knowledge discovery
TRANSCRIPT

Knowledge Discovery & Data Mining22nd ACM SIGKDD 2016André Karpištšenko

~80 sessions for 2,700 participants
• Business Applications and Frameworks at Scale
• Data Streams Mining
• DashOpt features
• Outlier Detection
• Bayesian Optimization
• Deep Learning
• Investing into AI and Data
• Bonus keywords
88 countries, 35% YoY, 15-20% acceptance

Business Application Examples
• Consumer Internet focus: Content Ranking, Recommendation, User Intent and Context Prediction
• Industrial Internet focus: Autonomy, Predictive Maintenance, Operational Intelligence, Production Planning
• B2B focus: Targeting, Lead Generation, Sales Development, Opportunity Management, Account Management
• Web content analytics: Image, Video, Text Classification for Relevance, Products Categorization, Sentiments
• Other: Cyber Security, Fraud/Spam Detection, NLP, Speech Recognition, Image/Video Recognition

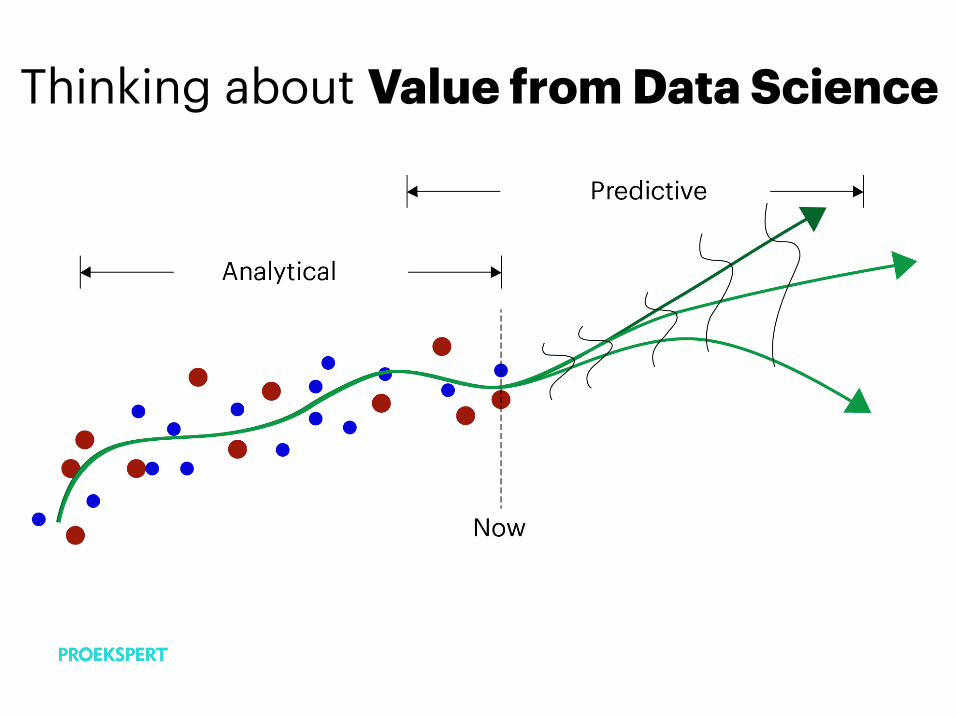
Predictive Modeling Flow
DashOpt
FeatureEngineering
RawData
RawFeatures Labels
FeatureIntegration
Featureswith Labels
DataPartitioning
Training Data
Validation Data
Testing Data
Model Training
Evaluate formodel selection
Compute offlineevaluation metrics
Best model
Offline scoringand indexing
Online/offline systems
Online A/B test
Labelpreparation Log data
Scoring features
Raw features
Featureintegration
ModelPerformance
Test Results

Data Technologies
• Most common: HDFS, MapReduce, Spark, Hive
• Decision spectrum: build, assemble, buy
• Factors: network, open-source, maturity, needs
Exploratory Production

