′(t) = f(t) fur 0 < t < 1mit u(0) = 0 und u(1) = 0.
a) Zeige: u(t) = c1 +c2t+∫ to F (s) ds
mit F (s) =∫ so f(x) dx und Konstan-
ten c1, c2 ∈ R ist die Losungsgesamt-heit der Differentialgleichung.
b) Zeige: die Losungsgesamtheit derDifferentialgleichung kann auch alsu(t) = c1+c2t+
∫ to (t−s)f(s) ds dar-
gestellt werden.
c) Zeige: Fur die Losung des Rand-wert-Problems gilt u(t) =∫ to (t− s)f(s) ds+ t
∫ 1o (s− 1)f(s) ds,
d.h. c1 =0 und c2 =∫ 1o (s− 1)f(s) ds.
d) Zeige: die Losung des Rand-wert-Problems laßt sich auchals u(t) =
∫ 1o G(t, s)f(s) ds mit
der Green-Funktion G(t, s) =s(t− 1) 0 ≤ s ≤ tt(s− 1) t < s ≤ 1
darstellen.
e) Lose das Randwert-Problem mitder Green-Funktion fur f(t) = 1.
f) Lose das Randwert-Problem mitder Green-Funktion fur f(t) = t.
g) Lose das Randwert-Problem mitder Green-Funktion fur f(t) = t2.
2. Gegeben das 2-Punkt Randwert-Problem u′′ = u fur 0 < t < b mitu(0) = α und u(b) = β.
a) Schreibe das Randwert-Problemals System von Differentialgleichun-gen erster Ordnung mit separiertenRandbedingungen.
b) Zeige: die Matrix derFundamental-Losungen desSystems linearer Differential-gleichungen ist gegeben durch
Y(t) =(
cosh t sinh tsinh t cosh t
).
c) Sind die Losungen der Differenti-algleichung stabil?
d) Bilde Q = BoY(0) + BbY(b) furdieses Randwert-Problem.
e) Bestimme die reskalierte Losungs-matrix Φ(t) = Y(t)Q−1.
f) Beurteile die Kondition von Q,die Norm von Φ(t) und die Stabilitatder Losung des Randwert-Problemsfur wachsendes b.
3. Gegeben sei das 2-Punkt Randwert-Problem u′′ = u3 + t fur a < t < b

10.3. Computer Problems – Rechner-Probleme 505
mit u(a) = α und u(b) = β.Fur das shooting-Verfahren brauchtman einen Startwert fur u′(a), denman mit einem einzigen Schritt desEuler-Verfahrens fur h = b − a ge-winnen kann.
a) Verfolge diesen Ansatz und stelledie algebraische Gleichung fur die-sen Startwert auf.
b) Welcher Startwert ergibt sich beidiesem Ansatz?
4. Die Hohe eines Projektils sei be-schrieben durch u′′ = −4. Die Hohey(0) beim Start in t = 0 und beider Landung in t = 1 sei jeweilsy(0) = 1 = y(1).
a) Lose das Randwert-Problem mitdem Schieß-Verfahren.
b) Lose dasselbe Randwert-Problemmit dem Finite-Differenzen-Verfah-ren fur h = 0.5. Welche Naherungder Hohe liefert das Verfahren furt = 0.5 ?
c) Lose dasselbe Randwert-Problemmit dem Kollokationsverfahren furh = 0.5: ein quadratisches Poly-nom approximiert die Losung beiVerwendung der Kollokationspunkte0, 0.5 und 1.
10.3 Computer Pro-
blems – Rechner-
Probleme
1. Gegeben das Randwert-Problemu′′ = 10u3 + 3u + t2 fur 0 < t < 1mit u(0) = 0 und u(1) = 1.
a) Lose mit dem Schieß-Verfahren.
b) Lose mit dem Finite-Differenzen-Verfahren. Spezifiziere dazu n + 2
aquidistante Punkte 0 = to < t1 <. . . < tn < tn+1 = 1.
c) Lose mit dem Kollokationsverfah-ren. Spezifiziere dazu n + 1 aquidi-stante Punkte 0 = to < t1 < . . . <tn−1 < tn = 1.
2. Lose das Randwert-Problem u′′ =−1 − eu fur 0 < t < 1 mit u(0) = 0und u(1) = 1 jeweils mit Hilfe desshooting, finite Differenzen und desKollokationsverfahrens.
3. Finde zwei verschiedene Losungendes 2-Punkte Randwert-Problemsu′′ = |u| fur 0 < t < 4 mit u(0) = 0und u(4) = −2. (Die eine Losunghat initial positive, die andere initialnegative Steigung!)
4. Finde zwei verschiedene Losungendes 2-Punkte Randwert-Problemsu′′ = −eu+1 fur 0 < t < 1 mitu(0) = 0 und u(1) = 0. (BeideLosungen haben initial positive Stei-gung!)
5. Die Kurve eines durchhangen-den Seils (Kettenlinie) istLosung des Randwert-Problemsy′1 =cos y3
y′2 =sin y3
y′3 =(cos y3 − (sin y3)| sin y3|)/y4
y′4 =sin y3 − (cos y3)| cos y3|
.
Dabei sind y1(t) und y2(t) diehorizontalen und vertikalen Koordi-naten des Seils, y3(t) ist der Winkelzwischen der Tangente an das Seilim Punkt (y1(t), y2(t)) und y4(t)ist die Spannung des Seils im Punkt(y1(t), y2(t)). Der Parameter t stehtfur die normalisierte Kurven-Lange:0 ≤ t ≤ 1.
a) Lose das Randwert-Problem mity(0) = e4 und y(1) = (0.75, 0, 0, 1)T
jeweils mit Hilfe des shooting

506 KAPITEL 10. BOUNDARY VALUE PROBLEMS
und des Finite-Differenzen-Verfah-rens. Stelle die Losung graphischdar.
s.a. errata???
b) Lose das Randwert-Problem nunmit y(0) = e4 und y(1) =(0.85, 0.5, 0, 1)T jeweils mit Hilfe desshooting und des Finite-Differenzen-Verfahrens. Diese Randwerte ent-sprechen einem straffen Seil. Stelledie Losung graphisch dar.
s.a. errata???
6. Die Durchbiegung eines waagerech-ten Balkens sei durch das 2-PunktRandwert-Problem u′′ = λ(−t2−1)ufur −1 < t < 1 mit u(−1) = 0 undu(1) = 0 beschrieben.
7. Die eindimensionale Schrodinger-Gleichung −ψ′′(x) + V (x)ψ(x) =E ψ(x) beschreibt die Wellen-Funktion ψ eines Partikels derEnergie E in einem Potential V .Das Quadrat ψ2 der Wellenfunktionkann als Aufenthaltswahrscheinlich-keit des Partikels in x aufgefaßtwerden.Angenommen, das Partikel kannsich nur innerhalb des Ein-heitsıntervalles [0, 1] frei bewegen,d.h. das Potential verschwindet in[0, 1] und ist unendlich außerhalb.Weil die Wahrscheinlichkeit, dasPartikel außerhalb [0, 1] vorzufin-den, verschwindet, muß auch dieWellenfunktion an den Randern desEinheitsintervalles verschwinden.Es liegt also ein EW-Problem furdie Differentialgleichung zweiterOrdnung −ψ′′(x) = E ψ(x) fur0 < x < 1 mit ψ(0) = 0 = ψ(1) vor.Die diskreten (!) EWe von E sinddie einzigen zulassigen Zustande.

10.4. Review Questions – Antworten auf Verstandnisfragen 507
10.4 Review Questions –
Antworten auf Verstandnisfragen
1. Welches spezifische Merkmal unterscheidet Randwert-Probleme von An-fangswert-Problemen? 422
In Randwert-Problemen sind die Nebenbedingungen zu mindestens zweiverschiedenen (Zeit-) Punkten gegeben, wahrend in Anfangswert-Problemendie Nebenbedingungen alle in genau einem (Zeit-) Punkt gegeben sind.
2. Was sind separierte Randwert-Bedingungen? 423
Die Randwert-Bedingungen g(y(a),y(b)) = 0 sind separiert, wenn in jederKomponente von g(y(a),y(b)) entweder a oder b, aber nicht beide zugleichvorkommen.
3. Hat ein Randwert-Problem zu einer gewohnlichen Differentialgleichung im-mer eine eindeutige Losung?
Sei bespielsweise u′′ = −u fur 0 < t < b mit u(0) = 0 und u(b) = β. Die 424Differentialgleichung mit u(0) = 0 hat die 1-parametrige Losungsgesamtheitu(t) = c sin t fur c ∈ R. Im Fall b ∈ πZ gilt c sin b = 0, so daß das Rand-wert-Problem unendlich viele Losungen fur β = 0 und keine Losung furβ 6= 0 hat.
4. Ist die Stabilitat eines Randwert-Problems immer dieselbe wie die des zu-gehorigen Anfangswert-Problems zur selben Differentialgleichung? 427
Nein, das zum stabilen??? Randwert-Problem y′ =
(1 00 −1
)y = Ay mit
y1(0) = 1 und y2(b) = 1 gehorende Anfangswert-Problem y′ = Ay mity(0) = 1 ??? ist nicht stabil.
???
5. Wie kann ein Verfahren zur Nullstellenbestimmung von Funktionen einerVeranderlichen verwendet werden, um das 2-Punkte Randwert-Problemu′′ = f(t, u, u′) mit u(a) = α und u(b) = β zu losen?
Uberfuhre u′′ = f(t, u, u′) in das System von zwei Differentialgleichun- 424/425
gen erster Ordnungy′1 = y2
y′2 = f(t, y1, y2). Sei y(t,x) die Losung des Anfangs-
wert-Problems zu derselben Differentialgleichung mit Anfangsbedingungy(a) = x. Eine solche Losung ist dann Losung des Randwert-Problems,
wenn g(x,y(b,x)) = 0 fur g(r, s) :=
(r1 − αs1 − β
)gilt, d.h. wenn x1 − α = 0
und damit y1(a) = α sowie zugleich y1(b, (α, x2)T ) − β = 0 gilt. Das
Randwert-Problem reduziert sich somit darauf, die Nullstelle der Funktiong2((α, x2)
T ,y(b, (α, x2)T )) = y1(b, (α, x2)
T )−β in der einen Veranderlichen

