analisi frequentista e bayesiana del problema 'stroke
TRANSCRIPT

Analisi frequentista e bayesiana del problema
Stroke
Francesco Curia, Stefania Cartolano
17 novembre 2015

INDICE
1. Introduzione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2. Approccio frequentista . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1 Verosimiglianza e analisi frequentista basate su dati ECASS3 . . . . . 4
3. Approccio bayesiano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.1 Distribuzione a priori basata su dati ECASS2 . . . . . . . . . . . . . 9
4. Distribuzione a posteriori . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
5. Verifica di ipotesi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
6. Distribuzione a priori soggettiva . . . . . . . . . . . . . . . . . . . . . . . . 15
7. Analisi non informativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
8. Approssimazione normale . . . . . . . . . . . . . . . . . . . . . . . . . . . 20

1. INTRODUZIONE
Lo schema di riferimento e un esperimento bernoulliano riguardo l’analisi bayesia-
na del problema denominato Stroke, presentato dagli autori Lasaffre e Lawson, in
merito ad uno studio clinico effettuato su le cause di danneggiamento delle cellule
cerebrali a causa di due fattori, uno ischemico e l’altro emoraggico.

2. APPROCCIO FREQUENTISTA
2.1 Verosimiglianza e analisi frequentista basate su dati ECASS3
Considerando un campione i.i.d abbiamo i seguenti risultati: La funzione di verosi-