Classic ML Platform at Scale
Workflows
HDFS Feature Mart Ground Truth Models Scores
MapReduce / Yarn
Workflow Scheduler & Manager
Workflows Workflows
Intelligence Engine
Metadata Store Pig, Hive,
Python, Scala, Shell script, …
Feature Engineering Libraries
Machine Learning Libraries
Drivers
Drivers
Application 1 Application 2 Application N…

http://github.com/szilard/benchm-ml
Baseline Performance Benchmark

https://sites.google.com/site/iotminingtutorial/
IoT Data Streams Mining
• 10 billion devices in 2015 -> 34 billion devices by 2020
• Continuous data, dynamic models, distributed, few seconds

Streams Mining: Actors Model
Data processing pipeline Distributed processing
Kappa Architecture https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102

Outlier Detection• Single point anomaly detection: likelihood over distribution
• Finding anomalous groups: divergence estimation
• Methods: percentage change, T-test, Chi-square test, Generalized ESD (Extreme Studentized Deviate) test, Seasonal Hybrid ESD, etc.
• Goal: move from detection to automated response

Outlier Detection in Practice
• Too many detections of too little value
• Use methods for thresholds
• Breakout detection and Concept Drift
• For changing distributions move baselines over time
• Risk of overfitting to known anomalies, not finding unknown anomalies

Bayesian aka Active Optimization
• Examples: Design of Experiments, hyper-parameters of supervised learning, algorithms tested with simulations
f is an unknown expensive black-box function with the goal to approximately optimize f with as few experiments as possible
• No free lunch theorem
• Other bio-inspired algorithms for optimization exploitation and exploration: neural networks, genetic algorithms, swarm intelligence, ant colony optimisation, etc.

Bayesian Optimization in Practice
• SigOpt experience: 20 dimensions, above human capacity.
• Uber ATC experience: scaling active optimization to high dimensions as the default works reliably for 5-7 dim.
• Variables are added during optimization.
• Choose fidelity using heuristics.

Deep Learning

Deep Learning
• Compute power, GPU, learning architectures and a lot of labeled data are what drive DL
• Applied for Vision and Speech: matches human performance
• Not possible where experiments are costly: biotech
• Kaggle winners are not DL models: tree ensembles, SVMs
• Common technologies: TensorFlow, Caffe, Theano, Keras
• Thousands of pieces of software: modules and layers
• Explainability and interpretability are the next big things
• EU regulation. Tradeoff: accuracy vs explainability.

Deep Learning Trends
• Vision nets are deeper and structured (Larsson 2016)
• Language nets have also dynamics, memory and attention (Rocktaschel 2016, Miller 2016)
• Probabilistic programming (Lake, Tenenbaum)
• Programs as networks (Riedel)
• The Neural Programmer and Interpreter for learning programs (Reed et al 2016)
• Computation graphs interacting with memory
• Loop for reasoning for nested questions (Miller 2016)
• Generative adversarial networks (Reed 2016). Models capable of imagining images, videos and text.

Investing into AI and Data
• Data acquisition, real-time detection and visualization not solved yet.
• Empower more people to do data science. Automate routines.
• Unsolved problems are learning from unlabeled data, planning, reasoning, problem solving, concept formulation, 1/10k compute.
• Key decisions: Timing, accuracy in what is hard, find verticals and focus, identify differentiation & size of the prize & people & partners
Business of outliers: 1% capital returns 526x, 48% returns 0
0
450
900
Q2'15 Q3'15 Q4'15 Q1'16 Q2'16
Peak Data Peak ML
VC assessment:

Bonus Keywords
• Lifelong Machine Learning: systems approach, transfer learning, never-ending learners. Useful for knowledge build.
• Graphons: graph convergence and limits through infinite number of vertices. Useful for privacy preserving mining.
• Computational Social Science: how individuals interact to produce collective behaviour. Individuals exert more effort by themselves than groups.
• Information Security: trusted key management is most sensitive. Secret must be changed frequently. Confidentiality easier to violate than authenticity. Integrity. Offence more lucrative than defence.
• Enterprise Data: in reality “random data salad” prone to constant change due to M&A, politics, dynamic schema DBs (e.g. Mongo), legacy burden, restructuring, leadership changes, data hoarding. Machine driven, human guided processes required.
Thinking about Value from Data Science