508 KAPITEL 10. BOUNDARY VALUE PROBLEMS
x2 zu bestimmen. M.a.W., fur welche Steigung x2 = y2(a) der Losung desAnfangswert-Problems gilt fur diese Losung y1(b) = β ?
6. Das Schieß-Verfahren und Finite-Differenzen-Verfahren sind zwei iterativeVerfahren zur Losung nichtlineare Randwert-Probleme. Das eine Verfahrenerfullt die zugehorige Differentialgleichung in jedem Iterationsschritt unddie Randwert-Bedingungen nur bei Konvergenz, das andere Verfahren da-gegen erfullt die Randwert-Bedingungen in jedem Iterationsschritt und dieDifferentialgleichung nur bei Konvergenz. Welches ist welches Verfahren?
Das Schieß-Verfahren lost das zugehorige Anfangswert-Problem fur ver-schiedende y′(a) solange, bis auch y(b) = β erfullt ist, d.h. das Schieß-Ver-427fahren lost in jeder Iteration die Differentialgleichung und erst im Grenz-prozess bei Konvergenz die Randbedingung.Das Finite-Differenzen-Verfahren approximiert die Ableitungen durch fi-nite Differenzen und uberfuhrt so das Randwert-Problem in ein System430algebraischer Gleichungen. Dessen Losungen approximieren die Differenti-algleichung und erfullen immer die Randwertbedingungen.
7. a) Fur welche Typen von zwei-Punkt Randwert-Problemen ist mehrfaches430Schieß-Verfahren vermutlich effektiver als das gewohnliche Schieß-Verfah-ren?
Das mehrfaches Schieß-Verfahren ist sicher dann effektiver, wenn fur be-stimmte Wahlen von y′(a) das Anfangswert-Problem unbeschrankt ist, sodaß y(b) = β nicht bedient werden kann.
b) Welche Nachteile weist das mehrfaches Schieß-Verfahren gegenuber demgewohnlichen Schieß-Verfahren auf?
Nachteilig ist sicherlich der Aufwand, nm Differentialgleichungen losen zumussen, wobei n die Ordnung der Differentialgleichungen und m die Anzahlder Teil-Intervalle bezeichne. Gegebenenfalls ergeben sich weitere Bedin-gungen fur bestimmte Eigenschaften der Losung, wie Stetigkeit, Glattheitusw.
8. Welche Eigenschaft von f bestimmt, ob das Finite-Differenzen-Verfahrenein Randwert-Problem in ein System linearer Gleichungen uberfuhrt?431yi+1−2yi+yi−1
h2 = f(ti, yi,yi+1−yi−1
2h ) fur i = 1, . . . , n ist ein System linearerGleichungen, wenn f = f(t, y, y′) linear in y und y′ ist.
9. Das Finite-Differenzen-Verfahren wie auch finite Elemente Verfahren uber-fuhren Randwert-Probleme in Systeme algebraischer Gleichungen. Wiesofallt der Aufwand, die sich ergebenden linearen Gleichgungssysteme zulosen, gewohnlich wesentlich geringer als aus O(n3) ?431
Das System linearer Gleichungen ist tridigonal, so daß der Aufwand nurO(n) statt O(n3) betragt.89

10.4. Review Questions – Antworten auf Verstandnisfragen 509
10. Das Finite-Differenzen-Verfahren wie auch das Kollokationsverfahren fuhrenbeide auf algebraische Gleichungen, deren Losungen sich jedoch in Bedeu-tung und Gebrauch unterscheiden.
a) Wie unterscheiden sich die Losungen der algebraischen Gleichungen inden beiden Verfahren?
Das Finite-Differenzen-Verfahren liefert als Losung yi diskrete Naherungender Funktionswerte u(ti) der gesuchten Funktion in Gitterpunkten ti. 430Fur das Kollokationsverfahren wird die Losung als gewichtete Summe geeig-neter Basis-Funktionen dargestellt: das Kollokationsverfahren liefert diese 432Gewichte und damit Naherung der Losungsfunktion.
b) Wie unterscheidet sich die Natur der Losungen der beiden Verfahren? 435
Das Finite-Differenzen-Verfahren liefert diskrete Naherungen yi fur u(ti).Das Kollokationsverfahren liefert eine Naherung der Losung. Als Line-arkombination der Basis-Funktionen hat diese Naherung dieselben Eigen-schaften – etwa Stetigkeit, Glattheit usw. – wie die Basis-Funktionen.
11. Warum ist es vorteilhaft, wenn die im collocation oder im Galerkin-Verfah-ren verwendeten Basis-Funktionen einen beschrankten Trager haben?
???
12. Welche Bedingungen mussen die naherungsweisen Losungen des Kollokati- 433onsverfahrens erfullen?
Das Kollokationsverfahren erzwingt, daß die naherungsweisen Losungen dasRandwert-Problem in den Kollokationspunkten exakt losen.
13. Ein 2-Punkte Randwert-Problem zu einer linearen Differentialgleichung zwei-ter Ordnung werde mit dem Finite-Differenzen-Verfahren gelost, das stan-dardmaßig die Ableitungen durch zentrierte finite Differenzen approximiert.Von welcher Art ist die Koeffizienten-Matrix des sich ergebenden Systemslinearer Gleichungen?
Das Gleichungssystem yi+1−2yi+yi−1
h2 = f(ti, yi,yi+1−yi−1
2h ) fur i = 1, . . . , n hateine tridiagonale Koeffizientenmatrix.
14. Ein 2-Punkte Randwert-Problem im Intervall [a, b] werde mit dem Schieß-Verfahren gelost. Wenn nun die Losungen der Differentialgleichung aufeinem Teilintervall instabil sind, reagiert die sich ergebende Folge von An-fangswert-Problemen sensitiv auf die Anfangsbedingungen, so daß es schwie-rig wird, die Randwert-Bedingung in b zu erfullen.
a) Wie kann man mit der schlechten Konditionierung fertig werden?
Man unterteilt [a, b] in Teilintervalle und fuhrt in jedem Teilintervall dasSchieß-Verfahren (multiple shooting) durch. Stetigkeitsanforderungen inden Stoßstellen liefern die Randbedingungen fur das Randwert-Problemin jedem Teilintervall.

510 KAPITEL 10. BOUNDARY VALUE PROBLEMS
b) Wie beeinflußt dies die zu losende nichtlineare algebraische Gleichung?
Die Anzahl der Gleichungen des Systems nichtlinearer Gleichungen ist pro-portional zur Anzahl der Teilintervalle.
15. Ein 2-Punkt Randwert-Problem werde mit Hilfe des Kollokationsverfahrensgelost. Stimmen dann die Funktionswerte der naherungsweisen Losung in432den Kollokationspunkten immer mit denen der exakten Losung uberein?
Die Funktionswerte der naherungsweisen Losung stimmen in den Kolloka-tionspunkten nicht immer mit denen der exakten Losung uberein, wie dasfolgende Beispiel zeigt: Ausgehend von der Losung u(t) =
√t spezifiziere
das 2-Punkt Randwert-Problem u′′ = −14
1√t3
fur 0 < t < 1 mit u(0) = 0
und u(1) = 1. Der polynomiale Ansatz v(t,x) = x1 + x2t + x3t2 mit
v′(t,x) = x2+2x3t und v′′(t,x) = 2x3 angewandt auf u(0) = 0 liefert x1 = 0,angewandt auf u(1) = 1 liefert x2 + x3 = 1 und angewandt auf v′′(0.5,x) =2x3 = −1
41√0.53
liefert x3 = −14
√2 und damit v(t) = 1
4(4 +
√2)t − 1
4
√2t2.
Insbesondere gilt v(0.5,x) = 18(4+
√2)− 1
16
√2 = 1
2+ 1
8
√2 6= 1
2
√2 = u(0.5).
10.5 Exercises – Ubungsergebnisse
1. Gegeben das 2-Punkt Randwert-Problem u′′(t) = f(t) fur 0 < t < 1 mitu(0) = 0 und u(1) = 0.
a) Zeige: u(t) = c1+c2t+∫ t
oF (s) ds mit F (s) =
∫ s
of(x) dx und Konstanten
c1, c2 ∈ R ist die Losungsgesamtheit der Differentialgleichung.
Fur u(t) = c1 + c2t +∫ t
oF (s) ds mit F (s) =
∫ s
of(x) dx und c1, c2 ∈ R gilt
u′(t) = c2 +∫ t
of(x) dx sowie u′′(t) = f(t). Also ist u(t) eine 2-parametrige
Losungsgesamtheit von u′′(t) = f(t).
b) Zeige: die Losungsgesamtheit der Differentialgleichung kann auch alsu(t) = c1 + c2t+
∫ t
o(t− s)f(s) ds dargestellt werden.
Partielle Integration liefert∫ t
o(t−s)f(s) ds = (t− s)F (s)|t0−
∫ t
o(−1)F (s) ds
= 0 +∫ t
oF (s) ds =
∫ t
o
∫ s
of(x) dx ds.
c) Zeige: Fur die Losung des Randwert-Problems gilt u(t) =∫ t
o(t−s)f(s) ds+
t∫ 1
o(s− 1)f(s) ds, d.h. c1 = 0 und c2 =
∫ 1
o(s− 1)f(s) ds.
Aus u(0) = 0 folgt c1 = 0 und aus u(1) = 0 folgt u(1) = c2+∫ 1
o(s−1)f(s) ds,
also zusammen u(t) =∫ t
o(t− s)f(s) ds+ t
∫ 1
o(s− 1)f(s) ds.
d) Zeige: die Losung des Randwert-Problems laßt sich auch als u(t) =∫ 1
oG(t, s)f(s) ds mit der Green-Funktion G(t, s) =
s(t− 1) 0 ≤ s ≤ tt(s− 1) t < s ≤ 1
darstellen.