miglianza associata al campione esaminato e
L(θ) = θs(1− θ)n−s
dove
s =n∑i=1
yi
Per lo stima di massima verosimiglianza, passiamo al calcolo della log-verosimiglianza
e alla derivazione della stessa, ponendola uguale a zero.
l(θ) = sln(θ) + (n− s)ln(1− θ)
che derivando rispetto a θ risulta
dl(θ)
dθ=s
θ− n− s
1− θ= 0
si ottiene che la stima e θMV =∑ni=1 yin
ossia la media campionaria. Utilizzando i
dati a disposizione, si ottiene che la stima e pari a 0.2. Possiamo calcolare l’intervallo
di confidenza per θ approssimato, che risulta per α = 0.05:
y ± Z1−α2
√y(1− y)
n
con i dati a disposizione abbiamo
0.2± 1.96 ∗ 0.0566
allora θ ∈ [0.089; 0.31].
Calcoliamo ora l’insieme di verosimiglianza approssimato
Lq =
[y − kq
√y(1− y)
n, y + kq
√y(1− y)
n
]

2. Approccio frequentista 5
dove kq =√−2lnq
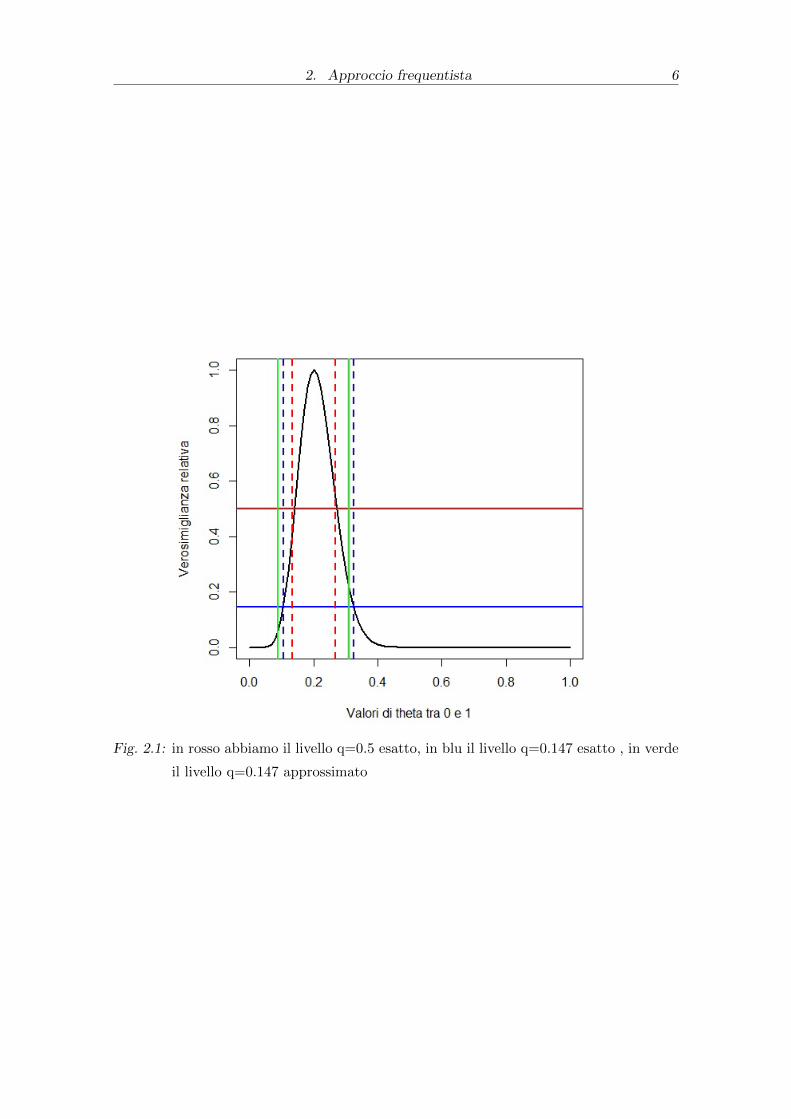
Per un fissato livello q=0.5, abbiamo quanto segue:
0.2± 1.1774 ∗ 0.0566
allora θ ∈ [0.133; 0.267]. Mentre considerando un calcolo esatto dell’insieme di
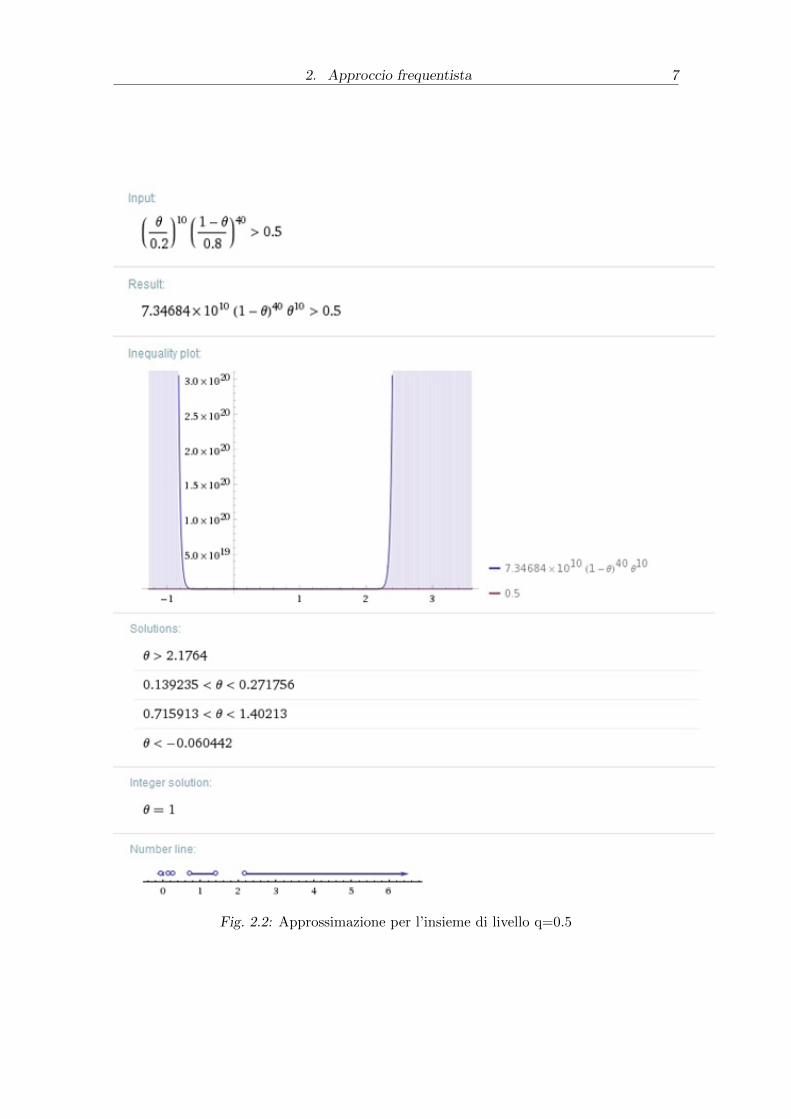
verosimiglianza per un livello q=0.5, procediamo con un metodo numerico il quale
considerando i dati e la funzione di verosimiglianza relativa, il polinomio associato
L(θ) =(θ)10
(0.2)10(1− θ)40
(0.8)40> 0.5
fornisce gli estremi dell’intervallo che sono per θ ∈ [0.14; 0.27]. In quanto si sono
considerate solo le radici reali del polinomio, escludendo tutti i valori fuori l’in-
tervallo [0;1].Per il calcolo appena svolto si e utilizzato l’applicativo Mathematica
Wolphram Alpha.Si noti che l’intervallo [0.14;0.27] coincide con quello trovato con
l’approssimazione normale.Mentre risulta molto diverso da quello ottenuto mediante
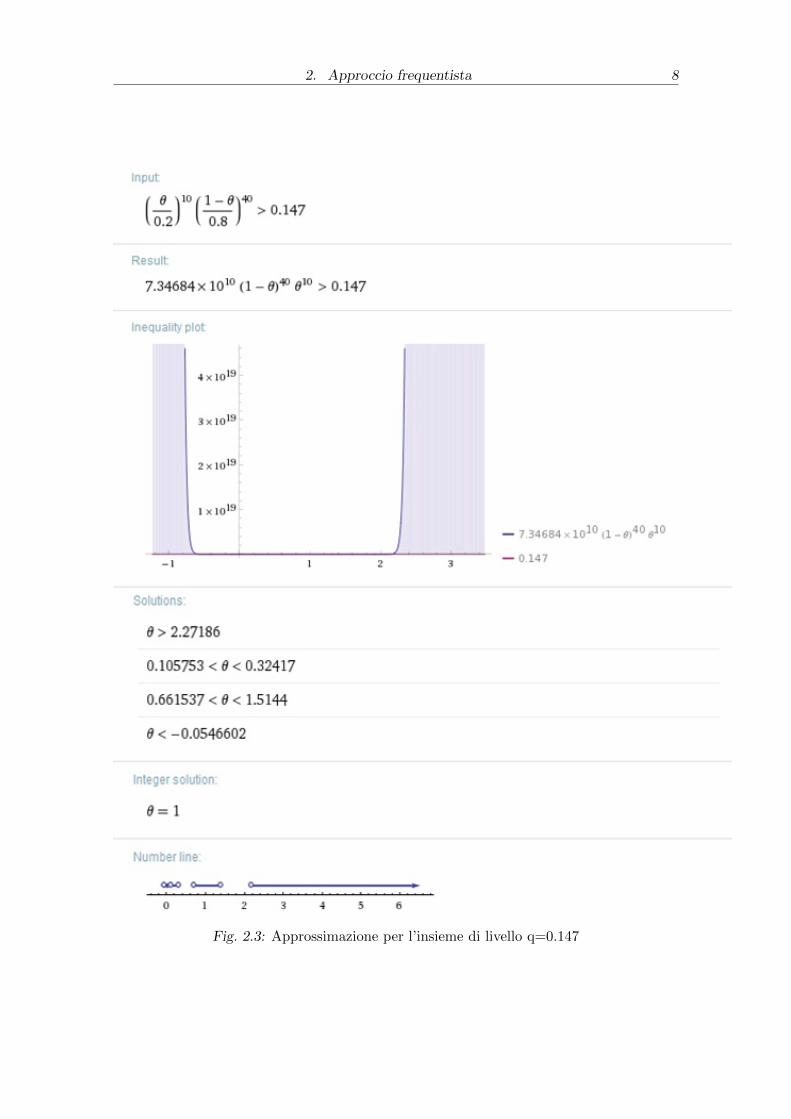
l’intervallo di confidenza approssimato. Ora considerando un livello q=0.147 si ha
per l’insieme di verosimiglianza approssimato
0.2± 1.95 ∗ 0.0566
allora in questo caso θ ∈ [0.089; 0.31] mentre attraverso metodo numerico otteniamo
questa volta che θ ∈ [0.10; 0.32]. Da un confronto oltre che analitico, anche grafico,
appare evidente che l’approssimazione normale differisce non di poco dal valore
esatto dell’intervallo.
2. Approccio frequentista 6
Fig. 2.1: in rosso abbiamo il livello q=0.5 esatto, in blu il livello q=0.147 esatto , in verde
il livello q=0.147 approssimato
2. Approccio frequentista 7
Fig. 2.2: Approssimazione per l’insieme di livello q=0.5
2. Approccio frequentista 8
Fig. 2.3: Approssimazione per l’insieme di livello q=0.147

3. APPROCCIO BAYESIANO
3.1 Distribuzione a priori basata su dati ECASS2
Continuiamo la nostra analisi considerando ora la determinazione della distribuzione
a priori π(θ), considerando i dati ECASS2: abbiamo che n0 = 100 e y0 = 8, dalla
nota relazione
π(θ|yn) = c ∗ π(θ)l(θ|yn)
otteniamo
π(θ) = c ∗ θ9−1(1− θ)93−1
dove
c =
∫ 1
0
θ9−1(1− θ)93−1dθ
Per quanto riguarda la determinazione della stima puntuale, come e noto per una
densita Beta, lo stimatore risulta θMV = αα+β
ovvero θMV = 9102
= 0.08.