10.5. Exercises – Ubungsergebnisse 511
u(t) =∫ 1
oG(t, s)f(s) ds =
∫ t
oG(t, s)f(s) ds+
∫ 1
tG(t, s)f(s) ds
=∫ t
os(t− 1)f(s) ds+
∫ 1
tt(s− 1)f(s) ds
=∫ 1
os t f(s) ds−
∫ t
os f(s) ds− t
∫ 1
tf(s) ds+ t
∫ t
of(s) ds− t
∫ t
of(s) ds
=∫ t
o(t− s)f(s) ds+ t
∫ 1
o(s− 1)f(s) ds = u(t)
e) Lose das Randwert-Problem mit der Green-Funktion fur f(t) = 1.
Einsetzen liefert u(t) =∫ 1
oG(t, s)f(s) ds =
∫ t
os(t− 1) ds+
∫ 1
tt(s− 1) ds =
(t− 1)12t2 + t(1
2− 1− 1
2t+ t) = 1
2t(t− 1).
f) Lose das Randwert-Problem mit der Green-Funktion fur f(t) = t.
u(t) =∫ 1
oG(t, s)f(s) ds =
∫ t
os(t − 1)s ds +
∫ 1
tt(s − 1)s ds = (t − 1)1
3t3 +
t(13− 1
2− 1
3t3 + 1
2t2) = 1
6t(t2 − 1).
g) Lose das Randwert-Problem mit der Green-Funktion fur f(t) = t2.
u(t) =∫ 1
oG(t, s)f(s) ds =
∫ t
os(t− 1)s2 ds+
∫ 1
tt(s− 1)s2 ds = (t− 1)1
4t4 +
t(14− 1
3− 1
4t4 + 1
3t3) = 1
12t(t3 − 1).
2. Gegeben das 2-Punkt Randwert-Problem u′′ = u fur 0 < t < b mit u(0) = αund u(b) = β.
a) Schreibe das Randwert-Problem als System von Differentialgleichungen 425erster Ordnung mit separierten Randbedingungen.
Mit u1 = u und u2 = u′ ist u′′ = u aquivalent zuu′1 =u1
u′2 =u1. Die Randbedin-
gungen u(0) = α und u(b) = β lassen sich durch die Funktion g(x,y) :=(1 00 0
)x +
(0 01 0
)y −
(αβ
)=: Bax + Bby − c = 0 darstellen, da dann
g(y(a),y(b)) = 0 gleichbedeutend mit u(0) = α und u(b) = β ist.
b) Zeige: die Matrix der Fundamental-Losungen des Systems linearer Dif- 425
ferentialgleichungen ist gegeben durch Y(t) =
(cosh t sinh tsinh t cosh t
).
Die Koeffizienten-Matrix der linearen Differentialgleichung y′ =
(y′1y′2
)=(
0 11 0
)(y′1y′2
)=: Ay hat die beiden EWe ±1. Etwa x1 = (1, 1)T ist EV
zum EW λ1 = 1 und etwa x2 = (1,−1)T ist EV zum EW λ2 = −1.Fur die Anfangsbedingung y(0) = e1 = 1
2(x1 + x2) hat das Anfangswert-
Problem die Losung y(t) = 12x1e
λ1t + 12x2e
λ2t = 12
(et + e−t
et − e−t
)=
(cosh tsinh t
).
Fur die Anfangsbedingung y(0) = e2 = 12(x1 − x2) hat das Anfangswert-
Problem die Losung y(t) = 12x1e
λ1t − 12x2e
λ2t = 12
(et − e−t
et + e−t
)=
(sinh tcosh t
).

512 KAPITEL 10. BOUNDARY VALUE PROBLEMS
Zusammen genommen ergibt sich also Y(t) =
(cosh t sinh tsinh t cosh t
).
c) Sind die Losungen der Differentialgleichung stabil?
eher nicht???
d) Bilde Q = BoY(0) + BbY(b) fur dieses Randwert-Problem.425
Q =
(1 00 0
)I +
(0 01 0
)(cosh b sinh bsinh b cosh b
)=
(1 0
cosh b sinh b
).
e) Bestimme die reskalierte Losungsmatrix Φ(t) = Y(t)Q−1.426
Mit Q−1 = 1sinh b
(sinh b 0
− cosh b 1
)gilt fur die reskalierte Losungsmatrix Φ(t) =
1sinh b
(cosh t sinh b− cosh b sinh t sinh tsinh b sinh t− cosh b cosh t cosh t
)= 1
sinh b
(sinh(b− t) sinh t
− cosh(b− t) cosh t
).
???f) Beurteile die Kondition von Q, die Norm von Φ(t) und die Stabilitat der426Losung des Randwert-Problems fur wachsendes b.
Es gilt erstens cond∞(Q) = ||Q||∞||Q−1||∞ = (| cosh b|+ | sinh b|) | cosh b|+1| sinh b| =
(| coth b|+ 1)(| cosh b|+ 1) mit limb→+∞ cond∞(Q) = +∞, zweitens???
3. Gegeben das 2-Punkt Randwert-Problem u′′ = u3 + t fur a < t < b mitu(a) = α und u(b) = β. Fur das Schieß-Verfahren braucht man einenStartwert fur u′(a), den man mit einem einzigen Schritt des Euler-Verfah-rens fur h = b− a gewinnen kann.
a) Verfolge diesen Ansatz und stelle die algebraische Gleichung fur diesenStartwert auf.
Sei y1 = u, y′1 = u′ = y2 und y2 = u′′ = y31 + t mit u(a) = α und
u(b) = β. Die Differentialgleichung u′′ = u3 + t wird uberfuhrt in y′ =(y′1y′2
)=
(u′
u3 + t
)=
(y2
y31 + t
)= f(t,y). Ein Schritt des Euler-Verfahrens
mit Schrittweite h = b− a liefert die Naherung y1 = yo + (b− a)f(a,yo) =(u(a)u′(a)
)+ (b− a)
(u′(a)
u3(a) + a
)=
(α
u′(a)
)+ (b− a)
(u′(a)α3 + a
).
b) Welcher Startwert ergibt sich bei diesem Ansatz?
Mit y(b) =
(u(b)u′(b)
)=
(β
u′(b)
)≈ y1 =
(α+ (b− a)u′(a)
u′(a) + (b− a)(α3 + a)
)gilt
α+(b−a)u′(a) = β und damit erwartungsgemaß als Ergebnis dieses Euler-Schrittes u′(a) ≈ β−α
b−a.
4. Die Hohe eines Projektils sei beschrieben durch u′′ = −4. Die Hohe y(0)beim Start in t = 0 und bei der Landung in t = 1 sei jeweils y(0) = 1 = y(1).
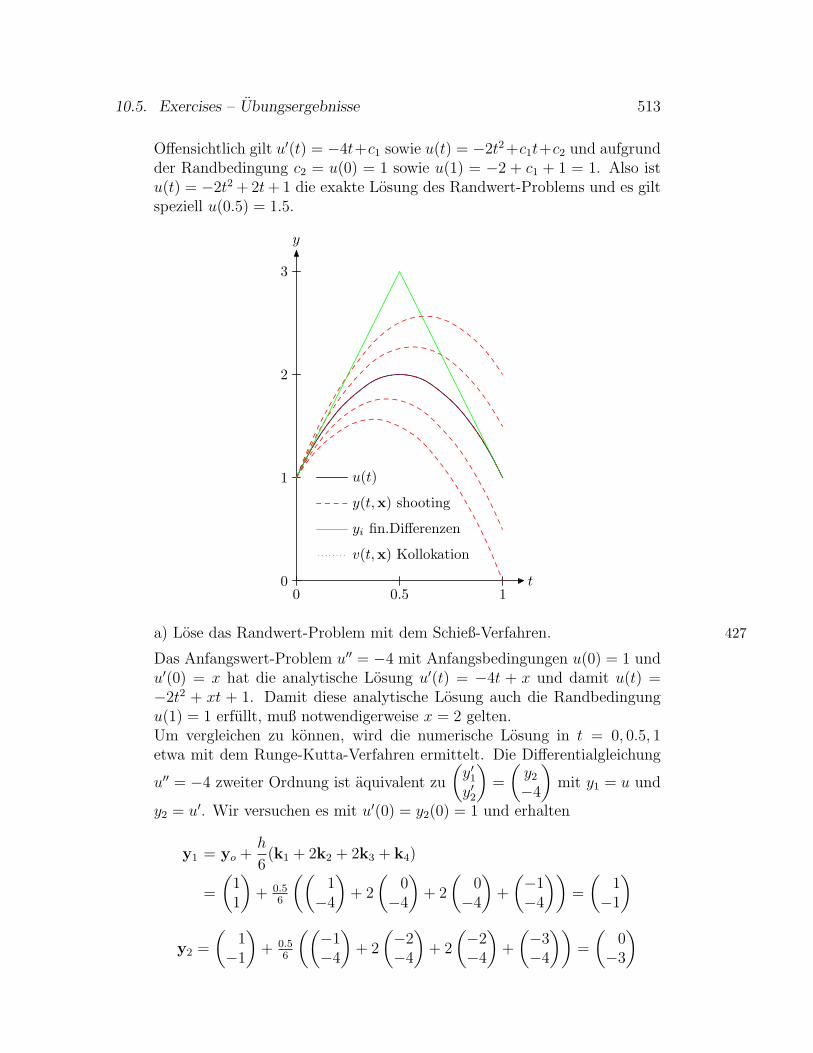
10.5. Exercises – Ubungsergebnisse 513
Offensichtlich gilt u′(t) = −4t+c1 sowie u(t) = −2t2+c1t+c2 und aufgrundder Randbedingung c2 = u(0) = 1 sowie u(1) = −2 + c1 + 1 = 1. Also istu(t) = −2t2 + 2t+ 1 die exakte Losung des Randwert-Problems und es giltspeziell u(0.5) = 1.5.
t
y
0 0.5 10
1
2
3
u(t)
y(t,x) shooting
yi fin.Differenzen
v(t,x) Kollokation
a) Lose das Randwert-Problem mit dem Schieß-Verfahren. 427
Das Anfangswert-Problem u′′ = −4 mit Anfangsbedingungen u(0) = 1 undu′(0) = x hat die analytische Losung u′(t) = −4t + x und damit u(t) =−2t2 + xt + 1. Damit diese analytische Losung auch die Randbedingungu(1) = 1 erfullt, muß notwendigerweise x = 2 gelten.Um vergleichen zu konnen, wird die numerische Losung in t = 0, 0.5, 1etwa mit dem Runge-Kutta-Verfahren ermittelt. Die Differentialgleichung
u′′ = −4 zweiter Ordnung ist aquivalent zu
(y′1y′2
)=
(y2
−4
)mit y1 = u und
y2 = u′. Wir versuchen es mit u′(0) = y2(0) = 1 und erhalten
y1 = yo +h
6(k1 + 2k2 + 2k3 + k4)
=
(11
)+ 0.5
6
((1
−4
)+ 2
(0
−4
)+ 2
(0
−4
)+
(−1−4
))=
(1
−1
)
y2 =
(1
−1
)+ 0.5
6
((−1−4
)+ 2
(−2−4
)+ 2
(−2−4
)+
(−3−4
))=
(0
−3
)

514 KAPITEL 10. BOUNDARY VALUE PROBLEMS
Wenn wir es dagegen mit y2(0) = 2 versuchen, erhalten wir
y1 =
(12
)+ 0.5
6
((2
−4
)+ 2
(1
−4
)+ 2
(1
−4
)+
(0
−4
))=
(1.50.0
)
y2 =
(1.50.0
)+ 0.5
6
((0
−4
)+ 2
(−1−4
)+ 2
(−1−4
)+
(−2−4
))=
(1
−2
)die Losung, die die Randbedingung u(1) = y1(1) = 1 erfullt.
b) Lose dasselbe Randwert-Problem mit dem Finite-Differenzen-Verfahren430fur h = 0.5. Welche Naherung der Hohe liefert das Verfahren fur t = 0.5 ?
Die Gleichung yi+1−2yi+yi−1
h2 = f(ti, yi,yi+1−yi−1
2h ) fur i = 1 liefert 1−2y1+11/4
=−4 und damit y1 = 3.
c) Lose dasselbe Randwert-Problem mit dem Kollokationsverfahren fur h =4320.5: ein quadratisches Polynom approximiert die Losung bei Verwendungder Kollokationspunkte 0, 0.5 und 1.
Aus dem Ansatz v(t,x) = x1 + x2t + x3t2 mit v′(t,x) = x2 + 2x3t und
v′′(t,x) = 2x3 ergibt sich zunachst x3 = −2. Aus v(0,x) = 1 folgt x1 = 1und aus v(1,x) = 1 folgt x2 = 2. Zusammen genommen gilt v(0.5,x) =1 + 2 · 0.5− 2 · 0.25 = 1.5.
10.6 Computer Problems –
Rechner-Problem-Losungen
1. Gegeben das Randwert-Problem u′′ = 10u3 + 3u + t2 fur 0 < t < 1 mitu(0) = 0 und u(1) = 1.
a) Lose mit dem Schieß-Verfahren.
b) Lose mit dem Finite-Differenzen-Verfahren. Spezifiziere dazu n+2 aqui-distante Punkte 0 = to < t1 < . . . < tn < tn+1 = 1.
c) Lose mit dem Kollokationsverfahren. Spezifiziere dazu n+1 aquidistantePunkte 0 = to < t1 < . . . < tn−1 < tn = 1.
2. Lose das Randwert-Problem u′′ = −1− eu fur 0 < t < 1 mit u(0) = 0 undu(1) = 1 jeweils mit Hilfe des Schieß-Verfahren, des finite Differenzen unddes Kollokationsverfahrens.
3. Finde zwei verschiedene Losungen des Randwert-Problems u′′ = |u| fur0 < t < 4 mit u(0) = 0 und u(4) = −2. (Die eine Losung hat initialpositive, die andere initial negative Steigung!)

10.6. Computer Problems – Rechner-Problem-Losungen 515
Der Ansatz u(t) = c sinh t mit c = −2/ sinh 4 < 0 bedient einerseits dieRandbedingungen u(0) = 0 sowie u(4) = −2 und erfullt andererseits wegenu′(t) = c cosh t sowie u′′(t) = c sinh t und damit u′′(t) = −|c| sinh t =−|c sinh t| = −|u(t)| die Differentialgleichung fur t > 0.
zweite Losung????
4. Finde zwei verschiedene Losungen des Randwert-Problems u′′ = −eu+1 fur0 < t < 1 mit u(0) = 0 und u(1) = 0. (Beide Losungen haben initialpositive Steigung!)
Der Ansatz u(t) = −2 ln cosh(2ct−c)cosh c
= ln cosh2 ccosh2(2ct−c)
fur geeignetes c ∈ R und
mit u(0) = −2 ln 1 = 0 = u(1) liefert einerseits eu(t)+1 = e cosh2 ccosh2(2ct−c)
und
andererseits u′(t) = −2 cosh ccosh(2ct−c)
2c sinh(2ct−c) = −4c cosh c tanh(2ct−c)sowie u′′(t) = −8c2 1
cosh2(2ct−c). Die Differentialgleichung u′′ = −eu+1 ist also
genau dann erfullt, wenn 8c2 = e cosh c gilt. Diese Gleichung hat (genau)eine Losung, da die stetige Funktion h(c) = e cosh c − 8c2 in 0 positiv ist(h(0) = e) und in 1 negativ ist (h(1) = e cosh 1−8 = e2+1
2−8 ≈ 5−8 = −3).
Die Funktion u(t) = −2 ln cosh(2ct−c)cosh c
mit c ≈ 0.642 ist also eine Losung derDifferentialgleichung.
zweite Losung????
5. Die Kurve eines durchhangenden Seils (Kettenlinie) ist Losung des Rand-
wert-Problems
y′1 = cos y3
y′2 = sin y3
y′3 = (cos y3 − (sin y3)| sin y3|)/y4
y′4 = sin y3 − (cos y3)| cos y3|
. Dabei sind y1(t) und y2(t)
die horizontalen und vertikalen Koordinaten des Seils, y3(t) ist der Winkelzwischen der Tangente an das Seil im Punkt (y1(t), y2(t)) und y4(t) ist die
Spannung des Seils im Punkt (y1(t), y2(t)). Der Parameter t steht fur dienormalisierte Kurven-Lange: 0 ≤ t ≤ 1.
a) Lose das Randwert-Problem mit y(0) = e4 und y(1) = (0.75, 0, 0, 1)T
jeweils mit Hilfe des Schieß-Verfahrens und des Finite-Differenzen-Verfah-rens. Stelle die Losung graphisch dar.
s.a. errata???
b) Lose das Randwert-Problem nun mit y(0) = e4 und y(1) = (0.85, 0.5, 0, 1)T
jeweils mit Hilfe des Schieß-Verfahrens und des Finite-Differenzen-Verfah-rens. Diese Randwerte entsprechen einem straffen Seil. Stelle die Losunggraphisch dar.
s.a. errata???

516 KAPITEL 10. BOUNDARY VALUE PROBLEMS
6. Die Durchbiegung eines waagerechten Balkens sei durch das 2-Punkt Rand-wert-Problem u′′ = λ(−t2−1)u fur −1 < t < 1 mit u(−1) = 0 und u(1) = 0beschrieben.
7. Die eindimensionale Schrodinger6-Gleichung −ψ′′(x) + V (x)ψ(x) = E ψ(x)beschreibt die Wellen-Funktion ψ eines Partikels der Energie E in einemPotential V . Das Quadrat ψ2 der Wellenfunktion kann als Aufenthalts-wahrscheinlichkeit des Partikels in x aufgefaßt werden.Angenommen, das Partikel kann sich nur innerhalb des Einheitsıntervalles[0, 1] frei bewegen, d.h. das Potential verschwindet in [0, 1] und ist unend-lich außerhalb. Weil die Wahrscheinlichkeit, das Partikel außerhalb [0, 1]vorzufinden, verschwindet, muß auch die Wellenfunktion an den Randerndes Einheitsintervalles verschwinden. Es liegt also ein EW-Problem fur dieDifferentialgleichung zweiter Ordnung −ψ′′(x) = E ψ(x) fur 0 < x < 1mit ψ(0) = 0 = ψ(1) vor. Die diskreten (!) EWe von E sind die einzigenzulassigen Zustande.
??? Die Schrodinger-Gleichung −ψ′′ = E ψ fuhrt mit y1 = ψ, y2 = ψ′ undy′2 = −E y1 auf die Differentialgleichung y′1 = y2 und y′2 = −E y1 oder
y′ =
(0 1−E 0
)y = Ay. Die Matrix A hat die EWe λ1,2 = ±i
√E mit
zugehorigen EVen x1,2 = (√E,±i E)T . Die Losungsgesamtheit ist also y =
c1 x1 eλ1t + c2 x2 e
λ2t und damit ψ(t) = y1(t) = c1√E eit
√E + c2
√E e−it
√E =
c3( cos(t√E) + i sin(t
√E)) + c4( cos(t
√E) − i sin(t
√E)) = c5 cos(t
√E) +
ic6 sin(t√E) fur c1, . . . , c6 ∈ R. Aus der Randbedingung ψ(0) = 0 folgt
ψ(t) = ic6 sin(t√E) und aus ψ(1) = 0 eben
√E ∈ πN.warum
komplex?
6 Erwin R. J. A. Schrodinger (1887-1961) www-history.mcs.st-andrews.ac.uk/Biographies/Schrodinger.html