Passando ora alla determinazione dell’insieme di credibilita ET per una Beta(9,93),
otteniamo che θ ∈ [0.04; 0.15], poiche come ben noto tale intervallo si trova appli-
cando la seguente formula:
CET1−α = [qα
2; q1−α
2]
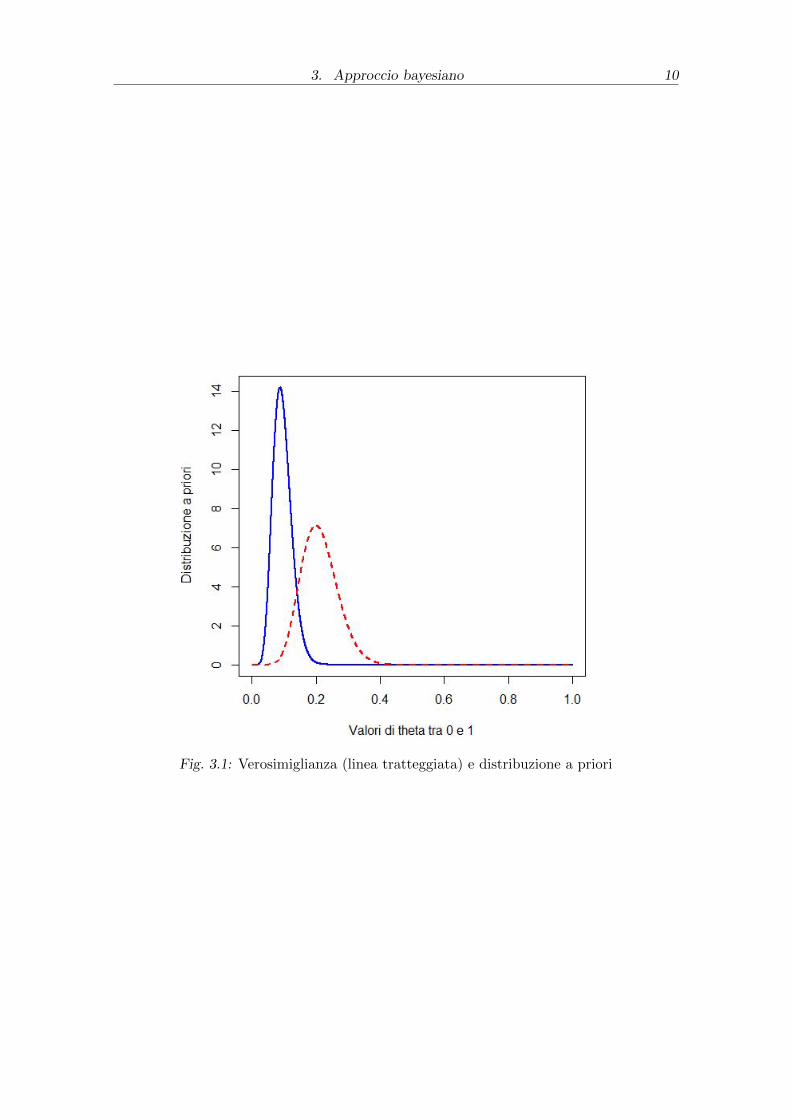
Per quanto riguarda l’insieme HPD determiniamo un insieme
S = [θ : π > h]
troviamo approssimativamente che θ ∈ [0.038; 0.145] che per un livello h=2.17
3. Approccio bayesiano 10
Fig. 3.1: Verosimiglianza (linea tratteggiata) e distribuzione a priori

4. DISTRIBUZIONE A POSTERIORI
Ricaviamo la distribuzione a posteriori tramite la nota relazione
π(θ|yn) = c ∗ π(θ)π(θ|yn)
allora dai dati che abbiamo ottenuto in precedenza possiamo scrivere
π(θ|yn) = θα+sn(1− θ)β+n−sn
sostituendo con i dati ECASS2 e ECASS3 si ottiene:
π(θ|yn) = θ19(1− θ)133
Passiamo alla stima puntuale, calcolando moda e valore atteso, rispettivamente
θModa =α + sn − 1
α + β + n− 2
θB = (1− wn)α
α + β+ wnyn
con wn = nα+β+n
sostituendo con i dati a disposizione abbiamo
θModa = 0.12
θB = 0.125
Da i risultati ottenuti si evince che moda e valore atteso sono molto simili. Proce-
diamo al calcolo dell’insieme di credibilita ET che risulta, per un valore α = 0.05
θ ∈ [0.077; 0.182]. Per il calcolo dell’insieme HPD relativo alla distribuzione a po-
steriori, possiamo procedere come si e fatto per quello della distribuzione priori.
Troviamo che per un livello h = 2.28 abbiamo θ ∈ [0.076; 0.181].
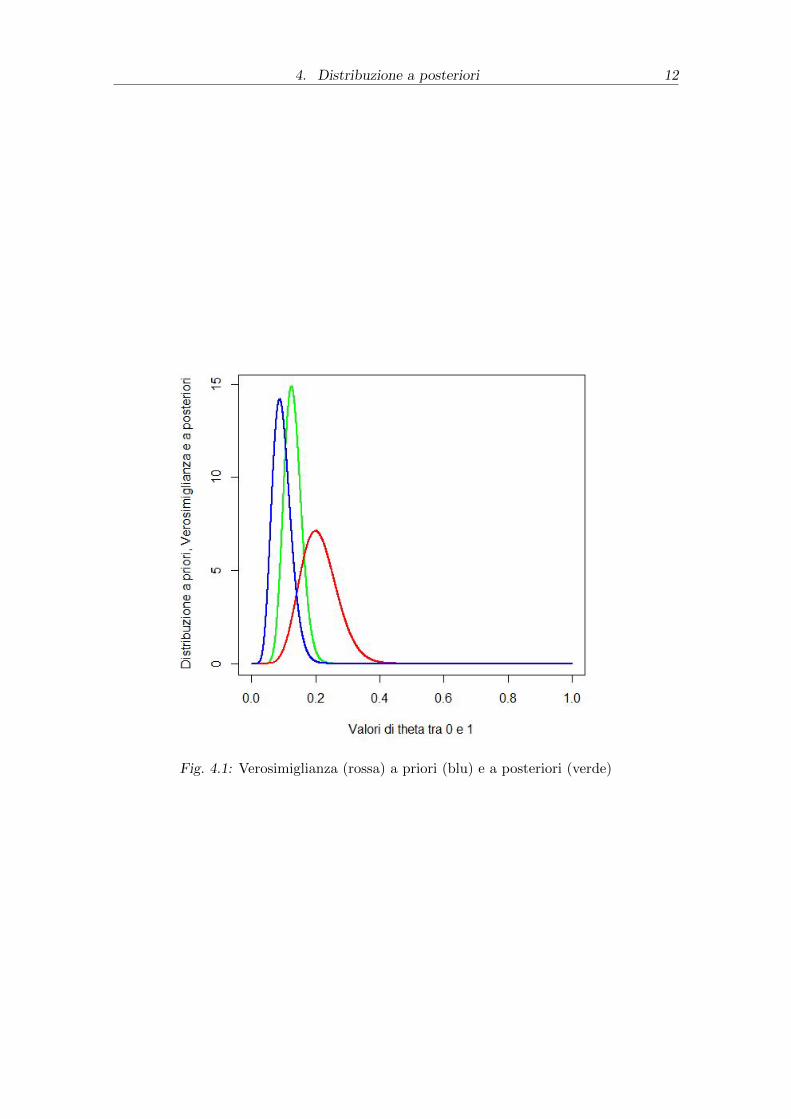
4. Distribuzione a posteriori 12
Fig. 4.1: Verosimiglianza (rossa) a priori (blu) e a posteriori (verde)

5. VERIFICA DI IPOTESI
Vogliamo ora formalizzare il seguente problema: si vuole calcolare la probabilita che
l’emorragia non superi il dieci percento: il problema puo considerarsi come:H0 : θ < 0.1
H1 : θ > 0.1
considerando α = 0.05 costruiamo la regione di rifiuto
R =
Y − θ0√θ0(1−θ0)
n
> Z1−α
ovvero
R = [Z > 1.64]
approssimando per un campione n=50 con una distribuzione N(0,1), abbiamo at-
traverso i dati, per un livello fissato α = 0.05, Toss = 2.35
R = [Toss > 1.64]
Allora rifiutiamo l’ipotesi nulla θ0 ad un livello di significativita del 95 percento. Il
valore-p , ottenuto con la formula
p = 1− Φ(2.35)
risulta 0.009, quindi minore del livello α = 0.05 e quindi conferma il rifiuto dell’ipo-
tesi nulla.