Kapitel 11
Partial Differential Equations
11.0.1 Partielle Differentialgleichungen
Def. Partielle Differentialgleichungen sind Differentialgleichungen, deren Losun-gen Funktionen mehrerer Variablen sind und die daher partielle Ableitungen nachdiesen Variablen enthalten. Klassische Beispiele partieller Differentialgleichungen stammen aus der Physik.
• Maxwell1-Gleichungen beschreiben elektromagnetische Felder.
• Navier2-Stokes3-Gleichungen beschreiben das Verhalten von Flussigkeiten.
• elasticity problems
• Schrodinger4-Gleichungen beschreiben das Quanten-mechanische Verhaltenvon Partikeln.
• Einstein5-Gleichungen beschreiben Gravitationsfelder der allgemeinen Re-lativitatstheorie.
disclaimer: hier nur eine partielle Differentialgleichung, d.h. keine Systeme vonpartiellen Differentialgleichungen
Z.B. Advektions- oder Einwegswellengleichung ut = −c ux fur konstantes c undt ≥ to = 0, x ∈ R mit Anfangswert u(0, x) = uo(x) fur x ∈ R. Ein derartigesreines Anfangswert-Problem heißt ubrigens auch Cauchy-Problem. Offensichtlichist u(t, x) = uo(x−ct) eine Losung der Advektionsgleichung. Die initiale Funktion
1 James Clerk Maxwell (1831-1879) www-history.mcs.st-andrews.ac.uk/Biographies/Maxwell.html
2 Claude Louis Marie Henri Navier (1785-1836) www-history.mcs.st-andrews.ac.uk/Biographies/Navier.html
3 George Gabriel Stokes (1819-1903) www-history.mcs.st-andrews.ac.uk/Biographies/Stokes.html
4 Erwin R. J. A. Schrodinger (1887-1961) www-history.mcs.st-andrews.ac.uk/Biographies/Schrodinger.html
5 Albert Einstein (1879-1955) www-history.mcs.st-andrews.ac.uk/Biographies/Einstein.html
517
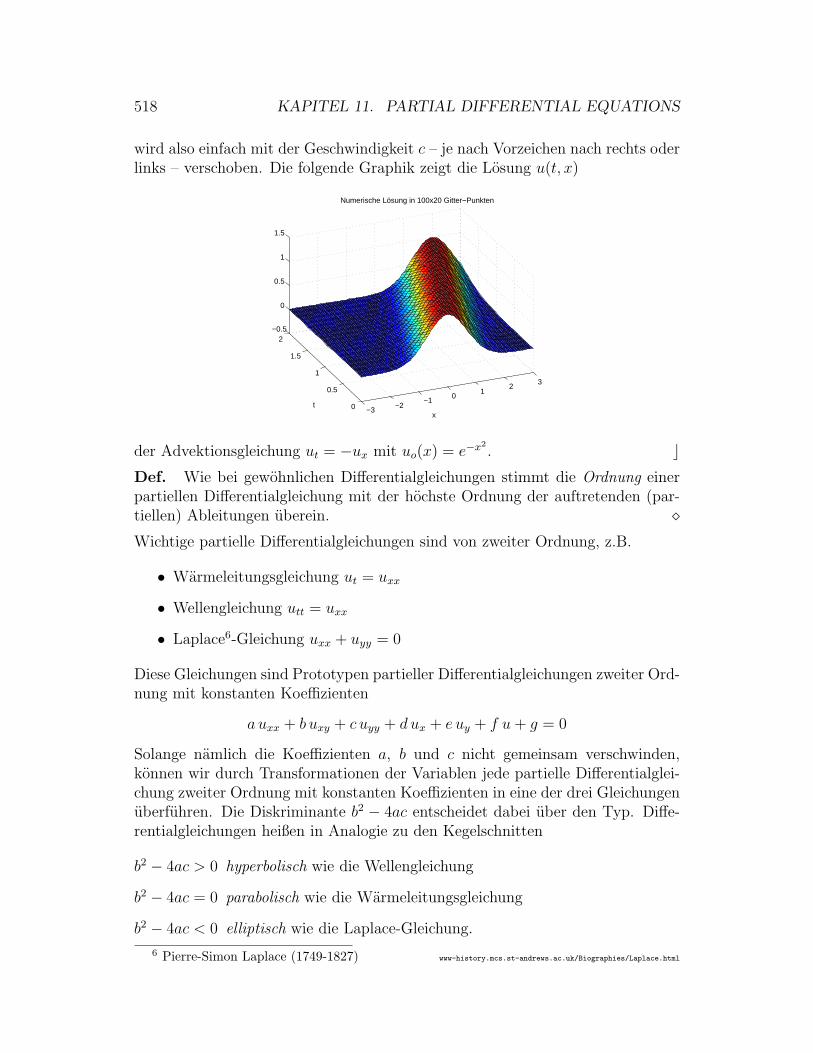
518 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS
wird also einfach mit der Geschwindigkeit c – je nach Vorzeichen nach rechts oderlinks – verschoben. Die folgende Graphik zeigt die Losung u(t, x)
−3−2
−10
12
3
0
0.5
1
1.5
2−0.5
0
0.5
1
1.5
x
Numerische Lösung in 100x20 Gitter−Punkten
t
der Advektionsgleichung ut = −ux mit uo(x) = e−x2. c
Def. Wie bei gewohnlichen Differentialgleichungen stimmt die Ordnung einerpartiellen Differentialgleichung mit der hochste Ordnung der auftretenden (par-tiellen) Ableitungen uberein. Wichtige partielle Differentialgleichungen sind von zweiter Ordnung, z.B.
• Warmeleitungsgleichung ut = uxx
• Wellengleichung utt = uxx
• Laplace6-Gleichung uxx + uyy = 0
Diese Gleichungen sind Prototypen partieller Differentialgleichungen zweiter Ord-nung mit konstanten Koeffizienten
a uxx + b uxy + c uyy + d ux + e uy + f u+ g = 0
Solange namlich die Koeffizienten a, b und c nicht gemeinsam verschwinden,konnen wir durch Transformationen der Variablen jede partielle Differentialglei-chung zweiter Ordnung mit konstanten Koeffizienten in eine der drei Gleichungenuberfuhren. Die Diskriminante b2 − 4ac entscheidet dabei uber den Typ. Diffe-rentialgleichungen heißen in Analogie zu den Kegelschnitten
b2 − 4ac > 0 hyperbolisch wie die Wellengleichung
b2 − 4ac = 0 parabolisch wie die Warmeleitungsgleichung
b2 − 4ac < 0 elliptisch wie die Laplace-Gleichung.
6 Pierre-Simon Laplace (1749-1827) www-history.mcs.st-andrews.ac.uk/Biographies/Laplace.html

519
11.0.2 Zeit-abhangige partielle Differentialgleichungen
Semidiskrete Verfahren
Eine erste Moglichkeit besteht darin, die Raum-Variablen zu diskretisieren. DieZeit bleibt eine stetige Variable. Dadurch entsteht eine System von gewohnlichenDifferentialgleichungen.
Z.B. Betrachten wir die Warmeleitungsgleichung ut = uxx fur x ∈ [0, 1] und t ≥ 0mit Anfangswerten u(0, x) = f(x) fur x ∈ [0, 1] und Randwerten u(t, 0) = 0 =u(t, 1) fur alle t ≥ 0. Wir definieren Gitterpunkte xi = i∆x fur i = 0, 1, . . . , n+1und ∆x = 1
n+1, approximieren die zweite Ableitung uxx durch die zentrierten
finiten Differenzen zweiter Ordnung uxx(t, xi) ≈ u(t,xi+1)−2u(t,xi)+u(t,xi−1)(∆x)2
fur i =1, 2, . . . , n und erhalten ein System von n gewohnlichen Differentialgleichungenin yi(t) ≈ u(t, xi)
yi(t) =c
(∆x)2 (yi+1(t)− 2yi(t) + yi−1(t)) fur i = 1, 2, . . . , n
mit Anfangswerten yi(0) = f(xi) fur i = 1, 2, . . . , n. Die Randwerte liefern diebeiden Losungen yo(t) = 0 = yn+1(t) fur t ≥ 0.Dieses Vorgehen heißt auch line-Verfahren, weil die Losungen yi(t) die Schnitteu(t, xi) approximieren.Die EWe der Koeffzientenmatrix A dieses semidiskreten Systems
y =
y′1y′2...y′n
=c
(∆x)2
−2 1 0 . . . 01 −2 1 . . . 0
0 1 −2. . . 0
.... . . . . . . . .
...0 . . . 0 1 −2
y1
y2...yn
= Ay
liegen zwischen −4c/(∆x)2 und 0. Betrachten wir namlich B = (∆x)2
cA. Laut des
Satzes von Gershgorin (vgl. 4.0.2 auf S. 201) liegt jeder EW in der Kreisscheibeum bkk = −2 mit Radius
∑j 6=k |bkj| ≤ 2. Die Matrix B ist reell symmetrisch und
damit einer reellen Diagonal-Matrix ahnlich. Also sind alle EWe von B reell undliegen somit zwischen −4 und 0. Das System y′ = Ay wird also umso steifer jekleiner ∆x. c
???Alternativ aproximieren wir die Losung durch eine Linear-Kombination von Basis-Funktionen derart, daß die Koeffizienten von der Zeit abhangen: u(t, x) ≈ v(t, x, α(t)) =∑n
j=1 αj(t)φj(x) mit geeigneten Basis-Funktionen φj(x) uber dem betreffendenGebiet im Raum und von der Zeit abhangigen Koeffizienten-Funktionen αj(t).Die Forderung, daß die Approximation v der Losung u die Differentialgleichungwenigstens in den Kollokationspunkten xi erfullt, liefert ein System von Differen-tialgleichungen in αj(t).

520 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS
Z.B. Betrachten wir wieder die Warmeleitungsgleichung ut = c uxx fur x ∈ [0, 1]und t ≥ 0 mit den obigen Anfangs- und Randwerten. Dann ergibt sich jetzt einSystem aus n gewohnlichen Differentialgleichungen in den Unbekannten αj(t)
ut ≈n∑
j=1
α′j(t)φj(xi) = c
n∑j=1
αj(t)φ′′j (xi) ≈ c uxx fur i = 1, 2, . . . , n
Setzen wir M = φj(xi) und N = φ′′j (xi), dann ergibt sich fur regulares M diegewohnliche Differentialgleichung α′(t) = cM−1Nα(t) in der ublichen Form. cAls Basis-Funktionen kommen sowohl solche mit lokalem Trager, wie B-Splines,als auch solche mit globalem Trager, wie Legendre oder Chebychev Polynomeoder trigonometrische Funktionen in Frage. Unser Ansatz lauft im ersten Fallauf ein Finite-Elemente-Verfahren, im zweiten Fall auf ein Spektral-Verfahrenhinaus. In beiden Fallen konnen wir auch
???
Volldiskrete Verfahren
Z.B. Betrachten wir erneut die Warmeleitungsgleichung ut = c uxx fur x ∈ [0, 1]und t ≥ 0 mit Anfangswerten u(0, x) = f(x) fur x ∈ [0, 1] und Randwertenu(t, 0) = α und u(t, 1) = β fur t ≥ 0. Neben den diskreten Raumpunktenxi = i∆x fur i = 0, 1, . . . , n+1 und ∆x = 1
n+1spezifizieren wir jetzt auch diskrete
Zeitpunkte tk = k∆t fur k = 0, 1, 2, . . . und bezeichnen die Naherung der Losungu im Gitterpunkt (tk, xi) mit uk,i ≈ u(tk, xi). Wenn wir nun ut durch forwardDifferenzen und uxx durch zentrierte Differenzen zweiter Ordnung approximieren,erhalten wir ein System algebraischer Gleichungen
ut(tk, xi) ≈uk+1,i − uk,i
∆t= c
uk,i+1 − 2uk,i + uk,i−1
(∆x)2fur i = 1, 2, . . . , n
und aufgelost nach uk+1,i eben
u(tk+1, xi) ≈ uk+1,i = uk,i + c∆t
(∆x)2 (uk,i+1 − 2uk,i + uk,i−1) fur i = 1, 2, . . . , n
Die Anfangswerte liefern u0,i = f(xi) fur i = 1, . . . , n, so daß wir aus den Wertenuk,i im letzten Zeitpunkt tk unter Verwendung der Randwerte uk,0 = α unduk,n+1 = β die Werte uk+1,i im nachsten Zeitpunkt tk+1 ermitteln konnen. Derlokale truncation error ist O(∆t) + O((∆x)2): das Genauigkeit des Verfahrensist in der Zeit von erster Ordnung und im Raum von zweiter Ordnung. cLax7 Aquivalenz-Satz
7 Peter David Lax (1926-) www-history.mcs.st-andrews.ac.uk/Biographies/Lax Peter.html