Calcoliamo ora la probabilita a posteriori delle due ipotesi :∫ 0.1
0
θ19(1− θ)133dθ = FBeta(α+sn,β−n+sn)(θ0) = FBeta(19,133)(0.1) = 0.18
mentre per l’ipotesi alternativa abbiamo∫ 0
0.1
θ19(1− θ)133dθ = 1− FBeta(α+sn,β−n+sn)(θ0) = 1− FBeta(19,133)(0.1) = 0.82

5. Verifica di ipotesi 14
FBeta(19,133)(0.1)
1− FBeta(19,133)(0.1)=
0.18
0.82= 0.22
Anche in questo caso il test conferma l’evidenza sperimentale contro l’ipotesi nulla.
Ripetiamo gli stessi calcoli ( di cui riportiamo solo i risultati numerici, in quanto il
procedimento e il medesimo) per quanto riguarda il test e il fattore di Bayes per la
distribuzione a priori: FBeta(9,93)(0.1) = 0.30 e 1− FBeta(9,93)(0.1) = 0.69
FBeta(9,93)(0.1)
1− FBeta(9,93)(0.1)=
0.69
0.30= 2.3
.
Il corrispondente fattore di Bayes, dato dal rapporto (Odds) e il seguente:
0.21
2.3= 0.09
Quindi in questo caso otteniamo il contrario di quanto ottenuto in precedenza, cioe
un’evidenza sperimentale a favore dell’ipotesi nulla.

6. DISTRIBUZIONE A PRIORI SOGGETTIVA
Considerando la valutazione di un esperto, il quale fornisce come valore piu plausibile
per θ = 0.4 e che un intervallo (0.2;0.6) contenga il vero valore del parametro con
probabilita al 90 percento; costruiamo quindi una distribuzione a priori ”soggettiva”
che indicheremo con πs(θ). Dobbiamo determinare α e β: consideriamo αα+β
= E(θ) = 0.4
αβ(α+β)2(α+β+1)
= Var(θ) = 0.1
considerando i valori trovati e che θ = 0.4 e considerando che se l’intervallo contiene il
vero valore di θ per ricavare la varianza σ imponiamo l’equazione 0.4−1.96√σ = 0.2
ricavando che σ = 0.01 che e uguale all’equazione 0.4 + 1.96√σ = 0.6. Mettendo
questo risultato nel sistema dei momenti, si ottiene: α = 9 e β = 13. allora si ha
πs(θ) = θ9−1(1− θ)13−1
La nuova distribuzione a posteriori ottenuta risulta
πs(θ|yn) = c ∗ θ19(1− θ)53
Calcoliamo la moda e il valore atteso della distribuzione a posteriori, considerando
questa volta la distribuzione πs, otteniamo:
θModa = 0.23
θMV = 0.24
Rispetto ai valori ottenuti con la distribuzioni a priori π, notiamo una leggera dif-
ferenza se consideriamo invece come distribuzione a priori πs. Consideriamo adesso
le probabilita a posteriori ottenute utilizzando la πs per la verifica delle’ipotesi:
la nuova distribuzione a posteriori e:
πs(θ|yn) = c ∗ θ19(1− θ)53

6. Distribuzione a priori soggettiva 16
Quindi abbiamo∫ 0.1
0
θ19(1− θ)53dθ = FBeta(α+sn,β−n+sn)(θ0) = FBeta(19,53)(0.1) = 0.00001
∫ 0
0.1
θ19(1− θ)53dθ = 1− FBeta(α+sn,β−n+sn)(θ0) = 1− FBeta(19,53)(0.1) = 0.99999
Per il fattore di Bayes abbiamo :
FBeta(19,53)(0.1)
1− FBeta(19,53)(0.1)=
0.18
0.82= 0.0000001
Per le probablita a priori abbiamo
0.01
0.99≈ 0
Allora il rapporto risulta per il fattore di Bayes tende ad esplodere a +∞. E facile
notare che i valori non sono molto diversi da quelli ottenuti in precedenza. Quindi
anche in questo caso abbiamo una forte evidenza sperimentale contro H0, in favore
dell’ipotesi alternativa.
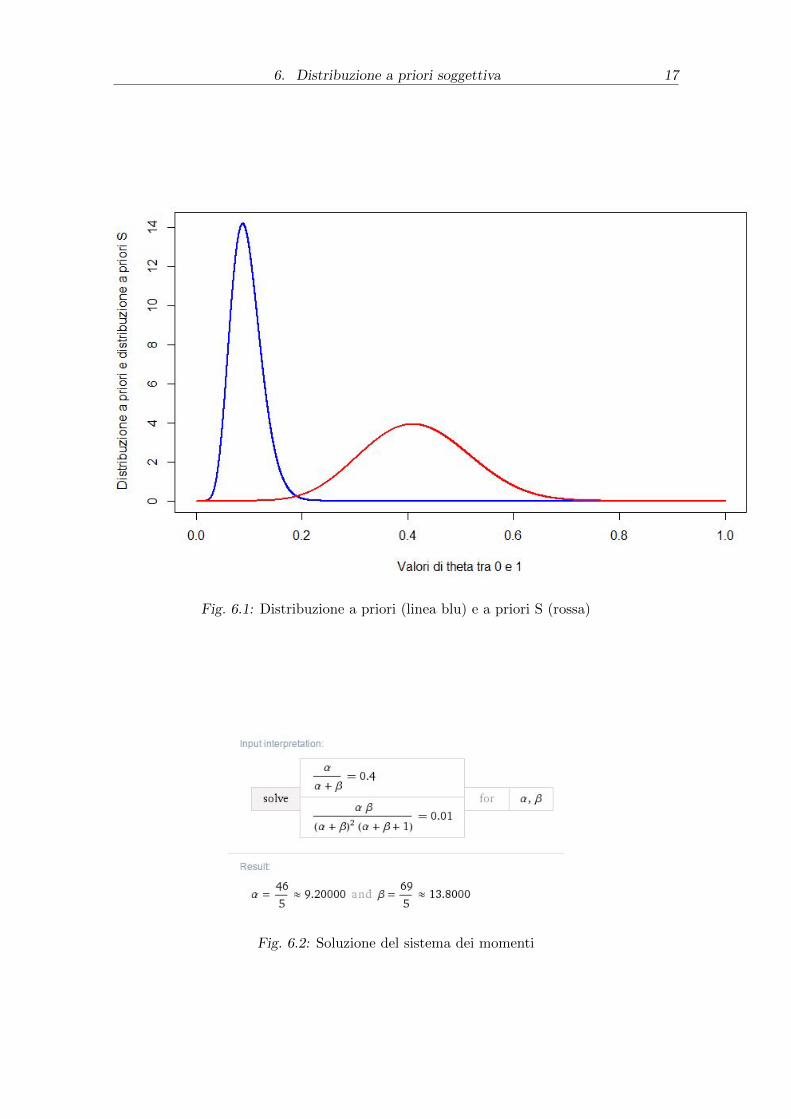
6. Distribuzione a priori soggettiva 17
Fig. 6.1: Distribuzione a priori (linea blu) e a priori S (rossa)
Fig. 6.2: Soluzione del sistema dei momenti

7. ANALISI NON INFORMATIVA
Per quanto riguarda l’analisi non informativa, utilizziamo una distribuzione del tipo:
π(θ) = θ−1(1− θ)−1
cioe poniamo α = β = 0 dando un peso di totale ignoranza sul fenomeno in esame.
La corrispondente distribuzione a posteriori risulta:
π(θ|yn) = c ∗ θ9(1− θ)39
La stima puntuale, media e moda, risultano rispettivamente:
θB = 0.187
θModa = 0.173
La totale assenza di conoscenza sui parametri giustifica i risultati che abbiamo ot-
tenuto, ossıa valori molto bassi rispetto a quelli ottenuti precedentemente.
Passiamo a calcolare ET ed HPD;
CET0.95 = [q0.025; q0.975] = [0.09; 0.308]
Per l’HPD abbiamo ( tramite calcolo con R) l’intervallo
CHPD0.95 = [0.092; 0.307]
per un livello h ≈ 1.205.
Per la verifica di ipotesi, consideriamo ancora il fattore di Bayes, in quanto si vuole
confrontare il rapporto (Odds) tra le due ipotesi: abbiamo∫ 0.1
0
θ9(1− θ)39dθ = FBeta(α+sn,β−n+sn)(θ0) = FBeta(9,39)(0.1) = 0.0411

7. Analisi non informativa 19
mentre per l’ipotesi alternativa abbiamo∫ 0
0.1
θ9(1− θ)39dθ = 1− FBeta(α+sn,β−n+sn)(θ0) = 1− FBeta(9,39)(0.1) = 0.9588
Per il fattore di Bayes abbiamo :
FBeta(9,39)(0.1)
1− FBeta(9,39)(0.1)=
0.0411
0.9588= 0.0428
Mentre il rapporto della distribuzione a priori e 1, in quanto posti α=β=0, non si e
dato nessun peso all’informazione del modello di Haldane considerato nell’analisi.