521
11.0.3 Zeit-unabhangige partielle Differentialgleichungen
Finite-Elemente-Verfahren
Z.B. Betrachten wir die Laplace-Gleichung uxx + uyy = 0 fur x, y ∈ [0, 1] mitRandwerten wie links in der folgenden Graphik dargestellt. Wir diskretisierenden Raum wie rechts dargestellt, d.h. (xi, yj) = (ih, jh) mit n = 2 und h = 1
n+1
x
y
0
0
1
0
x
y
0
0
1
0
sowie i, j = 0, 1, 2, 3 = n + 1 und approximieren uxx bzw. uyy durch die zen-trierten Differenzen zweiter Ordnung. Wir erhalten ein n2 × n2-System linearerGleichungen in den genaherten Losungen ui,j ≈ u(xi, yj) fur i, j = 1, 2, . . . , n
(uxx + uyy)(xi, yj) ≈ui+1,j − 2ui,j + ui−1,j
h2+ui,j+1 − 2ui,j + ui,j−1
h2= 0
wobei u0,j, un+1,j, ui,0 und ui,n+1 durch die Randwerte vorgegeben sind.
Ax =
4 −1 −1 0−1 4 0 −1−1 0 4 −10 −1 −1 4
u1,1
u2,1
u1,2
u2,2
=
u0,1 + u1,0
u3,1 + u2,0
u0,2 + u1,3
u3,2 + u2,3
=
0011
= b
A ist symmetrisch und positiv definit, weil A wegen det(A− λI) = λ4 − 16λ3 +92λ2 − 224λ + 192 = (λ − 2) ∗ (λ − 6) ∗ (λ − 4)2 nur positive EWe hat. Damitliefert vorzugsweise Cholesky-Faktorisierung die Losung x = 1
8(1, 1, 3, 3)T , deren
Symmetrie die Symmetrie der Laplace-Gleichung widerspiegelt. c...
11.0.4 Direkte Verfahren fur dunn besetzte lineare Sy-steme
...

522 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS
11.0.5 Iterative Verfahren fur lineare Systeme
...
conjugate gradient Verfahren
Man kann die Losung linearer Gleichungen auch durch Optimierung finden: SeiA eine symmetrische, positiv definite n× n-Matrix. Dann nimmt die Funktion
φ(x) =1
2xTAx− xTb
ihr Minimum x∗ genau dann an, wenn Ax∗ = b. Wir konnen also die Verfah-ren aus Kapitel 6 einsetzen. Meist minimieren diese iterativen Verfahren beimUbergang von xk zu xk+1 = xk + αsk die Zielfunktion entlang eine Geraden inSuchrichtung sk, d.h. α = argminαφ(xk + αsk).Erstens gilt nun hier
−∇φ(x) = b−Ax = r
Zweitens konnen wir das Minimum analytisch bestimmen:
0 =d
dαφ(xk+1) = (∇φ(xk+1))
T d
dαxk+1 = (Axk+1−b)
T d
dα(xk +αsk) = −rT
k+1sk
Wir drucken das neue Residuum rk+1 durch das alte Residuum rk aus, erhalten
rk+1 = b−Axk+1 = b−A(xk + αsk) = (b−Axk)− αAsk = rk − αAsk
setzen in 0 = rTk+1sk = rT
k sk − αsTk AT sk = rT
k sk − αsTk Ask ein und losen nach α
auf:
α =rT
k sk
sTk Ask
Der folgende Algorithmus heißt conjugate gradient Verfahren zur Losung linearerGleichungen.
x a l t = i n i t ( ) ; % initialisiere xo
r a l t = b − A∗ x a l t ; % initialisiere ro
s a l t = r a l t ; % initialisiere so
for ( k = 1 ; ; k++) % Abbruchbedingung?alpha = r a l t ’∗ s a l t /( s a l t ’∗A∗ s a l t ) ; % αk = rT
k sk/sTk Ask
x neu = x a l t + alpha∗ s a l t ; % xk+1 = xk + αsk
r neu = r a l t − alpha∗A∗ s a l t ; % neues Residuumbeta = r neu ’∗ r neu / r a l t ’∗ r a l t ;s neu = r neu + beta∗ s a l t ; % neue Suchrichtungx a l t = x neu ; r a l t = r neu ; s a l t = s neu ;
end

11.1. Review Questions – Antworten auf Verstandnisfragen 523
11.1 Review Questions –
Antworten auf Verstandnisfragen
1. Richtig/Falsch? Ein konsistentes und stabiles Finite-Differenzen-Verfahrenzur Losung von Zeit-abhangigen partiellen Differentialgleichungen konver-giert gegen die exakte Losung, wenn die Schrittweiten von Zeit und Raumzugleich gegen Null gehen.
Gemaß dem Lax Aquivalenz-Satz sind Konsistenz und Stabilitat notwendige 459und hinreichende Bedingungen fur die Konvergenz von Finite-Differenzen-Verfahren.
2. Richtig/Falsch? Das Gauß-Seidel-Verfahren zur iterativen Losung von li-nearen Gleichungen Ax = b ist immer konvergent.
Das iterative Gauß-Seidel-Verfahren konvergiert nicht fur alle A, vgl. 11Ex3. 471
3. Richtig/Falsch? Das Gauß-Seidel-Verfahren ist ein Spezialfall eines SOR-Verfahrens zur Losung von linearen Gleichungen.
Fur ω = 1 fallt das SOR-Verfahren zur Losung von linearen Gleichungenmit dem Gauß-Seidel-Verfahren zusammen. 471
4. Wie unterscheiden sich halbdiskrete von volldiskreten Verfahren zur LosungZeit-abhangiger partieller Differentialgleichungen?
Halbdiskrete Verfahren diskretisieren den Raum und behandeln die Zeit als 453stetige Variable. Volldiskrete Verfahren diskretisieren Zeit und Raum. 456
5. a) Erlautere das line-Verfahren zur Losung Zeit-abhangiger partieller Dif-ferentialgleichungen in einer Raum-Variablen.
Eine Zeit-abhangige partielle Differentialgleichung in einer Raum-Variablenx hat die Form f(t, x, u, ut, . . . , ut...t, ux, . . . , ux...x) = 0. Diskretisieren des 454Raumes liefert ein System von Differentialgleichungen in y(t) = (u(t, x0), . . . , u(t, xn+1)).
???b) Wie kann man das line-Verfahren verwenden, um ein reines Randwert-Problem fur eine Zeit-unabhangige partielle Differentialgleichung in zweiRaum-Variablen zu losen?
Eine Zeit-unabhangige partielle Differentialgleichung in den beiden Raum-Variablen x und y hat die Form f(x, y, u, ux, uy, uxx, uxy, uyy, . . .) = 0. Wennwir entweder x oder y diskretisieren,
???
6. Partielle Differentialgleichungen konnen durch das semidiskrete line-Verfah-ren in Systeme gewohnlicher Differentialgleichungen transformiert werden.Welche weitere Eigenschaft neben Stabilitat und Genauigkeit bestimmt die

524 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS
Wahl eines numerischen Verfahrens zur Losung dieser Systeme gewohnlicherDifferentialgleichungen?
Steifheit454???
7. Eine Zeit-abhangige partielle Differentialgleichung in einer Raum-Variablenx werde durch ein volldiskretes Finite-Differenzen-Verfahren gelost. Sinddie Schrittweiten ∆t und ∆x unabhangig?
Die Schrittweiten sind nicht unabhangig, wie das Beispiel der Warmelei-458tungsgleichung zeigt.
???
8. Volldiskrete Finite-Differenzen-Verfahren sowie Finite-Elemente-Verfahren(FEM) zur Losung von Randwert-Problemen uberfuhren die vorgegebeneDifferentialgleichung in ein System algebraischer Gleichungen. Warum istder Aufwand, das resultierende n×n-System linearer Gleichungen zu losen,wesentlich kleiner als der fur solche Probleme erwartete Losungsaufwand derGroßenordnung O(n3) ?
sparse462???
9. Welche der folgenden Typen von partiellen Differentialgleichungen sindZeit-abhangig?
a) elliptische partielle Differentialgleichungen451
Elliptische partielle Differentialgleichungen wie etwa die Laplace-Gleichunguxx + uyy = 0 sind Zeit-unabhangig.
b) parabolische partielle Differentialgleichungen451
Parabolische partielle Differentialgleichungen wie die Warmeleitungsglei-chung ut = uxx sind Zeit-abhangig.
c) hyperbolische partielle Differentialgleichungen451
Hyperbolische partielle Differentialgleichungen wie etwa die Wellengleichungutt = uxx sind Zeit-abhangig.
10. Klassifiziere die folgenden partiellen Differentialgleichungen nach Typ undZeit-Abhangigkeit bzw. Zeit-Unabhangigkeit.
a) Laplace-Gleichung450
Die Laplace-Gleichung uxx + uyy = 0 ist eine Zeit-unabhangige elliptischepartielle Differentialgleichung.
b) Wellengleichung450
Die Wellengleichung utt = uxx ist eine Zeit-abhangige hyperbolische parti-elle Differentialgleichung.
c) Warmeleitungsgleichung450