Rispetto a prima abbiamo un valore ancora piu basso, ma il peso a favore dell’ipotesi
alternativa contro l’ipotesi nulla e maggiore, questo dipende anche dal fatto che
abbiamo adottato una distribuzione a priori totalmente non informativa.

8. APPROSSIMAZIONE NORMALE
Come noto l’approssimazione normale della distribuzione a posteriori risulta
π(θ; yn) ∝ exp
[−1
2(θ − θ)2In(yn)
]dove θModa e la moda a posteriori che abbiamo calcolato considerando πs. Quindi
possiamo affermare che la distribuzione a posteriori ha distribuzione
θ|yn ∼ N(0.23, 0.05)
ovvero
π(θ; yn) ∝ exp
[−1
2(θ − 0.24)2(0.05)
]
Procediamo al calcolo degli insiemi ET ed HPD dell’approssimazione normale della
distribuzione a posteriori, che per α = 0.05 risultano:
CET0.95 = [0.24± 1.96 ∗ 0.05] = [0.14; 0.33]
che non differisce da tutti gli altri ET che abbiamo calcolato in precedenza. Mentre
l’HPD risulta
CHPD0.95 = [0.142; 0.34]
per un livello ( che come tutti gli HPD che abbiamo calcolato in precedenza e stato
calcolato come semi somma dei livelli h, in quanto mai simmetriche le distribuzioni)
h ≈ 1.11. Possiamo affermare con molta accuratezza che i duei intervalli ottenuti
sono pressoche uguali.
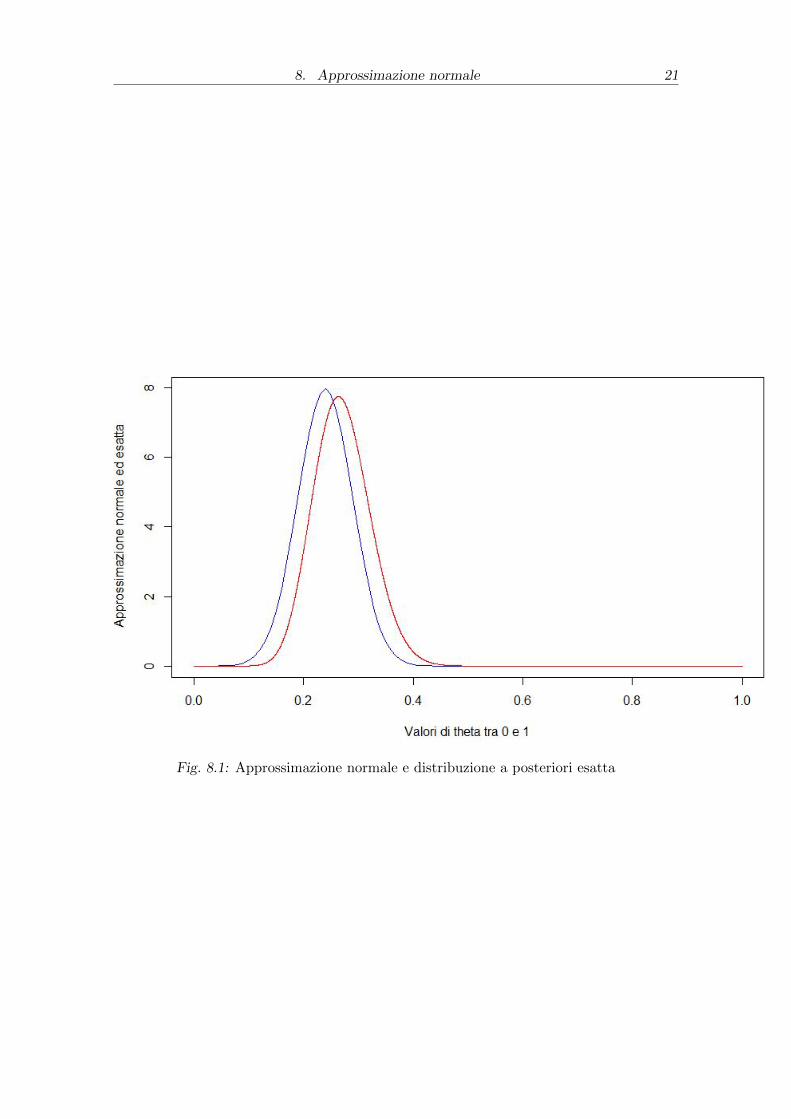
8. Approssimazione normale 21
Fig. 8.1: Approssimazione normale e distribuzione a posteriori esatta