11.1. Review Questions – Antworten auf Verstandnisfragen 525
Die Warmeleitungsgleichung ut = uxx ist eine Zeit-abhangige parabolischepartielle Differentialgleichung.
d) Poisson-Gleichungen 450
Poisson-Gleichungen uxx+uyy = f(x, y) sind wie der Spezialfall der Laplace-Gleichung uxx + uyy = 0 Zeit-unabhangige elliptische partielle Differential-gleichungen.
11. Was ist die Schablone eines Finite-Differenzen-Verfahrens zur numerischenLosung von partiellen Differentialgleichungen?
Die Schablone eines Finite-Differenzen-Verfahren stellt die Abhangigkei- 457ten der naherungsweisen Losung in einem Punkt von den naherungsweisenLosungen in raumlich und zeitlich benachbarten Punkten dar.
12. Die Warmeleitungsgleichung ut = uxx mit geeigneten Anfangs- und Rand-werten kann numerisch gelost werden, indem uxx durch zentrierte finiteDifferenzen approximiert und das entstehende System gewohnlicher Diffe-rentialgleichungen dann durch ein geeignetes numerisches Verfahren gelostwird.
a) Auf welchem Verfahren zur Losung gewohnlicher Differentialgleichungen 459basiert das Crank-Nicolson-Verfahren?
Trapez-Regel???
b) Welchen Vorteil bietet das Crank-Nicolson-Verfahren gegenuber dem 459backward Euler-Verfahren?
Die Genauigkeit des Crank-Nicolson-Verfahrens ist von zweiter Ordnung,die des backward Euler-Verfahren nur von erster Ordnung.
c) Welchen grundlegenden Vorteil haben Crank-Nicolson-Verfahren und 459backward Euler-Verfahren gegenuber dem Euler-Verfahren?
Beide Verfahren sind unbedingt stabil, wahrend das Euler-Verfahren nur 459unter zusatzlichen Bedingungen stabil ist. 397
???13. Die Laplace-Gleichung auf dem Einheitsquadrat werde mit dem ublichen
Finite-Differenzen-Verfahren (zentrierte Differenzen in beiden Dimensio-nen) gelost. Es entsteht ein System linearer Gleichungen. Maximal wievieleUnbekannte kommen in jeder dieser Gleichungen vor?
Diskretisierung der Ebenen-Koordinaten (x, y) in Gitter-Punkte (xi, yj) und 462Approximation der partiellen Ableitungen uxx bzw. uyy durch die zentrierteDifferenzen liefert die Gleichungen
(uxx + uyy)(xi, yj) ≈ui+1,j − 2ui,j + ui−1,j
h2+ui,j+1 − 2ui,j + ui,j−1
h2= 0

526 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS
fur die Naherungen ui,j der Funktionswerte u(xi, yj) der Losung u in deninneren Gitter-Punkten (xi, yj), d.h. fur i, j = 1, 2, . . . , n. Offensichtlichkommen in einer Gleichung maximal funf Unbekannte vor.
14. Die Warmeleitungsgleichung ut = c uxx werde durch ein voll diskretes Finite-Differenzen-Verfahren gelost, wobei die zweite Ableitung uxx wie ublichdurch die zentrierte Differenzen approximiert werde.
a) Warum ist das Euler-Verfahren ungeeignet, die Zeit zu integrieren?458
wegen des eingeschrankten Stabilitatsbereiches???
b) Welches Verfahren zur numerischen Losung der Warmeleitungsgleichung459ist unbedingt stabil und sowohl in der Zeit wie im Raum in zweiter Ordnunggenau?
Crank-Nicolson-Verfahren???
c) Auf welchem Verfahren zur Losung gewohnlicher Differentialgleichungen459basiert obiges Verfahren?
Das Crank-Nicolson-Verfahren basiert auf der Trapez-Regel.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24. Welche allgemeine Form hat ein stationares iteratives Verfahren zur Losungeines Systems Ax = b linearer Gleichungen?
25. a) Was bedeutet Zerlegung einer Matrix A ?468
Zerlegung einer Matrix A ist jdee Darstellung A = M − N von A mitregularer Matrix M.
b) Welche iterativen Verfahren zur Losung linearer Gleichungen Ax = b468resultieren aus solchen Zerlegungen?

11.1. Review Questions – Antworten auf Verstandnisfragen 527
Geeignete Zerlegungen liefern stationare Verfahren wie das Jacobi-Verfah-ren oder das Gauß-Seidel-Verfahren.
c) Welche Bedingung an die Zerlegung garantiert die lokale Konvergenz 470471des zugehorigen iterativen Losungsverfahrens?
Das Jacobi-Verfahren konvergiert lokal, falls A etwa zeilenweise diagonaldominant ist. Das Gauß-Seidel-Verfahren konvergiert lokal, falls A etwasymmetrisch und positiv definit ist.
d) Wie sieht die Zerlegung von A =
(4 11 4
)fur das Jacobi-Verfahren aus? 469
A = M−N mit M = D = diag(4, 4) und N = −(L + U) = −(
0 11 0
).
e) Wie sieht die Zerlegung von A =
(4 11 4
)fur das Gauß-Seidel-Verfahren 470
aus?
A = M−N mit M = D + L =
(4 01 4
)und N = −U = −
(0 10 0
).
26. Welche Eigenschaft der regularen Matrix A bedingt das sofortige Scheiterndes Jacobi-Verfahren zur Losung der linearen Gleichung Ax = b ?
Die Iterationen x(k+1) = D−1(b−(L+U)x(k)) des Jacobi-Verfahrens konnen 469offensichtlich nur berechnet werden, wenn D regular ist. Ein verschwinden-des Diagonal-Element von A laßt das Jacobi-Verfahren also scheitern.
27. Welches der folgenden Verfahren ist ein stationares iteratives Verfahren zurLosung linearer Gleichungen?
a) Jacobi-Verfahren 469
b) steepest descent
c) iterative refinement 469
d) Gauß-Seidel-Verfahren 470
e) conjugate gradient Verfahren 472
f) SOR-Verfahren 471
Jacobi-Verfahren, Gauß-Seidel-Verfahren, SOR-Verfahren sind stationareiterative Verfahren zur Losung linearer Gleichungen.
???
28. a) Wie unterscheiden sich Jacobi-Verfahren und Gauß-Seidel-Verfahren? 469470
Die beiden Verfahren unterscheiden sich in der Zerlegung der Koeffizienten-Matrix A: Die Zerlegung A = D − (−(L + U)) des Jacobi-Verfahrensliefert die Iteration x(k+1) = D−1(b− (L+U)x(k)), wahrend die Zerlegung

528 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS
A = (D + L) − (−U) des Gauß-Seidel-Verfahrens die Iteration x(k+1) =(D + L)−1(b−Ux(k)) liefert.
b) Welches Verfahren konvergiert schneller?470
Das Gauß-Seidel-Verfahren konvergiert schneller als das Jacobi-Verfahren,weil es neu gewonnen Informationen sofort wiederverwendet und nicht erstim nachsten Iterationsschritt.
b) Welches Verfahren braucht weniger Speicherplatz?469470 Das Jacobi-Verfahren muß Speicher fur neuen (x(k+1)) und alten (x(k))) Er-
gebnisvektor vorhalten, wahrend das Gauß-Seidel-Verfahren den Ergebnis-Vektor ’in place’ modifiziert.
29. Lineare Gleichungen Ax = b konnen durch direkte oder indirekte Verfahrengelost werden. Sind folgende Eigenschaften eher direkten Verfahren oderindirekten Verfahren zuzuordnen?
a) Die Elemente der Koeffizienten-Matrix A werden im Verlauf der Be-?469470
rechnung nicht verandert.
Um Speicherplatz zu sparen, verandern direkte Verfahren wie etwa Gaußoder Cholelsky die Elemente von A ’in place’, wahrend indirekte Verfahrenwie Jacobi oder Gauß-Seidel A bzw. die abgeleiteten Matrizen unverandertlassen und nur den Ergebnisvektor verandern.
b) Eine Schatzung x fur die Losung x vor Start des Verfahrens ist hilfreich.?? Direkte Verfahren konnen von x nicht profitieren, wahrend indirekte, lokal
konvergente Verfahren auf moglichst gute Schatzungen x fur den Startwertx(0) angewiesen sind.
c) Die Elemente von A werden explizit, beispielsweise in Feldern gespei-chert.
???d) Der Losungsaufwand hangt von der Kondition des Problems ab.?
474 Direkte Verfahren bestimmen die Losung unabhangig von der Kondition,wahrend die Konvergenzgeschwindigkeit etwa des conjugate gradient Ver-fahrens von der Kondition des Problems abhangt.
e) Ist Ax = b einmal gelost, so kann Ax = b′ fur eine andere rechte Seite?? leicht gelost werden.
Ist die Koeffizientenmatrix A im direkten Gauß-Verfahren einmal LU-fak-torisiert, so erleichtert diese Faktorisierung die Losung fur weitere rechteSeiten insofern, als nur noch substituiert werden muß. Weil die rechte Seitedagegen in die Iterationsformeln indirekter Verfahren eingeht, profitierendiese nicht von einer Losung zu einer bestimmten rechten Seite.
f) Typischerweise werden Beschleunigungsparameter oder Preconditioners

11.1. Review Questions – Antworten auf Verstandnisfragen 529
eingesetzt.
Derartige Hilfsmittel kommen nur fur indirekte Verfahren wie etwa dasSOR-Verfahren oder das conjugate gradient Verfahren in Frage.
g) Die maximale Genauigkeit ist verhaltnismaßig einfach zu erreichen.
???h) ’Black box’ Software ist verhaltnismaßig einfach zu implementieren.
???i) Die Matrix kann durch ihre Aktionen auf einem beliebigen Vektor defi-niert werden.
???j) Ublicherweise wird die Koeffizienten-Matrix faktorisiert.
Daß dies fur direkte Verfahren gilt, zeigen LU-Faktorisierung oder Cholesky-Faktorisierung. Fur die indirekte Verfahren wie das Jacobi-Verfahren oderdas Gauß-Seidel-Verfahren ist die Koeffizienten-Matrix dagegen in Sum-manden zu zerlegen.
k) Die Aufwand kann haufig vorweg bestimmt werrden.
Der Aufwand ist im Gegensatz zu indirekten Verfahren fur direkte Verfahrenvorab abschatzbar.
30. Die regulare Matrix A sei standardmaßig in strikt untere DreiecksmatrixL, Diagonal-Matrix D und strikt obere Dreiecksmatrix U zerlegt.
a) Gib das Iterationsschema des Jacobi-Verfahrens zur Losung von Ax = b 469an.
x(k+1) = D−1(b− (L + U)x(k)) fur k ≥ 0
b) Gib das Iterationsschema des Gauß-Seidel-Verfahrens zur Losung von 470Ax = b an.
x(k+1) = (D + L)−1(b−Ux(k)) fur k ≥ 0
31. Wie ist der Parameter ω im SOR-Verfahren ublicherweise beschrankt? 471
Das SOR-Verfahren konvergiert nicht , wenn nicht 0 < ω < 2, vgl. 11Ex7.
32. Ordne die folgenden Verfahren zur Losung linearer Gleichungen nach fal-lender Konvergenzgeschwindigkeit.
a) Gauß-Seidel-Verfahren
b) Jacobi-Verfahren
c) SOR-Verfahren mit optimalem Parameter ω
33. Das conjugate gradient Verfahren zur Losung eines symmetrischen, positivdefiniten Systems linearer Gleichungen ist im Prinzip ein direktes Verfahren.Warum wird es in der Praxis aber als iteratives Verfahren genutzt?

530 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS
34. Welche zwei Schlusseleigenschaften sind fur die Effizienz des conjugate gra-dient Verfahren zur Losung von großen sparlich besetzten, symmetrischer,positiv definiten Systeme linearer Gleichungen verantwortlich?
35. Wie kann man die Konvergenzrate des des conjugate gradient Verfahrenzur Losung von Systeme linearer Gleichungen Ax = b erhohen?
36. a) Was meint Prakonditionierung des conjugate gradient Verfahren?
b) Benenne zwei Prakonditionierer fur das conjugate gradient Verfahren.
37. Warum heißen stationare itewrative Verfahren zur Losung linearer Glei-chungssysteme smoothers?
38. Erlautere die Idee von Mehr-Gitter-Verfahren.
39. a) Erlautere den Unterschied von V-Zyklen und W-Zyklen in Mehr-Gitter-Verfahren.
b) Wie unterscheidet sich full multigrid von V-Zyklen und von W-Zyklen?
40. Ein System linearer Gleichungen, das von einem elliptischen Randwert-Problem herstammt, sei zu losen. Fur welchen Typ von Losungsverfahren,direkt oder iterativ, steigt der Losungsaufwand starker, wenn die Dimensiondes Problems vergroßert wird?
41. Gibt es bzw. kann es ein Verfahren zur Losung eines System linearer Glei-chungen, das von einem elliptischen Randwert-Problem herstammt, geben,dessen Laufzeit proportional zur Anzahl der Gitter-Punkte ist?
11.2 Exercises – Ubungsergebnisse
1. a) Lose∫ b
ag(t) dt vermittels des gegebenen Anfangswerteproblemlosers.
Sei f(t, y) = g(t) und der Anfangswert y(a) = 0. Dann liefert der Anfangs-werteproblemloser fur das Anfangswertproblem y′ = f(t, y) mit y(a) = 0
eine Stammfunktion y(t) von g und wegen y(a) = 0 gilt y(b) =∫ b
ag(t) dt.
b) Lose das 2=Punkte Randwertproblem u′′ = u2+tmit u(0) = 0, u(1) = 1.
Setze y1 = u und y′1 = u′ = y′1 sowie y′2 = u′′ = u2 + t = y21 + t, also y′ =(
y′1y′2
)=
(y2
y21 + t
)= f(t,y) mit Anfangswert y(0) =
(0c
)fur geeignetes c.
shooting approximiert fuer variierendes c die Losung des Randwertproblemsy(1) = 1.

11.2. Exercises – Ubungsergebnisse 531
c) ut = cuxx fur 0 ≤ x ≤ 1, t ≥ 0 und u(0, x) = g(x) sowie u(t, 0) = 0 =u(t, 1).
Sei xi = i∆x = i/(n + 1) f¨ur i = 0, 1, . . . , n + 1. yi(t) = u(t, xi) undy′i(t) = cui+1−2ui+ui−1
(∆x)2bzw. y′i(t) = cyi+1−2yi+yi−1
(∆x)2fur i = 1, 2, . . . , n. y′ =
c(∆x)2
−2 1 0 0 . . . 01 −2 1 0 . . . 0. . . . . . . . .
0 . . . 0 0 −2 1
y1
y2...yn
mit yi(0) = g(xi) und yo(t) ≡ 0 ≡
yn+1(t) fur alle t.
2. Gegeben die Poisson-Gleichung uxx + uyy = x+ y auf dem Einheitsquadrat[0, 1]2 mit den in der Graphik angegebenen Randwerten.
x
y
0
0
1
1
Verwende zentrierte finite Differenzen zweiter Ordnung, um die Losung imPunkt (0.5, 0.5) zu approximieren.
Sei ui,j ≈ u(xi, yj) wobei xi = i/2 und yj = j/2 fur i, j = 0, 1, 2. Aus
(uxx +uyy)(xi, yj) ≈ui+1,j − 2ui,j + ui−1,j
(∆x)2+ui,j+1 − 2ui,j + ui,j−1
(∆y)2= xi +yj
gewinnen wir ui+1,j−2ui,j +ui−1,j +ui,j+1−2ui,j +ui,j−1 = 14(xi+yj). so daß
u1,1 = 14(u2,1 +u0,1 +u1,2u1,0)− 1
16(x1 + y1) = 1
4(1+0+1+0)− 1
16(1
2+ 1
2) =
12− 1
16= 7
16folgt.
3. Zeige anhand von Beispielen, daß weder Konsistenz noch Stabilitat alleindie Konvergenz eines Finite-Differenzen-Verfahrens garantieren konnen. 459
???4. Illustriere das Muster der nicht verschwindenden Eintrage in der Matrix,
die ein Finite-Differenzen-Verfahren zur Losung der Laplace-Gleichung aufeinen d-dimensionalen Gitter mit k Gitterpunkten in jeder Dimension furd = 1, 2, 3 erzeugt. Bestimme die jeweiligen nicht verschwindenden Eintrage. 450
???5. a) Verifiziere das Muster der nicht verschwindenden Eintrage in der Matrix 464ff
der Laplace-Gleichung mit den dargestellten Randbedingungen

532 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS
x
y
0
0
1
0
x
y
0
0
1
0
und in ihrem Cholesky-Faktor.???
b) Verifiziere???
6. Zeige: wenn A zeilenweise diagonal dominant ist, dann konvergiert das ite-rative Jacobi-Verfahren gegen die Losung von Ax = b. Hinweis: verwendedie ∞-Norm.
A sei zeilenweise diagonal dominant, also gilt∑n
j=1,j 6=i |ai,j| < |ai,i| fur77460 i = 1, 2, . . . , n. Aus
∑nj=1,j 6=i |ai,j/ai,i| < 1 fur i = 1, 2, . . . , n folgt aber
0 < c := ||D−1(L + U)||∞ < 1 und damit eben
||x(k+1) − x||∞ = ||D−1(b− (L + U)x(k))− x||∞= ||D−1(Ax−(L+U)x(k)−Dx)||∞= ||D−1(L+U)(x−x(k))||∞≤ ||D−1(L + U)||∞ · ||x− x(k)||∞ < c||x− x(k)||∞
Wegen ||x(k+1) − x||∞ < ck||x(1) − x||∞ ist ||x(k) − x||∞ eine Nullfolge unddaher konvergiert die Folge x(k) gegen x.
7. Zeige: wenn ω 6∈ (0, 2), dann divergiert das SOR-Verfahren.
Sei wieder x(k) das Ergebnis des k-ten SOR-Schrittes. Dann gilt wegen471b = Ax = (D + L + U)x
(I + ωD−1L)x(k+1) = ((1− ω)I + ωD−1U)x(k) + ωD−1(D + L + U)x
und nach Subtraktion von (I + ωD−1L)x auf beiden Seiten
(I + ωD−1L)(x(k+1) − x) = ((1− ω)I + ωD−1U)(x(k) − x)
Bleibt zu zeigen, daß (I + ωD−1L)−1((1 − ω)I + ωD−1U) Norm großer 1o.a.
???
8. Zeige: die A-orthogonalen Suchrichtungen des conjugate gradient Verfah-rens erfullen eine three term recurrence, so daß jeder neue Gradient nurgegenuber den beiden Vorgangern orthogonalisiert werden muß.
???9. Zeige: die Unterraume, die durch die erstenm Suchrichtungen des conjugate
gradient Verfahrens aufgespannt werden, stimmen mit den durch die Folgero,Aro,A
2ro, . . . ,Am−1ro erzeugten Krylov Unterraumen uberein.
???10. Leite den Algorithmus des conjugate gradient Verfahrens her.
???

11.3. Computer Problems – Rechner-Problem-Losungen 533
11.3 Computer Problems –
Rechner-Problem-Losungen
1. Gegeben die Warmeleitungsgleichung ut = uxx fur 0 ≤ x ≤ 1 und t ≥ 0mit Anfangsbedingung u(0, x) = 2xχ0≤x<.5(x) + (2 − 2x)χ.5≤x≤1(x) sowieRandbedingungen u(t, 0) = 0 = u(t, 1) fur t ≥ 0.
a) Berechne die Losung fur 0 ≤ t ≤ 0.06 per vollstandiger Diskretisierungmit ∆x = 0.05 und ∆t = 0.0012 und prasentiere die Losung als Animation.
b) Wiederhole a) fur ∆t = 0.0013 und erlautere die Beobachtungen.

534 KAPITEL 11. PARTIAL DIFFERENTIAL EQUATIONS

Literaturverzeichnis
[1] Milon Abramowitz, Irene A. Stegun: Handbook of Mathematical Functions– ’AMS55, The Handbook’; National Bureau of Standards’ Applied Mathe-matics Series, Vol 55, 1964–1972http://dlmf.nist.gov/about/book info.html,www.math.sfu.ca/~cbm/aands/
[2] Gene H. Golub, Charles F. van Loan: Matrix Computations; The JohnHopkins University Press 1996
[3] Nicolas J. Higham: Accuracy and Stability of Numerical Algorithms; SIAM2002
[4] Charles F. van Loan: Introduction to Scientific Computating – A Matrix-Vector Approach Using MATLAB; Prentice Hall 1997
[5] Clive Moler: Numerical Computing with MATLAB; SIAM, Philadelphia2004
[6] William H. Press, Saul A. Teukolsky, William T. Vetterling, Brian P.Flannery: Numerical Recipes in C++, C, Pascal/FORTRAN – TheArt of Scientific Computing; Cambridge University Press, 1986–2004 s.a.http://www.nr.com/
Bis auf das Handbuch mathematischer Funktionen bieten diese Werke neben
[0] Michael T. Heath: Scientific Computing – An Introductory Survey; McGraw-Hill International Edition, 2nd edition 2002, ISBN 0-07-112229-Xhttp://www.cse.uiuc.edu/heath/scicomp/
wie auch www.weblearn.hs-bremen.de/risse/MAI/docs/numbiblio.pdf vieleweitere Referenzen.
535